pugixml
はじめに
XML は標準化されたマークアップ言語であり、階層的に構造化されたドキュメントを人間が読めるテキストベースのフォーマットに符号化する規則を定める。XML は広く利用され、非常に短い単純なドキュメント (例えば SOAP クエリ) から数ギガバイトのドキュメント (例えば OpenStreetMap)、そしてデータ間に複雑な関係があるドキュメント (例えば COLLADA) まで様々なドキュメントが XML によって表される。XML を処理するとき、通常ユーザーはドキュメントを表すテキストを何らかの内部表現に変換する「XML パーサー」と呼ばれる特別なライブラリを利用する。XML はパースのパフォーマンスと複雑性、そして人間にとっての可読性のバランスを取ったフォーマットである ── そのため、高速な XML パーサーがあればアプリケーションのデータモデルを記述するフォーマットとして XML がより好ましくなる。
本章では、非常に高パフォーマンスな XML パーサー pugixml を C++ で書く上で著者が行った様々な工夫を解説する。解説される工夫は XML パーサーに適用されたものであるものの、その多くは他のフォーマットのパーサーにも、ときにはパーサー以外のソフトウェアにも適用できる (例えばメモリ管理アルゴリズムはパーサー以外の多くのソフトウェアで利用できる)。
XML のパースには大きく異なるアプローチがいくつか存在するので、そしてパーサーは XML に慣れ親しんだ人さえ存在を知らないであろう処理を行うので、実装の詳細を解説する前に XML パーサーが行うタスクを概観する。
XML パースのモデル
XML のパースにはいくつかのモデルが存在する。それぞれ異なる状況で最適となり、パフォーマンスとメモリ使用量もそれぞれ異なる。広く使われるモデルを次に示す:
- SAX (Simple API for XML) モデル: ユーザーはドキュメントのストリームといくつかのコールバックをパーサーに渡す。コールバックは「タグの開始」「タグの終了」「タグ内の文字データ」などに対応し、SAX パーサーはドキュメント内のデータに応じてコールバックを呼び出す。SAX パーサーが必要とするコンテキストは「現在読んでいる要素の深さ」だけであり、メモリ要件は非常に低い。SAX パーサーは一度にドキュメントの一部分しか利用可能にならない (ストリーミングされる) ドキュメントに対しても利用できる。
- プル (pull) モデル: SAX モデルと似ている ── ドキュメントは要素ごとに読み込まれる ── ものの、制御が反転する。つまり、SAX パーサーを使うときパース処理はコールバックを通じてパーサーが制御するのに対して、プルパーサーを使うときパース処理はイテレータ風のオブジェクトを通じてユーザーが制御する。
- DOM (Document Object Model) モデル: ユーザーはドキュメント全体をテキストのストリームまたはバッファとしてパーサーに提供し、そこからパーサーがドキュメントオブジェクト ── ドキュメント全体を表す木構造のインメモリ表現 ── を生成する。このオブジェクトはドキュメントに含まれる全ての XML 要素と XML 属性に対応する個別のオブジェクトを持ち、それらのオブジェクトに対する「ノードの子要素を取得する」などの操作が定義される。pugixml はこのモデルを採用する。
パースモデルの選択はドキュメントのサイズと構造に応じて行われる場合が多い。pugixml は DOM パーサーなので、次の特徴を持つドキュメントに適している:
- メモリに収まる程度に小さい。
- 他のノードを参照する複雑な構造を持ち、その走査が必要となる。
- ドキュメントの複雑な変形が必要となる。
pugixml の設計
pugixml は基本的に DOM パーサーの機能しか持たない。なぜなら、pugixml が書かれた 2006 年に高速かつ軽量な SAX パーサー (例えば Expat) は存在したのに対して、プロダクションレディな XML 用 DOM パーサーは軽量でないか高速でない (たいていはどちらでもない) 状況だったためである。このため pugixml は非常に高速で軽量な DOM ベースの XML 操作ライブラリを作ることを主な目標として作成された。
XML を定義する W3C 勧告は二つの異なるパース処理を規定する: validating なパースと、non-validating なパースである。non-validating なパースは XML の構文を検証し、validating なパースはそれに加えてデータの意味論も検証する。non-validating なパーサーが行う構文の検証だけでも、リソースの消費は比較的大きい。
パフォーマンスが主目標のとき、完全な規格準拠を犠牲にすることが選択肢に入る。pugixml で規格準拠は次のように妥協された: well-formed な XML ドキュメントは完全にパースされ、そのとき必須の変形も全て施される。ただしドキュメントタイプ (DOCTYPE) の宣言は認識されない1。さらに、検証される規則は簡単に検証できるものに限られる。そのため well-formed でないドキュメントがエラーを出さずにパースされることがあり得る。
XML ドキュメントに含まれるデータに変形が必要になる場合がある。例えば、パーサーは改行文字の統一、属性の値の正規化、文字参照の展開などを施してからユーザーにデータを届けなければならない。こういった変形のコストはパフォーマンスに影響する: pugixml は変形を可能な限り最適化した上で、パフォーマンスを最大限に高めるために変形を無効化するオプションを提供する。
よって、行うべきタスクは「規格に準拠する XML ドキュメントをパースして必須の変形を施すことができる、可能な限り高速でプロダクションレディな DOM パーサーの作成」となる。パフォーマンスに関して「プロダクションレディ」とは、規格に準拠していないデータに対する耐性があることを言う。バッファオーバーランのチェックを飛ばしてパフォーマンスを向上させることは許されない。
次節では pugixml のパース処理を議論する。最後の節では pugixml が DOM を格納するために利用するデータ構造、およびそのデータ構造用のメモリをアロケートするために pugixml が利用するアルゴリズムを解説する。
パース
DOM パーサーの仕事は XML ドキュメントを表す文字列を入力として受け取り、そのドキュメントを表す木構造オブジェクトをメモリ上に構築することである。典型的なパーサーは字句解析器 (lexer) とパーサー (parser) の二つのステージから構成される。字句解析器は文字列を受け取ってトークン列を生成する。XML パーサーではトークンとして「山かっこ開き」「山かっこ閉じ」「引用符」「タグの名前」「属性の名前」などが考えられる。パーサーはトークン列を受け取り、文法に基づいて構文木を生成する。パーサーで利用できるアルゴリズムには再帰下降 (recursive decent) など様々なものがある。文字列データを持つトークン (例えば「タグの名前」) を読んだときは、字句解析器またはパーサーがその文字列データをヒープにコピーし、最終的な木構造オブジェクトにはその文字列への参照を格納する必要がある。
