Chrome のネットワークスタック
Google Chrome の歴史と中心的な設計指針
Google Chrome は 2008 年 9 月に Windows プラットフォーム向けのベータバージョンとして初めてリリースされた。Chrome を支える Google 製コード ── Chromium プロジェクトとして知られるもの ── も緩い BSD ライセンスで利用可能とされた。Google による一連の行動は、人々に驚きを持って受け止められた: ブラウザ戦争の再来か? Google は本当に優れたブラウザを開発できるのか?
あまりにも優れていたので、自分の考えを変えざるを得なかった...
── Eric Schmidt, Google Chrome の開発に対して最初に抱いた反対意見に関して
結局、Google には可能だった。現在 Chrome はウェブで最もよく使われるブラウザの一つである (StatCounter によると、35% 以上のマーケットシェアを持つ)。さらに、Chrome は Windows, Linux, OS X, Chrome OS, Android, iOS でも利用可能となった。Chrome の持つ機能と特徴がユーザーを捉えているのは明らかであり、Chrome がもたらしたイノベーションの中には後に他の有名なブラウザで採用されたものも多い。
Chrome のアイデアとイノベーションを紹介した 38 ページのコミックは Chrome という広く利用されるブラウザの背後にある考え方や設計プロセスを分かりやすく説明している。しかし、このコミックで説明されるのは最初の一歩でしかない。Chrome の開発を動機付けた次に示す中心的指針は、Chrome を改善する上でも重要な指針であり続けている:
- スピード
- 最も高速なブラウザを作る。
- セキュリティ
- 最もセキュアな環境を提供する。
- 安定性
- レジリエントで安定したウェブアプリケーションプラットフォームを提供する。
- 単純性
- 単純なユーザーエクスペリエンスを通して高度な技術を提供する。
Chrome 開発チームが目の当たりにしたように、私たちが現在利用するサイトの多くは単なるウェブページではなくアプリケーションである。そして、ますます野心的になるアプリケーションはスピード、セキュリティ、安定性を必要としている。こういった要素を説明するには、それぞれに一つの章が必要となるだろう。本書はパフォーマンスについての本なので、本章ではパフォーマンスに関する話題に集中する。
パフォーマンス
モダンなブラウザはプラットフォームであり、読者が今使っているオペレーティングシステム (OS) と大きくは変わらない。この事実を元に Chrome は設計されている。Chrome 以前の全ての主要なブラウザはモノリシックな単一プロセスアプリケーションとして構築されていた: 開かれた全てのページは同じアドレス空間を共有し、同じリソースを求めて競合する関係にあった。そのため、開かれた任意のページ (もしくはブラウザ) のバグが全体的なユーザーエクスペリエンスを悪化させるリスクがあった。
そういったブラウザとは対照的に、Chrome はマルチプロセスモデルを採用する。このモデルはプロセスとメモリの隔離、そして強固なセキュリティサンドボックスを各タブに提供する。マルチコアの重要性がますます高まっている世界において、プロセスを隔離する機能、そして開かれたタブを不穏な振る舞いをする他のタブから防護する機能があれば、それだけで競争相手よりもパフォーマンス面で大きく優位に立つことができる。実際、重要な事実として、他のブラウザも同様のアーキテクチャを採用したか、同じようなアーキテクチャへの移行の最中である。
プロセスのアロケートが完了すると、ウェブプログラムの実行には主に次の三つのタスクが関係する:
- リソースのフェッチ
- ページのレイアウトとレンダリング
- JavaScript の実行
レンダリングと JavaScript の実行は単一スレッドが細切れになった仕事を一つずつ行う実行モデルに従う ── 例えば、最終的に完成する Document Object Model (DOM) を並列に改変することはできない。これは JavaScript 自体が単一スレッドを前提とした言語である事実が理由の一つである。そのため、複数のプロセスで行われるレンダリングと JavaScript の実行を互いに干渉しないように最適化することは、アプリケーションを作成するウェブ開発者とブラウザを作成する開発者の両方にとって非常に重要となる。
Chrome は、レンダリングでは Blink と呼ばれる高速かつオープンソースで規格準拠なレイアウトエンジンを利用し、JavaScript の実行では V8 と呼ばれる高度に最適化された独自の JavaScript ランタイムを利用する。V8 はスタンドアローンのオープンソースプロジェクトとしても公開されており、Chrome 以外の様々な有名プロジェクト (例えば Node.js のランタイム) で利用されている。しかし、V8 の JavaScript 実行や Blink のパースとレンダリングパイプラインをいくら最適化したとしても、ネットワークがブロックされてリソースがいつまでも届かないならば意味がない。
ブラウザが各ネットワークリソースの順序、優先度、そしてレイテンシを最適化する機能はユーザーの体感するパフォーマンスにとって最も重要な要素の一つである。ユーザーは気が付かないかもしれないが、Chrome のネットワークスタックは各リソースのレイテンシコストを隠蔽・削減するために文字通り毎日のように賢くなっている: 例えば、近いうちに発生する可能性の高い DNS ルックアップを学習し、ウェブのトポロジーを記憶し、確立される可能性の高い接続を事前に確立する。外側から見ると、ネットワークスタックはリソースを取得するための単純な仕組みに思える。しかし内側から見ると、ネットワークスタックはウェブパフォーマンスを最適化してユーザーに最良のエクスペリエンスを提供する方法を示す巧妙で興味深いケーススタディとなる。
それでは見ていこう。
モダンなウェブアプリケーションとは何か?
ネットワークとの対話を最適化する具体的な方法の詳細に入る前に、取り組もうとしている問題のトレンドと概観を理解しておこう。つまり、モダンなウェブページやアプリケーションとは、どのようなものだろうか?
