The Bourne-Again Shell (bash)
導入
Unix シェルは、ユーザーとオペレーティングシステムとの間でコマンドによる対話を行うためのインターフェースを提供します。シェル自体も豊富な機能を持ったプログラミング言語であり、実行制御、変数の書き換え、ループ、条件文、基本的な数学演算、名前付き関数、文字列変数、シェルと起動したコマンドの間の双方向通信といった処理のための構文が用意されています。
シェルはターミナルや xterm のようなターミナルエミュレータを通して対話的に使うことができます。また非対話的に使うことも可能であり、そのときはコマンドがファイルから読み込まれます。bash を含む現代的なシェルにはコマンドライン編集機能が付いており、emacs あるいは vi と似たコマンドを使ってコマンドラインを編集できるほか、様々な形でコマンドの履歴を利用できます。
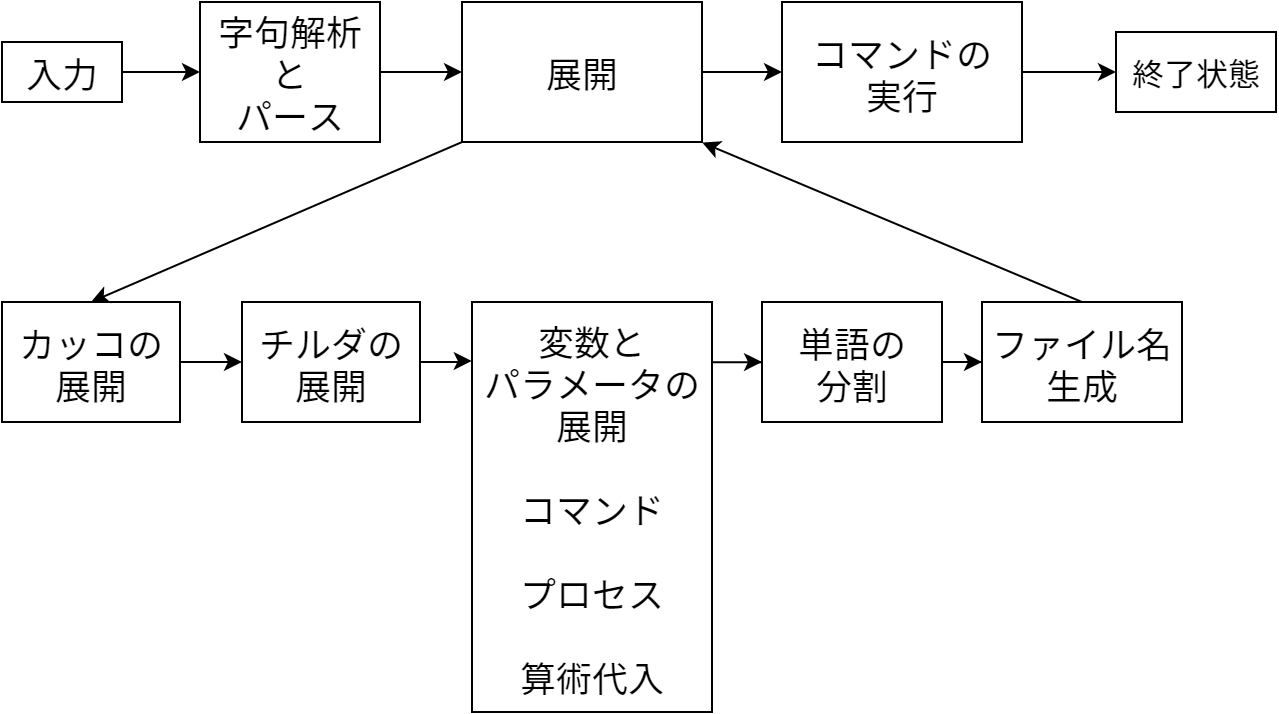
bash の処理はシェルのパイプラインとよく似ています。ターミナルまたはスクリプトから読まれたデータはいくつものステージを通過し、それぞれのステージで変形され、最終的にシェルがコマンドを実行して最終的な返り値が計算されます。
この章では bash の主要なコンポーネントをパイプラインという観点から説明します。具体的には、入力処理、パース、文字列の展開やコマンドの処理、コマンドの実行を見ていきます。これらのコンポーネントはキーボードやファイルからのデータを入力とするパイプラインとして機能し、最後にはコマンドの実行結果が出力されます。
bash
bash は GNU オペレーティングシステムで利用されているシェルです。Linux カーネル上で実装されることが多いですが、Mac OS X などの他の良く知られたオペレーティングシステムでも利用できます。bash は歴史的な sh の機能を対話処理とプログラミング処理の両方において拡張します。
bash という名前は Bourne-Again SHell を略したものです。Stephen Bourne (ベル研究所の Version 7 Unix に付属していた、現在の Unix シェル /bin/sh の直接の祖先にあたるプログラムの作者) の名前とかけており、再実装を通して新しく生まれ変わったことを表しています。bash のオリジナルの作者は Brian Fox で、彼は当時 Free Software Foundation で働いていました。私は現在 bash の開発者兼メンテナであり、オハイオ州クリーブランドのケース・ウェスタン・リザーブ大学で働いています。
他の GNU ソフトウェアと同じように、bash は高い移植性を持ちます。bash はほぼ全ての Unix とその他のオペレーティングシステムで動作します ──Cygwin や MinGW といった Windows でホストされる環境への独立した移植もありますし、QNX や Minix といった Unix ライクなシステムでは bash の移植がディストリビューションに含まれています。bash のビルドと実行に必要なのは、Microsoft の Service for Unix (SFU) といった Posix 環境だけです。
シンタックス上の単位とプリミティブ
プリミティブ
バッシュには基本的に三種類のトークンが存在します: 予約語 (reserved word)、単語 (word)、演算子 (operator) です。予約語はシェルとそのプログラミング言語において特別な意味を持ち、 if や while のような実行制御のための構文が多いです。演算子は一つ以上のメタ文字、つまり | や > のようなシェルにおいて特別な意味を持つ文字からなります。予約語と演算子以外は全て通常の単語です。代入式や数字のように、通常の単語であってもコマンドラインで現れる位置によっては特別な意味を持つ単語もあります。
変数とパラメータ
他のプログラミング言語と同じようにシェルにも変数があり、データや関数に名前を付けて保存できます。シェルにはユーザーが設定できる通常の変数のほか、パラメータと呼ばれる組み込みの変数もあります。シェルのパラメータが示すのはシェルの何らかの内部状態であることが多く、こういったパラメータは自動的に設定されるか、他の処理の副作用として設定されます。
変数の値は文字列です。文脈によって特殊な扱いを受ける値もありますが、これについては後述します。変数は name=value という形の文を使って代入されます。ここで value は省略可能であり、省略すると name には空文字列が代入されます。 value が空でなかった場合、シェルはその値を展開し、結果を name に代入します。シェルには変数が値を持つかどうかに応じて処理を変える構文がありますが、変数に値を持たせる方法は代入文だけです。値が代入されていない変数は、たとえ既に宣言されて属性を持っていたとしても、未設定とみなされます。
ドル記号 $ で始まる単語は変数およびパラメータへの参照となります。ドル記号を含んだ文字列がドル記号より後ろの部分と同じ名前を持つ変数の値に置き換わります。シェルにはたくさんの展開演算子があり、変数への参照を単純に値に置き換えるものから、変数の値のパターンにマッチした部分を変更あるいは削除するものまであります。
シェルにはローカル変数とグローバル変数が存在します。デフォルトでは全ての変数はグローバルです。単純なコマンド (simple command, コマンドの名前と引数とリダイレクトからなる、一番良く見る種類のコマンド) の前に代入文をつけると、その代入文で定義される変数はコマンドの実行中にだけ参照できるようになります。シェルには保存された手続き、つまり関数が実装されているので、関数にローカルな変数を持つこともできます。
変数の型付けは最小限です。値が文字列である単純な変数に加えて、値が整数および配列である変数があるだけです。整数型の変数は数値として扱われ、文字列を代入するとその文字列を算術式として展開した数値が代入されます。配列には、数字でアクセスするインデックス付き配列と、文字列でアクセスする連想配列があります。配列の要素は文字列ですが、必要ならば整数として扱うこともできます。配列は配列の要素になれません。
