頂点プロセッシング
現時点で、アプリケーションが発したドローコールは様々なドライバレイヤーを経てコマンドプロセッサに到達した。そしてついに、ドローコールに対応する何らかのグラフィックス処理が開始される! この章では頂点パイプラインについて説明する。ただその前に...
アルファベットスープを召し上がれ!
これから正真正銘の 3D パイプラインを見ていく。3D パイプラインは複数のステージから構成され、それぞれのステージが一つの特定の仕事を行う。このシリーズで解説する全てのステージの名前と省略形を次に示す──ほとんどは D3D10/11 の "公式な" 名前に従っている。この周遊旅行で各ステージをいずれ説明するが、全てをカバーするにはしばらく (数章分の) 時間がかかるだろう──真面目な話、私はカバーしたい話題に関して簡単なアウトラインを作ったのだが、それによると私はこのシリーズに最低でも二週間は取り組むことになるようだ! ともかく、見てほしい。各ステージの処理の簡単な説明も示した:
- IA ── インプットアセンブラ (input assembler)。インデックスデータと頂点データを読み込む。
- VS ── 頂点シェーダー (vertex shader)。入力に頂点データを受け取り、処理された頂点データを次のステージに書き出す。
- PA ── プリミティブアセンブリ (primitive assembly)。プリミティブを構成する頂点を読み込み、プリミティブを組み立てて次のステージに渡す。
- HS ── ハルシェーダー (hull shader)。パッチプリミティブを受け取り、変形した (または変形していない) パッチ制御点 (ドメインシェーダーに対する入力) およびテッセレーションで使われる追加データを書き出す。
- TS ── テッセレータステージ (tessellator stage)。テッセレートされた直線または三角形の頂点と接続関係を生成する。
- DS ── ドメインシェーダー (domain shader)。計算された制御点と追加データを HS から、テッセレートされた位置を TS から受け取り、再度頂点へと変形する。
- GS ── ジオメトリシェーダー (geometry shader)。省略可能な隣接情報が付いたプリミティブを受け取り、異なるプリミティブを出力する。SO に対する主要なハブでもある。
- SO ── ストリームアウト (stream-out)。GS の出力 (変形されたプリミティブ) を受け取り、メモリ上のバッファに書き込む。
- RS ── ラスタライザ (rasterizer)。プリミティブのラスタライズを行う。
- PS ── ピクセルシェーダー (pixel shader)。補間された頂点データを受け取り、ピクセルの色を出力する。アンオーダードアクセスビュー (unordered access view, UAV) に書き込むこともできる。
- OM ── 出力マージャー (output merger)。計算されたピクセルの色を PS から受け取り、アルファブレンドを行った上でピクセルをバックバッファに書き込む。
- CS ── コンピュートシェーダー (compute shader)。これ自身で一つのパイプラインとなる。定数バッファとスレッド ID だけが入力となる。バッファと UAV に書き込める。
これで名前は片付いたので、次は本シリーズでこれから解説するデータパスを示そう。IA, PA, RS, OM のステージはここに入れていないが、これは私たちが考える用途においてこれらのステージがデータに対しては何も行わないためである。つまりデータを組み替えたり並び替えたりするだけであり、本質的には "グルー" のステージと言える。
- VS→PS: 古くからあるプログラマーブルパイプライン。D3D9 にはこれしかない。普通のレンダリングで圧倒的に最も重要なパスである。本シリーズでは最初にこのパスを最後まで解説し、それが終わってからキラキラした機能を持つ他のパスについて話をする。
- VS→GS→PS: ジオメトリシェーディング (D3D10 で新しく追加された)。
- VS→HS→TS→DS→PS, VS→HS→TS→DS→GS→PS: テッセレーション (D3D11 で新しく追加された)。
- VS→SO, VS→GS→SO, VS→HS→TS→DS→GS→SO: ストリームアウト (テッセレーション付きおよびテッセレーション無し)。
- CS: コンピュート (D3D11 で新しく追加された)。
これで見通しが付いたと思う。ではインプットアセンブラと頂点シェーダーから解説を始めよう!
