MemShrink
はじめに
Firefox は長い間「メモリを使いすぎる」と批判されてきた。その正確さは時とともに変化してきたものの、この批判から Firefox が逃れることはなかった。ここ数年では新しい Firefox のバージョンがリリースされるたびに、懐疑的なユーザーから「メモリリークは直ったのか?」という声が聞かれた。長いベータサイクルを経てリリーススケジュールを何度が逃した後 2011 年 3 月 に Firefox 4 がリリースされたときも同様だった。Firefox 4 は動画の再生や JavaScript のパフォーマンス、グラフィックスアクセラレーションといった領域で大きな進歩を遂げたものの、残念ながらメモリ使用量は大きく増加した。
近年ウェブブラウザの競争は非常に激しい。モバイルデバイスの台頭、Google Chrome のリリース、Microsoft のウェブへの再投資によって、Firefox は瀕死の Internet Explorer ではなく潤沢な資金を持った強力な競争相手と対峙することになった。特に Google Chrome は高速でスリムなブラウジングエクスペリエンスを提供するために多大な労力を注ぎ込んでいる。私たちは優れたブラウザを作るだけでは不十分なことを高い代償を払って学んだ。Mozilla でエンジニアリングの主任を務める Mike Shaver は言った: 「これは私たちが望んだ世界であり、私たちが作った世界である」
これが 2011 年初頭の状況だった。Google Chrome が急速に広まる中で、Firefox のマーケットシェアは横ばいか下降ぎみだった。Firefox はパフォーマンスでは Google Chrome に迫りつつあったものの、メモリ使用量では大きく差をつけられていた。Firefox 4 が JavaScript 実行の高速化とグラフィックスアクセラレーションに注力した一方で、メモリ使用量は犠牲にされがちだったためである。Firefox 4 を公開した後、Nicholas Nethercote が率いるエンジニアのグループによって Firefox のメモリ使用量を把握・統制するための MemShrink プロジェクトが開始された。それから一年半が経過した現在までの間に、この取り組みは Firefox のメモリ使用量と評判を大きく改善した。多くのユーザーにとって「メモリリーク」は過去のものとなり、Firefox は競争相手と比較したとき最もスリムなブラウザの一つに挙げられるまでになった。本章では Firefox のメモリ使用量を削減するまでに私たちが行った工夫やそこから得られた教訓を説明する。
アーキテクチャの概観
私たちが直面した問題と発見した解決策を理解するには、Firefox の基本的な動作を簡単に理解しておく必要がある。
モダンなウェブブラウザは本質的に信頼できないコードを実行するための仮想機械と言える。ブラウザが実行する信頼できないコードは多くが HTML, CSS, JavaScript (JS) から構成され、サードパーティによって提供される。Firefox のアドオンやプラグインの形で提供されるコードもある。ウェブブラウザの仮想機械はコードの評価、テキストのレイアウトとスタイルの計算、画像処理、ネットワークアクセス、オフラインストレージの利用、さらにハードウェアを利用したグラフィックス処理といった機能を持つ。こういった機能の一部は特定のタスク専用に設計された API によって提供されるものの、多くは全く新しい用途にも利用可能な API によって提供され、実際に様々な用途で利用されてきた。ウェブが長い時間をかけて複雑に進化してきたためにウェブブラウザは入力に関して非常に寛容であり、そのため 15 年前に設計されたウェブブラウザが現代のマシンで高パフォーマンスなエクスペリエンスを提供できなくても不思議ではない。
Firefox はレイアウトエンジン Gecko と JS エンジン Spidermonkey を持つ。どちらも Firefox での利用を主目標として開発されたものの、独立に再利用可能な個別のコードでもある。広く使われる他のレイアウトエンジンや JS エンジンと同じように、Gecko と Spidermonkey は両方とも C++ で書かれている。Spidermonkey は JS 仮想機械を実装し、ガベージコレクション (GC) や異なる特徴を持つ複数の just-in-time (JIT) コンパイラを持つ。Gecko は DOM API、 ソフトウェアまたはハードウェアパイプラインを通したページのレンダリング、ページ要素とテキストのレイアウト、完全なネットワークスタックといった大量の機能を実装する。この二つが合わさって Firefox の土台となるプラットフォームを提供する。Firefox のユーザーインターフェース (例えばアドレスバーやナビゲーションボタン) は特別な権限で実行される特殊なウェブページに過ぎない。この権限によって通常のウェブページからは見えない様々な機能へのアクセスが提供される。この特別な権限を持つビルトインの専用ページをクローム (chrome, Google Chrome とは関係ない) と呼び、通常のページをコンテンツ (content) と呼ぶ。
