17. 同一オリジンポリシー
17.1 はじめに
同一オリジンポリシー (same-origin policy, SOP) は全てのモダンブラウザが備える重要なセキュリティ機構である。SOP はブラウザで実行されるスクリプトが他のスクリプトと通信できる条件 (簡単に言えば「同じウェブサイトから取得されていること」) を定める。Netscape Navigator に初めて搭載された SOP はウェブアプリケーションのセキュリティにおいて非常に重要な役割を果たしている。SOP が存在しないとしたら、アップロード者だけが閲覧できる設定で Facebook にアップロードされた他人の写真を取得したり、メールを盗み見たり、銀行講座を空にしたりといった行為が悪意あるハッカーにとって格段に簡単になるだろう。
しかし SOP は完璧からは程遠い。ときには制限が過剰であり、オリジンが異なるスクリプトがリソースを共有したい状況 (例えばマッシュアップ) で共有が不可能になる。ときには制限が足りず、クロスサイトリクエストフォージェリといった有名な攻撃に悪用されるコーナーケースが残される。さらに、SOP の設計は長い年月を経て有機的に進化してきたので、多くの開発者を混乱させている。
本章の目標は SOP という重要な ── そして誤解されることの多い ── 仕組みの中心的な機能を解説することである。具体的には、次の質問に答えることを試みる:
- なぜ SOP が必要なのか? どんな種類のセキュリティ侵害を SOP は防ぐのか?
- ウェブアプリケーションの振る舞いは SOP によってどんな影響を受けるか?
- SOP を迂回する仕組みにはどのようなものがあるか?
- そういった仕組みはどの程度セキュアなのか? そういった仕組みを利用することで発生する可能性のあるセキュリティ上の問題は何か?
SOP の完全な解説は気の遠くなるタスクである。SOP には複雑な話題 ── ウェブサーバー、ブラウザ、HTTP、HTML ドキュメント、クライアントサイドスクリプトなど ── が多く関連するので、それらの解説だけで頭がパンクしてしまうだろう。それに、500 行だけでは SOP 関連のコードは一行も書けないかもしれない。どうすれば煩雑な詳細を避けつつ SOP について厳密に議論できるだろうか?
17.2 Alloy によるモデリング
本章は本書の他の章といくらか異なる。本章では実際に動作する実装を作成するのではなく、単純でありつつも厳密な SOP の記述として機能する実行可能なモデルを構築する。実装と同様に、このモデルは実行してシステムの動的な振る舞いを調べることができる。一方で実装とは異なり、このモデルでは中心的な概念の理解を妨げかねない低レベルの詳細が省略される。
本章のアプローチは「アジャイルモデリング」と呼べるかもしれない。モデルを少しずつ組み立てる手法がアジャイルプログラミングに似ているからである。モデルは進化を繰り返すものの、全ての時点で実行可能となる。テストも形式化・実行していくので、最終的にはモデルだけではなくモデルが満たすプロパティ (property, 性質・特徴) の集合も作成される。
このモデルの作成では、ソフトウェアの設計をモデル化・解析するための言語 Alloy を用いる。Alloy で作成したモデルは伝統的なプログラムの実行と同じ意味では実行できない。その代わり、モデルは次の処理に利用できる:
- モデルが表すシステムの正当なシナリオや構成を表現するインスタンス (instance) と呼ばれるオブジェクトを生成する。
- モデルが期待通りのプロパティを満たすかどうかを検査 (check) する。
アジャイルモデリングとアジャイルプログラミングは上述の共通点を持つのに対して、次の重要な点で異なる: 私たちはテストを実行するものの、テストを書くことはない。Alloy の解析器 (Alloy Analyzer) がテストケースを自動的に生成するので、提供する必要があるのは検査したいプロパティだけとなる。言うまでもなく、この仕組みによって面倒ごと (特にテキスト量) が減る。Alloy Analyzer はスコープ (scope) と呼ばれる特定のサイズに収まるテストケースを全て生成し、操作と引数を一定のステップ数に達するまで選択し入力し続ける。非常に多くの (典型的には数億個の) テストが実行されるので、そして状態が取れる構成は (スコープの範囲内ではあるものの) 全てカバーされるので、この解析は伝統的なテスト手法より効率的にバグを見つけられることが多い。
単純化
SOP はブラウザ、サーバー、HTTP といった技術と連動するので、その完全な記述は私たちの手に余る。そのため、私たちが作成するモデルは (あらゆるモデルと同様に) 本質的でない側面を抽象化したものとなる。例えばネットワークパケットがどのように構造化されどのようにルーティングされるかはモデル化されない。さらに、SOP 自身に関しても単純化する部分があるので、本章のモデルが全てのセキュリティ脆弱性を捉えられるわけではない。
例えば、私たちのモデルは HTTP リクエストを遠隔手続き呼び出しのように扱い、リクエストの順序とレスポンスの順序が一致しない可能性がある事実を無視する。また、DNS (domain name service) は静的だとも仮定するので、DNS バインディングが対話中に変更される攻撃は考慮できない。理論上は、そういった要素をカバーするように本章のモデルを拡張することはできる。一方で、セキュリティ解析の本質的な性質として、どんなモデルを作ったとしても (たとえコードベース全体を表現したモデルであっても) それが完全だと保証することはできない。
17.3 ロードマップ
本章で SOP のモデルをどのように作っていくかを説明しよう。最初に、SOP について議論する上で必要となる三つの主要な構成要素の基本的なモデルを作成する: HTTP、ブラウザ、そしてクライアントサイドのスクリプト機構である。その後、この基本的なモデルの上でウェブアプリケーションがセキュアとはどういうことかを定義し、そこで必要となるプロパティを達成する仕組みとして SOP を導入する。
この時点のモデルでは、SOP の制限が過剰になってウェブアプリケーションの適切な動作が妨げられる場合がある。そこで、SOP が課す制限を迂回するために広く利用されるいくつかのテクニックを紹介する。
各節は自由な順番で読んで構わない。もし Alloy に触れるのが初めてなら、Alloy というモデリング言語の基本的な概念が説明される最初の三節 (HTTP、ブラウザ、スクリプト機構のモデル化) を読むことを勧める。本章を読むときは、Alloy Analyzer を使ってモデルを試しながら読み進めるとよいだろう。モデルを実行し、生成されたシナリオに目を通し、モデルを改変したとき何が変わるかを確認してみるとよい。Alloy は無料でダウンロードできる。
17.4 Web のモデル化
HTTP
Alloy でモデルを作成するときの最初のステップはオブジェクトの宣言である。リソースから始めよう:
sig Resource {}
キーワード sig は、このコードが Alloy のシグネチャ (signature) を宣言することを示す。このシグネチャ宣言によってリソースオブジェクトの集合が定義される。このリソースオブジェクトはインスタンス変数を持たないクラスのオブジェクト、あるいは識別子だけを持ち他には情報を持たないブロブと考えることができる。解析を実行すると、この集合が決定される。これはオブジェクト指向言語でクラスが実行時にオブジェクトの集合を表すのと同様である。
リソースは URL (uniform resource locator) によって特徴付けられる:
sig Url {
protocol: Protocol,
host: Domain,
port: lone Port,
path: Path
}
sig Protocol, Port, Path {}
sig Domain { subsumes: set Domain }
このコードでは五つのシグネチャが宣言され、URL の集合と、URL を構成する基礎単位に対応する四つの集合が導入される。Url の宣言では四つのフィールド (field) が使われている。シグネチャのフィールドはクラスのインスタンス変数のようなものと言える。例えば、u が URL を表すなら、u.protocol は (Java などと同様に) その URL のプロトコルを表す。ただし後で見るように、Alloy のフィールドは厳密には関係 (relation) である。つまり、シグネチャの各フィールドは二列のデータベーステーブルと考えることができる。例えば protocol は第一列に URL を、第二列にプロトコルを持つテーブルに等しい。そして一見すると何でもなさそうなドット演算子は実際には関係に対するジョインを一般化した操作であり、例えば protocol.p と書くと特定のプロトコル p を持つ全ての URL を表せる ── 詳しくは後述する。
URL と異なり、パスは構造を持たないものとして扱われる点に注意してほしい ── これは私たちが受け入れる単純化の一つである。port フィールドの宣言で使われているキーワード lone は「less than or equal to one (1 以下)」と読み、各 URL には最大で一つのポートが対応付くことを表す。URL のパス (Path) はホスト名に続く文字列であり、単純な静的サーバーではリソースのファイルパスに対応付く。パスは常に存在すると仮定しているものの、空文字列でも構わない。
続いてクライアントとサーバーを定義しよう。サーバーについては、パスをリソースに対応付けるのがサーバーだと考えることができる:
abstract sig Endpoint {}
abstract sig Client extends Endpoint {}
abstract sig Server extends Endpoint {
resources: Path -> lone Resource
}
extends キーワードは部分集合を定義する。例えば全てのクライアントを集めた集合 Client は全てのエンドポイントを集めた集合 Endpoint の部分集合となる。extends で定義される部分集合は任意の異なる二つが共通部分を持たないと解釈されるので、クライアントかつサーバーであるエンドポイントは存在しない。abstract キーワードは自身の部分集合が自身を被覆することを意味する。例えば Endpoint の宣言に付いている abstract は、任意のエンドポイントが Endpoint の部分集合 (現時点では Client と Server) のいずれかに必ず属することを意味する。サーバー s に対して、式 s.resources はパスからリソースへのマップを表す (マップは対応付けなので宣言で矢印が使われる)。任意のフィールドが実際にはそのフィールドを持つシグネチャを第一列に持つ関係だったことを思い出せば、resources フィールドは Server, Path, Resource という三つの列からなる関係を表すと分かる。
