14. シンプルなオブジェクトモデル
14.1 はじめに
オブジェクト指向プログラミングは現在使われている中で最も有名なプログラミングパラダイムの一つであり、多くの言語が何らかの形でオブジェクト指向の仕組みを提供する。異なるオブジェクト指向プログラミング言語がプログラマーに提供する仕組みは一見すると非常によく似ていても、詳細は大きく異なる場合がある。ほとんどの言語はオブジェクトと継承の一種を持つのに対して、クラスに関しては直接サポートしない言語が少なくない。例えば Self や JavaScript といったプロトタイプベースの言語はクラスの概念を持たず、オブジェクトは他のオブジェクトを直接継承する。
異なるオブジェクトモデルの相違点は興味深い対象である。相違点を考えることで言語間の類似点が明らかになることがよくある。新しい言語と既存の言語の関係を整理する上でも有用であり、新しいモデルの理解が容易になるだけではなく、プログラミング言語の設計空間を捉える上でも役立つ。
本章ではいくつかの非常に単純なオブジェクトモデルの実装を示す。最初のモデルは単純なインスタンスとクラス、そしてインスタンスのメソッドを呼び出す機能を持つ。これは「伝統的」なオブジェクト指向のアプローチであり、Simula 67 や Smalltalk といった初期のオブジェクト指向言語によって採用された。以降では、このモデルを少しずつ拡張する。次の二つのステップでは異なる言語設計の選択肢を示し、最後のステップではオブジェクトモデルの最適化テクニックを一つ見る。最終的なモデルは実際の言語のモデルではないものの、Python のオブジェクトモデルを理想化・単純化したものである。
本章で示すオブジェクトモデルは Python で実装される。コードは Python 2.7 と Python 3.4 の両方で動作する。コードの振る舞いや背後の設計判断を理解しやすくするために、本章ではオブジェクトモデルに対するテストも示していく。テストは pytest または nose で実行できる。
プログラミング言語の実装に Python を用いるのは全く現実的ではない。「本物」の VM は C/C++ などの低レベル言語で実装され、高効率な実装の作成には途方もない量の細かなエンジニアリングが必要となる。しかし、実装に使う言語が単純であればそれだけ、私たちは実装の詳細に振り回されることなく実際の振る舞いの相違点に集中できるようになる。
14.2 メソッドベースモデル
最初に見るオブジェクトモデルは Smalltalk が採用するモデルを極限まで単純化したものである。Smalltalk はオブジェクト指向言語であり、1970 年代に Xerox PARC で Alan Key らのグループによって設計された。Smalltalk はオブジェクト指向プログラミングを広く知らしめ、現代のプログラミング言語まで生き残る様々な機能を初めて搭載した。Smalltalk の言語設計の中心的な考え方は「全てはオブジェクト」である。現在使われている言語の中で Smalltalk の最も直接的な後継と言えるのは Ruby である。Ruby は C 風の構文を採用しつつも、Smalltalk とよく似たオブジェクトモデルを持つ。
本節で考えるオブジェクトモデルはクラス、クラスのインスタンス、オブジェクトの属性を読み書きする機能、オブジェクトのメソッドを呼び出す機能、そしてクラスが他のクラスの子クラスとなる機能を持つ。この最初の時点からクラスは完全に通常のオブジェクトであり、それ自体が属性やメソッドを持てる。
用語について一つ注意: 本章では「インスタンス」を「クラスでないオブジェクト」の意味で用いる。
言語実装のようなプログラムを書くときは、実装する振る舞いを確認するテストから書き始めるのが優れたアプローチである。本章で示す全てのテストは二つの部分からなる。一つ目の部分は数個のクラスを定義・利用する通常の Python コードであり、近年ますます高度になっている Python のオブジェクトモデルの機能を利用する。二つ目の部分は通常の Python クラスではなく本章で実装するオブジェクトモデルを使ったテストであり、一つ目の部分と同じ振る舞いをテストする。
通常の Python クラスを使ったテストと自分で実装したオブジェクトモデルを使ったテストの対応付けは手動で行われる。例えば、Python クラスを使った obj.attribute というコードには、独自のオブジェクトモデルを使った obj.read_attr("attribute") というコードが対応する。現実の言語実装では、こういった対応付けは言語のインタープリタまたはコンパイラによって行われる。
本章ではさらに、オブジェクトモデルを実装するコードとオブジェクトが持つメソッドを実装するコードを厳密に区別しない。現実のシステムでは、これら二つの部分は異なるプログラミング言語で実装されることが多い。
オブジェクトのフィールドを読み書きする簡単なテストから始めよう:
def test_read_write_field():
# Python を使ったコード
class A(object):
pass
obj = A()
obj.a = 1
assert obj.a == 1
obj.b = 5
assert obj.a == 1
assert obj.b == 5
obj.a = 2
assert obj.a == 2
assert obj.b == 5
# オブジェクトモデルを使ったコード
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("a", 1)
assert obj.read_attr("a") == 1
obj.write_attr("b", 5)
assert obj.read_attr("a") == 1
