LE-DAnCE
はじめに
分散リアルタイム組み込みシステム (distributed, real-time and embedded system, DRE システム) はエンタープライズ向け分散システムの特徴とリソース制約の厳しいリアルタイム/組み込みシステムの特徴を併せ持つ重要なアプリケーションの種別である。具体的には、DRE システムのアプリケーションは巨大な領域に分散される点でエンタープライズ向け分散システムとの共通点がある。さらに、リアルタイム/組み込みシステムのアプリケーションと同様に、DRE システムのアプリケーションはミッションクリティカルであり、安全性、信頼性、クオリティオブサービス (QoS) に関して厳しい要件を持つ。
上述の複雑性に加えて、DRE システムではアプリケーションとインフラストラクチャコンポーネントのデプロイに関しても独自の課題が存在する。まず、DRE システムのアプリケーションはデプロイ対象の環境 (GPS、センサー、アクチュエーター、リアルタイムオペレーティングシステムといった特定のハードウェア/ソフトウェアなど) に依存する場合がある。次に、デプロイ用のインフラストラクチャは有限のリソース (CPU、メモリ、ネットワーク帯域など) しか持たない環境で厳格なリソース要件を満たさなければならない。
コンポーネントベースドソフトウェアエンジニアリング[1] (Component-Based Software Engineering, CBSE) がアプリケーションをデプロイするためのパラダイムとして利用されるケースはエンタープライズシステム[2]と DRE システム[3]の両方で増加している。詳細に定義されたインターフェースを通して自身の環境および他のコンポーネントと対話するブラックボックスなコンポーネントの作成を開発者に促すことで、CBSE はシステマチックなソフトウェア再利用を容易にする。また、CBSE はアプリケーションの構成とライフサイクルを制御する標準化された仕組みを提供することで非常に複雑な分散システムのデプロイを単純化する[4]。この仕組みがあると、管理が容易な小さい単位 (例えば商用の既製品コンポーネントや既存アプリケーションの構成部品) を組み合わせて大規模で複雑なアプリケーションを構築できるようになる。そうして構築されるアプリケーションは説明用および構成用のメタデータと共にパッケージ化され、プロダクション環境へのデプロイが可能となる。
Common Object Request Broker Architecture (CORBA) 規格のオープンソース実装 The ACE ORB[5] (TAO) の開発から得られた知見を活かし、十年以上に渡って私たちは CBSE の考え方を DRE システムに応用してきた。こういった取り組みの結果として、Component Integrated ACEORB[6] (CIAO) と呼ばれる OMG CORBA Component Model (CCM) の高品質なオープンソース実装を私たちは開発した。CIAO は Lightweight CCM[7] と呼ばれる仕様を実装する。Lightweight CCM はリソースが制約される DRE システムに合わせて調整された、完全な CCM 規格の部分集合である。
CBSE の考え方を DRE システムに応用する中で、私たちは DRE システムでコンポーネントベースシステムのデプロイと構成を容易にするという同程度に困難な課題にも取り組んできた。コンポーネントベースシステムのデプロイと構成の管理は、次の理由により難易度の高い問題となる:
- コンポーネント間の依存関係とバージョンの管理: 個別のコンポーネントの間に複雑な要件や関係が存在する可能性がある。例えば「他のコンポーネントが必要」「特定のバージョンが必要」「特定のバージョンは使えない」といった関係が考えられる。こういった関係が記述・解決されなければ、アプリケーションはデプロイできない。それどころか、気が付きにくい形で非常に有害な誤動作を起こす可能性さえある。
- コンポーネントの構成情報の管理: 振る舞いを変更するための構成フックがコンポーネントによって公開され、デプロイ用インフラストラクチャが必要な構成情報を管理・設定しなければならない場合がある。さらに、複数のコンポーネントが関連し合う構成プロパティを持ち、それらのプロパティをデプロイ用インフラストラクチャがアプリケーション全体で一貫した値に保つ必要があるケースも存在する。
- 分散された接続とライフサイクルの管理: エンタープライズシステムでは、コンポーネントをリモートホストにインストールでき、接続とアクティベーションをリモートホストで管理できる必要がある。
こういった問題を解決するため、CIAO 用のデプロイエンジンの開発が 2005 年に開始された。このツールは Deployment and Configuration Engine[8] (DAnCE) と呼ばれ、OMG Deployment and Configuration[9] (D&C) 仕様を実装する。その歴史のほとんどを通して、DAnCE は修士学生がデプロイと構成の新しいアプローチを研究するときの土台として使われた。この事実は次の二つの点で実装に大きな影響を与えた:
- DAnCE は研究用の土台であるために、その開発タイムラインは主に論文の締め切りとスポンサーへの機能デモンストレーションによって決められた。その結果、テストされた DAnCE のユースケースは比較的単純で、対象領域も狭い。
- 一つの研究プロジェクトが終了して新しいプロジェクトが開始されるときに DAnCE の管理者が変更されたことが何度かあった。その結果、インフラストラクチャ全体に関する統一されたアーキテクチャ的展望は存在しないことが多かった。
この二つの事実は DAnCE にいくつかの影響をもたらした。例えば、狭いユースケースに焦点を絞っているために、実際のアプリケーションにおけるエンドツーエンドパフォーマンスの優先順位は低くなった。さらに、統一されたアーキテクチャ的展望が存在しない上に短い締め切りに追われるので、その場しのぎに下された拙速な判断が後から修正されないことがよくあった。商業スポンサーと協力して DAnCE を大規模な (数百から数千のコンポーネントと数万のハードウェアノードが関係する) デプロイに向けた作業を開始したとき、こういった問題は深刻になった。小規模で領域の狭いアプリケーションなら問題なくデプロイできても、大規模なデプロイには数時間単位の長い時間がかかっていた。
こういった問題に対処するため、私たちは DAnCE のアーキテクチャ・設計・実装を詳細に評価し、Locality-Enabled DAnCE[26] (LE-DAnCE) と呼ばれる新しい実装を作成した。本章では、LE-DAnCE を優れた DRE システムとする上でその中心部に適用された最適化パターンを解説する。表 6.1 に一般的なプログラムの最適化パターン[10]を示す。この多くは LE-DAnCE にも適用された。LE-DAnCE の開発中に特定された新しいパターンを紹介することも本章の目的である。
| 名前 | 考え方 | ネットワーキングにおける例 |
|---|---|---|
| 無駄を省く | 明らかな無駄使いを避ける | ゼロコピー[11] |
| 時間方向へのシフト | 計算を時間的に別の場所に移す (事前計算、遅延評価、費用の共有、バッチ処理) | コピーオンライト[12][13], integrated layer processing[13] |
| 仕様の緩和 | 仕様の要件を緩和する (パフォーマンスのために確実性・正確性を犠牲にして、計算を時間的に別の場所に移す) | 公平キューイング[14], IPv6 のフラグメンテーション |
| 他のコンポーネントの利用 | システム内の他のコンポーネントを利用する (局所性の活用、予算を犠牲にした速度の向上、ハードウェアの活用) | Luleå のアルゴリズム[15]による IP ルックアップ, TCP チェックサム |
| ハードウェアの追加 | ハードウェアを追加してパフォーマンスを向上させる | IP ルックアップのパイプライン化[16], カウンター |
| ルーチンの効率化 | 効率的なルーチンを作成する | UDP ルックアップ |
| 一般化の回避 | 不必要な一般化を避ける | Fbufs[17] |
| 仕様 vs 実装 | 仕様と実装を混同しない | upcall[18] |
| ヒントの提供 | インターフェースでヒントとなる情報を渡す | packet filter[19][20][21] |
| 情報の提供 | プロトコルヘッダーで情報を渡す | tag switching[22] |
| 典型的なケースの効率化 | 最も期待されるユースケースを効率化する | ヘッダーの予測[23] |
| 状態の活用 | 高速化のために状態を活用・追加する | アクティブ VC リスト |
| 自由度の活用 | 自由度を活用してパフォーマンスを得る | トライによる IP ルックアップ[24] |
| 宇宙の有限性の活用 | 宇宙が有限である事実を活用した特別な手法を使う | timing wheels[25] |
| データ構造の効率化 | 効率的なデータ構造を使う | レベル 4 スイッチ |
本章の残りの部分は次のように構成される: DAnCE の概観では、DAnCE が実装する OMG D&C 仕様を簡単に説明する。DAnCE に対する最適化パターンの適用では、DAnCE が抱えていたパフォーマンスに関する問題の最も大きな原因 (XML で書かれたデプロイ情報のパース、デプロイ情報の実行時解析、デプロイステップの逐次実行) を説明し、それをケーススタディとして使いながら LE-DAnCE に適用された最適化の考え方を一般的な DRE システムにも適用できる形で示す。結論では最後のまとめを述べる。
DAnCE の概観
