3. 合意によるクラスター構築
本章では、高信頼の分散計算をサポートするために設計されたネットワークプロトコルの実装を議論する。ネットワークプロトコルの正しい実装は難度が高いことから、バグを最小化する手法、そして残りの少数のバグを検出・修正する手法を見る。高信頼なソフトウェアの作成でも特殊な開発・デバッグ手法が必要となる。
3.1 現実世界の例
本章はプロトコルの実装に焦点を当てる。ただ、読者のモチベーションを上げるための例として最初は単純な銀行口座管理サービスを考えよう。このサービスでは口座番号で特定される各口座が残高を持つ。ユーザーは「引き出し」「振り込み」「残高照会」といった操作のリクエストを通して口座にアクセスする。「振り込み」操作は二つの口座が関わる操作であり、振り込み元口座の残高が少なすぎる場合は実行できない。
この銀行口座管理サービスが単一のサーバーでホストされるなら、振り込み操作は非常に簡単に実装できる: ロックを使って振り込み操作が同時に複数実行されないことを保証し、その上で振り込み元口座の残高が十分かどうかを確認すれば問題は起きない。しかし、口座残高というクリティカルな情報を扱うサービスを単一のサーバーでホストすることはできない。その代わり、このサービスは複数のサーバーにわたって分散される。分散されたサービスでは複数のサーバーが全く同じコードの個別のインスタンスを実行し、ユーザーはどのサーバーと対話したとしても操作を実行できる。
分散処理のナイーブな実装では、各サーバーが全口座残高のローカルコピーを保持する。このとき各サーバーは任意の操作を処理でき、何らかの操作で残高が変化した場合はその更新を他のサーバーに通知する。しかし、このアプローチは深刻な故障モードを持つ: 二つのサーバーが同じ口座に対する操作を同時に処理した場合、正しいのはどちらのサーバーが持つ口座だろうか? サーバーによって共有されるのが残高ではなく操作だったとしても、同時に処理される二つの振り込み操作によって口座残高がマイナスになってしまう可能性は残る。
本質的に、こういった故障モードは「サーバーが、自身の持つローカルの状態が他のサーバー上の状態と一致することを確認せずにローカルの状態を使った操作を処理する」ことで発生する。例えば、サーバー A が口座 101 から口座 202 への振り込み操作のリクエストを受け取ったとき、サーバー B は口座 101 の全残高を口座 202 に振り込む操作を実行した結果をサーバー A に伝える直前だったとする。この瞬間サーバー A が持つローカルの状態はサーバー B が持つ状態と異なるので、サーバー A は振り込み操作が実行可能であると誤って判断し、口座 101 の残高が負になってしまう。
3.2 分散状態機械
こういった問題を回避する手法の一つに分散状態機械 (distributed state machine) がある。「全てのサーバーが同一の決定的状態機械を同一の入力に対して実行する」が基本的なアイデアとなる。このとき状態機械の性質により、全てのサーバーが同じ出力を得る。「振り込み」や「残高照会」といった操作が (口座番号や振り込み額といったパラメータと共に) 状態機械に対する入力となる。
本章で解説するアプリケーションが持つ状態機械は単純である:
def execute_operation(state, operation):
if operation.name == 'deposit':
if not verify_signature(operation.deposit_signature):
return state, False
state.accounts[operation.destination_account] += operation.amount
return state, True
elif operation.name == 'transfer':
if state.accounts[operation.source_account] < operation.amount:
return state, False
state.accounts[operation.source_account] -= operation.amount
state.accounts[operation.destination_account] += operation.amount
return state, True
elif operation.name == 'get-balance':
return state, state.accounts[operation.account]
状態を改変しない操作 get-balance が状態機械の一部として実装されている点に注目してほしい。こうすることで、get-balance が返す口座残高がサーバークラスターが持つ最新の情報であり、単一のサーバーが持つローカルの (古い可能性のある) 情報でないことが保証される。
上に示した状態機械が情報科学の講義で学ぶ典型的な状態機械と違って見えたかもしれない。この状態機械の状態は遷移が関連付いた名前付きの状態の有限集合ではなく、口座残高の集合である。そのため可能な状態は無限に存在するものの、決定的状態機械の一般的な性質は成り立つ: 例えば、同じ状態から同じ操作を処理すると必ず同じ出力が得られる。
分散状態機械を使うと全てのサーバーで同じ操作が実行されることを保証できると分かった。しかし、その状態機械に対する入力をどのように一致させるのかという問題は残る。これは合意 (consensus) と呼ばれる問題であり、本章では Paxos アルゴリズムの一種を使って合意の問題を解決する方法を見る。
3.3 Paxos アルゴリズムを使った合意
Paxos は Leslie Lamport によって考案されたアルゴリズムであり、1990 年に投稿され 1998 年に出版された奇抜な論文 The Part-Time Parliament1 で発表された。Lamport の論文は Paxos アルゴリズムを本章よりはるかに詳細に議論しており、読み物としても面白い。本章の実装で採用した Paxos アルゴリズムの拡張は章末に示した参考文献で解説されている。
最も単純な形の Paxos アルゴリズムは、複数のサーバーが変化しない一つの値に関して合意する方法を与える。Paxos を基礎として拡張した Multi-Paxos アルゴリズムは番号付いた事実の列に関して一つずつ合意を形成する方法を与える。本章では Muti-Paxos を使って状態機械に対する入力に関する合意を形成してから実行するものとして分散状態機械を実装する。
単純な Paxos アルゴリズム
では「単純な」Paxos アルゴリズムから説明を始めよう。変化しない単一の値に関して合意を形成する方法を与えるのが Paxos アルゴリズムである。Paxos は The Part-Time Parliament に登場する架空の島の名前であり、そこで法律家は成立させる法律を投票で決定する。この仕組みを Lamport は Synod (教会会議) プロトコルと呼んだので、Paxos アルゴリズムを Synod プロトコルと呼ぶこともある。
以降で見るように、Paxos アルゴリズムはより複雑なアルゴリズムを構成する重要なパーツとなる。これまで考えていた例で言えば、Paxos アルゴリズムで合意される単一の値は「特定の日に銀行が処理する最初の取引」である。銀行は毎日多くの取引を処理するものの、特定の日の最初の取引は一つだけであり、変化しない。よって Paxos アルゴリズムを使えばその値に関する合意を形成できる。
Paxos アルゴリズムは投票を繰り返すことで動作する。この投票は提案者 (proposer) と呼ばれるクラスターの単一メンバーが開始する。各投票において、提案者からの値を受け取るメンバーを受理者 (acceptor) と呼ぶ。提案者の目標は (値が決定していないなら) 受理者の過半数に自身の値を受理させることである。
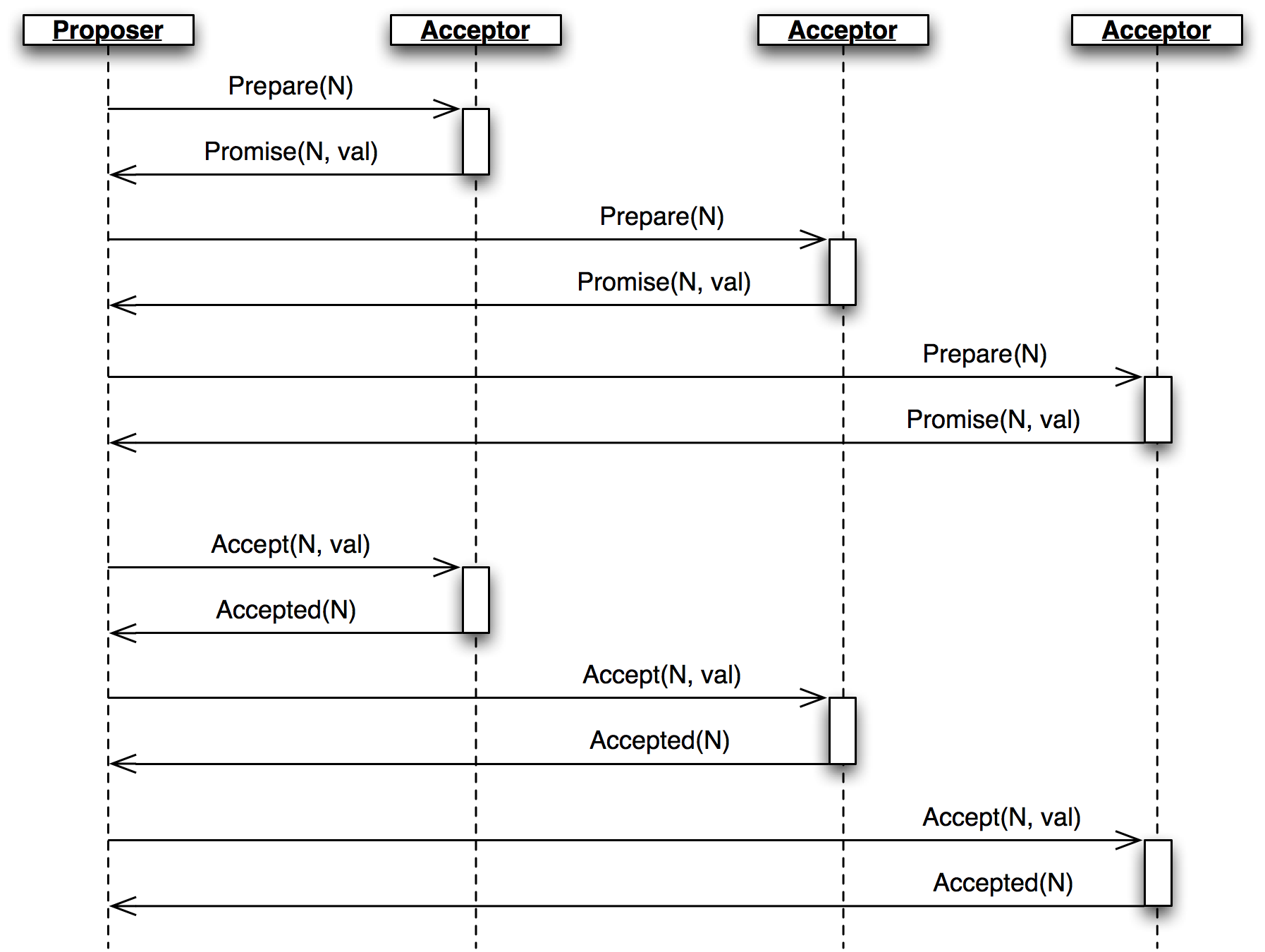
投票は提案者が投票番号を \(N\) とした Prepare メッセージを受理者に送信し、その過半数から返答を得るところから始まる (図 1)。
Prepare メッセージは各受理者に対する「受理済みの値であって対応する投票番号が \(N\) より小さいものがあるなら、その中で最大の投票番号と対応する値を教えてくれ」というリクエストである。Prepare メッセージを受け取った受理者は条件を満たす \(N\) と値を (もし存在するなら) 入れた Promise メッセージを返答し、これ以降は投票番号が \(N\) より小さい値を受理しないと約束する。もし受理者が \(N\) より大きい投票番号に対する同様の約束をしていたなら、その投票番号を Promise メッセージに入れて提案者に返答し、投票は無効であると伝える。このとき投票は終了するものの、提案者は新しい投票を (大きな投票番号を使って) 開始して構わない。
受理者の過半数から返答が得られたなら、提案者は投票番号と値を入れた Accept メッセージを全ての受理者に送信する。このとき、提案者はいずれの受理者からも Promise メッセージを通して既存の値を受け取らなかったら自身の値を Accept メッセージに入れる値として利用し、そうでなければ最も大きな投票番号を持つ値を利用する。
これを受けて受理者は、これまでの約束が破られないなら、Accept メッセージで受け取った値を受理したものとして記録し、その投票番号と値を入れた Accepted メッセージを返答する。提案者が受理者の過半数から自身が使ったのと同じ投票番号と値を伝えられたとき投票は終了し、値が決定する。
先述の例に戻ると、最初に受理された値は存在しないので、最初の投票で全ての受理者は値を持たない Promise メッセージを返答し、提案者は自身の値を入れた Accept メッセージを全ての受理者に送信する。例えば次のようなコードが使われるだろう:
operation(name='deposit', amount=100.00, destination_account='Mike DiBernardo')
合意が形成された後に \(N\) より小さな投票番号と異なる操作 (例えば 'Dustin J. Mitchell' への振り込み) に関する投票が他の提案者によって開始されたとしても、受理者は「投票番号が \(N\) より小さい値を受理しない」と約束しているのでそれを受理しない。また、\(N\) より大きな投票番号と異なる操作に関する投票があったとしても、受理者は Promise メッセージで 'Michael' による 100.00 の引き出しを提案者に伝えるので、提案者が Accept メッセージで受理者に伝えるのは 'Dustin J. Mitchell' への振り込みではなく 'Michael' による引き出しとなる。つまり新しい投票は受理されるものの、合意される値は最初の投票と同じになる。
実は、このプロトコルでは複数の投票が同時に起きたとしても、メッセージが遅延したとしても、受理者の過半数未満で障害が起きたとしても、二つの異なる値が決定することはない。
複数の提案者が同時に開始した投票がいずれも成功しない状況は容易に発生する。そして、この後に二つの提案者が投票をもう一度開始してタイミングが噛み合い続けると、デッドロックがいつまでも解消されないことがあり得る。次のシナリオを考えてみてほしい:
- 提案者 A が投票番号 1 に対する