本章において Spidermonkey と Gecko に関して最も興味深いのは、メモリの管理方法である。ブラウザで使われるメモリはアロケートされる方法と解放される方法の二つで分類できる。動的に (ヒープに) アロケートされるメモリはオペレーティングシステムから大きなチャンクで確保され、ヒープアロケータによってリクエストされたサイズに小分けにされて渡される。Firefox には主要なヒープアロケータが二つある: GC を持つ特定用途のヒープアロケータ (GC ヒープ) と、汎用の jemalloc である。GC ヒープは Spidermonkey で、jemalloc は Spidermonkey と Gecko の両方で利用される。メモリ解放の手段も複数存在し、Firefox がアロケートするメモリは「手動」「参照カウント」「GC」のいずれかで解放される。
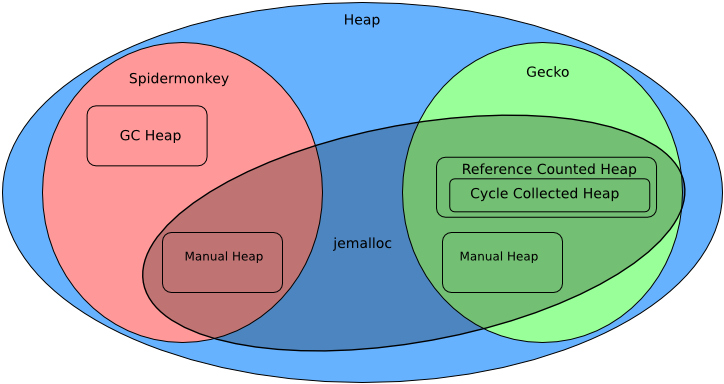
Spidermonkey の GC ヒープにはオブジェクトや関数といった JS の実行中に作成されるたいていのものが含まれる。また、寿命が GC ヒープ内のオブジェクトに関連付けられる実装詳細も GC ヒープに収められる。GC ヒープは非常に一般的なインクリメンタルマークアンドスイープをパフォーマンスと応答性に関して最適化して利用する。これは定期的に GC を起動して GC ヒープが保有する全てのメモリを調べなければならないことを意味する。マークアンドスイープは「ルート」 (ユーザーが開いているページが持つグローバルオブジェクトなど) から到達可能な全てのオブジェクトに「マーク」を付け、マークが付けられなかったオブジェクトを「スイープ」 (掃除) し、スイープしたメモリを以降のアロケートで再利用する。
Gecko ではメモリの大部分が参照カウントで管理される。特定のメモリ領域を指す参照の個数がカウントされ、カウントがゼロになるとメモリ領域は解放される。正確に言えば参照カウントも GC の一種であるものの、ここでの議論では不要なメモリの回収に専用のコード (ガベージコレクタ) の定期的な実行が必要となる GC の方式を参照カウントと区別する。単純な参照カウントは「メモリ A がメモリ B を参照し、同時にメモリ B がメモリ A を参照する」のような閉路が生じる状況を扱えない: このとき A と B の参照カウントが 1 より小さくならないので、メモリを解放できない。こういった閉路 (サイクル) を検出・解放するために、Gecko は特殊化されたトレーシングガベージコレクタを持つ。このガベージコレクタを本章ではサイクルコレクタ (cycle collector) と呼ぶ。サイクルコレクタは閉路を作る可能性があると分かっている一部のクラスだけを管理し、オプトインで閉路のメモリ解放を行う。そのためサイクルコレクタが管理するヒープは参照カウントが管理するヒープの部分集合だと考えることができる。また、サイクルコレクタは Spidermonkey のガベージコレクタと協調し、C++ から JS オブジェクトの参照を取得するといった言語をまたいだメモリ管理も行う。
これらの他にも、Spidermonkey と Gecko には手動で管理されるメモリが大量にある。そういったメモリは配列やハッシュテーブル、画像用バッファ、スクリプトのソースデータなどに用いられる。さらに、手動で管理されるメモリ向けの特定用途メモリアロケータも存在する。例えばアリーナアロケータ (arena allocator) がその例である。一度にまとめて解放できる小さなメモリ領域を大量にアロケートする場合にアリーナアロケータは利用される。このアロケータはメインのヒープアロケータからメモリの大きなチャンクを事前に確保し、アロケートのリクエストがあるとそこからメモリを切り出して渡す。アリーナアロケータは破棄されるとき自身が確保したチャンクをヒープに返すので、大量の小さな領域を個別に解放する必要はない。また、ポイズニング (デアロケートされたメモリをゼロで上書きして悪用を防ぐ) といったセキュリティ機能の実装でもアリーナアロケータが利用される。
Firefox には他にも様々な用途で使われる独自のメモリ管理システムがいくつかあるものの、今の議論には関係がない。以上で Firefox のメモリアーキテクチャが簡単に説明できたので、私たちが発見・解決した問題を議論する準備が整った。
計装機器の自作
問題を解決するための第一歩は何が問題かを理解することである。メモリリークの厳密な定義「オペレーティングシステム (OS) からアロケートしたメモリを必要なくなった時点で解放しないこと」は改善が必要な状況を全てカバーできない。次のような状況は厳密な意味では「メモリリーク」とみなされないものの、改善が必要である:
- データ構造が必要以上にメモリを消費する。
- 何らかのタイマーが発火するまで必要なくなったメモリが解放されない。
- 大きなバッファがプログラム中で何度もコピーされる。
さらに、Firefox が使用するヒープメモリの多くは何らかの GC の管理対象であり、そういったメモリは使用されなくなっても次回の GC が実行されるまで解放されない事実によって問題はさらに複雑になる。私たちは「メモリリーク」という言葉を「Firefox のメモリ効率が理論上で達成可能な値を下回る任意の状況」を意味する非常に大まかな単語として使うようになった。この使い方はユーザーと同じである: ほとんどのユーザーにとって、あるいはウェブ開発者にとってさえ、高いメモリ使用量の原因が「真の」メモリリークなのかどうかは分からない。
MemShrink プロジェクトが始まったとき、私たちは Firefox のメモリ使用量に関する知識をあまり持っていなかった。メモリが関係する問題の根本原因を特定するには、GDB のような低レベルツールや Massif といった複雑なツールが必要になる。ただ、こういったツールには欠点がいくつかある:
- 開発者のために設計されており、使いにくい。
- Firefox の内部構造 (様々なアロケータの実装詳細など) を認識できない。
- 「always on」 (常に有効) でない ── 問題が発生する瞬間に起動しておく必要がある。
これらの欠点を受け入れなければ非常に強力なツールを手に入れることはできなかった。これらの欠点を克服するため、ブラウザの振る舞いに関する洞察を少ない手間で手に入れるための独自ツールがいくつか開発されていった。
そういったツールの中で最初に開発されたのは about:memory だった。このツールは Firefox 3.6 で初めて導入され、最初はマップされたメモリ量といったヒープに関する簡単な統計情報を表示した。後に about:memory には「Firefox に組み込まれるデータベースエンジン SQLite が利用するメモリ量」や「アクセラレーションが有効なときグラフィックスサブシステムが利用するメモリ量」といった特定の開発者が必要とする情報が表示されるようになった。こういった計測の仕組みは memory reporter と呼ばれる。散発的に起こる機能追加を除けば、about:memory はメモリ使用量に関する統計情報をいくつか表示する原始的なツールであり続けた。また、Firefox で使用されるメモリの多くは対応する memory reporter を持たず、about:memory に表示されなかった。しかしそうだとしても、about:memory は Firefox の特別なビルドや特別なツールを用意せずともアドレスバーに about:memory と入力するだけで誰でも使うことができた。これは「キラーフィーチャー」だった。
MemShrink が皆の注目するプロジェクトとなるずっと前に、Firefox の JavaScript エンジンが用いるモノリシックなグローバル GC ヒープはコンパートメント (compartment) と呼ばれる小さなサブヒープの集合に分割された。コンパートメントは異なるウェブサイトで使われるメモリの分離を提供するのに加えて、クローム (特殊な権限を持つページ) とコンテンツ (特殊な権限を持たないページ) で使われるメモリの分離も提供する。コンパートメントが実装された主な動機はセキュリティだったものの、コンパートメントは MemShrink にとっても非常に有用なことに私たちは気が付いた。その後、それぞれのコンパートメントが使用するメモリの量と用途を表示するツール about:compartments がすぐにプロトタイプされた。about:compartments が直接 Firefox に追加されることはなかったものの、改変されたものが後に about:memory へと組み込まれた。
コンパートメントに関する情報を about:memory へ追加する間に、他のアロケータからも同様の情報を得られれば Massif のような専用ツールを使わずともヒープ全体に関する有用なプロファイルが得られる可能性があることに私たちは気が付いた。そこで about:memory は統計情報の概要を一覧で表示するのではなく、メモリ使用量を用途ごとにまとめた木構造で表示するように変更された。さらに、レイアウトサブシステムなどが行う大きなアロケートに対しても memory reporter が追加された。heap-unclassified (memory reporter が関知できていないメモリ) の量を減らすことは、私たちが最初に行ったメトリック駆動な取り組みの一つだった。適当な数字 10% が選択され、平均的な利用シナリオで heap-unclassified を 10% 以下にすることが目標とされた。ただ最終的には、10% という数字は低すぎることが判明した。ブラウザでは確保されてすぐに解放される小さなアロケートが大量に行われるので、heap-unclassified を安定して 15% 以下に保つことは不可能だった。heap-unclassified が小さくなれば、Firefox が利用するメモリに関する知識は増加する。
