Infinispan
はじめに
Infinispan1 はオープンソースのデータグリッドプラットフォームであり、インメモリの分散型 NoSQL キーバリューストアを提供する。ソフトウェア技術者が Infinispan のようなデータグリッドを利用するときは、パフォーマンスを改善するための分散インメモリキャッシュとしてリレーショナルデータベースといった高価で低速なストアの前段に配置されるか、そうでなければリレーショナルデータベースを置き換える分散型 NoSQL データストアとして利用される場合が多い。いずれの場合でも、ソフトウェアアーキテクチャにデータグリッドの追加を検討する主な目的はパフォーマンスである。高速かつ低レイテンシなアクセスへの需要は近年高まっている。
そのため、パフォーマンスは Infinispan の唯一の存在意義である。Infinispan のコードは極限までパフォーマンスに注意を払いながら書かれている。
概観
Infinispan を詳しく見ていく前に、Infinispan の典型的な用途を説明する。Infinispan はミドルウェアと呼ばれるソフトウェアのカテゴリに属する。Wikipedia によると、ミドルウェアは「ソフトウェアの糊」である ── サーバー上に配置され、アプリケーション (例えばウェブサイト) とオペレーティングシステムやデータベースの間を取り持つ。ミドルウェアはアプリケーション開発者の生産性を高め、管理が容易でテスト可能なアプリケーションを素早く効率良く生み出すために利用される場合が多い。こういった目標はモジュール化とコンポーネントの再利用によって達成される。Infinispan はアプリケーションの処理やビジネスロジックとデータストレージ層の間で使われることが特に多い。データの保存 (そして取得) はしばしば最大のボトルネックとなり、インメモリのデータグリッドをデータベースの前段に配置するとパフォーマンスが大きく改善されるケースがよくある。さらに、データストレージは単一の競合点や障害点になる場合が多い。この点に関しても、従来のデータストレージの前段に (あるいは従来のデータストレージを置き換えるものとして) Infinispan を使えばアプリケーションの弾性とスケーラビリティを大きく改善できる可能性がある。
誰が Infinispan を使うのか?
Infinispan は電気通信業界、金融サービス業界、ハイエンド電子商取引、生産管理システム、ゲーム、モバイルプラットフォームを含む様々な業界で使われてきた。一般にデータグリッドは金融サービス業界でよく使われてきた: 金融サービス業界は個別のマシンで発生する障害を隔離する方式を利用した巨大データに対する極限まで高速なデータアクセスを強く必要とする。近年この要件は他の業界にも広がり、それが理由で Infinispan も幅広いアプリケーションで採用されるようになった。
利用法: ライブラリとサーバー
Infinispan は Java (一部は Scala) で実装され、二つの異なる利用法を提供する。まず、Infinispan は Java アプリケーションに組み込むライブラリとして利用できる (図 7.1)。このときは Java プログラムが Infinispan の JAR ファイルをインクルードし、Infinispan のコンポーネントを参照・インスタンス化する。この方法では Infinispan コンポーネントがアプリケーションと同じ JVM に配置され、アプリケーションが持つヒープメモリの一部がデータグリッドノードとして利用される。
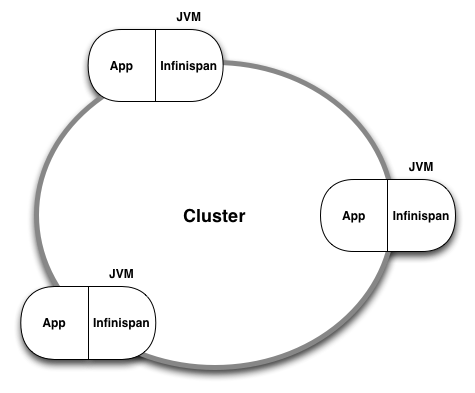
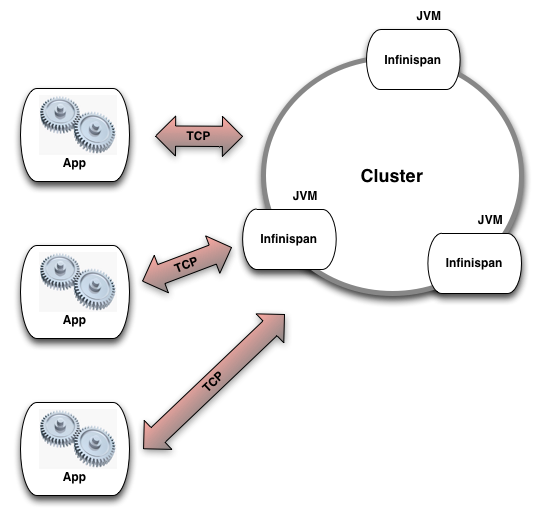
次に、Infinispan はリモートデータグリッドとしても利用できる。このとき、起動された複数の Infinispan のインスタンスがクラスターを形成し、クライアントは (様々なクライアントライブラリの一つを利用して) ソケット越しにクラスターへ接続する。この方式では Infinispan ノードのそれぞれが個別に隔離された JVM の中に存在し、JVM ヒープ全体を自身だけで利用する。
アーキテクチャ: ピアツーピア