Prepare/Promiseフェーズを実行する。 - 提案者 A の提案が受理される前に、提案者 B が投票番号 2 に対する
Prepare/Promiseを実行する。 - 提案者 A が投票番号 1 の
Acceptメッセージを最後に送信したとき、受理者は投票番号 2 より小さい投票番号を受理しないと約束しているので、Acceptメッセージを拒否する。 - 提案者 B が
Acceptメッセージを送信する前に、提案者 A はすぐに投票番号 3 に対するPrepareメッセージを送信する。 - その後に提案者 B が送信する
Acceptメッセージは拒否され、同じことが繰り返される。
タイミングが運悪く噛み合うと、このデッドロックが数ラウンドにわたって続く場合がある。メッセージの送信から返答の取得までの時間が長い長距離接続では発生頻度が高くなる。
Multi-Paxos
単一の静的な値に関する合意を形成するだけではそれほど有用な処理は実行ではない。銀行口座サービスなどのクラスターから構成されるシステムでは、時間が経過すると変化する特定の状態 (例えば口座の残高) に関する合意が必要となる。このような状況で Paxos アルゴリズムは単一の操作 (本質的には状態機械の遷移) に関する合意の形成に利用できる。
Multi-Paxos は事実上、連続する番号の付いた合意 (スロット) を「単純な」Paxos アルゴリズムで形成していく手続きと言える。状態の遷移に「スロット番号」が割り振られ、クラスターの全メンバーは遷移を必ずスロット番号の順番で実行する。クラスターの状態を変更する (例えば振り込み操作を処理する) には、次のスロットの操作に関する合意を形成する必要がある。より具体的に言えば、これはメッセージにスロット番号を追加し、プロトコルの状態を全てスロットごとに追跡するようにした上で Paxos アルゴリズムを実行することを意味する。
Paxos アルゴリズムの実行には提案者と各受理者の間で最低でも二度のラウンドトリップが必要なので、そのままスロットごとに実行すると時間がかかりすぎる。そこで Multi-Paxos では、全てのスロットで投票番号を使い回し、さらに全てのスロットに対する Prepare/Promise フェーズを一度に行うことで最適化を行う。
死ぬほど難しい Paxos
実際のソフトウェアにおける Multi-Paxos の実装は難しいことで悪名高い。Lamport による論文「Paxos Made Simple」を皮肉った「Paxos Made Practical」のような名前の論文がいくつも公開されているほどである。
まず、状態の更新頻度が高い環境ではクラスターの各メンバーが自身の操作をスロットに入れようとするので、複数の提案者が存在するときに起こる上述した問題が発生する可能性が高まる。この解決策として、「リーダー」を選出し、各スロットに対する投票を開始する役目をリーダーだけに負わせる手法がある。他のメンバーは実行したい新しい操作をリーダーに送信する。
この仕組みの下では Prepare/Promise フェーズがリーダーの選出処理としても機能する: 最後に約束された投票番号を持つクラスターメンバーがリーダーとなる。その後リーダーは最初のフェーズを繰り返すことなく Accept/Accepted フェーズに直接移行して構わない。なお後述するように、リーダーの選出処理は実際には非常に複雑である。
単純な Paxos アルゴリズムは合意が形成されたとき矛盾が起きないことを保証するのに対して、合意が形成されること自体は保証しない。例えば、最初の Prepare メッセージが喪失して受理者に届かない場合、提案者は決して到着しない Promise メッセージを延々と待ち続けるしかない。この問題を解決するには、注意深く調整された再送の仕組みが必要になる: 再送の頻度が低すぎればアルゴリズムの効率が下がり、高すぎればクラスターがパケットストームに苦しむことになる。
もう一つの問題として決定事項 (decision) の通知がある。単純な Decision メッセージのブロードキャストで通常のケースは処理できる。しかし、このメッセージが喪失すると一部のノードは決定事項を知る術を失うので、これ以降のスロットに収まる状態機械の遷移を適用できなくなる。つまり、Multi-Paxos の実装では決定済みの提案に関する情報を共有する何らかの仕組みが必要になる。
これまでに説明してきた例で分散状態機械を利用することを考えると、興味深い問題がさらに一つ姿を現す: スタートアップ (開始処理) である。新しく実行を開始したノードが既存のクラスターに加わるには、その時点でクラスターが持つ状態を学習する必要がある。決定事項を最初のスロットから一つずつ学習・実行していく方法も考えられるものの、成熟したクラスターは数百万個単位のスロットを持つ可能性がある。さらに、新しいクラスターを初期化する手段も必要となる。
ただ、理論とアルゴリズムの話はこれで十分だろう ── 次は実際のコードを見ていく。
3.4 Cluster ライブラリ
本章で解説する Cluster ライブラリは単純な形式の Multi-Paxos を実装する。Cluster は大規模なアプリケーションに合意形成サービスを提供するライブラリとして設計されている。
Cluster のユーザーは Cluster の正確性に依存したコードを書くだろう。そのため、仕様との対応関係が分かる ── そして、それをテストできる ── ようにコードを構成することが重要となる。複雑なプロトコルは複雑な障害を起こす可能性があるので、稀な障害の再現とデバッグを可能にする仕組みも作成しなければならない。
本章で解説する Cluster の実装は概念実証 (proof-of-concept) のコードである: 中心的な概念が実用可能であることを示すには十分であるものの、プロダクションで使うときに必要な多くの平凡な機能は含まれていない。ただ、そういった機能を最小限の変更で後から追加できるようにコードは構成されている。
それでは見ていこう。
型と定数
Cluster のプロトコルは 15 個の異なるメッセージを利用する。これらは Python の namedtuple (名前付きタプル) として表現される:
Accepted = namedtuple('Accepted', ['slot', 'ballot_num'])
Accept = namedtuple('Accept', ['slot', 'ballot_num', 'proposal'])
Decision = namedtuple('Decision', ['slot', 'proposal'])
Invoked = namedtuple('Invoked', ['client_id', 'output'])
Invoke = namedtuple('Invoke', ['caller', 'client_id', 'input_value'])
Join = namedtuple('Join', [])
Active = namedtuple('Active', [])
Prepare = namedtuple('Prepare', ['ballot_num'])
Promise = namedtuple('Promise', ['ballot_num', 'accepted_proposals'])
Propose = namedtuple('Propose', ['slot', 'proposal'])
Welcome = namedtuple('Welcome', ['state', 'slot', 'decisions'])
Decided = namedtuple('Decided', ['slot'])
Preempted = namedtuple('Preempted', ['slot', 'preempted_by'])
Adopted = namedtuple('Adopted', ['ballot_num', 'accepted_proposals'])
Accepting = namedtuple('Accepting', ['leader'])
各メッセージを namedtuple で表現するとコードが見やすくなり、さらに一部の単純なミスも回避できる。namedtuple のコンストラクタは受け取ったオブジェクトが正しい属性を持っていないと例外を送出するので、打ち間違いはすぐに検出される。また、タプルはログに適したフォーマットであり、辞書よりも消費されるメモリが少ない。
メッセージの作成に難しい部分は無い:
msg = Accepted(slot=10, ballot_num=30)
メッセージのフィールドには最小限の文字数でアクセスできる:
got_ballot_num = msg.ballot_num
このメッセージの意味は以降で解説される。メッセージの定義の後には定数の定義が続く。その多くは様々なメッセージのタイムアウトを定義する:
JOIN_RETRANSMIT = 0.7
CATCHUP_INTERVAL = 0.6
ACCEPT_RETRANSMIT = 1.0
PREPARE_RETRANSMIT = 1.0
INVOKE_RETRANSMIT = 0.5
LEADER_TIMEOUT = 1.0
NULL_BALLOT = Ballot(-1, -1) # 任意の投票より前にソートされる
NOOP_PROPOSAL = Proposal(None, None, None) # 空のスロットを埋める noop
最後に、プロトコルで使われる同名の概念に対応する二つの型がある:
Proposal = namedtuple('Proposal', ['caller', 'client_id', 'input'])
Ballot = namedtuple('Ballot', ['n', 'leader'])
コンポーネントモデル
人間が脳内のメモリに保持できる情報の量は限られている。Cluster のコード全体を一度に頭に入れて考えることはできない ── 単純に量が多すぎるので、細かい部分が見逃されやすくなる。同様の理由で、大規模でモノリシックなコードベースはテストが困難である: テストケースは多くの可動部分を操作しなければならず、コードを少しでも変更すれば壊れる不安定なものになる。
コードの可読性とテスト容易性を向上させるため、Cluster はプロトコルの説明にある「提案者」や「受理者」といった役割 (role) に対応するいくつかのクラスを定義する。これらのクラスはどれも次の Role クラスを継承する:
class Role(object):
def __init__(self, node):
self.node = node
self.node.register(self)
self.running = True
self.logger = node.logger.getChild(type(self).__name__)
def set_timer(self, seconds, callback):
return self.node.network.set_timer(self.node.address, seconds,
lambda: self.running and callback())
def stop(self):
self.running = False
self.node.unregister(self)
