VisTrails
VisTrails1 はデータの探索と可視化をサポートするオープンソースシステムであり、科学ワークフローシステムと可視化システムが持つ便利な機能を大きく拡張した形で持ちます。Kepler や Taverna といった科学ワークフローシステムと同様、VisTrails を使った計算プロセスの記述が可能であり、このプロセスには既存のアプリケーション、互いに結び付いたリソース、あるいはライブラリを規則に沿って追加できます。AVS や ParaView といった可視化システムと同様、VisTrails では高度な科学情報可視化技術が利用可能であり、ユーザーは自身のデータの異なる表現を探索・比較できます。こういった機能を使えば、データの収集や生成から複雑な解析、そして可視化という科学的発見の重要なステップを全て含んだ複雑なワークフローを作成でき、それが一つのシステムに統合されます。
VisTrails の特徴的な機能の一つが、その追跡インフラです [FSC+06]。VisTrails はユーザーがたどったステップおよび探索タスクの結果生まれるデータの生成過程についての詳細な履歴を記録・管理します。通常ワークフローは反復的なタスクを自動化するのに使われますが、データの解析と可視化のような何かを探索するのに使われるアプリケーションでは反復的な部分はほとんどありません ――全ては変更されます。ユーザーがデータに関する仮説を思いついてそれを評価するたびに、異なる (しかし関連性のある) ワークフローが作成され、何度も調整されます。
VisTrails はこういった素早く進化するワークフローを管理するために設計されました。データプロダクト (可視化やプロット)、データプロダクトを生み出すワークフロー、そしてその実行が全て VisTrails によって追跡管理されます。加えて、自動的にキャプチャされたデータの履歴を分かりやすくする注釈機能もあります。
結果を再現可能にする他にも、VisTrails は様々な操作およびユーザーインターフェースで追跡情報を利用し、ユーザーと協調してデータの解析を行います。中でも注目に値するのが、一時的な結果を保存しながら行う推論です。ユーザーは結果を生み出した操作を調べ、行ったり来たりしながら推論を進められます。ワークフローのバージョンを直感的に移動でき、結果を失うことなく変更を打ち消したり、複数のワークフローを比較したり、結果を可視化用スプレッドシートで並べて見ることができます。
ワークフローシステムや可視化システムを広く採用する上での障害となってきたユーザビリティの問題にも VisTrails は取り組んでいます。プログラミングの知識を持たない人々を含むたくさんのユーザーに対応するため、ワークフローの設計と利用を単純化する操作とユーザーインターフェースが提供されます [FSC+06]。例えば、類似するワークフローを使ってワークフローを作成・改良したり、例を使ってワークフローを問い合わせたり、推薦システムを使って対話的にワークフローを構築するための補間を提示できたりします [SVK+07]。またカスタムされたアプリケーションを作成するための新しいフレームワークも開発され、これを使うと (専門家でない) エンドユーザーに向けたさらに簡単にデプロイが可能です。
VisTrails の拡張性を可能にしているのは、ツールとライブラリの取り込みや新しい機能のプロトタイプの作成を簡略化するそのインフラです。幅広い応用分野で VisTrails を使う上で、この拡張性は重要です。例えば環境科学、精神医学、心理学、天文学、宇宙科学、高エネルギー物理学、量子物理学、分子モデリングといった分野で VisTrails は使われています。
システムをオープンソースで誰にとっても無料にするために、VisTrails は無料でオープンソースなパッケージだけを使って作成されています。VisTrails は Python を使って書かれ、GUI ツールキットとして Qt (の Python バインディング PyQt) を使います。様々なユーザーと応用を持つ VisTrails はポータビリティを念頭に設計されており、Windows, Max, Linux で動作します。
システムの概観
データの解析は本質的に創造的なプロセスです。ユーザーは関連性のあるデータを発見し、データを統合・可視化し、他のメンバーと協力して思いつく限りの解決法を探り、結果を多くの人に発表しなければなりません。科学のデータ探索におけるデータのサイズと解析の複雑さを考えれば、この創造的なプロセスをサポートするためのツールが必要となります。
こういったツールがユーザーと上手くやっていくための最低条件が二つあります。一つ目は、探索プロセスが形式的な記述を持ち、理想的にはその記述が実行できることです。二つ目は、ツールが履歴のキャプチャをシステムレベルでサポートし、探索プロセスの結果の再現性を担保しつつも問題解決までに試した異なるステップについて後から考えられるようにすることです。VisTrails はこの二つの要件を念頭に置きながら設計されました。
ワークフローとワークフローベースのシステム
ワークフローシステムは複数のツールを組み合わせたパイプライン (ワークフロー) の作成をサポートします。ワークフローシステムを使えば、反復的なタスクを自動化しさらに結果の再現性を得られます。ワークフローは機能の少ないシェルスクリプトを幅広いタスクにおいて置き換えており、ワークフローベースのアプリケーションには商用のもの (Apple の Mac OS X に付属する Automator や Yahoo! Pipes) から学術用のもの (NiPype, Kepler, Taverna) まであります。
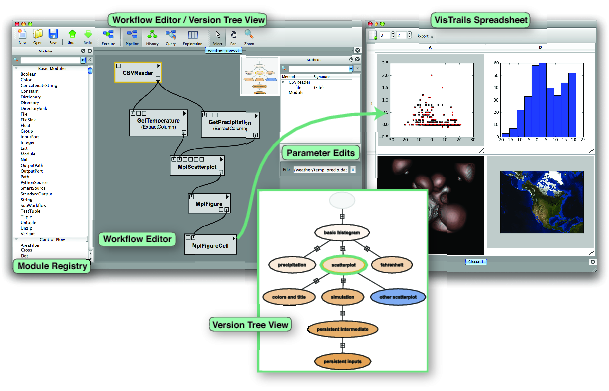
高レベル言語で書かれたスクリプトやプログラムと比較すると、ワークフローにはいくつもの利点があります。ワークフローとはプログラミングモデルであり、あるタスクの出力を別のタスクの入力につないで全体のプログラムを構成するという単純なものです。図 23.1 には、気候観測データを含んだ CSV ファイルを読んで値の散布図を作成するワークフローが示されています。
ワークフローシステムは普通よりも単純なプログラミングモデルを利用して直感的なプログラミングインターフェースを提供し、これによってプログラミングの知識をあまり持たないユーザーも使えるようになります。ワークフローが提供するのは分かりやすい構造です: ワークフローはグラフであり、頂点が処理 (あるいはモジュール) とそのパラメータを、辺が処理の間のデータの流れを表します。図 23.1 の例では、CSVReader というモジュールにファイル名 (/weather/temp_precip.dat) というパラメータが付いており、このモジュールがファイルを読み、そのデータを GetTemperature と GetPrecipitation というモジュールに流し込みます。すると気温と降水量のデータが散布図を生成する matplotlib の関数に送られます。
ほとんどのワークフローシステムは特定の分野に向けて書かれています。例えば Taverna は生物情報科学のワークフロー向けであり、NiPype はニューラル画像ワークフロー向けです。VisTrails は他のワークフローシステムで提供される機能も多くをサポートしますが、その設計は様々な分野の一般的な探索タスクをサポートしており、複数のツール・ライブラリ・サービスを統合できます。