HTTP Archive はウェブの構成要素を長年にわたって追跡しているプロジェクトであり、私たちの疑問に答えてくれる。HTTP Archive はコンテンツを求めてウェブをクロールするのではなく、世界的にアクセスの多いサイトを定期的にクロールし、埋め込まれたリソースの個数、コンテンツタイプ、ヘッダーといったメタデータをページごと解析し、そのデータを収集する。2013 年 1 月の統計は読者を驚かせるかもしれない。ウェブ上の 30 万個以上のページを平均すると、一つのページは:
- 1280 KB のサイズを持つ。
- 88 個のリソースを持つ。
- 15 個以上の異なるホストに接続する。
言い換えれば、ウェブページの平均サイズは 1 MB を超えており、ウェブページは 15 以上の異なるサードパーティホストから取得された 88 個のリソース (JavaScript, CSS, 画像など) から構成される。さらに、これらの数字は過去数年にわたって単調に増加しており、増加が止まる様子はない。今までより大規模で野心的なウェブアプリケーションが常に構築され続けている。
HTTP Archive が提供する数値から計算すると、ウェブ上の平均的なリソースのサイズが 1280 / 88 = 15 KB だと分かる。これは、ブラウザが行うネットワーク越しのデータ転送は多くがバースト的 (データを一度転送するだけ) で短いことを意味する。この事実から様々な問題が生まれる: 下位のトランスポートプロトコル (TCP) が大きなストリーミングダウンロードに最適化されているためである。ここではタマネギの皮をむいて、リソースの取得で使われるネットワークリクエストを詳しく見てみよう。
リソースリクエストの一生
W3C の Navigation Timing 規格はブラウザによるリクエストが発行されてから終了するまでの間に発生する様々なイベントのタイミングとパフォーマンスに関するデータの名称、およびそれらを取得するためのブラウザ API を定義する。これらのデータはどれも最良のユーザーエクスペリエンスを提供する上で非常に重要なので、一つずつ見ていこう:
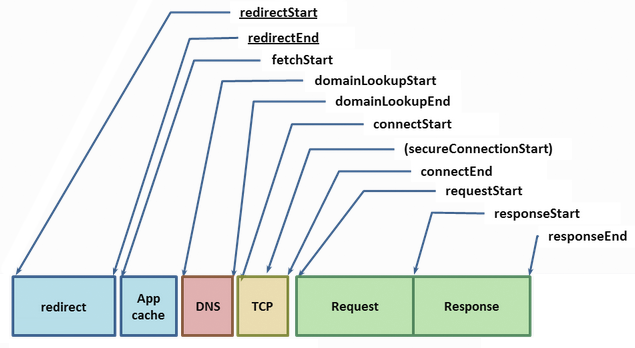
ウェブ上のリソースを指す URL が与えられたとき、ブラウザはまずアプリケーションのローカルキャッシュを確認する。もしリソースを以前にフェッチしたことがあり、レスポンスに適切なキャッシュヘッダー (Expires, Cache-Control など) が設定されていたなら、ローカルのコピーを返してフェッチを完了できる ── 最速のリクエストは存在しないリクエストである。そうでなければリソースのフェッチが必要となり、時間のかかるネットワークリクエストが発行される。
ホスト名とリソースパスが与えられると、Chrome はまずオープン済みの既存の接続を再利用できるかどうかを確認する ── ソケットは {scheme, host, port} の単位でプールされる。接続を再利用できない場合、もしプロキシまたは proxy auto-config (PAC) スクリプトが設定されているなら、Chrome は適切なプロキシを通じた接続を再利用できるかどうかを確認する。PAC スクリプトを使うと URL などに基づく規則を使って異なるプロキシを選択でき、それぞれのプロキシは独自のソケットプールを持つことができる。最後に、これら二つの条件のいずれにも該当しなければ、リクエストの処理はホストネームを IP アドレスに解決する処理 (DNS ルックアップ) から始めなければならない。
運が良ければ、ホストネームに対応する IP アドレスがキャッシュに存在し、事実上システムコール一回分だけのコストで DNS ルックアップのレスポンスが得られる。キャッシュが存在しなければ、他の処理を行う前に DNS クエリを発行しなければならない。DNS ルックアップにかかる時間はユーザーのインターネットプロバイダ、ユーザーが属する拠点の大きさ、ホスト名が中間キャッシュに存在する確率、ホスト名に対応する権威サーバーの応答時間などによって大きく異なる。つまり、DNS ルックアップには多くの変数が影響する。実際の DNS ルックアップで数百ミリ秒の時間がかかることも珍しくない。
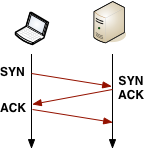
IP アドレスが解決されると、Chrome は宛先ホストとの TCP 接続をオープンできるようになる。TCP 接続を開くには SYN > SYN-ACK > ACK の「スリーウェイハンドシェイク」が必要となる (図 1.2)。このため、新しい TCP 接続を開くたびに少なくとも完全なラウンドトリップ一回分のレイテンシが加わる ── このレイテンシは避けられない。クライアントとサーバーの距離と選択されるルーティングパスに応じて、このレイテンシは数十ミリ秒から数千ミリ秒程度となる。この時間が経過するまで、アプリケーションが使うデータは 1 バイトも送信されない。
セキュアなサイトに (HTTPS で) 接続している場合、TCP ハンドシェイクの後さらに SSL ハンドシェイクが行われる。SSL ハンドシェイクではラウンドトリップ二回分のレイテンシが加わる。もし SSL セッションがキャッシュされていれば、追加されるレイテンシはラウンドトリップ一回分で済む。
これでようやく、Chrome は HTTP リクエストをディスパッチできる。この瞬間は 図 1.1 の requestStart に対応する。サーバーは受け取ったリクエストを処理し、レスポンスをクライアントに送り返す。ここでは最低でも一回のラウンドトリップ、そしてサーバーでの処理時間が必要になる。これが終われば、リクエストは完了する ── ただし、サーバーからのレスポンスが HTTP リダイレクトだったときは例外で、この場合は完全なリクエストをもう一度行わなければならない。深い理由もなくウェブページをリダイレクトにしたことがある? その判断は見直した方がいいかもしれない。
ここまでのレイテンシは合計でどれくらいだろうか? 問題を説明するために、典型的なブロードバンド接続における最悪のシナリオを考えよう: ローカルのキャッシュはヒットせず、比較的高速な 50 ms の DNS ルックアップ、TCP ハンドシェイク、SSL ハンドシェイク、そして比較的高速な 100 ms のリクエスト処理が行われるとする。ラウンドトリップタイム (RTT) が 80 ms (米国本土の回線の RTT として平均的な値) だとすれば、一度のリクエストで次のレイテンシが発生する:
- DNS ルックアップに 50 ms
- TCP ハンドシェイクに 80 ms (RTT)
- SSL ハンドシェイクに 160 ms (RTT の二倍)
- リクエストがサーバーに到着するまでに 40 ms
- サーバーでの処理に 100 ms
- レスポンスがクライアントに到着するまでに 40 ms
合計で 470 ms となる。実際にサーバーで行われる処理は 100 ms で完了するので、レイテンシの 80% はネットワークから生じている ── 明らかに何らかの対処が必要である。さらに言えば、470 ms というのは楽観的な推定値に過ぎない:
-
サーバーのレスポンスが TCP の輻輳ウィンドウサイズの初期値 (4~15 KB 程度) に収まらなければ、ラウンドトリップがさらに必要になる1。
- SSL のレイテンシは持っていない証明書の取得や Online Certificate Status Protocol (OSCP) を使った証明書の確認によってさらに長くなる可能性がある。どちらの操作も新しい TCP 接続が必要であり、数十ミリ秒 (ときには数百ミリ秒) のレイテンシが加わる。
「十分速い」とはどれくらいか?
前節で示した例では、様々なプロトコルが実行するハンドシェイクのネットワークオーバーヘッド、突き詰めればラウンドトリップタイムが全体のレイテンシを支配していた ── サーバーがレスポンスを用意するのにかかる時間は全体の 20% にも満たなかった。しかし、そもそもの話として、こういったレイテンシは重要なのだろうか? この文章を読んでいるなら、この質問の答えは知っているだろう: とても重要である。
ユーザーエクスペリエンスの研究は、私たち (ユーザー) がアプリケーションの応答性に関して期待することを一貫した形で示している:
| レイテンシ | ユーザーの反応 |
|---|---|
| 0 - 100 ms | 瞬間的 |
| 100 - 300 ms | 知覚可能な短い遅延 |
| 300 - 1000 ms | 「何か処理を行ったようだ」 |
| 1 s 以上 | 思考のコンテキストスイッチ |
| 10 s 以上 | 「後にしよう...」 |
表 1.1 には、ウェブパフォーマンスコミュニティで信じられている経験則も示されている: ページのレンダリング、あるいは最低でも何らかの視覚的フィードバックを 250 ms 以内に返さないと、ユーザーの関心を保つことはできない。スピードはただスピードのために追及されるのではない。Google, Amazon, Microsoft をはじめとした数千のウェブサイトで、レイテンシの増加はサイトで最も重要な指標に悪影響を及ぼすことが示されている: ウェブサイトを高速にすれば、閲覧数、エンゲージメント、コンバージョンレートが増加する。
というわけで、レイテンシは 250 ms 以下となるのが望ましい。しかし上述したように、典型的なシナリオでは DNS ルックアップ、TCP と SSL のハンドシェイク、そしてリクエストの伝播時間だけで 370 ms となり、予算を 50% ほどオーバーする。この中にサーバーの処理時間は含まれていない!
