Warp
Warp は純粋関数型プログラミング言語 Haskell で書かれた高パフォーマンス HTTP サーバーライブラリである。ウェブアプリケーションフレームワーク Yesod と HTTP サーバー mighty は両方とも Warp を利用する。私たちが行ったスループットベンチマークによると、mighty は nginx に相当するパフォーマンスを提供する。本章では Warp のアーキテクチャを概観し、そのパフォーマンスを達成するために必要だったことを説明する。Warp は Linux, 様々な BSD, Mac OS, Windows といった多くのプラットフォームで動作するものの、説明を簡単にするため、ここからは Linux で実行される Warp を想定して話を進める。
Haskell におけるネットワークプログラミング
関数型プログラミング言語は「遅い」あるいは「実用的でない」という主張を耳にすることがある。しかし、私たちの知る限り、Haskell は理想に近いネットワークプログラミングのアプローチを提供する。これは、最も有名な Haskell コンパイラ Glasgow Haskell Compiler (GHC) が軽量でロバストなユーザースレッド (別名グリーンスレッド) を提供するためである。本節では、サーバーサイドのネットワークプログラミングにおける有名なアプローチをいくつか簡単に紹介し、それらを Haskell におけるネットワークプログラミングと比較する。他のアプローチでは見られない、プログラム容易性とパフォーマンスの両立という特徴を Haskell が持つことが分かるだろう。Haskell が提供する利便性の高い抽象化により、プログラマーは明快で単純なコードを書くことができる。さらに、GHC の洗練されたコンパイラとマルチコアに対応したランタイムシステムにより、そのプログラムは手で書かれた最も高度なネットワークプログラムに非常によく似た動作をする。
ネイティブスレッド
古典的なサーバーのアーキテクチャはスレッドプログラミングと呼ばれる手法を利用する。このアーキテクチャでは、それぞれの接続が単一のネイティブスレッド (プロセス) で処理される。ネイティブスレッドは OS スレッドと呼ばれることもある。
このアーキテクチャはネイティブスレッドを作成する仕組みでさらに分類できる。スレッドプールを使うとき、複数のネイティブスレッドが事前に作成される。スレッドプールは prefork モードの Apache で利用される。他には、新しい接続が開始されるたびにネイティブスレッドが作成される手法が考えられる (図 11.1)。
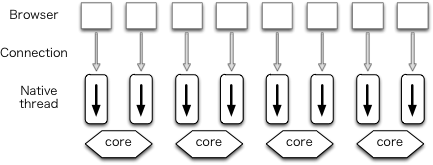
このアーキテクチャの利点としてコードの明快さがある。具体的に言えば、ネイティブスレッドを使うときプログラマーは慣れ親しんだ単純な処理の流れを持つコードを書くことができ、入力のフェッチや出力の送信を簡単な手続き呼び出しで行える。さらに、ネイティブスレッドを利用可能なコアに割り当てるのはカーネルなので、コアの利用率も公平になる。このアーキテクチャの欠点としては、カーネルとネイティブスレッドの間でコンテキストスイッチが大量に起こるためにパフォーマンスが低下することがある。
イベント駆動アーキテクチャ
高パフォーマンスサーバーの世界では、イベント駆動プログラミングを活用することが最近のトレンドである。イベント駆動アーキテクチャを持つサーバーは単一のプロセスが複数の接続を処理する (図 11.2)。このアーキテクチャを採用するウェブサーバーの例として Lighttpd がある。
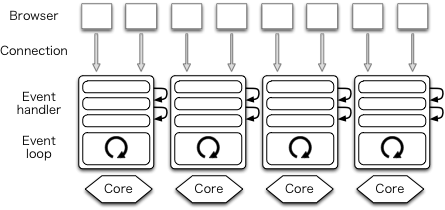
別の接続に処理を移すときプロセスを切り替える必要がないためにコンテキストスイッチが減少し、パフォーマンスが向上する。これがイベント駆動アーキテクチャの主な利点である。
一方で、イベント駆動アーキテクチャではプログラムが格段に複雑になる。特に、このアーキテクチャを使うときイベントループがプログラム全体の実行を制御するので、制御フローが逆転する。プログラマーは自身が行いたい処理をイベントハンドラとして書かれなければならず、イベントハンドラではノンブロッキングな処理しか行えない。この制約は I/O を手続き的に呼び出せないことを意味する: 複雑な非同期メソッドを使わなければならない。加えて、通常の方法で例外を使うこともできない。
各コアに一つのプロセス
CPU が持つコアの個数と同じだけのイベント駆動プロセスを作成するアイデア (図 11.3) は多くのシステムで採用されている。このとき各プロセスはワーカー (worker) と呼ばれる。サービスポートはワーカー間で共有される必要がある。ポートの共有は prefork と呼ばれる手法を使えば達成できる。
古典的なプロセスプログラミングでは、新しい接続に対するプロセスは接続が受理されてからフォークされる。これに対して、接続の受理より前にフォークを済ませる手法を prefork と呼ぶ。同じ名前を持つものの、この prefork という手法と Apache の prefork モードは異なるので注意が必要である。
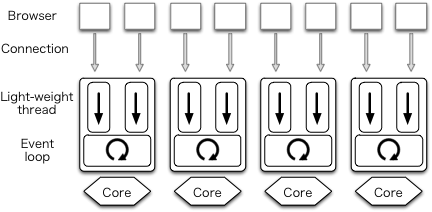
このアーキテクチャを採用するウェブサーバーとして nginx がある。以前の Node.js はイベント駆動アーキテクチャを利用していたものの、最近になって prefork も実装された。各コアに一つのプロセスを用意するアーキテクチャの利点として、全てのコアを利用できるためにパフォーマンスが向上することがある。しかし、このアーキテクチャでもハンドラとコールバック関数は多用されるので、プログラムが複雑になる問題は解決されない。
ユーザースレッド
コードが複雑になる問題は、GHC のユーザースレッドを使うと解決できる。具体的に言うと、それぞれの HTTP 接続を新しいユーザースレッドを使って処理できる。このスレッドは通常のスタイルでプログラムでき、論理的にブロッキングな I/O を呼び出しても構わない。プログラムは明快で単純になり、マルチコア CPU に対するワークディスパッチとノンブロッキング I/O の複雑性は GHC によって処理される。
縁の下では、GHC が少数のネイティブスレッドを使ってユーザースレッドを多重化する。GHC のランタイムシステムにはマルチコア対応のユーザースレッドスケジューラが含まれている。ユーザースレッドの切り替えは OS レベルのコンテキストスイッチが関係しないため高速に行える。