OMG D&C 仕様はコンポーネントベースアプリケーションが開発ライフサイクル中に用いるメタデータの標準交換フォーマット、そしてパッケージ化とプラニングで利用されるランタイムインターフェースを提供する。このランタイムインターフェースはデプロイ用インフラストラクチャを担うミドルウェアに対するデプロイ命令の送出で利用される。デプロイ命令の送出はコンポーネントデプロイプラン (component deployment plan) を使って行われ、コンポーネントインスタンスのデプロイ・構成に関する情報や関連する接続情報がそこで全て受け渡される。この情報を DRE システムは初期化時にパースし、コンポーネントを物理ハードウェアにデプロイし、適切なタイミングでシステムを有効化しなければならない。
本項では規格準拠な D&C 実装が提供しなければならない中心的なアーキテクチャ的要素と処理を簡単に説明する。この説明を基礎として、DAnCE が抱えていたパフォーマンスとスケーラビリティに関する重大な問題を次に議論する。はじめにで見たように、DAnCE は OMG Deployment and Configuration[9] (D&C) のオープンソース実装である。本節は次のように構成される。まず DAnCE ランタイムのアーキテクチャで DAnCE が持つデーモンとアクターを解説し、次に D&C のデプロイデータモデルでコンポーネントベースアプリケーションを記述する「デプロイプラン」の構造を詳しく見る。最後に D&C のデプロイプロセスで分散アプリケーションを実際にデプロイする処理の高レベルな概観を説明する。
D&C のランタイムアーキテクチャ
図 6.2 に示すように、OMG D&C 仕様が定義するコンポーネントのデプロイと構成に関するランタイムアーキテクチャは二つの層から構成される。
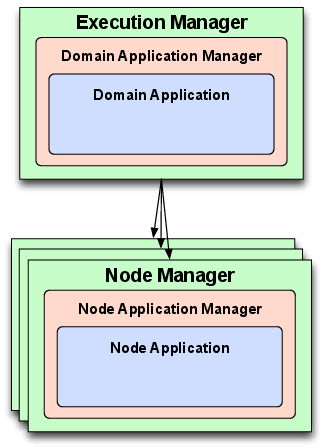
このアーキテクチャはデプロイを管理するグローバルな (システム全体で一つだけの) エンティティの集合と、コンポーネントのインスタンス化とコンポーネントの接続・QoS プロパティの構成に利用されるローカルな (ノードレベルの) エンティティから構成される。これらのグローバルな層とローカルな層に含まれるそれぞれのエンティティは次に示す三つの主要な役割のいずれかを持つ:
- Manager
- この役割はグローバル層では ExecutionManager と呼ばれ、ローカル層では NodeManager と呼ばれる。Manager は単一のコンテキスト内でデプロイに関わる全てのエンティティを管理するシングルトンデーモンを指す。Manager は全てのデプロイにおけるエントリーポイント、そして ApplicationManager の実装をインスタンス化するファクトリとして機能する。
- ApplicationManager
- この役割はグローバル層では DomainApplicationManager と呼ばれ、ローカル層では NodeApplicationManager と呼ばれる。ApplicationManager はコンポーネントベースアプリケーションの実行中にインスタンスのライフサイクルを管理する。それぞれの ApplicationManager は必ず一つのコンポーネントベースアプリケーションに対応し、そのアプリケーションのデプロイとティアダウンを起動するときに利用される。ApplicationManager は Application の実装をインスタンス化するファクトリとしても機能する。
- Application
- この役割はグローバル層では DomainApplication と呼ばれ、ローカル層では NodeApplication と呼ばれる。Application はコンポーネントベースアプリケーションのデプロイされたインスタンスを表す。アプリケーションに含まれる関連コンポーネントのインスタンスを構成し、デプロイされたコンポーネントベースアプリケーションの実行を開始するために Application は利用される。
D&C のデプロイデータモデル
上述したランタイムエンティティに加えて、D&C 仕様にはデプロイライフサイクルを通してコンポーネントベースアプリケーションの構成を一貫した形で記述するための詳細なデータモデルが含まれる。この仕様が定義するメタデータは次の用途での利用が意図されている:
- アプリケーションの作成で利用される様々なツール (アプリケーションのモデリング、パッケージ化、デプロイプラニング用のツールや開発ツールなど) 間の交換フォーマット
- ランタイムインフラストラクチャが利用する、デプロイと構成に関する情報が記述されたディレクティブ
D&C メタデータ内のエンティティの多くには、名前と値の組が並んだ列の形式で構成情報のセクションを含めることができる。ここで「値」には任意のデータ型が利用できるので、基本的な構成情報 (共有ライブラリのエントリーポイントやコンポーネントとコンテナ間の関係など) だけではなく複雑な構成情報 (QoS プロパティやユーザー定義のデータ型を使ったコンポーネント属性の初期値) もメタデータ内に記述できる。
このメタデータは packaging, domain, deployment という三つのカテゴリへと大まかに分類できる。packaging メタデータはコンポーネントのインターフェース・機能・要件を記述するためにアプリケーション開発の開始時から利用される。実装が作成された後も、このメタデータは個別のコンポーネントを一つにまとめるとき、共有ライブラリ (動的リンクライブラリ) といった実装の生成物との関係を記述するとき、そしてターゲットの環境にインストールされるパッケージ (メタデータと実装の両方が含まれる) を作成するときに利用される。domain メタデータは管理者がハードウェアの機能 (CPU、メモリ、ディスク空間、GPS 受信器といった特殊ハードウェアの有無など) を記述するときに利用される。
D&G のデプロイプロセス
コンポーネントベースアプリケーションのデプロイは四つのフェーズを通じて実行される。これらのフェーズの名前は OMG D&C 仕様が定めている。次に示すように、Manager と ApplicationManager は最初の二つのフェーズに、Application は最後の二つのフェーズに関係する:
- プランの準備: このフェーズでは、まずデプロイプランが ExecutionManager に提供される。その後 ExecutionManager はプランを解析してデプロイに参加するノードを計算し、全体のプランから「局所性が制約された」プランを各ノードに一つずつ作成する。この局所性が制約されたプランには単一のノードに関係する情報だけが含まれる。その後 ExecutionManager はデプロイに参加する各ノードの NodeManager と接続し、そのノードに対応するプランを送信する。自分用のプランを受け取った NodeManager は NodeApplicationManager を作成し、それに対する参照を ExecutionManager に送り返す。最後に、ExecutionManager は送り返されてきた参照を全て使って DomainApplicationManager を作成する。
- ローンチの開始: ローンチ開始の指示を受けた DomainApplicationManager は、その仕事を各ノード上の NodeApplicationManager に委譲する。その後 NodeApplicationManager は NodeApplication を作成し、必要な全てのコンポーネントのインスタンスをメモリに読み込み、準備的な構成処理を行い、デプロイプランに記述される全てのエンドポイントに対する参照を収集する。この参照は DomainApplicationManager が作成する DomainApplication インスタンスによってキャッシュされる。
- ローンチの終了: このフェーズは DomainApplication インスタンスが一つ前のフェーズで収集したオブジェクト参照を NodeApplication のそれぞれに分け与えることで開始される。コンポーネントのインスタンスが最終的な構成情報を受け取り、それを使って全ての接続が作成される。
- スタート: このフェーズも DomainApplication によって開始される。DomainApplication は NodeApplication のそれぞれに、インストールされたコンポーネントの実行を始めるよう指示を出す。
DAnCE に対する最適化パターンの適用
本節では、大規模なプロダクション DRE システムにおけるコンポーネントベースアプリケーションで DAnCE を使用する上で生じた最も深刻なパフォーマンスの問題を詳しく見る。まず、多くのパフォーマンスの問題に直面したケーススタディを紹介する。その後パフォーマンス低下の原因を説明し、その議論を通じて他の状況およびアプリケーションで生じるパフォーマンスの問題にも適用できる最適化のガイドラインを述べる。
SEAMONSTER プラットフォームの概観
DAnCE を利用したとき重大なパフォーマンスの問題が発生した DRE システムの例として、アラスカ大学との共同研究で扱った South East Alaska Monitoring Network for Science, Telecommunications, Education, and Research (SEAMONSTER) プラットフォームがある。SEAMONSTER は氷河と河川を観測するセンサーウェブであり、アラスカ大学サウスイースト校でホストされる。このセンサーウェブは氷河のダイナミクスと質量バランス、河川流域の変化、レモンクリーク流域とレモン氷河に人間が及ぼす影響やハザードに関する情報を監視・収集する。収集されたデータは氷河の速度、氷河湖の形成、河川流域の変化、温度の変動の間にある関係を研究するために利用される。