assert obj.read_attr("b") == 5
obj.write_attr("a", 2)
assert obj.read_attr("a") == 2
assert obj.read_attr("b") == 5
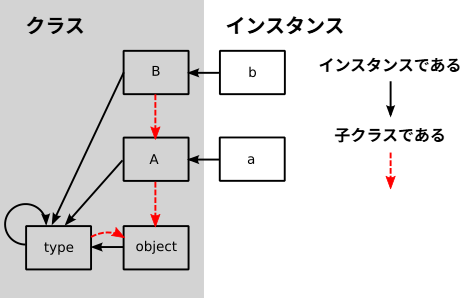
このテストでは、これから実装すべき三つの要素が使われている。Class クラスと Instance クラスは私たちのオブジェクトモデルにおけるクラスとインスタンスである。そして、OBJECT と TYPE はクラスの特別なインスタンスである。OBJECT は Python の object に対応し、継承階層の一番下に位置する基底クラスである。Type は Python の type に対応し、全てのクラスは Type 型を持つ。
Class と Instance のインスタンスに対する操作を提供するため、この二つのクラスはいくつかのメソッドを公開する共通の基底クラス Base を継承し、共通のインターフェースを実装する。
class Base(object):
""" オブジェクトモデルにおける全てのクラスが継承する基底クラス """
def __init__(self, cls, fields):
""" 全てのオブジェクトはクラスを持つ。 """
self.cls = cls
self._fields = fields
def read_attr(self, fieldname):
""" オブジェクトの属性を読み込む。 """
return self._read_dict(fieldname)
def write_attr(self, fieldname, value):
""" オブジェクトに属性を書き込む。 """
self._write_dict(fieldname, value)
def isinstance(self, cls):
""" オブジェクトがクラス cls のインスタンスなら True を返す。 """
return self.cls.issubclass(cls)
def callmethod(self, methname, *args):
""" args を引数として、オブジェクトのメソッド methname を呼び出す。 """
meth = self.cls._read_from_class(methname)
return meth(self, *args)
def _read_dict(self, fieldname):
""" オブジェクトが持つ辞書からフィールド fieldname を読み込む。 """
return self._fields.get(fieldname, MISSING)
def _write_dict(self, fieldname, value):
""" オブジェクトが持つ辞書にフィールド fieldname に書き込む。 """
self._fields[fieldname] = value
MISSING = object()
この Base クラスはオブジェクトに対するクラスの設定、そしてオブジェクトが持つフィールドの読み書きを実装する。
続いて Class と Instance を実装する必要がある。Instance のコンストラクタはインスタンス化するクラスを受け取り、field を空の辞書で初期化する。Instance は独自のコンストラクタを持つだけで、他には機能を追加しない非常に簡単な Base の子クラスである。
Class のコンストラクタはクラス名、基底クラス、フィールドを表す辞書、そしてメタクラスを受け取る。クラスでは、オブジェクトモデルのユーザーがフィールドをコンストラクタに提供する。Class のコンストラクタは基底クラスも受け取る。ここまでのテストで基底クラスは使われていないものの、次節で利用される。
class Instance(Base):
""" ユーザー定義クラスのインスタンス """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, {})
class Class(Base):
""" ユーザー定義クラス """
def __init__(self, name, base_class, fields, metaclass):
Base.__init__(self, metaclass, fields)
self.name = name
self.base_class = base_class
クラス自体もオブジェクトの一種なので、クラスは (間接的に) Base を継承する。そのため、クラスは何らかのクラスのインスタンスである必要がある: このクラスをメタクラス (metaclass) と呼ぶ。
先述のテストをパスさせるには、後は TYPE クラスと OBJECT クラスを定義すればよい。どちらのクラスも Class のインスタンスである。Smalltalk のモデルが持つメタクラスシステムは非常に複雑なので、この部分では Smalltalk と大きく異なる道を進む。私たちが採用するのは ObjVlisp1 と同様のモデルであり、このモデルは Python でも採用されている。
この ObjVlisp モデルでは、OBJECT と TYPE が互いに相手と結び付く。OBJECT は全てのクラスの基底クラスであり、従って OBJECT は基底クラスを持たない。TYPE は OBJECT の子クラスであり、デフォルトで全てのクラスは TYPE のインスタンスである。特に、TYPE と OBJECT は両方とも TYPE のインスタンスである。一方で、プログラマーが TYPE の子クラスとして新しいメタクラスを作成することもできる。
