テクスチャサンプラー
やぁおかえり。前章では頂点シェーダーについて説明し、GPU のシェーダーユニットにも一般的に軽く触れた。シェーダーユニットは基本的にただのベクトルプロセッサだが、他のベクトルプロセッサが持たないとあるリソースへのアクセスを持つ: テクスチャサンプラーである。テクスチャサンプラーは GPU パイプラインに欠かせない要素であり、記事一つを使った説明が正当化される程度の複雑さ (そして面白さ!) を持つ。それでは説明を始めよう。
テクスチャステート
実際のテクスチャリング操作を考える前に、まずテクスチャリングを制御する API ステートを見ていく。D3D11 では三つの異なる要素がある:
- サンプラーステート。フィルタモード、アドレッシングモード、最大の異方性などが含まれる。テクスチャサンプリングがどのように行われるかを一般的な方法で制御する。
- 下層のテクスチャリソース。これは突き詰めればメモリにある生のテクスチャビットを指すポインタである。他にも単一テクスチャとテクスチャ配列のどちらなのか、どのマルチサンプルフォーマットを持つのか (あるいは何も持たないのか)、テクスチャビットの物理レイアウトは何かなどを決定する。言い換えると、テクスチャリソースのレベルではメモリ内の値を正確にどう解釈するかは決まらず、そのメモリレイアウトだけが決定する。
- シェーダーリソースビュー (SRV)。サンプラーがテクスチャのビットをどう解釈するかを定める。D3D10+ ではシェーダーリソースビューが下層のテクスチャリソースと結び付くので、あなたがテクスチャリソースを明示的に指定することはない。
多くの場合、与えられたフォーマット (例えば「RGBA で各要素が 8 ビット」) のテクスチャリソースを作成した後は、それにマッチする SRV の作成だけが行われる。しかし「各要素が 8 ビットで型を持たない」としてテクスチャリソースを作成し、複数の異なる SRV を使って同じ下層データを異なるフォーマットで読む、例えば UNORM8_SRGB (sRGB 空間の符号無し 8 ビット値を 0...1 にマップした値) と UINT8 (符号無し 8 ビット整数) で読むといったこともできる。
テクスチャリソースとは別に SRV を作るというのは一見すると面倒なステップに思えるかもしれないが、ここでのポイントは API ランタイムが SRV の作成時に様々な型検査を行えることにある。もし正当な SRV が返ったなら、それは SRV とリソースのフォーマットに互換性があり、その SRV が存在する間は型検査がそれ以上必要ないことを意味する。言い換えれば、SRV は API の効率のために存在する。
話を戻そう。ハードウェアのレベルでは、こういった情報は詰まるところテクスチャサンプリング操作に関連付く一連のステート──サンプラーステート、利用するテクスチャ/フォーマットなど──であり、どこかに保存される必要がある (二章ではパイプライン化されたアーキテクチャでステートを管理する様々な方法について説明した)。よってここでも選択肢はいくつかある。極端な選択肢は「ステートが変更されるたびにパイプラインをフラッシュする」と「サンプラーを完全にステートレスにして、テクスチャリクエストごとに完全な情報を送る」であり、この中間にも様々な方法が考えられる。こういったことについて、あなたが頭を悩ませる必要はない──この部分についてはハードウェア技術者が腕を振るって費用便益分析を行い、複数の作業負荷をシミュレートし、その上で最も優れたものを選択する。重要なので繰り返しておく: PC プログラマーとして、プログラムを実行するハードウェアが特定のモデルを使うと仮定してはいけない。
