ピクセルプロセッシング ── フォークフェーズ
この章ではピクセルプロセッシングの前半部分、ディスパッチと実際のピクセルシェーディングを片付ける。実は、たいていのグラフィックスプログラマーがピクセルプロセッシングについて話をするとき実際に思い浮かべているのはこの部分である。次の章で触れるアルファブレンドとレイト Z/ステンシルのステージは最後に付く簡単な処理のように思える。しかしこれから見るように、ハードウェアでは話がもう少し複雑になる──ピクセルプロセッシングを二つの章に分けたのには理由がある。ただこの話はまだ早い。さて、このステージに入る時点で、シェーディングを行うピクセル (正確にはクアッド) の座標と対応するカバレッジマスクがラスタライザ/アーリー Z ユニットから到着する──このとき前章で説明したように、三角形はアプリケーションが送信したのと全く同じ順序で並ぶ。ここで行うべきなのは、その線形に並んだ仕事の列を数百個のシェーダーユニットに振り分けて実行し、結果が返ってきたらメモリ更新操作の線形ストリームとして一つにまとめるという処理である。
これは並列計算におけるフォーク/ジョインモデルの教科書的な例と言える。この章では計算を "広く" するフォークフェーズについて説明し、次の章では数百個のストリームを一つにまとめるジョインフェーズについて説明する。しかしまず、ラスタライズについて少し言っておくべきことがある。前述した「クアッドが流れるストリームが一つだけある」という説明は正確に言うと正しくないからだ。
ラスタライズを広くする
自己弁護をしておくと、前に伝えたことはかつて長いこと正しかった。しかしラスタライズはパイプラインの中でも逐次的な部分であり、問題の解決に 300 個以上のシェーダーユニットが利用できるとなれば、パイプラインの逐次的な部分がボトルネックとなる傾向がある。そのため GPU 設計者は複数のラスタライザを使い始めた。2010 年の時点で NVIDIA は四つのラスタライザを使っており、AMD は二つのラスタライザを使っている。余談だが、リンクに示した NVIDIA のプレゼンテーションには API が指定する順序で処理を行うために必要なことに関する言及がいくつかある。特に、ラスタライズとアーリー Z の前にプリミティブを正しい順序に並び替える (前章で触れた) 処理は本当に必要になる。アルファブレンドの直前でもできると思うかもしれないが、それでは上手く行かない。
複数のラスタライズに対する仕事の振り分けはアーリー Z や粗いラスタライズで見たのと同じタイルに基づいて行われる。フレームバッファがタイルと同じサイズの領域に分けられ、各領域に一つのラスタライザが割り当てられるということだ。三角形セットアップの後に三角形のバウンディングボックスが調べられ、どの三角形がどのラスタライザへ送られるかが計算される。大きな三角形は必ず全てのラスタライザに送られるが、一つのタイルしか覆わないような小さい三角形はそのタイルを担当する一つのラスタライザにだけ送られる。
このスキームの美しさは、仕事の振り分ける部分と粗いラスタライザ (タイルを走査する方) にだけ変更が必要となる点にある。個別のタイルやクアッドだけを扱う部分 (つまりパイプラインで階層的 Z テスト以降の部分) には変更が必要にならない。一方このスキームの問題はスクリーン上の位置に基づいて仕事を分割することで、これによってラスタライザにかかる負荷が平等でなくなる可能性がある (一つのタイルに小さな三角形が何百個もある状況を想像してほしい)。これについてはどうしようもない。ただ、パイプラインに順序制約を追加するステージ (Z テストや Z 書き込み、そしてブレンド) はどれも特定のフレームバッファ位置に関する順序を扱うので、スクリーン空間の分割を使っておけば API の順序を破らないで済む──こうしないと、タイルを使うレンダラがそもそも正しく動作しない。
もっと広く!
