Zotonic
Zotonic の紹介
Zotonic はフルスタックウェブ開発のためのオープンソースフレームワークであり、フロントエンドの機能とバックエンドの機能を両方持つ。Zotonic は少量のコア機能から構成され、軽量でありつつも拡張可能なコンテンツ管理システム (CMS) が最上部に実装されている。Zotonic の主目標は最初からスケールするパフォーマンスに優れたウェブサイトの作成を簡単にすることである。
Zotonic の機能や特徴は Django, Drupal, Ruby on Rails, WordPress といった他のウェブ開発フレームワークと共通する部分が多い。競争相手に対する優位性を Zotonic に与えているのは言語である: Zotonic は Erlang で書かれている。この言語 ── 元々は電話交換機のために開発された ── のおかげで、Zotonic の高い障害耐性と優れたパフォーマンスは可能になっている。
本書のタイトルにもあるように、本章では Zotonic のパフォーマンスに関する話題に集中する。これから Erlang がプログラミングプラットフォームとして選択された理由し、HTTP リクエストスタックの詳しい内部処理、そして Zotonic が用いるキャッシュ戦略を説明する。最後に、Zotonic のサブモジュールとデータベースに適用された最適化を説明する。
なぜ Zotonic? なぜ Erlang?
Zotonic の開発は 2008 年に始まった。多くのプロジェクトと同じように、Zotonic は「かゆい所に手が届く」ツールとして生まれた。Zotonic の主任技術者 Marc Worrell は当時アムステルダムの Mediamatic Lab で七年にわたって Anymeta と呼ばれる PHP/MySQL 製の Drupal 風 CMS に取り組んでいた。Anymeta が掲げたパラダイムは「セマンティックウェブへの実際的なアプローチ」であり、システム内の全てのものを一般的な「オブジェクト」としてモデル化した。Anymeta は成功したものの、その実装はスケーラビリティの問題を抱えていた。
Marc は Mediamatic を離れた後、数か月を費やして Anymeta 風の完全な CMS をゼロから設計した。Zotonic の主要な設計目標はフロントエンド開発者にとっての使いやすさだった。Zotonic はリアルタイムウェブインターフェースの簡単な開発をサポートし、それでいて長く保持される接続と多くの短命な接続を同時に扱えなければならない。また、Zotonic は詳細に理解されたパフォーマンス特性を持つ必要がある。さらに重要なこととして、従来のウェブ開発が採用するアプローチのパフォーマンスを制限していた一般的な問題を Zotonic は回避しなければならない ── 例えば「スラッシュドット効果」 (訪問者の突然の増加) でサーバーが落ちることは許されない。
PHP と Apache を使う古典的なアプローチの問題点
PHP の古典的なセットアップでは、Apache などのコンテナウェブサーバー内のモジュールとして PHP が実行される。リクエストごとに Apache が処理方法を判断し、PHP リクエストであれば mod_php5 を起動して PHP インタープリタにスクリプトの解釈を開始させる。このアプローチではスタートアップ時のレイテンシが大きくなる: 典型的には PHP の起動に 5 ms 程度かかり、その後 PHP コードの実行でさらに時間がかかる。この問題は、PHP スクリプトを事前コンパイルしてインタープリタを迂回する PHP アクセラレータを使うと多少は緩和できる。また、PHP-FPM などのプロセスマネージャを使うと PHP を起動するオーバーヘッドも削減できる。
しかし、こういったシステムは「shared nothing」 (何も共有されない) アーキテクチャの問題からは逃れられない。例えば、スクリプトがデータベース接続を必要とするとき、そのたびにスクリプト自身が接続を作らなければならない。他の I/O リソースについても同様となる。理想的にはリクエスト間でリソースが共有されるのが望ましい。この問題を解決するために持続的接続を提供するモジュールは存在するものの、PHP に一般的な解決策は存在しない。
また、長く持続するクライアント接続の扱いも問題となる。そういった接続はウェブサーバーを実行する個別のスレッドまたはプロセスをリクエストごとに必要とする。例えば、Apache と PHP-FPM のスタックは長く持続する接続が大量にあるときスケールしない。
モダンなウェブフレームワークの要件
モダンなフレームワークが処理する HTTP リクエストは三つに大別できる。第一に、動的に生成されるページがある: 動的にサーブされ、たいていはテンプレートプロセッサによって生成される。第二に、静的なコンテンツがある: 大小様々なサイズの変更されないファイル (JavaScript, CSS, メディアアセット) である。第三に、長く持続する接続がある: WebSocket やデータの収集に時間のかかるリクエストであり、ページに対話性や双方向通信を提供する。
Zotonic の開発に先立って、私たちは自分たちの設計目標 (高パフォーマンスと開発容易性) を達成でき、伝統的なウェブサーバーシステムでよくあるボトルネックを回避できるソフトウェアフレームワークとプログラミング言語を調査した。理想的には、次の要件が満たされるのが望ましい:
- 並列性: 並列に処理できる接続の個数が Unix プロセスあるいは OS スレッドの個数に制限されてはいけない。
- リソースの共有: リクエスト間でリソース (キャッシュやデータベース接続) を安価に共有する仕組みを持つ必要がある。
- コードのホットアップグレード: 開発を簡単にするため、そしてプロダクションシステムのホットアップグレードを可能にする (ダウンタイムを最小限にする) ために、稼働中のシステムに対してコードの変更を再起動せずに適用できるのが望ましい。
- マルチコア CPU サポート: 現在 CPU はクロック周波数ではなくコア数が増える傾向にあるので、モダンなシステムはコアの個数に関してスケールしなければならない。
- 障害耐性: 例外的な状況、「行儀の悪い」コード、異常な振る舞い、そしてリソースの枯渇に対処できる必要がある。理想的には、障害の起こった部分を自動的に再起動する監視メカニズムによって障害耐性が達成されるのが望ましい。
- 分散性: 理想的には、ハードウェア障害に対する耐性とパフォーマンスを高めるために、システムを複数ノードに分散する機能が組み込みかつ使いやすい形でサポートされるのが望ましい。
Erlang という救いの手
私たちの知る限り、Erlang は上述の要件を「箱から出した」状態で満たす唯一の言語である。過去も現在も、Erlang VM と Open Telecom Platform (OTP) の組み合わせ (Erlang/OTP) は必要な機能を全て提供し続けている。