次に、URL をサーバーに変換するドメインネームサーバーを集めた集合 Dns を定義する。ドメインネームサーバーはドメインからサーバーへの対応付けを持つ:
one sig Dns {
map: Domain -> Server
}
シグネチャ宣言に付いているキーワード one は、ドメインネームサーバーがちょうど一つしか存在しないと (議論を簡単にするために) 仮定することを表す。このため、式 Dns.map が表す DNS マッピングも一つしか存在しない。ここでも、サーバーのリソースと同様に、実際の DNS は動的である (そして DNS バインディングを対話中に変更するセキュリティ攻撃も知られている) ものの単純化している。
HTTP リクエストをモデル化するにはクッキー (cookie) の概念が必要になる。これを宣言しよう:
sig Cookie {
domains: set Domain
}
クッキーはドメインの集合で表されるスコープを持つ。これは、クッキーの Domain 属性に *.mit.edu を設定すると末尾に mit.edu を持つ任意のドメインでそのクッキーが利用できようになる事実に対応する。
最後に、これまでに宣言したシグネチャを利用して HTTP リクエストを構築する:
abstract sig HttpRequest extends Call {
url: Url,
sentCookies: set Cookie,
body: lone Resource,
receivedCookies: set Cookie,
response: lone Resource,
}{
from in Client
to in Dns.map[url.host]
}
HTTP のリクエストとレスポンスは単一のオブジェクトでモデル化される。url, sentCookies, body はクライアントが送信し、receivedCookies, response はサーバーが送信する。
HttpRequest シグネチャの定義では Call と呼ばれる一般的なシグネチャが利用されている。Call は何らかの呼び出しを表し、呼び出し元と呼び出し先をフィールドに持つ。Call シグネチャを定義する Alloy モジュールを利用するには、次の一行が必要になる:
open call[Endpoint]
call は多相的なモジュールなので、呼び出し元かつ呼び出し先である Endpoint を渡してインスタンス化する。call の詳細は章末の補遺を見てほしい。
HttpRequest の定義では、フィールドに続いて制約 (constraint) の集合が定義される。ここにある二つの制約は HTTP リクエストの集合に属する任意の要素に適用され、それぞれ「任意のリクエストはクライアントが送信する」そして「任意のリクエストは DNS マッピングで URL のホストに対応するサーバーのいずれかに送信される」を表す。
Alloy の優れた特徴の一つとして、どんなに単純あるいは複雑なモデルであっても実行してシステムインスタンスのサンプルを生成できることがある。run コマンドを利用して、ここまでに定義した HTTP モデルを Alloy Analyzer で実行してみよう:
-- 全てのシグネチャが最大でも三つのオブジェクトを持つようなインスタンスを生成する。
run {} for 3
Alloy Analyzer がシステムのインスタンスを見つけると、それを示す図が生成される (図 1)。
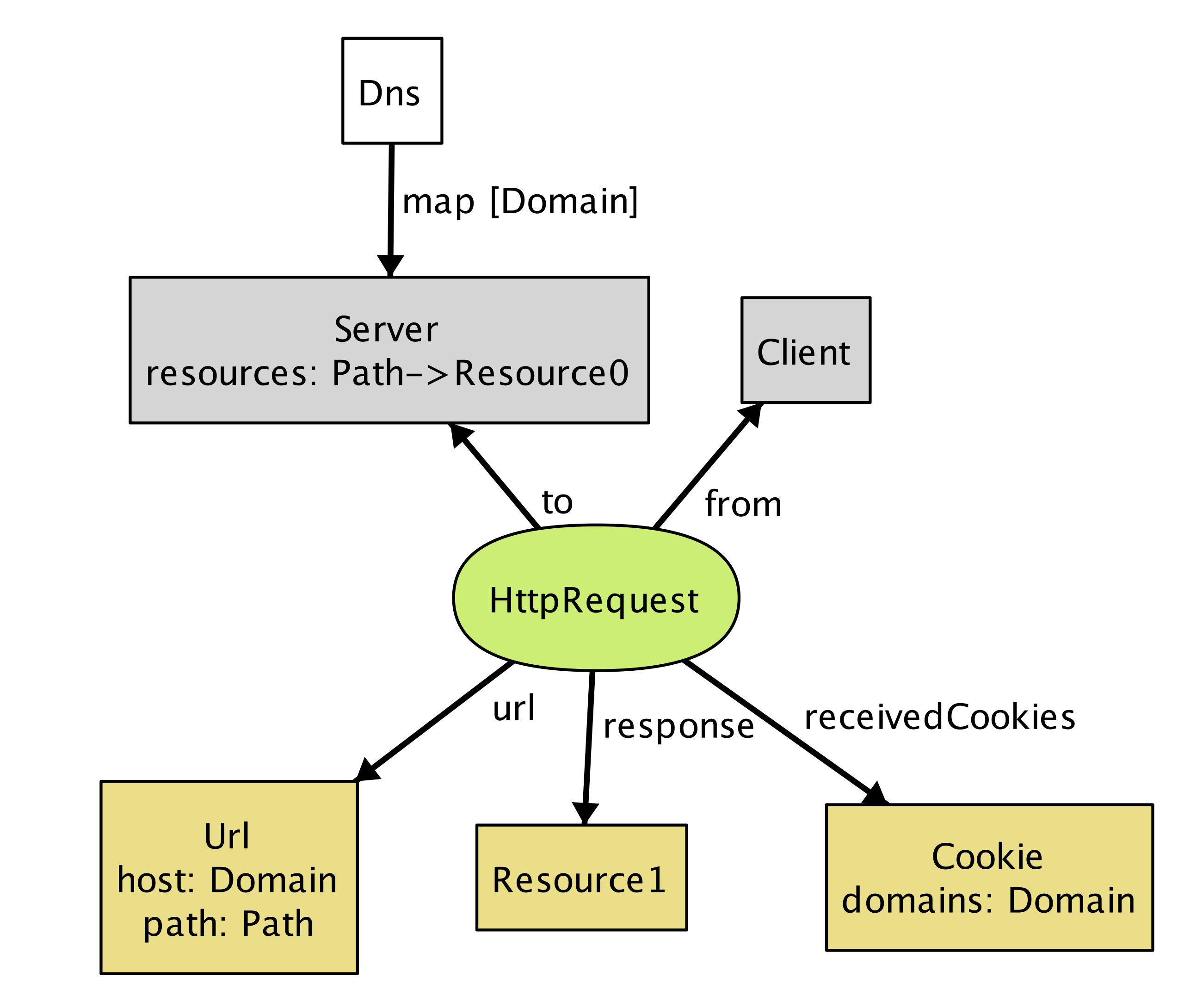
このインスタンスには Client と書かれたノードで表されたクライアントが HttpRequest を Server に送信し、これに対してサーバーがリソースオブジェクト Resource1 を返しつつ Domain の Cookie を保存するようクライアントに伝える様子が描かれている。
このインスタンスは詳細の多くを省略した非常に小さなものであるにもかかわらず、私たちのモデルが持つ問題を一つ明らかにしている。リクエストに対する返答 (Resource1) がサーバーに存在していない点に注目してほしい。サーバーに関する明らかな事実を指定し忘れている: 任意のリクエストに対する返答はサーバーが保持するリソースでなくてはならない。HttpRequest の定義に次の制約を追加しよう:
abstract sig HttpRequest extends Call { ... }{
...
response = to.resources[url.path]
}
この変更を加えてから再実行すると、問題を持たないインスタンスが生成される。
生成されたインスタンスのサンプルを見て考える代わりに、モデルが特定のプロパティを持つかどうかを検査 (check) するよう Alloy Analyzer に指示することもできる。例えば、HTTP リクエストに関するプロパティ「同じリクエストに対しては必ず同じレスポンスが返る」は成り立つだろうか? このプロパティを検査するには次のコードを実行する:
check {
all r1, r2: HttpRequest | r1.url = r2.url implies r1.response = r2.response
} for 3
check コマンドを使うと、Alloy Analyzer はシステムの可能な振る舞いを (指定されたスコープ内で) 全て調べ、プロパティを満たさないインスタンスを反例 (counterexample) としてユーザーに示す (図 2a, 図 2b)。
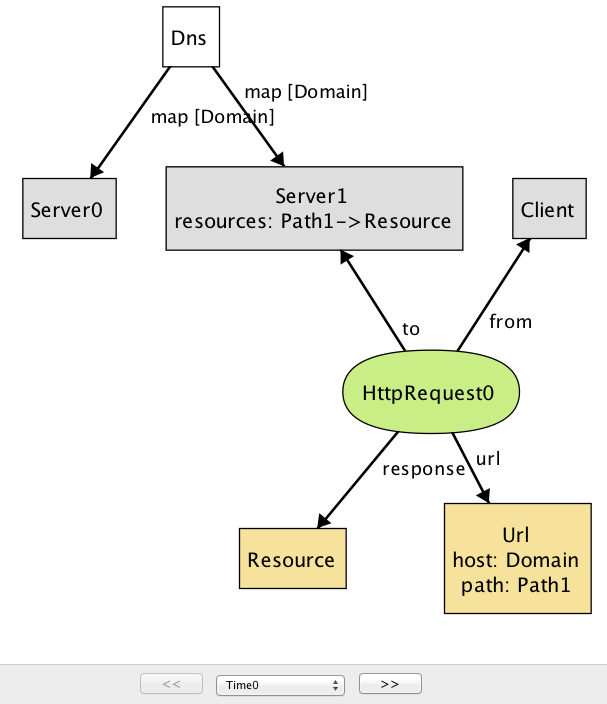
time=0)
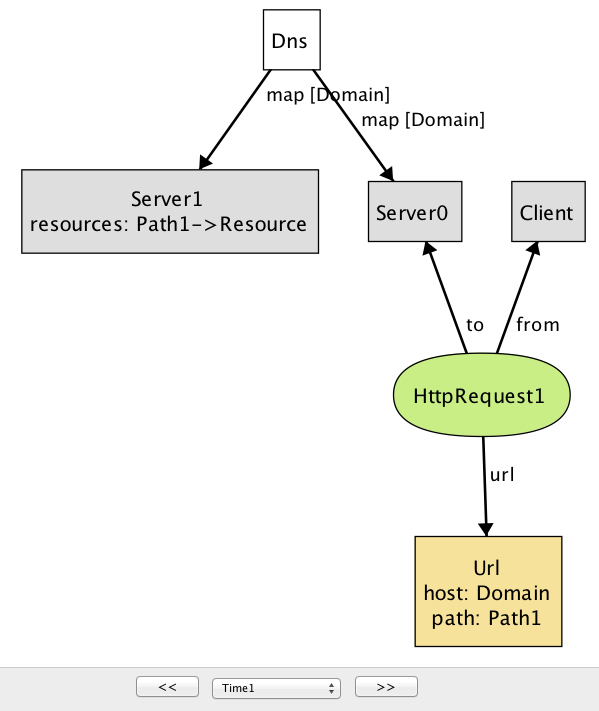
time=1)
この反例ではクライアントが送信する HTTP リクエストが二つ示されており、それぞれ送信先のサーバーが異なる。Alloy がインスタンスを描画するとき、同じシグネチャを持つオブジェクトは数値を後ろに付けることで区別される (オブジェクトが一つしかない場合は何も付かない)。この反例の図に示された文字列はオブジェクトの名前を表す。そのため ── 最初は困惑するかもしれないが ── 図中の Domain, Path, Resource, Url といった文字列はシグネチャではなくオブジェクトの名前を表す。
DNS が Domain を Server0 と Server1 の両方に関連付けている点に注目してほしい (これは負荷分散のために実際によく利用されるテクニックである)。Server1 だけが Path を受け取ってリソースオブジェクトを返せるので、server0 に送信される HeepRequest1 ではレスポンスが空となる: またモデルの問題が見つかった。この問題を解決するために、DNS が特定のホストに対応付ける任意のサーバーは同じリソースの集合を持つという事実 (fact) を Alloy に伝える:
fact ServerAssumption {
all s1, s2: Server |
(some Dns.map.s1 & Dns.map.s2) implies s1.resources = s2.resources
}
この事実を追加してから先述の check コマンドを再実行すると、Alloy Analyzer はプロパティに対する反例を報告しなくなる。スコープを大きくしたときに反例が見つかる可能性は残されているので、これでプロパティの正しさが証明されたわけではない。しかし、各シグネチャのオブジェクトを三個ずつ含むインスタンスを一つ残らずテストして反例が見つかっていないことから、プロパティが正しい可能性は高い。
もし望むなら、スコープを大きくして解析を再実行すればプロパティの正しさに対する自信を高めることができる。例えば、上述の check コマンドでスコープを 10 にしても反例は見つからないので、プロパティが正しい可能性はさらに高まる。ただし、スコープを大きくすると Alloy Analyzer がテストする必要のあるインスタンスの個数が増えて実行時間が長くなることは念頭に置いておく必要がある。
ブラウザ
続いてモデルにブラウザを追加しよう:
sig Browser extends Client {
documents: Document -> Time,
cookies: Cookie -> Time,
}
この Browser では動的フィールド (dynamic field) が初めて使われている。Alloy は「時間」や「振る舞い」といった概念を組み込みで持たないので、様々なイディオムが利用される。このモデルでは Time を使って時間の概念を導入し、時間が経過すると変化するフィールドの最終列に Time を追加している。例えば、式 b.cookies.t は特定の時刻 t にブラウザ b が保持するクッキーの集合を表す。同様に documents フィールドは各時刻でドキュメントの集合を各ブラウザに関連付ける (章末の補遺に追加の説明がある)。
ドキュメントは HTTP リクエストに対するレスポンスから作成される。ユーザーがタブやブラウザを閉じたときなどに破棄されるものの、この事実は私たちのモデルに取り入れない。ドキュメントは URL (ドキュメントが取得された URL) と、何らかのコンテンツ (DOM)、そしてドメインを持つ:
sig Document {
src: Url,
content: Resource -> Time,
domain: Domain -> Time
}
フィールド content, domain が最後に Time の列を持つことから、これらのフィールドが時間の経過とともに変化すると分かる。逆に src フィールドが Time を持たない事実はドキュメントの URL が変化しないことを意味する。
HTTP リクエストの中にはブラウザのレベルで生成されない (スクリプトによって生成される) ものが存在するので、HTTP リクエストのブラウザに対する効果をモデル化するには新しいシグネチャを定義する必要がある:
sig BrowserHttpRequest extends HttpRequest {
doc: Document
}{
-- リクエストはブラウザから生成される。
from in Browser
-- 送信されようとしているクッキーはリクエストを作成する時点でブラウザに存在する。
sentCookies in from.cookies.start
-- 送信される任意のクッキーのスコープはリクエストの URL を含む必要がある。
all c: sentCookies | url.host in c.domains
-- レスポンスのコンテンツを表示するために新しいドキュメントが作成される。
documents.end = documents.start + from -> doc
-- 新しいドキュメントはレスポンスをコンテンツに持つ。
content.end = content.start ++ doc -> response
-- 新しいドキュメントは URL のホストをドメインに持つ。
domain.end = domain.start ++ doc -> url.host
-- ドキュメントの src フィールドはリクエストの url フィールドに等しい。
