メモリとコマンドバッファ
ちょっと待った
前章では PC 上で 3D レンダリングコマンドが GPU の手に渡るまでに通過する様々なステージを説明した。短くまとめると: あなたが思うよりたくさんある。最後にコマンドプロセッサの名前を出して、細心の注意を払って準備したコマンドバッファを受け取ったコマンドプロセッサがついに何かするのだと説明した。さて、何と言えばいいか──私は嘘をついた。コマンドプロセッサには本章で初めてお目見えすることになるが、コマンドバッファはメモリを通して渡されるという事実を思い出してほしい。そのときは PCI Express (PCIe) でアクセスされるシステムメモリか、ローカルのビデオメモリが使われる。私たちはパイプラインを順番に見ていくことにしているので、コマンドプロセッサを説明する前に、メモリについて少し話をしよう。
メモリサブシステム
GPU はあなたが普通に考えるようなメモリサブシステムを持たない──汎用 CPU などのハードウェアが持つものとは大きく異なる。大きく異なる利用パターンを想定して設計されているためだ。GPU のメモリサブシステムと通常のマシンで見られるメモリサブシステムには二つの大きな違いがある。
一つ目の違いは GPU のメモリサブシステムが速いことだ。本当に速い。Core i7 2600K のメモリ帯域幅は (好調子の日、下り坂、追い風で) 19 GB/s 程度だが、GeForce GTX 480 のメモリ帯域幅は 180 GB/s 近くに達する──なんと一桁近い差がある!
二つ目の違いは GPU のメモリサブシステムが遅いことだ。本当に遅い。Nehalem (第一世代の Core i7) でキャッシュミスが起こってメインメモリを読みに行くと、140 サイクル程度の時間がかかる (この値は AnandTech が示しているメモリレイテンシにクロックレートを乗じると得られる)。しかし前述の GeForce GTX 480 ではメモリアクセスが 400-800 クロック程度のレイテンシを持つ。つまり言い換えると、平均して GeForce GTX 480 は Core i7 の四倍のメモリレイテンシを持つ。さらに Core i7 のクロックは 2.93 GHz なのに対して GeForce GTX 480 のシェーダークロックは 1.4 GHz なので、ここでも二倍遅くなる。というわけで、ここでも速度がほぼ一桁違う! 待て、何か面白いことが起こっている。俺ちゃんの常識がうずくね。これはニュースで何度も聞いたあのトレードオフに違いない!
その通り──GPU は帯域を大幅に増加させる代わりに、レイテンシも大幅に増加させている (実は消費電力もかなり大きくなっているのだが、これについてはこのシリーズの範囲を超える)。この裏には一般的なパターンがある──GPU はレイテンシを犠牲にしてとにかくスループットを優先する。使いたいデータがまだ用意できていないなら、それを待つのではなく他のことをするのだ!
以上が GPU のメモリに関して知っておくべきことのほぼ全てだが、加えてもう一つ、DRAM のチップは (物理的にも論理的にも) 二次元格子状に構成されることも後に重要になるので知っておくべきだろう。メモリには (水平な) 行ラインと (垂直な) 列ラインが並んでおり、その交点がトランジスタとキャパシタになっている。こういった要素からメモリがどのように構成されるのかを知りたいなら、Wikipedia があなたの友達になってくれる。ともかく注目すべき事実は、DRAM の位置を指すアドレスが行アドレスと列アドレスに分かれること、そして DRAM の読み込みと書き込みが内部では必ず指定された行にある全ての列へのアクセスとなることである。これは DRAM のちょうど一行にマップされるメモリ領域を読み込むと、複数の行にまたがる同じだけのメモリ領域を読むよりもずっと高速になることを意味する。これは今のところただの DRAM 豆知識に思えるかもしれないが、後で重要になる: 要するに、テストに出るから覚えておくように。一つ前の段落で示した値との関連で言うと、上述したメモリ帯域幅はピーク値であり、メモリ上の適当な位置から数バイト読むだけでは達成できない。メモリ帯域を飽和させるには DRAM の行全体を一度に読まなければならない。
PCIe ホストインターフェース
