Selenium WebDriver
Selenium はブラウザ自動化ツールであり、ウェブアプリケーションの end-to-end テストによく使われます。ブラウザ自動化ツールはその名の通りのことを行います: ブラウザの制御を自動化し、反復的なタスクを自動的に行います。単純な問題に見えるかもしれませんが、この章でこれから見る通り、裏で様々なことをしなければ上手く動きません。
Selenium のアーキテクチャを説明する前に、プロジェクトの各部分がどのように組み合わさっているかを見た方が分かりやすいでしょう。高いレベルで見ると、Selenium は三つツールの集合体です。一つ目のツールは Selenium IDE で、これはユーザーがテストを録画・再生するための Firefox 用の拡張機能です。録画・再生という考え方が使えないことも多いので、そのような場合には二つ目のツール Selenium WebDriver がより細かな制御や通常のソフトウェア開発への統合のための様々な言語用の API を提供します。最後のツール Selenium Grid を使うと、Selenium API でグリッドコンピューター上で複数のブラウザインスタンスを制御し、テストを並列に実行できます。プロジェクト内ではこの三つのツールはそれぞれ IDE, WebDriver, Grid と呼ばれています。この章が扱うのは Selenium WebDriver のアーキテクチャです。
この章が書かれたのは 2010 年後半、Selenium 2.0 のベータ期間です。もしそれ以降にこの本を読んでいるなら、物事は前に進んでいるはずであり、この章で説明されるアーキテクチャに関する決断がその後どのように展開したかを確認できるでしょう。もしそれ以前にこの本を読んでいるのなら: おめでとうございます! タイムマシンを手に入れたんですね! 宝くじの当選番号を教えてもらえませんか?
歴史
Jason Huggins は Selenium プロジェクトを 2004 年に開始しました。そのころ彼は ThoughtWorks で内製の Time and Expenses (T&E) システムに取り組んでおり、このシステムが JavaScript をフル活用していました。当時ブラウザは Internet Explorer が圧倒的でしたが、ThoughtWorks はその他のブラウザ (特に Mozilla 系のブラウザ) をいくつか利用しており、そういったブラウザで T&E アプリケーションが動かなかった場合にはバグとしてレポートしていました。利用可能だったオープンソースのテストツールは単一のブラウザ (たいていは IE) しか対応していないか、(HttpUnit のように) ブラウザのシミュレーションをしているだけでした。また商用ツールのライセンスは小さな社内プロジェクトの予算を超えており、テストの現実的な選択肢にも入っていませんでした。
テストの自動化が難しい場合には手動テストに頼るのが普通ですが、この手法はチームが小さいときあるいは非常に頻繁にリリースを行うときにはスケールしません。さらに自動化ができそうに思える手順を一ステップずつ実行するよう人に頼むのは人間性の浪費であり、さらに言えば、人間は退屈で反復的なタスクの実行が機械よりも遅く、エラーも多いです。手動テストは選択肢ではありませんでした。
幸いにも、テストしようとしているブラウザの全てが JavaScript をサポートしており、JavaScript を使ってアプリケーションの動作を検証するのが良さそうに思えました。FIT1 を参考にして、生の JavaScript ではなく表ベースのシンタックスが採用されました。これによりプログラミングをよく知らない人でもキーワードドリブンなテストを HTML ファイルに書くことが可能になります。このツールは Apache 2 ライセンスで 2004 年に“Selenium”という名前でリリースされ、後に“Selenium Core”と呼ばれるようになりました。
Selenium の表フォーマットは FIT の ActionFixture と似た構造をしています。表の各行は三つの列からなっており、第一列が実行するコマンドの名前、第二列が要素の識別子、第三列がオプショナルな値となっています。例えば識別子“q”を持つ要素に文字列“Selenium WebDriver”を打ち込む (type する) には次のようにします:
type name=q Selenium WebDriver
Selenium は純粋な JavaScript で書かれているので、初期の設計では Core とテストとテスト対象のアプリケーション (application under test, AUT) を同じサーバーでホストする必要がありました。ブラウザのセキュリティポリシーや JavaScript のサンドボックスとの衝突を防ぐためなのですが、こうするのは不便であり、不可能な場合さえあります。さらに悪いことに、コードであれば開発者の IDE を使ってコードを迅速に生成したり大規模なコードベースをナビゲートしたりできますが、HTML にはそのようなツールが存在しません。中規模サイズのテストスイートでさえ管理が難しくなってしまうということがすぐに判明しました2。
こういった問題を解決するために HTTP プロキシが開発され、全ての HTTP リクエストが Selenium を経由するようになりました。プロキシを使うことでブラウザの同一生成元ポリシー (現在のページが提供されたサーバー以外への通信を JavaScript に許さないというもの) による制限の多くを回避でき、最初に述べた問題が解決されます。またこの設計により他の言語で Selenium のバイディングを書くことが可能になります: 必要なのは HTTP リクエストを特定の URL に送信できることだけです。データのやり取りに使われるフォーマットは Selenium Core の表ベースのシンタックスを元にしており、このフォーマットは表ベースのシンタックスと共に“Selenese”として知られるようになりました。他言語へのバインディングを使えばブラウザを遠隔で制御できるので、このツールは“Selenium Remote Control”あるいは“Selenium RC”と呼ばれます。
Selenium の開発中に、もう一つの自動化フレームワークが ThoughtWorks 内で開発されていました: WebDriver です。最初のコードは 2007 年の初頭にリリースされています。WebDriver は end-to-end テストをテストツールから分離しようとしていたプロジェクトから生まれており、この分離はアダプターパターンを通じて行われていました。この手法がたくさんのプロジェクトでそのまま使われているという観察から WebDriver は生まれています。最初は HtmlUnit のラッパーであり、Internet Explorer と Firefox のサポートはリリース後すぐに追加されました。
WebDriver がリリースされたとき、WebDriver と Selenium RC の間には (両方ともブラウザの自動化 API というニッチなソフトウェアであるにもかかわらず) 大きな違いがありました。ユーザーから見て一番分かりやすい違いは、Selenium RC がディレクトリベースの API を持っており全てのメソッドが単一のクラスで公開されるのに対して、WebDriver はもっとオブジェクト指向な API を持っている点です。また WebDriver は Java しかサポートしないのに対して、Selenium RC は様々な言語をサポートします。技術的な差異もあります: (Selenium RC の下にある) Selenium Core は本質的に JavaScript アプリケーションであり、ブラウザのセキュリティサンドボックス内で動作します。これに対して WebDriver はブラウザとネイティブに連携するようになっており、フレームワーク開発にかかる大きなコストを費やしてまでブラウザのセキュリティモデルに割り込んでいます。
2009 年 8 月、二つのプロジェクトがマージされて Selenium WebDriver となることが発表されました。執筆時点で WebDriver は Java, C#, Python, Ruby に対するバインディングを持っており、Chrome, Firefox, Internet Explorer, Opera そして Android ブラウザと iPhone ブラウザをサポートします。また姉妹プロジェクトもいくつか存在します。これらのプロジェクトはメインのプロジェクトとソースコードを共有してはいないもののと緊密に連携を取っており、Perl バインディングと BlackBerry ブラウザ用の実装、そして「ヘッドレス」WebKit を提供します。ヘッドレス WebKit は継続的インテグレーションサーバーなどのディスプレイがない環境で有用です。オリジナルの Selenium RC メカニズムは現在でもメンテナンスされており、RC でなければサポートできないブラウザを WebDriver がサポートできるようになっています。
ジャーゴンに関する余談
残念ながら Selenium プロジェクトではたくさんのジャーゴンが使われます。これまでに登場したものを次にまとめます:
-
Selenium Core はオリジナルの Selenium 実装の心臓部であり、ブラウザを制御する JavaScript スクリプトの集合体です。Selenium Core は“Selenium”あるいは“Core”と呼ばれることがあります。
-
Selenium RC は Selenium Core に対する言語バインディングの名前です。紛らわしいことに、Selenium RC が“Selenium”あるいは“RC”と呼ばれることがよくあります。現在では Selenium WebDriver に置き換わっており、その中で RC の API は“Selenium 1.x API”と呼ばれます。
-
Selenium WebDriver は RC と同じようなものを指し、オリジナルの 1.x バインディングを含みます。Selenium WebDriver は言語バインディングと各ブラウザの制御コードの実装の両方を指します。“WebDriver”と呼ばれることが多く、“Selenium 2.0”と呼ばれることもあります。しかし時が経つにつれこれが“Selenium”に短縮されるのは間違いないでしょう。
賢明な読者は“Selenium”という言葉がとても広いものを指していることに気付くでしょう。幸い、話している人がどの Selenium を指しているのかは文脈から判断することが通常は可能です。
最後に、私が使うことになる語がもう一つあります (自然な紹介方法が無いのでここで紹介します)。「ドライバ」は特定の WebDriver API の実装を指します。例えば Firefox ドライバや Internet Explorer ドライバが存在します。
アーキテクチャの題目
個々の部分を見て互いがどう組み合わさるかを理解する前に、プロジェクトの設計と開発の全体に関わる題目を理解した方がよいでしょう。簡潔に示すと次のようになります:
-
コストを低く抑える。
-
ユーザーをエミュレートする。
-
ドライバの動作を実証する...