インプットアセンブラ
インプットアセンブラ (IA) で最初に起こるのはインデックスバッファの読み込みである──ただしこれが起こるのはインデックス付きバッチのときで、そうでなければ恒等インデックスバッファ (1, 2, 3, 4, ...) が代わりに使われる。インデックスバッファが存在するなら、その要素はこの時点でメモリから読み込まれる──正確に言うと直接読み込まれるのではなく、インデックスバッファと頂点バッファが持つアクセスの局所性を活用するためのデータキャッシュを IA は普通持っている。またインデックスバッファの読み込み (実は D3D10+ における任意のリソースアクセス) では境界検査が行われることにも注意してほしい: オリジナルのインデックスバッファの外側にある要素を参照しようとする (例えば 5 要素のバッファに対して IndexCount == 6 とした DrawIndexed を発行する) と、境界外の読み込みは全てゼロを返す。この動作は (この例では) 全く役に立たないが、定義された動作となっている。同様にインデックスバッファを NULL とした DrawIndexed の発行もできる──このときサイズがゼロのバッファがセットされたかのように振る舞う。つまり全ての読み込みが境界外となり、ゼロが返る。D3D10+ で未定義動作を踏むにはもう少し頑張らないといけない :)
インデックスが用意できれば、頂点ごとのデータとインスタンスごとのデータを入力の頂点ストリームから読み取る準備が整う (このステージのインスタンス ID はただのカウンターあり、難しいところはない)。この読み取りはとても簡単に行える──データレイアウトの宣言を持っているのだから、キャッシュまたはメモリからその通りに読んで、シェーダーコアが入力として要求する浮動小数点のフォーマットに変換すれば終わりだ。しかし、この読み込みはいつも行われるわけではない: ハードウェアはシェーダーを通過した頂点のキャッシュを管理するので、一つの頂点が複数の三角形で参照される (例えば閉で完全正則な三角形メッシュでは、各頂点が平均で六個の三角形から参照される!) なら、その頂点を毎回シェーダーに入力する必要はない──シェーダーを通過したデータが既にあるのだから、それを使えばよい!
頂点キャッシュと頂点シェーディング
注意: この節に書かれていることは、ある程度、当て推量を含んでいる。現代的な GPU に "精通" している人々がパブリックに発しているコメントを参考にして書かれてはいるが、そういったコメントを読んでも "what" が分かるだけで "why" は分からず、そこは自分で考えるしかない。この節の細かい部分は私が推定したものであるというわけだ。ただそうは言っても、全くお話にならないデタラメを書いているつもりはない──自分が説明していることが (一般的な意味で) 合理的で筋が通っていることには自信を持っている。ただ実際の HW でそうなっていること、およびトリッキーな詳細を見落としていないことは保証できない :)
本題に入ろう。長い間 (具体的にはシェーダーモデル 3.0 の GPU まで)、頂点シェーダーとピクセルシェーダーはパフォーマンスに関して異なるトレードオフを持つ異なるユニットで実装されており、頂点キャッシュは非常に単純な代物だった: 少数 (一、二ダース程度) の頂点を保持できる FIFO があるだけで、出力アトリビュートの最大数が収まるだけの空間が用意され、頂点インデックスがタグとして使われた。前述の通り、非常に単純なものである。
そんなときにユニファイドシェーダーがやってきた。元々は異なっていた二種類のシェーダーが統合されるとき、必ず妥協が生じることになる。一方の頂点シェーダーは通常の利用で一フレームごとに (当時) 最大でも 100 万個ほどの頂点に触れるが、もう一方のピクセルシェーダーはスクリーン全体を定数で埋めるだけでも 1920×1200 の解像度では 230 万個のピクセルに触れなくてはならない──複雑なレンダリングではこれよりずっと多くなる。さて、貧乏くじを引くのはどちらのユニットだろう?