グラフィックスプログラマーの視点から見ると、この部分はあまり面白くない。実は、おそらく GPU ハードウェア設計者も同じことを考えている。というのも PCIe インターフェースは実行があまりにも遅くなってここがボトルネックだと判明して初めて気にかける類のものであるためだ。この部分はよく知っている人物に任せて、ボトルネックにならないようにするしかない。それ以外のことといえば、さて、PCIe インターフェースはビデオメモリおよび様々な GPU レジスタへの読み込み/書き込みアクセスを CPU に提供し、メインメモリ (の一部) への読み込み/書き込みアクセスを GPU に提供する。ただしこういったトランザクションはどれもレイテンシがさらに大きいので、頭痛の種も提供する: シグナルがチップを出てスロットを通り、メインボード上を旅して CPU のどこかに収まるには一週間もかかる (CPU/GPU の速度と比較すればそれぐらいに感じる)。帯域幅自体は悪くない──現代的な GPU の大部分が使っている 16 レーン PCIe 2.0 接続では、(理論上の) ピーク総帯域幅は 8GB/s 程度になる。これは CPU メモリ帯域の半分か三分の一程度だから、使いものになる値と言える。AGP のような以前の規格とは違い PCIe はポイント・ツー・ポイントの対称なリンクであり、この帯域幅が両方向に存在する。AGP は CPU から GPU に向かう高速なチャンネルを持っていたが、反対方向のチャンネルは高速ではなかった。
さらにメモリに関して
これで 3D コマンドまでほんのあと少しだ! 匂いぐらいなら感じられるかもしれない。しかし、先に片付けなければならないことがもう少しある。GPU が扱えるメモリには (ローカルの) ビデオメモリとマップされたシステムメモリの二種類があるのだった。ビデオメモリとのやり取りは北への一日程度の旅路で、マップされたシステムメモリとのやり取りは PCI Express 高速道路を使った南への一週間程度の旅路である。進むべき道はどのように示すべきだろうか?
最も簡単な解決法は、どちらに向かうかを示すアドレスラインを追加するというものである。これは単純で、いままでに幾度となく問題を起こさず行われてきた。またゲームコンソールのような (PC とは異なる) ユニファイドメモリアーキテクチャでは、そもそも選択肢が存在しない: メモリが一つ存在するだけであり、必ずそこから読むだけだ。もっとキラキラしたものが欲しい場合はメモリ管理ユニット (memory management unit, MMU) を追加することもできる。MMU は完全に仮想化されたアドレスを提供し、頻繁にアクセスされるテクスチャを (高速な) ビデオメモリやシステムメモリの他の場所に移すといった便利なテクニックを可能にする。なおこのとき、大部分のデータはそもそもマップされない──使うときは魔法を使って合成されるか、そうでなければ魔法のディスク読み込みで 50 年程度の時間をかけて取り出される。なお、これは誇張ではない: 「メモリアクセス = 一日」という比喩を使うなら、単一のハードディスク読み込みにかかる時間は本当に 50 年程度になる。それもかなり高速なディスクで、である。ディスクはクソだ。おっと話がそれた。
MMU の話だった。これがあると、ビデオメモリが枯渇したときにコピーを行わずにアドレス空間をデフラグできる。素晴らしいことだ。また複数のプロセスが同じ GPU を共有するのがずっと簡単になる。GPU が MMU を持てない理由はないはずだが、要件となっているかどうか私はよく知らない (誰か教えてくれないだろうか? はっきりと分かれば記事を更新したいのだが、正直言って調べる気が起きない)。ともかく、MMU/仮想メモリは GPU が勝手に追加できるものではないが、かといって特定のステージに関連するものでもない──どこかで言及しなければならないので、ここでしておいた。
メモリのコピーを貴重な 3D ハードウェア/シェーダーコアを使わずに行える DMA エンジンも GPU には存在する。通常はシステムメモリとビデオメモリの間 (両方向) でコピーでき、ビデオメモリとビデオメモリの間でコピーできる場合もよくある (この機能は VRAM のデフラグを行うときに便利だ)。システムメモリとシステムメモリの間でコピーは普通できない: この DMA エンジンは GPU に存在しているのだから、システムメモリのコピーは CPU から行えばデータを PCIe 上を往復させないで済む!
