22. 単純なウェブサーバー
22.1 はじめに
過去二十年の間に、ウェブは途方もない変化を社会にもたらした。しかしウェブの核にある技術はそれほど変化しておらず、多くのシステムは Tim Berners-Lee が四半世紀前に考案した原則に従っている。具体的に言えば、ほとんどのウェブサーバーは原初のウェブと同様のメッセージを同様の方法でやり取りしている。
本章では典型的なウェブサーバーがメッセージをやり取りする仕組みを解説し、新しい機能を追加するとき書き直しが必要にならないソフトウェアシステムの設計方法を議論する。
22.2 前提知識
ウェブを利用するプログラムの圧倒的大部分は IP (Internet Protocol) と呼ばれるプロトコルを中心とする通信規格の集合を利用する。本章で注目するのは TCP (Transmission Control Protocol) であり、TCP はコンピューター間の通信をファイルの読み書きのように見せる役割を持つ。
IP を利用するプログラムはソケット (socket) を通して通信を行う。それぞれのソケットはポイント・ツー・ポイントの中心チャンネルにおける一つのエンドポイント (例えば電話通話における一方の電話) を表す。ソケットは特定のマシンを識別する IP アドレス (IP address)と、そのマシンにおけるポート番号 (port number) から構成される。IP アドレスは 8 ビットの数値を 4 つ並べて 174.136.14.108 のように表記する。DNS (domain name service) は数字の並びである IP アドレスと人間が記憶しやすい記号からなる aosabook.org のような名前の対応付けを管理する。
ポート番号は 0 から 65535 までの整数であり、ホストマシン上のソケットを識別する (IP アドレスが会社の電話番号だとすれば、ポート番号は内線番号に対応する)。ポート 0 から 1023 は OS 用に予約され、他の部分はアプリケーションから自由に使えることになっている。
HTTP (Hypertext Transfer Protocol) はプログラム同士が IP 越しにデータをやり取りする方法を定めるプロトコルの一つである。HTTP は意図的に単純な設計を持つ: クライアントは自分が望むデータを記したリクエストをサーバーと接続済みのソケットに対して送信し、サーバーはリクエストされたデータが含まれたレスポンスを返す (図 1)。レスポンスに含まれるデータはディスクから読み込まれる場合もあれば、プログラムによって動的に生成される場合もある。

HTTP リクエストの最も重要な特徴は、それが単なるテキストで構成される点である。HTTP リクエストの作成とパースができないプログラミング言語はまず存在しない。ただし、テキストが HTTP リクエストとして理解されるには、それが図 2 に示す形をしている必要がある。
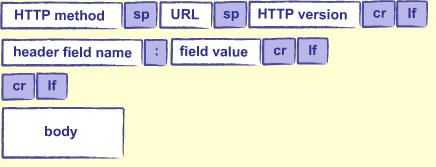
先頭の HTTP メソッドには、ほとんどの場合で GET (情報の取得) または POST (フォームデータなどのアップロード) が使われる。次の URL はクライアントが望むデータを指定する。URL が /research/experiments.html のようにディスク上のデータを指す場合もあるが、実際には完全に自由な文字列でありサーバーが解釈を決めて構わない (この事実は本章で重要な意味を持つ)。HTTP バージョンは通常 HTTP/1.0 または HTTP/1.1 が設定される。これらの違いは本章の議論に関係ない。
HTTP ヘッダーはキーとバリューからなるフィールド (field) と呼ばれる組を並べたものである。三つのフィールドからなる HTTP ヘッダーの例を次に示す:
Accept: text/html
Accept-Language: en, fr
If-Modified-Since: 16-May-2005
ハッシュテーブルのエントリーと異なり、HTTP ヘッダーでは同じ名前のキーに対するバリューを何回でも指定できる。この性質は例えば複数の種類のコンテンツを受け取りたい場合などに利用できる。
最後に、リクエストの本体 (body) はリクエストに関連付く追加データから構成される。ウェブフォームに入力されたデータを送信するときや、ファイルをアップロードするときにリクエストの本体が利用される。ヘッダーと本体の境界が見つけられるように、ヘッダーの最終行と本体の開始行の間には空白行が必須とされている。
リクエストの本体のサイズはヘッダーの Content-Length フィールドの値に等しい (単位はバイト)。
