モバイルネットワーク
はじめに
過去数年の間に、モバイルセルラーネットワークのパフォーマンスは大きく向上した。その一方でレイテンシの改善は鈍化しつつあるために、多くのモバイルアプリケーションは向上したパフォーマンスの恩恵を完全には得られていない。
レイテンシの問題は長い間モバイルネットワークに付いて回ってきた。近年進歩はあったものの、モバイルネットワークにおけるレイテンシの削減は速度の向上ほどには劇的でない。この格差の結果として、ネットワークトランザクションのパフォーマンスを制限する要因はスループットではなくレイテンシである場合が最も多い。
本章は大きく分けて二つの部分から構成される。前半ではレイテンシの問題を発生させているモバイルセルラーネットワークの特徴が解説され、後半では高いネットワークレイテンシのパフォーマンスに対する影響を最小化するためのソフトウェア的手法を紹介する。
何を待っているのか?
レイテンシ (latency) はデータパケットが (いくつかの) ネットワークを通り抜けるのにかかる時間を指す。様々な要因により、モバイルネットワークでは多くのインターネットベース通信に存在するレイテンシがさらに大きくなる。具体的には、ネットワークの種類 (例えば HSPA+ か LTE か)、キャリア (例えば AT&T か Verizon か)、環境 (例えば静止中か移動中か、場所はどこか、時間帯はいつか) などがレイテンシに影響を及ぼす。モバイルネットワークのレイテンシを正確な値で表すのは難しいものの、たいていは数十ミリ秒から数百ミリ秒程度となる。
ラウンドトリップタイム (round-trip time, RTT) はレイテンシの指標であり、データパケットが宛先まで行って帰ってくるまでにかかる時間を指す。RTT はあらゆるネットワークプロトコルのパフォーマンスに大きな影響を及ぼす。この理由は卓球という荘厳なスポーツを想像すると理解できる。
通常の卓球では、ボールが選手の間を飛んでいく時間は非常に短い。しかし選手が互いに離れていくと、その時間は長くなる。通常の距離なら 5 分で終わる試合でも、選手同士が 1000 フィートも離れていれば何時間もかかる (とてもおかしな光景だ)。二人の選手をサーバーとクライアントに、選手同士の距離を RTT に置き換えれば、何が問題かが分かるだろう。
ほとんどのネットワークプロトコルは通常の動作の中でデータパケットを卓球のようにやり取りする場面がある。この「ラリー」では論理的なネットワークセッションの確立 (TCP など) やサービスリクエストの遂行 (HTTP など) に必要なメッセージがやり取りされる。こういったメッセージをやり取りしている間はデータがほとんど転送されないので、ネットワーク帯域の大部分が使用されない。メッセージの往復には少なくともネットワークの RTT だけの時間がかかるので、このネットワーク使用率の低下にはレイテンシが大きく関係する。積み重なると、パフォーマンスに対する影響は無視できないほどになる。
10 KiB のオブジェクトをダウンロードする HTTP リクエストを行うために 4 個のメッセージを往復させる必要があるとしよう。RTT が 100 ms (モバイルネットワークで典型的な値) と仮定すれば、実効スループットは 10 KiB ÷ 400 ms = 25 KiB/s と計算できる。
この例で帯域が全く話に入っていない事実に注目してほしい ── ネットワークがどれだけ高速だったとしても、この HTTP リクエストにおけるスループットは 25 KiB/s で変わらない。こういった操作のパフォーマンスは「クライアントとサーバーの間で発生するメッセージの往復を減らす」という単一の明快な戦略で改善できる。
モバイルセルラーネットワーク