更新: 図を描いた。ここには説明したよりも細かいことが載っている──いまどきの GPU は複数のメモリコントローラを持ち、それぞれが複数のメモリバンクを制御する。前方にある広いメモリハブがこれらのメモリコントローラをまとめる。帯域を得るためなら何でもするのである :)
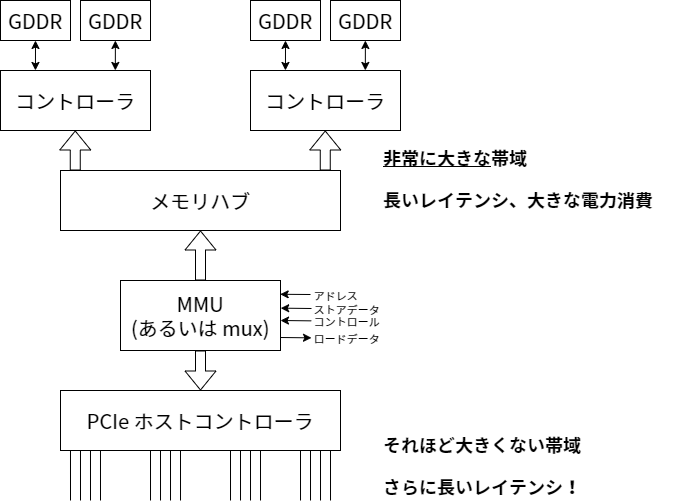
よし、チェックリストを確認しよう。コマンドバッファが CPU 側に準備された。PCIe ホストインターフェースを使えば CPU は準備ができたことを GPU に伝えて特定のレジスタにコマンドバッファのアドレスを書き込むことができる。そのアドレスをロードに変換して実際のコマンドバッファデータを取得するロジックもある──データがシステムメモリにあれば、データは PCIe を通ってやってくる。もしコマンドバッファをビデオメモリに置いたほうがいいと判断されたなら、KMD は DMA 転送を使って GPU 上のシェーダーコアと CPU がどちらもコマンドバッファの転送を気にしないで済むようにできる。そしてビデオメモリ上のコピーからは GPU 上のメモリサブシステムを使ってデータを取得できる。以上のパスを説明してようやく、コマンドを見ていく準備が整った!
ついに、コマンドプロセッサ!
コマンドプロセッサに関する議論は、最近の話題でよくあるように、次の単語から始まる:
"バッファが..."
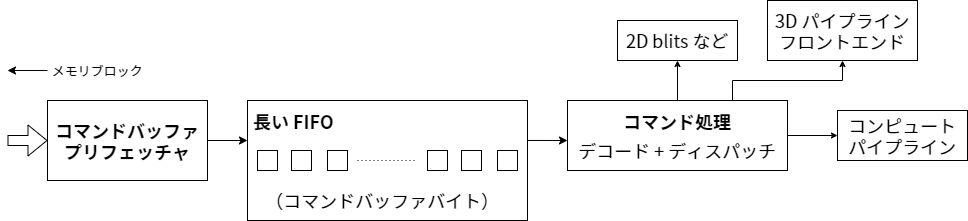
上述の通り GPU に至るまでのメモリパスは高い帯域と高いレイテンシを持つ。この特徴を活用するために GPU パイプラインの後半部分の多くで選ばれる手法は、独立したスレッドを大量に実行するというものだ。しかし今の段階ではコマンドプロセッサが一つあるだけであり、コマンドバッファに含まれるステートの変更や描画といったコマンドは決められた順番通りに口に運ばなければならない。そこで次善策が取られる: 十分大きなバッファを用意して、途中で詰まらないだけの量をプリフェッチするのである。
そのバッファからコマンドは実際のコマンドプロセスフロントエンドへ向かう。このフロントエンドは基本的にコマンドのパース方法を知っているステートマシンである (コマンドのフォーマットはハードウェアごとに異なる)。コマンドの中には 2D レンダリングを行う操作も含まれる──ただし 2D 用のコマンドプロセッサが存在する場合は別で、そのとき 3D フロントエンドは 2D に関するコマンドを全く目にしない。またいずれにせよ、現代的な GPU にも 2D 専用のハードウェアがどこかに隠れている。同様にテキストモード、4 ビット/ピクセルのビットプレーンモード、スムーズスクローリングといった機能をサポートする VGA チップもダイのどこかにある (ただ顕微鏡がないと見つけるのは不可能だ)。ともかく、そういったものも存在する。ただ以後この機能に言及することはない :) それから、コマンドプロセッサはプリミティブを 3D/シェーダーパイプラインに受け渡すコマンドも処理する。やっとお目見えだ! この部分については以降の章で触れる。パイプラインの設定などの様々な理由により 3D/シェーダーパイプラインに向かうが何も描画しないコマンドもある。これについてはさらに後で触れる。
他にステートを変更するコマンドが存在する。こういったコマンドは変数を変えているだけだとプログラマーは思うかもしれない。動作としてはそれで正しいのだが、GPU は大規模並列計算器である。並列システムでグローバル変数を適当に変更し、それで問題なく動くことを祈るというのは間違いだ──何らかの不変条件を通じて全てが正しく動くことを保証できないなら、いずれバグを踏むことになる。有名な解決法はいくつかあり、どのチップも異なるステートに対して異なる方法を使っている。考えられる選択肢をいくつか示す:
- ステートを変更するときに必ず、そのステートを参照する可能性のある進行中の仕事が全て終わっていることを要求する (つまり基本的にパイプラインを部分的にフラッシュする)。古いグラフィックスチップは大部分のステート変更をこの方法で処理していた──単純であり、バッチと三角形の個数が少なくてパイプラインが短いならコストもそれほど大きくない。しかしバッチと三角形の個数は膨れ上がりパイプラインは長くなったので、この種のアプローチのコストも大きくなってしまった。それでも一部のステート変更では今でも元気に活躍している。例えば頻繁に変更されないステート (パイプラインの部分フラッシュが一フレームにつき一ダースほどなら大きな問題にならない) や、より特定的なスキームを使って実装するのが難しい/コストがかかり過ぎるステートに使われている。
- ハードウェアユニットを完全にステートレスにする。つまりステート変更コマンドをそのステートが使われるステージまで通過させ、そのステージが現在のステートを下流に渡すデータへ毎サイクル付け加えるようにする。そのステートはどこにも保存されないが、常にどこかを漂うことになる。パイプラインの何らかのステージがステートから数ビットを読むのであれば、そのビットは渡されるのでいつでも行える (そのビットは使われたかどうかに関わらず次のステージに渡される)。考えているステートが数ビットだけなら、この方法は非常に安価で実践的になる。しかし考えているステートに例えばアクティブなテクスチャ全ての集合とサンプリングステートが含まれるなら、そうはならない。
- ステートのコピーを一つだけ保持し、それが変更されるたびにフラッシュする方法だと処理が直列化してしまう。そこでステートのコピーを二つ (あるいは四つ?) 用意すれば、ステートの変更を行うフロントエンドが少し先まで行けるようになる。全てのステートの二つのバージョンを保持できるだけのレジスタ ("スロット") があって、現在アクティブなジョブがスロット 0 を参照しているとする。このときスロット 1 を変更するためにジョブを止める必要はないし、変更してもジョブと干渉することはない。またこのときパイプラインにステート全体を渡す必要はない──コマンドごとに一ビット、スロット 0 と 1 のどちらを使うかを渡すだけで済む。ステートを変更するコマンドを処理するときにスロット 0 と 1 の両方がビジーとなった場合は当然待つ必要があるが、少なくとも一歩先には進める。同じテクニックは二つより多いスロットを使っても行える。
- サンプラーや
テクスチャシェーダーリソースビューのステートでは大量の値を同時に設定することはあっても、一度設定した後は変更しない可能性が高い。そのような場合に、必要かもしれないからといって二セットのステート (例えば 2*128 個のアクティブなテクスチャ) を用意するのは無駄が大きい。こういったケースではレジスタリネーミングのようなスキームを実装できる──128 個の物理テクスチャデスクリプタが入るプールを用意するのである。もし一つのシェーダーが 128 個のテクスチャ全てを必要とするなら、(残念ながら) ステートの変更は遅くなる。しかしシェーダーが 20 個程度のテクスチャを使うというより可能性の高いケースでは、複数のバージョンを同時実行するだけの空間の余裕が生まれる。
これは完全なリストとして示しているわけではない──重要なのは、アプリケーションに含まれる変数を一つ変更するという一見単純な問題であっても (あるいは UMD/KMD がコマンドバッファを変更するという問題も!)、計算を遅くしないためには自明でない量のハードウェアからのサポートが必要になるということである。
同期
最後に、CPU/GPU および GPU/GPU の同期に関するコマンド群がある。
