Ruby の型検査器 Sorbet の開発で使われた記録・再生テスト (翻訳)
2017 年から 2018 年にかけて、私 (と Paul Tarjan と Dmitry Petrashko) は Stripe で開始された Sorbet プロジェクトの初期メンバーを務めた。このプロジェクトでは Stripe が持つ数百万行の Ruby コードの生産性を向上させるために漸進的静的型検査システムを開発することが目標とされ、最終的に広く利用されるオープンソースツールが作成された。私は Sorbet に関してチームが成し遂げたこと (そして他の人々が開発を続ける事実) を誇りに思う。Sorbet プロジェクトは非常に大きな成功を収め、Sorbet チームは私が所属してきた中で様々な意味で最も優れたチームだと感じている。
このプロジェクトではアーキテクチャの実装からプロジェクト全体の戦略まで、多くのことが上手く行ったと私は考えている。本記事は Sorbet の設計と開発を振り返り、他のプロジェクトでも利用可能と思われる洞察を紹介するブログ記事シリーズの最初 (になるはず) の記事である。紹介するテクニックに新規性があると主張するつもりはない: 私たちが有用だと感じたテクニックが他の人にとって有用なケーススタディになることを願っている。
Sorbet におけるテスト
プロジェクトの初日から、私たちはテストとテストインフラに多大な労力を投入するべきだと考えていた。チームの誰もが、自身のキャリアで得てきた経験から、プロジェクト最初期におけるテストおよびテストインフラに対する投資は開発速度と最終的に完成するツールのクオリティの両方を大きく向上させると強く信じていた。Sorbet プロジェクトの履歴に残る最初のコミットには単純な "Hello, World" ユニットテストと、それをビルド・実行するインフラだけが含まれる。
また、将来 Sorbet のテストスイートの大部分は .rb ファイルとなり、そこには短い Ruby コードと型検査器が送出すべきエラーを示す何らかの注釈が記されることになることも私たちは分かっていた1。しかし、テストのパイプラインをゼロから構築するときは、個別のパスを作成する段階で (エラー報告用のインフラを構築する前から!) テスト可能にすることが望ましいとも考えていた。そういったテストは開発中に遭遇する問題を隔離・デバッグする上で有用になるだろうと期待された。
記録・再生テスト
Sorbet チームが最終的に採用したのは、私が「記録・再生テスト (record/replay testing)」と呼ぶ戦略である。テスト対象のコードを呼び出して結果を確認するユニットテストを開発者が人力で書くのではなく、ツールの現在の出力が一つ前のバージョンの出力と一致するかどうかを自動的に確認するフレームワークを私たちは作成した。このフレームワークを使うと、開発者は人力で書かれたサンプルプログラムの集合に対して型検査器を特定のフェーズまで実行した結果として得られる現在の内部表現をテキストとして記録できる。このテキストは git のソースツリーにチェックインされる。テストランナーはサンプルプログラムを同じフェーズまで再生し、最終的に得られる内部表現をテキストに変換したものがチェックインされたテキストと一致するかどうかを検証する。
この処理を可能にするために、型検査器が利用する中間表現を新しく実装するたびに人間が読みやすいフォーマットでその中間表現を出力する pretty-print 機能が実装された。また、中間表現を変換する様々なパスが実装されていく中で、指定されたパスまでパイプラインを実行した時点における中間表現を出力するコマンドラインオプションが追加された。こういった機能 (多くのコンパイラが何らかの形で持つ機能) はテストインフラで利用されるのに加えて人力のデバッグでも役立ったので、まさに一石二鳥だった。
例: 真偽値演算の脱糖
