khmer
はじめに
バイオインフォマティクスとビッグデータ
バイオインフォマティクスの分野は、主に遺伝情報とタンパク質情報の解析と関連付けを通して、地球上の生命が持つ分子メカニクスの理解を促進するツールと解析結果の提供を目指す。ゲノム配列と発現遺伝配列の両方を含む利用可能な遺伝情報は近年ますます増えているので、これまでより効率的で、特定的で、感度が高い解析の重要性も高まっている。
DNA シーケンスでは、化学的および工学的なプロセスが DNA と RNA に含まれる情報を「デジタル化」する。その情報はヌクレオチドごとにアルファベット一文字で記録され、ヌクレオチド鎖は最終的にアルファベットの配列となる。この配列には様々な解析が実行され、どのような要素を構成するか、あるいは他のシーケンスデータとどのように関連するかが調べられる。DNA シーケンスで得られるデータは生物学的進化や発達の研究、遺伝学、そして最近では医学といった分野の基礎となっている。
シーケンスにおいて、ヌクレオチド鎖が持つデータはリード (read) と呼ばれる断片ごとに生成される。大規模な構造やプロセスを解析するには、複数のリードを組み合わせる必要がある。リードを組み合わせる問題は単なるジグソーパズルではない: 全体像は事前に分からず、リードが重なり合うことが (よく) ある。さらに言えば、リードが完全に正確である保証はなく、ヌクレオチドを表す文字の追加・削除・置換といった誤りが混入する可能性がある。このため、冗長なリードを集めればリードのアセンブリ (パズルピースを組み合わせる問題) の難易度は低下するものの、問題が自明になるわけではない。データの量が増えれば誤りを含むリードもそれだけ増えるので、リードのアセンブリは厄介になる。
シーケンステクノロジが発展したことで、生成されるシーケンスデータの量はコンピューターハードウェアが古典的な方法を使って解析できる量を上回るようになった (最先端のシーケンステクノロジを用いると数十億にも及ぶリードを一度に生成でき、それぞれのリードは 50~100 個のヌクレオチドを表す)。このトレンドは今後も続くと見込まれている。爆発的に増加したシーケンスデータは、高パフォーマンスコンピューティング (HPC)、統計学、情報科学といった分野ではビッグデータ[1]と呼ばれる。ビッグデータを扱う問題ではハードウェアが制限要因となるので、ソフトウェア的な工夫でそういった問題を容易にするアプローチに注目が集まっている。本章では私たちが行ったソフトウェア的な工夫を紹介し、テラバイト単位のデータまでスケールさせるためにそれをどのように調整したかを説明する。
私たちの研究は効率的な前処理 (pre-processing) に関するものである。前処理はリードの部分的な削除やリード全体の破棄といった様々なフィルタリングとビニング (集約) を行い、下流の解析の質を改善する。前処理を個別に考えるアプローチには、リードを直接的に扱うことが多い下流の解析に変更が少なくて済む利点がある。
本章では私たちが実装した前処理におけるソフトウェア的な工夫を紹介し、増加し続けるデータを効率的に扱えるように前処理をスケール可能とするために必要だった細かな調整を説明する。
khmer の紹介
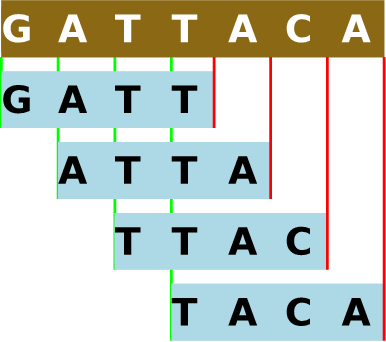
khmer[2] は従来のバイオインフォマティクスツールを使った解析に先立って大規模なゲノム配列データに対する前処理を行う、私たちが開発したソフトウェアツールの集合体を指す名前である ── 同名の東南アジアの民族とは関係ない。khmer という名前は k-mer という用語から来ている: 前処理の一部として、特定の長さ k の部分文字列全体の集合がゲノム配列から抽出される (図 12.1)。長い分子鎖はポリマー (polymer) と呼ばれるので、分子が特定の個数だけ連結した分子鎖 (そして前処理が生成する部分文字列) は k-mer と呼ばれる。リードに含まれる k-mer の個数は「ヌクレオチド鎖の個数 - k + 1」であり、ほぼ全てのリードが多くの重複する k-mer に分割される。
本章ではオープンソースソフトウェアのパフォーマンスを測定・改善した手法を解説したいので、裏側にある DNA シーケンスの理論には触れない。全てのリードに含まれる各 k-mer の個数を数える処理 (k-mer counting, k-mer の数え上げ) が中心的な操作だと知っていれば十分だろう。膨大な k-mer をコンパクトに数え上げるために、Bloom filter[3] と呼ばれるデータ構造が使われることが多い。k-mer の数え上げが完了すると、以降の処理で不必要な冗長性の高いデータを削除できるようになる。この冗長データの削除はデジタル正規化 (digital normalization) と呼ばれる。また、出現頻度が低い配列データを誤りとみなして削除することもできる。こういった正規化と誤り削除は価値のあるデータの大部分を保存しつつ、以降の処理が扱うシーケンスデータを大きく削減する。
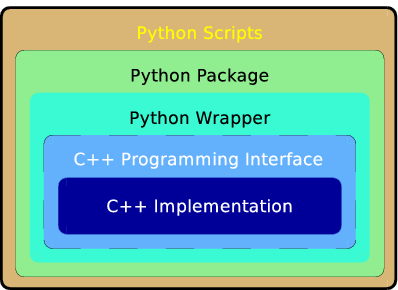