GHC のユーザースレッドは軽量であり、モダンなマシンは 100,000 個のユーザースレッドを軽々と実行できる。ロバストでもあり、非同期な例外さえ捕捉できる (Warp のアーキテクチャとファイルディスクリプタに対するタイマーで説明するように、この機能はタイムアウトハンドラで利用される)。さらに、スケジューラはマルチコアに対応した負荷分散アルゴリズムを使って利用可能な全てのコアの利用率を高める。
ユーザースレッドが論理的にブロッキングな I/O 操作 (例えばソケットに対するデータの送受信) を呼び出すと、実際にはノンブロッキングな操作が試みられる。このノンブロッキングな操作が成功するなら、ユーザースレッドの実行は I/O マネージャやスレッドスケジューラに妨げられずに進行する。I/O 操作の呼び出しがブロックするなら、ユーザースレッドはランタイムシステムの I/O マネージャに関連するイベントを登録し、自身がそのイベントを待機していることをスケジューラに伝える。その後 I/O マネージャスレッドがイベントを監視し、待機しているイベントが発生するとスレッドの実行が再スケジュールされる。以上の処理はユーザースレッドのコードから見えない場所で行われるので、Haskell プログラマーは気にする必要がない。
Haskell では大部分の計算が非破壊的に行われる。これは、ほとんどの関数がスレッドセーフであることを意味する。GHC はユーザースレッドのコンテキストを安全に切り替えられる地点としてデータのアロケーションを利用する。関数型プログラミングのスタイルで書かれたプログラムでは新しいデータが頻繁に作成されるので、データアロケーションの頻度は十分なコンテキストスイッチが発生する程度に高くなる。
ユーザースレッドを提供する言語は過去にいくつか存在したものの、軽量かつロバストでないために広く使われることはなかった。一部の言語はライブラリレベルでコルーチンを提供するものの、コルーチンはプリエンプティブではないことに注意してほしい。なお Erlang では「プロセス」、Go では「goroutine」という名前で軽量ユーザースレッドが提供される。
執筆時点において、mighty は prefork の手法を使ってプロセスをフォークすることで多くのコアを活用する (この機能を Warp は持たない)。prefork の手法を使って Haskell でウェブサーバーを書くときのアーキテクチャを図 11.4 に示す。ブラウザ接続は単一のユーザースレッドによって処理され、各 CPU コアで実行されるプロセス内の単一のネイティブスレッドがいくつかの接続に対するタスクを実行する。
私たちは、GHC ランタイムシステムに含まれる I/O マネージャ自体がパフォーマンスのボトルネックであることを発見した。この問題を解決するために、コアごとのイベント登録テーブルとイベントモニタを利用してマルチコア環境におけるスケーリングを大きく向上させる並列 I/O マネージャが開発された。並列 I/O マネージャを持つ Haskell プログラムは単一プロセスとして実行され、複数の並列 I/O マネージャがネイティブスレッドとして実行されることで複数の CPU コアが利用される (図 11.5)。それぞれのユーザースレッドはいずれかのコアで実行される。
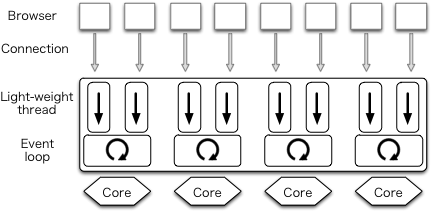
並列 I/O マネージャを含んだ GHC バージョン 7.8 のリリースは2013 年秋に予定されている。GHC バージョン 7.8 に切り替えればコードを全く変更しなくても Warp が図 11.5 のアーキテクチャを使うようになり、mighty で prefork を使う必要はなくなる。
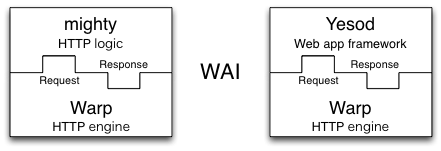
Warp のアーキテクチャ
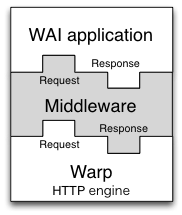
Warp は Web Application Interface (WAI) 向けの HTTP エンジンであり、HTTP を利用する WAI アプリケーションの実装で利用される。先述したように、Yesod と mighty は WAI アプリケーションの例である。これらの WAI アプリケーションと Warp の関係を図 11.6 に示す。
WAI アプリケーションの型は次のように表せる:
type Application = Request -> ResourceT IO Response
Haskell では二つの型を右向き矢印でつなぐことで関数の型が表され、矢印の左側は引数の型、右側は返り値の型をそれぞれ表す。また、ResourceT IO Response は「リソースが管理された I/O を行い、最終的に Response を返す」を意味する。つまり、この型は「WAI (Application) はリクエスト (Request) を受け取り、リソースが管理された I/O 行いつつレスポンス (Response) を返す」と読める。
新しい HTTP 接続が受理されると、その接続専用のユーザースレッドが作成される。そのユーザースレッドはクライアントからの HTTP リクエストをパースして Request に変換する。その後 Warp が Request を WAI アプリケーションに渡し、Response を受け取る。最後に、Warp が Response から HTTP レスポンスを構築してクライアントに送り返す。以上の処理を図 11.7 に示す。
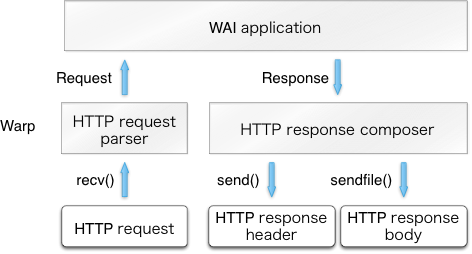
ユーザースレッドは同じ手続きを必要なだけ繰り返し、ピアが接続をクローズするか不正なリクエストを受け取るかすると実行を終了する。また、一定の時間にわたって少量のデータしか送られてこない (タイムアウトした) 場合にもユーザースレッドは実行を終了する。
Warp のパフォーマンス
Warp のパフォーマンスを改善する方法を説明する前に、私たちが行ったベンチマークの結果を紹介する。このベンチマークではバージョン 2.6.4 の mighty (Warp のバージョンは 1.3.8.1) とバージョン 1.4.0 の nginx の性能が測定された。ベンチマーク環境は次の通りである:
- 1 Gbps イーサネットで接続された 2 つの「12 コア」マシン (6 コア CPU Intel Xeon E5645 のツーソケット) を利用する。