パースのパフォーマンスを向上させるために、pugixml は次の点で典型的なアプローチと異なる手法を採用する。
トークン列の不使用
先述したように、典型的なパーサーは字句解析器を使って文字列をトークン列に変換する。パーサーがバックトラッキングを何度も行う必要がある場合には、この変換によってパフォーマンスが向上する。しかし XML パーサーでは、字句解析ステージは文字ごとのオーバーヘッドを増やすだけの余計なレイヤーとなる。このため pugixml ではパーサーがトークン列ではなく文字列を処理する。
入力はたいてい UTF-8 文字列であり、pugixml は文字列をバイトごとに読み込む。UTF-8 として正当なバイト列では 128 より小さいバイトは全て単独で ASCII 文字を表す (複数のバイトで一つの文字を構成することがない) ので、特定の非 ASCII 文字を検索するのでない限り UTF-8 バイト列をパースする必要はない2。
インプレースのパース
パーサーの典型的な実装には効率的でない点がいくつかある。その一つがヒープへの文字列データのコピーである: 可変サイズ (数バイトから数メガバイト) のメモリブロックをアロケートし、さらに文字列をコピーしなければならない。このコピー操作を回避できれば、両方のオーバーヘッドが排除される。インプレースのパース (別名 in situ のパース) と呼ばれる手法を使うと、パーサーは入力文字列にあるデータをそのまま利用できる。pugixml はこの手法を採用する。
インプレースのパースはメモリの連続領域に確保されたバッファに格納された文字列を入力として受け取り、文字列を一文字ずつスキャンしながら最終的な木構造を構築する。タグ名といったデータモデルの一部である文字列を読むと、パーサーはその地点へのポインタと文字列の長さを保存する3 (文字列全体をヒープに保存することはしない)。
ここにはパフォーマンスとメモリ使用量のトレードオフが存在する。インプレースのパースは文字列をヒープにコピーする通常のパースより通常は高速になるものの、多くのメモリを消費する。インプレースのパースを使うとき、パーサーはドキュメントを表す木構造に加えて入力として受け取った文字列全体も保持しなければならない。インプレースでないパースでは入力として受け取った文字列の必要な部分だけがヒープに移される。

さらに複雑な問題がもう一つある: XML ファイル内の文字列表現とプログラム内で使う文字列表現が異なる可能性がある。規格準拠な XML パーサーはドキュメントの文字列を表現された文字列にデコードしなければならない。この処理をノードオブジェクトへのアクセス時に行うとパフォーマンスが予測不能になってしまうので、パース時に行うのが望ましい。コンテンツタイプに応じて、規格準拠な XML パーサーは次の変換を行うことが求められる:
- 文字列参照の展開: XML は文字のエスケープをサポートし、十進数または十六進数で表した Unicode 符号位置で文字を表現できる。例えば
aはaに、øはøに展開しなければならない。 - エンティティ参照の展開: XML は一般的なエンティティ参照をサポートし、
&name;でnameという名前に対応する値を表せる。事前に定義されたエンティティとして<(<),>(>),"("),'('),&(&) の五つがある。 - 属性の値の正規化: 参照の展開に加えて、パーサーは属性の値を読むときに空白文字を正規化する必要がある。空白文字 (スペース、タブ、キャリッジリターン、ラインフィード) は全て単一のスペースに正規化される。さらに属性の種類によっては、先頭および末尾の空白を削除し、中間にある連続する空白を一つにする必要がある。
- 改行文字の統一: 入力文字列には異なる改行文字が含まれていて構わないものの、パーサーはキャリッジリターン (
0xD) とラインフィード (0xA) からなる二バイト、および単独のキャリッジリターンを単一のラインフィードに置き換えて正規化しなければならない。例えば、文字列`line1\xD\xAline2\xDline3\xA\xA`は、次のように変換される:
`line1\xAline2\xAline3\xA\xA`
こういった変換を入力文字列の改変を通してサポートするには、「変換が文字列を長くしない」という条件が満たされる必要がある。この条件が満たされないと、展開後の文字列がドキュメントの重要な部分を上書きする可能性が生まれる。幸い、この条件は上述した変換の全てで満たされる4。
正確に言うと、一般的なエンティティ参照の展開はこの条件を満たさない。ただ、pugixml は DOCTYPE 宣言をサポートせず、このとき独自のエンティティを定義する手段が存在しないので、pugixml がサポートするドキュメントは必ずインプレースにパースできる5。

興味深いことに、インプレースのパースはメモリマップドファイルと共に利用できる6。ただし、テキストのヌル終端化と上述の変換をサポートするには、copy-on-write と呼ばれるオプションを使ってファイルをマップしたメモリ領域に対する改変がディスク上に書き込まれるのを防ぐ必要がある。
インプレースのパースでメモリマップドファイルを使うと、次の利点がある:
- カーネルはキャッシュページをプロセスのアドレス空間に直接マップするので、通常のファイル I/O で発生するメモリコピーが発生しない。
- ファイルがキャッシュに存在しないときカーネルはファイルに対応するセクションをディスクからプリフェッチするので、事実上 I/O とパースを並列に行える。
- 改変されたページに対してだけ物理メモリがアロケートされるので、長いテキストを持つドキュメントでメモリ使用量が大きく削減される。
文字ごとの操作の最適化
パーサーを最適化するためにできるのは「文字列のコピーを避ける」だけではない。パーサーのパフォーマンスを比較する上で有用なメトリックに「各文字に費やされるプロセッサのサイクル数の平均値」がある。この値はパースするドキュメントやプロセッサのアーキテクチャによって異なるものの、似た構造のドキュメントを同じマシンでパースする場合はそれなりに安定することが知られている。そのため、このメトリックを最適化するのは理にかなっている。このための明らかな最初の一歩は各文字に対して行われる操作の最適化である。
そういった操作の中で最も重要なのは文字集合に属するかどうかの判定である: 入力文字列に含まれる文字が一つ与えられたとき、それは特定の文字集合に含まれるか?
