Mercurial
Mercurial はモダンな分散型バージョン管理システム (VCS) であり、多くの部分が Python で、一部が高速化のために C で書かれています。この章では Mercurial のアルゴリズムとデータ構造を設計するうえで生じた判断を議論します。まずはバージョン管理システムの簡単な歴史を見ていきながら、これからの説明に必要なコンテキストを説明しましょう。
バージョン管理の簡単な歴史
この章では主に Mercurial のソフトウェアアーキテクチャについて説明しますが、登場する概念の多くは他のバージョン管理システムでも見られるものです。そこで Mercurial について実りの多い議論を行うために、まずは異なるバージョン管理システムで見られる概念や操作に名前を付けるところから始めます。また広い視野を持って分野を見渡せるように、VSC の歴史も簡単に説明します。
バージョン管理システムは複数の開発者が同時にソフトウェアシステムの開発に取り組むために生み出されました。これを使えばソースコードの完全なコピーをやり取りしたり、ファイルの変更を人の手で管理する必要がなくなるというわけです。その後に扱えるものがソフトウェアのソースコードから任意のファイルツリーへと一般化されました。バージョン管理の主な機能の一つはファイルツリーへの変更を伝えることであり、基本的なサイクルは次のようになります:
- どこかから最新のファイルツリーを入手する。
- ファイルツリーに対して変更を行う
- 変更を公開して他の人が入手できるようにする。
最初のファイルツリーをローカルにコピーする処理をチェックアウトと言います。変更を入手したり公開したりするときに使う場所をレポジトリと言い、チェックアウトの結果手に入るファイルツリーを作業ディレクトリまたは作業ツリーあるいは作業コピーと言います。作業コピーをレポジトリにある最新のものに更新することは、アップデートと呼ばれます。アップデートのときにマージが必要になることもあります。マージとは、一つのファイルに対する複数のユーザーからの変更を一つにまとめる処理のことです。diff コマンドを使うとファイルやツリーの二つのリビジョン間の変更を確認できます。diff コマンドが一番よく使われるのは、作業コピーに対するローカルの (まだ公開していない) 変更を確認するときです。変更はコミットコマンドを実行することで公開され、このコマンドによって作業ディレクトリの変更がレポジトリに保存されます。
中央集権型バージョン管理
最初のバージョン管理システムである Source Code Control System (SCCS) が提案されたのは 1975 年のことです。このシステムが考えていたのは単一のファイルに対する差分を保存することで全体のコピーを保存せずに済ませることであり、その差分を他の人が見れるように公開する機能はありませんでした。このアイデアは 1982 年の Revision Control System (RCS) に受け継がれます。RCS は SCCS を進化させた自由ソフトウェアであり、GNU プロジェクトによって現在でもメンテナンスされています。
RCS の後に登場したのが Concurrent Versioning System (CVS) です。最初 1986 年にリリースされたときの CVS は RCS ファイルを生成するスクリプトを集めたものに過ぎませんでしたが、現在では独自のプログラムとなっています。CVS が革新的だったのは、複数のユーザーが同時に編集を行える、並列編集という概念です (ただし最後にはマージが行われました)。これによって編集の衝突という概念も生まれました。つまり開発者が新しいバージョンをコミットできるのは、ローカルのバージョンがレポジトリで利用可能な最新のバージョンに基づいているときだけであるということです。もしレポジトリと作業ディレクトリから変更されている場合には、その間の変更で生じる衝突 (同じ行への変更) を自分で解決しなければなりません。
CVS はブランチという概念も発明しました。ブランチを使うと開発者は違うことに同時に取り組むことができます。またあるバージョンに対する名前の付いた永続参照を意味するタグという概念も CVS が発明しました。初期の CVS では差分のやり取りに同じファイルシステムにあるレポジトリが使われていましたが、後に (インターネットなどの) 大規模なネットワークを通したクライアント-サーバーアーキテクチャが実装されました。
2000 年、三人の開発者が力を合わせ、CVS の大きな問題点を修正することを目標に新しい VCS を作成し、Subversion という名を与えました。Subversion で最も重要なのは、変更がツリー全体に対して同時に行われる点です。つまりリビジョンに対する変更は原始性、一貫性、独立性、永続性を持ちます。Subversion の作業コピーにはチェックアウトされたリビジョンが手つかずの状態で含まれるので、よく使われる diff 操作 (チェックアウトされたリビジョンとローカルツリーとの比較) がローカルで高速に行えます。
Subversion で興味深いのが、タグとブランチがプロジェクトツリーに含まれる点です。Subversion プロジェクトは通常 tags, branches, trunk という三つの部分からなっており、この設計はバージョン管理システムを良く知らないユーザーにとって非常に直感的であることが判明しています。ただこの設計により柔軟性が損なわれ、数々の変換ツールにおいて問題が起こっています。 tags や branches が他のシステムよりも構造化された表現を持っているのが主な理由です。