DNS, TCP, SSL から生じるレイテンシはほとんどのユーザーにとって、さらにほとんどのウェブ開発者にとってさえ「目に見える」ものではなく、彼らがまず意識しないネットワークレイヤーで生まれる。しかし、ネットワークレイヤーの処理はどれもユーザーエクスペリエンスに対する影響が非常に大きい。Chrome のネットワークスタックが単純なソケットハンドラより格段に複雑なのはこれが理由である。
これで問題が説明できたので、続いて実装の詳細を見ていく。
Chrome のネットワークスタックの概観
Chrome のマルチプロセスアーキテクチャは各ネットワークリクエストの処理方法に重要な影響を及ぼす。Chrome はユーザーの見えないところで四つの異なる実行モデルを持ち、それぞれプロセスのアロケート方法が異なる。
Chrome はデフォルトでは「サイトごとに一つのプロセス」の実行モデルを用いる。このモデルでは異なるサイトが互いに隔離され、同じサイトのインスタンスは同じプロセスにまとめられる。ただ、議論を単純にするために、ここでは最も単純なケースを考える: 開かれているタブのそれぞれに個別のプロセスが割り当てられると仮定する。ネットワークパフォーマンスの視点からすると、この違いはあまり重要でない。そして、「タブごとに一つのプロセス」の実行モデルの方がずっと理解しやすい。
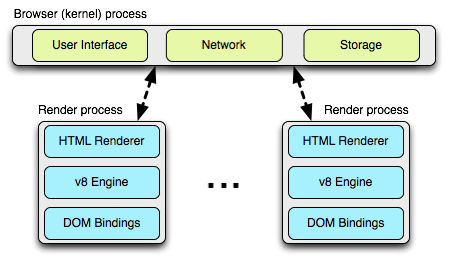
Chrome のマルチプロセスアーキテクチャでは、各タブにレンダープロセスが一つずつ割り当てられる。それぞれのレンダープロセスはレイアウトエンジン Blink と JavaScript エンジン V8 のインスタンス、そしてこれらのコンポーネントを橋渡しするグルーコードなどが含まれる2。
これらのレンダープロセスはサンドボックス化された環境で実行され、ユーザーのコンピューターに対するアクセスが制限される ── ネットワークに対するアクセスも制限される。レンダープロセスがネットワークなどのリソースに対するアクセスを得るには、メインのカーネルプロセス (ブラウザプロセスとも呼ばれる) と通信する必要がある。この通信でカーネルプロセスは各レンダープロセスに対してセキュリティの保証やアクセスポリシーの管理を行う。
Chrome ではレンダープロセスとカーネルプロセスの通信が全てプロセス間通信 (inter-process communication, IPC) で行われる。Linux と OS X では、非同期通信用の名前付きパイプを提供する socketpair 関数が利用される。レンダープロセスからのメッセージはシリアライズされてから専用の I/O スレッドに渡され、このスレッドがメインのカーネルプロセスにデータをディスパッチする。メッセージを受け取るカーネルプロセスはメッセージのフィルタ (ResourceMessageFilter) を持ち、これを使って Chrome は IPC によるリソースリクエストの中でネットワークスタックが処理すべきものを振り分ける。
このアーキテクチャの利点の一つとして、全てのリソースリクエストが I/O スレッドだけによって処理され、UI が生成した動作とネットワークイベントが互いに干渉しないことがある。カーネルプロセスの I/O スレッド内で実行されるリソースフィルタはリソースリクエストメッセージを確認し、同じくカーネルプロセスが持つ ResourceDispatcherHost のシングルトンにメッセージを転送する。
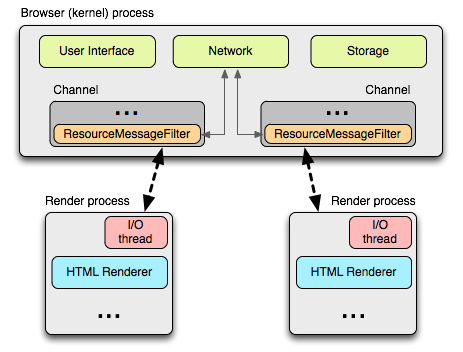
ResourceDispatcherHost のシングルトンが持つインターフェースを使って Chrome は各レンダープロセスのネットワークに対するアクセスを制御する。さらに、そのとき効率的で一貫したリソース共有も行う。例えば次のような処理が行われる:
- 接続の最大個数の制限: ブラウザは同時にオープンできるソケットの最大個数をプロファイルごと (256)、プロキシごと (32)、
{scheme, host, port}ごと (6) に制限する。この制限の下では、同じ{host, port}に対する 6 個の HTTP 接続と 6 個の HTTPS 接続をオープンできることに注意してほしい。 - ソケットの再利用: ソケットプール内の TCP 接続はリクエストを完了した後も一定の時間だけ保持され、その間は再利用が可能となる。接続が再利用されれば、新しい接続のオープンで生じる DNS, TCP, SSL (利用される場合) をセットアップするオーバーヘッドが回避される。
- ソケットの遅延バインディング: リクエストと内部の TCP 接続の関連付けは、ソケットがアプリケーションリクエストをディスパッチする準備が整った段階で初めて作成される。これによって細かい優先度付け (例えば、ソケットがオープンしている間に高優先度のリクエストを受け取るケース) やスループットの向上 (例えば、新しい TCP 接続をオープンしている途中に他の「暖かい」TCP 接続が利用可能になるケース) が可能になる。また、TCP preconnect を利用する汎用的な仕組みや他の様々な最適化も可能になる。
- 一貫したセッション状態: 認証、クッキー、キャッシュ済みデータが全てのレンダープロセスで共有される。
- リソースとネットワークのグローバルな最適化: ブラウザは全てのレンダープロセスとそれらからのリクエストを見て何をするかを判断できる。例えば、ユーザーがディスプレイに表示しているタブが送ったリクエストのネットワーク優先度を高くするといった処理が可能になる。
- 投機的最適化: 全てのネットワークトラフィックを観測できるので、Chrome は予測モデルの改良を通してパフォーマンスを改善できる。
レンダープロセスの視点に立てば、以上の処理はリクエストするメッセージ (ユニークなリクエスト ID でタグ付けされる) を IPC でカーネルプロセスに送るだけで自動的に行われる。本筋の処理は全てカーネルプロセスが行う。
クロスプラットフォームなリソース取得
Chrome のネットワークスタックを実装する上で最も重要な問題の一つに、様々なプラットフォームにおける互換性がある: Chrome は Linux, Windows, OS X, Chrome OS, Android, iOS の全てで動作しなければならない。この問題を解決するため、Chrome のネットワークスタックは基本的に単一スレッドで動作するクロスプラットフォームなライブラリとして実装される。これによって Chrome は異なるプラットフォームで同じインフラストラクチャの利用と同じパフォーマンス最適化の提供が可能になる。さらに、プラットフォームをまたいだ最適化の機会も多くなる。
ネットワーク関連のコードも当然オープンソースであり、net ディレクトリから確認できる。ここに含まれるコンポーネントを一つずつ解説することはしないものの、コードの構成からコンポーネントの機能や結び付きは想像できるだろう。ネットワークスタックのコンポーネントの例を表 1.2 に示す。
| コンポーネント | 説明 |
|---|---|
net/android |
Android ランタイムへのバインディング |
net/base |
一般的なネットワークユーティリティ (ホスト解決、クッキー、ネットワークの変更検出、SSL 証明書の管理など) |
net/cookies |
HTTP クッキーの保存、管理、取得の実装 |
net/disk_cache |
ウェブリソース用のディスクキャッシュとメモリキャッシュの実装 |
net/dns |
非同期 DNS リゾルバの実装 |
net/http |
HTTP プロトコルの実装 |
net/proxy |
プロキシ (SOCKS と HTTP) の構成、解決、スクリプト取得など |
net/socket |
TCP ソケット、SSL ストリーム、ソケットプールのクロスプラットフォーム実装 |
net/spdy |
SPDT プロトコルの実装 |
net/url_request |
URLRequest, URLRequestContext, URLRequestJob の実装 |
net/websockets |
WebSocket プロトコルの実装 |
各コンポーネントのソースコードは興味ある読者にとって価値ある資料となるだろう ── よくドキュメントされており、ユニットテストも大量にある。
モバイルプラットフォームのアーキテクチャとパフォーマンス
モバイルブラウザの利用者数は最も控えめな観測においてさえ指数的なペースで増加している。デスクトップブラウザの利用者数を上回る日も近いだろう。言うまでもなく、最適化されたモバイルエクスペリエンスの提供は Chrome チームにとって最も優先度の高いタスクである。Chrome for Android は 2012 年初頭にアナウンスされ、Chrome for iOS も数か月後に続いた。
