WebGPU - コアの全てを canvas 抜きで (翻訳)
- これは Surma 著 WebGPU — All of the cores, none of the canvas の翻訳です。英語版は Creative Commons Attribution 4.0 International License で公開されています。
- この翻訳は Creative Commons Attribution 4.0 International License の許諾に基づいて公開されます。
WebGPU は低レベルで汎用な GPU アクセスを提供する Web API であり、現在策定が進んでいる。
私はグラフィックスが専門というわけではない。OpenGL でゲームエンジンを作るチュートリアルを読んで WebGL について何となく理解し、Inigo Quilez が ShaderToy で 3D メッシュやモデル無しにシェーダーだけで素晴らしいことをするのを見てシェーダーについて学んだ。そうして私は PROXX の背景アニメーションなどを作れるようになったものの、WebGL を使っていて気持ちが安らぐことはなかった。この理由は後で簡単に説明する。
私は WebGPU が自分のレーダーの視界に入ったときに試して見たいと思ったのだが、複数の人物から「WebGPU は WebGL よりさらにボイラープレートが多い」と警告を受けた。私は決意を曲げず、しかし最悪を予期しながら、チュートリアルや仕様を見つけられるだけ集めた。WebGPU は生まれて間もなかったので見つけられる資料は多くなかった。資料を読み進めると、WebGPU のボイラープレートは WebGL より格段に多いわけではなく、それでいて WebGPU は WebGL よりずっと気持ちが安らぐ API であることを私は発見した。
というわけでこの記事である。この記事では私が GPU と WebGPU を理解しようと頭を悩ませる中で学んだことを共有する。目標は WebGPU をウェブ開発者にとって身近にすることだ。しかし最初に注意事項が一つある: 私は WebGPU を画像の生成には使わない。その代わり、GPU が提供する生の計算力へアクセスするのに WebGPU を利用する。WebGPU を使ってスクリーンにレンダリングを行う方法に関するフォローアップの記事を後で書くかもしれないが、その点に関する資料は既に多くある。それから、WebGPU を理解するため、そして願わくば読者が WebGPU を効果的に──必ずしも効率的にではない── 扱えるようにするために必要なときは細かい部分を説明する。あなたを GPU パフォーマンスの専門家にすることはできない: 主な理由は私がそうでないからだ。
注意書きはここまでだ。この記事は長い。シートベルトをお忘れなく!
WebGL
2011 年に誕生した WebGL は、当時ウェブから GPU にアクセスする唯一の低レベル API だった。WebGL の API は OpenGL ES2.0 の API にウェブ互換にするための薄いラッパーとヘルパーを追加したものに過ぎない。WebGL と OpenGL の標準化は Khronos Group が行う。Khronos Group は簡単に言えば 3D グラフィックスの W3C である。
OpenGL の API が作られたのはさらに前のことで、そのため現在の基準からすれば優れた API とは言い難い。グローバルなステート (状態) を保持するオブジェクトが内部に存在し、このオブジェクトを中心とした設計となっている。この設計は任意の呼び出しで GPU とやり取りするデータの量を最小化するという観点からすれば理にかなってはいるものの、心理的なオーバーヘッドは大きい。
OpenGL が内部に持つステートオブジェクトは基本的にポインタの集合である。API を呼び出すと、ステートオブジェクトそのものに加えてステートオブジェクトが指すオブジェクトも影響を受ける。そのため API 呼び出しの順序が非常に大きな意味を持つ。この事実は抽象化やライブラリの構築を難しくしていると私は常々思っている。細心の注意を払って、これから行う API 呼び出しの邪魔にならないようポインタをはじめとしたステートの値を正しい値に設定し、加えて API 呼び出しの後には抽象化された他の部分と正しく組み合わさるよう以前のステートを復元しなければならない。黒い画面 (WebGL で報告されるエラーといえば、これがほぼ全てだ) を突き付けられて、どのポインタが正しく動いていないのかをしらみつぶしに探すことがよくある。正直言って ThreeJS がどうやってあれほど柔軟になっているのか全く理解できないのだが、何らかの方法で上手くやっているのだろう。多くの人が WebGL を直接使うのではなく ThreeJS を使うことを選ぶ理由はそこにあると私は思う。
機械学習やニューラルネットワーク、そして (敢えて名前を出すなら) 仮想通貨が現れると、GPU が利用できるのは画面に三角形を描画する処理だけではないことが示された。GPU を任意の種類の計算に使うことは 汎用 GPU (General Purpose GPU, GPGPU) と呼ばれるが、WebGL 1 は GPGPU を上手く扱えなかった。GPU で任意データを処理したいときは、データをテクスチャとしてエンコードし、それをシェーダーでデコードして計算を行い、結果をテクスチャとして再度エンコードしなけばならない。この処理は WebGL 2 の Transform Feedback でかなり簡単になったものの、Safari が WebGL 2 を 2021 年 9 月までサポートしなかったので、これは実質的な選択肢にならなかった (他のブラウザの多くは 2017 年 1 月には WebGL 2 をサポートした)。さらに WebGL 2 でも制限があり、不格好だった。
WebGPU
同じころウェブの外では、グラフィックスカードへの低レベルなインターフェースを公開する新世代のグラフィックス API が策定されていった。これらの新しい API は OpenGL が設計されたときに存在しなかった新しいユースケースと制約を考慮している。GPU はほぼユビキタスとなり、モバイルデバイスにも高性能な GPU が搭載された。この結果、モダンなグラフィックスプログラミング (3D レンダリングおよびレイトレーシング) と GPGPU の両方がさらに一般的になった。またデバイスのほとんどはマルチコアのプロセッサを持つので、複数のスレッドから GPU と対話できることも重要な最適化の方向性となった。WebGPU の取り組みが進む中で、メンバーは以前の設計判断に立ち返り、GPU が行うべきとされていたバリデーション処理の多くを GPU の性能を向上させるためにフロント部に移していった。
最も有名な新世代 GPU API は Khronos Group による Vulkan, Apple による Metal, そして Microsoft の DirectX 12 である。こういった API が持つ新しい機能をウェブにもたらすために WebGPU は生まれた。WebGL は OpenGL の薄いラッパーだったのに対して、WebGPU は異なるアプローチを取っている。WebGPU では独自の抽象化が導入され、上述のネイティブ API のいずれとも完全には同じでない。全てのシステムで利用可能な単一の API が存在しないことがこの理由の一つだが、多くの概念 (例えば非常に低レベルなメモリ管理) がウェブと対話する API として不格好であることも理由である。こういった概念を取り入れる代わりに、WebGPU は「ウェブらしさ」を残しつつ、どのネイティブグラフィックス API の上にも深く腰を下ろせるようにしながらもそれぞれの API の独自性を抽象化するように設計されている。標準化は W3C で行われ、主要なブラウザベンダーはいずれも取り組みに参加している。WebGPU は比較的低レベルな性質と大きな能力を持つので、多少急な学習曲線と比較的面倒なセットアップを持つ。できる限り分かりやすく説明しよう。