ここまでに登場したシステムはどれも中央集権型 (centralized) と呼ばれます。つまり CVS 以降のシステムには変更をやり取りする仕組みがあり、レポジトリの履歴の管理を他のコンピューターに任せることも可能です。これに対して分散型 (distributed) バージョン管理システムでは、レポジトリの作業ディレクトリを持つそれぞれのコンピューターがレポジトリの履歴の管理のほぼ全てを担当します。
分散型バージョン管理
Subversion は確かに CVS の弱点を克服しましたが、それでもいくつか欠点があります。まず、中央集権型システムではレポジトリの履歴が一つの場所に集約されるために、チェンジセット1のコミットと公開が本質的に同じになります。そのためネットワークアクセスが無い場合にはコミットが行えません。また、中央集権型システムでレポジトリにアクセスするとネットワーク越しのやり取りが一度以上必ず必要になるので、ローカルアクセスで済む分散システムと比べると処理が遅くなります。さらに、今までに紹介したシステムはどれもマージの管理に難があります (いくつかは後に修正されましたが)。大きなグループが同時に開発に取り組む状況を考えると、バージョン管理システムが新しいリビジョン2に含まれる変更を記録するときには、その情報が失われることなく以降のマージで利用できることが重要です。最後に、昔ながらの VCS が要求する中央集権というのは、ときに人工的に感じられ、全てをまとめるための単一の場所が必要になります。これに対する分散型 VCS の支持者の意見は、システムをもっと分散させれば好きな時点で変更をプッシュしたり統合できるようになって有機的な組織でも使用可能になるというものです。
これらの欠点を修正するためのツールが多数開発されました。私が見渡せる範囲 (オープンソースの世界) で、2011 年時点で最もよく知られているのは Git, Mercurial, Bazaar の三つです。Git と Mercurial はどちらも 2005 年に開発が始まっており、その理由は Linux カーネル開発者たちがプロプライエタリな BitKeeper システムを使うのをやめようと決断したためです。どちらも Linux カーネルの開発者 (それぞれ Linus Torvalds と Matt Mackall) によって開発され、数万のファイルに対する数十万のチェンジセットを持つプロジェクト (例えば Linux カーネル) を扱うことが可能です。Matt と Linus は両人とも Monotone VCS から大きな影響を受けていました。Bazaar はこれとは別に開発されましたが、同時期に広いユーザーを獲得しました。Canonical が全てのプロジェクトに Bazaar を採用したのが大きいです。
分散型バージョン管理システムの作成には困難が当然いくつかあり、どんな分散型システムも直面する先天的な問題も多くあります。例えば、中央集権型システムでは中央の制御サーバーが常に完全な履歴を持っていましたが、分散型 VCS にはそういったものは存在しません。そのため複数のチェンジセットが並列にコミットされるので、履歴の管理のためにレポジトリ内のリビジョンを一時的に一列に整列させることはできません。
この問題の解決策として広く使われているのは、チェンジセットを管理するのに直線的な順序ではなく有向非巡回グラフ (directed acyclic graph, DAG) を使うというものです。つまり、新たにコミットされたチェンジセットは元となるリビジョンの子となり、自分自身の子や自分の子孫の子となることはできません。このスキームでは三種類の特別なリビジョンが存在します: 親を持たないルートリビジョン(レポジトリが複数のルートを持つことは可能です)、複数の親を持つマージリビジョン、そして子を持たないヘッドリビジョンです。レポジトリは空のルートから始まってチェンジセットを追加することで成長し、任意の時点で一つ以上のヘッドが存在します。例えば二人のユーザーが独立にコミットを行い、片方がもう一人の変更をプルしようとしたときには、その人はもう一人の変更を新しいリビジョンに明示的にマージし、そのリビジョンをマージリビジョンとしてコミットしなければなりません。
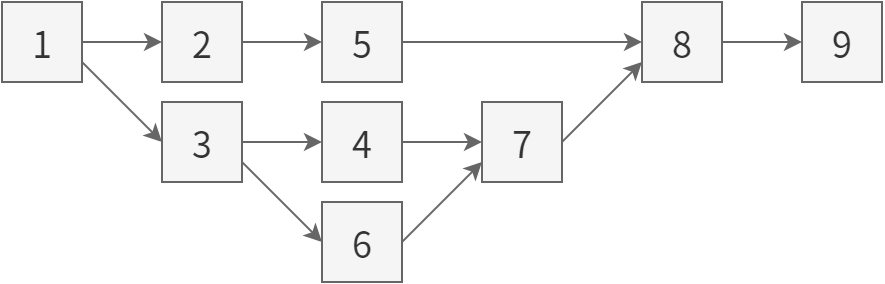
中央集権型バージョン管理システムでは解決が難しい問題も、この DAG モデルを使えば解決できます。例えばマージリビジョンは新しくまとめられた分かれ道を表すので、たくさんの並行するブランチを表現しつつも、それらのブランチを少ないグループにマージしていき、最終的には重要な意味を持つ特別な単一のブランチにマージすることが可能です。