よし、状況を整理しよう: 古い頂点シェーダーユニットでは (大まかに言って) 頂点を一つずつシェーダーに入力していた。しかしユニファイドシェーダーユニットという新たな怪物はレイテンシではなくスループットを最大化するように設計されており、そのため大きなバッチで仕事をすることを望んでいる (どれくらいの大きさか? 現在、シェーダーにバッチとしてまとめて入力される頂点の個数を表すマジックナンバーは 16 から 64 程度であるようだ)。
つまり頂点シェーディングの効率を落とさないためには、16 個から 64 個の頂点キャッシュミスが起こるのを待ってからそれらを頂点シェーダーに対する一つのロードとしてまとめてディスパッチする必要がある。しかし、頂点キャッシュミスをまとめて一つのバッチにするこのアイデアと FIFO は上手く噛み合わない。問題はこれだ: 複数の頂点をバッチとしてまとめてシェーダーに入力するということは、それらに対するシェーダーの処理が終わるまで三角形のアセンブルを始められないことを意味する。バッチに含まれる頂点 (以降では 32 個とする) 全てを FIFO の終端に追加するとき、最も古い 32 個の頂点が FIFO から削除されることになるが、その頂点はアセンブルしようとしている現在のバッチに含まれる三角形の頂点に対する頂点キャッシュヒットであるかもしれない! うーむ、これではだめだ。明らかに、最も古い 32 個の頂点は頂点キャッシュヒットとみなしてはいけない。そのヒットを参照するときには削除されてしまうのだから! この FIFO はどれくらいの大きさにすればよいだろうか? 一つのバッチに 32 個の頂点が含まれるなら、FIFO は最低でも 32 エントリー分の容量を持つ必要がある。しかし最も古い 32 個のエントリーは (バッチの結果によって押し出されるために) 使えないので、容量が 32 エントリー分しかないと全てのバッチが空の FIFO を持って始まることになる。なら少し大きくしよう。64 エントリー分ならどうだろう? しかし、これは非常に大きい。頂点キャッシュの検索では FIFO に含まれる全てのタグ (頂点インデックス) と考えている頂点のタグを比較する必要があることに注意しなければならない──これは全て並列に実行できるが、電力食い虫でもある。なにせ、これはフルアソシアティブ方式のキャッシュを実装しているのに実質等しいのだ。また、シェーダーへのロードとして 32 個の頂点をディスパッチしてから結果を受け取るまで何をしていればよいのだろう? ただ待つ? シェーダーの処理は数百サイクルかかるので、ただ待つのは馬鹿なアイデアに思える! では二つのシェーダーロードを同時に並列実行してはどうか? いやそうすると、FIFO は最低でも 64 エントリー分の容量を持たなければならず、最も古い 64 個のエントリーは (バッチの結果で押し出されるので) 頂点キャッシュヒットとみなせなくなる。というかそもそも、シェーダーコアが大量にあるのに FIFO が一つだけなのはどうなのか? アムダールの法則はここでも成り立つ──絶対に直列でなければならない要素を他の部分は完全に並列なパイプラインに加えるというのは、ボトルネックを作る確実な方法と言える。
つまり FIFO はどうやってもこの環境に上手く適合させることができない。というわけで、このアイデアは捨ててしまおう。最初からやり直しだ。ここでの狙いは何だろう? それは、それなりの個数の頂点からなるバッチをシェーダーに入力しつつも、必要より (はるかに) 多い頂点をシェーダーに入力しないようにすることである。
なら、単純にしよう: バッチに送る頂点を入れる 32 頂点 (= バッチ一つ分) のバッファと 32 エントリーのキャッシュタグ用の空間 (キャッシュタグアレイ) を用意し、全てのエントリーが空の状態からスタートする。インデックスバッファに含まれるプリミティブごとに、各頂点が現在処理中のキャッシュタグアレイに含まれるかどうかの探索を行う: 含まれるなら、なにもしない。含まれないなら、一バッチ分の大きさを持つ前述のバッファにスロットを一つアロケートし、現在のインデックスをキャッシュタグアレイに加える。新しいプリミティブを加えるだけの空間がバッファに無くなったら、バッファをバッチとして頂点シェーダーにディスパッチして、キャッシュタグアレイ (つまり今シェーダーに送った 32 頂点のインデックス) を保存し、次のバッチを埋める処理を始める。そのとき次のバッチの処理は空のキャッシュから始まり、全てのバッチが完全に独立することが保証される。
