13. 3D モデラー
13.1 はじめに
人間は生まれながらにして創造的な生き物である。私たちは有用で、新奇で、興味深いものを絶え間なく設計・構築してきた。現代では、設計と製造のプロセスを補助するソフトウェアが作成されるようになった。CAD (computer-aided design, コンピューター支援設計) ソフトウェアを利用すれば、建築物、橋、ゲームのグラフィック、映画のモンスター、3D プリント可能な物体といった様々なものを物理的なバージョンを作成する前に設計できる。
CAD ツールの核にあるのは、三次元の設計を抽象化して二次元の画面上で確認・編集できるようにする仕組みである。この仕組みのために CAD ツールが提供しなければならない基礎的な機能が三つある。第一に、設計対象のオブジェクトを表現するデータ構造が必要になる。このデータ構造を通して、コンピューターはユーザーが構築しようとする三次元世界を理解する。第二に、三次元の設計をユーザーの画面に表示する手段が必要になる。ユーザーが設計するのは三次元空間に存在する物理的なオブジェクトであるのに対して、コンピューターのスクリーンは二つの次元しか持たない。CAD ツールは人間がオブジェクトを認識する仕組みをモデル化し、そのモデルを利用してユーザーが三次元的に理解できる形でオブジェクトをスクリーンに描画しなければならない。第三に、設計対象のオブジェクトと対話する手段が必要となる。ユーザーが設計を追加・修正して自身の望む結果を得ることが可能でなければならない。さらに、全てのツールはディスクを使った設計の保存・読み込みをサポートする必要がある。この機能をツールが持たないと、ユーザーは自身の作業を保存・共有・利用できない。
ドメイン固有 CAD ツールは特定の分野が必要とする追加機能を提供する。例えば、建築用 CAD ツールは気候が建築物に及ぼす影響をテストする物理シミュレーションを提供するだろうし、3D プリンタ用 CAD ツールはオブジェクトが実際に印刷できるかどうかを判定する機能を持つだろう。電気設計用 CAD ツールは銅線を伝わる電流の物理的挙動をシミュレートし、映画用の特殊エフェクトスイートは炎の動きを正確にシミュレートする機能を持つに違いない。
しかし、どんな CAD ツールも上述した三つの機能を持っている: 三次元の設計を表現するデータ構造、そのデータ構造を画面に表示する機能、そして設計と対話する仕組みは欠かせない。
この事実を念頭に置いた上で、三次元物体の設計を表現して、画面に表示して、それと対話する方法をどうしたら 500 行の Python で実装できるかを考えよう。
13.2 レンダリング
3D モデラーで必要になる設計判断の多くはレンダリングプロセスから生じる。ユーザーが設計する複雑なオブジェクトを表現・描画しなければならず、同時にレンダリング関連のコードの複雑性は低く抑えたい。そこでレンダリングプロセスを見ていきながら、任意に複雑なオブジェクトを単純なレンダリングロジックで描画できるデータ構造について考えよう。
インターフェースとメインループの管理
レンダリングを始める前に必要な準備がいくつかある。まず、設計を表示するウィンドウを作成しなければならない。次に、そのウィンドウへレンダリングするためにグラフィックスドライバと対話する必要がある。グラフィックスドライバと直接対話するのは面倒なので、OpenGL と呼ばれるクロスプラットフォームの抽象化レイヤー、そして GLUT (OpenGL Utility Toolkit) と呼ばれるライブラリを利用する。
OpenGL について
OpenGL はクロスプラットフォーム開発用のグラフィックス API (application programming interface) であり、異なるプラットフォームで動作するグラフィックスアプリケーションの開発で標準的な API として利用される。OpenGL には二つの主要なモードがあり、それぞれ「レガシー OpenGL」と「モダン OpenGL」と呼ばれる。
OpenGL のレンダリングは頂点と法線で定義されるポリゴンを利用する。例えば、立方体をレンダリングするときは 4 個の頂点と各面の法線を OpenGL に伝える。
レガシー OpenGL は「固定機能パイプライン (fixed function pipeline)」を提供する。プログラマーはグローバル変数の設定を通してライティング・色付け・背面カリングといった組み込み機能を有効にするかどうかを指定し、OpenGL は有効な機能だけを使ってシーンをレンダリングする。現在この機能は非推奨である。
これに対して、モダン OpenGL は「プログラム可能レンダリングパイプライン (programmable rendering pipeline)」を提供する。プログラマーは専用グラフィックスハードウェア (GPU) で実行される「シェーダー (shader)」と呼ばれる小さなプログラムを書いて OpenGL に指定する。モダン OpenGL のプログラム可能レンダリングパイプラインはレガシー OpenGL の固定機能パイプラインを置き換えた。
本プロジェクトでは、非推奨であることを承知で、レガシー OpenGL を利用する。レガシー OpenGL の固定機能パイプラインはコードサイズを小さく保つ上で非常に役立つ。必要となる線形代数の知識が減り、コードも単純になる。
GLUT について
GLUT は OpenGL に付属するライブラリであり、 ユーザーインターフェースに対するコールバック機構や OS ウィンドウの作成機能を提供する。GLUT が提供する機能は基礎的であるものの、私たちには十分である。ウィンドウとユーザーインターフェースの管理に関して GLUT より豊富な機能を持ったライブラリが必要な場合は、GTK や Qt といった完全なウィンドウツールキットの利用を選択肢に入れることになる。
Viewer クラス
GLUT と OpenGL のセットアップを管理するため、そしてモデラーの残りの部分を制御するために、まず Viewer クラスを作成する。アプリケーション全体で作成される Viewer クラスのインスタンスは一つだけであり、それがウィンドウ作成とレンダリングの管理やメインループの実行などを担当する。Viewer クラスのコンストラクタでは、GUI ウィンドウの作成と OpenGL の初期化が行われる。
init_interface メソッドはモデラーを描画するウィンドウを作成し、設計のレンダリングが必要になったとき呼ばれる関数を設定する。init_opengl メソッドはプロジェクトが必要とする OpenGL の設定をセットアップする。具体的には行列を設定し、背面カリングを有効化し、シーンを照らすライトを登録し、OpenGL にオブジェクトを色付けるよう指示する。init_scene メソッドは Scene オブジェクトを作成し、作業を開始するユーザーに表示するいくつかの初期ノードを配置する。Scene が用いるデータ構造はすぐに説明される。最後に、init_interaction がユーザーとの対話で用いられるコールバックを登録する。このコールバックについては後述する。
Viewer の初期化が終わると、glutMainLoop が呼び出されてプログラムの制御が GLUT に移る。この関数は返らず、これまでに登録した GLUT イベントに対するコールバックが発生したイベントに応じて呼び出される。
class Viewer(object):
def __init__(self):
""" Viewer を初期化する。 """
self.init_interface()
self.init_opengl()
self.init_scene()
self.init_interaction()
init_primitives()
def init_interface(self):
""" ウィンドウを初期化し、描画関数を登録する。 """
glutInit()
glutInitWindowSize(640, 480)
glutCreateWindow("3D Modeller")
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGB)
glutDisplayFunc(self.render)
def init_opengl(self):
""" シーンをレンダリングするための OpenGL の設定を初期化する。 """
self.inverseModelView = numpy.identity(4)
self.modelView = numpy.identity(4)
glEnable(GL_CULL_FACE)
glCullFace(GL_BACK)
glEnable(GL_DEPTH_TEST)
glDepthFunc(GL_LESS)
glEnable(GL_LIGHT0)
glLightfv(GL_LIGHT0, GL_POSITION, GLfloat_4(0, 0, 1, 0))
glLightfv(GL_LIGHT0, GL_SPOT_DIRECTION, GLfloat_3(0, 0, -1))
glColorMaterial(GL_FRONT_AND_BACK, GL_AMBIENT_AND_DIFFUSE)
glEnable(GL_COLOR_MATERIAL)
