12. Python で書かれた Python インタープリタ
12.1 はじめに
Byterun は Python で実装された Python インタープリタである。Byterun に取り組む中で、Python インタープリタの基礎的な構造が 500 行のサイズ制限に軽々と収まることに私は驚き、満足した気分になった。本章では Byterun の構造を説明しつつ、さらに詳しく理解するために必要な背景知識を読者に与える。目標はインタープリタに関して知っておくべき全ての事項を説明することではない ── プログラミングと計算機科学の様々な興味深い分野と同じように、このテーマを深く理解するために何年もの時間かけることができるだろう。
Byterun は Paul Swartz が書いたコードを拡張する形で Ned Batchelder と私によって書かれた。その構造は主要な Python 実装である CPython と似ているので、Byterun を理解すれば一般的なインタープリタ、そして特に CPython に関する理解が深まるだろう (もし自分が使っている Python 実装が分からなければ、あなたはおそらく CPython を使っている)。実装は非常に短いにもかかわらず、Byterun は単純な Python プログラムのほとんどを実行するだけの機能を持つ1。
Python インタープリタ
コードを書き始める前に「Python インタープリタ」の意味を確定させておこう。Python の話をしているとき「インタープリタ」という言葉はいくつかの意味で使われる。コマンドラインで python を実行したときに起動する対話プロンプト (Python REPL) を「インタープリタ」と呼ぶこともあれば、文字列で表された Python コードを受け取ってそれを実行するプログラム全体を「インタープリタ」と呼ぶこともある。本章で「Python インタープリタ」はもっと狭い意味を持つ: Python プログラムを実行するプロセスの最後のステップを指す。
インタープリタの前に Python が実行するステップが三つある: 字句解析、構文解析、そしてコンパイルである。これら三つのステップはプログラマーが書いた Python コードを表す文字列を構造化されたコードオブジェクト (code object) に変換する。このコードオブジェクトにはインタープリタが理解できる命令が含まれる。コードオブジェクトを受け取り、そこに含まれる命令を実行することがインタープリタの仕事となる。
Python コードを実行するステップに「コンパイル」があると知って驚いた読者もいるかもしれない。よくある説明では、Python は Ruby や Perl と同じ「インタープリタ言語」であり、C や Rust のような「コンパイル言語」とは異なるとされる。しかし、この区別がそれほど明確な意味を持つわけではない。Python を含めた多くのインタープリタ言語はコンパイルステップを持つ。Python が「インタープリタ言語」と呼ばれる理由は、コンパイル言語と比較的してコンパイルステップで行われる処理が少ない (そしてインタープリタの処理が多い) ためである。本章でも見るように、C コンパイラなどと比べたとき Python コンパイラはプログラムの振る舞いに関する情報をほんの少ししか持たない。
Python で書かれた Python インタープリタ
Byterun は Python で書かれた Python インタープリタである。この事実を奇妙に感じたかもしれないが、C で書かれた C コンパイラと何も違いはない (実際、広く使われている C コンパイラ gcc は C で書かれている)。ほぼ全ての言語で Python インタープリタを書くことができるだろう。
Python インタープリタを Python で書くことには利点もあれば欠点もある。最も大きな欠点は速度である: Byterun による Python コードの実行は、C で書かれ注意深く最適化された CPython による実行より格段に遅い。しかし、Byterun は最初から習作として設計されているので、速度は重要でない。Python を使う最大の利点は、インタープリタ「だけ」を簡単に実装できることである。Python ランタイムの他の部分、特にオブジェクトシステムを実装する必要がない。例えば、Byterun でクラスの作成が必要になったら「本物の」Python クラスにフォールバックできる。また、Byterun は高レベル言語 (Python!) で書かれているので理解しやすいことも利点として挙げられる (Byterun ではインタープリタの最適化は目指さない ── ここでも単純さと分かりやすさを実行速度より優先する)。
12.2 インタープリタの作成
Bytecode のコードを見ていく前に、インタープリタの構造を高いレベルで簡単に理解しておく必要がある。Python のインタープリタはどのように動作するのだろうか?
Python のインタープリタは仮想機械 (virtual machine)、つまり物理的なコンピューターを模倣するソフトウェアである。Byterun はその中でもスタックマシンと呼ばれる仮想機械に分類され、いくつかのスタックの操作を通して命令を実行する (スタックマシンと対になるのはレジスタマシンであり、こちらは特定のメモリ位置へのデータの読み書きを通して命令を実行する)。
Byterun はバイトコードインタープリタ (bytecode interpreter) でもある: バイトコード (bytecode) と呼ばれる命令の集まりが Byterun への入力に含まれる。プログラマーが書いた Python コードが字句解析・構文解析・そしてコンパイラで処理を受けると、インタープリタの処理対象であるコードオブジェクトが生成される。コードオブジェクトは実行すべき命令の集合 (バイトコード) の他にも、インタープリタが必要とする様々な情報が含まれる。バイトコードは Python コードの中間表現 (intermediate representation) である: プログラマーが書いたソースコードと同じ処理を、インタープリタが理解できる形式で表現する。これはアセンブリ言語が C コードとハードウェアの間をつなぐ中間表現となるのに似ていると言える。
小さなインタープリタ
この説明を具体的に理解するために、非常に小さなインタープリタを書いてみよう。このインタープリタは数字の加算しかできず、三つの命令しか理解できない。実行できるのは次の三つの命令を組み合わせたコードだけである:
LOAD_VALUEADD_TWO_VALUESPRINT_ANSWER