このアプローチではチェンジセット同士の親子関係を記録する必要があります。チェンジセットのやり取りが簡単にできるように、各チェンジセットの親を記録することが多いです。そしてこれを行うためには、チェンジセットに何らかの ID が必要になります。UUID などのスキームを使っているシステムもありますが、Git と Mercurial は両方ともチェンジセットの内容の SHA1 ハッシュを使っています。これによりチェンジセットの ID を使ってチェンジセットの内容を検証することも可能になります。実はリビジョンのハッシュデータにはその親が含まれていることから、あるリビジョンからルートへ向かう任意のリビジョンをハッシュで検証できます。新しいリビジョンのファイルの内容だけでなく作者の名前、コミットメッセージ、タイプスタンプといったチェンジセットのメタデータもハッシュされるので、メタデータの検証も可能になります。タイムスタンプにはコミットした時間が記録されることから、レポジトリ内のファイルのタイプスタンプが線形に進む必要はありません。
中央集権型 VCS だけを使ってきた人は、以上の機能に慣れるまでに時間がかかるかもしれません。中央集権型システムではリビジョンをグローバルに名前付けする 16 進 40 文字は存在しないからです。さらに、分散型システムにはリビジョン間のグローバルな順序というものが一切存在せず、あるのはローカルな順序だけです。それも“順序”として存在するのは DAG であり、一列に並んでいるわけではありません。また中央集権型 VCS では既に子を持っている親リビジョンに対して新しいヘッドをコミットすると警告を受けますが、分散型では警告が出ません。これも混乱の原因となるでしょう。
幸い木構造を可視化するためのツールがあり、さらに Mercurial には曖昧さの無いように短縮したチェンジセットハッシュやローカルでのみ使える線形の ID があります。このローカル ID はチェンジセットがクローンされてからの順番を表し、コミットのたびに単調に増加します。この順番はクローンするたびに変わるので、ローカルでない操作には使うことができません。
データ構造
DAG の概念がいくらか明確になったところで、Mercurial で DAG がどのように保持されているかを見ていきましょう。DAG モデルは Mercurial の内部動作において重要な働きを持ち、ディスクに保存されたレポジトリ (およびコードで使われるインメモリの構造) にはいくつかの DAG が含まれます。この節ではこれら DAG がどんなもので、どのように連携するかを説明します。
課題
実際のデータ構造の前に、Mercurial が誕生した環境に関するコンテキストを説明します。Mercurial のアイデアが最初に示されたのは 2005 年 4 月 20 日に Matt Mackall が Linux カーネルのメーリングリストに投稿した E メールであり、カーネルの開発で BitKeeper の使用を中止することが決定されてすぐのことでした。Matt はメールの冒頭で、新しいシステムの目標は単純さ、スケーラビリティ、そして効率であることを説明しています。
Matt が [Mac06] で主張したのは、モダンな VCS は数百万のファイルを含むツリーと数百万のチェンジセットを扱わなければならず、さらに数千人のユーザーが新しいリビジョンを作り、開発が数十年にわたって続いた場合にも対応できるようスケールしなければならないということでした。この目標を設定した上で、彼は達成を阻むのは次の技術的制約であると指摘しました:
- 速度: CPU
- 容量: ディスクとメモリ
- 帯域: メモリ、LAN、ディスク、WAN
- ディスクのシーク速度
ディスクのシーク速度と WAN の帯域は現在でも制約となっており、最適化が必要です。この論文では次にバージョン管理システムのファイル単位のパフォーマンスを評価するための共通シナリオと基準を示しています:
-
ストレージの圧縮: ファイルの履歴をディスクに保存するのに最も適している圧縮方式はどれか?CPU 時間がボトルネックにならない程度に I/O パフォーマンスを最適化するにはどのアルゴリズムを使うべきか?
-
任意のファイルリビジョンの取得: 多くのバージョン管理システムが採用しているリビジョンの保管方法では、新しいリビジョンを (差分を使って) 構築するときに古いリビジョンをたくさん読み込まなければならない。古いリビジョンの取得が高速になるようにしつつこれを制御するのが望ましい。
-
ファイルリビジョンの追加: 新しいリビジョンは定期的に追加されるが、そのときに毎回古いリビジョンを上書きするのは望ましくない。そうするとリビジョンが増えるとともに処理が遅くなってしまう。
-
ファイルの履歴の表示: 特定のファイルを変更する全てのチェンジセットをリストにして閲覧できるのが望ましい。これによってアノテーションが可能になる。つまり、現在のファイルの各行に対するチェンジセットを閲覧できるようになる (このためのコマンドは CVS で
blameと呼ばれていたが、ネガティブな意味を取り除くためにannotateと改名された)。
論文はこの後プロジェクト単位でのパフォーマンスを評価するためのシナリオを示しています。具体的にはリビジョンのチェックアウト、新しいリビジョンのコミット、作業ディレクトリ中の差分の取得です。最後のシナリオは巨大なツリーで特に低速になります (例えば Mercurial を使ってバージョン管理を行っている Mozilla のプロジェクトや NetBeans プロジェクトなど)。
高速なリビジョンストレージ: revlog