doc.src = url
-- 新しいクッキーはブラウザによって保存される。
cookies.end = cookies.start + from -> sentCookies
}
この種類のリクエストは新しいフィールド doc を持つ。リクエストが返したリソースからブラウザが作成したドキュメントが doc フィールドによって表される。HttpRequest と同様に、このシグネチャを持つオブジェクトの振る舞いは制約の集合を通して表現される。いくつかの制約は呼び出し (Call) の引数に関連する: 例えば、クッキーは適切なスコープを持たなければならない。呼び出しの効果に関する制約もある。そういった制約では、呼び出し前の関係の値と呼び出し後の関係の値が一般的なイディオムを使って関連付けられる。
例えば、制約 documents.end = documents.start + from -> doc が何を意味するかを理解するには、documents がブラウザ・ドキュメント・時間という三つの列からなる関係であることを思い出す必要がある。start と end は Call シグネチャのフィールドであり、それぞれ呼び出しが始まった時間と完了した時間を表す (これまでに Call の定義は示していないが、章末の補遺に示してある)。そのため、式 documents.end は呼び出しが完了した時点におけるブラウザからドキュメントへの対応付けを表す。つまり制約 documents.end = documents.start + from -> doc は「呼び出しが完了した時点における document の値は、呼び出し前の値に from を doc に対応付ける新しいエントリーを追加したものに等しい」を意味する。
一部の制約が使っている ++ 演算子は関係を上書きする: e1 ++ e2 は e2 に含まれるタプル、そして e1 に含まれるタプルの中で同じ第一要素を持つタプルが e2 に存在しないものから構成される。例えば、制約 content.end = content.start ++ doc -> response は「呼び出しが終わった後、content は doc が content に対応付くように更新される」を意味する (doc に関する以前の対応付けは上書きされる)。ここで和集合演算子 + を使うと、呼び出し後のドキュメントが (誤って) 複数のリソースに関連付けられてしまう可能性が生まれる。
スクリプト
続いて、HTTP とブラウザのモデルの上にクライアントサイドスクリプトのモデルを定義する。次のシグネチャはブラウザドキュメント (context) の内部で実行される (たいていは JavaScript の) コードを表す:
sig Script extends Client { context: Document }
スクリプトは動的なエンティティであり、二種類の異なる操作を実行できる:
- HTTP リクエスト (いわゆる Ajax リクエスト) の送信
- ドキュメントのコンテンツおよびプロパティの取得・変更
クライアントサイドスクリプトのこういった柔軟性は Web 2.0 が素早く広まった主な要因であるとともに、SOP が作成された元々の理由でもある。SOP が存在しないと、スクリプトは任意のサーバーにリクエストを送信でき、ブラウザ内のドキュメントを自由に書き換えることができる ── 悪意あるスクリプトを一つでも実行したら、その時点でお手上げとなる。
スクリプトは次の XmlHttpRequest を送信することでサーバーと通信する:
sig XmlHttpRequest extends HttpRequest {}{
from in Script
noBrowserChange[start, end] and noDocumentChange[start, end]
}
XmlHttpRequest はスクリプトがサーバーとリソースをやり取りするときに利用される。ただし BrowserHttpRequest と異なり、XmlHttpRequest は新しいページの作成やブラウザ・ドキュメントに対する変更に必ず結び付くわけではない。呼び出しがシステムのそういった部分を改変しないことを表明するために、述語 noBrowserChange と noDocumentChange が定義される:
pred noBrowserChange[start, end: Time] {
documents.end = documents.start and cookies.end = cookies.start
}
pred noDocumentChange[start, end: Time] {
content.end = content.start and domain.end = domain.start
}
スクリプトはドキュメントに対してどのような操作を行えるだろうか? まず、スクリプトから呼び出せるブラウザ API 関数の集合を表すブラウザ操作 (browser operation) という一般的な概念を定義する:
abstract sig BrowserOp extends Call { doc: Document }{
from in Script and to in Browser
doc + from.context in to.documents.start
noBrowserChange[start, end]
}
doc フィールドは呼び出しによってアクセスまたは改変されるドキュメントを指す。シグネチャに書かれた二つ目の制約は「スクリプトが実行されるドキュメント (from.context) と doc が両方ともブラウザ内に存在しなければならない」を意味する。最後に、BrowserOp はドキュメントの状態を改変できるのに対して、ブラウザに保存されたドキュメントの集合やクッキーは変更できない (実際にはドキュメントにクッキーを関連付けるとブラウザ API で改変できるが、現時点ではこの詳細を無視する)。
スクリプトはドキュメントの様々な部分に対して読み書き操作を実行できる (ドキュメントの構成要素は DOM 要素と呼ばれることが多い)。典型的なブラウザには document.getElementById などの DOM にアクセスするための API 関数が大量に実装されている。ただ、それらを全てここに並べて書くことは重要でない。そういった関数を ReadDom と WriteDom の二つにグループ化すれば ── そしてドキュメントの改変を全く新しいドキュメントへの置き換えとしてモデル化すれば ── 十分となる。
sig ReadDom extends BrowserOp { result: Resource }{
result = doc.content.start
noDocumentChange[start, end]
}
sig WriteDom extends BrowserOp { newDom: Resource }{
content.end = content.start ++ doc -> newDom
domain.end = domain.start
}
ReadDom は操作対象のドキュメントのコンテンツを返し、そのとき改変はしない。一方で WriteDom は操作対象のドキュメントのコンテンツを新しく newDom に設定する。
この他にも、スクリプトはドキュメントの幅・高さ・ドメイン・タイトルといった様々な属性を改変できる。SOP を議論する上で意味を持つのはドメイン属性だけであり、これは以降の節で定義される。
17.5 アプリケーションの例
以前に見たように、run または check のコマンドを実行すると Alloy Analyzer は定義されたモデルおよびシステムと矛盾しないシナリオを (もし存在するなら) 生成する。デフォルトでは矛盾しないシナリオが (スコープの範囲で) 任意に選ばれ、シナリオに含まれるシグネチャのインスタンスには Server0 や Browser1 といった数字の識別子が付いた名前が付けられる。
ときには、サーバーとクライアントがランダムな構成を持ったシナリオを探索するのではなく、特定のウェブアプリケーションの振る舞いを解析したい場合もある。例えば、Gmail のようなブラウザ内で実行されるメールアプリケーションを作成しているとしよう。メールに関する基本的な機能を提供するのに加えて、サードパーティの広告サービスが配信するバナーを表示する必要があるとする。このバナーは悪意あるアクターによって制御される可能性がある。
以前に Dns の定義で使ったように、Alloy ではキーワード one sig でちょうど一つのオブジェクトを含むシングルトン (singleton) シグネチャを定義できる。この構文は具体的なオブジェクトを指定するのにも利用できる。例えば、受信箱ページと広告バナー (いずれもドキュメント) が一つずつしか存在しないなら、次のように書ける:
one sig InboxPage, AdBanner extends Document {}
この宣言があると、Alloy が生成するシナリオは必ずこれら二つの Document を含むようになる。
同様に特定のサーバーやドメインを指定することもできるし、それらに対して制約を加えることもできる。次のコードでは制約に Configuration という名前を付けている:
one sig EmailServer, EvilServer extends Server {}
one sig EvilScript extends Script {}
one sig EmailDomain, EvilDomain extends Domain {}
fact Configuration {
EvilScript.context = AdBanner
InboxPage.domain.first = EmailDomain
AdBanner.domain.first = EvilDomain
Dns.map = EmailDomain -> EmailServer + EvilDomain -> EvilServer
}
例えば、最後の制約はシステム内の二つのサーバーに対応するドメイン名が DNS に設定されていることを表す。この制約が存在しないと、Alloy Analyzer は EmailDomain を EvilServer に対応付ける意味のないシナリオを生成してしまう (実際には、こういった対応付けは DNS spoofing と呼ばれる攻撃によって引き起こされる可能性がある。ただ、そういった攻撃を防ぐように SOP は設計されていないので、私たちのモデルでは考えない)。
さらに二つのアプリケーションを定義する。オンラインカレンダーとブログ執筆サイトである:
one sig CalendarServer, BlogServer extends Document {}
one sig CalendarDomain, BlogDomain extends Domain {}
上記の DNS マッピングに関する制約を更新し、新しい二つのドメイン名を組み込む必要がある:
fact Configuration {
...