シェルの変数の格納にはハッシュテーブルが使われ、変数のスコープの実装にはこれらのハッシュテーブルをつないだ連結リストが使われます。シェルの関数にある代入文とコマンドの前につく代入文では別のスコープが作られます。コマンドの前に代入文が付いている場合などには、シェルは変数の参照を解決するためにスコープをたどる順番を保持しなければならず、bash は連結リストを使ってこれを行います。実行時のネストの深さに応じて、探索しなければならないスコープの数はとても大きくなる可能性もあります。
シェルのプログラミング言語
ほとんどの読者が最もなじみのあるであろう単純なシェルコマンド (simple command) は、 echo や cd といったコマンドの名前と、ゼロ個以上の引数とリダイレクトからなります。リダイレクトを使うと、起動するコマンドへの入力およびコマンドからの出力を制御できます。また単純なコマンドの実行するときに、その実行の間だけ有効となるローカルな変数の定義も可能です。
予約語を使うと、さらに複雑なシェルコマンドを実行できます。どんな高レベルプログラミング言語にもみられるような、 if-then-else や while といった構文もありますし、配列の要素に対して反復処理を行う for ループや、整数を使った C 風の for ループもあります。これらの複雑なコマンドを使うと、条件文を評価してその値に基づいて異なる処理を実行したり、コマンドを複数回実行したりできます。
Unix がコンピューターの世界にもたらした優れた概念の一つが、パイプラインです。シェルにおけるパイプラインとは、コマンドが一列に並び、それぞれのコマンドの出力が一つ後ろのコマンドの入力となっている状況を指します。パイプラインの途中で複雑なシェルの構文を使うこともでき、コマンドがループにデータを供給するパイプラインはよく使われます。
bash には起動するコマンドの標準入力、標準出力、標準エラー出力を他のファイルやプロセスにリダイレクトする機能が実装されています。シェルのプログラマーはリダイレクトを使うことで、現在のシェル環境にあるファイルの開閉を行うこともできます。
シェルの関数およびシェルスクリプトを使うと、bash のシェルプログラムを保存して後で何度も使うことができます。シェルの関数とシェルスクリプトはどちらも、いくつかのコマンドを束ねて他のコマンドと同じように実行するための方法です。シェルの関数の定義は特殊なシンタックスを使って行われ、定義は同じシェルのコンテキストで有効となります。シェルスクリプトはコマンドをファイルに書き込んだものであり、実行するときにはシェルの新しいインスタンスが作られます。シェルの関数の実行コンテキストは、関数を呼んだシェルと同じです。これに対してシェルスクリプトは新しく作られるシェルで実行されるので、元の環境と共有されるのはプロセスの間で明示的に渡されるものだけです。
補足
これ以降を読み進めるときには、シェルの機能の実装にはほんの少しのデータ構造しか使われていないことに注意してください。ほとんど全てのシェルの機能は、配列、木、単純連結リスト、双方向連結リスト、ハッシュテーブルのうちどれかを使って実装されています。
シェルが情報を次のステージに渡すとき、そして各ステージにおいてデータを処理するときに使う基本的なデータ構造は次の WORD_DESC です:
typedef struct word_desc {
char *word; /* ヌル終端文字列 */
int flags; /* この単語に関するフラグ */
} WORD_DESC;
引数などのために複数の単語がまとめられるときには、次の単純連結リストが使われます:
typedef struct word_list {
struct word_list *next;
WORD_DESC *word;
} WORD_LIST;
WORD_LIST はシェルのコードのあちこちに登場します。単純なコマンドは単語のリストであり、展開の結果は単語のリストであり、組み込みのコマンドの引数は単語のリストです。
入力処理
bash のパイプラインにおける最初のステージは入力の処理です。このステージはターミナルまたはファイルから文字列を受け取り、行ごとに分け、行をシェルのパーサーに入力し、コマンドの列を出力します。分かると思いますが、ここで言う行とは改行で終わる文字列です。
readline とコマンドラインの編集
bash は対話モードなら入力をターミナルから読み、そうでないなら引数で指定されるファイルから読みます。対話モードではユーザーはタイプしながらコマンドラインを編集でき、emacs や vi といったエディタと似た編集コマンドが利用可能です。
bash におけるコマンドラインの編集には、readline ライブラリが使われています。このライブラリの関数を使うと、コマンドラインの編集、コマンドラインの保存と復元、以前のコマンドの検索、csh 風の履歴展開などを行えます。bash は readline の一番のお得意様であり、二つのプログラムは同時に開発されました。ただし readline に bash 専用のコードは存在せず、bash 以外にもたくさんのプロジェクトが readline の持つターミナルの行編集インターフェースを使っています。
readline では、任意の長さのキーストロークに任意の数の readline コマンドを割り振ることができます。readline のコマンドで行える処理は、カーソルを動かす、テキストに挿入する、テキストを削除する、一つ前の行を取得する、途中までタイプされた単語を補間するなど様々です。さらに、readline では特定のキー入力によって特定の文字列を入力するマクロを定義できます。マクロの定義にはキーバインドと同じシンタックスが使われ、マクロを使うと簡単な文字列の置換や省略形による入力が行えます。
readline の構造
