WebAssembly Interface Types で全てが連携する!
ブラウザ外での WebAssembly の利用が盛り上がっています。
盛り上がりはスタンドアローンのランタイムを使った WebAssembly の実行だけではありません。Python, Ruby, Rust といった言語からの WebAssembly の実行にも注目が集まっています。
なぜそんなことが望まれるのでしょうか? 理由はいくつかあります:
-
「ネイティブ」をもっと簡単に
Node あるいは Python の CPython のようなランタイムでは、C++ などの低レベル言語でもモジュールを書ける場合があります。低レベル言語を使った方が高速なためです。Node のネイティブモジュールや Python の拡張モジュールを利用できるのですが、これらのモジュールはユーザーのデバイスでコンパイルが必要であり、使いやすいとは言えません。WebAssembly の「ネイティブ」モジュールを使えば、コンパイル無しにほぼ同等の速度を得られます。
-
ネイティブコードのサンドボックス化をもっと簡単に
これに対して Rust のような低レベル言語が WebAssembly を使うのは速度のためではなく、セキュリティのためです。WASI のアナウンスでもお伝えした通り、WebAssembly はデフォルトで軽量のサンドボックスを利用します。Rust などから WebAssembly を使えば、ネイティブコードをサンドボックス化できます。
-
プラットフォーム間でのネイティブコードの共有
異なるプラットフォーム (ウェブアプリとデスクトップアプリなど) で同じコードベースを共有できれば、時間と保守コストを削減できます。これはスクリプトと低レベルの両方について言えます。コードベースの共有に WebAssembly を使えば、異なるプラットフォーム上での実行が遅くなることはありません。

つまり WebAssembly は他の言語が抱える重要な問題で役に立ちます。
しかし現在の WebAssembly をこう使いたいとは思わないでしょう。WebAssembly を上述した環境で実行することはできますが、それだけでは不十分です。
現在の WebAssembly は対話に数値だけを使います。そのため二つの言語は互いの関数を呼び出せます。
しかし関数の引数や返り値が数値以外である場合には、事態が複雑になります。可能なのは次のどちらかです:
-
数値のみを使う非常に使いにくい API を持つモジュールを公開する... モジュールのユーザーは不便を強いられる。
-
モジュールを実行する全ての環境に対してグルーコードを追加する... モジュールの開発者は不便を強いられる。
しかし、こうしなければいけない理由などありません。
単一の WebAssembly モジュールを公開すれば全ての場所で実行できるべきです... そうすればモジュールのユーザーも開発者も不便を感じません。
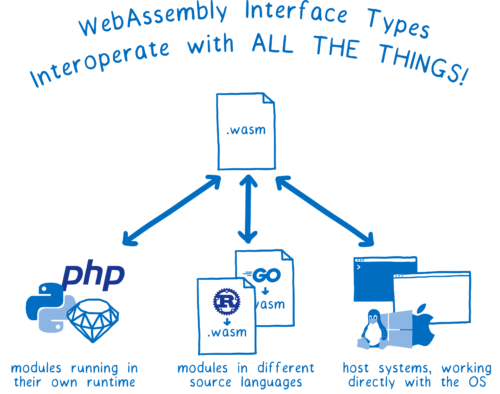
つまり同じ WebAssembly モジュールが、複雑な型を持つ機能豊富な API を使って次の要素と対話できるべきです:
-
ネイティブのランタイムで実行されるモジュール (例えば Python ランタイムで実行される Python モジュール)
-
異なるソース言語で書かれた他の WebAssembly モジュール (例えばブラウザ内で実行される Rust モジュールと Go モジュール)
-
ホストのシステム (例えばオペレーティングシステムへのシステムインターフェースを提供する WASI、あるいはブラウザの API)
初期段階にある新しい提案で、私たちはこれを「動作™」させる方法を掴み始めています。このデモで確認できます:
ではこの動作について見ていきます。まずは、現在の状況と解決する問題について説明します。
