10. 考古学的データベース
10.1 はじめに
ソフトウェア開発は仕様を受け取って動作する製品を生成する厳格なプロセスだとみなされることが多い。しかしソフトウェア開発者は人であり、彼らが持つ考え方やバイアスによって開発されるソフトウェアには様々な特徴が加わる。
本章では、一般的なものとは異なる考え方を持ったときにデータベースという深く研究されてきたソフトウェアの設計と実装がどのように変化するかを見る。
データベースシステムはデータの格納と取得を可能にする。これは情報を扱う全ての労働者が行う操作である。しかし設計するのは計算機科学者なので、現代的なデータベースシステムは計算機科学者が考える「データ」の定義とデータに対する操作の定義に影響を受けている。
例えば、現代的なデータベースの多くはデータを更新するとき古いデータを新しいデータで上書きし、そのとき古いデータを削除する。Rich Hickey が「位置指向プログラミング (place-oriented programming)」と呼んだこの仕組みを使うとストレージを節約できるのに対して、特定のレコードの履歴は取得不可能になる。この設計判断は「データの履歴よりストレージの空間の方が重要である」という計算機科学者の考え方を反映したものと言える。
古いデータを見つけられる場所を計算機科学者ではなく考古学者に尋ねたとしたら、彼らは「運が良ければ地面の下に埋まっているかもしれない」と答えるだろう。
(注意: 私は典型的な考古学者の理解をいくつかの博物館、いくつかの Wikipedia 記事、そして全てのインディジョーンズ映画から得ている。)
考古学者のようにデータベースを設計する
友人の考古学者にデータベースの設計を頼んだとしよう。その考古学者は発掘現場で発見される遺物を思い浮かべながら、次の要件を挙げるかもしれない:
- 全てのデータは発見された現場でカタログ化される。
- 深く掘り進めると、それだけ古い遺物が発見される。
- 同じ層から見つかる遺物は同じ時代のものである。
- 一つの遺物が異なる複数の時期の状態を有していることがある。
例えば、壁のある層にローマ時代のシンボルが描かれ、その下の層にギリシャ時代のシンボルが描かれている可能性がある。この観察はどちらも壁の状態として記録される必要がある。
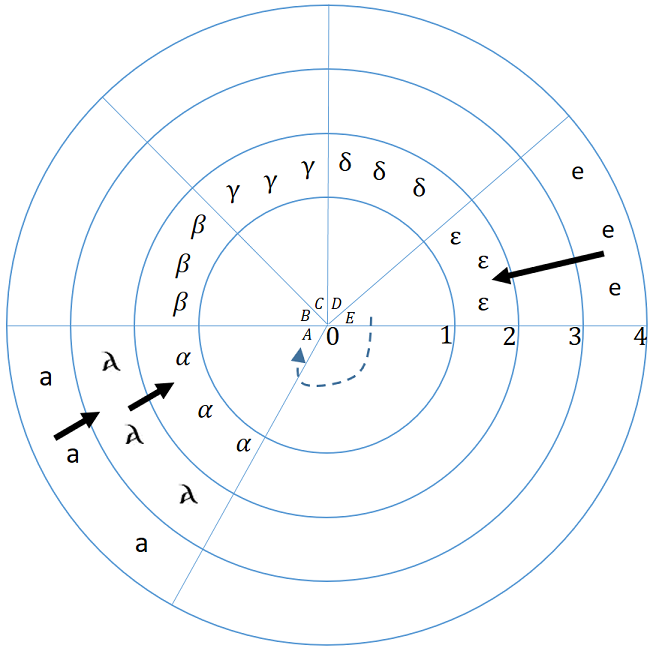
図 1 に発掘現場で見つかった遺物を整理する図を示す。
- 円全体が発掘現場を表す。
- それぞれの円は層を表す。この例では 0 から 4 までの数字が割り振られている。
- それぞれの扇形の部分は遺物を表す。この例では A から E までのラベルが割り振られている。
- 遺物は記号で表される属性を持つ。空白は属性に変化がないことを示す。
- 矢印付きの実線は層の間でシンボルが変わったことを示す。
- 矢印付きの破線は遺物間の任意の関係を表す。この例では E が A に対して何らかの関係を持つ。
考古学者の言葉をデータベース設計者の用語に置き換えてみよう:
- 発掘現場はデータベースである。
- ラベル付きの遺物は ID を持ったエンティティ (entity) である。
- エンティティは属性 (attribute) を持つ。属性は時間が経過すると変化する可能性がある。
- 属性は特定の時刻で特定の値 (value) を一つ持つ。
この設計は読者が慣れ親しんできた「データベース」の設計と大きく異なって見えるかもしれない。関数型プログラミングの分野で生まれたアイデアを使っているので、この設計を「関数型データベース (function database)」と呼ぶこともある。本章ではこれから関数型データベースを実装する方法を説明する。
関数型データベースを作るので、Clojure という関数型言語を使うことにする。
Clojure はデフォルトの不変性、高階関数、メタプログラミング機能といった関数型データベースの実装で有用となる機能をいくつか持つ。しかし突き詰めれば、ほとんどのプログラミング言語が持たないクリーンで厳格な設計を持っていることが Clojure を選択した理由である。
10.2 土台を作る
データベースを構成する中心的な構造体の宣言から始めよう:
(defrecord Database [layers top-id curr-time])
データベースは次の要素から構成される:
-
layers: エンティティが積み重なったレイヤーの集合: 同じレイヤーに含まれる全てのエンティティは同じタイムスタンプを持つ (図 1 における一つの輪に対応する)。 top-id: 利用可能な次の IDcurr-time: データベースが最後に更新された時刻
(defrecord Layer [storage VAET AVET VEAT EAVT])
レイヤーは次の要素から構成される:
storage: エンティティを扱えるデータストア- データベースに対するクエリを高速化するために利用されるインデックス (名前の意味などの詳細は後述)
この設計では概念的には一つの「データベース」が複数の Database インスタンスを持つことがある。そのとき、それぞれの Database インスタンスは異なる curr-time におけるデータベースのスナップショットを表す。複数の Layer が全く同じエンティティを共有することもある。その場合、二つのレイヤーが表す時刻の間でエンティティは変化しない。
エンティティ
格納するエンティティが何か分からないデータベースは役に立たないので、続いて Entity を定義する。先述した通り、エンティティは属性のリストと ID を持つ。作成には make-entity 関数を利用する:
(defrecord Entity [id attrs])
(defn make-entity
([] (make-entity :db/no-id-yet))
([id] (Entity. id {})))
属性
任意の属性は名前、値、最後の更新のタイムスタンプ、そして二番目に新しい更新のタイムスタンプから構成される。また、属性は自身の型 type と濃度 cardinality を表すフィールドを持つ。
属性が他のエンティティとの関係を表すのに利用されるケースでは、その属性の type は :db/ref となり、値は関係するエンティティの ID となる。この単純な型システムは拡張ポイントとしての役割も果たす。データベースのユーザーは独自の型の定義を通して自身のデータに関するセマンティクスを追加して構わない。
属性の cardinality は、その属性の値が単一の値を表すのか、それとも値の集合を表すのかを定める。このフィールドは属性に対して許される操作を判定するときに利用される。
属性の作成は make-attr 関数で行う:
(defrecord Attr [name value ts prev-ts])
(defn make-attr
([name value type ; 必須パラメータ
& {:keys [cardinality] :or {cardinality :db/single}} ]
{:pre [(contains? #{:db/single :db/multiple} cardinality)]}
(with-meta (Attr. name value -1 -1) {:type type :cardinality cardinality})))
このコンストラクタ関数では興味深いパターンがいくつか使われている:
- Clojure の「契約による設計 (Design by Contract)」パターンを利用し、パラメータ
cardinalityに渡されたのが許可された値であることを確認する。 - Clojure の分割代入 (destructuring) の仕組みを利用し、