Dns.map = EmailDomain -> EmailServer + EvilDomain -> EvilServer +
CalendarDomain -> CalendarServer + BlogDomain -> BlogServer
}
加えて、メール・ブログ・カレンダーの三つのアプリケーションは同じ組織で開発され、共通のベースドメインを持つとする。例えば EmailServer と CalendarServer はそれぞれ email および calendar というサブドメインを持ち、上位ドメイン example.com は共通する。これをモデル化するために、他のドメイン名を包含 (subsume) するドメイン名という概念を定義する:
one sig ExampleDomain extends Domain {}{
subsumes = EmailDomain + EvilDomain + CalendarDomain + this
}
subsumes に this が含まれるは、任意のドメインは自身を含むためである。
ここでは一部を省略しているので、完全なモデルを確認したい場合は example.als を見てほしい。これらのアプリケーションは以降で例として使用される。
17.6 セキュリティに関するプロパティ
SOP の話に入る前に、今までに議論してこなかった重要な質問を考える: システムがセキュア (secure) とは厳密に何を意味するのだろうか?
驚くことではないが、この質問に答えるのは難しい。本章では、情報セキュリティの分野で広く研究されてきた機密性 (confidentiality) と完全性 (integrity) という二つの概念を採用する。いずれの概念も、情報がシステムの様々な部分をどのように通過するかに関する性質を意味する。大まかに言って、信頼できるとみなされる部分だけが重要なデータにアクセスできるときシステムは機密性を持つと言い、信頼できるとみなされる部分が利用するデータが悪意を持って改竄されないときシステムは完全性を持つと言う。
データフローに関するプロパティ
これらのセキュリティに関するプロパティをさらに正確に表現するには、データがシステムのある部分から別の部分に流れるとは何を意味するかを定義する必要がある。これまでに考えて生きたモデルでは、二つのエンドポイント間の通信が呼び出し (Call) で実行されるとしてきた。例えば、ブラウザは HTTP リクエストを送信することでサーバーと対話し、スクリプトはブラウザ操作 API を呼び出すことでブラウザと対話する。こういった呼び出しでは、呼び出しの引数 (argument) または返り値 (return value) として何らかのデータが一方のエンドポイントからもう一方のエンドポイントまで流れる。この事実を表現するため、モデルに DataflowCall というシグネチャを定義し、args と returns というデータを表すフィールドを持たせる:
sig Data in Resource + Cookie {}
sig DataflowCall in Call {
args, returns: set Data, -- この呼び出しの引数と返り値
}{
this in HttpRequest implies
args = this.sentCookies + this.body and
returns = this.receivedCookies + this.response
...
}
例えば、HttpRequest に含まれる呼び出しでクライアントは sentCookies と body を引数としてサーバーに送信し、receivedCookies と response を返り値としてサーバーから受信する。
より一般的に言えば、引数は呼び出し元から呼び出し先へ流れ、返り値は呼び出し先から呼び出し元に流れる。これは、エンドポイントが新しいデータを手にする手段は次の二つしかないことを意味する:
- 自身が受け入れた呼び出しの引数として受け取る。
- 自身が起動した呼び出しの返り値として受け取る。
そこで DataflowModule というシグネチャを定義し、各タイムステップでモジュールがアクセスできるデータ要素の集合を表すフィールド accesses をそこに定義する:
sig DataflowModule in Endpoint {
-- このコンポーネントが最初から持っているデータの集合
accesses: Data -> Time
}{
all d: Data, t: Time - first |
-- このエンドポイントが時刻 t にデータ d へアクセスできるのは、
-- 次の条件が成り立つときに限る:
d -> t in accesses implies
-- (1) 直前のタイムステップでアクセスできていた。
d -> t.prev in accesses or
-- (2) 次の条件を満たす、時刻 t に完了する呼び出し c が存在する。
some c: Call & end.t |
-- (a) このエンドポイントが c を受け取り、c の引数に d が含まれる。
c.to = this and d in c.args or
-- (b) このエンドポイントが c を呼び出し、c の返り値に d が含まれる。
c.from = this and d in c.returns
}
また、モジュールが呼び出しの引数または呼び出しの返り値として提供できるデータ要素を制限する必要もある。そうしないと、モジュールが自身のアクセスできないデータを引数にして呼び出しを実行する奇妙なシナリオが可能になってしまう。
sig DataflowCall in Call { ... } {
-- (1) 引数は呼び出し側からアクセス可能でなければならない。
args in from.accesses.start
-- (2) 返り値は呼び出し先からアクセス可能でなければならない。
returns in to.accesses.start
}
システムの異なる部分間でやり取りされるデータの流れを記述する手段が以上で手に入ったので、私たちが興味を抱いているセキュリティに関するプロパティを記述する準備が (ほぼ) 整った。ただ、機密性と完全性が文脈依存 (context-dependent) な概念だったことを思い出してほしい。こういったプロパティを表現するには、システムの特定の部分が信頼できる (または悪意を持つ) ことを表現する手段が必要になる。また、 機密とみなされるデータ要素と悪意あるデータ要素、そしてどちらでもないデータ要素を区別する必要もある:
sig TrustedModule, MaliciousModule in DataflowModule {}
sig CriticalData, MaliciousData in Data {}
以上の定義があれば、重要なデータがシステムの信頼できない部分に移動する流れに関するアサーション (assertion) として機密性プロパティを表現できる:
// 信頼できないモジュールが重要なデータにアクセスできてはいけない。
assert Confidentiality {
no m: Module - TrustedModule, t: Time |
some CriticalData & m.accesses.t
}
完全性プロパティは機密性プロパティの双対となる:
// 悪意あるデータが信頼されているモジュールに流れてはいけない。
assert Integrity {
no m: TrustedModule, t: Time |
some MaliciousData & m.accesses.t
}
脅威モデル
脅威モデル (thread model) とは、システムのセキュリティに関するプロパティを無効化するために攻撃者が実行する操作を言う。セキュアなシステムの設計で脅威モデルの作成は重要なステップとなる。脅威モデルがあればシステムおよびシステムの環境に関する仮定事項が (存在するかどうかも含めて) 明らかになり、軽減する必要のある異なる種類のリスクに優先順位を付けられるようになる。
私たちのモデルでは、攻撃者はサーバー、スクリプト、クライアントとして振る舞えると仮定する。サーバーとして振る舞う攻撃者は、悪意あるウェブページを作成して注意を払っていないユーザーを誘導することで、知らず知らずのうちに機密情報を HTTP リクエストで自身に送信するよう仕向けるだろう。スクリプトとして振る舞う攻撃者は、他のページから読み込んだデータを攻撃者のサーバーに送信する DOM 操作を含んだ悪意あるスクリプトをユーザーに実行させるだろう。最後に、クライアントとして振る舞う攻撃者は、通常のユーザーとしてサーバーに悪意あるリクエストを送信し、他のユーザーのデータに対するアクセスを試みるだろう。異なるネットワークエンドポイント間の接続を盗聴する攻撃者は考えないものとする。このシナリオは実際の脅威ではあるものの、SOP はそういった種類の脅威を防ぐものとして設計されていないので、モデルには取り入れない。
プロパティの確認
セキュリティに関するプロパティと攻撃者の振る舞いを定義できたので、次は Alloy Analyzer を使って攻撃者が存在する場合でもセキュリティに関するプロパティが保持されることを自動的に検査できるかどうかを試してみよう。check コマンドを指示すると、Alloy Analyzer はシステムで可能なデータフローの組み合わせを全て調べ、与えられたアサーションが成り立たない状況を例示する反例の生成を試みる:
check Confidentiality for 5
例えば、以前に例として示したアプリケーションに対してモデルの機密性プロパティを検査すると、図 3a と図 3b に示す反例が生成される。これは EvilScript が重要なデータ MyInboxInfo を盗むシナリオを示している。
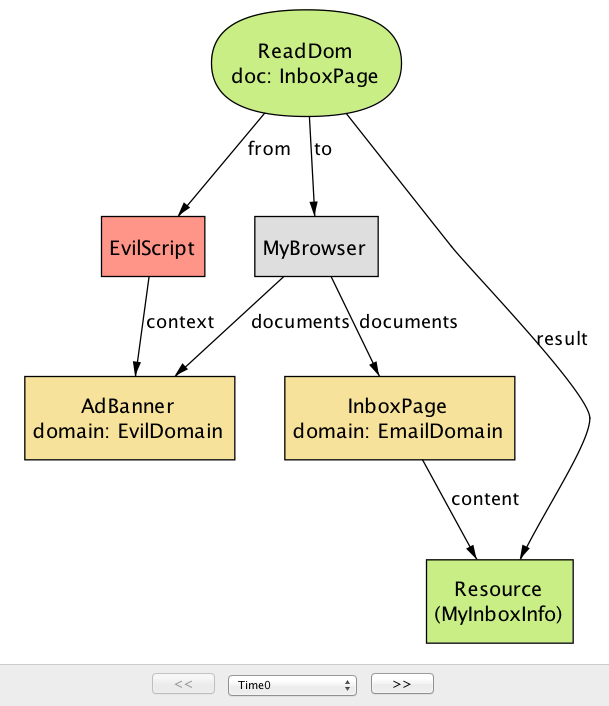
time=0)