- 一つのマシンはバージョン 3.2.0 の Linux (Ubuntu 12.04 LTS) を直接実行する。
- もう一つのマシンは FreeBSD 9.1 を直接実行する。
ベンチマークツールをいくつか調査したところ、httperf が候補に挙がった。しかし httperf は select 関数を利用するシングルプロセスのプログラムなので、マルチコアマシンで実行される HTTP サーバーに十分な負荷を生成できなかった。そこで、代わりに weighttp を利用することになった。weighttp は libev (epoll ファミリーの関数を使うライブラリ) をベースとしており、複数のネイティブスレッドを利用できる。ベンチマークでは FreeBSD の weighttp を次のように実行した:
weighttp -n 100000 -c 1000 -t 10 -k http://<ip_address>:<port_number>/
これは 10 個のネイティブスレッドをスポーンし、毎秒 1,000 個の HTTP 接続を確立し、それぞれの接続が 100 個のリクエストを送信することを意味する。
ベンチマーク対象のウェブサーバーは Linux 上でコンパイルされた。全てのリクエストに対しては同じ index.html ファイルが返される。このファイルは nginx の index.html (151 バイト) である。
Linux/FreeBSD は制御可能なパラメータを多く持つので、その設定を注意深く行う必要がある。Linux のパラメータチューニングについては ApacheBench & HTTPerf に詳しい解説がある。また、私たちは mighty と nginx を次のように設定した:
- ファイルディスクリプタのキャッシュを有効化する。
- ログを無効化する。
- レート制限を無効化する。
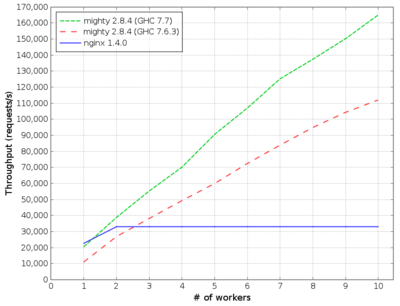
ベンチマーク結果を図 11.8 に示す。
nginx のパフォーマンス
横軸はワーカーの個数、縦軸はスループット (1 秒間に処理されたリクエストの個数) を表す。mighty に関する詳細は次の通りである:
- mighty 2.8.4 (GHC 7.7) は GHC のバージョン 7.7.20130504 (バージョン 7.8 の一つ前) でコンパイルされた。このバージョンではワーカーを一つしか持たない並列 I/O マネージャが利用される。GHC のランライムオプションは
+RTS -qa -A128m -N<x>であり、ここで<x>はコアの個数を、128mはガベージコレクタが用意するアロケーションアリーナのサイズを表す。 - mighty 2.8.4 (GHC 7.6.3) は GHC のバージョン 7.6.3 (最新の安定バージョン) でコンパイルされた。
鍵となる考え方
Haskell で高パフォーマンスサーバーを実装する上で、私たちが意識した鍵となる考え方が四つある:
- システムコールの呼び出しを減らす。
- 特殊化された関数を実装し、再計算を避ける。
- ロックを避ける。
- 適切なデータ構造を利用する。
システムコールの呼び出しを減らす
モダンなオペレーティングシステムにおけるシステムコールのコストは小さいものの、呼び出しが頻繁になれば無視できなくなる。Warp はリクエストごとに recv, send, sendfile (ファイルのゼロコピーを可能にするシステムコール) といったシステムコールを呼び出す。なお、Warp はファイルディスクリプタに対するタイマーで説明されるキャッシュの仕組みを持つので、open, stat, close といったシステムコールがリクエストごとに呼ばれることはない。
実際に呼び出されるシステムコールは strace コマンドで確認できる。以前に nginx の振る舞いを strace で確認したところ、私たちが知らなかったシステムコール accept4 の存在に気が付いたことがあった。
リッスンを行うソケットは Haskell の標準ネットワークライブラリを利用してノンブロッキングのフラグを設定した状態で作成される。そうしてリッスンを開始したソケットが新しい接続を受理するときは、新しい接続に対応するソケットにもノンブロッキングのフラグが必要となる。ネットワークライブラリはこれをシステムコール fcntl を二回呼び出すことで実装する: 一度目の呼び出しで現在のフラグを取得し、二度目の呼び出しでノンブロッキングのフラグを追加で設定する。
Linux では、リッスン中のソケットにノンブロッキングのフラグが設定されていたとしてもシステムコール accept が返す新しい接続を表すソケットにはノンブロッキングのフラグが設定されない。システムコール accept4 は accept を拡張したバージョンであり、新しい接続のフラグを直接指定できる。そのため accept4 を使えば、二回の fcntl の呼び出しを回避できる。Linux で accept4 を利用する私たちが作成したパッチはネットワークライブラリにマージされている。
特殊化された関数を実装し、再計算を避ける
GHC はプロファイラを持つものの、一つ制限がある: プログラムがフォアグラウンドで実行され、かつ子プロセスをスポーンしないときに限って正しいプロファイルが行える。そのため実行中のサーバーをプロファイルするには、特別な工夫が必要になる。
mighty には、この問題に対処する仕組みが実装されている。mighty の設定ファイルで設定されたワーカーの個数を N とする。N が 2 以上のとき、mighty は N 個の子プロセスと一個の親プロセス (シグナルの伝達役) を作成する。しかし N が 1 のとき、mighty は子プロセスを作成せず、自身が HTTP サーバーとなって動作する。また、デバッグモードが有効なとき mighty はターミナルに接続された状態で動作する。
mighty のプロファイル結果から判明した驚くべき事実として、CPU 時間の大部分が時刻を文字列にフォーマットする標準関数に費やされていたことがある。HTTP サーバーは Date や Last-Modified といったヘッダーフィールドに次の形をした GMT 時刻文字列を設定する必要がある:
Date: Mon, 01 Oct 2012 07:38:50 GMT