Matt が Mercurial のために考案した解決法は revlog と呼ばれるものです (revision log の略です)。revlog はリビジョンに含まれるファイルを効率良く保存するための仕組みです (各ファイルには以前のバージョンからの変更も含まれます)。前節で説明したようなシナリオに対応するために、revlog にはアクセス時間 (つまりディスクのシーク時間) とストレージ容量の両方について高い効率が求められます。これを達成するために、revlog はディスク上の二つのファイルからなっており、それぞれインデックスファイルとデータファイルと呼ばれます。
| 長さ | 内容 |
|---|---|
| 6 バイト | ハンクへのオフセット |
| 2 バイト | フラグ |
| 4 バイト | ハンクの長さ |
| 4 バイト | 非圧縮時の長さ |
| 4 バイト | ベースリビジョン |
| 4 バイト | リンクリビジョン |
| 4 バイト | 親リビジョン 1 |
| 4 バイト | 親リビジョン 2 |
| 32 バイト | ハッシュ |
インデックスファイルには固定長のレコードが並んでおり、それぞれのレコードは Table 12.1 のようになっています。レコードが固定長なので、ローカルのリビジョン番号からリビジョンに直接 (定数時間で) アクセスすることが可能です。インデックスファイル中のそのリビジョンの場所 (インデックスの長さ×リビジョン番号) がすぐに分かるからです。インデックスとデータを分けておくことでインデックスデータを読み込むときにデータファイルの分をシークしなくて済むので、インデックスデータの読み込みが高速化されます。
ハンクへのオフセットとハンクの長さによって、圧縮されたリビジョンのデータを手に入れるためにデータファイルのどこを読めばよいのかが分かります。実際のデータを手に入れるにはベースリビジョンから初めて差分を適用していくことになりますが、ここで重要なのがベースリビジョンを新しく作るタイミングです。このタイミングは圧縮されたリビジョンの長さと差分の累積サイズの比率で決まります (データはディスクに書き込まれるときにも zlib 圧縮されます)。ベースリビジョンの後に連なる差分の長さを制限することで、リビジョンのデータの再構築をするときに読み込みと適用が必要になる差分の数を抑えています。
リンクリビジョンは“最初の”revlog を指し (次の図を参照)、親リビジョンはローカルのリビジョン番号の整数で表されます。ここでも関連する revlog の検索が高速に行えるようになっています。ハッシュはチェンジセットの一意な識別子として機能します。SHA1 が必要とするのは 20 バイトですが、将来の拡張に備えて 32 バイトを確保しています。
三つの revlog
revlog は履歴データを表す一般的な構造であり、ファイルツリーに対応するデータモデルを表すのには revlog の上のレイヤーを使います。それは changelog, manifest, filelog という三種類の revlog です。changelog には各リビジョンのメタデータおよび manifest revlog に対するポインタ (menifest revlog に含まれるあるリビジョンのノード ID) が含まれます。そして manifest はファイル名のリストと各ファイルのノード ID が含まれるファイルであり、その各ノード ID はファイルの filelog revlog に含まれるあるリビジョンを指します。実際のコード中には changelog, manifest, filelog のそれぞれに対してクラスが存在します。三つのクラスは一般的な revlog クラスを継承しており、両方の機能を明快にレイヤー化します。
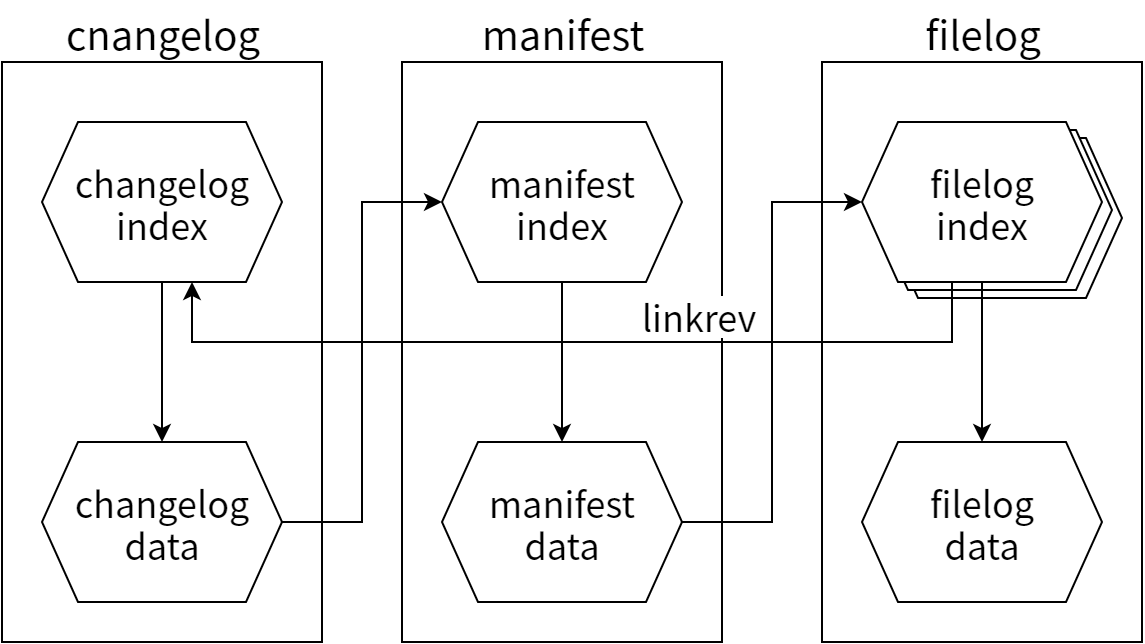
changelog のリビジョンは次のようになっています:
0a773e3480fe58d62dcc67bd9f7380d6403e26fa
Dirkjan Ochtman <dirkjan@ochtman.nl>
1276097267 -7200
mercurial/discovery.py
discovery: fix description line
これは revlog レイヤーから得られる値であり、changelog レイヤーはこの値を単純なリストに変換します。最初の行が manifest のハッシュを表し、その後に作者名、日時 (Unix タイムスタンプとタイムゾーンのオフセット)、編集されたファイルのリスト、説明メッセージと続きます。changelog には任意のメタデータを付けることができますが、ここでは省略しています。またタイムスタンプの後には後方互換性のために追加のビットが存在しますが、これも省略しています。
次に登場するのが manifest です:
.hgignore\x006d2dc16e96ab48b2fcca44f7e9f4b8c3289cb701
.hgsigs\x00de81f258b33189c609d299fd605e6c72182d7359
.hgtags\x00b174a4a4813ddd89c1d2f88878e05acc58263efa
CONTRIBUTORS\x007c8afb9501740a450c549b4b1f002c803c45193a
COPYING\x005ac863e17c7035f1d11828d848fb2ca450d89794
...