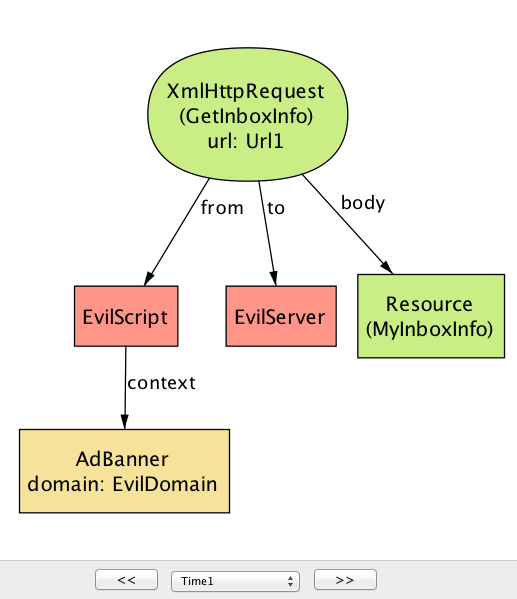
time=1)
この反例は二つのステップからなる。図 3a が示す最初のステップでは、EvilDomain が配信する AdBanner の中で実行される EvilScript が EmailDomain をドメインとする IndexPage のコンテンツ MyInboxInfo を読む操作を実行している。図 3b に示す次のステップでは、EvilScript が最初のステップで読み込んだコンテンツ MyInboxInfo を EvilServer に送信する XmlHttpRequest を実行している。この動作を可能にしている中心的な問題は、あるドメインから取得されたスクリプトが別のドメインから取得されたドキュメントのコンテンツを読む操作を実行できることにある。次節で見るように、これは SOP を使えば避けられるシナリオの一つである。
一つのアサーションに対して反例がいくつも存在する場合もある。異なる形でシステムの機密性プロパティが破られるシナリオを図 4 に示す。
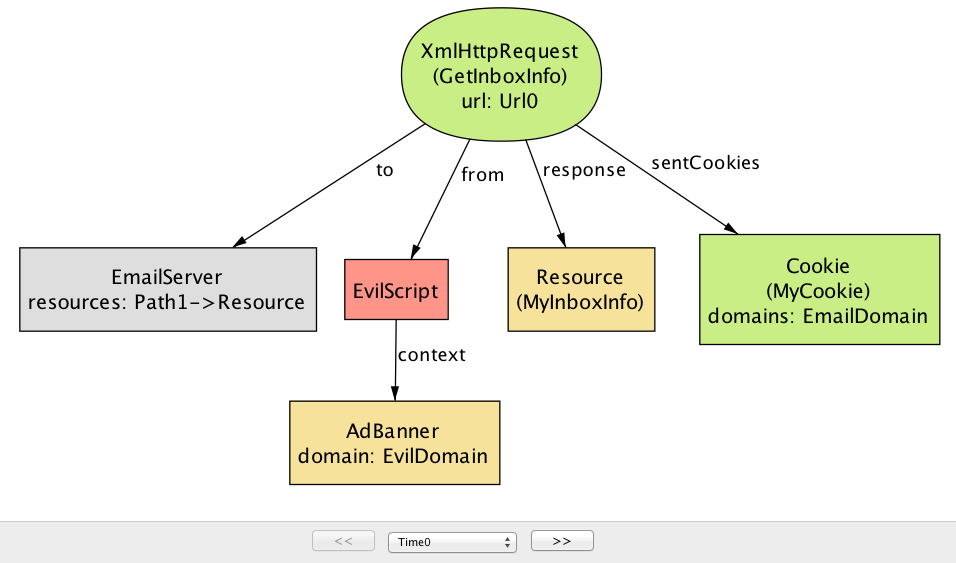
このシナリオで EvilScript は受信箱ページのコンテンツを読むのではなく、直接 EmailServer に GetInboxInfo リクエストを送信する。リクエストに付属するクッキー MyCookie は宛先サーバーと同じドメインをスコープに持つことに注目してほしい。これは危険である: クッキーはユーザーの識別子 (セッションクッキーなど) として使われることもある。EvilScript は事実上ユーザーになりすまし、MyInboxInfo のようなユーザーのプライベートな情報をサーバーから騙し取ることが可能になる。ここでも問題はスクリプトが異なるドメインの情報に対する自由なアクセスを持つことが関係している ── 具体的には、あるドメインから取得されたスクリプトが異なるドメインのサーバーに対して HTTP リクエストを送信できることが問題となる。
これら二つの反例は、スクリプトの振る舞いを制限する追加の仕組みが必要なことを示す。スクリプトが悪意を持つ可能性がある事実を考えればなおさらである。まさにここで SOP が登場する。
17.7 同一オリジンポリシー
SOP を表明する前に、オリジン (origin) の概念を定義する必要がある。オリジンはプロトコルとホスト、そして省略可能なポートからなる:
sig Origin {
protocol: Protocol,
host: Domain,
port: lone Port
}
利便性のため、URL からオリジンを作成する関数を定義しておく:
fun origin[u: Url] : Origin {
{o: Origin | o.protocol = u.protocol and o.host = u.host and o.port = u.port }
}
SOP は二つの部分からなり、それぞれスクリプトによる DOM API 呼び出しと HTTP リクエストの送信を制限する。一つ目の部分は、スクリプトがドキュメントに対する読み込みまたは書き込みの操作を実行するとき、スクリプトとドキュメントは同じオリジンを持たなければならないと定める:
fact domSop {
all o: ReadDom + WriteDom | let target = o.doc, caller = o.from.context |
origin[target] = origin[caller]
}
この domSop があるとき、前節で最初に示したシナリオは不可能となる。Script は異なるオリジンを持つドキュメントに対して ReadDom を実行できないためである。
SOP の二つ目の部分は、スクリプトが HTTP リクエストをサーバーに送信できるのは、宛先 URL とスクリプトのコンテキストが同じオリジンを持つときに限ると定める:
fact xmlHttpReqSop {
all x: XmlHttpRequest | origin[x.url] = origin[x.from.context.src]
}
ここから分かるように、SOP は悪意あるスクリプトが利用可能な二種類の脆弱性を除去するように設計されている。SOP が存在しなければ、ウェブは現在より格段に危険な場所になっていただろう。
一方で実際の運用からは、SOP の制限が過剰になる場合があると判明した。例えば、異なるオリジンを持つ二つのドキュメント間の通信が必要になるケースが存在する。上述したオリジンの定義だと、foo.example.com から取得されたスクリプトは bar.example.com のコンテンツを読むことができず、www.example.com に HTTP リクエストを送信することもできない。これらは異なるホストとみなされるためである。
必要な場合にはオリジン間通信 (cross-origin communication) を可能とするために、ブラウザは SOP の制限を緩める仕組みを数多く実装している。その中には熟慮の末に実装された仕組みもあれば、そうでないものもある。また、使い方を誤ると SOP が提供するセキュリティに穴を開けてしまう仕組みもある。以降の節では、こういった仕組みの中で最も一般的なものを説明しながら、それらが潜在的に持つセキュリティ上の落とし穴について議論する。
17.8 SOP を迂回するテクニック
SOP は機能とセキュリティの間にある緊張関係を示す典型的な例と言える: プログラマーはサイトを頑強かつ実用的にしたいと考える一方で、サイトをセキュアにするための仕組みが邪魔になることがある。実際 SOP が初めて導入されたとき、開発者は正当なクロスドメイン通信 (マッシュアップなど) ができないという問題に直面した。
この節では、SOP が課す制限を迂回するためにウェブ開発者が考案した仕組みの中で頻繁に利用されている次の四つを議論する:
document.domainプロパティ- JSONP
postMessage関数- CORS
これらは価値あるツールであるものの、注意して使わないとウェブアプリケーションは SOP が本来防ごうとしていた種類の攻撃に対して脆弱になってしまう。
これら四つのテクニックはいずれも驚くほど複雑であり、完全な解説には一つの章が必要になる。そのため、ここでは動作の簡単な説明、潜在的なセキュリティ上の問題、その問題を防ぐ方法を議論する。特に、以前に定義したセキュリティに関する二つのプロパティを Alloy Analyzer に検査させることで、攻撃者がテクニックを悪用できるどうかを確認する:
check Confidentiality for 5
check Integrity for 5
そして Alloy Analyzer が生成した反例を詳しく見ながら、セキュリティ上の落とし穴を避けながらテクニックを安全に使う上でのガイドラインを議論する。
document.domain プロパティ
最初に紹介するテクニックは document.domain プロパティを利用して SOP を迂回する。このテクニックの裏にあるアイデアは、異なるオリジンを持つドキュメント間の相互アクセスを document.domain の設定を通して許可するというものである。例えば、email.example.com から取得されたスクリプトに calendar.example.com から取得されたドキュメントの DOM に対する読み書きを許可するには、document.domain を example.com に設定するスクリプトを両方のドキュメントで実行する (両方のソース URL が同じプロトコルとポートを使うことが仮定されている)。
document.domain プロパティを変更する操作を BrowserOp の一種 SetDomain としてモデル化する:
// document.domain プロパティを変更する。
sig SetDomain extends BrowserOp { newDomain: Domain }{
doc = from.context
domain.end = domain.start ++ doc -> newDomain
-- ドキュメントのコンテンツは変化しない。
content.end = content.start
}
newDomain フィールドが変更後の新しい値を表す。ここで注意点が一つある: スクリプトが document.domain プロパティに設定できる値は、そのスクリプトのホスト名の完全修飾された接尾辞に限られる。例えば email.example.com から取得されたスクリプトは document.domain を example.com に設定できるのに対して、google.com には設定できない。このサブドメインに関する規則は fact を使ってモデル化する:
// スクリプトが document.domain プロパティを変更するとき、
// 変更後の値はホスト名の完全修飾された接尾辞でなければならない。
fact setDomainRule {
all d: Document | d.src.host in (d.domain.Time).subsumes
}
この規則が存在しないと、任意のサイトで実行されるスクリプトが document.domain を完全に自由に設定できる。これは、悪意あるサイトが document.domain を銀行のドメインに設定した上で iframe から銀行口座ページを読み込むと、そのページの DOM を読み込めることを意味する (ただし正確に言えば、この攻撃が成功するには銀行ページも document.domain プロパティを設定している必要がある)。
SOP の最初の定義に戻って、document.domain プロパティを考慮するように DOM アクセスの制限を緩めてみよう。このプロパティを同じ値に設定した二つのスクリプトは (加えてプロトコルとポートが同じなら) お互いの DOM を読み書きできる。