アダプターとデバイス
あなたが最初に出会う WebGPU の抽象化はアダプター (adapter) と 論理デバイス (logical device) である。

物理デバイス (physical device) は現実の GPU を指す。物理デバイスは内蔵 GPU (built-in GPU) と専用 GPU (discrete GPU) の二つに大別される。普通のデバイスには GPU が一つだけ存在するものの、二つ以上の GPU が存在することもある。例えば Microsoft の Surface Book は消費電力の少ない内蔵 GPU と高性能な専用 GPU を持っており、オペレーティングシステム (OS) が必要に応じてどちらを使うかを切り替えることで有名である。
ドライバ (driver) は GPU メーカーが提供するプログラムであり、GPU の機能を OS が理解できる形で期待される通りに OS へ公開する。それを受けて OS は自身が対応するグラフィックス API (Vulkan や Metal など) を通して GPU の機能をアプリケーションに公開する。
GPU は共有リソースである。多くのアプリケーションによって同時に使われるだけではなく、モニタに映るものの制御も行う。それぞれのアプリケーションが自身の UI をスクリーンに設置したときに他のアプリケーションと干渉を起こさないように、あるいは他のアプリケーションのデータを悪意を持って読み込めないようにするために、複数のプロセスが GPU を同時に使えるようにするための処理が必要となる。それぞれプロセスは物理 GPU の制御を自身だけが握っているかのように振る舞うものの、当然それは正しくない。この部分の多重化は主にドライバと OS によって行われる。
その次のアダプター (adapter) は OS のネイティブグラフィックス API から WebGPU への変換レイヤーである。ブラウザは複数のウェブアプリケーションを実行するのに対して OS レベルではアプリケーションの一つに過ぎないので、ここでも多重化が必要となる。この多重化のおかげで、それぞれのウェブアプリケーションは自身だけが GPU を制御しているかのように振る舞える。この部分は WebGPU で論理デバイスという概念でモデル化される。
アダプターにアクセスするには navigator.gpu.requestAdapter() を呼ぶ。執筆時点において requestAdapter() に渡せるオプションは非常に少ないが、ハイパフォーマンスなアダプターと低消費電力なアダプターの選択などを行える。
requestAdapter() が成功したら、つまり返り値のアダプターが null でないなら、アダプターの機能の検査や adapter.requestDevice() による論理デバイスのリクエストが行える。
if (!navigator.gpu) throw Error("WebGPU not supported.");
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) throw Error("Couldn't request WebGPU adapter.");
const device = await adapter.requestDevice();
if (!device) throw Error("Couldn't request WebGPU logical device.");
オプションを付けないとき、requestDevice() が返すデバイスの機能は物理デバイスの機能と合致するとは限らず、WebGPU チームが選定した全ての GPU の最大公約数的な機能となる。この機能の詳細は WebGPU 規格にある。例えば私の PC の GPU はサイズが 4GiB までのバッファを扱えるものの、requestDevice() が返す deviceはサイズが 1GiB までのバッファしか作成できず、それより大きいバッファの作成を拒否する。不便な仕様だと思うかもしれないが、実はとても役に立つ: もしあなたの WebGPU アプリケーションがデフォルトデバイスで実行できるなら、そのアプリケーションは大部分のデバイスで実行できる。もし必要なら、物理 GPU の本当の機能限界を adapter.limits で調べてからオプションオブジェクトを requestDevice() に渡すことで限界を上げられる。
シェーダー
WebGL を少しでも触ったことがあるなら、おそらく頂点シェーダーとフラグメントシェーダーを使ったことがあるだろう。簡単に説明すると、伝統的なセットアップ処理は次のように行われる: まずデータバッファを GPU にアップロードして、そのデータをどう解釈すれば三角形の並びになるかを GPU に伝える。そのデータバッファには頂点のリストが含まれており、それぞれの頂点は三次元空間における位置および補助的情報 (色、テクスチャ ID、法線など) を保持する。このリストに含まれる全ての頂点は頂点ステージ で GPU によって処理される。頂点ステージで実行されるのが頂点シェーダー (vertex shader) であり、頂点シェーダーは移動・回転・透視変換などを適用する。
続いて GPU は三角形をラスタライズする。つまり GPU は三角形のそれぞれが画面のどのピクセルを覆うかを計算する。三角形に覆われるピクセルはその後フラグメントシェーダーで処理される。フラグメントシェーダーからはピクセル座標やピクセルの色を決定するために必要な補助データにアクセスできる。正しく使えば、ピクセルシェーダーで素晴らしいグラフィックスを生成できる。
データを頂点シェーダーとフラグメントシェーダーに通し、出力をスクリーンに直接書き込む一連のシステムはパイプライン (pipeline) と呼ばれる。WebGPU ではプログラマーがパイプラインを定義する必要がある。
パイプライン
現在、WebGPU で作成できるパイプラインにはレンダーパイプライン (Render Pipeline) とコンピュートパイプライン (Compute Pipeline) の二つがある。名前の通り、レンダーパイプラインは何かを描画する。これは二次元画像を作成することを意味するが、その画像が画面である必要はない: レンダーパイプラインでメモリ (フレームバッファと呼ぶ) に描画することもできる。コンピュートパイプラインはこれより一般的で、任意の種類のデータを持ったバッファを返せる。私はレンダーパイプラインをコンピュートパイプラインを特殊化/最適化したものと考えるのが好きなので、これから本記事ではコンピュートパイプラインに集中する。これは歴史的に逆行した考え方であり、加えてレンダーパイプラインでは GPU 上の物理的に異なる回路が使われるという事実をひどく軽視している。しかし API の視点から言えば、このメンタルモデルは有用だと私は感じている。将来的には新しい種類のパイプライン ──おそらくレイトレーシングパイプライン (Raytracing Pipeline)──が WebGPU に追加される可能性が高い。
WebGPU のパイプラインは一つ以上のプログラム可能なステージから構成され、各ステージはシェーダーとエントリーポイントで定義される。コンピュートパイプラインは compute という単一のステージを持ち、レンダーパイプラインは vertex と fragment という二つのステージを持つ。単純なコンピュートパイプラインを作成するコードを示す:
const module = device.createShaderModule({
code: `
@stage(compute) @workgroup_size(64)
fn main() {
// 何もしない!