両方の利用法において、Infinispan インスタンスはネットワーク内の他の Infinispan インスタンスを検出し、クラスターを形成し、データの共有を開始し、クラスターに含まれる全てのサーバーを透過的に被覆するインメモリデータ構造をアプリケーションに提供する。クラスターにノードを追加して全体のキャパシティを増やしていくとき、Infinispan がアプリケーションに提供できるインメモリストレージの容量に理論上の制限はない。
Infinispan では、クラスター内の全てのインスタンスが平等な役割を持つピアツーピアのテクノロジが利用される。これは単一の障害点やボトルネックが存在しないことを意味する。さらに重要なこととして、インスタンスの追加によって水平にスケール可能な弾性のあるデータ構造がアプリケーションに提供される。さらに、一部のインスタンスをシャットダウンして規模を縮小することもできる。このときアプリケーションは通常の動作を継続でき、アプリケーションとしての機能が利用不可能になることは一切ない。
Infinispan のベンチマーク
Infinispan のような分散データ構造をベンチマークする上で最も厄介な問題はツールである。Infinispan の開発が始まったころ、データの格納・取得のパフォーマンスをデータの量を変化させながら測定する小さくて素敵なツールは存在していたのに対して、構成やクラスターサイズなどを変えたときのパフォーマンスを測定して比較解析を行うツールは存在しなかった。この問題を解決するため、Radar Gun が開発された。
Radar Gun は Radar Gun の節で詳しく見る。他のツール (Yahoo Cloud Serving Benchmark, The Grinder, Apache JMeter) はここでしか言及されないものの、Infinispan のベンチマークでは非常に重要である。こういったツールに関する文献はオンラインで大量に公開されている。
Radar Gun
Radar Gun2 はオープンソースのベンチマークフレームワークであり、比較可能な (そして競争し合う) ベンチマークの実行、スケーラビリティの測定、収集されたデータ点からのレポート作成をサポートする。Radar Gun は Infinispan といった分散データ構造をベンチマークするために特別に作られており、Infinispan の開発中にボトルネックを特定・修正するために広く使われてきた。
Yahoo Cloud Serving Benchmark
Yahoo Cloud Serving Benchmark3 (YCSB) はリモートデータストアに対して様々なサイズのデータを読み書きするときのレイテンシをテストするために作成されたオープンソースのツールである。YCSB はどんなデータストアも単一のリモートエンドポイントとして扱うので、クラスターのノード数が増減したときのスケーラビリティは測定できない。また、YCSB は分散データ構造という概念を持たないので、クライアント/サーバーモードで動作する Infinispan しかベンチマークできない。
Grinder と Apache JMeter
Grinder4 と Apache JMeter5 はオープンソースのシンプルな負荷生成プログラムである。ソケットにリッスン中の任意のサーバーに対して負荷をかけることができ、スクリプトによる非常に柔軟な制御が行える。YCSB と同様、Grinder と Apache JMeter はクライアント/サーバーモードで動作する Infinispan に対してしか使えない。
Radar Gun
開発初期
Radar Gun は Infinispan のコア開発チームによって作成されたベンチマークツールであり、元々は Cache Benchmarking Framework6 という名前の Sourceforge プロジェクトとして始まった。当初は異なるモードや構成で動作する組み込みの Java キャッシュのベンチマークに利用された。結果が比較できるように設計されていたので、同じベンチマークを様々なキャッシングライブラリや同じライブラリの異なるバージョンに対して自動的に実行し、パフォーマンスのリグレッションをテストする使い方が可能だった。
その後 Cache Benchmarking Framework は Radar Gun に改名され、GitHub で公開されるようになり、たくさんの機能が追加された。
分散データ構造のベンチマーク
