5. asyncio コルーチンを利用したウェブクローラ
5.1 はじめに
古典的な計算機科学は計算を可能な限り早く完了させる効率的なアルゴリズムに焦点を当ててきた。しかし、ネットワークを利用する多くのプログラムが実行時間を費やすのは計算ではなく、オープンした大量の接続 (それも低速だったり、イベントの頻度が低かったりする接続) を保持する処理である。そういったプログラムは計算の高速化とは大きく異なる問題に直面する: 大量のネットワークイベントを待つ処理を効率的に行わなければならない。この問題に対する現代的なアプローチとして async (asynchronous I/O, 非同期 I/O) がある。
本章では簡単なウェブクローラを解説する。ウェブクローラは多くのレスポンスを待つ必要があり、自身では計算をほとんど行わないので、典型的な async アプリケーションと言える。一度に取得できるページが増えればそれだけ、ウェブクローラは処理を早く完了できる。実行中のリクエストそれぞれにスレッドを割り当てたとしたら、リクエストの同時発行数が増加したときソケットが足りなくなる前にメモリまたはスレッドに関連したリソースが足りなくなるだろう。非同期 I/O を使えばスレッドを使う必要がなくなる。
ウェブクローラの解説は三つの部分に分かれる。まず、async イベントループを示し、それとコールバックを使ったウェブクローラを簡単に説明する。このウェブクローラは非常に効率的であるものの、より複雑な問題を扱おうとするとコードは管理不能なスパゲッティコードとなってしまう。次に、Python のコルーチンが効率的かつ拡張可能であることを示し、ジェネレータ関数を使って単純なコルーチンを Python で実装する。最後に、Python の標準ライブラリ asyncio1 に含まれる完全な機能を持ったコルーチンを説明し、非同期キューを使ってコルーチンを管理する例を示す。
5.2 すべきこと
ウェブクローラはウェブサイト上の全てのページを見つけ、ダウンロードする。ウェブクローラはルートの URL だけが含まれるキューと共に処理を始め、キューから URL を一つ取り、URL にあるページをダウンロードする。ダウンロードしたページをパースし、そこにダウンロードしていないページへのリンクが含まれれば、その URL をキューに積む。ウェブクローラは以上の処理をキューが空になるまで続ける。
この処理は複数のページを同時にダウンロードすることで高速化できる。ウェブクローラが新しいリンクを見つけるたびに、個別のソケットで新しいページをダウンロードする処理を開始すればよい。ウェブクローラは返ってきたレスポンスをパースし、そこに含まれる新しいリンクをキューに積む。ただし、並行性を増やせばいくらでもパフォーマンスが向上するわけではないので、同時に発行するリクエスト数に上限を設け、それ以上のリクエストは他のリクエストが完了してから発行する必要がある。
5.3 古典的なアプローチ
どうすればクローラを並行化できるだろうか? 古典的なアプローチはスレッドプールを利用する。このとき、それぞれのスレッドは自身に割り当てられたソケットを使って一つのページをダウンロードする。例えば、xkcd.com のページは次のコードでダウンロードできる:
def fetch(url):
sock = socket.socket()
sock.connect(('xkcd.com', 80))
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(url)
sock.send(request.encode('ascii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
# ページがダウンロードされた
links = parse_links(response)
q.add(links)
デフォルトでは、ソケットの操作はどれもブロッキングな処理である: スレッドが connect や recv といったメソッドを呼び出すと、その操作が完了するまでスレッドの実行が停止する2。そのため複数のページを同時にダウンロードするには、複数のスレッドが必要になる。手の込んだアプリケーションは手の空いているスレッドをスレッドプールに保持し、新しいタスクの実行が必要になったときスレッドプールに含まれるスレッドにそれを実行させることでスレッド作成のコストを償却する。これはソケットを保持する接続プールと同じ考え方である。
しかし、スレッドは高価であり、OS はプロセス、ユーザー、マシンごとに作成可能なスレッド数に再設定不可能な上限を設けている。Jesse のシステムでは、一つの Python スレッドは約 50KB のメモリを消費し、数万個のスレッドを起動しようとしたところ失敗した。つまりソケットごとにスレッドを用意するアプローチだと、同時に行う操作の個数が数万に達した時点でソケットではなくスレッドが足りなくなる。ボトルネックとなるのは各スレッドのオーバーヘッドまたはシステムが設けるスレッド数の制限である。
Dan Kegel は有名な記事 The C10K problem で、I/O を並行に扱う手段としてのマルチスレッディングが持つ制約を指摘した。彼の次の言葉で記事を始めている:
現代的なウェブサーバーは 1 万個のクライアントを同時に扱えるべきだ。そう思わないか? 今のウェブは巨大なのだから。
Kegel が「C10K」という用語を考案したのは 1999 年のことだった。現在では 1 万接続の同時処理など可愛いものだが、変化したのは問題の量だけで、問題そのものが消え去ったわけではない。1999 年当時、接続ごとにスレッドを用意する方式で C10K を達成するのは非現実的だった。ただ現在では、この方式で処理可能な接続数は数桁も大きくなった。実を言えば、この方式を使ったとしても本章で作成する簡単なウェブクローラで何か問題が発生するわけではない。しかし数十万個の接続を同時に扱う非常に大規模なアプリケーションでは、1999 年と同じ問題が発生する: それだけのソケットは作れても、それだけのスレッドは作れない。どうすればいいだろうか?
5.4 非同期 I/O
非同期 I/O フレームワークはノンブロッキングソケットを利用して単一のスレッドで複数の操作を並行に処理する。ノンブロッキングソケットを使用するには、サーバーに接続する前にソケットをノンブロッキングに設定する:
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
いらだたしいことに、ノンブロッキングソケットを使った connect は操作を通常通り終えた場合でも例外を送出する。この例外は内部で呼ばれている C 関数のいらだたしい振る舞いを再現したものである: C 関数 connect は操作が開始されたことを呼び出し側に伝えるために errno を EINPROGRESS に設定する。
この後 HTTP リクエストを送信するには、接続が確立されたかどうかを知る手段が必要になる。接続の確立を確認しつつ HTTP リクエストを送信する処理を単純な無限ループで行うコードを示す:
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(url)
encoded = request.encode('ascii')
while True:
try:
sock.send(encoded)
break # 送信が開始された
except OSError as e:
pass
print('sent')
この方法は電力を無駄に消費するだけではなく、複数のソケットを効率的に待つことができない。はるか昔の BSD Unix は、この問題に対する解決法としてノンブロッキングソケットおよびその小さな配列に対するイベントを待つ C 関数 select を持っていた。現在では大量の接続を用いるインターネットアプリケーションの需要が大きく高まったので、BSD では poll と kqueue が、Linux では poll が代替として用意されている。これらの関数は select と似たインターフェースを持ち、大量の接続に対しても高い効率で動作する。
Python 3.4 の DefaultSelector はシステムで利用可能な select 風の関数の中で最も優れたものを自動的に利用する。ネットワーク I/O に関する通知を受け取るには、ノンブロッキングソケットを DefaultSelector に登録する:
from selectors import DefaultSelector, EVENT_WRITE
selector = DefaultSelector()
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
def connected():
selector.unregister(sock.fileno())
print('connected!')