データとワークフローの追跡
結果 (およびデータプロダクト) の追跡を保持することの重要性は科学コミュニティに広く知られています。データプロダクトの追跡 (provenance, またの名を audit trail, lineage, pedigree) 情報には、データプロダクトを得るためのデータと処理方法が記されます。追跡情報は結果の検証だけではなく、データを保存し、データのクオリティと著者を提示し、結果の再現を可能にするために重要なドキュメントです。
追跡において重要なのが、因果関係に関する情報です。つまり、データとパラメータからデータプロダクトを生成する「処理」の (ステップごとの) 説明です。そのため追跡情報には結果を生み出したワークフロー (あるいはその集合) の構造が含まれます。
実は、科学界でワークフローシステムが広く使われるようになったきっかけは、システムを使うと追跡を自動で簡単にキャプチャできるためでした。初期のワークフローシステムでは追跡キャプチャが後から追加されたのに対して、VisTrails は追跡をサポートするよう設計されています。
ユーザーインターフェースと基本的な機能
VisTrails が持つユーザーインターフェースのコンポーネントを 図 23.1 と 図 23.2 にいくつか示しました。ユーザーは Workflow Editor を使ってワークフローを作成します。
ワークフローグラフを作るときには、ユーザーは Module Registry からモジュールをドラッグし、Workflow Editor に落とします。VisTrails には組み込みのモジュールがいくつかあり、ユーザーが独自のモジュールを追加することもできます (詳細は 23.3 節 を見てください)。VisTrails はパラメータを (Parameter Edits エリアに) 表示し、ユーザーがそこから値を設定できるようになっています。
ワークフローを変えるとシステムが変更を検出し、後述の Version Tree View を更新します。ユーザーがワークフローやその結果と対話するときに使われるのが VisTrails Spreadsheet であり、このスプレッドシートの各セルがワークフローインスタンスに対応するビューを表します。図 23.1 では、WorkFlow Editor にあるワークフローの結果が VisTrails Spreadsheet の左上のセルにあります。ユーザーはワークフローのパラメータを直接編集でき、さらに VisTrails Spreadsheet で異なるセルにあるパラメータを同期することもできます。
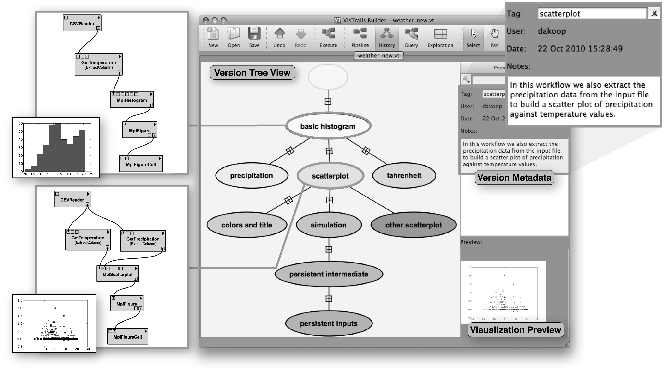
Version Tree View を使うと、ワークフローの異なるバージョンへ簡単にアクセスできます。図 23.2 に示すように、Version Tree の頂点をクリックするとワークフローや関連する結果 (Visualization Preview)、そしてメタデータを閲覧できます。製作者のユーザー ID や作成日時のように自動的に作られるメタデータもありますが、ユーザーからもメタデータを追加できます。例えばワークフローを表すタグや言葉による説明です。

プロジェクトの歴史
VisTrails の最初のバージョンは Java と C++ で書かれました [BCC+05]。C++ バージョンは少数のアーリーアダプターに配布され、彼らからのフィードバックはシステムの要件を形作る助けとなりました。
いくつかの科学コミュニティにおいて Python ベースのライブラリとツールが増えていたのを見て、VisTrails の基礎を Python とする決断が下されました。Python は科学ソフトウェアをつなぐモダンでユニバーサルなグルー言語としての地位を急速に高めており、Fortran, C, C++ といった異なる言語で書かれたたくさんのライブラリが Python を使ってスクリプトの機能を提供しています。異なるソフトウェアライブラリをワークフローで協調動作させるのが VisTrails の目的なので、純粋な Python で実装されていれば好都合です。特に Python には動的にコードを読み込む (LISP 環境でよく見られる) 機能があり、さらに開発者コミュニティはずっと大きく、標準ライブラリもずっと充実しています。2005 年の終わりごろ、私たちは Python/PyQt/Qt を使った現在のシステムの開発を開始し、これによりシステムの拡張機能 (中でもモジュールとパッケージ) が大きく単純化されました。
VisTrails システムのベータバージョンは 2007 年の一月に初めてリリースされました。それから VisTrails は 25,000 回以上ダウンロードされています。
VisTrails の内部
VisTrails のアーキテクチャの高レベルな概観図 (図 23.3) に、上述のユーザーインターフェース機能をサポートする内部コンポーネントを示します。ワークフローの実行は Workflow Engine が管理し、個のコンポーネントは行った操作やそのパラメータの記録やワークフロー実行の追跡のキャプチャ (Execution Provenance) も行います。VisTrails はワークフローを実行するときに、中間結果をメモリとディスクの両方にキャッシュします。23.3.2 項 でも説明しますが、再実行されるのは新しいモジュールのパラメータの組だけであり、実行には適切な外部ライブラリ (matplotlib など) の関数が使われます。ワークフローの結果をその追跡と共に埋め込んだ電子ドキュメントも作成できます (23.4.6 項 で扱います)。
ワークフローの変更に関する情報は Version Tree がキャプチャし、種々のストレージバックエンド (例えばローカルの XML ファイルやリレーショナルデータベース) を使ってディスクに書き込みます。さらに VisTrails は追跡情報を閲覧するためのクエリエンジンを持ちます。
VisTrails はインタラクティブなツールとして設計されてはいますが、サーバーモードでの利用も可能です。ワークフローを一度作成してしまえば、VisTrails サーバーでそれを実行できます。この機能は様々なシナリオで有用であり、例えばウェブベースのインターフェースでワークフローを作成したり、ハイパフォーマンスコンピューティング環境でワークフローを実行したりできます。
Version Tree: 変更ベースの追跡
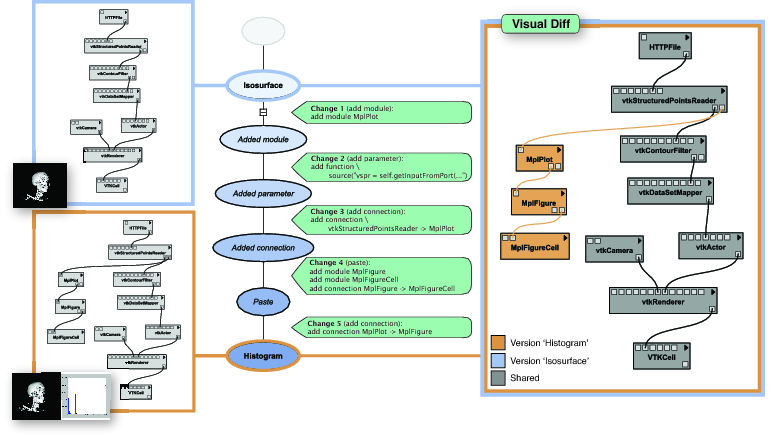
VisTrails はワークフローの成長の追跡 (provenance) という新しい概念を導入しました [FSC+06]。生成されたデータプロダクトに対する追跡しか管理しないそれまでのワークフローシステムやワークフローベースの可視化システムとは違い、VisTrails はワークフローを第一級のデータ項目として扱い、その追跡をキャプチャします。ワークフローの成長に関する追跡の存在は、因果関係の調査を可能にします。複数の推論を結果を失わずに同時に調整でき、加えて中間結果がシステムによって保存されるので、この情報から何が起きているかを考察できます。さらに探索プロセスの単純化も可能になります。例えばワークフローとその結果を視覚的に比較し、タスクに対するワークフローの空間 (図 23.4)、および (より広大な) パラメータの空間を容易に探索できます。また追跡情報を問い合わせて例示からデータについて学ぶこともできます。