HTTP レスポンスは図 3 に示す HTTP リクエストと同様のフォーマットを持つ。
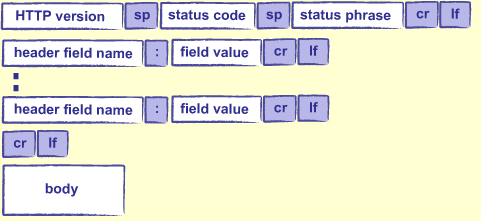
HTTP レスポンスのバージョン、ヘッダー、本体は HTTP リクエストと同じ意味とフォーマットを持つ。ステータスコードはリクエストで何が起きたかを示す: 例えば 200 は「成功した」を表し、404 は「見つからなかった」を表す。他にも様々なステータスコードが定義されている。ステータスフレーズは OK や not found といった文章でステータスコードの意味を人間が読める形で示す。
ここまでに説明した事項を除けば、本章の議論を理解するために必要な HTTP に関する知識は二つしかない。
まず、HTTP はステートレス (stateless) である: リクエストは一つずつ個別に処理され、原則としてサーバーはリクエスト間で何の情報も記憶しない。アプリケーションがユーザーの識別情報などの情報を記録したい場合は、自身でその処理を用意しなければならない。
リクエスト間で情報を記憶する必要がある処理ではクッキー (cookie) が使われることが多い。クッキーはサーバーがクライアントに送信する短い文字列であり、クライアントは以降のリクエストに受け取ったクッキーを付けて送信する。ユーザーが複数のリクエストにまたがって情報の記憶が必要な操作を実行すると、サーバーは新しいクッキーを作成してデータベースに保存し、それをクライアントに送信する。その後ユーザーのブラウザがクッキーを付けたリクエストを送信すると、サーバーはクッキーをデータベースに照合してユーザーが実行中の操作に関する情報を取得する。
HTTP に関して知っておくべき二つ目の事実として、URL にはパラメータを使って追加のデータを付けることができる。例えば検索エンジンでは検索する文字列をユーザーが指定する。このとき、検索結果ページの URL はどうするべきだろうか? 検索文字列を URL の一部とする選択肢も考えられるものの、実際には検索文字列をパラメータに持った URL にすべきとされる。URL の末尾に ? を付け、その後 key=value の形をした組を & で区切って並べると URL のパラメータとして解釈される。例えば URL https://www.google.ca/search?q=Python を開くと Google で Python を検索した結果が表示される。この URL は一つのパラメータを持ち、それはキー q とバリュー Python を持つ。http://www.google.ca/search?q=Python&client=Firefox のような長い URL が使われることもある。この場合はクライアントが Firefox ブラウザを使っていることが Google のサーバーに伝わる。URL には自由にパラメータを付けられる。しかしここでも、どのパラメータを解釈するかを決められるのはウェブサイトで実行されるアプリケーションだけである。
URL で ? と & は特殊文字なので、これらをエスケープする方法が当然存在しなければならない。二重引用符で囲まれた文字列の中で二重引用符をエスケープする方法が存在するのと同様である。URL の符号化方法を定める規格は特殊文字を % に二桁のコードを続けた文字列で表し、スペースを + で表すと定めている。そのため、例えば空白を含んだ文字列 grade = A+ を検索したときの URL は http://www.google.ca/search?q=grade+%3D+A%2B となる。
ソケットのオープン、HTTP リクエストの構築、そして HTTP レスポンスのパースを一から書くのは面倒なので、多くのプログラマーはライブラリを利用してこれらの処理を実装する。Python の標準ライブラリにも urllib2 と呼ばれる (前身の urllib を置き換える) ライブラリが存在するものの、このライブラリは多くの人が決して触れたいと思わないであろう細かなインターフェースを公開している。そこで本章では urllib2 を使いやすくラップした Requests というライブラリを使用する。このライブラリを使って本書のウェブサイトからページをダウンロードするコードを次に示す:
import requests
response = requests.get('http://aosabook.org/en/500L/web-server/testpage.html')
print 'status code:', response.status_code