khmer のコアは C++ で書かれている。このコアは、データポンプ (オンラインストレージから物理 RAM へのデータ移動を担うコンポーネント)、よく使われるいくつかのフォーマットに対応したリードパーサー、そして複数の k-mer 数え上げ実装からなる。この上には、コアにアクセスするためのアプリケーションプログラミングインターフェース (application programming interface, API) が用意される。この API は当然 C++ プログラムから利用できる (khmer のテストドライバが利用している) のに加えて、khmer の Python ラッパーの基礎にもなる。Python ラッパーの上には Python パッケージがあり、このパッケージを使って書かれた Python スクリプトは数多く公開されている。まとめると、khmer は高速化のために C++ で書かれたコアコンポーネントと、操作の利便性のために Python で公開される高レベルインターフェース、そして様々なツールスクリプトの集合体であり、バイオインフォマティクスにおける多様なタスクを簡単に実行する手段を提供する (図 12.2)。
khmer は複数のフェーズからなるバッチ操作をサポートする。各フェーズの入出力は個別のデータであり、例えば「リードの集合を入力として受け取り、k-mer の数え上げを実行し、その後 (オプションで指定されたなら) 後から使えるように Bloom filter のハッシュテーブルを保存する」といった操作を行える。このフェーズの後には「保存されたハッシュテーブルを入力として受け取り、冗長な k-mer のフィルタリングを実行し、結果を保存する」というフェーズが続くかもしれない。以前の出力の再利用、そして保存するデータの指定ができる柔軟性により、ユーザーは自身の要望やストレージ制約に沿った手続きを指定できるようになる。
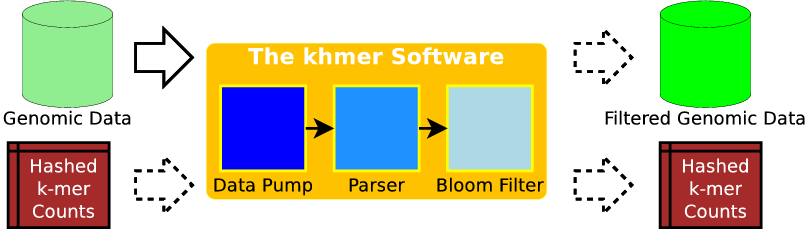
khmer は数テラバイトにおよぶ可能性のある途方もない量のデータをディスクから物理 RAM に移動させる必要がある。ディスクと物理 RAM 間のスループットは物理 RAM と CPU 間のスループットより格段に (典型的には三桁、場合によっては四桁) 遅いので、効率的なデータポンプが不可欠となる。また、一部のフォーマットでは圧縮の解凍が必要になる。いずれのケースでも、パーサーは最終的なデータを効率的に扱わなければならない。パースは可変長の行を読む処理を基本とするものの、失敗したリードを考慮しなければならず、さらに配列フラグメントの先頭と末尾の組といった特定の生物学的情報を以降のアセンブリが活用できるように保存する必要もある。そこで、リードからは k-mer の集合が抽出され、それぞれの k-mer をキーとする Bloom filter が構築される。このとき以前に保存された Bloom filter を利用するなら、それをストレージから読み込まなくてはならない。また、Bloom filter の更新や保存ではストレージへの書き込みが必要になる。
khmer のデータポンプはファイルに対するアクセスを必ず連続的に行い、ファイルからデータを大きなチャンクで一度に読み込むオプションを持つ。このデータポンプについて、次の疑問が自然に思い浮かぶ:
- データに対するアクセスが連続的である事実を十分に活用できているか?
- アクセスレイテンシを最小化するのに十分なデータがメモリにプリフェッチされているか?
- 同期的でなく非同期的な読み込みを利用できないか?
- システムキャッシュを迂回して、ファイルのデータをメモリ上のバッファに直接コピーできないか?
- データポンプは不必要なアクセッサや判断ロジックによるオーバーヘッドが生じないスタイルでデータを公開しているか?
パーサーの入力は自由度の高い文字列フォーマットであり、それをパーサーが内部表現に変換しなければ以降の処理は開始できない。そのため、パーサーの効率は非常に重要である。各データレコードは比較的小さい (100~200 バイト程度) ものの、レコードの個数は数百万から数億にまで達する。そのため、私たちは大きな労力をかけてパーサーを最適化してきた。パーサーの中心部には、データストリームをリードごとに分割し、初期バリデーションを行いつつリードをレコードに格納するループがある。
パーサーの効率に関する懸念事項がいくつかある:
- パーサーがメモリ上のデータに触れる回数は最小か?
- データストリームからリードをパースするとき、バッファ間のコピーは最小か?
- パースを実行するループで関数呼び出しのオーバーヘッドは最小か?
- パーサーは綺麗でないデータ (例えば曖昧な塩基、短すぎるリード、大文字と小文字の不統一など) を扱えなければならない。こういったデータに対処する DNA 配列のバリデーション処理は可能な限り高速に行えているか?
一つのリードに含まれる k-mer を走査してハッシュを計算する処理では、次の懸念事項がある:
- k-mer の走査をメモリと実行速度の両方に関して最適化できないか?
- Bloom filter のハッシュ関数を最適化できないか?
- ハッシュ関数がメモリ上のデータに触れる回数は最小か?
- ハッシュの出現回数をバッチで更新することで、温かいキャッシュを活用できないか?