selector.register(sock.fileno(), EVENT_WRITE, connected)
sock.connect が送出する偽りのエラーを無視して、ノンブロッキングソケットのファイルディスクリプタを selector.register に渡している。このとき一緒に渡される EVENT_WRITE は通知を待つイベントの種類を示す。つまり、ここではソケットが「書き込み可能」になるまで待機する。selector.register の第三引数は Python 関数 connected であり、この関数は指定したイベントが起きたときに実行される。こういった使われ方をする関数をコールバック (callback) と呼ぶ。
selector からの I/O 通知を実際に処理するループを次に示す:
def loop():
while True:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
コールバック connected は event_key.data に含まれるので、ノンブロッキングソケットが接続を確立したときにこれを取り出して実行する。
sock.send を成功するまで呼び出す先述したループと異なり、このループで呼び出される select は次の I/O イベントが発生するまで返らない。なお、select が返ったとしても未完了の操作がさらに存在する可能性はある。そういった操作 (および対応するコールバック) は将来の select の呼び出しで処理される。
このコードは何を示しているのだろうか? ここに示したのは「操作を開始して、操作の準備が整ったらコールバックを実行する」処理である。非同期フレームワークは、この二つの概念 ── ノンブロッキングソケットとイベントループ ── を基礎として、単一のスレッドで複数の操作を同時に処理する。
ただし、こうして達成されるのは並行性 (concurrency) であって並列性 (parallelism) ではない。つまり、上記のコードはオーバーラッピング I/O を行う小さなシステムであり、他の操作が実行中だったとしても新しい操作を開始できる機能を持つ。しかし、複数のコアを利用して計算を実行しているわけではない。このシステムは CPU バウンドではなく I/O バウンドの問題に適している3。
上記のイベントループは接続ごとにスレッドリソースを消費することがないので、効率的に並行 I/O を行える。ただ、次の点は誤解されやすいので強調しておく: 非同期 I/O がマルチスレッディングより常に速いとは限らない。非同期 I/O の方が遅いこともよくある ── 特に、データのやり取りが非常に多い小数の接続を扱う場合、Python では上述したようなイベントループがマルチスレッディングより遅くなる可能性が高い。インタープリタがグローバルなロックを使用しないランタイムを持つ言語では、そういったワークロードでマルチスレッディングの性能がさらに高くなると考えられる。非同期 I/O が適しているのは、データのやり取りが少なくイベントの頻度が低い接続が大量に存在するアプリケーションである4。
5.5 コールバックを使ったプログラミング
上述したコールバックによる非同期 I/O を使ってウェブクローラを書くとしたら、どのようなプログラムになるだろうか? 実は、単純な URL フェッチを行うプログラムでさえ書くのに苦痛が伴う。
まず、これからフェッチすべき URL とこれまでに発見済みの URL を収めるグローバルな集合オブジェクト urls_todo と seen_urls を定義する:
urls_todo = set(['/'])
seen_urls = set(['/'])
seen_urls は urls_todo に含まれる URL と、フェッチが完了した URL を含む。二つの集合オブジェクトはルート URL "/" を唯一の要素として初期化される。
ページをフェッチするにはコールバックがいくつか必要になる。connected コールバックはソケットが接続を確立したときに呼ばれ、GET リクエストをサーバーに送信する。その後はレスポンスを待つ必要があるので、別のコールバックを用意しなければならない。そのコールバックが呼ばれてもレスポンスが完全に受信できているとは限らないので、そのときはもう一度同じコールバックを登録することになる。
こういったコールバックを Fetcher オブジェクトで管理することにしよう。このオブジェクトは URL とソケットオブジェクト、そしてレスポンスのバイト列を保持する:
class Fetcher:
def __init__(self, url):
self.response = b'' # 空のバイト列
self.url = url
self.sock = None
URL のフェッチは Fetcher.fetch の呼び出しから始まる:
# Fetcher クラスのメソッド
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
# 次の処理を行うコールバックを登録する
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected)
この fetch メソッドはソケットを作成し、フェッチ対象のサーバーとの接続確立を開始する。このメソッドは実際に接続が確立される前に返ることに注目してほしい。待機してよいのはイベントループだけであり、このメソッドはイベントループに制御を返す必要がある。アプリケーション全体のコードを見ると、この点をより理解できるだろう:
# http://xkcd.com/353/ のフェッチを開始する
fetcher = Fetcher('/353/')
fetcher.fetch()
while True:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
全てのイベント通知はイベントループで select を呼び出したときに処理されるので、fetch メソッドはイベントループに制御を返さなければならない。ソケットが接続されると select が返り、fetch メソッドの最後で登録された connected コールバックがそのとき初めて実行される。
connected メソッドの実装を示す:
# Fetcher クラスのメソッド
def connected(self, key, mask):
print('connected!')
selector.unregister(key.fd)
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(self.url)
self.sock.send(request.encode('ascii'))
# 次の処理を行うコールバックを登録する
selector.register(key.fd,
EVENT_READ,
self.read_response)
この connected メソッドは GET リクエストを送信する。本格的なアプリケーションでは send の返り値を確認し、全てのデータが一度に送信できていないケースに対処する必要がある。ただ、今回は小さなリクエストを送信するアプリケーションを非同期 I/O の例として作っているだけなので、この処理は省略した。このメソッドは軽率に send を呼び出し、その後レスポンスを待機する。もちろん、レスポンスを待機するにはコールバックを登録してイベントループに制御を返す必要がある。次の (そして最後の) コールバックである read_response メソッドはサーバーからの返答を処理する:
# Fetcher クラスのメソッド
def read_response(self, key, mask):
global stopped
chunk = self.sock.recv(4096) # 4KB のチャンクごとに読み込む
if chunk:
self.response += chunk
else:
selector.unregister(key.fd) # 読み込みが完了した
links = self.parse_links()
# Python の set が持つメソッドを使って新しい URL を走査する
for link in links.difference(seen_urls):
urls_todo.add(link)
Fetcher(link).fetch() # 新しい Fetcher を作成する
seen_urls.update(links)
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
この read_response メソッドはソケットが「読み込み可能」になったときイベントループから呼び出される。この「読み込み可能」とは、ソケットがデータを受け取ったか、接続をクローズしたことを意味する。
read_response メソッドはソケットから 4KB のデータを読み込もうとする。読み込み可能なデータが 4KB より少ないなら、そのデータが全て読み込まれる。読み込み可能なデータが 4KB より多いなら、ちょうど 4KB のデータだけが chunk に読み込まれ、以降のデータは読み込み可能な状態でソケットに残される。残されたデータはイベントループが再度 read_response を呼び出したときに処理される。レスポンスを全て受信したときはサーバーがソケットをクローズするので、chunk は空となる。
ここに示されていない parse_links メソッドは self.response に含まれる URL を要素とする集合を返す。parse_links の返り値に含まれる新しい URL のそれぞれに対して新しい Fetcher オブジェクトが作成され、このとき並行に処理される操作の個数に制限は無い。コールバックによる非同期 I/O を使ったプログラミングが持つ優れた特徴の一つに注目してほしい: seen_urls といった共有データを変更するときにミューテックスが必要にならない。マルチスレッディングと異なり非プリエンプティブなマルチタスキングなので、コードの実行が任意の箇所で中断されることはない。