glClearColor(0.4, 0.4, 0.4, 0.0)
def init_scene(self):
""" Scene オブジェクトを初期化して、と初期シーンを作成する。 """
self.scene = Scene()
self.create_sample_scene()
def create_sample_scene(self):
cube_node = Cube()
cube_node.translate(2, 0, 2)
cube_node.color_index = 2
self.scene.add_node(cube_node)
sphere_node = Sphere()
sphere_node.translate(-2, 0, 2)
sphere_node.color_index = 3
self.scene.add_node(sphere_node)
hierarchical_node = SnowFigure()
hierarchical_node.translate(-2, 0, -2)
self.scene.add_node(hierarchical_node)
def init_interaction(self):
""" ユーザーとの対話機構とコールバックを初期化する。 """
self.interaction = Interaction()
self.interaction.register_callback('pick', self.pick)
self.interaction.register_callback('move', self.move)
self.interaction.register_callback('place', self.place)
self.interaction.register_callback('rotate_color', self.rotate_color)
self.interaction.register_callback('scale', self.scale)
def main_loop(self):
glutMainLoop()
if __name__ == "__main__":
viewer = Viewer()
viewer.main_loop()
render メソッドを見ていく前に、線形代数について少し議論する。
座標空間
本章の議論では、座標空間とは原点と三つの基底ベクトルを集めたものである。三つの基底ベクトルは \(x\) 軸、\(y\) 軸、\(z\) 軸であることが多い。
点
三次元空間内の任意の点は \(x\) 軸方向、\(y\) 軸方向、\(z\) 軸方向に関する原点との距離で表現できる。この点の表現は座標空間に依存し、同じ点でも座標空間が変われば表現が変化する。三次元空間内の任意の点は任意の三次元座標空間で表現できる。
ベクトル
ベクトルは三つの実数 \(x\), \(y\), \(z\) の集めたものであり、それぞれ \(x\) 軸方向、\(y\) 軸方向、\(z\) 軸方向に関する特定の二点の差を表す。
変換行列
コンピューターグラフィックスでは、異なる種類の点・ベクトルに対して異なる座標空間を使えると便利な場合がある。変換行列 (transformation matrix) を使うと、ある座標空間で表現された点・ベクトルを別の座標空間に移すことができる。何らかの座標空間で表現された点またはベクトル \(x\) の異なる座標おける表現は、対応する変換行列 \(M\) を使って \(v^{\prime} = M v\) と計算できる。よく使われる変換行列に移動行列、拡大行列、回転行列がある。
座標空間: モデル・ワールド・ビュー・投影
[訳注: 諸事情により図 1 は掲載できませんでした。お手数ですが英語版から確認してください。]
画面に何かを描画するには、いくつかの異なる座標空間を経由する変換が必要になる。
図 11 の右側に示された、視線空間 (eye space) からビューポート空間 (viewport space) への変換で利用される変換行列は全て OpenGL によって計算される。
視線空間から同時クリップ空間 (homogeneous clip space) への変換では gluPerspective を、同次クリップ空間から正規デバイス空間の変換では glViewport を利用して変換行列が計算され、二つの行列の積が GL_PROJECTION に設定される。これらの行列の詳細を知らなくても本プロジェクトは理解できる。
これに対して、図 1 の左側に示された変換で使われる変換行列は自分たちで管理する必要がある。モデル空間で表現されたモデル (メッシュとも呼ばれる) をワールド空間に変換する変換行列はモデル行列 (model matrix) と呼ばれる。同様に、ワールド空間から視線空間への変換行列はビュー行列 (view matrix) と呼ばれる。本プロジェクトでは、これら二つの行列の乗じて得られるモデルビュー行列 (model view matrix) が GL_MODELVIEW に設定される。
レンダリングパイプライン (およびそこで使われる座標空間) について詳しく学びたい場合は、Real Time Rendering の第二章または何らかのコンピューターグラフィックスの入門書を参照してほしい。
レンダリング
render メソッドはレンダリング時に設定が必要な OpenGL の状態を最初にセットアップする。その後 init_view メソッドで射影行列を初期化し、ユーザーとの対話を担当する Interaction クラスのインスタンスから読み取った値を使ってモデルビュー行列を設定する。Interaction クラスについては後述する。glClear で画面をクリアした後シーンにレンダリングを指示して、最後にグリッドをレンダリングする。
グリッドをレンダリングする前に OpenGL が提供するライティングの機能は無効化される。ライティングが無効のとき OpenGL は光源からの光の影響の計算を省くので、レンダリング結果は単色になる。こうすると、シーンと異なる見た目でグリッドを描画できる。最後に glFlush を呼び出して、バッファをフラッシュしてスクリーンにレンダリング結果を表示するようグラフィックスドライバに伝える。
# Viewer クラス
def render(self):
""" シーンのレンダーパス """
self.init_view()
glEnable(GL_LIGHTING)
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
# トラックボールの現在状態を使ってモデルビュー行列を組み立てる。
glMatrixMode(GL_MODELVIEW)
glPushMatrix()
glLoadIdentity()
loc = self.interaction.translation
glTranslated(loc[0], loc[1], loc[2])
glMultMatrixf(self.interaction.trackball.matrix)
# 現在のモデルビュー行列の逆行列を記録する。
currentModelView = numpy.array(glGetFloatv(GL_MODELVIEW_MATRIX))
self.modelView = numpy.transpose(currentModelView)
self.inverseModelView = inv(numpy.transpose(currentModelView))
# シーンをレンダリングする。シーンに含まれる各オブジェクトに対して
# render メソッドが呼ばれる。
self.scene.render()
# グリッドをレンダリングする
glDisable(GL_LIGHTING)
glCallList(G_OBJ_PLANE)
glPopMatrix()
# バッファをフラッシュしてシーンを表示させる。
glFlush()
def init_view(self):
""" 射影行列を初期化する。 """
xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT)
aspect_ratio = float(xSize) / float(ySize)
# 射影行列を読み込む (いつでも同じ)
glMatrixMode(GL_PROJECTION)
glLoadIdentity()
glViewport(0, 0, xSize, ySize)
gluPerspective(70, aspect_ratio, 0.1, 1000.0)
glTranslated(0, 0, -15)
レンダリングするもの: Scene クラス
ワールド座標空間で描画を行うためのレンダリングパイプラインが以上で初期化できた。では、何をレンダリングするのだろうか? 私たちの目標は 3D モデルからなる設計を作成することだった。この設計を表現するデータ構造が必要であり、そのデータ構造は設計のレンダリングを可能にしなければならない。上記のコードでは Viewer のレンダリングループが self.secne.render() を呼び出している。この self.scene とは何だろうか?