本章では字句解析・構文解析・コンパイルを考えないので、これらの命令がどのように生成されるかは問題とならない。7 + 5 のようなソースコードを入力すると上記の三命令が並んだ列を含む何らかのデータ構造を生成するコンパイラが存在すると考えればよい。あるいは、Lisp の構文で書かれたソースコードを同様のデータ構造に変換するコンパイラを書くこともできるだろう。そういった詳細はインタープリタに影響を及ぼさない。インタープリタが正しい形式をしたデータ構造を受け取ることだけが重要となる。
次のソースコードをコンパイラに入力したとする:
7 + 5
このとき、コンパイラによって次のデータ構造が生成されたとしよう:
what_to_execute = {
"instructions": [("LOAD_VALUE", 0), # 一つ目の数値
("LOAD_VALUE", 1), # 二つ目の数値
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5] }
Byterun はスタックマシンであり、二つの数値を足すためにスタックを操作する (図 1)。まずインタープリタは最初の命令 LOAD_VALUE を実行し、一つ目の数値をスタックにプッシュする。次の命令も LOAD_VALUE なので、同様に二つ目の数値をスタックにプッシュする。三つ目の命令 ADD_TWO_VALUE を実行するとき、インタープリタはスタックから二つの数値を取り出し、それらの和を計算し、それをスタックにプッシュする。最後の PRINT_ANSWER はスタックから数値を一つ取り出し、取り出した値を出力することで実行される。
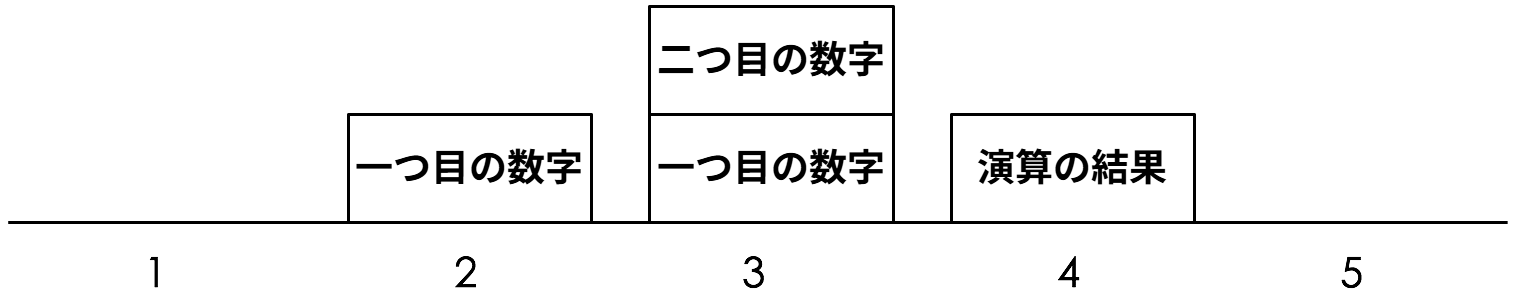
LOAD_VALUE 命令は数値を一つスタックにプッシュするようインタープリタに指示する。しかし、この命令だけではプッシュすべき数値は分からない。そのため LOAD_VALUE 命令にはプッシュすべき数値を指定する情報が付け足されており、この情報を使ってインタープリタは数値を特定する。そのため、インタープリタが入力として受け取るデータ構造は二つの部分からなる: 実行すべき命令列と、命令列が必要とする定数のリストである (Python では、それぞれの命令を「バイトコード」と呼び、バイトコードの列を含む実行可能なオブジェクトを「コードオブジェクト」と呼ぶ)。
命令の中に数値を埋め込まないのはどうしてだろうか? 数値ではなく文字列を加算する状況を考えてみてほしい。文字列の長さは可変なので、命令の中に文字列を埋め込むことはできない。また、定数のリストを用意する設計は各オブジェクトのコピーが定数リストの中に最大でも一つしか存在しないことを意味する。例えば 7 + 7 のコンパイル結果に含まれる「数値」は 7 のみとなる。
上記の例で ADD_TWO_VALUES 以外の命令が必要なのかと疑問に思った読者もいるかもしれない。正直、二つの数値を加算する単純なケースだけを考えるなら、この例は人工的と言われても仕方がない。しかし、この例はより複雑なプログラムを考えるための基礎となる。例えば、これまでに登場した命令を使えば三つの ── そして任意の個数の ── 数値を足すことができる。スタックはインタープリタの状態を管理するシンプルな仕組みを提供し、これから様々な機能がスタックに足されていく。
では、インタープリタの作成に取り掛かろう。インタープリタオブジェクトが持つスタックはリストで表現する。また、各命令を実行するメソッドをインタープリタクラスに持たせる。例えば LOAD_VALUE メソッドは指定された数値をスタックにプッシュする:
class Interpreter:
def __init__(self):
self.stack = []
def LOAD_VALUE(self, number):
self.stack.append(number)
def PRINT_ANSWER(self):
answer = self.stack.pop()
print(answer)
def ADD_TWO_VALUES(self):
first_num = self.stack.pop()
second_num = self.stack.pop()
total = first_num + second_num
self.stack.append(total)
インタープリタが理解する三つの命令に対応する三つのメソッドが実装されている。必要な要素がもう一つある: これらのメソッドを使って実際にコードを実行する手段が必要になる。この処理を実装するのが run_code メソッドであり、上述の例で見た構造を持つ辞書 what_to_execute を引数として受け取る。このメソッドは命令列を走査し、命令の引数が存在するなら取得し、対応するメソッドを呼び出して命令を実行する:
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
numbers = what_to_execute["numbers"]
for each_step in instructions:
instruction, argument = each_step
if instruction == "LOAD_VALUE":
number = numbers[argument]
self.LOAD_VALUE(number)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
以上のコードをテストするには、Interpreter オブジェクトのインスタンスを作成し、上記の例で示した 7 + 5 に対応するデータ構造 (辞書) を引数として run_code を呼び出せばよい:
interpreter = Interpreter()
interpreter.run_code(what_to_execute)
期待通りの出力 12 が得られる。
このインタープリタは非常に限られた機能しか持たないものの、その処理は実際の Python インタープリタが二つの数値を足すときの処理とほとんど変わらない。この小さな例にさえ、注目すべき点がいくつかある。
まず、一部の命令は引数を必要とする。実際の Python バイトコードでは約半分の命令が引数を持ち、ここで示した例と同様に引数は命令に埋め込まれる。命令の引数は実行時に呼び出されるメソッドの引数と異なる点に注意してほしい。
次に、ADD_TWO_VALUES は引数を取らず、加算される二つの値はインタープリタが持つスタックからポップされる。これはスタックベースのインタープリタ特有の特徴である。
以前に指摘したように、入力を変更すればインタープリタを変更しなくても三つ以上の数値を足すことができる。次のデータ構造をインタープリタに入力すると、何が起こるだろうか? 常識的なコンパイラがあるとき、どんなコードを入力すればこのデータ構造が出力されるだろうか?