オーケー、というわけでクアッドの座標とカバレッジマスクは単一の線形ストリームからやって来るのではなく、二つあるいは四つの線形ストリームからやって来る。それでも数百個あるシェーダーユニットに対する仕事の振り分けは行わなくてはならない。もう一つのディスパッチユニットの時間だ! しかしシェーダーユニットに送るバッチのサイズはどれくらいだろうか? ここでは NVIDA の数字を使うが、これは NVIDIA がパブリックなホワイトペーパーでこの値に言及しているためだ。おそらく AMD もどこかでこの情報を公開しているが、私は AMD の用語についてあまり詳しくないので直接調べられなかった。話を進めると、NVIDIA のハードウェアでシェーダーユニットへのスレッドのディスパッチは 32 スレッドを一単位として行われ、この一単位を「Warp」と呼ぶ。一つのクアッドは四ピクセルで構成され一つのスレッドは一ピクセルのシェーディングを行うので、ラスタライザからクアッドを八つ受け取って始めてバッチをシェーダーユニットに送信できるということになる (シェーダーの切り替えやパイプラインのフラッシュがあった場合はもっと少なくてもバッチが送信される)。
それと、ここはレンダリングで 2x2 のピクセルからなるクアッドを扱っていて、ピクセルを個別に扱わない理由を説明するいい機会だろう。大きな理由は微分係数である。四章で説明したように、テクスチャサンプラーはスクリーン空間におけるテクスチャ座標の微分係数を使ってミップマップの選択とフィルタリングを行う。またシェーダーモデル 3.0 以降では、同じ手法を使って微分係数を求める命令がピクセルシェーダーで利用可能になっている。この命令は有限差分法 (最終的には何回かの引き算) を使って x 方向と y 方向に関するパラメータの微分係数の近似を計算する。つまりピクセルシェーディングを必ず 2x2 ピクセルのグループで実行すると定めることで、微分係数を非常に低いコストで計算できるようにしている。これは大きな三角形の内部では問題にならないものの、三角形の端では 25% から 75% のシェーディング処理が無駄になることを意味する: 被覆されるピクセルが一つであっても、視えているそのピクセルで正しい微分係数を計算するために、シェーディングは必ずクアッド単位で行わなければならない。視えていないにもかかわらずシェーディングされるピクセルは「ヘルパーピクセル」と呼ばれる。次の図に小さい三角形とクアッドの関係を示す:
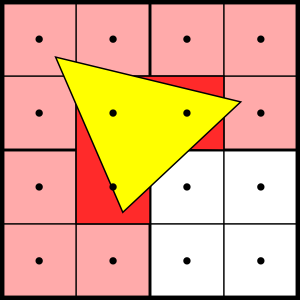
この三角形は四つのクアッドと交わっているが、三つのクアッドでだけ視えるピクセルを生成する。さらに三つのクアッドそれぞれについて、一つのピクセルしか被覆されていない──ピクセル領域内のサンプル点は黒い丸で示され、被覆されるピクセルは赤く塗られている。部分的に被覆されたクアッドに含まれる残りのピクセルはヘルパーピクセルであり、ピンクに塗られている。この図からは、小さい三角形ではシェーディングされるピクセルの大部分がヘルパーピクセルになることが分かる。この事実に注目し、隣り合う三角形に対応するクアッドをマージする手法を示した研究がいくつかある。こういった最適化は賢いものの、現在の API の規則では許されておらず、現在のハードウェアは行っていない。しかし、クアッド内で無駄になるシェーディング処理の問題は無視できないほど大きいとハードウェアベンダーが判断した場合は、当然この事実も変わるだろう。
アトリビュートの補間
ピクセルシェーダーに特有の機能がアトリビュートの補間である──ピクセルシェーダー以外のシェーダーは全て──今までに見たもの (VS) も見ていないもの (GS, HS, DS, CS) も──直前のシェーダーステージあるいはメモリから入力を直接取得するが、ピクセルシェーダーでは入力を補間する追加ステップが前に存在する。これについては前章で Z テストを議論したときにも少し触れたが、Z は私たちが最初に目にした補間されるアトリビュートである。
その他の補間されるアトリビュートも非常に似た形で扱われる。三角形セットアップで平面方程式が計算され (GPU はこの計算を遅らせて、例えば三角形のタイルが最低でも一つ階層的 Z テストを通過したときに初めて計算するといった処理を行うこともできるが、これは今の話題には関係ない)、ピクセルシェーディングではクアッド内におけるピクセル位置とその平面方程式を使ってアトリビュートの補間を行う個別のユニットが利用される。