# Python と同様 (ObjVlisp モデル) のクラス階層をセットアップする。
# OBJECT は任意のクラスの基底クラス
OBJECT = Class(name="object", base_class=None, fields={}, metaclass=None)
# TYPE は Object の子クラス
TYPE = Class(name="type", base_class=OBJECT, fields={}, metaclass=None)
# TYPE は TYPE 自身のインスタンス
TYPE.cls = TYPE
# OBJECT は TYPE のインスタンス
OBJECT.cls = TYPE
新しいメタクラスを定義するには、TYPE の子クラスを作成すれば十分となる。ただ、本章でメタクラスを新たに定義することはなく、全てのクラスは TYPE をメタクラスに持つ。
これで最初のテストがパスするようになった。続いて、クラスに対しても属性の読み書きができることを確認するテストを書く。このテストを書くのは簡単で、パスさせるのに新しい実装は必要ない。
def test_read_write_field_class():
# クラスもオブジェクト
# Python を使ったコード
class A(object):
pass
A.a = 1
assert A.a == 1
A.a = 6
assert A.a == 6
# オブジェクトモデルを使ったコード
A = Class(name="A", base_class=OBJECT, fields={"a": 1}, metaclass=TYPE)
assert A.read_attr("a") == 1
A.write_attr("a", 5)
assert A.read_attr("a") == 5
isinstance による判定
オブジェクトがクラスを持つ事実はこれまで活用されてこなかった。続いて isinstance の仕組みを使うテストを実装しよう:
def test_isinstance():
# Python を使ったコード
class A(object):
pass
class B(A):
pass
b = B()
assert isinstance(b, B)
assert isinstance(b, A)
assert isinstance(b, object)
assert not isinstance(b, type)
# オブジェクトモデルを使ったコード
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
b = Instance(B)
assert b.isinstance(B)
assert b.isinstance(A)
assert b.isinstance(OBJECT)
assert not b.isinstance(TYPE)
オブジェクト obj が特定のクラス cls のインスタンスかどうかを判定するには、obj のクラスが cls の親クラスかどうかを判定すればよい。あるクラス A が別のクラス B の親クラスかどうかを判定するには、親クラスの鎖を B から OBJECT までたどればよい。この鎖の中に判定対象のクラス A が含まれているとき、かつそのときに限って、A は B の親クラスである。あるクラスの親クラスからなる鎖 (そのクラス自身を含む) を、そのクラスの「メソッド解決順序 (method resolution order)」と呼ぶ。メソッド解決順序は再帰を使って簡単に計算できる:
class Class(Base):
...
def method_resolution_order(self):
""" クラスのメソッド解決順序を計算する。 """
if self.base_class is None:
return [self]
else:
return [self] + self.base_class.method_resolution_order()
def issubclass(self, cls):
""" self は cls の子クラスか? """
return cls in self.method_resolution_order()
このコードがあれば、先述のテストはパスする。
メソッドの呼び出し
後はオブジェクトのメソッドを呼び出す機能を実装すれば、初期バージョンのオブジェクトモデルの機能が揃う。本章では単純な単一継承のモデルを実装する。
def test_callmethod_simple():
# Python を使ったコード
class A(object):
def f(self):
return self.x + 1
obj = A()
obj.x = 1
assert obj.f() == 2
class B(A):
pass
obj = B()
obj.x = 1
assert obj.f() == 2 # 子クラスからも呼び出せる。
# オブジェクトモデルを使ったコード
def f_A(self):
return self.read_attr("x") + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("f") == 2
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 2)
assert obj.callmethod("f") == 3
オブジェクトに対して呼び出されたメソッドの正しい実装を見つける処理では、オブジェクトのクラスのメソッド解決順序が走査される。順番にクラスを確認して、メソッドと同じ名前のフィールドを持つクラスが見つかったら、そのフィールドの値が呼び出すべき実装である:
class Class(Base):
...