現在のコードベースにあるテストを一つ例として示そう。コンパイラでよくあるように、Sorbet はパイプラインの早い段階で a || b を if a then else b end に変換する。二つの式は同一の意味論を持つものの、この変換 (「脱糖」と呼ばれる) によって以降のパスが || を理解・処理する必要がなくなる。
この変換のテストで利用されるファイルが二つある。test/testdata/desugar/ops.rb には || と && を使った短いコードが含まれ、test/testdata/desugar/ops.rb.desugar-tree.exp には脱糖した結果として期待される AST を表すテキストが含まれる。期待される結果が記されたファイルの名前に付いている .desugar-tree.exp は、対応する ops.rb ファイルを「desugar」パスまで実行し、その結果の AST を pretty-print し、その出力を記録された .desugar-tree.exp と比較するよう Sorbet のテストランナーに伝える。
.exp ファイルの管理
重要な事実として、全ての .exp ファイルは自動的に再生成できる。tools/scripts/update_exp_files.sh スクリプトを実行すると、Sorbet レポジトリに存在する全ての .exp ファイルが検索され、現在のコードを使って対応する .rb ファイルから .exp ファイルが再生成される。このスクリプトは新しいテストの作成でも利用される: テストしたいコードを .rb ファイルに書き、テストしたいパスに対応する空の .exp ファイルを作成したら、後は update_exp_files.sh を実行するだけで最初の「記録」が .exp ファイルに書き込まれる。
.exp ファイルは (特に開発初期には) 頻繁に更新された。システムのあらゆる部分が進化していったので、内部表現やそれらに対する変換パス、そして型システムも変更されたからである。変換パスを変更するといくつかの .exp が変更されるのに対して、内部表現が変更されるとその内部表現を利用する全ての .exp ファイルが更新される可能性が生じる。
私たちは「プルリクエストを送信するときは、.exp ファイルの更新を個別のコミットにする」というルールを採用した。こうすると、コードのレビュアーは更新されるコードのレビューと内部表現に対する影響の確認を個別に行える。これはレポジトリの履歴からも確認できる: バグの修正と exp ファイルの更新は個別のコミットとなる。
humans-in-the-loop
このテストスタイルに関して私が興味深いと感じたのが、それぞれのテストが何を確認しているのか正確に説明するのが難しい点である。記録・再生テストは何らかの処理の出力が期待される出力と完全に一致するかどうかをチェックする。しかし、特にツールをゼロから開発するときは、この出力は処理を洗練させる中で間違いなく何度も更新される。そこで、私たちはコードを変更したときのテストの更新をスクリプトの再実行だけで簡単に行えるようにした。そのため「そんな方式は事実上何もテストしていない」と主張することもできる: テストが失敗したとしても、更新スクリプトを実行すればテストは必ずパスする!
ただそうだとしても、この方式には十分な価値があると私は考えている。なぜなら、以前の記事で言及したように、主な目的が正しさの確認ではないテストも存在するからである。つまり、一部のテストはプロジェクトに参加する開発者が作業を高速かつ自信を持って進めるための助けとなるツールとして存在する。このためのツールとして、記録・再生テストは Sorbet で大きな役割を果たした。このテスト方式が他の方式より上手く行った理由として、次の点を指摘できる:
期待される出力の更新をレビューした
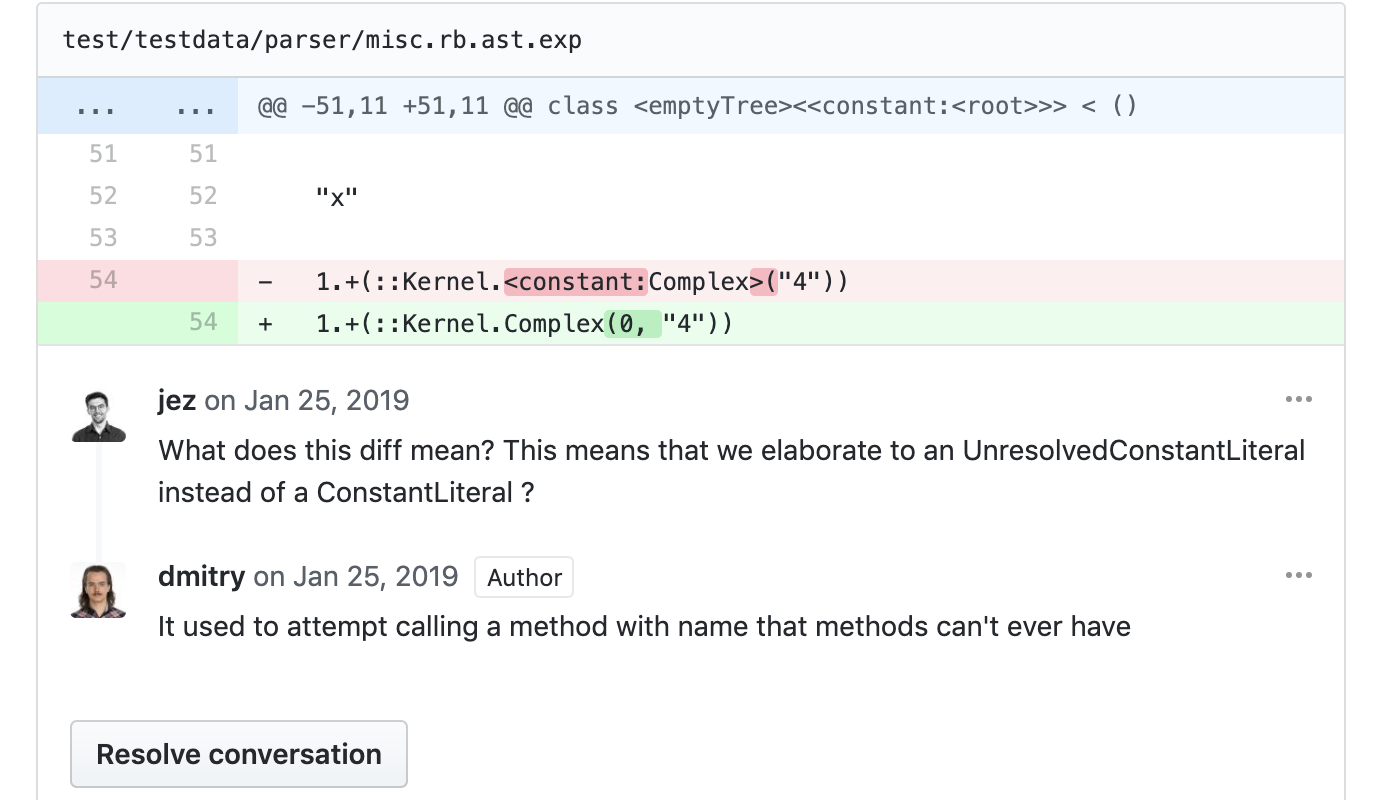
.exp ファイルに対する変更の詳細に関する会話
チームの中で合意されたルールとして、.exp ファイルの更新はプルリクエストの作成者とレビュアーの両者がレビューした。このステップは次の性質を確認する上で非常に重要だった:
- コードの変更が期待されるファイルにだけ影響する。例えば、型検査器の特定のパスを変更したときそれより前方のパスの出力が変わったり、特定の言語機能に関する処理の変更したときその機能を利用しないテストの出力が変わったりしたときは、誤ってレグレッションを起こした可能性があると分かる。
.expファイルの変更が期待されるものである。.expファイルは人間が読めるように設計されコードと共にレポジトリに保存されるので、それなりに可読性の高い diff を GitHub から確認できる。変更されたコードの期待されない振る舞いを理解するために.expファイルやその diff に目を通すこともあった。
.exp ファイルの更新 (特に新しく追加されるもの) は、機械によって動作が確認された動作例としてレビュアーの助けにもなった。変更が達成したい動作の具体例を変更の作者がテストケースとして提供し、その動作が今後保たれることはプロジェクトのテストインフラが保証する。
.exp ファイルの更新を簡単にした
開発者との会話でテストが話題になるとき頻繁に聞かれる不満として、テストの「脆さ」がある: 変更のたびに事実上毎回 (実際の機能は全く変わっていない場合でも) 破壊され修正が必要となるテストは開発者を幸せにしない。Sorbet のテストは出力が完全一致するかどうかを確認するので、非常に脆いと言える: ほとんどの変更がテストを破壊するように設計されている。しかし、テストの更新が完全に自動化されているので、最小限の時間と労力で壊れたテストを更新できる。そのため実際の開発で感じる脆さは人力でアサーションを書く場合より低かった。開発初期の Sorbet のように進化の途上にある厳密な仕様を持たないシステムでは中心的な仮定の変更が頻繁に起こるので、どんなテストも脆さからは逃れられない。テストを頑健にする代わりにテストの修正にかかる手間を最適化したことは価値のあるトレードオフだった。
テストの追加を非常に簡単にした
新しいテストを追加するには、テストしたい機能やパターンを記した Ruby ソースファイルを書き、空の .exp ファイルを一つまたは複数 touch し、更新スクリプトを実行するだけで済む。先述したファイル単位のエラー検査アプローチは後に拡張され、.exp ファイルを作成する必要さえなくなった。テストの追加・更新を簡単にしたことは、一つ残らず全ての機能に対してテストを書くよう開発者を促す効果もあった。
また、パイプラインのストレステスト用に fuzzer が開発の途中で追加された。fuzzer がクラッシュを見つけると、そのテストケースがレグレッションテストとしてコーパスに保存される。
Sorbet が成長するにつれて、正確性のチェックを強くしていった
プロジェクトが始まってすぐのころ、Sorbet はどこにもデプロイされず、ユーザーも存在しなかった。そのためレグレッションのコストも低かった: 私たち開発者が補足・デバッグ・修正するだけであり、チームの外側には何の影響もなかった。.exp ファイルの変更が見過ごされてレグレッションが起きるとしても、テストシステムによって全体の開発を高速化されるなら受け入れられるコストだった。レグレッションが見つかった場合でも .exp ファイルに対して git log すれば原因となるコミットがたいていは見つかるので、git bisect の必要はなかった。
開発が進んで Stripe の他のチームに向けて Sorbet を公開したころから、私たちはエンドツーエンドの正確性をチェックするテストを増やしていった。Sorbet のユーザーが遭遇するレグレッションを減らすためである。このテストには先ほど説明した # error: テストを大規模にしたもの、そして Sorbet に対する全ての PR を Stripe の Ruby アプリケーション全体に対して実行する CI ジョブが含まれる。これらのテストによってユーザーが利用する振る舞いが壊れていない確率が高まる。開発が進むにつれて、この方式のテストは私たちが中心的に使用するテストとなっていった。記録・再生テストは内部表現の重要あるいは細かな詳細をチェックするものが少数だけ残された。