ワークフローの成長は変更ベースの追跡モデルを使ってキャプチャされます。図 23.4 に示すように、VisTrails はワークフローに対する操作と変更 (モジュールの追加、パラメータの変更など) を保存します。これはデータベースのトランザクションログのようなものです。この情報は木としてモデル化され、その頂点がワークフローのバージョンを、辺が親に行うと子が得られる変更を表します。これからは、この木をバージョン木 (version tree) あるいは vistrail (visual trail の略) と呼びます。この変更ベースのモデルではパラメータの値の変更とワークフローの定義の変更が同じようにキャプチャされる点に注意してください。バージョン木から得られる変更の列からはデータプロダクトの追跡が得られ、さらにワークフローが時を経てどのように成長してきたかもわかります。このモデルは単純かつコンパクトです。なぜなら、このモデルが必要とする空間はワークフローの全てのバージョンを保存するよりも格段に少ないからです。
このモデルの利点はたくさんあります。図 23.4 には二つのワークフローを比較するための機能が示されています。ワークフローはグラフで表されますが、変更ベースのモデルを使うと二つのワークフローの比較が非常に簡単になります: ワークフローの一方をもう一方に変形する操作の列がバージョン木をたどれば見つかるからです。
変更ベースの追跡モデルのもう一つの重要な利点が、バージョン木を使った協同編集のサポートです。ワークフローの設計はとても難しいタスクなので、ときには複数のユーザーが同時に取り組む必要があります。バージョン木を使えば異なるユーザーからの操作を直感的に可視化できる (ワークフローの頂点に作ったユーザーに対応する色をつけるなど) だけでなく、モデルが単調なので複数のユーザーが行う変更の同期が単純なアルゴリズムで行えます。
追跡情報はワークフローを実行するときに簡単にキャプチャできます。実行が完了した後には、データプロダクトと追跡 (つまり、データプロダクトを生成するワークフローとパラメータと入力ファイル) の間の強いリンクが重要になります。データファイルや追跡が移動・変更されると、追跡に対応するデータやデータに対応する追跡を見つけるのが困難になるからです。VisTrails は永続ストレージメカニズムを使って入力データ、中間データ、出力データのファイルを保存し、追跡とデータをつなぐリンクを強固にします。このメカニズムにより追跡情報で参照されるデータが (変更されない状態で) 必ず存在することが保証されるので、再現性が向上します。また中間データのキャッシュを他のユーザーと共有できるのもこのモデルの利点の一つです。
ワークフローの実行とキャッシュ
VisTrails の実行エンジンでは新しいツールと既存のツールを統合できます。サードパーティの科学的可視化ソフトウェアや計算ソフトウェアをラップするのに広く使われている異なるスタイルを許容することを私たちは目指しました。具体的に言うと VisTrails では、コンパイル済みバイナリとして配布されファイルで入出力を行うシェルから実行するアプリケーションライブラリ、そして C++/Jata/Python の内部オブジェクトを入出力につかうクラスライブラリの両方を統合できます。
VisTrails はデータフロー実行モデルを採用します。各モジュールが計算を実行し、生み出されたデータがモジュールをつなぐフローに流れます。モジュールの実行は「下から」行われます。入力は必要になったときに計算され、その指令が再帰的に上流のモジュールに伝わります (モジュール A が B の上流であるとは、A から B に向かう接続があることを言います)。中間データは一時的に保存され、保存にはメモリ (Python オブジェクト) またはディスク (データへのアクセス方法を付けた Python オブジェクト) が使われます。
ユーザーが VisTrails に独自の機能を追加できるように、拡張可能なパッケージシステムが作られました (23.3.4 項)。ユーザーはパッケージを使って自身のモジュールあるいはサードパーティのモジュールを VisTrails ワークフローに追加できます。パッケージ開発者は計算モジュールを指定し、そのモジュールそれぞれについて入力ポートと出力ポートと計算を定義します。既存のライブラリに対しては、入力ポートからそのライブラリの関数のパラメータへの変換および返り値から出力ポートへの変換を計算メソッドで指定する必要があります。
探索タスクでは、構造が同じ似たワークフローを連続して実行することがよくあります。ワークフローの計算を高速化するために、VisTrails は計算の中間結果をキャッシュし再計算を最小化します。前回の実行を使い回すので、キャッシュ可能なモジュールは関数的です: つまり同じ入力に対するモジュールの出力は同一です。これによりクラスの振る舞いに制限が加わりますが、これは妥当なものであると私たちは考えています。
しかし、この振る舞いが明らかに不可能な場合があります。例えば、リモートサーバーにファイルをアップロードするモジュールやディスクにファイルを保存するモジュールは大きな副作用を持ちます (その代わり出力が比較的重要ではありません)。あるいは乱数を使っていて、計算が決定的でない方が望ましいモジュールもあるでしょう。そういったモジュールには「キャッシュ不可能」とフラグを立てることができます。ただし、普通に考えると関数的でないモジュールの中には関数的になるように変換できるものもあります: 例えばデータを二つのファイルに書き込む関数をラップして、その内容を出力するようにできるかもしれません。
データのシリアライズと保存
追跡をサポートするシステムで重要となるコンポーネントの一つが、データのシリアライズと保存を行う部分です。初期の VisTrails は各内部オブジェクト (例えばバージョン木、モジュールなど) が持つ fromXML 関数と toXML 関数を使ってデータを XML で保存していました。オブジェクトスキーマの更新をサポートするために、これらの関数はスキーマバージョン間の変換処理も持ちます。プロジェクトが成長しユーザーベースが拡大したのを受けて、リレーショナルストアなどの新しいシリアライズ方法をサポートすることになりました。加えてスキーマオブジェクトが大きくなって来ていたので、データ管理でよくある機能、例えばバージョンスキーマ、バージョン間の変換、エンティティ同士の関係のサポートが必要でした。このために新しく追加されたのがデータベース (db) レイヤーです。
db レイヤーは三つの中心的なコンポーネントからなります。ドメインオブジェクト、サービスロジック、永続化メソッドの三つです。ドメインオブジェクトと永続化メソッドはバージョン付けされ、各スキーマバージョンが独自のクラスを持ちます。こうするとスキーマの各バージョンを読むコードが管理され、異なるスキーマバージョンを持つオブジェクトを変換するクラスも存在することになります。サービスロジックのクラスはデータを使うメソッドを提供し、スキーマバージョンの検出と変換を行います。