WebAssembly と JS の対話
WebAssembly はウェブでしか使えないわけではありませんが、今までの WebAssembly の開発はウェブに集中してきました。
そうしてきた理由は、具体的な使用例に集中することでより良い設計が可能になるためです。WebAssembly は間違いなくウェブで実行されるので、最初にウェブを考えるのが理にかなっていました。
これによって十分な機能を持った MVP が完成しました。この時点の WebAssembly が対話する必要があった言語はただ一つ JavaScript だけです。
この対応は比較的簡単でした。ブラウザでは WebAssembly と JS が効率的な対話を双方向に行えるように、両方が同じエンジンで実行されます。
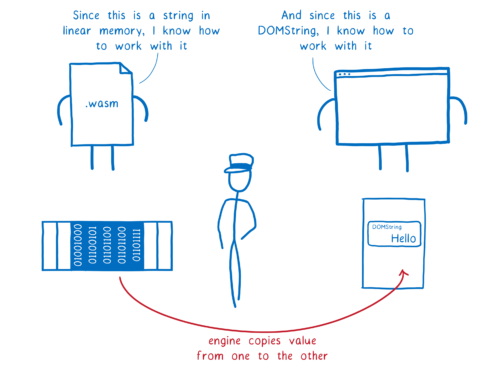
ただし JS と WebAssembly の対話には一つだけ問題があります... 型が違うのです。
現在の WebAssembly は対話に数値だけを使います。JavaScript にも数値はありますが、他の型がたくさんあります。
そして数値にもいろいろあります。WebAssembly は int32, int64, float32, float64 という四種類の数値を持ちますが、現在の JavaScript は Number しか持ちません (ただし近いうちに BigInt という新しい数値型が追加されます)。
違いは型の名前だけではありません。メモリに保存する方法も異なります。
まず、JavaScript ではどんな値も型にかかわらずボックスと呼ばれるものに格納されます (boxing は別の記事で詳しく説明しました)。
一方 WebAssembly では、数値が静的な型を持ちます。そのため WebAssembly は JS のボックスを必要としません (し、理解もしません)。
この違いにより両者の間の通信が難しくなります。

しかしある数値型から別の数値型に値を変換したいのであれば、非常に簡単な規則が存在します。
この規則はとても単純なので、書くのも簡単です。WebAssembly の JS API 仕様書 に書かれています。

このマッピングはエンジンにハードコードされます。
これはエンジンがリファレンス本を持っているようなものです。エンジンが JS と WebAssembly の間でパラメータを渡したり値を返したりするときには、このリファレンス本を戸棚から取り出して値の変換方法を確認します。

型の種類が少ない (数値しかない) ので、このマッピングは非常に簡単です。これは MVP にとって都合が良く、決めなければならない厄介な設計判断が減ります。
一方で WebAssembly を使う開発者から見ると、これによって事態は複雑になります。JS と WebAssembly の間で文字列を渡すには、まず文字列を数値の配列に変換し、さらに数値の配列を文字列に変換しなければなりません。これは前回の記事でもお伝えしました。

この処理は難しくありませんが、面倒です。そこで抽象化を行うツールが開発されました。
例えば Rust の wasm-bindgen や Emscripten の Embind を使うと、文字列から数値への変換を行う JS グルーコードで WebAssembly モジュールを自動的にラップできます。
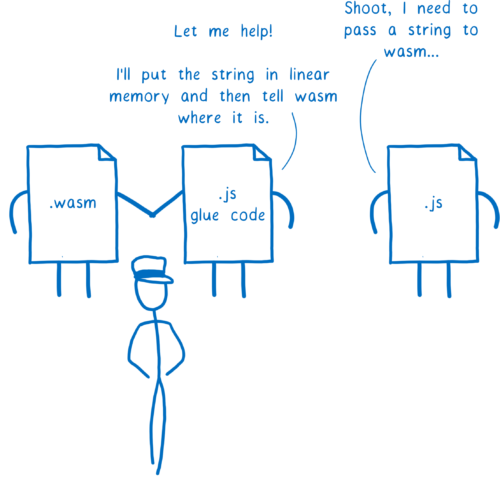
こういったツールは、プロパティを持った複雑なオブジェクトといった高レベルの型に対しても同様の変換ができます。
これは問題なく機能します。しかし完璧ではないのが明らかなケースがいくつかあります。
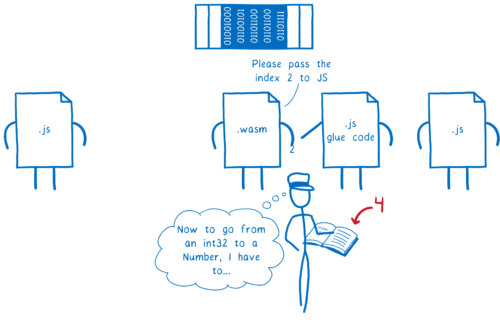