モバイルセルラーネットワークのレイテンシを紐解く上で避けては通れないコンポーネントや概念をここで簡単に紹介する。
モバイルセルラーネットワークは高度に特殊化された機能を持つ相互に接続された一連のコンポーネントとして表現できる。それぞれのコンポーネントは何らかの形でネットワークレイテンシを増加させるものの、程度はそれぞれ異なる。モバイルセルラーネットワークに特有な概念にもレイテンシに関係するもの (例えば無線リソースの管理) が存在する。
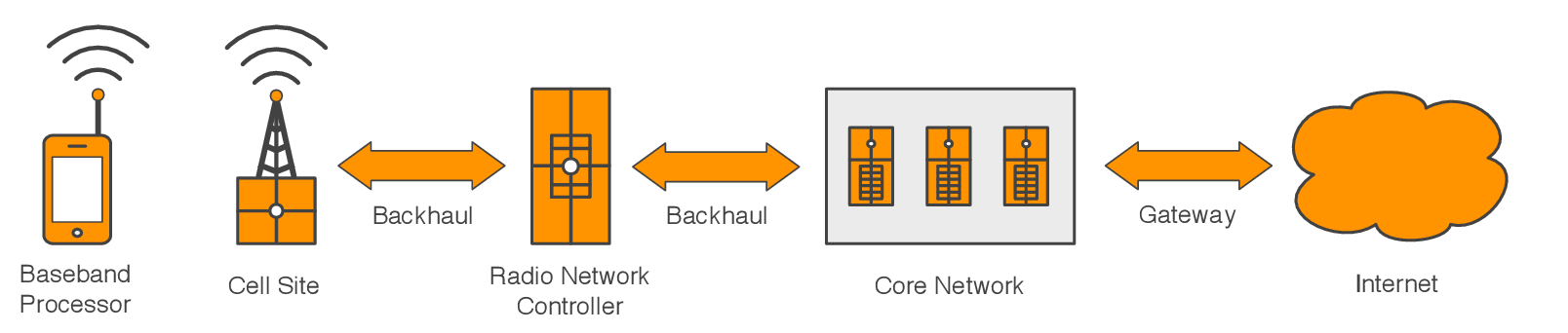
ベースバンドプロセッサ
ほとんどモバイルデバイスには二つの非常に洗練されたプロセッサが含まれている。一つ目のアプリケーションプロセッサはオペレーティングシステムとアプリケーションのホストに利用され、これはデスクトップ PC やノート PC にも存在するプロセッサに相当する。もう一つのベースバンドプロセッサは無線ネットワークに関する全ての機能を担当し、これは電話線ではなく無線を利用するコンピューターモデムに相当する1。
ベースバンドプロセッサは一貫してはいるものの無視できないレイテンシの発生源である。高速無線ネットワークが必要とする処理は恐ろしいほどに複雑であり、その処理が必要とする洗練された信号処理が原因で多くのネットワーク通信に固定された長さ (マイクロ秒からミリ秒程度の) のレイテンシが加わる。
セルサイト
セルサイト (sell site) はモバイルネットワークに対するアクセスポイントとして機能する。無線基地局 (transceiver base station) あるいはセルタワー (cell tower) とも呼ばれる。セル (cell) と呼ばれる一定の領域にネットワーク機能を提供することがセルサイトの仕事である。
セルサイトが接続を提供するモバイルデバイスと同様に、セルサイトでも高速無線ネットワークを可能にするための洗練された信号処理が必要となる。そのため、ほぼ無視できる程度のレイテンシがセルサイトで発生する。ただし、セルサイトは数百から数千のモバイルデバイスに対して同時に接続を提供しなければならない。システム全体の負荷が変動すれば、スループットとレイテンシも変動する。イベントなどで人が密集した時にネットワークパフォーマンスが低くなったり安定しなくなったりするのは、セルサイトの負荷が処理限界を超えていることが原因の場合が多い。
最新世代のモバイルネットワークでは、セルサイトの役割が自身の担当するモバイルデバイスの直接的な管理にまで拡張されている。つまり、ネットワークの登録管理や転送のスケジュールといった以前は無線ネットワークコントローラー (radio network controller) によって実行されていた処理の多くがセルサイトによって行われる。本章で後述される様々な理由により、こうした役割の移管は最新世代のモバイルセルラーネットワークでレイテンシ削減が達成された大きな要因の一つである。
バックホールネットワーク
バックホールネットワーク (backhaul network) はセルサイト、セルサイトのコントローラー、コアネットワークをつなぐ専用の WAN 接続を言う。バックホールネットワークは今までも、そしてこれからも、悪名高いレイテンシの発生源である。
以前のバックホールネットワークにおけるレイテンシの発生源は、古い世代のモバイルネットワーク (GSM や EV-DO など) が採用する回線交換方式あるいはフレームベース方式のトランスポートプロトコルだった。そういったプロトコルでは、事前に割り当てられた短い時間しかデータを送受信できないチャンネルによって論理的な接続が表されるために生まれる本質的な同期性がレイテンシを生んでいた。これに対して、最新世代のモバイルネットワークは IP ベースのパケット交換方式でバックホールネットワークを構築するので、非同期なデータ転送をサポートする。この切り替えによってバックホールネットワークのレイテンシは大きく削減された。