センサーウェブ SEAMONSTER は氷河と河川に配置された耐候性コンピュータープラットフォームとセンサーを持ち、そこから科学研究用のデータを収集する。センサーが収集したデータは無線ネットワークを通じてサーバークラスターに送信され、そこでフィルタ・関連付け・解析が行われる。データ収集アプリケーションを SEAMONSTER の現場ハードウェアへ効率的にデプロイし、環境条件とリソース制約の動的な変化に適応することは、SEAMONSTER の効率的な運用における大きなソフトウェア的課題となる。SEAMONSTER サーバーは潤沢な計算リソースを持つのに対して、現場ハードウェアの計算リソースは制限される。
センサーウェブの現場ノードが測定できる現象は自身の管轄する領域内で大量に発生する。そういった現象の種別、持続時間、頻度は一定でない: 時間が経過して環境が変化したり、環境内で一時的な事象が発生したり、センサーウェブが担う科学ミッションの目標や目的が変化したりする可能性がある。さらに、ノードが利用可能な電力、処理性能、ストレージ、ネットワーク帯域はどれも制限され、そんな中でもノードは望ましい頻度で望ましい精度を持った測定を続ける必要がある。環境条件の動的な変更と利用可能なリソースの制限があるために、センサーウェブに含まれる個々のノードは自身のリソースを最大限活用するために現在および将来の運用プランを素早く変更できる必要がある。
こういった問題を解決するため、私たちはデータの収集と解析を CIAO と DAnCE ベースのミドルウェアプラットフォームに移行することを提案し、ランタイムプラナー[29]を開発した (CIAO と DAnCE ははじめにとDAnCE の概観で説明した)。このランタイムプラナーはセンサーノードによる物理的測定を解析し、その情報 ── そしてネットワークの運用目標 ── に基づいて望ましいソフトウェア構成を記述したデプロイプランを生成する。
しかし、実際に DAnCE を使ってランタイムプラナーが要求するデプロイの変更を適用してみると、パフォーマンスの問題が多く明らかになった。この問題は現場ハードウェアのパフォーマンスが低いこと、ノード間を結ぶネットワークが遅いこと、そしてシステムが厳しいリアルタイム要件を持つことによって悪化した。DAnCE を利用したときに明らかとなった問題をこれから見ていく。
デプロイプランのパースの最適化
OMG D&C におけるコンポーネントベースアプリケーションのデプロイは、コンポーネントのインスタンスに関連する全ての構成メタデータと必要な接続情報が含まれるデータ構造によって記述される。このデータ構造はディスク上の XML ファイルにシリアライズされ、その XML ファイルの構造は D&C が定義する XML スキーマによって記述される。この XML スキーマはモデリングツール間でデプロイプランを交換する時に利用できる単純な交換フォーマットを提供する[30]。
例えば SEAMONSTER のケーススタディにおいて、この XML スキーマはプランを作成するフロントエンドとデプロイを行うインフラストラクチャの間で情報を交換するための簡便なフォーマットを提供した。このフォーマットの生成・操作は有名なプログラミング言語で広く利用可能な XML モジュールで行える。さらに、単純な変更やデータマイニングであれば perl, grep, sed, awk といったテキスト処理ツールでも行える。
問題
デプロイプランを記した XML ファイルはデプロイ時あるいは実行時に読み込まれる。しかし、この読み込み処理によってパフォーマンスが大きく低下するケースがある。原因としては次の二つがある:
- デプロイに関係するインスタンスと接続の個数が増えると、デプロイプランを記した XML ファイルが非常に大きくなる。XML ファイルをメモリに読み込むときの I/O と、スキーマに準拠しているかどうかを検証する処理がオーバーヘッドとなる。
- デプロイ用のインフラストラクチャは OMG Interface Definition Language (IDL) と呼ばれるフォーマットを利用する CORBA アプリケーションなので、最初に XML を IDL に変換しなければならない。
DRE システムでは数千個のコンポーネントがデプロイされることも珍しくない。さらに、コンポーネント同士が密に接続することもよくある。この二つの要因により、プランは巨大化する。しかし、システムに大きな影響を与えない形でプランを小さくできるケースはある。上述した SEAMONSTER のケーススタディにおいてプランは大きくなかったものの、計算リソースが非常に制限されるために小さいプランの処理にさえ時間がかかる状況だった。
デプロイプランのパースに対する最適化パターンの適用
XML で記述されるデプロイプランのパースに関する前項で説明した問題を解決するために行ったことが二つある。
1. XML から IDL への変換の最適化
DAnCE は XML Schema Compiler[31] (XSC) と呼ばれる語彙固有の XML データバインディングツールを利用する。XSC は D&C の XML スキーマを読み込み、Document Object Model (DOM) 形式の API で XML を操作するための C++ 実装を生成する。DOM API を使うときは処理を始める前にドキュメント全体を木構造の表現に変換する必要があるので、時間と空間の両方が多く消費される。デプロイプランを表すデータ構造は内部相互参照を多く含むので、イベントベースの Simple API for XML (SAX) といった DOM 以外のパース方式を使ったとしても状況は改善しない。
XSC が生成する C++ データバインディングには XML スキーマの内容に対応する多くのクラスが含まれ、それらによって XML ドキュメントに含まれるデータに対する強く型付けられたオブジェクト指向のアクセスが提供される。さらに、このインターフェースでは C++ STL の機能が活用されるので、効率的かつコンパクトにデータを扱うコードを簡単に書くことができる。XSC が生成するコードは最初に XML ドキュメントを DOM XML パーサーでパースし、その後 DOM ツリーをパースして生成されたクラス階層を生成することで動作する。STL が提供するアルゴリズムおよびファンクタとの互換性を向上させるため、XSC は内部で STL のコンテナクラスにデータを格納する。
初期バージョンの XSC が生成するコードは非常にパフォーマンスが悪かった。数百から数千のコンポーネントしか存在しない比較的小規模なデプロイでさえ三十分近くの時間がかかっていた。Rational Quantify といったツールで実行を解析すると、非常に簡単な問題が明らかになった: XSC が生成するコードは内部のデータ構造 (std::vector) に要素を一つずつ挿入していた。この結果、新しい要素を挿入するときに発生するリアロケートとデータのコピーに法外な時間がかかっていた。
開発者が意識すべき考え方を次に示す:
- 抽象化のコストに注意する: C++ STL のコンテナクラスのような高レベル抽象化があればエラーが発生しやすい複雑な (多くが似た形をした) 低レベルコードを何度も書く必要がなくなるので、プログラムは大きく単純化される。抽象化を書くときはドキュメントを書き、抽象化を使うときは高レベルな操作に隠れたコストを理解することが重要である。
- 用途に合った適切な抽象化を使う: 似た機能を提供する抽象化が複数存在する場合も多い。例えば
std::vectorとstd::listが提供する機能は似ている。しかし、それぞれの選択肢には利点と欠点がある。XSC では子ノードに対するランダムアクセスが望まれたためにstd::vectorが使われていたものの、要素の挿入が遅いためにパースのパフォーマンスが非常に低かった。しかし私たちの用途では逐次アクセスしか必要にならないので、挿入が高速なstd::listの方がずっと優れている。
私たちは XML スキーマを XSC に入力して生成されるコードの用途 (ほとんどのノードに対して順番通りに一度だけアクセスする) を理解することで、「典型的なケースの効率化」の最適化パターンを適用できた。このとき他の最適化パターンも使われている: 効率的なランダムアクセスが可能なコンテナ std::vector を使わないことで「一般化の回避」のパターンが、一般性を持たない効率的なデータ構造を使うことで「効率的なデータ構造を使う」のパターンが適用されていると言える。
2. XML ファイルの前処理
XML から IDL への変換にかかる時間は上述の最適化によって削減されたものの、このステップにかかる時間は依然としてデプロイプロセス全体にかかる時間の大きな部分を占めていた。このオーバーヘッドは、異なる最適化パターンを適用することで回避できた:
- 可能なら、時間のかかる計算をクリティカルパスの外で実行する: 多くのケースで、時間のかかる手続きや計算は事前に実行して保存しておいた結果を取得する処理に置き換えられる。これは XML で表現されたデプロイプランのような生成されてから必要となるまで変更されないファイルに対する処理で特に当てはまる。
このアプローチは最適化パターン「時間方向へのシフト」の適用例と言える: XML で表現されたデプロイプランを効率的なバイナリフォーマットに変換する時間のかかる処理がアプリケーションデプロイのクリティカルパスの外に移動されている。このパターンを適用する上で、私たちはデプロイプランをまず実行時に必要な IDL 表現に変換し、さらにそれを CORBA 仕様が定める Common Data Representation[32] (CDR) というバイナリフォーマットに変換するようにした。SEAMONSTER のオンラインプラナーが XML ベースのデプロイプランの代わりにバイナリ化されたデプロイプランを利用すれば、レイテンシを大きく削減できる。