-
...しかし全てを理解する必要があってはいけない。
-
バス係数を上げる。
-
JavaScript 実装に寄り添う。
-
全てのメソッド呼び出しは RPC である。
-
我々はオープンソースプロジェクトである。
コストを低く抑える
X 個のブラウザを Y 個のプラットフォームでサポートするというのは本質的に高く付く作業であり、それは初期開発であれメンテナンスであれ変わりません。他の原則を破ることなくプロダクトの質を高く保つ方法があるなら、それこそが私たちの進む道です。この考え方が最も明らかになるのは、可能な限り JavaScript を使うという私たちの方針です。これについては後で見ます。
ユーザーをエミュレートする
WebDriver はユーザーとウェブアプリケーションの対話を正確にシミュレートするように設計されています。ユーザーの入力をシミュレートするために使われる共通の手法は、JavaScript を使って実際のユーザーが行ったときと同じ一連のイベントを合成・発火させるというものです。しかしこの「イベント合成」による手法は困難を伴います。というのも違うブラウザが発火させるイベントはブラウザの種類、ときにはブラウザのバージョンによって異なるからです。問題をさらに複雑にするのは、セキュリティ上の理由でたいていのブラウザがファイルからの入力要素といったフォーム要素を使ったこの方法によるユーザーとの対話を禁止している点です。
そのため WebDriver は可能な限り OS レベルでイベントを発火させるというもう一つの方法を使います。この「ネイティブイベント」がブラウザによって捕捉されるために、合成イベントが直面するセキュリティ制限を回避できます。さらにネイティブイベントは OS に固有なので、一つのブラウザで動いてしまえばそのコードを利用して同じ OS の他のブラウザで動作させるのは比較的簡単です。残念ながらこのアプローチが可能なのは WebDriver とブラウザが緊密に連携でき、ネイティブイベントをフォーカスされていないブラウザに送る方法を開発者が発見できた場合だけです (Selenium の実行には長い時間がかかるので、その間に他のことができた方が便利です)。そのため執筆時点でネイティブイベントが利用可能なのは Linux と Windows だけであり、Mac OS X では利用できません。
WebDriver がどのようにユーザーの入力をエミュレートするのであれ、私たちはユーザー同じ入力を可能な限り正確に再現できるように取り組んでいます。これはユーザーが行う処理よりもはるかに低いレベルの処理を行う API の RC とは対照的です。
ドライバの動作を実証する
これは理想主義的で、「ママとアップルパイ」的な題目かもしれません。しかし正しい動作しないコードを書く意味は無いと私は信じています。Selenium プロジェクトにおけるドライバ動作の実証には、徹底的な自動テストが用意されています。テストは「統合テスト」であることが多く、コードをコンパイルしてウェブサーバーと対話するブラウザで実際に動作することが求められます。ただし可能な場合には「ユニットテスト」も書かれており、ここでは統合テストと異なり全体の再コンパイル無しにテストを行うことができます。執筆時点では 500 個の統合テストと 250 個のユニットテストが存在し、全てのブラウザで実行できます。テストは問題を解決したときや新しいコードを書いたときに追加され、私たちはより多くのユニットテストを書くことに注力しています。
全てのテストが全てのブラウザに対して実行されるわけではありません。一部のブラウザがサポートしていない機能やブラウザによって動作が異なる機能のテストがあるためです。例えば新しい HTML5 の機能は全てのブラウザでサポートされているわけではありません。ただし、デスクトップ用の主要なブラウザでは実行すべきテストの大部分が共通します。想像が付くとは思いますが、 500 個以上のテストをブラウザごとに複数のプラットフォームで実行するのは非常に困難であり、プロジェクトが現在も格闘している問題です。
全てを理解する必要があってはいけない
私たちが用いる言語と技術の全てに精通している開発者はほとんどいません。そのため開発者が自身の才能を最も活かせる部分だけに集中でき、触れたくない部分のコードベースには触れなくて済むようなアーキテクチャが必要です。
バス係数を上げる
ソフトウェア開発には「バス係数 (bus factor)」と呼ばれる (あまり正式ではない) 指標があります。これはコア開発者のうち何人が不幸な最期を遂げる (例えばバスに轢かれる) とプロジェクトが継続不可能な状態になるかを表します。ブラウザの自動化のような複雑なプロジェクトではこの値が低くなりやすいので、バス係数を高くするための様々なアーキテクチャ上の判断が取られています。
JavaScript 実装に寄り添う
ブラウザを制御する方法が他に無い場合、WebDriver は純粋な JavaScript を利用します。これが意味するのは、私たちが追加するどんな API も、JavaScript の実装に「寄り添って」いなければならないということです。具体例としては HTML5 で追加された LocalStorage があげられます。これはクライアントサイドで構造化されたデータを保存するための API であり、ブラウザでは SQLite を使って実装されることが多いです。これを自然に実装すれば、JDBC などを使って内部で利用しているデータストアと接続するというものになっていたでしょう。しかし私たちが最終的に実装したのは、内部の JavaScript 実装を忠実にモデル化した API でした。典型的なデータベースアクセス API が JavaScript 実装に寄り添っていなかったためです。
全てのメソッド呼び出しは RPC である
WebDriver が制御するのは別プロセスで実行されるブラウザです。見落としやすいのですが、これは API を通した全ての関数呼び出しが RPC であり、フレームワークのパフォーマンスがネットワークレイテンシに支配されることを意味します。この事実は通常の操作においてはほとんど影響を及ぼしません (たいていの OS はローカルホストへの通信を最適化するため) が、ブラウザとテストコードの間のネットワークレイテンシが増加すると、効率良く見えていたものが API 設計者とユーザーの両方にとってそうでもなくってしまいます。
これによって API の設計が一筋縄ではいかなくなります。粗い関数を持った大規模な API を作れば複数の関数呼び出しをまとめることでレイテンシを下げることができますが、そのときに API の表現能力と使いやすいさを犠牲にすることはできないからです。例えば、ある要素がエンドユーザーに見えているかどうかを判定するときにはチェックすべき項目がいくつかあります。親要素を見ていきながらその要素および親要素に適用される様々な CSS プロパティをチェックし、さらに要素の大きさもチェックする必要があるでしょう。最小限の API しか用意しない場合にはそれぞれのチェックを別々に行うことになりますが、WebDriver では全てのチェックを isDisplayed メソッドにまとめています。
最後に: Selenium はオープンソースである
正確に言えばアーキテクチャとは関係ありませんが、Selenium はオープンソースのプロジェクトです。これまでの全ての題目に関係するのが、新しい開発者がコントリビュートしやすい環境をできるだけ整えるということです。必要となる知識をなるべく狭くし、必要な言語を減らし、何も壊れていないことの検証に自動テストを使うことで、プロジェクトへのコントリビューションが簡単になっていると私たちは願っています。
最初 Selenium プロジェクトは複数のモジュールに分かれていました。ブラウザを表すモジュールがいくつかと共通のコードや補助コード用のモジュールが存在しており、バインディングのためのソースツリーはモジュールの中にありました。このやり方は Java や C# といった言語では上手く行きますが、Rubyist や Pythonista にとっては扱いにくいものでした。このことはコントリビューターの数に分かりやすく表れており、Python と Ruby バインディングに興味を持ち、実際に取り組んでいる人はごく少数でした。この問題を解決するために 2010 年の 10 月と 11 月にソースコードの構成が変更され、Ruby と Python のコードは言語ごとに単一のトップレベルディレクトリに収められるようになりました。この結果ソースツリーは二つの言語を使うオープンソース開発者が期待するものに近くなり、コミュニティからのコントリビューションはすぐに目に見えて増加しました。
複雑さと向き合う
ソフトウェアはこぶだらけです。ここで言う「こぶ」とは複雑さであり、API の設計者である私たちはこの複雑さをどこに追いやるかを決めなければなりません。一つの極端な方法は複雑さを可能な限り公平に広げるというものであり、これは全ての API ユーザーが複雑さと直面することを意味します。これと正反対なのが複雑さをできるだけまとめ、一つの場所に隔離するというものです。この隔離場所は暗黒空間となり、その場所の探検は多くの人にとって恐ろしいものになるでしょう。その代わり実装に深入りする必要がなくなる API ユーザーにとっては、複雑さのコストが前払いされていることになります。
WebDriver 開発者は発見した複雑さをいくつかの場所に隔離するようにしており、散らかしておくようなことはしません。こうする理由の一つはユーザーです。バグリストを一目見れば分かる通り彼らはバグや問題を見つけるのが非常に得意なのですが、彼らの多くは開発者でないために複雑な API は上手く扱えないのです。そのため私たちは正しい方向にユーザーを導くような API を目指すようになりました。例えばオリジナルの Selenium API には input 要素の値を設定するための関数がこれだけありました:
- type
- typeKeys
- typeKeysNative
- keydown
- keypress
- keyup
- keydownNative
- keypressNative
- keyupNative
- attachFile
WebDriver API でこれに対応するのは次の関数です:
- sendKeys
前述した RC と WebDriver の思想の違いがここにも表れています。つまり WebDriver はユーザーをエミュレートするのに尽力するのに対して、RC は低レベルな API を提供するためにユーザーからは使いにくかったり見つけられなかったりするということです。typeKeys と typeKeysNative の違いは、前者が常に合成イベントを使うのに対して後者は AWT Robot を使ってキーを入力しようと試みる点です。残念ながら AWT Robot はキープレスをフォーカスのあるウィンドウに送るので、キーがブラウザに送られるとは限りません。これに対して WebDriver のネイティブイベントはウィンドウハンドルに直接キーを送るので、ブラウザのウィンドウがフォーカスされていなくても構いません。