Erlang は (ほぼ) 関数的なプログラミング言語とランタイムシステムからなる。Erlang (および OTP) は元々電話交換機のために開発され、高い障害耐性と並列性を持つことで知られている。Erlang はアクターベースの並列モデルを採用する: それぞれのアクターが軽量の「プロセス」 (グリーンスレッド) であり、プロセス同士が状態を共有する方法はメッセージの交換のみに制限される。OTP は標準的な Erlang ライブラリの集合であり、障害耐性やプロセス監視といった機能を提供する。
Erlang のプログラミングパラダイムの心臓部にあるのは障害耐性である: Erlang システムで重要な考え方に「クラッシュさせよ (let it crash)」がある。プロセスは状態を一切共有しない (共有するにはメッセージを送信するしかない) ために、あるプロセスの状態は他のプロセスの状態から隔離される。そのため、一つのプロセスがクラッシュしてもシステム全体が落ちることは決してない。プロセスがクラッシュしたときは、そのプロセスを監視するプロセスがクラッシュを適切に処理し、再起動するかどうかを判断する。
「クラッシュさせよ」の考え方が実践されていると、プログラマーはエラーが発生しない幸せなケースの処理を書くだけで十分となる。さらに、パターンマッチングと関数ガードによってエラー処理コードは短くなり、たいていは綺麗で、簡潔で、読みやすいコードが書かれる。
Zotonic のアーキテクチャ
Zotonic のパフォーマンス最適化を議論する前に、Zotonic のアーキテクチャを説明しよう。図 9.1 に Zotonic の最も重要なコンポーネントを示す。
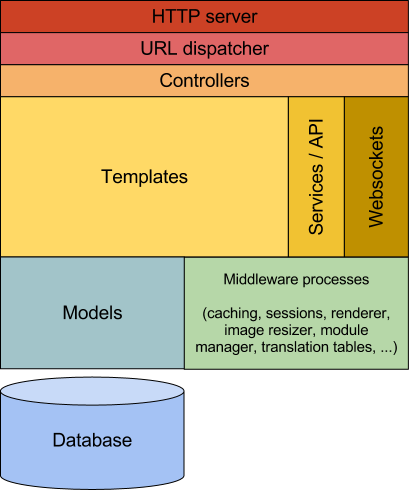
この図には HTTP リクエストが通過する Zotonic のレイヤーが示されている。パフォーマンスを議論するには、これらのレイヤーの動作とパフォーマンスに対する影響を理解しておく必要がある。
まず、Zotonic は組み込みのウェブサーバー Mochiweb を持つ (Mochiweb 自体は Zotonic と独立した Erlang プロジェクトである)。このため、ユーザーがウェブサーバーを別に用意する必要はない。これにはデプロイ時の依存関係が減る効果もある1。
多くのウェブフレームワークと同様に、リクエストをコントローラーにマッチさせる処理では URL ルーティングシステムが利用される。コントローラーは Webmachine ライブラリを使ってリクエストを RESTful に処理する。
コントローラーは意図的に「バカ」にされる。つまり、コントローラーはアプリケーション固有のロジックを多くは持たない。Zotonic には簡単なウェブアプリケーションで利用できる様々なコントローラーが搭載されており、それで十分な場合も多い。例えば controller_template は指定されたテンプレートをレンダリングすることで HTTP GET リクエストに応える処理だけを持つ。
テンプレートのレンダリングでは有名な Django Template Language の Erlang 実装 ErlyDTL が使われる。Zotonic の一般的な原則として「テンプレートがデータリクエストを駆動する」がある。つまりテンプレートが必要なデータを判断し、それをモデルから取得する。
モデルは様々なデータソース (データベースなど) からデータを取得する関数を公開する。モデルはテンプレートに API を公開し、データの取得方法を定める。取得したデータをメモリ上にキャッシュするのもモデルの責務である: どのファイルをいつまでキャッシュするかをモデルは判断する。データの取得が必要になったテンプレートは、モデルを (グローバル変数であるかのように) 呼び出す。
それぞれのモデルは Erlang のラッパーモジュールであり、特定のデータを担当する。モデルにはアプリケーションが必要とする形でデータを取得・格納するのに必要な関数が含まれる。例えば、Zotonic で中心的な役割を果たすモデルは m.rsc と呼ばれ、一般的なリソース (「page」) に対するアクセスを提供する。データベースが利用される場合はモデル m_rsc.erl がデータベース接続を利用してデータを取得し、それをテンプレートに渡しつつ可能な場合はキャッシュに保存する。
この「テンプレートがデータリクエストを駆動する」アプローチは、Ruby on Rails や Django といった他のウェブフレームワークが採用する「コントローラーがテンプレートにデータを割り当てる」古典的な MVC アプローチとは異なる。Zotonic は「コントローラー中心」ではないので、テンプレートを書くだけで典型的なウェブサイトを構築できる。
Zotonic はデータの永続化に PostgreSQL を利用する。この選択の理由はデータモデル: SQL を使ったドキュメントデータベースで説明される。
その他の Zotonic のコンセプト
本章で説明するのは主にウェブリクエストスタックのパフォーマンス特性であるものの、Zotonic の心臓部にあるコンセプトの中には知っておくべきものがいくつか存在する。
- 仮想ホスティング
- 典型的な Zotonic インスタンスは複数のサイトをサーブする。Zotonic はドメインエイリアスや SSL サポートを含めて仮想ホスティングが可能なように設計されている。Erlang のプロセス隔離のおかげで、一つのサイトがクラッシュしたとしても同じ VM で実行される他のサイトが影響を受けることはない。
- モジュール
- Zotonic では機能をまとめたものをモジュールと呼ぶ。それぞれのモジュールには一つのディレクトリが与えられ、その中に Erlang ソースコード、テンプレート、アセットといったファイルが配置される。モジュールはサイトごとに有効化するかどうかを選択できる。また、モジュールはアドミンシステムにフックを追加することもできる: 例えば
mod_backupモジュールはページエディタにバージョン管理の機能を追加し、一日一回データベースのバックアップを行う。他にも、mod_githubモジュールは Zotonic サイトを GitHub からプル、リビルド、リロードすることで継続的デプロイを提供するwebhookを提供する。 - 通知
- コードの疎結合性と拡張性を高めるために、モジュールとコアコンポーネント間の通信は通知 (notification) の仕組みを使って行われる。この仕組みは、特定の名前を持つ通知の監視元に対して map もしくは fold を実行する。モジュールは通知にリッスンすることで、特定の振る舞いを簡単にオーバライドもしくは拡張できる。map と fold のどちらを利用するかは通知の定義で指定される。例えば、
admin_menuという通知は fold を利用し、アドミンメニューの項目を追加・削除する。 - データモデル
- Zotonic が利用するメインのデータモデルは Drupal の Node モジュールと同様に「全てはモノである」の考え方を採用する。このデータモデルは階層的に分類されたリソースから構成され、リソース同士はラベル付きの辺で接続される。Zotonic がアイデアを得た Anymeta CMS と同じく、このデータモデルも元をたどればセマンティックウェブの考え方に基づいている。