readline は read/dispatch/execute/redisplay (読み込み/ディスパッチ/実行/再描画) ループという構造を持ちます。readline への最初の入力はキーボードからの文字列を read などの関数を使って読んだ文字列か、マクロの展開結果です。入力の各文字はキーマップ (ディスパッチテーブル) へのインデックスとして使われ、コマンドが検索されます。キーマップの鍵は 8 ビットの文字一つですが、値は複数あることもあります。キーマップには複数の文字に対応する値も存在し、複数のストロークからなるキーシーケンスはこれを使って実現されます。
キーマップの鍵が beginning-of-line などの readline コマンドである場合、そのコマンドが実行されます。例えば self-insert コマンドが実行されると、引数として渡された文字が編集バッファに付け足されます。キーシーケンスにコマンドをバインドし、さらにそのシーケンスの一部を別のコマンドにバインドすることも可能です (比較的最近になって追加された機能です)。この機能はキーマップに特別なインデックスを加えることで実装されています。キーシーケンスにマクロをバインドすると、様々なことを行えます。例えば任意の文字列をコマンドラインに挿入したり、複雑な編集操作のためのキーボードショートカットを定義したりできます。
readline が文字バッファと文字列の管理に使うのは C の char の配列だけであり、マルチバイト文字は必要に応じて配列から計算されます。内部で wchar_t を使わないのは速度と容量を考えてのことですが、他の理由として、編集操作のコードが書かれた当時マルチバイトのサポートが一般的でなかったというのもあります。マルチバイト文字をサポートするロケールでは、readline は自動的にマルチバイト文字全体を読んで編集バッファに加えます。マルチバイト文字列を編集コマンドにバインドすることも可能ですが、バインドはキーシーケンスとして書かなくてはなりません。不可能ではありませんが、複雑なので普通は誰もやろうとしないでしょう。例えば組み込みの emacs と vi のコマンドはマルチバイト文字を全く使っていません。
キーシーケンスが編集コマンドに変換されると、readline はターミナルのディスプレイを更新し、その結果を表示します。この処理はコマンドで何が起ころうと行われます。バッファに新しく文字が挿入された場合、編集位置が移動した場合、行の一部または全部が置換された場合にはもちろんディスプレイが更新されます。またバインド可能な編集コマンドの中には履歴の操作のように編集バッファの内容を変更しないものもありますが、このようなコマンドが実行されたときにもディスプレイは更新されます。
ターミナルのディスプレイを更新する処理は単純に見えますが、実はとても入り組んでいます。この処理において、readline は次の三つを管理しなければなりません: (1) 編集バッファのうち現在スクリーンに表示されている部分、(2) 表示するバッファのうち更新された部分、(3) スクリーンに表示されている部分。さらにマルチバイト文字がある場合には表示されている文字数がバッファのサイズと対応せず、再描画エンジンはそのことを考慮する必要があります。
再描画を行うときには、readline は現在表示しているバッファの要素と更新されたバッファを比較し、両者の間の違いを見つけ、現在のディスプレイを変更して更新されたバッファとするための一番コストの低い方法を計算します。最後の部分は長年に渡ってたくさん研究がされてきた問題です (文字列修正問題, string-to-string correction problem)。readline の取ったアプローチは、二つのバッファが異なる部分を一続きの文字列として見つけ、その部分だけを更新するとして最低コストの編集操作を求めるというものです (例えばバッファの文字を削除してから挿入するコマンドと、現在のスクリーンの要素を上書きするだけのコマンドではどちらが効率的か、など)。コストにはカーソルを動かす回数も含まれます。その後はその最小コストの編集操作を行い、行の終わりに残っている文字があれば消し、最後にカーソルを正しい位置に移動させます。
再描画エンジンが readline の中で一番重点的に変更される部分であることは間違いありません。変更のほとんどは新しい機能を追加するものです。重要なものとしては、プロンプトに印字不可能文字を (例えば色を変えるために) 追加する機能、あるいはマルチバイト文字への対応などがあります。
以上の処理が終了すると、readline は編集バッファの内容をアプリケーションに返却します。これを受けて、アプリケーションは変更されている可能性のあるその結果を履歴リストに保存するかどうかを判断します。
アプリケーションによる readline の拡張
readline にはデフォルトの動作を拡張、カスタマイズする方法がいくつもありますが、アプリケーションから readline のデフォルトの機能を拡張する方法も提供されます。まず、バインド可能な realine 関数は標準的な引数を受け取って決まった形の結果を返すので、アプリケーション固有の関数を使って readline を拡張するのは簡単です。例えば bash は 30 以上のバインド可能なコマンドを readline に追加しており、bash 固有の単語補間やシェルの組み込みコマンドへのインターフェースを実装しています。
アプリケーションが readline の動作を拡張する二つ目の方法は、ポインタを使って関数の名前と呼び出すときのインターフェースをフックするというよくある方法です。この方法を使うと、アプリケーションは readline の内部を一部書き換えて readline の前に処理を追加でき、アプリケーションに固有の変換を行えます。
非対話入力処理
readline を使わない場合、bash は stdio または独自のバッファ入力ルーチンを使って入力を取得します。ただしシェルが対話モードでないときには、 stdio ではなく bash 独自の入力パッケージを使うことの方が望ましいです。というのも、Posix には入力の読み込みについて奇妙な制限があるからです。シェルが入力を読み込むときにはコマンドにパース必要な分だけが読み込まれ、残りの部分は実行されるプログラムに回されます。シェルは入力をいくらでも読むことができますが、それをしてよいのはパーサーが最後に処理した文字までファイルをロールバックできるときだけです。つまりこの読み込み処理を実装するとなると、パイプのようなシーク不可能なデバイスの場合には文字を一文字ずつ読んでバッファにコピーしなければならないのです。一方で、最初からバッファを使えばファイルの内容を自由に飛ばしながら読み込むことができます。