コンパイラ以外での利用
コンパイラや型検査器の開発に関して私が特に気に入っているのは、少なくとも巨視的には、処理全体を String → String 型の巨大な純粋関数と捉えられる点である: いくつかのファイルを受け取ってエラーや警告と共にゼロ個以上のファイルを出力するだけであり、通常は内部表現が永続化されない。この特徴があるために、コンパイラと型検査器は比較的テストがしやすい部類のソフトウェアに属する。他にも、この二つのソフトウェアは私が取り組んだ経験のある他のソフトウェアの多くより処理が理解しやすい。
そうだとしても、ここまでに説明したテクニックやアイデアの一部は複雑で込み入ったインターフェースを持つシステムの開発でも有用だと私は考えている。再生・記録テストはコードの変更が特定の振る舞いを変更しないことを確認する安価な手法であり、記録の更新を自動化しておけば振る舞いが変更される場合でも無駄になる時間は非常に短い。
同様のテクニックを他のシステムで利用する方法に関して考えたことを次に示す。多くの提案事項は記録・再生テストの範囲を超えているものの、記録・再生テストの視点から書くようにした。
ネットワークサービス
ネットワークサービスは HTTP や RPC によるネットワーク境界を持つので、コンパイラと同様にテストがしやすいソフトウェアである。入力と出力をテキストとして記録する代わりに、入力リクエストおよび期待されるレスポンス (生の HTTP プロトコルそのもの、または人間が理解・操作しやすいように整形したもの) をテキストとして記録することもできる。
内部状態や外部依存性を (それほど) 持たないサービスでは、このテクニックがローカルのプログラムと同程度に強力かつ便利になる場合が多い。
状態の管理
システムが内部に状態を持つとき、単一の処理を表現する入力と出力を記録するだけでは処理をテストするのに十分でない。入力と関連する状態の両方があって初めて出力が決定する。こういったシステムで再生・記録テストを利用するために「記録」処理を一般化する戦略を私は二つ知っている。両者を組み合わせることもできる:
- 状態を記録に含める。例えば、テストしたい状態に到達するための API 呼び出しを記録する。あるいは、状態に直接デシリアライズできるミニフォーマットを定義して、それを使って初期条件を記述してもよい。
- テストの実行で利用される「デフォルト」の状態を (フィクスチャ風に) 事前に作成しておく。例えば、よくある名前を持った数人のユーザーや頻繁に使われるオブジェクトを持つ状態を用意して、「再生」処理ではその状態に対する決め打ちの ID を使った操作や対話を実行する。
外部依存性
外部依存性を持つ──例えば他のマイクロサービスや外部のプロバイダと対話する──サービスで再生・記録テストを可能とするには、その対話をある程度制御できる必要がある。ここでも、私は二つの戦略を知っている。いずれも状態を管理するための先述した二つの戦略に緩く対応する:
- 対話を記録する: テスト中のサービスが対話する可能性のある外部サービスのレスポンスを「記録」に含めておき、外部サービスの代わりにテストフレームワークが要求されたレスポンスを返す。このアプローチは柔軟性が高い一方で、外部サービスと対話する処理で使うとテストが脆くなる (気付かないうちに正しさが保証されなくなる) 危険性がある。また、本物の外部サービスに対するアクセスを持たない場合、トレースの自動的な再生成が不可能になり、面倒な人力によるテスト更新が必要になる可能性がある。
- 外部サービスの「フェイク」を作成する: 依存する API を決定的に振る舞うように実装し直したものを私は「フェイク」と呼んでいる。フェイクを作ってテストで利用すれば、脆い対話記録を参照せずに処理を進められるので、テストは明確かつ頑健になる。しかし、複雑な依存コードのフェイクを作るには大量のコードが必要になる場合がある。