例えば文字列が WebAssembly を通過する場合です。つまり、JavaScript 関数が WebAssembly 関数に文字列を渡し、その WebAssembly 関数が別の JavaScript 関数に文字列を渡すケースです。
このとき次の処理が起こります:
-
最初の JavaScript 関数が文字列を JS グルーコードに渡す。
-
JS グルーコードが文字列オブジェクトを数値に変換し、その数値をメモリ上に線形に並べる。
-
そして数値 (文字列の先頭を指すポインタ) を WebAssembly に渡す。
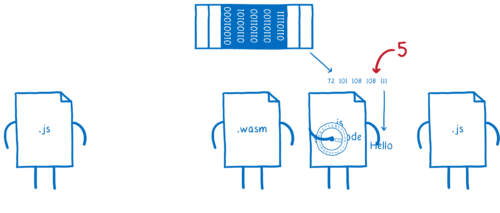
-
WebAssembly 関数がその数値を逆側の JS グルーコードに渡す。
-
JS グルーコードがメモリの線形領域から数値を読み、文字列オブジェクトにデコードする。
-
その文字列オブジェクトが二番目の JavaScript 関数に渡される。
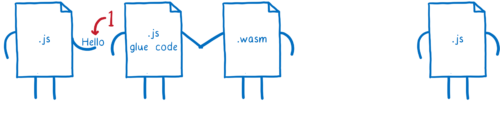
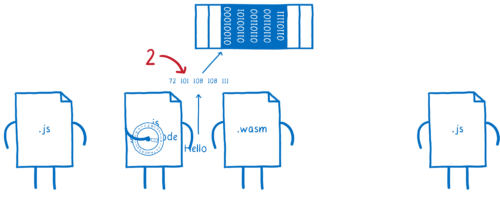
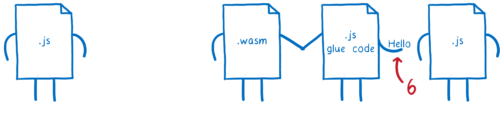
つまり、片側の JS グルコードの処理をもう片方のグルーコードが逆回ししています。基本的に同一のオブジェクトを作り直す処理に結構な時間をかけているわけです。
もしオブジェクトを変換せずに WebAssembly 内を通過させることができたら、もっと簡単なはずです。
もしそうすると、WebAssembly は文字列に対して何もできなくなります 型も理解できません。型の問題は解決できなくなります。
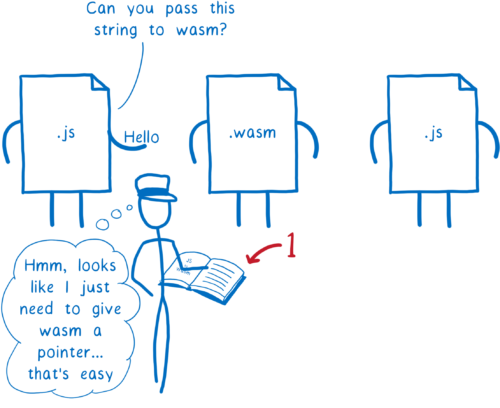
しかし、WebAssembly は二つの JS 関数との文字列オブジェクトのやり取りなら行えます。なぜなら JS 関数は型を理解するからです。
これが理由の一つとなって、WebAssembly reference types proposal が提出されました。この提案は anyref と呼ばれる新しい基本型を WebAssembly に追加します。
anyref を使った場合、JavaScript は WebAssembly に参照オブジェクト (本質的にはメモリアドレスを公開しないポインタ) を渡します。この参照ポインタは JS ヒープにあるオブジェクトを指します。WebAssembly がこのポインタを他の JS 関数に渡せば、その関数からオブジェクトを利用できます。
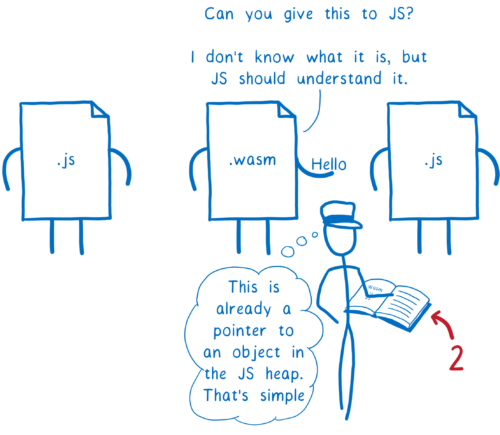
この提案により JavaScript との連携で生じる最も厄介な問題の一つが解決されます。しかしブラウザにおいて解決しなければならない問題はこれだけではありません。
ブラウザには別種類の、はるかに巨大な型の集合が存在します。パフォーマンスを改善するには、そういった型との連携も WebAssembly に必要です。
WebAssembly とブラウザの直接の対話
JS はブラウザの一部分でしかありません。ブラウザには他にも Web API と呼ばれる関数がたくさんあります。
内部の Web API 関数は C++ か Rust で書かれています。オブジェクトをメモリに保存する方法も関数ごとに異なります。
Web API のパラメータと返り値は様々な型を持つので、全ての型に対してマッピングを手で作るのは困難です。物事を簡単にするために、こういった型の構造をやり取りする方法が標準化されました Web IDL です。
通常 Web API 関数を使うときは JavaScript から使用します。そのため JS の型を持った値が関数に渡されます。JS の型から Web IDL の型への変換はどのように行われるのでしょうか?