プロファイルと計測
パフォーマンスを気にしながらソースコードを読むだけでも数多くの改善点を見つけることができる。しかし、khmer ではコードの様々な箇所で費やされる時間をシステマチックに定量化する手段が望まれた。このために、私たちは GNU Profiler (gprof) と Tuning and Analysis Utilities (TAU) というプロファイラを利用した。また、ソースコード内には計装命令 (instrument) が配置されており、主要なパフォーマンス指標を細かく確認できる。
コードレビュー
システム (あるいはソフトウェア) のパフォーマンスを測定するツールを盲目的に利用することが良いアイデアであるケースは少ない。一般に、パフォーマンスの測定を始める前にシステムをいくらか理解するのが望ましい。そのため、私たちは最初に人の目でコードレビューを行った。
慣れていないコードの実行パスを自分の手で追ってみるのは良いアイデアである (著者の一人 Eric McDonald はプロジェクトに参加したとき khmer に触れたことがなかったので、これを行った)。プロファイラといったツールを使えばコールグラフは手に入るものの、コールグラフは抽象的な情報でしかない。コードパスを実際に目で追って呼び出される関数を確認する方が、没入感の高い啓発的な体験となる。デバッガを使って実行の流れを追うこともできるものの、そうすると実行されにくいコードパスを追うのは難しい。また、実行パスをステップごとに移動するのは面倒でもある。通常の実行が特定のコードを通るかどうかはブレークポイントを使えばテストできるものの、ブレークポイントを配置するにはコードに関する知識がいくらか必要になる。コードの知識が何もないときは、複数のペインを持ったエディタが便利である。ペインが四つもあれば、人間が必要とする (頭の中に保持できる) 量の情報を全て表示できるだろう。
このコードレビューにより様々な問題点が見つかった (ただ、その全てがプロファイラによって裏付けられたわけではない)。コードレビューとプロファイルを通して私たちが気付いたことをいくつか示す:
- 最も時間がかかるのは k-mer の数え上げ処理だと推定された。
- 頻繁に呼び出されるコード領域に
toupper関数の冗長な呼び出しがあった。 - パース時に入力がオンデマンドに一行ずつ読み込まれ、先読みが使われていなかった。
- パースされた正当なリードのそれぞれに対して、リードを表す構造体の値によるコピー (copy-by-value) が起こっていた。
ずいぶんレベルの低い自己批判だと思うかもしれないが、初期の khmer 開発が利便性と正確性を重視してきた事実は強調しておきたい。私たちの目標は (ほぼ) 正しく動く既存のソフトウェアを最適化することであり、新しいソフトウェアを最初から開発することではなかった。
ツール
プロファイルツールは特定のコード領域に費やされた時間を測定するために、計装命令 (instrument) をコードのコンパイル時に挿入する。この計装命令は関数のサイズを変化させるので、インライン化の判断に影響する。また、計装命令自体もオーバーヘッドとなる。特に、頻繁に実行されるコード領域をプロファイルするとき計装命令は大きなオーバーヘッドとなる。そのためコードの実行時間を測定するときは、プロファイル自身の実行時間への影響を考慮しなければならない。/usr/bin/time といった単純な外部プログラムを利用してプロファイル時と非プロファイル時の実行時間を比較すれば、プロファイルツールによる測定の妥当性を確認できる。
プロファイルの影響を調べるため、私たちはプロファイル時と非プロファイル時の実行時間を様々な k に対して測定した。k が小さいときリードに含まれる k-mer の個数は増加するので、プロファイラの影響が大きくなると予想できる。実際の測定では、プロファイル時の実行時間と比べたときの非プロファイル時の実行時間は k = 20 のとき 19% 短く、k = 30 のとき 14% 短かった。
パフォーマンスを最適化する前に行った測定の結果からは、私たちの予想通り k-mer の数え上げロジックに最も時間がかかっていることが判明した。意外だったのはそれが占める割合で、実行時間全体の実に 83% が数え上げロジックに費やされていた。これに対して、ストレージに対する I/O 操作は (帯域の利用率が小程度から中程度のとき) 実行時間の 5% に過ぎなかった。テストで利用されるデータセットは 500 MB および 5 GB 程度だったので、この原因はキャッシュの効果を妨げるものが何もないことだと考えられた1。しかし、キャッシュの効果を抑えたとしても I/O 操作には最大でも数秒しかかからず、これは全体の実行時間のエラーバーと同程度の長さだった。この計測結果から、コード最適化プロセスのこの時点では、主要なボトルネックは I/O でないと私たちは理解した。
khmer の並列化を始めるにあたって、私たちは様々なコンポーネントの並列化をテストするドライバプログラムを OpenMP[4] を利用して書いた。gprof は単一スレッドの実行をプロファイルすることには長けているものの、複数のスレッドが存在する状況で各スレッドの実行を追う機能を持たず、そもそも OpenMP を始めとした並列化のメカニズムを理解しない。C/C++ コードの OpenMP による並列化はコンパイラのプラグマ (pragma) によって行われる。例えば GNU C/C++ コンパイラ (のバージョン 4.X) では、 -fopenmp スイッチをコンパイラに渡すと OpenMP のプラグマが有効となる。OpenMP のプラグマが有効なとき、コンパイラはプラグマが付いたコード領域 (ブロックや for/while ループなど) にスレッドを処理する命令を挿入する。