fact domSop {
-- 任意の成功した DOM の読み書き操作 o に対して次の少なくとも一方が成り立つ:
all o: ReadDom + WriteDom | let target = o.doc, caller = o.from.context |
-- (1) 操作対象と呼び出したドキュメントが同じオリジンを持つ。
origin[target] = origin[caller] or
-- (2) 両者の document.domain プロパティが改変されており、
(target + caller in (o.prevs <: SetDomain).doc and
-- 改変後のオリジンが等しい。
currOrigin[target, o.start] = currOrigin[caller, o.start])
}
ここで currOrigin[d, t] は時刻 t におけるドキュメント d の document.domain プロパティをホスト名に持つオリジンを返す関数である。
document.domain プロパティが両方のドキュメントで明示的に設定される必要がある点は注目に値する。ドキュメント A が example.com から、ドキュメント B が calendar.example.com から読み込まれ、ドキュメント B で document.domain プロパティが example.com に設定されたとする。このとき二つのドキュメントは同じオリジンを持つように見えるものの、お互いの通信は許可されない。ドキュメント A も document.domain を example.com に設定して初めて通信が可能になる。一見すると奇妙な振る舞いに思えるかもしれないが、こう定めておかないと様々な攻撃が可能になってしまう。例えば、サブドメインからのクロスサイトスクリプティング攻撃を受ける可能性が生じる: ドキュメント B の悪意あるスクリプトが document.domain プロパティを example.com に変更すれば、それだけで一方的にドキュメント A の DOM を操作できるようになる。
解析: こうして SOP の制限を緩めて特定の状況でオリジン間通信が可能になった後でも、SOP が提供するセキュリティ保証は成り立つだろうか? 攻撃者が document.domain プロパティを悪用してユーザーの重要なデータを読み書きするシナリオを Alloy Analyzer に生成させてみよう。
制限を緩めた新しい SOP の定義を使って検査を実行すると、Alloy Analyzer は機密性プロパティに対する反例となるシナリオを生成する:
check Confidentiality for 5
このシナリオは五つのステップからなる。最初の三ステップは document.domain プロパティを使う典型的な操作であり、異なるオリジンを持つ二つのドキュメント CalendarPage, InboxPage が document.domain プロパティの値を共通の値 ExampleDomain に設定した上で通信を行う。最後の二ステップでドキュメント BlogPage は悪意あるスクリプトを実行し、最初のステップで登場した二つのドキュメントのコンテンツにアクセスする。
シナリオの最初の二ステップを図 5a と 図 5b に示す。InboxPage と CalendarPage は入手元のドメインが異なる (それぞれ EmailDomain と ExampleDomain) ので、お互いの DOM にアクセスすることをブラウザは許可しない。二つのドキュメントでそれぞれ実行されるスクリプト InboxScript と CalendarScript は document.domain プロパティの値を ExampleDomain に変更する。この操作は、ExampleDomain が変更前のドメインの上位ドメインであるために許可される。
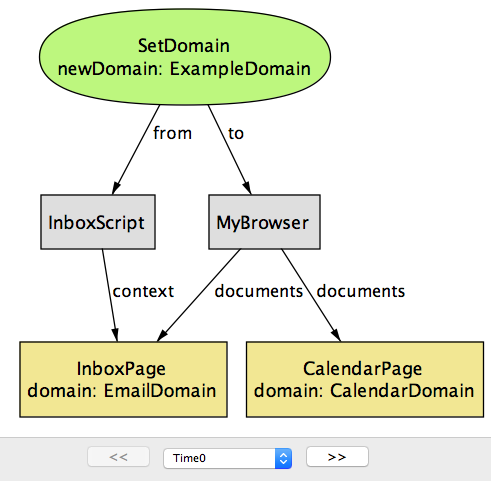
document.domain のセキュリティリスク (time=0)
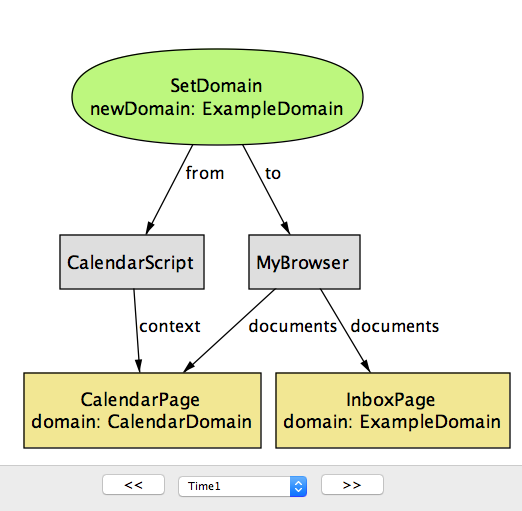
document.domain のセキュリティリスク (time=1)
この変更が終わると、二つのドキュメントは ReadDom と WriteDom を使ってお互いの DOM に対して読み書き操作を実行できる。この様子を図 5c に示す。
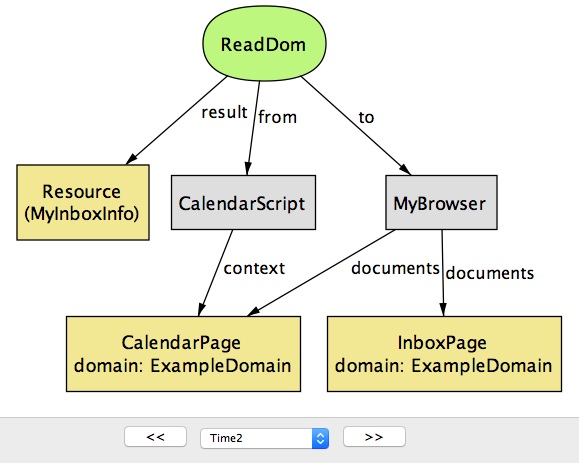
document.domain のセキュリティリスク (time=2)
こうして二つのドキュメントが document.domain プロパティの値を email.example.com および calendar.example.com から共通の example.com に変更したとき、この二つのドキュメント同士が通信可能になるだけではなく、blog.example.com などの example.com を上位ドメインに持つ任意のページとも通信が可能になることに注目してほしい。この事実に気が付いた攻撃者は、自身のブログページ BlogPage で特別なスクリプトを実行させるかもしれない。 図 5d に示す反例シナリオの次のステップでは、スクリプト EvilScript が SetDomain 操作を実行し、BlogPage の document.domain プロパティを ExampleDomain に変更する。
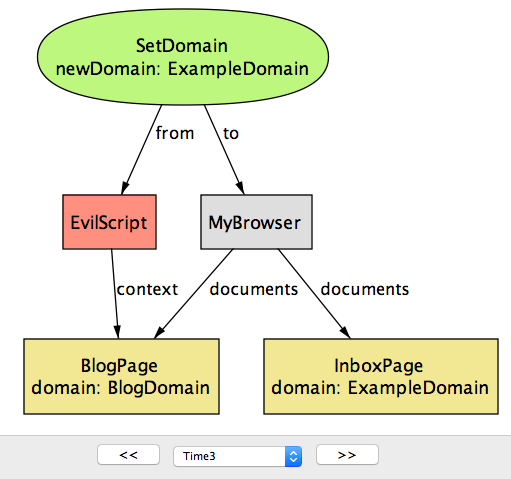
document.domain のセキュリティリスク (time=3)
この時点で BlogPage は二つのドキュメントと同じ document.domain の値を持つので、そのコンテンツに対して ReadDOM 操作を実行できる (図 5e)。
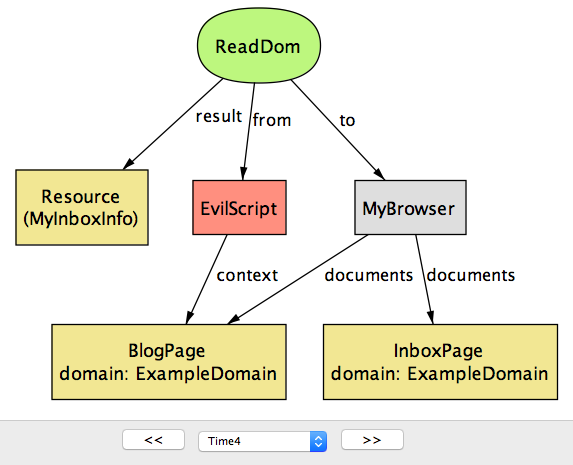
document.domain のセキュリティリスク (time=4)
この攻撃は、オリジン間通信に document.domain プロパティを用いる手法の決定的な弱点を示している。この手法を用いるアプリケーションのセキュリティは、同じベースドメインを共有する全てのページの中で最も弱いものと同程度にしかならない。後に議論する postMessage を利用する手法を使うと、よりセキュアなオリジン間通信をより一般的な範囲の通信に提供できる。
JSONP
後述する CORS が考案されるまで、SOP が XMLHttpRequest に課す制限を迂回するテクニックとしておそらく最も有名だったのが JSONP (JSON with padding) である。このテクニックは現在でも広く使われている。JSONP は HTML が持つスクリプトを埋め込むタグ <script> が SOP の例外とされる事実を利用する1。つまり、スクリプトは任意の URL から取得でき、ブラウザは取得したスクリプトを現在のドキュメントで快く実行する:
<script src="http://www.example.com/myscript.js"></script>
通常 script タグはコードを取得するために利用される。では、どうすれば script タグを使って異なるドメインからデータ (例えば JSON オブジェクト) を取得できるだろうか? 問題は、src 属性で指定されるデータをブラウザが JavaScript コードとして扱う点にある。そのため src 属性にデータソース (JSON ファイルや HTML ファイル) をそのまま指定するだけでは構文エラーが出てしまう。
一つのワークアラウンドとして、やり取りしたいデータをブラウザが正当な JavaScript コードとみなす文字列に変換する方法がある。この文字列をパディング (padding) と呼ぶ場合がある (「JSONP」の「P」はここから来ている)。このパディングは JavaScript のコードであれば何でも構わないものの、サーバーが返すデータを引数とする (リクエスト元のドキュメントで定義済みの) コールバック関数の呼び出しとすることが慣習になっている。JSONP を利用するための script タグの例を次に示す:
<script src="http://www.example.com/mydata?jsonp=processData"></script>
www.example.com のサーバーは、これが JSONP リクエストだと認識し、要求されたデータを引数として jsonp パラメータで指定された関数を呼び出す JavaScript コードを返す:
processData(MY_DATA)
これは正当な JavaScript コードであり、ブラウザによって現在のドキュメントで実行される。
私たちのモデルで JSONP は、コールバック関数の識別子をフィールド padding に持った HTTP リクエストの一種としてモデル化される。JSONP リクエストを受け取ったサーバーは、要求されたリソース (payload, ペイロード) とコールバック関数 (cb) からなるレスポンスを返す:
sig CallbackID {} // コールバック関数の識別子
// ブラウザが <script> タグを読み込んだときに送信されるリクエスト
sig JsonpRequest in BrowserHttpRequest {
padding: CallbackID
}{
response in JsonpResponse
}
sig JsonpResponse in Resource {
cb: CallbackID,
payload: Resource
}
このレスポンスを受け取ったブラウザは、ペイロードを引数としてコールバック関数を実行する:
sig JsonpCallback extends EventHandler {