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("LOAD_VALUE", 1),
("ADD_TWO_VALUES", None),
("LOAD_VALUE", 2),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5, 8] }
ここまで来ると、インタープリタが持つ拡張可能な構造が見え始めただろう: インタープリタオブジェクトにメソッドを追加すれば (そしてコンパイラを追加された命令に対応させれば) 処理できる命令を増やせる。
変数
続いて変数に関する機能をインタープリタに追加しよう。変数を扱うには、変数の値を保存する STORE_NAME 命令、変数の値を取得する LOAD_NAME 命令、そして変数の名前と値の対応付けが必要になる。名前空間とスコープについて今は考えないことにして、変数の名前と値の単純な対応付けをインタープリタオブジェクトに持たせよう。最後に、what_to_execute に変数の名前のリストを定数のリストとは別に持たせる必要がある:
>>> def s():
... a = 1
... b = 2
... print(a + b)
# 常識的なコンパイラは 's' を次のデータ構造に変換する
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("STORE_NAME", 0),
("LOAD_VALUE", 1),
("STORE_NAME", 1),
("LOAD_NAME", 0),
("LOAD_NAME", 1),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [1, 2],
"names": ["a", "b"] }
新しい実装を以下に示す。名前に対応する値を記録する environment という辞書を __init__ で初期化している。また、STORE_NAME メソッドと LOAD_NAME メソッドは最初に変数の名前を取得してから変数の値を記録または取得する。
新しい命令の追加により、命令の引数は二つの異なる意味を持つようになった: 命令の引数は "numbers" リストにおける位置、または "names" リストにおける位置を意味する。インタープリタは実行中の命令を見てどちらの意味で解釈すべきかを判断する。次のコードでは、このロジック ── そして命令から引数の意味への対応付け ── を個別のメソッドとして切り出している。
class Interpreter:
def __init__(self):
self.stack = []
self.environment = {}
def STORE_NAME(self, name):
val = self.stack.pop()
self.environment[name] = val
def LOAD_NAME(self, name):
val = self.environment[name]
self.stack.append(val)
def parse_argument(self, instruction, argument, what_to_execute):
""" 命令の引数の意味を解釈し、意味する値を返す。 """
numbers = ["LOAD_VALUE"]
names = ["LOAD_NAME", "STORE_NAME"]
if instruction in numbers:
argument = what_to_execute["numbers"][argument]
elif instruction in names:
argument = what_to_execute["names"][argument]
return argument
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
if instruction == "LOAD_VALUE":
self.LOAD_VALUE(argument)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
elif instruction == "STORE_NAME":
self.STORE_NAME(argument)
elif instruction == "LOAD_NAME":
self.LOAD_NAME(argument)
五つの命令しか実装していないにもかかわらず、run_code メソッドは長くて読みにくくなってきた。この調子で命令を追加していくと、if 文による分岐が命令の数だけ増えていく。この問題に対しては Python の動的なメソッドルックアップを利用できる。このインタープリタでは命令を実行するメソッドの名前が命令の名前と一致するので、Python の getattr 関数を使って動的にメソッドを取得すれば if による長い分岐を避けられる。このテクニックを使って書き換えた run_code メソッドを次に示す:
def execute(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
bytecode_method = getattr(self, instruction)
if argument is None:
bytecode_method()
else:
bytecode_method(argument)
12.3 実際の Python バイトコード
人工的に作った簡単な命令を考えるのはここまでにして、次は実際の Python バイトコードを見ていこう。実際のバイトコードの構造は今まで考えてきたインタープリタが扱う冗長な命令に似ているものの、各命令は長い名前ではなく 1 バイトの定数で特定される。その構造を理解するために、短い関数のバイトコードをこれから説明する。次の関数を考える:
>>> def cond():
... x = 3
... if x < 5:
... return 'yes'
... else:
... return 'no'
...
Python は内部で利用するデータ構造の多くを実行時に公開しており、REPL からでもアクセスできる。cond が関数オブジェクトのとき、その関数に関連付くコードオブジェクトは cond.__code__ で、そのバイトコードはcond.__code__.co_code で参照できる。Python コードを普通に書くだけなら、こういった属性を直接使う理由はまず存在しない。しかし、ここから得られる情報は様々な「いたずら」をする ── あるいは Python の内部処理の理解を深める ── のに利用できる。
>>> cond.__code__.co_code # バイトコードをバイト列として表示
b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x00\x00S'
>>> list(cond.__code__.co_code) # バイトコードを数字の列として表示
[100, 1, 0, 125, 0, 0, 124, 0, 0, 100, 2, 0, 107, 0, 0, 114, 22, 0, 100, 3, 0, 83,
100, 4, 0, 83, 100, 0, 0, 83]
バイトコードをただ表示しただけではバイトが並んでいるだけで、意味のある情報は何も得られないように思える。しかし幸いにも、このバイト列を理解するための強力なツールが存在する: Python 標準ライブラリの dis モジュールである。
dis モジュールはバイトコードのディスアセンブラを実装する。ディスアセンブラは機械のために書かれた低レベルコード (アセンブリコードやバイトコード) を受け取り、それを人間が読めるフォーマットで出力する。dis.dis 関数を実行すると、引数に渡した関数のバイトコードを説明する文字列が出力される。
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (5)
12 COMPARE_OP 0 (<)
15 POP_JUMP_IF_FALSE 22
4 18 LOAD_CONST 3 ('yes')
21 RETURN_VALUE
6 >> 22 LOAD_CONST 4 ('no')
25 RETURN_VALUE
26 LOAD_CONST 0 (None)
29 RETURN_VALUE
出力の意味を説明しよう。LOAD_CONST を含む最初の行に注目する。最初の列にある数字 2 は Python ソースコードにおける行数を表し、二列目の 0 はバイトコード配列における命令の位置を表す。三行目は命令を人間に読める名前に変換したものであり、四列目は (存在するなら) 命令の引数を、五行目は (存在するなら) 引数の意味する値に関するヒントを表す。
このバイトコードの最初の六バイト [100, 1, 0, 125, 0, 0] に注目しよう。この六バイトは二つの命令とそれらの引数を表す。dis.opname は命令を表すバイトから命令を表す文字列への対応付けであり、これを使えば 100 と 125 が表す命令を確認できる:
>>> dis.opname[100]
'LOAD_CONST'
>>> dis.opname[125]
'STORE_FAST'
二番目と三番目のバイト 1, 0 は LOAD_CONST の引数であり、五番目と六番目のバイト 0, 0 は STORE_FAST の引数である。最初に考えた簡単な命令と同様に、LOAD_CONST は読み込む定数を見つける必要があり、STORE_FAST は保存する変数の名前を見つける必要がある (Python の LOAD_CONST は以前のインタープリタの LOAD_VALUE に、LOAD_FAST は LOAD_NAME に対応する)。よって、これらの 6 バイトは最初の行 x = 3 に対応すると分かる (引数が 2 バイトなのはどうしてだろうか? 定数の特定に 1 バイトしか使えないとしたら、一つのコードオブジェクトに関連付けられる定数・名前の個数が最大でも 256 個に制限されてしまう。2 バイトを使えるようにすれば、定数・名前の最大個数は 256 倍の 65,356 個まで増える)。
条件文とループ
これまでインタープリタは命令を一つずつ順番に実行してきた。しかし、このままでは実行できない種類のコードが存在する: 何らかの条件が成り立つときに特定の部分をスキップしたり、何度も実行したりするコードである。条件文とループを実行するには、インタープリタが命令列の任意の箇所に実行を移せる必要がある。ある意味で、Python は条件文とループをバイトコードにおける GOTO で処理する! cond 関数のディスアセンブリをもう一度見よう:
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (5)
12 COMPARE_OP 0 (<)
15 POP_JUMP_IF_FALSE 22
4 18 LOAD_CONST 3 ('yes')
21 RETURN_VALUE
6 >> 22 LOAD_CONST 4 ('no')
25 RETURN_VALUE
26 LOAD_CONST 0 (None)
29 RETURN_VALUE
cond のソースコード 3 行目にある条件分岐 if x < 5 は LOAD_FAST, LOAD_CONST, COMPARE_OP, POP_JUMP_IF_FALSE という四つの命令にコンパイルされている。x < 5 に対応する最初の三命令は x を読み込み、5 を読み込み、二つの値を比較する。そして最後の POP_JUMP_IF_FALSE が条件分岐を実装する。この命令を実行するときインタープリタはスタックから値を一つポップし、それが真なら何もしない (Python で値が「真である」の意味は「リテラルオブジェクト True に等しい」だけではない ── True 以外にも真になるオブジェクトが存在する)。もし値が偽なら、インタープリタは通常と異なる命令にジャンプする。
条件文などの命令で条件が成り立った時に実行が移される先をジャンプ対象 (jump target) と呼ぶ。POP_JUMP_IF_FALSE 命令では、ジャンプ対象は引数によって指定される。位置 15 の POP_JUMP_IF_FALSE 命令の引数は 22 であり、これは位置 22 の LOAD_CONST 命令 (ソースコード 6 行目に対応) を指す。dis.dis の出力では、ジャンプ対象の位置に >> の印が付いている。つまり、もし x < 5 の結果が偽ならインタープリタは 6 行目の return "no" までジャンプし、4 行目の return "yes" をスキップする。こうしてインタープリタはジャンプ命令を使って特定の部分を選択的にスキップする。
Python ではループもジャンプを利用して実装される。次に示すバイトコードにおいて、while x < 5 の行が先ほどの if x < 5 のコンパイル結果とほとんど同じ命令にコンパイルされていることに注目してほしい。両方の場合において、比較を実行した後に POP_JUMP_IF_FALSE が次に実行する命令を制御する。第 4 行 ── ループ本体の最後の行 ── に対応する命令列の最後には、ループの先頭である位置 9 への無条件ジャンプがある。x < 5 の評価結果が偽になると、POP_JUMP_IF_FALSE がインタープリタをループの先 (位置 34) にジャンプさせる。
>>> def loop():
... x = 1
... while x < 5:
... x = x + 1
... return x
...
>>> dis.dis(loop)
2 0 LOAD_CONST 1 (1)
3 STORE_FAST 0 (x)
3 6 SETUP_LOOP 26 (to 35)
>> 9 LOAD_FAST 0 (x)
12 LOAD_CONST 2 (5)
15 COMPARE_OP 0 (<)
18 POP_JUMP_IF_FALSE 34
4 21 LOAD_FAST 0 (x)
24 LOAD_CONST 1 (1)
27 BINARY_ADD
28 STORE_FAST 0 (x)
31 JUMP_ABSOLUTE 9
>> 34 POP_BLOCK
5 >> 35 LOAD_FAST 0 (x)
38 RETURN_VALUE
バイトコードを詳しく調べるための質問
自分で書いた関数に dis.dis を実行してみることを勧める。次の質問の答えを見つけてみるとよい:
- Python インタープリタから見た
forループとwhileループの違いは何か? - どうすれば全く同じバイトコードを生成する異なる関数を書けるか?
elifはどのように動作するか? リストの内包表記はどうか?
12.4 フレーム
これまでに、Python インタープリタが使用する仮想機械はスタックマシンだと学んだ。インタープリタは命令列を行ったり来たりしながら、スタックに対してプッシュやポップを行う。ただ、この処理と私たちのメンタルモデルの間には依然としてギャップがある。上述の例で最後の命令は RETURN_VALUE だった。これはソースコードの return に対応する。では、この命令を実行したときに「リターン」すべき場所とはいったいどこだろうか?
この質問に答えるには、複雑性をもたらす新たな概念を一つ導入しなければならない: フレーム (frame) である。フレームは特定の領域のコードが持つ情報とコンテキストを集めたものであり、Python コードが実行されるとき動的に作成・破棄される。例えば、関数の呼び出しごとにフレームが一つ作成される: 一つのフレームには一つのコードオブジェクトが関連付くのに対して、一つのコードオブジェクトには複数のフレームが関連付く可能性がある。例えば自分自身を再帰的に 10 回呼び出す関数があるなら、その関数を呼び出すと同じコードオブジェクトが関連付いたフレームが 11 個 ── 再帰的なものを含めて呼び出しごとに一つずつ ── 作成される。一般的に言えば、フレームは Python プログラムのスコープごとに作成される。例えばインタープリタがモジュール・関数呼び出し・クラス定義を処理するときスコープは作成される。
フレームはコールスタック (call stack) 上に作成される。コールスタックはこれまでに考えてきたスタックとは全く異なるスタックである (ただ、コールスタックは Python プログラマーが最も慣れ親しんでいるスタックでもある ── 例外が送出されてトレースバックが表示されたとき、File 'program.py', line 10 といった形をした行はコールスタックに含まれる一つのフレームに対応する)。今まで説明してきた、インタープリタがバイトコードを実行するときに値をプッシュしたりポップしたりするスタックを、本章ではデータスタック (data stack) と呼ぶ。スタックはもう一種類あり、この三つ目のスタックはブロックスタックと呼ばれる。ブロックは特定の種類の制御フロー (ループや例外処理) で利用される。コールスタック上のフレームはそれぞれが固有のデータスタックとブロックスタックを持つ。
例を使って具体的に説明しよう。Python インタープリタが次のコードで (3) の印の付いた行を実行していると仮定する。インタープリタは foo の呼び出し (1) を処理している途中であり、foo には bar の呼び出し (2) が含まれる。このときコールスタックに含まれるフレーム、そして各フレームが持つブロックスタックとデータスタックの模式図を図 2 に示す。この時点でコールスタックの一番底にあるフレームは foo の呼び出しを処理しており、その上のフレームは foo の最終行を、さらにその上の (一番上の) フレームは bar の最初の行を処理している。
>>> def bar(y):
... z = y + 3 # <--- (3) ... インタープリタがここに到達する。
... return z
...
>>> def foo():
... a = 1
... b = 2
... return a + bar(b) # <--- (2) ... 返り値の計算中に bar が呼び出され ...
...
>>> foo() # <--- (1) foo の呼び出しの処理中に...