上記のコードではイベントループを制御するグローバル変数 stopped が追加されている。イベントループは次のように変更される:
stopped = False
def loop():
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
全てのページがダウンロードされると Fetcher は stopped を true に設定してイベントループを停止させ、プログラムは終了する。
非同期 I/O の持つ問題は以上の例から明らかだろう: スパゲッティコードである。計算と I/O 操作の列を表現し、複数のそういった列をスケジュールして並行に実行する手段を私たちは必要としている。しかしスレッドを使わなければ、計算と I/O 操作が混じった列を単一の関数とすることはできない。関数が I/O 操作を始めるたびに、将来必要になる状態を全て保存して関数から抜けなければならない。どの状態をどのように保存するかを考えるのはプログラマーの責任となる。
もう少し詳しく説明しよう。通常のブロッキングソケットを使って単一のスレッド上で URL をフェッチするコードがどれだけ単純かを見てほしい:
# ブロッキングバージョン
def fetch(url):
sock = socket.socket()
sock.connect(('xkcd.com', 80))
request = 'GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n'.format(url)
sock.send(request.encode('ascii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
# ページがダウンロードされた
links = parse_links(response)
q.add(links)
この関数がソケット操作の間で記憶している状態は何だろうか? ソケット sock, URL url, レスポンス response がある。何らかのスレッド上で実行中の関数はプログラミング言語の基礎的な機能を使って一時的な状態をローカル変数としてスタック上に保存する。また、実行中の関数は「継続 (continuation)」を持つ ── つまり、I/O 操作の完了後に実行するコードを関数は知っている。ランタイムはスレッドの命令ポインタを保存することで継続を記録する。I/O 操作が完了したときローカル変数と継続を復元する処理を考える必要はない。その処理は言語に組み込まれている。
しかしコールバックベースの非同期 I/O フレームワークでは、こういった言語機能が使えなくなる。I/O 操作を開始して関数から返るとスタックフレームが失われるので、関数は状態を明示的に保存しなければならない。以前の例では、ローカル変数が使えない代わりに sock, response を Fetcher クラスのインスタンス self の属性に保存していた。また、命令ポインタが使えない代わりに connected と read_response というコールバックを登録することで継続を記録していた。
さらに悪いことに、例外の送出場所が分からなくなる。コールバックが次のコールバックをスケジュールする前に例外を送出したらどうなるだろうか? 例えば、先ほどの例で HTML のパースが失敗して parse_links メソッドから例外が発生すると、次のスタックトレースが表示される:
Traceback (most recent call last):
File "loop-with-callbacks.py", line 111, in <module>
loop()
File "loop-with-callbacks.py", line 106, in loop
callback(event_key, event_mask)
File "loop-with-callbacks.py", line 51, in read_response
links = self.parse_links()
File "loop-with-callbacks.py", line 67, in parse_links
raise Exception('parse error')
Exception: parse error
このスタックトレースからはイベントループが実行中のコールバックが分かるだけで、それにどのように至ったかは分からない。コールバックの「鎖」は両側から途切れている: コールバックがどこから来て、どこへ行くかに関する情報はいずれも失われる。このコンテキストの消失は「スタックの断絶 (stack ripping)」と呼ばれる。スタックが断絶されるために、コールバックの鎖の途中に例外ハンドラを仕込むこともできない: try ... except ブロックで関数の一部とそこから呼び出される関数を包む方法が使えない5。
ここから分かるように、マルチスレッディングと非同期 I/O のどちらが効率的かという長く議論されてきた話題とは別に、誤りのないコードを書きやすいのはどちらかという話題も存在する。マルチスレッディングでは同期の誤りからデータ競合が発生する可能性があり、コールバックによる非同期 I/O ではスタックの断絶によりデバッグが非常に困難になる。
5.6 コルーチン
魅力的な話がある。マルチスレッディングのコードが持つ古典的なコードと同様の簡潔な構造と、コールバックによる非同期 I/O が持つ高い効率を併せ持つ非同期コードを書くことは可能である。この構造と効率の両立は「コルーチン」と呼ばれるパターンによって達成される。Python 3.4 の標準ライブラリ asyncio とパッケージ aiohttp を使うと、URL をフェッチするコルーチンは非常に直接的に書ける6:
@asyncio.coroutine
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
コルーチンはスケーラブルでもある。Jesse のシステムで一つのスレッドは 50KB のメモリを消費するのに対して、一つのコルーチンが消費するメモリは 3KB にも満たない。Python は数十万個のコルーチンを軽々と起動できる。
コルーチンは計算機科学の黎明期からある単純な概念である: コルーチンとは停止と再開が可能なサブルーチンを言う。スレッドは OS によってプリエンプティブにスケジュールされるのに対して、コルーチンは協調的マルチタスキングを通じてスケジュールされる: 実行の停止と再開、次に実行されるコルーチンの選択はコルーチンが自ら行う。
コルーチンには様々な実装が存在する。Python に限っても実装はいくつかある。Python 3.4 の標準ライブラリ asyncio に含まれるコルーチンはジェネレータ、Future クラス、そして yield from 文を基礎として用いる。Python 3.5 からコルーチンは言語のネイティブ機能となった7。ただ、既存の言語機能を利用する Python 3.4 における最初の実装を理解しておけば、Python 3.5 におけるネイティブなコルーチンの理解が簡単になる。
Python 3.4 が持つジェネレータベースのコルーチンを説明するために、これから Python のジェネレータを簡単に説明し、asyncio のコルーチンがジェネレータをどのように使うかを解説する。私たちが以降の解説を楽しみながら書いたのと同じように、あなたが楽しみながら解説を読むことを願っている。ジェネレータベースのコルーチンの説明が終わったら、いよいよ非同期ウェブクローラを実装する。
5.7 Python のジェネレータ
Python のジェネレータの前に、まずは Python の関数の動作を理解する必要がある。通常、Python の関数がサブルーチンを呼び出すと、そのサブルーチンは値を返すか例外を送出するまで実行を続ける。サブルーチンの実行が終了すると、実行は呼び出し側に戻る:
>>> def foo():
... bar()
...
>>> def bar():
... pass
標準の Python インタープリタは C で書かれている。Python 関数を実行するときに呼び出される C 関数には PyEval_EvalFrameEx という美しい名前が付いている。この関数は Python のスタックフレームを表すオブジェクトを受け取り、そのフレームのコンテキストで Python バイトコードを評価する。上記の foo 関数のバイトコードを次に示す:
>>> import dis
>>> dis.dis(foo)
2 0 LOAD_GLOBAL 0 (bar)
3 CALL_FUNCTION 0 (0 positional, 0 keyword pair)
6 POP_TOP
7 LOAD_CONST 0 (None)
10 RETURN_VALUE
foo 関数は bar をスタックに読み込み、bar を呼び出し、返り値をスタックからポップし、None をスタックに読み込み、その None を返す。
PyEval_EvalFrameEx 関数がバイトコード CALL_FUNCTION を読み込むと、新しい Python スタックフレームを作成して再帰的に PyEval_EvalFrameEx を呼び出す。つまり、bar を実行するための新しいスタックフレームを引数として PyEval_EvalFrameEx が呼び出される。
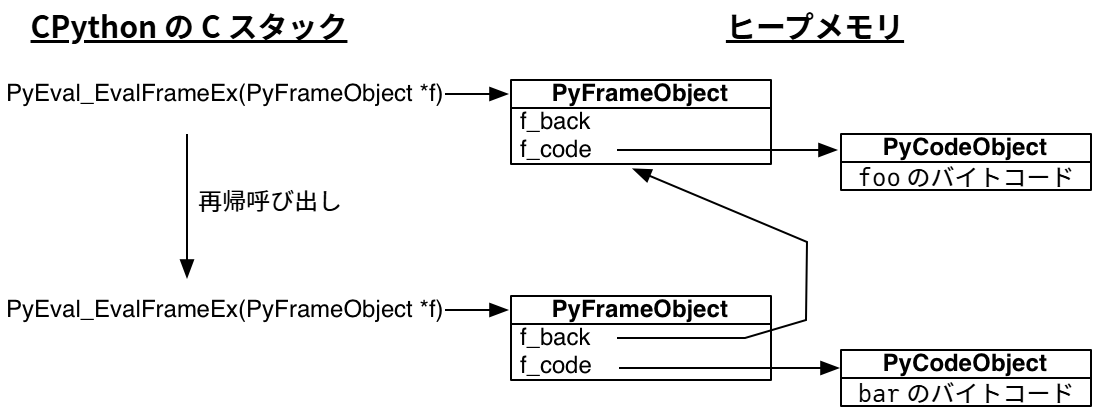
Python のスタックフレームが (スタックではなく) ヒープメモリにアロケートされる点は重要なので理解を確認してほしい! Python インタープリタは通常の C プログラムと変わらないので、そのスタックフレームにも特別な部分はない。しかし Python のインタープリタが操作する Python のスタックフレームはヒープに確保される。そのため、Python のスタックフレームは関数の呼び出しが返っても失われないといった意外な特徴を持つ。bar 関数の中で現在のフレームを保存するようにすれば、この事実を対話的に確認できる:
>>> import inspect
>>> frame = None
>>> def foo():
... bar()
...