このコードを書くのは反復的で面倒なので、オブジェクトレイアウト (およびメモリ上のインデックス) とシリアライズのコードにはテンプレートとメタスキーマが使われています。メタスキーマは XML で書かれ、これ拡張すれば VisTrails がデフォルトでサポートする XML とリレーショナルマッピング以外に対するシリアライズ処理を定義できます。これは Hibernate2 や SQLObject3 が使うオブジェクト-リレーショナルマッピングと同様ですが、VisTrails には識別子の再マッピングやスキーマバージョン間のオブジェクトの変換といったタスクを自動化するための特別なルーチンがあります。さらに同じメタスキーマを使った他言語のシリアライズコードの自動生成も可能です。最初はメタスキーマから取得した変数を使ってドメインと永続化のコードを作るメタ Python コードが存在していましたが、最近になって Mako テンプレートエンジンに切り替わりました。
ユーザーがシステムの新しいバージョン向けにデータを変換するときには、自動的な変換が重要になります。この変換が開発者から利用しやすいように、VisTrails の設計にフックが追加されました。各バージョンのコードはコピーが保存されているので、変換コードが行うのはバージョンのマッピングだけです。ルートレベルではバージョン間の変換方法を指定するマップを定義するだけで済みます。バージョンが大きく離れている場合には中間のバージョンへの変換が何回か行われます。最初この変換は新しいバージョンにだけ変換する「前方向だけの」マップでしたが、新しいスキーママッピングでは逆方向のマップも追加されました。
各オブジェクトには update_version 関数があり、この関数は異なるバージョンのオブジェクトを受け取って現在のバージョンのオブジェクトを返します。デフォルトでは、オブジェクトのマッピングフィールドを使ってオブジェクトを再帰的に新しいバージョンにアップグレードします。デフォルトのマッピングは各フィールドを同じ名前のフィールドにコピーしますが、フィールドにメソッドを用意してこの動作を「オーバーライド」することが可能です。オーバライドメソッドは古いオブジェクトを受け取って新しいオブジェクトを返します。スキーマの変更の多くはフィールドの一部にしか影響しないので、ほとんどの場合はデフォルトのマッピングでカバーでき、オーバーライドは細かな変更を定義するのに使われます。
パッケージと Python を使った拡張
最初の VisTrails のプロトタイプでは、あらかじめ決められたモジュールしか使えませんでした。これは VisTrails のバージョン木や実行のキャッシュ化を開発するには理想的な環境でしたが、長期的な実用性は大きく制限されました。
私たちは VisTrails を計算科学のインフラとして開発しています。これは、VisTrails から他のツールやプロセスを使うための「足場」が提供されるべきであることを意味します。このシナリオにおける重要な要件は拡張性です。拡張性を達成するためによくあるのが、新しくターゲット言語を定義してインタープリタを書くというやり方です。実行を細かく制御でき、さらにキャッシュとの相性も良いので魅力的ですが、完全なプログラミング言語の実装は大変な仕事であり、私たちの目標ではありません。さらに重要なこととして、VisTrails をちょっと試すだけのユーザーが新しい言語を一つ覚え無ければならないというのは問題外です。
私たちが望んだのはユーザーが独自の機能を簡単に追加できるシステムであり、VisTrails には複雑なソフトウェアを表現できるパワフルな機能が必要でした。例えば VisTrails は VTK4 という可視化ライブラリをサポートしますが、VTK には 1000 個のクラスが含まれ、コンパイル・構成・オペレーティングシステムによって利用可能なものが異なります。全ての場合についてコードを書くのは非生産的で実質不可能なので、パッケージが提供する VisTrails モジュールを動的に決定する仕組みが必要になりました。そして VTK は複雑なパッケージの例として目標とされました。
私たちがターゲットとした分野は計算科学であり、VisTrails を設計した頃には Python が「グルーコード」を書く言語として科学者の間で広く使われていました。ユーザーが定義する VisTrails モジュールの動作を Python で書けるようにすれば、VisTrails を採用するときの大きな障壁を完全に取り除けます。さらに Python は動的に定義されるクラスやリフレクションに対する優れたインフラを持ち、Python におけるほぼ全ての定義は同じ意味のファーストクラスの式を持ちます。VisTrails のパッケージシステムで重要になった Python のリフレクション機能は次の二つです:
-
typeを呼ぶことで Python のクラスを動的に定義できる。返り値がクラスの表現であり、普通に定義した Python クラスと全く同じ操作を行える。 -
__import__を呼ぶことで Python モジュールをインポートでき、返り値を通常のimport文でインポートした識別子と同じように使える。モジュールのパスも実行時に指定できる。
もちろん Python には欠点もあります。まず何と言っても、Python が動的であるために VisTrails パッケージの型安全性といったものは保証できなくなります。さらに重要なのが、VisTrails モジュールの要件、特に後述する参照透過性に関する要件が Python レベルで強制できないことです。しかしそれでも、この点に注意を払いながら文化的メカニズムを通して許可される文を制限する意味はあると私たちは信じています。ソフトウェアの拡張を考えると、Python は非常に魅力的な言語です。
VisTrails のパッケージとバンドル
VisTrails のパッケージはいくつかのモジュールをまとめたものであり、ディスク上では通常 Python のパッケージとして表されます (この名前の衝突は残念です)。Python のパッケージはいくつかの Python ファイルからなり、Python ファイルは関数やクラスといった Python の値を定義します。VisTrails パッケージは特定のインターフェースに沿った Python パッケージであり、特定の関数と変数を定義したファイルが含まれます。一番単純な VisTrails パッケージは __init__.py と init.py という二つのファイルを持つディレクトリです。
最初のファイル __init__.py は Python パッケージの要件であり、いくつかの定数だけが含まれることになっています。この条件を確かめる方法はないものの、こうなっていない VisTrails パッケージはバグがあるとみなされます。このファイルで定義される値には、ワークフローが特殊化されたときにモジュールを区別するためのグローバルにユニークな識別子や、パッケージのバージョン (23.4.5 項 で説明しますが、ワークフローやパッケージのアップグレードを処理するときにはバージョン情報が重要です) が含まれます。また同じファイルに package_dependencies 関数および package_requirements 関数を含めることもできます。VisTrails モジュールは (ルートの Module クラスに限らず) 他の VisTrails モジュールの子クラスとして定義すれば、VisTrails パッケージを他のパッケージの拡張としても定義できます (その場合には初期化の順序が保たれます)。package_dependencies 関数はパッケージ間の依存関係を指定し、package_requirements 関数はシステムレベルのライブラリを指定します。バンドルの抽象化を使って VisTrails が自動的に必要なライブラリを取得する場合もあります。