3
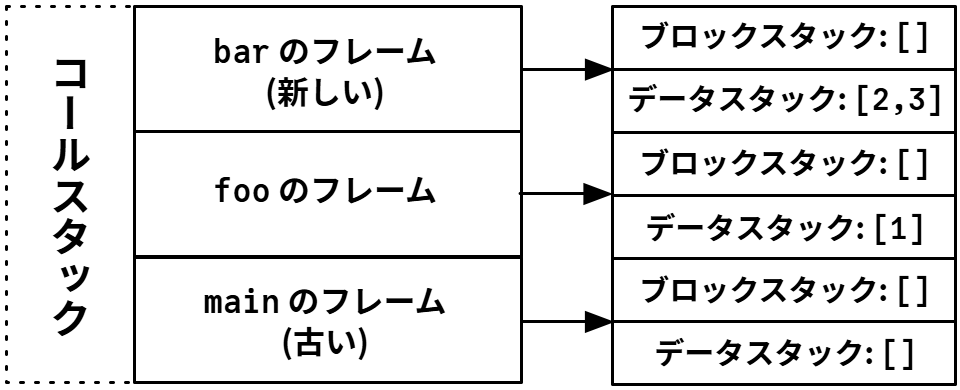
コールスタックには三つのフレームが存在する: モジュール main の読み込みに対応するフレーム、関数 foo の呼び出しに対応するフレーム、そして関数 bar の呼び出しに対応するフレームである。bar が返るとコールスタックがポップされ、bar の呼び出しに対応するフレームは破棄される。
バイトコード命令 RETURN_VALUE はフレームをまたいで値を受け渡すようインタープリタに指示する。インタープリタはコールスタックの一番上にあるフレームのデータスタックから値をポップし、その値を一つ下のフレームのデータスタックにプッシュし、最後にコールスタックをポップして一番上にあるフレームを丸ごと破棄する。
Ned Batchelder と私が Byterun に取り組んでいたとき、私たちの実装には重大な誤りが長く含まれたままになっていた。各フレームに固有のデータスタックを持たせるのではなく、仮想マシン全体で一つのデータスタックを使うようにしていたのである。Byterun には数十個のテストが存在し、短い Python コードを Byterun と実際の Python インタープリタの両方で実行して結果が一致することを確かめていた。ほとんどテストはパスしたものの、唯一ジェネレータを利用するコードだけは正しく動作しなかった。最終的には CPython のコードをこれまでより注意深く読むことで誤りに気が付くことができた2。各フレームが固有のデータスタックを持つようにしたところ問題は解決された。
このバグを思い返して驚くのは、各フレームが異なるデータスタックを持つ事実を利用する Python の機能がとても少ないことである。Python インタープリタが実行するほとんど全ての操作は実行が完了した時点でデータスタックが実行前の状態に戻るので、異なるフレームが同じスタックを共有していたとしても問題は生じない。例えば上記の例では、bar の実行が終わるとデータスタックは空になる。そのため foo のデータスタックが bar と同じだったとしても、返り値は問題なく受け渡される。しかしジェネレータを使うコードではフレームを抜けて他のフレームに返ったとしても、後から同じフレームに戻ったときに以前と全く同じ状態が復元されなければならない。
12.5 Byterun
Byterun を詳しく見ていくのに必要な Python インタープリタに関する知識はこれで以上である。
Byterun には四種類のオブジェクトが存在する:
VirtualMachineクラス: 高レベルなデータ構造 (フレームを収めたコールスタックや命令から操作への対応付けなど) を管理する。最初の例におけるIntepreterクラスに機能を追加したものと言える。Frameクラス: 実行中に作成されるフレームを表す。Frameクラスのインスタンスには、単一のコードオブジェクト、実行に必要な状態 (グローバルおよびローカルの名前空間など)、呼び出し側フレームへの参照、そして最後に実行したバイトコード命令の位置が含まれる。Functionクラス: Python の関数を扱うために利用される。関数の呼び出しを処理するときインタープリタが新しいフレームを作成することを思い出してほしい。Functionクラスは新しいフレームの作成を制御するために存在する。Blockクラス: 単なるラッパークラスであり、ブロックが持つ三つの属性を含む (ブロックの詳細は Python インタープリタの中心的要素ではないので詳しくは説明しない。Byterun が現実の Python コードを実行できるように実装される)。
VirtualMachine クラス
Python プログラムを実行するとき Python インタープリタは一つしか必要とならないので、VirtualMachine のインスタンスは一つだけ作成される。VirtualMachine はコールスタック、例外の状態、そしてフレーム間で受け渡される返り値を管理する。コード実行のエントリーポイントは run_code メソッドであり、コンパイルされたコードオブジェクトを引数に受け取る。引数を受け取った run_code は新しいフレームを作成して実行を開始する。このフレームが新しい別のフレームを作成する可能性があり、コールスタックはプログラムの実行中に伸びることもあれば縮むこともある。最初のフレームの実行が終了すると、プログラムの実行が完了する。
class VirtualMachineError(Exception):
pass
class VirtualMachine(object):
def __init__(self):
self.frames = [] # フレームからなるコールスタック
self.frame = None # 現在のフレーム
self.return_value = None
self.last_exception = None
def run_code(self, code, global_names=None, local_names=None):
""" 仮想機械を使ってコードを実行するときのエントリーポイント """
frame = self.make_frame(code, global_names=global_names,
local_names=local_names)
self.run_frame(frame)
Frame クラス
続いて Frame クラスを見よう。このクラスは属性を保持するためのクラスであり、メソッドを持たない。先述の通り、コンパイラが生成するコードオブジェクト、ローカル・グローバル・組み込みの名前空間、一つ前のフレームへの参照、データスタック、ブロックスタック、そして最後に実行した命令の位置が Frame に含まれる (Python は一部の組み込みモジュールの名前空間を特別扱いするので対処が必要になるが、これは仮想機械にとって重要なことではない)。
class Frame(object):
def __init__(self, code_obj, global_names, local_names, prev_frame):
self.code_obj = code_obj
self.global_names = global_names
self.local_names = local_names
self.prev_frame = prev_frame
self.stack = []
if prev_frame:
self.builtin_names = prev_frame.builtin_names
else:
self.builtin_names = local_names['__builtins__']
if hasattr(self.builtin_names, '__dict__'):
self.builtin_names = self.builtin_names.__dict__
self.last_instruction = 0
self.block_stack = []
続いて、フレームを操作するメソッドを VirtualMachine クラスに追加しよう。フレームに関連するヘルパー関数が三つある: 新しいフレームを作る関数 (新しいフレームの名前空間を設定する責務を負う)、そしてコールスタックに対するフレームのプッシュ・ポップのそれぞれを行う二つの関数である。四つ目のメソッド run_frame はフレームの実行という最大のタスクを担う。このメソッドについては後述する。
class VirtualMachine(object):
[... 省略 ...]