物理インフラストラクチャが持つ帯域の制限は依然としてボトルネックである。多くのバックホールネットワークは現在の高速モバイルネットワークが扱うほどのトラフィック負荷を想定して設計されておらず、輻輳が起こるとレイテンシとスループットが大きく変動する場合が多い。キャリアはそういったネットワークを可能な限り速くアップグレードしようとしているものの、それらは多くのネットワークインフラストラクチャの弱点として残っている。
無線ネットワークコントローラー
従来の方式では、無線ネットワークコントローラー (radio network controller) が付近のセルサイトとそれらが接続を提供するモバイルデバイスを管理する。
無線ネットワークコントローラーはシグナリングと呼ばれるメッセージベースの管理方式を用いてモバイルデバイスのアクティビティを直接管理する。トポロジーの都合上、モバイルデバイスと無線ネットワークコントローラー間のメッセージトラフィックは必ず高レイテンシのバックホールネットワークを通過しなければならない。この事実だけでも理想的ではない上に、ネットワークの登録管理や通信のスケジュールといった処理はメッセージの往復を何度も必要とする。このため、無線ネットワークコントローラーはレイテンシの主要な発生源として以前から知られている。
先述したように、最新世代のモバイルセルラーネットワークではデバイス管理が無線ネットワークコントローラーで行われず、それぞれのセルサイトが自身の担当するデバイスを直接管理する。この設計判断により、多くのネットワーク機能からバックホールネットワークのレイテンシが取り除かれた。
コアネットワーク
コアネットワーク (core network) はキャリアのプライベートネットワークとパブリックインターネットの間にあるゲートウェイとして機能する。クオリティオブサービスポリシーの施行や使用帯域の測定を行うインラインのネットワーク機器がキャリアによって設置されるのはコアネットワークである。そういった機器で生じる実際のレイテンシは無視できる程度であるものの、その存在は記しておく。
電源の節約
モバイルセルラーネットワークにおけるレイテンシの最も大きな発生源の一つには、携帯電話のバッテリーが制限される事実が大きく関係する。
高速モバイルデバイスに搭載される無線モジュールの中には、動作中の消費電力が 3 ワットを超えるものがある。このペースで絶え間なく電力を消費すると、iPhone 5 のバッテリーは 1 時間ほどで使い尽くされてしまう。このため、モバイルデバイスは可能な場合は必ず無線回路の電源を切るか消費電力を少なくする。これはバッテリーの寿命を伸ばす上では理想的であるのに対して、データの送受信を始めるときに無線回路の電力を回復させる必要が生じるので、スタートアップのレイテンシは増加する。
全てのモバイルセルラーネットワーク規格は電源を節約するための無線リソース管理 (radio resource management, RRM) の方式を定式化する。ほとんど RRM は Active, Idle, Disconnected の三つの状態を定義し、それぞれでスタートアップのレイテンシと消費電力のトレードオフを異なる形で解決する (図 10.2)。
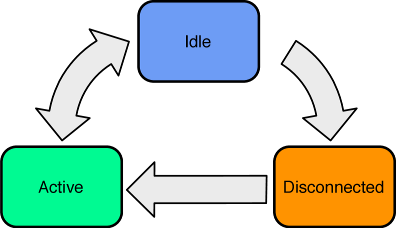
Active
Active はデータの高速な送受信を最小限のレイテンシで行える状態を表す。
この状態だと処理をしていなくても大きな電力を消費する。一定の時間 (たいていは一秒未満) にわたってネットワークが使用されないと、Idle 状態への遷移が起こる。この仕組みが持つパフォーマンスに対する影響に注目してほしい: ネットワーク越しのトランザクションに時間をかけすぎると、デバイスで状態遷移が起こってレイテンシが増加する。