gprof は私たちが望む複数スレッドの細かいプロファイルと OpenMP サポートを提供しないので、他のツールを使うことになった。Tuning and Analysis Utilities[5] (TAU) はオレゴン大学が主導した共同研究で生まれたソフトウェアである。並列プロファイルツールは数多く存在し、多くは Message Passing Interface (MPI) という一部の科学計算タスクで広く利用されるライブラリを対象とする。TAU は MPI を利用するプログラムのプロファイルもサポートするものの、khmer の方向性を考えると MPI が採用される可能性は非常に低いので、TAU の MPI に関する側面は無視される。同様に、TAU はスレッド単位のプロファイルを提供する唯一のツールではない。私たちが TAU を採用したのは、TAU がスレッド単位のプロファイル機能と OpenMP との密接な連携を両方とも持つためである。また、TAU が完全にオープンソースであり、特定のベンダーと関係を持たない点も魅力的だった。
gprof は必ずコンパイル時に挿入される計装命令 (およびリンクされる少量の外部コード) でプロファイルを行うのに対して、TAU では計装の選択肢が他にも存在する。例えばライブラリの書き換え (主に MPI プロファイルで使われる) や、バイナリに対する計装命令の動的な挿入を通した計装をサポートする。こういった選択肢をサポートするために、TAU は tau_exec と呼ばれる実行ラッパーを提供する。コンパイル時に計装命令を挿入する選択肢は tau_cxx.sh と呼ばれるラッパースクリプトを通してサポートされる。
TAU でアクティビティをプロファイルするには、追加で設定が必要になる。例えば OpenMP との密接な統合を利用するには、OPARI のサポートを有効にして TAU をビルドしなければならない。同様に、新しいバージョンの Linux カーネルで公開されるパフォーマンスカウンターを利用するには、PAPI のサポートを有効にして TAU をビルドしなければならない。TAU のビルドが完了したら、利便性のために TAU をビルドシステムに統合することが望ましいだろう。例えば、私たちは TAU によるプロファイルが有効なときはラッパースクリプト tau_cxx.sh を C++ コンパイラとして利用するようにビルドシステムを設定した。TAU は gprof と比べればずっと強力な機能を持つものの、gprof のような直感的で簡単な操作を持つとは決して言えない。
手動の計装
独立した外部プロファイラでソフトウェアの一部分のパフォーマンスを調査することは、ソフトウェアの様々な部分の実行時間に関する簡単な知識を得るための手軽な手段である。しかし、一般にプロファイラは特定の関数で特定のスピンロックが消費した時間、あるいはデータの入力レートといった細かい情報を報告できない。外部プロファイラの機能を補強するには、手動の計装が必要になる。また、手動の計装は計測対象のコードを直接管理できるので、自動的な計装よりプログラムへの影響が少ない。そこで、スループット、反復回数、アトミック操作などの細かな操作のタイミングといった指標を khmer の内側から計測できる拡張可能なフレームワークを私たちは作成した。正確性を検証するために、このフレームワークは外部プロファイラの測定結果と比較できる数値も測定するようになっている。
コードの異なる領域では、異なる指標の集合を収集する必要がある。しかし、指標の集合には共通点がいくつかある。指標の多くはタイミングデータであり、実行の間に収集・集積される必要がある点が一つである。また、一貫したデータ報告の仕組みが必要な点も共通点と言える。こういった観察から、指標の集合を表す抽象基底クラス IPerformanceMetrics が用意された。IPerformanceMetrics クラスは start_timers, stop_timers, timespec_diff_in_nsecs といった便利なメソッドをいくつか提供する。start_timers と stop_timers はスレッド単位の CPU 時間と実時間の両方を記録する。timespec_diff_in_nsecs は標準 C ライブラリに含まれる timespec 構造体の値を二つ受け取り、両者の差をナノ秒の単位 (私たちの用途では十分以上の精度) で返す。
手動で挿入される計装命令のオーバーヘッドがプロダクションビルドに影響しないように、計装命令は条件付きコンパイルディレクティブで注意深く囲まれ、ビルド時にオプションで除外できるようになっている。
パフォーマンスチューニング
ソフトウェアの最適化は、特に数テラバイトのデータを目の前にして行うとき、非常に愉快な経験である。ここからは khmer を最適化するために私たちが行った工夫を説明する。本節は二つの部分からなる: 前半では入力データの読み込みとパースの最適化が説明され、後半では Bloom filter の操作に関する最適化が説明される。
一般的なパフォーマンスチューニング
khmer に施された工夫の詳細を見ていく前に、一般的なパフォーマンスチューニングの選択肢をいくつか紹介する。プロダクションコードは安全で単純な最適化を有効にしてビルドされる場合が多い: そういった最適化はコードの意味論を変化させない (バグを生まない) ことが通常は証明されており、たいていはコンパイルプロセスの単一パスで実行できる。ただし、こういった単純な最適化の他にも、コンパイラは「aggressive optimization」 (コンパイラの文献では非常に一般的な用語) や「profile-guided optimization[6]」を提供する (この二つは厳密には独立した概念ではないものの、典型的には異なるアプローチが使われる)。
aggressive optimization とは安全とは限らない (バグを生む可能性がある)、もしくはパフォーマンスを改善するとは限らない最適化を言う。aggressive optimization が安全でない理由には「浮動小数点演算が正確でなくなる」や「異なるオペランドが異なるメモリアドレスに関連付くと仮定される」など様々なものがある。aggressive optimization は特定の CPU ファミリーに特有な場合もある。profile-guided optimization はプロファイル情報を利用する最適化であり、実際の実行頻度に関する情報を使って優れたコンパイルとリンクを可能にする。よく適用される profile-guided optimization の一つに局所性の最適化がある ── 同時に実行されることが多い関数を実行イメージのテキストセグメント上で近くに配置することで、それらが実行時に同じメモリページに読み込まれるようにする。
