SnowFlock
クラウドコンピューティングは魅力的な価格で計算プラットフォームを提供します。ユーザーは物理サーバーの購入と設定にかかる時間・金銭的な初期投資なしに、何回かクリックするだけでクラウド上にある「サーバー」を一時間あたり 10 セントという価格で借りることができます。クラウドのプロバイダがコストを低く保てている鍵は物理的なコンピューターではなく仮想マシン (virtual machine, VM) を使っていることであり、ここでは仮想マシンモニタ (virtual machine monitor, VMM) と呼ばれる物理マシンのエミュレートを行う仮想化ソフトウェアが重要な役割を果たします。ユーザーは「ゲスト」VM に安全に隔離され、「ホスト」物理マシンを他のユーザーと共有していることを忘れて自分の仕事に集中できます。
SnowFlock の紹介
クラウドはアジャイルな組織に欠かすことができません。物理サーバーを使うとなると、サーバー購入の承認を (苦労して) 得て、サーバーを発注し、サーバーの出荷を待ち、さらにオペレーティングシステム (OS) とアプリケーションスタックのインストールと設定しなければならず、その間ユーザーは他人が仕事を終えるのを長い間待つことになります。クラウドなら使えるようになるまで何週間も待つ必要はなく、ユーザーは新しいスタンドアローンのプロセスを数分で開始できます。
しかし、クラウドサーバーが独立して存在することはまずありません。利用量に応じた課金モデルと素早い起動を実現するために、クラウドサーバーは通常サーバーのプールとして構築されます。このプールは定まった大きさを持たず、各サーバーは似たような設定の下で並列計算やデータマインニング、ウェブページの提供といったダイナミックでスケーラブルなタスクを実行します。サーバーでは同一の静的テンプレートを使ったインスタンスの起動が繰り返されるので、商用クラウドでは真にオンデマンドな計算を行うことができません。クラウドにはサーバーを起動した後にもクラスターのメンバーシップを管理したり新しいサーバーの追加を仲介したりする仕事があるからです。
SnowFlock はこの問題を VM Cloning を使って解決します。VM Cloning は私たちの提案するクラウド API です。アプリケーションコードがシステムコールを通じて OS サービスを起動するように、VM Cloning を使えば同様のインターフェースを通じてクラウドサービスを起動できます。SnowFlock の VM Cloning を使えば、リソースの確保、クラスター管理、アプリケーションロジックの全てを組み合わせたプログラムを作成し、単一の論理的操作として扱うことが可能です。
VM Cloning を呼び出すと複数のクラウドサーバーインスタンスが起動します。起動した時点の各インスタンス (クローン) は VM Cloning を呼び出した親の完全な複製です。クローンは論理的に親の全ての内部状態を受け継ぎ、例えば OS レベルおよびアプリケーションレベルのキャッシュは同一です。加えてクローンはプライベートな内部ネットワークに自動的に追加され、これによって動的でスケーラブルなクラスターに参加します。同一の設定を持つ VM でカプセル化された計算リソースをその場で作成し、必要に応じて拡張することが可能です。
実際の環境で利用するにあたって、VM のクローンは使いやすく、効率的で、高速であることが求められます。この章で説明するのは、SnowFlock における VM Cloning の実装がどのように異なるプログラミングモデルやフレームワークと効率良く連携しているか、アプリケーションランタイムとプロバイダのオーバーヘッドを最小化するための VM Cloning の実装がどうなっているか、そして数十もの新しい VM を 5 秒以内に作成するときに VM Cloning がどののように使われているかです。
SnowFlock は VM Cloning をプログラムから制御するための C, C++, Ptyhon, Java バインディングを持っており、非常に高い柔軟性と幅広い用途を持ちます。私たちは SnowFlock を使って全く異なるシステムのプロトタイプをいくつか実装することに成功しています。並列計算のシナリオにおいては、ワーカー VM を明示的にクローンして負荷を多数の物理ホストの間で調整することで素晴らしい結果を得ました。Message Passing Interface (MPI) を利用し専用サーバーのクラスターで実行されるような並列アプリケーションにおいては、MPI のスタートアップマネージャを変更することで、アプリケーションのコードの変更なしに高いパフォーマンスと低いオーバーヘッドを達成しました。ここでは新しいクローンのクラスターが実行ごとに必要に応じて供給されます。最後に大きく異なる利用例をあげると、私たちは SnowFlock を使ってエラスティックサーバーの効率と性能を上昇させることに成功しました。今のクラウドベースのエラスティックサーバーはサービス利用量のスパイクに応じて新しい「冷えた」ワーカーを起動しますが、SnowFlock ではその代わりに実行されている VM をクローンすることで、新しいワーカーを 20 倍高速に用意できます。さらにクローンされた VM は親と同じバッファを持ち「温まって」いるので、ピークパフォーマンスに素早く到達します。
VM のクローン
名前から分かるように、VM のクローンは親の VM と (ほぼ) 同一です。小さな違いがいくつかありますが、どれも MAC アドレスの衝突といった問題を避けるために必要なものです (後述します)。クローンを作るためにはローカルのディスクとメモリ全てへのアクセスが必要であり、これによって重要な設計上のトレードオフが生じます: 状態のコピーは最初に全て行うべきでしょうか? それとも必要に応じて行うべきでしょうか?