Zotonic は拡張可能なシステムなので、拡張された機能がパフォーマンスを害する可能性が常にある。例えばウェブリクエストに割り込むモジュールを追加すると、全てのリクエストに何らかの処理が行われる。こういったモジュールによってシステム全体のパフォーマンスが低下する可能性は否定できないものの、この問題は本章で考えないことにする。以降では Zotonic の中心部におけるパフォーマンスの問題だけを議論する。
問題: スラッシュドット効果
多くのウェブサイトはウェブ上のどこか目立たない場所に位置し、穏やかな毎日を送る。しかし、ウェブサイト内のページが CNN, BBC, Yahoo といった有名なウェブサイトのトップページに掲載されると、生活は一変する。その瞬間、秒間のリクエスト数は数十あるいは数百、ときには数千にまで急上昇する。
こういった負荷の急上昇があると、古典的なウェブサーバーは到達不可能になる。この現象を指す「スラッシュドット効果」という言葉はウェブサイトを圧倒する訪問者を生み出しがちだったウェブサイトにちなんで命名された。さらに悪いことに、サーバーが過負荷状態になると再起動さえ非常に困難になる場合がある: 新しく起動されたサーバーはキャッシュを持たず、データベース接続を持たず、テンプレートのコンパイルが完了していないためである。
同じ時間帯に全く同じページをリクエストする大量の匿名訪問者はサーバーを過負荷状態にするべきではない。この問題は Varnish などのキャッシュプロキシを使えば簡単に解決できる。キャッシュプロキシは静的ページのコピーをキャッシュし、折を見てページの更新を確認する。
全ての訪問者に対して動的なページを配信するとき、トラフィックの増加はさらに挑戦的な問題となる: キャッシュは利用できない。私たちは Zotonic で、動的なページに対するアクセスが多いときの負荷低減を試みた。
まず、私たちは多くのウェブサイトが次の特徴を持つことを認識した:
- 非常にアクセスの多いページの数は少ない。
- アクセスの少ないページのロングテールがある。
- 全てのページに共通するパーツが多くある (メニュー、アクセス上位ページのリスト、更新情報のリストなど)。
そこで、私たちは次のアプローチを採用した:
- ホットなデータをメモリ上にキャッシュし、アクセス時に通信が発生しないようにする。
- テンプレートやサブテンプレートのレンダリング結果をリクエスト間およびウェブサイトのページ間で共有する。
- サーバーの起動・再起動時に高負荷が生じないようにシステムを設計する。
ホットデータのキャッシュ
外部ソース (データベースや memcached) から数ミリ秒前にフェッチしたデータを、必要になったからといってもう一度フェッチする必要はない。単純なデータリクエストは必ずキャッシュされる。キャッシュの仕組みは次節で詳しく説明する。
テンプレートのレンダリング結果のキャッシュ
ページのレンダリングやテンプレートのインクルードを行うとき、開発者はキャッシュを指示するディレクティブを指定できる。このディレクティブがあると、レンダリング結果が一定の時間だけキャッシュされる。
テンプレートのキャッシュが指示されると、私たちが「メモ化」と呼ぶ機能が起動される: そのテンプレートがレンダリングされる間に他のプロセスが同じレンダリングをリクエストすると、そのプロセスはブロックされる。そしてレンダリングが完了すると、その結果が待機中の全てのプロセスに渡される。
このメモ化があると ── これ以外のキャッシュを行わなくても ── 並列に実行されるテンプレート処理が大きく減少し、パフォーマンスが大きく向上する。
サーバーの起動・再起動時の負荷の軽減
Zotonic には意図的に作られたボトルネックがいくつかある。それらのボトルネックは限られたリソースや (CPU あるいはメモリに関して) 高価な処理へのアクセスを制限する。現在、意図的なボトルネックはテンプレートコンパイラ、画像処理、データベース接続プールに存在する。
ボトルネックはリクエストされた操作を実行するワーカープールのサイズを制限することで実装される。例えば CPU またはディスクを多く必要とする画像処理などの処理では、リクエストを処理するスレッドは最大でも一つとなる。プロセスが処理をリクエストすると、処理に対応する Erlang のリクエストキューにそのリクエストが積まれ、プロセスは処理の完了までブロックする。リクエストがタイムアウトすると対応するプロセスはクラッシュし、HTTP ステータスコード 503 (Service Unavailable) が返答される。
待機中のプロセスはリソースを消費しないので、ホットページに含まれるテンプレートの変更に伴う再レンダリングや画像の置き換えに伴うクロッピングとリサイズが必要になった場合でも人為的なボトルネックのおかげで負荷の上昇が回避される。
まとめると: リクエストが殺到してサーバーがビジーになったとしてもテンプレート、コンテンツ、画像の更新は進行し、それでいてサーバーが高負荷状態になることはない。さらにリクエストをクラッシュさせることもでき、その場合でもシステムは停止しない。
データベース接続プール
データベース接続に関して話題がもう一つある。Zotonic では、データベース接続を望むプロセスはデータベース接続のプールから接続をフェッチする。この仕組みにより、多くの並列プロセスが非常に限られた数しか存在しないデータベース接続を共有できるようになる。全てのリクエストが新しくデータベース接続をオープンし、リクエストの完了まで接続を保持する PHP を含む多くのシステムと Zotonic を比べてみてほしい。
Zotonic は一定の時間使われていないデータベース接続をクローズする。ただし、新しいリクエストやバックグラウンド操作を素早く処理するために、一つのデータベース接続は常にオープンされる。動的な接続プールによってオープンされるデータベース接続の個数が大幅に減少し、ほとんどの Zotonic ウェブサイトではデータベース接続が一つか二つしかオープンされない。
キャッシュレイヤー
キャッシュで最も難しいのはキャッシュの無効化である: キャッシュされたデータが古くなったら削除し、再度フェッチしてデータを最新に保つ必要がある。この問題を解決するために、Zotonic は依存関係をチェックできる中央集権的なキャッシュの仕組みを利用する。
本節では Zotonic が採用するキャッシュの仕組みをトップダウンに説明する: ブラウザからデータベースに向かってキャッシュを見ていく。
クライアントサイドのキャッシュ
クライアントサイドのキャッシュはブラウザによって行われる。ブラウザは CSS, JavaScript, 画像ファイルをキャッシュする。Zotonic はクライアントサイドで HTML ページのキャッシュを許さず、全てのページを必ず動的に生成する。HTML ページのキャッシュを禁止すれば、ユーザーがログイン、ログアウト、コメント投稿を行った後に古いページが表示される事態を防ぐことができる。さらに、ページの生成は (前節で説明したように) 非常に効率的に行える。