以上の細かいことを置いておけば、非対話入力時におけるシェルが行う処理の出力は readline を使った場合と同じです。つまり、末尾に改行の付いた文字列のバッファが出力されます。
マルチバイト文字
マルチバイト文字の処理がシェルに追加されたのは最初の実装から長い時間が経ってからのことでした。そのため、マルチバイト文字の実装は既存のコードへの影響が最小限になるように設計されています。マルチバイト文字をサポートするロケールにある場合、シェルが最初に入力をバイト (C の char) のバッファに保存した段階で、その文字列はマルチバイトの可能性がある文字列として扱われます。readline はマルチバイト文字を正しく描画する方法 (文字のスクリーン上での幅がどれだけか、文字を表示させたらバッファは何バイト進むか) を知っており、カーソルを動かすときには (1 バイトずつではなくて) 一文字ずつ動かすことも知っています。その部分を除けば、マルチバイト文字はシェルの入力処理に大きな影響を及ぼしません。これから説明するシェルの他の部分では、入力に含まれるマルチバイト文字を考慮しなければならないこともあります。
パース
パースエンジンの最初の仕事は字句解析、つまり、文字のストリームを単語ごとに分割し、分割された単語それぞれに意味を持たせる処理です。この単語がパーサーの処理における基本単位となります。単語の終わりはメタ文字 (metacharacter)、つまりスペースやタブなど通常の分離文字、またはセミコロンやアンパサンドなどのシェル言語特有の分離文字です。
Tom Duff も Plan 9 shell (rc) の論文の中で語っていることですが、長い歴史を持つ bash には、文法を完全に理解している人が誰もいないという問題があります。このことを考えると、Posix シェル委員会が Unix シェルの文法の決定版を制定できたのは大きな称賛に値すると思います。その文法に問題がないわけではなく、例えば伝統的な Bourne シェルのパーサーがエラーを出さないコードに Posix の文法がエラーを出すこともありますが、きちんと定まっている文法の中では一番優れています。
bash のパーサーは Posix 文法の初期バージョンをもとにしています。また私の知っている限り、Bourne スタイルのシェルのパーサーの中で唯一 Yacc と Bison を使っています。そのために生じる問題がいくつかあります。例えばシェルの文法が yacc スタイルでパースできるようになっていないために、字句解析が複雑になり、パーサーと字句解析機の間で頻繁なやり取りが必要になります。
ともかく、字句解析機は readline または他のソースから入力を受け取り、メタ文字でトークンに分割し、文脈に基づいてトークンを特定し、最後にパーサーに渡して文やコマンドを組み立てます。字句解析においては文脈が大きく関係します。例えば for という文字列は、予約語にも、識別子にも、代入文の一部にも、通常の単語にもなれます。次に示すのは完全に合法なコマンドであり、 for を表示します:
for for in for; do for=for; done; echo $for
ここで少し脱線して、エイリアシングについて話しておきます。bash には、単純なコマンドの最初の単語を任意の文字列で置き換える、エイリアシングという機能があります。この置き換えは全く字句的なので、エイリアシングを使ってシェルの文法を変更する (そして悪用する) ことができます。bash が提供していないような合成コマンドを実装するエイリアスを書くことも可能です。パーサーが字句解析機にエイリアシングの展開について伝えた後は、エイリアシングの処理は字句解析のフェーズのみで処理されます。
多くのプログラミング言語と同じように、文字をエスケープしてその文字が持つ特別な意味を消す機能がシェルにもあります。これによって & などのメタ文字をコマンドで使用できます。クオートには三種類あり、クオートされる文章の解釈が少しずつ異なります。バックスラッシュは次の文字をエスケープし、一重引用符は囲まれた文章を文字列のまま解釈し、二重引用符は囲まれた文章を文字列のまま解釈するが、一重引用符と違って特定の単語の展開を行います (バックスラッシュの扱いも違います)。字句解析機がクオートされた文字(列)を見つけた場合、パーサーがその文字(列)を予約語やメタ文字と扱わないような処理をします。 $'...' と $"..." という特殊ケースもあり、前者ではバックスラッシュでエスケープされた文字が ANSI C と同じ扱いを受け、後者では文字が標準の国際化関数を使って翻訳されます。前者は広く使われていますが、後者はそうでもありません。うまく使える場面がほとんどないためと思われます。
残りの部分におけるパーサーと字句解析機のやり取りは単純です。パーサーはいくつかの状態を字句解析機と共有することで、文脈に依存したシェル文法の字句・構文解析を行います。例えば字句解析機はそれぞれの単語に対して予約語、単語、代入文などのトークンの種類を割り振っていきますが、このときにはコマンドのパースの進捗に関する情報が必要です。つまり、処理しているのが複数行にまたがる文字列 (“ヒアドキュメント (here-document)”と呼ばれるもの) なのか、 case 文なのか、条件文コマンドなのか、拡張されたシェルパターンなのか、複合代入文なのか、といった情報です。
パースステージにおいてコマンド置換の終わりを見つけるための処理は、ほとんどが parse_comsub という一つの関数に詰め込まれています。この関数には不安になるほど大量のシェルのシンタックスが埋め込まれています。またトークンを読むコードが何度もコピペされており、最適であるとは言えません。この関数はヒアドキュメント、シェルのコメント、メタ文字、単語の境界、クオート、どの予約語があり得るか (case 文中かどうか、など) について知っておく必要があるからです。この関数を正しく実装するのにはかなりの時間がかかりました。
