4. Contingent: 完全に動的なビルドシステム
4.1 はじめに
ビルドシステムがコンピュータープログラミングの世界で標準的なツールとなって久しい。
代表的なビルドシステムに make がある。後に開発者が ACM ソフトウェアシステム賞を受賞する make は 1976 年に開発された。make では出力ファイルが (一つ以上の) 入力ファイルに依存することを宣言できるだけではなく、その宣言を再帰的に行うことができる。例えば、プログラムがいくつかのオブジェクトファイルに依存し、それぞれのオブジェクトファイルは対応するソースコードに依存するとしよう。この依存関係は make で次のように表される:
prog: main.o
cc -o prog main.o
main.o: main.c
cc -C -o main.o main.c
起動された make がオブジェクトファイル main.o の最終変更時刻よりソースコードファイル main.c の最終変更時刻の方が新しいことを検出すると、make は main.o の再ビルドだけではなく prog の再ビルドも行う。
ビルドシステムは計算機科学を学ぶ学部生がセメスター単位で取り組む課題のプロジェクトとしてよく採用される ── その理由はビルドシステムがほぼ全てのソフトウェアプロジェクトで使われるためだけではなく、有向グラフに関する基礎的なデータ構造とアルゴリズムがビルドシステムで利用されるためでもある (本章でも詳しく解説する)。
ビルドシステムは数十年にわたって実際のプロジェクトで利用され、教育でも利用されてきた。この事実から、現在使われているビルドシステムは完全に汎用的であり、最も極端な利用法にも対応できると思うかもしれない。しかし実際には、ビルド生成物の間でよく見られる動的な相互参照と呼ばれる種類の関係を多くのビルドシステムは全く上手く扱えない。そのため、本章で私たちは make が利用した古典的なアルゴリズムとデータ構造を復習するだけではなく、それらを大きく拡張して適用可能な領域を大きく広げることになる。
というわけで、問題は相互参照である。相互参照はどこで発生するだろうか? 文章、ドキュメント、そして印刷される本で発生する!
4.2 問題: ドキュメントシステムの構築
ソースからフォーマットされたドキュメントを作成するシステムは、どれも再ビルド時に必要以上の仕事をするか、必要なだけの仕事をしないかのどちらかに思える。
ソースを少しだけ変更したときに関係ない章のパース・フォーマットが実行されるなら必要以上の仕事をしており、最終的な生成物が不完全な状態なら必要な仕事をしていない。
例として Sphinx を考えよう。Sphinx はドキュメントビルダーであり、Python 言語の公式ドキュメントをはじめとして Python コミュニティ内の様々なプロジェクトで利用されている。典型的な Sphinx プロジェクトの index.rst には次のような目次 (Table of Contents) が含まれる:
目次
=================
.. toctree::
install.rst
tutorial.rst
api.rst
各章に対応するファイル名からなるリストは、ビルド時に出力ファイル index.html を生成するとき章題をテキストとする各章へのリンクを生成するよう Sphinx に伝える。また、各章に含まれる節へのリンクも生成される。上に示したタイトルと toctree コマンドを処理した結果のテキスト (からマークアップを取り去ったもの) の一例を示す:
目次
• インストール
• ニューカマー向けチュートリアル
• ハローワールド
• ログ機能の追加
• API リファレンス
• 便利な関数
• 奇妙なクラス
ここから分かるように、この目次は四つの異なるファイルから抽出した情報をもとに作られる。目次の順序や構造は index.rst に記述されるものの、各章と各節のタイトルは三つの章に対応するソースファイルに存在する。
index.rst を作成した後にチュートリアルの章題を変更したとする ── ユーザーはワイオミングに到着した開拓者ではないのだから「ニューカマー」は古風すぎると考えて、tutorial.rst の最初の行を次のように改善したとしよう:
-ニューカマー向けチュートリアル
+初心者向けチュートリアル
==================
チュートリアルにようこそ!
このドキュメントでは基礎的な使い方を...
その後 Sphinx を実行して再ビルドすると、正しい処理が行われる! Sphinx はチュートリアルのページと目次のページを両方とも再ビルドする (Sphinx の出力を cat にパイプすると、進捗を表す情報が上書きされずに全て表示される)。
$ make html | cat
writing output... [ 50%] index
writing output... [100%] tutorial
Sphinx は tutorial.html のタイトルを新しいものに置き換え、さらに index.html の目次にも新しい章題を出力する。この例で Sphinx は整合性の取れた出力を生成するために必要な処理を全て行っている。
tutorial.rst の変更がもっと小さかったらどうなるだろうか?
初心者向けチュートリアル
==================
-チュートリアルにようこそ!
+私たちのプロジェクトのチュートリアルにようこそ!
このドキュメントでは基礎的な使い方を...
章題ではなく内部の段落が変更されるだけなので、この変更で目次は変化しない。そのため index.html を再ビルドする必要はない。しかし意外なことに、この例で Sphinx は賢い処理を行えない! Sphinx は index.html を不必要に再ビルドし、全く同じファイルを生成する:
writing output... [ 50%] index
writing output... [100%] tutorial
二つの出力を diff すれば、段落を変更したとき index.html が全く変化しないことを確認できる ── にもかかわらず、Sphinx は index.html を再ビルドする。
一瞬でコンパイルできる小さなドキュメントの再ビルドが無駄に実行されたとしても影響は軽微だと思うかもしれない。しかし、ドキュメントが複雑で巨大だったり、プロットやアニメーションのようなマルチメディアの生成が必要だったりすると、ワークフローへの影響は大きくなる。Sphinx は全ての章を常に再ビルドするよりも賢い処理を行っている ── 例えば tutorial.rst を変更したときに install.html と api.html は再ビルドしない ── ものの、必要以上の処理を行っているのは確かである。
ただ、Sphinx がさらにひどく失敗する場合もある: 必要なだけの処理を行わず、整合性を持たない出力が得られる状況が存在する。このとき誤った出力はユーザーが気付くまでそのままとなる。
これから最も単純な失敗例を示す。まず、API ドキュメントの先頭に相互参照を一つ追加する:
API リファレンス
=============
+このページを読む前に、:doc:`tutorial` を読んでください!
+
このページはライブラリが提供する全ての関数、そして
全てのクラスとメソッドを...