こういったコマンドは一般に「もしイベント X が起こったら、Y をせよ」という形をしている。これから「Y をせよ」の部分を先に説明する──Y として考えられる形態は実質二つしかない: GPU が CPU に向かって何かをせよと叫ぶプッシュモデル (「おい! CPU! 私はこれからディスプレイ 0 の垂直帰線消去期間に入るからな。ティアリングさせずにバッファをフリップしたいなら今のうちだぞ!」) と、GPU が発生したイベントを覚えておいて後から CPU が尋ねるプルモデル (「あの、GPU さん、最後に開始したコマンドバッファのフラグメントはどれですか?」「どれどれ...シーケンス番号 303 のやつだよ」) である。プッシュモデルは通常 (コストがとても高い) 割り込みを使って実装されるので、頻度が低く重要度の高いイベントに対してのみ使われる。プルモデルを実装するには、CPU から見える GPU レジスタと、特定のイベントが起こったときにコマンドバッファからそのレジスタに値を書き込む仕組みが必要となる。
そういったレジスタが 16 個あるとする。このとき例えば currentCommandBufferSeqId をレジスタ 0 に割り当てるといったことができる。すると GPU に送信したコマンドバッファの全てに (KMD で) シーケンス番号が割り当てられ、「コマンドバッファをここまで進んだら、レジスタ 0 にこのシーケンス番号を書き込むこと」という注意書きが各コマンドバッファの先頭に付与される。するとあら不思議、GPU が現在どのコマンドを実行しているのかが分かるようになる! コマンドプロセッサがコマンドを必ず順序通りに終了させることを私たちは知っているから、例えばコマンドバッファ 303 が実行されているなら 302 までのコマンドバッファは全て終了していることが分かる。KMD は 302 までのコマンドバッファを再度送信できるし、改変、解放しても、安っぽい遊園地にしても構わない。
ここには X の例も含まれている: 「もしここまで進んだら」だ──おそらくもっとも単純な例だが、これだけでも十分有用である。X には他に「もしコマンドバッファのこの点より前のバッチが要求する全てのテクスチャ読み込みが全てのシェーダーで完了したなら」(テクスチャやレンダーターゲットのメモリを安全に再利用できる点を示す) や「全てのアクティブなレンダーターゲット/UAV へのレンダリングが終わったなら」(レンダリング結果をテクスチャとして安全に利用できる点を示す) あるいは「この点までの全ての操作が完全に完了したら」などが考えられる。
ついでに言っておくと、こういった操作は「フェンス (fence)」と呼ばれる。また状態レジスタに書き込む値の選択肢はいくつかあるが、少なくとも私の考えでは、逐次カウンター (もしくは逐次カウンターに数ビットの情報を追加したもの) を使わないと意味がない。脈絡もなく適当な情報を書いてしまっているが、あなたの役に立つだろうと思ってのことだ。後でこのシリーズとは別にブログ記事として掘り下げるかもしれない :)
さて、これで同期の問題の半分が片付いた──GPU の状態を CPU に書き戻すことができれば、ドライバは常識的なメモリ管理を行えるようになる (特に、頂点バッファ・コマンドバッファ・テクスチャといったリソースが利用するメモリを安全に再利用できるタイミングが分かるようになる)。しかし、同期の問題が全て説明できたわけではない──パズルのピースはまだ欠けている。例えば、完全に GPU 側だけで同期を行いたい場合はどうすればよいのだろうか? 前に触れたレンダーターゲットの例で言えば、レンダーターゲットはレンダリングが実際に終了するまでテクスチャとして使うことができない (正確にはレンダリングの他にも処理があるのだが、これについてはテクスチャユニットを説明したときに触れる)。この問題は「レジスタ M の値が N になるまで待て」という「待機」形式の命令によって解決される。条件節には等価判定または未満の判定 (ラップアラウンドに注意が必要だ!) あるいはもっと複雑な判定などが使えるが、ここでは簡単のため等価性の判定だけができるとする。これがあるとレンダーターゲットとの同期をバッチの送信に先立って行えるようになる。また GPU を完全にフラッシュする操作も可能になる: 「進行中のジョブが全て終わったら、レジスタ 0 を ++seqId に設定せよ」と「レジスタ 0 の値が seqId になるまで待機せよ」で一丁上がりだ。これで GPU/GPU 同期の問題も解決した──DX11 でコンピュートシェーダーが導入され、さらに細かい同期が可能になるまでは、これが GPU 側で行える唯一の同期操作であることが普通だった。通常のレンダリングでは、単にこれ以上の同期動作は必要にならない。