各バッチはシェーダーユニットをしばらくの間 (おそらく最低でも数百サイクル!) 忙しくするが、シェーダーユニットは大量に存在するので問題にならない──バッチを実行するたびに違うユニットを選ぶことができる! 並列性の魔法だ。しばらくすると結果が返ってくるので、保存しておいたキャッシュタグアレイと元のインデックスバッファのデータを使ってプリミティブの組み立てを行い、完成したプリミティブをパイプラインの次のステージへ送信する (これが後で触れる「プリミティブアセンブリ」の処理である)。
ところで、前の段落で「結果が返ってくる」と言ったが、これは何を意味しているのだろう? 返ってきたデータはどこに収まるのか? 主な選択肢は次の二つだ:
- 専用のバッファ
- 一般的なキャッシュ/スクラッチパッドメモリ
かつては 1. が使われていて、専用のバッファは頂点データを元に設計された固定の構成を持っていた (頂点ごとにアトリビュート用の float4 が 16 個、など)。しかし最近の GPU は 2. に移行しているように思える。つまり "ただのメモリ" にデータを格納するのである。こうすれば柔軟性が増す上に、このメモリを他のシェーダーステージで使えるという明確な利点もある。これに対して専用の頂点キャッシュのようなものは、(例えば) ピクセルシェーディングやコンピュートパイプラインで使うことができない。
更新: ここまでに説明した頂点シェーディングのデータフローを示す図を描いた。
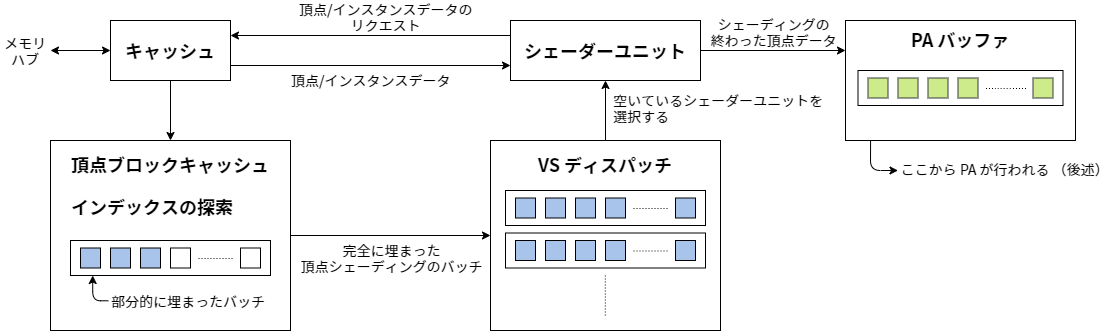
シェーダーユニットの内部構造
短く言うと: HLSL コンパイラの出力をディスアセンブリした結果から想像できる通りになっている (fxc と dumpbin が友達だ!)。何って、そういった種類のコードをシェーダーユニットは超高速に実行できなければならない。ハードウェアでそれを実現するときはシェーダーのバイトコードによく似たものを読めるようにする方法が取られる。ここまで説明してきたトピックとは異なり、この部分は非常によくドキュメントされている──もし興味があるなら、AMD や NVIDIA のカンファレンスプレゼンテーションや CUDA/Stream SDK のドキュメントを確認してほしい。
話を進めよう。エグゼクティブサマリを示す:
- FMAC (Floating Multiply-ACcumulate) ユニットからなる高速な ALU を持つ。
- (最低でも) 逆数・平方根・log2・exp2・sin・cos に対する何らかのハードウェアサポートを持つ。
- レイテンシを犠牲にしてスループットと密度を高める最適化がされている。
- そのレイテンシをカバーするために大量のスレッドを使って実行する。
- スレッドごとレジスタ数は少なめ (スレッドは山ほど実行されるから!)。
- 直線的なコードの実行に非常に優れる。
- 条件分岐が苦手 (特にコヒーレントでないコードが苦手)。
以上はどれもほぼ全ての実装で共通しているが、一部違いもある。例えば AMD ハードウェアは HLSL/GLSL とシェーダーバイトコードが想定する 4-way SIMD を直接使ってきたが、NVIDIA はしばらく前から 4-way SIMD をスカラー命令に変換する方式を取っている (ただ最近は AMD も 4-way SIMD の方式から離れているように思える)。繰り返しになるが、こういった話はウェブを探せば見つかる。
興味深いのは、様々なシェーダーステージの間で異なる部分である。一言でまとめると、違いはほとんどない。例えば算術命令と論理命令は全てのステージで全く同じものが使える。一部のステージでしか使えない操作もいくつかある (例えば微分係数の計算やアトリビュートの補間はピクセルシェーダーでしか使えない) が、基本的に入出力するデータの種類 (とフォーマット) だけが各ステージ間の違いとなっている。
シェーダーに関連して一つ特別に触れておきたいことがあるが、それは大きな話題なので一つの章を使って解説する。その話題とはテクスチャサンプリング (とテクスチャユニット) であり、これは次章のトピックとなる! この章はここまでだ。また会おう。
最後に
「頂点キャッシュと頂点シェーディング」の節で示した注意をもう一度繰り返しておく。この部分には私が考えた仮説が含まれているので、話半分で聞いておくべきだ。話一割ぐらいでもいいかもしれない。知らないが。
それから、キャッシュとスクラッチパッドメモリの管理については何も話さなかった。バッファサイズが影響を受けるのは(主に) 処理するバッチのサイズと出力頂点アトリビュートの個数であり、バッファサイズとバッファの管理は性能のために非常に重要となる。しかし、それをここで有意義に説明することはできないし、したくもない。バッファは興味深い話題であるもののハードウェアごとに話が大きく異なるので、説明をしても得られるものが少ないためだ。