}
`,
});
const pipeline = device.createComputePipeline({
compute: {
module,
entryPoint: "main",
},
});
ここで WebGPU Shading Language (WGSL) が登場する。WGSL は Rust と GLSL のクロスオーバーのように私は感じている。Rust らしい構文と GLSL のグローバル関数 (dot, norm, len, ...)、型 (vec2, mat4x4, ...)、そして swizzling 記法 (some_vec.xxy など) が存在する。ブラウザは与えられた WSGL をコンパイルして内部のシステムが期待するフォーマットに変換する。DirectX 12 であれば HLSL, Metal であれば MSL, Vulkan であれば SPIR-V となるだろう。
上のコードで作成するシェーダーモジュールでは main という関数を作成し、コンピュートステージのエントリーポイントとして使うことを示す印として @stage(compute) 属性を付与している。一つのシェーダーモジュールに含まれる複数の関数にエントリーポイントの印を付けても構わない。そうした上で entryPoint オプションを通して異なる関数を起動するようにすれば、同じシェーダーモジュールから異なるパイプラインを作成できる。では @workgroup_size(64) という属性は何だろうか?
並列性
GPU はレイテンシを犠牲にしてスループットを最適化している。この点を理解するには GPU のアーキテクチャを少し詳しく見る必要がある。全てを説明したくはない (正直に言うと、できない) ので、必要なだけ説明する。ここにあるより詳しく GPU のアーキテクチャを知りたいなら、Fabian Giesen による 13 本のブログ記事シリーズ [拙訳] が非常に優れている。
GPU に関してよく知られているのが、膨大なコアを持つ GPU は大規模並列処理を行えるという事実だ。ただマルチコア CPU のプログラミングであなたが経験するほどには GPU のコアは独立していない。第一に、GPU のコアは階層的にグループ化される。それぞれの階層の名前は異なるベンダーと API の間で一貫していない。Intel は GPU のアーキテクチャの高レベルな概要を説明する優れたドキュメントを公開しており、他の GPU も少なくとも同じように動作すると仮定しても問題ないと私は聞いている。ただし各 GPU の正確なアーキテクチャは NDA で保護された機密である。
Intel の用語ではコアのグループの最も下の階層は実行ユニット (Execution Unit, EU) と呼ばれ、複数 (Intel では 7 個) の SIMT コアから構成される。これは 7 個のコアがロックステップで動作し、常に同じ命令を実行することを意味する。ただし各コアは個別のレジスタとスタックポインタを持つので、同じ命令を実行しつつも異なるデータを処理できる。これは GPU パフォーマンスに気を使うプログラマーがブランチ (if/else やループ) を避ける理由でもある: if/else を実行する EU では、全てのコアが両方の分岐を計算しなければならない (たまたま全てのコアが同じ分岐となったときは例外)。それぞれのコアに対しては命令を無視するよう個別に指示できるものの、他の計算に使えたであろう貴重なサイクルが明らかに無駄になる。同じことはループに関しても言える! 一つのコアがループを早く終えたとしても、そのコアは他の全てのコアがループを終えるまでループを実行するふりをしなければならない。
次に、GPU のコアは高い周波数を持つのに対して、メモリからデータ (あるいはテクスチャからピクセル) を読むのにはいまだに比較的長い時間がかかる──Fabian は数百クロックサイクルかかると述べている。この数百サイクルは他の計算に利用できる。何もしなければ無駄になるこういったアイドルサイクルを利用するために、各 EU には実行できる分を大きく超える仕事が割り当てられる。EU がアイドル (メモリからの値を待機している状態) になることを検出すると、EU は他の仕事に実行を切り替え、その新しい仕事が何かを待機し始めたとき (あるいは仕事が完了したとき) に限って元の仕事に実行を戻す。これは GPU がレイテンシを犠牲にしてスループットを最適化する上で鍵となるトリックである: 他の仕事に実行を切り替えると個別の仕事は必要より長くかかるようになるかもしれないが、全体を見たときの使用率は高まるのでスループットは大きくなる。GPU は EU をどんなときでも忙しくするだけの仕事を用意するために多大な労力を払っている。

EU は GPU コアの最も下の階層に過ぎない。複数の EU はまとめられ、Intel がサブスライス (SubSlice) と呼ぶグループとなる。サブスライスに含まれる全ての EU は小さな (Intel の GPU では 64 KiB 程度の) 共有ローカルメモリ (Shared Local Memory, SLM) へのアクセスを持つ。同期用の共有メモリを持つのはサブスライスだけなので、同期コマンドを持つプログラムは同じサブスライスで実行される必要がある。
最後のレイヤーとして、複数のサブスライスをまとめたスライス (Slice) がある。スライスは GPU を構成する。Intel の内蔵 GPU は全部で 170-700 個程度のコアを持つ。専用 GPU のコア数は 1500 を軽々と超える。繰り返しておくと、これらの用語は Intel から取ったものである。他のベンダーはおそらく異なる名前を使うが、一般的なアーキテクチャはどの GPU でも大きくは変わらない。
このアーキテクチャを最大限に活用するには、純粋にプログラム的な GPU スケジューラの利用率を最大化するための特別なセットアップがプログラムに必要になる。結果として、グラフィックス API は仕事をこの形に自然に分解できるようなスレッディングモデルを公開している。この話題に関連する WebGPU で重要なプリミティブはワークグループ (workgroup) である。
ワークグループ
伝統的レンダーパイプラインでは頂点シェーダーが頂点ごとに一度ずつ起動され、フラグメントシェーダーはピクセルごとに一度ずつ起動される (もちろん詳細はもっと複雑だが)。GPGPU のコンピュートパイプラインでは、コンピュートシェーダーがプログラマーがスケジュールしたワークアイテム (work item) ごとに一度ずつ起動される。