cardinalityが設定されていない場合はデフォルト値:db/singleを設定する。 - Clojure のメタデータ機能を利用して、属性のデータ (名前、値、タイムスタンプ) とメタデータ (型と濃度) を区別する。Clojure ではメタデータの処理に
with-meta関数とmeta関数を用いる。
属性はエンティティの一部となって初めて意味を持つ。属性とエンティティの関連付けは add-attr 関数で行う。この関数はエンティティが持つ属性を収めたマップ :attrs に属性を追加する。Clojure でマップを使うときの典型的な作法に従って、属性の名前を直接使うのではなくキーワードに変換している点に注意してほしい:
(defn add-attr [ent attr]
(let [attr-id (keyword (:name attr))]
(assoc-in ent [:attrs attr-id] attr)))
ストレージ
ここまでは何をデータベースに格納するのかを話題にするだけで、それをどこに格納するかは考えてこなかった。本章では最も単純なストレージの仕組みを利用する: 全てのデータをメモリに保存する。この仕組みは明らかに信頼性が低いものの、開発とデバッグは簡単になり、私たちはプログラムのもっと面白い部分に集中できるようになる。
ストレージに対するアクセスは単純なプロトコル (protocol) を通して行う。プロトコルを利用すれば、データベースのユーザーは異なるストレージプロバイダを独自に定義できるようになる。
(defprotocol Storage
(get-entity [storage e-id])
(write-entity [storage entity])
(drop-entity [storage entity]))
このプロトコルのインメモリ実装を次に示す。マップが格納場所として利用される:
(defrecord InMemory [] Storage
(get-entity [storage e-id] (e-id storage))
(write-entity [storage entity] (assoc storage (:id entity) entity))
(drop-entity [storage entity] (dissoc storage (:id entity))))
インデックスの作成
以上でデータベースの基礎的な要素が定義できた。続いてデータベースに対するクエリを考えよう。これまでに定義してきたデータの構成を考えると、クエリが問い合わせるのはエンティティの ID もしくはエンティティが持つ属性の名前または値である。この三つ組 (entity-id, attribute-name, attribute-value) はクエリの処理で非常に重要となるので、名前を付けておく: この三つ組を今後 datom と呼ぶ。
datom が重要なのは、datom が事実を表し、事実を積み重ねたものがデータベースだからである。
データベースシステムを使った経験があるなら、インデックス (index) という概念を知っているだろう。インデックスとは平均クエリ時間を短くするために追加の空間を消費して作成される補助的データ構造のことを言う。私たちのデータベースには、datom の構成要素を特定の順序で格納した三つの層からなるインデックスが存在する。それぞれのインデックスには datom の構成要素を格納する順序に従って名前が付けられる。
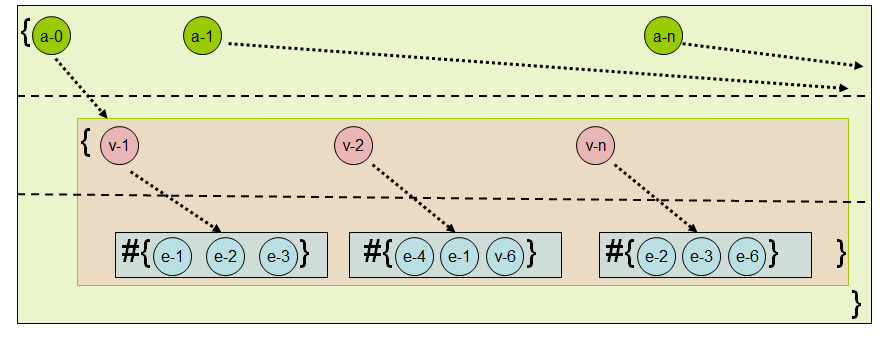
例えば、図 2 に示したインデックスは各層に次のデータを格納する:
- 最初の層はエンティティの ID を格納する。
- 二番目の層は、一層目のエンティティが持つ属性の名前を格納する。
- 三番目の層は、一層目のエンティティが持つ二層目の名前の属性の値を格納する。
このインデックスは EAVT と呼ばれる。なぜなら最初にエンティティ (entity) の ID があり、次に属性の名前 (attribute name) と値 (value) が続くためである。最後の T はデータベースの各レイヤーが独自のインデックスを持てる事実を示しているものの、今の議論では無視して構わない。
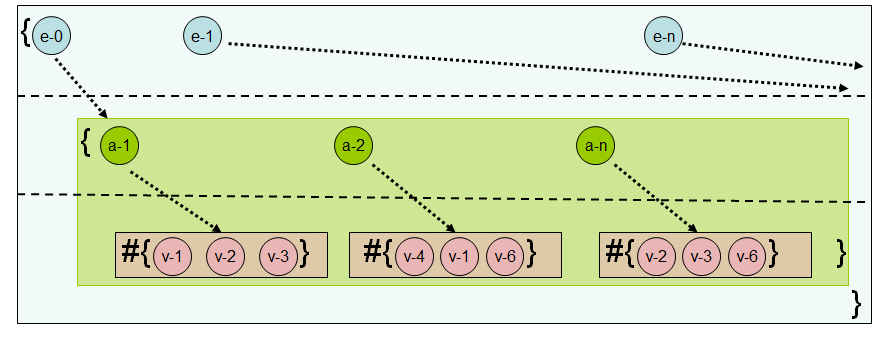
AVET と呼ばれるインデックスを図 3 に示す。AVET と呼ばれる理由は次の通りである:
- 最初の層は属性の名前を格納する。
- 二番目の層は、一層目の名前を持つ属性の値を格納する。
- 三番目の層は、一層目の名前と二層目の値からなる属性を持つエンティティの ID を格納する。
これらのインデックスはマップのマップとして実装される。つまり外側のマップのキーがインデックスの最初の層に対応し、内側のマップのキーが二番目の層に、バリューが三番目の層に対応する。三番目の層の要素は集合であり、インデックスの葉を保持する。
それぞれのインデックスは datom の構成要素 EAV (エンティティの ID、属性の名前、属性の値) を何らかの順序で格納する。しかし、インデックスの外側で作成される datom は「正準な」 EAV の順序で作成される。そのため、各インデックスは正準な順序と自身が期待する順序の間で変換を行う from-eav 関数と to-eav 関数を持つ。
多くのデータベースシステムではインデックスが省略可能なコンポーネントとして提供される。例えば PostgreSQL や MySQL といった RDBMS (リレーショナルデータベース管理システム) では、ユーザーによって指定されるテーブルの特定のカラムに対してだけインデックスが作成される。この機能を実装するため、各インデックスは属性をインデックスに含めるかどうかを判断する usage-pred 関数を持つ。
(defn make-index [from-eav to-eav usage-pred]
(with-meta {} {:from-eav from-eav :to-eav to-eav :usage-pred usage-pred}))
(defn from-eav [index] (:from-eav (meta index)))
(defn to-eav [index] (:to-eav (meta index)))
(defn usage-pred [index] (:usage-pred (meta index)))
私たちのデータベースは四つのインデックスを持つ: EAVT (図 2)、AVET (図 3)、VEAT、VAET である。これらには indexes 関数が返すベクトルを通してアクセスできる。
(defn indexes[] [:VAET :AVET :VEAT :EAVT])
インデックスの仕組みの全容を示すために、五つのエンティティを持つデータベースと作成されるインデックスの完全な例を次に示す:
- Julius Caesar (JC) が住む (lives-in) のは Rome である。
- Brutus (B) が住むのは Rome である。
- Cleopatra (Cleo) が住むのは Egypt である。
- Rome の川 (river) は Tiber である。
- Egypt の川は Nile である。
| EAVT | AVET |
|
|
| VEAT | VAET |
|
|
データベース
これでデータベースの全ての構成要素が定義できた。データベースの初期化は次の処理を意味する:
- データを持たない空のレイヤーを作成する。
- 空のインデックスを作成する。
top-idとcurr-timeを0に設定する。
(defn ref? [attr] (= :db/ref (:type (meta attr))))
(defn always[& more] true)
(defn make-db []
(atom
(Database.