Zotonic は次の二つの工夫でクライアントサイドのパフォーマンスを改善する:
- 静的ファイル (CSS, JavaScript, 画像) のキャッシュを許可する。
- 一度のレスポンスに複数の CSS ファイルまたは JavaScript ファイルを含める。
一つ目の工夫は適切な HTTP ヘッダーをレスポンスに付けることで実装される2:
Last-Modified: Tue, 18 Dec 2012 20:32:56 GMT
Expires: Sun, 01 Jan 2023 14:55:37 GMT
Date: Thu, 03 Jan 2013 14:55:37 GMT
Cache-Control: public, max-age=315360000
複数の CSS ファイルや JavaScript ファイルを単一のファイルに連結する二つ目の工夫は、チルダを利用して一つの URL で複数のファイル名を表すことで実装される:
http://example.org/lib/bootstrap/css/bootstrap
~bootstrap-responsive~bootstrap-base-site~
/css/jquery.loadmask~z.growl~z.modal~site~63523081976.css
最後の数字は最も新しいファイルのタイムスタンプを表す。必要な CSS リンクあるいは JavaScript スクリプトタグはテンプレートタグ {% lib %} で生成される。
サーバーサイドのキャッシュ
Zotonic は大規模なシステムであり、様々な部分が何らかの形でキャッシュを利用する。ここでは興味深いキャッシュの工夫をいくつか説明する。
静的な CSS, JavaScript, 画像ファイル
静的ファイルを扱うコントローラーには静的ファイル用の最適化が実装されている。まず、このコントローラーは複数のファイルを要求するファイルリクエストから個別のファイルのリストを抽出できる。
また、HTTP リクエストの If-Modified-Since フィールドもチェックされ、適切な場合には HTTP ステータスコード 304 (Not Modified) が返答される。
リクエストが初めて受け取ったものである場合、静的ファイル用コントローラーはリクエストされた全ての静的ファイルを一つのバイト列 (Erlang の binary) に連結する3。このバイト列は未圧縮の状態と (gzip で) 圧縮された状態で中央の depcache にキャッシュされる。ブラウザが設定した Accept-Encoding の値に応じて、Zotonic は未圧縮もしくは圧縮済みのバイト列をクライアントに返す。
このキャッシュの仕組みは非常に効率的であり、ウェブサーバーによって完全に制御されるにもかかわらず、そのパフォーマンスは多くのキャッシュプロキシと同程度となる。以前のバージョンの Zotonic と一般的なハードウェア (2008 年の 2.4 GHz クアッドコア Xeon) を使った実験では、毎秒 6000 リクエストのスループットが観測され、小さな (20 KB 程度の) 画像ファイルのリクエストでギガビットイーサネット接続の帯域を使い切ることができた。
テンプレートのレンダリング結果のキャッシュ
テンプレートは Erlang モジュールにコンパイルされ、そのバイトコードがメモリ上に保存される。コンパイルされたテンプレートは通常の Erlang 関数と同じように呼び出せる。
テンプレートシステムは実行時にテンプレートファイルの変更を自動的に検出し、テンプレートを再コンパイルする。コンパイルが終了すると、Erlang が持つコードのホットアップグレードの仕組みを利用して新しくコンパイルされた Erlang モジュールが読み込まれる。
メインのページコントローラーとテンプレートコントローラーはテンプレートのレンダリング結果をキャッシュするオプションを持つ。キャッシュを匿名の (ログインしていない) 訪問者に対してだけ有効にすることもできる: ほとんどのウェブサイトでは大部分のリクエストが匿名の訪問者によって生成され、そのレスポンスはパーソナライズされず (ほぼ) 同一である。テンプレートのレンダリング結果は中間生成物であり、最終的な HTML ではない点に注意してほしい。この中間生成物には未翻訳の文字列や JavaScript フラグメントといった要素が含まれる。最終的な HTML はレンダリング結果をパースし、JavaScript フラグメントを一つに結合する処理や適切な訳語の選択などを適用して生成される。
結合された JavaScript フラグメントは一意なページ ID と共にテンプレートタグ {% script %} の位置に配置される (このテンプレートタグは </body> の直前にあるはずである)。一意なページ ID はレンダリングされたページと Erlang プロセスの関連付け、そしてページで発生する WebSocket/Comet の対話で使われる。
あらゆるテンプレート言語と同じように、Zotonic のテンプレートは他のテンプレートをインクルードできる。インクルードされるテンプレートは通常インラインにコンパイルされるので、インクルードを使ってもパフォーマンスは低下しない。
実行時のインクルードが強制される特別なオプションもいくつかある。そのようなオプションの一つにキャッシュの扱いを指示するオプションがある。これを使うと、キャッシュを匿名の訪問者に対するページでのみ有効化したり、キャッシュ可能な期間を設定したり、キャッシュの依存関係を追加したりできるようになる。キャッシュの依存関係はリソースの変更から無効化すべきレンダリング結果を計算するときにも用いられる。
テンプレートの一部をキャッシュする別の方法として、ブロックタグ {% cache %} ... {% endcache %} を使う方法がある。このタグはインクルードタグと同様にキャッシュ可能なブロックを作成する。インクルードタグと比較すると、このタグには既存のテンプレートに追加しやすいという利点がある。
インメモリのキャッシュ
Zotonic のキャッシュは全て Erlang VM 内部のメモリを利用する。キャッシュされたデータにアクセスしたとしてもオペレーティングシステムや他のマシンとの通信は発生しない。この事実によって、キャッシュされたデータの利用が大幅に単純かつ効率的になる。
比較しておくと、memcached サーバーに対するアクセスには 0.5 ms 程度の時間がかかる。これに対して、同じプロセスのメインメモリへのアクセスは CPU キャッシュがヒットすれば 1 ns 程度、キャッシュがヒットしなくても 100 ns 程度で行える ── さらに当然、メモリとネットワークではデータ転送の速度が大きく異なる4。
Zotonic はインメモリキャッシュの仕組みを二つ5持つ:
- depcache
- プロセス辞書を使ったメモキャッシュ (Process Dictionary Memo Cache)
depcache
depcache (dependency cache) は全ての Zotonic サイトが必ず持つ中央集権的なキャッシュの仕組みである。depcache はインメモリのキーバリューストアであり、格納されるキーの間の依存関係も保持する。