そこで、私たちは GMT 時刻文字列を生成するための特別なフォーマット関数を実装した。criterion ベンチマークライブラリを利用して Haskell 標準の実装と比較すると、私たちの特殊化した関数は格段に高速だった。また、HTTP サーバーが一秒間に二つ以上のリクエストを受け取るときは同じ文字列が何度も生成されるので、GMT 時刻文字列をキャッシュする仕組みも実装された。
関数の特殊化と再計算の回避という考え方は HTTP レスポンスのコンポーザーでも言及される。
ロックを避ける
不必要なロックはプログラミングにおいて悪である。Warp のコードでは、ランタイムシステムやライブラリがロックを使うことが原因で不必要なロックが使われているケースがある。高パフォーマンスサーバーを実装するには、そういったロックを可能な限り特定して回避しなければならない。また、並列 I/O マネージャを利用するときロックの悪影響がずっと大きくなる点にも注意が必要となる。ロックを特定・回避する方法については接続に対するタイマーとメモリアロケーションで説明する。
適切なデータ構造を利用する
Haskell の標準ライブラリは文字列を表すデータ構造として String を持つ。String は Unicode 文字の連結リストとして実装される。リストを使ったプログラミングは関数的プログラミングで非常に重要なので、String は様々な用途で有用となる。しかし、連結リストで表された文字列では高パフォーマンスサーバーに十分な速度は達成できない。さらに、HTTP プロトコルのメッセージはバイトストリームとして解釈されるので、HTTP プロトコルの処理に使われる文字列ライブラリが Unicode を認識する必要はない。そのため、Warp は ByteString で文字列 (およびバッファ) を表現する。ByteString はメタデータを持ったバイト配列である。このメタデータがあることで、コピーを行わない要素の置き換えが可能になる。この手法はパーサーの実装で説明される。
Warp の開発中に適切なデータ構造が選択された例として他には Builder と IORef がある。それぞれ HTTP レスポンスのコンポーザーと接続に対するタイマーで説明される。
HTTP リクエストのパース
マルチコア環境における効率的な並列化と I/O に関する様々な問題を解決するのに加えて、Warp は中心的なコンポーネントのそれぞれでタスクを効率良く実行する必要もある。この話題に最も関係するのは HTTP リクエストに対する処理である。この処理は内向きソケットからバイト列を受け取り、そのバイト列からリクエストラインとヘッダーをパースし、以降のリクエストボディをアプリケーションのために取り置く。この処理によって、アプリケーション (Yesod アプリケーションや mighty など) がレスポンスを構築するのに利用するデータ構造が生成される。
リクエストボディの扱いにも厄介な点がある。Warp はチャンクに分割されたリクエストボディと HTTP パイプラインを完全にサポートする。そのため、チャンクに分割されたリクエストボディを結合してからアプリケーションに渡す必要がある。また、HTTP パイプラインが有効だと複数のリクエストが単一の接続を通して送られるので、Warp は次のリクエストのヘッダーが含まれる部分をアプリケーションに渡さないように注意する必要がある。さらに、リクエストボディの末尾にある余計なデータを捨てる必要もある: そうしないと、残りの部分が次のリクエストとして誤解される可能性が生じる。
例えば、クライアントから次のリクエストを受け取ったとする:
POST /some/path HTTP/1.1
Transfer-Encoding: chunked
Content-Type: application/x-www-form-urlencoded
0008
message=
000a
helloworld
0000
GET / HTTP/1.1
HTTP リクエストパーサーはパス名 /some/path と Content-Type ヘッダーを抽出し、アプリケーションに渡す。さらに、リクエストボディからチャンクヘッダー (0008 と 000a) を除去した実際のコンテンツ message=helloworld もアプリケーションに渡す。チャンクの末尾 0000 以降のバイトはパイプライン化された次のリクエストなので、この部分をアプリケーションに渡してはいけない。
パーサーの実装
Haskell は強力なパーサーを書くのに適した言語として知られている。Haskell で書かれた古典的なパーサージェネレータだけではなく、Parsec や Attoparsec といったパーサーコンビネータライブラリも存在する。Parsec と Attoparsec のテキストモジュールは Unicode を完全に認識するスタイルで動作する。しかし HTTP ヘッダーは ASCII であることが保証されているので、Unicode を認識する機能はオーバーヘッドを生むだけの余計な機能となる。
一応 Attoparsec はバイト配列をパースするインターフェースも提供する。しかし、Attoparsec ほどに高速なライブラリであっても、手で書いたパーサーと比べればオーバーヘッドは存在する。そのため Warp ではパーサーライブラリを使用せず、手書きのコードでパースをすることになった。
このとき疑問が生まれる: 実際のバイナリデータをどう表すべきだろうか? 私たちが採用した答えは ByteString である。ByteString は本質的に「メモリを指すポインタ」「ポインタからデータの開始位置までのオフセット」「データのサイズ」という三つのデータから構成される。
オフセットの情報は冗長に思える: ポインタが指す位置をデータの開始位置と定めれば、オフセットを記録する必要はない。しかしオフセットを用意すると、データの共有が可能になる。つまり、複数の ByteString が同じメモリ領域の異なる部分をさせるようになる (この手法はスプライシングと呼ばれる)。ByteString 型の値は (Haskell のほとんどの値と同様に) 改変不可能なので、データが破損する心配はない。特定のメモリ領域へのポインタが全て破棄されると、対応するメモリバッファがデアロケートされる。
この組み合わせは Warp にとって完璧だった。クライアントがソケット越しにリクエストを送信すると、Warp はそのデータを比較的大きな (現在 4096 バイトの) チャンクを使って読み込む。多くのケースで、リクエストラインと全てのリクエストヘッダーは一つのチャンクに収まる。その後、Warp は手書きのパーサーを使ってチャンクを行に分割する。この処理は、次の理由により効率的に行える:
- メモリバッファに対して改行文字だけが検索される。この処理を行うヘルパー関数が
ByteStringライブラリに存在し、memchrといった低レベルの C 関数を使って実装されている (複数行にまたがるヘッダーが存在するので処理はこれほど単純ではないものの、基本的なアプローチは変わらない)。 - データを保持するメモリバッファを別にアロケートする必要がない。オリジナルのバッファに対する参照を作成すれば済む。データの大きなチャンクに含まれる様々な要素を参照として切り出す様子を図 11.9 に示す。次の点は強調に値する: この手法を使ったパースはイディオマティックな C で書いたパースより効率的になる。C では文字列がヌル終端を持つので、バッファから部分文字列を切り出すには新しいメモリバッファのアロケートとデータのコピー、そしてヌル終端の追加が必要になる。
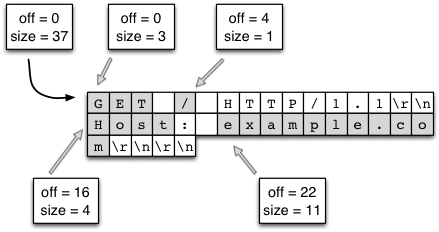
ByteString の一部を参照として切り出す (スプライシング)
バッファが行ごとに分割されると、同様の処理でヘッダー行がキーとバリューの組に分割される。リクエストラインのパースでは、リクエストパスの取り扱いが少し複雑になる。例として次のリクエストラインを考えよう:
GET /buenos/d%C3%ADas HTTP/1.1
このとき、パーサーは次のステップを実行する必要がある:
- リクエストラインをリクエストメソッド、パス、バージョンに対応する三つの部分に分割する。
- パスを前向きスラッシュで分割し、
["buenos", "d%C3%ADas"]を得る。 - パーセントでエスケープされた文字をデコードし、
["buenos", "d\195\173as"]を得る。 - 十進でエスケープされた部分を UTF-8 としてデコードし、最終的な結果
["buenos", "días"]を得る。
この処理で可能な最適化がいくつかある:
- 改行文字の検索と同じように、前向きスラッシュの検索もライブラリ関数で行う。
- 十六進文字を数値に変換するときは、ルックアップテーブルを利用する。分岐のない一度のメモリ読み込みで変換が行える。
- UTF-8 のデコードは text パッケージの非常に最適化された関数を利用する。同様に、text パッケージを使うと効率的な詰めた表現でデータを表せる。
- Haskell は遅延評価なので、以上の計算は必要になってから行われる。もしアプリケーションがパスのテキスト表現を必要としないなら、これらのステップは実行されない。
パースの最後の処理として、リクエストボディを構成するチャンクの結合が行われる。この処理はリクエストのパースほどは難しくない。十六進数を一つ読み、それだけのバイトを読めば済む。読んだバイトはそのまま (バッファにコピーされずに) アプリケーションに渡される。
Conduit
本章ではリクエストボディをアプリケーションに渡す処理に何度か言及してきた。リクエストボディを受け取ったアプリケーションはレスポンスをサーバーに返し、サーバーはソケットを使ったデータの送受信を行う。最後に紹介する要素としてミドルウェア (middleware) がある。ミドルウェアはサーバーとアプリケーションの間に配置され、リクエストやレスポンスの改変を行う。ミドルウェアの型は次のように書ける:
type Middleware = Application -> Application
簡単に言えば、ミドルウェアはリクエストに事前処理を施し、その結果を「内部」のアプリケーションに渡し、そのアプリケーションからのレスポンスに後処理をして返す。分かりやすい例として gzip ミドルウェアがある: このミドルウェアはレスポンスのボディを自動的に圧縮する。
ミドルウェアの作成を可能にするには、入力および出力のデータストリームを改変する手段が必要になる。Haskell の世界では lazy I/O がこういった問題に対する標準的なアプローチである。lazy I/O を使うと、値のストリームを単一の純粋データ構造として表せる。このデータ構造にデータをリクエストすると、ソースに対して I/O 操作が実行されてデータが返される。lazy I/O は非常に高い合成可能性を提供する。しかし、高スループットサーバーでは大きな障害が一つある: lazy I/O では、リソースのファイナライズが非決定的になる。つまり、lazy I/O をサーバーで使うと高負荷時にファイルディスクリプタがすぐに不足する。
さらに、lazy I/O を使うとき低レベルな抽象化は使えなくなるので、読み込みと書き込みを行う関数は直接呼び出せない。Haskell が持つ利点の一つは明快なコードを可能にする高レベルな抽象化であるものの、それをウェブアプリケーションの作成で生じる一般的な問題の解決にも利用できるかどうかには一考の余地がある。例えば、最初に一定量のデータを読んで処理した後、残りの部分はコードベースの他の部分 (ウェブアプリケーション) で読み込むようなバッファリングが必要になるケース (リクエストヘッダーの処理など) もある。
このジレンマを解消するため、WAI プロトコル (そして Warp) は conduit パッケージを使って実装される。conduit はデータのストリームを表す抽象化を提供する。lazy I/O が持つ合成可能性をほぼ保ちつつ、バッファリングの細かな制御と決定的なリソース管理を conduit は提供する。また、例外は「純粋」なデータ構造に隠されるのではなく、I/O を扱うユーザーのコードまで伝達される。
Warp ではクライアントからの内向きバイトストリームを Source と呼び、クライアントに送信する外向きバイトストリームを Sink と呼ぶ。Application は Source を通してリクエストボディを受け取り、レスポンスも Source として提供する。ミドルウェアはリクエストまたはレスポンスを表す Source に割り込み、そのデータを改変する。図 11.10 に Warp とアプリケーションの間に配置されるミドルウェアを示す。conduit パッケージの高い合成可能性により、この操作は簡単かつ効率的に行える。