しばらくして Radar Gun は分散データ構造をベンチマークできるように拡張された。メインのターゲットは組み込みライブラリで変わらないものの、複数のフレームワークインスタンスを異なるサーバーで起動し、それぞれのインスタンスで分散キャッシングライブラリを起動することが Radar Gun から可能になった。その後はクラスターの各ノードでベンチマークが並列に実行される。ベンチマークが終了するとマスターの Radar Gun が結果を収集し、レポートを作成する。クラスターのサイズ (数ノードから数百・数千ノードまで) を手動で調整しながらベンチマークを実行するのは事実上不可能なので、ノードの自動的な追加と削除はスケーラビリティをテストする上で非常に重要となる。
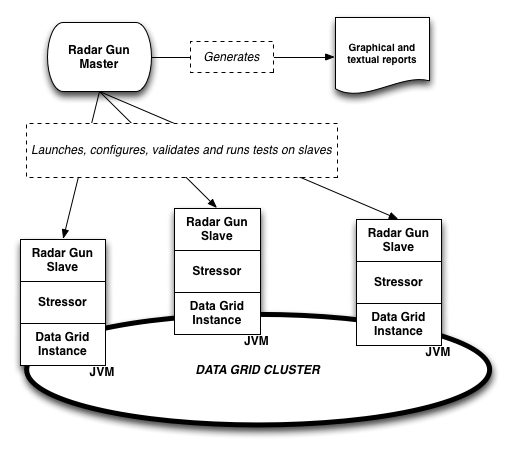
速くても間違っていたら意味はない
ベンチマークの各ステージを実行する前にステータスをチェックしてクラスターが正常な状態にあることを確認する機能が Radar Gun に後から追加された。この機能によって誤った結果の早期検出が可能になり、ベンチマーク全体が終了するのを待ってから手動で再実行しないで済むようになった ── ベンチマークの実行には数時間単位の時間がかかる場合もある。
プロファイル
Radar Gun はプロファイラのインスタンスを起動して各データグリッドノードに関連付け、プロファイラのスナップショットを作成する。このスナップショットがあると、高負荷時に各ノードで何が起こっているかが分かりやすくなる。
メモリのパフォーマンス
Radar Gun はメモリ消費量を測定する機能を持つ。インメモリデータストアの「パフォーマンス」には読み込みと書き込みの速度だけではなく、データ構造のメモリ消費量も含まれる。Java ベースのシステムではガベージコレクションがシステムの応答性に悪影響を及ぼす場合があるので、メモリに関するパフォーマンスが特に重要となる。ガベージコレクションについては後述する。
メトリック
Radar Gun はパフォーマンスを一秒間に実行できるトランザクションの個数として測定する。この値は各ノードでキャプチャされ、マスターによって収集される。書き込みと読み込みのパフォーマンスは別々にグラフ化されるものの、両者は (現実的な負荷を持ったテストとするために) 同時に実行される。加えて、Radar Gun は読み込みと書き込みのトランザクションにかかる時間の平均値、中間値、標準偏差、最大値、最小値をキャプチャする。ただし、これらがグラフに表示されるとは限らない。また、メモリのパフォーマンスも各イテレーションにおけるメモリ消費量としてキャプチャされる。
拡張性
Radar Gun は拡張可能なフレームワークである。独自のデータアクセスパターン、データ型、データサイズを使ってベンチマークを実行できる。さらに、任意のデータ構造、キャッシングライブラリ、NoSQL データベースもアダプターを追加すればテストできる。
データグリッドの異なる構成のパフォーマンスを比較するエンドユーザーにも Radar Gun の利用が推奨される。
有力な容疑者
パフォーマンスのボトルネックだろうと見込まれた Infinispan のサブシステムがいくつかある。こういったサブシステムは詳しい調査の対象となり、必要だと分かれば最適化が行われた。順に見ていく。
ネットワーク
ピア間の通信やクライアントとグリッド間の通信といったネットワーク通信は Infinispan で最も時間のかかる部分である。
ピアネットワーク
Infinispan はピアツーピア形式でノード間通信を行うオープンソースのグループ通信ライブラリ JGroups7 を利用する。JGroups はネットワークプロトコルとして TCP と UDP (UDP マルチキャストを含む) をサポートし、UDP などの低信頼プロトコルを使った場合でもメッセージの確実な転送や再送といった高レベル機能を提供する。
ユーザーが利用するネットワークやアプリケーションの特性に合わせて JGroups のオプション (time-to-live、バッファサイズ、スレッドプールサイズなど) を正しく調整することは非常に重要である。また、JGroups がバンドリング (複数の小さなメッセージを一つのネットワークパケットにまとめる処理) とフラグメンテーション (大きなネットワークパケットを複数の小さなメッセージに分割する、バンドリングの逆処理) を行う方法にも注意する必要がある。