Scene クラスは本プロジェクトで設計を表現するのに用いるデータ構造に対するインターフェースである。このクラスはデータ構造の詳細を抽象化し、設計との対話で必要となるインターフェース関数 (例えばレンダリング、アイテムの追加、アイテムの編集) を公開する。Viewer は Scene オブジェクトを一つだけ保持する。この Scene オブジェクトはシーン内の全アイテムのリスト node_list を持ち、選択されたアイテムも記憶する。Scene クラスの render メソッドは node_list の各要素に対して render を呼び出すことしかしない。
class Scene(object):
# 新しく配置されるオブジェクトとカメラの距離
PLACE_DEPTH = 15.0
def __init__(self):
# 表示されるノードのリストを保持する。
self.node_list = list()
# 選択中のノードを記録する。
# 選択中のノードがあるかどうかで操作の動作を変えられる。
self.selected_node = None
def add_node(self, node):
""" シーンに新しいノードを追加する。 """
self.node_list.append(node)
def render(self):
""" シーンをレンダリングする。 """
for node in self.node_list:
node.render()
Node クラス
Scene クラスの render メソッドは、Sceneが持つ node_list の各要素に対して render を呼び出す。この要素とは何なのだろうか? 各要素はノード (node) と呼ばれる。概念的には、シーンに配置できる任意のものをノードと呼ぶ。オブジェクト指向ソフトウェアでは、Node を抽象基底クラスとして用いることがよくある。シーンに追加できるオブジェクトを表現する任意のクラスを Node から派生させる手法である。このように基底クラスを利用すると、シーンに対して抽象的な操作が可能になる。コードベースの他の部分は表示されるオブジェクトの詳細を知る必要がない: ただ Node クラスの子クラスだと知っておくだけで処理を記述できる。
Node の子クラスは自身のレンダリング方法およびその他の対話における振る舞いを定義する。Node 自身が持つ重要なデータもある: 移動行列、拡大行列、色などのデータは Node が持つ。ノードの移動行列に拡大行列を乗じると、ノードのモデル座標空間からワールド座標空間への変換行列が得られる。また、Node にはモデルの AABB (axis-aligned bounding box, 軸平行境界ボックス) も格納される。AABB についてはモデルの選択を議論するとき詳しく説明する。
Node クラスの最も単純な具象実装は Primitive クラスである。このクラスはシーンに追加可能な単一の形状を表す。本プロジェクトでは Cube や Sphere といった Primitive が存在する。
class Node(object):
""" シーンに追加可能な要素に対する基底クラス """
def __init__(self):
self.color_index = random.randint(color.MIN_COLOR, color.MAX_COLOR)
self.aabb = AABB([0.0, 0.0, 0.0], [0.5, 0.5, 0.5])
self.translation_matrix = numpy.identity(4)
self.scaling_matrix = numpy.identity(4)
self.selected = False
def render(self):
""" この要素をレンダリングする。 """
glPushMatrix()
glMultMatrixf(numpy.transpose(self.translation_matrix))
glMultMatrixf(self.scaling_matrix)
cur_color = color.COLORS[self.color_index]
glColor3f(cur_color[0], cur_color[1], cur_color[2])
if self.selected: # 選択中のノードを光らせる。
glMaterialfv(GL_FRONT, GL_EMISSION, [0.3, 0.3, 0.3])
self.render_self()
if self.selected:
glMaterialfv(GL_FRONT, GL_EMISSION, [0.0, 0.0, 0.0])
glPopMatrix()
def render_self(self):
raise NotImplementedError(
"The Abstract Node Class doesn't define 'render_self'")
class Primitive(Node):
def __init__(self):
super(Primitive, self).__init__()
self.call_list = None
def render_self(self):
glCallList(self.call_list)
class Sphere(Primitive):
""" 球プリミティブ """
def __init__(self):
super(Sphere, self).__init__()
self.call_list = G_OBJ_SPHERE
class Cube(Primitive):
""" 立方体プリミティブ """
def __init__(self):
super(Cube, self).__init__()
self.call_list = G_OBJ_CUBE
ノードのレンダリングでは各ノードが持つ変換行列が利用される。この変換行列は拡大行列と移動行列の積である。どんな種類のノードであっても、モデル座標空間をビュー座標空間に変換するモデルビュー行列を OpenGL に伝えることがレンダリングの最初のステップとなる。OpenGL に更新された行列を設定したら render_self メソッドを呼び出し、必要な OpenGL 関数を使ったレンダリングを実行させる。最後に、処理中のノードが変更した OpenGL 状態を元に戻す。ノードのレンダリングで使うモデルビュー行列の更新と破棄には OpenGL 関数 glPushMatrix と glPopMatrix が利用される。ノードには色・位置・拡大率が保存され、これらの値がレンダリング開始前に OpenGL 状態に設定される点にも注目してほしい。
選択中のノードを光らせる設定も render メソッドには含まれる。こうすることで、ユーザーは自身が選択したノードを視覚的に確認できる。
プリミティブのレンダリングでは、コールリスト (call list) と呼ばれる OpenGL の機能が利用される。コールリストとは、いくつかの OpenGL 関数の呼び出しを一つにまとめて名前を付けたものを言う。まとめられた呼び出しは glCallList(LIST_NAME) で一度に実行できる。それぞれのプリミティブ (Sphere と Cube) は自身のレンダリングに必要なコールリストを定義する (ここには示されていない)。