WebDriver の設計
開発チームは WebDriver の API は「オブジェクトベース」であると言います。インターフェースは明確に定義され、単一の役割や責任を持つようになっています。しかし全ての HTML タグを一つのクラスとしてモデル化しているわけではなく、あるのは WebElement インターフェースだけです。こうすることで、自動補間機能を持つ IDE を使う開発者に次のステップを示せます。例えば (Java における) コーディングは次のようになります:
WebDriver driver = new FirefoxDriver();
driver.<スペース>
ここで比較的少ない 13 個のメソッドを表示するリストが表れます。ユーザーはこの中から一つを選択します:
driver.findElement(<スペース>)
たいていの IDE はここで引数の型に関するヒントを表示します。ここでの引数の型は By であり、この型に対して事前に定義されたファクトリメソッドがスタティックメソッドとして By クラスに定義されています。そのためユーザーは次のようなコードをすぐに書くことができます:
driver.findElement(By.id("some_id"));
UnsupportedOperationExceptions などは望ましくありませんが、それでも一部のユーザーが必要なものは公開する必要があり、そのとき他の大部分のユーザーが使う API を汚してはいけません。これを達成するために、WebDriver はロールベースのインターフェースを多用しています。例えば JavascriptExecutor インターフェースは現在のページのコンテキストにおいて任意の JavaScript を実行する機能を提供します。WebDriver のインスタンスを特定のインターフェースにキャストできるかどうかを見れば、そのインターフェースのメソッドが動作するかどうかが分かります。
単純化された Shop クラスを考えます。このショップには毎日在庫の補充が行われ、Stockist が新しい在庫を運んでくるとします。加えて月に一度、従業員への給料と税金の支払いがあります。簡単のため、この処理を Accountant が行うとしましょう。モデル化の一例を次に示します:
public interface Shop {
void addStock(StockItem item, int quantity);
Money getSalesTotal(Date startDate, Date endDate);
}
Shop と Accountant と Stockist の間の境界線には二つの可能性があります。一つ目の可能性は 図 16.1 に示すような理論的な線です。
つまり Accountant と Stockist の両方がメソッドで Shop を引数として受け取るようにするということです。しかしここで気になるのが、Accountant が棚に商品を置くことはなく、Stockist が Shop の行う値上げを気にすることはない点です。そのため、図 16.2 に示すように線を引いた方が都合がよくなります:
こうすると Shop は二つのインターフェースを実装することになりますが、そのインターフェースは明確に定義され、Shop が Accountant と Stockist を管理します。これがロールベースのインターフェースです:
public interface HasBalance {
Money getSalesTotal(Date startDate, Date endDate);
}
public interface Stockable {
void addStock(StockItem item, int quantity);
}
public interface Shop extends HasBalance, Stockable {
}
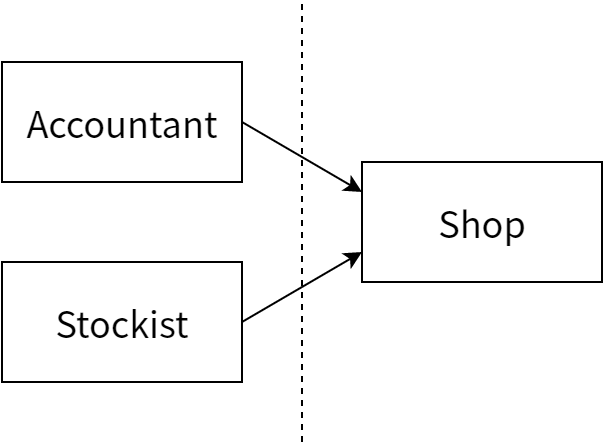
Accountant と Stockist が Shop に依存する
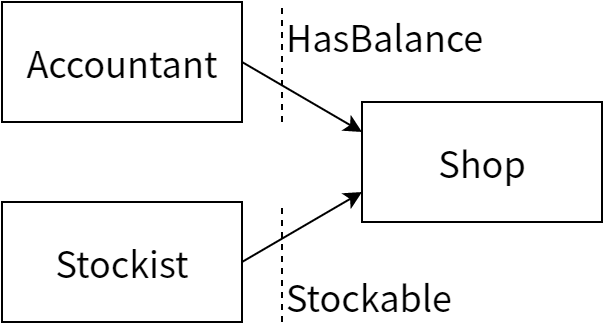
Shop が HasBalance と Stockable を実装する
組み合わせ爆発に対処する
WebDriver がサポートしなければならない言語とブラウザの多様さからすぐに明らかとなる問題の一つが、注意深くならない限りメンテナンスのコストがすぐに膨れ上がってしまう点です。X 個のブラウザと Y 個の言語があるとすると、X×Y 個の実装をメンテナンスする羽目になってしまいます。
WebDriver がサポートする言語の数を減らすというのはコスト削減の一つの方法ですが、こうしたくない理由が二つあります。まず、言語を切り変えるのには認知的負荷がかかります。フレームワークのユーザーにとって開発の多くが行われる言語でテストを書けるというのは魅力的です。そして、一つのプロジェクトに複数の言語を混ぜるというのは不都合な場合があり、企業のコード規約が単一の技術の採用を強制することもよくあります (ただ幸いにも二番目の問題は最近そうでもなくなっているようです)。そのためサポートする言語の数を減らすことは選択肢に入りません。
サポートするブラウザの数を減らすというのも選択肢に入りません。WebDriver が Firefox 2 のサポートを切ったときには激しい議論が交わされました。この決断をしたときのブラウザマーケットにおけるシェアは 1% 以下だったにもかかわらずです。
残された唯一の道は、言語バインディングから全てのブラウザが同一に見えるようにすることです。このためには様々な言語から簡単に利用可能な統一されたインターフェースが必要であり、さらに言語バインディング自身も簡単に書けるようそのインターフェースは軽量でなければなりません。これを達成するために、私たちは可能な限り多くのロジックを内部のドライバに詰め込んでいます。ドライバに入れられない機能はサポートする全ての言語で実装することになるので、大変な量の作業が発生します。
例えば IE のドライバでは IE を探索して起動する部分がメインのドライバロジックに入っています。そのため驚くほど多くのコードがドライバに書かれることになり、言語バインディングにおける新しいインスタンスを作成する関数はドライバ内のそのメソッドの呼び出しだけで済みます。一方で Firefox ドライバはこれができていません。Java だけを見たとしても、これによって Firefox を構成・起動するための 1300 行からなる三つの主要なクラスが必要となります。このクラスは FirefoxDriver を Java サーバーを起動することなくサポートする全ての言語に複製されることになるので、追加のメンテナンスのコストは膨大です。
WebDriver の設計の問題
上述のように機能を公開することの問題は、特定のインターフェースの存在に気付くまで WebDriver がその機能をサポートすることに気付けない点です。つまり API の探索性が損なわれます。実際 WebDriver が生まれて間もない頃には人々に特定のインターフェースを使わせるために多くの時間が費やされました。ただそれから私たちはドキュメントの整備に懸命に取り組み、API も広く使われるようになったので、ユーザーが必要な情報を手に入れるのは簡単になっています。
API が特に貧弱だと私が思う部分が一つあります。RenderedWebElement というインターフェースは様々なメソッドの寄せ集めであり、レンダリングされた要素の状態を問い合わせるもの (isDisplayed, getSize, getLocation)、その要素に対して操作を行うもの (hover やドラッグアンドドロップに関するメソッド)、特定の CSS プロパティの値を取り出すための便利なメソッドなどが含まれます。このインターフェースが作られたのは当時 HtmlUnit ドライバが必要な情報を公開していなかったためなのですが、Firefox ドライバと IE ドライバは公開していました。また最初は要素の状態を問い合わせるメソッドしか存在しなかったのですが、私は API をどう進化させるかよく考えることなく他のメソッドを追加してしまいました。このインターフェースは現在広く使われており、不格好な API を残しておくか、それとも削除するかは難しい問題です。私の意見はこの「割れた窓」を放置してはいけないというもので、そのためには Selenium 2.0 がリリースされるまでに API を修復する必要があります。この章をあなたが読む頃には、RenderedWebElement は削除されているでしょう。
実装する人の視点に立つと、ブラウザと密に結合するのは (避けられないとはいえ) 設計上の問題です。新しいブラウザのサポートには膨大な労力が必要であり、何度も試行錯誤する必要があることが多いです。具体的な数字を出すと、Chrome ドライバは四回の完全な書き直しを経ており、IE ドライバは主要な部分が三回書き直されています。ブラウザとの密結合の利点は、細かい制御が可能になる点です。
レイヤーと JavaScript
ブラウザ自動化ツールは基本的に三つの部分から構成されます:
-
DOM を問い合わせる手段。
-
JavaScript を実行するメカニズム。
-
ユーザーの入力をエミュレートする何らかの手段。
この節は最初の部分、DOM の問い合わせメカニズムに焦点を当てます。ブラウザの共通言語は JavaScript であり、DOM の問い合わせにもこの言語が適しています。JavaScript の選択は自明に思えるかもしれませんが、この言語を使うことで生じる興味深い困難や、バランスを取る必要のある競合する要件があります。
多くの大規模なプロジェクトと同様、Selenium もライブラリをレイヤー化します。一番の下にあるのは Google の Closure Library であり、ソースファイルを密で小さく保つためのプリミティブとモジュール化メカニズムを提供します。その上にあるのがユーティリティライブラリで、これは属性の値を取得するような単純な処理から、エンドユーザーから要素が見えるかどうかを計算する処理、あるいはクリックを合成イベントを使ってシミュレートする処理いった複雑なものまで様々な関数を提供します。これらの関数はプロジェクト内でブラウザ自動化の最小単位として取り扱われるので、このライブラリは Browser Automation Atoms あるいは単に atoms と呼ばれます。最後にその上にあるのが、atoms を WebDriver と Core の API と嚙み合わせるためのアダプターレイヤーです。
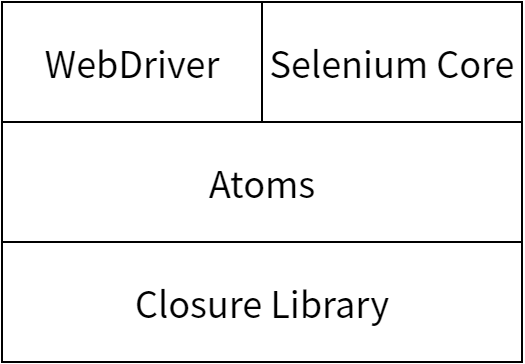