ユーザーのオペレーティングシステム (OS) およびネットワーク機器 (スイッチとルーター) が持つネットワークスタックも JGroups の構成に合わせて調整するべきである。OS の TCP 実装が持つ送信バッファ、受信バッファ、フレームサイズ、ジャンボフレーム利用の有無といった要素の調整は、データグリッド内の最も高価なコンポーネントを最適に振る舞わせる上で重要な役割を果たす。
パケットの解析では netstat や wireshark といったツールが有用となる。グリッドの負荷を確認するときは Radar Gun が利用できる。ボトルネックを見つけるために Infinispan の JGroups レイヤーをプロファイルすることも Radar Gun で行える。
サーバーソケット
Infinispan はサーバーソケットの作成と管理に Netty8 という有名なフレームワークを利用する。Netty は Java 内蔵の非同期フレームワーク NIO のラッパーであり、NIO は OS の非同期ネットワーク機能を利用して実装されている。Netty を利用すると、コンテキストスイッチのコストが増加する代わりにリソースの効率的な利用が可能になる。一般に、Netty は高負荷時でも非常によく動作する。
最適なパフォーマンスを保証するために、Netty はバッファやスレッドプールのサイズといった調整可能なオプションをいくつかのレベルで提供する。こういった値は OS と合わせる必要がある。
データのシリアライズ
データをネットワークに流すとき、Infinispan はアプリケーションオブジェクトをバイト列にシリアライズし、そのバイト列をネットワーク、グリッド、そして最終的にはピアに対して送信する。このバイト列は受信側でアプリケーションオブジェクトにデシリアライズされ、アプリケーションによって読み込まれる。最も典型的な構成では、リクエストの処理にかかる時間の約 20% がシリアライズとデシリアライズに費やされる。
Java 内蔵のシリアライズ (およびデシリアライズ) 処理は非常に効率が悪いことで悪名高い ── 消費される CPU サイクル数と生成されるバイト列の長さがいずれも必要以上に大きい場合が多い。長いバイト列が生成されると、ネットワークに送られるデータも大きくなる。
そこで、Infinispan は独自の方式でシリアライズを行う。この方式では完全なクラス定義がバイト列に書き込まれることはなく、送られる可能性のある型がマジックナンバーを使って単一のバイトで表される。こうすることでシリアライズとデシリアライズが大幅に高速化され、加えてネットワーク越しに転送されるバイト列も短くなる。データ型とマジックナンバーの対応付けは externalizer と呼ばれるオブジェクトを通して登録される。この externalizer は型に結び付き、オブジェクトとバイト列を両方向に変換するロジックを持つ。
この手法は Infinispan が内部で使うオブジェクトなどの既知の型をピアノード同士で交換するときは問題なく動作する。コマンドやエンベロープといった内部オブジェクトには対応する externalizer とマジックナンバーが定義される。しかし、アプリケーションが利用するオブジェクトはどうするべきだろうか? デフォルトでは、externalizer を持たない型のオブジェクトに遭遇した Infinispan は Java 内蔵のシリアライズ処理にフォールバックする。このように定めておけば Infinispan は何も設定しなくても動作する ── パフォーマンスは犠牲になるものの、アプリケーションが利用する任意のオブジェクトを正しく扱える。
パフォーマンスの低下を避けるために、アプリケーションが自身の利用する型に対する externalizer を登録する仕組みを Infinispan は持つ。この仕組みを利用すれば、アプリケーションが利用するオブジェクトにも高速かつ効率的で強力なシリアライズが提供される。ただし、アプリケーション開発者は型のそれぞれに対して externalizer を実装して登録する必要がある。
externalizer のコードは JBoss Marshalling9 と呼ばれる再利用可能な個別のライブラリとして公開されている。Infinispan のディストリビューションと一緒にパッケージ化されるものの、シリアライズのパフォーマンスを向上させるために JBoss Marshalling を利用するオープンソースのプロジェクトは多くある。