更新: Marco Salvi による指摘 (英語版ページのコメント欄を参照) の通り、補間を行う専用ユニットが存在したのは以前の話で、今はこのユニットに重心座標を返させて、シェーダーユニットでそれを平面方程式に代入するのがトレンドとなっている。実際の評価 (アトリビュートごとに二度の積和) はシェーダーユニットで行われる。
こういった処理に驚くような部分はないと思うが、議論しておくべき補間のタイプがさらにいくつか存在する。まず "定数" 補間、つまりプリミティブ全体に渡って (なんと!) 定数を返す補間がある。各頂点アトリビュートに対する値は先頭頂点 (leading vertex) と呼ばれるプリミティブセットアップで設定される頂点から読み込まれる。ハードウェアは定数補間用の高速パスを持っていても構わないし、対応する平面方程式をセットアップして済ませても構わない: どちらでも正しく動作する。
それから非透視補間がある。通常これは平面方程式を異なる方法でセットアップすることで実装される。透視的に正しい補間で使われる平面方程式は、各頂点におけるアトリビュートの値を対応する \(w\) で割って作る \(X\) または \(Y\) ベースの補間のための方程式、あるいは三角形の辺ベクトルを構築して作る重心座標を使った補間のための方程式のいずれかである。しかし非透視なアトリビュートの補間では、各頂点における値を \(w\) で割らずに作った \(X\) または \(Y\) ベースの補間のための平面方程式が最も簡単に評価できる式となる。
トリッキーな centroid 補間
続いて「centroid」補間1がある。これはフラグであって、個別のモードではない。つまり透視および非透視の補間モードと組み合わせることができる (定数補間のモードと組み合わせることはできない: そうする意味がない)。かなりひどい名前の付いたこの補間はマルチサンプルが有効になっていない限り noop となる。マルチサンプルが有効だと、この補間はとある現実的な問題に対するいくらかハックじみた解決法になる。その問題は、マルチサンプルが有効なときラスタライザで三角形のカバレッジは複数のサンプル点を使って判定されるが、実際のシェーディングはピクセルごとに一度だけ行われることに関係する。このためテクスチャ座標などのアトリビュートはまるでピクセル全体がプリミティブに覆われるかのようにピクセルの中心で補間されてしまう。このため次のような状況で問題が発生する:
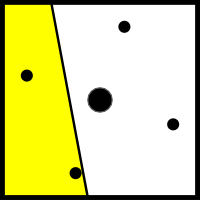
図中のピクセルはプリミティブ (黄色) によって部分的に被覆されている。四つの小さな円が四つのサンプル点 (つまり 4x MSAA が使われている) を表し、中心の大きな円がピクセルの中心を表す。大きな円がプリミティブの外側にあることに注目してほしい。これは "補間" によってその点における値として計算される値が実際には線形補外であることを意味する。これは例えばアプリケーションがテクスチャアトラスを使うときに問題となる。三角形のサイズによっては、ピクセルの中心における値が本来あるべき値から大きく離れる可能性もある。この問題を解決するのが centroid サンプリングである。オリジナルの説明はプリミティブによって被覆される全てのサンプルを GPU が受け取り、その幾何重心を計算し、その位置でサンプルを行うというものだった (名前もここから来た)。ただし、これは計算モデルに過ぎず、GPU はサンプルする点をプリミティブの内部から自由に選べるという説明が普通この後に追加される。
被覆されるサンプルを数えて、足し上げて、その和を個数で割るなんて処理を本当にハードウェアがやるのだろうかと思ったなら、私も同意見だ。実際には次の処理が起こる:
- もしプリミティブが全てのサンプル点を被覆するなら、ハードウェアは補間を通常通りに、つまりピクセルの中心で行う (サンプル点の常識的な配置パターンでは、ピクセルの中心が必ずサンプル点の幾何中心になる)。