def _read_from_class(self, methname):
for cls in self.method_resolution_order():
if methname in cls._fields:
return cls._fields[methname]
return MISSING
Base クラスには _read_from_class メソッドを使う callmethod メソッドを実装してあるので、これでテストはパスする。
引数を持ったメソッドを扱えること、そしてメソッドのオーバーライドが正しく実装されることを確認するために、上記のものより少しだけ複雑な次のテストを追加する。このテストは現在の実装のままでパスする。
def test_callmethod_subclassing_and_arguments():
# Python を使ったコード
class A(object):
def g(self, arg):
return self.x + arg
obj = A()
obj.x = 1
assert obj.g(4) == 5
class B(A):
def g(self, arg):
return self.x + arg * 2
obj = B()
obj.x = 4
assert obj.g(4) == 12
# オブジェクトモデルを使ったコード
def g_A(self, arg):
return self.read_attr("x") + arg
A = Class(name="A", base_class=OBJECT, fields={"g": g_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("g", 4) == 5
def g_B(self, arg):
return self.read_attr("x") + arg * 2
B = Class(name="B", base_class=A, fields={"g": g_B}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 4)
assert obj.callmethod("g", 4) == 12
14.3 属性ベースモデル
本章で扱う最も単純なオブジェクトモデルが以上で完成したので、次はこれを変更する方法を考えよう。本節ではメソッドベースモデルと属性ベースモデルの違いを見る。これは Smalltalk, Ruby, JavaScript などの言語と Python, Lua などの言語を分ける違いである。
メソッドベースモデルでは、メソッドの呼び出しがプログラム実行におけるプリミティブとなる:
result = obj.f(arg1, arg2)
属性ベースモデルでは、メソッドの呼び出しが「メソッドの名前を持った属性の値の取得」と「取得した値の呼び出し」という二つの操作に分かれる:
method = obj.f
result = method(arg1, arg2)
属性ベースモデルの振る舞いを確認するテストを示す:
def test_bound_method():
# Python を使ったコード
class A(object):
def f(self, a):
return self.x + a + 1
obj = A()
obj.x = 2
m = obj.f
assert m(4) == 7
class B(A):
pass
obj = B()
obj.x = 1
m = obj.f
assert m(10) == 12 # 子クラスからも呼び出せる。
# オブジェクトモデルを使ったコード
def f_A(self, a):
return self.read_attr("x") + a + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 2)
m = obj.read_attr("f")
assert m(4) == 7
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 1)
m = obj.read_attr("f")
assert m(10) == 12
このテストのセットアップはメソッド呼び出しのテストと同様であるものの、メソッドの呼び出し方が異なる。最初に、メソッドの名前を使ってオブジェクトが持つ属性の値が取得される。この操作で取得されるのはオブジェクトとそのクラスに関連付くメソッドが合わさったオブジェクトであり、束縛メソッド (bound method) と呼ばれる。続いて、この束縛メソッドに対して呼び出しの操作が実行される2。
この振る舞いを実装するには、Base.read_attr の実装に変更が必要になる: オブジェクトが持つ辞書に属性が存在しないとき、そのクラスが持つ辞書から属性の取得を試みるようにする。クラスが持つ辞書から呼び出し可能な属性の値が見つかった場合は、その値を束縛メソッドに変える必要がある。束縛メソッドのエミュレートでは Python のクロージャをそのまま用いる。Base.read_attr の変更に加えて、Base.callmethod も新しいアプローチを使うように変更すると今までのテストがパスするようになる。
class Base(object):
...