depcache が各キーに対して格納するデータは次の通りである:
- キーに対応するバリュー
- シリアル番号 (リクエストごとに 1 だけ増加するグローバルな整数値)
- キーの有効期限 (単位は秒)
- キーが依存する他のキー (キャッシュされたテンプレートで表示されるリソース ID など) からなるリスト
- キーに対応するバリューが計算中なら、バリューを待っているプロセスのリスト
リクエストを受け取ると、depcache はリクエストが指定するキーが存在し、その有効期限が切れておらず、そのシリアル番号が依存するキーのシリアル番号より小さいかどうかを確認する。全ての条件が満たされるならキーは有効なので、対応するバリューが返される。そうでなければ、キーとバリューがキャッシュから削除され undefined が返される。
あるいは、キーに対応するバリューが計算中なら、リクエストしたプロセスがキーの待機リストに追加される。
depcache の実装は Erlang Term Storage (ETS) を利用する。ETS は Erlang/OTP ディストリビューションに含まれる標準的なハッシュテーブルの実装である。Zotonic は depcache で次の ETS テーブルを作成する:
- Meta テーブル: depcache に格納されたキー、その有効期限、シリアル番号、依存するキーが全て格納される。このテーブルのレコードは
#meta{key, expire, serial, deps}と書ける。 - Deps テーブル: 各キーのシリアル番号が格納される
- Data テーブル: 各キーのバリュー (データ) が格納される。
- 待機 PID 辞書: キーのバリューが計算されるのを待っているプロセスの ID のリストが格納される。
ETS テーブルは並列の読み取りに最適化され、通常は呼び出し側のプロセスから直接アクセスされる。そのため、呼び出し側のプロセスと depcache プロセスの間で通信は必要にならない。
depcache プロセスは次の場合に利用される:
- 他のプロセスで計算される値をメモ化する。
- リクエストを格納する。同時にシリアル番号の増加を逐次化する。
- リクエストを消去する。同時に depcache に対するアクセスを逐次化する。
depcache は非常に大きくなる可能性がある。depcache を小さく保つために、ガベージコレクタを持ったプロセスが用意される。このガベージコレクタは depcache 全体をゆっくり走査し、有効期限切れのキーや無効なキーを削除する。depcache のサイズが特定の閾値 (デフォルトでは 100 MiB) に達するとガベージコレクタは実行速度を速め、走査したレコードの 10% を無条件に削除する。この無条件の削除はキャッシュのサイズが閾値を下回るまで行われる。
データベースのサイズが数 TB に達する可能性があることを考えると、depcache の最大サイズが 100 MiB で足りるのだろうかと疑問に思うかもしれない。しかし、depcache に格納されるのはテキストデータであり、100 MiB もあれば多くのウェブサイトのホットデータを格納できる。もし容量が足りなければ、サイズは設定から変更できる。
プロセス辞書を使ったメモキャッシュ
Zotonic が採用するもう一つのインメモリキャッシュの仕組みはプロセス辞書を使ったメモキャッシュ (Process Dictionary Memo Cache) と呼ばれる。先述したように、データのアクセスパターンはテンプレートによって決定される。プロセス辞書を使ったメモキャッシュは単純なヒューリスティックでデータアクセスを最適化する。
この最適化では、リクエストを処理する Erlang プロセスが持つ辞書を使ったデータのキャッシュが重要となる。プロセス辞書は単純なキーバリューストアであり、プロセスと同じヒープに格納される。簡単に言うと、プロセス辞書は関数型言語の Erlang に状態を追加する。これはプロセス辞書が一般に避けられる理由であるものの、インプロセスのキャッシュでは有用となる。
リソースにアクセスがあると、そのリソースはプロセス辞書にコピーされる (リソースは Zotonic において中心的なデータ単位であることを思い出してほしい)。計算処理 (アクセス権限の確認など) の結果や設定といったデータもプロセス辞書にコピーされる。
リソースのプロパティ ── 例えば題名、要約、本体テキスト ── をページに表示するには、アクセス権限を確認してからリクエストしたプロパティをリソースからフェッチしなければならない。リソースのプロパティとアクセス権限を全てキャッシュするとデータの利用が大幅に高速化され、テンプレートの予測困難なデータアクセスパターンが持つ欠点の多くを克服できる。
ページやプロセスが利用するデータは膨大になる可能性があるので、プロセス辞書のメモキャッシュにはいくつか制限がある:
- キーの個数が 10,000 を超えると、プロセス辞書全体がフラッシュされる。これはリソースの長いリストをループする場合などに辞書が大きくなるのを防ぐためにある。ただし
$ancestorsといった特別な Erlang 変数は削除されない。 - プロセス辞書を使ったメモキャッシュの機能はプログラムから有効化される必要がある。ただし、内向き HTTP/WebSocket リクエストの処理とテンプレートのレンダリングでは自動的に有効化される。
- HTTP/WebSocket リクエストの処理が完了するとプロセス辞書はフラッシュされる (連続する HTTP/WebSocket リクエストは同じプロセスで処理されるため)。
- プロセス辞書を使ったメモキャッシュは依存関係を追跡しない。depcache で削除が起きると、削除を実行したプロセスのプロセス辞書全体がフラッシュされる。
プロセス辞書を使ったメモキャッシュの機能が無効化されるとき全てのルックアップは depcache によって処理されるので、depcache プロセスとのメッセージとデータのやり取りが生じる。
Erlang VM
Erlang の仮想機械 (Erlang VM) はパフォーマンスに関する重要な特徴をいくつか持つ。
プロセスは安い
Erlang VM は多くの処理を並列に実行するために特別に設計されており、VM 内にマルチプロセッシングの独自実装を持つ。Erlang プロセスは reduction と呼ばれる値に基づいてスケジュールされる: 大まかに言って、関数の呼び出されると reduction が 1 だけ減少する。プロセスは入力 (他のプロセスからのメッセージ) を待機するまで、あるいは事前に設定された reduction を使い切るまで実行を許される。この上で独自の実行キューを持ったスケジューラが各 CPU コアに一つずつ起動される。Erlang アプリケーションが数千あるいは数百万のプロセスを同時に保持することも珍しくない。