>>> def bar():
... global frame
... frame = inspect.currentframe()
...
>>> foo()
>>> # フレームは 'bar' のコードを実行していた
>>> frame.f_code.co_name
'bar'
>>> # フレームのバックポインタは 'foo' のフレームを指している
>>> caller_frame = frame.f_back
>>> caller_frame.f_code.co_name
'foo'
これで Python のジェネレータを説明する準備が整った。ジェネレータを構成する部品は関数と同じ ── バイトコードとスタックフレーム ── であるものの、ジェネレータを使うと素晴らしく有用な処理が書けるようになる。
ジェネレータ関数の例を次に示す:
>>> def gen_fn():
... result = yield 1
... print('yield の返り値: {}'.format(result))
... result2 = yield 2
... print('二度目の yield の返り値: {}'.format(result2))
... return 'done'
...
gen_fn をバイトコードにコンパイルしようとした Python は、その本体に yield 文が含まれることに気が付き、gen_fn が通常の関数ではなくジェネレータ関数だと理解する。この事実は設定されるフラグから確認できる:
>>> # ジェネレータ関数かどうかを表すフラグは 5 番目のビットにある
>>> generator_bit = 1 << 5
>>> bool(gen_fn.__code__.co_flags & generator_bit)
True
呼び出された関数がジェネレータ関数を表すフラグを持っている場合、Python は関数の実行を開始しない。その代わり、ジェネレータを作成する:
>>> gen = gen_fn()
>>> type(gen)
<class 'generator'>
Python のジェネレータは何らかのコード (今の例では gen_fn の本体) への参照とスタックフレームを持つ:
>>> gen.gi_code.co_name
'gen_fn'
このコードは gen_fn を呼び出して作成される全てのジェネレータによって共有される。しかし、それぞれのジェネレータは独自のスタックフレームを持つ。このスタックフレームは実際のスタックに載っているわけではなく、ヒープメモリに確保され個別に利用される。
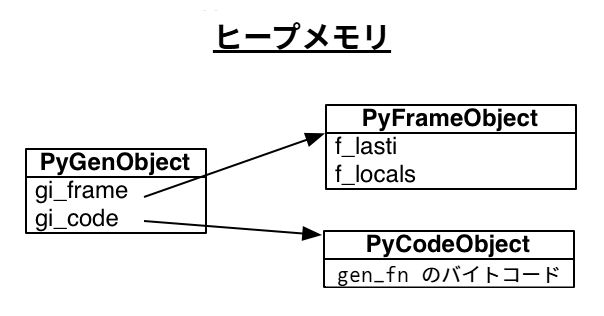
フレームは最後に実行した命令を指す「最終命令」ポインタを持つ。初期状態で最終命令ポインタは -1 であり、これはジェネレータが開始されていないことを表す:
>>> gen.gi_frame.f_lasti
-1
ジェネレータの send メソッドを呼び出すと、ジェネレータは最初の yield 文まで実行を進める。send の返り値は yield に渡された値であり、今の例では 1 となる:
>>> gen.send(None)
1
これでジェネレータの最終命令ポインタは 3 バイトコード分だけ進む。これはコンパイルされた長さ 56 の Python バイトコードの途中である:
>>> gen.gi_frame.f_lasti
3
>>> len(gen.gi_code.co_code)
56
ジェネレータの実行は好きなときに好きな関数から再開できる。なぜならジェネレータが持つスタックフレームがスタックではなくヒープに存在するためである。呼び出し階層におけるジェネレータの位置は固定されておらず、通常の関数が従う先入れ後出しの順序と関係を持たない。ジェネレータは束縛を受けず、雲のように自由に浮かんでいる。
send メソッドの引数はジェネレータに渡され、yield 式の評価結果となる。例えば、次のコードでジェネレータは値 "hello" を受け取り、yield 2 まで実行を進める:
>>> gen.send('hello')
yield の返り値: hello
2
ジェネレータのスタックフレームを確認すると、ローカル変数 result が存在すること分かる:
>>> gen.gi_frame.f_locals
{'result': 'hello'}
gen_fn() によって作成される他のジェネレータはそれぞれが異なるスタックフレームとローカル変数を持つ。
もう一度 send メソッドを呼び出すと、ジェネレータは二つ目の yield の直後から実行を再開し、StopIteration という特別な例外を送出して実行を終了する:
>>> gen.send('goodbye')
二度目の yield の返り値: goodbye
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration: done
この例外にはジェネレータの返り値が含まれる: 今の例では文字列 "done" である。
5.8 ジェネレータを利用したコルーチン
というわけで、ジェネレータは実行の停止、値を受け取ってからの実行の再開、そして値の返却を行える。スパゲッティのように絡み合ったコールバックを持たない非同期プログラミングモデルの構成要素として適しているように思える! これから作成する「コルーチン」は、プログラムが持つ他のコルーチンと協調的にスケジュールされる。ここで示すのは Python の標準ライブラリ asyncio が持つコルーチンを単純化したものであり、asyncio と同様にジェネレータ、Future クラス、そして yield from 文を利用する。
まず、コルーチンが待機する対象である将来の結果を表現する手段が必要となる。この役割を担う Future クラスを次に示す:
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
Future は最初「処理中」の状態であり、set_result を呼ぶことで「完了」の状態になる8。
先述した Fetcher を Future とコルーチンを使って書き換えてみよう。以前の fetch はコールバックを使っていた:
class Fetcher:
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected)
def connected(self, key, mask):
print('connected!')
# 省略...
Fetcher の fetch メソッドはソケットの接続を開始し、ソケットの準備が完了したときに実行すべきコールバック connected を登録する。この二つのステップは一つのコルーチンにまとめることができる:
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connected():
f.set_result(None)
selector.register(sock.fileno(),
EVENT_WRITE,
on_connected)
yield f
selector.unregister(sock.fileno())
print('connected!')