Idle
Idle は電力消費とスタートアップ時間のバランスを取った状態を表す。
デバイスはネットワークに接続されるものの、アプリケーションデータの送受信はできない。ただし、応答に Active 状態が必要となるネットワークリクエストの受信はできる。一定の時間 (たいていは一分程度) にわたってネットワークが使用されないと、デバイスは Disconnected 状態に遷移する。
Idle 状態は二つの点でレイテンシを増加させる。まず、無線に電力供給を開始してアナログ回路を同期するのに一定の時間がかかる。次に、電力をさらに節約するために無線は断続的にしか使用されないので、あらゆるネットワーク通知に対するレスポンスに少量のレイテンシが加わる。
Disconnected
Disconnected は最も低い電力消費と最も大きいスタートアップ時間を持つ状態を表す。
デバイスはモバイルネットワークから切断され、無線は無効化される。ただし無線は定期的に (低い頻度で) 有効化され、特別なブロードキャストチャンネル越しのネットワークリクエストが確認される。
Disconnected 状態は Idle 状態と同じだけのレイテンシ発生源を持つのに加えて、モバイルネットワークへの再接続というレイテンシ発生源も持つ。モバイルネットワークへの接続はメッセージの往復が何度も必要となる複雑な処理 (シグナリング) である。この処理にかかる時間は最低でも数百ミリ秒であり、数秒かかることも珍しくない。
ネットワークプロトコルのパフォーマンス
続いて、私たちがいくらか制御できる部分を見ていこう。
ネットワークトランザクションのパフォーマンスはラウンドトリップタイム (RTT) から不釣り合いなほど大きな影響を受ける。ほとんどのネットワークプロトコルはメッセージの往復を基礎的な操作単位として用いるためである。本章の残りの部分では、メッセージの往復が発生する理由、そしてメッセージの往復の削減あるいは排除する手法を説明する。
TCP
Transport Control Protocol (TCP) はセッション指向のトランスポートプロトコルであり、IP ネットワークの機能を利用して動作する。TCP は誤りが発生しない全二重通信チャンネルを提供し、HTTP や TLS といった他のプロトコルに欠かせない基礎となる。
TCP では、避けるべきとこれまで説明してきたメッセージの往復が大量に行われる。メッセージの往復は Fast Open といったプロトコル拡張の活用や、initial congestion window (輻輳ウィンドウの初期サイズ) などのシステムパラメータの調整で減らすことができる。本節では両方のアプローチを紹介しつつ、TCP の詳細に関する背景も説明する。
TCP Fast Open
TCP 接続の確立では、スリーウェイハンドシェイクと呼ばれる処理で三通のメッセージがやり取りされる。TCP Fast Open は TCP の拡張であり、通常のスリーウェイハンドシェイクで発生するラウンドトリップ遅延を削減する。
TCP のスリーウェイハンドシェイクでは、ロバストな両方向通信を可能にするためにクライアントとサーバーの間で動作パラメータが交渉される。最初の SYN (synchronize) メッセージはクライアントの接続リクエストを表す。この接続リクエストを受理するなら、サーバーは SYN-ACK (synchronize-acknowledge) メッセージを返答する。最後に、クライアントは ACK メッセージをサーバーに送り返す。この時点で論理的な接続が確立され、クライアントはデータの送信を開始できる。以上の説明を理解できていれば、スリーウェイハンドシェイクによって現在の RTT だけの遅延が発生することが分かるだろう。