heap-unclassified を小さくするために、未報告のヒープアロケートを詳しく調べるためのツール Dark Matter Detector (DMD) が開発された。DMD はヒープアロケータを置き換え、about:memory の報告プロセスに自身を割り込ませて報告されたブロックとアロケートされたブロックを照合することで動作する。その後 DMD は未報告のメモリアロケートを呼び出し場所ごとにまとめて報告する。Firefox セッションに DMD を実行すると、heap-unclassified を生じさせた呼び出し場所が一覧で表示される。この情報があれば対応するコンポーネントがすぐに分かるので、開発者は memory reporter を素早く追加できる。数か月の間に、私たちは「あなたが Firefox で開いている Facebook ページは全体で 250 MB のメモリを消費している。その内訳は次の通りである」といった情報を伝えられるツールを手にした。
また、特定されたメモリの問題をデバッグするための Measure and Save と呼ばれるツールも開発された。このツールはサイクルコレクタが管理する C++ ヒープと JS ヒープの両方をファイルにダンプする。ダンプされたヒープを走査する解析スクリプトも用意され、これを使えば「このオブジェクトを生存させているオブジェクトはどれ?」といった質問に答えられる。これによって「ヒープグラフを調べて存在してはいけないリンクを見つける」や「調べたい特定のオブジェクトに対してブレークポイントを設定する」といった様々なデバッグの手法が可能になった。
こういったツールの大きな利点として、Massif のようなツールと異なり、問題が発生した後に起動できることがある。Massif を含む多くのヒーププロファイラはプログラムの起動時に起動しておく必要があり、問題が発生した後に途中から有効にする使い方はできない。また、他のマシンで問題が起きたときに再現ができなくてもダンプされた情報さえあれば問題を解析できることも利点である。この二つの利点が合わされば「ユーザーのマシンで発生した問題を開発者が再現できないとき、ユーザーに情報のキャプチャ・送信を指示して、開発者が受け取った情報を解析する」ことが可能になる。ウェブブラウザのユーザーに GDB や Massif を使うよう指示するのは (相手がバグトラッカーにバグを報告する高度なユーザーであったとしても) 負担が大きすぎて現実的でない。しかし、about:memory を開いて短い JavaScript スニペットを実行してデータを取得し、それをバグレポートに添付するだけなら格段に少ない負担で済む。汎用のヒーププロファイラは大量の情報をキャプチャできるものの、コストも大きい。私たちは自分たちが必要とする特定の機能を持った一連のツールを開発することで、汎用ツールより格段に大きな恩恵を得た。
独自ツールへの投資が必ず割に合うとは限らない: GDB を使うのをやめて新しいソフトウェアの各部分に対して新しいデバッガを開発することは当然ない。しかし既存のツールで得たい情報を上手く取得できない今回のような状況では、独自ツールの開発が大きな価値を持つ。一方で、about:memory を完全と言える状態にするには約一年にわたるパートタイムの開発が必要だった。さらに、memory reporter には現在でも新しい機能が追加され続けている。独自ツールは大きな投資である。この話題に関する詳しい議論は本章の範囲を超えるものの、独自ツールを開発する場合は始める前に利点とコストを注意深く検討する必要がある。
低く実っていた果実
こうして開発されたツールによって Firefox のメモリ使用量は以前よりずっと詳しく確認できるようになり、しばらく利用すると予想通りの結果が得られる部分とそうでない部分が明らかになった。振る舞いが普通でない (バグを持つ可能性が高い) 箇所を見つけるのは非常に簡単だった。heap-unclassified が memory reporter を追加していないマイナーなウェブ機能を指していたり、Gecko の内部で発生するリークが見つかったりした。JS エンジンといった奇妙な箇所での高いメモリ使用量は、実行中のコードが最適化されていないケースや病的なケースを踏んだことを意味する場合が多い。この情報を使うことで、Firefox が抱える最も厄介な種類のバグを発見・解決できた。