非決定性
再生・記録テストはシステムが決定的なことを要求する: 同じ入力から何らかの理由で異なる出力が得られたときテストは失敗とみなされる。一般に、システムを決定的なものとして構築する (少なくとも決定的に動作するオプションを作成する) ことはテストとデバッグのために極めて有用だと私は考えている。そのため、非決定性を持つシステムをテストするとき私の最初のアプローチはシステムの振る舞いを決定的にできるかどうかを見極めることである。このとき利用できるテクニックの例を示す:
- 固定されたタイムスタンプを仮定するオプションを作成する: 言語あるいは OS レベル で可能な場合もある (例えば Ruby では Timecop がある)。テストで使用するタイムスタンプを指定できるようにリファクタリングしてもよい。
- シードを設定できる決定的な PRNG (疑似乱数生成器) を利用する: 単純なケースでは RNG を
return 4に置き換えるだけで十分である! - 適切な箇所でリストを明示的にソートする: 例えばプログラムがファイルシステムの順序でファイルのリストを読み込むとき、複数のスレッドを使って結果を得られた順に集めたり、順序無しハッシュテーブルを使っていたりすると、コードに一見ランダム性が無くても非決定性が生じる。適切なタイミングで
sortを呼び出せば予測可能な振る舞いを取り戻せる。この問題は Sorbet でも様々な箇所で姿を現すので、テスト関係のコードには決定性を保証するための sort が多く存在する。
出力フォーマットから関係ない情報を除去することでテストの脆さを改善できる場合もある。例えば、Ruby では多くのオブジェクトがポインタアドレスを含んだ #<Object:0x00005c62fdd14978> のような文字列として出力される。Stripe の他のプロジェクトでは、バックトレースを取った後そこに含まれるアドレスを全て 0 にして、同じプログラムを再び実行したとき同じ文字列が出力されるようにする処理がよく書かれている。Sorbet では再生・記録テスト用に出力から一部の情報を除去するコマンドラインオプションが実装されている。
非決定性を抑え込めない場合は、「期待される出力」ファイルに対する何らかのパターンマッチングを実装することが選択肢の一つとなる。例えば文字列に対しては完全一致ではなく正規表現のマッチが利用できるかもしれない。このルートに進む場合、上手く行けばテストは強力になり、可読性も (余計な詳細を省略できるので) 向上する。しかしテストインフラは複雑になり、テストの再生成が難しくなる可能性もある。使うなら自己責任で!
結論
私たちが採用したテスト戦略は Sorbet プロジェクトが成功した多くの理由の一つだと私は考えている。このアイデアを私たちが初めて採用したわけでは決してないものの、採用されたテストのアプローチ、そして私がテストについて考えていることをまとめた本記事が外部の人にとって有用で興味深いものとなることを願っている。
最後に、もしあなたが新しいプロジェクトで再生・記録テストの採用を考えているなら、次の点は強調しておきたい: テストインフラを整備してテストを書く目的は (少なくとも私にとって!)、プロジェクトを高速かつ安全に進めること、そして様々な意味で生産的になることである。もし本記事で紹介したアイデアやテクニックが自分に合っていないと感じるなら、異なるアプローチを試したほうがいい。テストを削除することさえ選択肢に入れてもいいかもしれない。もし本記事の内容を活用して何かを作ることができたなら、ぜひ教えてほしい!
-
そういったテスト用
.rbファイルは現在のコードベースにも存在する。# error:で始まるコメントが期待されるエラーを表す。テストファイルを型検査した結果として異なるエラーが送出されるとき、もしくは注釈に書かれたエラーが送出されなかったときテストは失敗する。このスタイルのテストはT.reveal_typeとT.assert_type!によって非常に簡潔に書けるようになっている。 ↩︎