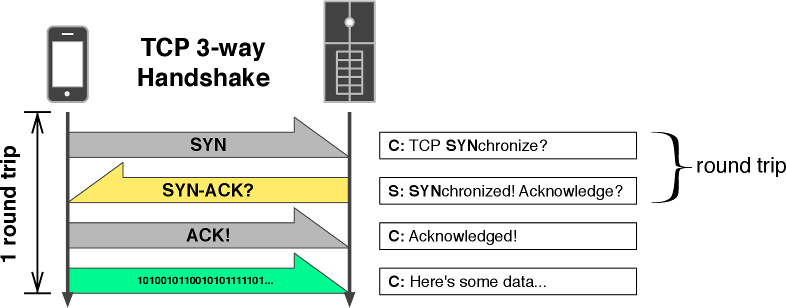
接続を再利用する場合を除いて、従来の TCP ではスリーウェイハンドシェイクによる遅延を回避する方法は存在しなかった。しかし、この事実は最近になって導入された IETF 仕様 TCP Fast Open によって変化した。
TCP Fast Open (TFO) を使うと、クライアントは論理的な接続が確立する前にデータの送信を開始できる。これによって、スリーウェイハンドシェイクからラウンドトリップ遅延が排除される。この最適化による性能向上は非常に大きく、Google の研究は TFO がページの読み込み時間を 40% 削減したと報告している。現在 TFO はドラフト仕様であるものの、主要なブラウザ (Chrome 22 以降) とプラットフォーム (Linux 3.6 以降) でサポートされており、他のベンダーもサポートを明言している。
TFO はスリーウェイハンドシェイクを変更し、小さなデータペイロード (例えば HTTP リクエスト) を SYN メッセージに配置できるようにする。この SYN メッセージを受け取ったサーバーは通常通りにスリーウェイハンドシェイクを進めつつ、ペイロードをアプリケーションに届ける。
TFO に似た拡張の提案は以前にも行われていたものの、それらは最終的にセキュリティの懸念から受理されなかった。TFO では、通常のスリーウェイハンドシェイクによる接続確立時にセキュアトークン (クッキー) をクライアントに割り当て、それを TFO で最適化されたリクエストの SYN メッセージに配置することでセキュリティの問題を回避する。
TFO の利用では注意すべき点がいくつかある。最も重要な注意点として、最初の SYN メッセージと共に渡すリクエストデータに対する冪等性の保証は存在しない。TCP には重複して受信側に届くパケット (実際のネットワークで頻繁に発生する) を無視する機能があるものの、この機能は接続確立時のパケットには提供されない。この問題に対する解決策を標準化する取り組みがドラフト仕様で進んでいるものの、現時点では TFO を安全に利用できるのは冪等なトランザクションのみに限られる。
Initial Congestion Window
initial congestion window は TCP の変更可能な設定であり、輻輳ウィンドウの初期サイズを表す。この値を適切に調整すれば、小さなネットワークトランザクションを高速化できる可能性がある。
最近公開された IETF RFC は initial congestion window の値をよく使われる 3 セグメント (パケット) から 10 セグメントに増加させることを推奨している。この提案は Google による大規模な研究を受けたものである。この研究は initial congestion window の値を 10 セグメントに増やすとパフォーマンスが平均で 10% 増加すると報告している。この提案の目的と想定される影響を説明するには、TCP の輻輳ウィンドウ (congestion window, cwnd) をまず説明する必要がある。
TCP は低信頼なネットワークで行われるクライアントとサーバー間の通信に信頼性を提供する。これは、全てのデータが送信された通りにクライアントに届く (少なくともそのように見える) ことを意味する。信頼性を達成する上ではパケットロスが最大の障壁となる: パケットロスは検出、修正、回避を必要とする。