Closure Library が選ばれたのにはいくつか理由があります。一番の理由は Closure Compiler がライブラリのモジュール化の仕組みを理解する点です。Closure Compiler は JavaScript へのコンパイルを行い、その「コンパイル」の間に依存が解決する順番にファイルを並べ替え、ファイルを結合・フォーマットし、コードを最小化し、最小化や未到達コードの削除を行います。また JavaScript の作業を担当したチームが Closure Library のことをよく知っていたというのも疑いの無いもう一つの利点です。
この「原子的な」ライブラリのコードは、DOM の問い合わせが必要なプロジェクト内の至る場所で使われています。大部分が JavaScript からなるドライバと RC では Closure は直接呼び出され、そのときにはモノリシックなスクリプトにコンパイルされていることが多いです。Java で書かれるドライバでは、WebDriver のアダプターレイヤーの関数が最大限に最適化された状態でコンパイルされ、生成された JavaScript がリソースとして JAR ファイルに同梱されます。iPhone や IE などの C などで書かれたドライバでは、各関数が最適化されてコンパイルされるだけではなく、生成された出力が文字列定数となってヘッダーファイルに書き込まれ、ドライバが持つ通常の JavaScript 実行メカニズムを通して必要に応じて呼び出せるようになります。変なことをしていると思うかもしれませんが、こうすることでソースを複数個所に公開することなく JavaScript が内部のドライバから利用可能になります。
全ての場所で atoms が使われていることから、異なるブラウザで一貫した動作を保証できるようになります。またライブラリが JavaScript で書かれ実行に権限の昇格を必要としないことから、開発サイクルは簡単で高速です。Closure Library は依存コードを動的に読み込むことができるので、Selenium 開発者はテストを書いたらそれをブラウザから読み込むことができ、その後コードをさらに変更したとしても更新ボタンを押すだけで済みます。さらにテストがあるブラウザで通ったなら、それを別のブラウザで読み込ませて試すのも簡単です。Closure Library はブラウザ間の差異を上手く抽象化しており通常はこれで十分ですが、サポートするブラウザの全てでテストスイートを実行する継続的ビルドシステムがあったら素晴らしいでしょう。
最初 Core と WebDriver には同じ動作を違った方法で行うコードがたくさん存在していました。私たちが atoms に取り組み始めたとき、こういった関数は人の目でチェックされ、「最善の組み合わせ」が残されました。結局二つのプロジェクトはコードの中で徹底的に使われていたので安定しており、このコードを捨ててゼロから書き直すというのは無駄で、馬鹿げていました。atom を一つずつ取り出し、その関数が使われていた場所を検索し、その atom を使うように切り替えていきました。例えばもともと 50 行あった Firefox のドライバの getAttribute メソッドは空行を入れて 6 行に縮んでいます:
FirefoxDriver.prototype.getElementAttribute =
function(respond, parameters) {
var element = Utils.getElementAt(parameters.id,
respond.session.getDocument());
var attributeName = parameters.name;
respond.value = webdriver.element.getAttribute(element, attributeName);
respond.send();
};
最後から二行目の respond.value に値を代入するところで WebDriver の atoms ライブラリが使われています。
atoms は前述したプロジェクトのアーキテクチャの題目の実例です。API の実装は JavaScript に寄り添うことを自然に強制されます。同じライブラリがコードベース中で共有される点はさらに優れています。かつてはバグが見つかったら複数の実装を修正しなければならなかったのが一度修正すればそれで済むようになり、ファイル変更のコストが減少し安定性と効率が向上します。また atoms はプロジェクトのバス係数を高めます。通常の JavaScript のユニットテストを使って修正が正しく動くかどうかを確認できるので、全てのドライバの動作に関する知識が必要だった時代に比べてプロジェクトに参加するハードルは大きく下がるからです。
atoms にはこのほかにも利点があります。既存の RC 実装を WebDriver でエミュレートするレイヤーは、安定した方法で新しい WebDriver API を導入しようとしているチームにとって重要なツールです。Selenium Core が atoms を使って書かれていることから個々の関数を個別にコンパイルすることが可能であり、このエミュレートレイヤーはより簡単かつ正確に書けるようになります。
言うまでもなくこのアプローチには欠点もあります。一番重要なこととして、JavaScript を C の const にコンパイルするというのはとても奇妙なやり方であり、C コードに取り組み始めた新しいコントリビューターを驚かせてしまいます。また全てのブラウザの全てのバージョンを持っていて、それでいて全てのブラウザでテストを実行してくれる開発者というのはほとんどいません。誰かがうっかり予期せぬ場所にバグを発生させてしまった場合には、問題の特定にしばらく時間がかかるでしょう (特に継続ビルドシステムが頼りないとき)。
atoms は異なるブラウザからの返り値を正規化するので、予期せぬ値が返ってくることがあります。次の HTML を考えます:
<input name="example" checked>
checked 属性の値はブラウザによって異なりますが、atoms はこういった属性および HTML5 の仕様で定められた Boolean 属性の値を“true”または“false”へと正規化します。コードベースにこの atom が導入されたときには、返り値について多くの人がブラウザに依存する思い込みをしていたことが判明しました。この変更によって返り値は一貫したものになったのですが、コミュニティに何が起こったのか、そしてそれはなぜかを説明するのに長い時間が費やされました。
リモートドライバ、特に Firefox ドライバ
リモート WebDriver はもともと必要以上に持ち上げられていた RPC メカニズムに過ぎませんでした。しかしそれから進化を続け、今では WebDriver のメンテナンスのコストを削減するための主要なメカニズムの一つとなりました。リモート WebDriver は言語バインディングのコードが利用できる統一されたインターフェースを提供します。言語バインディングのロジックはできる限りドライバに移されましたが、もし各ドライバが固有のプロトコルを使って通信する必要があったなら、全ての言語バインディングに同じようなコードが大量に含まれることになっていたでしょう。
リモート WebDriver プロトコルは外部プロセスで実行中のブラウザインスタンスとの通信に必ず使われます。このプロトコルの設計には様々な懸案事項があります。その多くは技術的なものですが、オープンソースであるこのプロトコルには、考慮すべき社会的要素もあります。
RPC メカニズムは転送とエンコードの二つに分かれます。リモート WebDriver プロトコルをどう実装するにせよ、クライアントで使用する言語でこの両方が必要になることは分かっていました。設計の最初の反復は Firefox ドライバの開発の一部として行われました。
Mozilla および Firefox はマルチプラットフォームのアプリケーションであると開発者から認識されています。開発を促進するために、Mozilla は Microsoft の COM に影響されたフレームワークを開発しました。このフレームワークは XPCOM (cross-platform COM) と呼ばれ、個々のコンポーネントを開発・連携することが可能です。XPCOM インターフェースは IDL を使って宣言され、C や JavaScript といった言語へのバインディングがあります。XPCOM は Firefox で使われており JavaScript のバインディングも持つことから、Firefox 拡張機能で XPCOM オブジェクトを利用することもできます。
通常の Win32 COM と同様にインターフェースにリモートでアクセスできるようにしようという計画が以前 XPCOM にはあり、Darin Fisher によって XPCOM ServerSocket の実装が追加されました。結局この D-XPCOM 計画が実現することはありませんでしたが、私たちはこの計画が残した実装を利用し、ごく基本的なサーバーを実現する独自の Firefox 拡張機能を作成しました。この拡張機能には Firefox を制御するための全てのロジックが含まれます。使われていたプロトコルはテキストを一行ずつ読むもので、UTF-2 を使って文字列をエンコードし、リクエストとレスポンスは終わりまでに含まれる改行の数を表す数字で始まりました。ここで重要だったのは、このスキームが JavaScript で実装するのが簡単であった点です。当時の Firefox の JavaScript エンジン SeaMonkey が JavaScript の文字列を 16 ビット符号無し整数として保存していたためです。
独自のエンコーディングプロトコルを生のソケットを通して遊ぶのはいい暇つぶしですが、欠点もいくつかあります。独自プロトコルには利用可能なライブラリが無いので、サポートする全ての言語で実装しなければなりません。コードが増えることで、新しい言語バインディングを開発に参加するオープンソースのコントリビューターの数も減ってしまうでしょう。また行ベースのプロトコルはテキストデータを送受信するだけなら問題ありませんが、画像 (スクリーンショットなど) をやり取りするときには問題となります。
最初に実装したこの RPC メカニズムが実際の使用に耐えないことがすぐに明らかになりました。ただ幸いにも、よく知られた転送プロトコルであってほぼ全ての言語でサポートされ、さらに私たちのしたいことができるものが存在します: HTTP です。