[(Layer.
(fdb.storage.InMemory.) ; storage
(make-index #(vector %3 %2 %1) #(vector %3 %2 %1) #(ref? %)) ; VAET
(make-index #(vector %2 %3 %1) #(vector %3 %1 %2) always) ; AVET
(make-index #(vector %3 %1 %2) #(vector %2 %3 %1) always) ; VEAT
(make-index #(vector %1 %2 %3) #(vector %1 %2 %3) always))] ; EAVT
0 0)))
ここで一つ厄介な点がある: Clojure では全てのコレクションが不変である。データベースにおいて書き込み操作は非常にクリティカルなので、データベースは Atom として定義される。Atom は Clojure における参照型であり、アトミックな書き込み機能を提供する。
AVET, VEAT, EAVT のインデックスで always 関数が使われ、VAET のインデックスで述語 ref? が使われているのを不思議に思ったかもしれない。これにはインデックスの用途が関係している。詳しい理由はクエリの詳細と共に説明する。
基礎的なアクセッサ
データベースに対するクエリに関連した複雑な機能を作成する前に、特定の時刻におけるデータベースの要素をシステムの他の部分から取得するための低レベル API を提供する必要がある。この要素の取得ではタイムスタンプとエンティティの ID が使われる。この API はデータベースのコンシューマも利用できるものの、この上に作られた豊富な機能を持つコンポーネントを使う可能性の方が高い。
低レベル API は次の四つのアクセッサ関数から構成される:
(defn entity-at
([db ent-id] (entity-at db (:curr-time db) ent-id))
([db ts ent-id] (get-entity (get-in db [:layers ts :storage]) ent-id)))
(defn attr-at
([db ent-id attr-name] (attr-at db ent-id attr-name (:curr-time db)))
([db ent-id attr-name ts] (get-in (entity-at db ts ent-id) [:attrs attr-name])))
(defn value-of-at
([db ent-id attr-name] (:value (attr-at db ent-id attr-name)))
([db ent-id attr-name ts] (:value (attr-at db ent-id attr-name ts))))
(defn indx-at
([db kind] (indx-at db kind (:curr-time db)))
([db kind ts] (kind ((:layers db) ts))))
データベースを通常の値と同様に扱っているので、それぞれの関数はデータベースを引数に受け取る。各要素は関連付いた識別子とタイムスタンプを使って取得される。タイムスタンプは省略可能で、省略した場合はデータベースの「現在時刻」が使われる。タイムスタンプは対応する識別子の検索を適用すべきレイヤーを見つけるために利用される。
進化
基礎的なアクセッサを使って、まずは「過去の読み込み」API を作成しよう。この操作が可能なのは、私たちのデータベースにおいて書き込みが (上書きではなく) 新しいレイヤーの追記によって行われるためである。そのためレイヤーの prev-ts プロパティをたどれば、履歴をさかのぼって注目している属性がどのように進化してきたかを知ることができる。
この操作には次の evolution-of 関数を用いる。この関数の返り値は組の列であり、各要素はタイムスタンプと更新された属性の値に等しい:
(defn evolution-of [db ent-id attr-name]
(loop [res [] ts (:curr-time db)]
(if (= -1 ts) (reverse res)
(let [attr (attr-at db ent-id attr-name ts)]
(recur (conj res {(:ts attr) (:value attr)}) (:prev-ts attr))))))
10.3 データの振る舞いとライフサイクル
ここまでの議論ではデータの構造に注目してきた: データの構成要素と、その配置である。続いてシステムの動的な部分を見ていく: 時間の経過とともにデータが追加・更新・削除されるときの振る舞い、つまりデータのライフサイクルを説明する。
以前に議論したように、考古学者の世界におけるデータは実際には変化しない。一度作成されたデータはいつまでも存在し続け、新しいレイヤーの追加によって見えない状態になる以外に変更を受けない。この「見えない」という言葉に大きな意味が込められている: 古いデータは「消えて無くなる」のではなく、古いレイヤーを掘り進めば必ず発見できる。このため、データの更新は新しいレイヤーを追加して古いデータを見えなくする操作であり、データの削除は「削除された」を意味する新しいレイヤーの追加に等しい。
そのためデータのライフサイクルを考えるときは、どのようなレイヤーを追加するかを考えることになる。
最低限必要な機能
データのライフサイクルは次の基礎的な操作から構成される:
add-entity関数でエンティティを追加する。remove-entity関数でエンティティを削除する。update-entity関数でエンティティを更新する。
これらの関数は一見するとエンティティが可変であるかのような印象を与えるもののそうではなく、どれもレイヤーを新しく追加する関数である点に注意してほしい。また、内部では Clojure の永続データ構造が利用されるので、呼び出し側から見たときのコストは「置き換え」の変更と同程度 (無視できる程度) であり、それでいてデータ構造を利用するコードには不変性が提供される。
エンティティの追加
エンティティを追加するには、次の三つの操作が必要になる:
- 追加するエンティティを準備する (ID とタイムスタンプを割り当てる)。
- エンティティをストレージに配置する。
- 必要に応じてインデックスを更新する。
これらの操作は次の add-entity 関数によって実行される:
(defn add-entity [db ent]
(let [[fixed-ent next-top-id] (fix-new-entity db ent)
layer-with-updated-storage
(update-in (last (:layers db)) [:storage] write-entity fixed-ent)
add-fn (partial add-entity-to-index fixed-ent)
new-layer (reduce add-fn layer-with-updated-storage (indexes))]
(assoc db :layers (conj (:layers db) new-layer) :top-id next-top-id)))
エンティティの準備は fix-new-entity 関数と補助関数 next-id, next-ts, update-creation-ts が担当する。next-ts 関数はデータベースの次のタイムスタンプを返し、update-creation-ts 関数はエンティティに作成時刻を表すタイムスタンプを設定する。エンティティに作成時刻を表すタイムスタンプを設定するとは、各属性の :ts フィールドを更新することを意味する。
(defn- next-ts [db] (inc (:curr-time db)))
(defn- update-creation-ts [ent ts-val]
(reduce #(assoc-in %1 [:attrs %2 :ts ] ts-val) ent (keys (:attrs ent))))
(defn- next-id [db ent]
(let [top-id (:top-id db)
ent-id (:id ent)
increased-id (inc top-id)]
(if (= ent-id :db/no-id-yet)
[(keyword (str increased-id)) increased-id]
[ent-id top-id])))
(defn- fix-new-entity [db ent]
(let [[ent-id next-top-id] (next-id db ent)
new-ts (next-ts db)]
[(update-creation-ts (assoc ent :id ent-id) new-ts) next-top-id]))
ストレージに対するエンティティの追加では、データベースが持つ最新のレイヤーが取得され、そのレイヤーのストレージを更新したものが layer-with-updated-storage に格納される。
最後に、インデックスも更新する必要がある。add-entity 関数の中で部分適用した add-entity-to-index と reduce を組み合わせることで、それぞれのインデックスに対して次の処理が実行される:
- インデックスされるべき属性を取得する (
add-entity-to-indexでfilterとインデックスのusage-predを使う部分)。 - エンティティの ID からインデックスパスを構築する (