# フレームを操作するメソッド
def make_frame(self, code, callargs={}, global_names=None, local_names=None):
if global_names is not None and local_names is not None:
local_names = global_names
elif self.frames:
global_names = self.frame.global_names
local_names = {}
else:
global_names = local_names = {
'__builtins__': __builtins__,
'__name__': '__main__',
'__doc__': None,
'__package__': None,
}
local_names.update(callargs)
frame = Frame(code, global_names, local_names, self.frame)
return frame
def push_frame(self, frame):
self.frames.append(frame)
self.frame = frame
def pop_frame(self):
self.frames.pop()
if self.frames:
self.frame = self.frames[-1]
else:
self.frame = None
def run_frame(self):
pass
# 後述
Function クラス
Function クラスの実装はいくらか入り組んでおり、そのほとんどはインタープリタを理解する上で重要でない。一つ重要な点として、関数を呼び出す ── 特殊メソッド __call__ を起動する ── と新しい Frame オブジェクトが作成され、その実行が開始されることを確認してほしい。
class Function(object):
""" インタープリタが期待する要素を持った、本物に近い関数オブジェクトを作成する。 """
__slots__ = [
'func_code', 'func_name', 'func_defaults', 'func_globals',
'func_locals', 'func_dict', 'func_closure',
'__name__', '__dict__', '__doc__',
'_vm', '_func',
]
def __init__(self, name, code, globs, defaults, closure, vm):
""" この部分を深く理解しなくてもインタープリタは理解できる。 """
self._vm = vm
self.func_code = code
self.func_name = self.__name__ = name or code.co_name
self.func_defaults = tuple(defaults)
self.func_globals = globs
self.func_locals = self._vm.frame.f_locals
self.__dict__ = {}
self.func_closure = closure
self.__doc__ = code.co_consts[0] if code.co_consts else None
# 本物の Python 関数が必要になる場合もあるので、用意しておく
kw = {
'argdefs': self.func_defaults,
}
if closure:
kw['closure'] = tuple(make_cell(0) for _ in closure)
self._func = types.FunctionType(code, globs, **kw)
def __call__(self, *args, **kwargs):
""" Function が呼び出されたら、新しいフレームを作成して実行する。 """
callargs = inspect.getcallargs(self._func, *args, **kwargs)
# callargs が引数の名前から値への対応付けを提供する
frame = self._vm.make_frame(
self.func_code, callargs, self.func_globals, {}
)
return self._vm.run_frame(frame)
def make_cell(value):
""" 本物の Python クロージャを作り、セルを取得する。 """
# このトリックを教えてくれた Alex Gaynor に感謝する。
fn = (lambda x: lambda: x)(value)
return fn.__closure__[0]
続いて VirtualMachine クラスに戻り、データスタックを操作するヘルパー関数をいくつか追加する。データスタックを操作するバイトコードは必ず現在のフレームのデータスタックを変更する。この事実を利用すると、POP_TOP や LOAD_FAST などのスタックに触れる命令の実装を読みやすくできる。
class VirtualMachine(object):
[... 省略 ...]
# データスタックの操作
def top(self):
return self.frame.stack[-1]
def pop(self):
return self.frame.stack.pop()
def push(self, *vals):
self.frame.stack.extend(vals)
def popn(self, n):
"""
データスタックから n 個の値をポップし、ポップされた値からなる
リストを返す (最も深い位置にあった値が先頭)。
"""
if n:
ret = self.frame.stack[-n:]
self.frame.stack[-n:] = []
return ret
else:
return []
フレームの実行を始める前に、さらに二つのメソッドが必要になる。
一つ目のメソッド parse_byte_and_args は現在の命令を取得し、それが引数を持つかどうかを確認し、持つ場合は引数をパースする。その後フレームの last_instruction 属性を更新し、「現在の命令」を次の命令に進める。引数を持たない命令の長さは 1 バイトであり、引数を持つ命令の長さは 3 バイトである (最後の 2 バイトが引数を表す)。引数の意味は命令によって異なる。例えば、先述した POP_JUMP_IF_FALSE 命令では引数がジャンプ対象を表す。また、BUILD_LIST 命令では引数がリストの要素数を表し、LOAD_CONST では引数が定数リストに対する添え字を表す。
引数が単なる数値を表す命令もあれば、引数の意味を理解するのに仮想機械による多少の処理が必要になる命令もある。Python 標準ライブラリの dis モジュールには引数の意味を説明したチートシートのようなデータが公開されており、これを使うと引数をパースするコードを短く書ける。例えば dis.hasname リストからは、LOAD_NAME, IMPORT_NAME, LOAD_GLOBAL などの九個の命令に対する引数が同じ意味を持つと分かる: これらの命令の引数はコードオブジェクトに含まれる名前リストに対する添え字を表す。
class VirtualMachine(object):
[... 省略 ...]
def parse_byte_and_args(self):
f = self.frame
opoffset = f.last_instruction
byteCode = f.code_obj.co_code[opoffset]
f.last_instruction += 1
byte_name = dis.opname[byteCode]
if byteCode >= dis.HAVE_ARGUMENT:
# バイトコードにおける位置
arg = f.code_obj.co_code[f.last_instruction:f.last_instruction+2]
f.last_instruction += 2 # 命令ポインタを進める
arg_val = arg[0] + (arg[1] * 256)
if byteCode in dis.hasconst: # 定数を取得する
arg = f.code_obj.co_consts[arg_val]
elif byteCode in dis.hasname: # 名前を取得する
arg = f.code_obj.co_names[arg_val]
elif byteCode in dis.haslocal: # ローカルな名前 (変数名) を取得する
arg = f.code_obj.co_varnames[arg_val]
elif byteCode in dis.hasjrel: # 相対的ジャンプを計算する
arg = f.last_instruction + arg_val
else:
arg = arg_val
argument = [arg]
else:
argument = []
return byte_name, argument
次のメソッド dispatch は与えられた命令に対応する操作を取得して実行する。CPython インタープリタでは、このディスパッチが 1500 行にわたる巨大な switch 文で実装される! 幸い、私たちは Python を使っているのでコードはもっとコンパクトになる。バイトコード命令と同じ名前のメソッドが定義されているので、getattr を使えば命令に対応するメソッドを取得できる。最初に実装したインタープリタと同様に、命令の名前が FOO_BAR のとき対応するメソッドは byte_FOO_BAR という名前を持つ。ここでは命令を実行するメソッドをブラックボックスとして扱う。命令を実行するメソッドは None または文字列を返す。この文字列は why と呼ばれ、一部のケースでインタープリタが必要とする追加情報を表す。命令を実行するメソッドが返す値はインタープリタの内部状態に対する指示として利用されることに注意してほしい ── 実行中のフレームの返り値とは関係がない。
class VirtualMachine(object):
[... 省略 ...]