def read_attr(self, fieldname):
""" オブジェクトの属性を読み込む。 """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
raise AttributeError(fieldname)
def callmethod(self, methname, *args):
""" args を引数として、オブジェクトのメソッド methname を呼び出す。 """
meth = self.read_attr(methname)
return meth(*args)
def _is_bindable(meth):
return callable(meth)
def _make_boundmethod(meth, self):
def bound(*args):
return meth(self, *args)
return bound
他の部分のコードに変更は必要とならない。
14.4 メタオブジェクトプロトコル
多くの動的言語では、プログラムによって呼び出される「通常の」メソッドと異なる特殊メソッド (special method) がサポートされる。これらのメソッドはプログラマーから直接呼び出されることを意図したものではなく、オブジェクトシステムによって呼び出される。Python では、こういった特殊メソッドは __init__ のように二つのアンダースコアで始まる名前を持つ。特殊メソッドはプリミティブ操作をオーバーライドして独自の振る舞いを定義する手段を提供する。つまり、特殊メソッドはオブジェクトモデルの仕組みに特定の処理をするよう伝えるためのフックである。Python のオブジェクトモデルは数十個の特殊メソッドを持つ。
メタオブジェクトプロトコルを初めて搭載した言語は Smalltalk だったものの、CLOS などの Common Lisp のオブジェクトシステムにおいてさらに本格的に利用された。特殊メソッドの集合を指すメタオブジェクトプロトコル (meta-object protocol) という言葉も CLOS に関する研究で生まれた3。
本章では、オブジェクトモデルに対するこういったメタフックを三つ実装する。これらのメタフックは属性の読み書きを細かくカスタマイズするために利用される。最初に実装するのは __getattr__ と __setattr__ であり、これらは Python に存在する同じ名前の特殊メソッドと同様の機能を持つ。
属性の読み書きのカスタマイズ
__getattr__ メソッドはオブジェクトモデルが通常の手段で属性の値を見つけられなかったとき、つまり探している属性がインスタンスにもクラスにも見つからなかったときに呼び出される。このメソッドは探している属性の名前を引数に受け取る。__getattr__ メソッドと同じ機能を持つ特殊メソッドは初期の Smalltalk システムで doesNotUnderstand: という名前で提供された4。
__setattr__ の処理はこれと少し異なる。存在しない属性を設定すると属性が新しく作成されるので、__setattr__ は常に呼び出される。__setattr__ メソッドの存在を保証するため、OBJECT クラスに __setattr__ メソッドが新しく定義される。このベース実装の処理は今までと同様であり、オブジェクトが持つ辞書に属性を書き組む。ユーザー定義の __setattr__ で OBJECT.__setattr__ を利用することもできる。
これら二つの特殊メソッドのテストを次に示す:
def test_getattr():
# Python を使ったコード
class A(object):
def __getattr__(self, name):
if name == "fahrenheit":
return self.celsius * 9. / 5. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.celsius = (value - 32) * 5. / 9.
else:
# ベース実装を呼び出す。
object.__setattr__(self, name, value)
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86 # __getattr__ のテスト
obj.celsius = 40
assert obj.fahrenheit == 104
obj.fahrenheit = 86 # __setattr__ のテスト
assert obj.celsius == 30
assert obj.fahrenheit == 86
# オブジェクトモデルを使ったコード
def __getattr__(self, name):
if name == "fahrenheit":
return self.read_attr("celsius") * 9. / 5. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.write_attr("celsius", (value - 32) * 5. / 9.)
else:
# ベース実装を呼び出す。
OBJECT.read_attr("__setattr__")(self, name, value)
A = Class(name="A", base_class=OBJECT,
fields={"__getattr__": __getattr__, "__setattr__": __setattr__},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86 # __getattr__ のテスト
obj.write_attr("celsius", 40)
assert obj.read_attr("fahrenheit") == 104
obj.write_attr("fahrenheit", 86) # __setattr__ のテスト
assert obj.read_attr("celsius") == 30
assert obj.read_attr("fahrenheit") == 86
このテストをパスさせるには、Base.read_attr と Base.write_attr に変更が必要になる:
class Base(object):
...
def read_attr(self, fieldname):