こうしたとき fetch は通常の関数ではなくジェネレータ関数となる (yield 文を含むため)。fetch は「処理中」状態の Future を作成し、それを yield してソケットの準備が完了するまで実行を停止する。内部関数 on_connected は Future の状態を「完了」に変えるためにある。上記のコードで yield f は「ここで実行を停止して、f の値が定まったら再開する」を意味する。
Future の値が求まったとして、誰がジェネレータを再開するのだろうか? 実行を統括する「ドライバ」が必要となる。ここでは Task と呼ぼう:
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
# http://xkcd.com/353/ のフェッチを開始する
fetcher = Fetcher('/353/')
Task(fetcher.fetch())
loop()
Task はジェネレータ関数 fetch が返すジェネレータに None を渡して実行を開始させる。その後 fetch は yield するまで実行を続け、yield された Future は step メソッドのローカル変数 next_future に格納される。ソケットの接続が確立されるとイベントループが内部関数 on_connected を呼び出し、この Future が「完了」の状態となり、step が呼び出されて fetch の実行が再開される。
5.9 yield from を使ったコルーチンのリファクタリング
ソケットの接続を確立した後は HTTP GET リクエストを送信し、サーバーからのレスポンスを読み込む必要がある。これらのステップをコールバックごとに複数の関数に分ける必要はもはやなく、一つのジェネレータ関数にまとめることができる:
def fetch(self):
# ... 上述の接続確立ロジック ...
sock.send(request.encode('ascii'))
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(),
EVENT_READ,
on_readable)
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
# 読み込みが完了した
break
ソケットからメッセージ全体を読み込むこのコードは一般的な有用性を持つように思える。どうすれば fetch をサブルーチンとして切り出せるだろうか? ここで颯爽と登場するのが Python 3 で導入された yield from である。yield from を使うと、あるジェネレータを他のジェネレータに委譲できる。
その意味を理解するために、最初に示したジェネレータの簡単な例をもう一度考えよう:
>>> def gen_fn():
... result = yield 1
... print('yield の返り値: {}'.format(result))
... result2 = yield 2
... print('二度目の yield の返り値: {}'.format(result2))
... return 'done'
...
yield from を使うと、このジェネレータを他のジェネレータから呼び出せる:
>>> # ジェネレータ関数
>>> def caller_fn():
... gen = gen_fn()
... rv = yield from gen
... print('yield from の返り値: {}'
... .format(rv))
...
>>> # ジェネレータ関数からジェネレータを作る
>>> caller = caller_fn()
こうして作られるジェネレータ caller は委譲先のジェネレータ gen であるかのように振る舞う:
>>> caller.send(None)
1
>>> caller.gi_frame.f_lasti
15
>>> caller.send('hello')
yield の返り値: hello
2
>>> caller.gi_frame.f_lasti # 進んでいない
15
>>> caller.send('goodbye')
二度目の yield の返り値: goodbye
yield-from の返り値: done
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
caller が yield from gen すると、caller の実行はそこで停止する。yield from されたジェネレータ gen が yield 文から次の yield 文へと実行を進める間、caller の命令ポインタが yield from 文のある 15 で停止していることに注目してほしい9。caller を呼び出した側からは、yield される値が caller からの値なのかそうでないのかは分からない。yield from 文は値を受け流す「パイプ」であり、gen が完了するまで gen が生成した値をそのまま生成する。
コルーチンは yield from を使って他のコルーチンにタスクを委譲し、その結果を自身の結果とできる。上記の例で caller が「yield from の返り値: done」と出力している点に注目してほしい。gen が完了すると、その返り値が caller が呼び出した yield from の返り値となる:
rv = yield from gen
以前にコールバックによる非同期プログラミングが持つ欠点を説明したとき、最も重大な問題は「スタックの断絶」だと指摘した: コールバックが例外を送出するとき、ほとんどの場合でスタックトレースは役に立たない。イベントループがそのコールバックを実行していることが分かるだけで、どのようにしてそのコールバックを実行するに至ったかはスタックトレースを見ても分からない。コルーチンではどうだろうか?
>>> def gen_fn():
... raise Exception('my error')
>>> caller = caller_fn()
>>> caller.send(None)
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "<input>", line 3, in caller_fn
File "<input>", line 2, in gen_fn
Exception: my error
ずっと有用な情報が得られた! スタックトレースを見ると、caller_fn が gen_fn に処理を委譲し、その gen_fn が例外を送出したと分かる。さらに心強いことに、通常のサブルーチンと同じように try ... except ブロックの中でサブコルーチンを呼び出し、送出された例外をハンドラで処理することもできる:
>>> def gen_fn():
... yield 1
... raise Exception('uh oh')
...
>>> def caller_fn():
... try:
... yield from gen_fn()
... except Exception as exc:
... print('caught: {}'.format(exc))
...
>>> caller = caller_fn()
>>> caller.send(None)
1
>>> caller.send('hello')
caught: uh oh
つまり、通常のサブルーチンを使うのと同じ要領でサブコルーチンを使ってロジックを整理できる。上述の fetch からサブコルーチンを切り出してみよう。次の read コルーチンは、4KB のチャンク一つ分のデータを読み込む:
def read(sock):
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f # チャンク一つ分データを読む
selector.unregister(sock.fileno())
return chunk
read を使えば、メッセージを全て読み込む read_all コルーチンを実装できる:
def read_all(sock):
response = []
# メッセージ全体を読む
chunk = yield from read(sock)
while chunk:
response.append(chunk)
chunk = yield from read(sock)
return b''.join(response)
上手く目を細めて yield from を見えないようにすると、read_all 関数がブロッキング I/O を使って書いた古典的な関数とよく似ていることが分かる。しかし read と read_all はコルーチンであり、read に含まれる yield f によって read_all の実行は I/O が完了するまで停止する。read_all の実行が停止すると asyncio のイベントループに実行が移り、そこで他の処理や I/O イベントの待機が行われる。イベントループが進み待機中のイベントが利用可能になると read が値を返し、read_all が実行を再開する。
スタックの頂上では、fetch が read_all を呼び出す:
class Fetcher:
def fetch(self):