テクスチャの切り替えが高価だと仮定してはいけない──ステートレスなテクスチャサンプラーを使って完全にパイプライン化されていて、事実上コストがかからないかもしれない。かといってテクスチャの切り替えにコストがかからないと仮定してもいけない──完全にパイプライン化されていなかったり、パイプラインで一度に使えるテクスチャステートの集合の個数に制限があったりするかもしれない。固定されたハードウェアを持つコンソール用のプログラムを開発していない限り (あるいはターゲットに含まれる全世代のグラフィックスハードウェアに対してエンジンを手動で最適化するのでない限り)、どのモデルが使われるかは分からないのである。そのため最適化のときは、明らかなこと──マテリアルでソートして不必要なステート変更を避けるなど──を行って最低でも API の仕事を減らしておけば、それ以上は何も行わなくてよい。目の前にあるハードウェアが採用する特定のモデルに基づいて高度な最適化を行うのは避けなければならない。そのモデルはハードウェアの世代が更新されるだけですぐに変わってしまう可能性がある (おそらく変わる!) のだから。
テクスチャリクエストの解析
では、一度のテクスチャサンプルのリクエストでどれくらいの情報を送る必要があるだろうか? これはテクスチャのタイプとサンプル命令の種類によって変わるので、ここでは 2D テクスチャを仮定する。2D テクスチャのサンプルを 4x 異方性フィルタリングと共に行うとき、テクスチャサンプラーに送るべき情報は次の通りだ:
- 二次元のテクスチャ座標──二つの浮動小数点数。このシリーズでは D3D の用語に従って、テクスチャ座標を \(s\), \(t\) ではなく \(u\), \(v\) と呼ぶことにする。
- スクリーンの "x" 方向に沿った \(u\) と \(v\) の偏微分係数 (勾配): \(\frac{\partial{u}}{\partial{x}}\), \(\frac{\partial{v}}{\partial{x}}\)
- 同様に、スクリーンの "y" 方向に沿った \(u\) と \(v\) の偏微分係数 (勾配): \(\frac{\partial{u}}{\partial{y}}\), \(\frac{\partial{v}}{\partial{y}}\)
つまり、ごく普通の (SampleGrad に似た種類の) 2D サンプリングをリクエストするだけで六個の浮動小数点数が必要となる──思ったよりも多いはずだ。四つの勾配値はミップレベルの選択と異方性フィルタリングカーネルのサイズと形状の選択に使われる。なおミップレベルを明示的に指定するテクスチャサンプリング命令 (HLSL の SampleLevel) も存在する。そういった命令は勾配を必要としないので LOD パラメータを含む値が一つあれば十分だが、異方性フィルタリングは行えない──最大でもトライリニアだ! 話を戻して、しばらくは六個の浮動小数点数を考えよう。これは間違いなく大きな数字だ。テクスチャリクエストのたびに本当にそんな多くのデータを送らないといけないのだろうか?
答えは「場合による」だ。ピクセルシェーダー以外の全ての場所では、答えは「本当に送らないといけない」となる (異方性フィルタリングを望むなら、だが)。しかし PS では、答えは意外にも「送る必要はない」となる。任意の値の勾配を計算する命令が PS で可能になるトリックが存在し (つまり PS で何らかの値を計算したら、ハードウェアに向かって「この値のスクリーン空間における勾配の近似値はいくつだ?」と尋ねることができ)、同じトリックをテクスチャサンプラーで採用すれば座標から偏微分を計算できるためだ。よって PS からの 2D サンプル命令で実際に送る必要があるのは二つの座標だけで、他の値はそれらから計算できる。ただしここでは、サンプラーユニットで行われる計算が増えても構わないことが仮定されている。
面白そうだから話のタネとして、一度のテクスチャサンプルで必要になるパラメータ数の最悪値を求めてみよう。現在の D3D11 パイプラインにおける最悪のパラメータ数はキューブマップ配列に対する SampleGrad で起こる。集計してみるとこうなる:
- 三次元のテクスチャ座標 \(u\), \(v\), \(w\): 浮動小数点数が三つ。
- キューブマップ配列のインデックス: 整数が一つ (ここでは単純に一つの浮動小数点数と同じコストだと考えよう)。
- スクリーンの x 方向および y 方向に関する (\(u\), \(v\), \(w\)) の勾配: 浮動小数点数が六つ。
よって合計では十個の値がサンプルされるピクセルごとに必要になる──そのまま格納すれば 40 バイトである。もしかしたら (特に配列のインデックスと勾配では) 32 ビット全ては必要にならないかもしれないが、それでも送るデータはかなり多い。
さらに、今考えている操作の帯域がどれくらいなのかを確認してみよう。テクスチャの大部分は 2D (キューブマップはいくつかあるだけ) で、テクスチャサンプリングのリクエストは大半がピクセルシェーダーで行われ、頂点シェーダーではテクスチャのサンプルがほとんどなく、通常の Sample 型のリクエストが最もよく使われ、次点で SampleLevel だとする (以上の仮定はゲームにおける実際のレンダリングで典型的なものだ)。これはピクセルごとにテクスチャユニットへ送られる 32 ビットの浮動小数点数の個数が平均して 2 (u+v) と 3 (u+v+w あるいは u+v+lod) の間であることを意味する。ここでは 2.5 個、つまり 10 バイトとする。
解像度は中くらい、具体的には 1280x720 (約 92 万ピクセル) とする。平均的なゲームのピクセルシェーダーは何回のテクスチャサンプルを持つだろうか? 最低でも三回というのはそう遠くない値だと私は思う。またそれなりのオーバードローが起こっていて、3D レンダリングフェーズにおいてスクリーン上の各ピクセルの色はおよそ二回ずつ計算されるとする。加えてポストプロセッシングを行うために、テクスチャ操作の多いフルスクリーンパスが最後にいくつか付くとしよう。これによってピクセルごとに六回のサンプルが追加されるだろう (この値の推定ではポストプロセッシングの一部が低解像度で行われるという事実を考えに入れている)。これらをまとめれば、92 * (3*2+6) = 1100 より 1100 万回のテクスチャサンプルが一フレームごとに行われることになる。30 fps なら毎秒 3 億 3000 万回であり、リクエスト一回につき 10 バイトだったから、テクスチャリクエストのペイロードだけで 3.3 GB/s の帯域が必要ということになる。この他にもオーバーヘッドはある (すぐに触れる) ので、この値は下限である。なお、ここまでに示した値はどれも *咳をする音* "多少" 小さく見積もっていることに注意してほしい :) それなりの性能を持つ DX11 カードで実行される最近のゲームであればどんなものでも、解像度はずっと高く、もっと複雑なシェーダーを持ち、オーバードローは同じか少ない程度 (ディファードシェーディング/レンダリングが救いだ!) で、フレームレートは高く、ずっと複雑なポストプロセッシングを持つ。試しにバイラテラルアップサンプリングを使うクオリティの高い SSAO パスを四分の一の解像度で行うときのテクスチャリクエスト帯域を封筒の裏で計算してみるとよい...
要するに、テクスチャ操作で必要となる帯域は通常のメモリサブシステムで自然に達成できるレベルではない。テクスチャサンプラーはシェーダーコアの一部ではなくチップ上の離れた場所にある個別のユニットであり、一秒間に数ギガバイトのやり取りは何の工夫もなく行えることではない。これは真剣に取り組むべきアーキテクチャの問題である──全てのテクスチャに対してキューブマップ配列用の SampleGrad を使わずに済むのは良いことなのだ :)
テクスチャサンプルを一つだけ取得することはあるのか?