print 'content length:', response.headers['content-length']
print response.text
status code: 200
content length: 61
<html>
<body>
<p>Test page.</p>
</body>
</html>
request.get 関数は引数に渡された URL に HTTP GET リクエストを送信し、レスポンスを表すオブジェクトを返す。返り値のオブジェクトの status_code 属性はレスポンスのステータスコードを表し、content_length 属性は本体のバイト数、text 属性は本体 (この例では HTML テキスト) を表す。
22.3 ハローウェブ
これで単純なウェブサーバーを書く準備が整った。基本的なアイデアは難しくない:
- クライアントが接続して HTTP リクエストを送信するのを待機する。
- リクエストをパースする。
- 何が要求されたかを理解する。
- 要求されたデータを取得する (もしくは動的に生成する)。
- データを HTML に成形する。
- 成形した HTML を本体に持つレスポンスをクライアントに送り返す。
ステップ 1, 2, 6 はどのウェブアプリケーションでも大きくは変わらないので、Python の標準ライブラリの BaseHTTPServer モジュールに実装されている。残りのステップ 3, 4, 5 を実装してサーバーを実行する簡単なコードを次に示す:
import BaseHTTPServer
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
'''固定された内容のページを返すことで HTTP リクエストを処理する。'''
# 送り返すページ
Page = '''\
<html>
<body>
<p>Hello, web!</p>
</body>
</html>
'''
# GET リクエストを処理する。
def do_GET(self):
self.send_response(200)
self.send_header("Content-Type", "text/html")
self.send_header("Content-Length", str(len(self.Page)))
self.end_headers()
self.wfile.write(self.Page)
#----------------------------------------------------------------------
if __name__ == '__main__':
serverAddress = ('', 8080)
server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler)
server.serve_forever()
BaseHTTPServer モジュール の BaseHTTPRequestHandler クラスは送られてきた HTTP リクエストをパースして要求されたメソッドを確認する。もしメソッドが GET なら、Pytyon の do_GET メソッドが呼び出される。上記のクラス RequestHandler は単純なページを動的に生成する処理で do_GET メソッドをオーバーライドしている。送り返されるレスポンスの本体はクラス変数 Page が保持するテキスト、レスポンスコードは成功を意味する 200 を持ち、ヘッダーは本体が HTML であることを示す Content-Type、そして本体の長さを表す Content-Length からなる。end_headers メソッドの呼び出しはヘッダーと本体を区切る空行を出力するためにある。
RequestHandler を定義して終わりではない: サーバーの実行を開始する最後の三行が必要になる。最初の行はサーバーのアドレスを表すタプルを定義する: 第一要素の空文字列は「現在のマシンでサーバーを実行する」を表し、第二要素の 8080 はポート番号を表す。その後アドレスと RequestHandler クラスを渡して BaseHTTPServer.HTTPServer オブジェクトを構築し、serve_forever メソッドを呼び出して制限時間を設けずに (Ctrl-C でプロセスを終了させるまで) サーバーを実行する。
このプログラムをコマンドラインから実行すると、実行した直後には何も表示されない:
$ python server.py
プログラムを実行したままブラウザで http://localhost:8080 を開くと、ブラウザに次のテキストが表示される:
Hello, web!