本記事ではワークアイテム全ての集合をワークロード (workload) と呼ぶ。ワークロードはワークグループ (workgroup) に分割され、ワークグループに含まれるワークアイテムは同時に実行されるようスケジュールされる。WebGPU でワークロードは三次元格子としてモデル化され、格子を構成する「立方体」の一つ一つがワークアイテムに、ワークアイテムがいくつかまとまった「直方体」がワークグループになる。

これでようやく @workgroup_size(x, y, z) という属性を説明する準備が整った。といっても、その意味はここまでの解説からほとんど明らかだろう: この属性を使うと、シェーダーを実行するときのワークグループのサイズを GPU に伝えることができる。上の画像で言えば、@workgroup_size 属性は赤い縁の直方体のサイズを指定する。つまり \(x \times y \times z\) が一つのワークグループに含まれるワークアイテムの個数となる。指定されなかったパラメータは \(1\) とみなされるので、@workgroup(64) は @workgroup(64, 1, 1) と等しい。
当然だが、チップ上の実際の EU が三次元格子状に並んでいるわけではない。ワークグループを三次元格子でモデル化するのは、局所性を高めるためだ。ここで裏にある考えを説明すれば「隣接するワークグループはメモリ上の同じような領域にアクセスする傾向にあるから、隣接するワークグループを順番に実行すれば必要なデータがキャッシュにある可能性が高まり、メモリからデータを取ってくるための数百サイクルを節約できるだろう」となる。ただ、たいていのハードウェアでは @workgroup_size(64) が付いたシェーダーと @workgroup_size(8, 8) が付いたシェーダーの実行時間の違いが無視できる程度なので、ワークグループは単純に番号順に実行されているようだ。そのためワークグループの次元という概念はいくらかレガシーとみなされている。
なお、ワークグループには様々な制約がある。device.limits には知るに値する多くのプロパティが含まれる:
// device.limits
{
// ...
maxComputeInvocationsPerWorkgroup: 256,
maxComputeWorkgroupSizeX: 256,
maxComputeWorkgroupSizeY: 256,
maxComputeWorkgroupSizeZ: 64,
maxComputeWorkgroupsPerDimension: 65535,
// ...
}
ワークグループのサイズの各次元の値に制約がある。ただし各次元の値がそれぞれ制約を満たすだけでは不十分で、積 \(x \times y \times z\) に対する制約も満たさなければならない。それから起動できるワークグループの個数にも次元ごとに制約がある。
では正しいワークグループのサイズはいくつだろうか? 正しいサイズはワークアイテムの座標が持つ意味に大きく左右される。この答えが役立たずなことは私にも分かる。そこで Corentin が私にくれたアドバイスをここに繰り返しておこう: 「ターゲットの GPU が分かるとき、あるいはワークロードが何か奇妙なことをしているときを除けば、[ワークグループのサイズとして] 64 を使うといい」
コマンド
これでシェーダーが書けて、パイプラインのセットアップもできた。後はパイプラインを実際に実行するよう GPU に伝えるだけだ。GPU は専用のメモリチップを持つ完全に個別のカードである可能性があるので、その制御はコマンドバッファ (command buffer) とコマンドキュー (command queue) を通して行われる。コマンドキューは GPU が実行するコマンドをエンコードしたデータを保存するためのメモリ領域である。このエンコード処理は GPU ごとに大きく異なり、ドライバが担当する。WebGPU では CommandEncoder を使ってこの機能にアクセスする:
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.dispatch(1);
passEncoder.end();
const commands = commandEncoder.finish();
device.queue.submit([commands]);
commandEncoder には GPU バッファ間でデータをコピーしたりテクスチャを操作したりするためのメソッドがいくつかある。パイプラインのセットアップや起動を行う命令のエンコード処理を担当する PassEncoder の作成も commandEncoder から行える。今考えている例ではコンピュートパイプラインを実行したいので、コンピュートパスを作成し、事前に宣言されたパイプラインを使うように設定し、最後に dispatch(w_x, w_y, w_z) を呼び出して作成するワークグループの個数を次元ごとに GPU に伝えなければならない。言い換えると、以上の設定によって全部で \(w_x \times w_y \times w_z \times x \times y \times z\) 個のコンピュートシェーダーが起動される。ところでパスエンコーダー (pass encoder) は WebGPU が用意した抽象化であり、本記事の冒頭で私が文句を言った内部のグローバルなステートオブジェクトを避けるために存在する。GPU パイプラインを実行するのに必要なデータとステートは全てパスエンコーダーを通して明示的に指定される。
このコードを実行すると何もしない 64 個のスレッドが実際に GPU 上に生成される。ただ WebGPU は動作したということだ。素晴らしい。次は処理するデータを GPU に渡す方法について話そう。
データのやり取り
冒頭で述べた通り、本記事では WebGPU をグラフィックスの用途に直接は用いない。その代わり GPU 上で物理シミュレーションを実行し、その結果を Canvas2D を使って描画するのが面白いだろうと私は考えた。「物理シミュレーション」というのは言い過ぎかもしれない──これから行うのは球をたくさん生成して、それらを互いに衝突させながら平面上を移動させるという処理である。