次の Node クラスはネットワーク上の単一のノードを表し、クラスターにおいてノードが担う役割を管理する。この役割は実行が進むにつれて追加および削除される。ノードが受け取ったメッセージはアクティブな役割に転送される: 具体的には、メッセージの型の先頭に do_ を付けた名前のメソッドが (存在すれば) 呼び出される。この do_XXX メソッドはメッセージの属性をキーワード引数として受け取るので、メッセージの属性に簡単にアクセスできる。Node クラスには利便性のための send メソッドも存在し、このメソッドは functools.partial を使って Network クラスの同名のメソッドに引数を渡す。
class Node(object):
unique_ids = itertools.count()
def __init__(self, network, address):
self.network = network
self.address = address or 'N%d' % self.unique_ids.next()
self.logger = SimTimeLogger(
logging.getLogger(self.address), {'network': self.network})
self.logger.info('starting')
self.roles = []
self.send = functools.partial(self.network.send, self)
def register(self, roles):
self.roles.append(roles)
def unregister(self, roles):
self.roles.remove(roles)
def receive(self, sender, message):
handler_name = 'do_%s' % type(message).__name__
for comp in self.roles[:]:
if not hasattr(comp, handler_name):
continue
comp.logger.debug("received %s from %s", message, sender)
fn = getattr(comp, handler_name)
fn(sender=sender, **message._asdict())
アプリケーションインターフェース
アプリケーションはクラスターの各メンバー上で Member を作成して start メソッドを呼び出す。このときアプリケーション固有の状態機械とピアのリストもアプリケーションから提供される。既存のクラスターに参加する場合は Member オブジェクトに Bootstrap の役割が追加され、新しくクラスターを作成する場合は Seed の役割が追加される。Network.run を通じたプロトコルの実行は個別のスレッドで行われる。
アプリケーションは invoke メソッドを通してクラスターと対話する。このメソッドは状態遷移のための提案を開始する。提案が決定すると状態機械が実行され、invoke は状態機械の出力を返す。invoke メソッドはプロトコルを実行するスレッドからの結果を待機するために単純な同期キューである Queue を使用する。
class Member(object):
def __init__(self, state_machine, network, peers, seed=None,
seed_cls=Seed, bootstrap_cls=Bootstrap):
self.network = network
self.node = network.new_node()
if seed is not None:
self.startup_role = seed_cls(self.node, initial_state=seed, peers=peers,
execute_fn=state_machine)
else:
self.startup_role = bootstrap_cls(self.node,
execute_fn=state_machine, peers=peers)
self.requester = None
def start(self):
self.startup_role.start()
self.thread = threading.Thread(target=self.network.run)
self.thread.start()
def invoke(self, input_value, request_cls=Requester):
assert self.requester is None
q = Queue.Queue()
self.requester = request_cls(self.node, input_value, q.put)
self.requester.start()
output = q.get()
self.requester = None
return output
役割クラス
Cluster が持つ役割クラスを一つずつ見ていこう。
Acceptor
Acceptor クラスはプロトコルにおける受理者の役割を実装する。そのため、このクラスは最新の約束に対応する投票番号、そして各スロットに対する決定事項を保持し、プロトコルに従って Prepare と Accept のメッセージに応答する。ライブラリの設計のおかげで、Acceptor はプロトコルの記述と簡単に比較できる短いクラスとなる。
Multi-Paxos の受理者は単純な Paxos とよく似ており、メッセージにスロット番号を付ける点だけが異なる。
class Acceptor(Role):
def __init__(self, node):
super(Acceptor, self).__init__(node)
self.ballot_num = NULL_BALLOT
self.accepted_proposals = {} # {slot: (ballot_num, proposal)}
def do_Prepare(self, sender, ballot_num):
if ballot_num > self.ballot_num:
self.ballot_num = ballot_num
# 大きい投票番号を伝えてきた sender は次のリーダーかもしれない
self.node.send([self.node.address], Accepting(leader=sender))
self.node.send([sender], Promise(
ballot_num=self.ballot_num,
accepted_proposals=self.accepted_proposals
))
def do_Accept(self, sender, ballot_num, slot, proposal):
if ballot_num >= self.ballot_num:
self.ballot_num = ballot_num
acc = self.accepted_proposals
if slot not in acc or acc[slot][0] < ballot_num:
acc[slot] = (ballot_num, proposal)
self.node.send([sender], Accepted(
slot=slot, ballot_num=self.ballot_num))
Replica
Replica は最も複雑な役割クラスである。このクラスは密接に関連するいくつかの責務を持つ:
- 新しい提案を作成する。
- 提案が決定したらローカルの状態機械を実行する。
- 現在のリーダーを追跡する。
- 新しく起動したノードをクラスターに追加する。
Replica クラスはクライアントから Invoke メッセージを受け取ると新しい提案を作成し、未使用と自身が信じているスロットを選択して Propose メッセージを現在のリーダーに送信する (図2)。選択したスロットを使用する自身のものでない合意が形成された場合は、別のスロットで提案を再作成する。
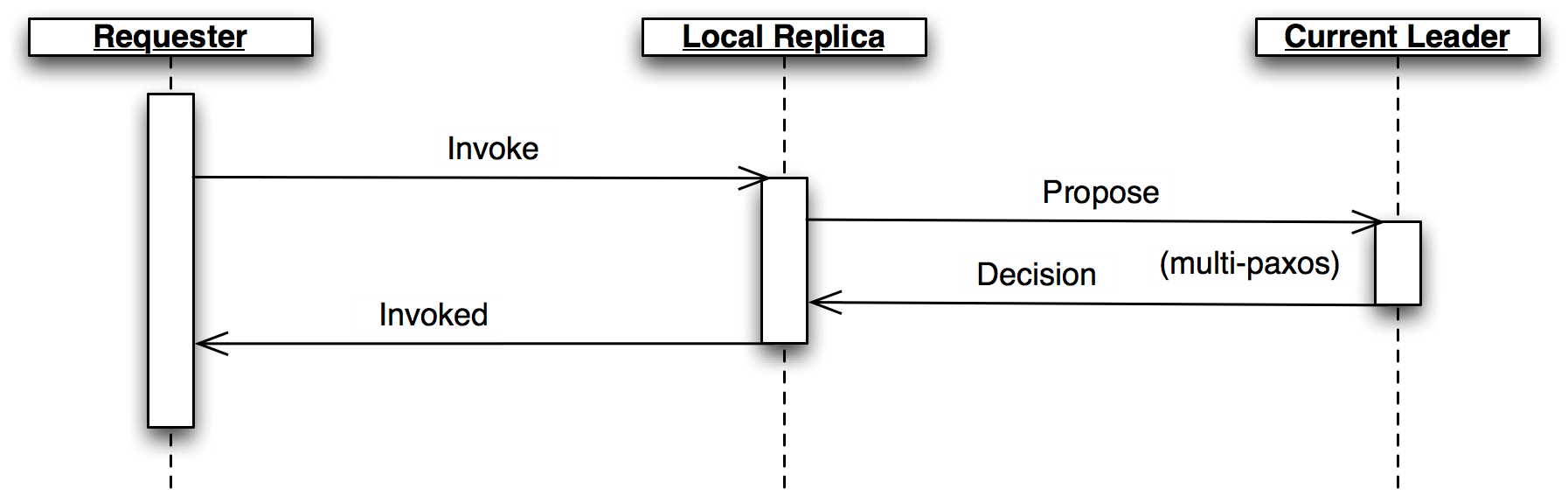
Replica の制御フロー
Decision メッセージはクラスターが合意を形成したスロットと合意内容を伝える。Decision メッセージを受け取った Replica は新しい決定事項を保存し、合意が形成されていないスロットまで状態機械を実行する。Replica は決定済み (decided) のスロットと実行済み (committed) のスロットを区別する。前者はクラスターが合意を形成したスロットを表し、後者はローカルの状態機械が処理したスロットを表す。スロットの合意が順番通りに形成されるとは限らないので、決定済みであって実行済みでないスロットが存在する可能性がある。スロットを実行した Replica は、操作の結果を入れた Invoked メッセージをリクエストしたクライアントに送信する。
場合によっては、あるスロットが決定していないにもかかわらずそのスロットに対するアクティブな提案が存在しない状況があり得る。状態機械はスロットを一つずつ実行しなければならないので、このときクラスターはスロットを埋めるための合意を形成しなければならない。この状況に対処するため、Replica は「noop (何もしない処理)」の提案を使ってスロットの埋め合わせる。このスロットに対する提案が決定されると、状態機械は何も実行せずに次のスロットに移る。
また、同じ提案に対する合意が二度形成される可能性もある。Replica は重複した決定事項に対しては状態機械を実行せず、状態を遷移させない。
Replica は Propose メッセージの送信先である現在の (アクティブな) リーダーを知っておく必要がある。後述するように、これを正しく行うには驚くほど細かな処理が必要になる。それぞれの Replica はアクティブなリーダーを三つの情報元を使って追跡する。
アクティブになったリーダーは Adopted メッセージを同じノードの Replica に送信する:

Adopted メッセージ
Acceptor は新しいリーダーに Promise メッセージを送信するとき、Accepting メッセージをローカルの Replica に送信する:

Accepting メッセージ
アクティブなリーダーはハートビートとして Active メッセージを定期的に送信する (図 5)。このメッセージを LEADER_TIMEOUT の間に受け取らなかった Replica は、リーダーが消失したと考えて次のリーダーの選出処理を開始する。この場合、全ての Replica が同じ新しいリーダーを選出することが重要となる。これはソートしたメンバーのリストで次のメンバーを選ぶことで達成される。
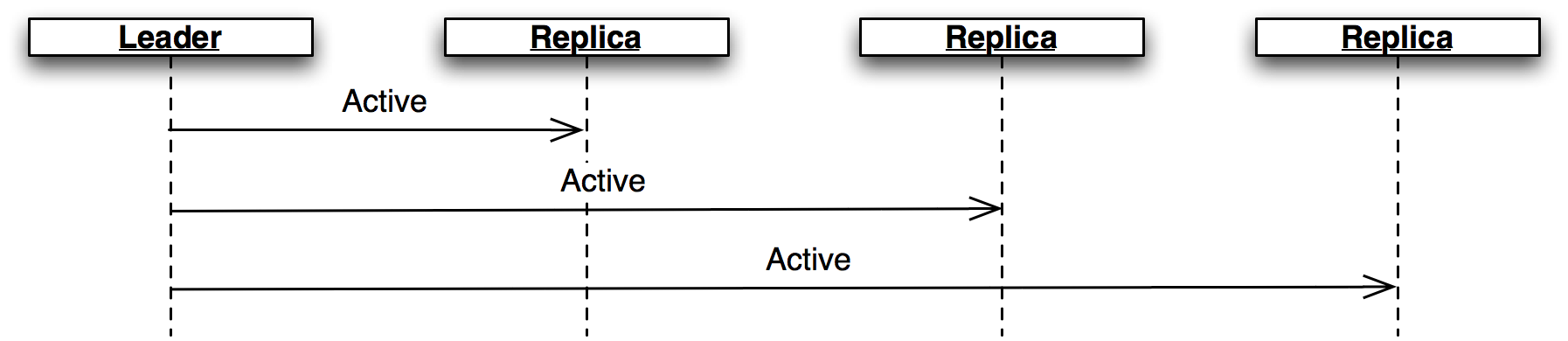
Active メッセージ
最後に、ノードがネットワークに参加すると、役割クラス Bootstrap が Join メッセージを Replica に送信する。Replica は最新の状態を入れた Welcome メッセージを返答するので、新しいノードはクラスターに参加する準備を素早く整えられる。
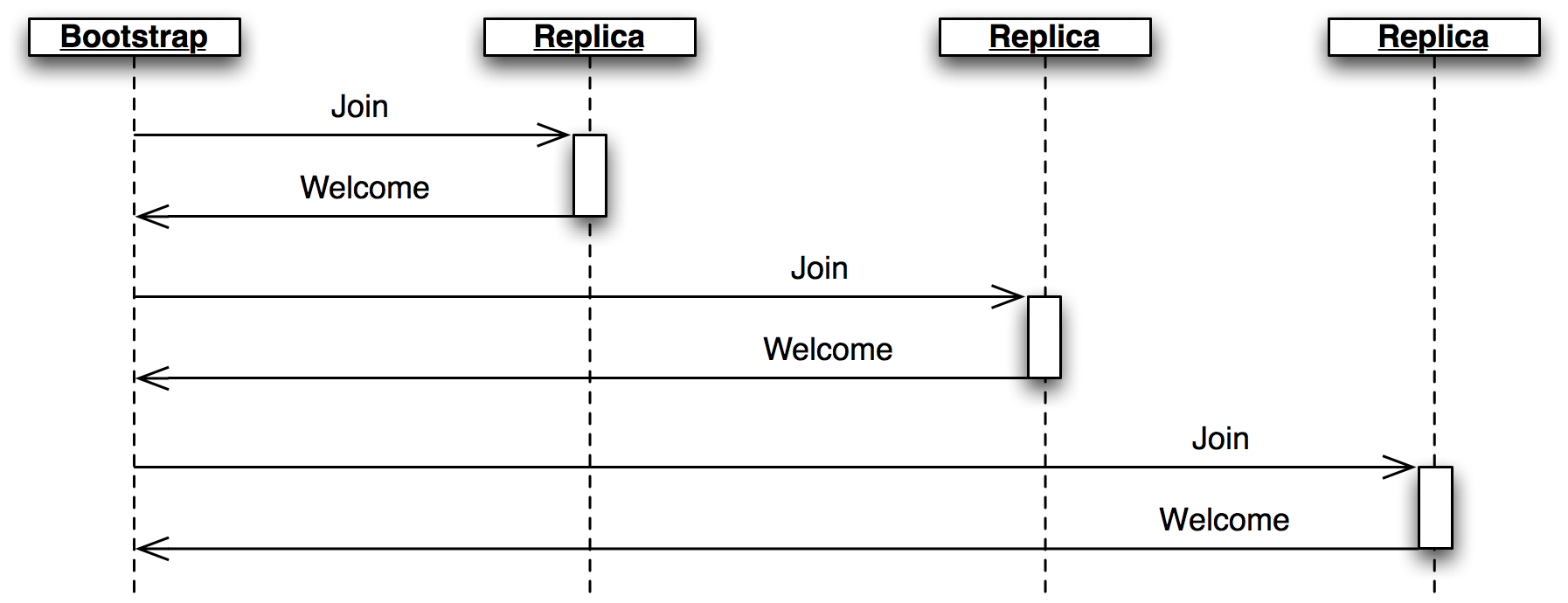
Join メッセージ
class Replica(Role):
def __init__(self, node, execute_fn, state, slot, decisions, peers):