デプロイプランをディスク上に保存するときに使われるプラットフォーム依存のバイナリフォーマット CDR は、実行時にネットワークを通じてデプロイプランを送信するときにも利用される。このアプローチの利点として、内部の CORBA 実装が提供する高度に最適化されたデシリアライズハンドラを利用できることがある。このハンドラはディスク上のバイナリストリームからデプロイプランを表すデータ構造のメモリ上表現を素早く構築する。
デプロイプラン解析の最適化
コンテキスト
コンポーネントのデプロイプランがメモリ上表現として読み込まれた後、実際のデプロイ処理が始まる前にデプロイ用インフラストラクチャのミドルウェアによる解析が行われる。この解析は D&G のデプロイプロセスで説明した「プランの準備」フェーズで行われる。この解析では、デプロイプランに含まれる独立したデプロイと、独立したデプロイのそれぞれに属するコンポーネントが計算される。
D&G のデプロイプロセスで言及したように、この解析の出力は「局所性が制約された」小プランの集合である。それぞれの小プランはデプロイを正しく実行するために必要なメタデータを全て持つ。そのため、小プランにはオリジナルのデプロイプランが持つ情報 (参考: D&C のデプロイデータモデル) のコピーが含まれる。
実行時のデプロイプラン解析は「プランの準備」フェーズ中に二回に分けて行われる: 最初にグローバルなレベルで一度行われ、その後に各ノードでもう一度行われる。グローバルな解析でデプロイプランはコンポーネントのインスタンスが割り当てられるノードに応じて分割される。解析を二段階に分けることで、各ノードはインスタンスや接続情報をはじめとしたメタデータを自身が必要とする分だけ受け取るようになる。
私たちの D&C 仕様の実装 DAnCE がプランの分割で利用するアルゴリズムは単純だった: プランでデプロイが指定される各コンポーネントに対して、どの小プランに含まれるかを判定し、その小プランに対応する適切なデータ構造を取得 (もしくは新しく作成) する。この関係が全て計算されると、コンポーネントのインスタンスが必要とする全てのメタデータ (接続、実行形式のメタデータ、依存する共有ライブラリなど) が小プランを表すデータ構造にコピーされる。
問題
このアプローチの考え方は単純であるものの、偶有的な複雑性を多くはらんでおり、実際の処理は効率的でなかった:
- IDL における参照の表現: デプロイプランは通常ネットワーク越しに転送されるので、CORBA IDL 言語が定めるマッピング規則に従う必要がある。IDL は参照やポインタといった概念を持たないため、プランの要素間の関係を記述するには別の仕組みが必要となる。デプロイプランは主要な要素を配列として格納するので、他の要素への参照はその配列に対する添え字として簡単に表現できる。この実装には定数時間で参照を取得できる利点があるものの、プランの要素が小プランにコピーされると参照が無効になる欠点がある。元々のデプロイプランにおける位置は小プランにおける位置と意味が異なるためである。また、特定の参照が指す要素が既に小プランへコピーされたかどうかを判定するには小プランを検索するしかないので、この処理には時間がかかる。
- 配列を構築するときのメモリアロケート: CORBA IDL のマッピングは配列の要素が連続するメモリアドレスに格納されることを要求する。そのため、配列のサイズが変更されるとき、多くの場合で全ての要素をメモリ上の他の場所にコピーしなければならない。上述したアプローチでは、このコピーのオーバーヘッドはデプロイプランのサイズが大きくなるにつれて非常に大きくなる。これはリソースが制限されるシステム (私たちが行った SEAMONSTER のケーススタディなど) で特に問題となる: そういったシステムでは、実行時のメモリをアプリケーションのコンポーネント用に取っておかなければならない。デプロイ用インフラストラクチャが非効率的でリソースを無駄使いすると、利用可能なメモリが足りなくなって大量のスラッシングが発生する (デプロイのレイテンシとフラッシュストレージの寿命に影響する)。
- 効率的に並列化不能なプラン解析: 上述したアルゴリズムにおいて単一のコンポーネントを解析して小プランにコピーすべき要素を判定する処理はコンポーネントごとに独立するので、並列化で大きく高速化できそうに思える。しかし、このアルゴリズムをマルチスレッド化したとしても、インスタンスのメタデータをコピーするときデータ破損を防ぐために小プランへのアクセスを逐次化しなければならないので、効率的にならない。多くの場合でデプロイプランはモデリングツールから生成され、デプロイプランに含まれるコンポーネントのインスタンスはノードやプロセスごとにグループ化される。その結果、複数のスレッドが同じ小プランに対するロックを求め、「並列」アルゴリズムがほぼ逐次的に実行される。リソースが制限される DRE システム (例えば SEAMONSTER) で並列化は使えないとされてきたものの、最近ではシングルボードコンピューターでもマルチコアプロセッサが利用可能になってきており、そういった環境では並列化が選択肢に入る。
デプロイプランの解析に対する最適化パターンの適用
このパフォーマンスの課題は「仕様 vs 実装」の最適化パターンと、上述した XSC ツールのケースと同じ最適化の考え方「抽象化のコストに注意する」と「用途に合った適切な抽象化を使う」で解決できる。例えば、異なる要素を参照するときに配列に対する添え字ではなくポインタを使えば、要素をコピーするときに参照を書き換える必要はなくなる。同様に、配列ではなく連想コンテナ (std::map など) を使えば要素の挿入を高速化できる可能性がある。
こういった最適化の選択肢は誘惑的であるものの、その魅力は D&C 規格の要件が持つ本質的な複雑性によって低減される。小プランはデプロイプロセス中に各ノードへ転送しなければならないので、解析用の効率的な表現を使うとデプロイプロセスで変換がさらに必要となる。この変換は新しい表現がもたらす効率向上を打ち消すだろう。
次に示す異なる最適化の考え方を使うと、より魅力的な結果が得られる:
- 以前に計算された結果を使い回す: これは「時間方向へのシフト」と「状態の活用」のパターンの適用例と言える。単純な解析ステップは後で行うより事前に行った方が高速な場合がある。今考えているケースでは、プランを最初に走査して最終的な小プランのサイズを計算しておけば、その情報を後で活用できる。
- 可能な場合はデータ構造を事前にアロケートする: 上述の事前解析から得られた状態を利用すれば「無駄を省く」のパターンを適用できる。例えば、配列全体を事前にアロケートしておけば、新しい要素が見つかるたびにリアロケートする必要はない。
-
並列化できるようにアルゴリズムを設計する: これは「ハードウェアの追加」のパターンだと思うかもしれないが、ワードサイズやキャッシュの振る舞いといったハードウェアの本質的な特徴を活用している側面が大きい。さらに、特定の計算のために特定用途のハードウェアを追加している側面もある。
複数の汎用プロセッサを活用することは近年重要性が増している考え方である。マルチコアの CPU はデスクトップとサーバーで当たり前になり、最近では組み込み領域でも普通になっている。そのため、この重要なハードウェア機能を活用する設計の重要性も増している。そこで、並列化を意識してアルゴリズムやインターフェースを設計する「並列化を念頭に置いた設計」という新たな最適化パターンを私たちは提案する。
-
同期が必要ないように共有データに対するアクセスを調整する: 同期 (ミューテックスを使って共有データに対するアクセスを保護すること) は面倒であり、エラーも発生しやすい。さらに、同期を使いすぎた結果アルゴリズムを並列化する意味が完全になくなるケースもよくある。同期を削除できるようにアルゴリズムを設計する方が格段に好ましいアプローチとなる: 共有データに対する書き込みアクセスを共有するよりも、読み込みアクセスだけを共有する方が望ましい。
この最適化の考え方は上述した「並列化を念頭に置いた設計」のパターンと対になるだけではなく、一般的なプログラミングのプラクティスでもある。誤った同期によるデッドロックや競合状態は影響が大きく、バグの診断が難しい。実際、私たちが最近取り組んだ分散型衛星 (fractionated spacecraft) 用のソフトウェアフレームワーク[33]では、アプリケーションコードから同期処理が完全に取り除かれるコンポーネントモデルを提案した。そこで、私たちは新しい最適化パターン「同期の回避」を提案する。同期とロックの過度な使用は避けるべきである。
こういった考え方を上述のアルゴリズムに適用すると、最適化が格段に容易なアルゴリズムを作成できる。新しいアルゴリズム (そして使われている最適化パターン) を次に示す:
- 生成される小プランの個数を計算する: このフェーズでは、一つのスレッドがデプロイプランに含まれるコンポーネントインスタンスを走査し、必要な小プランの個数を計算する。この計算はグローバル層で実行でき、インスタンスごとに定数時間しかかからない。仮にローカル層で実行するとしたら、局所性の制約 (D&C のデプロイデータモデルで説明した) をまず計算しなければならない。このフェーズは場合によっては長い時間がかかる可能性があり、結果はキャッシュされるので、「時間方向へのシフト」と「状態の活用」のパターンが使われていると言える。
- 小プラン用のデータ構造を事前にアロケートする: 一つ目のフェーズから得られた情報を利用して、小プランを組み立てるのに必要なデータ構造を事前にアロケートする。このとき、小プランが持つ配列も事前にアロケートしておけばサイズの変更とコピーを避けられる。配列の長さは一つ目のフェーズで得られた統計情報から効率的に計算できる。これは「無駄を省く」のパターンを適用した例である。