cb: CallbackID,
payload: Resource
}{
causedBy in JsonpRequest
let resp = causedBy.response |
cb = resp.@cb and
-- JSONP リクエストの結果はコールバックの引数として渡される。
payload = resp.@payload
}
(EventHandler は特別な種類の呼び出しであり、別の呼び出し causedBy の後に実行されなければならない呼び出しを表す。ブラウザが送信した JSONP リクエストに対してサーバーが応答した後に実行される操作をモデル化するのに EventHandler を利用している。)
実行されるコールバック関数はレスポンスに含まれるものと同じ (cb = resp.@cb ) であるものの、それが最初の JSONP リクエストに含まれる padding と同じ保証は存在しないことに注意してほしい。言い換えれば、JSONP 通信においてサーバーにはリクエストに含まれるパディングをコールバック関数の名前として用いるレスポンスを送り返す (JsonRequest.padding = JsonpResponse.cb を成り立たせる) 責任がある。サーバーは理論上コールバック関数の名前を任意に選択でき、そもそもレスポンスをコールバック関数の呼び出しではなく任意の JavaScript のコードにできる。これは JSONP が持つ潜在的なリスクを示している: JSONP リクエストを受け取るサーバーはクライアントに任意の JavaScript コードを実行させる能力を持つので、信頼できてセキュアでなければならない。
解析: Alloy Analyzer で機密性プロパティ Confidentiality を検査すると、JSONP の潜在的なセキュリティリスクを示す反例が生成される (図 6a)。このシナリオでは、カレンダーアプリケーション (CalendarServer) が JSONP エンドポイント GetSchedule を通してサードパーティからリソースを利用可能にしている。リソースに対するアクセスを制限するために、CalendarServer はリクエストにユーザーを識別するクッキーが含まれる場合にのみユーザーのスケジュールを持ったレスポンスを送り返す。
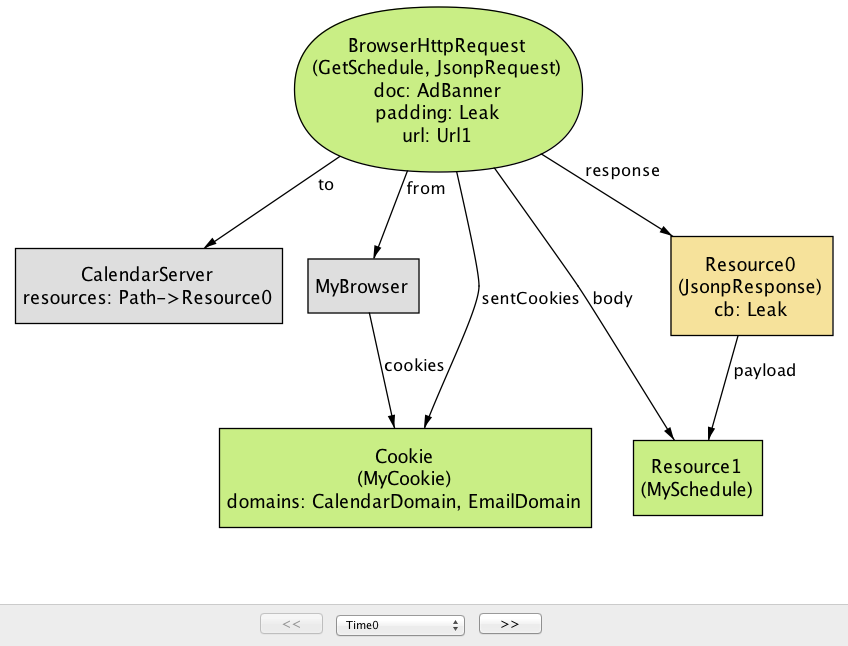
time=0)
サーバーが JSONP サービスを提供する HTTP エンドポイントを公開するとき、誰でも JSONP リクエストを送信でき、その中には悪意あるサイトも含まれる点に注目してほしい。このシナリオでは、EvilServer から取得された広告バナーに含まれる script タグによって GetSchedule リクエストが送信される。このリクエストの padding は Leak である。通常 AdBanner は被害者ユーザーのセッションクッキー MyCookie にアクセスできないものの、ブラウザは CalendarServer に送信される JSONP リクエストに MyCookie を自動的に含める。MyCookie を持った JSONP リクエストを受け取った CalendarServer は被害者のリソース MySchedule をパディング Leak に入れたレスポンスを返す。
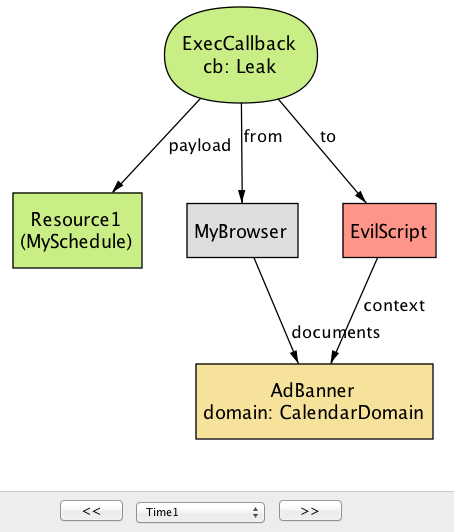
time=1)
次のステップ (図 6b) では、JSONP レスポンスをブラウザが解釈し、コールバック関数の呼び出し Leak(MySchedule) を実行する。以降の攻撃は難しくない: 入力の引数を EvilServer に転送するように Leak を定義しておけば、攻撃者は被害者の重要なデータにアクセスできる。
この攻撃はクロスサイトリクエストフォージェリ (cross-site request forgery, CSRF) の一種であり、JSONP に内在する弱点を示している: ウェブ上の任意のサイトが script タグを含めるだけで JSONP リクエストを送信でき、パディング内のペイロードにもアクセスできる。このリスクを軽減する方法として「JSONP リクエストからは重要なデータを返さない」や「リクエストの認証にクッキー以外の仕組み (セッショントークンなど) を用いる」がある。
postMessage
postMessage は HTML5 で新しく追加された機能であり、異なるオリジンを持つ二つのドキュメントから取得されたスクリプト間の相互通信を可能にする。document.domain プロパティを設定する方法より統制の取れたオリジン間通信を提供するものの、特有のセキュリティリスクも存在する。
postMessage はブラウザ API 関数であり、二つの引数を取る:
message: 送信するデータtargetOrigin: メッセージを受け取るドキュメントのオリジン
BrowserOp の一種としての定義を次に示す:
sig PostMessage extends BrowserOp {
message: Resource,
targetOrigin: Origin
}
他のドキュメントからのメッセージを受け取るには、postMessage を受けて起動されるイベントハンドラを登録する必要がある:
sig ReceiveMessage extends EventHandler {
data: Resource,
srcOrigin: Origin
}{
causedBy in PostMessage
-- "ReceiveMessage" イベントは適切なコンテキストを持ったスクリプトに送信される。
origin[to.context.src] = causedBy.targetOrigin
-- メッセージはそのまま渡される。
data = causedBy.@message
-- srcOrigin パラメータには送信元スクリプトのオリジンが渡される。
srcOrigin = origin[causedBy.@from.context.src]
}
ブラウザは ReceiveMessage に二つのパラメータを渡す: 送信されたメッセージに対応するリソース data と、送信側ドキュメントのオリジン srcOrigin である。シグネチャに含まれる四つの制約は ReceiveMessage が自身を起動した PostMessage に対応付くことを保証する。
解析: ここでも、PostMessage がオリジン間通信を実行するセキュアな方法かどうかを Alloy Analyzer に質問してみよう。今回は完全性プロパティ Integrity に対する反例が生成される。つまり、攻撃者は PostMessage の脆弱性を利用して信頼されているアプリケーションに悪意あるデータを送信できる。
デフォルトで postMessage の仕組みは誰が postMessage を送信できるかを制限しない点に注目してほしい。言い換えれば、ReceiveMessage ハンドラを登録済みのドキュメントに対しては任意のドキュメントから postMessage を送信できる。Alloy Analyzer が生成した反例インスタンス (図 7a) では、AdBanner 内で実行される EvilScript が悪意ある PostMessage を EmailDomain 宛てに送信する。
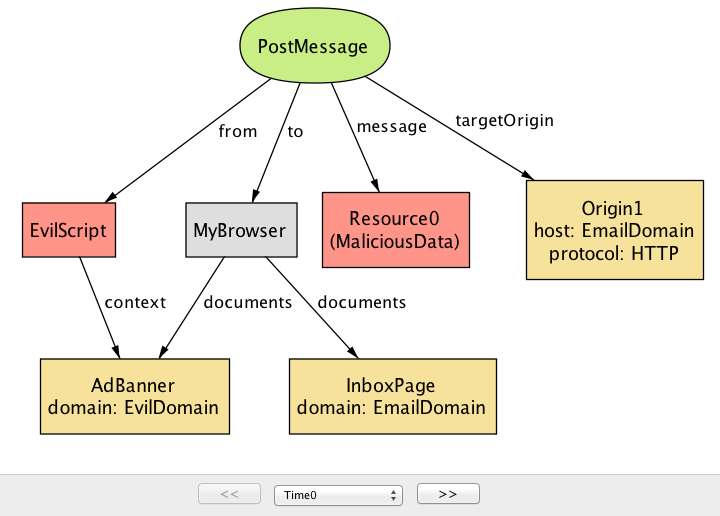
postMessage のセキュリティリスク (time=0)
ブラウザは受け取ったメッセージを宛先のオリジンを持つドキュメント (この例ではInboxPage だが、複数ある可能性もある) に転送する。InboxScript が ReceiveMessage の srcOrigin フィールドを確認して想定外のオリジンからのメッセージを除去する処理を実装していないと、InboxPage は悪意あるデータを受け取ることになり、セキュリティ攻撃につながる可能性が生まれる (例えば、XSS 攻撃を実行するための JavaScript コードがメッセージに埋め込まれているかもしれない)。
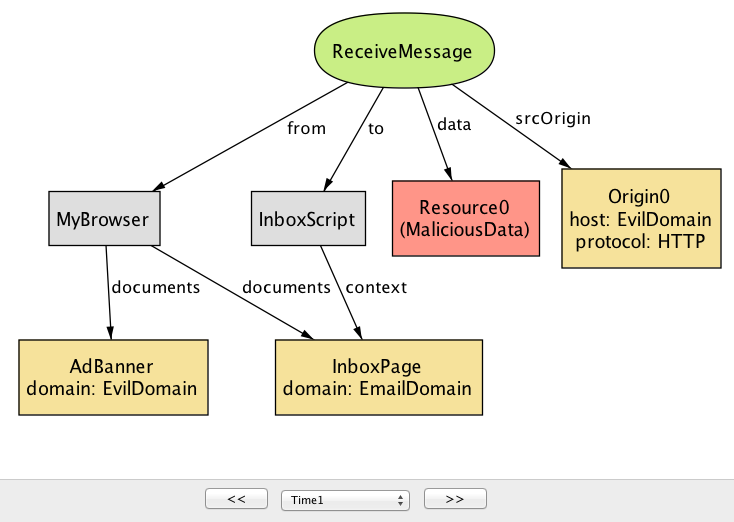
postMessage のセキュリティリスク (time=1)
この例から分かるように、PostMessage はデフォルトの状態ではセキュアではなく、宛先となるドキュメントが srcOrigin パラメータを確認して信頼できるドキュメントから送信されたメッセージだけを受け取ることが求められる。しかし残念ながら、実際に使われているスクリプトの多くはこの確認を省略しており、悪意あるドキュメントによる postMessage を通じた望ましくないデータの注入が可能になってしまっている2。
ただ、オリジンの確認が実装されない原因がプログラマーの注意不足だけとは限らない。postMessage を受け取ったときにオリジンが適切かどうかを判定する処理の実装が困難な場合もある: 一部のアプリケーションでは、postMessage の送信元となれる信頼されたオリジンのリストを事前に決定するのが難しい (このリストが動的に変更されるケースもある)。これもまた、セキュリティと機能の間にある緊張関係を表す例と言える。postMessage を使えばセキュアなオリジン間通信が可能になるものの、それは信頼できるオリジンのホワイトリストが分かっているときに限られる。
CORS
CORS (Cross-Origin Resource Sharing, オリジン間リソース共有) は異なるオリジンを持つサイトとのリソース共有をサーバーに許可する仕組みである。特に、CORS を利用するとスクリプトは自身と異なるオリジンを持つサーバーにリクエストを送信できるようになるので、SOP がオリジン間 Ajax リクエストに課す制限を迂回できる。
簡単に説明すると、典型的な CORS は二つのステップからなる:
- 外部サーバーのリソースに対するアクセスが必要になったスクリプトは、自身のオリジンを
Originヘッダーに記したリクエストをサーバーに送信する。 - サーバーは自身のリソースに対するアクセスが許可されるオリジンのリストを
Access-Control-Allow-Originに記したレスポンスを返す。
CORS を使わないときブラウザは SOP に従って一切のオリジン間リクエストをスクリプトに許可しない。しかし CORS が有効だと、ブラウザは Access-Control-Allow-Origin で指定されたオリジンをリクエストが持つときに限ってリクエストの送信とレスポンスに対するアクセスをスクリプトに許可する。
(CORS にはプリフライトリクエスト (preflight request) という概念がある。プリフライトリクエストは単純な GET や POST ではない複雑なオリジン間リクエストをサポートするために存在するが、本章では議論しない。)
Alloy で CORS リクエストをモデル化するために、origin, allowedOrigins フィールドを追加で持つ特別な種類の XmlHttpRequest を定義する:
sig CorsRequest in XmlHttpRequest {
-- クライアントが送信するリクエストの "Origin" ヘッダー
origin: Origin,
-- サーバーが送信するレスポンスの "Access-Control-Allow-Origin" ヘッダー
allowedOrigins: set Origin
}{
from in Script
}
正当な CORS リクエストを構成する条件は次の corsRule でモデル化される:
fact corsRule {
all r: CorsRequest |
-- CORS リクエストの origin ヘッダーがスクリプトのコンテキストと一致する。
r.origin = origin[r.from.context.src] and
-- 指定されたオリジンが許可されるオリジンに含まれる。
r.origin in r.allowedOrigins
}
解析: CORS を誤って使用したとき、サイトのセキュリティが弱まって攻撃者が利用できる隙が生まれる可能性はあるだろうか? Alloy Analyzer に検査を指示すると、機密性プロパティ Confidentiality に対する反例 (図 8) が生成される。
この反例では、カレンダーアプリケーションが CORS を使って他のアプリケーションとリソースを共有している。残念ながら、開発者は CalendarServer が返す CORS レスポンスの Access-Control-Allow-Origin ヘッダーを * に設定している。この * は全てのオリジンからなる集合を表すので、EvilDomain を含む任意のオリジンから取得されたスクリプトは CalendarServer にオリジン間リクエストを送信し、そのレスポンスを読むことができる。
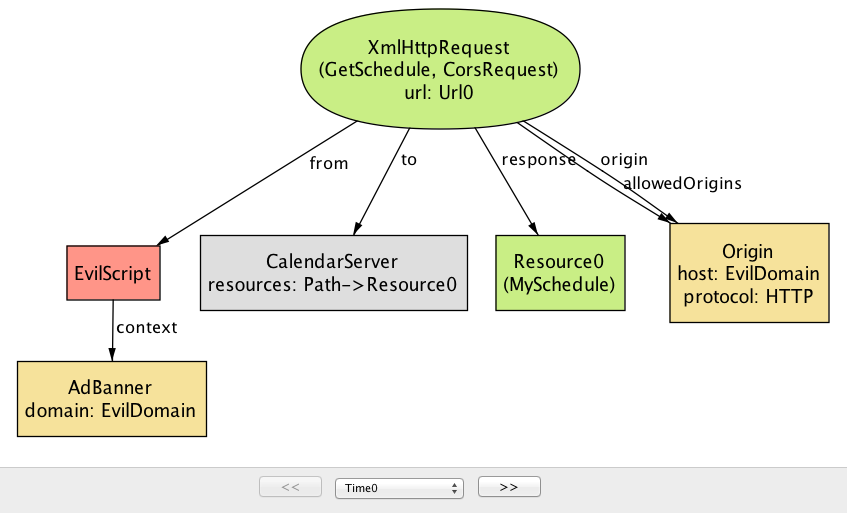
この例は CORS を利用する開発者が犯しがちな誤りを示している: レスポンスの Access-Control-Allow-Origin ヘッダーにワイルドカード * を指定すると、サーバーのリソース取得が任意のサイトに許可される。ワイルドカード * の設定はリソースをパブリックにして誰からでもアクセス可能にする目的なら問題ない。しかし、プライベートなリソースに対しても * をデフォルト値として使用し、悪意あるスクリプトから CORS リクエストで取得可能にしてしまっているサイトが数多く存在することが判明している3。
どうして開発者はワイルドカードを使うのだろうか? 実行時にアクセスが許可されるオリジンを設計時に確定させるのが難しいことが理由の一つである (上述した postMessage でも同様の理由でセキュリティリスクが生じていた)。例えば、リソースに対するアクセスを許可するサードパーティアプリケーションを登録制で動的に管理するサービスもある。
17.9 結論
筆者たちは本章で、Alloy と呼ばれる言語で SOP のモデルを作成するプロセスを通して SOP とそれに関連する仕組みの明確な理解を提供する文書の作成を目指した。本章で作成した SOP のモデルは伝統的な意味での実装ではなく、本書の他の章で示されるプログラムのように実際にデプロイして利用できるわけではない。このモデルでは筆者たちの考える「アジャイルモデリング」が持つ次の重要な要素の例示を試みた:
- 抽象的で小さなモデルから始めて、詳細を必要に応じて段階的に追加する。
- システムが満たすと期待されるプロパティを指定する。
- システムの設計が持つ潜在的な弱みを厳密な解析を通して調べる。
もちろん、本章が執筆された時点で SOP が考案されてから長い時間が経過していたのは事実である。しかし、こういった種類のモデリングをシステム設計の初期段階で行えば有用性がさらに増すと筆者たちは信じている。
SOP 以外にも、Alloy は幅広い分野の様々なシステムのモデル化・解析に使用されてきた ── ネットワークプロトコル、セマンティックウェブ、バイトコードのセキュリティから、電子投票や医療システムまで多岐にわたる。こういったシステムの多くで、Alloy による解析は開発者の目を場合によっては何年も逃れかねないバグや設計の欠陥を発見してきた。読者もぜひ Alloy 公式ページを訪れて、好きなシステムのモデルを作ってみてほしい!
17.10 補遺: Alloy におけるモジュールの再利用
本章の最初で触れたように、Alloy はモデル化されるシステムの振る舞いに関して何も仮定しない。組み込みのパラダイムが存在しないために、ユーザーはコアとなる少量の言語要素を使って自身が取り組むモデル化で有用となる様々なイディオムを作成できる。例えば、システムのモデル化に状態機械を使うこともできるし、複雑な不変状態を持つデータモデル、あるいはグローバルクロックを持った分散イベントモデルを使うこともできる。よく使われるイディオムを汎用的なモジュールとして保存すれば、複数のシステムからの再利用が可能になる。
本章で作成した SOP のモデルでは、呼び出し (call) を通じて通信し合うエンドポイントの集合としてシステムをモデル化した。「呼び出し」は非常に一般的な概念なので、その定義は一つの Alloy モジュールとして個別にカプセル化してある。通常のプログラミング言語が持つライブラリと同じように、このモジュールは他のモジュールからインポートできる。call.als の先頭にあるモジュール call の宣言を次に示す:
module call[T]
このモジュール宣言に含まれる T は型パラメータを表し、モジュールをインポートするときに具体的な型にインスタンス化できる。型パラメータの利用例は後述する。
システムの実行をグローバルな時間軸を使って表現すると呼び出しの間に時間的な前後関係が生まれ、議論がしやすくなる場合が多い。時間の概念を表現するために、新しいシグネチャ Time を定義する:
open util/ordering[Time] as ord
sig Time {}
Alloy の組み込みモジュール util/ordering は型パラメータとして渡された集合に全順序を課すので、ordering[Time] とインポートすることで全順序集合のように振る舞う Time オブジェクトの集合が得られる。
Time に関して特別なことは何もない点に注目してほしい: Step や State のような別の名前を付けたとしても、モデルの振る舞いは全く変わらない。関係に新しい列を追加してシステム実行中の異なる時点におけるフィールドの値を表現する手段を追加しているだけに過ぎない。例えば Browser シグネチャの cookies フィールドに対応する関係は Time の列を最後に持つ。この意味で、Time オブジェクトはインデックスとして使われるヘルパーオブジェクト以外の何物でもない。
呼び出しは二つの時点の間で発生する ── ある時点で開始 (start) し、別の時点で終了 (end) する。また、呼び出し元 (from) と呼び出し先 (to) も Call に関連付けられる:
abstract sig Call { start, end: Time, from, to: T }
HTTP リクエストの議論で、call というモジュールをインポートするとき Endpoint を型パラメータとして渡したことを思い出してほしい。このインポートによって型パラメータ T が Endpoint となってモジュールがインスタンス化され、呼び出し元と呼び出し先が Endpoint である Call オブジェクトの集合が定義される。モジュールは何度でもインポートできる: 例えば、UnixProcess というシグネチャを定義した上で call に UnixProcess を渡してインスタンス化すれば、Unix プロセスが Unix プロセスに対して指示する呼び出しを表現する Call オブジェクトが得られる。
-
この例外扱いがないと、jQuery などの JavaScript ライブラリを他のドメインから読み込めなくなる。 ↩︎
-
Sooel Son and Vitaly Shmatikov. The Postman Always Rings Twice: Attacking and Defending postMessage in HTML5 Websites. Network and Distributed System Security Symposium (NDSS), 2013. ↩︎
-
Sebastian Lekies, Martin Johns, and Walter Tighzert. The State of the Cross-Domain Nation. Web 2.0 Security and Privacy (W2SP), 2011. ↩︎