super(Replica, self).__init__(node)
self.execute_fn = execute_fn
self.state = state
self.slot = slot
self.decisions = decisions
self.peers = peers
self.proposals = {}
self.next_slot = slot
self.latest_leader = None
self.latest_leader_timeout = None
# 提案の作成
def do_Invoke(self, sender, caller, client_id, input_value):
proposal = Proposal(caller, client_id, input_value)
slot = next((s for s, p in self.proposals.iteritems() if p == proposal), None)
# 提案を送信 (既存の slot が存在するなら再送信) する
self.propose(proposal, slot)
def propose(self, proposal, slot=None):
""" 提案をリーダーに送信 (slot が指定されたなら再送信) する """
if not slot:
slot, self.next_slot = self.next_slot, self.next_slot + 1
self.proposals[slot] = proposal
# 動作中のリーダーを見つける - 最後に自身に知らされたリーダー、または自分自身
# (後者の場合は自分をリーダーにするための処理が起動される)
leader = self.latest_leader or self.node.address
self.logger.info(
"proposing %s at slot %d to leader %s" % (proposal, slot, leader))
self.node.send([leader], Propose(slot=slot, proposal=proposal))
# 決定された提案の処理
def do_Decision(self, sender, slot, proposal):
assert not self.decisions.get(self.slot, None), \
"next slot to commit is already decided"
if slot in self.decisions:
assert self.decisions[slot] == proposal, \
"slot %d already decided with %r!" % (slot, self.decisions[slot])
return
self.decisions[slot] = proposal
self.next_slot = max(self.next_slot, slot + 1)
# noop でない提案のスロットが失われたなら、再提案する
our_proposal = self.proposals.get(slot)
if (our_proposal is not None and
our_proposal != proposal and our_proposal.caller):
self.propose(our_proposal)
# 実行待ちの決定済み提案を実行する
while True:
commit_proposal = self.decisions.get(self.slot)
if not commit_proposal:
break # まだ決定していない
commit_slot, self.slot = self.slot, self.slot + 1
self.commit(commit_slot, commit_proposal)
def commit(self, slot, proposal):
""" 決定済みの提案を順番通りに実行する """
decided_proposals = [p for s, p in self.decisions.iteritems() if s < slot]
if proposal in decided_proposals:
self.logger.info(
"not committing duplicate proposal %r, slot %d", proposal, slot)
return # この提案は複数回決定された
self.logger.info("committing %r at slot %d" % (proposal, slot))
if proposal.caller is not None:
# クライアントがリクエストした操作を実行する
self.state, output = self.execute_fn(self.state, proposal.input)
self.node.send([proposal.caller],
Invoked(client_id=proposal.client_id, output=output))
# リーダーの追跡
def do_Adopted(self, sender, ballot_num, accepted_proposals):
self.latest_leader = self.node.address
self.leader_alive()
def do_Accepting(self, sender, leader):
self.latest_leader = leader
self.leader_alive()
def do_Active(self, sender):
if sender != self.latest_leader:
return
self.leader_alive()
def leader_alive(self):
if self.latest_leader_timeout:
self.latest_leader_timeout.cancel()
def reset_leader():
idx = self.peers.index(self.latest_leader)
self.latest_leader = self.peers[(idx + 1) % len(self.peers)]
self.logger.debug("leader timed out; tring the next one, %s",
self.latest_leader)
self.latest_leader_timeout = self.set_timer(LEADER_TIMEOUT, reset_leader)
# 新しいクラスターメンバーの追加
def do_Join(self, sender):
if sender in self.peers:
self.node.send([sender], Welcome(
state=self.state, slot=self.slot, decisions=self.decisions))
Leader, Scout, Commander
リーダーの主な仕事は、新しい投票の開始を要求する Propose メッセージを受け取り決定事項を生成することである。リーダーが「アクティブ」とは、プロトコルの Prepare/Promise フェーズを正しく実行できることを言う。アクティブなリーダーは Propose メッセージを受け取るとすぐに Accept メッセージを返答する。
一つのクラスに一つの役割を持たせるモデルを保つため、リーダーは Scout と Commander にプロトコルの処理を一つずつ委譲する。
class Leader(Role):
def __init__(self, node, peers, commander_cls=Commander, scout_cls=Scout):
super(Leader, self).__init__(node)
self.ballot_num = Ballot(0, node.address)
self.active = False
self.proposals = {}
self.commander_cls = commander_cls
self.scout_cls = scout_cls
self.scouting = False
self.peers = peers
def start(self):
# LEADER_TIMEOUT が経過する前に自身がアクティブであることを通知する
def active():
if self.active:
self.node.send(self.peers, Active())
self.set_timer(LEADER_TIMEOUT / 2.0, active)
active()
def spawn_scout(self):
assert not self.scouting
self.scouting = True
self.scout_cls(self.node, self.ballot_num, self.peers).start()
def do_Adopted(self, sender, ballot_num, accepted_proposals):
self.scouting = False
self.proposals.update(accepted_proposals)
# 未決定の提案は Replica が再提案するので、
# ここで Commander の再作成はしない
self.logger.info("leader becoming active")
self.active = True
def spawn_commander(self, ballot_num, slot):
proposal = self.proposals[slot]
self.commander_cls(self.node, ballot_num, slot, proposal, self.peers).start()
def do_Preempted(self, sender, slot, preempted_by):
if not slot: # Scout から
self.scouting = False
self.logger.info("leader preempted by %s", preempted_by.leader)
self.active = False
self.ballot_num = Ballot((preempted_by or self.ballot_num).n + 1,
self.ballot_num.leader)
def do_Propose(self, sender, slot, proposal):
if slot not in self.proposals:
if self.active:
self.proposals[slot] = proposal
self.logger.info("spawning commander for slot %d" % (slot,))
self.spawn_commander(self.ballot_num, slot)
else:
if not self.scouting:
self.logger.info("got PROPOSE when not active - scouting")
self.spawn_scout()