gzip ミドルウェアを例に取って説明しよう。conduit があることで、このミドルウェアは最適に近い動作が可能となる。アプリケーションが提供するオリジナルの Source は gzip ミドルウェアの Conduit に接続される。新しいデータチャンクが生成されると zlib ライブラリに入力され、圧縮されたバイト列がバッファに書き込まれる。バッファが埋まると、その中身が Warp もしくは次のミドルウェアに渡される。次のコンポーネントは圧縮されたバッファを受け取り、ミドルウェアなら特定の処理を行ってから、さらに次のコンポーネントに送信する。次のコンポーネントが送信を完了した時点で gzip ミドルウェアはバッファの再利用または解放が可能となる。こうするとメモリ使用量は最適となり、ネットワークで障害が発生したときに余計なデータが生成されることはなく、ランタイムシステムのガベージコレクションからの負荷も小さい。
conduit は大きなトピックなので、これ以上詳しくは説明しない。conduit は Warp の高いパフォーマンスを可能にする要因の一つだと記しておけば十分だろう。
slowloris 攻撃に対する対策
最後に懸念事項が一つある: slowloris 攻撃である。これはサービス拒否 (Denial of Service, DoS) 攻撃の一種であり、サーバーに接続した大量のクライアントが非常に少量のデータを送信する。このとき、クライアント側 (攻撃者) は同じハードウェアと帯域で通常より多い接続を保持できる。ウェブサーバーではオープンされた接続のそれぞれが転送されるデータの量と関係ない一定のオーバーヘッドを持つので、これは効率的な攻撃となる。そのため、Warp は少量しかデータを送信していない接続を検出してクローズする必要がある。
slowloris 攻撃対策の最も重要な要素であるタイムアウトマネージャについては後で詳しく議論する。リクエストを処理するコードでは、データをクライアントから受け取ったときにタイムアウトハンドラをリセットするだけでよい。Warp は conduit レベルでこれを行う。先述したように、内向きのデータストリームは Source として表される。Source が行う処理の一貫として、新しいデータチャンクを受け取るたびにタイムアウトハンドラをリセットする。タイムアウトハンドラのリセットはコストが非常に低い操作 (一度メモリに書き込むだけ) なので、この slowloris 攻撃対策によって個別の接続のパフォーマンスが大きく低下することはない。
HTTP レスポンスのコンポーザー
本節では HTTP レスポンスを組み立てる Warp のコンポーネント (コンポーザー) を説明する。Warp で WAI のレスポンスを表す Response 型はコンストラクタを三つ持つ:
ResponseFile Status ResponseHeaders FilePath (Maybe FilePart)
ResponseBuilder Status ResponseHeaders Builder
ResponseSource Status ResponseHeaders (Source (ResourceT IO) (Flush Builder))
ResponseFile は静的ファイルの配信で利用され、ResponseBuilder と ResponseSource はメモリ上に構築される動的コンテンツの配信で利用される。どのコンストラクタも Status と ResponseHeaders を引数に持つ。ResponseHeaders はレスポンスのヘッダーを表すキーバリューペアのリストとして定義される。
HTTP レスポンスヘッダーのコンポーザー
以前の Warp は Builder という rope 風のデータ構造を使って HTTP レスポンスヘッダーを組み立てていた。まず、Warp は Status と ResponseHeaders の各要素を Builder に変換する。それぞれの変換は O(1) 時間で完了する。その後、Warp は Builder を一つに連結する。Builder の性質により、二つの Builder の連結は O(1) 時間で完了する。最後に、Builder から HTTP レスポンスヘッダーがバッファ上に構築される。この処理には O(N) の時間がかかる。
Builder は多くのケースで十分なパフォーマンスを持つものの、高パフォーマンスサーバーで使うには速度が十分でないことを私たちは発見した。Builder のオーバーヘッドを削減するため、Warp では徹底的にチューニングされた C 関数 memcpy を利用する特別なコンポーザーが実装された。
HTTP レスポンスボディのコンポーザー
ResponseBuilder と ResponseSource では、アプリケーションによって提供される Builder の値が ByteString のリストに変換される。そのリストの先頭に組み立てられたヘッダーをつけたものが send によって固定バッファに送信される。
ただし、ResponseFile ではレスポンスヘッダーにだけ send が利用され、レスポンスボディには sendfile が利用される。このケースは図 11.7 の右下に示されている。なお、接続に対するタイマーで説明されるキャッシュの仕組みがあるために、この処理で open, stat, close といったシステムコールが余計に呼ばれることはない。次項では ResponseFile の処理のパフォーマンスチューニングを説明する。
ヘッダーとボディをまとめて送信する
Warp で静的ファイルを配信するときのパフォーマンスを測定したところ、並列性が高い (複数の接続を同時に処理する) ときは優れた結果が得られるのに対して、並列性を 1 にすると Warp が非常に遅くなることが判明した。
tcpdump コマンドの結果を確認したところ、この原因は Warp がヘッダーに writev を利用し、ボディに sendfile を利用することにあった。こうすると、HTTP レスポンスのヘッダーとボディが個別の TCP パケットで送信される (図 11.11)。
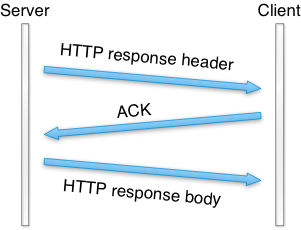
可能な場合は一つの TCP パケットでレスポンスを送信するために、新しい Warp では writev ではなく send を使うようになった。send には MSG_MORE フラグが付けられ、続く sendfile の呼び出しがバッファに格納されたヘッダーとファイル両方の送信を開始する。スループットベンチマークによると、この工夫によってスループットは少なくとも 100 倍になった。
タイマーを使ったクリーンアップ