プロジェクトが最適化を始める段階に進んだとき、私たちは意識的に aggressive optimization と profile-guided optimization を避け、目標を絞ったアルゴリズム的な改善を優先した ── アルゴリズム的な改善は CPU アーキテクチャに関係なく適用できる。さらに、ビルドシステムの複雑性を考えると、aggressive optimization を使うとポータビリティの問題が発生し、profile-guided optimization を使うと失敗する可能性のある可動部分が増える。khmer では様々なアーキテクチャに対するコンパイル済み実行形式が配布されず、さらに khmer の典型的なユーザーはソフトウェア開発やビルドシステムに詳しいわけではないので、こういった欠点は利点を上回るだろうと私たちは判断した。khmer の最適化で私たちが集中したのはアルゴリズムの最適化であり、他の種類のチューニングではない。
データポンプとパーサーの最適化
プロファイルの結果からは、k-mer の数え上げにかかる時間がストレージから入力を読み込むのにかかる時間より圧倒的に長いことが明らかになった。この興味深い事実からすると、Bloom filter のパフォーマンスを改善することに全ての労力を費やすべきと思うかもしれない。しかし、データポンプとパーサーを見ておくべきだった理由がいくつかある。第一に、複数スレッドの利用をサポートしてスケーラビリティを高める上では当時のデータポンプとパーサーの設計に変更が必要だった。第二に、データポンプとパーサーを改善してメモリからメモリへのコピーを減らすと、Bloom filter がパーサーとやり取りするときの効率も改善する。第三に、いずれ k-mer の数え上げにかかる時間がデータの読み込みにかかる時間と同程度になれば、積極的な先読みやデータのプリフェッチといった最適化も必要になる。また、パフォーマンスのチューニングとは関係ないものの、管理容易性や拡張性といった問題もある。
こういった理由から、データポンプとパーサーの設計が一新された。この設計のスレッドセーフ性に関する側面は後で議論する。ここでは、メモリからメモリへのコピーを削減する最適化とデータの積極的なプリフェッチによる最適化を説明する。
典型的に、プログラムがブロックストレージデバイス (例えばハードディスク) からデータを取得すると、オペレーティングシステム (OS) によって特定の個数のブロックがキャッシュされる。このキャッシュを作成する処理から生じるオーバーヘッドが存在する。加えて、このキャッシュにプリフェッチされるデータの量は細かく調整できない。さらに、このキャッシュにはユーザープロセスから直接アクセスできないので、キャッシュからユーザープロセスのアドレス空間へのコピーが必ず発生する。これはメモリからメモリへのコピーである。
Linux などの一部の OS では、ファイルの読み込みで使われる先読みウィンドウのサイズをいくらか調整できる。例えば、ファイルディスクリプタに対して呼び出せる posix_fadvise(2) 関数や readahead(2) 関数が用意されている。しかし、こういった関数を使っても細かい制御が可能になるわけではなく、キャッシュは迂回できない。khmer のようなプロジェクトでは OS が管理するキャッシュを迂回してデータを取得する手段が望まれる。実は、O_DIRECT フラグを有効にしてファイルを開けば (サポートされている限り) キャッシュは利用されなくなる。しかし、O_DIRECT フラグによって有効になる読み込み処理は複雑であり、読み込みのサイズはストレージ媒体のブロックサイズの定数倍でなければならず、さらにブロックサイズの倍数であるアドレスから始まるメモリ領域にしかデータを読み込めない。このとき、通常はファイルシステムが管理する情報をプログラムが管理することになる。khmer には O_DIRECT フラグを有効にした読み込み処理が (必要な情報管理処理と共に) 実装されている。しかし、このアプローチは一部のケースで利用できなかったり望ましくなかったりするので、先読みウィンドウを調整するアプローチも試されている。khmer ではストレージに対するアクセスが連続的なので、posix_fadvise(2) を通してファイルを通常より先まで読み込むよう OS に伝えるアプローチが有効となる。
バッファからバッファへのコピーを最小化することはデータポンプとパーサーに共通する課題である。理想的なシナリオでは、ストレージからバッファに一度だけデータが読み込まれ、そのバッファをパースすることでオフセットと長さで表されたリードの列が生成される。しかし、バッファを管理するロジックとバッファをパースするロジックはどちらも非常に複雑なので、プログラマーの理解を助けるために中間の「行バッファ」が用意される。この影響を抑えるため、行バッファを使うコードでは積極的なインライン化がコンパイラに指示される。この部分のパフォーマンスが十分大きな問題になれば、最終的に行バッファを削除する可能性もある。ただ当然、行バッファの削除はソフトウェアの設計に悪影響を及ぼすだろう。
Bloom filter の最適化
khmer が扱う DNA データは A, C, G, T という四つのアルファベットが並んだ文字列である。これらのアルファベットは大文字と小文字のどちらで表されるのだろうか? khmer はユーザーによって提供されるデータを直接処理するので、各塩基が大文字あるいは小文字のいずれかで表されると仮定することはできない: シーケンスプラットフォームや他のバイオインフォマティクスパッケージがどちらを使うかは分からない。大文字と小文字の両方に対応する処理は簡単に書けるものの、その処理は数百万あるいは数億のリードに対して実行される!