そしてプログラムからは次の文字列が出力される:
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET /favicon.ico HTTP/1.1" 200 -
最初の行は難しくない: ファイルを指定していないので、ブラウザは / (ルートディレクトリ) に対するリクエストを送信する。二行目が出力されるのは、ブラウザがアドレスバーのアイコンに表示する画像を取得しようとして /favicon.ico に対するリクエストを自動的に送信するためである。
22.4 リクエストに含まれる値の表示
上記のウェブサーバーを改変して、 HTTP リクエストに含まれる値を表示するようにしてみよう (この処理はデバッグでよく必要になるので、ここで練習しておいて損はない)。コードを整理するため、ページの作成と送信を個別のメソッドとする:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
# ...ページのテンプレート...
def do_GET(self):
page = self.create_page()
self.send_page(page)
def create_page(self):
# ...これから埋める...
def send_page(self, page):
# ...これから埋める...
send_page メソッドは以前のコードとほとんど変わらない:
def send_page(self, page):
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(page)))
self.end_headers()
self.wfile.write(page)
ページのテンプレートを次に示す。HTML の table 要素と、フォーマットのためのプレースホルダーが含まれる:
Page = '''\
<html>
<body>
<table>
<td>
<tr>
Header
</td>
<td>
Value
</td>
</tr>
<td>
<tr>
Date and time
</td>
<td>
{date_time}
</td>
</tr>
<td>
<tr>
Client host
</td>
<td>
{client_host}
</td>
</tr>
<td>
<tr>
Client port
</td>
<td>
{client_port}s
</td>
</tr>
<td>
<tr>
Command
</td>
<td>
{command}
</td>
</tr>
<td>
<tr>
Path
</td>
<td>
{path}
</td>
</tr>
</table>
</body>
</html>
'''
このテンプレートを使ってページを作成する create_page メソッドを次に示す:
def create_page(self):
values = {
'date_time' : self.date_time_string(),
'client_host' : self.client_address[0],
'client_port' : self.client_address[1],
'command' : self.command,
'path' : self.path
}
page = self.Page.format(**values)
return page
プログラムのメイン処理は変わらない: アドレスとリクエストハンドラを渡して HTTPServer クラスのインスタンスを作成し、serve_forever メソッドを呼び出してリクエストの処理を開始させる。ブラウザから http://localhost:8080/something.html にアクセスすると、次の文字列が表示される:
Date and time Mon, 24 Feb 2014 17:17:12 GMT
Client host 127.0.0.1
Client port 54548
Command GET
Path /something.html
something.html はディスク上にファイルとして存在しないにもかかわらず 404 エラーは発生しないことに注目してほしい。ウェブサーバーは単なるプログラムなので、リクエストを受け取ったときに実行できる処理に制限はない: 一つ前のリクエストがリクエストしたファイルを返すこともできるし、ランダムな Wikipedia ページを返すこともできる。何をしても構わない。
22.5 静的なページの配信
自然な次のステップとして、ページを動的に生成するのではなくディスク上に保存された静的なページを配信するサーバーを書いてみよう。まず do_GET メソッドを変更する:
def do_GET(self):
try:
# リクエストされたファイルのパスを作成する。
full_path = os.getcwd() + self.path
# full_path が存在しないなら例外を送出する。
if not os.path.exists(full_path):
raise ServerException("'{0}' not found".format(self.path))
# full_path がファイルなら処理する。
elif os.path.isfile(full_path):
self.handle_file(full_path)
# full_path がファイルでなければ例外を送出する。
else:
raise ServerException("Unknown object '{0}'".format(self.path))
# エラーをまとめて処理する。
except Exception as msg:
self.handle_error(msg)
このメソッドは、サーバーが実行されるディレクトリ (os.getcwd 関数の返り値) から到達できる任意のファイルは配信して構わないことを仮定している。BaseHTTPRequestHandler クラスは URL で指定されたパス ('/' から始まる文字列) を self.path に格納するので、現在のディレクトリと self.path を連結すればリクエストされたファイルのパスが得られる。
リクエストされたパスが存在しない、またはファイルでない場合は、例外を送出・捕捉することでエラーを報告する。ファイルが存在する場合は、ヘルパーメソッド handle_file を呼び出してファイルの内容を含んだレスポンスを返す。このメソッドはファイルを読み込み、以前に定義した send_content メソッドを使ってファイルの内容をクライアントに送り返す:
def handle_file(self, full_path):
try:
with open(full_path, 'rb') as reader:
content = reader.read()
self.send_content(content)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(self.path, msg)
self.handle_error(msg)
open 関数の第二引数に 'b' を含む文字列を渡すことでファイルをバイナリモードで開いている点に注目してほしい。こうしないと、Windows などの環境では Python が「気を利かせて」ファイルに含まれる改行文字を置き換えてしまう。また、ファイルの内容を全てメモリに読み込んでからレスポンスを組み立てるのは望ましくない: 現実のサーバーでは配信するファイルが数 GB のサイズを持つ可能性がある。この状況に対する対処は本章の範囲を超える。
最後に、エラーを処理するメソッドとエラー報告ページで使われるテンプレートを定義する必要がある:
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
def handle_error(self, msg):
content = self.Error_Page.format(path=self.path, msg=msg)
self.send_content(content)
このプログラムは一見すると正しく動作するように見える。しかし、リクエストされたページが存在しない場合にもステータスコード 200 を返すのは望ましい動作ではない。もちろんエラーページには英語でメッセージが書いてあるものの、ブラウザは英語を読めないのでリクエストが失敗したことを検出できない。この問題を修正するために handle_error と send_content を次のように修正する:
# リクエストされたファイルが存在しない場合を処理する。
def handle_error(self, msg):
content = self.Error_Page.format(path=self.path, msg=msg)
self.send_content(content, 404)
# リクエストされたファイルを送り返す。
def send_content(self, content, status=200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(content)))
self.end_headers()
self.wfile.write(content)
ファイルが見つからないとき ServerException を送出せず、代わりにエラーページを作成して送り返している点に注目してほしい。ServerException はサーバーのコードにおける内部エラーを表す ── つまり、私たちが書いたコードのエラーを表すのに利用される。一方で handle_error メソッドが作成するエラーページが表すのは URL が指定するファイルが存在しないことであり、これはユーザーの入力から生じたエラーである1。
22.6 ディレクトリに含まれる要素の列挙
次のステップとして、URL で指定されたパスがファイルではなくディレクトリのとき、そこに含まれる要素を列挙したページを返すようにウェブサーバーを改変してみよう。さらに、ディレクトリに index.html が存在する場合はそれを表示して、存在しないときに限って要素を列挙したいとする。
ただ、こういったロジックを do_GET メソッドに詰め込むのは望ましくない: 特別な振る舞いを制御する長い if 文が生まれてしまう。視点を一歩引いて一般的な問題を考えると優れたアプローチを導ける。書き直した一般的な do_GET メソッドを次に示す:
def do_GET(self):
try:
# リクエストされたファイルのパスを作成する。
self.full_path = os.getcwd() + self.path
# パスの処理方法を決める。
for case in self.Cases:
handler = case()
if handler.test(self):
handler.act(self)
break
# エラーを処理する。
except Exception as msg:
self.handle_error(msg)
リクエストされた完全パスを作成する最初のステップは変わらないものの、その後はコードが大きく異なる。その場でパスを調べるのではなく、リストに保存されたケースハンドラを走査する。各ケースハンドラは二つのメソッドを持つ: リクエストを処理できるかどうかを判断する test と、リクエストに対して処理を実行する act である。上記のコードでは、リクエストを処理できるケースハンドラの中で最初に見つかったものを使用している。
これまでに実装してきた振る舞いをケースハンドラとして実装する三つのクラスを次に示す:
class case_no_file(object):
'''ファイルまたはディレクトリが存在しない。'''
def test(self, handler):
return not os.path.exists(handler.full_path)
def act(self, handler):
raise ServerException("'{0}' not found".format(handler.path))
class case_existing_file(object):
'''ファイルが存在する。'''
def test(self, handler):
return os.path.isfile(handler.full_path)
def act(self, handler):
handler.handle_file(handler.full_path)
class case_always_fail(object):
'''他の全てのハンドラで処理できなかったとき用のベースケース'''
def test(self, handler):
return True
def act(self, handler):
raise ServerException("Unknown object '{0}'".format(handler.path))
これらのクラスをインスタンス化する処理を RequestHandler クラスの定義の先頭に追加する:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
'''
リクエストされたパスがファイルなら、そのファイルを送り返す。
処理できないリクエストに対してはエラーページを作成して送り返す。
'''
Cases = [case_no_file(),
case_existing_file(),
case_always_fail()]
...以降は前と同じ...