初期に発見された異常な振る舞いの一つに、閉じられたページが使っていたコンパートメントが GC を何度実行しても解放されないことがあった。そういったコンパートメントはいつの間にか解放されることもあれば、いつまでたっても解放されないこともあったので、「ゾンビコンパートメント」と呼ばれた。ウェブページは基本的に際限なくメモリを使えるので、これは最も深刻な種類のメモリリークである。Gecko と Firefox の UI コードのバグをいくつも修正する中で、ゾンビコンパートメントが最も多く生まれる場所がアドオンであることが判明した。本章で後に解説される解決策が見つかるまで、この問題は私たちを数か月にわたって悩ませた。Firefox とアドオンで生まれるゾンビコンパートメントの多くは、寿命の長い JS オブジェクトが寿命の短い JS オブジェクトに対する参照を保持し続けることで生まれていた。典型的には寿命の長い JS オブジェクトはブラウザウィンドウまたはグローバルなシングルトンで、寿命の短いオブジェクトはウェブページが持つオブジェクトだった。
DOM と JS の仕様により、ウェブページ内のオブジェクトへの参照が一つでも残っていればページ全体とそのグローバルオブジェクト (およびそこから到達可能な全てのオブジェクト) は解放できない。これによって数メガバイトのメモリが容易に消費される。ガベージコレクションを利用するシステムに関して見過ごされやすい事実として、GC が解放するのは到達不能なメモリであって、プログラマーが使い終わったメモリではない。使い終わったメモリを到達不能にする責任はプログラマーにある。参照するオブジェクトと参照されるオブジェクトで寿命が大きく異なるとき、誤って参照を削除し忘れたときの影響は大きくなる。比較的近い将来に再利用されるはずのメモリ (例えばウェブページ用のメモリ) が長く生き続ける参照側 (例えばブラウザウィンドウやアプリケーション本体) のメモリに関連付けられることになる。
JS ヒープのフラグメンテーションも同じような理由で問題となった。大量のタブを閉じたときに (OS が報告する) Firefox のメモリ使用量があまり減少しないことがよくあった。JS エンジンは数メガバイトのチャンクを一単位として OS からメモリをアロケートし、そのチャンクを小分けにして異なるコンパートメントで利用する。チャンクは全体が未使用になったときに限って OS に返却される。新しいチャンクのアロケートはまず間違いなくコンテンツからのメモリ要求によって行われたのに対して、チャンクの解放を妨げているのはクロームのコンパートメントである場合が多いことを私たちは発見した。寿命の短いオブジェクトが詰まったチャンクに寿命の長いオブジェクトが少しでもあると、そのチャンクはページが閉じられたときに解放できなくなる。この問題はクロームとコンテンツでコンパートメントに使用するチャンクを分けることで解決された。この結果として、タブを閉じたときに OS に返却されるメモリの量が大きく増加した。
フラグメンテーションを避ける工夫が原因の一つとなって生まれた別の問題も発見された。Firefox が主に利用するヒープアロケータは Windows と Mac OS X でも動作するように改造された jemalloc である。jemalloc はフラグメンテーションによるメモリの無駄を小さくするように設計されている。フラグメンテーションを避ける工夫の一つとして、jemalloc はアロケートを特定のサイズまで切り上げ、メモリの連続領域から同じサイズのアロケートを切り出していく。こうすると解放されたメモリを再利用できる可能性が高まる一方で、切り上げによって空間の効率は低下する。切り上げによって無駄になる空間を私たちはスロップ (slop) と呼ぶ。jemalloc はアロケートのサイズを次の 2 の冪まで切り上げる。そのため最悪のケースはアロケートのサイズが 2 の冪を少しだけ上回るとき (例えば 17 バイトが 32 バイトに、1025 バイトが 2048 バイトに切り上げられるとき) であり、このときアロケートされる空間の約 50% がスロップとなる。
メモリをアロケートするとき、サイズは変えられない場合が多い。クラスのインスタンスを収めるためのメモリをアロケートするときに必要より多いメモリをアロケートしたとしても、余分なメモリはまず有効活用できない。ただ、これより柔軟性があるケースは存在する: 文字列用のメモリをアロケートしているなら、本来必要なサイズより多いメモリをアロケートすることで文字列の末尾に他の文字列が追加されたときの再アロケートを回避できる可能性がある。この柔軟性が存在するなら、アロケートのサイズを次の 2 の冪 (jemalloc が切り上げないサイズ) まで大きくすることが正当化される。このとき通常であればスロップとして「無駄」になっていた部分がコスト無しに手に入る。これまでに存在したほぼ全てのアロケータはサイズが 2 の冪のアロケートを上手く扱えるので、この手法は jemalloc 以外のアロケータでも効果がある。