このとき、Sphinx は (先述したように必要最低限の処理ではないものの) API リファレンスと目次の両方を忠実に再ビルドする:
writing output... [ 50%] api
writing output... [100%] index
出力されるファイル api.html を確認すると、<a> タグを使ったチュートリアルページへの相互参照リンクに章題が付けられているのが分かる:
<p>このページを読む前に、
<a class="reference internal" href="tutorial.html">
<em>初心者向けチュートリアル</em>
</a>を読んでください!</p>
ここからさらに tutorial.rst の先頭にあるタイトルを変更したら何が起こるだろうか? このとき、三つの出力ファイルの次の箇所で更新が必要となる:
tutorial.htmlの先頭にあるタイトルindex.htmの目次にある章題api.htmlの第一段落にある相互参照リンクのテキスト
Sphinx はどうするだろうか?
writing output... [ 50%] index
writing output... [100%] tutorial
おっと。
二つのファイルしか再ビルドされておらず、Sphinx はドキュメントの再ビルドに失敗した。
この HTML をウェブに公開すると、ユーザーは api.html の先頭にある相互参照リンクのテキストがリンク先のページ tutorial.html のタイトルと一致しないことに気が付くだろう。この状況は Sphinx がサポートする様々な種類 (章題、節題、段落、クラス、メソッド、関数など) の相互参照で発生する。
4.3 ビルドシステムと整合性
上記の問題は Sphinx だけが持つわけではない。LaTeX などの他のドキュメントシステムでも見られる上に、プロジェクトのコンパイルステップを由緒ある make で管理しているだけのプロジェクトでも管理下のファイル (アセット) が複雑に相互参照する場合には同様の問題が発生する。
この長い歴史を持つ普遍的な問題には、同じく古くから伝わる万能の解決策が存在する:
$ rm -r _build/
$ make html
出力を全て削除すれば、完全な再ビルドが保証される! clean ターゲットで rm -r を呼び出すようにして、make clean で全ての出力ファイルを削除できるプロジェクトもよくある。
rm -r はビルド中に生成されるアセットを一つ残らず削除するので、次回のビルドはキャッシュを持たない状態から開始される ── 以前のビルドが残した残留物を使って不整合な出力が生成される心配はない。
しかし、これより優れたアプローチも可能ではないだろうか?
ビルドシステムを常駐のプロセスとして、あるドキュメントのソースコードから別のドキュメントのテキストに受け渡される章題、節題、相互参照リンクのテキストといった情報を検出したらどうだろうか? そうすれば単一のソースファイルが変更されたときに再ビルドすべき他のドキュメントを正確に判断でき、出力の整合性が保たれる。
このアプローチを採用するビルドシステムは make などの古典的な静的ツールに似ているものの、ビルド対象のファイル間の依存関係を学習できる ── ドキュメントが更新されて相互参照が追加・削除されれば、学習された依存関係も動的に更新される。
本章ではこれから、この機能を持った Contingent という Python 製ツールを解説する。Contingent は動的な依存関係を正確に認識し、最小限の再ビルドステップを実行する。このアイデアは様々な問題領域に適用できるものの、Contingent はドキュメントのビルドという上述した小さな問題だけを扱う。
4.4 タスクをつないでグラフを作る
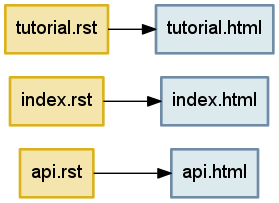
どんなビルドシステムにも入力と出力をつなげる仕組みが必要となる。例えば、以前に議論した三つのマークアップテキストからは、それぞれ対応する HTML ファイルが生成される。この依存関係は箱と矢印を使うと自然に表現できる ── 数学の言葉を使えば、頂点 (node) と辺 (edge) からなるグラフ (graph) が依存関係を表現するのに適している:
どの言語でビルドシステムを実装するにしても、その言語が持つデータ構造を使って頂点と辺からなるグラフを表現することになる。
Python ではグラフをどう表現できるだろうか?
Python には特別扱いされる汎用的なデータ構造が四つある。これらの「ビッグフォー」のデータ構造は言語の構文を通して直接サポートされ、リテラル表現をソースコードに書くことで新しいインスタンスを作成できる。また、これらのデータ構造を表す型オブジェクトは組み込みシンボルなので、インポートせずに利用できる。一つずつ見ていこう。
タプル (tuple) は読み込み専用のオブジェクト列である。各要素には異なる意味を持つオブジェクトが格納されることが多い。例えば、タプルを使えば次のようにホスト名とポート番号を一つにまとめることができる。この例からも分かるように、タプルでは要素の順序を変えると意味が変化する:
('dropbox.com', 443)
リスト (list) は改変可能なオブジェクト列である。各要素は同じ型のオブジェクトである場合が多く、たいていは「同じもの」として扱われる。与えられた順序で入力の列を保持したり、有用な順序にソートした入力の列を保持したりするときにリストは利用できる:
['C', 'Awk', 'TCL', 'Python', 'JavaScript']
集合 (set) は順序を無視するオブジェクトの集まりである。集合は特定の値が追加されたかどうかだけを記録し、追加された回数は記録しない。そのため、集合は値のストリームから重複を除去する処理で利用できる。例えば、次の二つの集合は両方とも同じ三要素集合を表す:
{3, 4, 5}
{3, 4, 5, 4, 4, 3, 5, 4, 5, 3, 4, 5}
辞書 (dict) は連想配列であり、格納されたバリューにはキーを使ってアクセスする。タプルとリストでは添え字が必ず整数であるのに対して、辞書では添え字に使う値をプログラマーが選択できる。バリューの検索ではハッシュテーブルが使われるので、辞書の要素数が数十でも数百万でも検索速度は変化しない。辞書の例を次に示す:
{'ssh': 22, 'telnet': 23, 'domain': 53, 'http': 80}
Python を柔軟に活用するには、これらのデータ構造が合成可能である事実を利用することが重要となる。四つのデータ構造は自由に入れ子にできるので、単純なリテラル構文を組み合わせることで複雑なデータ構造を作成できる。
グラフの辺は少なくとも始点と終点の情報を持つ必要があるので、最も単純な表現はタプルである。例えば、図 1 の一番上にある辺は次のタプルで表現できる:
('tutorial.rst', 'tutorial.html')