こうしたことでコードは単純というよりは複雑になったように思える: 行数は 74 から 99 に増加し、機能はそのままで間接参照のレベルが追加された。しかし、本節の最初で説明した index.html ページの配信とディレクトリに含まれる要素の列挙という機能を追加しようとすると、その利点が明らかになる。前者の機能を実装するクラスを次に示す:
class case_directory_index_file(object):
'''ディレクトリが持つ index.html を配信する。'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
return os.path.isdir(handler.full_path) and \
os.path.isfile(self.index_path(handler))
def act(self, handler):
handler.handle_file(self.index_path(handler))
このクラスでは、ヘルパーメソッド index_path が index.html ファイルのパスを作成する。この処理がケースハンドラのクラスに収まることで、メインの RequestHandler のコードが複雑になることが防がれる。test メソッドはパスが index.html ファイルを含むディレクトリかどうかを判定し、act メソッドはメインのリクエストハンドラに index.html を配信するよう指示する。
RequestHandler に必要となる唯一の変更は、case_directory_index_file オブジェクトをリスト Case に対する追加のみである:
Cases = [case_no_file(),
case_existing_file(),
case_directory_index_file(),
case_always_fail()]
index.html ファイルを持たないディレクトリに対する処理はどうなるだろうか? test メソッドは case_directory_index_file クラスの test メソッドと同様に (not を追加するだけで) 書ける。act メソッドは少し複雑になるものの、これまでに定義してきた RequestHandler のメソッドと Python の標準ライブラリにある os.listdir 関数を使えば難しくない:
class case_directory_no_index_file(object):
'''
index.html ファイルを持たないディレクトリに含まれる要素を
列挙したページを配信する。
'''
# ディレクトリに含まれる要素を表示するページのテンプレート
Listing_Page = '''\
<html>
<body>
<ul>
{0}
</ul>
</body>
</html>
'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
return os.path.isdir(handler.full_path) and \
not os.path.isfile(self.index_path(handler))
def act(self, handler):
try:
entries = os.listdir(handler.full_path)
bullets = ['<li>{0}</li>'.format(e) for e in entries if not e.startswith('.')]
page = self.Listing_Page.format('\n'.join(bullets))
handler.send_content(page)
except OSError as msg:
msg = "'{0}' cannot be listed: {1}".format(handler.path, msg)
handler.handle_error(msg)
22.7 CGI プロトコル
もちろん、多くの人はウェブサーバーに新しい機能を追加するためにウェブサーバーのソースコードを直接編集したいとは思わないだろう。その手間を省くために、たいていのウェブサーバーは CGI (Common Gateway Interface) と呼ばれる仕組みを持つ。CGI は外部プログラムを実行してリクエストを処理する標準的な手続きを定める。
例えば、アクセス時刻を表示する HTML ページを作成したいとしよう。CGI を利用すれば、次のプログラムを書いたファイルを新しく用意するだけでこの機能を実装できる:
from datetime import datetime
print '''\
<html>
<body>
<p>Generated {0}</p>
</body>
</html>'''.format(datetime.now())
このプログラムをウェブサーバーから実行する仕組みは次のクラスで実装できる:
class case_cgi_file(object):
''' Python プログラムを実行する。 '''
def test(self, handler):
return os.path.isfile(handler.full_path) and \
handler.full_path.endswith('.py')
def act(self, handler):
cmd = "python " + handler.full_path
p = subprocess.Popen(cmd, shell=True,
stdin=PIPE, stdout=PIPE, stderr=PIPE, close_fds=True)
child_stdin, child_stdout = (p.stdin, p.stdout)
child_stdin.close()
data = child_stdout.read()
child_stdout.close()
handler.send_content(data)