バンドルはシステムレベルのパッケージであり、VisTrails は RedHat の RPM や Ubuntu の APT といったシステムごとのツールを使って管理を行います。VisTrails からパッケージを直接 Python モジュールとしてインポートすれば、適切な変数にアクセスしてパッケージのプロパティを判定できます。
二つ目のファイル init.py には全ての VisTrails モジュールの定義に対するエントリーポイントが含まれます。このファイルの一番重要なのは initialize と finalize という二つの関数です。initialize 関数はパッケージが起動して依存パッケージの起動が終了したときに呼ばれ、パッケージの全てのモジュールに関するセットアップ処理を行います。逆に finalize はランタイムのリソースを解放するのに使われます (パッケージが作成した一時ファイルを削除するなど)。
VisTrails のパッケージに含まれる各モジュールは一つの Python クラスで表され、パッケージ開発者は add_module を各 VisTrails モジュールに対して呼んでこのクラスを VisTrails に登録します。任意の Python クラスを VisTrails のモジュールにできますが、いくつか要件があります。まず、モジュールのクラスは VisTrails が定義する基底 Python クラスの子である必要があります (Module という面白くない名前のクラスです)。VisTrails モジュールでは多重継承を利用できますが、含んでよい VisTrails モジュールは一つだけです ――VisTrails モジュールの木でダイアモンド継承は許されていません。多重継承はクラスのミックスインの定義に特に便利です: 単純な処理を (複数の) 親クラスに実装し、それを組み合わせて複雑な処理を行うクラスを作成できます。
利用可能なポートの集合が VisTrails のインターフェースを決め、モジュールの表示方法だけでなく他のモジュールとの接続形態もこれで決まります。このポートの集合は VisTrails の基盤に対して明示的に提示されます。具体的には add_input_port および add_output_port を initialize 中に呼ぶか、VisTrails モジュールを表すクラスごとに _input_ports と _output_ports を定義します。
各モジュールは compute メソッドをオーバーライドして行うべき計算を指定し、モジュール間でデータを受け渡すときにはポートが使われます。このポートは get_input_from_port メソッドと set_result メソッドで指定します。よくあるデータフロー環境では実行順序がデータのリクエストに応じてその場で決定されますが、VisTrails ではワークフローモジュールのトポロジカル順序で決定されます。キャッシュアルゴリズムが非巡回グラフを必要とするので、実行はトポロジカル順序の逆順に行われ、関数の呼び出しが上流のモジュールを起動します。この順序はよく考えて定められています: モジュールの振る舞いを他のモジュールから切り離せるので、キャッシュ戦略は単純かつ頑健になります。
一般的なガイドラインとして、VisTrails モジュールは副作用のある関数を compute メソッドで呼ぶべきではありません。23.3.2 項で議論したように、この要件によりワークフローの一部のキャッシュが可能になります: モジュールがこの要件を満たす限り、その動作は上流モジュールから出力の関数となるからです。非巡回部分グラフを一度だけ計算すれば済み、結果を再利用できます。
データをモジュールとして渡す
VisTrails モジュール間の通信が持つ特に変わった機能の一つが、VisTrails のモジュールを別のモジュールに渡せる機能です。VisTrails にはモジュールクラスとデータクラスの間に単一の階層があります。例えばモジュールは自分自身を計算の結果として出力できます (実は全てのモジュールにはデフォルトで self を出力するポートがあります)。こうすると計算とデータの区別というデータフローベースのアーキテクチャでよく見られる特徴が失われますが、大きな利点が二つあります。一つは、オブジェクト型システムが Java や C++ のものに近づくことです。もちろんこうしているのは意図的であり、その理由は VTK などの大規模なクラスライブラリを自動的にラップできるのが非常に重要なためです。こういったライブラリではオブジェクトの計算結果として他のオブジェクトが返る場合があるので、計算とデータの区別が曖昧になっています。
二つ目の利点は、ワークフローの定数やユーザーが設定するパラメータがシステムの他の部分と自然に結び付く点です。例えば定数で指定されるウェブ上の場所からファイルを読み込むワークフローを考えます。今はこの値を GUI で指定していて、URL がパラメータだとしましょう (Parameter Edits エリアについては 図 23.1 を見てください)。このワークフローの自然な変更として、どこか上流で計算された URL をフェッチするという変更が考えられます。このときにはワークフローの他の部分への変更が最小限であることが望まれます。もしモジュールが自分自身を出力できるなら、目的の値を持った文字列をパラメータに対応するポートにつなぐだけで済みます。定数の評価値はそれ自身なので、動作は実際に定数が指定された場合と同一となります。
定数に関しては他にも考慮すべきことがあります。定数の種類によって値を設定するのに適した GUI インターフェースが異なる問題です。例えば VisTrails では定数ファイルモジュールはファイル選択のダイアログを提供しており、Boolean 値にはチェックボックスが、色には OS ネイティブのカラーピッカーが用意されています。これを一般的に行うために、開発者は Constant という基礎クラスから派生したクラスを定義し、適した GUI ウィジェットと文字列表現を指定するオーバーライドをそこで提供しなければなりません (文字列表現が必要なのは、任意の定数をシリアライズしてディスクに書き込むためです)。
ここで、簡単なプロトタイプのための VisTrails 組み込みモジュール PythonSource を紹介しておきます。PythonSource モジュールを使うとワークフローにスクリプトを直接埋め込むことができ、設定ウィンドウ (図 23.5) で実行する Python コードおよび複数の入力・出力ポートを設定できます。
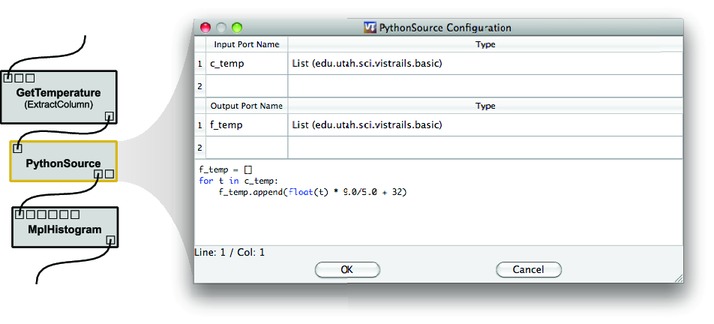
PythonSource モジュールでプロトタイプする
コンポーネントと機能