複数の辺を表現するにはどうすべきだろうか? 辺を表すタプルを要素とするリストを使えばいいと思うかもしれない。しかし、リストを使った表現には欠点がいくつかある。まず、リストの要素は順序付けられるものの、グラフの辺の順序を考える意味はない。次に、リストは複数の同じ要素を保持できるものの、例えば tutorial.rst から tutorial.html に向かう辺の個数は 0 か 1 であることが望ましい。以上の議論から、使うべきデータ構造は集合だと分かる。例えば、図 1 のグラフが持つ辺は次の集合で表現できる:
{
('tutorial.rst', 'tutorial.html'),
('index.rst', 'index.html'),
('api.rst', 'api.html'),
}
こうすれば全ての辺の走査、単一の辺の追加・削除、そして特定の辺の存在判定が高速に実行可能になる。ただ残念ながら、これら以外にも必要となる操作がある。
Contingent のようなビルドシステムは、特定の頂点を始点とする全ての辺に関する情報を保持する必要がある。例えば api.rst が変更されたとき、Contingent は完全なビルドを作成するために必要な最小限のタスクを知る必要がある。そのためには「api.rst を始点とする辺の終点は何か?」という情報、つまり api.rst の外向き辺 (outgoing edge) に関する情報が利用できなければならない。
さらに、依存関係を表すグラフを作成するには各頂点に対する入力に関する情報も必要になる。例えば、出力ファイル tutorial.html のビルドで使われる入力ファイルはどれだろうか? Contingent は各頂点への入力を監視することで「api.html は api.rst に依存し、tutorial.html に依存しない」といった事実を学習する。ソースの変更を検知して再ビルドを実行するときも、Contingent は利用されるリソースを監視することで変更があった各頂点に向かう辺を再学習する。
上述したようにタプルの集合でグラフを表現するとき、これら二つの処理は簡単に行えない。例えば api.html とグラフの他の部分との関係を調べるには、集合全体を走査して api.html を始点または終点に持つ辺を見つけるしかない。
Python の辞書 (連想配列) を使うと、特定の頂点を含む辺の直接的な検索が可能になる:
{
'tutorial.rst': {('tutorial.rst', 'tutorial.html')},
'tutorial.html': {('tutorial.rst', 'tutorial.html')},
'index.rst': {('index.rst', 'index.html')},
'index.html': {('index.rst', 'index.html')},
'api.rst': {('api.rst', 'api.html')},
'api.html': {('api.rst', 'api.html')}
}
こうすれば特定の頂点から出る辺の検索は非常に高速になるものの、全ての辺は二度保存されることになる: 始点に対応する集合と終点に対応する集合にそれぞれ一度ずつ保存される。また、辞書のバリューに含まれる辺においてキーの頂点が始点なのか終点なのかは辺を調べなければ判定できない。さらに、頂点の名前を辺の集合に何度も書かなければならないのは面倒でもある。
こういった問題は外向き辺と内向き辺を個別の連想配列に格納すると解決できる。頂点を何度も記述する必要がなくなり、特定の頂点の外向き辺と内向き辺を高速に検索できるようになる:
incoming = {
'tutorial.html': {'tutorial.rst'},
'index.html': {'index.rst'},
'api.html': {'api.rst'},
}
outgoing = {
'tutorial.rst': {'tutorial.html'},
'index.rst': {'index.html'},
'api.rst': {'api.html'},
}
このコード中の outgoing が図 1 の表すグラフを Python の構文で簡潔に表現している事実に注目してほしい。ソースコード中の outgoing の定義で左側にあるドキュメントからは、右側にあるドキュメントが生成される。この単純な例では各ソースから一つの出力が得られている ── 出力の集合が全て単元集合である ── ものの、複数の出力が関連付けられた入力ファイルの例をすぐに考える。
こうしてバリューに集合を持つ辞書を二つ使ってグラフを表すとき、全ての辺は二度表現される。例えば辺 tutorial.rst → tutorial.html は tutorial.rst の外向き辺として一度、そして tutorial.html の内向き辺としてもう一度現れる。ただ、この冗長性のおかげで Contingent が必要とする高速な検索がサポートされる。
4.5 クラスを正しく使う
Python のデータ構造に関するこれまでの議論でクラスが言及されないことに驚いた読者もいるかもしれない。実際のところ、クラスはアプリケーションの構造化でよく利用される仕組みであり、人々が絶え間なく熱い議論を戦わせる議題でもある。かつてクラスは非常に重要な概念とみなされ、プログラミング教育のカリキュラム全体がクラスを中心に構成されるほどだった。また、広く使われるプログラミング言語の多くはクラスの定義と利用に関する特別な構文を持つ。
ただ、現在ではデータ構造の設計とクラスの設計は直交する場合が多いと認識されている。クラスは全く異なる形式のデータモデリングパラダイムを提供するのではなく、通常のデータ構造の見た目を変えたものに過ぎない:
- クラスインスタンスは
dictとして実装される。 - クラスインスタンスは改変可能なタプルとして利用される。
クラスはキーによるバリューの検索を簡単な構文で提供する: graph["incoming"] ではなく graph.incoming と書ける。しかし、実際のコードを書く上でクラスを汎用的なキーバリューストアとして使うことはまずない。クラスは、属性を通じて関連するものの異なるデータを整理し、実装詳細を記憶しやすい一貫したインターフェースにカプセル化するために利用される。
例えばホスト名とポート番号をタプルで表現すると、どちらを先に書くべきかはっきりしない。この問題は、Address クラスを用意してインスタンスに host 属性と port 属性を持たせれば回避できる。このとき無名タプルを受け渡していた場所で Address オブジェクトを受け渡すことになる。クラスによってコードの読み書きは簡単になるものの、データの設計で直面する上述してきたような問題に対する新たな解決法が提供されるわけではない。クラスは見た目が良い名前付きのコンテナに過ぎない。
つまり、クラスの真価はデータ設計という学問を根本から変えることではなく、あなたが考えたデータ設計をプログラムの他の部分から隠蔽することにある!