WebAssembly の型から JavaScript の型へのマッピングと同じように、JavaScript の型から Web IDL の型へのマッピングが存在します。
つまりエンジンがリファレンス本をもう一冊持っていて、そこに JS を Web IDL に変換する方法が書かれています。そしてこのマッピングはエンジンにハードコードされます。
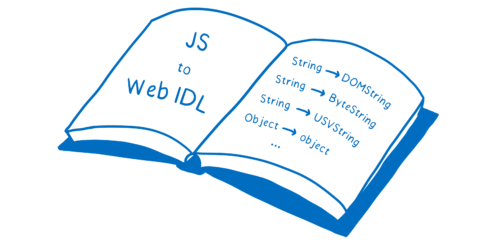
多くの型については JavaScript から Web IDL へのマッピングはとても単純です。例えば DOMString といった型は JS の String と互換性があるので、直接マッピングできます。
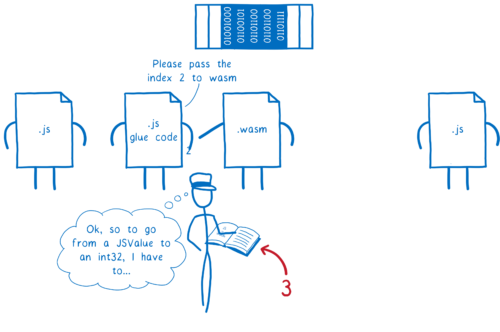
それでは、Web API を WebAssembly から呼ぶと何が起こるでしょうか? 問題が起こるのはここです。
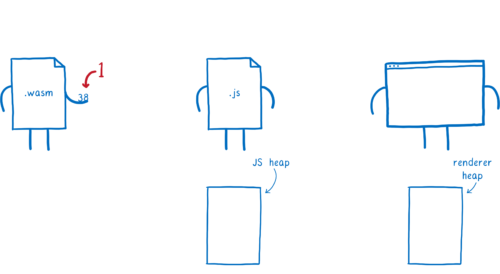
WebAssembly の型から Web IDL の型へのマッピングは現在ありません。そのため数値のような単純な型であっても、関数呼び出しは JavaScript を経由する必要があります。
つまり、次の処理が起こります:
-
WebAssembly が JS に値を渡す。
-
そのときエンジンが値を JavaScript の型に変換し、メモリ上の JS ヒープに配置する。
-
それから、その JS の値が Web API 関数に渡される。そのときエンジンは JS の値を Web IDL の型に変換し、メモリ上の他の場所 (レンダラのヒープ) に配置する。
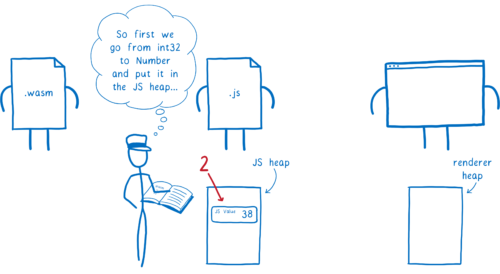
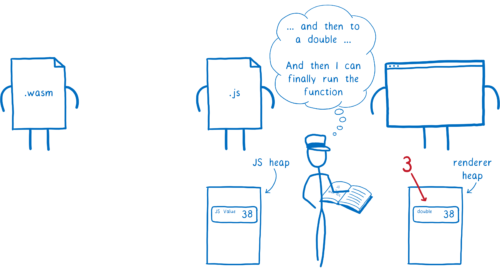
この処理は必要以上に時間がかかり、メモリの使用量も増えます。
この問題には明らかな解決法があります WebAssembly から Web IDL への直接のマッピングを作ることです。しかし、これは見かけほど簡単ではありません。
boolean や unsigned long (数値) といった単純な Web IDL の型に対しては、WebAssembly から Web IDL への明確なマッピングが存在します。
しかし多くの場合で、Web API のパラメータはもっと複雑な型を持ちます。例えば API が受け付けるのが辞書型であれば対応するのはプロパティを持ったオブジェクトであり、シーケンスであれば配列が対応します。
WebAssembly の型と Web IDL の型の間で明解なマッピングを作成するには高階型が必要です。私たちはこれに GC proposal で取り組んでいます。これを使うと、WebAssembly から GC オブジェクト (構造体や配列) を作成できるようになります。GC オブジェクトがあれば Web IDL 型へのマッピングも可能になります。
しかし、Web API を利用する唯一の方法が GC オブジェクトを使うものであったとすると、C++ や Rust のように GC オブジェクトを使わない言語からの利用が不便になってしまいます。Web API と対話するたびに新しい GC オブジェクトを作成し、値をメモリの線形領域からそのオブジェクトへコピーする必要があるからです。
これでは現在の JS のグルーコードを使ったやり方がほんの少し改善されるだけです。
GC オブジェクトを作成するために JS グルーコードを使いたくはありません 時間と空間の無駄です。しかし同じ理由で、WebAssembly モジュールにもそれを行わせたくはありません。
メモリの線形領域を使う (Rust や C++ のような) 言語でも、エンジンに組み込みの GC を使う言語と同じぐらい簡単に Web API を呼び出せることが望まれます。つまりメモリの線形領域にあるオブジェクトから Web IDL の型へのマッピングも必要になります。
しかしここで、メモリの線形領域の使い方が言語によって異なるという問題があります。またある言語の表現を一つ選ぶこともできません。他の言語から利用したときの効率が落ちます。
メモリ上における正確なレイアウトは異なることが多いものの、抽象的な概念の中には多くの言語に共通するものもあります。