- ノード固有の小プランを組み立てる: このフェーズは本節の最初で説明したものに似た新しい解析処理である。主な違いは事前に行った解析の結果がキャッシュされ、小プランの作成で利用されることにある。そのため、オリジナルの DAnCE のようにインスタンスを一つずつ走査して複数の小プランを少しずつ組み立てるのではなく、LE-DAnCE はノードごとに関連するインスタンスを処理して完全な小プランを一つずつ組み立てる。このアプローチは簡単に並列化できる: 小プランごとに一つのスレッドを割り当てれば、オリジナルのプランに対する読み込み専用アクセスを共有するだけで済むので、小プランに対するアクセスを保護するためのロックは必要にならない。ここで適用されたのは「並列化を念頭に置いた設計」と「同期の回避」のパターンである。
この改善されたアルゴリズムは以前のものより大幅に効率的なプラン解析の実装であり、SEAMONSTER で使われることが多い単一コアの組み込みプロセッサでさえパフォーマンスが向上した。これは新しいアルゴリズムがメモリ効率に優れるためである: メモリ使用量が小さく、配列のサイズ変更も少ない。マルチコアの組み込みプロセッサを用いれば、元々のアルゴリズムと比べてパフォーマンスは大きく向上する。
デプロイタスクの逐次実行に対する最適化
コンテキスト
これから説明される複雑性にはデプロイタスクの逐次 (非並列) 実行が関連する。DAnCE におけるレイテンシの原因はグローバル層とローカル層の両方に存在する。グローバル層の並列性の欠如は、DAnCE が利用する CORBA トランスポートが原因で生じる。一方で、ローカル層の並列性の欠如は、ターゲットコンポーネントモデルとのやり取りで使われるインターフェース (D&C 仕様が定めるインターフェース) のカスタマイズ性の低さが原因で生じる。
D&G のデプロイプロセスで説明したように、D&C のデプロイプロセスではグローバルなエンティティがデプロイプロセスをノード固有のサブタスクに分割する。各サブタスクは単一の遠隔呼び出しを使って対応するノードにディスパッチされ、その後ノードによって生成されたデータがグローバルなエンティティに送り返される。この送り返されるデータは IDL で記述されるオペレーションシグネチャの「out」パラメータに対応する。DAnCE の実装で利用される CORBA メッセージングプロトコルの同期的な性質 (リクエスト/レスポンス方式) により、通常のアプローチだとサブタスクは逐次的にディスパッチされる。このアプローチは実装が簡単という利点がある。対照的に、CORBA asynchronous method invocation[34] (AMI) の仕組みを用いると実装が複雑になる。
問題
最初の DAnCE 実装では複雑性を最小化するために、同期的なディスパッチが採用された (近視眼的な判断だったことは否定できない)。このグローバルな同期性はコンポーネントが 100 個程度の比較的小さなデプロイでは問題なかったものの、ノードに割り当てるインスタンスとノードの個数が増えると、グローバルおよびローカルの逐次性が原因でデプロイのレイテンシが非常に大きく増加した。
デプロイプロセスの逐次実行は SEAMONSTER のケーススタディで最も重大なパフォーマンス低下を引き起こした。現場ハードウェアの計算リソースが限られるので、デプロイの完了に数分の時間がかかることも珍しくない。そういったレイテンシが各ノードで発生するので、全体のレイテンシはひどいものだった。具体的には、数十ノードに対する比較的小規模なデプロイであってもデプロイのレイテンシが 30 分以上に及んでいた。
一方で、逐次化の問題はグローバルノードからローカルノードに対するタスクディスパッチだけが持っていたわけではない: インフラストラクチャのノード固有な部分にも逐次性は存在した。D&C 仕様は NodeApplication が CORBA Component Model (CCM) などのターゲットコンポーネントモデルとやり取りするときのインターフェースを定めず、実装詳細として未規定としている。
図 6.3 に示すように、DAnCE では D&C アーキテクチャが三つのプロセスで実装される。
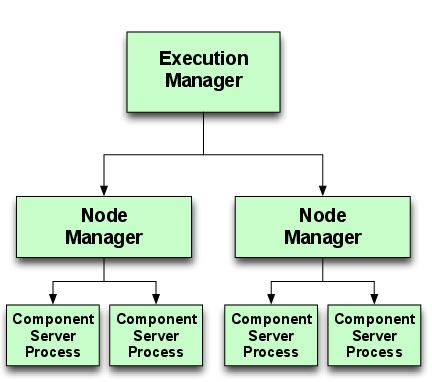
ExecutionManager と NodeManager のプロセスは自身が担当する ApplicationManager と Application を自身のアドレス空間でインスタンス化する。また、NodeApplication は具象コンポーネントインスタンスをインストールするとき必要に応じて一つ以上のプロセスをスポーンする。これらのアプリケーションプロセスは古いバージョンの CCM 仕様を継承したインターフェースを利用する。このインターフェースがあるために、NodeApplication はコンテナとコンポーネントインスタンスを個別にインスタンス化できる。このアプローチは航空交通管制システムなどのエンタープライズ DRE システムで採用されている CARDAMOM[35] (オープンソースの CCM 実装) が使っているものと同様である。
図 6.3 に示す DAnCE のアーキテクチャには、インスタンスのインストール・構成・接続に必要な全てのロジックが (図 6.4 のように) NodeApplication の実装に統合されるという問題があった:

NodeApplication の実装は一部の処理だけを行って、本筋のデプロイロジックはアプリケーションプロセスに任せるのが望ましい。全てのロジックがこうして密接に統合されていたために、次の理由でノード層で行われるインストール作業の並列化が難しかった:
- 汎用のデプロイロジック (NodeApplication の実装がプランを解釈する部分) によって多くのデータが利用され、そのデータを固有のデプロイロジック (特定のコンポーネントを操作する部分) が変更する。
- 異なるアプリケーションプロセスにインストールされる同じコンポーネントの集合が個別のデプロイサブタスクとなり、それぞれ逐次的に実行される。
逐次的フェーズを削減する最適化パターン
以前と同じように、この問題では逐次化がパフォーマンスを害している。しかし今回のケースでは、デプロイプロセスのアルゴリズム的なアプローチではなく、システムのアーキテクチャ的な設計に見直しが必要になった。DAnCE には次に示す最適化の考え方が適用された:
- 仕様に設計を過度に制約させない: システムフレームワークやソフトウェアフレームワークを仕様に沿って実装するときは、仕様だけを考えて、仕様の暗黙な仮定さえ見逃さないように設計を行うのが自然である。しかし、仕様に従いながらも実装や振る舞いを変えられる場合はよくある。これは「仕様 vs 実装」と「自由度の活用」のパターンと言える。
-
関心の分離を徹底的に行う: システムがレイヤーあるいはモジュールから構成され、それらが詳細に定義されたインターフェースを通して対話することを徹底しなければならない。そうすれば各レイヤー (モジュール) の状態が自己充足的になり、アプリケーションの論理的に異なる他の部分との対話が単純化される。結果として「並列化を念頭に置いた設計」のパターンを適用しやすくなる効果がある。さらに、自己充足的な状態には「同期を避ける」のパターンも適用しやすい。
加えて、ソフトウェアの設計をモジュール化する中で様々な最適化パターンが適用できる箇所が見つかる場合も多い。そこで、関心の分離を意識してアーキテクチャをモジュール化することを指す「関心の分離」という最適化パターンを私たちは提案する。モジュール化を厳密に行うとインダイレクションが増えてパフォーマンスに悪影響が出ると伝統的には言われているものの、他の最適化が適用できる機会が見つかることもある。
- レイヤー (モジュール) 間の非同期な対話を可能にする: アーキテクチャ内のレイヤー (モジュール) が同期的な操作を仮定したインターフェースしか持たない場合、並列性を活用したパフォーマンス向上が難しくなる。インターフェースが本質的に同期的だったとしても、抽象化などの手法を利用すれば非同期的な対話が可能になるケースも多い。同期的な対話を避けることは「並列化を念頭に置いた設計」パターンの重要な適用例と言える。
こういった考え方をグローバル層 (例えば ExecutionManager) に適用するとき、関心の分離はノード層のリソースが個別のプロセス (加えて、多くの場合で異なる物理ノード) に属する事実によって保たれる。CORBA Asynchronous Method Invocation (AMI) を活用すればクライアント (グローバル層インフラストラクチャ) が同期的サーバーインターフェース (ノード層インフラストラクチャ) を使った場合でも対話が非同期的となり、各ノードに対して複数のリクエストを並列にディスパッチできるので、非同期性は簡単に達成できた。これは仕様がエンティティ間の非同期対話を禁止していない事実を利用した最適化であり、「自由度の活用」パターンの適用例と言える。
一方で、この考え方をノード層インフラストラクチャに適用するのは難易度が高かった。上述したように、私たちの最初の実装では関心の分離が徹底的ではなかったので、ノード層で実行の流れを複数に分けてデプロイ処理を並列化するのは困難を極めた。この問題に対処するため、私たちは LocalityManager と呼ばれる新しい抽象化をノード層に作成した。LocalityManager は上述した最適化の考え方を適用した結果として誕生した。
LE-DAnCE の LocalityManager の概観