上述の通り、VisTrails は探索計算タスクの作成と実行を簡単にする機能とユーザーインターフェースを提供します。そのいくつかをここで紹介します。また VisTrails が詳細な追跡情報の作成をサポートする計算インフラの基礎として利用できることについても軽く触れます。VisTrails とその機能についてさらに詳しくは、VisTrails のオンラインドキュメント5を参照してください。
Visual Spreadsheet
VisTrails では、異なるワークフローの結果を Visual Spreadsheet を使って比較・探索できます (図 23.6)。このスプレッドシートは一つの VisTrails パッケージであり、シートとセルからなる独自のインターフェースを持ちます。シートはセルの集合であり、そのレイアウトはカスタマイズ可能です。セルはワークフローが生成する結果を視覚的に表現し、設定に応じて多様なデータを表示します。
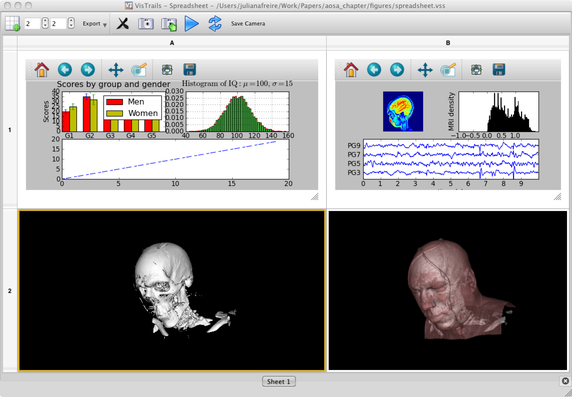
スプレッドシートにセルを表示するには、SpreadsheetCell モジュールから派生したモジュールをワークフローに追加します。一つの SpreadsheetCell がスプレッドシート内の一つのセルに対応するので、ワークフローから複数のセルを作成することもできます。SpreadSheetCell の compute メソッドは Execution Engine (図 23.3) とスプレッドシートの間で情報のやり取りを行います。スプレッドシートは実行時にセルの種類に応じて必要ならばセルを生成しますが、そのときには Python の動的なクラス作成機能を利用します。つまり SpreadsheetCell クラスの子クラスを作成し、その compute メソッドで所望のセルの種類をスプレッドシートに送ればカスタマイズされた視覚化が可能になります。例えば 図 23.1 のワークフローでは MplFigureCell が SpreadSheetCell モジュールを継承しており、matplotlib が作る画像を表示します。
スプレッドシートの GUI バックエンドは PyQt なので、セルウィジェットは PyQt の QWidget の子クラスである必要があります。さらに updateContents メソッドも必要です。これは新しいデータが到着したときにウィジェットを更新する関数で、スプレッドシートが呼びます。その他にも各セルは独自のツールバーを toolbar メソッドで定義でき、セルが選択されたときにスプレッドシートのツールバーエリアに表示されます。
図 23.6 に VTK セルを選択したときのスプレッドシートを示します。このときツールバーのウィジェットが変化し、PDF 画像として出力する、カメラの位置を保存してワークフローに戻る、アニメーションを作る、という操作が可能になっています。スプレッドシートパッケージにはカスタマイズ可能な QCellWidget が定義され、このウィジェットは履歴の再生 (アニメーション) やマルチタッチイベントのフォワーディングといったよく使われる機能を提供します。QWidget の代わりに QCellWidget を利用すれば、新しい種類のセルを素早く開発できます。
スプレッドシートは PyQt ウィジェットだけをセルとして受け付けますが、他の GUI ツールキットで書かれたウィジェットを組み込むことも可能です。ウィジェットがその要素をネイティブプラットフォームにエクスポートし、PyQt がそれを感知するという処理を行います。このアプローチは VTKCell で使われました。VTK のウィジェットが C++ で書かれていたためです。VTKCell は実行時にウィンドウ ID, Win32, X11, Cocoa/Carbon ハンドルを取得し、それをスプレッドシートのキャンバスにマップします。
セルと同様シートもカスタマイズできます。デフォルトではシートがタブビューでセルが表レイアウトですが、シートをスプレッドシートから切り離して複数のシートを同時に表示することもできます。またシートのレイアウトも変更でき、これは PyQt ウィジェットである StandardWidgetSheet の子クラスを作って行います。StandardWidgetSheet はセルのレイアウトを管理し、編集モード中のスプレッドシートとの対話も処理します。編集モードとは、セルレイアウトの調整やセルに対する細かな操作といったセルの内容ではない部分を調整するモードです。例えばアナロジー (23.4.2 項) を適用したり、パラメータをいじって新しいワークフローのバージョンを作るといった操作を行います。
視覚的差異とアナロジー
VisTrails を設計するとき、追跡情報をキャプチャするだけではなく利用できるようにもしたいと私たちは考えました。最初はバージョン間の差異を分かりやすく表示できればそれでいいだろう思ったのですが、他のワークフローとの差異を使ったもっと便利な機能を追加できることに気付きました。この二つのタスクが可能なのは、VisTrails がワークフローの成長に関する情報を保持するためです。
バージョン木は変更を全て記録し全ての操作は打ち消せるので、あるバージョンを他のバージョンに変換するための完全な操作列が見つけられます。互いに打ち消す操作もあるので、この操作列を圧縮できる場合もあります。例えばモジュールを追加してその後削除したなら、差異を計算するときにそのモジュールを考慮する必要はありません。さらに、ヒューリスティックを使って操作列をさらに短くできることもあります: 例えば両方のワークフローに同じモジュールがあるなら、違う操作で追加されていたとしても操作を一つにできます。
変更の集合がいくつか与えられれば、VisTrails はそれからモジュール・接続・パラメータの共通部分および異なる部分を分かりやすく示した画像を作成できます (図 23.4)。両方のワークフローに登場するモジュールや接続は灰色で表され、片方にしか登場しないものにはワークフローを表す色が付けられます。両方に登場するモジュールでパラメータが異なるものは明るい灰色で塗られ、ワークスペースごとのパラメータの違いを表で確認できます。
アナロジーと呼ばれる操作を使うと、ワークスペースの差異を取ってそれを別のワークフローに適用できます。ユーザーが既存のワークフローを変更した (例えば出力画像の解像度やファイルフォーマットを変更した) ときには、アナロジーを使えばその変更を他のワークフローに適用できます。これを行うには、変更を生成するソースとターゲットとなるワークフローを選択し、さらにアナロジーを適用するワークフローを選択します。VisTrails は最初の二つのワークフローからテンプレートとなる差異を計算し、それから差異を三番目のワークフローに適用するためのマッピングを計算します。ソースと異なるワークフローに差異を適用することもあるので、モジュール間の対応関係を表すマッチングは柔軟に作成する必要があります。このマッチングがあれば、差異を再マッピングすることで、変更を選択されたワークフローに適用できます [SVK+07]。この方法は完全ではなく、ユーザーが思ったのとは異なるワークフローが生成されることもあります。そのような場合にはミスを修正する、あるいは前のバージョンに戻って変更を手動で適用させることになります。