単語の展開の一環として行われるコマンド置換の展開では、bash が構文の正しい終端を見つけるのにパーサーが使われます。これは eval において文字列をコマンドに変換するのと似ていますが、ここではコマンドが文字列の終端によって途切れているわけではありません。この場合パーサーは右カッコをコマンドの終端として扱う必要があるので、文法の生成規則において (適切な文脈では) 右カッコを EOF として扱う特殊ケースがあります。また yyparse が再帰的に呼ばれるときには、パーサーは状態を保存しなければなりません。これはコマンド置換を展開している途中でさらにコマンド置換がパース・実行されることがあるからです。入力関数が先読みを実装していることから、この関数は最後に bash の入力ポインタを正しい位置に戻す必要があります。これは bash が文字列、ファイル、ターミナル (readline) のどれから入力を読んでいても必要な処理であり、入力を失わないためだけではなく、コマンド置換を展開した結果の文字列が正しく実行されるためにも重要です。
同じような問題はプログラム可能な単語補間でも起こります。この処理ではコマンドをパースする段階で任意のコマンドの実行が可能であり、実行するコマンドを読むときにはパーサーの状態が格納されます。
クオートは互換性が破れやすい要素であり、議論の付きない要素でもあります。Posix シェルの規格が制定されて二十年以上が経っていますが、規格のワーキンググループのメンバーは未だにはっきりしないクオートの処理について議論を交わしています。しかしここでも、Bourne シェルは動作を確認するための参考実装にしかなりません。
パーサーは一つのコマンドを表す C の構造体を返します (ループコマンドなどの場合には複数のコマンドが含まれます)。そしてこの構造体がシェルの次のステージである単語の展開に渡されます。コマンド構造体はコマンドオブジェクトと単語のリストからなります。単語のリストにあるほとんどの単語は文脈に応じて様々な変換を受けますが、この変換について次の節で説明します。
単語の展開
パースの後、実行の前に、パースステージで出力された単語は一回以上の展開を受けます。例えば $OSTYPE は "linux-gnu" という文字列で置換されます。
パラメータと変数の展開
変数の展開は最もよく目にする展開でしょう。少数の例外を除けばシェルの変数は型を持たず、文字列として扱われます。展開の処理によって変数は別の単語に変換され、単語のリストが更新されます。
変数の値の文字列をさらに変換する展開処理もあります。例えば文字列の長さを得たり、特定のパターンにマッチする部分を接頭部または接尾部から取り除いたり、特定のパターンにマッチする部分を置換したり、大文字・小文字を切り替えたりできます。
加えて、変数が値を持つかどうかによって処理が変わる展開処理もあります。例えば、 ${parameter:-word} は parameter に値があるならその値に、値が無い (空文字列である) なら word に展開されます。
その他もろもろ
bash にはほかにもたくさんの種類の展開処理があり、どれも一風変わった規則で展開されます。最初に処理される展開はかっこ展開 (Brace Expansion) であり、次の文字列:
pre{one,two,three}post
が、次の文字列に展開されます:
preonepost pretwopost prethreepost
コマンドの実行と変数の設定という機能を組み合わせた、コマンド置換 (command substitution) という機能もあります。シェルはコマンドを実行し、出力を収集し、その出力を展開の値として使います。
コマンド置換に関する問題の一つは、展開のときにコマンドが即時に実行され、完了まで何もできない点です。つまり、コマンド置換を使うとシェルからコマンドに入力を送ることができません。この問題は名前付きプロセス置換 (named process substitution) という機能によって解決されます。これはパイプとコマンド置換を組み合わせたような機能であり、バックグラウンドで実行されるコマンドの出力をコマンドへの入力にできます。ここで鍵となるのは、bash が新しいプロセスとの間のパイプを作成し、そのパイプを入力および出力のファイルとして使う点です。
次に行われるのはチルダ展開 (tilde expansion) です。この機能はもともと ~alan のような文字列を Alan のホームディレクトリに変換するために作られましたが、長年に渡って改良され、様々なディレクトリを参照できるようになりました。
最後に算術式展開 (arithmetic expansion) があります。 $((expresssion)) と書くと expression が C 言語と同じ規則で評価され、文字列が評価結果で置き換えられます。
変数を展開する処理では、一重引用符と二重引用符の違いが明確になります。一重引用符では展開が行われない (間の文字列が展開処理を受けない) のに対して、二重引用符ではいくつかの展開が行われます。単語の展開とコマンド置換、算術式展開、プロセス置換は行われますが、ブレース展開とチルダ展開は行われません。なお二重引用符は展開処理には影響せず、展開結果がこの後のステージでどう扱われるかだけに影響します。
単語の分割
単語の展開の結果はシェルの変数 IFS を分かれ目として単語に分解されます。これによって一つの単語が二つ以上に変換されます。 $IFS に含まれる文字1が展開結果に表れるたびに、bash はその単語を二つに分けます。一重引用符と二重引用符があるときには単語の分割が行われません。
グロブ
展開結果が分割されると、シェルはコマンドに含まれる単語をパターンであるとみなした上でファイル名およびディレクトリ名とのマッチが無いかを調べます。
実装
シェルの基本的なアーキテクチャを一つのパイプラインとみなすなら、単語の展開はその中にある独立したもう一つのパイプラインとみなすことができるでしょう。単語の展開の各ステージは単語を受け取り、変換を何回か行ってから、次のステージに渡します。全ての展開が完了すると、コマンドが実行されます。