Python アプリケーション設計の成否は、Python が提供する強力な組み込みデータ構造を最大限に活用できるかどうか、そしてプログラマーが自分で細々と管理しなければならない詳細を最小化できるかどうかにかかっている。この厄介な問題を解決する仕組みを提供するのがクラスである: クラスを上手く使えば、システムの一部分を全体の設計から分離できる。分離された一部分 (例えば Graph) に取り組むとき、他の部分に関して意識する必要があるのはインターフェースだけであり、その実装詳細は忘れてしまって構わない。プログラマーはシステムを作成する中で様々な抽象化のレベルを扱う: ときには特定のサブシステムが使用するデータモデルや実装詳細を調整し、ときには高レベルの概念をインターフェースで接続する作業を行う。
例えば、先述したグラフライブラリの外側で新しい Graph インスタンスを作るには、次のコードだけで済む:
>>> from contingent import graphlib
>>> g = graphlib.Graph()
このとき Graph の動作を細かく知っておく必要はない。Graph を利用する側のコードがグラフを改変するときは、そのインターフェースだけを利用できる。例えば辺の追加は次のように行う:
>>> g.add_edge('index.rst', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial.html')
>>> g.add_edge('api.rst', 'api.html')
注意深い読者は、グラフに辺を追加するとき「頂点」オブジェクトや「辺」オブジェクトが作成されていないことに気が付くだろう。上の例では文字列が直接使われている。他の言語や慣習の経験があれば、システムに存在する全ての概念に対してユーザー定義のクラスとインターフェースを期待するかもしれない:
Graph g = new ConcreteGraph();
Node indexRstNode = new StringNode("index.rst");
Node indexHtmlNode = new StringNode("index.html");
Edge indexEdge = new DirectedEdge(indexRstNode, indexHtmlNode);
g.addEdge(indexEdge);
Python 言語と Python コミュニティは単純な汎用データ構造を使った問題解決を意図的かつ明示的に推奨し、取り組んでいる問題のあらゆる概念に対応する独自クラスを作ることは推奨しない。これは「Pythonic」な考え方の一つである: 構文的なオーバーヘッドを最小限にして、Python が組み込みで持つ強力なツールや幅広い標準ライブラリを活用して問題を解決することが Pythonic とされる。
こういった事項を理解した上で、データ構造とクラスインターフェースの相互作用に注目しつつ先述した Graph クラスの設計と実装を確認してみよう。Graph クラスの新しいインスタンスを作ると、以前に説明した辺の情報を格納する二つの辞書がこの時点で作成される:
class Graph:
""" ビルドタスク間の関係を表す有向グラフ """
def __init__(self):
self._inputs_of = defaultdict(set)
self._consequences_of = defaultdict(set)
_inputs_of と _consequences_of の先頭に付いているアンダースコアは属性がプライベートであることを示す。これは Python コミュニティで広く使われる慣習であり、他のプログラマーや将来の自分にメッセージや警告を伝える手段の一つとして利用される。オブジェクトのプライベートな属性とパブリックな属性を区別するための簡潔で一貫したサインとして、Python コミュニティは単一のアンダースコアを属性名の先頭に付けることを採用した。そのような属性はクラスの内部機構で利用され、外側からは読み書きすべきでないとされる。
標準の dict ではなく defaultdict を使っているのはなぜだろうか? Python で辞書を他のデータ構造から使用するとき、存在しないキーの扱いで問題が発生することがよくある。通常の辞書では、存在しないキーを取得すると KeyError が送出される:
>>> consequences_of = {}
>>> consequences_of['index.rst'].add('index.html')
Traceback (most recent call last):
...
KeyError: 'index.rst'
通常の辞書を使う限り、このケースに対処するコードが様々な箇所で必要となる。例えば新しい辺の追加は次のように書かなければならない:
# 新しいタスクが追加された場合を特別に扱う
if input_task not in self._consequences_of:
self._consequences_of[input_task] = set()
self._consequences_of[input_task].add(consequence_task)
この問題は非常に一般的なので、Python には存在しないキーに対するバリュー (を返す関数) を設定できる辞書 defaultdict が存在する。defaultdict(set) とすれば、存在しないキーに対して例外ではなく空の set が返る:
>>> from collections import defaultdict
>>> consequences_of = defaultdict(set)
>>> consequences_of['api.rst']
set()
defaultdict を使えば、特定の集合に対する初めての要素の追加と二回目以降の要素の追加は同じコードとなる:
>>> consequences_of['index.rst'].add('index.html')
>>> 'index.html' in consequences_of['index.rst']
True
このテクニックを念頭に置いて add_edge の実装を見てみよう。これは以前に図 1 のグラフを構築するときに利用したメソッドである:
def add_edge(self, input_task, consequence_task):
"""
辺を追加する。追加される辺は「consequence_task は input_task の出力を
利用する」という関係を表す。
"""
self._consequences_of[input_task].add(consequence_task)
self._inputs_of[consequence_task].add(input_task)
Graph の実装は辺を両方向に保持するので、新しい辺を追加するには二つのコンテナを操作する必要がある。しかし、その事実は add_edge メソッドのインターフェースによって隠蔽されている。add_edge メソッドは新しい辺の始点と終点が以前に使われた頂点かどうかを確認しない点に注目してほしい。使用される二つのデータ構造は両方とも defaultdict(set) なので、 add_edge メソッドはキーの新規性を気にしないで済む ── 必要な場合は defaultdict が新しい set オブジェクトを作成する。上述したように、defaultdict を使わなければ add_edge メソッドは三倍ほど長くなる。さらに重要なことして、最終的なコードは理解しにくくなる。この実装は「単純・直接・簡潔」を重視する Pythonic な問題解決アプローチを示す例である。
グラフの辺全体からなるリストを取得する edges メソッドも存在する。呼び出し側が Graph のデータ構造を走査する方法を知っておく必要はない:
def edges(self):
"""
(input_task, consequence_task) の形をしたタプルのリストとして
全ての辺を返す。
"""
return [(a, b) for a in self.sorted(self._consequences_of)
for b in self.sorted(self._consequences_of[a])]
Graph.sorted メソッドは頂点を自然な順序でソートする。グラフを一貫した形でユーザーに示したいときに便利である。
edges メソッドを使えば、以前に構築した g が図 1 のグラフを表していることを確認できる:
>>> from pprint import pprint
>>> pprint(g.edges())
[('api.rst', 'api.html'),
('index.rst', 'index.html'),
('tutorial.rst', 'tutorial.html')]
これでグラフを図ではなく実際の Python オブジェクトとして表現できたので、興味深い質問に答える準備が整った! 例えば api.rst が変更されたとき、Contingent は「api.rst に依存するファイルはどれか?」という質問に答える必要がある。この質問の解答は次のコードで得られる:
>>> g.immediate_consequences_of('api.rst')
['api.html']
Graph オブジェクト g は「api.rst が変更されるとき api.html も変更されるので、再ビルドが必要となる」と Contingent に伝える。
index.html についてはどうだろうか?