有用なアプローチの一つとして「各文字を添え字とする真偽値テーブルを用意して、文字が集合に属するとき true を、属さないとき false をテーブルの要素とする」というものがある。この真偽値テーブルで使うべきデータ構造とサイズはエンコーディングによって異なる:
- 全ての文字が 8 ビット (以下) で表されるエンコーディングでは、256 要素の配列で十分となる。
- UTF-8 では、符号位置が 127 より大きい文字が全て対象の文字集合に属さない (もしくは属する) 場合に限ってバイトを添え字とする配列を利用できる。この条件が満たされる場合、256 要素の配列で判定が行える。この配列の前半の 128 要素は (文字集合に属するかどうかに応じて)
trueまたはfalseで埋まり、後半の 128 要素は同じ値で埋まる。ここでは「UTF-8 が 127 より大きい符号位置を必ず 127 より大きいバイトの列としてエンコードする」事実が利用されている。 - UTF-16 と UTF-32 では、大きな配列を用意する方法は現実的でない。UTF-8 で考えたのと同じ条件が満たされる場合は、128 要素または 256 要素の配列を用意した上で符号位置が 127 より大きいかどうかを判定する比較を行えば高速化できる。
true または false を保存するには 1 ビットしか必要とならないので、ビットマスクを使えば 8 つの異なる文字集合を 256 バイトの配列に格納できる。pugixml はこのアプローチを採用してキャッシュ空間を節約している: x86 アーキテクチャにおいて、真偽値の確認とバイト内のビットの確認は (ビットの位置がコンパイル時定数であるという仮定の下で) 同じコストを持つ。このアプローチを実装する C コードを次に示す:
enum chartype_t {
ct_parse_pcdata = 1, // \0, &, \\r, <
ct_parse_attr = 2, // \0, &, \\r, ', "
ct_parse_attr_ws = 4, // \0, &, \\r, ', ", \\n, tab
// ...
};
static const unsigned char table[256] = {
55, 0, 0, 0, 0, 0, 0, 0, 0, 12, 12, 0, 0, 63, 0, 0, // 0-15
// ...
};
bool ischartype_utf8(char c, chartype_t ct) {
// unsigned char へのキャストによって添え字が 0..255 内に収まることが保証される。
return ct & table[(unsigned char)c];
}
bool ischartype_utf16_32(wchar_t c, chartype_t ct) {
// unsigned へのキャストによって添え字が負でないことが保証される。
return ct & ((unsigned)c < 128 ? table[(unsigned)c] : table[128]);
}
判定しようとしている集合が単一の区間として表されるなら、テーブルのルックアップではなく比較を使った方が良いこともある。そのとき符号無し算術を上手く使えば比較は一度しか必要とならない。例えば、文字が数値かどうかを判定する関数は次のように書かれる場合が多い:
bool isdigit(char ch) {
return (ch >= '0' && ch <= '9');
}
しかし、この関数は比較を一度だけ使うように書き直せる:
bool isdigit(char ch) {
return (unsigned)(ch - '0') < 10;
}
入力文字列を文字ごとに処理する場合、ここまでに説明してきた関数をさらに改善することは通常できない。ただし、チェックをベクトル化して複数の文字を一度に処理できる場合がある。もしターゲットのシステムが SIMD 命令をサポートするなら、16 文字の (あるいはそれより大きい) グループに対する高速な命令を利用できる。
文字に対する処理はプラットフォーム固有の命令セットを利用せずにベクトル化できる可能性がある。例えば、UTF-8 バイト列に含まれる 4 つの連続するバイトが全て ASCII 符号位置を表すかどうかは次のコードで判定できる7:
(*(const uint32_t *)data & 0x80808080) == 0
最後に指摘しておきたい点として、どんなアプローチを採用するのであれ、標準ライブラリの is.* 関数 (例えば isalpha 関数) はパフォーマンスが重要なコードで使ってはいけない。最も優れた実装であっても現在のロケールが "C" かどうかを確認しなければならず、この処理はテーブルのルックアップより時間がかかる。実装によっては、最良の実装より二桁も遅い場合がある8。
文字列変換の最適化
pugixml において、値の読み込みと変換は特に時間のかかる処理である。例として、XML タグに囲まれる文章といったプレーン文字データ (plain-character data, PCDATA) を読み込む処理を考えよう。先述したように、規格準拠な XML パーサーは PCDATA を読み込むときに参照の展開と改行文字の統一を必ず行わなければならない9。
例えば、PCDATA
A < B.
は、次のように変換される:
A < B.