test メソッドに難しいところはない: ファイルが存在して、拡張子 .py を持つかどうかを判定する。この条件が満たされるなら、そのファイルが act メソッドで実行される。このメソッドはセキュリティ的に絶望的なので気を付けてほしい。サーバーマシン上にある任意の Python ファイルが実行されるので、無限ループなどの実行されるべきでない処理が実行される可能性がある。
act メソッドは次の単純な処理を行う:
- 子プロセスでプログラムを実行する。
- 子プロセスが標準出力に書き込んだ内容をキャプチャする。
- キャプチャした文字列をクライアントに送り返す。
完全な CGI プロトコルはこれより豊富な機能を持つ。特に、外部プログラムから URL のパラメータにアクセスする方法が提供される ── 上記のコードでサーバーから外部プログラムに引数を渡すようにすれば実装できるので、全体のアーキテクチャに変更が必要なわけではない。
続いて、リスト RequestHandler.Cases の要素 (ケースハンドラ) は同じインターフェースを持つので、基底クラスを用意してリファクタリングをしてみよう。このとき index_path メソッドのように複数のクラスで利用される処理は基底クラスのメソッドにできる。リファクタリング後の RequestHandler クラスを次に示す:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
Cases = [case_no_file(),
case_cgi_file(),
case_existing_file(),
case_directory_index_file(),
case_directory_no_index_file(),
case_always_fail()]
# エラーページのテンプレート
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
# リクエストを識別・処理する。
def do_GET(self):
try:
# リクエストされたファイルのパスを作成する。
self.full_path = os.getcwd() + self.path
# 処理方法を決定する。
for case in self.Cases:
if case.test(self):
case.act(self)
break
# エラーを処理する。
except Exception as msg:
self.handle_error(msg)
# エラーページを送り返す。
def handle_error(self, msg):
content = self.Error_Page.format(path=self.path, msg=msg)
self.send_content(content, 404)
# コンテンツを送り返す。
def send_content(self, content, status=200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(content)))
self.end_headers()
self.wfile.write(content)
ケースハンドラの基底クラスは次のようになる:
class base_case(object):
'''ケースハンドラの基底クラス'''
def handle_file(self, handler, full_path):
try:
with open(full_path, 'rb') as reader:
content = reader.read()
handler.send_content(content)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(full_path, msg)
handler.handle_error(msg)
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
assert False, 'Not implemented.'
def act(self, handler):
assert False, 'Not implemented.'
このとき、例えば静的ファイルを配信するケースハンドラは次のように書ける:
class case_existing_file(base_case):
'''ファイルが存在するケース'''
def test(self, handler):
return os.path.isfile(handler.full_path)
def act(self, handler):
self.handle_file(handler, handler.full_path)
他のケースハンドラも同様に書き換えられる。
22.8 議論
最初に書いたコードとリファクタリング後のコードの違いは二つの重要な考え方を示している。まず、クラスを関連するサービスの集合として捉える考え方がある。RequestHandler と base_case が具体的な判断を下したり処理を実行したりするわけではない。これらのクラスは他のクラスがそういったことを行う上で利用するツールを提供している。
次に、拡張性を意識する考え方がある: 本章で作成したウェブサーバーに新しい機能を追加するには、外部 CGI プログラムまたはケースハンドラのクラスを書く必要がある。後者では RequestHandler に一行の変更 (Cases リストに新しいケースハンドラを追加する) が必要になるものの、ケースハンドラを記述する構成ファイルを用意すればその手間も省ける。そうすれば、両方の場合で機能を追加するプログラマーが低レベルの詳細を気にする必要はなくなる。これは、BaseHTTPRequestHandler クラスのおかげで私たちがソケット接続の管理や HTTP リクエストのパースの詳細を気にする必要がないのと同様である。
これらの考え方は様々な場面で有用となる。ぜひ自分のプロジェクトで利用機会を探ってみてほしい。
-
本章で
handle_errorメソッドを利用する場面は何度かあるものの、その中にはステータスコード 404 が適当でないケースも含まれる。どうすればレスポンスコードを設定可能にできるか考えてみてほしい。 ↩︎