# ... 上述の接続ロジックの後 ...
sock.send(request.encode('ascii'))
self.response = yield from read_all(sock)
驚くべきことに、このとき Task クラスを変更する必要はない。Task は fetch コルーチンを以前と全く同じように扱える:
Task(fetcher.fetch())
loop()
read が Future 型の値 f を yield すると、f はいくつかの yield from を経て Task まで受け渡される。これは fetch 関数が直接 yield f するのと変わらない。イベントループが進行して f の結果が設定されると Task はその結果を fetch に受け渡すものの、最終的に結果を受け取るのは read である。これは read が直接結果を受け取るのと変わらない:

yield from (矢印の長さは意味を持たない)
コルーチン実装を完全なものにするため、最後に次の点を改善する: 現在のコードでは Future を待つとき yield を使うのに対して、サブコルーチンに処理を委譲するときは yield from を使っている。コルーチンの実行を中断させるときは必ず yield from 使うようにしてみよう。このときコルーチンが待機する対象が何であっても同じ構文が使えるようになる。
この仕組みの実装では、Python でジェネレータとイテレータが非常によく似ている事実が利用できる。呼び出し側の視点では、ジェネレータを進める処理とイテレータを進める処理は変わらない。そのため、特殊メソッド __iter__ を実装することで Future クラスをイテレート可能にできる:
# Future クラスのメソッド
def __iter__(self):
# 自身の実行を中断し、Task に「自分の値が設定されたら、自分の
# 実行を再開してくれ」と伝える。
yield self
return self.result
この __iter__ メソッドは自身を yield するコルーチンである。こうした上で、次のコード:
# f は Future のインスタンス
yield f
を、次のコードに書き換える:
# f は Future のインスタンス
yield from f
すると実行結果は同じになる! 全体の実行を管理する Task は send の返り値として Future 型の値を受け取り、その Future の結果が設定されるとその結果をコルーチンに受け渡す。
全ての箇所で yield from を使う利点は何だろうか? Future の待機を yield で、サブコルーチンへの委譲を yield from で行うより優れる理由はなんだろうか? それは、メソッドの実装をいくら変更しても呼び出し側に影響を及ぼさない点である。いずれ決定する値を保持する Future を返す通常の関数なのか、それとも yield from を持ち最終的に値を返すコルーチンなのかを意識する必要はない。いずれの場合でも、呼び出し側はメソッドを yield from してその返り値を利用すればよい。
賢明なる読者諸君、以上で asyncio のコルーチンを紹介する愉快な旅は終了となる。ジェネレータの仕組みや Future, Task の実装を詳しく解説した。また、asyncio が「スレッドより効率的な並行 I/O」と「コールバックより読みやすいコード」という二つの世界の良い部分を合わせ持つことも説明した。もちろん、実際の asyncio ライブラリはここで簡単に紹介したものより格段に洗練されており、ゼロコピー I/O、公平なスケジューリング、例外処理といった数多くの機能を持つ。
asyncio ライブラリを利用することだけを考えるなら、今までの説明を理解しなくてもコルーチンを使うプログラムは書ける。私たちはコルーチンを yield と yield from だけから実装して見せたので、コールバックや Task, Future といった概念が登場し、select の呼び出しやノンブロッキングソケットさえ意識する必要があった。しかし asyncio ライブラリを使ってアプリケーションを作るとき、そういった概念はアプリケーションのコードに現れない。以前に約束したように、URL のフェッチは次の通り滑らかに行える:
@asyncio.coroutine
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
これで説明は十分だろう。続いて最初に考えていた問題に取り掛かる: asyncio ライブラリを使って、非同期ウェブクローラを書く。
5.10 コルーチンの協調動作
本章で作成するウェブクローラに期待される動作は本章の最初で説明した。これから asyncio のコルーチンを使ってそれを実装していく。
本章で作成するウェブクローラは最初のページをフェッチし、そのページをパースして含まれるリンクを抽出し、それらのリンクをキューに追加し、キューからリンクを一つ取り出して同じ処理を繰り返す。この処理を続けるとウェブクローラは最初のページから到達可能なページを全て見つけ、それらのページを並行にフェッチする。ただし、クライアントとサーバーの負荷を抑えるため、実行されるワーカーの個数には最大値を設けることが望ましい。決まった個数だけ存在するワーカーがページのフェッチを行い、それぞれのワーカーはフェッチを終えるとすぐにキューからリンクを取り出し、そのフェッチを始めるという動作である。フェッチすべきリンクが一時的に枯渇する状況も考えられるので、ワーカーは停止できなければならない。一方で、ワーカーが新しいリンクを大量に含むページをフェッチしたときはキューが一気に長くなるので、停止しているワーカーは目を覚まして仕事を始めなければならない。最後に、フェッチするリンクがなくなった場合はプログラムを終了する必要がある。
ワーカーがスレッドだとしよう。このとき、上述したウェブクローラのアルゴリズムはどのように表現できるだろうか? Python 標準ライブラリに含まれる同期キュー10 Queue を使う方法が考えられる。同期キューにはリンクが入れられ、キューは内部に持つ「タスク」のカウントを上下させる。ワーカースレッドはリンクの処理を終えると task_done を呼び出し、メインスレッドは Queue.join を呼び出してブロックし、キューに入れられた全てのリンクに対応する task_done が呼び出されたら終了する。
asyncio ライブラリを利用するキュー11 JoinableQueue を使うと、全く同じパターンをコルーチンで実装できる。まずは JoinableQueue をインポートする:
try:
from asyncio import JoinableQueue as Queue
except ImportError:
# asyncio.JoinableQueue は Python 3.5 で Queue に統合された
from asyncio import JoinableQueue as Queue
全てのワーカーが共有する状態を Crawler クラスにまとめ、このクラスの crawl メソッドにメインロジックを書くことにする。crawl の実行をコルーチン上で開始し、crawl が完了するまで asyncio のイベントループを実行することでクロールを行う:
loop = asyncio.get_event_loop()
crawler = crawling.Crawler('http://xkcd.com', max_redirect=10)
loop.run_until_complete(crawler.crawl())
Crawler クラスとコンストラクタはルートの URL と max_redirect を受け取る。max_redirect は対象の URL がリダイレクトだった場合にリダイレクトを最大で何回たどるかを表す (この値が必要な理由は後述する)。
class Crawler:
def __init__(self, root_url, max_redirect):
self.max_tasks = 10
self.max_redirect = max_redirect
self.q = Queue()
self.seen_urls = set()
# 接続プールと HTTP keep-alive の管理は aiohttp に任せる
self.session = aiohttp.ClientSession(loop=loop)
# (URL, max_redirect) をキューに積む
self.q.put((root_url, self.max_redirect))
このコンストラクタが完了すると、キューに未完了のタスクが一つ積まれた状態となる。メインのスクリプトに目を戻すと、コンストラクタの後には crawl メソッドの呼び出しとイベントループの起動がある:
loop.run_until_complete(crawler.crawl())
この crawl コルーチンがワーカーを起動する。crawl が「メインスレッド」だと考えることができる: join を呼び出して全ての処理が完了するまでブロックし、他のワーカーに実行を進めさせる。
@asyncio.coroutine
def crawl(self):
""" 全ての処理が完了するまでクローラを実行する。 """
workers = [asyncio.Task(self.work())
for _ in range(self.max_tasks)]
# 仕事が全て終わったら、終了する。
yield from self.q.join()
for w in workers:
w.cancel()
もしワーカーではなくスレッドを使っているのなら、ここで全てのワーカーを起動することは避けたいはずである。コストが高いスレッドの作成を確実に必要となるタイミングまで遅らせるために、典型的なスレッドプールはスレッドの個数をオンデマンドに増加させる。しかしコルーチンのコストは低いので、ここでは許される最大個数のコルーチンを最初に作成している。
クローラの終了処理に注目してほしい。yield from self.q.join() が返ったとき、それぞれのワーカータスクはまだ生きており、実行を停止している状態である: 新しい URL が供給されるのを待っている。そのため、メインのコルーチンは自身が終了する前に全てのワーカーを終了させる必要がある。これを忘れると、Python インタープリタが終了するとき全てのオブジェクトのデストラクタを呼び出すので、次のエラーメッセージが表示されることになる:
ERROR:asyncio:Task was destroyed but it is pending!