- もしプリミティブが一部のサンプル点だけを被覆するなら、ハードウェアは被覆されるサンプル点を適当に選んでそこで補間を行う。被覆されるサンプル点は (定義により) プリミティブの内部だから、この選択に問題はない。
この選択はかつて恣意的に行えた (ハードウェアに任されていた)。しかし現在では DX11 がどのように行うかを規定しているはずである。ただしこれが規定されるのは異なるハードウェアで結果を一致させるためであり、API ユーザーが実際に気にするためではない。前述の通りこれはハックじみている。また部分的に被覆されたピクセルが含まれるクアッドでは微分係数の計算が変になることが多い──残念ながら。つまり、この手法は産業用途のダクトテープではあるが、ダクトテープであることには変わりないということだ。
最後に、「プルモデル」のアトリビュート補間がある (これは DX11 で追加された!)。通常のアトリビュート補間はピクセルシェーダーが始まる前に自動的に行われるが、プルモデルでは補間を行う命令が直接ピクセルシェーダーに追加される。これがあると値をサンプルする位置をピクセルシェーダーで独自に計算したり、一部のブランチでだけアトリビュートを補間したりできるようになる。内部では実行中のピクセルシェーダーから補間ユニットへ追加のリクエストを出せるようにすることでサポートされる。
実際のシェーダー本体
ここでも、シェーダーに関する一般的な事柄は API ドキュメントで詳しく解説されているので、個別の命令の動作を説明することはしない。基本的に答えは「あなたが想像する通りに動作する」である。ただピクセルシェーダーの実行に関連して話しておくべき興味深い話題がいくつかある。
最初の話題は...テクスチャサンプリング! 待て、テクスチャサンプラーについては四章で熱く語ったのでは? 確かにその通りだが、話したのはテクスチャサンプラー側の話題だった──もし覚えていれば、テクスチャではキャッシュミスがとても多いので、サンプラーは一度のリクエスト (16 ピクセルから 32 ピクセル程度だった、思い出そう!) につき少なくとも一つのキャッシュミスをストールさせることなくメインメモリに読みに行けるように設計されていると説明した。このキャッシュミスで消費されるサイクルはかなり多い──数百サイクルである。サンプラーでメモリの読み込みが起こっている間 ALU をアイドルにして放置するのは、準備万端な ALU の大変な無駄使いと言える。
そこで実際のシェーダーユニットは、テクスチャサンプルを発行した後に異なるバッチへ実行を切り替える。そして切り替え先のバッチがテクスチャサンプラーを発行する (あるいは実行を終了する) と、シェーダーユニットは元のバッチに戻ってテクスチャサンプルが到着しているかどうかを確認する。各シェーダーユニットが数個のバッチを持っていれば任意の時点で何かしらの処理を進められるので、この方法を使うとリソースを有効活用できる。個別のバッチの完了を考えたときのレイテンシは確かに増加する──ここでもまたレイテンシとスループットのトレードオフである。ここまで読んできた読者なら、GPU でどちらが勝つかは想像が付くだろう: スループットだ! 必ずこちらが勝つ。ただし一点、複数のバッチ (NVIDIA では「Warp」と呼ばれ、AMD では 「Wavefront」と呼ばれるもの) を同時に実行するには多くのレジスタが必要となる点に注意が必要である。もしレジスタが足りないと、テクスチャサンプルの結果を待っていない実行可能なバッチがいつか不足する可能性が高くなる。運悪く実行可能なバッチが存在しないと、結果が一つ返ってくるまでストールしなければならない。これは残念だが、こういった処理ではハードウェアリソースに制限がある──メモリが足りないなら、メモリが足りないのだ。何もできることはない。