本節では Warp における接続のタイムアウトとファイルディスクリプタのキャッシュの実装を説明する。
接続に対するタイマー
slowloris 攻撃に対する対策として、クライアントが一定の時間にわたってデータを少量しか送信しない場合、そのクライアントとの接続はクローズされる。Haskell の標準ライブラリには timeout 関数があり、次の型を持つ:
Int -> IO a -> IO (Maybe a)
一つ目の引数はタイムアウトの秒数 (単位はマイクロ秒) を表す。二つ目の引数は入出力 (IO) を処理する操作を表す。timeout 関数は IO コンテキストの Maybe a を返す。Maybe は次のように定義される:
data Maybe a = Nothing | Just a
Nothing はエラーを (理由は明示せずに) 表し、Just は成功した処理の結果 a を表す。そのため、timeout 関数が Nothing を返すとき、操作は指定された時間の間に完了していない。操作が時間通りに完了すれば、操作の返り値が Just に包まれて返る。timeout 関数は Haskell の高い合成可能性を示す例と言える。
timeout 関数は様々な用途で有用となる。しかし、高パフォーマンスサーバーの実装で使えるほどのパフォーマンスは持たない。問題は timeout 関数が呼び出されるたびにユーザースレッドをスポーンすることにある。ユーザースレッドはシステムスレッドよりはコストが低いものの、呼び出されるたびに積み重なるオーバーヘッドが存在する。このため、Warp はユーザースレッドを一つだけ利用するタイムアウトシステムを持つ。このユーザースレッドはタイムアウトマネージャを実行し、全ての接続のタイムアウトを管理する。このシステムの中心的なアイデアは次の二つである:
- 二つの
IORef - 安全な swap and merge アルゴリズム
接続の状態が Active と Inactive の二つで表されるとする。非アクティブな接続を削除するために、タイムアウトマネージャは各接続の状態を定期的に確認する。もし Active な接続がタイムアウトしたら、タイムアウトマネージャは状態を Inactive に切り替える。もし Inactive な接続がタイムアウトしたら、タイムアウトマネージャは対応するユーザースレッドを kill する。
各接続は一つの IORef で表される。IORef は値を破壊的に更新できる参照であり、タイムアウトマネージャに加えて、各ユーザースレッドも接続がアクティブに持続する限り自身が持つ IORef を通して定期的に接続の状態を Active に変更する。
タイムアウトマネージャは各接続の状態をまとめた IORef のリストを保持する。新しい接続に対応するユーザースレッドがスポーンすると、新しく作成された Active 状態に対する IORef がタイムアウトマネージャのリストに追加される。このため、このリストに対する操作はクリティカルセクションに属し、リストの一貫性を保つにはアトミック命令が必要となる。
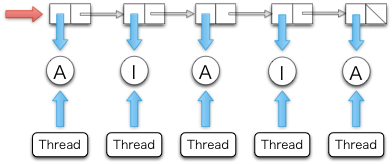
A は Active を表し、I は Inactive を表す)
Haskell で一貫性を保つための標準的な方法として MVar がある。しかし MVar は自家製のロックを使ってアクセスを保護するので遅い。そこで、Warp はリスト自体に対する IORef を用意して、それを atomicModifyIORef で操作する。atomicModifyIORef は IORef の値をアトミックに更新する関数であり、ロックではなく compare-and-swap (CAS) 命令を使うので高速に動作する。
安全な swap and merge アルゴリズムのアウトラインを次に示す:
do xs <- atomicModifyIORef ref (\ys -> ([], ys)) -- 空リスト [] と置き換える
xs' <- manipulates_status xs
atomicModifyIORef ref (\ys -> (merge xs' ys, ()))
まずタイムアウトマネージャはリストを空のリストにアトミックに置き換える。その後、接続状態の変更や kill されたユーザースレッドに対応する不必要な状態の削除といった操作をリストに加える。この処理の間も新しい接続の作成は可能であり、新しい接続の状態を指す IORef は対応するユーザースレッドの atomicModifyIORef によってリストに挿入される。その後、タイムアウトマネージャは操作が完了したリストと新しいリストをマージする。Haskell の遅延評価のおかげで merge 関数の適用は O(1) 時間で完了し、O(N) 時間がかかるマージ操作は値が実際に利用されるまで遅延される。
ファイルディスクリプタに対するタイマー
Warp が特定のファイル全体を sendfile で送信するケースを考えよう。残念なことに、Linux の sendfile は送信するバイト数を要求するので、最初に stat を呼び出してファイルのサイズを取得する必要がある (FreeBSD/MacOS の sendfile は 0 を「ファイルの末尾まで」を意味するマジックナンバーとして解釈する)。
WAI アプリケーションがファイルのサイズを知っているなら、Warp で stat を呼び出す必要はない。WAI アプリケーションはファイルのサイズや最終更新時刻といった情報を簡単にキャッシュできる。キャッシュのタイムアウトを短く (例えば 10 秒に) 設定しておけば、キャッシュの一貫性はそれほど問題にならない。また、キャッシュは安全にクリーンアップできるので、メモリのリークも問題にならない。
sendfile はファイルディスクリプタを要求するので、ファイルを送信するナイーブなアプローチは「open, sendfile, close を毎回呼び出す」となる。本節では、ファイルディスクリプタをキャッシュして open と close の呼び出しを最小限にする方法を説明する。ファイルディスクリプタのキャッシュは次のように動作するはずである: クライアントがファイルの送信をリクエストすると、そのファイルがサーバーで open される。その直後に別のクライアントが同じファイルをリクエストした場合、以前に open されたファイルディスクリプタが再利用される。どのユーザースレッドにも使われない時間がしばらく続けば、ファイルディスクリプタは close される。