ところで、もしこういったレジスタに CPU 側から書き込めるなら、それは逆方向に利用できる──特定の値に対する待機命令を含んだコマンドバッファを情報の欠けた状態で送っておいて、GPU ではなく CPU からそのレジスタを変更するという手法である。これは、送信するバッチにその時点では CPU 側でロックされている (おそらくは他のスレッドから書き込まれている) 頂点バッファ/インデックスバッファを含めるという D3D11 スタイルのマルチスレッディングを実装するのに利用できる。実際の描画操作の呼び出しの直前に待機命令を入れておき、その頂点バッファ/インデックスバッファが解放されたら CPU が待機命令に対応するレジスタを書き換えるだけでよい。そのレジスタを CPU が書き換えるより先に GPU がコマンドバッファの待機命令まで到達した場合はデータが届くまで (コマンドプロセッサの) 時間が無駄になる。しかし CPU の方が早ければ、待機命令は noop になる。かなりイケてるんじゃないだろうか? 実を言うと、こういった操作は CPU から書き込める状態レジスタが存在しなくても、コマンドバッファを送信した後に変更する機能とコマンドバッファの「ジャンプ」命令があれば実装できる。詳細は興味の湧いた読者に任せる :)
もちろん、レジスタ設定/レジスタ待機を使うこのモデルがどうしても必要というわけではない。GPU/GPU 同期ではレンダーターゲットが利用可能であることを確認する「レンダーターゲットバリア」命令と「全てをフラッシュする」コマンドだけがあれば十分である。ただレジスタ設定/レジスタ待機のモデルだと一つの優れた設計で二羽の鳥 (使用中リソースの CPU への報告、および GPU の自己同期) を落とせるので、私はこちらを気に入っている。
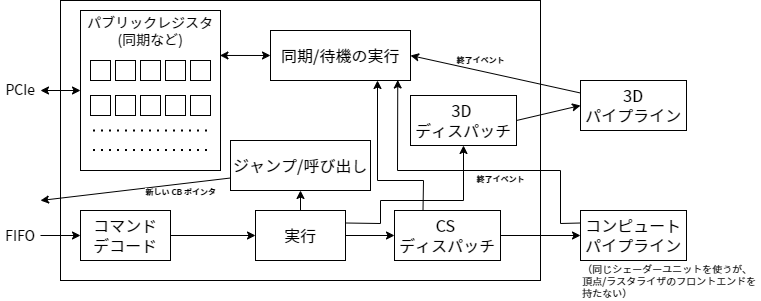
更新: 図を描いたので見てほしい。少し複雑になったので、これからは説明の詳細を省くことにする。基本的なアイデアはこれである: コマンドプロセッサは最初に FIFO、次にコマンドデコードロジックを持つ。実行は様々なブロックによって処理され、2D ユニットや 3D フロントエンド (通常の 3D レンダリング) あるいは直接シェーダーユニット (コンピュートシェーダー) とのやり取りが行われる。その後には同期/待機コマンドを処理するブロック (前述の CPU から見えるパブリックなレジスタを持つのはここだ)、およびジャンプ/呼び出しを処理するブロック (FIFO を指すカレントフェッチアドレスを変更する) がある。また仕事をディスパッチされたユニットは全て、その実行を終えたときに終了イベントを送り返さなければならない。こうすることで、例えばテクスチャが使用されないためにそのメモリを再利用できるタイミングが分かるようになる。
最後に
次のステップは実際のレンダリングを行う最初のモジュールとなる。ついに、GPU を解説するこのシリーズの第三章でようやく、私たちは頂点データを見ていくことになる! (ただ、三角形はまだラスタライズされない。それはもっと後だ)
実は早くもこのステージで、パイプラインの分岐が起こる: コンピュートシェーダーを実行しているなら、次のステップは ... コンピュートシェーダーの実行となる。しかし今はこれを考えない。コンピュートシェーダーは最後の章のトピックに回して、通常のレンダリングパイプラインを最初に見ていく。
注意: ここでも、私が説明したのは概略に過ぎない。必要なとき (あるいは面白そうなとき) は詳細を説明したが、信じてほしい、たくさんの事項が説明しやすいように (あるいは理解しやすいように) 省略されている。そうは言っても、非常に重要なトピックを無視したつもりはない。もちろん私が間違っている可能性もあるので、バグを見つけたらぜひ教えてほしい!
次章に続く...