HTTP を転送に使うことを決めると、次に決めるのは単一エンドポイント (SOAP式) と複数エンドポイント (REST スタイル) のどちらを使うかです。オリジナルの Selenium プロトコルは単一エンドポイントを使っており、コマンドと引数をクエリ文字列に埋め込んでいました。このアプローチは上手く行っていましたが、どうも「正しい感じ」がしませんでした。ブラウザのリモート WebDriver インスタンスに接続してサーバーの状態を見られるようにしたかったためです。最終的には“RESTっぽい”方式に落ち着きました。複数のエンドポイント URL を用意し、HTTP のリクエストメソッドを使ってリクエストの意味を明確にするというものです。ただし真に RESTful なシステムが持つべき制約はいくつも破っており、例えば状態の保存場所やキャッシュに関する制約は守られていません。その主な理由は、アプリケーションの状態が動作する場所が一つしかないためです。
HTTP ではコンテンツタイプのネゴシエーションを通してデータを複数の方法でエンコードできますが、私たちはリモート WebDriver の全ての実装が扱うことができる共通の形式を常に利用することに決定しました。このようなフォーマットの選択肢はたくさんあります: 具体的には HTML, XML, JSON です。しかし XML はすぐに選択肢から外されました。XML 自体には何の問題もなく、ほとんど全ての言語でサポートされているのですが、オープンソースコミュニティにおいてはあまり好かれていないというのが私の感触でした。加えて返り値が何らかの共通の形をしているとはいえ、後からその形が変わることが十分あり得たというのもあります3。こういった拡張機能も XML の名前空間を使えばモデル化できますが、こうすると「またもう一つの」複雑さをクライアントコードに追加することになるので避けたかったのです。HTML も良い選択肢とは言えません。HTML ではデータのフォーマットを定義する必要があり、もちろんマイクロフォーマットを埋め込んで使うこともできますが、これは卵を割るのにハンマーを使うようなものだからです。
最後に残された選択肢は JavaScript Object Notation (JSON) です。ブラウザからは eval を呼び出して文字列をオブジェクトに変換することが可能であり、最近のブラウザでは JavaScript オブジェクトと文字列をセキュアに副作用なく相互変換するプリミティブが利用できます。現実のコードを考えても、JSON は人気の高いデータフォーマットであり、ほとんど全ての言語でライブラリが利用可能です。さらにクールなキッズもみんな大好きなので、選択の余地はないでしょう。
以上の議論に基づいてリモート WebDriver プロトコルの二回目の反復では HTTP を転送に利用し、情報の受け渡しには UTF-8 でエンコードされた JSON がデフォルトで使われるようになりました。UTF-8 がデフォルトである理由は、UTF-8 が ASCII と互換性があるためにサポートされていない言語でもクライアントを簡単に書くことができるためです。サーバーに送られるコマンドは URL でコマンドの名前を表し、配列でパラメータをエンコードします。
例えば WebDriver.get("http://www.example.com") は POST リクエストに変換され、そのときの URL はセッション ID の後に /url が付いたもの、パラメータの配列は ['http://www.example.com'] のような値となります。返ってくるリザルトはもう少し構造化されており、返り値とエラーコードのためのプレースホルダーを持ちます。しばらくして三回目の反復が行われ、リクエストのパラメータ配列が名前付きパラメータを使った辞書に置き換わりました。これによってリクエストのデバッグが非常に楽になり、クライアントがパラメータを間違った順番で並べてしまうこともなくなるので、システム全体がより頑健になります。また自然な場合には通常の HTTP エラーコードを使って特定の値やレスポンスを表すようになりました。例えばユーザーが呼び出した URL に対応する関数が無い場合、あるいは「空のレスポンス」を送りたい場合などに利用します。
リモート WebDriver プロトコルは二段階のエラー処理を持ちます。一つは不正なリクエスト用で、もう一つは失敗したコマンド用です。不正なリクエストの例としては、サーバー上にないリソースに対するリクエスト、あるいはリソースが理解できない HTTP メソッド (現在のページの URL とやり取りしているリソースへの DELETE コマンドなど) などがあります。そのような場合には通常の HTTP 4xx レスポンスが送信されます。コマンドが失敗した場合のレスポンスは 500 (Internal Server Error) であり、返されるデータには上手く行かなかった処理の詳細が含まれます。
データを含んだレスポンスがサーバーから送信される場合には、次の形をした JSON オブジェクトとなります:
| キー | 説明 |
|---|---|
| sessionId | サーバーがセッション固有のコマンドの送り先を決めるために使う不透明なハンドル。 |
| status | コマンドの結果を要約するステータスコード (数値)。ゼロでない値はコマンドの失敗を表す。 |
| value | レスポンスの JSON 値。 |
レスポンスの例を次に示します:
{
sessionId: 'BD204170-1A52-49C2-A6F8-872D127E7AE8',
status: 7,
value: 'Unable to locate element with id: foo'
}
このようにレスポンスにはステータスコードが含まれ、ゼロでない値は何かが上手く行かなかったことを示しています。このステータスコードを最初に取り入れたのは IE ドライバで、共通のワイヤプロトコルはこれと同じ値を使っています。エラーコードはドライバ間で同一なので、特定の言語で書いたエラー処理コードを全てのドライバで共有することが可能です。これによってクライアントサイドの実装がより簡単になります。
Remote WebDriver Server はマルチプレクサとして働く単純な Java サーブレットであり、受け取ったコマンドを適切な WebDriver インスタンスに転送します。大学院の二年生なら書けるようなプログラムでしょう。Firefox ドライバはこれに加えてリモート WebDriver プロトコルも実装しており、興味深いアーキテクチャをしています。そこで言語バインディングから呼び出されたリクエストが、バックエンドを通ってユーザーに返ってくるまでに何が起こるのかを見ていきましょう。
Java を使っているとして、element が WebElement のインスタンスであるとします。まず次のようにしたとします:
element.getAttribute("row");
element は内部に不透明な ID を持っており、サーバーはこれを使って要素を識別します。説明のためにこの ID が some_opaque_id であるとしましょう。上述の呼び出しは Java の Command オブジェクトにエンコードされ、このオブジェクトの Map (現在では名前付き) にはパラメータ id に要素 ID が、name に問い合わせている属性の名前が含まれます。
テーブルを検索すれば、正しい URL が次の形であることがすぐに分かります:
/session/:sessionId/element/:id/attribute/:name
URL の中でコロンで始まっている部分は変数であり、置換の対象となります。パラメータの id と name の値はこれまでに出てきています。sessionId はルーティングのための不透明なハンドルであり、サーバーが複数のセッションを同時に処理するときに利用されます (Firefox ドライバではこの機能は使えません)。 この URL は次のように展開されます:
http://localhost:7055/hub/session/XXX/element/some_opaque_id/attribute/row
余談として触れておくと、WebDriver のリモートワイヤプロトコルが開発されたのは URL Template が RFC のドラフトとして提案されたのと同時期でした。WebDriver が URL を指定するのに使う方式と URL Template はどちらも変数の展開 (および派生) が可能でした。URL Template は同時期に提案されていましたが、残念ながら私たちがこれに気付いたのは比較的時間が経ってからであり、ワイヤプロトコルでは使われていません。
今実行しているメソッドは冪等4なので、使うべき HTTP メソッドは GET です。HTTP を処理できる Java ライブラリ (Apache HTTP Client) にサーバーと通信する処理を行わせます。
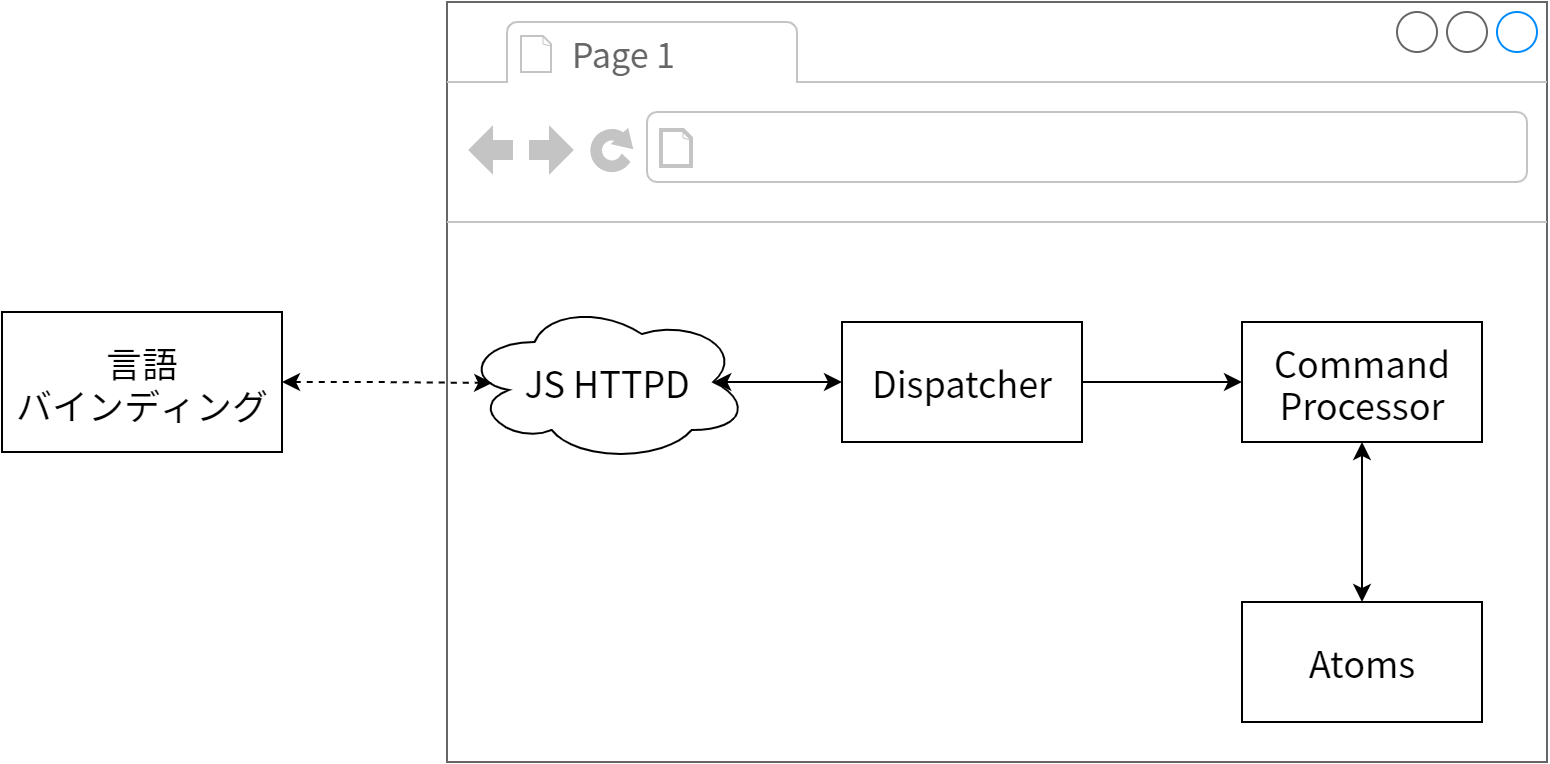
Firefox ドライバは Firefox の拡張機能として実装されており、その基本的な設計は 図 16.4 に示す通りです。変わっているのが、HTTP サーバーが埋め込まれている点です。最初は自分たちで書いたものを使っていましたが、XPCOM で HTTP サーバーを書くというのは私たちが得意とすることではありません。そのため時機を見て Mozilla の開発者によって書かれた基本的な HTTPD サーバーに置き換えられました。この HTTPD がに受信されたリクエストはほぼそのまま dispatcher オブジェクトに渡されます。
dispatcher はリクエストを受け取り、サポートする既知の URL リストを見ていってリクエストにマッチするものを検索します。このマッチングはクライアントサイドで行われる変数の置換の結果で行われます。HTTP メソッドを含めて完全にマッチするものが見つかると、実行するコマンドを表す JSON オブジェクトが構築されます。今の例では次のようになります:
{
'name': 'getElementAttribute',
'sessionId': { 'value': 'XXX' },
'parameters': {
'id': 'some_opaque_key',
'name': 'rows'
}
}
その後これは JSON 文字列として XPCOM コンポーネントに渡されます。このコンポーネントは私たちが書いたものであり、CommandProcessor と呼ばれます。コードを示します:
var jsonResponseString = JSON.stringify(json);
var callback = function(jsonResponseString) {
var jsonResponse = JSON.parse(jsonResponseString);
if (jsonResponse.status != ErrorCode.SUCCESS) {
response.setStatus(Response.INTERNAL_ERROR);
}
response.setContentType("application/json");
response.setBody(jsonResponseString);
response.commit();
};
// Dispatch the command.