例えば、Cube クラスが持つコールリストは立方体の 6 個の面をレンダリングする。中心が原点で、各辺の長さは 1 である:
# Cube の定義の疑似コード
# 左面
((-0.5, -0.5, -0.5), (-0.5, -0.5, 0.5), (-0.5, 0.5, 0.5), (-0.5, 0.5, -0.5)),
# 背面
((-0.5, -0.5, -0.5), (-0.5, 0.5, -0.5), (0.5, 0.5, -0.5), (0.5, -0.5, -0.5)),
# 右面
((0.5, -0.5, -0.5), (0.5, 0.5, -0.5), (0.5, 0.5, 0.5), (0.5, -0.5, 0.5)),
# 前面
((-0.5, -0.5, 0.5), (0.5, -0.5, 0.5), (0.5, 0.5, 0.5), (-0.5, 0.5, 0.5)),
# 底面
((-0.5, -0.5, 0.5), (-0.5, -0.5, -0.5), (0.5, -0.5, -0.5), (0.5, -0.5, 0.5)),
# 上面
((-0.5, 0.5, -0.5), (-0.5, 0.5, 0.5), (0.5, 0.5, 0.5), (0.5, 0.5, -0.5))
こういったプリミティブしか使えないとしたら、モデリングアプリケーションの機能は非常に限られたものになるだろう。典型的な 3D モデルにはいくつものプリミティブが含まれる (プリミティブだけではなく三角メッシュも含まれるが、本プロジェクトでは三角メッシュを扱わない)。幸い、Node クラスの設計のおかげで、複数のプリミティブから構成されるノードを Scene に追加するのは難しくない。実は、ノードの自由なグループ化をサポートしたとしても複雑性は増加しない。
この機能の必要性を理解するために、とても簡単なモデルを考えよう: 三つの球からなる [欧米で] 典型的な雪だるまのモデルを作りたいとする。このモデルは三つの球プリミティブから構成されるものの、全体を一つのオブジェクトとして扱えるのが望ましい。
こういった状況で利用されるのが HierarchicalNode クラスである。このクラスは Node を継承し、自身の「子」からなるリストを管理する。HierarchicalNode の render_self メソッドは自分の子に対して render_self メソッドを呼び出す。このクラスがあると、シーンへのモデルの追加が非常に簡単になる。雪だるまのモデルを表す SnowFigure クラスの定義は、それを構成するモデルとその位置・サイズを指定するだけで完了する。
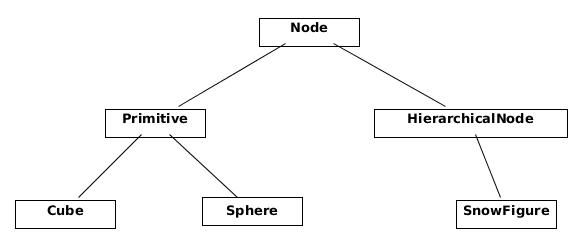
Node を継承するクラスの関係
class HierarchicalNode(Node):
def __init__(self):
super(HierarchicalNode, self).__init__()
self.child_nodes = []
def render_self(self):
for child in self.child_nodes:
child.render()
class SnowFigure(HierarchicalNode):
def __init__(self):
super(SnowFigure, self).__init__()
self.child_nodes = [Sphere(), Sphere(), Sphere()]
self.child_nodes[0].translate(0, -0.6, 0) # scale 1.0
self.child_nodes[1].translate(0, 0.1, 0)
self.child_nodes[1].scaling_matrix = numpy.dot(
self.scaling_matrix, scaling([0.8, 0.8, 0.8]))
self.child_nodes[2].translate(0, 0.75, 0)
self.child_nodes[2].scaling_matrix = numpy.dot(
self.scaling_matrix, scaling([0.7, 0.7, 0.7]))
for child_node in self.child_nodes:
child_node.color_index = color.MIN_COLOR
self.aabb = AABB([0.0, 0.0, 0.0], [0.5, 1.1, 0.5])
HierarchicalNode があると Node オブジェクトが木構造を構築できることに気が付いたかもしれない。render メソッドを呼び出すと、この木構造に対する深さ優先探索が実行される。この探索の中でモデルビュー行列のスタックが管理され、ワールド空間への変換に利用される。各ステップはモデルビュー行列の初期値をスタックに積み、自身の子ノードのレンダリングが完了するとスタックからモデルビュー行列を取り除く。このためノードのレンダリングは自身の親ノードのモデルビュー行列がスタックの頂上にある (最初と同じ) 状態で終了する。
こうして Node クラスを拡張可能にしておけば、新しい種類の形状を追加するときにシーンの操作やレンダリングに関するコードに変更が一切必要にならない。ノードという概念による抽象化を通して Scene オブジェクトが多くの子を持てる事実を隠蔽するデザインパターンは Composite と呼ばれる。
ユーザーとの対話
シーンの表現と描画が可能になったので、続いてシーンと対話する仕組みを考えよう。サポートが必要な対話は二種類ある。まず、シーンを描画するときの視点を変更できる必要がある。「目」あるいは「カメラ」をシーンの中で移動できなければならない。次に、シーンに新しいノードの追加する機能、そして既存のノードを編集する機能が必要になる。
ユーザーと対話するには、ユーザーがキー入力やマウス操作を行った瞬間を知る必要がある。幸い、こういったイベントの発生は OS によって捕捉され、GLUT を使えば特定のイベントが発生したときに呼び出される関数を登録できる。よってプログラマーはキー入力とマウス操作を解釈する関数を書き、対応するイベントが発生したときその関数を呼び出すよう GLUT に指示すればよい。ユーザーが入力したキーが分かれば、ユーザーが意図した操作をシーンに対して実行できる。
OS イベントに対するリッスンや OS イベントの解釈に関するロジックは Interaction クラスに含まれる。先述した Viewer クラスは Interaction クラスのインスタンスを一つ保持する。GLUT が提供するコールバックの仕組みを利用して、マウスボタンが押されたとき (glutMouseFunc)、マウスが移動したとき (glutMotionFunc)、キーが押されたとき (glutKeyboardFunc)、矢印キーが押されたとき (glutSpecialFunc) に呼び出される関数が登録される。登録される関数の詳細は後述する。