""" オブジェクトの属性を読み込む。 """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
meth = self.cls._read_from_class("__getattr__")
if meth is not MISSING:
return meth(self, fieldname)
raise AttributeError(fieldname)
def write_attr(self, fieldname, value):
""" オブジェクトに属性を書き込む。 """
meth = self.cls._read_from_class("__setattr__")
return meth(self, fieldname, value)
新しい read_attr メソッドは属性が見つからない場合でも __getattr__ メソッドが存在するなら例外を送出せず、属性の名前を引数として __getattr__ メソッドを呼び出す。この特殊メソッドの取得は (Python の全ての特殊メソッドと同様に) クラスに対してしか実行されず、self.read_attr("__getattr__") の再帰的呼び出しは起こらない点に注意してほしい。オブジェクトに __getattr__ メソッドが定義されていないとき read_attr の再帰呼び出しが停止しないためである。
属性の書き込みは全て __setattr__ メソッドに委譲される。そのため、OBJECT クラスにデフォルトの振る舞いを実装する __setattr__ メソッドが必要になる:
def OBJECT__setattr__(self, fieldname, value):
self._write_dict(fieldname, value)
OBJECT = Class("object", None, {"__setattr__": OBJECT__setattr__}, None)
OBJECT__setattr__ の振る舞いはこれまでの write_attr と同様である。以上の改変を加えれば、テストはパスする。
記述子プロトコル
上記の例で示した異なる温度の単位を自動的に変換する仕組みは正しく動作するものの、__getattr__ と __setattr__ で属性の名前を明示的にチェックしなければならず、書きやすいとは言えない。この問題に対処するため、Python は記述子プロトコル (descriptor protocol) と呼ばれる仕組みを提供する。
__getattr__ と __setattr__ は読み書きする操作の対象となるオブジェクトを引数に取るのに対して、記述子プロトコルはオブジェクトに対する操作の結果を引数に取る。これはメソッドがオブジェクトを束縛する仕組みの一般化と考えることができる ── 実際、メソッドがオブジェクトを束縛する仕組みは記述子プロトコルを通して実装される。メソッドの束縛の他にも、Python では @staticmethod, @classmethod, @property の実装で記述子プロトコルが利用される。
ここではオブジェクトの束縛に関係する記述子プロトコルの部分集合を実装する。この実装では特殊メソッド __get__ が用いられる。このメソッドの動作を理解するには例を見るのが一番だろう:
def test_get():
# Python を使ったコード
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.celsius * 9. / 5. + 32
class A(object):
fahrenheit = FahrenheitGetter()
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86
# オブジェクトモデルを使ったコード
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.read_attr("celsius") * 9. / 5. + 32
A = Class(name="A", base_class=OBJECT,
fields={"fahrenheit": FahrenheitGetter()},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86
obj のクラスから属性 fahrenheit を取得すると、それは __get__ メソッドを持つクラス FahrenheitGetter のインスタンスだと分かる。これを受けてオブジェクトシステムは、そのインスタンスの __get__ メソッドを呼び出す。そのとき引数には最初に属性の取得が試みられたオブジェクトが渡される5。
この振る舞いは簡単に実装できる。_is_bindable と _make_boundmethod を次のように変更すればよい:
def _is_bindable(meth):
return hasattr(meth, "__get__")
def _make_boundmethod(meth, self):
return meth.__get__(self, None)
これだけでテストはパスする。先述の束縛メソッドに関するテストもパスする: Python の関数オブジェクトは束縛メソッドオブジェクトを返す __get__ メソッドを持つためである。
実際の言語が持つ記述子プロトコルはここに示したものより格段に複雑となる。例えば、属性に値を設定する操作の意味を属性ごとにオーバーライドするための特殊メソッド __set__ がサポートされるだろう。また、現在の実装では省略している詳細がいくつかある。_make_boundmethod が呼び出すのが meth.read_attr("__get__") ではなく __get__ メソッドである点に注目してほしい。こうする必要があるのは、この実装が関数 (そしてメソッド) を Python から借用しており、オブジェクトモデルにおける関数の表現が存在しないためである。より完全なオブジェクトモデルを作る場合は、この問題も解かなくてはならない。
14.5 インスタンスの最適化
ここまでに示した三種類のオブジェクトモデルは振る舞いがそれぞれ異なっていた。最後となる本節では、振る舞いを変えない最適化を見る。この最適化はマップ (map) と呼ばれ、プログラミング言語 Self の VM で初めて実装された6。現在でも最も重要なオブジェクトモデルの最適化の一つであり、V8 などのモダンな JavaScript VM や PyPy でも使われている。この最適化は V8 で隠れクラス (hidden class) と呼ばれる。