Components.classes["@googlecode.com/webdriver/command-processor;1"].
getService(Components.interfaces.nsICommandProcessor).
execute(jsonString, callback);
コードは多いですが、主な処理は二つだけです。まずオブジェクトを JSON 文字列に変換し、その後 HTTP レスポンスを送るメソッドを実行するコールバックを渡しています。
CommandProcessor の execute メソッドは呼び出す関数の名前を検索し、そしてそれを実行します。実装を行う次の関数の最初のパラメータは respond オブジェクト (もともとはレスポンスをユーザーに返すだけの関数だったのでこう呼ばれます) であり、送信される値をカプセル化するだけではなくレスポンスをユーザーに送り返すためのメソッドや DOM の情報を取得するためのメカニズムも用意されています。二番目のパラメータは前に触れた parameter オブジェクトの値 (id と name) です。この方式の利点は、各関数がクライアントサイドのデータ構造に対する統一インターフェースを持ち、両サイドのコードが似たメンタルモデルを持てる点です。次に示すのは 16-5 節 で説明した getAttribute の実装です:
FirefoxDriver.prototype.getElementAttribute = function(respond, parameters) {
var element = Utils.getElementAt(parameters.id,
respond.session.getDocument());
var attributeName = parameters.name;
respond.value = webdriver.element.getAttribute(element, attributeName);
respond.send();
};
最初の行はキャッシュにある要素を不透明 ID で検索しています。これは要素に対する参照を一貫させるためです。Firefox ドライバでは不透明 ID は UUID で、「キャッシュ」はただのマップです。getElementAt メソッドは加えて指定された要素が DOM に知られているかどうか、そしてアタッチされているかどうかもチェックします。いずれかのチェックが失敗した場合には、その ID は (必要なら) キャッシュから取り除かれ、例外が送出されてユーザーに返ります。
最後から二行目は前述の atoms を使ってブラウザ自動化を行っています。ここでは atoms はモノリシックなスクリプトにコンパイルされ、拡張機能としてロードされます。
最後の行では send メソッドが呼ばれます。このメソッドはレスポンスが一度だけ送られていることを簡単にチェックしてから execute メソッドに渡されたコールバックを実行します。ユーザーに送り返される文字列は JSON 文字列であり、次のような形をしています (要素が見つからず、getAttribute が 7 を返したとしています):
{
'value': '7',
'status': 0,
'sessionId': 'XXX'
}
それから Java クライアントは status フィールドをチェックします。この値がゼロでなければ、クライアントは数字のステータスコードを対応する種類の例外に変換してそれを送出し、そのとき value フィールドを使ってユーザーに送るメッセージを設定します。status がゼロであれば value の値がユーザーに返されます。
以上のやり方の多くは納得のいくものだと思いますが、賢明な読者は疑問に感じるところがあったでしょう: 「dispather が execute メソッドを呼ぶ前にオブジェクトを文字列に変換するのはなぜ?」
この理由は、Firefox ドライバが純粋な JavaScript で書かれたテストの実行をサポートするためです。通常これは非常にサポートしにくい機能となります。テストはブラウザの JavaScript セキュリティサンドボックス内のコンテキストで実行されるので、ドメイン間を移動したりファイルをアップロードしたりといったテストで必要な処理を行うことができないためです。しかし Firefox の WebDriver 拡張機能にはサンドボックスを脱出するハッチが用意されています。このハッチは document 要素に webdriver というプロパティを追加すると宣言でき、WebDriver の JavaScript API がこれを検出すると、JSON でシリアライズされたコマンドオブジェクトを document 要素の command プロパティに配置できると判断します。そして独自の webdriverCommand を発火させ、response プロパティが設定されている要素からの webdriverResponse イベントによる通知を待ちます。
このため WebDriver 拡張機能をインストールした Firefox でウェブを閲覧するのは非常に危険です。他人が容易にリモートからブラウザを制御できるようになってしまうためです。
裏側には DOM メッセンジャーがあり、webdriverCommand を待っています。メッセンジャーはシリアライズされた JSON オブジェクトを読み、コマンドプロセッサで execute を実行します。ここでコールバックは document 要素の response 属性を設定して webdriverResponse イベントを発火させるという単純なものになっています。
IE ドライバ
Internet Explorer は興味深いブラウザです。いくつもの COM インターフェースが組み合わさってできており、JavaScript エンジンさえ COM インターフェースでできています。慣れ親しんだ JavaScript 変数も実際の姿は内部の COM インスタンスであり、JavaScript の window は COM インターフェース IHTMLWindow の、document は IHTMLDocument のインスタンスです。Microsoft は既存の動作を保ちながらブラウザを拡張する仕事をとても上手く行っており、IE6 で公開されていた COM クラスは IE 9 でもそのまま動作します。
Internet Explorer ドライバのアーキテクチャは時間をかけて進化してきました。設計を形作った主な要件の一つが、インストーラを作らないことです。これは少し変わった要件なので少し説明が必要でしょう。こうする一つ目の理由は、WebDriver を使う開発者がパッケージをダウンロードしてすぐに使い始められるという「五分基準」がインストーラを使うと守られなくなることです。さらに重要なこととして、WebDriver のユーザーは自身のマシンにソフトウェアをインストールできないことが多いという理由もあります。また IE をテストする継続的インテグレーションサーバーでインストーラを実行するためだけにログインしておく必要もなくなります。最後に、JAR ファイルを CLASSPATH に配置するだけで動作するというのは Java の慣習となっており、私の経験から言ってインストーラが必要となるライブラリは好まれておらず、あまり使われてもいません。
こんなわけで、インストーラは無しです。この判断にはいくつかの帰結があります。
Windows で使うプログラミング言語の自然な選択肢は .NET が動く言語、例えば C# です。IE ドライバは Windows の全てのバージョンに付属する IE COM Automation インターフェースを使うことで IE と密接に連携しています。例えば IE ドライバは MSHTML や ShDocVw といった DLL に含まれる COM インターフェースを利用しますが、この DLL はどちらも IE に付属します。C# 4 よりも前では、CLR と COM の相互運用は別々の Primary Interop Assembly (PIA) を使うことで達成されています。この PIA を一言で言えば、CLR が管理する世界と COM が管理する世界をつなぐ橋です。
残念なことなのですが、C# 4 を使うと .NET ランタイムの非常に新しいバージョンを使うことになり、安定性やバグが既知であることを求めて最先端のバージョンを避ける多くの会社がユーザーベースから排除されてしまいます。一方で PIA を使う場合にも不都合があります。例えばライセンスの制限です。Microsoft に確認したところ、Selenium プロジェクトは MSHTML や ShDocVw ライブラリの PIA を頒布する権利を持たないことが判明しました。さらにその権利がもし保証されたとしても、ライブラリのバージョンは Windows と IE インストールごとに固有であり、大量のライブラリを頒布しなければなりません。PIA のビルドに通常ユーザーのマシンにはインストールされていない可能性のある開発者ツールが必要となるので、クライアントで行わせることもできません。
このような理由により、コーディングの大部分を行うのに魅力的な C# を使うことはできなくなります。少なくとも IE との通信を「ネイティブ」に行う言語が必要です。次の自然な選択肢は C++ であり、私たちは最終的にこれを選択しました。C++ を使えば PIA を使わずに済みますが、静的にリンクしない限り Visual Studio C++ ランタイム DLL を再頒布することになります。DLL を再配布するにはインストーラが必要になるので、IE との通信を行うライブラリは静的にリンクすることになります。
インストーラを使わないという要件を満たすためのコストはかなり高く付きますが、それでも複雑さをどこに封じ込めるかという題目に戻って考えれば、ユーザーの使い勝手を大きく向上させるこの判断は投資に見合う利点を持っています。ただしこの判断は現在の私たちの基準に沿って再検討されています。というのもユーザーにとっての使い勝手の向上は、プロジェクトにコントリンビュートできる開発者の潜在的な数の減少によって成り立っているからです。高度な C++ のオープンソースプロジェクトにコントリビュートできる開発者の数は C# プロジェクトのそれに比べてかなり少ないでしょう。
IE ドライバの初期の設計を 図 16.5 に示します。