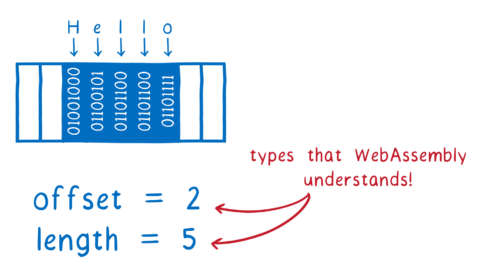
例えば文字列は多くの場合、文字列の開始メモリアドレスと文字列の長さで表されます。そして文字列の内部表現がもっと複雑なものであったとしても、外部 API を呼び出す場合にはこの形への変換が通常は必要です。
つまり文字列は WebAssembly が理解できる型に落とし込めます 二つの i32 です。
こういったマッピングをエンジンにハードコードすることもできます。つまりエンジンに WebAssembly から Web IDL へのマッピングを記したリファレンス本をさらにもう一冊与えるということです。
しかしここで問題があります。WebAssembly は型検査される言語であり、エンジンはセキュリティのため呼び出し側のコードから渡された値が呼ばれた側が期待する型であるかを検査します。
こうしている理由は、型の不一致を利用すると攻撃者がエンジンに意図しない動作をさせることが可能なためです。
文字列を受け取る関数に整数を渡すと、エンジンが大声を上げます。ここでエンジンは大声を上げるべきです。
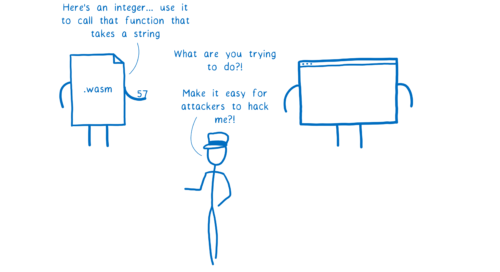
必要なのは、モジュールがエンジンに向かって「Document.createElement() が文字列を取るのは知ってるよ。でも今は二つの整数を渡すから、これを使って私が管理するメモリの線形領域から DOMString を作ってくれ。最初の整数が文字列の開始アドレスで、二つ目の整数が文字列の長さだから」と伝える手段です。
Web IDL proposal が行うのがまさにこれです。Web IDL proposal は WebAssembly モジュールの使う型と Web IDL の型の間でマッピングを作成する方法を提供します。
このマッピングはエンジンにハードコードされません。そうでなくて、マッピングを記した小冊子がモジュールに付きます。
これを使うと、エンジンに「この関数については、二つの整数が文字列であるかのように型検査をしてくれ」と伝えられます。
この小冊子がモジュールに付属する理由は他にもあります。
通常は文字列をメモリの線形領域に保存するモジュールであっても、anyref や GC 型を特定の場所で利用する場合があります。例えば JS 関数から受け取った DOM ノードのようなオブジェクトを Web API に渡す場合です。
そのためモジュールは関数ごと (さらには引数ごと) に異なる型をどう扱うかを選択できる必要があります。このマッピングがモジュールから提供されれば、マッピングをモジュールに応じて細かく調整できます。

この小冊子はどうやって生成するのでしょうか?
コンパイラがこの情報を処理して、WebAssembly モジュールに独自のセクションを追加してくれます。多くの言語ツールチェインにおいて、プログラマーがすべきことは多くありません。
例として、Rust ツールチェインが単純なケースをどう処理するかを見ましょう。次の関数は文字列を alert 関数に渡します。
#[wasm_bindgen]
extern "C" {
fn alert(s: &str);
}
#[wasm_bindgen] という注釈を使ってこの関数を小冊子に含めるようコンパイラに指示を出せば、プログラマーの仕事は終わりです。コンパイラはデフォルトで文字列がメモリの線形領域に並んでいるとみなし、正しいマッピングを生成します。異なる処理 (anyref を使うなど) が必要な場合には、二番目の注釈を使ってコンパイラにそれを伝えます。
こうすれば、中間の JS を取り除けます。WebAssembly と Web API は高速に値をやり取りでき、さらに JS のコードも減ります。
そして、サポートする言語の種類は犠牲になっていません。様々な種類の言語を WebAssembly にコンパイルでき、その全ての言語が自身の型から Web IDL の型へのマッピングを提供できます 線形メモリを使う言語、GC オブジェクトを使う言語、あるいはその両方でも構いません。
この解決法を振り返ったとき、もっと大きな問題が解決できていることに私たちは気が付きました。
WebAssembly とあらゆる物の対話
ここで最初の話題に戻りましょう。
言語ごとに異なる型システムを使いながら、WebAssembly とあらゆる言語が連携する実現可能な方法はあるでしょうか?