単語の展開の実装には、以前に説明した基礎的なデータ構造が使われています。パーサーから出力される単語は一つずつ展開され、一つ以上の単語となります。この展開において必要となる情報は、全て WORD_DESC データ構造が保持します。この構造体のフラグが次のステージへの情報を伝達します。例えば、パーサーは展開ステージとコマンド実行ステージに対してある単語が代入文かどうかをフラグを使って伝えます。また単語の展開では、展開を抑制するフラグや、クオートされた空文字列 ($x が設定されていないときの "$x") があることを示すフラグが必要です。展開される単語に対する追加情報を文字列で表していたら、実装はもっと難しくなっていたでしょう。
パースと同様に、単語の展開もマルチバイト文字を処理できます。例えば変数の長さの展開 (${#variable}) は、文字列のバイト長ではなく文字数をカウントし、そのときには展開の終端や特殊なマルチバイト文字を正しく認識します。
コマンドの実行
bash 内部のパイプラインにおけるコマンド実行ステージは、実際の動作が起こる場所です。ほとんどの場合において、展開された単語の列がコマンドの名前と引数の列に分解され、オペレーティングシステムに渡されます。先頭の単語が実行するファイルの名前となり、他の部分が argv となります。
以上の説明は、Posix が呼ぶところの単純なコマンド (simple command)、つまりコマンドの名前と引数の列からなるコマンドを呼ぶときの説明でしかありません。 この種類のコマンドが最もよく使われますが、他にもコマンドの種類はたくさんあります。
コマンド実行ステージへの入力はコマンドを表す構造体と展開された単語列であり、どちらもパーサーによって作られます。このステージにおいて、本当のプログラミング言語 bash が登場します。これまでに説明した通りこのプログラミング言語は変数と展開という機能を持ちますが、他にもループ、条件文、置き換え、グループ化、選択、パターンマッチに基づく条件的実行、式の評価といった高レベルプログラミング言語でよく見られる構文が実装されています。またシェルに特有の高レベルな構文もいくつかあります。
リダイレクト
オペレーティングシステムとのインターフェースとしてのシェルの機能の一つに、起動したコマンドの入出力をリダイレクトする機能があります。リダイレクトのシンタックスを見ると、初期のシェルのユーザーが洗練されていたことが分かります。というのも、ごく最近まで、ユーザーはファイルディスクリプタを自分で管理し、標準入出力と標準エラー出力以外にリダイレクトするときにはリダイレクト先を数字で指定する必要があったのです。
最近になって追加されたリダイレクトのシンタックスを使うと、シェルに適当なファイルディスクリプタを取ってこさせ、それを変数に代入できます。このシンタックスを使えばユーザーはディスクリプタを選ぶ必要がありません。プログラマーはこれによってディスクリプタの管理から解放されますが、シェルの仕事は増えます。つまりシェルは正しい位置にファイルディスクリプタを複製し、その上で指定された変数に割り当てなければなりません。これは情報が字句解析機からパーサーを通ってコマンドの実行まで伝わっていく良い例と言えるでしょう。最初、字句解析機は変数代入を含んだリダイレクトとして単語を読みます。次にパーサーは適切な生成規則に基づいてリダイレクトオブジェクトを作り、代入が必要であることを示すフラグを付けます。最後にリダイレクトを処理するコードがこのフラグを解釈し、ファイルディスクリプタを正しい変数に割り当てます。
リダイレクトの実装で一番難しいのは、リダイレクトを元に戻す方法を覚えておく部分です。シェルは、新しく作られるプロセス上でファイルシステムから実行されるコマンドと、シェル自身が実行する (“組み込みの”) コマンドの区別を意図的にユーザーに見えないようにしているのですが、コマンドがどう実行されるにせよ、リダイレクトの影響がコマンドが終了した後に残ってはいけません2。例えば、組み込みのコマンドの出力をリダイレクトしたまま何もせずにコマンドの実行を終えると、シェルの標準出力が変化してしまいます。そのため、シェルはリダイレクトを元に戻す処理をリダイレクトごとに覚えておく必要があります。この処理は確保したファイルディスクリプタを閉じるか、そうでなければコマンドの実行前に保存したディスクリプタを dup2 を使って復元することで行われ、bash はそれぞれのディスクリプタをどうやって元に戻すかを知っています。パーサーによって作成されるリダイレクトオブジェクトはコマンドの種類に関わらず同じであり、同じ関数で処理されます。
複数のリダイレクトはオブジェクトの単純なリストとして実装されているため、元に戻すときに使われるリダイレクトは別のリストに保存されています。このリストはコマンドの実行が終了したときに処理されますが、シェルの関数や組み込みの "." を実行していく中で新しくリダイレクトが作られた場合には、そのリダイレクトが閉じられるまで待つ必要があります。また組み込みの exec にリダイレクトだけを付けてコマンドを起動することなく使った場合には、元に戻すためのリストが更新されることはありません。 exec に付くリダイレクトはシェルの環境を置き換えるからです。
bash の来歴によって複雑になっている部分もあります。Bourne シェルの古いバージョンでは、ユーザーは 0 から 9 までのファイルディスクリプタを自由に使うことができ、10 以上のファイルディスクリプタはシェル内部での使用のために予約されていました。bash ではこの制限は緩和され、ユーザーはプロセスが開くことのできる上限までファイルディスクリプタを使うことができます。しかしこれにより、bash は自身が使うファイルディスクリプタを自分で管理し、場合によってはあちこちに移動させなければなりません。例えば外部ライブラリが開く、シェルとは直接関係のないディスクリプタにしてもそうです。大量のファイルディスクリプタを覚えておく必要があり、close-on-exec フラグを使ったヒューリスティックも使われ、コマンドの実行期間を管理するためのリダイレクトのリストがもう一つ追加されます。
組み込みコマンド