def dispatch(self, byte_name, argument):
"""
byte_name 命令を対応するメソッドにディスパッチする。
例外は捕捉され、仮想機械によって処理される。
"""
# ブロックスタックを巻き戻すとき、その理由を覚えておく必要がある。
why = None
try:
bytecode_fn = getattr(self, 'byte_%s' % byte_name, None)
if bytecode_fn is None:
if byte_name.startswith('UNARY_'):
self.unaryOperator(byte_name[6:])
elif byte_name.startswith('BINARY_'):
self.binaryOperator(byte_name[7:])
else:
raise VirtualMachineError(
"unsupported bytecode type: %s" % byte_name
)
else:
why = bytecode_fn(*argument)
except:
# 命令を実行中に遭遇した例外に対処する。
self.last_exception = sys.exc_info()[:2] + (None,)
why = 'exception'
return why
def run_frame(self, frame):
"""
フレームを (何らかの理由で) 値が返るまで実行する。
例外が送出されるか、フレームの返り値が返る。
"""
self.push_frame(frame)
while True:
byte_name, arguments = self.parse_byte_and_args()
why = self.dispatch(byte_name, arguments)
# ブロックの管理処理を必要なだけ行う
while why and frame.block_stack:
why = self.manage_block_stack(why)
if why:
break
self.pop_frame()
if why == 'exception':
exc, val, tb = self.last_exception
e = exc(val)
e.__traceback__ = tb
raise e
return self.return_value
Block クラス
それぞれのバイトコード命令に対応するメソッドを実装していく前に、ブロックについて簡単に議論する。ブロックは一部のフロー制御 (具体的には例外処理とループ) で利用され、実行が完了したときデータスタックを適切な状態に保つ処理を行う。例えばループの実行では、特別なイテレータオブジェクトをスタックに残しておき、ループが終了したときにポップしなければならない場合がある。インタープリタはループが続くのか止まるのかを毎回確認しなければならない。
この追加情報を記録するためのフラグをインタープリタは持つ。このフラグは why というローカル変数として実装される。why は None または文字列 "continue", "break", "exception", "return" のいずれかの値を取り、ブロックスタックとデータスタックに対して必要となる操作を表す。イテレータの例に戻ると、ブロックスタックの一番上にあるのが loop ブロックの状況で why が "continue" なら、イテレータオブジェクトをデータスタックからポップしてはいけない。一方で why が "break" なら、イテレータオブジェクトをポップする必要がある。
ブロックに関する操作の詳細は面倒なだけであまり面白くないので、これ以上の説明はしない。興味のある読者には時間をかけてコードを読んでみることを勧める。
Block = collections.namedtuple("Block", "type, handler, stack_height")
class VirtualMachine(object):
[... 省略 ...]
# ブロックスタックの操作
def push_block(self, b_type, handler=None):
stack_height = len(self.frame.stack)
self.frame.block_stack.append(Block(b_type, handler, stack_height))
def pop_block(self):
return self.frame.block_stack.pop()
def unwind_block(self, block):
""" 受け取ったブロックに対応するデータスタックの値をポップする。 """
if block.type == 'except-handler':
# 例外の型・値・トレースバックがスタック上に存在する。
offset = 3
else:
offset = 0
while len(self.frame.stack) > block.level + offset:
self.pop()
if block.type == 'except-handler':
traceback, value, exctype = self.popn(3)
self.last_exception = exctype, value, traceback
def manage_block_stack(self, why):
""" why が指示する操作をブロックスタックに対して実行する。 """
frame = self.frame
block = frame.block_stack[-1]
if block.type == 'loop' and why == 'continue':
self.jump(self.return_value)
why = None
return why
self.pop_block()
self.unwind_block(block)
if block.type == 'loop' and why == 'break':
why = None
self.jump(block.handler)
return why
if (block.type in ['setup-except', 'finally'] and why == 'exception'):
self.push_block('except-handler')
exctype, value, tb = self.last_exception
self.push(tb, value, exctype)
self.push(tb, value, exctype) # yes, twice
why = None
self.jump(block.handler)
return why
elif block.type == 'finally':
if why in ('return', 'continue'):
self.push(self.return_value)
self.push(why)
why = None
self.jump(block.handler)
return why
return why
12.6 命令
最後に残ったのはそれぞれの命令に対応する数十個のメソッドの実装である。命令の実装はインタープリタで最もつまらない部分なので、本章では一部だけを示す。完全な実装は GitHub レポジトリから確認できる (以前にディスアセンブリを示したコードの実行で必要になる命令の実装はここで示される)。
class VirtualMachine(object):
[... 省略 ...]
## スタック操作
def byte_LOAD_CONST(self, const):
self.push(const)
def byte_POP_TOP(self):
self.pop()
## 名前
def byte_LOAD_NAME(self, name):
frame = self.frame
if name in frame.f_locals:
val = frame.f_locals[name]
elif name in frame.f_globals:
val = frame.f_globals[name]
elif name in frame.f_builtins:
val = frame.f_builtins[name]
else:
raise NameError("name '%s' is not defined" % name)
self.push(val)
def byte_STORE_NAME(self, name):
self.frame.f_locals[name] = self.pop()
def byte_LOAD_FAST(self, name):
if name in self.frame.f_locals:
val = self.frame.f_locals[name]
else:
raise UnboundLocalError(
"local variable '%s' referenced before assignment" % name
)
self.push(val)
def byte_STORE_FAST(self, name):
self.frame.f_locals[name] = self.pop()
def byte_LOAD_GLOBAL(self, name):
f = self.frame
if name in f.f_globals:
val = f.f_globals[name]
elif name in f.f_builtins:
val = f.f_builtins[name]
else:
raise NameError("global name '%s' is not defined" % name)
self.push(val)
## 演算子
BINARY_OPERATORS = {
'POWER': pow,
'MULTIPLY': operator.mul,
'FLOOR_DIVIDE': operator.floordiv,
'TRUE_DIVIDE': operator.truediv,
'MODULO': operator.mod,
'ADD': operator.add,
'SUBTRACT': operator.sub,
'SUBSCR': operator.getitem,
'LSHIFT': operator.lshift,
'RSHIFT': operator.rshift,
'AND': operator.and_,
'XOR': operator.xor,