プロセスは安価に起動できるだけではなく、サイズも 327 ワード (64 ビットマシンでは約 2.5 KiB) と非常に小さい6。これに対して Java では約 500 KiB、pthreads ではデフォルトで 2 MiB である。
プロセスが非常に安価に利用できるので、リクエストの結果に必要ない処理は全て新しい個別のプロセスで実行される。個別のプロセスで実行できるタスクの例としてメールの送信やログの記録がある。
データのコピーは高い
Erlang VM ではプロセス間メッセージのコストが比較的大きい: Erlang がプロセスごとにガベージコレクタを持つために、メッセージを宛先のプロセスにコピーする必要があるためである。そのため、データのコピーを避けることが重要となる。これが理由となって、Zotonic の depcache は任意のプロセスからアクセスできる ETS テーブルを利用している。
大きなバイト配列に対する個別のヒープ
プロセス間で発生するデータコピーには大きな例外が一つある。64 バイトより大きいバイト配列は別のプロセスに渡すときでもコピーされない。そういったバイト配列は個別のヒープに収められ、個別にガベージコレクションされる。
この仕組みがあれば大きなバイト配列を別のプロセスに送信した場合でも参照だけがコピーされるので、コストは小さくて済む。ただし、バイト配列のメモリを解放するには全ての参照が失われたことを確認しなければならないので、ガベージコレクションは複雑になる。
大きなバイト配列の一部に対する参照が渡されるケースもある: 正しくガベージコレクションを行うには、そういった参照も追跡しなければならない。このため、大きなバイト配列を解放できるようになる場合はバイト配列を意図的にコピーすることも最適化となる。
文字列処理は高い
Erlang は多くの関数型言語と同様に文字列を整数の連結リストとして表現し、さらにデータを破壊的に変更できないので、文字列処理のコストが高くなる。
文字列がリストとして表現されるとき、文字列処理はパターンマッチングと末尾再帰を使って書かれる。これは関数型言語では自然な選択肢であるものの、連結リストを使った表現に大きなオーバーヘッドがあること、そして連結リストを他のプロセスに送信するにはリスト全体をコピーしなければならないことが問題となる。そのためパフォーマンスを考えるとき、連結リストは文字列の表現として最適でない。
この問題に対して、Erlang は io-list と呼ばれる中道的な解決策を持つ。io-list はリストであり、その要素はリスト、整数 (一つのバイト値)、バイト列、他のバイト列への参照のいずれかである。io-list は非常に使いやすく、追記、接頭部の取得、データ挿入のコストはどれも小さい。そういった操作で必要なのは比較的短いリストへの変更だけで、データのコピーが一切起こらない7。
io-list は「ポート」 (ファイルディスクリプタ) に送信できる。送信された io-list はバイトストリームに平滑化され、そのバイトストリームがソケットに書き込まれる。
io-list の例を示す:
[ <<"Hello">>, 32, [ <<"Wo">>, [114, 108], <<"d">>]].
この io-list は次のバイト配列に平滑化される:
<<"Hello World">>.
興味深いことに、ウェブアプリケーションで行われる文字列処理は多くが次の操作からなる:
- 最終的なページに対するデータ (動的または静的) の追加
- HTML のエスケープとコンテンツのサニタイズ
Erlang の io-list は一つ目の操作を行うのに完璧なデータ構造である。また、二つ目の操作のコストはコンテンツをデータベースに格納する前に積極的にサニタイズを実行することで削減できる。
この二つの事実は、Zotonic においてレンダリングされたページがバイト配列と事前にサニタイズされた値をいくつも連結した単一の io-list であることを意味する。
Zotonic の Context
Zotonic は Context と呼ばれる比較的大きなデータ構造を多用する。Context はリクエストの処理に必要な全てのデータを含むレコードであり、次の要素を持つ:
- リクエストのデータ: ヘッダー、リクエストの引数、本体データなど
- Webmachine の状態
- ユーザー情報 (ユーザー ID やアクセス権限など)
- 優先される言語
User-Agentクラス (テキスト、スマートフォン、タブレット、デスクトップなどを表す)- ウェブサイトが持つ特別なプロセスへの参照 (通知用プロセスや depcache 用プロセスなど)
- リクエストに対する一意 ID (生成されるページ ID となる)
- セッション ID とページ処理 ID
- このトランザクションで利用されるデータベース接続プロセス
- リプライデータ (データ、レンダリングされたテンプレート、JavaScript ファイルなど) の集積場所
こういったデータを全て合わせたデータ構造 Context は大きいので、リクエストを処理する別のプロセスに Context を送信するとコピーによる膨大なオーバーヘッドが発生する。
このため、Zotonic はリクエストの処理を可能な限り単一のプロセス (リクエストを受け付ける Mochiweb プロセス) で行う。追加されるモジュールや拡張機能はプロセス間メッセージではなく関数呼び出しによって起動される。
拡張機能が個別のプロセスを使って実装される場合もある。この場合、拡張機能が Context と拡張機能プロセスの ID を受け取る関数を提供し、拡張機能プロセスへ効率的にメッセージを送信する責任はそのインターフェース関数が負う。
Zotonic はキャッシュ可能なサブテンプレートをレンダリングするときもメッセージを送信する必要がある。このときは Context から中間生成物や必要でないデータ (ログ情報など) を取り除いたデータがサブテンプレートのレンダリングを行うプロセスに送信される。
バイト配列をメッセージで送信することは大きな問題にならない: 多くの場合でバイト配列は 64 バイトより大きく、プロセス間のコピーは起こらない。
大きな静的ファイルを配信する場合は、Linux のシステムコール sendfile を使ってファイルの送信をオペレーティングシステムに任せるオプションを使うこともできる。
Webmachine ライブラリへの変更
Webmachine は HTTP プロトコルの抽象化を実装するライブラリである。Mochiweb ライブラリがアクセスの受理やヘッダーのパースといった低レベルな HTTP 機能を実装し、Webmachine は Mochiweb の上に実装される。
Zotonic のコントローラーはコールバック関数を実装する Erlang モジュールを定義することで作成される。コールバック関数の例としては resource_exists, previously_existed, authorized, allowed_methods, process_post などがある。Webmachine はリクエストパスとディスパッチ規則のマッチングも行う。つまり、リクエスト引数をパースし、HTTP リクエストを処理する正しいコントローラーを選択する。