ディスクへの書き込み
インメモリのデータ構造に加えて、Infinispan はディスクに対するデータの永続化もオプションでサポートする。
データの永続化は耐久性を高めるため、もしくは Infinispan でメモリが足りなくなったときの予備スペースを確保するために行われる。前者の場合、ノードの再起動や障害が起こっても問題が起きないようにメモリ上の全てのデータがディスクにも書き込まれる。後者の場合、永続化の振る舞いは OS が行うディスクを使ったページングと似ており、メモリ上の空きスペースを増やす必要が生じたときにだけデータがディスクに書き込まれる。
耐久性のために行う永続化は、オンラインに行う方法とオフラインに行う方法の二つがある。前者ではデータが安全にディスクに書き込まれるまでアプリケーションスレッドがブロックされ、後者ではディスクに対するデータのフラッシュが定期的に非同期実行される。オフラインの永続化を使うときアプリケーションスレッドはブロックされないものの、その代わりデータがディスクに永続化されたどうかを知ることはできない。
Infinispan は複数のキャッシュストアを着脱可能な形でサポートする ── ディスクをはじめとした任意の二次ストレージを永続化で利用するためのアダプターが実装されている。現在のデフォルト実装は単純なハッシュバケットと連結リストを利用し、各ハッシュバケットがファイルシステム上のファイルで表される。使いやすくはあるものの、この実装のパフォーマンスは最適でない。
現在、ファイルシステムベースのネイティブキャッシュストアを二種類実装することがロードマップにある。予定では両方とも C で書かれ、システムコールに加えて利用可能な環境 (例えば Unix システムなど) ではダイレクト I/O を利用することでカーネルのバッファやキャッシュを迂回する。
一方の実装はページングシステムとしての利用に最適化される。そのためランダムアクセスが必要であり、おそらく B 木が使われることになる。
もう一方の実装は耐用性を高めるための利用に最適化されるので、メモリに保管されるデータと似た構造を持つことになる。また、おそらく高速な書き込みのために設計された追記専用の構造が利用され、読み込みやシークが高速化されるとは限らない。
同期・ロック・並列化
多くのエンタープライズ向けミドルウェアと同じように、Infinispan の設計はモダンなマルチコアシステムと対称型マルチプロセッシング (SMP) システムを仮定している部分が多い。こういったシステムで利用可能な多数のハードウェアスレッドが提供する並列性を活用するため、ネットワークやディスクとの通信におけるノンブロッキング非同期 I/O に加えて、Infinispan のコアにあるデータ構造では共有データに対する並列アクセスを提供するためにソフトウェアトランザクショナルメモリの手法が利用される。これによってロックやミューテックスなどの明示的な同期が最小化され、共有データ構造の更新ではループを伴う compare-and-set 命令といった手法で正しさが保証される。こういった手法はマルチコアシステムと SMP システムで CPU 使用率を向上させることが示されており、コードは複雑になるものの、使えば高負荷時の全体的なパフォーマンスが改善する。
ソフトウェアトランザクショナルメモリのアプローチは現在の Infinispan に恩恵をもたらすのに加えて、将来への備えにもなる ── 同期をサポートする CPU 命令 (ハードウェアトランザクショナルメモリ) が利用可能になったときに必要となる Infinispan の設計の変更が最小限で済む。
Infinispan で使われるデータ構造のいくつかはアカデミックな研究論文からそのまま取られている。実際、ノンブロッキングかつロックフリーな dequeue10 は Infinispan が初めて Java で実装した。他の例としては、ロックの償却が可能な設計11や適応的なキャッシュ追い出しポリシー12がある。
スレッドとコンテキストスイッチ
Infinispan のサブシステムは個別のスレッドで実行される非同期操作を利用するものが多い。例えば、JGroups はネットワークソケットを監視するためのスレッドをいくつかアロケートし、これらのスレッドはメッセージをデコードしてメッセージ転送スレッドにデータを受け渡す。これを受けてメッセージ転送スレッドはディスク上のキャッシュストアにデータを格納する ── この操作も非同期であり、個別のスレッドが利用される。リスナーに変更が通知される可能性もあり、この通知も設定によっては非同期に行われる。