TCP は積極的確認応答 (positive acknowledgement) と呼ばれる規則を使って失われたパケットを検出する。つまり、TCP では送信側から受け取った全てのパケットに対して確認通知を送り返すことが受信側に要求され、送信側は確認通知が返ってこないパケットは転送中に失われたと判断する。確認通知を待っている間、転送されたパケットは輻輳ウィンドウと呼ばれる特別なバッファに保存される。このバッファが満杯になる状況は cwnd exhaustion と呼ばれ、cwnd exhaustion が発生すると受信側からの確認応答が送信側に届いて輻輳ウィンドウに空きが生まれるまでデータ転送がストップする。cwnd exhaustion は TCP のパフォーマンスに大きく影響する。
ネットワーク帯域を除くと、TCP のスループットは突き詰めれば cwnd exhaustion の頻度によって制限される。そして cwnd exhaustion の頻度は輻輳ウィンドウのサイズに影響を受ける。TCP でピークパフォーマンスを達成するには、現在のネットワーク条件に合ったサイズの輻輳ウィンドウが必要になる: 輻輳ウィンドウが大きすぎるとネットワークで輻輳が起きる ── ネットワークが混雑し、パケットロスが大量に発生する。しかし輻輳ウィンドウが小さすぎると貴重な帯域が未使用となる。論理的には、ネットワークの現在状況に関する情報が多ければ多いほど最適な輻輳ウィンドウを選べる可能性が高まる。しかし現実には、容量やレイテンシといったネットワークの指標を測定するのは難しく、さらに常に変動している。加えて、インターネットベースの TCP 接続は数多くのネットワークを経由する事実によっても事態は複雑になる。
ネットワーク容量を正確に特定する手段が存在しないために、TCP はネットワークで起きている輻輳の状態から容量を推定する。つまり、TCP はパケットロスが発生するまで輻輳ウィンドウを拡張し、ネットワークが現在の転送レートを処理できていないと判明した時点で輻輳ウィンドウを縮小する。この輻輳回避 (congestion avoidance) の仕組みを採用することで、TCP は cwnd exhaustion の発生を最小化しつつ、自身が利用可能な接続容量を使い切ることを試みる。ようやくこれで、TCP における initial congestion window の用途と重要性を説明する準備が整った。
ネットワークの輻輳はパケットロスの兆候がなければ検出できない。新しい (あるいはアイドルの) 接続はパケットロスの記録を持たないので、最適な輻輳ウィンドウサイズを見つけることができない。このため TCP は輻輳を起こす可能性が最も低いサイズで輻輳ウィンドウを初期化する。初期の TCP 実装では initial congestion window が 1 セグメント (約 1480 バイト) に設定され、しばらくの間はこの値が推奨されていた。しかし後に実施された実験からは、initial congestion window を 4 セグメント程度まで大きくすると効率が向上することが示されている。実際に使われる実装では initial congestion window が 3 セグメント (約 4 KiB) に設定される場合が多い。
小さなネットワークトランザクションの速度を考えるとき、initial congestion window の存在は望ましくない。その理由は簡単に理解できる。initial congestion window の値が典型的な 3 セグメントに設定されるとき、3 パケット (約 4 KiB) を送信しただけで cwnd exhaustion が発生する。パケットが連続で送信されると仮定すれば、最初の 3 パケットに対する確認通知は RTT だけ時間が経過するまで返ってこない。例えば RTT が 100 ms なら、この間の実効通信レートはわずか 40 KiB/s となる。時間が経過すれば TCP が輻輳ウィンドウを広げて利用可能な容量を全て使うようになるものの、最初は非常にゆっくりとしかデータを送信できない。実は、この挙動はスロースタートと呼ばれる。