まだ話していない話題にもう一つ、シェーダーにおける動的分岐 (ループと条件文) がある。シェーダーユニットではバッチの全要素がロックステップで (足並みをそろえて) 進む。つまり全ての "スレッド" が同じコードを同じタイミングで実行する。これは if が少し厄介になることを意味する: もし「then」ブランチを実行したいスレッドが一つでも存在すれば、全てのスレッドが then ブランチを実行しなければならない──しかしほとんどのスレッドはそもそも then ブランチを実行したくないので、predication というテクニックを使って結果が捨てられる。「else」ブランチでも同様となる。これは条件文が要素間でコヒーレント (一致する傾向にある) なら問題ないが、条件文が多少でもランダムなら問題になる。最悪の場合には、全ての if で両方の分岐を実行しなくてはならなくなる。これは痛い。ループの動作も同様で、少なくとも一つのスレッドがループの実行を続ける限り、そのバッチ/Warp/Wavefront に含まれる全てのスレッドも実行を続ける。
もう一つピクセルシェーダーに特有な話題として discard (破棄) 命令がある。これはピクセルシェーダーが現在のピクセルを "殺す" ことでフレームバッファに対する書き込みが起こらないようにする命令である。ここでも、バッチ内の全てのピクセルが破棄された場合シェーダーユニットはその時点で実行を止めて別のバッチへ移行できる。一方でピクセルが一つでも残っていれば、他のスレッドもそれに付き合わなければならない。DX11 では出力のピクセルカバレッジをピクセルシェーダーから書き込めるようにすることでこの部分の細かい制御が可能になっている (この書き込みは必ず元の三角形/Z テストカバレッジと AND が取られて、プリミティブの外側へ書き込まれないことが保証される)。この機能によりピクセルシェーダーはピクセル全体ではなく個別のサンプルを破棄できるようになり、例えば独自のディザリングアルゴリズムを使うアルファトゥカバレッジの実装がピクセルシェーダーで可能になる。
ピクセルシェーダーは出力のデプスにも書き込むことができる (この機能はしばらく前から存在する)。私の経験では、これはアーリー Z テスト、階層的 Z テスト、Z 圧縮をまとめて撃ち落とす素晴らしい手段であり、一般にデプスに書き込むと可能な中で最も遅いパスが手に入る。ここまで来れば、遅くなる理由は内部の動作から想像できるはずだ :)
ピクセルシェーダーは複数の出力を生成できる。一般に出力はレンダーターゲット一つにつき四要素のベクトルが一つであり、レンダーターゲットは (現在) 最大で八つ設定できる。それからピクセルシェーダーはその結果をパイプラインにおける次のステージ、D3D が呼ぶところの「出力マージャー」に受け渡す。これが次章の話題となる。
サインオフする前に、最後に D3D11 でピクセルシェーダーができるようになったことを一つ紹介する: アンオーダードアクセスビュー (unordered access view, UAV) への書き込みである──これはコンピュートシェーダーとピクセルシェーダーだけが行える。一般的に言うと、UAV はコンピュートシェーダーにおけるレンダーターゲットの役割を果たす。ただしレンダーターゲットと異なり、シェーダーは UAV に書き込む位置を自分で決めることができ、API が指定する順序で書き込みが起こるという暗黙の保証は存在しない (だから「順序無し (unordered)」という名前が付いている)。今はこの機能の存在に言及するだけにして、コンピュートシェーダーの話をするときに詳しく説明する。
更新: コメントで Steve から正しい AMD の用語について指摘を受けた (「Wavefront」という言葉を私が忘れていたので、本章の最初のバージョンでは使われていなかった)。また GPU におけるシェーダーの実行を説明した Kayvon Fatahalian による素晴らしいプレゼンテーションも教えてくれた。ここには私が面倒で作らなかった図がたくさん載っている :) シェーダーコアの動作に興味があるなら、読んでみることを強くおすすめする。
そして...これで終わりだ! 今回は長い注意書きのリストはない。もし何かが欠けているなら、それは私が忘れているからであって、このシリーズには難しすぎるあるいは細かすぎると私が判断したからではない。書かれていないことに気付いたら、できることはするのでコメントから教えてほしい。
-
訳注: 「centroid」は「幾何中心」のこと。通常の補間モードを表す「barycenter」は「質量中心 (重心)」のこと。ただ本文中にもある通り、この二つの単語が対応する補間モードの説明になっているとは言い難い。[return]