class Interaction(object):
def __init__(self):
""" ユーザーとの対話を管理する。 """
# 現在入力されているマウスボタン
self.pressed = None
# カメラの現在位置
self.translation = [0, 0, 0, 0]
# 回転を計算するためのトラックボール
self.trackball = trackball.Trackball(theta = -25, distance=15)
# マウスの現在位置
self.mouse_loc = None
# あまり高度でないコールバックの仕組み
self.callbacks = defaultdict(list)
self.register()
def register(self):
""" GLUT を使ってコールバックを登録する。 """
glutMouseFunc(self.handle_mouse_button)
glutMotionFunc(self.handle_mouse_move)
glutKeyboardFunc(self.handle_keystroke)
glutSpecialFunc(self.handle_keystroke)
OS イベントに対するコールバック
ユーザーからの入力を意味ある形で解釈するには、マウス位置、マウスボタン、キーボードから得られる情報を組み合わせる必要がある。ユーザーからの入力を実行可能な操作へと変換するには多くのコードが必要になるので、個別のクラスに分けてメインのコードパスから分離する。Interaction クラスは OS レベルのイベントをアプリケーションレベルのイベントに変換する処理を担当し、関係が薄い複雑性をコードベースの他の部分から切り離す。
# Interaction クラス
def translate(self, x, y, z):
""" カメラを移動する。 """
self.translation[0] += x
self.translation[1] += y
self.translation[2] += z
def handle_mouse_button(self, button, mode, x, y):
""" マウスボタンが押されたとき、および離されたときに呼び出される。 """
xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT)
y = ySize - y # OpenGL の y 軸は反転しているので変換する。
self.mouse_loc = (x, y)
if mode == GLUT_DOWN:
self.pressed = button
if button == GLUT_RIGHT_BUTTON:
pass
elif button == GLUT_LEFT_BUTTON: # 選択
self.trigger('pick', x, y)
elif button == 3: # マウスホイールの上回転
self.translate(0, 0, 1.0)
elif button == 4: # マウスホイールの下回転
self.translate(0, 0, -1.0)
else: # マウスボタン
self.pressed = None
glutPostRedisplay()
def handle_mouse_move(self, x, screen_y):
""" マウスが移動したときに呼び出される。 """
xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT)
y = ySize - screen_y # OpenGL の y 軸は反転しているので変換する。
if self.pressed is not None:
dx = x - self.mouse_loc[0]
dy = y - self.mouse_loc[1]
if self.pressed == GLUT_RIGHT_BUTTON and self.trackball is not None:
# 回転は必ず原点中心なので、 更新されたカメラ位置を無視する。
self.trackball.drag_to(self.mouse_loc[0], self.mouse_loc[1], dx, dy)
elif self.pressed == GLUT_LEFT_BUTTON:
self.trigger('move', x, y)
elif self.pressed == GLUT_MIDDLE_BUTTON:
self.translate(dx/60.0, dy/60.0, 0)
else:
pass
glutPostRedisplay()
self.mouse_loc = (x, y)
def handle_keystroke(self, key, x, screen_y):
""" キーが入力されたときに呼び出される。 """
xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT)
y = ySize - screen_y
if key == 's':
self.trigger('place', 'sphere', x, y)
elif key == 'c':
self.trigger('place', 'cube', x, y)
elif key == GLUT_KEY_UP:
self.trigger('scale', up=True)
elif key == GLUT_KEY_DOWN:
self.trigger('scale', up=False)
elif key == GLUT_KEY_LEFT:
self.trigger('rotate_color', forward=True)
elif key == GLUT_KEY_RIGHT:
self.trigger('rotate_color', forward=False)
glutPostRedisplay()
内部コールバック
上記のコードを見ると、Interaction はユーザーからの入力を変換した後、アプリケーションが行うべき操作の種類を表した文字列を引数として self.trigger を呼び出しているのが分かる。Interaction クラスの trigger メソッドはアプリケーションレベルのイベントを処理するのに利用される単純なコールバックシステムの一部である。以前に示した Viewer クラスの init_interaction メソッドで、register_callback を呼び出して Interaction インスタンスにコールバックを登録していたことを思い出してほしい:
# Interaction クラス
def register_callback(self, name, func):
self.callbacks[name].append(func)
ユーザーインターフェースのコードがシーンに対するイベントを発火させると、そのイベントに対して登録された全てのコールバックを Interaction クラスが呼び出す:
# Interaction クラス
def trigger(self, name, *args, **kwargs):
for func in self.callbacks[name]:
func(*args, **kwargs)
アプリケーションレベルのコールバックシステムは OS からの入力を抽象化することで、他の部分のコードが OS からの入力を直接扱わないようにする。それぞれのコールバックはアプリケーションレベルの何らかのリクエストを表す。Interaction クラスは OS レベルのイベントからアプリケーションレベルのイベントへの翻訳者として振る舞う。このため、このモデラーを後に GLUT 以外のツールキットへ移植することになったとしても、変更が必要となるのは Interaction クラスだけとなる。新しいツールキットからの入力を以前と同じアプリケーションレベルのコールバックに対応付ければ残りの部分は正しく動作する。本アプリケーションで定義されるコールバックを次の表に示す。
| コールバック | 引数 | 用途 |
|---|---|---|
pick |
x: number, y: number |
マウスポインタの位置にあるノードを選択する。 |
move |
x: number, y: number |
選択中のノードをマウスポインタの位置に移動させる。 |
place |
shape:string, x:number, y:number |
指定された種類の形状をマウスポインタの位置に配置する。 |
rotate_color |
forward:boolean |
選択中のノードの色を変更する。色のリストで次または後の色が選択される。 |
scale |
up:boolean |
選択中のオブジェクトを拡大または縮小する。 |
この単純なコールバックシステムが本プロジェクトで必要な機能を全て提供する。しかしプロダクションの 3D モデラーでは、ユーザーインターフェースに対応するオブジェクトが動的に作成・破棄される。その場合は、イベントに対するリッスンの仕組みをここに示したものより高度にする必要がある。具体的には、オブジェクトがイベントに対するコールバックの登録と登録解除を両方行える必要がある。
シーンのインターフェース
上記のコールバックの仕組みがあれば、ユーザーの入力イベントに関する情報を Interaction クラスから受け取ることができる。ユーザーが意図した操作を Scene に適用する準備がこれで整った。
シーンの移動
本プロジェクトではカメラの移動をシーンに適用する変換行列を変更することで実現する。言い換えれば、カメラは特定の位置に固定され、ユーザーからの入力はカメラではなくシーンを移動させる。カメラの位置は常に [0, 0, -15] であり、ワールド空間の原点を向く (異なる選択肢として、射影行列を変更するようにすればシーンではなくカメラを移動させることができる。どちらの設計を採用するかはプロジェクトの他の部分にほとんど影響を与えない)。Viewer クラスの render メソッドを見返すと、Interaction クラスのインスタンスが持つ状態を使用して OpenGL の行列を変形してから Scene のレンダリングに移っているのが分かる。Scene に対する操作は二種類ある: 回転と移動である。
トラックボールを使ったシーンの回転
シーンの回転はトラックボール (trackball) と呼ばれるアルゴリズムを使って実装する。トラックボールは三次元空間内に存在するシーンを操作するための直感的なインターフェースとして知られている。シーンを囲む透明な球を用意して、その球に手を置いて回転させることでシーン全体を回転させるというのがトラックボールというインターフェースの基本的な考え方である。これと同じ要領で、画面に表示されたトラックボールを右クリックしてドラッグするとシーンが回転する。詳しい理論は OpenGL Wiki から確認できる。本プロジェクトでは Glumpy に含まれるトラックボールの実装を利用する。
トラックボールとの対話は drag_to メソッドを通して行う。マウスの現在位置と、ドラッグの開始位置からの差が引数として渡される:
self.trackball.drag_to(self.mouse_loc[0], self.mouse_loc[1], dx, dy)
この呼び出しによって行列 trackball.matrix が計算される。この計算結果は Viewer がシーンをレンダリングするときに利用される。
余談: クオータニオン
よく知られた回転の表現方法が二つある。一つは各軸周りの回転角を用いるもので、それぞれの軸に関する回転角からなる浮動小数点数の三要素タプルとして格納される。もう一つの、より一般的な回転の表現はクオータニオン (quaternion) と呼ばれる。クオータニオンは四つの実数 \(x\), \(y\), \(z\), \(w\) から構成されるベクトルであり、軸ごとの回転角を使った表現が持たない優れた特徴を多く持つ。例えば、クオータニオンの方が数値的な安定性が高く、ジンバルロック (gimbal lock) などの問題はクオータニオンでは発生しない。クオータニオンの欠点としては、概念が直感的ではなく理解するのが難しいことがある。そんなクオータニオンをもっと学びたいという勇気ある読者にはこの記事を勧める。
本プロジェクトで利用するトラックボールの実装はシーンの回転を内部で表すのにクオータニオンを利用することでジンバルロックを回避する。幸い、トラックボールオブジェクトの matrix メンバーを参照すれば回転を行列として取得できるので、私たちがクオータニオンを扱う必要はない。
シーンの移動
シーンを移動 (スライド) させる処理は回転よりずっと簡単に実装できる。シーンの移動は左マウスボタンのドラッグまたはマウスホイールの回転によって実行される。左マウスボタンのドラッグはシーンの \(x\) 座標と \(y\) 座標のみを変更し、マウスホイールの回転は \(z\) 座標 (カメラから見た距離) だけを変更する。Interaction クラスがシーンの現在位置を記録し、それを translate メソッドで変更する。Viewer クラスはレンダリング時に Interaction インスタンスからカメラ位置を取得し、その情報を使って glTranslated 関数を呼び出す。
シーンオブジェクトの選択
これでシーンを移動・回転させて自由に視点を設定できるようになった。次のステップとして、シーンを構成するオブジェクトをユーザーが変更・操作する機能を追加しよう。
シーン内のオブジェクトをユーザーが操作可能とするには、まずユーザーがオブジェクトを選択できる必要がある。
オブジェクトの選択では、現在の射影行列を利用してマウスクリックを表すレイが作成される (マウスポインタがシーンに向けて光線を放つ様子を想像してほしい)。このレイと交わるオブジェクトの中で最もカメラに近いものがユーザーの意図する選択対象である。よってオブジェクトを選択する問題はレイとオブジェクトの交差を判定する問題に帰着された。では、どうすればレイとオブジェクトが交わるかどうかを判定できるだろうか?