小さいデータをダウンロードするときのパフォーマンスに対するスロースタートの影響を考慮すると、initial congestion window の値を導いたリスクとリワードの仮定に再考が必要となる。Google の研究によると、initial congestion window を 10 セグメント (約 14 KiB) にしたとき最大のスループットと最低の輻輳を得られたという。現実世界での実験では読み込み時間が 10% 減少したことが確認されている。RTT が大きい接続ではパフォーマンスの改善がこれより大きくなるだろう。
initial congestion window の値をデフォルトから変更するのは簡単な操作ではない。この値はシステム全体に影響する設定なので、ほとんどのサーバーオペレーティングシステムでは権限を持ったユーザーにしか設定できない。また、特権を持たないアプリケーションからクライアントが利用する TCP の設定を変更できることはまずない。なお、重要な点として、initial congestion window の値をサーバーで大きくするとダウンロードが高速化されるのに対して、クライアントで大きくするとアップロードが高速化される。initial congestion window の値をクライアントで変更できない事実は、リクエストのペイロードサイズの最小化に特別な労力をかけるべきであることを意味する。
HTTP
本項では、Hypertext Transfer Protocol (HTTP) で発生する大きなラウンドトリップ遅延を小さくする手法を議論する。
キープアライブ
キープアライブ (keepalive) は連続する HTTP リクエストで同じ TCP 接続を使い回す HTTP の機能である。最低でもリクエストごとに (TCP のスリーウェイハンドシェイクで必要となる) 一度のラウンドトリップが回避されるので、数十ミリ秒から数百ミリ秒が節約される。さらに、言及されないことが多いものの、キープアライブには TCP の輻輳ウィンドウのサイズがリクエスト間で保存され、cwnd exhaustion の発生が抑えられるという利点もある。
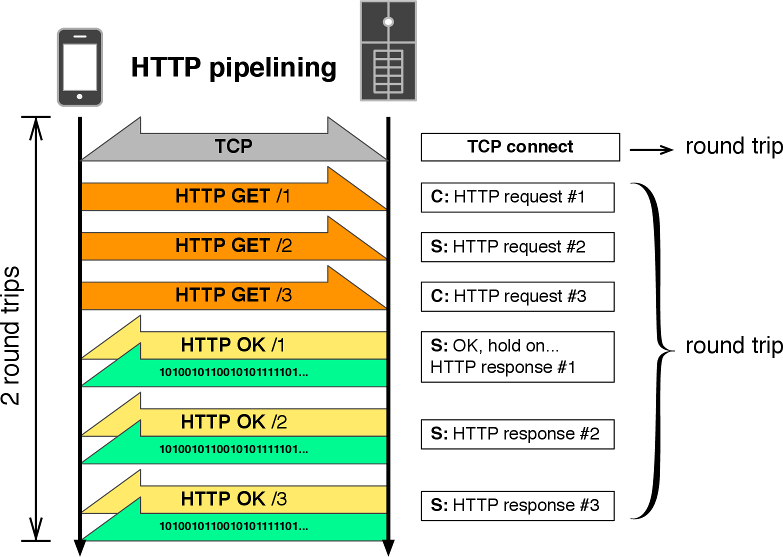
キープアライブを使うとき HTTP はパイプライン化され、一度のラウンドトリップ遅延が複数の HTTP リクエストで分割されると考えることもできる。例えば RTT が 100 ms の場合に 5 個の HTTP リクエストをパイプライン化すれば、一つの HTTP リクエストあたりの平均ラウンドトリップ遅延は 20 ms となる。同じ条件で 10 個の HTTP リクエストをパイプライン化できれば、平均ラウンドトリップ遅延は 10 ms となる。
HTTP のパイプライン化にはよく知られた欠点があり、それが理由で広く採用されていない。具体的には、HTTP プロキシが上手くサポートできないこと、そしてサービス拒否 (DoS) 攻撃に弱いことが欠点とされている。
TLS
Transport Layer Security (TLS) はパブリックネットワークを通じたデータのセキュアなやり取りを可能にするセッション指向のネットワークプロトコルである。TLS を使うとき通信は非常にセキュアとなるものの、レイテンシの大きいネットワークではパフォーマンスが低下する。