答えはもちろん: 「ない」だ。テクスチャリクエストはシェーダーユニットから送られるわけだが、知っての通りシェーダーユニットは 16 個から 64 個のピクセル/頂点/制御点…をまとめて処理する。そのためシェーダーはテクスチャサンプルを個別に送信せずに、いくつかのサンプルをまとめてディスパッチする。平方数でない 32 は少し都合が悪いので、これからの例では 16 を一つの単位として話を進める。さて、まとめて起こる 16 個のテクスチャリクエストには、ペイロードの構築、サンプラーに何をすべきかを伝えるコマンドフィールドの追加、使うべきテクスチャステートとサンプラーステートを伝えるフィールド (ステートについては上述の注意点を参照) の追加、そしてこれらの情報をどこかにあるテクスチャサンプラーに送信する処理が含まれる。
これには少し時間がかかる。
いや、本当に時間がかかる。すぐに分かる理由によりテクスチャサンプラーは非常に長いパイプラインを持つので、テクスチャサンプリング操作が必要とする時間はシェーダーユニットが待機状態で待っていられるよりもはるかに長い。さてここでまた、あれが登場する。今度は一緒に口に出そう: 「「スループット」」 何が起こるかと言うと、テクスチャサンプルをリクエストしたシェーダーユニットは自動的に他のスレッド/バッチに切り替わって他の仕事を進め、しばらくして結果が返ってきた後に元の仕事へ戻るのである。シェーダーユニットが行える独立した仕事が十分にある限りこうしても問題は起こらない!
テクスチャ座標が届いたとき...
最初に行うべき計算がたくさんある: (以降では単純なバイリニアサンプルを仮定する。後述するようにトライリニアフィルタリングと異方性フィルタリングではさらに計算が必要となる。)
Sample型またはSampleBias型のリクエストなら、最初にテクスチャ座標の勾配を計算する。- ミップレベルが明示的に与えられていないなら、サンプルすべきミップレベルを勾配から計算し、指定されていれば LOD バイアスをそこに加える。
- 計算されたサンプル位置のそれぞれに対してアドレスモード (ラップ/クランプ/ミラーなど) を適用し、サンプルを行う実際の位置を取得する。この位置は正規座標 \([0,1]^2\) に収まる。
- キューブマップのサンプルではこれに加えて、どのキューブフェイスからサンプルを行うかを決定し、除算を使って座標を単位立方体 \([-1,1]^3\) に収まるように射影する必要がある。さらに三つの座標の一つは (決定されたキューブフェイスに基づいて) 捨てられ、残りの二つはスケール/バイアスされて通常のテクスチャサンプルで使われる正規座標 \([0,1]\) に移される。
- 続いて、\([0,1]\) の正規座標はサンプルで使われる固定小数点のピクセル座標に変換される──このときバイリニア補間のためいくらかの小数部も必要になる。
- これでやっと、整数 \(x, y, z\) とテクスチャ配列のインデックスからテクセルを読むアドレスが計算できる。ここまで来たのだから、乗算と加算がもう何回かあるくらい許してくれるだろう。
以上の処理が多すぎないかと感じたなら、これは単純化された説明であることを思い出してほしい。キューブマップの辺/頂点におけるサンプリングやテクスチャボーダーのような面白い問題には触れてさえいない。信じてほしい、現時点でこれほど多い処理だが、ここで起こるべきことを全てコードにして書かなければならないとしたら、それは恐ろしい仕事になる。これをやってくれるハードウェアがあってよかった :) さて、これでデータを読むメモリアドレスが手に入った。そしてメモリアドレスのあるところには必ず、キャッシュの一つや二つが近くに潜んでいる。
テクスチャキャッシュ