これはチェンジセット 0a773e が指すマニフェストのリビジョンであり、ツリーに含まれる全てのファイルを表す単純なリストです (Mercurial の UI では ID を曖昧でない範囲で短縮できます)。ファイル名の終端はヌル文字であり、その後に 16 進でエンコードされたそのファイルの filelog ノード ID が続きます。ツリー内のディレクトリが別々に保存されることはなく、ファイルパスにスラッシュを入れることで表現されます。manifest も他の revlog と同様に差分の形でディスクに保存されるので、revlog レイヤーは任意のリビジョンについて変更されたファイルと新しいハッシュだけを保存するだけで済みます。Mercurial の Python コード内の manifest はハッシュテーブルに似た構造で表され、ファイル名がキーでノードがバリューとなります。
三種類目の revlog は filelog です。filelog は Mercurial 内部の store ディレクトリに、追跡しているファイルとほぼ同じ名前で保存されます。このとき名前は全ての主要オペレーティングシステムで動作するように多少変更されます。例えば Windows と Mac OS X のファイルシステムは大文字と小文字が区別されませんし、Windows ではファイル名に使えない文字があります。さらにファイルシステムによって文字コードも異なります。想像がつくとは思いますが、この処理をバグを出さずに実装するのはとても手間がかかります。一方で filelog のリビジョンの中身はそのままファイルの内容であり、ごく単純です。ただしコピーや名前の変更の追跡などに使われるメタデータがファイルの最初に付きます。
Mercurial レポジトリに含まれるデータはこのデータモデルでアクセス可能なものが全てですが、このまま使うのは不便です。Mercurial が使っているこのモデルはデータを垂直に保存する (一つのファイルごとに一つの filelog) のですが、Mercurial 開発者は一つのリビジョンの全てのファイルについて考えることが多いためです。つまり changelog のとあるチェンジセットから始まって、そのリビジョンの manifest と filelog に素早くアクセスしたいという場合が多いということです。このような状況を扱うための context と呼ばれるレイヤーが revlog の上に後から追加されています。
revlog の分離による利点の一つが、revlog の間に順序を付けられる点です。新しい revlog を複数書き込むことになったとき、最初に filelog、次に manifest、最後に changelog と書き込むことで、レポジトリを常に整合状態に置くことができます。つまり、ある書き込みが行われている間に他のプロセスがいずれかの changelog を読み込んだとしても、そこから伸びるポインタが指す revlog が存在することが保証されます。これによって同じ状況で起こりがちな問題を解決できます。また Mercurial には、並列に revlog を書き込むプロセスが最大でも一つであることを強制するための明示的なロックも存在します。
作業ディレクトリ
最後に紹介する重要なデータ構造は私たちが dirstate と呼んでいるものです。dirstate は現在の作業ディレクトリに存在するファイルを表します。dirstate の最も重要な役割はチェックアウトされたリビジョンの記録です。このリビジョンは status や diff といったコマンドが比較対象として利用され、次にコミットされるチェンジセットの親となります。 merge コマンドでいくつかの変更を他のブランチにマージしようとしている場合には、dirstate に二つの親が存在することになります。
status と diff は非常に頻繁に行われる操作なので、Mercurial は最後に走査した作業ディレクトリの状態を dirstate に保存し、最終更新日時のタイムスタンプとファイルのサイズを比較することでファイルツリーの走査を高速化します。また dirstate はファイルが追加された、削除された、作業ディレクトリにマージされた、といったファイルの状態も記録します。これによって作業ディレクトリの走査がさらに高速化され、コミット処理が快適になります。
バージョン付けの仕組み
Mercurial が内部で使うデータモデルとコードの構造について理解できたところで、次は少しレイヤーを上がって、前節で上げた基礎的な概念の上に Mercurial がどのようバージョン管理を実装しているかを見ていきましょう。
ブランチ
ブランチの良くある使用例は、異なる開発ラインを分離しておいて後で統合するというものです。この目的は例えば誰かが新しい機能の実験を行っているときでもメインの開発ラインをシップできる状態に保っておくためだったり (フィーチャーブランチ)、古いリリースに対する修正を素早くリリースできるようにするためだったりします (メンテナンスブランチ)。どちらのアプローチもよく使われるので、モダンなバージョン管理システムの全てでサポートされています。DAG ベースのバージョン管理システムでは名前の付かないブランチが普通であり、名前付きブランチ (チェンジセットのメタデータに名前が保存されるもの) はあまり見られません。
最初 Mercurial ではブランチに名前を付けることができず、ブランチはクローンをもう一つ作って別の場所に公開することで作られていました。オーバーヘッドがほとんど無いこの方法は実行が速く、理解も簡単で、特にフィーチャーブランチに対しては上手く働きました。しかし大規模なプロジェクトだとクローンが非常に重い処理となってしまいます。レポジトリの保管にはファイルシステムのハードリンクが使えますが、作業ツリーを別に作るのは時間がかかる処理であり、大量のディスク容量が必要になるためです。