update-attr-in-index関数でfrom-eavと部分適用されたupdate-entry-in-indexを使う部分)。 - そのパスをインデックスに追加する (
update-entry-in-index関数)。
(defn- add-entity-to-index [ent layer ind-name]
(let [ent-id (:id ent)
index (ind-name layer)
all-attrs (vals (:attrs ent))
relevant-attrs (filter #((usage-pred index) %) all-attrs)
add-in-index-fn
(fn [ind attr]
(update-attr-in-index
ind ent-id (:name attr) (:value attr) :db/add))]
(assoc layer ind-name (reduce add-in-index-fn index relevant-attrs))))
(defn- update-attr-in-index [index ent-id attr-name target-val operation]
(let [colled-target-val (collify target-val)
update-entry-fn
(fn [ind vl]
(update-entry-in-index
ind ((from-eav index) ent-id attr-name vl) operation))]
(reduce update-entry-fn index colled-target-val)))
(defn- update-entry-in-index [index path operation]
(let [update-path (butlast path)
update-value (last path)
to-be-updated-set (get-in index update-path #{})]
(assoc-in index update-path (conj to-be-updated-set update-value))))
これらの要素はデータベースの新しいレイヤーに追加される。最後にデータベースのタイムスタンプと top-id フィールドを更新する。この最後のステップは add-entity 関数の最終行で実行され、更新されたデータベースを返す。
複数のエンティティを一度の呼び出しで追加する add-entities 関数も利便性のため提供される。add-entity 関数をデータベースに繰り返し適用することで動作する。
(defn add-entities [db ents-seq] (reduce add-entity db ents-seq))
エンティティの削除
データベースからエンティティを削除するとは、そのエンティティを消去したレイヤーを新しく追加することを意味する。必要な操作は次の三つである:
- エンティティを削除する。
- 削除されるエンティティを参照する他のエンティティの属性を更新する。
- インデックスからエンティティを取り除く。
この「エンティティを除去したレイヤーを追加する」処理は次の remove-entity 関数が実行する。この関数は add-entity 関数と非常によく似ている:
(defn remove-entity [db ent-id]
(let [ent (entity-at db ent-id)
layer (remove-back-refs db ent-id (last (:layers db)))
no-ref-layer (update-in layer [:VAET] dissoc ent-id)
no-ent-layer
(assoc no-ref-layer :storage
(drop-entity (:storage no-ref-layer) ent))
new-layer
(reduce (partial remove-entity-from-index ent) no-ent-layer (indexes))]
(assoc db :layers (conj (:layers db) new-layer))))
参照の削除は次の remove-back-refs 関数が行う:
(defn- remove-back-refs [db e-id layer]
(let [reffing-datoms (reffing-to e-id layer)
remove-fn (fn[d [e a av]] (update-entity db e a av :db/remove))
clean-db (reduce remove-fn db reffing-datoms)]
(last (:layers clean-db))))
最初に reffing-to を使って与えられたレイヤーで削除しようとしているエンティティを参照するエンティティを全て取得する。この関数が返すのは三つ組の列であり、それぞれの三つ組は参照を持つエンティティの ID、属性の名前、そして削除されるエンティティの ID (の単元集合) から構成される。
(defn- reffing-to [e-id layer]
(let [vaet (:VAET layer)]
(for [[attr-name reffing-set] (e-id vaet)
reffing reffing-set]
[reffing attr-name #{e-id}])))
この組のそれぞれに update-entity を適用し、削除されたエンティティへの参照を更新する (update-entity の動作は後述)。
remove-back-refs の最後のステップはインデックスからの参照の削除である。参照の情報を保持しているのは VAET インデックスだけなので、実際に更新されるのは VAET インデックスだけとなる。
エンティティの更新
このデータベースにおけるエンティティの更新とは、突き詰めれば何らかのエンティティの属性の値を変更する操作に等しい。属性の値の変更で可能な処理は属性の濃度 (cardinality) によって異なる: 濃度が :db/multiple の属性は集合を保持するので、要素の追加と削除、そして別の集合との置き換えが行える。一方で濃度が :db/single の属性は単一の値を保持するので、その値の置き換えしか行えない。
また、エンティティの更新では属性の名前と値をキーとして直接用いるインデックスにも変更が必要になる。
add-entity や remove-entity と同じように、update-entity 関数は属性の値を直接書き換えることはせずに属性の値が更新された新しいレイヤーを追加する。
(defn update-entity
([db ent-id attr-name new-val]
(update-entity db ent-id attr-name new-val :db/reset-to))
([db ent-id attr-name new-val operation]
(let [update-ts (next-ts db)
layer (last (:layers db))
attr (attr-at db ent-id attr-name)
updated-attr (update-attr attr new-val update-ts operation)
fully-updated-layer (update-layer layer ent-id
attr updated-attr
new-val operation)]
(update-in db [:layers] conj fully-updated-layer))))
属性の値の更新では、attr-at で属性を見つけてから update-attr で更新を実行する。
(defn- update-attr [attr new-val new-ts operation]
{:pre [(if (single? attr)
(contains? #{:db/reset-to :db/remove} operation)
(contains? #{:db/reset-to :db/add :db/remove} operation))]}
(-> attr
(update-attr-modification-time new-ts)
(update-attr-value new-val operation)))
ここでは二つのヘルパー関数が利用されている。update-attr-modification-time はタイムスタンプを更新し、図 1 の黒い実線に対応する情報を属性に追加する:
(defn- update-attr-modification-time
[attr new-ts]
(assoc attr :ts new-ts :prev-ts (:ts attr)))
update-attr-value は属性の値を更新する:
(defn- update-attr-value [attr value operation]
(cond
(single? attr)
(assoc attr :value #{value})
; 属性の値は集合である
(= :db/reset-to operation)
(assoc attr :value value)
(= :db/add operation)
(assoc attr :value (CS/union (:value attr) value))
(= :db/remove operation)
(assoc attr :value (CS/difference (:value attr) value))))