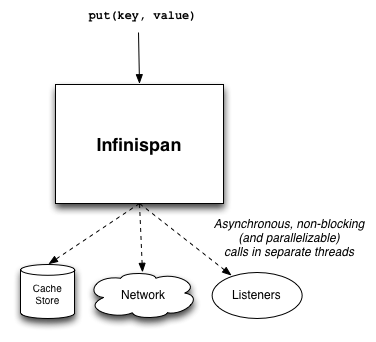
こういった非同期なタスクの実行にスレッドプールを使うとき、コンテキストスイッチのオーバーヘッドが必ず存在する。また、スレッド自体も安価なリソースではない。Infinispan が持つ非同期機能を使う場合は、適切に設定された適切なサイズのスレッドプールをアロケートすることが重要となる。
特に重要なスレッドプールとして、非同期データ転送で使われるスレッドプールがある。この機能を使うときは、スレッドプールのサイズを少なくとも各ノードが受け取ると期待される並列な更新の個数と同じにする必要がある。同様に、JGroups をチューニングするときは、OOB 受信用スレッドプール13のサイズを最低でも期待される並列な更新の個数と同じにするべきである。
ガベージコレクション
Java ベースのソフトウェアでは、JVM のガベージコレクション (GC) に関する一般的なプラクティスを守ることが重要となる。Infinispan も例外ではない。それどころか、Infinispan のようなデータグリッドでは非常に長く保持されるコンテナオブジェクトと特定の操作やトランザクションに関連付く一時的なオブジェクトが混在するので、GC の扱いは重要性を増す。さらに、GC が引き起こす実行の一時的な中断は分散データ構造で非常に有害となる: その間ノードは応答できず、他のノードから障害が起きたと認識される可能性がある。
こういった事実は Infinispan の設計と実装で考慮されたものの、Infinispan を実行する JVM を設定するときに念頭に置くべき事実も多くある。全く同じ JVM は存在しない。ただし、Infinispan を実行する JVM の最適な設定を調べた研究14が存在する。例えば、OpenJDK15 や Oracle の HotSpot JVM16 では、JVM に約 12 GB のヒープを割り当て、並列マークアンドスイープ GC 17 とラージページ18 を使うのが最適と見られている。
また、GC が大きな問題となる場合はポーズレスな GC (例えば Azul's Zing JVM19 で使われる C420) も選択肢に入る。
結論
Infinispan のようなパフォーマンスが重要なミドルウェアでは、計画、設計、開発の全てのステップでパフォーマンスを意識しなければならない。ノンブロッキングかつロックフリーな最良のアルゴリズム、生成されるガベージの特徴、JVM におけるコンテキストスイッチのオーバーヘッド、必要な場合は JVM の外で問題を解決すること (ネイティブな永続化コンポーネントの開発など) はどれも Infinispan の開発で重要な考え方である。さらに、ベンチマークとプロファイルで正しいツールを利用し、継続的インテグレーションのスタイルでベンチマークを実行すれば、追加された機能がパフォーマンスを犠牲にしていないことを確認しやすくなる。
-
http://www.md.chalmers.se/~tsigas/papers/Lock-Free-Deques-Doubly-Lists-JPDC.pdf ↩︎
-
http://www.jgroups.org/manual/html/user-advanced.html#d0e328/4 ↩︎
-
http://howtojboss.com/2013/01/08/data-grid-performance-tunin/g/ ↩︎
-
http://www.oracle.com/technetwork/java/javase/downloads/inde/x.html ↩︎
-
http://www.oracle.com/technetwork/java/javase/gc-tuning-6-14/0523.html#cms ↩︎
-
http://www.oracle.com/technetwork/java/javase/tech/largememo/ry-jsp-137182.html ↩︎
-
http://www.azulsystems.com/technology/c4-garbage-collector ↩︎