>>> g.immediate_consequences_of('index.html')
[]
返り値の空リストは、index.html を始点とする辺が存在しないので、このファイルが変更されたとき他のファイルの再ビルドが必要にならないことを表す。Graph は辞書を二つ使って辺を保持するので、このクエリには非常に簡単に答えられる:
def immediate_consequences_of(self, task):
""" task を入力とするタスクを返す """
return self.sorted(self._consequences_of[task])
本章冒頭の議論で登場したタスク同士の関係の中で、図 1 に示されていないものが一つある: 目次ページが各章の章題に依存するような関係である。これを表現するには、各章のファイルをパースしたときに生成される章題の文字列に対応する頂点を作成すればよい:
>>> g.add_edge('api.rst', 'api-title')
>>> g.add_edge('api-title', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial-title')
>>> g.add_edge('tutorial-title', 'index.html')
こうして構築されるグラフを図 2 に示す。このグラフを使えば、本章の最初で議論した章題が変更されるシナリオでも index.html を適切に再ビルドできる。
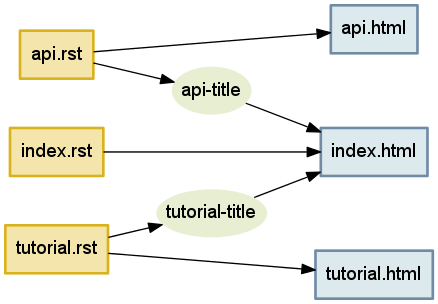
index.html を再ビルドできるグラフ
Contingent に行わせる処理を説明するステップバイステップのウォークスルーは以上で終了となる。ここに説明した方法で、Contingent はプロジェクトのドキュメントが生成する様々な生成物の間にある入力と出力の関係をグラフで表現する。
4.6 依存関係の学習
Contingent でタスク間の依存関係を表現する方法がこれで手に入った。しかし図 2 を詳しく見ると、具体的でない曖昧な部分がまだある: Contingent は api.rst から api.html をどのように生成するのだろうか? index.html の生成に tutorial.rst に含まれる章題が必要なことをどのように知るのだろうか? そして、こういった依存関係をどのように解決するのだろうか?
グラフを手動で組み立てているなら、こういった質問の解答は「HTML ファイル」「目次」「章題」といった概念から直感的に分かる。しかし残念ながらコンピューターは直感を持たないので、すべきことをプログラマーが正確に指示しなければならない。
入力から出力を生成するためにどのようなステップが必要だろうか? この「ステップ」はどのように定義され、実行されるだろうか? そして、ステップ同士の関係をどうすれば知ることができるだろうか?
Contingent において、ビルドタスクは関数と引数でモデル化される。関数は特定のプロジェクトで必要になる処理を定義する。引数は処理に詳細情報を提供する: 例えば、読み込む入力ドキュメントや必要となるブログのタイトルは引数によって指定される。タスクを表す関数を実行している間に他のタスクを表す関数を呼び出すこともできる。そのときの引数は呼び出しごとに適切な値に設定される。
この動作を説明するために、これから本章の最初で紹介したドキュメントビルダーを実際に実装する。細々とした詳細に時間を費やすのを避けるため、ここでは入力と出力のフォーマットを次のように単純化する。入力ドキュメントの最初の行にはタイトルがあり、次の行はハイフンだけからなり、以降の行に本文がある。相互参照はファイル名をバックティックで囲んだ文字列で表され、その部分は出力でドキュメントのタイトルに置き換わる。
index.txt, api.txt, tutorial.txt の例を次に示す。どれも前段落で示したフォーマットのドキュメントであり、タイトル・本文・相互参照が含まれている:
>>> index = """
... 目次
... -----------------
... * `tutorial.txt`
... * `api.txt`
... """
>>> tutorial = """
... 初心者向けチュートリアル
... ------------------
... チュートリアルにようこそ!
... """
>>> api = """
... API リファレンス
... -------------
... 最初に `tutorial.txt` を読むことを推奨します。
... """
これで操作対象となるサンプルができた。続いて、Contingent ベースのドキュメントビルダーが必要とする関数を考えよう。
上に示した単純な例では、出力の HTML ファイルを入力から直接生成できる。しかし現実のシステムでは、入力をマークアップに変換する処理にいくつかのステップが存在する: ディスクから生のテキストを読み込み、テキストを処理しやすい内部表現にパースし、ディレクティブがあれば処理し、相互参照やインクルードなどの外部依存関係を解決し、それから一つ以上の変換を通して内部表現を出力フォーマットに変換する。
Contingent はタスクを Project という単位にまとめることで管理する。Project はビルドシステムにおける「何でも屋」であり、ビルドプロセスの様々な場所で姿を現す。タスク同士の関係を表すグラフを構築するときにタスクが他のタスクと情報をやり取りするときにも使われる。
>>> from contingent.projectlib import Project, Task
>>> project = Project()
>>> task = project.task
これから、本章の最初で考えた例を扱えるビルドシステムが必要とするタスクを見ていく。
read タスクはディスクからファイルを読み込む。ただし、今考えている例で入力テキストは変数で定義されるので、ファイル名を使ってテキストを取得するだけで済む:
>>> filesystem = {'index.txt': index,
... 'tutorial.txt': tutorial,
... 'api.txt': api}
...