Webmachine があると HTTP プロトコルの扱いが簡単になるので、Zotonic を Webmachine の上に作ることは開発初期に決定していた。
ただ、Zotonic の開発を進める中で、Webmachine の問題がいくつか発見された:
- (Zotonic の開発が始まった時点では) ディスパッチ規則のリストを一つしかサポートしなかった。ホスト (サイト) ごとにディスパッチ規則のリストを用意することは不可能だった。
- ディスパッチ規則はアプリケーションの環境で構築され、ディスパッチが起こるとリクエストプロセスにコピーされていた。
- 一部のコールバック関数 (
last_modifiedなど) がリクエストの処理中に何度も呼ばれていた。 - リクエストの処理中に Webmachine がクラッシュした場合にリクエストロガーがログエントリーを作成していなかった。
- HTTP Upgrade をサポートせず、WebSocket のサポートが難しかった。
一つ目の問題 (ディスパッチ規則を分割できない) は面倒なだけで、本質的な問題ではない。ディスパッチ規則のリストが直感的でなくなり、解釈が難しくなる。
二つ目の問題 (全てリクエストでディスパッチ規則のリストがコピーされる) は Zotonic にとって非常に重大な問題だと判明した。このリストは非常に大きくなるので、そのコピーがリクエスト処理時間の大部分を占める可能性すらあった。
三つ目の問題 (同じ関数が何度も呼ばれる) があるためにコントローラーの作者は独自にキャッシュの仕組みを実装する必要があり、誤りが起こりがちだった。
四つ目の問題 (クラッシュ時にログが作成されない) によってプロダクションで起こる問題が分かりにくくなる。
五つ目の問題 (HTTP Upgrade がサポートされない) があるために、Webmachine が提供する WebSocket 接続の優れた抽象化を Zotonic では利用できなかった。
以上の問題は非常に深刻だったので、私たちは Webmachine を自分たちの用途に合うように作り変えた。
まず、「ディスパッチャ」が新しく追加された。ディスパッチャはリクエストとディスパッチ規則のリストのマッチングを行う dispatch/3 関数を実装するモジュールである。ディスパッチャは HTTP の Host ヘッダーを利用して正しいサイト (仮想ホスト) を選択する。単純な「hello world」コントローラーをテストしたとき、この変更によってスループットは三倍になった。また、多くの仮想ホストと長いディスパッチ規則リストを持つシステムでスループットの向上が大きいことも確認された。
Webmachine が管理する主要なデータ構造が二つある。一つはリクエストデータ、もう一つは内部で実行されるリクエスト処理の状態を表す。これらのデータ構造は互いを参照し合っており、ほとんどの場合で同時に使われていたので、一つのデータ構造にまとめられた。これによってプロセス辞書の利用を回避しやすくなり、Webmachine 内部の全ての関数の引数に新しいデータ構造が追加された。この工夫でリクエストの処理時間は 20% 減少した。
これら以外にも Webmachine には様々な最適化が行われた。その全てを説明することはできないものの、最も重要な最適化を次に示す:
- 一部のコントローラーのコールバック関数 (
charsets_provided,encodings_provided,content_types_provided,last_modified,generate_etag) が返す値をキャッシュする。 - プロセス辞書の利用をさらに減らす (グローバルな状態が減り、コードが分かりやすくなり、テストが容易になる)。
- ログ用プロセスをリクエストごとに個別に用意する (リクエストがクラッシュしたとしても、クラッシュした時点までのログが得られる)。
forbiddenアクセスをチェックするステップの後に HTTP Upgrade コールバックを追加し、WebSocket をサポートする。- リソースを配信するコードの呼称「リソース」を「コントローラー」に変更し、配信されるリソース (データ) とリソースを配信するコードの区別を明確にする。
- リクエストのサイズと処理速度を測定するための計装命令を追加する。
データモデル: SQL を使ったドキュメントデータベース
「リソース」 (Zotonic における中心的なデータ単位) のどんなプロパティもデータベースの視点から見れば単なるバイナリオブジェクトである事実は強調に値する。「本物」のデータベースにおいてキー、クエリ、外部キー制約にはカラムだけが使われる。
一つ以上のプロパティ (例えばテキストカラム全体や日付プロパティ) に対する「ピボット」のフィールドとテーブルを個別に作成することもできる。この場合はインデックス化が必要となる。
リソースが更新されると、データベースはそのリソース ID をピボットキューに追加する。ピボットキューは個別のバックグラウンド Erlang プロセスによって消費される。このプロセスはいくつかのリソースのインデックスを単一のトランザクションでまとめて作成する。
SQL (PostgreSQL) を選択したことで、私たちは新しいことに腰を据えて取り組めるようになった。PostgreSQL は非常によく知られたクエリ言語を持ち、安定性に優れ、パフォーマンス特性は既知であり、素晴らしいツールを持ち、商用および非商用のサポートがある。
さらに、データベースは Zotonic のパフォーマンスを制限する要素ではない。仮にクエリがボトルネックとなった場合は、データベースのクエリアナライザを使って特定のクエリを最適化することが開発者のタスクとなる。
最後に、任意のデータベースを使うときのパフォーマンスに関する黄金律は「データベースに触れるな。ディスクに触れるな。ネットワークに触れるな。キャッシュを使え」である。
ベンチマーク・統計・最適化
私たちはベンチマークをそれほど重視していない。ベンチマークはシステムの非常に小さな部分しかテストできず、システム全体のパフォーマンスを捉えられないことがよくあるためである。Zotonic のように可動部分が多く、設計の不可欠な要素としてキャッシュの仕組みと頻出アクセスパターンの効率的な処理を持つシステムでこれは特に当てはまる。
単純化されたベンチマーク
ベンチマークが示す可能性があることの一つに、システムの中で次に最適化すべき箇所がある。
この考え方を念頭に置いて、私たちは TechEmpower JSON benchmark と呼ばれるベンチマークで Zotonic のパフォーマンスを計測した。このベンチマークはリクエストディスパッチャ、JSON エンコーダー、HTTP リクエスト処理、TCP/IP スタックをテストする。
ベンチマークはクアッドコアの Intel i7 M620 @ 2.67 GHz で実行された。実行コマンドは wrk -c 3000 -t 3000 http://localhost:8080/json である。結果を表 9.1 に示す。
| プラットフォーム | 1000 リクエスト/秒 |
|---|---|