パフォーマンスのチューニングが始まる前のコードでは、DNA 文字列のバリデーションとアルファベットの符号化 (二ビットの整数への変換) を行うまで大文字と小文字が区別されていなかった。バリデーションでは、C 標準ライブラリの toupper 関数を何度も呼びだす次のマクロが使われていた:
#define is_valid_dna(ch) \
((toupper(ch)) == 'A' || (toupper(ch)) == 'C' || \
(toupper(ch)) == 'G' || (toupper(ch)) == 'T')
そして符号化には次のマクロが使われていた:
#define twobit_repr(ch) \
((toupper(ch)) == 'A' ? 0LL : \
(toupper(ch)) == 'T' ? 1LL : \
(toupper(ch)) == 'C' ? 2LL : 3LL)
toupper 関数のマニュアルページまたは GNU C ライブラリのヘッダーを確認すれば分かるように、toupper 関数はロケールに対応した非自明な関数であり、単純なマクロではない。そのため、上記のマクロには最低でも関数呼び出しのオーバーヘッドが (少なくとも GNU C ライブラリが使われるとき) 存在する。さらに、khmer が扱うのは四つの ASCII 文字からなる文字列なので、ロケールを認識する機能は無駄でしかない。よって関数の呼び出しを減らすのに加えて、より効率的なアプローチを使う必要がある。
まず、入力文字列をバリデーションに先立って大文字に正規化することになった (当然、バリデーションは符号化の前に実行される)。この正規化はパーサーで実行するのが理想であるものの、入力文字列がパーサーを経由しない別のルートで Bloom filter に格納されるケースが存在することが判明したので、執筆時点ではバリデーションの直前に正規化が実行される。こうするとバリデーションと符号化で toupper を呼び出す必要がなくなる。
入力文字列の正規化はテラバイト単位のデータに対して実行されるので、可能な限りの最適化が必要になる。考えられるアプローチの一つを示す:
#define quick_toupper( c ) (0x60 < (c) ? (c) - 0x20 : (c))
このマクロを使うとき、一度の比較と一度の分岐、そして省略されることのある一度の加算が入力文字列の各バイトに行われる。もっと高速にできないだろうか? 「ASCII ではアルファベットの大文字が小文字より 32 だけ小さい」という事実がある。32 は 2 の冪なので、これは同じアルファベットの大文字と小文字を表すビット列が 1 ビットだけ異なることを意味する。この観察は「ビットマスク!」と叫んでいる:
c &= 0xdf; // 高速な toupper
この処理はビット操作命令が一つだけであり、比較も分岐もない。大文字のアルファベットはそのままとなり、小文字のアルファベットは大文字となるので動作に問題はない。この工夫によって、khmer 全体の実行時間は 13% (!) 改善した。
Bloom filter のハッシュテーブルは...「高価」である。符号化された k-mer に対するカウントを増加させるには、フィルタがアロケートしたハッシュテーブルとほぼ同じ個数のメモリページに触れる必要がある。多くのケースで連続する k-mer は全く異なるので、必要なメモリページも異なる。このため、メインメモリからのページの取得が多くなり、キャッシュを活用できなくなる。仮に 79 文字のリードを長さ 20 の k-mer に分割していて、4 個のハッシュテーブルが使われているなら、最大で 236 (= 59 × 4) 個の異なるメモリページがリードごとにアクセスされる。5000 万個のリードを処理する状況を考えれば、これがどれだけのコストになるかは想像できるだろう。どうするべきだろうか?
私たちの解決策は「ハッシュテーブルの更新をバッチ (ひとまとめ) にする」である。k-mer に対する符号を計算したら一旦ローカルに記録しておき、定期的にテーブルごとにカウントをまとめて増加させる。こうすれば、キャッシュの利用率が大幅に向上する可能性がある。このアプローチの初期実験は非常に有望な結果を示しており、この変更は読者が本章を読むころには khmer のコードに完全に組み込まれていると予想される。先述の性能計測とプロファイルの議論では触れなかったものの、こういった最適化の有効性を正確に検証する上では cachegrind (オープンソースのツールスイート Valgrind[7] に含まれるプログラム) が非常に有用となる。
並列化
現在ではマルチコアのアーキテクチャが急激に広まったので、その並列性を使うことは魅力的に思える。しかし、他の多くの問題領域 (例えば計算流体力学や分子動力学) と異なり、khmer が直面するビッグデータの問題で重要なのはデータを高いスループットで処理することである ── そういった問題は、ある地点まで並列化を進めると必ず本質的に I/O バウンドとなる。その地点を超えると、スレッドを追加しても効率が向上しなくなる: ストレージ媒体との帯域が飽和しているので、新しく追加されたスレッドでは I/O を待ってブロックする時間が長くなってしまう。ただ、スレッドを全く使わなくて構わないわけではない。特に、処理するデータを物理 RAM 上に保持できるなら、オンラインストレージの帯域より格段に高い物理 RAM の帯域を飽和させるために並列化が必要になる可能性が高い。先述したように、khmer にはプリフェッチバッファと O_DIRECT フラグによる直接読み込みが実装されている。後述するように、プリフェッチバッファは複数のスレッドから同時に利用できる。最後に、複数のスレッドが共有する有限のリソースは I/O 帯域だけではない。k-mer の数え上げで使われるハッシュテーブルもそうである。ハッシュテーブルに対する並列アクセスについても後述される。
スレッドセーフとスレッディング
詳細に入る前に、用語を簡単に整理しておいた方がいいだろう。マルチスレッドで実行できるコードはスレッドセーフと誤って考えている人も多い。コードがスレッドセーフとは、複数のスレッドが同時に実行した場合でも正しく動作する (例えばデータ構造に対する書き込みや読み込みが正しい結果を返す) ことを言う。マルチスレッドで実行されるコードとは、複数の実行の流れによって同時に実行されるコードを言う。