else:
self.logger.info("got PROPOSE while scouting; ignored")
else:
self.logger.info("got PROPOSE for a slot already being proposed")
非アクティブな Leader が Propose メッセージを受け取ると、その Leader は Scout を作成して自身をアクティブにする処理を開始させる。Scout は Prepare メッセージを送信 (必要なら再送信) し、過半数のピアから Promise メッセージを受け取るか処理が中断されるまで待機する。その後 Scout は Adopted または Preempted メッセージを Leader に送信する。
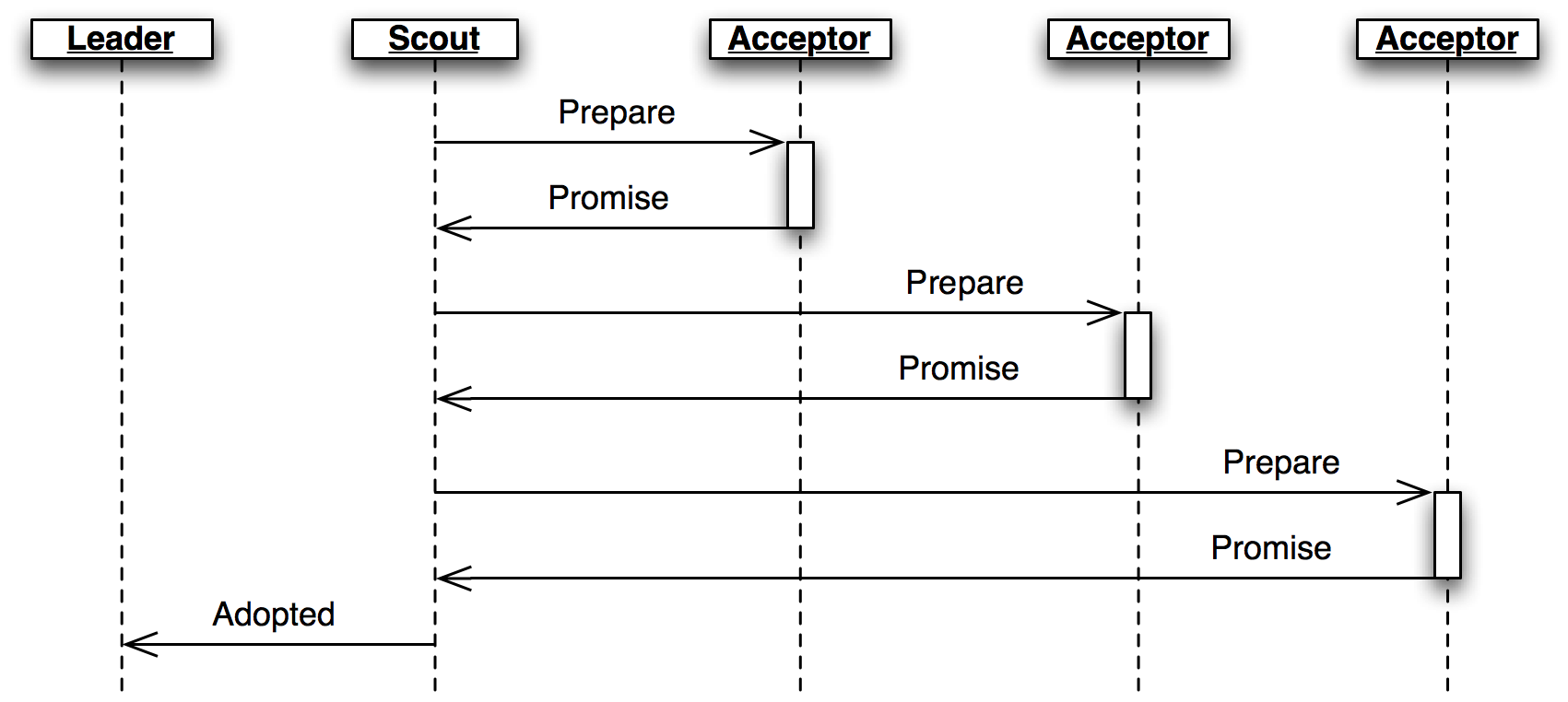
Scout の役割
class Scout(Role):
def __init__(self, node, ballot_num, peers):
super(Scout, self).__init__(node)
self.ballot_num = ballot_num
self.accepted_proposals = {}
self.acceptors = set([])
self.peers = peers
self.quorum = len(peers) / 2 + 1
self.retransmit_timer = None
def start(self):
self.logger.info("scout starting")
self.send_prepare()
def send_prepare(self):
self.node.send(self.peers, Prepare(ballot_num=self.ballot_num))
self.retransmit_timer = self.set_timer(PREPARE_RETRANSMIT, self.send_prepare)
def update_accepted(self, accepted_proposals):
acc = self.accepted_proposals
for slot, (ballot_num, proposal) in accepted_proposals.iteritems():
if slot not in acc or acc[slot][0] < ballot_num:
acc[slot] = (ballot_num, proposal)
def do_Promise(self, sender, ballot_num, accepted_proposals):
if ballot_num == self.ballot_num:
self.logger.info("got matching promise; need %d" % self.quorum)
self.update_accepted(accepted_proposals)
self.acceptors.add(sender)
if len(self.acceptors) >= self.quorum:
# self.accepted_proposals から投票番号を取り除き、
# 受理された提案のリストを得る。
accepted_proposals = \
dict((s, p) for s, (b, p) in self.accepted_proposals.iteritems())
# 採用された: しかし、アクティブなリーダーが他に存在しないとは限らない
# そういった衝突は Commander によって処理される
self.node.send([self.node.address],
Adopted(ballot_num=ballot_num,
accepted_proposals=accepted_proposals))
self.stop()
else:
# この Acceptor は自分より大きな投票番号を約束しているので、自分は負け
self.node.send([self.node.address],
Preempted(slot=None, preempted_by=ballot_num))
self.stop()
リーダーはアクティブなプロポーザルが存在するスロットごとに役割クラス Commander を作成する (図 8)。Scout と同様に、Commander は Accept メッセージを送信 (および再送信) して過半数のノードから Accepted を受け取るか、処理が中断されるのを待機する。提案が受理されると、Commander は Decision メッセージを全てのノードにブロードキャストする。Leader には Decided または Preempted メッセージが返答される。
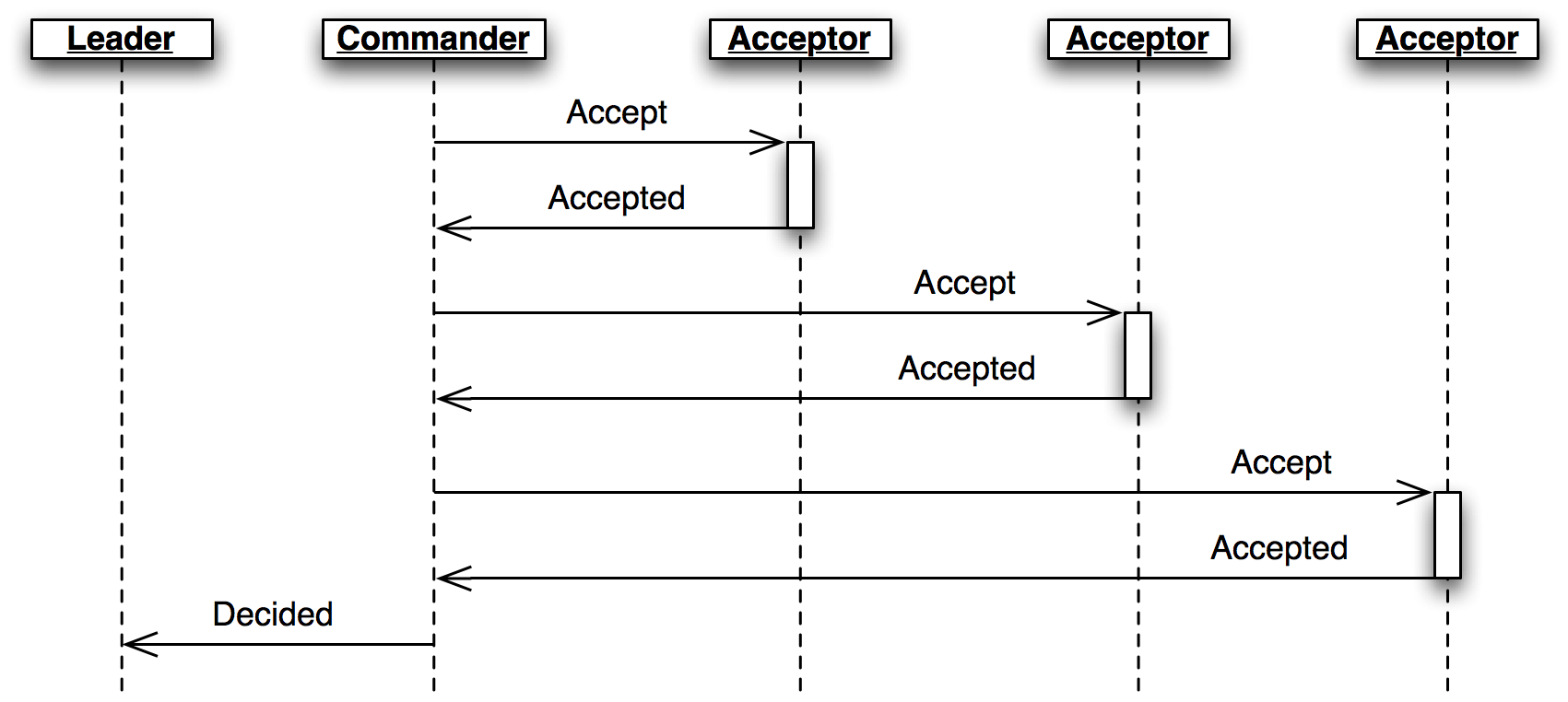
Commander クラス
class Commander(Role):
def __init__(self, node, ballot_num, slot, proposal, peers):
super(Commander, self).__init__(node)
self.ballot_num = ballot_num
self.slot = slot
self.proposal = proposal
self.acceptors = set([])
self.peers = peers
self.quorum = len(peers) / 2 + 1
def start(self):
self.node.send(set(self.peers) - self.acceptors, Accept(
slot=self.slot, ballot_num=self.ballot_num, proposal=self.proposal))
self.set_timer(ACCEPT_RETRANSMIT, self.start)
def finished(self, ballot_num, preempted):
if preempted:
self.node.send([self.node.address],
Preempted(slot=self.slot, preempted_by=ballot_num))
else:
self.node.send([self.node.address],
Decided(slot=self.slot))
self.stop()
def do_Accepted(self, sender, slot, ballot_num):
if slot != self.slot:
return
if ballot_num == self.ballot_num:
self.acceptors.add(sender)
if len(self.acceptors) < self.quorum:
return
self.node.send(self.peers, Decision(
slot=self.slot, proposal=self.proposal))
self.finished(ballot_num, False)
else:
self.finished(ballot_num, True)
余談: この部分を開発しているとき、非常に厄介なバグに遭遇した。ネットワークシミュレーターを使ってノード内のメッセージに対してもパケットロスを加えたとき、全ての Decision メッセージが喪失したときプロトコルが進行不能になることが判明した。Replica は Propose メッセージの再送を続けるものの、Leader はそのスロットに提案を既に持っているのでそれを無視する。Replica が聞き漏らした決定事項を知るための処理を行っても、他の誰も決定事項を知らないので知ることはできない。この問題はローカルのメッセージが確実に転送されることを (実際のネットワークスタックと同様に) 保証することで解決された。
Bootstrap
ノードがクラスターに参加するとき、そのノードはプロトコルに参加する前に現在のクラスターの状態を知る必要がある。この処理は役割クラス Bootstrap が担当する。Bootstrap は Join メッセージを Welcome メッセージが返ってくるまで順に各ピアに送信し、現在のクラスターの状態を取得する。Bootstrap の通信ダイアグラムは図 6 に示した。
初期バージョンの実装では、新しいノードで全ての役割クラス (Replica, Leader, Acceptor) をインスタンス化した上でそれぞれに Welcome メッセージを通した「スタートアップ」処理を開始させていた。こうすると初期化ロジックがそれぞれの役割クラスに分散し、必要なテストが増える。最終的な設計では Bootstrap の初期化が完了した時点で他の役割クラスを作成し、初期状態はコンストラクタを通して受け渡される。
class Bootstrap(Role):
def __init__(self, node, peers, execute_fn,
replica_cls=Replica, acceptor_cls=Acceptor, leader_cls=Leader,
commander_cls=Commander, scout_cls=Scout):
super(Bootstrap, self).__init__(node)
self.execute_fn = execute_fn
self.peers = peers
self.peers_cycle = itertools.cycle(peers)
self.replica_cls = replica_cls
self.acceptor_cls = acceptor_cls
self.leader_cls = leader_cls
self.commander_cls = commander_cls
self.scout_cls = scout_cls
def start(self):
self.join()
def join(self):
self.node.send([next(self.peers_cycle)], Join())
self.set_timer(JOIN_RETRANSMIT, self.join)
def do_Welcome(self, sender, state, slot, decisions):
self.acceptor_cls(self.node)
self.replica_cls(self.node, execute_fn=self.execute_fn, peers=self.peers,
state=state, slot=slot, decisions=decisions)
self.leader_cls(self.node, peers=self.peers, commander_cls=self.commander_cls,
scout_cls=self.scout_cls).start()
self.stop()
Seed
通常の動作において、クラスターに参加するノードはクラスターが稼働中で、少なくとも一つのノードが Join メッセージに応答できると期待する。しかしクラスターを新しく開始するときはどうすればいいだろうか? 一つの方法として、Bootstrap に「他の全てのノードと通信できなければ自身がクラスターの一つ目のノードだと判断する」ロジックを追加する方法が考えられる。しかし、これには二つの問題がある。まず、大規模なクラスターでは全ての Join メッセージのタイムアウトを待つのに長い時間がかかる。次に、さらに重要な点として、ネットワークの分割 (network partition) が発生したとき既存のクラスターに追加された新しいノードが他のノードと通信できず、新しいクラスターの作成を開始してしまう可能性がある。