こういった処理では参照カウントが使われることが多い。ただ、ロバストな参照カウントを私たちが本当に実装できるかどうかは分からなかった。ユーザースレッドが予期しない理由で実行を停止したら? 参照カウントを減らす処理が飛ばされると、対応するファイルディスクリプタはリークする。その後、接続のタイムアウトを処理する方式がファイルディスクリプタのキャッシュにも利用できることに私たちは気が付いた。この方式なら参照カウントを使わないで済む。ただ、タイムアウトマネージャを単純に再利用できない理由がいくつか存在する。
各ユーザースレッドは自身の状態を持つ ── その状態は共有されない。しかし、open と close を避けるためにファイルディスクリプタをキャッシュするには、状態を共有しなければならない。そのため、キャッシュされたファイルディスクリプタを一元管理する場所を用意して、リクエストされたファイルに対するファイルディスクリプタはそこから検索することになる。この検索は高速でなければならないので、データ構造としてリストは利用できない。また、リクエストは並列に処理されるために同じファイルに対する複数のファイルディスクリプタが存在する状況があり得るので、複数のファイルディスクリプタを単一のファイル名に関連付けられる必要がある。こういった特徴を持つデータ構造として multimap がある。
私たちが実装したのは検索が O(log N) 時間で枝刈りが O(n) 時間の赤黒木であり、非空のリストをノードに持つ。赤黒木は二分探索木なので、探索はノードの個数を N として O(log N) 時間で実行できる。また、順序付きリストへの変換も O(N) 時間で実行できる。私たちの実装では、このステップで close すべきファイルディスクリプタを持つノードの枝刈りも行われる。順序付きリストを赤黒木に O(N) 時間で変換するアルゴリズムも実装されている。
予定されている機能
Warp を改善するアイデアはいくつかある。ここでは二つを説明する。
メモリアロケーションの最適化
パケットを送受信するとき、バッファがアロケートされる。このバッファは recv や send といった C 関数に渡せる必要があるので、Warp は「ピン止め」された (ガベージコレクトされない) バイト配列としてパケット送受信用バッファをアロケートする。システムコールごとに読み書きするバイトは多い方が望ましいので、こういったバッファはそれなりの大きさを持つ。残念ながら、GHC で大きな (64 ビットマシンでは 409 バイトより大きい) ピン止めバイト配列をアロケートすると、ランタイムシステムでグローバルなロックが取得される。コアのユーザースレッドが頻繁にバッファをアロケートする場合、このロックはコアが多いシステムにおけるスケールでボトルネックとなる。
初期調査として、私たちは HTTP レスポンスヘッダーの生成においてピン止めバイト配列のアロケートが持つパフォーマンスに対する影響を測定した。こういった測定で利用できるツールとして、GHC はランタイムシステム内のイベントをタイムスタンプと共に記録する eventlog を提供する。ユーザーイベントを記録する関数でメモリをアロケートする関数を包んでから mighty を再コンパイルし、eventlog でイベントを記録した。この測定結果を次に示す:
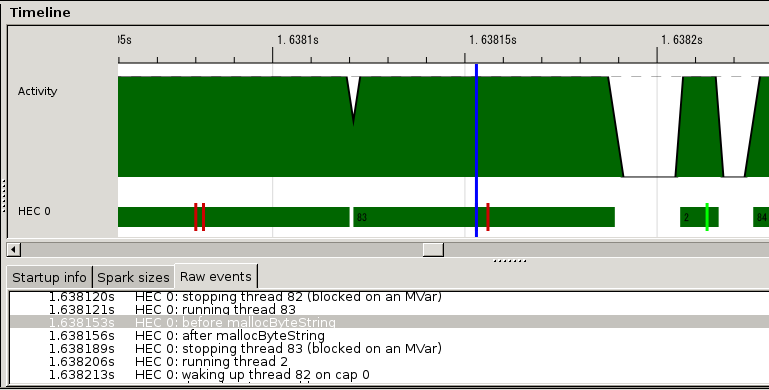
eventlog による測定結果
赤い縦線がユーザーイベントを表し、二つの赤い縦線に囲まれた部分がメモリアロケーションにかかった時間を表す。測定結果からは HTTP セッションの約 1/10 がメモリアロケーションに費やされていると判明した。私たちはロックを使わないメモリアロケーションの実装を議論している。
新しい thundering herd
thundering herd は「古くて新しい」問題である。事前に fork された複数のプロセス (またはネイティブスレッド、以下省略) が共通のソケットにリッスンし、accept で接続を待機しているとする。古い Linux と FreeBSD の実装では、新しい接続が作成されたときに全てのプロセスがブロックを解かれていた。しかし accept が返るのは一つのプロセスだけであり、その他のプロセスはすぐにブロックされた状態に戻る。このときコンテキストスイッチが大量に引き起こされ、パフォーマンスの問題が生じる。この問題を thundering herd と呼ぶ。最近の Linux と FreeBSD の実装では一つのプロセスでだけブロックが解除されるので、この問題は過去のものとなった。
最近のネットワークサーバーは epoll ファミリーの関数を利用することが多い。複数のワーカーが同じソケットにリッスンし、epoll ファミリーの関数で接続を操作する状況では、thundering herd がまた姿を現す。epoll ファミリーの関数が全てのプロセスに通知を行うためである。この「新しい」 thundering herd 問題は nginx と mighty の両方で発生する。
Warp の並列 I/O マネージャでは新しい thundering herd 問題が発生しない。一つの I/O マネージャだけが epoll ファミリーの関数で新しい接続を受理するアーキテクチャを採用しているためである。他の I/O マネージャは確立済みの接続を処理する。
結論
Warp は高機能なウェブサーバーライブラリであり、多くの用途に対応する高効率の HTTP 通信を提供する。高いパフォーマンスを達成するために、ネットワーク通信、スレッド管理、リクエストパースといった様々なレベルで最適化が行われている。
そういったコードベースを書く上で、Haskell は素晴らしい言語だった。「値はデフォルトで改変不能」といった機能によってスレッドセーフなコードが書きやすくなり、余計なバッファのコピーも減る。また、マルチスレッド対応のランタイムによってイベント駆動コードが格段に書きやすくなる。さらに、GHC の強力な最適化機能は、高レベルなコードを書いたとしても多くのケースで高いパフォーマンスの恩恵を受けられることを意味する。高いパフォーマンスにもかかわらず、Warp のコードベースは比較的小さい (執筆時点で 1300 SLOC 以下)。メンテナンスが容易で、効率的で、並列なコードを書きたいと思っているなら、Haskell は有力な選択肢となるはずである。