PCDATA をパースする関数は PCDATA の開始地点を指すポインタを受け取り、そこから PCDATA の終わりまで読み進めながら変換とヌル終端化をインプレースに行う。
参照の展開と改行文字の統一が有効かどうかで行うべき処理は異なるので、PCDATA をパースする関数には 4 つのバリエーションがある。pugixml は短くない時間を書けてフラグを実行時に確認するのではなく、真偽値のテンプレート引数を利用してコンパイル時にフラグを確認している ── つまり単一のテンプレートから 4 つの異なる関数がコンパイルされ、パーサーは実行時のフラグの値に応じて適切な関数を呼び出す。
この方式を利用すると特殊化された関数のそれぞれでフラグの確認が不必要になるのに加えて、未使用コードの削除も可能となる。これとは異なる重要な点として、それぞれの関数のパースを行うループでは文字集合判定を利用して PCDATA の一部である文字を素早く読み飛ばし、特殊な動作を引き起こす文字だけを詳しく見ることができる。実際のコードは次のようになる:
template <bool opt_eol, bool opt_escape> struct
strconv_pcdata_impl {
static char_t* parse(char_t* s) {
gap g;
while (true) {
while (!PUGI__IS_CHARTYPE(*s, ct_parse_pcdata)) ++s;
if (*s == '<') { // PCDATA はここで終わる
*g.flush(s) = 0;
return s + 1;
} else if (opt_eol && *s == '\r') { // '\r' もしくは "\r\n"
*s++ = '\n'; // 単一の '\n' に置き換える
if (*s == '\n') g.push(s, 1);
} else if (opt_escape && *s == '&') {
s = strconv_escape(s, g);
} else if (*s == 0) {
return s;
} else {
++s;
}
}
}
};
これとは別に、実行時のフラグに応じて適切な実装の関数ポインタを返す関数も用意される。この関数は例えば &strconv_pcdata_impl<false, true>::parse を返す。
このコードのまだ解説していない部分として gap クラスがある。以前に説明したように、文字列の変換では一部の文字が削除され、最終的な文字列が元の文字列より短くなる場合がある。この処理を行う方法はいくつか考えられる。
一つ目の (pugixml が採用しない) 方法は、同じバッファの内部を指す二つのポインタ read と write を用意して、read ポインタで現在の読み込み位置を、write ポインタで現在の書き込み位置を追跡するというものである。このとき不変条件 write <= read が常に成り立つ。この方法では、最終的な文字列に含まれる全ての文字を write ポインタの指す先に書き込む必要がある。こうすればナイーブに文字削除を毎回行うときの二次関数的振る舞いは避けられるものの、文字列を全く変更しない場合でも全ての文字をコピーしなければならないために効率的とは言えない。
このアイデアの簡単な拡張として、元の文字列の変更されない最長の接頭部を飛ばして、その接頭部の次の文字から書き込みを行うというものがある ── 実は、std::remove_if などの関数が採用するアルゴリズムは通常このような動作をする。
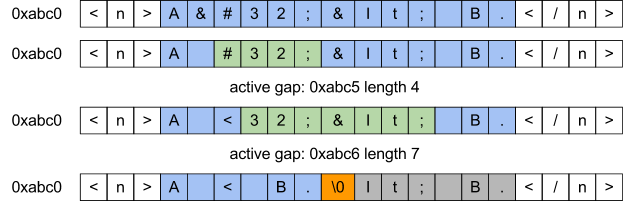
gap の例
pugixml は異なるアプローチを採用する (図 4.3)。このアプローチでは任意の時点でギャップが一つしか存在しない事実が利用される。このギャップは最終的な文字列の一部でない部分に対応する。置換が起こって新しいギャップが生まれる (例えば " を & に置き換えて 5 文字分のギャップが生まれる) とき、二つのギャップに挟まれるデータを一つ目のギャップの開始地点に移すことで二つのギャップを一つにできる。複雑性を考えると、このアプローチは read と write のポインタを使うアプローチと変わらない。しかしギャップを一つにする処理では高速なルーチンが利用できる (pugixml ではギャップの長さと C ランライムの実装の条件が満たされるとき文字ごとのループより効率的な memmove が用いられる)。
制御フローの最適化
pugixml のパーサーは再帰下降パーサーに分類される。ただし、パフォーマンスのため再帰はループに変換される。具体的には、ノードを指すポインタのスタックを用意して、開始タグを読んだときに新しいノードのポインタをスタックに積み、終了タグを読んだときにスタックの先頭からポインタを取り除く。こうすると入力文字列の長さ・複雑さに関わらずプログラムとしてのスタック使用量は一定に保たれ、ロバスト性が増し、時間がかかる可能性のある関数呼び出しも回避される。
pugixml のパーサーは「入力ストリームから文字を一つ読み、タグの種類を判定するために (一文字目から決まる量だけ) さらに読み、判明した種類のタグをパースする関数を呼び出す」というディスパッチループを持つ。例えば最初の文字が < なら、読んでいるのが「開始タグ」「終了タグ」「コメント」「他の種類のタグ」のどれかを判定するために最低でも一文字をさらに読む必要がある。一部のケースで pugixml は goto 文を利用してディスパッチループを最初から実行することを回避する ── 例えば、テキストコンテンツのパースはストリームの終端もしくは文字 < を読んだときに終了する。このとき、もし次の文字が < だと分かっているなら、ディスパッチループの最初に戻って「次の文字」が何かを確認する必要はなく、直接 < を読んだときの (終了タグをパースする) コードにジャンプして構わない。
こういったコードで重要な最適化として、分岐の並べ替えとコードの局所性の向上の二つがある。
パーサーでは様々なコードが様々な形態の入力を処理する。コードの中には明らかに頻繁に実行される部分 (例えばタグの名前や属性のパース) もあれば、明らかにほとんど実行されない部分 (例えば DOCTYPE のパース) もある。コードの小さな部分に注目した場合にも、分岐の確率が前もって分かるケースが多い。例えばパーサーが山かっこ開き (<) を読んだとき、次の文字として最も確率が高いのはタグの名前となれる文字である。次に確率が高いのは /10 で、その後は !, ? が続く。