モバイルバージョンの Chrome に関して最初に言っておきたいのは、それがデスクトップブラウザをそのまま移植したものではないという事実である ── そのまま移植したのでは、最良のユーザーエクスペリエンスを提供できない。モバイル環境は、その根本的な性質によりリソースが制約されており、様々な運用上のパラメータが本質的に異なる:
- デスクトップユーザーはマウスを使ってページをナビゲートし、重なり合う複数のウィンドウを表示でき、大きな画面を持ち、たいていは電源が制限されず、普通は安定したネットワーク接続を持ち、大きなストレージとメモリを持つ。
- モバイルユーザーはタッチとジェスチャーでページをナビゲートし、画面は格段に小さく、バッテリーと電源が制限され、従量課金接続の場合が多く、小さなストレージとメモリしか持たない。
さらに、「典型的なモバイルデバイス」は存在しない: 様々なハードウェア機能を持った幅広いデバイスが存在する。最良のパフォーマンスを提供するには、全てのデバイスが持つ運用上の制約を一つ残らず考慮しなければならない。ただ幸いにも、Chrome の多様な実行モデルを使えばこの問題に対応できる。
Android デバイスでは、Chrome はデスクトップバージョンと同様のマルチプロセスアーキテクチャを利用する ── カーネルプロセスが一つと、一つ以上のレンダープロセスが存在する。デスクトップバージョンと異なる点として、メモリが制限されるモバイルバージョンの Chrome は開かれたタブのそれぞれに対してレンダープロセスを用意できない可能性がある。そのため、Chrome は利用可能なメモリ量 (などのデバイスが持つ制約) から最適なレンダープロセスの個数を決定し、多くのタブが開かれたときは複数のタブで一つのレンダープロセスを共有する。
最低限のリソースしか利用できない場合、あるいは Chrome から複数のプロセスを起動できない場合には、Chrome は単一プロセス/複数スレッドの実行モデルに切り替わる。実は iOS デバイスでは、下位プラットフォームが持つサンドボックス制限により、この対応が行われる ── 複数のスレッドを持つ単一のプロセス内で Chrome が実行される。
ネットワークパフォーマンスについてはどうだろうか? まず、Chrome は Android と iOS でも他のプラットフォームと同じネットワークスタックを利用する。これによって同じネットワーク最適化を全てのプラットフォームに届けられるようになり、パフォーマンスの大きなアドバンテージとなる。ただし、Chrome が実行されているデバイスとネットワークに応じて変化する要素もある。例えばソケットの管理やタイムアウトに関するロジック、投機的最適化の優先度、キャッシュのサイズなどがこれに該当する。
例えば、モバイルの Chrome はバッテリーを節約するためにアイドルなソケットのクローズを遅らせる機能をオプトインで持つ ── 新しいソケットを開くときまでクローズを遅らせれば FIN が送信されないので、電波が使われないで済む。同様に、事前レンダリング (後述) はネットワークとプロセッシングのリソースを大量に消費するので、デフォルトではユーザーが Wi-Fi でインターネットに接続しているときに限って有効化される。
Chrome 開発チームにとって、モバイルのブラウジングエクスペリエンスを向上させることは最も優先度の高い事項の一つである。さらなる改善が今後数か月そして数年の間にもたらされると考えてもらって構わない。正直に言って、これは一つの章が必要な話題である ── もしかしたら The Performance of Open Source Applications シリーズの次の巻で触れることになるかもしれない。
投機的最適化と Predictor
Chrome は使えば使うほど高速になる。この特徴はメインのカーネルプロセスが持つ Predictor というシングルトンオブジェクトによってもたらされる。Predictor はネットワークパターンを監視し、ユーザーが将来行う可能性の高い操作を予測・学習するためだけに存在する。Predictor が処理するシグナルの例を示す:
- ユーザーがリンクにマウスを合わせたなら、近いうちにナビゲーションイベントが起こる可能性が高い。このとき Chrome は対象のホスト名に対して投機的 DNS ルックアップ (DNS プリフェッチ) を行い、さらに場合によっては投機的 TCP ハンドシェイク (TCP preconnect) を開始する。ユーザーがマウスをリンクに合わせてからクリックするまでの平均時間は 200 ms 程度であることが知られているので、リンクをクリックする瞬間には DNS ルックアップと TCP ハンドシェイクが完了している可能性が高い。この仕組みによってナビゲーションイベントで発生する数百ミリ秒のレイテンシが節約される。
- Omnibox (URL バー) にタイプされた文字を見れば、ユーザーが次に訪れるページが非常に高い確率で分かる。ここでも Chrome は DNS プリフェッチと TCP preconnect を行う。表示されないタブに事前レンダリングを行う場合さえある。
- 毎日のように訪れるお気に入りのサイトが誰にでもある。Chrome はそういったサイトのサブリソースを学習し、それらを前もって投機的に解決しておくことでブラウジングエクスペリエンスを向上させる。ときにはサブリソースの取得まで行う場合もある。
Chrome はユーザーのブラウジングパターンだけではなくウェブのトポロジーも学習する。処理が上手く噛み合えば、数百ミリ秒のレイテンシが各ナビゲーションイベントから取り除かれ、「瞬間的ページロード」の聖杯にずっと近づく。Chrome が利用する四つの中心的な最適化手法を表 1.3 に示す。
| 手法 | 説明 |
|---|---|
| DNS プリフェッチ | ホスト名を前もって解決し、DNS ルックアップのレイテンシを回避する。 |
| TCP preconnect | 宛先サーバーに前もって接続し、TCP ハンドシェイクのレイテンシを回避する。 |
| リソースのプリフェッチ | ページで重要なリソースを前もってフェッチし、ページのレンダリングを速める。 |
| ページの事前レンダリング | 完全なページと全てのリソースを前もってフェッチし、ユーザーがイベントを発火させた瞬間にナビゲーションを行えるようにする。 |
これらの手法 (の一部もしくは全て) を使用するかどうかは、多くの制約を考慮して判断される。どの手法も本質的に投機的最適化なので、本来必要でない処理やネットワークトラフィックを引き起こす可能性がある。それどころか、ユーザーが起動した実際のナビゲーションの読み込み時間を長くする可能性さえある。
この問題を Chrome はどのように解決するのだろうか? Predictor は可能な限り多くのシグナルを消費しようとする。シグナルにはユーザーが起動した操作やブラウザの履歴データを含むシグナルや、レンダープロセスやネットワークスタックから直接送られるシグナルが存在する。
Chrome 内で行われるネットワークアクティビティを調整する ResourceDispatcherHost と同様に、Predictor はユーザーとネットワークが生成したアクティビティに対するフィルタをいくつか持つ:
- IPC チャンネルフィルタはレンダープロセスからのシグナルを監視する。
- 各リクエストには
ConnectInterceptorオブジェクトが追加され、このオブジェクトがトラフィックパターンの監視とリクエストの成功指標の記録を行う。
実際の例を次に示す。レンダープロセスは次の ResolutionMotivation 列挙体 (url_info.h) で定義されるヒントを付けたシグナルをカーネルプロセスに送ることができる:
enum ResolutionMotivation {
MOUSE_OVER_MOTIVATED, // ユーザーによるマウスオーバー
OMNIBOX_MOTIVATED, // Omnibox の予測入力
STARTUP_LIST_MOTIVATED, // リソースはスタートアップリストの上位 10 件にある。
EARLY_LOAD_MOTIVATED, // 実際のリクエストを発行する前にプリフェッチャーで
// 接続を「温める」場合がある。
// 次のヒントはナビゲーションによって起動される投機的最適化に関係する。
// これらのヒントが使われるときは referring_url_ がセットされる。
STATIC_REFERAL_MOTIVATED, // この解決は外部データベースが提案した。
LEARNED_REFERAL_MOTIVATED, // この解決は以前のナビゲーションから推測された。
SELF_REFERAL_MOTIVATED, // この解決は二次接続の必要性から予測された。
// <省略> ...