bash にはシェル自身が実行するコマンドがたくさんあります。これらのコマンドはシェルによって実行され、新しいプロセスが作られることはありません。
コマンドを組み込みにする一番の理由はシェルの内部状態を変更するためです。 cd はいい例でしょう。「 cd が外部のコマンドとして実装できないのはなぜか?」 という質問は Unix 入門講座におなじみの練習問題です。
bash の組み込み関数のために使われる内部プリミティブはシェルの他の部分と同じです。組み込み関数は C 言語を使って、単語のリストを引数として取る関数として実装されます。ほとんどの場合において組み込み関数の展開規則は他の通常のコマンドと同じですが、いくつか例外があります。bash の組み込み関数のうち代入文を引数に取るもの (例えば declare や export) は、引数の代入文を展開するときに通常の変数代入文と同じ規則を使います。そのときには WORD_DESC 構造体の flag メンバーを使って情報がシェルの内部パイプラインのステージをまたいで伝達されます。
単純なコマンドの実行
単純なコマンド (simple command) は最も良く使われるコマンドです。今までの説明に加えてファイルシステムを使ったコマンドの検索と実行、そして終了状態の回収を説明すれば、シェル全体の機能のほとんどがカバーされます。
シェルの変数代入文 (var=value の形をした単語) はそれ自体が単純なコマンドの一種です。変数代入の後にはコマンドが続くか、そうでなければコマンドラインが代入文だけからなります。コマンドが続く場合には、変数は実行されるコマンドの環境に渡されます (組み込みコマンドやシェルの関数が続く場合にも実行の間だけ変数が有効になりますが、いくつか例外があります)。コマンドが続かない場合には、代入文はシェルの状態を変更します。
与えられたコマンドの名前がシェルの関数でも組み込み関数でもない場合、bash はファイルシステムからコマンドと同じ名前の実行形式を検索します。 PATH 変数の値が探索対象のディレクトリのコロンで分割されたリストとして使われます。スラッシュなどの分割文字を含むコマンドは検索されず、直接実行されます。
PATH の検索によってコマンドが見つかれば、bash はコマンドの名前とそのファイルの完全パスをハッシュテーブルに保存し、次回以降の PATH の検索で使えるようにします。コマンドが見つからなかった場合には、bash に特別な名前の付いた関数が設定されていれば、見つからなかったコマンドの名前を引数としてその関数を実行します。Linux ディストリビューションの中には、この機能を使ってコマンドのインストールを提案するものもあります。
bash が実行すべきファイルを見つけると、フォークを行い、新しい実行環境を作り、新しい実行環境の中でプログラムを実行します。新しく作られる実行環境は基本的にシェルの環境のコピーですが、シグナルの処理やリダイレクトのために開閉されているファイルが多少異なります。
ジョブの制御
シェルはコマンドをフォアグラウンドまたはバックグラウンドで実行します。フォアグラウンドでコマンドを実行するとは、そのコマンドの終了状態を取得するまでシェルの実行を止めることを言います。バックグラウンドでコマンドを実行するとは、実行を始めたらすぐに次のコマンドを読みに行くことを言います。ジョブの制御という機能を使うと、プロセス (実行されているコマンド) の実行をフォアグラウンドとバックグラウンドの間で切り替えたり、実行を停止させたり再開させたりできます。bash のジョブ (job) という概念はこの機能を実装するために導入されたました。ジョブとはコマンドを実行しているプロセスのことですが、ジョブに対応するプロセスが一つだけとは限りません。例えばパイプラインは一つのジョブですが、一つのパイプラインでも複数のプロセスを使います。ジョブに対応する複数のプロセスをまとめるのには、プロセスグループが使われます。ターミナルにもプロセスグループ ID があるので、その ID がフォアグラウンドプロセスグループの ID となります。
シェルにおけるジョブの制御の実装にはいくつかの単純なデータ構造が使われます。例えば子プロセスを表す構造体があり、プロセス ID、状態、終了状態などがメンバーとして含まれます。ジョブを表す構造体もこれに似ており、プロセスのリスト、状態 (実行中、停止中、終了したなど)、プロセスグループ ID などが含まれます。このプロセスのリストは通常一つのプロセスからなり、一つのジョブに複数のプロセスが結び付けられるのはパイプラインを使ったときだけです。ジョブにはそれぞれ異なるプロセスグループ ID があり、ジョブに含まれるプロセスの中でプロセス ID がプロセスグループ ID と等しいものはプロセスグループリーダーと呼ばれます。ジョブの集合は配列で管理され、これはユーザーへの表示のされ方と非常に似ています。ジョブの状態と終了状態は含まれるプロセスの状態と終了状態を調べ上げることで計算されます。
シェルの他の部分と同じように、ジョブの実装において複雑なのは管理の部分です。シェルがプロセスにプロセスグループを割り当てるときには、子プロセスの生成とグループの割り当てが同時に行われ、さらにターミナルのプロセス ID が適切に設定されるようにしなければなりません。またフォアグラウンドのジョブはターミナルのグループ ID によって決定されるので、この設定を戻し忘れると、シェルはターミナルの入力を読むことができなくなります。シェルのコマンドの実行はプロセスが深く絡んでくるので、 for や while のループを一つの単位として停止・再開できるように複合コマンドを実装するのは一筋縄ではいきません。また実際にそうしているシェルはほとんどありません。
複合コマンド
複合コマンドは一つ以上の単純なコマンドのリストからなり、 if や while といったキーワードで始まります。複合コマンドを使うと、シェルの持つプログラミングの能力が最大限に発揮されます。
複合コマンドの実装は驚くほどのものではありません。様々な構文に対応するオブジェクトがパーサーによって作成され、そのオブジェクトをたどることで実行が行われます。各複合コマンドは対応する C の関数で実装され、その関数が適切な展開、コマンドの実行、コマンドの終了状態に基づいた実行フローの制御を行います。