この手法は Gecko のコードで多く使われていたものの、いくつかの箇所では使い方が間違っていた。具体的には、アロケータが上手く扱えるサイズまで切り上げたつもりが、何らかの間違いでそれより大きくしてしまっていた。このとき、jemalloc では 50% 近くのメモリがスロップとして無駄になる。特にひどかったのがレイアウト用のとあるデータ構造に対して使われていたアリーナアロケータの実装で、チャンクがちょうど 4 KB であるにもかかわらずアロケートを補助情報用の数ワードと共に行っており、4 KB を少しだけ超えるサイズをアロケートしていた。このとき切り上げられた 8 KB が消費される。この間違いを直しただけで、Gmail を開いたときのスロップが 3 MB も減少した。レイアウト要素が多いテストケースではスロップが 700 MB 減少し、ブラウザ全体のメモリ使用量が 2 GB から 1.3 GB となった。
似た問題は SQLite でも遭遇した。Gecko は履歴やブックマークといった機能の実装でデータベースエンジンとして SQLite を使用する。SQLite は自身を組み込むアプリケーションにメモリアロケーションの細かい制御を与えるように書かれており、非常に几帳面なメモリ使用量の計測機能を持つ。しかし、この計測機能を有効にすると全てのアロケートに数ワードが加わるので、調整したアロケートサイズが次の 2 の冪に切り上げられてしまう。そのため皮肉にも、メモリ使用量を記録するための補助情報によってメモリ使用量がほぼ倍になり、しかも SQLite はその事実を報告できない状況となっていた。この種のバグは「clownshoes (ピエロの靴)」と呼ばれた。ピエロの靴のように大きな空間が無駄になる、笑えるほど悪質なバグだからである。
責任がなくても問題はある
MemShrink プロジェクトが始まって数か月の間に、Firefox のメモリ使用量の削減とメモリリークの修正に関しては大きな進捗があった。しかし、その恩恵を全てのユーザーが感じているわけではなかった。明らかになったのは、ユーザーが体験するメモリの問題の多くはアドオンが原因で発生している事実だった。メモリリークを起こしているアドオンを調査するバグトラッカーには最終的に 100 件以上の確認済みレポートが記録されることになる。
長い間 Mozilla は Firefox のアドオンに対してはっきりしない態度を取ってきた。「Firefox は豊富なアドオンの選択肢を持つ拡張可能なブラウザです」と宣伝する一方で、アドオンのパフォーマンスに問題があると報告してきたユーザーには「そのアドオンを使うな」と言ってきたのである。しかしメモリリークを起こすアドオンが大量に存在することが判明したので、この態度は維持できなくなった。多くのアドオンは Mozilla が運営する https://addons.mozilla.org (AMO) で配布される。AMO はアドオンでよくある問題を見つけるためのレビューポリシーを持つ。AMO レビュアーが about:memory などのツールを使ってアドオンのメモリリークをテストし始めると、問題の規模が明らかになった。テストされたアドオンの中にはゾンビコンパートメントといった問題を持つものが多くあった。私たちはアドオンの作者に連絡を取り、よくあるメモリリークの原因とベストプラクティスをまとめたページを公開した。しかし残念ながら、この施策はあまり成功しなかった。一部のアドオンは作者によって修正されたものの、多くはそのままだった。
この施策が効果的でなかった理由はいくつか考えられる。まず、全てのアドオンが定期的に更新されるわけではない。アドオンの作者はボランティアであり、自身のスケジュールと優先事項を持つ。 次に、メモリリークのデバッグは (特に問題を手元で再現できないとき) 難易度が高い。ヒープをダンプする先述のツールは非常に強力であり、それを使えば情報の収集は簡単に行える。しかし収集した情報の解析は複雑な処理なので、アドオンの作者にはおそらく行えない。最後に、メモリリークを修正する強いインセンティブが存在しない。質の悪いソフトウェアをユーザーに届けたいと思っている開発者はいないものの、全ての不具合を修正できるわけではない。加えて、アドオンの開発者が私たちの望むことより自分の望むことを優先するのは自然なことである。
メモリリークを修正するインセンティブを作ることについて私たちは長い時間をかけて話し合った。アドオンは Mozilla で他のパフォーマンスの問題も引き起こしていたので、AMO あるいは Firefox 内部でアドオンのパフォーマンスデータを可視化するアイデアが議論された。インストールした (あるいはインストールしようとしている) アドオンが持つパフォーマンスに対する影響をユーザーに伝えることができれば、アドオンを使うかどうかの判断で利用できる情報が増えるので望ましいと思われた。ただ問題は、ウェブブラウザのような消費者が直接使うソフトウェアの平均的なユーザーはそういった情報を手にしたとしてもトレードオフを考慮した公平な判断を行えないことだった。「メモリリーク」が何かを理解していて、メモリリークとアドオンの価値を天秤にかけられるのは Firefox のユーザー 4 億人のうち何人だろうか? また、アドオンが持つパフォーマンスの影響を公開するには、Mozilla に関連する様々なコミュニティからの賛同が必要な点も問題だった。例えば、アドオンのコミュニティは「バンハンマー」を持ったシステム管理者がアドオンを叩いて回るのを快くは思わない。最後に、AMO を通じてインストールされない (他のソフトウェアに付属する) Firefox アドオンが多く存在した。そういったアドオンをブロックできるだけの影響力を Firefox は持っていなかった。こういった理由により、インセンティブを作る試みは放棄された。