LE-DAnCE では、NodeManager, NodeApplicationManager, NodeApplication というノード層アーキテクチャが OMG D&C アーキテクチャのグローバルな部分を単一ノードに制約したバージョンとして機能する。NodeApplication が具象コンポーネントインスタンスのインストールを直接起動することはなく、このタスクは LocalityManager インスタンスに委譲される。ノード層インフラストラクチャはグローバル層から受け取ったプランをさらに「分割」し、コンポーネントインスタンスを一つ以上のアプリケーションプロセスにグループ化する。その後 NodeApplication は LocalityManager プロセスをいくつか起動し、「プロセス制約解決済みの」(特定のプロセスに関連するコンポーネントと接続情報だけが含まれる) プランを各プロセスに対して並列に委譲する。
LocalityManager は「仕様 vs 実装」パターンの適用例と言える。仕様は NodeApplication がコンポーネントミドルウェアと対話する最後のエンティティであることを示唆している。しかし、LocalityManager という抽象化レイヤーを追加で用意することで、様々な最適化パターンの適用が可能になった。
以前の DAnCE における NodeApplication 実装と異なり、LE-DAnCE の LocalityManager は「プラン解析に必要な汎用のデプロイロジック」と「具象化されたコンポーネントミドルウェアインスタンスのインストールとライフサイクル管理に必要な固有のデプロイロジック」の間で関心をはっきりと分離する汎用のアプリケーションプロセスとして機能する。この分離は InstallationHandler と呼ばれるエンティティが具象コンポーネントインスタンスのライフサイクル (インストール、削除、接続、切断、アクティベートなど) を管理するための詳細に定義されたインターフェースを提供することで達成される。InstallationHandler は NodeApplication が LocalityManager プロセスのライフサイクルを管理するときにも利用される。
この InstallationHandler は「自由度の活用」パターンの適用例である。コンポーネントミドルウェアとの明示的な対話を特定すれば、対話を独自に設計する自由がもたらされる。そうする中で「関心の分離」パターンも適用された。
LocalityManager を利用したデプロイステップにおける逐次実行の削減
新しく追加された LocalityManager と InstallationHandler によって、LE-DAnCE は DAnCE より格段に並列化が容易になった。LocalityManager と NodeApplication は DeploymentScheduler と呼ばれるエンティティを使って並列化される (図 6.5)。
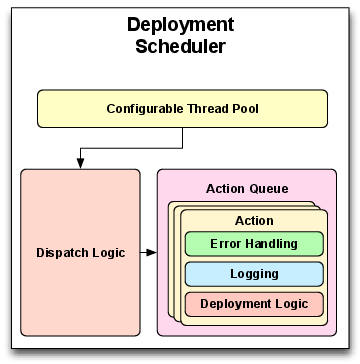
DeploymentScheduler は Command パターン[36]と Active Object パターン[37]を利用する。個別のデプロイ操作 (コンポーネントインスタンスのインストールや接続など) は必要なメタデータと共に Action オブジェクトに包まれる。各デプロイ操作は InstallationHandler のメソッドを起動することに対応するので、デプロイターゲットごとに Action を書き直す必要はない。エラー処理やロギングロジックも Action 内で行われるので、LocalityManager はさらに単純化される。
デプロイ操作の実行はスレッドプールによってスケジュールされる。このスレッドプールはアプリケーションの要件に応じて単一スレッドまたは複数スレッド、もしくはユーザーが選択した振る舞いで動作する。コンポーネントインスタンスのインストール順序をプランに記されたメタデータに基づいて動的に入れ替える優先度ベースのスケジュールアルゴリズムを使うこともできる。
LocalityManager はデプロイの各フェーズで行うべき操作を計算し、各操作を表す Action オブジェクトを作成する。Action オブジェクトは DeploymentScheduler に渡され、その後メインスレッドは DeploymentScheduler からの完了シグナルを待機する。操作が全て完了すると、LocalityManager は完了した操作の返り値もしくはエラーコードを収集し、現在のデプロイフェーズを完了する。
同じノード上に存在する LocalityManager インスタンスの間に並列性を提供するため、LE-DAnCE は LocalityManager プロセスに対する InstallationHandler を利用するのに加えて、NodeApplication の実装で DeploymentScheduler を利用する。この層で DeploymentScheduler を使うことで、デプロイにおけるレイテンシの大きな原因が除去される。LocalityManager インスタンスのスポーンにはコンポーネントインスタンスのデプロイ時間より格段に長い時間がかかる可能性があるので、この処理を並列化すると多数の LocalityManager を持つノードでアプリケーションをデプロイするときのレイテンシが大きく削減される。
デプロイ順序の動的な入れ替えと LocalityManager インスタンスの並列インストールは、SEAMONSTER においてデプロイのレイテンシを改善する有望なアプローチである。重要なデプロイ操作 (例えば発生中の自然現象を測定するセンサーの起動や設定の変更) に高い優先度を割り当てれば、DAnCE はミッションに不可欠なニーズをタイムリーに提供できる。さらに、この設計が提供する並列性によって、LocalityManager が I/O でブロックしている間に他の LocalityManager が実行可能になり、新型のマルチコア組み込みプロセッサの活用も可能になる。
結論
本章では最初に OMG Deployment and Configuration (D&C) 仕様の実装 Deployment And Configuration Engine (DAnCE) を概観した。当初 DAnCE は研究用ツールとして、DRE システムにおけるコンポーネントベースアプリケーションのデプロイと構成 (D&C) の新しい手法を試す実験で利用されていた。そのパフォーマンスは論文を書いてデモを行うための小規模で領域の狭い実験では十分だったものの、大規模なプロダクション DRE システムでは不十分だった。アーキテクチャ的な展望が欠けていたこと、所有者が何度も変更されたこと、デモ用の機能を中心に開発が進んだことなどが理由となり、初期に下された賢明とは言えない様々な設計判断がアーキテクチャと設計に留まり続け、パフォーマンスに深刻な悪影響を与えていた。
続いて DAnCE の典型的なユースケースとして South East Alaska Monitoring Network for Science, Telecommunications, Education, and Research (SEAMONSTER) プラットフォームを紹介し、DAnCE で最適化が可能だった箇所を説明した。このユースケースを下敷きとして、ネットワーキングの分野で定式化された様々な最適化パターンを活用して DAnCE の設計と実装を再評価・再構築し、上述の欠点を克服したことを示した。加えて、私たちは三つの新しい最適化パターンを説明した: 「並列化のための設計」「同期の回避」「関心の分離」である。こういったパターンを元々のパターンと組み合わせることで、DAnCE のパフォーマンスと信頼性を向上させた LE-DAnCE が開発された。私たちが特定したものを含む最適化パターンのカタログを表 6.2 に示す。こういったパフォーマンス改善の詳細な定量的議論は [27] に示されている。
| パターン | 説明 | DAnCE における適用例 |
|---|---|---|
| 無駄を省く | 明らかな無駄遣いを避ける | デプロイプランをパースするときメモリを事前にアロケートする |
| 時間方向へのシフト | 計算を時間的に別の場所に移す (事前計算、遅延評価、費用の共有、バッチ処理) | デプロイプランをバイナリフォーマットへ事前に変換する (可能ならプランの分割も計算する) |
| 仕様の緩和 | 仕様の要件を緩和する (パフォーマンスのために確実性・正確性を犠牲にして、計算を時間的に別の場所に移す) | 可能ならプランの分割を事前に計算する |
| 他のコンポーネントの利用 | システム内の他のコンポーネントを利用する (局所性の活用、予算を犠牲にした速度の向上、ハードウェアの活用) | (特になし) |
| ハードウェアの追加 | ハードウェアを追加してパフォーマンスを向上させる | (特になし) |
| ルーチンの効率化 | 効率的なルーチンを作成する | XML から IDL への変換 |
| 一般化の回避 | 不必要な一般性を避ける | プランのパース処理の最適化 |
| 仕様 vs 実装 | 仕様と実装を混同しない | LocalityManager |
| ヒントの提供 | インターフェースでヒントとなる情報を渡す | 可能ならプランの分割を事前に計算する |
| 情報の提供 | プロトコルヘッダーで情報を渡す | (特になし) |
| 典型的なユースケースの効率化 | 最も期待されるユースケースを効率化する | XML から IDL への変換 |
| 状態の活用 | 高速化のために状態を活用・追加する | プラン解析中に小プランを事前アロケートする |
| 自由度の活用 | 自由度を活用してパフォーマンスを得る | LocalityManager, InstallationHandler |
| 宇宙の有限性の活用 | 宇宙が有限である事実を活用した特別な手法を使う | (特になし) |
| データ構造の効率化 | 効率的なデータ構造を使う | XML-IDL 間のデータバインディング |
| 並列化のための設計 | 並列化を意識して設計を最適化する | 小プランを並列に処理する |