レイとオブジェクトの正確な交差判定はコード量的にも計算量的にも難易度の高い問題である。普通に実装すると、レイとの交差を判定するメソッドが全てのプリミティブに必要になる。さらに、多くの面を持つ複雑なメッシュに対しては全ての面を一つずつ試すしかないので、計算に時間がかかる。
コードをコンパクトに保ちつつパフォーマンスの低下を防ぐために、本プロジェクトでは単純で高速な近似を使ってレイとオブジェクトの交差判定を行う。各ノードに自身のオブジェクトが占める空間を近似した AABB (axis-aligned bounding box, 軸平行境界ボックス) を持たせ、この AABB とレイの交差判定でレイとオブジェクトの交差判定を近似する。このように実装すると、どんな種類のノードであっても接触判定のコードが同じになり、パフォーマンスに対する影響も小さい定数となる。
# Viewer クラス
def get_ray(self, x, y):
"""
始点が near 平面上にあり、スクリーン座標 (x, y) を向いたレイを返す。
入力: スクリーン上のマウスの位置 (x, y)
出力: レイの始点と方向
"""
self.init_view()
glMatrixMode(GL_MODELVIEW)
glLoadIdentity()
# レイが通る二点を計算する。
start = numpy.array(gluUnProject(x, y, 0.001))
end = numpy.array(gluUnProject(x, y, 0.999))
# 計算された二点からレイを計算する。
direction = end - start
direction = direction / norm(direction)
return (start, direction)
def pick(self, x, y):
""" シーン内のオブジェクトを選択する。 """
start, direction = self.get_ray(x, y)
self.scene.pick(start, direction, self.modelView)
クリックされたオブジェクトを見つけるために、シーンを走査して各ノードがレイと交差するかどうかを判定する。交差する点が最もレイの始点に近いオブジェクトを持つノードが選択され、現在選択されているノードを置き換える。
# Scene クラス
def pick(self, start, direction, mat):
"""
オブジェクトを選択する。
start と direction はレイを表す。
mat は現在のシーンに対するモデルビュー行列の逆行列を表す。
"""
if self.selected_node is not None:
self.selected_node.select(False)
self.selected_node = None
# 最も近い交点を記録する。
mindist = sys.maxint
closest_node = None
for node in self.node_list:
hit, distance = node.pick(start, direction, mat)
if hit and distance < mindist:
mindist, closest_node = distance, node
# レイが何かに当たっていたら、それを選択する。
if closest_node is not None:
closest_node.select()
closest_node.depth = mindist
closest_node.selected_loc = start + direction * mindist
self.selected_node = closest_node
Node クラスの pick 関数は自身の AABB がレイと交差するかどうかを判定する。ノードが選択されたときは select メソッドが呼び出され、対応する状態が変更される。AABB を表すクラスの ray_hit メソッドは AABB の座標空間からレイの座標空間に変換する変換行列を第三引数に受け取る点に注目してほしい。各ノードは自身の変換行列を引数に受け取った行列に乗じてから self.aabb.ray_hit メソッドを呼び出す。
# Node クラス
def pick(self, start, direction, mat):
"""
レイがオブジェクトと交差するかどうかを返す。
引数:
start, direction: 交差を判定するレイ
mat: レイを変換するモデルビュー行列
"""
# このノードの位置・拡大率でモデルビュー行列を変形する。
newmat = numpy.dot(
numpy.dot(mat, self.translation_matrix),
numpy.linalg.inv(self.scaling_matrix)
)
results = self.aabb.ray_hit(start, direction, newmat)
return results
def select(self, select=None):
""" 選択されているかどうかの状態を切り替える。 """
if select is not None:
self.selected = select
else:
self.selected = not self.selected
レイと AABB の交差判定を用いる以上のアプローチは非常に単純に理解・実装できる。ただし、間違った結果が得られる状況が存在する。

例えば、Sphere プリミティブの AABB は球オブジェクトと各面の中央でしか接しない。そのためユーザーのクリック地点が Sphere の AABB の端だと、ユーザーが意図していないであろう離れた位置にある Sphere との交差が検出されてしまう (図 3)。
こういった複雑性・正確性・性能のトレードオフはコンピューターグラフィックス以外にもソフトウェアエンジニアリングの様々な場面で現れる。
シーンオブジェクトの編集
続いて、選択したノードを編集する機能を追加する。ユーザーは選択したノードの移動・リサイズ・色の変更を行うとする。ユーザーがノードを編集するコマンドを入力すると、Interaction クラスが入力をユーザーの意図した操作に変換し、対応するコールバックを呼び出す。
ノード編集操作を指示するイベントに対するコールバックを受け取った Viewer は、Scene クラスの適切なメソッドを呼び出す。そのメソッドでは選択中の Node またはシーン全体に対する操作が適用される。
# Viewer クラス
def move(self, x, y):
""" シーンに対して move コマンドを実行する。 """
start, direction = self.get_ray(x, y)
self.scene.move_selected(start, direction, self.inverseModelView)
def rotate_color(self, forward):
"""
選択中のノードの色を次の色または前の色に変更する。
引数 forward は次の色にするか前の色にするかを表す。
"""
self.scene.rotate_selected_color(forward)
def scale(self, up):
""" 選択中のノードを拡大する。 """
self.scene.scale_selected(up)
色の変更
色の編集は事前に用意された色のリストを使って行われる。ユーザーは矢印キーを使って色を環状に選択できる。Scene は色の変更コマンドを選択中のノードにディスパッチする。
# Scene クラス
def rotate_selected_color(self, forwards):
""" 選択中のノードの色を次または前の色にする。 """
if self.selected_node is None: return
self.selected_node.rotate_color(forwards)
各ノードは自身の色を保持し、色の変更は rotate_color メソッドで行う。この色はレンダリング時に glColor 関数を通じて OpenGL に渡される。
# Node クラス
def rotate_color(self, forwards):
self.color_index += 1 if forwards else -1
if self.color_index > color.MAX_COLOR:
self.color_index = color.MIN_COLOR
if self.color_index < color.MIN_COLOR:
self.color_index = color.MAX_COLOR
Node の拡大
色の変更と同様に、Scene クラスは選択中のノードに拡大率変更の操作をディスパッチする。選択中のノードが存在しなければ何もしない。
# Scene クラス
def scale_selected(self, up):
""" 選択中のノードを拡大する。 """
if self.selected_node is None: return
self.selected_node.scale(up)
各ノードは現在の拡大率を記録する行列を持つ。\(x\) 軸、\(y\) 軸、\(z\) 軸方向に沿ったそれぞれ \(x\) 倍, \(y\) 倍, \(z\) 倍の拡大を表す行列は次の式で表される:
ノードの拡大率をユーザーが編集すると、ノードが持つ拡大行列に定数の拡大行列が乗じられる:
# Node クラス
def scale(self, up):
s = 1.1 if up else 0.9
self.scaling_matrix = numpy.dot(self.scaling_matrix, scaling([s, s, s]))