アドオンのメモリリークを修正するインセンティブを作ることを諦めたのは、問題を解決する全く異なる方法が発見されたからでもある。最終的に、Firefox のアドオンが起こしたメモリリークを「掃除」する方法を私たちは発見した。これは多くのアドオンを壊さずには行えないと長い間思われていたものの、実験は続いていた。その実験の中で、ほとんどのアドオンに悪影響を与えずにメモリを回収する手法が実装された。この手法はコンパートメント間の境界を活用してページのナビゲートやタブのクローズが起こったときにクロームのコンパートメントからコンテンツのコンパートメントへの参照を「切る」ことで動作する。こうするとクロームのコンパートメントに何も参照しないオブジェクトが生まれる。この処理で削除可能となるオブジェクトは多くの場合で使われないので、削除して構わないことが判明した。実際にはアドオンがウェブページのオブジェクトを誤って不必要にキャッシュしている場合が多いので、それらを勝手に削除しても問題はまず起こらない。結局、私たちは技術的な問題に対する社会的な解決策を探していたのである。
優秀さの代償はいつまでも残り続けること
MemShrink プロジェクトは Firefox が抱えるメモリの問題を大きく改善したものの、行うべき作業はまだ大量に残っている。これまでに簡単な問題は多くが解決されたので、残っている作業には相当な工数が必要となる。JS ヒープのフラグメンテーションを削減するために、ヒープの統合が可能なムービングガベージコレクタ (moving garbage collector) の開発を進める計画がある。また、画像を高いメモリ効率で扱えるようにする書き直しも進んでいる。これまでに完了した変更と異なり、こういった作業には複雑なサブシステムの大規模なリファクタリングが必要となる。
こういった新しい作業と同程度に重要なのが、過去に行われた改善を打ち消さないことである。2006 年以降の Mozilla にはリグレッションテストを重視する文化がある。Firefox のメモリ使用量を削減する中で、メモリ使用量を監視するリグレッションテストを書くことに対する願望が強まっていった。一般にパフォーマンスのテストは機能のテストより難しい。最も難しいのはテスト対象のソフトウェアに対する現実的な負荷を定義する部分である。既存のブラウザ用メモリテストは現実的な負荷を少しも再現できていない。例えば MemBuster は様々な wiki やブログを新しいウィンドウで開くことを素早く繰り返してテストを行う。しかし現在のユーザーは新しいウィンドウではなく新しいタブでページを開き、開かれるページは wiki やブログより格段に複雑なことも少なくない。同じタブで大量のページを開くベンチマークも存在するが、これも現在のウェブブラウザの挙動としては現実的でない。そこで、私たちはそれなりに現実的と思われる負荷を新しく考案した。この負荷は固定された 30 個のタブで 100 個のページを一定の間隔を空けて開く。この間隔はページをユーザーが閲覧する時間の推定値である。開かれるページは Mozilla が持っていた Tp5 と呼ばれるページセットから選ばれた。Tp5 は Alexa Top 100 から取ったページの集合であり、ページ読み込みのパフォーマンスを測定する既存のインフラストラクチャで利用されていた。この負荷はメモリ使用量をテストする上で有用なことが判明している。
テストに関してはもう一つ、何をテストするかという問題がある。私たちが開発したテストシステムはテスト実行中に三つの異なる時点でメモリ使用量を計測する:
- 最初のページを読み込む前
- 全てのページを読み込んだとき
- 全てのタブを閉じたとき
それぞれの時点では「30 秒間何もせず放置したとき」と「GC を強制的に実行したとき」のメモリ使用量も計測される。これらの計測は過去に解決した問題が再発していないことを確認する上で役立つ。例えば、30 秒後の計測と GC 実行後の計測に大きな違いがあるなら、GC の実行タイミングを決めるヒューリスティックが保守的すぎると分かる。また、ページを開く前の計測とページを閉じた後の計測に大きな違いがあるなら、おそらくメモリがリークしている。それぞれの計測では、resident set size (RSS, プロセスが確保して実際に利用している物理メモリの量)、「明示的な」メモリ量 (malloc や mmap がリクエストしたメモリ量の合計)、about:memory で特定のカテゴリ (例えば heap-unclassified) に属するメモリ量といった様々な値が計測される。