ネットワークの分割はクラスターを利用するアプリケーションにとって最も厄介な障害である。ネットワークが分割が発生されると、クラスターのメンバーが全て起動した状態のままで一部のメンバー間の通信が不可能になる。例えば、ベルリンと台湾を結ぶネットワークリンクが切断されると、両地域にノードを持つクラスターでネットワークの分割が発生する。分割されている間も両地域のノードがクラスターとして動作を続ける場合、ネットワークリンクが修復された後に二つの小クラスターを一つにする処理は難易度が高い。Multi-Paxos を実行するクラスターでは、二つの小クラスターが同じスロット番号に異なる決定事項を持つことになる。
この問題を回避するため、新しいクラスターの作成はユーザーが手動で指示する操作とされる。クラスターの中でちょうど一つのノードが役割クラス Seed を持つことができる。Seed は Join メッセージをピアの過半数から受け取るのを待ち、その後 Welcome メッセージを通じて状態機械の初期状態と決定事項の空集合を各ピアに送信する。Seed は最後に Bootstrap を作成し、新しく開始されたクラスターにノードを追加する。
Seed は Bootstrap と Replica の間で交わされる Join/Welcome メッセージと同様のやり取りを各ピアと行う。通信ダイアグラムは Replica と同様となる。
class Seed(Role):
def __init__(self, node, initial_state, execute_fn, peers,
bootstrap_cls=Bootstrap):
super(Seed, self).__init__(node)
self.initial_state = initial_state
self.execute_fn = execute_fn
self.peers = peers
self.bootstrap_cls = bootstrap_cls
self.seen_peers = set([])
self.exit_timer = None
def do_Join(self, sender):
self.seen_peers.add(sender)
if len(self.seen_peers) <= len(self.peers) / 2:
return
# クラスターの準備完了 - 他のピアを招き入れる
self.node.send(list(self.seen_peers), Welcome(
state=self.initial_state, slot=1, decisions={}))
# 新しく作成したクラスターからの JOIN を全て受け取れるように十分待つ
if self.exit_timer:
self.exit_timer.cancel()
self.exit_timer = self.set_timer(JOIN_RETRANSMIT * 2, self.finish)
def finish(self):
# 自身が開始したクラスターに自身のノードをブートストラップする
bs = self.bootstrap_cls(self.node,
peers=self.peers, execute_fn=self.execute_fn)
bs.start()
self.stop()
Requester
役割クラス Requester は分散状態機械に対するリクエストを管理する。Requester は単に Invoke メッセージを Invoked メッセージが返るまでローカルの Replica に送信し続けるだけである。通信ダイアグラムは Replica のものを参照してほしい。
class Requester(Role):
client_ids = itertools.count(start=100000)
def __init__(self, node, n, callback):
super(Requester, self).__init__(node)
self.client_id = self.client_ids.next()
self.n = n
self.output = None
self.callback = callback
def start(self):
self.node.send([self.node.address],
Invoke(caller=self.node.address,
client_id=self.client_id, input_value=self.n))
self.invoke_timer = self.set_timer(INVOKE_RETRANSMIT, self.start)
def do_Invoked(self, sender, client_id, output):
if client_id != self.client_id:
return
self.logger.debug("received output %r" % (output,))
self.invoke_timer.cancel()
self.callback(output)
self.stop()
まとめ
Cluster が持つ役割クラスは次の通りである:
Acceptor: 約束の管理と提案の受理を行う。Replica: 分散状態機械を管理する: 提案を送出し、決定事項を実行し、Requesterに応答する。Leader: Multi-Paxos アルゴリズムのラウンドを主導する。Scout: リーダーとして Multi-Paxos アルゴリズムのPrepare/Promiseフェーズを実行する。Commander: リーダーとして Multi-Paxos アルゴリズムのAccept/Acceptedフェーズを実行する。Bootstrap: 既存のクラスターに新しいノードを追加する。Seed: 新しいクラスターを作成する。Requester: 分散状態機械に対する操作をリクエストする。
Cluster を動作させるには、最後にもう一つパーツが必要となる: 全てのノードが通信で利用するネットワークである。
3.5 ネットワーク
ネットワークプロトコルにはメッセージを送受信する機能と、将来の何らかの時点における関数の呼び出しをリクエストする手段が必要となる。
Network は単純なネットワークシミュレーションを提供するクラスであり、上述の機能に加えてパケットロスとメッセージの転送遅延をシミュレートする機能を持つ。
タイマーは Python 組み込みの heapq モジュールで処理されるので、次のイベントを効率的に選択できる。タイマーを設定すると Timer オブジェクトがヒープにプッシュされる。ヒープからの要素の削除は効率的でないので、キャンセルされたタイマーは削除されずに「キャンセルされた」という印が付けられる。
メッセージの転送処理はタイマー機能を利用して宛先のノードに対するメッセージの転送をスケジュールし、そのときランダムな遅延を加える。また、ここでも functools.partial を使って転送完了時に宛先ノードの receive メソッドを適切な引数と共に呼び出す処理がある。
シミュレーションの実行はタイマーをヒープからポップして、それがキャンセルされておらず宛先ノードが生きていれば転送を実行するだけで行える。
class Timer(object):
def __init__(self, expires, address, callback):
self.expires = expires
self.address = address
self.callback = callback
self.cancelled = False
def __cmp__(self, other):
return cmp(self.expires, other.expires)
def cancel(self):
self.cancelled = True
class Network(object):
PROP_DELAY = 0.03
PROP_JITTER = 0.02
DROP_PROB = 0.05
def __init__(self, seed):
self.nodes = {}
self.rnd = random.Random(seed)
self.timers = []
self.now = 1000.0
def new_node(self, address=None):
node = Node(self, address=address)
self.nodes[node.address] = node
return node
def run(self):
while self.timers:
next_timer = self.timers[0]
if next_timer.expires > self.now:
self.now = next_timer.expires
heapq.heappop(self.timers)
if next_timer.cancelled:
continue
if not next_timer.address or next_timer.address in self.nodes:
next_timer.callback()
def stop(self):
self.timers = []
def set_timer(self, address, seconds, callback):
timer = Timer(self.now + seconds, address, callback)
heapq.heappush(self.timers, timer)
return timer
def send(self, sender, destinations, message):
sender.logger.debug("sending %s to %s", message, destinations)
# クロージャにメッセージのディープコピーを入れることで、
# 同じオブジェクトが異なる箇所で使われるのを防ぐ
def sendto(dest, message):
if dest == sender.address:
# ローカルのメッセージは遅延無く確実に転送される
self.set_timer(sender.address, 0,
lambda: sender.receive(sender.address, message))
elif self.rnd.uniform(0, 1.0) > self.DROP_PROB:
delay = self.PROP_DELAY + self.rnd.uniform(-self.PROP_JITTER,
self.PROP_JITTER)
self.set_timer(dest, delay,
functools.partial(self.nodes[dest].receive,
sender.address, message))
for dest in (d for d in destinations if d in self.nodes):
sendto(dest, copy.deepcopy(message))