cancel はどのように動作するのだろうか? ジェネレータには今までに説明しなかった機能がある。それは、ジェネレータの外側から例外を発生させる機能である:
>>> gen = gen_fn()
>>> gen.send(None) # 通常通りにジェネレータを開始する
1
>>> gen.throw(Exception('error'))
Traceback (most recent call last):
File "<input>", line 3, in <module>
File "<input>", line 2, in gen_fn
Exception: error
throw を呼び出すとジェネレータの実行は再開されるものの、再開した瞬間に例外が発生する。ジェネレータのコールスタックで例外が捕捉されないと、その例外は一番上まで到達して実行が止まる。このため Task からコルーチンを停止するメソッドは次のように書ける:
# Task クラスのメソッド
def cancel(self):
self.coro.throw(CancelledError)
yield from に到達して実行が停止されたジェネレータに対して throw を呼び出すと、実行が再開して例外が送出される。Task の step メソッドは次のようにワーカーのキャンセルを処理する:
# Task クラスのメソッド
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration:
return
next_future.add_done_callback(self.step)
これで Task は自身がキャンセルされたかどうかを知ることができるので、インタープリタの終了時に実行停止中のワーカーが消えゆく光に向かって怒声を上げる事態は避けられる。
crawl メソッドが全てのワーカーをキャンセルすると、実行が完了して値を返す。するとイベントループがコルーチンの実行完了を (後述する方法で) 検知し、自身も終了する:
loop.run_until_complete(crawler.crawl())
crawl メソッドにはメインのコルーチンが行うべき処理が含まれる。キューから URL を取り出し、その URL のページをフェッチし、フェッチしたページをパースして新しいリンクを取り出すのはワーカーコルーチンの仕事となる。それぞれのワーカーは独立して work コルーチンを実行する:
@asyncio.coroutine
def work(self):
while True:
url, max_redirect = yield from self.q.get()
# ページをダウンロードして、新しいリンクを self.q に追加する
yield from self.fetch(url, max_redirect)
self.q.task_done()
Python はこのコードが yield from を含むことに気が付き、このコードをジェネレータ関数としてコンパイルする。そのためメインのコルーチンが crawl に含まれる self.work() を 10 回呼び出したとしても、そのコードは実行されない: その呼び出しは、work メソッドのコードを参照するジェネレータを 10 個作成する。その後ジェネレータは Task に渡される。Task はジェネレータが yield する Future を受け取り、その値が決定したときに send を呼び出す処理を通じてジェネレータの実行を管理する。それぞれのジェネレータは固有のスタックフレームを持ち、独立に実行され、個別のローカル変数と命令ポインタを持つ。
ワーカー同士はキューを通して連携する。新しい URL の待機は次のコードで行われる:
url, max_redirect = yield from self.q.get()
キューの get メソッド自体はコルーチンである: 誰かがキューに要素を入れるまで実行を中断し、実行が再開したら新しい要素を返す。
偶然にも、ここはメインのコルーチンがクロール処理の最後にワーカーをキャンセルするときワーカーが待機している場所でもある。コルーチンの視点で言えば、このコードを含むループは yield from self.q.get() が CancelledError 例外を送出すると終了する。
ワーカーがフェッチしたページをパースして新しいリンクをキューに追加すると、task_done を呼び出してキューのカウンターを減少させる。ワーカーが動作を続けると、フェッチしたページに新しいリンクが含まれず、かつキューが空である状態となる。このときワーカーが task_done を呼び出すとキューのカウンターが 0 になり、キューの join メソッドを待機していた crawl が実行を再開し、最後まで実行を進める。
続いて以前に予告した通り、キューの要素が組である理由を説明する。例えば次のような組がキューに入れられる:
# 「フェッチする URL」と「残りのリダイレクト回数」の組
('http://xkcd.com/353', 10)
新しい URL は「残りのリダイレクト回数」を 10 に設定した状態でキューに追加される。 上記の URL http://xkcd.com/353 をフェッチすると、末尾にスラッシュが付いた URL http://xkcd.com/353/ へのリダイレクトが返る。このときワーカーは次の要素をキューに追加する:
# 末尾にスラッシュが付いた新しい URL / 「残りのリダイレクト回数」は 9 となる
('http://xkcd.com/353/', 9)
aiohttp パッケージはデフォルトでリダイレクトを適切に処理し、最終的なレスポンスを返す。しかしここでは、その動作をしないように設定した上でクローラがリダイレクトを直接管理する。これは、異なる URL が同じ URL にリダイレクトされる状況で無駄にページをフェッチしないようにするためである: リダイレクト先のページを以前に処理したことがあるなら、その URL は self.seen_urls にあり、それ以降の全てのリダイレクトも同様となる。
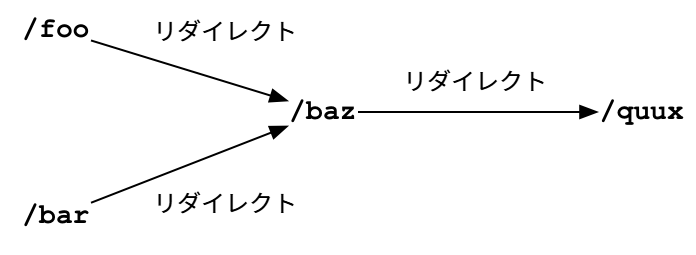
上図のような状態でクローラが /foo をフェッチすると、/foo は /baz へのリダイレクトだと判明し、seen_urls に /baz が追加される。その後に /bar をフェッチしたとしても /baz は seen_urls に追加されない。/baz がリダイレクトではなくページである場合は、フェッチした後にページをパースして新しいリンクをキューに入れる処理が加わる点を除いて同様の処理となる。
@asyncio.coroutine
def fetch(self, url, max_redirect):
# リダイレクトを直接管理する
response = yield from self.session.get(
url, allow_redirects=False)
try:
if is_redirect(response):
if max_redirect > 0:
next_url = response.headers['location']
if next_url in self.seen_urls:
# この URL は以前に処理した
return
# この URL を処理したことを記録する
self.seen_urls.add(next_url)
# リダイレクトを追う / 「残りのリダイレクト回数」は 1 減らす
self.q.put_nowait((next_url, max_redirect - 1))
else:
links = yield from self.parse_links(response)
# Python 組み込みの set を使ったロジック
for link in links.difference(self.seen_urls):
self.q.put_nowait((link, self.max_redirect))
self.seen_urls.update(links)
finally:
# プールに接続を返す
yield from response.release()
もしマルチスレッディングでこのコードを書くとしたら、競合状態を回避するために複雑なロジックが必要になるだろう。例えば、ワーカーは「特定の URL が seen_url に含まれるかどうかを確認し、もし含まれないなら seen_url にその URL を追加する」処理を実行する。この処理に含まれる二つの操作の間に別のスレッドに実行が切り替わり、別のワーカーが同じ URL を発見し、seen_url にそれが含まれないことを確認する可能性がある。もしそうなると同じ URL が二度キューに追加されることになり、最低でも無駄な処理が増え、クロールの統計が不正確になる。
これに対して、Python のコルーチンでは yield from でしか実行の切り替わりが起きない。これはスレッドとの重要な違いであり、コルーチンを使ってコードを書くとマルチスレッディングを使うより格段にミスが起きにくい理由である。マルチスレッディングのコードではロックを取得して明示的にクリティカルセクションに入らない限り、実行の切り替わりが任意のタイミングで起きる可能性がある。一方 Python のコルーチンでは実行の暗黙の切り替わりはデフォルトで不可能であり、明示的に yield from しない限り制御が他のコルーチンに移らない。
コールバックベースのプログラムに存在した Fetcher クラスはもはや必要ない。Fetcher はコールバックの欠点によって生まれたクラスと言える: ローカル変数は関数が返ると使えなくなるので、I/O を待機するとき状態を格納する場所が必要だった。これに対してコルーチンの fetch は状態を通常の関数と同じようにローカル変数に格納できるので、クラスは用済みとなる。
fetch がサーバーから受け取ったレスポンスの処理を終えると、制御は fetch を呼び出した work メソッドに戻る。work はキューの task_done メソッドを呼び出し、次にフェッチする URL をキューから取り出す。
fetch メソッドが新しいリンクをキューに追加すると、キューが内部に持つ未完了タスクの個数を表すカウンターが増加し、self.q.join() を待機しているメインのコルーチンは待機したままとなる。一方で、未処理のリンクが見つからず、さらに処理した URL がキューの最後の要素だった場合は、work が task_done を呼び出すと未完了のタスクが 0 個となる。この場合は join の実行が再開し、メインのコルーチンが終了する。
ワーカーとメインのコルーチンを連携させるキューのコードは次のような形をしている12:
class Queue:
def __init__(self):
self._join_future = Future()
self._unfinished_tasks = 0
# ... その他の初期化処理 ...
def put_nowait(self, item):