この処理を行うには、まずシミュレーションのパラメータと初期条件を GPU へ送信し、次に GPU 上でシミュレーションを実行し、最後にシミュレーションの結果を GPU から読み込む必要がある。これらの部分にはデータのジャグリング (意味がなさそうに思えるコピーというわけではない) が多いので WebGPU で最も頭がこんがらがる部分だが、このジャグリングのおかげで WebGPU は高いレベルのパフォーマンスを持つデバイス非依存な API となれている。
バインドグループレイアウト
データを GPU とやり取りするには、以前に示したパイプラインの定義をバインドグループレイアウト (bind group layout) で拡張する必要がある。バインドグループとはパイプラインを実行している間にアクセス可能となる GPU 要素 (メモリバッファ、テクスチャ、サンプラーなど) のことを言う。バインドグループレイアウトはそういった GPU 要素の型、用途、使い方を事前に定義したもので、これがあると GPU はパイプラインを効率良く実行する方法を実行前に決定できるようになる。最初は簡単に、一つのメモリバッファへのアクセスをパイプラインに与えてみよう:
const bindGroupLayout =
device.createBindGroupLayout({
entries: [{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
}],
});
const pipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module,
entryPoint: "main",
},
});
binding に指定する数値は自由に指定でき、このバインドグループレイアウトのこのスロットのバッファを WGSL コード中の変数と関連付けるときに binding の値が使われる。上記の bindGroupLayout では "storage" というバッファの用途も定義されている。"storage" 以外の選択肢には "read-only-storage" がある。これは読み込み専用ストレージを (当然!) 表し、GPU はこの用途が指定されたバッファに対して書き込みが起こらず、同期の必要もないことを前提とした踏み込んだ最適化を行える。バッファの用途にはもう一つ "uniform" もあるが、これはコンピュートパイプラインにおいては "storage" と等価である。
これでバインドグループレイアウトが指定できた。続いてバインドグループレイアウトが期待する GPU 要素の実際のインスタンスを持つバインドグループを作成する。正しいバッファを持ったバインドグループを用意すれば、コンピュートシェーダーでそこにデータを書き込み、それを GPU から読み込むことができる。ただ、ここにハードルが一つある: ステージングバッファだ。
ステージングバッファ
もう一度言っておこう: GPU はレイテンシを犠牲にしてスループットを大きく最適化している。このスループットを無駄にしないためには、GPU はコアに対して対して非常に高速なレートでデータを与える必要がある。Fabian は 2011 年にブログ記事 [拙訳] で簡単な計算を行い、1280x720 の解像度でレンダリングを行うとき GPU はテクスチャのサンプリングだけで秒間 3.3GB のデータを利用するという結論を得ている。今日のグラフィックスの要求に応えるには、GPU はデータをさらに高速にデータを掴まなければならない。これを達成するには GPU のメモリをコアと密に結合させるほかない。こうしてメモリとコアを密結合にすると、同じメモリをホストマシンから読み書きできるように公開することは難しくなる。
そのため、GPU にはコアと密に結合されておらず速度は劣るもののホストマシンからアクセス可能な追加のメモリバンクが存在する。この中間的なメモリ領域にアロケートされるのがステージングバッファ (staging buffer) であり、ステージングバッファはマップしてホストシステムから読み書きを行うことができる。GPU からデータを読むときは、内部の高性能なバッファからステージングバッファにデータを移し、そのステージングバッファをホストマシンへマップし、それからメインメモリにデータを読み込むことになる。書き込みではこの逆を行う。
私たちのコードに戻ろう: これから書き込み可能なバッファを作成し、それをバインドグループに加える。これによってコンピュートシェーダーからそのバッファに書き込めるようになる。バッファの作成時にはバッファの用途を宣言する usage というビットマスクを指定する。これを受けて GPU は指定された全ての用途に対応したバッファをアロケートすべき領域を決定する (与えられたフラグの組み合わせが実現不可能ならエラーを出す)。
const BUFFER_SIZE = 1000;
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [{
binding: 1,
resource: {
buffer: output,
},
}],
});
createBuffer() が ArrayBuffer ではなく GPUBuffer を返すことに注意してほしい。ホストからの読み込みや書き込みはまだ行えない。そのためにはマップが必要であり、マップを行う API は GPUBufferUsage.MAP_READ あるいは GPUBufferUsage.MAP_WRITE を指定したバッファに対してしか呼び出せない。
@webgpu/types をメンテナンスしているので、正確な自動補完を享受できる。
これでバインドグループレイアウトに加えて実際のバインドグループも作成できたので、次はこのバインドグループを使ってパイプラインを起動するコードを書き換えよう。その後にステージングバッファをマップして計算結果を JavaScript に読み戻す:
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64));
passEncoder.end();
commandEncoder.copyBufferToBuffer(
output,
0, // Source offset
stagingBuffer,
0, // Destination offset
BUFFER_SIZE
);