VM のクローンを実現する一番単純な方法は、VM の「マイグレーション」機能を利用することです。普通マイグレーションが行われるのは実行されている VM が別のホストに移動されるときであり、例えばホストの負荷が高くなり過ぎた場合やメンテナンスのためにホストをシャットダウンする場合などです。VM は純粋にソフトウェアなので、データファイルに全てのデータを格納でき、それを新しいホストにコピーして実行を再開できます (ただし少しの間実行が中断されます)。よくある VMM がこれを実現するのに使っているのは、VM の「チェックポイント」をファイルに保存するという方法です。このファイルにはローカルのファイルシステム、メモリイメージ、仮想 CPU (VCPU) レジスタといったものが含まれます。マイグレーションにおいては新しくブートされたコピーがオリジナルを置き換えますが、プロセスにクローンをさせつつオリジナルの実行を止めないということもできます。この「貪欲な」方法では VM の全ての状態が前もって転送され、初期状態のパフォーマンスが最大化されます。VM の実行される段階で全てのデータが配置されるからです。貪欲な複製の欠点は、実行を開始する前に VM 全体のコピーという時間のかかる処理を実行する必要があり、起動が大幅に遅くなる点です。
これと正反対なのが、SnowFlock が採用した「怠惰な」状態複製です。VM が必要とする可能性のある全てのデータをコピーする代わりに、SnowFlock はシステムに重要を転送したらその時点で実行を開始し、残りの部分は必要になったときにのみ転送します。この方法には二つの利点があります。一つ目は、最初の仕事を可能な限り減らすことで初期化のレイテンシが最初化される点です。二つ目は、クローンが実際に利用する状態だけをコピーすることで効率が高くなる点です。もちろんこの効率はクローンされた VM の動作に依存しますが、全てのメモリと全てのローカルのファイルシステムのファイルを必要とするアプリケーションというのはほとんどありません。
しかし、怠惰な状態複製の利点にはコストも付いて回ります。状態の転送が必要になるまで先延ばしされるので、クローンが実行を停止して状態の到着を待たなければならない瞬間が生じます。この状況はタイムシェアリングワークステーションにおいてメモリをディスクにスワップしたときの状況に似ています: レイテンシの大きい場所から状態をフェッチするときにアプリケーションがブロックされるということです。SnowFlock においてもこのブロッキングによってクローンのパフォーマンスがいくらか低下します。低下の度合いはアプリケーションの種類によります。高パフォーマンス計算を行うアプリケーションにおいてはほとんど低下しませんが、クローンされたデータベースサーバーはしばらくの間性能が落ちます。この影響が一時的なものであることも注意しておきます: 数分も経てば必要な状態がほとんど転送されるので、クローンのパフォーマンスは親と同程度になります。
余談ですが、もしあなたが VM に詳しいなら、ここまで読んで「ライブマイグレーションが使っている最適化をここでも使えるのではないか」と思うかもしれません。ライブマイグレーションが使っているこの最適化を使うと、オリジナルの VM が停止してから新しいコピーが実行を再開するまでの時間を短縮できます。その最適化とは、仮想マシンモニタ (VMM) が VM の状態をオリジナルが実行している間に前もってコピーしておくというものです。こうすることで最近になって変更されたページだけを転送すれば済むようになります。しかしこのテクニックはマイグレーションのリクエストからクローンが実行を開始するまでの時間を短縮しないので、貪欲な VM クローンの初期化レイテンシを低減させることはできません。
SnowFlock のアプローチ