こういった欠点を解決するために、Mercurial にはブランチを作るための二つ目の方法があります: ブランチの名前をチェンジセットのメタデータに書き込むというものです。 branch コマンドが現在の作業ディレクトリに対するブランチ名を設定するために追加され、このコマンドを使うと次のコミットからブランチに設定した名前が付くようになりました。ブランチ名の変更は通常の update コマンドで行われ、あるブランチでコミットされたチェンジセットはそのブランチに関連付けられます。このアプローチは名前付きブランチと呼ばれます。ただし Mercurial にブランチを閉じる仕組みが追加されたのは数リリース後のことでした (閉じられたブランチはブランチリストに表示されなくなります)。ブランチを閉じるとチェンジセットのメタデータにそのことを示す追加のフィールドが書き込まれます。ブランチが二つ以上のヘッドを持っている場合、全てのヘッドが閉じられない限りレポジトリのブランチリストからそのブランチが消えることはありません。
もちろんブランチを行う方法はこれだけではありません。例えば Git は参照を使ってブランチに名前を付けます。参照とは Git の履歴内の他のオブジェクト (通常はチェンジセット) を指す名前です。このため Git のブランチは一時的なものになります: その参照を取り除くと、ブランチの存在が履歴ごと全て無くなってしまいます。これは Mercurial で別のクローンで行った開発を元のクローンにマージしたときに起こる処理に似ていると言えます。この仕組みだとローカルでブランチを作るのが簡単になり、さらにブランチリストが大量のブランチで散らかってしまうのを防ぐことができます。
Git が持つこのブランチ手法は多くの人によって使われるようになり、現在では Mercurial の名前付きブランチやクローンによるブランチよりもはるかに広まっています。これを受けて開発されたのが bookmark という拡張機能です。これは参照を記録しておくためのバージョン管理されない簡単なファイルであり、おそらくは将来の Mercurial に組み込まれるでしょう。Mercurial がデータのやり取りに使うワイヤプロトコルは bookmark に関する情報を扱えるよう拡張されています。
タグ
一見しただけでは、Mercurial のタグの実装は分かりにくいです。タグを初めて (tag コマンドで) 追加すると .hgtags という名前のファイルがレポジトリに追加され、コミットされます。このファイルの各行にはチェンジセットのノード ID とそのノードに対するタグの名前が含まれます。そのためタグファイルはレポジトリ内の他のファイルと同じように扱われます。
タグの実装がこうなっているのには三つの理由があります。一つ目の理由は、タグを変更できるようにしなければならないためです。ミスは起こるものなので、修正や削除が可能である必要があります。二つ目の理由は、タグがチェンジセット履歴の一部であるのが望ましいためです。タグがいつ誰によってなんのために作られたのか、あるいは変更されたのかを確認できるのは重要です。三つ目の理由は、過去のチェンジセットにタグを付けられるべきであるためです。例えばあるリビジョンのビルド結果に対してリリース前に徹底的なテストを行うプロジェクトもあります。
.hgtags を使った設計では以上の機能が簡単に手に入ります。作業ディレクトリに .hgtags があることで混乱してしまうユーザーがいるのも確かですが、これによってタグと Mercurial の他の部分 (例えば他のレポジトリクローン) のやり取りがとても単純になります。もし (Git のように) タグがソースツリーの外に存在していたら、違う場所を指す同じ名前のタグに対処するために、タグがいつ追加されたかを確認する処理が必要になるでしょう。この状況が起こるのは稀ですが、最初から問題が起こらない設計にするのが得策です。
こういったことを全てを上手くまとめるために、Mercurial の .hgtags は追記専用となっています。これによって異なるクローンでタグが並行して作られたとしてもマージ処理が可能になります。タグに関連付けられているノード ID の中で一番新しいものが優先され、ヌル ID を追加することでタグの削除が行えます (ヌル ID は全てのレポジトリにおいて空のルートリビジョンを表します)。Mercurial はレポジトリが持つ全てのブランチからタグを集めますが、このときにも最新のノード ID を選択します。
全体の構造
Mercurial はほぼ全てが Python で書かれており、アプリケーション全体のパフォーマンスに関わるほんの少しの部分にだけ C が使われています。Python は動的言語であり高レベルの概念を表現するのが非常に簡単なので、コードのほとんどの部分に対する最適な言語であるように思われました。コードの大部分はパフォーマンスに関係しないので、コーディングの簡単さを優先した結果としてパフォーマンスが多少悪くなっても問題ありません。
Python では一つのファイルが一つのモジュールに対応します。モジュールにはいくらでも多くのコードを書くことができるので、モジュールを上手く使うことがコードを整理する鍵です。他のモジュールにある型や関数を使うときはインポートを明示的に書く必要があります。 __init__.py モジュールを持つディレクトリはパッケージと呼ばれ、このファイルに含まれるモジュールとパッケージが全て Python のインポーターに公開されます。
Mercurial がデフォルトで Python にインストールするパッケージは mercurial と hgext の二つです。 mercurial パッケージには Mercurial を実行するために必要なコアのコードが含まれ、 hgext パッケージにはコアと共に配布するに値する様々な拡張機能が含まれます。ただし拡張機能を使うには手動で設定ファイルを書き換える必要があります (後述)。
はっきりさせるために言っておくと、Mercurial はコマンドラインアプリケーションです。つまりユーザーとの対話は hg スクリプトにコマンドを付けたものという単純なインターフェースを通して行われます。コマンド (log, diff, commit など) にはオプションがいくつか付くこともあり、全てのコマンドに付けられるオプションもあります。コマンドラインから入力を受け取った後は次の三つの処理が行われます:
hgがユーザーの要求やステータスメッセージを表示する。hgが必要であればコマンドラインプロンプトからのさらに入力を読む。hgが必要であれば外部プログラムを起動する (コミットメッセージのためのエディタやコードの衝突をマージするためのプログラムなど)。
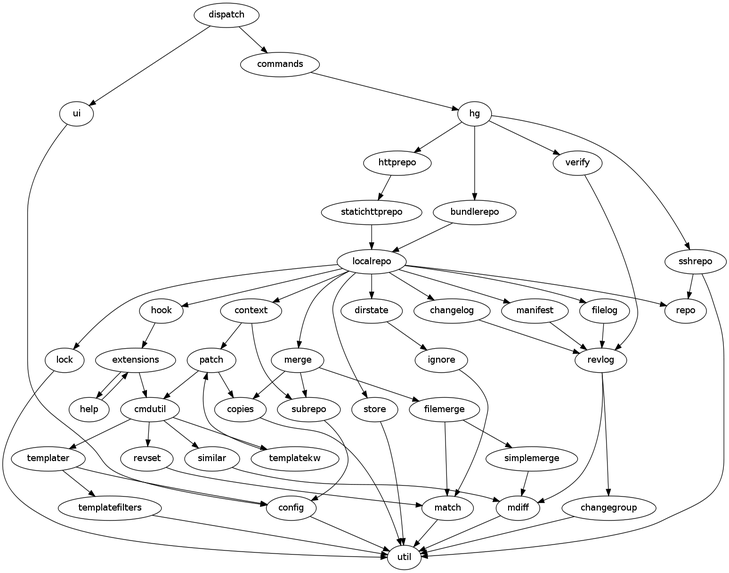
図 12.3 の上部にこの処理の始まりが示されています。コマンドライン引数は dispatch モジュールの関数に渡され、まず ui オブジェクトがインスタンス化されます。 ui クラスはそれから設定ファイルをいくつかの場所 (ホームディレクトリなど) から検索し、設定オプションを ui オブジェクトに読み込みます。設定をこの時点で読み込む必要があるのは拡張機能へのパスが含まれるためです。コマンドラインに渡されたグローバルのオプションもここで ui オブジェクトに保存されます。
次にレポジトリオブジェクトを作る必要があるかが判定されます。コマンドの多くはローカルのレポジトリ (localrepo モジュールの localrepo クラス) を必要としますが、リモートのリポジトリ (HTTP、SSH などの形式) を使うコマンドもありますし、レポジトリを全く使うことなく実行されるコマンドもあります。例えば新しいレポジトリを作る init コマンドはレポジトリを使わないコマンドの例です。
コアのコマンドは全て commands モジュールの一つの関数として表されており、これによってコマンドに対応するコードを見つけるのが非常に簡単になっています。他にも commands モジュールにはコマンドの名前から関数へのハッシュテーブルやコマンドのオプションの説明が含まれ、似たオプションを使い回せるようになっています (例えば log コマンドに付くオプションは他の多くのコマンドにも付きます)。 dispatch モジュールはこのオプションの説明を使って与えられたコマンドとオプションの組が正しいかを確認し、オプションの値をコマンド関数が必要とするものに変換します。コマンドを実装する関数のほぼ全てには ui オブジェクトと repository オブジェクトが与えられます。
拡張性
Mercurial の強みの一つが拡張性です。Python は比較的簡単に始められる言語であり、Mercurial の API は多くの部分できちんと設計されていることが高い拡張性の理由です (ドキュメントが追いついていない部分もありますが)。Mercurial を拡張するために Python を学び始めたという人もいるほどです。
拡張機能の記述
拡張機能は Mercurial が起動時に読む設定ファイルに書きます。そのときに書き込むのは拡張機能の名前と Python モジュールへのパスです。Python コードから機能を追加するときには次の方法が使えます:
- 新しいコマンドの追加
- 既存のコマンドのラップ
- 使用されるレポジトリのラップ
- Mercurial の任意の関数のラップ
- 新しいレポジトリタイプの追加
新しいコマンドの追加は cmdtable と言う名前のハッシュテーブルを拡張機能のモジュールに追加することで行われます。このハッシュテーブルは拡張機能ローダーによって読み込まれ、コマンドのディスパッチで使われるコマンドテーブルに追加されます。同様に uisetup や reposetup を定義しておけば、UI やレポジトリがインスタンス化されたときにディスパッチコードによって呼び出されます。よくあるのは、レポジトリの子クラスで reposetup を定義してレポジトリをラップするという使い方です。こうすると全ての基本的な振る舞いを拡張機能から変更できます。例えば私が書いたとある拡張機能では、SSH の認証情報に基づいて ui.username を設定する機能を uisetup に追加しています。
さらに過激な拡張機能として、レポジトリタイプを追加することも可能です。例えば hgsubversion プロジェクト (Mercurial には含まれていません) は Subversion レポジトリ用のレポジトリタイプを登録します。これを使うと Subversion レポジトリをまるで Mercurial であるかのようにクローンでき、Subversion レポジトリにプッシュすることさえ可能です。二つのシステムの間で上手くかみ合わない部分がいくらかありますが、ユーザーインターフェースは完全に透過的になっています。
Mercurial を根本から変更したい場合には、動的言語において“モンキーパッチ”と呼ばれるテクニックを使います。拡張機能は Mercurial と同じアドレス空間で実行され、とても柔軟性のある Python には幅広いリフレクション機能があるので、Mercurial に含まれる任意の関数とクラスを書き換えることが可能です (それもとても簡単です)。醜いハックかもしれませんが、とても強力なメカニズムです。例えば hgext に入っている highlight という拡張機能は組み込みのウェブサーバーを書き換え、ファイルの閲覧に使用されるレポジトリブラウザのページにシンタックスハイライトを追加します。
Mercurial を拡張する方法がもう一つあります。この方法はエイリアスと呼ばれ、これまでのものよりずっとシンプルです。設定ファイルでエイリアスを定義するとコマンドにオプションを付けたものに新しい名前を付けることができます。また既存のコマンドに短い名前を付けることも可能です。さらに最近のバージョンの Mercurial ではシェルコマンドをエイリアスとして呼び出す機能が追加され、シェルスクリプトだけを使って複雑なコマンドを作れるようになっています。
フック
バージョン管理システムでは古くからフックを使って VCS イベントと外界の間でやり取りをさせることが可能でした。例えば通知を継続的インテグレーションシステムに送ったり、ウェブサーバー上の作業ディレクトリを更新して外から利用可能にしたりするのに使われます。もちろん Mercurial にもこのようなフックを起動するためのサブシステムがあります。