const commands = commandEncoder.finish();
device.queue.submit([commands]);
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
BUFFER_SIZE // Length
);
const copyArrayBuffer =
stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
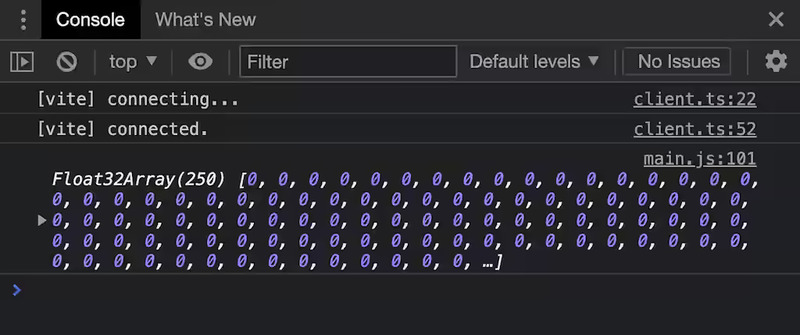
console.log(new Float32Array(data));
バインドグループレイアウトをパイプラインに追加したので、バインドグループを指定しないで起動すると失敗する。コンピュートパイプラインを実行する「パス」を定義した後、コンピュートシェーダーの出力バッファからステージングバッファへデータをコピーする別のコマンドを追加してからコマンドバッファをコマンドキューに送っている。この後 GPU はコマンドキューに送られたコマンドの実行を始める。GPU がコマンドの実行を終える正確なタイミングは分からないにもかかわらず、その後 stagingBuffer.mapAsync で stagingBuffer をマップする要求がすぐに送られる。この関数は非同期であり、処理を進めるにはコマンドキューが完全に処理されるまで待つ必要がある。mapAsync が返すプロミスが解決した時点でバッファはマップされるものの、まだ JavaScript からは見えていない。stagingBuffer.getMappedRange を使うとマップされたバッファの一部分 (あるいは全体) を古き良き ArrayBuffer として JavaScript から見えるようにできる。この関数が返すのはマップされた実際のメモリを指す ArrayBuffer であり、stagingBuffer がアンマップされると消えてしまう ("detached" 状態になる)。そこで slice() を使って JavaScript によって保持されるコピーを作成している。
ゼロでない値を格納した方が説得力がおそらく増すだろうから、GPU 上で複雑な計算を始める前に、パイプラインが本当に意図通りに動作していることの証明として人工的なデータをバッファに入れてみよう。新しいシェーダーのコードを次に示す。分かりやすいように改行を余計に入れてある:
@group(0) @binding(1)
var<storage, write> output: array<f32>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
@builtin(local_invocation_id)
local_id : vec3<u32>,
) {
output[global_id.x] = f32(global_id.x) * 1000. + f32(local_id.x);
}
最初の 2 行で output というモジュールスコープの変数が宣言される。output は動的サイズの f32 配列である。属性 @group(0) @binding(1) はデータがどこから来るかを表す: 最初 (0 番目) のバインディンググループに含まれる、binding が 1 のエントリーが持つバッファが output となる。配列 output の長さには内部のバッファの長さを f32 のサイズで割った値が自動的に反映される (小数部分切り捨て)。
let が不変な変数を宣言する点で Rust の流れを汲んでいる。変数を可変にしたいときに使うべきキーワードは var である。
上記のコードで main 関数のシグネチャには二つのパラメータ global_id, local_id が追加されている。これらの変数名は自由に選べる──その値はパラメータに付いた属性によって決定される。global_invocation_id 属性が付いた変数はワークアイテムのグローバルな識別子となり、そこにはワークアイテムのワークロード内における x/y/z 座標が代入される。local_invocation_id 属性が付いた変数はワークアイテムのローカルな識別子となり、そこにはワークアイテムのワークグループ内における x/y/z 座標が代入される。
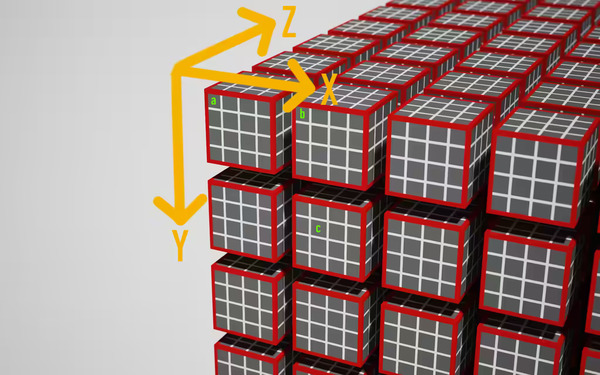
上の画像に @workgroup_size(4, 4, 4) を持つワークロードにおけるワークアイテムの座標の解釈の一つを示す。この座標系は用途に応じて好きに定義できる。この画像にある a, b, c というワークアイテムにおいて、main のパラメータ global_id, local_id は次の値となる:
- a:
global_id=(x=0, y=0, z=0)local_id=(x=0, y=0, z=0)
- b:
global_id=(x=4, y=0, z=0)local_id=(x=0, y=0, z=0)
- c:
global_id=(x=5, y=5, z=0)local_id=(x=1, y=1, z=0)
上記のシェーダーでは @workgroup_size(64, 1, 1) だから、local_id.x は 0 から 63 までの値を取る。output[global_id.x] = f32(global_id.x) * 1000. + f32(local_id.x); は global_id と local_id を一つの値に「エンコード」して簡単に確認できるようにしている。なお WGSL は強い型付けを持つことに注意してほしい: global_id と local_id はどちらも vec3<u32> 型なので、array<f32> 型の出力バッファ output に代入するには f32 への明示的なキャストが必要になる。
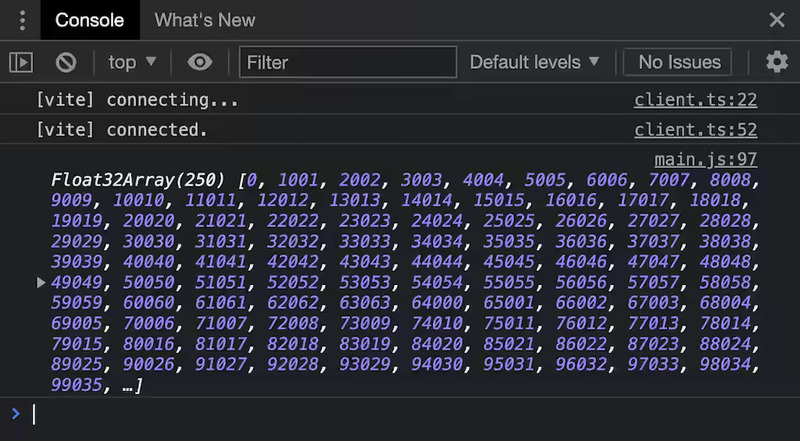
出力配列の各要素に対してコンピュートシェーダーが起動され、それぞれが異なる値を計算して出力していることがこれで確認できた。データが埋まっていく順序を私たちは知らないが、これは意図的に指定されていないのであり、GPU のスケジューラによって勝手に決められる。
オーバーディスパッチング