最近の GPU はどれも二レベルのテクスチャキャッシュを使っているようだ。レベル 2 (L2) のキャッシュは完全にごく普通のキャッシュであり、たまたまテクスチャデータを保持するキャッシュメモリとして使っているだけである。レベル 1 (L1) のキャッシュは追加の特殊処理を持っており、それほど標準的ではない。また L1 キャッシュのサイズはあなたが思うよりも小さいはずだ──サンプラーごとに 4 キロバイトから 8 キロバイト程度のオーダーしかない。意外に思う人の多いであろうこのサイズについて最初に話をしよう。
重要な事実はこれだ: 大部分のテクスチャサンプリングはピクセルシェーダーでミップマップを有効にした状態で行われ、そのときミップレベルはスクリーンピクセルとテクセルの比がおよそ 1:1 になるように選ばれる──ミップマップはそのために存在するのだった。しかしこれは、テクスチャの全く同じ位置を何度もリクエストしない限り、各テクスチャサンプリング操作で平均して 1 テクセル分のキャッシュミスが起こることを意味する1。バイリニアフィルタリングを使ったときの実測値は 1.25 キャッシュミス/リクエスト程度である (ピクセルを個別に追跡した場合)。さらに、この値はテクスチャキャッシュのサイズを変更してもあまり変わらず、テクスチャキャッシュがテクスチャ全体を持てるだけのサイズになると急激に小さくなることが判明している (普通のテクスチャは数百キロバイトから数メガバイトだから、それを丸ごと L1 キャッシュに載せるのは全く現実的でない)。
要するに、どんなテクスチャキャッシュでも大きな恩恵をもたらす (バイリニアサンプルにつき 4 回のメモリアクセスが 1.25 回まで減る)。しかし CPU やシェーダーコアの共有メモリとは異なり、サイズを例えば 4 キロバイトから 16 キロバイトに増やしても得るものはほとんど何もない。そのサイズよりも大きなテクスチャデータをいずれにせよキャッシュを通してストリーミングするためだ。
もう一つ重要なことがある: 平均してサンプルごとに 1.25 回のキャッシュミスがあるので、テクスチャサンプラーのパイプラインにはサンプルごとにメモリからの完全な読み込み一度分をストールせずに保持できるだけの長さが必要になる。言い換えよう: メモリ読み込みには 400-800 サイクルがかかるにもかかわらず、テクスチャサンプラーのパイプラインは一度のメモリ読み込みでストールしないほど長くなければならない。本当に長いパイプラインがそこにはある──まさに文字通りの "管の連なり" である。メモリの読み込みが終わるまで、各パイプラインレジスタから次のパイプラインレジスタへ何も処理せずにデータを移動させる処理が数百サイクルに渡って行われる。
というわけで、小さい L1 キャッシュと長いパイプラインだ。さっき言った「追加の特殊処理」とは何かって? ほら、圧縮テクスチャフォーマットがある。PC では S3TC (別名 DXTC) というフォーマットが使われるが、これは BC1~BC3 および D3D10 で導入された BC4 と BC5 (以上の五つは DXT の代替)、そして D3D11 で導入された BC6H と BC7 の総称である。ブロックベースの方法であり、4x4 のピクセルからなるブロックを個別にエンコードする。もしテクスチャサンプリング時にデコードを行うとすれば、サイクルごとに最大で四つのブロックをデコードしてそれぞれから一つのピクセルを取得できる必要がある (効率が最低になるのはバイリニアサンプルの四点全てが異なるブロックにまたがる最悪の構成を踏んだときだ)。これは、率直に言って、ばかげた話でしかない。