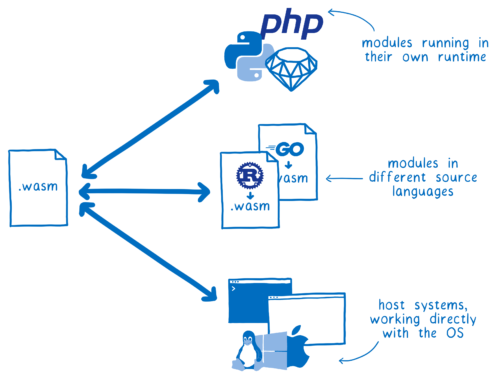
選択肢をいくつか見ていきます。
エンジンへのマッピングのハードコードもやろうと思えばできます。WebAssembly と JS、および JS と Web IDL と同様です。
しかしこのためには、全ての開発者が自身のマッピングを作成し、エンジンが全てのマッピングをサポートし、どちらかが変更されるたびにもう片方を更新しなければなりません。これはめちゃくちゃです。
これは初期のコンパイラの設計に似ています。初期のコンパイラには全てのソース言語から全ての機械語に対するパイプラインがありました。WebAssembly についての最初の記事で触れた通りです。

こんなに複雑なものは望んでいません。全ての言語とプラットフォームがお互いに対話できつつも、スケーラブルなことが求められます。
何か別の方法... 現代的なコンパイラのアーキテクチャのようなものが必要です。現代的なコンパイラはフロントエンドとバックエンドに分かれています。フロントエンドがソース言語を抽象中間言語 (abstract intermediate language, IR) に変換し、バックエンドがこの IR をターゲットの機械語に変換します。
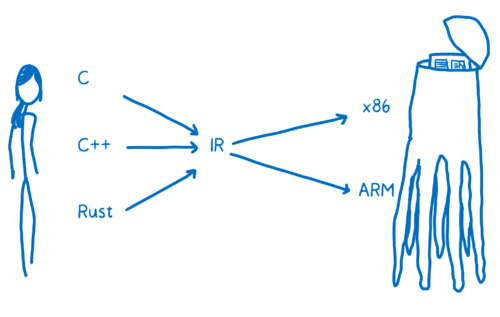
ここで Web IDL の経験が活きます。よく見れば、Web IDL と IR が似ていることに気付くはずです。
今の Web IDL はウェブでしか使えませんが、ウェブの外で WebAssembly の利用が広まっています。そのため今の Web IDL が優れた IR だとは言えません。
では、Web IDL のアイデアを元に新しい抽象型の集まりを作ったら?
こうして WebAssembly interface types proposal が生まれました。
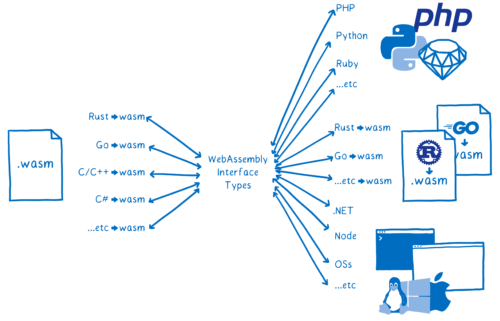
interface type (インターフェース型) は具体的な型ではなく、現在の WebAssembly における int32 や float64 とは異なります。また WebAssembly ではそういった型に対する操作は定義されません。
例えば WebAssembly に文字列の結合操作は追加されません。そうでなくて、全ての操作は両端の具体的な型で実行されます。
これが可能になる重要なポイントが、インターフェース型によってつながる二つの言語が表現を共有しないことです。そうでなくて、相手へ値をコピーするのがデフォルトです。
この規則の例外になるケースが一つあります: 前述の新しい参照型 (anyref など) です。この場合はオブジェクトへのポインタが二つの言語の間でコピーされ、両方のポインタが同じものを指します。そのため理論上は、両側が表現を共有する必要があります。
前に説明した anyref の例のように参照が WebAssembly モジュールを通り抜けるだけならば、表現の共有は必要ありません。WebAssembly モジュールはどのみち型を理解せず、他の関数に渡しているだけだからです。
しかし両側が表現を共有したいこともあるでしょう。例えば GC proposal には型の定義を作成して表現を共有する仕組みがあります。こういった場合には、表現をどの程度共有するかの選択は API を設計する開発者に委ねられます。
これによりモジュールが簡単に様々な言語と対話できるようになります。
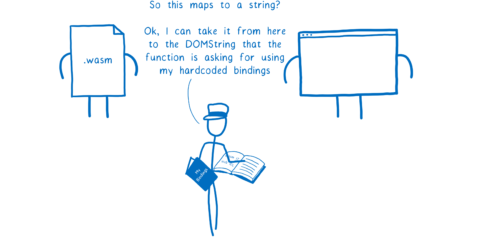
ブラウザなどのケースでは、インターフェース型からホストの具体的な型へのマッピングがエンジンに埋め込まれることになるでしょう。
そうするとマッピングの一部はコンパイル時に埋め込まれ、その他はロード時にエンジンに渡されるようになります。
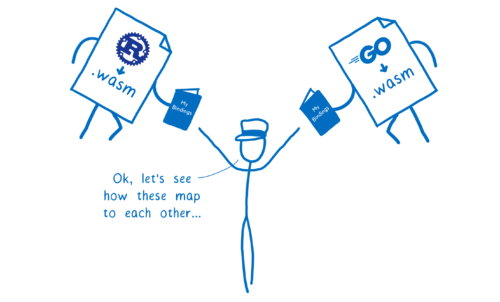
その他の、二つの WebAssembly モジュール同士の対話などの場合には、両者が小冊子を提示します。この小冊子が自身の関数の型と抽象型の間のマッピングを提供します。
異なるソース言語で書いたモジュールを互いに対話させるのに必要なのはこれだけではありません (将来もっと記事を書くつもりです) が、インターフェース型はそれに向けた大きな一歩です。
"why" が理解出来たと思うので、次は "how" を見ていきます。
インターフェース型は実際どうなっている?