実はここでも二種類の方法があります。一つ目は昔ながらのバージョン管理システムにおけるフックと同様に、シェルでスクリプトを起動する方法です。二つ目はもっと面白いもので、Python のモジュールと関数を登録しておいてフックから起動する方法です。二つ目の方法は同じプロセスで実行されるので高速であり、さらに repo オブジェクトと ui オブジェクトを関数に渡せるので、VCS 内部との複雑な対話が簡単に行えます。
Mercurial のフックには pre-command、post-command、controlling、miscellaneous という種類があります。最初の二つは任意のコマンドに対して定義でき、設定ファイルのフックセクション内の pre-command と post-command というキーで設定します。後ろの二つはあらかじめ定義されたイベントで起動されます。controlling フックだけは他のフックと異なり、何かが起こる前に起動され、その結果に応じて処理を止めることが可能です。これは中央サーバーでチェンジセットを検証するときなどに使うことができます。Mercurial は分散型なので、この検証をコミット時に行うことはできません。例えば Python プロジェクトでは、コードベース全体にコードスタイルを強制させることができます。チェンジセットにスタイルに反するコードが含まれる場合には、プッシュが中央レポジトリから拒否されます。
フックのもう一つの興味深い使用例は、Mozilla などの企業によって利用されている pushlog です。pushlog は各プッシュ (チェンジセットが複数含まれることもある) がいつ誰によって行われたかを記録し、レポジトリに一種の監査機能を追加します。
教訓
Matt が Mercurial の開発を始めたときに決めていたことの一つが、開発を Python で行うことです。Python は素晴らしい柔軟性 (拡張機能とフックで使われるもの) を持ち、コーディングも簡単です。さらに異なるプラットフォームで動作させるために必要な作業の多くを Python に任せることができるので、Mercurial を主要三 OS で動作させるのは比較的簡単になりました。ただ一方で Python は他の (コンパイル) 言語と比べると低速です。これは長い間実行されたままのプロセスであれば気になりませんが、VCS のような短い時間で何度も起動されるツールでは問題になります。
コミットしたチェンジセットをなるべく変更できないようにすることは開発の初期に決定していました。リビジョンの変更には必ずハッシュ ID の変更が伴うので、一度インターネットで公開されたチェンジセットを“破棄”するのは不都合が大きいのです。そのため Mercurial は意図的にこれを行うのを難しくしています。ただし公開されていないリビジョンを変更するのは問題ないことが多いので、この処理は簡単に行えるようにリリース直後に変更されました。リビジョンを変更する問題を解決しようとしている拡張機能はいくつかありますが、どれも Mercurial を普通に使ってきたユーザーにとって分かりにくい学習ステップが必要となってしまうようです。
revlog はディスクシークの削減に貢献し、changelog と manifest と filelog でレイヤー化されたアーキテクチャはとても上手く働いています。コミットは高速で、リビジョンが必要とするディスク容量も比較的小さめです。しかし、異なる名前のファイルには異なるリビジョンのストレージが使われるので、ファイルのリネームなどのケースは効率良く扱えません。これは今後修正される予定ですが、抽象レイヤーを破るハックじみた方法が必要になるでしょう。同様の理由でファイルごとの DAG はあまり使われていません。これは filelog ストレージの探索を助けるための機能なのですが、リネームされたファイルのデータを管理するコードがオーバーヘッドになる可能性があるためです。
Mercurial がもう一つ集中して取り組んできたのが、学習を簡単にすることです。必要となる機能のほとんどを少数のコアコマンドに持たせ、コマンドが一貫したオプションを持つようにしています。その狙いは Mercurial の多くを段階的に学んでいけるようにすることであり、特に別の VCS を使ったことのあるユーザーを念頭に置いています。拡張機能を使って Mercurial を特定の使用目的のためにカスタマイズできるようにするアイデアはこの考えから生まれました。さらに同じ理由から Mercurial の UI は他の VCS (特に Subversion) と似せてあります。またドキュメントはトピックとコマンドの間で相互参照が整備された質の高いものとなっており、Mercurial と一緒についてきます。エラーメッセージの質にもこだわっており、例えば操作が失敗したことだけではなく次にすべきことのヒントも一緒に示すようにしています。
新しいユーザーを驚かせている細かい部分の選択がいくつかあるようです。例えば作業ディレクトリ内のファイルを使ったタグの管理 (この章で解説したもの) は新規ユーザーに嫌われることが多いですが、この仕組みは望ましい機能を提供してくれるので採用されています (欠点もありますが)。同様に、他の VSC ではプッシュのときにチェックアウトされたチェンジセットとその子孫だけをリモートに送るという動作がデフォルトのことが多いですが、Mercurial はコミットされたチェンジセットでリモートが持っていないものを全て送ります。どちらの方法でも特に問題は起こらないので、ユーザーは開発スタイルにあった方を選択するべきです。
どんなソフトウェアプロジェクトでもそうであるように、Mercurial にはたくさんのトレードオフが存在します。Mercurial は良い選択をしてきたと私は考えていますが、それでも経験を積んだ今考えればもっと上手くやれたのではないかと思う部分もあります。Mercurial は歴史的に見て、どこででも使用できるほど成熟した分散型バージョン管理システムの第一世代と言えます。私は一個人として、次の世代がどのようなものになるのかを楽しみにしています。