そこでこうする代わりに、4x4 ブロックは L1 キャッシュへ運ばれるときにデコードされる: 例えば BC3 (別名 DXT5) でエンコードされた一つの 128 ビットブロックをテクスチャ L2 キャッシュからフェッチすると、デコードされたピクセル最大 16 個が L1 テクスチャキャッシュに格納される。すると突然、サンプルごとに四つのブロックをデコードする必要があったのが、1.25/(4*4) ≒ 0.08 ブロック/サンプルで済むようになる。テクスチャのアクセスパターンがコヒーレントで、要求したピクセル以外の 15 ピクセルにヒットがあるなら、という仮定は付くが :) この 15 ピクセルの一部が使われる前に L1 から追い出されることになったとしても、大きな改善が得られる。
このテクニックが使えるのが DXT ブロックだけというわけでもない: キャッシュフィルパスは D3D11 が要求する 50 個以上の異なるテクスチャフォーマットの間の違いの大部分を吸収し、このパスは実際のピクセルリードパス三回につき一回の頻度でヒットする──素晴らしい。例えば UNORM sRGB テクスチャを扱うときは、sRGB のピクセルから 16 ビット整数/チャンネル (または 16 ビット浮動小数点数/チャンネル) への変換が行われ、フィルタリングはその後に (正しく) 線形空間で行われる (望むなら 32 ビット浮動小数点数への変換だって行える)。ただし、L1 キャッシュ内のテクセルが占めるデータ量が増えることには注意がいる。そのため L1 キャッシュのサイズを増やしたくなる場合もあるかもしれない: ただしそれはキャッシュするテクセルが太ったためであり、より多くのテクセルをキャッシュする必要が生じたためではない。いつも通り、ここにはトレードオフがある。
フィルタリング
ここまでくれば、バイリニアフィルタリングの処理自体はとても簡単に行える。四つのサンプルをテクスチャキャッシュから持ってきて、小数部を持つサンプル位置を使って混ぜ合わせればよい。これまで世話になってきた積和ユニットをもういくつか使うだけだ (四つのチャンネルに対して同時に行うので、細かく言えば結構使うが...)。
トライリニアフィルタリング? バイリニアフィルタリングのサンプルを二回行って、その結果を線形補間するだけだ。積和ユニットをさらに積めば計算できる。
異方性フィルタリング? これに関してはパイプラインの最初の方、サンプル対象のミップレベルを計算するあたりで追加の処理が必要になる。何をするかというと、テクスチャ座標の勾配からテクセル空間におけるスクリーンピクセルの面積だけではなく形状も計算するのだ。もし幅と高さがほぼ同じなら、通常のバイリニア/トライリニアのサンプルを行う。一方でいずれかの方向に細長くなっているなら、長い方向に関しては複数のサンプルを行って混ぜ合わせたものを結果とする。異方性フィルタリングではサンプルすべき位置が複数生成されるので、バイリニア/トライリニアの完全なパイプラインを何度かループしなければならない。またサンプル位置と重みを決める必要もあるが、これはハードウェアベンダーが決める値であり、門外不出の秘密とされている。ベンダーはこの問題に長年に渡って取り組んでいるので、低いハードウェアコストで超優れた値を計算する方法を見つけている。実際に何をしているかをここで推定することはしない: 異方性フィルタリングが壊れておらず、ひどいアーティファクトを生成したり絶望的に遅かったりしない限り、グラフィックスプログラマーが内部で使われるアルゴリズムを気にかける必要はない。
というわけで、必要なサンプルをループするためのセットアップとループの進行ロジックを除けば、フィルタリングがテクスチャサンプラーパイプラインに大量の計算を追加することはない。また異方性フィルタリングで必要な重み付き和を計算するのに十分な量の積和ユニットはこれ以外の操作を行うために必要になるので、フィルタリングステージのためにハードウェアが山ほど追加されることもない :)