最後にインデックスに対して古い値の削除と新しい値の追加を実行し、更新の完了した新しいレイヤーを作成する。都合のいいことに、エンティティの追加・削除で以前に書いたコードをここでも利用できる。
トランザクション
これらの低レベル API はどれも単一のエンティティを対象とする。しかし、ほとんど全てのデータベースは複数の操作を一つのトランザクションとして実行する機能を持つ。これは次のことを意味する:
- バッチ (複数の操作の集まり) が単一の不可分な操作として見える: 全ての操作が完了した状態と一つの操作も完了していない状態しか外部から観測できない。
- トランザクションの前後でデータベースは正当な状態にある。
- バッチが隔離されて実行されるように見える: 一部の操作だけが適用された状態のデータベースが他のクエリから観測されることはない。
いくつかの操作をデータベースにまとめて適用し、その結果を返す関数を作ればトランザクションを実装できるように思える。しかし問題がある: 一つのトランザクションを処理したとき作成される新しいレイヤーは一つだけでなければならない。現在の低レベル API の実装は操作のたびにレイヤーを新しく作成するので、\(n\) 個の操作があれば \(n\) 個のレイヤーが作成される。
重要な観察として、トランザクションに含まれる操作を現在の低レベル API を使って順に処理したとき最終的にデータベースの一番上に積まれるレイヤーは、そのトランザクションを処理したとき唯一生成されるべきレイヤーに等しい。よってトランザクションは次の方法で実装できる: 含まれる操作を低レベル API で順に処理して、最後の操作で作成されたレイヤーだけを元々のデータベースに追加する (中間のレイヤーは全て破棄する)。データベースのタイムスタンプは全ての処理が終わった後に更新すればよい。
この処理は transact-on-db 関数で行われる。この関数はデータベースの初期値と操作の列を受け取り、操作の列をトランザクションとしてデータベースに適用した結果の値を返す。
(defn transact-on-db [initial-db ops]
(loop [[op & rst-ops] ops transacted initial-db]
(if op
(recur rst-ops (apply (first op) transacted (rest op)))
(let [initial-layer (:layers initial-db)
new-layer (last (:layers transacted))]
(assoc initial-db :layers (conj initial-layer new-layer)
:curr-time (next-ts initial-db)
:top-id (:top-id transacted))))))
前段落の最後で「結果の値」という言葉を使ったのは、transact-on-db を呼び出したコードだけが更新された状態を観測できる事実を強調するためである (データベースは値であり、Clojure で値は変更できない)。複数のユーザーが状態を変更できるシステムでは、ユーザーが直接データベースと対話できてはならず、追加の間接参照がさらに必要になる。この間接参照は Clojure が持つ参照型 Atom を使って実装される。トランザクションの実装で活用される Atom の機能が三つある:
- 値を参照する。
- 参照している値を取得する。
- トランザクションの実行を通して参照する値を別の値に更新する (Clojure のソフトウェアトランザクショナルメモリが使われる)。トランザクションは
Atom型の値と関数からなる。その関数はAtomが参照する値を受け取って新しい値を返し、トランザクションを実行するとAtom型の値は関数の返り値を参照するようになる。
Clojure の Atom と transact-on-db が行う処理の間には、まだ橋渡しが必要なギャップが存在する: トランザクションを正しく作成・起動しなければならない。最も理解しやすく単純な API を作成するため、ユーザーが提供するのは Atom 型の値 (データベース) と操作の列のみとしたい。
トランザクションによるデータベースの更新では次の順に関数・マクロが呼ばれる:
transact → _transact → swap! → transact-on-db
ユーザーは Atom 型の値 (データベース) と実行したい操作の列を transact に渡して呼び出し、transact は Atom 型の値を更新する swap! と受け取った引数を _transact に渡して呼び出す。
(defmacro transact [db-conn & txs] `(_transact ~db-conn swap! ~@txs))
_transact は swap! を呼び出す準備を整える。具体的には、最初に swap! があり、その後に Atom 型の値、transact-on-db シンボル、そして操作の列が並んだリストを作成する。
(defmacro _transact [db op & txs]
(when txs
(loop [[frst-tx# & rst-tx#] txs res# [op db `transact-on-db] accum-txs# []]
(if frst-tx#
(recur rst-tx# res# (conj accum-txs# (vec frst-tx#)))
(list* (conj res# accum-txs#))))))
swap! は transact-on-db を準備された引数と共にトランザクションとして実行し、transact-on-db は新しいデータベースの状態を作成して返す。
ここまでのコードを利用すれば、コードを少しだけ変更することで「仮に...したときの結果 (what-if)」を計算する手段を提供できる。_transact に swap! ではなくシステムを変更しない操作を渡せばよい。ユーザーは what-if を呼び出し、そこから次のように関数・マクロが呼び出される:
what-if → _transact → _what-if → transact-on-db
ユーザーはデータベースの値と操作の列を what-if に渡して呼び出し、what-if は受け取った引数に _what-if を加えて _transact を呼び出す。_what-if は swap! と同じ API を持つものの、データベースを変更しない。
(defmacro what-if [db & ops] `(_transact ~db _what-if ~@ops))
_transact は _what-if の呼び出しを準備する。具体的には、最初に _what-if があり、その後に transact-on-db シンボル、そして操作の列があるリストを作成する。このリストが表す _what-if の呼び出しは先述のトランザクション処理と基本的に同じであるものの、最後にシステムの状態を更新しない点だけが異なる。
(defn- _what-if [db f txs] (f db txs))
これまでのコードで関数ではなくマクロが多く使われていることに注目してほしい。マクロを使えば呼び出しの引数がすぐに評価されないので、Clojure における他の関数と同じ方法で操作の列を表現する簡潔な API が可能になる。
transact を呼び出したときの動作を追いかけてみよう。まず、ユーザーはトランザクションを行うために transact を呼び出す:
(transact db-conn (add-entity e1) (update-entity e2 atr2 val2 :db/add))
この呼び出しは _transact の呼び出しに変形される:
(_transact db-conn swap! (add-entity e1) (update-entity e2 atr2 val2 :db/add))
これはさらに次の呼び出しへと変形される:
(swap! db-conn transact-on-db [[add-entity e1] [update-entity e2 atr2 val2 :db/add]])
what-if を使う場合、ユーザーは次のようなコードを書く:
(what-if my-db (add-entity e3) (remove-entity e4))
この呼び出しの展開結果を示す:
(_transact my-db _what-if (add-entity e3) (remove-entity e4))
これはさらに次のコードとなる:
(_what-if my-db transact-on-db [[add-entity e3] [remove-entity e4]])
最終的に次の関数呼び出しとなる:
(transact-on-db my-db [[add-entity e3] [remove-entity e4]])
10.4 ライブラリとしてのインサイト抽出
以上でデータベースの中心的機能は手に入った。続いてデータベースの存在理由であるインサイト抽出の仕組みを追加する。本章では、インサイト抽出などの機能をライブラリとして追加可能にすることで、データベースの用途ごとに異なる仕組みを作らないで済むようにするアプローチを採用する。
グラフ走査
エンティティの属性が :db/ref の型を持つとき、二つのエンティティ間に参照関係が作成される。つまり、その属性は他のエンティティの ID を値に持つ。他のエンティティを参照する属性を持つエンティティがデータベースに追加されると、その参照は VAET インデックスに記録される。VAET インデックスが保持する情報を使うと、特定のエンティティに向かう全ての内向きリンクを抽出できる。この事実を利用した incoming-refs 関数を次に示す。この関数は VAET インデックスで特定のエンティティから到達可能な属性の値を収集する:
(defn incoming-refs [db ts ent-id & ref-names]
(let [vaet (indx-at db :VAET ts)
all-attr-map (vaet ent-id)
filtered-map (if ref-names
(select-keys ref-names all-attr-map)
all-attr-map)]
(reduce into #{} (vals filtered-map))))
特定のエンティティの属性を走査しながら :de/ref 型を持つ属性の値を集めれば、そのエンティティを始点とする全ての外向きリンクを抽出でき、それらのリンクが参照するエンティティも収集できる。この処理は outgoing-refs で実装される:
(defn outgoing-refs [db ts ent-id & ref-names]
(let [val-filter-fn (if ref-names #(vals (select-keys ref-names %)) vals)]
(if-not ent-id []
(->> (entity-at db ts ent-id)
(:attrs) (val-filter-fn) (filter ref?) (mapcat :value)))))
これらの二つの関数はグラフを走査する様々な操作の基礎単位となる。抽象化のレベルを上げてエンティティと属性を頂点と辺とみなせば、データベースの走査はグラフの走査となるからである。データベースをグラフとして扱う機能が揃えば、様々なグラフ走査やクエリ API を提供できる。この実装は読者への練習問題とする。本章のソースコード graph.clj に解答例がある。
クエリ
二番目に紹介するライブラリはクエリ機能を提供する。強力なクエリ機構を持たないデータベースをユーザーが喜んで使うとは思えない。クエリ機能はクエリ言語と共にユーザーに公開されることが多い。クエリ言語は取得したいデータを宣言的に表現するために利用される。
私たちのデータモデルは時間が経過する中で記録されてきた事実 (datom) の集まりをデータとみなしている。このモデルにおける適切なクエリ言語を考えるときは、論理プログラミング (logic programming) と呼ばれる分野が参考になる。論理プログラミングに影響された有名なクエリ言語に Datalog がある。Datalog は私たちのデータモデルに適しているのに加えて、Clojure の構文と組み合わせても違和感がない。これから Datomic データベースが利用する Datalog 言語のサブセットを実装するクエリエンジンを作成する。
クエリ言語
これから実装するクエリ言語の例を最初に示す。次のクエリは「ピザが好きで、英語を話し、今月が誕生日である人物の名前と誕生日は?」という質問を表現する:
{ :find [?nm ?bd]
:where [
[?e :likes "pizza"]
[?e :name ?nm]
[?e :speak "English"]
[?e :bday (bday-mo? ?bd)]]}
構文
クエリの基本的な構文は Clojure のデータリテラルの構文を直接利用する。こうすれば専用のパーサーを書かなくて済む上に、Clojure プログラマーが慣れ親しんだ読みやすい構文を提供できる。
クエリとは、次の二つの要素を持ったマップである:
:whereをキーに持ち、ルール (rule) をバリューに持つ要素: ルールは節 (clause) を要素とするベクトルであり、節は三つの述語 (predicate) からなる。それぞれの述語は datom の各要素に対応する。上述の例では[?e :likes "pizza"]が一つの節である。:whereに対応するベクトルはデータベースが持つ datom に対するフィルタとして振る舞うルールを定義する (SQL のWHERE節に対応)。:findをキーに持ち、ベクトルをバリューに持つ要素: このベクトルは選択された datom の中で結果として収集すべき構成要素を指定する (SQL のSELECT節に対応)。
この説明が省略している重要な機能がある: 異なる節で同じ値を参照する (JOIN 操作を実行する) 機能と、見つかった値を使った出力の構築方法を指定する (キー :find に対応するバリューで利用される) 機能である。
この二つの機能は変数を使って実装される。変数は最初に ? が付いた識別子で表される。ただし唯一の例外として _ は「どんな値でも構わない (don't-care, ドントケア)」を表す変数として利用される。
クエリに含まれる節はそれぞれ三つの述語を持つ。このクエリ言語で述語として振る舞える値を次の表にまとめる:
| 名前 | 意味 | 例 |
|---|---|---|
| 定数 | 注目している datom の要素の値が定数に等しいかどうかを返す。 | :likes |
| 変数 | 注目している datom の要素の値を変数に束縛し、true を返す。 |
?e |
| ドントケア | 常に true を返す。 |
_ |
| 単項演算子 | 注目している datom の要素の値を変数に束縛し、その値で変数を置き換えたときの演算子の評価結果を返す。変数が _ なら束縛はしない。 |
(bday-mo? _) |
| 二項演算子 | 注目している datom の要素の値を変数に束縛し、その値で変数を置き換えたときの演算子の評価結果を返す。変数が _ なら束縛はしない。 |
(> ?age 20) |
言語の制限
エンジニアリングとはトレードオフの管理が全てであり、それはクエリ言語の設計でも変わらない。ここで解決しなければならないのは機能の豊富さと複雑さのトレードオフである。このトレードオフを解決するには、想定されるシステムの用途で受け入れられる制限とは何かを判断する必要がある。
私たちのデータベースでは、次の制限を持つクエリエンジンを作成することにした:
- ユーザーは節同士の論理演算子を定義できない。節は常に
ANDされる (この制限は単項演算子や二項演算子を使えば回避できる場合もある)。 - クエリが二つ以上の節を持つとき、全ての節の同じ位置に現れる変数が少なくとも一つ存在しなければならない。この変数はジョイン変数 (joining variable) と呼ばれ、
JOIN操作の対象となる。この制限はクエリ最適化を単純化する。 - クエリは単一のデータベースに対してのみ実行される。
これらの設計判断により、実装されるクエリ言語は Datalog より機能が少ない。そうだとしても、このクエリ言語は様々な種類の単純かつ有用なクエリを処理できる。
クエリエンジンの設計
クエリ言語はユーザーがアクセスする対象を表現する一方で、それにアクセスする方法に関する詳細は表現しない。受け取ったクエリが表現するデータの取得を担当するデータベースのコンポーネントはクエリエンジンと呼ばれる。
クエリエンジンの処理は次の四つのステップからなる:
- 内部表現の作成: テキストとして受け取ったクエリを、クエリプランナーが理解できるデータ構造に変換する。
- クエリプランの作成: 指定されたクエリの結果を生成する効率的なプランを決定する。このクエリエンジンでは、クエリプランは実行される関数に等しい。
- クエリプランの実行: 決定したクエリプランを実行し、結果を次のフェーズに受け渡す。
- 結果の単一化と報告: 報告の必要がある結果だけを指定されたフォーマットで報告する。
フェーズ 1: 変換
このフェーズでは、ユーザーが理解しやすい形式で表現されたクエリを変換し、クエリプランナーが効率的に処理できる形式に変換する。
クエリの :find 部は変数の名前の集合に変換される:
(defmacro symbol-col-to-set [coll] (set (map str coll)))
クエリの :where 部は変換後も入れ子になったベクトルの構造を保つものの、節の構成要素は上述の定義に従って述語 (一引数関数) で置き換わる。この処理は次の clause-term-expr が行う:
(defmacro clause-term-expr [clause-term]
(cond
(variable? (str clause-term)) ; 変数
#(= % %)
(not (coll? clause-term)) ; 定数
`#(= % ~clause-term)
(= 2 (count clause-term)) ; 単項演算子
`#(~(first clause-term) %)
(variable? (str (second clause-term)))
; 第一オペランドに変数を持つ二項演算子
`#(~(first clause-term) % ~(last clause-term))
(variable? (str (last clause-term)))
; 第二オペランドに変数を持つ二項演算子
`#(~(first clause-term) ~(second clause-term) %)))
各節に対して、その節で使われる変数の名前からなるベクトルが節のメタデータとして構築される。この処理は次の clause-term-meta が行う:
(defmacro clause-term-meta [clause-term]
(cond
(coll? clause-term)
(first (filter #(variable? % false) (map str clause-term)))
(variable? (str clause-term) false)
(str clause-term)