この最適化は次の観察を利用する: これまでに実装してきたオブジェクトモデルでは、全てのインスタンスが属性を格納するために完全な辞書を持っていた。辞書はハッシュマップを使って実装されるので、メモリ消費量が大きい。そして、同じクラスのインスタンスが持つ辞書は同じキーを持つ可能性が高い。例えば、Point クラスの任意のインスタンスは辞書に "x" と "y" のキーを持つだろう。
この事実を利用するのがマップ最適化である。マップ最適化では、任意のインスタンスが持つ辞書を次の二つの部分に分割する:
- 属性の値を並べたリスト
- 属性の名前をキー、一つ目のリストに対する添え字をバリューとする辞書 (この辞書を「マップ」と呼ぶ)
そして、属性の名前からなる集合が同じインスタンスの間でマップ (二つ目の部分) を共有する。こうすれば、各インスタンスは共有されるマップへの参照と、属性の値を並べたリスト (メモリ消費量は辞書よりずっと小さい) だけを保持するだけで済む。
この仕組みの簡単なテストを次に示す:
def test_maps():
# 実装を調べるホワイトボックステスト
Point = Class(name="Point", base_class=OBJECT, fields={}, metaclass=TYPE)
p1 = Instance(Point)
p1.write_attr("x", 1)
p1.write_attr("y", 2)
assert p1.storage == [1, 2]
assert p1.map.attrs == {"x": 0, "y": 1}
p2 = Instance(Point)
p2.write_attr("x", 5)
p2.write_attr("y", 6)
assert p1.map is p2.map
assert p2.storage == [5, 6]
p1.write_attr("x", -1)
p1.write_attr("y", -2)
assert p1.map is p2.map
assert p1.storage == [-1, -2]
p3 = Instance(Point)
p3.write_attr("x", 100)
p3.write_attr("z", -343)
assert p3.map is not p1.map
assert p3.map.attrs == {"x": 0, "z": 1}
このテストは本章でこれまで書いてきたテストと異なる特徴を持つことに注意してほしい。これまでのテストはどれも公開されたインターフェースを利用してクラスの振る舞いを確認するものだった。しかし、このテストは内部の属性を読み取って期待される値と比較することで Instance クラスの実装詳細を確認している。こういったテストはホワイトボックステスト (whitebox test) と呼ばれる。
二つ目の assert から、p1 が持つマップの attrs 属性は辞書 {"x": 0, "y": 1} だと分かる。これは、このインスタンスが二つの属性を持ち、それらの名前が "x" と "y" であり、それぞれの値はインスタンスが持つストレージ storage の位置 0 および 1 に格納されることを意味する。インスタンス p2 を新しく作って同じ二つの属性を同じ順番で追加すると、同じマップがインスタンスに関連付けられる。一方で、p3 のように異なる属性が追加されたなら当然マップは共有されない。
Map クラスを次に示す:
class Map(object):
def __init__(self, attrs):
self.attrs = attrs
self.next_maps = {}
def get_index(self, fieldname):
return self.attrs.get(fieldname, -1)
def next_map(self, fieldname):
assert fieldname not in self.attrs
if fieldname in self.next_maps:
return self.next_maps[fieldname]
attrs = self.attrs.copy()
attrs[fieldname] = len(attrs)
result = self.next_maps[fieldname] = Map(attrs)
return result
EMPTY_MAP = Map({})
Map クラスは二つのメソッド get_index と next_map を持つ。get_index は属性の名前を受け取り、その属性の値がオブジェクトのストレージで何番目に位置するかを返す。next_map はオブジェクトに新しい属性が追加されるときに利用され、新しい属性を追加した Map を返す。このメソッドはこれまでに作成したマップをキャッシュした辞書 next_maps を利用する。こうすることで、同じレイアウトを持つオブジェクトの間で同じ Map オブジェクトが共有される。
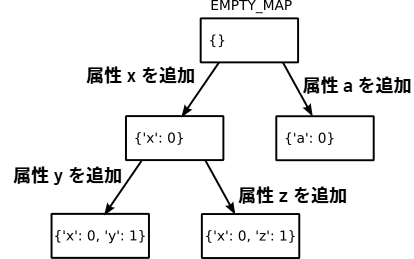
Map の遷移
マップを利用する Instance の実装を次に示す:
class Instance(Base):
""" ユーザー定義クラスのインスタンス """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, None)
self.map = EMPTY_MAP
self.storage = []
def _read_dict(self, fieldname):
index = self.map.get_index(fieldname)
if index == -1:
return MISSING
return self.storage[index]
def _write_dict(self, fieldname, value):
index = self.map.get_index(fieldname)
if index != -1:
self.storage[index] = value
else:
new_map = self.map.next_map(fieldname)
self.storage.append(value)
self.map = new_map