テクスチャの返却
これでテクスチャサンプラーパイプラインの終端にかなり近づいた。ここまでの処理で何が手に入るだろう? リクエストされたテクスチャサンプルごとに最大で四つの値 (r, g, b, a) である。テクスチャリクエストのサイズは種類によって大きく異なるが、ここではシェーダーが四つの値を全て消費するというケースが圧倒的に最も多い。しかしそれでも四つの浮動小数点数を返す処理は帯域的に馬鹿にならないので、ここでもビットを削る必要が生じる可能性がある。シェーダーがチャンネルごとに 32 ビットの浮動小数点数のテクスチャをサンプルしているなら、32 ビットの浮動小数点数を返すので問題ない。しかしもし 8 ビット UNORM sRGB のテクスチャを読んでいるなら、32 ビットの値を返すのはやり過ぎでしかない。そのときはリターンパスで小さいフォーマットを使うことで帯域を節約できる。
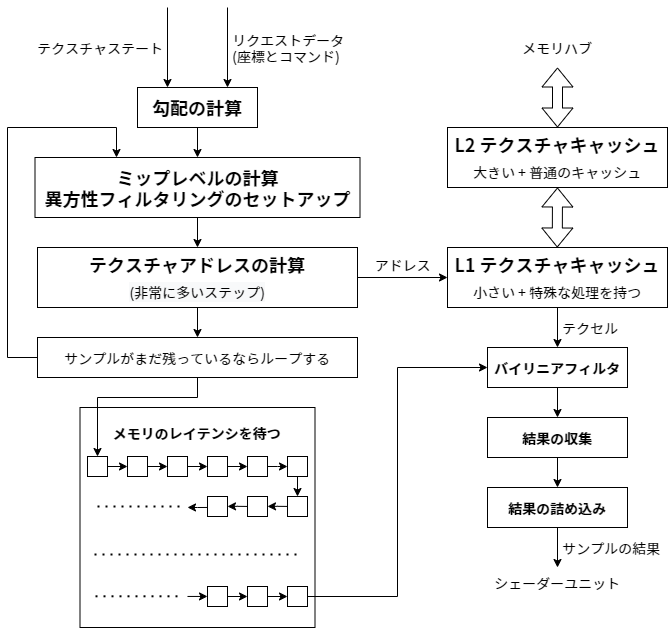
そして、これで終わりだ──シェーダーユニットはテクスチャサンプルを受け取り、あなたが送信したバッチの実行を再開する──この章もこれで終わる。次の章でまた会おう。次回はプリミティブのラスタライズを始める前に必要な処理について話をする。更新: テクスチャサンプリングパイプラインをまとめた図を描いた。ここでは省略しているが、このパイプラインにはブレンドウェイトと「このサンプルは最後か?」という情報も流れる。後者は結果を返すタイミングが分かるように存在する。
いつもの後書き
今回は、大きな注意事項はない。帯域の例で示した値は正直に言うとその場で作った架空の値なのだが、これは現在のゲームにおける実際の値を調べる気が起きなかったからである :) しかしこの点を除けば、本章で説明したことは現在の GPU で起きていることと非常に近いはずだ。ただしフィルタリングではコーナーケースをいくつか省略した (この詳細は面倒で、あまりためにならないというのが主な理由だ)。
L1 テクスチャキャッシュに圧縮解除されたデータが載るという点についてだが、私の知る限り現在のハードウェアにおいてこれは正しい。古いハードウェアでは圧縮されたフォーマットで L1 テクスチャキャッシュにデータを保持していたが、前述の「キャッシュサイズが非常に大きくない限り、どんなサイズでも 1.25 キャッシュミス/サンプルになる」というパターンがあるので、こうしても得るものは少なく、おそらく複雑さと釣り合わないだろう。そういったハードウェアは今では存在しないと思われる。
興味深い話題に、組み込み/電力に最適化されたグラフィックスチップ (例えば PowerVR) がある。このシリーズでは読者の PC に載っているような高パフォーマンスのチップに関して話をするつもりなのでこういったチップについて詳しく話をするつもりはないが、もし興味があるなら前章のコメントに少し書いたので確認してほしい。話を戻すと、PowerVR チップは独自のテクスチャ圧縮フォーマットを持っている。これはブロックベースではなくチップのフィルタリングハードウェアと密接に統合されているので、L1 キャッシュでもテクスチャは圧縮された状態で保持されるのではないかと私は思っている (実を言うと、PowerVR が L2 キャッシュを持つかどうかさえ私には確かなことが分からない!)。興味深い手法であり、おそらくは面積および消費電力と実際に行われる仕事のバランスの取れたスイートスポットなのだろう。ただし「L1 キャッシュでは圧縮解除する」手法の方が全体のスループットは向上すると思われる。何度でも言おう、ハイエンド PC の GPU ではスループットが何よりも優先されるのだ :)