アナロジーで使う柔軟なマッチングの計算では、局所的なマッチ (同一または非常に似たモジュール) と大域的なワークフローの構造のバランスを取る必要があります。部分グラフ同型問題が困難なので完全なマッチの計算さえ効率良く行えず、ヒューリスティックを使う必要がある点に注意してください。ヒューリスティックを短く言うと、もし二つのワークフローのあるモジュールとそれに隣り合うモジュールが似ていれば、その二つは同じような役割を持つとしてマッチさせるというものです。より形式張って言うと、頂点が元のモジュールのペアに対応し辺が共有する接続を表す直積グラフを作成し、それから各頂点にスコアを割り振って辺を伝って拡散させます。これは Google の PageRank に似たマルコフ過程であり、大域的な情報を含んだスコアが各頂点に対して計算されます。その後、閾値を使って似ていないモジュールをペアを削除し、このスコアを使って最小のマッチングを計算します。
追跡の問い合わせ
VisTrails がキャプチャする追跡は、独自の構造を持つワークフロー、メタデータ、実行ログからなります。ユーザーがこういった情報を探索できることが重要です。VisTrails はテキストベースおよび視覚的な (WYSIWYG の) クエリインターフェースを持ちます。タグ、注釈、日時といった情報に対してはキーワードを使った検索が可能であり、そのときにはマークアップも利用できます。例えば、plot というキーワードを持つワークフローで user:~dakoop によって作成されたものを検索できます。これに対して、ワークフローの特定の部分グラフを使ったクエリでは例示を使ったビジュアルインターフェースが使われます。ユーザーはゼロから作ったクエリまたは既存のパイプラインの一部を使ったクエリが発行できます。
この例示によるクエリのインターフェースの設計ではコードの多くを Workflow Editor から借用し、パラメータの構文について多少の変更を行いました。パラメータでは正確な値よりも何らかの範囲を指定できた方が便利なので、パラメータ値のフィールドにモディファイアが追加されています。ユーザーがパラメータ値を追加または編集するとこのモディファイアの選択欄が表れます (デフォルトは正確なマッチです)。クエリを視覚的に構築できるのに加えて、クエリの結果も視覚的に表示されます。マッチしたバージョンはバージョン木でハイライトされ、それを選択すればワークフローのマッチした部分が強調されます。他のクエリを始めるかリセットボタンを押せばクエリ結果モードから抜けます。
永続データ
VisTrails は結果の導き方および各ステップの詳細に関する追跡を保存しますが、必要とされるデータが無ければワークフローの再現は困難となります。加えて実行時間の長いワークフローでは、中間データも永続データとして保存した方が再計算を避けられて便利かもしれません。
多くのワークフローシステムではファイルシステムにおけるデータへのパスを追跡として保存しますが、このやり方には問題があります。ユーザーがファイルの名前を変えるかもしれませんし、データをコピーせずにワークフローだけ別のマシンにコピーしたり、データの内容を変える可能性もあります。いずれの場合でも、追跡としてパスを保存するだけでは不十分です。データをハッシュしてそのハッシュ値を追跡に保存すればデータの変更を検知できますが、別の場所に移動したデータを使えなくなります。この問題を解決するために私たちは Persistence Package を作成しました。これはバージョンコントロールの基盤を使ってデータを管理し、追跡からの利用を可能にする VisTrails パッケージです。現在はデータ管理に Git を利用しますが、他のシステムも簡単に利用できます。
データの特定には UUID (universally unique identifier) を使い、バージョンの参照には Git のハッシュ値を使います。新しく実行を始めるときにデータが変更されていれば、データの新しいバージョンがレポジトリにチェックインされます。つまり (uuid, version) というタプルが任意の状態にあるデータを特定します。さらにデータのハッシュに加えて、データを生み出したワークフローの上流部のシグネチャも (データが入力でなければ) 保存されます。こうすると異なる方法で識別されるデータのリンクや、同じ計算を実行するときのデータの再利用が可能になります。
このパッケージを設計する上での大きな懸案事項が、ユーザーがデータを選択、取得する方法でした。またデータが入力、出力、中間データのどれであっても全てのデータを同じレポジトリに置くことを考えていました (あるワークフローの出力が別のワークフローの入力になる可能性があるためです)。ユーザーがデータを指定する方法は二つあります: 新しい参照を作るか、既存のデータを利用するかです。新しい参照を使ったとしても最初の実行時に永続化されるので、それからは既存の参照となります。必要ならば新しい参照を作ることもできますが、こうするのは稀なケースです。通常ユーザーは最新バージョンのデータを使うので、バージョンが指定されない参照は最新版のバージョンとして解釈されます。
VisTrails はモジュールを実行する前に全ての入力を再帰的に更新すると前に説明しました。永続データモジュールはその上流の計算が既に実行されていれば入力を更新しません。この判定のために上流の部分ワークフローのシグネチャが永続レポジトリに存在するか確認し、シグネチャが存在すれば計算済みの値を取得します。加えてデータ識別子とバージョンは追跡として記録され、特定の計算が再現できるようになっています。
アップグレード
def handle_module_upgrade_request(controller, module_id, pipeline):
module_remap = {'GetItemsFromDirectory':
[(None, '1.6', 'Directory',
{'dst_port_remap':
{'dir': 'value'},
'src_port_remap':
{'itemlist': 'itemList'},
})],
}
return UpgradeWorkflowHandler.remap_module(controller, module_id, pipeline,
module_remap)
追跡付き結果の共有と公開
再現性は科学的手法の基礎であるものの、計算実験を発表する出版物の多くはその結果を確かめたり一般化するのに十分な情報を提供できていません。最近になって、再現性のある結果の公開というテーマには新たな注目が集まっています。そしてこの流れの大きな障害物となるのが、結果を再現・検証するのに必要な全ての要素 (データ、コード、パラメータの設定) をひとまとめにしたバンドルを作成するのが困難であるという事実です。
追跡のキャプチャおよびこれまでに説明した様々な機能を通して、VisTrails はシステム内で行われた計算実験に対するこのプロセスを単純化しています。しかし、ドキュメントをリンクし、追跡情報を公開するための仕組みが次に必要となります。
私たちは論文で示される結果とその追跡を “深いキャプション” のようにリンクする VisTrails パッケージを開発しました。開発した LaTeX パッケージを使えば、VisTrails ワークフローへのリンクを持つ図を作成できます。次の LaTeX コードはワークフローの結果を含んだ図を生成します:
\begin{figure}[t]
{
\vistrail[wfid=119,buildalways=false]{width=0.9\linewidth}