この事実を念頭に置けば、実行が高速になるようにコードの順序を入れ替えることができる。まず、ほとんど実行されない「冷たい」コード ── pugixml では「開始タグ」「終了タグ」「属性」「テキスト要素」以外の全ての XML 要素に関するコード ── はディスパッチループの外に配置される個別の関数とする。関数の内容やコンパイラにもよるものの、その関数に noinline といった属性を付けた方が良い場合もある。メインのディスパッチループにインライン化されるコードを「暖かい」コードに制限することがここでのアイデアである。こうすると制御フローグラフが小さくなるので、コンパイラはディスパッチループを上手く最適化できる。加えて、暖かいコードを近くに配置することで、命令キャッシュのキャッシュミスが減る効果もある。
さらに、温かいコードと冷たいコードの両方で、条件文が並ぶときは確率が高い順に分岐を並べるのが望ましい。例えば、次のようなコードは典型的な XML を高速にパースできない:
if (data[0] == '<')
{
if (data[1] == '!') { ... }
else if (data[1] == '/') { ... }
else if (data[1] == '?') { ... }
else { /* 開始タグもしくは認識不能なタグ */ }
}
次のようにした方が高速になる:
if (data[0] == '<')
{
if (PUGI__IS_CHARTYPE(data[1], ct_start_symbol)) { /* 開始タグ */ }
else if (data[1] == '/') { ... }
else if (data[1] == '!') { ... }
else if (data[1] == '?') { ... }
else { /* 認識不能なタグ */ }
}
このバージョンでは確率が高い分岐が最初に、確率が低い分岐が最後にあるので、条件文判定と条件付きジャンプの平均実行回数が最小化される。
メモリ安全性の保証
メモリ安全性はパーサーにとって重要な懸念事項である。どんな入力を受け取ったとしても (入力が不当な XML であったとしても)、パーサーは入力バッファの範囲外に対して読み書きしてはいけない。この要件を満たす方法は少なくとも二つある。一つ目は「現在の読み込み位置がバッファの終端を超えていないことをチェックする」であり、もう一つは「入力をヌル終端文字列として、ヌル終端を読んだかどうかをチェックする」である。pugixml は後者を拡張したアプローチを利用する。
読み込み位置のチェックを行うと認識可能な程度のパフォーマンスのオーバーヘッドが生じる。これに対して、ヌル終端の判定は存在判定に自然に組み込めることがよくある。例えば、次のループ
while (PUGI__IS_CHARTYPE(*s, ct_alpha))
++s;
は、連続するアルファベット文字をスキップし、アルファベットでない文字またはヌル終端を読むと停止する。このときヌル終端のための特別なチェックは必要ない。
また、あらゆる場所でバッファの終端を保存するとレジスタを圧迫するので、そこからも速度が低下する。さらに、関数に渡す引数が二つ (現在位置とバッファの終端) になることで関数呼び出しにかかる時間も増加する。
一方で、入力にヌル終端文字列を要求するのはライブラリのユーザーにとっては不便である。XML 文字列はバッファに読み込まれることがよくあるので、ヌル終端を付け足すだけの空間を持たない可能性がある。クライアントにとってメモリバッファとはポインタとサイズであり、ヌル終端は自然でない。
pugixml ではインプレースのパースのために内部のメモリバッファが改変可能でなければならないので、この問題は簡単に解決できる: pugixml は入力を読み込んだバッファの最後の文字をヌル終端に置き換え、置き換わった元々の文字を保存しておく。こうするとき、最後の文字が意味を持つのは正当なドキュメントが最後の一文字で終わるときに限られる。そういった状況は XML のパースでは多くない11ので、この工夫はパフォーマンスを改善する12。
pugixml のパーサーを広範囲の XML ドキュメントに対して高速にしている最も興味深い工夫と設計判断が以上で解説できた。しかし、パーサーのパフォーマンスに大きな影響を与える要素であって議論に値するものがまだ一つ残っている。
DOM を表すデータ構造
XML ドキュメントは木構造を持つ: XML ドキュメントは一つ以上のノードを持ち、それぞれのノードも一つ以上のノードを持つことができる。ノードは異なる種類の XML データ (例えば要素やテキスト) を表現し、要素ノードは一つ以上の属性を持つことができる。
ノードの表現には、メモリ使用量と様々な操作のパフォーマンスの間にトレードオフが存在する場合が多い。例えば、意味論上はノードに子ノードの集合が含まれるとみなせる。子ノードの集合は何らかのデータ構造で、具体的には配列または連結リストで表現できる。配列で表現すれば添え字による高速なアクセスが可能になり、連結リストで表現すれば挿入と削除が定数時間で可能になる13。
pugixml はノードの集合と属性の集合をどちらも連結リストで表現することを選択した。なぜ配列を使わないのだろうか? 配列が持つ大きな利点は添え字による高速なアクセス (pugixml では特に重要でない) とメモリ局所性 (pugixml では異なる手段で達成される) である。
添え字による高速なアクセスはたいてい必要にならない: XML の木構造を処理するコードは子ノードを全て走査するか、そうでなければ何らかの属性の値を指定して特定のノードを取得する (例えば「id 属性の値が X に等しい子ノード」など14)。また、改変可能な XML ドキュメントでは添え字によるアクセスが壊れやすい: 例えば XML コメントを後から加えると、それ以降の兄弟ノードは持つ添え字は変化する。
連結リストを使うときメモリの局所性が生まれるかどうかはメモリをアロケートするアルゴリズムに依存する。正しいアルゴリズムを使えば、要素が連続領域にアロケートされるとき配列と同程度に効率的となる連結リストを実装できる (詳しくは後述)。
子ノードを配列に保存する木構造 (pugixml が使わない方式) は基本的に次の形をしている場合が多い15:
struct Node {
Node* children;
size_t children_size;
size_t children_capacity;
};
子ノードを連結リストに保存する木構造 (pugixml が使う方式だが、詳細は異なる) は基本的に次の形をしている場合が多い:
struct Node {
Node* first_child;
Node* last_child;
Node* prev_sibling;
Node* next_sibling;
};
ここで last_child は逆順の走査と末尾への追加を定数時間でサポートするために必要となる。
連結リストを使う設計には、異なる種類のノードをサポートする場合でもメモリの消費が抑えられるという利点がある。例えば要素ノードは属性リストを持つのに対して、テキストノードは持たない。配列を使う設計では全ての種類のノードが同じサイズを持たなければならず、メモリが無駄に消費される。