};
こういったシグナルを受け取った Predictor の目標は、解決の成功確率を推測し、リソースが利用可能なら解決を起動することである。ヒントには成功確率、優先度、有効期限が関連付けられ、Predictor はこれらの情報を使って内部に持つ優先度付きキューにシグナルを積んでいく。最後に、このキューからディスパッチされた全てのイベントに対しても成功確率が追跡され、将来の判断を最適化するために利用される。
Chrome のネットワークアーキテクチャのまとめ
- Chrome はマルチプロセスアーキテクチャを採用し、レンダープロセスとカーネルプロセスを分離する。
- Chrome はリソースディスパッチャの単一インスタンスを持つ。このインスタンスはカーネルプロセスによって保有され、全てのレンダープロセスで共有される。
- ネットワークスタックはクロスプラットフォームであり、基本的に単一スレッドライブラリである。
- ネットワークスタックは全てのネットワーク操作をノンブロッキングな API で管理する。
- 共有されたネットワークスタックによってリソースの効率的な優先度付けと再利用、そして実行中の全プロセスを考慮したグローバルな最適化が可能になる。
- 各レンダープロセスは IPC を通じてリソースディスパッチャと通信する。
- リソースディスパッチャは独自の IPC フィルタでリソースリクエストを監視する。
Predictorはリソースのリクエストとレスポンスを監視してトラフィックパターンを学習し、将来のネットワークリクエストを最適化する。Predictorは学習したトラフィックパターンを利用して DNS プリフェッチと TCP preconnect を投機的にスケジュールする。場合によってはリソースリクエストそのものをスケジュールする場合もある。投機的にスケジュールされたリクエストをユーザーが実際に利用すれば、数百ミリ秒が節約される。
ブラウザセッションの一生
Chrome のネットワークスタックを 10,000 フィート上空から理解できたと思うので、続いてブラウザ内で有効化されユーザーが実際に体感する種類の最適化を見ていく。具体的には、新しい Chrome プロファイルを作った状況を想像してほしい。
スタートアップの最適化
Chrome が新しく起動されるとき、Chrome はユーザーのお気に入りのサイトやナビゲーションパターンについて何の知識も持たない。しかし、ユーザーの多くはスタートアップ時に同じようなルーチンに従う: メールの受信箱、お気に入りのニュースサイト、SNS、社内ポータルといったサイトを確認する。具体的なサイトは異なるものの、この類似性を Predictor が利用すればスタートアップ時のユーザーエクスペリエンスを改善できる。
Chrome はブラウザ起動直後にユーザーがアクセスする可能性が高い上位 10 件のホスト名を記憶する ── ブラウザの起動中を通してアクセスの多いホスト名ではなく、ブラウザが新しく起動されたときにアクセスが多いホスト名である。新しく起動された Chrome はスタートアップ処理の早い時点でそれらのアクセスされる可能性の高いホスト名への DNS プリフェッチを行う。もし興味があるなら、新しいタブを開いて chrome://dns にアクセスすると DNS プリフェッチが行われるホスト名を確認できる3。このページの先頭には、ユーザーのプロファイルでスタートアップ時に開かれる確率の高いサイト上位十件が表示される。

筆者の Chrome プロファイルで chrome://dns を開いたときの例を図 1.5 に示す。私が Chrome でブラウジングをするときは Google Docs を開いて (本記事のような) 文章を執筆することが多いので、このリストには Google 関連のホスト名が多く並んでいる。
Omnibox の最適化
Chrome がもたらしたイノベーションの一つに Omnibox がある。Chrome 以前のブラウザが持っていた URL バーと異なり、Omnibox はウェブページの URL の入力場所にとどまらない様々な機能を持つ。ユーザーが過去に訪れた URL を記憶するだけではなく、履歴の全文検索を提供し、さらにユーザーが選択した検索エンジンとも密に連携する。
ユーザーが Omnibox に文字列を入力すると、Omnibox は自動的に入力候補を提案する。実際に提案されるのはナビゲーション履歴から推測した URL、または検索クエリである。内部では、提案される各候補にはクエリに対するスコアと過去の成績が関連付く。Omnibox の入力補完に関して Chrome が記録・計算するデータは chrome://predictors から確認できる。
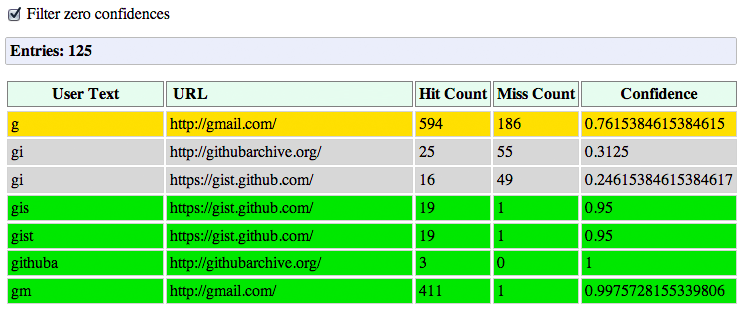
Chrome はユーザーが入力した接頭辞、提案された入力候補、そして各候補が選択された割合を記録する。図 1.6 を見ると、筆者のプロファイルでは「g」が Omnibox に入力されたときは 76% の確率で Gmail に向かっていることが分かる。「g」の次に「m」が続くと、Gmail に向かう確率は 99.8% に上昇する ── 「gm」は 412 回入力されており、その中で Gmail 以外のサイトに向かったケースは一度しかない。
これがネットワークスタックと何の関係があるだろうか? 黄色と緑色で示された確率の高い候補は ResourceDispatcher にとって重要なシグナルとなる。もし確率の高い候補 (黄色) があるなら、Chrome はそのホストに対する DNS プリフェッチを実行するだろう。もし確率の非常に高い候補 (緑色) があるなら、Chrome はホスト名の解決が終わり次第 TCP preconnect も行うだろう。最後に、もし両方の処理が終わってもユーザーがまだ入力を完了させないなら、Chrome は表示されないタブにページ全体を事前レンダリングする可能性もある。
あるいは、入力された接頭辞にマッチする候補がこれまでのナビゲーション履歴から見つからなかった場合、Chrome は DNS プリフェッチと TCP preconnect を検索プロバイダに対して行うことで、これから送信される可能性の高い検索リクエストに備えるだろう。
平均的なユーザーは、クエリ文字列を入力して提案された補完候補の中から自分が望むものを選択するのに数百ミリ秒を費やす。その間に Chrome は DNS プリフェッチ、TCP preconnect、そして場合によってはページの事前レンダリングを行う。このためユーザーがエンターキーを押すころには、ネットワークレイテンシの大きな部分が取り除かれている。
キャッシュパフォーマンスの最適化
最も望ましく最も高速なリクエストは発行されないリクエストである。キャッシュに言及しないパフォーマンスの議論はまず間違っている ── 読者は自分が作るウェブサイトの全てのリソースに Expires, ETag, Last-Modified, Cache-Control といったレスポンスヘッダーを適切に付けていることだろう。付けていない? 修正してから読み進めてほしい。私はここで待っていよう。