}
\caption{Visualizing a binary star system simulation. This is an image that was generated by embedding a workflow directly in the text.}
\label{fig:astrophysics}
\end{figure}
このドキュメントを pdflatex でコンパイルすると \vistrail コマンドが Python スクリプトを引数と共に呼び出し、このスクリプトが VisTrails サーバーへ id 199 の XML-RPC メッセージを送信します。同じスクリプトがワークフローの結果をサーバーから受け取り、それを PDF ドキュメントに埋め込みます。そのときにはハイパーリンクされた \includegraphics コマンドが指定されたオプション width=0.9\linewidth と共に使われます。
VisTrails の結果はウェブページ、ウィキ、Word ドキュメント、PowerPoint プレゼンテーションにも埋め込むことができます。Microsoft PowerPoint と VisTrails のリンクは Component Object Model (COM) と Object Linking and Embedding (OLE) というインターフェースで行われます。VisTrails のオブジェクトが PowerPoint と対話するには、COM のインターフェース IOleObject, IDataObject, IPersistStorage を全て実装する必要があります。内部で使っている QAxAggregated が COM インターフェース実装の抽象化なので、IDataObject と IPersistStorage は Qt によって自動的に処理されます。そのため実装する必要があるのは IOleObject インターフェースだけです。このインターフェースにおける一番重要な関数呼び出しは DoVerb であり、これは PowerPoint で行われる操作 (例えばオブジェクトの選択) に対して VisTrails が反応するために使われます。私たちの実装では、VisTrails オブジェクトが選択されると VisTrails アプリケーションが読み込まれ、ユーザーが挿入するパイプラインを閲覧、編集、選択します。VisTrails を閉じるとパイプラインの結果が PowerPoint に表示され、パイプラインの情報が OLE オブジェクトと共に保存されます。
ユーザーが追跡と共に結果を簡単に共有できるよう、私たちは crowdLabs を作成しました。crowdLabs は便利なツールとスケーラブルなインフラを持つソーシャルウェブサイトであり、科学者が協同でデータの解析と可視化を行うための環境を提供します。crowdLabs は VisTrails と密接に結びつきます。VisTrails で得た結果を共有する場合には、ユーザーは VisTrails から crowdLabs に直接接続して必要な情報をアップロードできます。情報がアップロードされたワークフローはブラウザからの閲覧、実行が可能になります。ワークフローは crowdLabs が持つ VisTrails サーバーで実行されます。VisTrails を使った再現可能な結果の公表について詳しくは、http://www.vistrails.org を参照してください。
教訓
追跡をサポートするデータ探索・可視化システムの開発について 2004 年に考え始めたとき、幸運にも私たちはそれがどれほど難しいものであるか、そしてどれほど長い時間がかかるかについて想像もしませんでした。もししていたら、始めなかったでしょう。
初期に上手く行ったのが、新しい機能を素早くプロトタイプして一部のユーザーに見せるというやり方です。彼らからの最初のフィードバックと励ましはプロジェクトを前進させる大きな助けとなりました。ユーザーからのフィードバックがなければ、VisTrails の設計は不可能だったでしょう。このプロジェクトで注目すべき点を一つあげるとすれば、それはユーザーからのフィードバックが直接システムを形作った点です。ただし、ユーザーの要求を正確に実行することが、ユーザーに寄り添うことを必ずしも意味しない点には注意が必要です。システムにきちんと収まるよう機能を (再) 設計する必要がしばしば生じました。
ユーザーを中心として開発が進んだのなら全ての機能が頻繁に使われているはずだ、と思うかもしれませんが、残念ながらそうでもありません。この理由の一つは、機能が他のツールに存在しない「普通でない」機能だからというものです。例えばアナロジー、あるいはバージョン木さえ、多くのユーザーにとって見慣れない概念であり、使いこなすには時間がかかります。もう一つの大きな問題がドキュメント (の不足) です。他の多くのオープンソースプロジェクト同様、私たちが新しい機能の実装する腕は既存の機能をドキュメントする腕よりも早く上達します。このドキュメントされるまでのラグにより便利な機能が使われなくなり、メーリングリストを飛び交う質問が増えることになります。
VisTrails のようなシステムを使う上で問題となるのが、それがあまりにも一般的であることです。私たちはユーザビリティを高めるために努力してきましたが、VisTrails は複雑なツールであり、ユーザーによっては学習曲線が急になります。これから時間をかけて、より良いドキュメント、システムの改善、応用や分野を絞ったチュートリアルを通して、VisTrails を様々な分野に導入する障壁が小さくなるものと信じています。またそのころには追跡 (provenance) という概念が広まり、VisTrails の開発で採用した哲学がユーザーにとって理解しやすいものになるでしょう。
謝辞
VisTrails へコントリビュートを行った全ての才能ある開発者に感謝します: Erik Anderson, Louis Bavoil, Clifton Brooks, Jason Callahan, Steve Callahan, Lorena Carlo, Lauro Lins, Tommy Ellkvist, Phillip Mates, Daniel Rees, Nathan Smith. プロジェクトの展望を形作るのに手を貸してくれた Antonio Baptista、そして追跡付き結果の公開機能の開発とリリースの推進をはじめシステムの改善に尽力した Matthias Troyer に特別な感謝を送ります。VisTrails システムの研究と開発の資金は National Science Foundation (IIS 1050422, IIS-0905385, IIS 0844572, ATM-0835821, IIS-0844546, IIS-0746500, CNS-0751152, IIS-0713637, OCE-0424602, IIS-0534628, CNS-0514485, IIS-0513692, CNS-0524096, CCF-0401498, OISE-0405402, CCF-0528201, CNS-0551724), Department of Energy SciDAC (VACET and SDM centers), IBM Faculty Awards によって提供されました。