このテストシステムが完成すると、Firefox の最新開発バージョンで定期的に実行されるようにセットアップされた。さらに、およそ Firefox 4 までの過去バージョンでもテストが実行された。得られた結果は豊富な過去データと (ほぼ) 継続的に統合される。いくらかのウェブ開発の後、メモリテストインフラストラクチャで収集された全てのデータを表示するウェブベースのパブリックインターフェース https://areweslimyet.com [リンク切れ] が公開された。公開されてから現在までに、このサイトは Firefox の様々な部分に対する作業が生み出したリグレッションを何度か検出した。
コミュニティ
MemShrink プロジェクトの成功に寄与した最後の要因として、幅広い Mozilla コミュニティからのサポートがある。最近では Firefox に取り組むエンジニアの多く (全員では決してない) が Mozilla によって雇用されているものの、テスト、ローカライゼーション、QA、マーケティングなどの様々な場面で Mozilla は活発なボランティアコミュニティからサポートを受けている。このサポートがなければ Mozilla プロジェクトは機能しないだろう。私たちは意図的に MemShrink をコミュニティからのサポートを得られるような構造にした。MemShrink のコアメンバーは少数の有給エンジニアだったものの、バグ報告、テスト、アドオンの修正を通して受け取ったコミュニティからのサポートは私たちの作業を後押しした。
Mozilla コミュニティの中でさえ、メモリ使用量の問題は昔から頭痛の種だった。問題を自分で体験しているメンバーもいれば、友人や家族を通して問題を認識していたメンバーもいた。そうでない幸運なメンバーも、Firefox のメモリ使用量に関する不満や、自分が労力を注いだソフトウェアの新しいバージョンがリリースするたびに寄せられる「メモリリークは直ったのか?」のコメントを目にしていたことは間違いない。自分が関わった成果物に対する批判、特に自分が関わっていない部分に対する批判を快く思う人はいない。ほとんどのメンバーが感じていた古くからある問題を解決することは、コミュニティのサポートを得る上での素晴らしい最初の一歩だった。
「問題を解決します」と宣言するだけでは十分でない。私たちが真剣であり、実際に問題の解決に向けて進捗を生んでいることを示す必要があった。そのために私たちは公開のミーティングを毎週開催し、報告されたバグのトリアージや進行中のプロジェクトをそこで議論した。また、Nicholas はミーティングのたびに進捗報告をブログにまとめ、参加していない人にも私たちが何をしているかが分かるようにした。実装された改善、バグの個数の変化、そして新しく報告されたバグのまとめを公開することで、私たちが MemShrink に費やしている労力を明らかにしていった。また、低く実っていた果実を収穫する初期の改善は、私たちが確かにメモリ使用量の問題を解決できると示す上で大きく役立った。
最後のピースは、幅広いコミュニティと MemShrink に取り組む開発者のフィードバックループを閉じることだった。先述のツールが開発されたので、以前であれば「再現できず」のタグが付いて忘れられていたであろうバグ報告が解決できるようになった。また、私たちは進捗報告のブログに対して寄せられる不満、コメント、反応を精査し、問題の修正で必要な箇所を特定した。全てのバグ報告にはトリアージを行い、優先度を割り当てた。さらに、修正が必要ないものを含む全てのバグ報告を時間と労力をかけてチェックした。こういった作業によってバグの報告者は報告の価値を実感でき、加えて誰かに時間ができればバグが修正される状態を作ることもできる。結果として、コミュニティからバグ報告とテストにおける貴重なヘルプの形でサポートを受けられる強い基盤が構築された。
結論
MemShrink プロジェクトが始まってからの約二年間で、Firefox のメモリ使用量は大きく改善した。MemShrink チームはメモリ使用量を Firefox のユーザーが最も不満を抱く問題点から Firefox のセールスポイントへと変貌させ、多くの Firefox ユーザーが体感するユーザーエクスペリエンスを向上させた。
MemShrink に関わった Justin Lebar, Andrew McCreight, John Schoenick, Johnny Stenback, Jet Villegas, Timothy Nikkel、そしてメモリに関する問題の解決に手を貸した全てのエンジニアに感謝する。特に、MemShrink を立ち上げ、Spidermonkey のメモリ使用量を削減し、二年にわたってプロジェクトを運営し、その他にも数え切れないほどの活躍をした Nicholas Nethercote に最大限の感謝を捧げる。本章をレビューした Jet と Andrew にも感謝する。