TLS のハンドシェイクは複雑であり、クライアントとサーバーの間でメッセージの往復が二度行われる。このため、HTTP トランザクションを TLS でセキュア化すると人間が認識できるほど速度が落ちる可能性がある。「TLS は遅い」という意見が正確には「TLS のハンドシェイクプロトコルで発生するラウンドトリップ二回分の遅延が遅い」を意味しているケースがよくある。
DNS
一般に、ホスティングプラットフォームは DNS クエリが頻繁に発行されるのを防ぐためにキャッシュを実装する。DNS クエリの意味論は単純であり、各 DNS レスポンスに含まれる TTL (time-to-live, 有効期間) 属性がキャッシュの許される期間を表す。TTL には数秒から数日まで様々な値を設定できるものの、通常は数分のオーダーに設定される。一分に満たない非常に短い TTL は、サーバーの置き換えあるいは ISP の障害発生時のダウンタイムを最小化するため、もしくは負荷分散で DNS を利用するために利用される。
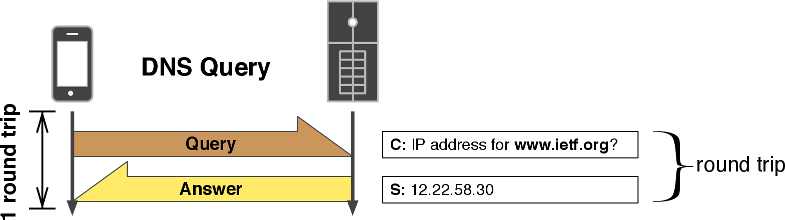
ほとんどのプラットフォームが持つネイティブの DNS キャッシュ実装は、モバイルネットワークにおける大きな RTT を考慮していない。多くのモバイルアプリケーションはキャッシュを長く保持することでパフォーマンスを改善できる。つまり、アプリケーションの用途によってキャッシュの戦略を切り替えれば、不必要な DNS クエリによるランダムで意味のないレイテンシを削減できる可能性がある。
障害時の DNS 更新
典型的な高可用システムは自身の IP アドレス空間内にホストされた冗長なインフラストラクチャに依存する。低 TTL の DNS エントリーは障害が発生したときに参照するアドレスを素早く更新できる利点があるものの、その代わり DNS クエリが多く発行される。つまり、TTL を変更することでダウンタイムとクライアントパフォーマンスのトレードオフを調整できる。
サーバーの障害は例外的な状況なので、それに対処するためにクライアントのパフォーマンスを犠牲にするのは一般に良いアイデアではない。ただ、このジレンマには簡単な解決法が存在する: TTL に厳密に従うのを止めて、TCP や HTTP といった上位プロトコルが修復不可能なエラーを検出したときに限って DNS エントリーを更新すればよい。この手法を使ったとしても多くの場合で DNS キャッシュの振る舞いは変化せず、それでいて DNS ベースの高可用ソリューションで起こりがちなパフォーマンス低下が避けられることが知られている。
注意が必要な点として、このキャッシュ手法は DNS ベースの負荷分散スキームが使われる場合には利用できない可能性が高い。
DNS の非同期更新
DNS の非同期更新は提示される TTL に (ほぼ) 従いながらも頻繁な DNS クエリによるレイテンシを避ける TTL キャッシュのアプローチである。このアプローチの実装では c-ares などの非同期 DNS クライアントライブラリが必要になる。
非同期更新のアイデアは難しくない: 期限が切れた DNS キャッシュエントリーの更新をリクエストすると、キャッシュを更新するノンブロッキングな DNS クエリがバックグラウンドでスケジュールされ、古い結果が返される。非常に古いエントリーに対するブロッキング (同期的) なクエリをフォールバックとして実装するとき、これは DNS ベースのフェイルオーバーや負荷分散と互換性を持った、DNS 遅延をほぼ発生させない手法となる。
結論
モバイルセルラーネットワークの大きなレイテンシの影響を低減させるには、ネットワーク越しのラウンドトリップを減らす必要がある。この手強い問題を乗り越えるには、プロトコルメッセージのラウンドトリップを減らすことだけに集中したソフトウェア最適化が不可欠である。
-
実際の携帯電話は多くがAT ライクなコマンドセットのベースバンドプロセッサを持つ。 ↩︎