この実装では使っていないものの、コンポーネントモデルを使えば実際のネットワークを通じて実際のサーバーと通信する本当のネットワーク実装を他のコンポーネントを変更することなく使用できるようにコードを書ける。テストとデバッグはシミュレートされたネットワークで行い、プロダクションでは実際のネットワークハードウェアを利用することが可能となる。
3.6 デバッグ機能
Cluster のような複雑なシステムを開発していると、単純な NameError といった自明なバグは、プロトコルを (シミュレーション環境で) 数分にわたって実行して初めて発生する厄介な障害へとすぐに姿を変える。こういったバグの発生原因を特定するには、エラーが起こった箇所から実行を逆方向に追う必要がある。対話的なデバッガは実行を順方向にしか追えないので、ここでは役に立たない。
Cluster が持つ最も重要なデバッグ機能は決定的シミュレーターである。現実のネットワークと異なり、Cluster のシミュレーターは実行のたびに全く同じように振る舞い、乱数生成器には同じシードが設定される。これはデバッグ用のチェックやログ出力のコードを追加してシミュレーションを再実行すれば、同じ障害を詳細に確認できることを意味する。
もちろん、バグに関する情報の多くはクラスター内のノード間でやり取りされるメッセージにあるので、ログは最初から自動的に作成される。このログにはメッセージを送信または受信した役割クラス、そして SimTimeLogger クラスが提供するシミュレーション内のタイムスタンプが含まれる。
class SimTimeLogger(logging.LoggerAdapter):
def process(self, msg, kwargs):
return "T=%.3f %s" % (self.extra['network'].now, msg), kwargs
def getChild(self, name):
return self.__class__(self.logger.getChild(name),
{'network': self.extra['network']})
Cluster が利用するプロトコルのようにレジリエントな (回復力のある) プロトコルでは、長い時間にわたって実行されてからバグが発生することがよくある。例えば Cluster の開発をしているとき、全ての Replica が同じ decisions 辞書を共有してしまうバグがあった。これは、あるノードで決定事項が処理されると、その処理結果が瞬時に他のノードから観測できてしまうことを意味する。これほど深刻なバグであったにもかかわらず、クラスターがデッドロックを起こしたのは数個のトランザクションに対して正しい結果を生成した後だった。
こういった誤りを早期に検出する上でアサーションは重要なツールとなる。アルゴリズムの設計から示せる不変条件を全て確認するアサーションを仕込むべきである。コードが想像通りに動作していないとき、期待される振る舞いに対するアサーションは動作がおかしくなった箇所を調べる上で重要な手掛かりとなる。
assert not self.decisions.get(self.slot, None), \
"next slot to commit is already decided"
if slot in self.decisions:
assert self.decisions[slot] == proposal, \
"slot %d already decided with %r!" % (slot, self.decisions[slot])
コードを読みながら正しい前提条件を特定することはデバッグ技法の一つである。上に示したのは Replica.do_Decision メソッドに存在するアサーションであり、次に実行するスロットにある Decision が self.decisions に存在するために無視されるバグが開発中に発生したのを受けて追加された。そのときで破られていた前提条件は「次に実行するスロットは決定済みでない」であり、これを確認するアサーションを do_Decision の先頭に追加することで間違っていた部分が判明し、素早い修正につながった。また、同じスロットに異なる提案が決定されるバグも存在した ── 重大なバグである。
プロトコルの開発中には他にも多くのアサーションが利用されたものの、行数を少なくするために最終的なコードでは削除されている。
3.7 テスト
過去十年のどこかのタイミングでようやく、テストを書かないコーディングはシートベルトをしない運転と同じくらい常軌を逸した行為とみなされるようになった。テストを持たないコードはおそらく間違っており、コードの振る舞いが変化しないことを確認する方法が用意されていなければコードの変更にリスクが伴う。
コードがテスト可能性を念頭に置いて構成されているとき、テストは最も効率的となる。テストに関してはいくつかの流派が存在するものの、Cluster で採用したのは「個別にテストできる疎結合な単位にコードを細かく分割する」というアプローチだった。これは役割モデルと相性が良かった: それぞれの役割は固有の目的を持ち独立して動作可能なので、役割クラスはコンパクトで自己充足的となる。
Cluster は独立性を可能な限り高めるように書かれている: 役割間の通信は (新しい役割の作成を除いて) 全てメッセージで行われる。そのため、メッセージを送信して応答を確認することで役割の大部分をテストできる。
ユニットテスト
Cluster が持つユニットテストは単純で短い:
class Tests(utils.ComponentTestCase):
def test_propose_active(self):
""" Commander を起動中のアクティブな Leader が PROPOSE を受け取る """
self.activate_leader()
self.node.fake_message(Propose(slot=10, proposal=PROPOSAL1))
self.assertCommanderStarted(Ballot(0, 'F999'), 10, PROPOSAL1)
このメソッドは単一のユニット (Leader クラス) の単一の振る舞い (Commander の起動) をテストする。ここでは有名な「準備・実行・確認」パターンが使われている: アクティブな Leader を初期化し、メッセージを送信し、結果を確認する。
依存性の注入
役割クラスでは「依存性の注入 (dependency injection)」と呼ばれるテクニックが使われる。ネットワークに異なる役割クラスを追加する役割クラスは、コンストラクタの (デフォルト値付き) 引数でクラスオブジェクトを受け取る。例えば、Leader のコンストラクタを次に示す:
class Leader(Role):
def __init__(self, node, peers, commander_cls=Commander, scout_cls=Scout):
super(Leader, self).__init__(node)
self.ballot_num = Ballot(0, node.address)
self.active = False
self.proposals = {}
self.commander_cls = commander_cls
self.scout_cls = scout_cls
self.scouting = False
self.peers = peers
spawn_scout メソッド (および spawn_commander メソッド) では、self.scout_cls で役割クラスのインスタンスが作成される:
class Leader(Role):
def spawn_scout(self):
assert not self.scouting
self.scouting = True
self.scout_cls(self.node, self.ballot_num, self.peers).start()
この仕組みがあれば、Leader のコンストラクタにフェイククラスを渡すことで Leader のテストを Scout および Commander と独立した状態で実行できる。
インターフェースの正しさ
小さいユニットのテストに集中していると、ユニット間のインターフェースのテストがおろそかになる危険性がある。例えば、Acceptor のユニットテストは Promise メッセージの accepted 属性のフォーマットを検証し、Scout のユニットテストには accepted 属性が「正しい」フォーマットを持つ値が渡される。しかし、いずれのテストも両者のフォーマットが一致することを検証しない。
この問題を解決するアプローチの一つとして、インターフェースの正しさが自動的に保証される仕組みの利用がある。Cluster は名前付きタプルとキーワード引数を使うことで、メッセージの属性名が一致しないバグを回避する。役割クラス同士はメッセージを通してのみ対話するので、この仕組みによってインターフェースの多くの部分をカバーできる。
accepted_proposals のフォーマットといった個別の問題に対しては、現実のデータとテスト用データの両方を同じ関数 (例えば verifyPromiseAccepted) で検証する手法が利用できる。この関数を使って Acceptor のテストは送り返される Promise メッセージを検証し、Scout のテストは全てのフェイク Promise メッセージを検証する。
統合テスト
インターフェースの問題と設計の誤りを検出するための最後の防波堤として統合テストがある。統合テストは複数のユニットを同時に使ったときに何が起こるかをテストする。Cluster において統合テストとは、いくつかのノードからなるネットワーク上にクラスターを実際に構築し、そこにリクエストを送信して結果を確認することを意味する。もしユニットテストが発見できなかったインターフェースの問題があれば、統合テストはすぐに落ちるはずである。
Cluster が用いるプロトコルはノードの障害を問題なく扱えるので、障害シナリオのテストも必要になる。アクティブなリーダーが厄介なタイミングで障害を起こすテストも存在する。
様々な要素が絡み合う統合テストはユニットテストより書くのが難しい。Cluster において、この事実はリーダーで障害が起きる状況のテストを考えると分かる: 任意のノードがアクティブなリーダーになる可能性がある。ネットワークが決定的だとしても、メッセージを一つでも変えれば乱数生成器の状態が変わって以降のイベントが変化する。そのためテストコードで期待されるリーダーをハードコードすることはできず、内部状態を調べてアクティブなリーダー (だと自身を認識している) ノードを見つける必要がある。
fuzz テスト
レジリエントなコードをテストするのは非常に難しい: バグがあって障害が起きたとしても、そこから回復できてしまう可能性が高い。非常に重大なバグであっても統合テストで検出できるとは限らない。また、考えられる全ての故障モードに対するテストを想像して実装するのも難しい。
この種の問題に対してよく用いられるアプローチとして fuzz テストがある: 入力をランダムに変化させてコードを実行し、何かが壊れるかどうかを確認する手法である。何かが壊れるとき、全てのデバッグ機能が非常に重要となる。もし障害が再現できず、バグを見つけるのに十分な情報を残すこともできないなら、バグは修正できない!