例として、 for コマンドを実装する関数の処理を追ってみましょう。最初、予約語 in の後に続く単語を展開し、展開された結果に含まれる単語に対してループを回します。ループの先頭では適切な変数に値が代入され、 for の本体にあるコマンドのリストが実行されます。 for ではコマンドの実行結果によって実行を切り替える必要はありませんが、組み込み関数 break と continue には注意する必要があります。リストにある単語を全て使いきると、 for コマンドは値を返します。これを見れば分かるように、ほとんど部分において実装と説明はほぼ同一です。
教訓
重要だと判明したもの
二十年以上に渡ってbash と関わってきて、いくつかのことを発見したように思います。一番重要なのは ──どれだけ強調しても強調しすぎることはありません──、変更履歴 (change log) を詳細に書くことです。当時の変更履歴を見ればなぜある変更が行われたかを確認できるというのは良いものです。変更がバグ報告と結びついていればさらに良く、再現可能なテストケースや提案と一緒になっていれば完璧です。
プロジェクトを最初から作るなら、大々的なレグレッションテストを可能な限り作っておくことをお勧めします。bash には数千のテストケースがあり、非対話的な機能のほぼ全てがカバーされています。対話的な機能のテストを作ることも考えました ──Posix には独自の適合テストスイートがあります──が、テストのためにフレームワークの配布が必要となったので、断念しました。
標準規格は重要です。bash は標準規格を実装することで多大な恩恵を受けています。作っているソフトウェアの標準化に参加するのは重要です。機能や動作を議論できるだけではなく、拠り所とできる規格の存在は役に立ちます。もちろん、うまくいかない場合もありますが、それは規格の問題です。
外部で決められる規格は重要ですが、内部で決められる規格を持つのも間違いではありません。私は幸運にも GNU プロジェクトのいくつかの規格の制定に参加でき、そこで設計と実装に関する良質で現実的なアドバイスを多く受けました。
高品質なドキュメントも不可欠です。他人にプログラムを使ってほしいなら、分かりやすくて簡潔なドキュメントを用意しておいた方がよいでしょう。ソフトウェアが成功すればたくさんのドキュメントが書かれるでしょうから、そのような場合には開発者自身が信頼できるバージョンを書くことが重要です。
良いソフトウェアはたくさんあります。使えるものは使いましょう。例えば gnulib には (gnulib フレームワークから切り離すことができれば) 便利なライブラリ関数がたくさんありますし、BSD や Mac OS X もそうです。ピカソが言ったように、「偉大な芸術家は盗む」のです。
ユーザーコミュニティを巻き込みましょう、ただし批判を受ける準備はしておくべきです。ときにはガツンと来る批判も受けるでしょう。アクティブなユーザーコミュニティは非常に有益ですが、結果としてメンバーが熱狂的になりすぎてしまうこともあります。批判を個人的なものと考えないようにしましょう。
違う方法でやったであろうこと
bash が持つ数百万人のユーザーを通して、後方互換性の重要性について学んできました。ある意味では後方互換性さえ保っておけば 「すいませんでした」 と言わなくて済むのですが、話はそう単純ではありません。破壊的な変更が避けられなかったことが何回かあり、ほぼ毎回それなりの数のユーザーから不平が聞かれました。私はその変更に対するきちんとした理由があり、過去の誤った判断を正したり、設計の間違った機能を直したり、シェルの部分同士の非互換性を修正するためだったのですが。もしやり直せるなら、正式な“bash 互換性レベル”のようなものを早いうちに導入するでしょう。
bash の開発がオープンにされたことはなく、bash-4.2 のようなマイルストーンリリースと個別のパッチリリースという形を取っているのですが、私はこのアイデアを気に入っています。これを行うのには理由があります: 私にとっては、長期のリリースタイムラインを持つベンダーの世界の方が、自由ソフトウェアやオープンソースの世界よりも自然なのです。またベータのソフトウェアが私が望まないほどに広がってしまった経験があるというのもあります。ただもし最初からやり直せるなら、もっとパブリックなリポジトリを使って、リリースの頻度を上げるでしょう。
実装についての懸案事項がこのリストに入らないなどありえません。何度もしようと考えて結局していないことの一つに、bash のパーサーを再帰下降で書き直して、bison を使うのをやめるというのがあります。かつて私は Posix に準拠したコマンド置換を実装するにはこの書き換えを行わなければいけないのではないかと考えたこともあったのですが、この問題はそれほど苦労せずに解決できてしまいました。ただもし bash をゼロから書くなら、パーサーは手で書くでしょう。その方が物事が簡単になるのは間違いありません。
結論
bash は巨大で複雑な自由ソフトウェアの良い例です。二十年以上に及ぶ開発によって、成熟したパワフルなソフトウェアとなっています。いたるところで実行されており、毎日数百万人のユーザーが利用し、bash を使っていると気が付いていない人も大勢います。
bash はたくさんのソースからの影響を受けており、古くは Stephen Bourne によって書かれたオリジナルの Version 7 Unix シェルまでさかのぼります。一番の影響を受けているのは Posix 規格であり、bash の動作の大部分は Posix 規格に従っています。規格の準拠と後方互換性の両立にはいくつもの困難がありました。
bash は GNU プロジェクトの一部となることで恩恵を受けています。GNU プロジェクトは bash が生まれるためのムーブメントとフレームワークを提供しました。GNU プロジェクトが無ければ、bash も存在しなかったでしょう。bash は他にも活発で刺激的なユーザーコミュニティからの助力も受けています。彼らのフィードバックがあってこそ、bash は現在の形になることができました ──自由ソフトウェアの素晴らしさが証明されたと思います。