| Node.js | 27 |
| Cowboy (Erlang) | 31 |
| Elli (Erlang) | 38 |
| Zotonic | 5.5 |
| Zotonic (アクセスログ無効) | 7.5 |
| Zotonic (アクセスログ無効; ディスパッチャプール有効) |
8.5 |
Zotonic は HTTP プロトコルの抽象化と動的ディスパッチャを持つので、こういったマイクロベンチマークではスコアが低くなる。これに対処するのは比較的簡単であり、次の解決策が計画されている:
- Webmachine 標準のロガーを効率的なものに置き換える。
- ディスパッチ規則のリストを Erlang モジュールにコンパイルする (現在ディスパッチ規則のリストは単一のプロセスによって解釈される)。
- MochiWeb の HTTP ハンドラを Elli の HTTP ハンドラに置き換える。
- Webmachine でバイト配列を利用する (現在は文字リストが利用されている)。
現実世界におけるパフォーマンス
2013 年のオランダ女王の退位、そして退位に伴う新たなオランダ国王の就任に関連して、国民向けの投票サイトが Zotonic を使って構築された。クライアントは 100% の可用性と 1 時間に 100,000 回の投票を処理できる高いパフォーマンスをリクエストした。
このために、4 つの仮想サーバーを持つシステムが利用された。それぞれの仮想サーバーは 2 GB の RAM を持ち、独立した Zotonic システムを実行する。3 つの仮想サーバーが投票を処理し、残りの 1 つが管理を担当する。全てのノードは独立するものの、全ての投票は 3 つのノードで処理されるので、1 つのノードがクラッシュしたとしても投票が無効になることはない。
投票を一度行うには、静的アセット (CSS や JavaScript) と動的 HTML (複数言語に対応するため) の取得、そして Ajax で約 30 回の HTTP リクエストが必要となる。投票先の三つのプロジェクトを選択するページ、そして投票者の情報を入力するページを取得するときに複数のリクエストが必要だった。
私たちが行った投票シミュレーションによるテストでは、システムを最大限に使わなくてもクライアントの要件は容易に満たせると示された。そのシミュレーションは最大で 1 時間に 500,000 回の投票を実行し、そのとき 400 Mbps の帯域が消費され、99% のリクエストは 200 ms 以内に処理された。
この結果から、Zotonic がアクセスの多い動的ウェブサイトを扱えることは明らかである。現実のハードウェアでは (特に下位の I/O やデータベースに関係する) パフォーマンスがさらに向上することも分かっている。
結論
コンテンツ管理システムやウェブフレームワークの開発では、アプリケーションの全てのスタックを考慮することが重要となる。ウェブサーバーからリクエスト処理システム、キャッシュ、データベースに至るまで、全ての部分が上手く噛み合わなければ高いパフォーマンスは達成できない。
データの事前処理は大きくパフォーマンスを向上させる。事前処理の例としては、データベースにデータを格納する前にエスケープとサニタイズを行う最適化がある。
頻繁にアクセスされるページとそうでないページが明確に分かれるウェブサイトでは、ホットデータのキャッシュが優れた戦略となる。リクエストを処理するコードと同じメモリ空間にキャッシュを配置すると、個別のキャッシュサーバーを用意する場合と比べて速度と単純性の両方が大きく向上する。
さらに、訪問者の急激な増加に対処するための最適化として「似たリクエストを動的にまとめて、同じ結果を一度だけ計算する」というものがある。この最適化が上手く実装できると、プロキシを用意せずに全ての HTML ページを動的に生成しても問題が発生しない。
Erlang は軽量なマルチプロセッシング、障害耐性、メモリ管理を提供するので、ウェブベースの動的なシステムで使う言語として良い選択肢となる。
Erlang を使うことで、Zotonic は非常に高機能かつ高パフォーマンスのコンテンツ管理システムおよびフレームワークとなり、個別のウェブサーバーやキャッシュプロキシ、memcache サーバー、メールハンドラは必要なくなった。これによってシステム管理の仕事が大きく単純化される。
モダンなハードウェアで実行される単一の Zotonic サーバーは 1 秒間に数千個の動的ページのリクエストを処理できる。このため、ワールドワイドウェブ上のウェブサイトの圧倒的大部分は Zotonic でサーブできる。
Erlang を利用しているために、Zotonic は将来現れるであろう数十のコアを持つ CPU と数十 GBのメモリを搭載するシステムに対応する準備もできている。
謝辞
著者は Michiel Klønhammer (Maximonster Interactive Things), Andreas Stenius, Maas-Maarten Zeeman and Atilla Erdődi に感謝する。
-
他のウェブサーバー (例えば同じサーバーで実行される他のウェブシステム) を Zotonic の前段に配置することはできる。ただし、これは通常の用途では必要とならない。他のフレームワークで利用される典型的な最適化に「キャッシュを担当する Varnish などのウェブサーバーをアプリケーションサーバーの前段に配置し、静的なファイルはそこを通して配信する」があるのに対して、この最適化は静的ファイルをメモリにキャッシュする Zotonic では必要にならないのは興味深い。 ↩︎
-
Zotonic が ETag を設定しないことに注目してほしい。一部のブラウザはファイルを利用するとき毎回サーバーにリクエストを発行して ETag をチェックする。これではキャッシュでリクエストを減らすという考え方が台無しになってしまう。 ↩︎
-
binaryはバイト列を表す Erlang ネイティブのデータ型である。長さが 64 バイト以下のバイト列はプロセス間でコピーされ、それより長いバイト列はプロセス間で共有される。Erlang にはバイト列の一部を参照の形でプロセス越しに共有する仕組みもある。参照を使うとコピーが起こらないので、binaryは効率的で使いやすいデータ型である。 ↩︎ -
CPU が様々なコンポーネントにアクセスするのにかかる時間については Latency Numbers Every Programmer Should Know に詳しい解説がある。 ↩︎
-
ここに示した二つ以外にデータベースサーバーも簡単なインメモリキャッシュの仕組みを持つものの、これは本章の範囲を超える。 ↩︎
-
http://www.erlang.org/doc/efficiency_guide/advanced.html#id68921 に詳しい解説がある。 ↩︎
-
Erlang はバイト配列の一部を参照で共有できるので、データのコピーが回避される。また、バイト配列への挿入は「変更されていない接頭部、挿入された値、変更されていない接尾部」という三つの要素を持つ io-list で表現できる。 ↩︎