Cluster では開発中に手動の fuzz テストをいくらか実行した。完全な fuzz テストインフラは本プロジェクトの範囲を超える。
3.8 権力争い
アクティブなリーダーが多く存在するクラスターは非常にやかましい空間となる。多数の Scout が増加を続ける投票番号を Acceptor に送信し、そうでありながら投票は一つも完了しない。一方でアクティブなリーダーを持たないクラスターは静かであるものの、投票を一切進められない。ほとんどの時点でクラスターがちょうど一つのリーダーに合意するように実装を調整することは非常に難しい。
リーダーの地位争いは簡単に回避できる: リーダーになろうとして失敗したとき、そのまま諦めるようにすればよい。ただ、こうするとアクティブなリーダーが存在しない状況に陥るので、アクティブでないリーダーは Propose メッセージを受信するたびにアクティブになろうと試みる。
クラスターがアクティブなリーダーに合意できないと障害が発生する: 異なる Replica が Propose メッセージを異なるリーダーに送信し、その後 Scout が衝突する。そのため、リーダーの選出を素早く完了させること、そしてクラスターの全メンバーが選出されたリーダーを可能な限り素早く見つけることが重要となる。
Cluster はリーダーの変更を可能な限り素早く検出することでこの問題に対処する: Acceptor が Promise メッセージを送信するとき、送信先のメンバーが次のリーダーになる可能性が高い。また、障害はハートビートのプロトコルで検出される。
3.9 さらなる拡張
もちろん、Cluster の現在の実装は様々な方法で拡張できる。
新しいノードの参加処理
「純粋な」Multi-Paxos では、メッセージを受信し損ねたノードはクラスターの他のノードに置いて行かれる。分散状態機械の状態に対するアクセスが状態遷移の実行時にのみ起こるときに限り Multi-Paxos は正しく動作する。そのため状態を確認したいだけの場合でも、クライアントは状態を変化させない遷移をリクエストし、その結果として状態を受け取る必要がある。この状態を変化させない遷移はクラスター全体で「実行」され、提案されたスロットにおける状態に全てのクラスターが合意した後にクライアントに状態が返される。
最速のケースでさえ、この処理には時間がかかる: 値を一つ読むだけの処理に数回のラウンドトリップが必要となる。もし分散オブジェクトストアが全てのオブジェクトアクセスにこのようなリクエストを作成していたら、そのパフォーマンスは悲惨なものになるだろう。さらに、リクエストを受け取るノードの処理が遅れると、そのノードはまずクラスターの他のメンバーに追いついてからでなければ提案が成功しないので、リクエストの処理時間がさらに長くなる。
この問題に対する単純な解決法の一つとして、ゴシップ形式のプロトコルがある: 各 Replica は定期的に互いに通信し、自身の知っている最も値の大きいスロットと自身が知らないスロットに対するリクエスト情報を交換し合う。そうしておけば、Decision メッセージが喪失した場合でも宛先の Replica は他の Replica から決定事項をすぐに知ることができる。
一貫したメモリ管理
クラスター管理ライブラリは信頼性の低いコンポーネントの存在下で信頼性を提供する。そのためライブラリ自身が低信頼性を追加してはならない。例えば、Cluster が使用するメモリの量やメッセージのサイズが際限なく大きくなり続けるとしたら、Cluster を長時間実行することはできなくなる。
Cluster が用いるプロトコルでは Acceptor と Replica がプロトコルの記憶を形成するので、これらのクラスは全てを記録する必要がある。古いスロットに対するリクエスト (例えば処理が遅れている Replica やリーダーからのリクエスト) をいつ受信するか分からないので、クラスターが開始されてからの決定事項を一つ残らず記憶しなければならない。さらに悪いことに、Welcome メッセージにはクラスターが合意した全ての決定事項が含まれるので、長く実行されるクラスターでは巨大なメッセージが送信されることになる。
この問題を解決するテクニックの一つとして、ノードの状態を収めた「チェックポイント」を定期的に作成する手法がある。こうすればクラスターが保持すべき決定事項の個数は低く抑えられる。他のノードに大きく後れを取ったノードが最新のチェックポイントに到達していない状況になった場合、そのノードはクラスターから一度離脱して再度参加することで自身を「リセット」する。
永続ストレージ
Cluster のプロトコルではクラスターのメンバーの一部で障害が起きても問題はないものの、Acceptor が受理した値や行った約束を「忘れる」と問題が起こる。
そして厄介なことに、障害を起こしたクラスターのメンバーが再起動すると、まさしくその状況が発生する: 新しく初期化された Acceptor インスタンスは以前のインスタンスが行った約束を覚えていない。ここでの問題は新しいインスタンスが古いインスタンスを置き換えることにある。
この問題を解決する方法は二つ考えられる。一つ目の単純な解決法は、Acceptor の状態をディスクに書き込んで開始時に読み込ませるものである。これより複雑な二つ目の解決法は、障害を起こしたメンバーをクラスターから削除し、新しいメンバーとして再参加することを強制するものである。こういったクラスターに所属するノードの動的な変更を「ビュー改変 (view change)」と呼ぶ。
ビュー改変
オペレーションエンジニアは負荷や可用性の要件に合わせてクラスターの規模を調整できる必要がある。始まったばかりの単純なテストプロジェクトであれば、三つのノードからなる小さなクラスターを使ったとしてもノードの障害は問題にならない。しかし、そのプロジェクトが「実戦」に投入されたなら、大きな負荷を処理するために大規模なクラスターが必要となるだろう。
現在の Cluster でクラスターに属するピアの集合を変更するにはクラスター全体を再起動しなければならない。理想的には、クラスターは所属するメンバーに関する合意を (状態機械の遷移に関する合意と同様に) 保持できるはずである。これは、クラスターを構成するメンバーの集合 (ビュー) を特別な「ビュー改変」提案を通じて変更できることを意味する。ただ、Paxos アルゴリズムはクラスターのメンバーを全メンバーが知っていることを前提としているので、各スロットに対してビューを関連付ける必要がある。
Lamport は Paxos Made Simple の最後の段落で、この問題に対する解決策を提示している:
合意アルゴリズムの \(i + \alpha\) 番目のインスタンスを実行するサーバーの集合を \(i\) 番目の状態機械コマンドの実行後の状態が規定すると定めれば、リーダーがコマンド \(\alpha\) 個分だけ先に進むようにできる。 (Lamport, 2001)
つまり Paxos アルゴリズムの各インスタンス (スロット) が \(\alpha\) スロットだけ前の時点におけるビューを使用するというアイデアである。このときクラスターが同時に処理できるスロット数は最大で \(\alpha\) 個に制限されるので、\(\alpha\) を非常に小さくすると並列性が減少する。一方で、\(\alpha\) を非常に大きくするとビューの変更が反映されるまでの遅延が長くなる。
Cluster の初期のドラフト (義務感から git 履歴に残してある!) では、この方式を使ったビューの変更を \(\alpha = 3\) として実装していた。この変更は一見すると簡単に見えるものの、実装の複雑性は大きく増加した:
- 最新の \(\alpha\) 個のスロットが利用するビューを保持して、その情報を新しいノードと正しく共有する。
- 使用可能なスロットが見つからない提案は無視する。
- 障害を起こしたノードを検出する。
- 競合する複数のビュー変更を適切に逐次化する。
- ビューの情報をリーダーと
Replicaの間でやり取りする。
完成したコードは本書で扱えないほど大きくなってしまった!
3.10 参考情報
Lamport によるオリジナルの Paxos 論文とそれに続く Paxos Made Simple2 に加えて、 本章で示した実装では他の資料で提案された拡張を追加している。役割の名前は Paxos Made Moderately Complex3 のものを採用した。Paxos Made Live4 はスナップショットに関して、Paxos Made Practical は (本章で紹介したものとは異なる種類の) ビュー変更に関して有用だった。Liskov の Viewstamped Replication to Byzantine Fault Tolerance5 はビュー変更に対する異なる視点を提供した。最後に、この Stack Overflow での議論はシステムに対するメンバーの追加・削除について学ぶ上で役に立った。
-
L. Lamport, The Part-Time Parliament, ACM Transactions on Computer Systems, 16(2):133–169, May 1998. ↩︎
-
L. Lamport, Paxos Made Simple, ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) 51-58. ↩︎
-
R. Van Renesse and D. Altinbuken, Paxos Made Moderately Complex, ACM Comp. Survey 47, 3, Article 42 (Feb. 2015). ↩︎
-
T. Chandra, R. Griesemer, and J. Redstone, Paxos Made Live - An Engineering Perspective, Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing (PODC '07). ACM, New York, NY, USA, 398-407. ↩︎
-
B. Liskov, From Viewstamped Replication to Byzantine Fault Tolerance, In Replication, Springer-Verlag, Berlin, Heidelberg 121-149 (2010). ↩︎