pugixml は連結リストベースのアプローチを採用する。このときノードの改変は常に定数時間で行える。さらに、配列ベースのアプローチでは子ノードの個数に応じて様々なサイズ (数十バイトから数メガバイトまで) のブロックをアロケートしなければならないのに対して、連結リストを使うアプローチでは数種類の異なるアロケートしか必要とならない。アロケートのサイズが固定されるとき、高速なアロケータの設計は簡単になる。これは pugixml が連結リストベースのアプローチを採用するもう一つの理由である。
メモリ使用量を配列ベースのアプローチと同程度に小さくするために、pugixml は last_child ポインタを省略する。ただし、最後の子へのアクセスを定数時間で行うために、次のように prev_sibling_cyclic を導入して連結リストを環状にしている:
struct Node {
Node* first_child;
Node* prev_sibling_cyclic;
Node* next_sibling;
};
この構造体のフィールドは次のように設定される:
first_childは最初の子ノードを指す。子ノードが存在しなければNULLとなる。prev_sibling_cyclicは左隣の (ドキュメントにおいて自身の直前にある) 兄弟ノードを指す。もし自身が左端のノードなら、prev_sibling_cyclicは一番後ろの兄弟を指す。兄弟ノードが存在しない (一人っ子の) 場合、prev_sibling_cyclicは自身を指す。prev_sibling_cyclicはNULLとならない。next_siblingは右隣のノードを指す。自身が最後の子ノードならNULLとなる。
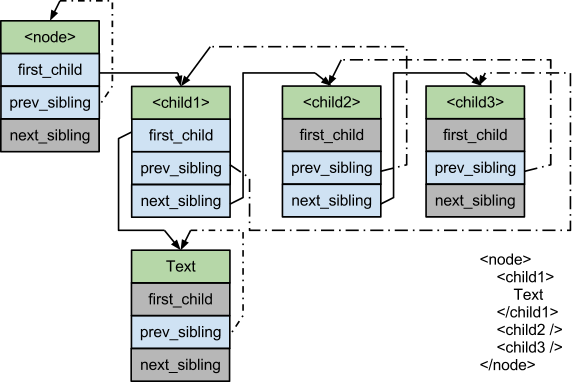
この構造体があると、次の二つの操作がどちらも定数時間で実行できる:
Node* last_child(Node* node) {
return (node->first_child) ?
node->first_child->prev_sibling_cyclic :
NULL;
}
Node* prev_sibling(Node* node) {
return (node->prev_sibling_cyclic->next_sibling) ?
node->prev_sibling_cyclic :
NULL;
}
環状の兄弟リストのトリックを使うとき、連結リストを用いるアプローチは配列を用いるアプローチとメモリ使用量が等しくなる。ただし、64 ビットシステムのみで可能な最適化として、サイズと容量を 32 ビット整数で表すことで配列を用いるアプローチのノードを小さくできる16。pugixml では、連結リストの他の利点がこのコストを上回る。
以上でデータ構造が説明できたので、パズルの最後のピースを説明するときが来た ── メモリのアロケートで使われるアルゴリズムである。
スタックベースのメモリアロケート
高速なメモリアロケータは高速な DOM パーサーに必要不可欠である。インプレースのパースを使えば文字列データのアロケートは避けられるものの、それでも DOM ノードのアロケートは必要となる。さらに、木の改変をサポートするには可変サイズの文字列のアロケートが必要となる。木の走査では、アロケートされるメモリの局所性がパフォーマンスのために重要となる: 連続するメモリアロケートが隣り合うメモリブロックを返すようにすれば、木の構築時にメモリの局所性を簡単に保証できる。最後に、アロケートされたメモリを破棄する処理 (デアロケート) の速度も重要となる: デアロケートが定数時間で行えるのに加えて、特定のドキュメント用にアロケートされたメモリを (全てのノードを走査することなく) 一度に全てデアロケートできると大きなドキュメントの破棄が大幅に高速化される。
pugixml が実際に採用するメモリのアロケート方式を議論する前に、pugixml が (しようと思えば) 採用できる他の選択肢をまず見ていく。
DOM ノードは必要なアロケートサイズで見るとき種類が少ないので、フリーリストを用いるメモリプールをサイズごとに用意する標準的な方式も選択肢の一つとなる。それぞれのプールは空きブロックを要素とする連結リストを保持し、空きブロックはプールごとに同じサイズを持つ。アロケートのリクエストがあったときフリーリストが空なら、ブロックの配列を持つ新しいページがアロケートされる。新しいブロックは単一の連結リストにまとめられ、それがアロケータの新しいフリーリストとなる。フリーリストが空でないなら、先頭のブロックが取り除かれてユーザーに渡される。デアロケートは返却されたブロックをフリーリストに追加するだけで完了する。
このアロケート方式にはメモリの再利用が確実に行える利点がある ── ノードを一つ以上デアロケートしてからアロケートすると、以前に使われたメモリが必ず再利用される。しかし、メモリページをヒープに返すには使用中のブロックをページごとに全て記録しなければならない。さらに、アロケートされるブロックの局所性がアロケータの使用履歴に依存するので、木の走査のパフォーマンスが低下する可能性がある。
pugixml は木の改変をサポートするので、任意サイズのアロケートをサポートすることが求められる。パースのパフォーマンスを落とすことなく任意サイズのアロケートをはじめとした必要な機能をフリーリスト型のアロケータに追加できるかどうかは明らかでない。dlmalloc などの汎用メモリアロケータで採用される複雑な汎用アルゴリズムも選択肢にはならない ── そういったアロケータは単純なフリーリストを使う実装より遅く、手の込んだ実装と比べるとさらに遅い。pugixml にはもっと単純で高速なアロケータが必要となる。
最も単純なアロケータはスタックアロケータである。これは次のように動作する: メモリ内に確保されたバッファと使用済みのバッファサイズを表すオフセットが管理され、アロケートは要求されたサイズだけオフセットを増加させるだけで完了する。確保すべきバッファのサイズを事前に予測することは当然できないので、オンデマンドに複数のバッファが確保される。
一般的なアイデアを示すコードを次に示す:
const size_t allocator_page_size = 32768;
struct allocator_page {
allocator_page* next_page;
size_t offset;
char data[allocator_page_size];
};
struct allocator_state {
allocator_page* current;
};
void* allocate_new_page_data(size_t size) {
size_t extra_size = (size > allocator_page_size) ?