self._unfinished_tasks += 1
# ... item を格納する ...
def task_done(self):
self._unfinished_tasks -= 1
if self._unfinished_tasks == 0:
self._join_future.set_result(None)
@asyncio.coroutine
def join(self):
if self._unfinished_tasks > 0:
yield from self._join_future
メインのコルーチン crawl は yield from self.q.join() を実行する。そのため最後のワーカーが task_done メソッドを呼び出して未完了のタスクの個数が 0 になると、それが crawl の実行を再開する合図となり、crawl の実行は終了する。
もう一息だ。プログラムは最初 crawl の呼び出しから始まる:
loop.run_until_complete(self.crawler.crawl())
このプログラムはどのように終了するのだろうか? crawl はジェネレータ関数なので、その呼び出しはジェネレータを返す。このジェネレータを制御するために、asyncio ライブラリは次のようにジェネレータをタスクで包む:
class EventLoop:
def run_until_complete(self, coro):
""" コルーチンを終了するまで実行する。 """
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
class StopError(BaseException):
""" イベントループを停止するために送出される。 """
def stop_callback(future):
raise StopError
タスクが完了すると StopError 例外が送出される。この例外は実行が通常終了したことを run_until_complete に伝える。
Task クラスのメソッド add_done_callback とは何だろう? 前に実装した Future でも似たようなメソッドがあった気がすると思ったなら、その直感は正しい。実は、Task クラスに関する重要な事実を今まで隠していた:
class Task(Future):
""" Future に包まれたコルーチン """
通常 Future の値は別の誰かが set_result メソッドを呼び出すことで設定される。しかし、Task はコルーチンが停止したとき自分自身の値を設定する。次のコードを読むときは、Python のジェネレータを説明したときに触れた、ジェネレータが値を返すと特別な StopIteration 例外が送出される事実を思い出してほしい:
# Task クラスのメソッド
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration as exc:
# Task は coro の返り値を自分自身に設定する
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
このためイベントループが task.add_done_callback(stop_callback) を呼び出すと、タスクによって停止される準備が整う。もう一度 run_until_complete メソッドを示す:
# イベントループのメソッド
def run_until_complete(self, coro):
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
タスクが StopIteration を捕捉して自身の値を設定すると、設定されたコールバックが StopError を送出する。この例外はループを抜け、コールスタックは run_until_complete まで巻き戻る。こうしてプログラムは終了する。
5.11 結論
モダンなプログラムは CPU バウンドではなく I/O バウンドであることがますます多くなっている。そういったプログラムを書くとき、Python は二つの世界の悪い部分を併せ持つ: インタープリタがグローバルなロックを持つため計算を並列に実行できず、プリエンプティブにコンテキストスイッチが起こるため競合状態を回避しなければならない。非同期 I/O を使えば上手く行く場合も多いものの、コールバックベースの非同期フレームワークで複雑な処理を書くとコードが解読不能になる恐れがある。こういった欠点を克服する優れた選択肢がコルーチンである。処理をサブルーチンへと自然に切り分けることができ、例外処理やスタックトレースも通常通り動作する。
目を細めて yield from を見えないようにすると、コルーチンは古典的なブロッキング I/O を行うスレッドと変わらない。マルチスレッディングで使われるプログラミングパターンをコルーチンで使うことさえできるので、再発明の必要はない。そのため、コールバックと比較したとき、コルーチンはマルチスレッディングの経験があるコーダーにとってより魅力的な手法と言える。
一方で、目をこらして yield from に注目すると、コルーチンが制御を手放して他のコルーチンの実行を許す地点を示したのが yield from だと分かる。スレッドと異なり、コルーチンではコードの実行が切り替わる地点 (そして切り替わらない地点) がコードを見れば明らかである。Glyph Lefkowitz は示唆に富んだエッセイ Unyielding13 で「スレッドはコードの局所的な理解を困難にする。そして局所的な理解はソフトウェア開発で最も重要なこと」であり、明示的な yield を使えば「ルーチンの振る舞い (そして正しさ) の理解が、システム全体ではなくルーチンだけに注目するだけで」可能になると述べた。
本章は Python の非同期処理がルネッサンス期を迎えたころに書かれた。ここで示したジェネレータベースのコルーチンは 2014 年 3 月にリリースされた Python 3.4 で asyncio モジュールに搭載され、2015 年 9 月には言語自体にコルーチンが組み込まれた Python 3.5 がリリースされた。このネイティブコルーチンは新しい構文 async def を使って宣言され、yield from ではなく await キーワードを使って他のコルーチンへの委譲や Future の待機を表現する。
こういった進化はあったものの、核となるアイデアは変わっていない。Python の新しいネイティブコルーチンはジェネレータと構文的には異なるものの、動作は非常に似ている: 実際、Python インタープリタでは実装の一部が共有される。Task, Future とイベントループは asyncio ライブラリで重要な役割を担い続けている。
これで asyncio コルーチンの動作が理解できただろう。細かい部分は小奇麗なインターフェースに隠蔽されるので、もう詳細は忘れてしまって構わない。しかし、基礎部分を理解した経験はモダンな非同期環境で効率的で正しいコードを書く助けになるはずである。
-
Guido は標準ライブラリ
asyncioを PyCon 2013 で発表した。 ↩︎ -
sendの呼び出しさえブロックする可能性がある。受信側によるメッセージの確認応答が遅かったり、システムの送信バッファが満杯だったりするとsendはブロックする。 ↩︎ -
Python のインタープリタはグローバルなロック (global interpreter lock, GIL) を持つので、一つのプロセスで Python のコードを並列に実行することは現実的でない。CPU バウンドなアルゴリズムを Python で並列化するには、複数のプロセスを使うか、並列な部分を C で書くしかない。ただ、この話題は本章と関係がない。 ↩︎
-
Jesse は非同期 I/O を使うべき場面と使うべきでない場面を What Is Async, How Does It Work, And When Should I Use It? で紹介している。また、Mike Bayer による Asynchronous Python and Databases は様々なワークロードで非同期 I/O とマルチスレッディングのスループットを比較している。 ↩︎
-
この問題に対する複雑な解決法の一つが http://www.tornadoweb.org/en/stable/stack_context.html で説明されている。 ↩︎
-
デコレータ
@asyncio.coroutineは魔法ではない。実際、@asyncio.coroutineがジェネレータ関数をデコレートし、環境変数PYTHONASYNCIODEBUGが設定されていないとき、@asyncio.coroutineはフレームワークの他の部分が利用する_is_coroutine属性を定義される関数に設定するだけで事実上何もしない。@asyncio.coroutineでデコレートされていないジェネレータをそのままasyncioで使うこともできる。 ↩︎ -
Python 3.5 組み込みのコルーチンは PEP 492 – Coroutines with async and await syntax で説明されている。 ↩︎
-
この
Futureクラスには足りない機能が多くある。例えばFutureの値が決定したとき、そのFutureをyieldしたコルーチンの実行はすぐに再開されなければならないものの、このFutureではそうなっていない。完全な実装はasyncioライブラリのFutureクラスを見てほしい。 ↩︎ -
実は、CPython では
yield fromがこの通りに実装されている。通常インタープリタは命令を実行する前に命令ポインタを 1 だけ進めるものの、yield fromの実行後には命令ポインタを 1 だけ戻し、同じyield fromがもう一度実行されるようにする。yield fromしたジェネレータから値がyieldされた場合は、その値を自身がyieldした値として呼び出し側に返す。ジェネレータがStopIteration例外を送出したときに初めて、インタープリタは命令ポインタを 1 だけ進めて次の命令に進む。 ↩︎ -
asyncio.Queueの実際の実装では、本章の説明でFutureが使われた箇所でasyncio.Eventが使われている。EventとFutureの違いはEventがリセット可能な点にある。Futureでは値を設定した後に「計算中」の状態に戻すことはできない。 ↩︎