>>> @task
... def read(filename):
... return filesystem[filename]
parse タスクはファイルに含まれる生のテキストをドキュメントのフォーマットに変換する。今考えている例のフォーマットは非常に単純である: 最初の行がタイトルで、二行目は装飾であり、三行目以降が本文となる:
>>> @task
... def parse(filename):
... lines = read(filename).strip().splitlines()
... title = lines[0]
... body = '\n'.join(lines[2:])
... return title, body
フォーマットが非常に単純なので、パーサーを個別に用意することが馬鹿馬鹿しく思えるかもしれない。ただ、このタスクはパーサーが持つ「生のテキストを解釈する」という責務を説明するために存在する (テキストの一般的なパースは非常に興味深い分野であり、パースを扱った書籍は多くある)。Sphinx などのシステムでは、パーサーがシステムによって定義される様々なマークアップトークン、ディレクティブ、コマンドを理解した上で入力テキストをシステムの他の部分が扱える形式に変換する必要がある。
parse と read の関係に注目してほしい ── parse は最初に read を呼び出すことで指定されたファイルの内容を取得する。
title_of タスクは指定されたファイルに含まれるドキュメントのタイトルを返す:
>>> @task
... def title_of(filename):
... title, body = parse(filename)
... return title
このタスクはドキュメント処理システムにおける責務の分離を示す良い例である。title_of 関数はメモリ上に構築されたドキュメントの内部表現 ── 具体的に言えば Python のタプル ── を扱い、タイトルを見つけるためだけにドキュメント全体を再度パースすることはない。システムの仕様に沿ってメモリ上表現を生成するのは parse 関数だけであり、その後 title_of などの他の関数は parse の出力を所与のものとして扱う。
古典的なオブジェクト指向の設計に慣れている読者は、この関数的な設計にとまどったかもしれない。オブジェクト指向の設計では parse 関数が Document オブジェクトを返し、その Document オブジェクトが title_of というメソッドあるいはプロパティを持つことになるだろう。実際、Sphinx はそのような設計をしている: Parser サブシステムが「Docutils ドキュメントツリー」オブジェクトを生成し、システムの他の部分はそのオブジェクトを利用する。
Contingent は一つの設計パラダイムに傾倒せず、どのアプローチも同じようにサポートする。本章では説明を単純にするために関数型の設計を用いている。
最後のタスク render はドキュメントのメモリ上表現を出力形式に変換する。この処理は事実上 parse の逆と言える。parse は仕様に準拠する入力ドキュメントをメモリ上表現に変換し、render はメモリ上表現を仕様に準拠する出力ドキュメントに変換する。
>>> import re
>>>
>>> LINK = '<a href="{}">{}</a>'
>>> PAGE = '<h1>{}</h1>\n<p>\n{}\n<p>'
>>>
>>> def make_link(match):
... filename = match.group(1)
... return LINK.format(filename, title_of(filename))
...
>>> @task
... def render(filename):
... title, body = parse(filename)
... body = re.sub(r'`([^`]+)`', make_link, body)
... return PAGE.format(title, body)
ここまでに実装してきたロジックを全て利用する例を次に示す ── tutorial.txt をレンダリングして表示する:
>>> print(render('tutorial.txt'))
<h1>初心者向けチュートリアル</h1>
<p>
チュートリアルにようこそ!
<p>
render('tutorial.txt') を呼び出したときに実行されるタスクを図 3 に示す。レンダリングを行うには入力ファイルの読み込みとドキュメントのパースが必要なことが示されている。

実は図 3 は本章のために筆者が作ったものではなく、Contingent から直接生成されている! このグラフの作成が可能なのは、Project オブジェクトが独自のコールスタックを持つためである。Python が現在の関数の実行終了後に返るべき箇所を記録するために利用する実行フレームのスタックと同様の仕組みを Project オブジェクトは持つ。
新しいタスクが呼び出されると、Contingent は現在スタックのトップにあるタスクが新しいタスクを呼び出した ── そして新しいタスクの出力を利用する ── と仮定する。スタックを適切に管理するには、タスク T が呼び出されたときに追加でいくつか処理が必要になる:
Tをスタックにプッシュする。Tを実行する。Tがさらに他のタスクを呼び出した場合も適切に処理する。Tをスタックからポップする。- 結果を返す。
タスクを実装する関数を呼び出す処理に割り組むために、Project は関数デコレータ (function decorator) と呼ばれる Python の重要な機能を利用する。関数デコレータを利用すると、関数の定義時に関数を処理・変形できる。関数デコレータ Project.task はタスクを実装する関数を wrapper と呼ばれるラッパー関数で包み、Project のためにグラフとスタックを管理する処理とタスクが行うドキュメントの処理を明確に分離する。関数デコレータ Project.task のボイラープレートを次に示す:
from functools import wraps
def task(function):
@wraps(function)
def wrapper(*args):
# ラッパーの本体: function() の呼び出しも含まれる
return wrapper
典型的な関数デコレータは上のコードと全く同じ形をしている。関数を定義する def の一つ前の行に @ と関数デコレータの名前を続けて書けば、その関数の定義に関数デコレータを適用できる:
@task
def title_of(filename):
title, body = parse(filename)
return title
この定義が処理されると、識別子 title_of は関数デコレータの本体で定義される wrapper 関数を指すようになる。この wrapper 関数では関数デコレータが付与された元々の関数に function という識別子でアクセスでき、呼び出すこともできる。Contingent.task の完全な定義を次に示す:
def task(function):
@wraps(function)
def wrapper(*args):
task = Task(wrapper, args)
if self.task_stack:
self._graph.add_edge(task, self.task_stack[-1])
self._graph.clear_inputs_of(task)
self._task_stack.append(task)
try:
value = function(*args)
finally:
self._task_stack.pop()
return value
return wrapper
この wrapper 関数は非常に重要な管理ステップをいくつか実行する:
- 利便性のため、タスクを構成する関数と引数をまとめた小さなオブジェクトを作成する。
Task(wrapper, args)におけるwrapperはタスク関数のラッパー (関数デコレータが返す関数) を意味する。 - 実行中の他のタスクから呼び出されたときは、このタスクが呼び出し元のタスクの入力である事実を表すグラフの辺を追加する。
- このタスクに対する入力に関して以前に学習した情報を全て忘れる。今回の実行で異なるタスクが呼び出される可能性があるためである。例えば API ガイドのソーステキストからチュートリアルの言及が削除されると、API ガイドの
renderタスクでチュートリアルドキュメントのtitle_ofタスクが呼ばれなくなる。 - タスクをスタックのトップにプッシュする。
- タスクを
try...finallyブロック内で実行し、例外が発生した場合でもタスクが正しくスタックからポップされることを保証する。 - タスクの返り値を返す。このとき呼び出し側は呼び出した関数が実際にはラッパーである事実に気が付かない。
ステップ 4 と 5 がスタックの管理であり、タスクからなるスタックを作成する本来の目的である入出力関係を表すグラフの構築はステップ 2 で行われる。
それぞれのタスクに対して固有のラッパー関数が生成されるので、タスクを通常通りに呼び出して実行するだけで依存関係を表すグラフが副作用として生成される。以前にタスクを実装する関数を定義したときに @task が先頭に付いていたのはこのためである:
@task
def read(filename):