(size - allocator_page_size) :
0;
return malloc(sizeof(allocator_page) + extra_size);
}
void* allocate_oob(allocator_state* state, size_t size) {
allocator_page* page = (allocator_page*)allocate_new_page_data(size);
// ページをページリストに追加
page->next_page = state->current;
state->current = page;
page->offset = size;
// ユーザーデータはページの先頭
return page->data;
}
void* allocate(allocator_state* state, size_t size) {
if (state->current->offset + size <= allocator_page_size) {
void* result = state->current->data + state->current->offset;
state->current->offset += size;
return result;
}
return allocate_oob(state, size);
}
ページサイズより大きいアロケートをサポートするのは難しくない。通常よりも大きな (要求されたサイズより大きい) ページをアロケートし、後は通常通りに処理すれば済む17。
スタックアロケータは非常に高速であり、制約はあるものの、おそらく最も高速なアロケータである。ベンチマークによるとフリーリストを用いるアロケータより高速となる (フリーリストを用いるときは、ページサイズに応じて正しいリストを特定しなければならない)。スタックアロケータはメモリの局所性に関しても完璧に近い: 新しいページがアロケートされる場合を除けば、連続するアロケートが必ず隣り合う領域を返す。
スタックアロケータでは小さいアロケートを何度も行ったとしても無駄になるメモリは非常に小さい。ただし、メモリが大きく無駄になるようなアロケートパターンは存在し、そのようなパターンは実際に起こり得る。例えばページサイズが 32768 バイトのとき 64 バイトと 65536 バイトを交互にアロケートすると毎回新しいページが作成され、アロケートされるメモリの 30% が無駄になる。このため、pugixml が持つスタックアロケータの実装は上に示したコードとは少しだけ異なる振る舞いを持つ: 要求されたサイズがデフォルトのページサイズの 25% より大きいとき、そのサイズの新しいページがアロケートされ、それはページリストの二番目に追加される。こうすると、大きいアロケートの後に起こる小さいアロケートが途中まで埋まったページを使うようになる。
allocate_oob 関数が「冷たい」ことに注目してほしい ── つまり、この関数は現在のページを使い終わったときに限って実行されるので、ほとんど実行されない。このため、allocate_oob 関数をインライン化しないよう明示的にコンパイラに伝えることでパフォーマンスが改善する可能性がある18。また、この事実は allocate_oob 関数が複雑な ── 例えば、大きいアロケートを異なる方法で扱う ── ロジックを持っていたとしてもアロケータ全体のパフォーマンスにほとんど影響しないことを意味する。
最後に、アロケートされるメモリはいずれかのページに含まれ、アロケータは全てのページのリストを状態として持つので、そのリストに含まれるページを全て解放すればアロケートされたメモリを全て解放できる。この処理はメモリ上にあるページのヘッダーにしか触れないので、非常に高速に実行できる。
スタックアロケータにおけるデアロケートのサポート
前節で議論したスタックアロケータの実装はメモリを解放・再利用する手段を持たない。
興味深いことに、この事実はスタックアロケータが使われる多くの場面で問題とならない。ドキュメントを破棄するときにアロケータが管理するページを全て解放すればアロケートされたメモリも全て解放される19ので、ドキュメントのパースや新しいドキュメントの作成で余計なメモリが消費されることはない。しかし、ドキュメントの大部分を削除してからノードを大量に追加するような場合には問題となる。メモリの再利用ができないので、ピーク時のメモリ使用量が非常に大きくなる可能性が生じる。
アロケートのパフォーマンスを保ったまま細かなメモリの再利用を実装することは不可能に思える。しかし、妥協点は存在する: 各ページで行われたアロケートの個数をカウントし、デアロケート時に対応するページのカウントを 1 だけ小さくすると定めれば、カウントが 0 になったページは利用されておらず解放して構わないと確信できる。
この方式を実装するには、デアロケートされるメモリからアロケート元のページが分かる必要がある。ページを指すポインタをアロケートされるメモリに保存せずにページを取得できるようにする手法は存在するものの、実装が難しい20。このため、pugixml ではアロケートされるメモリにページのポインタを保存する方式を使っている。
アロケートされるメモリの全てにそれが属するページを記録する上で、メモリオーバーヘッドを削減するために pugixml が行う工夫が二つある。
まず、一部のケースではページのポインタがいずれにせよ保存しなければならない数ビットのデータと共にポインタ一つ分のサイズを持つフィールドにページのポインタを格納する。アロケータは全てのページを 32 バイトにアラインするので、ページを指すポインタの下位 5 ビットは必ず 0 になる。そのため、この部分には好きに利用できる。XML ノードのメタデータは 5 ビットに収まるので都合がいい: 3 ビットはノードの種類を、2 ビットはノードの名前と値がインプレースのバッファに位置するかどうかを表すのに利用される。
また、アロケートされるメモリにページの先頭からのオフセットが記録されるケースもある。このときページのポインタは次のように取得できる:
(allocator_page*)((char*)(object)
- object->offset
- offsetof(allocator_page, data))
ページサイズが最大 216 = 65536 バイトなら、このオフセットは 16 ビットで表現できる。つまりページを 4 バイトではなく 2 バイトで表現できる。pugixml はヒープアロケートの文字列に対してこのアプローチを用いる。