self.aabb.scale(s)
scaling 関数は \(x\) 軸、\(y\) 軸、\(z\) 軸に沿った拡大率を受け取り、対応する拡大行列を返す:
def scaling(scale):
s = numpy.identity(4)
s[0, 0] = scale[0]
s[1, 1] = scale[1]
s[2, 2] = scale[2]
s[3, 3] = 1
return s
ノードの移動
ノードの移動では、ノードを選択する処理と同様のレイの計算が行われる。現在のマウス位置に対応するレイが Scene クラスの move メソッドに渡され、このレイ上の点がノードの新しい位置として計算される。レイ上のどの点が新しい位置かを決定するために、カメラとノードの距離が利用される。ノードの位置とカメラからの距離はノードを選択するとき (pick メソッド) で記憶しているので、計算する必要はない。ノードが選択されたときのカメラとの距離と同じだけレイに沿って進んだ点が新しいノードの位置となる。最後に新しい位置から移動ベクトルを計算してノードを移動させる。
# Scene クラス
def move_selected(self, start, direction, inv_modelview):
"""
選択中のノードを移動させる。ノードを選択していなければ何もしない。
引数:
start, direction: ノードの移動を拘束するレイ
inv_modelview: シーンのモデルビュー行列の逆行列
"""
if self.selected_node is None: return
# 選択されたノードのカメラとの距離、および現在位置を取得する。
node = self.selected_node
depth = node.depth
oldloc = node.selected_loc
# 引数のレイに沿って depth だけ進んだ点がノードの新しい位置となる。
newloc = (start + direction * depth)
# モデルビュー行列の逆行列を使って translation を変形する。
translation = newloc - oldloc
pre_tran = numpy.array([translation[0], translation[1], translation[2], 0])
translation = inv_modelview.dot(pre_tran)
# ノードを移動させ、新しい位置を記録する。
node.translate(translation[0], translation[1], translation[2])
node.selected_loc = newloc
元々の位置 oldloc と新しい位置 newloc がカメラ座標空間で定義されていることに注意してほしい。移動はワールド座標空間で計算する必要があるので、カメラ座標空間で表された移動にモデルビュー行列の逆行列を乗じている。
拡大率と同様に、各ノードは移動を表す行列を保持する。移動行列は次の形をしている:
ノードを移動させるには、その移動を表す移動行列を作成し、それを現在ノードが持つ移動行列に乗じてレンダリング時に使われる移動行列を作成する:
# Node クラス
def translate(self, x, y, z):
self.translation_matrix = numpy.dot(
self.translation_matrix,
translation([x, y, z]))
translation 関数は移動行列を返す関数であり、引数として \(x\) 軸、\(y\) 軸、\(z\) 軸に沿った移動距離を受け取る:
def translation(displacement):
t = numpy.identity(4)
t[0, 3] = displacement[0]
t[1, 3] = displacement[1]
t[2, 3] = displacement[2]
return t
ノードの配置
新しいノードを配置する処理では、ノードの選択で使ったテクニックとノードの移動で使ったテクニックの両方が利用される。配置場所の計算では、マウス位置に対応するレイが利用される:
# Viewer クラス
def place(self, shape, x, y):
""" 新しいプリミティブをシーンに配置する。 """
start, direction = self.get_ray(x, y)
self.scene.place(shape, start, direction, self.inverseModelView)
新しいノードを配置するには、まずノードの種類に対応するクラスの新しいインスタンスを作成してシーンに追加する。ノードの配置場所はユーザーのマウスがある場所であり、それはレイ上の点に対応する。後はカメラからの距離を固定すれば単一の点が計算できる。ここでもレイはカメラ座標空間で表されるので、計算された配置場所をワールド座標空間で表すにはモデルビュー行列の逆行列による乗算が必要になる。最終的に計算された点に新しいノードを移動させれば処理が完了する。
# Scene クラス
def place(self, shape, start, direction, inv_modelview):
"""
新しいノードを配置する。
引数:
shape: 追加する形状を表す文字列
start, direction: 配置場所を拘束するレイ
inv_modelview: シーンのモデルビュー行列の逆行列
"""
new_node = None
if shape == 'sphere': new_node = Sphere()
elif shape == 'cube': new_node = Cube()
elif shape == 'figure': new_node = SnowFigure()
self.add_node(new_node)
# カーソル位置に対応するレイからカメラ座標空間における配置場所を計算する。
translation = (start + direction * self.PLACE_DEPTH)
# translation をワールド座標空間に変換する。
pre_tran = numpy.array([translation[0], translation[1], translation[2], 1])
translation = inv_modelview.dot(pre_tran)
new_node.translate(translation[0], translation[1], translation[2])
13.3 まとめ
おめでとう! これで小さな 3D モデラーを実装できた!

本章では、シーン内のオブジェクトを表現する拡張可能なデータ構造を作成する方法を見た。Composite と呼ばれるデザインパターンと木構造のデータ構造を利用するとレンダリング時に必要なシーンの走査が簡単になり、複雑性を加えることなく新しい種類のノードを追加できるようになる。このデータ構造を活用してユーザーが作成した設計を画面に表示し、シーングラフを走査しながら OpenGL 行列を操作した。アプリケーションレベルのイベントを処理する非常に簡単なコールバックシステムを作成し、OS レベルのイベント処理を隠蔽するのに利用した。レイとオブジェクトの交差判定の実装をいくつか議論し、それぞれの正確性・複雑性・性能のトレードオフを議論した。最後に、シーン内のオブジェクトを操作する処理を実装した。
こういった基礎的な構成単位はプロダクションの 3D ソフトウェアにも含まれている可能性が高い。シーングラフ構造と相対的な座標空間は CAD ツールやゲームエンジンといった様々な種類の 3D グラフィックスソフトウェアで用いられる。本プロジェクトではユーザーインターフェースを大きく単純化した。プロダクションの 3D モデラーが持つような完全なユーザーインターフェースでは、私たちが実装した単純なコールバックシステムよりも格段に高度なイベントシステムが必要になる。
さらなる実験として、本プロジェクトに新しい機能を追加することもできるだろう。次の処理を実装してみるとよい:
- 新しい
Node型を追加して、任意の形状を扱える三角メッシュをサポートする。 - 操作を要素とするスタックを追加して、モデラーの操作に対する「元に戻す」と「やり直す」を実装する。
- DXF などの 3D ファイルフォーマットを使った設計の保存と読み込みを実装する。
- レンダリングエンジンを統合する: 写実的なレンダラで利用できる形式で設計をエクスポートする。
- 交差判定処理を改善し、レイとオブジェクトの交差判定を正確にする。
13.4 さらなる探求
現実の 3D モデリングソフトウェアに関する洞察を得たい場合は、次のオープンソースソフトウェアに目を通すことを勧める。
Blender は完全な機能を持つオープンソースの 3D アニメーションスイートであり、映像作品やゲームで使用される特殊効果を作成するための完全な 3D パイプラインを提供する。モデラーは Blender の小さな部分でしかないので、モデラーを大規模なソフトウェアスイートに組み込む良い例となるだろう。
OpenSCAD はオープンソースの 3D モデリングツールである。OpenSCAD はインタラクティブではなく、シーンの生成方法を記したスクリプトファイルを読み込んで動作する。このため設計者には「モデリングプロセスに対する完全な制御」が提供される。
コンピューターグラフィックスに関するアルゴリズムやテクニックをさらに知りたい場合は Graphics Gems が優れたリソースである。
-
: この画像を作成した Anton Gerdelan 博士に感謝する。彼が執筆した OpenGL チュートリアルは http://antongerdelan.net/opengl/ で公開されている。 ↩︎