スタックを下 (図中右) から見ていくと、まず IE の COM Automation インターフェースが使われているのが分かります。このインターフェースについて頭の中で考えやすくするために、生のインターフェースをメインの WebDriver インターフェースと似た形の C++ クラスでラップしています。Java クラスと C++ の間のやり取りには JNI が使われており、JNI メソッドの実装にはこの COM インターフェースを抽象化した C++ クラスが使われます。
Java が唯一のクライアント言語であった間はこれで何も問題はありませんでしたが、サポートするそれぞれの言語で下層のライブラリを置き換える必要が生じた場合には複雑で使いにくいものとなります。そのため JNI は上手く問題を解決してはいるものの、抽象化のレベルが適切とは言えません。
どれくらいの抽象化がちょうどいいのでしょうか? サポートされるどの言語にも C コードを読み出す仕組みは存在していました。C# には PInvoke があり、Ruby には FFI、Python には ctypes があります。さらに Java には JNA (Java Native Architecture) と呼ばれる素晴らしいライブラリがありました。よってこれらの最大公約数的な API の公開が必要になります。そのために私たちはオブジェクトモデルを「平らに」する、つまり各メソッドの最初に二、三文字の接頭語を付けることでどのインターフェースに属するのかを明示したメソッドの作成を行いました。例えば WebDriver には wd、WebDriver Element には wde という接頭語を付け、WebDriver.get は wdGet となり、WebElement.getText は wdeGetText となります。こういったメソッドはステータスコードを表す整数を返し、out というパラメータを変更することでその他の値を返します。つまりメソッドのシグネチャは次のようになります:
int wdeGetAttribute(WebDriver*, WebElement*, const wchar_t*, StringWrapper**)
呼び出すコードにおいては WebDriver, WebElement, StringWrapper といった型は不透明です。どの値を与えれば良いかが分かりやすいように異なる型の表現を使っていますが、void * と書くこともできます。またテキストにワイド文字列を使っているのは国際化されたテキストを適切に扱うためです。
Java の側ではインターフェースを通してこの関数のライブラリを公開し、そのときには WebDriver が使う通常のオブジェクト指向的なインターフェースを使うことができます。例えば getAttribute メソッドの Java 実装は次のようになっています:
public String getAttribute(String name) {
PointerByReference wrapper = new PointerByReference();
int result = lib.wdeGetAttribute(
parent.getDriverPointer(), element, new WString(name), wrapper);
errors.verifyErrorCode(result, "get attribute of");
return wrapper.getValue() == null ? null : new StringWrapper(lib, wrapper).toString();
}
以上をまとめると 図 16.6 に示すような設計となります。
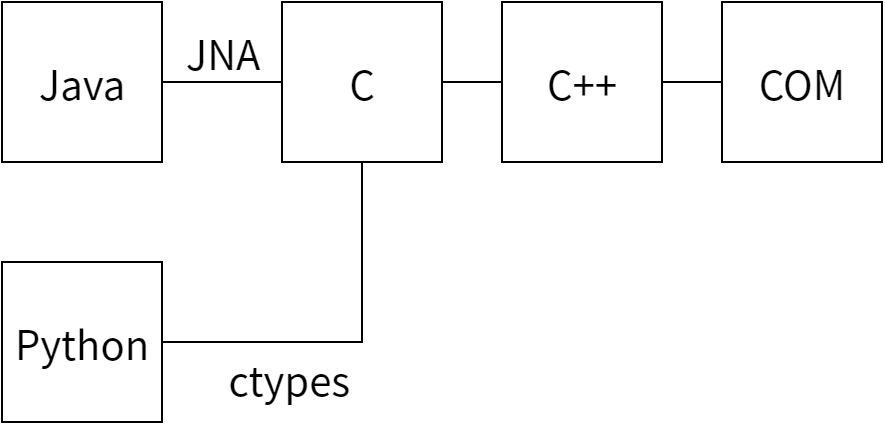
当時のテストは全てローカルのマシンで実行されていました。これで特に問題はなかったのですが、IE ドライバをリモートの WebDriver で使い始めたところランダムなタイミングでロックアップが発生しました。この問題を追及していくと、IE COM Automation インターフェースに行き着きました。このインターフェースは「シングルスレッドアパートメント」モデルであり、原則的に同じスレッドからしかインターフェースを呼び出せないのです。ローカルに実行している限りデフォルトで同じスレッドが使われますが、Java アプリケーションサーバーは複数のスレッドを立てて負荷を分散させます。そのため IE ドライバにアクセスするのが必ず同じスレッドであるという確証がなくなっていたのです。
この問題に対する解決策として考えられるのは、アプリケーションサーバーで Future を使ってそれを IE ドライバ上で実行されるシングルスレッドの Executer で処理することで全てのアクセスを逐次化するというものです。少しの間私たちはこの設計を選択しましたが、複雑さを呼び出し側に押し付けるのは不公平に感じられましたし、IE ドライバを誤って複数のスレッドから使ってしまうミスがあまりにも簡単にできすぎるのも問題でした。そのため複雑さをドライバ自身に押し込めることが決定しました。これは Win32 API の PostThreadMessage を使ってスレッド同士で通信を行い、IE インスタンスを複数のスレッドで保持することで達成されています。そのため執筆時点における IE ドライバは 図 16.7 のようになっています。
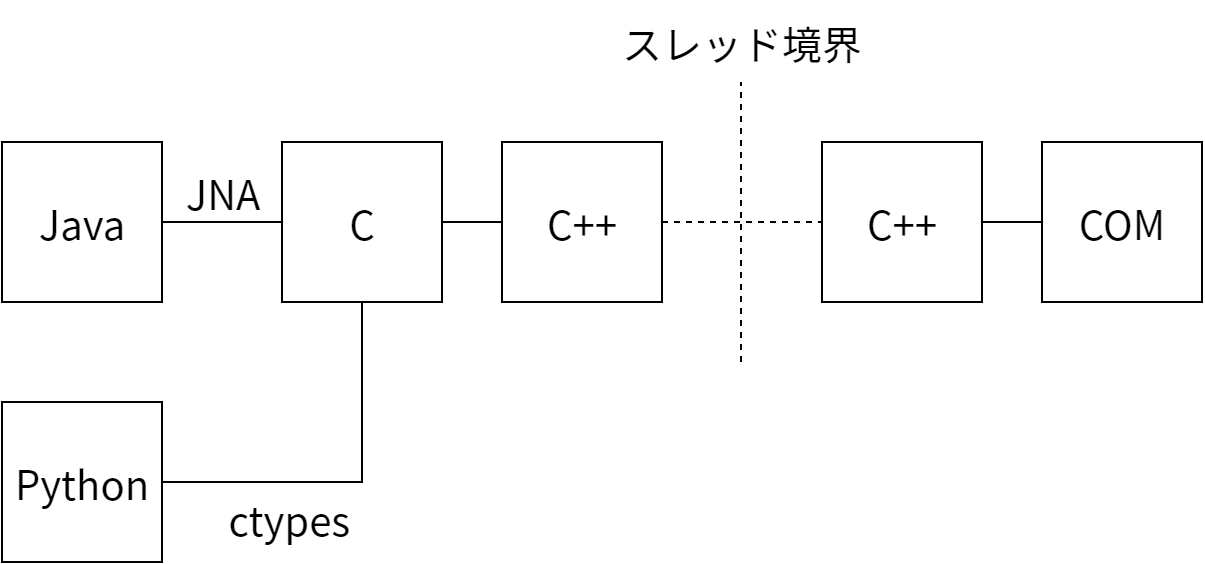
これは私が進んで選ぶような設計ではありません。しかしこの設計には実際に動作し、さらにユーザーが直面してきた惨事を生き延びているという利点があります。
この設計の欠点の一つが、IE インスタンスがロックを持っているかどうかを確実に確認することが難しくなる場合がある点です。これは DOM と対話しているときにモーダルダイアログを開いたり、スレッド境界の向こう側で致命的な障害が起きたりしたときに発生します。そのためスレッド間のメッセージにはタイムアウトが設定されており、値は比較的寛容な二分となっています。メーリングリストにあったユーザーからのフィードバックによるとこの仮定は多くのケースで適切であるものの、十分でない場合もあるようです。そのため以後のバージョンの IE ドライバではタイムアウトの値が設定可能になっているでしょう。
もう一つの欠点が、内部のデバッグが非常に難しくなる点です。スピードも求められますし (コードをトレースするのにかけられる時間は最大でも二分)、ブレークポイントはよく考えて設置しなければならず、スレッドをまたいで実行されるコードパスを理解しなければなりません。言うまでもなくオープンソースプロジェクトには解決すべき興味深い問題がいくつも転がっており、この種の地味な仕事に手が付けられることはほとんどありません。これによってシステムのバス係数が大きく下がってしまうので、私はプロジェクトマネージャーとしてこれを憂慮しています。
この問題に対処するために、IE ドライバの基礎を Firefox ドライバや Selenium Core と同じ Automation Atoms とする書き直しが進んでいます。使われている atoms を一つずつコンパイルし、それを定数として公開する C++ のヘッダーファイルを作成するというやり方です。その上で実行時にその定数を使って動作する JavaScript を用意しておきます。このアプローチでは IE ドライバの大部分を C コンパイラを使わずに開発・テストできるようになり、バグの発見と開発に関われる人の数が大きく増えます。最終的な目標は対話 API だけをネイティブコードに残し、他のできるだけ多くの部分を atoms で行うことです。
私たちが試しているもう一つのアプローチが、IE ドライバを軽量な HTTP サーバーを利用する形で書き直すというものです。こうすると IE ドライバをリモート WebDriver として扱えるようになります。もしこれが現実になればスレッドによって追加された複雑さの大部分は取り除かれ、コードの量は減り、制御フローは大きく単純化されるでしょう。
Selenium RC
特定のブラウザとは緊密に連携が取れないことがあります。そのような場合には WebDriver は Selenium が利用するオリジナルのメカニズムにフォールバックします。つまり Selenium Core という JavaScript フレームワークを利用するということであり、完全に JavaScript サンドボックスの中で実行されるこのフレームワークにはたくさんの欠点があります。WebDriver API のユーザーからすると、これはサポートされているブラウザがいくつかの区分に分かれることを意味します。緊密に連携できるブラウザでは完全な制御が可能ですが、その他のブラウザでは JavaScript が使われるためにオリジナルの Selenium RC と同程度の制御しか行えません。
図 16.8 に示すように、この設計は概念上はとても単純です。
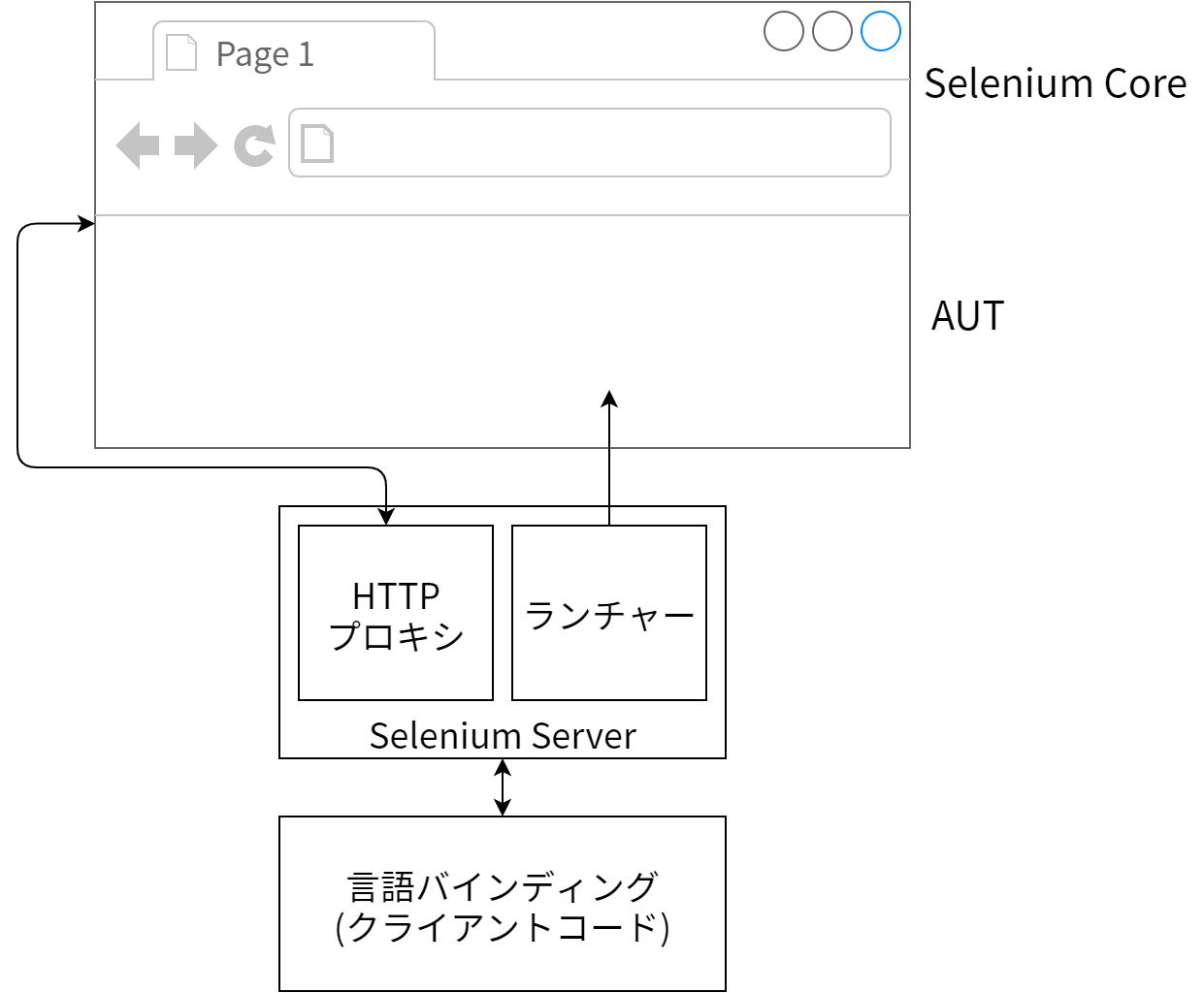
Selenium RC には三つの部分があります: クライアントコード、中間サーバー、そしてブラウザで実行される Selenium Core の JavaScript コードです。クライアントサイドはコマンドをシリアライズしてサーバーサイドに送る HTTP クライアントです。リモートの WebDriver とは違いエンドポイントは一つだけであり、リクエストメソッドはほとんど意味を持ちません。この主な理由は Selenium RC プロトコルが Selenium Core が提供するテーブルベースの API から派生したものであり、全ての API が三つの URL クエリパラメータで表されるためです。
クライアントが新しいセッションを開始すると、Selenium サーバーはリクエストされた「ブラウザ文字列」を使ってブラウザのランチャーを検索します。このランチャーはブラウザのインスタンスの構成と起動を受け持ちます。例えば Firefox では様々な拡張機能 (終了コマンドを処理するものや document.readyState を処理するもの。document.readyState はサポートされている古い Firefox リリースではサポートされない) がインストールされた事前にビルド済みのプロファイルを展開するという単純な処理を行います。この構成で重要なのが、サーバーがブラウザのプロキシとなって一部のリクエスト (例えば /selenium-server に対するもの) がそこを通るようになることです。Selenium RC は次の三つのモードのうちどれかで動作します: 単一のウィンドウのフレームを制御する「シングルウィンドウ」モード、個別ウィンドウで AUT を制御する「マルチウィンドウ」モード、そしてプロキシを使って自身をページに注入する「プロキシインジェクション」モードです。操作のモードによっては全てのリクエストがプロキシされることになります。