# ...
@task
def parse(filename):
# ...
@task
def title_of(filename):
# ...
@task
def render(filename):
# ...
こうしてラッパーを生成しておけば、parse('tutorial.txt') を呼び出すだけで parse と read の間の依存関係が学習される。この呼び出しを表す Task オブジェクトを生成し、その出力が変化したとき影響を受けるタスクを確認すれば、この依存関係を確認できる:
>>> task = Task(read, ('tutorial.txt',))
>>> print(task)
read('tutorial.txt')
>>> project._graph.immediate_consequences_of(task)
[parse('tutorial.txt')]
この実行結果からは、ファイル tutorial.txt の変化を検出した (read('tutorial.txt') の値が変化した) ときは tutorial.txt を再度パースする (parse('tutorial.txt') を再度実行する) 必要があると分かる。全てのドキュメントをレンダリングしたら何が起こるだろうか? Contingent はビルドプロセス全体について正しく学習できるだろうか?
>>> for filename in 'index.txt', 'tutorial.txt', 'api.txt':
... print(render(filename))
... print('=' * 30)
...
<h1>Table of Contents</h1>
<p>
* <a href="tutorial.txt">初心者向けチュートリアル</a>
* <a href="api.txt">API リファレンス</a>
<p>
==============================
<h1>初心者向けチュートリアル</h1>
<p>
チュートリアルにようこそ!
<p>
==============================
<h1>API リファレンス</h1>
<p>
最初に <a href="tutorial.txt">初心者向けチュートリアル</a> を読むことを推奨します。
<p>
==============================
正しい出力が得られた! 入力ドキュメントに含まれる相互参照が対応するドキュメントのタイトルに正しく置き換わっているので、Contingent はドキュメントのビルドに必要なタスク間の依存関係 (図 4) を学習できている。
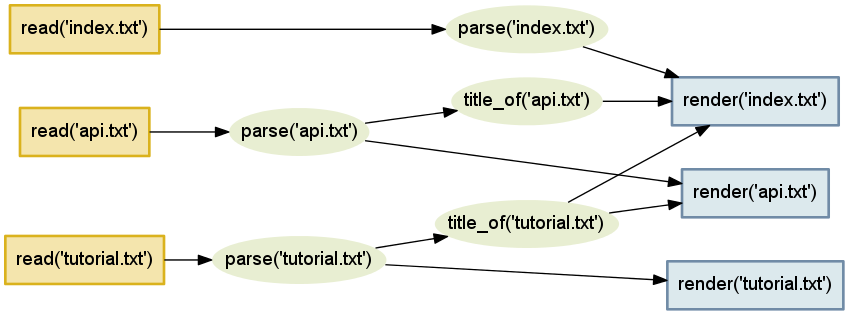
関数デコレータ task で作成されるラッパーを利用してタスクの呼び出しに割り込むことで、Project は入力と出力の依存関係を表すグラフを自動的に学習する。Contingent は完全な依存関係グラフを手にするので、任意のタスクの出力が変化したときに再実行すべきタスクを正確に把握できる。
4.7 依存関係の追跡
最初のビルドが完了した後、Contingent は入力ファイルの変更を監視する必要がある。ユーザーが編集を追えて「保存」を実行したとき、read タスクとそれに依存する全てのタスクを再実行しなければならない。
この処理はグラフを作成時と逆の順序で走査すると行える。例えば、ドキュメントに対する render は parse を呼び出し、parse は read を呼び出す。そのため read の返り値が変化したときは parse の再実行が必要であり、さらに parse の返り値が変化したときは render の再実行が必要となる。
あるタスクを呼び出すタスクがさらに別のタスクによって呼び出される可能性があるので、再実行すべきタスクの特定は再帰的に行わなければならない。この再帰的な処理を手動で行うと次のようになる:
>>> task = Task(read, ('api.txt',))
>>> project._graph.immediate_consequences_of(task)
[parse('api.txt')]
>>> t1, = _
>>> project._graph.immediate_consequences_of(t1)
[render('api.txt'), title_of('api.txt')]
>>> t2, t3 = _
>>> project._graph.immediate_consequences_of(t2)
[]
>>> project._graph.immediate_consequences_of(t3)
[render('index.txt')]
>>> t4, = _
>>> project._graph.immediate_consequences_of(t4)
[]
(Python REPL では _ で直前のプロンプトの返り値を参照できる。)
あるタスクに直接依存するタスクを探す処理は、どのタスクにも依存されないタスクが見つかるまで続く。この再帰的な処理はグラフに対する非常に基礎的な操作なので、Graph クラスのメソッドで直接サポートされる:
>>> # pprint を使って横幅を調整する
>>> _pprint = pprint
>>> pprint = lambda x: _pprint(x, width=40)
>>> pprint(project._graph.recursive_consequences_of([task]))
[parse('api.txt'),
render('api.txt'),
title_of('api.txt'),
render('index.txt')]
recursive_consequences_of は実際には先ほどの説明より賢い処理を行う。特定のタスクが複数のタスクを呼び出す場合、そのタスクは出力のリストに一度しか現れず、さらにリストの後方 (自身が呼び出す任意のタスクより後) に配置される。これは「深さ優先探索によるトポロジカルソート」という古典的なアルゴリズムで実装される。再帰的なヘルパー関数を使えば、このアルゴリズムは Python で簡単に実装できる。詳細は graphlib.py を見てほしい。
この再帰的な依存タスクの特定処理で見つかるタスクをファイルの変更を検知するたびに実行すれば、Contingent がビルドしなければならないファイルをビルドしないままにする事態は回避できる。しかし、もう一つの問題としてビルドしなくても構わないファイルをビルドしてしまう事態も回避しなければならない。例えば図 4 の状況において、tutorial.txt が変更されるたびに三つの出力ファイル全てを再ビルドする必要はおそらくない。なぜなら、tutorial.txt に対する変更の大部分は本文だけを変更し、タイトルは変更しないからである。どうすれば再ビルドを最小限にできるだろうか?