新しい Instance クラスは Base クラスが持つフィールド辞書を利用しないので、Base のコンストラクタの辞書を表す引数には None が渡される。このため _read_dict メソッドと _write_dict メソッドのオーバーライドが必要になる。実際の言語の実装では、このタイミングで Base をリファクタリングしてフィールド辞書を削除するだろう。ただ、ここでは None を設定しておけば十分である。
新しく作成された Instance インスタンスは EMPTY_MAP を持つ。このマップは属性を持たず、従ってストレージも空である。新しい _read_dict メソッドは、属性の名前に対応する添え字をマップから取得し、その添え字を使ってストレージから取得した要素を返す。
フィールド辞書に対する書き込みは二つの場合に分かれる。まず、既存の属性の値が変更される場合がある。このときはストレージの対応する位置にある値を変更するだけで済む。次に、存在しない属性の値が設定される場合がある。このときは next_map メソッドを使ったマップの遷移 (図 2) が必要となる。新しい属性の値はストレージの末尾に付け足される。
この最適化で何が達成されたのだろうか? 「同じレイアウトを持つインスタンスが多く存在する」という頻出ケースでメモリ消費量が低くなる。ただし、これは万能の最適化ではない: 大きく異なる属性を持った大量のインスタンスを作成するコードでは、以前よりメモリ消費量が増える可能性がある。
これは動的言語の最適化でよく発生する問題である。高速化や省メモリ化を全てのケースで達成できる最適化は見つけられない場合が多い。現実には、言語の典型的な利用法に沿った最適化が選択される。これは、非常に動的な機能を利用するプログラムでは性能が低下する可能性があることを意味する。
マップ最適化の興味深い特徴としてもう一つ、これはメモリ消費量を抑えるための最適化であるものの、JIT (just-in-time) コンパイラを備えた実際の VM ではプログラムの高速化も達成される点がある。JIT はマップを利用して属性の取得をオブジェクトのストレージに対する固定オフセットアクセスにコンパイルし、辞書からの値の取得を完全に消し去ることができる7。
14.6 可能な拡張
本章で示したオブジェクトモデルを拡張して様々な言語設計の選択肢を試すことは難しくない。いくつか例を示す:
- 最も簡単な変更として新しい特殊メソッドの追加がある。
\_\_init\_\_,\_\_getattribute\_\_,\_\_set\_\_などは簡単に追加できるものの興味深い。 - 多重継承を可能にする変更も非常に簡単に実装できる。全てのクラスに基底クラスのリストを持たせた上で
Class.method_resolution_orderメソッドを適切に変更すればよい。単純なメソッド解決順序として重複を無視する深さ優先探索が考えられる。より複雑ではあるものの実用性の高いメソッド解決順序は C3 アルゴリズムを使うと得られる。このアルゴリズムはダイアモンド型多重継承の扱いに優れ、意味をなさない継承パターンを検出できる。 - より根本的な変更としてはプロトタイプモデルへの変更がある。この変更ではクラスとインスタンスの区別を撤廃する必要がある。
14.7 結論
オブジェクト指向プログラミング言語の設計において中心的な役割を果たす概念の一つが、言語が採用するオブジェクトモデルの詳細である。小さなオブジェクトモデルのプロトタイプを書くことは、既存の言語の内部動作を深く理解し、オブジェクト指向言語の設計空間に関する洞察を得るための楽しくて簡単な手段である。オブジェクトモデルを改造して遊ぶことは、パースやコード実行といった言語実装における退屈な部分を飛ばして言語設計の様々なアイデアを実験する優れた機会となる。
そういったオブジェクトモデルは実験器具としてだけではなく実際のコードでも有用となる。独立したオブジェクトモデルを他の言語に埋め込んで利用することが可能だからである。このアプローチの例は多くある: C で書かれた GObject オブジェクトモデルは GLib などの Gnome ライブラリで使われている。また、JavaScript で実装されたクラスシステムも数多くある。
-
P. Cointe, Metaclasses are first class: The ObjVlisp Model, SIGPLAN Not, vol. 22, no. 12, pp. 156–162, 1987. ↩︎
-
この説明と例だけを見ると、属性ベースモデルの方がメソッドベースモデルより概念的に複雑に思える。メソッドの呼び出しに属性の取得と取得結果の呼び出しの両方が必要となるからである。しかし実際には、何かを呼び出す操作は特別な属性
__call__の取得と呼び出しとして定義されるので、複雑性に違いがあるわけではない。ただ、この仕組みは本章で実装されない。 ↩︎ -
G. Kiczales, J. des Rivieres, and D. G. Bobrow, The Art of the Metaobject Protocol. Cambridge, Mass: The MIT Press, 1991. ↩︎
-
A. Goldberg, Smalltalk-80: The Language and its Implementation. Addison-Wesley, 1983, page 61. ↩︎
-
Python では属性が見つかったクラスも第二引数に渡されるが、この引数は本章では利用しない。 ↩︎
-
C. Chambers, D. Ungar, and E. Lee, An efficient implementation of SELF, a dynamically-typed object-oriented language based on prototypes, in OOPSLA, 1989, vol. 24. ↩︎
-
この最適化の詳細は本章の範囲を超える。私は数年前に書いた論文で詳しい説明を試みたことがある。その論文では本章で示したオブジェクトモデルを改変したものを主に議論している: C. F. Bolz, A. Cuni, M. Fijałkowski, M. Leuschel, S. Pedroni, and A. Rigo, Runtime feedback in a meta-tracing JIT for efficient dynamic languages, in Proceedings of the 6th Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems, New York, NY, USA, 2011, pp. 9:1–9:8. ↩︎