Chrome には内部キャッシュの実装が二つある: ローカルディスクを利用するものと、全てをメモリに保存するものである。後者のインメモリの実装は incognito mode (プライベートウィンドウ) で利用され、ウィンドウを閉じるとキャッシュされたデータは消去される。両方の実装が持つ内部のインターフェースは同じ (disk_cache::Backend と disk_cache::Entry) であり、この事実によってアーキテクチャは大きく単純化される。独自のキャッシュ実装を実験することも (しようと思えば) 可能である。
ディスクキャッシュの実装は独自のデータ構造を持っており、そのデータ構造はプロファイルごとに存在する単一のキャッシュフォルダに収まるようになっている。このフォルダの中にはインデックスファイルとデータファイルがあり、インデックスファイルはブラウザ起動時にメモリマップされ、データファイルは実際のリソースと補助情報 (HTTP ヘッダーなど) を保持する4。最後に、必要なくなったデータを追い出すために、ディスクキャッシュは Least Recently Used (LRU) を基本とした方式でキャッシュを管理する。ただし、追い出しの判断ではリソースのアクセス頻度や取得してからの時間といった指標も考慮される。
実行中の Chrome が保持しているキャッシュの状態に興味があるなら、新しいタブを開いて chrome://net-internals/#httpCache にアクセスすると確認できる。また、キャッシュされた実際のレスポンスと HTTP メタデータを確認したい場合は chrome://cache から行える。このページで興味のあるリソースを検索し、URL をクリックすればキャッシュされたヘッダーとレスポンスのバイト列を確認できる。
プリフェッチによる DNS の最適化
DNS プリフェッチについては何度か言及してきた。そこで実装を解説する前に、DNS プリフェッチが起動されるケースとその理由を振り返っておこう:
- レンダープロセスで実行される Blink のドキュメントパーサーは、現在のページに含まれるホスト名のリストを提供できる場合がある。このリストは DNS プリフェッチに利用できる。
- レンダープロセスはマウスオーバーなどのイベントをユーザーのナビゲーションが迫っている兆候とみなし、DNS プリフェッチをリクエストする場合がある。
- Omnibox は可能性の高い補完候補に対して DNS プリフェッチをリクエストする場合がある。
Predicatorは過去のナビゲーションとリソースリクエストのデータから DNS プリフェッチをリクエストする場合がある。- ページの作成者が明示的に DNS プリフェッチを Chrome に指示する場合がある。
これらの全てのケースで、DNS プリフェッチのリクエストはヒントとして扱われる。Chrome は DNS プリフェッチが行われることを保証せず、様々な要素を考慮した上で行うかどうかを判断する。「最悪の」ケースでは DNS プリフェッチが間に合わず、明示的な DNS ルックアップと TCP 接続確立をしてからユーザーがリクエストしたリソースのフェッチが開始される。しかし、この状況が発生した事実は Predictor によって記録され、将来の判断が調整される ── Chrome は使い続けると速く、賢くなる。
これまでに言及していない最適化の一つに、ウェブサイトのトポロジーを学習して将来の訪問先を高速化する機能がある。平均的なページは 88 個のリソースを持ち、それらは 15 個以上の異なるホストから取得される事実を思い出してほしい。Chrome はナビゲーションのたびにページで何度も使われるリソースのホスト名を記録し、以降の訪問先でそれらのホスト名 (の一部または全部) を DNS プリフェッチや TCP preconnect の候補とする。
Chrome が記録しているサブリソースのホスト名は chrome://dns から確認できる。筆者のプロファイルでは、Google+ のサイトで Chrome が記録したサブリソースのホスト名が六つ示されている。この他にも、DNS プリフェッチと TCP preconnect が行われた回数、それぞれの接続が処理するリクエストの個数の推測値なども確認できる。こうして記録された統計が Predictor による最適化を支えている。
こういった「内部からの」シグナルに加えて、サイトの作成者は次のようなマークアップでホスト名の事前解決をブラウザに指示することもできる :
<link rel="dns-prefetch" href="//host_name_to_prefetch.com">
ブラウザが持つ自動的な DNS プリフェッチの仕組みに頼らないのはなぜだろうか? 一部のケースでは、ページで全く言及されないホスト名を事前に解決することが求められる。リダイレクトは代表的な例である: ページに含まれるリンクが示すのは中継点 ── 例えばアクセス解析サービス ── で、実際に遷移するのは別のサイトである場合がある。このパターンを Chrome はページから認識できないので、実際のホスト名を前もってブラウザに解決させるにはヒントを手動で与える必要がある。
マークアップによる DNS プリフェッチはどのように実装されるのだろうか? Chrome では改善された新しい最適化が常に実験中なので、これまでに解説してきた様々な最適化と同じように、この質問に対する答えは Chrome のバージョンによって異なる。しかし大まかに言って、Chrome の DNS インフラストラクチャは二つの実装を持つ。当初の Chrome はプラットフォーム依存のシステムコール getaddrinfo() を利用し、実際の DNS ルックアップを OS に委譲してきた。しかし、このアプローチは Chrome が独自に実装した非同期 DNS リゾルバで置き換えられつつある。
OS が提供するシステムコールに依存するオリジナルの実装にも利点はある: コードは短く単純になり、OS の DNS キャッシュを活用できる。しかし getaddrinfo はブロッキングな関数であり、Chrome は複数の DNS ルックアップを並列に行うために専用のワーカースレッドプールを作成・管理しなければならない。このスレッドプールが保持できるワーカースレッドは最大六個であり、この閾値は最も低性能なハードウェアに合わせて経験的に決められている ── これ以上のリクエストを並列に発行すると、一部のユーザーが使用するルーターが圧倒されてしまうことが判明している。
DNS プリフェッチにスレッドプールを使うとき、Chrome は getaddrinfo の呼び出しをディスパッチするだけで処理が完了する。これを受けていずれかのワーカースレッドが getaddrinfo を呼び出し、レスポンスが返るまでブロックし、レスポンスが返ってきたら何もせずに次のプリフェッチリクエストに進む。DNS ルックアップの結果は OS の DNS キャッシュに保存されるので、将来の getaddrinfo の呼び出しは瞬間的に返ることが期待できる。これは単純かつ効率的であり、実際の環境でも上手く動作する。