:no-variable-in-clause nil))
次の pred-clause は節を構成する項を走査し、各項の内部表現である一引数関数と節のメタデータを構築する:
(defmacro pred-clause [clause]
(loop [[trm# & rst-trm#] clause exprs# [] metas# []]
(if trm#
(recur rst-trm# (conj exprs# `(clause-term-expr ~ trm#))
(conj metas# `(clause-term-meta ~ trm#)))
(with-meta exprs# {:db/variable metas#}))))
節からなるベクトル (:where に対応するバリュー) の走査は q-clauses-to-pred-clauses が行う:
(defmacro q-clauses-to-pred-clauses [clauses]
(loop [[frst# & rst#] clauses preds-vecs# []]
(if-not frst# preds-vecs#
(recur rst# `(conj ~preds-vecs# (pred-clause ~frst#))))))
マクロが引数を積極評価しない事実がここでも活用されている。この事実のおかげで、変数名を ?name といったシンボルで表現する単純な API が可能になる。変数を "?name" のように文字列にしたり、'?name のようにクオートしたりする面倒がクエリエンジンの都合でユーザーに押し付けられることはない。
このフェーズが終わると、 上述したクエリの :find 部に対しては次の値が生成される:
#{"?nm" "?bd"}
そして :where 部に対しては次の表に示す要素を持つベクトルが生成される。この表の中央にある、節の要素に対応する述語からなる三要素ベクトルを述語節 (predicate clause) と呼ぶ。
| クエリの節 | 生成される述語節 | 生成される 節のメタデータ |
|---|---|---|
[?e :likes "pizza"] |
[#(= % %) #(= % :likes) #(= % "pizza")] |
["?e" nil nil] |
[?e :name ?nm] |
[#(= % %) #(= % :name) #(= % %)] |
["?e" nil "?nm"] |
[?e :speak "English"] |
[#(= % %) #(= % :speak) #(= % "English")] |
["?e" nil nil] |
[?e :bday (bday-mo? ?bd)] |
[#(= % %) #(= % :bday) #(bday-mo? %)] |
["?e" nil "?bd"] |
以降のフェーズは、こうして生成されるデータ構造を「クエリ」と認識してクエリプランの決定・実行と結果の報告を行う。
フェーズ 2: クエリプランの決定
このフェーズではクエリの構造を詳しく調べ、それが表現する結果を生成する優れた計画を作成する。
一般に、クエリプランを決定するプロセスは適切なインデックスを選択する処理と関数の形でプランを組み立てる処理から構成される。私たちのクエリエンジンは、ジョイン変数 (全ての節に現れる変数) の中から一つを適当に選び、それを使って次の表の通りにインデックスを選択する。このため、選択されたインデックスは一種類の要素しか扱えない。
| ジョイン変数の対象 | 利用されるインデックス |
|---|---|
| エンティティの ID | AVET |
| 属性の名前 | VEAT |
| 属性の値 | EAVT |
このようにインデックスを選択する理由は、クエリプランを実際に作成する処理を見ると明らかになる。現時点では、ジョイン変数の対象を最も下層に持つインデックスが選択されると理解してほしい。
ジョイン変数に対応するインデックスの選択は次の index-of-joining-variable が行う:
(defn index-of-joining-variable [query-clauses]
(let [metas-seq (map #(:db/variable (meta %)) query-clauses)
collapsing-fn (fn [accV v] (map #(when (= %1 %2) %1) accV v))
collapsed (reduce collapsing-fn metas-seq)]
(first (keep-indexed #(when (variable? %2 false) %1) collapsed))))
最初にクエリの各節に含まれるメタデータが抽出される。ここで抽出されるメタデータは三要素のベクトルであり、三つの要素それぞれは変数の名前か nil である。メタデータのベクトルが抽出されると、それは reduce を使って変数の名前もしくは nil を要素とする一つのベクトルに変換される。このベクトルに含まれる変数の名前は全ての節で同じ位置に含まれるのでジョイン変数だと分かる (クエリ言語の構文規則により、そのような変数は必ず一つ存在する)。よって、そのジョイン変数に対応するインデックスを上記の表を参考にして選べばよい。
インデックスを選択したら、続いてクエリプランを作成する。クエリプランとはクエリとインデックスを保持したクロージャであり、データベースを受け取って必要な操作を実行し、クエリの結果を返す。
(defn build-query-plan [query]
(let [term-ind (index-of-joining-variable query)
ind-to-use (case term-ind 0 :AVET 1 :VEAT 2 :EAVT)]
(partial single-index-query-plan query ind-to-use)))
上記の例ではジョイン変数がエンティティの ID に対応するので、AVET インデックスが選択される。
フェーズ 3: クエリプランの実行
一つ前のフェーズで作成したクエリプランは single-index-query-plan を呼び出していた。この関数は次の処理を行う:
- 各述語節を使ってインデックスをフィルタリングする (述語ごとに、適切なインデックス階層が利用される)。
- フィルタリング結果の AND を取る。
- 結果を単純なデータ構造にまとめる。
(defn single-index-query-plan [query indx db]
(let [q-res (query-index (indx-at db indx) query)]
(bind-variables-to-query q-res (indx-at db indx))))
この処理を詳しく説明するために、次のエンティティを持つデータベースを例として考える:
| エンティティの ID | 属性の名前 | 属性の値 |
|---|---|---|
1 |
|
|
2 |
|
|
3 |
|
|
では query-index 関数を詳しく見ていこう。この関数でようやく、クエリの結果が生成され始める:
(defn query-index [index pred-clauses]
(let [result-clauses (filter-index index pred-clauses)
relevant-items (items-that-answer-all-conditions (map last result-clauses)
(count pred-clauses))
cleaned-result-clauses (map (partial mask-path-leaf-with-items
relevant-items)
result-clauses)]
(filter #(not-empty (last %)) cleaned-result-clauses)))
この関数は最初に各述語節を使って先ほど選択されたインデックスをフィルタリングする。一つの述語節によるフィルタリングの結果を結果節 (result clause) と呼ぶ。結果節の主な特徴を次に示す:
- 三つの要素から構成される。それぞれの要素はインデックスの異なる階層から得られたものであり、対応する述語によるチェックをパスする。
- 三つの要素はインデックスの階層構造と同じ順序で並ぶ (述語節は常に EAV の順序で並ぶ)。この並び替えはインデックスの
from-eavを述語節に適用することで行われる。 - 述語節と同じメタデータを持つ。
結果節は次の filter-index 関数で作成される:
(defn filter-index [index predicate-clauses]
(for [pred-clause predicate-clauses
:let [[lvl1-prd lvl2-prd lvl3-prd] (apply (from-eav index) pred-clause)]
[k1 l2map] index ; 一番目の階層のキーとバリュー
:when (try (lvl1-prd k1) (catch Exception e false))
[k2 l3-set] l2map ; 二番目の階層のキーとバリュー
:when (try (lvl2-prd k2) (catch Exception e false))
:let [res (set (filter lvl3-prd l3-set))] ]
(with-meta [k1 k2 res] (meta pred-clause))))
上記のクエリを上記のデータベースに対して 7 月 4 日に実行したときに得られる結果節を次の表に示す:
| 結果節 | 結果節のメタデータ |
|---|---|
[:likes Pizza #{1}] |
["?e" nil nil] |
[:name USA #{1}] |
["?e" nil "?nm"] |
[:speak "English" #{1, 3}] |
["?e" nil nil] |
[:bday "July 4, 1776" #{1}] |
["?e" nil "?bd"] |
[:name France #{2}] |
["?e" nil "?nm"] |
[:bday "July 14, 1789" #{2}] |
["?e" nil "?bd"] |
[:name Canada #{3}] |
["?e" nil "?nm"] |
[:bday "July 1, 1867" #{3}] |
["?e" nil "?bd"] |
全ての述語節に対応する結果節が手に入ったら、続いてそれらの AND を計算する。これで全ての述語節をパスする要素が手に入る:
(defn items-that-answer-all-conditions [items-seq num-of-conditions]
(->> ;; tems-seq (集合のベクトル) を手に取る
items-seq
;; それぞれのコレクション (集合) をベクトルにする
(map vec)
;; 全体を一つのベクトルにする
(reduce into [])
;; それぞれの要素が元々のコレクション (集合) に属する回数を数える
(frequencies)
;; 全ての述語節のチェックをパスする要素だけを残す
(filter #(<= num-of-conditions (last %)))
;; 登場回数を削除して、要素だけを取る
(map first)
;; 集合にして返す
(set)))
上記の例では、この関数は #{1} を返す (1 は USA を表すエンティティの ID である)。
続いて条件を満たさない要素を結果節から削除する:
(defn mask-path-leaf-with-items [relevant-items path]
(update-in path [2] CS/intersection relevant-items))
最後に、この処理で「空」になった (最後の要素が空になった) 結果節を削除する。この処理は query-index 関数の最終行で行われる。例として考えているクエリに対する以上の処理の結果を次の表に示す:
| 結果節 | 結果節のメタデータ |
|---|---|
[:likes Pizza #{1}] |
["?e" nil nil] |
[:name USA #{1}] |
["?e" nil "?nm"] |
[:bday "July 4, 1776" #{1}] |
["?e" nil "?bd"] |
[:speak "English" #{1}] |
["?e" nil nil] |
これで結果を報告する準備が整った。結果節のままだと扱いづらいので、まずインデックスに似た ── 大幅に改変した ── データ構造 (マップのマップ) に変換する。
その改変を理解するには、束縛組 (binding pair) という概念を定義する必要がある。束縛組とは、変数の名前とその値からなる組を言う。変数の名前は述語節に含まれ、変数の値は結果節に含まれる。
結果を報告するために構築されるデータ構造は、インデックスが持つ「エンティティの ID・属性の名前・属性の値」の代わりに「エンティティの ID を値に持つ変数の束縛組・属性の名前を値に持つ変数の束縛組・属性の値を値に持つ変数の束縛組」を持つ:
(defn bind-variables-to-query [q-res index]
(let [seq-res-path (mapcat (partial combine-path-and-meta (from-eav index))
q-res)
res-path (map #(->> %1 (partition 2)(apply (to-eav index))) seq-res-path)]
(reduce #(assoc-in %1 (butlast %2) (last %2)) {} res-path)))
(defn combine-path-and-meta [from-eav-fn path]
(let [expanded-path [(repeat (first path)) (repeat (second path)) (last path)]
meta-of-path (apply from-eav-fn (map repeat (:db/variable (meta path))))
combined-data-and-meta-path (interleave meta-of-path expanded-path)]
(apply (partial map vector) combined-data-and-meta-path)))
フェーズ 3 の終了時点で、例として考えているクエリからは次のデータ構造が作成される:
{[1 "?e"] {
{[:likes nil] ["Pizza" nil]}
{[:name nil] ["USA" "?nm"]}
{[:speaks nil] ["English" nil]}
{[:bday nil] ["July 4, 1776" "?bd"]}
}
}
フェーズ 4: 結果の単一化と報告
フェーズ 3 の最後で手に入ったデータ構造には、ユーザーが最初にリクエストした結果を生成できるだけの情報が含まれている。次のフェーズでは、そこからユーザーが望む形の値を抽出する。このプロセスを単一化 (unification) と呼ぶ: ユーザーがクエリの :find 部で指定した変数名のベクトルと計算された束縛組の情報を一つにまとめることで、ユーザーの望む値を計算する。
(defn unify [binded-res-col needed-vars]
(map (partial locate-vars-in-query-res needed-vars) binded-res-col))
単一化の各ステップは locate-vars-in-query-result 関数が行う。この関数はクエリの結果 (束縛組がインデックスと同じ構造に並んだデータ構造) を走査し、ユーザーがリクエストした変数と値を全て検出する。
(defn locate-vars-in-query-res [vars-set q-res]
(let [[e-pair av-map] q-res
e-res (resultify-bind-pair vars-set [] e-pair)]
(map (partial resultify-av-pair vars-set e-res) av-map)))
(defn resultify-bind-pair [vars-set accum pair]
(let [[ var-name _] pair]
(if (contains? vars-set var-name) (conj accum pair) accum)))
(defn resultify-av-pair [vars-set accum-res av-pair]
(reduce (partial resultify-bind-pair vars-set) accum-res av-pair))
このフェーズが終わると、例として考えているクエリからは次の結果が得られる:
[("?nm" "USA") ("?bd" "July 4, 1776")]
ショー開演
これでようやく、クエリの仕組みをユーザーに提供するために必要なコンポーネントが作成できた。ユーザーは次の q マクロを使ってデータベースに対するクエリを実行する。
(defmacro q
[db query]
`(let [pred-clauses# (q-clauses-to-pred-clauses ~(:where query))
needed-vars# (symbol-col-to-set ~(:find query))
query-plan# (build-query-plan pred-clauses#)
query-internal-res# (query-plan# ~db)]
(unify query-internal-res# needed-vars#)))
10.5 まとめ
私たちの旅路は異なる種類のデータベースを認識するところから始まり、最終的に次の特徴を持つデータベースが作成された:
- ACI トランザクションをサポートする (データをインメモリにしか保持しないので、永続性は失われている)。
- 「もし ... したらどうなる? (what if ...?)」の形をした質問に答えられる。
- 時間が関係する質問に答えられる。
- 単純な Datalog クエリを、インデックスで最適化された形で処理できる。
- グラフクエリに対する API を提供する。
- 「進化的クエリ」の概念が存在し、実装されている。
改善できる点は多くある: いくつかのコンポーネントにキャッシュを加えればパフォーマンスを改善できるだろう。クエリ機能の充実や、本物のストレージのサポートを通じたデータ永続性の提供なども考えられる。
しかし、本章で作成したデータベースは非常に多くの機能を持つ。わずか 488 行の Clojure コードで実装され、そのうち 73 行は空白行で、55 行はドキュメント用の文字列である。
最後に、一つ欠けているものがある: 名前である。インデックスで最適化され、クエリをサポートし、ライブラリ開発者に優しく、時間を扱うことのできる、360 行の Clojure コードで実装されたインメモリの関数型データベースにふさわしい名前は「CircleDB」しかないだろう。