ブラウザが構成され開始されると、初期 URL は Selenium サーバーでホストされるページ (RemoteRunner.html) となります。このページは Selenium Core に必要な JavaScript ファイルを全て読み込んでプロセスの準備を行います。準備が完了すると runSeleniumTest 関数が呼び出され、この関数が Selenium オブジェクトのリフレクションを使って利用可能なコマンドのリストを初期化してからメインのコマンド処理ループを開始します。
その後ブラウザ内で実行される JavaScript は待機中のサーバー (/selenium-server/driver) に対して XMLHttpRequest を開き、この接続がサーバーが以降の全てのリクエストをプロキシするようになります。このサーバーがまず行うのはリクエストの生成ではなく、前回に実行したコマンドのレスポンス、あるいはブラウザがちょうど起動したばかりなら“OK”というメッセージの生成です。サーバーはユーザーのテストからクライアントを通して新しいコマンドが届くまでリクエストを開けたままにして、受け取った内容を待機している JavaScript にレスポンスとして送ります。この仕組みは最初“Response/Request”と呼ばれていましたが、近いうちに“Comet with AJAX long polling”と呼ばれるようになるでしょう。
RC がこのように動作するのはなぜでしょうか? サーバーがプロキシとして構成されている理由は、JavaScript の「同一生成元」ポリシーに違反することなく任意のリクエストの間に割りいるためです。同一生成元ポリシーは JavaScript がリクエストできるリソースをスクリプトが送られてきたのと同じサーバーからのものだけに限定します。これはセキュリティ対策として実装されていますが、ブラウザ自動化フレームワークの開発者からすれば非常に邪魔な存在であり、上述のようなハックが必要になります。
XmlHTtpRequest 通信を行う理由は二つあります。一番大事な最初の理由は、HTML5 で WebSockets が登場し主要なブラウザで利用可能になるまで、ブラウザ内でサーバープロセスを起動する信頼できる方法が存在しなかったことです。このためサーバーはどこか別の場所に建てる必要がありました。二つ目の理由は、XMLHttpRequest の呼び出しはレスポンスコールバックを非同期に呼び出すので、通信中に通常の実行が待たされないことです。もしこうなっていなければ、ユーザーテストのレイテンシが増加するか、そうでなければ JavaScript からビジーループを使うことになって CPU 使用率が青天井に増加し、ブラウザ内の他の JavaScript が実行できなくなるでしょう (一つのウィンドウコンテキストで JavaScript を実行するスレッドは一つしかないため)。
Selenium Core 内部には二つの大きなパーツがあります。メインの selenium オブジェクトは全てのコマンドのホストとして動作し、ユーザーに提供される API をミラーします。もう一つの browserbot はブラウザ間の違いを抽象化して共通のブラウザ機能を提供し、selenium はこれを利用します。このため selenium は分かりやすくなってメンテナンスがしやすくなり、browserbot は一つの機能に集中できるようになります。
Core は Automation Atoms を利用するように書き変えが進んでいます。selenium と browserbot には公開する API のためのコードが大量にあるので、完全に書き換わることはおそらくないでしょう。ただし最終的にはガワだけのクラス (シェルクラス) となり、処理を atoms に任せるようになると思われます。
過去の振り返り
ブラウザ自動化フレームワークを作るのは部屋にペンキを塗っていくのに似ています。一見すると非常に簡単なことに思えます: 何回かペンキを塗って、それで終わりです。しかし問題となるのが、タスクの量と注意が必要な細かいことが増えていくにつれ必要となる時間が増加することです。ペンキ塗りの例で言えば、照明器具や冷暖房の周り、あるいは壁下の幅木に時間が取られるでしょう。同様にブラウザ自動化フレームワークでは、ブラウザの機能の微妙な差異や変な動作によって状況が複雑になります。これは私の隣に座って Chrome ドライバに取り組んでいた Daniel Wagner-Hall が分かりやすく表現していました。彼はイライラして机をたたき「何もかもエッジケースだ!」と呟いたのです。時間を戻してこのこと当時の私に伝え、さらにプロジェクトに予想よりもはるかに時間がかかることを教えられたら良いのですが。
自動化のための atoms といったレイヤーが必要になることをもっと早く特定しすぐに実装をしていたら、プロジェクトは今ごろどうなっていただろうと考えずにはいられません。私たちが内外で直面した問題は技術的にも社会的にも簡単になったでしょう。Core と RC は JavaScript と Java だけを集中的に使って書かれることになり、Jason Huggins の言う「ハック可能性」が生まれて Selenium プロジェクトに参加するのはもっと簡単になるはずです。現在の WebDriver においてこのレベルのハック可能性が発揮されているのは atoms だけです。atoms が広く使われるようになった理由は Closure Compiler を使ったことであり、atoms は Closure がオープンソースとしてリリースされてすぐに採用しています。
上手く行ったことについて考えてみるのも面白いでしょう。フレームワークをユーザーの視点から作るという判断は正しかったと私は考えています。開発の初期においてアーリーアダプターは改善が必要な領域をすぐに見つけることができ、ツールの素早い改良につながりました。その後 WebDriver がもっと困難なことをするようになり開発者の数が増えていったときにも、この判断があるおかげで API は注意深い検討を経てから追加されるようになり、プロジェクトが引き締まります。私たちが達成しようとしていることを考えれば、これは非常に重要です。
ブラウザとの緊密に連携には良い面もあれば悪い面もあります。良いのはユーザーのエミュレートとブラウザの制御が非常に細かく行える点であり、悪いのは実装が技術的に非常に難しくなる点です。特にブラウザへ入り込む部分は難しくなります。IE ドライバが何度も進化を遂げているのもこれが理由であり、この章では触れませんでしたが Chrome ドライバにも似た歴史があります。いずれこの複雑さに対処する必要があるでしょう。
未来の展望
WebDriver が緊密に連携できないブラウザというのは必ず存在するので、Selenium Core はこれからも必要とされるでしょう。昔からそのままになっている Selenium Core の設計については、atoms と同じ Closure Library を使うモジュール化された設計に変更する作業が現在進行中です。さらに WebDriver 実装の中に atoms を今より深くに埋め込む予定になっています。
WebDriver が最初に掲げた目標の一つは他の API やツールの構成要素となることです。Selenium は孤立無援に生きているわけでは当然なく、オープンソースのブラウザ自動化ツールは他にもあります。例えば Watir (Web Application Testing in Ruby) というツールがあり、WebDriver コアの上に Watir API を実装する作業に Selenium と Watir の開発者が協力して取り組んでいます。全てのブラウザを正しく制御するのは困難なタスクなので、私たちは他のプロジェクトと協力することに熱心になっています。誰もが使える安定したカーネルの存在は素晴らしいものであり、私たちは WebDriver がそのカーネルになれると願っています。
この未来へ向けた第一歩とも言える事例が Opera Software によって示されました。彼らは WebDriver API を独自に実装し、動作の検証に WebDriver のテストスイートを利用し、それを OperaDriver としてリリースする予定です。また Selenium チームのメンバーは Chromium チームと協力して Chromium のフックや WebDriver を改良しており、この改良は Chrome でも拡張機能を通して利用可能になります。私たちは FirefoxDriver にコードをコントリビュートしている Mozilla や Java で書かれた有名なブラウザエミュレータ HtmlUnit の開発者たちと良好な関係を築いています。
私たちはこのトレンドが続くと見ています。異なるブラウザの自動化フックが統一された方法で公開されることになるでしょう。ウェブアプリケーションのテストを書く人にとっての利点は明確であり、ブラウザ製作者にとっての利点も明らかです。例えば手動のテストは比較的コストが高いので、たくさんの大規模プロジェクトが自動テストを利用しています。特定のブラウザのテストが不可能 (あるいは非常に難しい) の場合にはそのブラウザに対するテストは実行されないだけですが、そのブラウザ上における複雑なアプリケーションの安定性への波及効果は避けられないでしょう。この自動化フックが WebDriver をベースにするかどうかはまだ分かりませんが、そうであることを祈りましょう!
これからの数年は非常に面白いものになるでしょう。せっかく Selenium はオープンソースプロジェクトなのですから、あなたも http://selenium.googlecode.com/ から私たちとの旅に参加しませんか?
-
この状況は FIT とよく似ています。FIT プロジェクト発起人の一人 James Shore はこの設計の欠点のいくつかを http://jamesshore.com/Blog/The-Problems-With-Acceptance-Testing.html で語っています。[return]
-
例えばリモートサーバーは例外の発生時に base64 でエンコードされたスクリーンショットをデバッグ用に返しますが、Firefox ドライバは返しません。[return]
-
常に同じ値を返すということです。[return]