しかし、この「効率的」は十分ではない。getaddrinfo を使うとき、Chrome は様々な有用な情報を見逃してしまう: 例えば各 DNS レコードに対する time-to-live (TTL) や DNS キャッシュ自体に関する情報は見逃される。そこでパフォーマンスを改善するため、Chrome チームはクロスプラットフォームの非同期 DNS リゾルバを実装することを決断した。
新しい非同期 DNS リゾルバによって DNS ルックアップの処理が Chrome 内部に移動し、多数の新しい最適化が可能になった:
- 再送タイマーを細かく制御する。
- 複数のクエリを並列に実行する。
- 新しく取得可能になった DNS レコードの TTL を利用して、よく使われる DNS レコードを自動的に再取得する。
- デュアルスタック実装 (IPv4 と IPv6) に対する振る舞いを改善する。
- 異なるサーバーへのフェイルオーバーを RTT などの値に応じて行う。
ここに示したのは Chrome チームで行われている実験と改善のためのアイデア (の一部) である。ここで明らかな疑問がある: こういったアイデアを実装したとき、その影響をどのように計測するのだろうか? 答えは単純で、Chrome はネットワークスタックの詳細な統計情報をプロファイルごとに記録している。収集された DNS に関するメトリックは新しいタブで chrome://histograms/DNS にアクセスすると確認できる。筆者のプロファイルにおける結果を図 1.8 に示す。

このヒストグラムを見ると、DNS プリフェッチのレイテンシの分布が分かる: 約 50% の DNS プリフェッチは 26 ms 以内に完了している。これは最近のブラウジングセッションにおける 2621 サンプルを示したものである点に注意してほしい。このデータはユーザーだけが利用できる。もしユーザーが「仕様統計レポートの送信」にオプトインしていれば、このデータの要約が匿名化された上でエンジニアリングチームに定期的に送信され、そこで様々な実験の影響が確認される。
TCP preconnect による接続管理の最適化
Chrome がホスト名を前もって解決し、発生確率の高いナビゲーションイベントを (Omnibox や Predictor から) 推定する方法をこれまでに解説した。さらにもう一歩進んで、投機的にホストとの接続を確立し、ユーザーがリクエストをディスパッチする前に TCP ハンドシェイクを完了させてはどうだろうか? こうすればラウンドトリップ一回分のレイテンシが節約されるので、ユーザーが体感するレイテンシは数百ミリ秒ほど減少するはずである。TCP preconnect がまさにこの処理を行う。
新しいタブを開いて chrome://dns にアクセスすると、TCP preconnect が使用されたホストを確認できる (図 1.9)。

Chrome は次のように TCP preconnect を行う。まず、ソケットプールに接続したいホストとの接続が残っていないかどうかを確認する。もし残っていれば、そのソケットを再利用する ── TCP ハンドシェイクとスロースタートによるペナルティを回避するために、処理を完了したソケットは keep-alive 状態のまま一定の時間だけソケットプールに保持される。そのようなソケットがなければ、TCP ソケットを初期化してプールに配置する。こうしておけば、ユーザーがナビゲーションを発火させた瞬間に HTTP リクエストを素早くディスパッチできる。
興味のある読者は、chrome://net-internals#sockets にアクセスして Chrome がオープンしているソケットに関する情報を確認してみるとよい。筆者が取得したこのページのスクリーンショットを図 1.10 に示す。
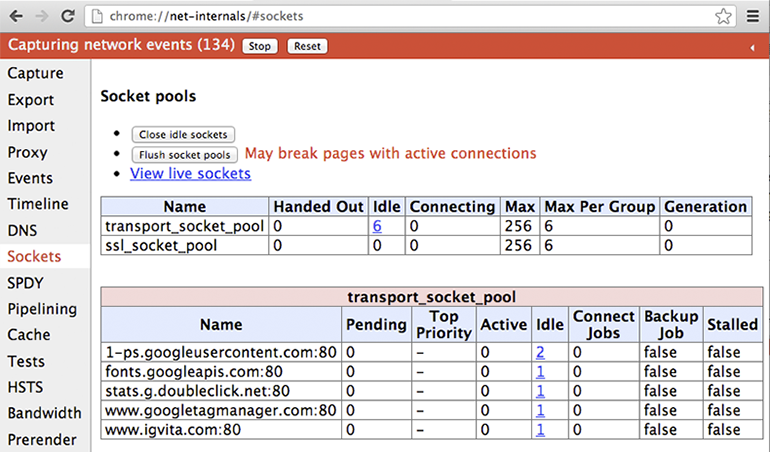
各ソケットのタイムラインを確認することもできる。接続やプロキシの開始時刻、各パケットの到着時間などが表示されるだろう。さらに、これらのデータをエクスポートして詳細な解析やバグ報告に使うこともできる。優れた計装機器はパフォーマンス解析の鍵であり、Chrome のネットワークレイヤーに関する情報は chrome://net-internals に集積されている ── 詳しく見たことがないなら、ぜひ見てみるべきだろう。
プリフェッチヒントを使ったリソース読み込みの最適化
ウェブページの作者はブラウザのユーザーエクスペリエンスを改善させるためのヒントとして、サイトのレイアウトや構造に応じた追加のナビゲーションあるいはページのコンテキストを提供できる場合がある。Chrome はこういったヒントに対応し、ページのマークアップに埋め込まれた次のようなヒントを理解する:
<link rel="prefetch" href="/static/big.jpeg">
<link rel="subresource" href="/javascript/myapp.js">
rel="prefetch" と rel="subresource" は些細な違いに思えるかもしれないが、意味論は大きく異なる。rel="prefetch" が指定された link 要素は「リンク先のリソースが将来のナビゲーションで必要になる可能性がある」ことをブラウザに伝える。言い換えれば、ページをまたいだヒントとして機能する。これに対して、rel="subresource" が指定された link 要素は「リンク先のリソースが現在のページで利用される」ことをブラウザに伝える。このヒントがあるとき、ブラウザはドキュメントを読み込んでリソースへのリンクを見つけるより早い段階でリソースに対するリクエストをディスパッチできる。
簡単に想像できるように、異なる意味論を持つ二つのヒントに対してリソースローダーが行う処理は大きく異なる。rel="prefetch" が指定されたリソースには低い優先度が割り当てられ、リソースのフェッチは行われるとしても現在のページの読み込みが終了した後に行われる。これに対して rel="subresource" が指定されたリソースには高い優先度が割り当てられ、対応する link 要素を読んだ段階でリソースのフェッチが始まる。そのため、このリソースは現在のページが持つ他のリソースと競争関係にある。
二つのヒントはどちらも、正しい状況で使われれば、ウェブサイトのユーザーエクスペリエンスを大幅に改善する可能性を秘めている。最後に重要な点として、執筆時点において rel="prefetch" は HTML5 仕様の一部であり、Firefox と Chrome によってサポートされる。これに対して rel="subresource" は Chrome でしかサポートされていない。
ブラウザの prefresh を利用したリソース読み込みの最適化
残念なことに、全てのサイト作成者がマークアップを通じてサブリソースのヒントをブラウザに提供できるわけではないし、提供するわけでもない。さらに、仮にヒントが提供されたとしても、HTML ドキュメントがサーバーから届くのを待たなくてはヒントの解釈とサブリソースのフェッチを始められない ── サーバーの応答時間やクライアントとサーバー間のレイテンシによって、この待機時間は数百ミリ秒から数千ミリ秒に達する可能性がある。