| 同期の回避 | 同期とロックを避ける | プラン解析で親プランへのアクセスを非同期にする |
| 関心の分離 | 関心の分離を徹底し、アーキテクチャをモジュール化する | LocalityManager |
本章で説明した最適化パターンを LE-DAnCE に適用して結果を観察する中で、私たちは次の教訓を学んだ:
- 並列化を非常に重要な最適化の機会として考える: マルチコアプロセッサが組み込みデバイスでさえ標準的になりつつある現在、並列化を念頭にアルゴリズムやプロセスを設計することはこの上なく重要である。並列化のためにアルゴリズムやプロセスを最適化するときは、同期の利用に慎重にならなければならない。並列システムでロックを誤って使用すると動作が逐次的になるばかりか、場合によっては気が付きにくい形で非常に有害な誤動作を起こす可能性さえある。
- 可能なら、時間のかかる操作をクリティカルパスから時間的に移動させる: D&C プロセスにおけるデプロイプラン解析の最適化 (デプロイプランの解析) は大規模なデプロイにおける全体のレイテンシを削減したものの、さらなる最適化は「時間方向へのシフト」のパターンを適用することで可能となった。例えば XML ファイルの解析結果はプランが XML として生成された時点で決定する場合が多い (デプロイプランのパースの最適化)。事前に行った解析の結果を D&C インフラストラクチャに提供すれば、レイテンシをさらに改善できる。事前に計算されたプランを渡すこと (プランのグローバルな分割とローカルな分割の両方) は「ヒントの提供」パターンの適用例と言える。
- DRE システムにおけるパフォーマンスの問題は多くが処理の逐次実行から生まれる: 分散システムの設計において、タスクの逐次的な実行は概念的な単純さと実装の単純さを提供する。しかし、その単純さにパフォーマンスに対する多大なペナルティが伴うことがよくある。設計が複雑になったとしても、非同期操作の追加が割に合う場合が多い。
- アーキテクチャや技術に関する明確なリーダーシップの不在はオープンソースプロジェクトにとって有害である: オープンソースプロジェクトにコントリビュートする開発者の多くは、自身が興味を持つ狭い領域の問題だけを解決し、その後はプロジェクトから離れる。明確なリーダーシップが存在しないと、個人のコントリビューターによる賢明でないアーキテクチャ的・技術的な判断が積み重なってプロジェクトの有用性が損なわれる可能性がある。
TAO, CIAO, LE-DAnCE は https://download.dre.vanderbilt.edu/ にてオープンソースで公開されている。
参考文献
[1] G. T. Heineman and B. T. Councill, Component-Based Software Engineering: Putting the Pieces Together. Addison-Wesley, 2001. ↩
[2] A. Akkerman, A. Totok, and V. Karamcheti, "Infrastructure for Automatic Dynamic Deployment of J2EE Applications in Distributed Environments," in 3rd International Working Conference on Component Deployment (CD 2005), Grenoble, France, 2005, pp. 17–32. ↩
[3] D. Suri, A. Howell, N. Shankaran, J. Kinnebrew, W. Otte, D. C. Schmidt, and G. Biswas, "Onboard Processing using the Adaptive Network Architecture," in Proceedings of the Sixth Annual NASA Earth Science Technology Conference, 2006. ↩
[4] J. White, B. Dougherty, R. Schantz, D. C. Schmidt, A. Porter, and A. Corsaro, "R&D Challenges and Solutions for Highly Complex Distributed Systems: a Middleware Perspective," the Springer Journal of Internet Services and Applications special issue on the Future of Middleware, vol. 2, no. 3, dec 2011. ↩
[5] D. C. Schmidt, B. Natarajan, A. Gokhale, N. Wang, and C. Gill, "TAO: A Pattern-Oriented Object Request Broker for Distributed Real-time and Embedded Systems," IEEE Distributed Systems Online, vol. 3, no. 2, Feb 2002. ↩
[6] Institute for Software Integrated Systems, "Component-Integrated ACEORB (CIAO)." www.dre.vanderbilt.edu/CIAO, Vanderbilt University. ↩
[7] Lightweight CCM FTF Convenience Document, Ptc/04-06-10. Object Management Group, 2004. ↩
[8] G. Deng, J. Balasubramanian, W. Otte, D. C. Schmidt, and A. Gokhale, "DAnCE: A QoS-enabled Component Deployment and Configuration Engine," in Proceedings of the 3rd Working Conference on Component Deployment (CD 2005), 2005, pp. 67–82. ↩
[9] Deployment and Configuration of Component-based Distributed Applications, v4.0, Document formal/2006-04-02. OMG, 2006. ↩
[10] G. Varghese, Network Algorithmics: An Interdisciplinary Approach to Designing Fast Networked Devices. San Francisco, CA: Morgan Kaufmann Publishers (Elsevier), 2005. ↩
[11] V. S. Pai, P. Druschel, and W. Zwaenepoel, "IO-Lite: A Unified I/O Buffering and Caching System," ACM Transactions of Computer Systems, vol. 18, no. 1, pp. 37–66, 2000. ↩
[12] M. Accetta, R. Baron, W. Bolosky, D. Golub, R. Rashid, A. Tavanian, and M. Young, "Mach: A New Kernel Foundation for UNIX Development," in Proceedings of the Summer 1986 USENIX Technical Conference and Exhibition, 1986, pp. 93–112. ↩
[13] D. D. Clark and D. L. Tennenhouse, "Architectural Considerations for a New Generation of Protocols," in Proceedings of the Symposium on Communications Architectures and Protocols (SIGCOMM), ACM, 1990, pp. 200–208. ↩
[14] M. Shreedhar and G. Varghese, "Efficient Fair Queueing using Deficit Round Robin," in SIGCOMM '95: Proceedings of the conference on Applications, technologies, architectures, and protocols for computer communication, ACM Press, 1995, pp. 231–242. ↩
[15] M. Degermark, A. Brodnik, S. Carlsson, and S. Pink, "Small Forwarding Tables for Fast Routing Lookups," in Proceedings of the ACMSIGCOMM '97 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, ACM Press, 1997, pp. 3–14. ↩