'OR': operator.or_,
}
def binaryOperator(self, op):
x, y = self.popn(2)
self.push(self.BINARY_OPERATORS[op](x, y))
COMPARE_OPERATORS = [
operator.lt,
operator.le,
operator.eq,
operator.ne,
operator.gt,
operator.ge,
lambda x, y: x in y,
lambda x, y: x not in y,
lambda x, y: x is y,
lambda x, y: x is not y,
lambda x, y: issubclass(x, Exception) and issubclass(x, y),
]
def byte_COMPARE_OP(self, opnum):
x, y = self.popn(2)
self.push(self.COMPARE_OPERATORS[opnum](x, y))
## 属性と添え字アクセス
def byte_LOAD_ATTR(self, attr):
obj = self.pop()
val = getattr(obj, attr)
self.push(val)
def byte_STORE_ATTR(self, name):
val, obj = self.popn(2)
setattr(obj, name, val)
## データ構造の構築
def byte_BUILD_LIST(self, count):
elts = self.popn(count)
self.push(elts)
def byte_BUILD_MAP(self, size):
self.push({})
def byte_STORE_MAP(self):
the_map, val, key = self.popn(3)
the_map[key] = val
self.push(the_map)
def byte_LIST_APPEND(self, count):
val = self.pop()
the_list = self.frame.stack[-count] # peek
the_list.append(val)
## ジャンプ
def byte_JUMP_FORWARD(self, jump):
self.jump(jump)
def byte_JUMP_ABSOLUTE(self, jump):
self.jump(jump)
def byte_POP_JUMP_IF_TRUE(self, jump):
val = self.pop()
if val:
self.jump(jump)
def byte_POP_JUMP_IF_FALSE(self, jump):
val = self.pop()
if not val:
self.jump(jump)
## ブロック
def byte_SETUP_LOOP(self, dest):
self.push_block('loop', dest)
def byte_GET_ITER(self):
self.push(iter(self.pop()))
def byte_FOR_ITER(self, jump):
iterobj = self.top()
try:
v = next(iterobj)
self.push(v)
except StopIteration:
self.pop()
self.jump(jump)
def byte_BREAK_LOOP(self):
return 'break'
def byte_POP_BLOCK(self):
self.pop_block()
## 関数
def byte_MAKE_FUNCTION(self, argc):
name = self.pop()
code = self.pop()
defaults = self.popn(argc)
globs = self.frame.f_globals
fn = Function(name, code, globs, defaults, None, self)
self.push(fn)
def byte_CALL_FUNCTION(self, arg):
lenKw, lenPos = divmod(arg, 256) # KWargs not supported here
posargs = self.popn(lenPos)
func = self.pop()
frame = self.frame
retval = func(*posargs)
self.push(retval)
def byte_RETURN_VALUE(self):
self.return_value = self.pop()
return "return"
12.7 動的型付け: コンパイラが知らないこと
Python は「動的 (dynamic)」な言語である、あるいは 「動的型付け (dynamically typed)」の言語である、と聞いたことがあるかもしれない。ここまでに学んだ知識があれば、これらの言葉の意味がいくらか明らかになる。
この文脈で「動的」とは、実行時に多くの処理が実行されることを意味する。以前に説明したように、Python コンパイラは実行されるコードに関する情報をあまり持たない。例えば次に示す短い関数 mod を見てほしい。mod は二つの引数を受け取り、一つ目の引数を二つ目の引数で割ったときの余りを返す。対応するバイトコードを確認すると、変数 a, b が読み込まれた後に BINARY_MODULO で余りの計算が行われている。
>>> def mod(a, b):
... return a % b
>>> dis.dis(mod)
2 0 LOAD_FAST 0 (a)
3 LOAD_FAST 1 (b)
6 BINARY_MODULO
7 RETURN_VALUE
>>> mod(19, 5)
4
19 % 5 を計算すると 4 になる ── 何もおかしな点はない。しかし、異なる引数を渡したらどうなるだろうか?
>>> mod("by%sde", "teco")
'bytecode'
何が起こったのだろう? ここで使われた構文は読者も見たことがあるはずだが、使われ方は異なっていたかもしれない:
>>> print("by%sde" % "teco")
bytecode
記号 % を使った文字列フォーマットは、BINARY_MODULO 命令の実行に等しい。この命令を実行するとき、インタープリタはスタックからポップした二つの値に剰余演算を適用する ── このときポップされる値が文字列なのか、整数なのか、ユーザーが定義したクラスのインスタンスなのかは確認されない。バイトコードは関数がコンパイルされるとき (事実上、定義されるとき) に生成され、異なる種類の引数に対しても同じバイトコードが利用される。
Python コンパイラは処理結果のバイトコードが表す具体的な処理に関して比較的少ない情報しか持たない。BINARY_MODULO 命令の対象となるオブジェクトの型を確認して正しい処理を選ぶのはインタープリタの仕事となっている。Python が動的型付けの言語と呼ばれるのはこのためである: 関数の引数の型は、実際に実行してみるまで分からない。これに対して静的型付け (statically typed) の言語では、プログラマーが引数などの型を前もって指定する (コンパイラが自動的に推論する場合もある)。
このコンパイラの知識不足は Python コードの最適化や静的な解析において問題となる ── バイトコードを見ただけでは各命令が何をするか分からず、確かめるには実行するしかない! 実際、__mod__ メソッドを実装したクラスのインスタンスに % を適用すると、その __mod__ メソッドが Python によって呼び出される。そのため BINARY_MODULO 命令は文字通り任意の処理を実行できる!
問題はこれだけではない。例えば次のコードにおいて、一回目の a % b の計算は無駄に思える:
def mod(a,b):
a % b
return a % b
しかし残念ながら、静的解析 ── コードを実行せずに行える種類のコード解析 ── では一回目の a % b が本当に何もしないかどうかを判定できない。% によって呼び出される __mod__ メソッドがファイルに何かを書き込むかもしれないし、プログラムの他の部分と対話するかもしれない。それどころか、Python で可能なことなら何でもできてしまう。Russell Power と Alex Rubinsteyn は有名な論文 How fast can we make interpreted Python? で「このように型情報が広く欠落しているので、各命令を INVOKE_ARBITRARY_METHOD (任意のメソッドの呼び出し) として扱わなければならない」と記している。
12.8 結論
Byterun は CPython より簡単に理解できるコンパクトな Python インタープリタであり、「バイトコードと呼ばれる命令セットを処理するスタックベースのインタープリタ」という CPython の主要な構造的特徴を模倣する。Byterun は実行する命令の位置を進めたりジャンプさせたりしながら、データスタックに対するプッシュとポップを利用して命令を実行する。関数・ジェネレータの呼び出しや return 文を実行すると、フレームの作成・破棄、そしてフレーム間のジャンプが発生する。Byterun は実際の Python インタープリタが持つ欠点も持っている: Python は動的型付けなので、そのインタープリタは実行時にたくさんの処理を通してプログラムの正しい振る舞いを決定しなければならない。
自分で書いたプログラムをディスアセンブルして、その結果を Byterun で実行してみることを勧める。本章で示した短いバージョンの Byterun で実装されていない命令がすぐに見つかるだろう。Byterun の完全な実装は GitHub レポジトリから確認できる ── あるいは、CPython インタープリタの ceval.c を注意深く読んで自分で実装してみるのもいいかもしれない!
12.9 謝辞
本プロジェクトを開始して私がコントリビューションできるよう導いてくれた Ned Batchelder、コードのデバッグと文章の推敲を手伝ってくれた Michael Arntzenius、編集を担当してくれた Leta Montopoli、そして支援と感心を寄せてくれた Recurse Center コミュニティ全体に感謝する。なお、全ての誤りは私の責任である。