しかし前述したように、Chrome は頻繁に利用されるリソースのホスト名を記憶し、DNS プリフェッチを行う。では、もう一歩進んで TCP preconnect とリソースのフェッチも投機的に行ってはどうだろうか? 投機的なリソースフェッチは Chrome で prefresh と呼ばれ、次のように行われる:
- ユーザーが URL をリクエストする。
- Chrome は
Predictorにクエリを発行し、その URL に関連付いたサブリソースを学習する。 - Chrome は学習したサブリソースに対する DNS プリフェッチ、TCP preconnect、prefresh を開始する。
- このとき、サブリソースがキャッシュに存在すれば、そのデータがディスクからメモリに読み込まれる。
- 学習したサブリソースがキャッシュに存在しないか期限切れであれば、ネットワークリクエストが発行される。
リソースの prefresh は Chrome における実験的な最適化が正式版に採用されるまでのワークフローを示す優れた例である。 ── 理論上は prefresh によってパフォーマンスが向上するものの、実際には多くのトレードオフが存在する。特定の最適化が Chrome の正式版に採用されるかどうかを誰もが納得する形で決める方法は一つしかない: 実装して、プリリースチャンネルを通して実際のユーザー、実際のネットワーク、実際のブラウジングパターンで A/B テストをするしかない。
2013 年初頭の時点で、Chrome チームは prefresh の実装に関する議論を始めた段階にある。収集された結果が満足いくものであれば、prefresh は年内にも Chrome に組み込まれるだろう。Chrome のネットワークパフォーマンスを改善する作業が終わることはない ── チームは常に新しいアプローチ、新しいアイデア、新しい手法を実験している。
事前レンダリングによるナビゲーションの最適化
これまでに解説してきた最適化はどれも、ユーザーがナビゲーションをリクエストした瞬間からレンダリングされたページがタブに表示される瞬間までのレイテンシを小さくすることに主眼を置いていた。しかし、真に「瞬間的な」エクスペリエンスはどうすれば達成できるだろうか? 表 1.1 のデータによるとユーザーが「瞬間的」と感じるレイテンシは 100 ms 以下であり、ネットワークレイテンシより格段に短い。レンダリングされたページを 100 ms 以内に届けることは可能だろうか?
もちろん、読者は答えを知っている。多くのユーザーが利用する次のパターンである: 複数のタブを開いておけば、タブの切り替えることで現在のタブから同じページにナビゲーションするより圧倒的に速くページを表示できる。この処理を明示的に行う API がブラウザから提供されてもいいのではないだろうか? 例えば次のように:
<link rel="prerender" href="http://example.org/index.html">
実は、 Chrome の事前レンダリングはこれを行う。rel="prefetch" のように単一のリソースをダウンロードすべきであることを伝えるのではなく、rel="prerender" はページを (サブリソースを全て取得した上で) 表示されないタブに事前レンダリングすべきであることを Chrome に伝える。事前レンダリングが行われるタブはユーザーからは見えないものの、ユーザーがナビゲーションを発火させると現在のタブと置き換えられ、「瞬間的な」ページ遷移が行われる。
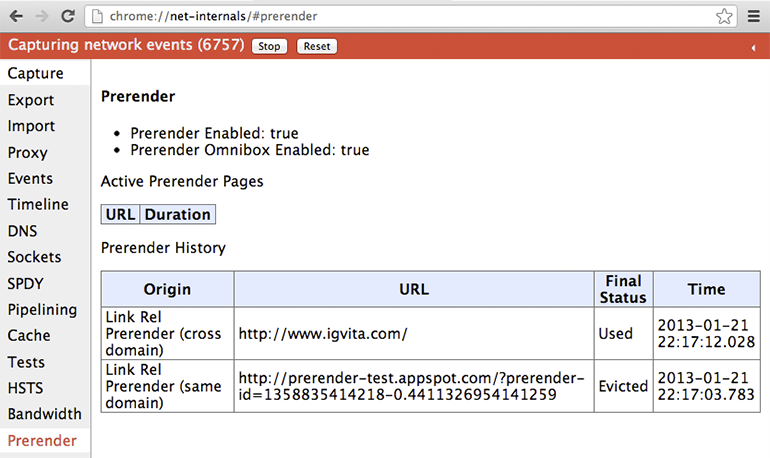
もし試してみたいなら、ハンズオンデモが http://prerender-test.appspot.com に用意されている。また、chrome://net-internals/#prerender からは事前レンダリングされたページの履歴とステータスが確認できる (図 1.11)。
簡単に想像できるように、表示されないタブにページ全体をレンダリングする処理は CPU とネットワークのリソースを多く必要とする。そのためレンダリングされるページが利用される確率が高いときにだけ事前レンダリングを使わなければならない。例えばユーザーが Omnibox を使っているなら、確度の高い補完候補だけが事前レンダリングの対象となり得る。他にも、Google 検索はクリックされる可能性が高い検索結果のマークアップに事前レンダリングのヒントを挿入することがある (この機能は Instant Pages と呼ばれる)。
自分の作成するウェブサイトに事前レンダリングのヒントを加えることもできる。ただし事前レンダリングには制限があるので、試すときは注意が必要である:
- 事前レンダリング用のタブは一つだけ用意され、全てのプロセスが共有する。
- HTTP 認証を用いるページと HTTPS は使えない。
- 非冪等なリクエストが必要となるリソース (またはサブリソース) が存在するとき、事前レンダリングは中止される (
GETだけが許される)。 - 全てのリソースには最も低いネットワーク優先度が割り当てられる。
- ページは最も低い CPU 優先度でレンダリングされる。
- ページのメモリ使用量が 100 MB を超えると事前レンダリングは中止される。
- プラグインの初期化は遅延され、ページが HTML5 のメディア要素を含むとき事前レンダリングは中止される。
言い換えれば、Chrome は事前レンダリングの実行を保証せず、ページが安全なときに限って実行する。また、JavaScript などのロジックが表示されないページで実行される可能性があるので、Page Visibility API を使ってページがユーザーから見えているかどうかを検出することがベストプラクティスである ── なお、この処理は事前レンダリングかどうかに関わらず行うべきとされる。
Chrome は使い続けると高速になる
言うまでもなく、Chrome のネットワークスタックは単純なソケットマネージャよりずっと複雑である。この弾丸ツアーでは、ユーザーがウェブを閲覧する間に気が付かないうちに実行される可能性のある様々なレベルの最適化を紹介した。Chrome がウェブのトポロジーとユーザーのブラウジングパターンを学習すれば、それだけ優れた最適化が可能になる。まるで魔法のように、Chrome は使い続けると高速になる。ただし、Chrome は魔法を使わない: ここまで読んだ読者なら具体的な処理を理解できたことだろう。
最後に、Chrome チームがパフォーマンス改善の新しいアイデアの実験を続けている事実は強調に値する。この文章を読者が読むころには、新しい実験や最適化が開発・テスト・デプロイされている可能性が高い。ウェブ上の全てのページを瞬間的に (100 ms 以内に) 読み込むという目標を達成できたなら、私たちは休憩を取れるかもしれない。しかしそれまでは、やるべき仕事が無くなることはない。