[16] J. Hasan and T. N. Vijaykumar, "Dynamic pipelining: Making IP-lookup Truly Scalable," in SIGCOMM '05: Proceedings of the 2005 Conference on Applications, technologies, architectures, and protocols for computer communications, ACM Press, 2005, pp. 205–216. ↩
[17] P. Druschel and L. L. Peterson, "Fbufs: A High-Bandwidth Cross-Domain Transfer Facility," in Proceedings of the $14^th$ Symposium on Operating System Principles (SOSP), 1993. ↩
[18] N. C. Hutchinson and L. L. Peterson, "Design of the x-Kernel," in Proceedings of the SIGCOMM '88 Symposium, 1988, pp. 65–75. ↩
[19] S. McCanne and V. Jacobson, "The BSD Packet Filter: A New Architecture for User-level Packet Capture," in Proceedings of the Winter USENIX Conference, 1993, pp. 259–270. ↩
[20] J. C. Mogul, R. F. Rashid, and M. J. Accetta, "The Packet Filter: an Efficient Mechanism for User-level Network Code," in Proceedings of the 11th Symposium on Operating System Principles (SOSP), 1987. ↩
[21] D. R. Engler and M. F. Kaashoek, "DPF: Fast, Flexible Message Demultiplexing using Dynamic Code Generation," in Proceedings of ACMSIGCOMM '96 Conference in Computer Communication Review, ACM Press, 1996, pp. 53–59. ↩
[22] Y. Rekhter, B. Davie, E. Rosen, G. Swallow, D. Farinacci, and D. Katz, "Tag Switching Architecture Overview," Proceedings of the IEEE, vol. 85, no. 12, pp. 1973–1983, dec 1997. ↩
[23] D. D. Clark, V. Jacobson, J. Romkey, and H. Salwen, "An Analysis of TCP Processing Overhead," IEEE Communications Magazine, vol. 27, no. 6, pp. 23–29, jun 1989. ↩
[24] S. Sahni and K. S. Kim, "Efficient Construction of Multibit Tries for IP Lookup," IEEE/ACM Trans. Netw., vol. 11, no. 4, pp. 650–662, 2003. ↩
[25] G. Varghese and T. Lauck, "Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility," IEEE Transactions on Networking, dec 1997. ↩
[26] W. R. Otte, A. Gokhale, and D. C. Schmidt, "Predictable Deployment in Component-based Enterprise Distributed Real-time and Embedded Systems," in Proceedings of the 14th international ACM Sigsoft Symposium on Component Based Software Engineering, ACM, 2011, pp. 21–30. ↩
[27] W. Otte, A. Gokhale, D. Schmidt, and A. Tackett, "Efficient and Deterministic Application Deployment in Component-based, Enterprise Distributed, Real-time, and Embedded Systems," Elsevier Journal of Information and Software Technology (IST), vol. 55, no. 2, pp. 475–488, feb 2013. ↩
[28] D. R. Fatland, M. J. Heavner, E. Hood, and C. Connor, "The SEAMONSTER Sensor Web: Lessons and Opportunities after One Year," AGU Fall Meeting Abstracts, dec 2007.
[29] J. S. Kinnebrew, W. R. Otte, N. Shankaran, G. Biswas, and D. C. Schmidt, "Intelligent Resource Management and Dynamic Adaptation in a Distributed Real-time and Embedded Sensor Web System," Vanderbilt University, ISIS-08-906, 2008. ↩
[30] A. Gokhale, B. Natarajan, D. C. Schmidt, A. Nechypurenko, J. Gray, N. Wang, S. Neema, T. Bapty, and J. Parsons, "CoSMIC: An MDA Generative Tool for Distributed Real-time and Embedded Component Middleware and Applications," in Proceedings of the OOPSLA 2002 Workshop on Generative Techniques in the Context of Model Driven Architecture, ACM, 2002. ↩
[31] J. White, B. Kolpackov, B. Natarajan, and D. C. Schmidt, "Reducing Application Code Complexity with Vocabulary-specific XML language Bindings," in ACM-SE 43: Proceedings of the 43rd annual Southeast regional conference, 2005. ↩
[32] The Common Object Request Broker: Architecture and Specification Version 3.1, Part 2: CORBA Interoperability, OMG Document formal/2008-01-07. Object Management Group, 2008. ↩
[33] A. Dubey, W. Emfinger, A. Gokhale, G. Karsai, W. Otte, J. Parsons, C. Czabo, A. Coglio, E. Smith, and P. Bose, "A Software Platform for Fractionated Spacecraft," in Proceedings of the IEEE Aerospace Conference, 2012, IEEE, 2012, pp. 1–20. ↩
[34] A. B. Arulanthu, C. O'Ryan, D. C. Schmidt, M. Kircher, and J. Parsons, "The Design and Performance of a Scalable ORB Architecture for CORBA Asynchronous Messaging," in Proceedings of the Middleware 2000 Conference, Pallisades, New York: ACM/IFIP, 2000. ↩
[35] ObjectWeb Consortium, "CARDAMOM - An Enterprise Middleware for Building Mission and Safety Critical Applications." cardamom.objectweb.org, 2006. ↩
[36] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1995. ↩
[37] D. C. Schmidt, M. Stal, H. Rohnert, and F. Buschmann, Pattern-Oriented Software Architecture: Patterns for Concurrent and Networked Objects, Volume 2. New York: Wiley & Sons, 2000. ↩