詳細に入る前に、もう一度言っておきます: この提案はまだ開発中です。最終的な提案は大きく異なるものになる可能性があります。
それから、ここで説明されるのは全てコンパイラの仕事です。そのためもしこの提案が完成したとしても、あなたが知る必要があるのは利用するツールチェインが受け付ける注釈だけです (前述の wasm-bindgen など)。内部で起きていることを知る必要は本当はありません。
しかし提案の詳細は良く詰まっているので、この考えを見ていきましょう。
解決すべき問題
解決すべき問題は、あるモジュールと別のモジュールとの対話 (あるいはブラウザなどのホストとの直接の対話) において異なる型の値を変換する問題です。
変換が必要になる場所が四つあります:
エクスポートされた関数
-
パラメータを呼び出し側から受け取る
-
返り値を呼び出し側に返す
インポートされた関数
-
関数にパラメータを渡す
-
関数からの返り値を受け取る
この四つはどれも次の二つの方向のいずれかであるとみなせます:
-
持ち上げ (lifting): モジュールを離れる値に対する、具体的な型からインターフェース型への変換
-
引き下げ (lowering): モジュールに入る値に対する、インターフェース型から具体的な型への変換
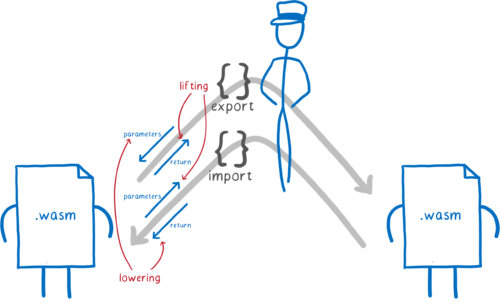
具体的な型とインターフェース型の変換方法をエンジンに伝える
関数のパラメータと返り値に対して適用すべき変換をエンジンに伝える方法が必要です。どうすればいいでしょうか?
インターフェースアダプター (interface adapter) を定義します。
例として、WebAssembly にコンパイルされた Rust モジュールを考えます。このモジュールは greeting_ 関数をエクスポートし、この関数はパラメータを受け取ることなく挨拶メッセージを返します。
現在この関数は (WebAssembly のテキストフォーマットで) 次のようになります:

この関数は二つの整数を返します。
しかし私たちはこの関数が string というインターフェース型を返すようにしたいのでした。そのためにインターフェースアダプターと呼ばれるものを追加します。
インターフェース型に対応するエンジンがこのインターフェースアダプターを発見すると、オリジナルのモジュールをそのインターフェースでラップします。

string を返す」
エンジンは greeting_ をエクスポートしなくなり、オリジナルの関数をラップする greeting 関数だけがエクスポートされます。新しい greeting 関数が返すのは文字列であり、二つの数値ではありません。
これで後方互換性が手に入ります。interface type に対応しないエンジンはオリジナルの greeting_ 関数 (二つの整数を返す関数) をエクスポートできるからです。
ではインターフェースアダプターが二つの整数を文字列に変換するようエンジンに伝えるときにどうするのでしょうか?
インターフェースアダプターはアダプター命令 (adapter instruction) を使います。

この例では二つのアダプター命令が使われています。どちらも interface type の提案が規定する (小数の) 新しい命令の一つです。
この二つの命令は次のように動作します:
-
アダプター命令
call-exportはオリジナルのgreeting_関数を呼ぶ。この関数は元のモジュールがエクスポートするものであり、二つの数値を返す。この二つの数値はスタックに積まれる。 -
アダプター命令
memory-to-stringは文字列を表すバイト列をこの二つの数値から作る。"mem" が付いているのは、将来 WebAssembly モジュールが複数のメモリを持つことが想定されているためである。この部分が使うメモリを指定する。これを受けてエンジンはスタックの頂上から二つの数値 (文字列の先頭ポインタと長さ) を取り、どのバイトを使うのかを計算する。
これが完全な機能を持ったプログラミング言語であるかのように見えるかもしれませんが、この部分に制御フローなく、ループや条件分岐は使えません。そのためエンジンに命令を与えてはいますが、この部分は宣言的です。
この関数が文字列のパラメータ (例えば挨拶する人の名前) を取るとしたら、どうなるでしょうか?