並列化の作業の一環として、私たちは C++ で書かれる khmer コアの一部を特定のスレッディング方式やライブラリを仮定しないスレッドセーフなコードに作り変えた。この結果、例えばコア実装の Python ラッパーでは Python の threading モジュールを利用でき、コア実装を利用する C++ ドライバでは先述した OpenMP のような高レベル抽象化や pthreads による明示的なスレッディングを利用できる。スレッディング方式の独立性とスレッドセーフ性を既存の C++ ライブラリが持つインターフェースを破壊せずに達成することは、興味深いソフトウェアエンジニアリングの課題である。私たちは、スレッドセーフなものとして公開される API にスレッドごとの状態オブジェクトを関連付ける方式を用いた。これらの状態オブジェクトは C++ 標準テンプレートライブラリ (STL) の map であり、スレッド識別番号がキーとなる。スレッド識別番号はスレッドが呼び出すシステムコールで OS カーネルから取得される。この解決策では API を通じて公開される全ての関数でスレッド識別番号の取得が必要になるために少量のオーバーヘッドが避けられないものの、単一スレッドで実行されるものとして書かれた既存のインターフェースを破壊しないで済む。
データポンプとパーサーの並列化
HPC の世界ではマルチコアマシンが複数のメモリコントローラーを持ち、CPU との距離 (信号が伝達するのにかかる時間) がメモリコントローラーごとに異なる場合がある。そういったアーキテクチャを NUMA (Non-Uniform Memory Access) アーキテクチャと呼ぶ。NUMA アーキテクチャのマシンは、物理アドレスによってメモリフェッチの時間が大きく異なるという厄介な特徴を持つ。バイオインフォマティクスのソフトウェアは多くのメモリを必要とするので、そういったマシンで実行される場合が多い。その場合、各スレッドは異なる NUMA ノードに割り当てられる可能性があるので、物理 RAM の局所性を考慮しなければならない。このため khmer では、プリフェッチバッファをスレッドと同じ個数のセグメントに分割し、各スレッドに自身が担当するセグメントをアロケートさせる手法が取られた。セグメントは状態オブジェクトを通して割り当てられ、スレッド単位で管理される。
Bloom filter の並列化
Bloom filter のハッシュテーブルは khmer が消費するメインメモリの大きな部分を占め、それでいてスレッドごとに分割できない。ハッシュテーブルの単一の集合が全てのスレッドによって共有される必要がある。このため Bloom filter に対する競合が発生する。二つ以上のスレッドがメモリの同じ位置に対して同時にアクセスするのを防ぐには、メモリバリア[8] または何らかのロックの仕組みが必要になる。khmer ではハッシュテーブルに格納されるカウンターをアトミック加算命令で増加させている。こういったアトミック命令[9] は様々なプラットフォームでいくつかのコンパイラスイート (例えば GNU コンパイラ) によってサポートされ、特定のスレッディング方式やライブラリに依存しない。アトミック命令は更新されるオペランドの周りにメモリバリアを張ることで、特定の命令をスレッドセーフに実行する。
これまでに言及しなかったパフォーマンスのボトルネックとして、k-mer の数え上げが完了した後にハッシュテーブルをストレージに書き出す処理がある。書き出しにかかる時間は Bloom filter のサイズに対して定数であり、入力データの量とは独立する。そのため、この処理を高速化する必要性を私たちが強く感じていたわけではない。例えばベンチマークに利用される 5 GB のデータセットでは、k-mer の数え上げにハッシュテーブルの書き出しの五倍の時間がかかっていた。データセットが大きくなれば、この倍率はさらに大きくなる。ただ結局は、この部分も最適化の対象となった。ハッシュテーブルの書き出しを最適化するアプローチの一つとして、書き出しのコストを k-mer の数え上げに「組み入れる」手法がある。URL 短縮サイト bit.ly は dablooms[10] と呼ばれる数え上げ用 Bloom filter 実装を公開しており、dablooms はハッシュテーブルが利用するメモリに出力ファイルをマップすることで書き出しコストの「組み入れ」を行う。このアイデアを借用し、さらにハッシュテーブルのバッチ更新と組み合わせた khmer は、事実上プロセスが生きている間を通して非同期にバーストで出力処理を実行する。プロセスの終了時にハッシュテーブル全体を書き出すことはない。出力にはカウントのテーブルに加えて、いくらかのメタデータを示すヘッダーも含まれる: そのため、メモリマップはよく考えて注意深く実装する必要がある。
スケーリング
khmer をスケーラブルにするために注がれた労力にはそれだけの価値があったのだろうか? 価値はあったと私たちは考えている。完璧に線形な高速化が達成できたわけでは当然ないものの、現在の khmer ではコア数を 2 倍にすると速度が約 1.9 倍になる:
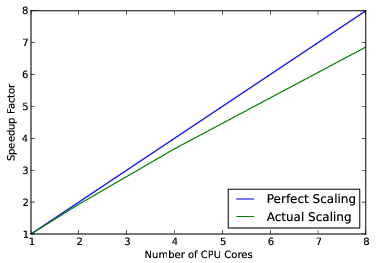
並列計算では Amdahl の法則[11] と収穫逓減の法則を意識する必要がある。Amdahl の法則は \(S(N) = \frac{1}{(1 - P) + \frac{P}{N}}\) と表される場合が多い。ここで \(S(N)\) は \(N\) 個の CPU コアが使われたときの高速化係数、\(P\) は並列化できるコードの割合をそれぞれ表す。\(\lim_{N\to\infty} S(N) = \frac{1}{(1 - P)}\) は \(P < 1\) のとき有限の定数なので、CPU コアを追加することで達成できる高速化には理論上の限界があると分かる。khmer が多用するストレージ媒体の I/O 帯域は有限であり、スケーラブルでない: そのため I/O 操作があるとき \(1 - P\) は非ゼロとなる。さらに、並列コードで共有リソースへの競合が起こるなら、\(\frac{P}{N}\) が実際には \(\frac{P}{N^l}\) (\(l < 1\), 理想的なケースでは \(l = 1\)) となる。このため、CPU コアを増やしたときの収穫逓減は上述の式が示すよりさらに速い。