注意深い読者は、起動されたシェーダーの個数 Math.ceil(BUFFER_SIZE / 64) * 64 が出力配列の長さより大きいことに気が付いたかもしれない。f32 のサイズは 4 バイトなので、出力配列の長さは 250 要素分しかない。幸い WGSL における配列アクセスには暗黙の丸めによる安全装置が付いており、配列の最終要素より後ろの要素への書き込みは最終要素への書き込みになる1。上記のシェーダーに早期リターンを追加すれば範囲外への書き込みを防止できる:
fn main( /* ... */) {
if (global_id.x >= arrayLength(&output)) {
return;
}
output[global_id.x] =
f32(global_id.x) * 100. + f32(local_id.x);
}
もし行いたいなら、https://surma.dev/things/webgpu/step1/index.html からこの時点でのプログラムの実行とソースコードの確認が行える。
構造体の奇妙な振る舞いには理由がある
本記事の目標は互いに小気味好く衝突しながら二次元空間を移動するたくさんの球をシミュレートすることだ。このためには、球の半径と位置、そして速度ベクトルが必要になる。array<f32> をそのまま使い続けて「最初の float は一つ目の球の x 座標で、その次の float は一つ目の球の y 座標で...」とすることはできるものの、これが書きやすいとは私は思わない。幸い WGSL には複数のデータを一つにまとめるために独自の構造体を定義する機能がある。
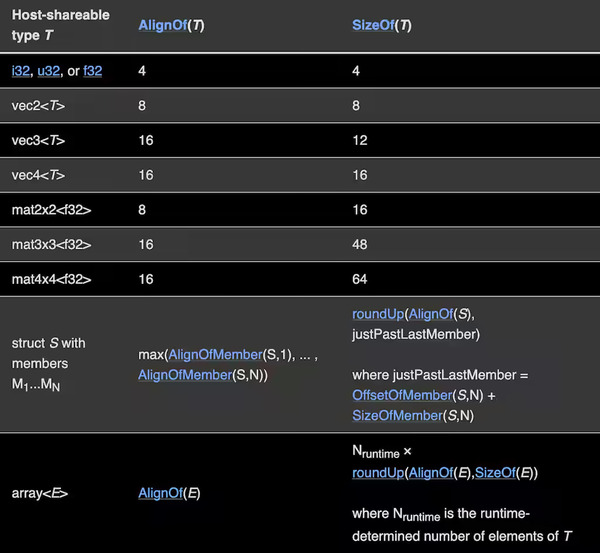
球を記述する要素を持った Ball 構造体を定義して、array<f32> を array<Ball> にするのが理にかなっている。しかしこのとき面倒なのが、アライメントについて話さなければいけないことだ。
struct Ball {
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
}
@group(0) @binding(1)
var<storage, write> output: array<Ball>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id) global_id : vec3<u32>,
@builtin(local_invocation_id) local_id : vec3<u32>,
) {
let num_balls = arrayLength(&output);
if(global_id.x >= num_balls) {
return;
}
output[global_id.x].radius = 999.;
output[global_id.x].position = vec2<f32>(global_id.xy);
output[global_id.x].velocity = vec2<f32>(local_id.xy);
}
このシェーダーを実行する (https://surma.dev/things/webgpu/step2/index.html) と、次の出力がコンソールに表示される:
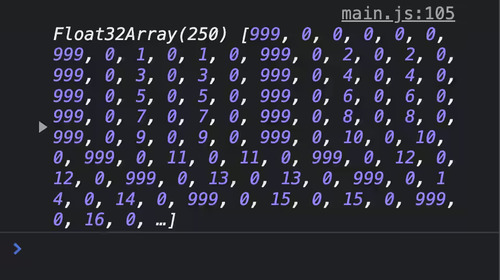
構造体の切れ目が分かりやすいように、構造体の最初のフィールド radius に 999 を書き込んでいる。出力を見ると、999 から次の 999 まで 6 要素離れているのが分かる。これは奇妙に思える: Ball 構造体は radius, position.x, position.y, velocity.x, velocity.y という 5 つの数値しか持っていないからだ。また出力をよく見ると、radius の後の値が常に 0 であることが分かる。こういった振る舞いはアライメントがあるために生じる。
WGSL の各データ型は正式に定義されたアライメント要件を持つ。あるデータ型のアライメント要件が \(N\) の場合、そのデータ型の値は \(N\) の倍数であるメモリアドレスにしか格納できない。例えば f32 型のアライメントは 4 で、vec2<f32> 型のアライメントは 8 である。上記の Ball 構造体がアドレス 0 から始まるとしよう。このとき 0 は f32 型のアライメント 4 の倍数だから、radius フィールドはアドレス 0 に格納できる。しかし次のフィールド position の型 vec2 のアライメントは 8 であり、アドレス 4 には格納できない。そこでコンパイラはアドレスが 8 の倍数になるように 4 バイトのパディング (隙間) を radius の後に追加する。先ほど DevTools コンソールに使っていない 0 が表示されたのはこれが理由である。
シェーダーで定義した構造体がメモリにどのように格納されるかが理解できたので、次は JavaScript でボールの初期状態を生成し、さらに計算結果を読み戻して可視化してみよう。
入出力
GPU からデータを読み、JavaScript に移して「デコード」することには成功した。続いて逆方向の処理を行おう。ボールの初期状態を生成し、それを GPU に渡し、そのデータを使ってコンピュートシェーダーを実行させるということだ。初期状態の生成は比較的簡単に行える:
let inputBalls = new Float32Array(new ArrayBuffer(BUFFER_SIZE));
for (let i = 0; i < NUM_BALLS; i++) {
inputBalls[i * 6 + 0] = randomBetween(2, 10); // radius
inputBalls[i * 6 + 1] = 0; // padding
inputBalls[i * 6 + 2] = randomBetween(0, ctx.canvas.width); // position.x
inputBalls[i * 6 + 3] = randomBetween(0, ctx.canvas.height); // position.y
inputBalls[i * 6 + 4] = randomBetween(-100, 100); // velocity.x
inputBalls[i * 6 + 5] = randomBetween(-100, 100); // velocity.y
}
buffer-backed-object が役立つかもしれない!