ほとんど同様です。アダプター関数にパラメータを追加してインターフェースを変更し、アダプター命令を二つ追加すれば済みます。

string を取る」 「渡された文字列オブジェクトの参照をスタックに積む」 「文字列オブジェクトからバイト列を取り出し、メモリの線形領域に配置する」
新しい命令を説明します:
-
arg.get命令は文字列オブジェクトの参照を取り出し、それをスタックに積む。 -
string-to-memory命令はそのオブジェクトからバイト列を取り出し、それをメモリの線形領域に配置する。ここでもバイト列を配置するメモリを指定する必要がある。加えてメモリの確保方法も伝える。メモリの確保方法はアロケータ関数を渡すことで伝える (オリジナルモジュールがエクスポートする関数となる)。
このように命令を使うと嬉しいのが、後から命令を拡張できる点です。WebAssembly コアの命令を拡張できるのと同じです。私たちは現在定義している命令が良いものだと思っていますが、どんなときにも使わなければならない唯一の命令であるとは考えていません。
もっと深く理解したいなら、Explainer にずっと詳細な説明があります。
エンジンに命令を送る
この命令をエンジンに送るにはどうするのでしょうか?
こういった注釈情報はバイナリファイルのカスタムセクションに追加されます。
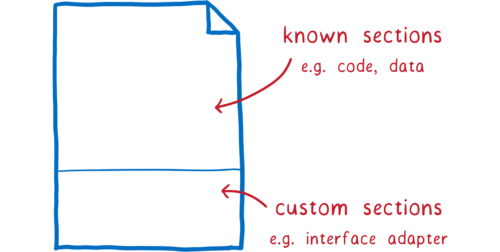
エンジンがインターフェース型を知っていれば、カスタムセクションを利用します。もし知らなければエンジンはカスタムセクションを無視しますが、カスタムセクションを読んでグルーコードを作成する polyfill を利用できます。
CORBA や Protocol Buffers と何が違うのか?
同じ問題を解決しているように思える規格がいくつかあります 例えば CORBA, Protocol Buffers, Cap'n Proto です。
何が違うのでしょうか? 実は、こういった規格はずっと難しい問題に取り組んでいます。
これらはどれもメモリを共有しないシステムとの対話が可能なように設計されています 異なるプロセスで実行されるシステム、あるいはネットワークの向こう側で動作する異なるマシン上のシステムです。
そのためシステムの境界を越えたデータのやり取りが可能でなければなりません オブジェクトの「中間表現」が必要です。
そのためこういった規格は、境界を効率良く行き来できるシリアライズフォーマットを定義しなければなりません。規格の多くを占めるのがこの定義です。
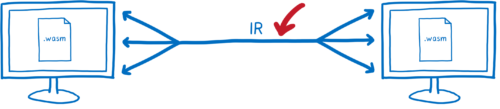
これは似たような問題に見えますが、実はほぼ正反対の問題です。
インターフェース型を使った場合には、この「中間表現」がエンジンの外に出ることはありません。モジュールにさえ見えません。
モジュールが目にするのは処理結果としてエンジンが寄越すものだけです 自身のメモリの線形領域にコピーされるか、参照として渡されます。エンジンに型のレイアウトを伝える必要はないので、規定もされません。
規定されるのは、エンジンとの対話方法です。つまりエンジンに渡す例の小冊子で使える宣言的言語が規定されます。
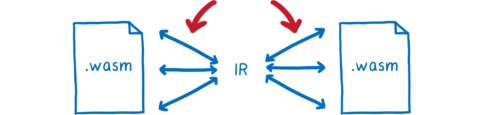
嬉しい副作用もあります: この言語は宣言的なので、エンジンは変換が不必要な場合 例えば両方のモジュールが同じ型を使う場合 には変換を完全にスキップできます。
試すには?
上述の通りこれはまだ初期段階の提案です。速いペースで変更されるので、プロダクションでは使わないでください。
それでも試してみたいのであれば、私たちが WebAssembly Interface Types を実装した生成から実行までのツールチェインがあります:
-
Rust ツールチェイン
-
wasm-bindgen
-
WebAssembly ランタイム Wasmtime
これらのツールを管理するのは規格に取り組む私たちなので、開発が規格から取り残されることはありません。
ツールは改定を続けますが、その変更は同時に行うようにしています。そのため全てのツールを最新のバージョンにしておけば、ツールが壊れることはないはずです。
このような方法で試すことができます。最新のバージョンについてはデモレポジトリを参照してください。
謝辞
-
多くの言語とランタイムにまたがる様々な要素をまとめ上げたチームに感謝します: Alex Crichton, Yury Delendik, Nick Fitzgerald, Dan Gohman, Till Schneidereit.
-
提案の作業に取り組んだ提案の協同代表者とその仲間に感謝します: Luke Wagner, Francis McCabe, Jacob Gravelle, Alex Crichton, Nick Fitzgerald.
-
この記事の執筆を知識とフィードバックで支えてくれた素晴らしいコントリビューター Luke Wagner と Till Schneidereit に感謝します。
Lin Clark について
Lin は Mozilla の Advanced Development で働いており、Rust と WebAssembly にフォーカスしています。