ハードディスクドライブ (HDD) の代わりにソリッドステートドライブ (SSD) などの高速なストレージシステムを利用すれば I/O 帯域を増加 (\(1 - P\) を減少) させることができるものの、これはソフトウェアの範囲を超える。ハードウェアに関して私たちができることは少ないものの、\(l\) を大きくすることはおそらくできる。ハッシュテーブルのメモリといった共有リソースに対するアクセスパターン、そしてスレッド単位の状態オブジェクトの使い方には改善の余地があると私たちは考えている。この二つの部分を改善すれば、おそらく \(l\) も大きくできるだろう。
結論
khmer の目標は常に揺れ動いてきた。新しい機能が定期的に追加され、それらの機能をバイオインフォマティクスコミュニティで利用される様々なソフトウェアスタックで使えるようにするための作業を私たちは行っている。アカデミアで開発・利用されるソフトウェアでよくあるように、khmer は探索的なプログラミングの実験として誕生し、そこから研究コードにまで進化した。過去も現在も、プロジェクトの主要な目標は正確性だった。パフォーマンスとスケーラビリティを完全に後回しにすることはできないにしても、正確性と利便性に比べれば優先度は低かった。しかし、パフォーマンスとスケーラビリティに関する私たちの取り組みは、単一スレッドで実行する場合の高速化、そして複数スレッドの利用による実行時間の大幅な削減といった優れた成果を生んできた。パフォーマンスとスケーラビリティの問題に取り組む中でデータポンプとパーサーは再設計された。今後、これらのコンポーネントはスケーラビリティだけではなく管理容易性や拡張可能性に関しても恩恵を受けると予想される。
今後の方向性
今後、基本的なパフォーマンスの問題が解決された後に予定されている作業としては、プログラマーに公開される API の改良、詳細にテストされたサンプルコードとドキュメンテーションの提供、そして大規模なパイプラインに khmer を組み込むための使いやすいコンポーネントの提供がある。さらに遠い将来には、一部のケースで低メモリデータ構造の最先端理論を活用したいとも考えている。また、近い将来に直面すると予想される現在よりさらに規模の大きなデータセットに対応するための分散アルゴリズムの調査にも興味がある。
khmer 開発における他の懸念事項としては、一重らせん DNA に対して異なるハッシュ関数を使うオプションの追加、k > 32 に対応するためのローリングハッシュ関数の実装がある。
私たちは khmer の開発を続けることを楽しみにしつつ、分子生物学やバイオインフォマティクスの研究者が直面するビッグデータの問題に何らかの形で貢献できることを願っている。科学領域で用いられる高パフォーマンスなオープンソースソフトウェアを解説した本章を読者が楽しんで読んでもらえたなら幸いである。
謝辞
コメントと議論に関して Alexis Black-Pyrkosz と Rosangela Canino-Koning に感謝する。
参考文献
[1] Various, "big data." http://en.wikipedia.org/w/index.php?title=Big_data&oldid=521018481. ↩
[2] C. T. Brown et al., "khmer: genomic data filtering and partitioning software." http://github.com/ged-lab/khmer. ↩
[3] Various, "Bloom filter." http://en.wikipedia.org/w/index.php?title=Bloom_filter&oldid=520253067. ↩
[4] O. members, "OpenMP." http://openmp.org. ↩
[5] A. D. Malony et al., "TAU: Tuning and Analysis Utilities." http://www.cs.uoregon.edu/Research/tau/home.php. ↩
[6] Various, "profile-guided optimization." http://en.wikipedia.org/w/index.php?title=Profile-guided_optimization&oldid=509056192. ↩
[7] J. Seward et al., "Valgrind." http://valgrind.org/. ↩
[8] Various, "memory barrier." http://en.wikipedia.org/w/index.php?title=Memory_barrier&oldid=517642176. ↩
[9] Various, "atomic operations." http://en.wikipedia.org/w/index.php?title=Linearizability&oldid=511650567. ↩
[10] b. software developers, "dablooms: a scalable, counting Bloom filter." http://github.com/bitly/dablooms. ↩
[11] Various, "Amdahl's Law." http://en.wikipedia.org/w/index.php?title=Amdahl%27s_law&oldid=515929929. ↩
-
I/O パフォーマンスのベンチマークで利用されるデータよりキャッシュが大きい場合、ベンチマークを何度も実行するとデータが本来のソースではなくキャッシュから取得されることになり、測定結果が一貫しなくなる。データをキャッシュより大きくすればキャッシュでデータの循環が起こることが保証され、反復しないデータの連続的なストリームを処理したときのようなパフォーマンスを安定して測定できる。 ↩︎