以上のアルゴリズムが持つ興味深い特徴として、アロケータを用いるコードが持つ参照局所性が活用される。つまり、アロケートのリクエストに局所性があるとアロケートされるメモリの空間局所性が高まり、デアロケートのリクエストに局所性があるとページを解放できる可能性が高まる。木構造のアロケートに使うとき、これは大きな部分木を削除すると対応するメモリの大部分が解放されることを意味する。
もちろん、アロケートとデアロケートのパターンによってはドキュメント全体が破棄されるまで何も解放されない可能性もある。例えば、一つのページが 32000 バイトのアロケータで 32 バイトのアロケートを 100 万回行い、その後 1000 個ごとに要素を一つだけ残してメモリを全て解放したとする。このとき、全てのページが一つの要素を持つので、解放できるページは一つもない。このとき実際に使われているメモリは 1000×32 = 32000 バイトにもかかわらず、その 1000 倍のメモリが保持されたままとなる。こういった状況ではメモリのオーバーヘッドが極端に高くなるものの、そういったパターンが生じる可能性は非常に低い。pugixml では、このアルゴリズムの利点が欠点を上回る。
結論
ソフトウェアの最適化は難しい。実際にパフォーマンスを改善するには、メモリ、パフォーマンス、実装の複雑さといった様々な要素のバランスを取りながら、低レベルの細かい最適化と高レベルのパフォーマンス指向の設計、そして注意深いアルゴリズムの選択とチューニングを行わなければならない。pugixml は非常に高速でプロダクションレディな XML パーサーを提供するためにこういったアプローチの全てが必要となった例と言える ── 目標の達成には妥協も必要だった。他の言語のパーサーを書くのであれ、全く異なるものに取り組むのであれ、異なるプロジェクトやタスクで変更が必要となる実装詳細は大量に存在する。私が行った工夫を解説した本章を読者が楽しんで読み、解説された工夫のいずれかが他のプロジェクトで活用されることを私は願っている。
-
DOCTYPEの宣言はパースされるものの、その内容は無視される。この判断はパフォーマンスに対する影響、実装の複雑性、将来必要になる可能性を考慮して下された。 ↩︎ -
規格準拠な XML パーサーには特定の Unicode 符号位置を受け付けないことが要求されることに注意してほしい。パフォーマンスを向上させるために、pugixml はこの確認を行わない。 ↩︎
-
このとき寿命の依存関係が生まれる ── この手法を動作させるためには、入力バッファ全体が構築されるドキュメントノードより長く生き残る必要がある。 ↩︎
-
この事実は文字列参照の展開に対してのみ自明でない。Unicode 符号位置を十進または十六進で表した文字列は、その符号位置を UTF-8 または UTF-16 でエンコーディングしたバイト列のいずれよりも短くなる。そのため文字列参照の展開で文字列が長くなることはない。 ↩︎
-
エンティティ参照を表す特別なノードを用意すれば、インプレースのパースで一般的なエンティティ参照の展開をサポートすることはできる。このアプローチは Microsoft の XML パーサーで採用されている (ただしエンティティ参照をサポートするために採用されたのではない)。 ↩︎
-
当然、
dataは適切にアラインされている必要がある。さらに、この手法は C/C++ 規格が要求する strict aliasing rules を破るので、思った通りの振る舞いをしない可能性がある。 ↩︎ -
pugixml は二つの処理 (のいずれかまたは両方) を実行時に無効化する機能を持つ。この機能はパフォーマンスもしくはデータ保存のために利用される。例えば、何らかの理由で改行文字をそのままにしなければならないドキュメントを操作することもあるかもしれない。また、XML パーサーにエンティティ参照を無視させ、後で独自の処理をする使い方も考えられる。 ↩︎
-
/の確率がタグの名前となれる文字より低いのは、開始タグには必ず対応する終了タグが存在するのに加えて、<node/>の形をした空要素タグも存在するためである。 ↩︎ -
例えばタグの名前をパースしているときにヌル終端を読んだなら、パース中のドキュメントは正当でない。最後の文字の一つ前がタグの名前であるような XML ドキュメントは正当でないためである。 ↩︎
-
もちろん、パースを行うコードの複雑性は増加する。最後の文字を考慮しなければならない条件文もあれば、パフォーマンスのために最後の文字を無視しなければならない条件文もある。高いコードカバレッジを持つユニットテストスイートと fuzz テストによって、全ての入力ドキュメントに対する pugixml のパーサーの正しさは保たれている。 ↩︎
-
木の改変は重要である ── 改変不能な木を pugixml より格段に効率的に表現する方法も存在する。しかし、木を改変する機能はドキュメントをゼロから構築するとき、そして既存のドキュメントを変更するときどうしても必要となる。 ↩︎
-
もっと複雑なロジックを使うこともできる。 ↩︎
-
children_capacityフィールドは子ノードの追加を償却定数時間で行うために必要となる。詳細は http://en.wikipedia.org/wiki/Dynamic_array を参照してほしい。 ↩︎ -
このとき子ノードは最大で 232 個に制限される。 ↩︎
-
パフォーマンスのために、ここに示した実装はポインタのアライメントを調整する処理を行わない。格納される型はポインタ型のアライメントを持つアドレスに格納でき、全てのアロケートがポインタ型のサイズの定数倍だけのサイズを要求することが仮定されている。 ↩︎
-
pugixml では観測可能なパフォーマンスの改善があった。 ↩︎
-
当然、これはドキュメントを作らずにノードあるいは属性を作成できないことを意味する ── C++ において、これはノードの所有権に関する理にかなった設計判断と言える。 ↩︎
-
ページサイズ以上のアライメントを持つページ (例えば 64k バイトのアライメントを持つ 64k バイトのページ) を使えば余計なデータを保存せずにデアロケートをサポートできる。しかし、大きなアライメントを持つメモリ領域のアロケートをポータブルな形で行おうとすると、大きなメモリオーバーヘッドが生じてしまう。 ↩︎