バッファをシェーダーに伝える方法は既に知っている。まずパイプラインのバインドグループレイアウトを変更してバッファをもう一つ追加する:
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage",
},
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
},
],
});
そして GPU バッファを作成し、それをバインドグループに追加するだけだ:
const input = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: input,
},
},
{
binding: 1,
resource: {
buffer: output,
},
},
],
});
続いて GPU へのデータの送信という新しい処理がある。細かく言えば、ここでもデータの読み込みと同じようにステージングバッファを作ってマップし、そのステージングバッファにデータを移し、ステージングバッファのデータをストレージバッファにコピーするコマンドを発行しなければならない。しかし WebGPU にはストレージバッファにデータを移す最も効率的な手段を自動で選択する便利な関数が存在する。この関数は必要なときは一時的なステージングバッファの作成さえ行う:
device.queue.writeBuffer(input, 0, inputBalls);
これだけ? これだけだ! コマンドエンコーダーさえ必要にならない。このコマンドは直接コマンドキューに載せられる。device.queue はテクスチャに対する同様の便利な関数を提供する。
この新しいバッファを WGSL の変数に束縛し、何か処理をしてみよう:
struct Ball {
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
}
@group(0) @binding(0)
var<storage, read> input: array<Ball>;
@group(0) @binding(1)
var<storage, write> output: array<Ball>;
let TIME_STEP: f32 = 0.016;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
) {
let num_balls = arrayLength(&output);
if (global_id.x >= num_balls) {
return;
}
output[global_id.x].position =
input[global_id.x].position +
input[global_id.x].velocity * TIME_STEP;
}
本記事をここまで読んだ読者がこのコードの大部分に対して少しも驚かないことを願う。
最後に output バッファを JavaScript に読み戻し、Canvas2D を使ってバッファの内容を書き出す処理を書いて、全ての処理を requestAnimationFrame のループに入れれば可視化が完了する。この時点でのプログラムは https://surma.dev/things/webgpu/step3/index.html から試せる。
性能
このデモは各ボールを速度ベクトルに沿って動かしているだけであり、面白くもなければ複雑な計算が絡むわけでもない。作ったものの性能特性を見ていく前に、それらしい物理計算をシェーダーに追加しよう。この詳細は説明しない──本記事は十分長い ──ものの、私は最もナイーブなアプローチを選択した: 全ての球が他の全ての球との衝突を判定している。もし興味があるなら、最終的なデモ (https://surma.dev/things/webgpu/step4/index.html) のソースコードを見てみてほしい。ここには物理に関するコードを書くときに私が参考にした資料のリンクも示してある。
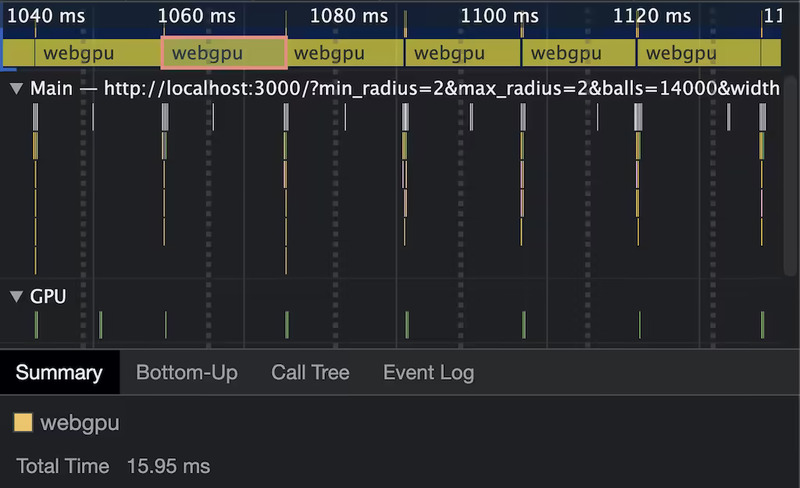
物理アルゴリズムも WebGPU の利用法も最適化していないので、この実験に対する正確な実行速度の測定はあまりしたくない。しかし、このナイーブな実装でさえ (私の M1 MacBook Air で) 非常に高い性能を示す事実は素晴らしいことだと感じる。球を約 2500 個に増やすとフレームレートが 60 fps を切ったが、WebGPU の計算ではなくシーンを描画する Canvas2D がボトルネックであることはトレースから明らかだった。
続いて WebGPU の本当の速さを測定するために、Canvas2D によるレンダリングを無効化したときに球の個数をどこまで増やせばフレームのバジェット 16ms が使い果たされるかを performance.measure で測定した。私のマシンにおけるこの測定結果は 14000 個だった。ここまで最適化をしていないプログラムがここまで速く動くとは、WebGPU がもたらす計算力に私は全く酔いしれてしまった。
安定性 & 可用性
WebGPU の策定作業は長い間続いており、標準化グループは早く API を安定と宣言したがっているのではないかと私は思う。ただそうは言っても、Chrome と Firefox では特別なフラグを有効にしないと WebGPU を利用できない。Safari も WebGPU をいずれ実装するだろうとは思っているが、執筆時点では Safari TP に WebGPU は実装されていない。
安定性について言うと、私が本記事を書くために調査をしている間にもいくつか変更があった。例えばシェーダーで属性を付与する構文は [[stage(compute), workgroup_size(64)]] から @stage(compute) @workgroup_size(64) に変わった2。執筆時点において、Firefox は古い構文を使い続けている。また passEncoder.end はかつて passEncoder.endPass だった。他にも仕様には存在するにもかかわらずどのブラウザでも実装されていない機能 (シェーダー定数 など) やモバイルデバイスで利用できない API が存在する。
基本的に私が言いたいのはこれだ: ブラウザ開発と標準化活動に関わる人々は✨安定✨に向けた旅路の最終フェーズに入っているものの、多少の破壊的変更は起こるものと思った方がいい。
結論
GPU と対話するモダンな API がウェブに誕生するのは非常に興味深いものになるだろう。いくらかの時間を投資して最初の急な学習曲線を乗り越えた後、私は JavaScript を使って大規模並列なワークロードを GPU 上で実行できるという大きな力を得たように感じた。また WebGPU API を Rust で実装するライブラリ wgpu があるので、ブラウザの外でも WebGPU を実行できる。wgpu は WebAssembly をコンパイルターゲットとしてサポートするので、WebGPU をブラウザの外ではネイティブに、ブラウザの中では WebAssembly を通じて実行することもできる。豆知識: Deno は WebGPU を初期状態でサポートした初めてのランタイムである (wgpu を使っている)。
疑問があったり、問題に直面したりしたときは、WebGPU の Matrix チャンネルがある。ここでは多くの WebGPU ユーザー、ブラウザエンジニア、標準化活動のメンバーが私を助けてくれた。手始めにやってみてほしい! ワクワクする時間になるはずだ。
本記事の校正をしてくれた Brandon Jones と私の疑問の全てに答えてくれた WebGPU Matrix チャンネルに感謝する。