この問題を Contingent はキャッシュを利用することで解決する: 変更の影響を受けるタスクを再帰的に実行しながらグラフを進んでいくとき、タスクの出力が前回の実行から変化していなければその時点で引き返す。
この最適化のために、Project に本章で紹介する最後のデータ構造を追加する。Project の _todo プロパティは集合であり、少なくとも一つの入力が変更された (再実行が必要な) タスクを保持する。_todo に属するタスクだけが再実行を必要とするので、そこに属さないタスクは全てスキップして構わない。
ここでも、ソースコードと統合された利便性の高い Python の設計のおかげで、この機能は非常に簡単に実装できる。タスクオブジェクトはハッシュ可能なので、_todo にはタスクをそのまま入れることができる ── 同じタスクが二度追加される事態は起こらない。また、前回の実行における返り値を収める _cache にはタスクをキーとする辞書を利用できる。
さらに具体的に言えば、再ビルドステップは _todo が空になるまで次の処理を繰り返す:
_todoを引数としてrecursive_consequences_ofを呼び出す。返り値はタスクを要素とするトポロジカルソートされたリストであり、_todoに含まれるタスクに加えて_todoからグラフをたどって到達できる全てのタスクが含まれる。言い換えれば、この返り値には再実行が必要になる可能性があるタスクが全て含まれる。- リストを先頭から走査し、タスクが
_todoに含まれるかどうかを判定する。_todoに含まれないタスクは実行する必要がない。なぜなら、そういったタスクの上流にあるタスクはいずれも返り値が変化していないからである。 - リストの走査中に
_todoに含まれるタスクが見つかったときは、そのタスクを再実行する。返り値がキャッシュされた前回の値と一致しないなら、そのタスクからグラフをたどって到達できる全てのタスクを_todoに追加してから次のタスクに移る。
リストの走査が一度完了した時点で、再実行が必要な全てタスクの実行が完了している (_todo が空である) 可能性が高い。ただ、タスクの実行中に依存関係が大きく変化すると _todo が空にならないこともあるので、そのときは同じ処理を繰り返す。どれほど依存関係が大きく変化していたとしても、_todo はすぐに空になる。ただし、閉路 ── タスク A がタスク B に依存し、同時にタスク B がタスク A に依存するような関係 ── が存在し、返り値が安定しない場合にはループが止まらない可能性がある。幸い、現実の典型的なビルドタスクは閉路を持たない。
このシステムの動作を例とともに確認しよう。
tutorial.txt を編集し、タイトルと本文の両方を変更したとする。この改変は filesystem 辞書を使ってシミュレートできる:
>>> filesystem['tutorial.txt'] = """
... プログラマー向けチュートリアル
... ------------------
... 新しい、改善された第一段落...
... """
これでファイルの内容が変化したので、Project に read タスクを再実行させる。次のコードで使われるコンテキストマネージャ cache_off は、タスクの返り値のキャッシュを無効化して値を確実に再計算させるためにある:
>>> with project.cache_off():
... text = read('tutorial.txt')
これで新しいチュートリアルのテキストがキャッシュに格納された。このとき再実行が必要なタスクはどれだろうか?
この質問に答えるために、Project クラスは再ビルド時に再実行されたタスクを表示するトレーシング機能を持つ。今回加えた tutorial.txt への変更はタイトルと本体の両方に影響するので、tutorial.txt に関係する全てのタスクが再実行されるのが分かる:
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
calling render('api.txt')
calling render('index.txt')
図 4 を確認すると、ここに表示されるタスクが read('tutorial.txt') から矢印をたどって到達できる全てのタスクに等しいことが分かる。
では、タイトルをそのままにして本文だけを変更した場合はどうなるだろうか?
>>> filesystem['tutorial.txt'] = """
... プログラマー向けチュートリアル
... ------------------
... プログラマー向けチュートリアルにようこそ!
... 上から下に読んでください。
... """
>>> with project.cache_off():
... text = read('tutorial.txt')
この小規模な変更は tutorial.txt 以外のドキュメントに影響を及ぼさないはずである。確認しよう:
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
成功だ! tutorial.txt に関するタスクだけが再実行された。title_of は変更された入力ドキュメントを受け取っても以前と同じ値を返すので、title_of を利用する他のタスクは再実行されない。
4.8 結論
一部のプログラミング言語やプログラミング設計技法では、Contingent を作るために問題ドメインの全ての概念に難解な名前を付け、息の詰まるほど大量の小さなクラスを定義することになる。
しかし Python で Contingent を書くとき、TaskArgument, CachedResult, ConsequenceList といった作成されてもおかしくないクラスは作成されなかった。その代わり私たちは「一般的な問題を一般的なデータ構造で解決する」という Python で重視される考え方を利用した。この結果として、核となる小数のデータ構造 (タプル、リスト、集合、辞書) を繰り返し利用するコードが得られた。
この考え方に問題はないのだろうか?
例えば、一般的なデータ構造は本質的に「匿名」にもなる。Contingent の Project._cache は辞書であり、Graph._inputs_of と Graph._consequences_of も辞書である。このため set の一般的なエラーメッセージを見ただけでは、Contingent プロジェクトとグラフライブラリのどちらでエラーが起きたか分からないかもしれない!
しかし実際には、その心配はない。
注意深いカプセル化がある ── Graph のコードだけがグラフに関する辞書に触れることを許され、Project のコードだけが Contingent プロジェクトに関する辞書に触れることを許される ── ために、set が異なる箇所で使われる場面でも曖昧性が生じることはない。エラーが発生した時点のコールスタックで最も深いメソッドを見れば、誤りのあったクラスと辞書が正確に分かる。「名前の最初にアンダーバーが付いた属性にはクラスの外側からアクセスしない」という規則を守ってさえおけば、set を継承した子クラスを用途ごとに一つずつ作る必要はない。
Contingent は Facade パターン (画期的な書籍 Design Patterns で示されたデザインパターンの一つ) が上手く設計された Python プログラムにおいて非常に重要であることを示してもいる。Python プログラムでは全てのデータ構造やデータの断片がクラスで表されるわけではない。クラスの利用は控えめであり、複雑な概念 (例えば「依存グラフ」) が内部に持つ単純な一般的データ構造の詳細を建物の正面で見えないようにまとめるときにだけクラスが利用される。
Facade の外側にあるコードは、自身が必要とする複雑な概念や自身が実行する操作に固有の名前を付ける。一方で Facade の内側のコードは、プログラミング言語 Python が持つ小さくて便利な部品を組み合わせてその操作を実現する。