SnowFlock が VM クローンの実装に使っているのは「VM Fork」と呼ばれるプリミティブです。VM Fork は Unix の fork と似ていますが、重要な違いがいくつかあります。第一に、VM Fork が複製するのは単一のプロセスではなくて VM 全体であり、メモリ、プロセス、仮想デバイス、ローカルファイルシステムといったもの全てが複製されます。第二に、VM Fork は同一の物理ホストで実行される単一のコピーを生成するだけではなく、複数のコピーを同時に生成できます。そして最後に、VM を複数の物理サーバーに fork することが可能であり、クラウドのフットプリントを必要に応じて素早く拡大できます。
SnowFlock で重要な概念を次に示します:
-
仮想化: VM は計算環境をカプセル化し、クラウドとマシンのクローンを可能にする。
-
怠惰な伝播: VM の状態は必要になるまでコピーされず、クローンは数秒で起動する。
-
マルチキャスト: クローンの兄弟が必要とする VM 状態は似通っている。マルチキャストを使えば、数十のクローンを一つのクローンを起動するのと変わらない時間で起動できる。
-
ページフォルト: まだ存在しないメモリをクローンが読もうとすると、ページフォルトが起きて親へのリクエストが生成される。そのページが到着するまでクローンの実行はストップする。
-
コピーオンライト (Copy on Write, CoW): 親 VM が上書きを行うときにメモリとディスクページのコピーを作っておくことで、親 VM の実行を続けながらもクローンが利用可能な「凍った」コピーを用意できる。
SnowFlock は仮想化システム Xen を使って実装されているので、ここで Xen 固有の用語を説明しておきます。Xen 環境において、VMM はハイパーバイザ (hypervisor) と呼ばれ、VM はドメイン (domain) と呼ばれます。物理マシン (ホスト) ごとに特権を持ったドメインが一つ存在し、“domain 0” (dom0) と呼ばれます。このドメインはそのホストと物理デバイスへの完全なアクセスを持ち、追加のゲスト VM (ユーザー) の管理も行います。ユーザーが使う VM は “domain U” (domU) と呼ばれます。
大雑把に言うと、SnowFlock は Xen ハイパーバイザへの変更の集合体です。存在しないリソースへのアクセスからのスムーズな復帰や、dom0 内で実行され VM 状態の転送をサポートするプロセス・システムがこの変更によって可能になっています。これ以外にもクローン VM の内部で実行される OS への (オプショナルな) 変更もいくつか含まれます。SnowFlock の主要な部分は次の六つです:
-
VM Descriptor: この小さなオブジェクトはクローンを配置するのに利用され、実行を開始に必要な VM の最小限の骨格を保持する。その他に意味のある仕事は行わず、行うこともできない。
-
Multicast Distribution System (
mcdist): 親で使われるこのシステムは、VM 状態に関する情報を他の全てのクローンに同時に伝える。 -
Memory Server Process: 親で実行されるこのプロセスは、親の状態の「凍った」コピーを管理し、必要に応じて
mcdistを通じてクローンから利用可能にする。 -
Memtap Process: クローンで実行されるこのプロセスは、クローンの代理としてメモリサーバーと通信を行い、必要になったにもかかわらず用意されていないページのリクエストを行う。
-
Clone Enlightenment: このゲストカーネルはクローン内部で実行され、VMM へヒントを提供することで VM のオンデマンド転送を助ける。これは必須なわけではないが、効率のためには利用が強く求められる。
-
Control Stack: 各物理ホストで実行されるデーモンであり、他のコンポーネントを総括し、SnowFlock の親 VM とクローン VM の管理を行う。
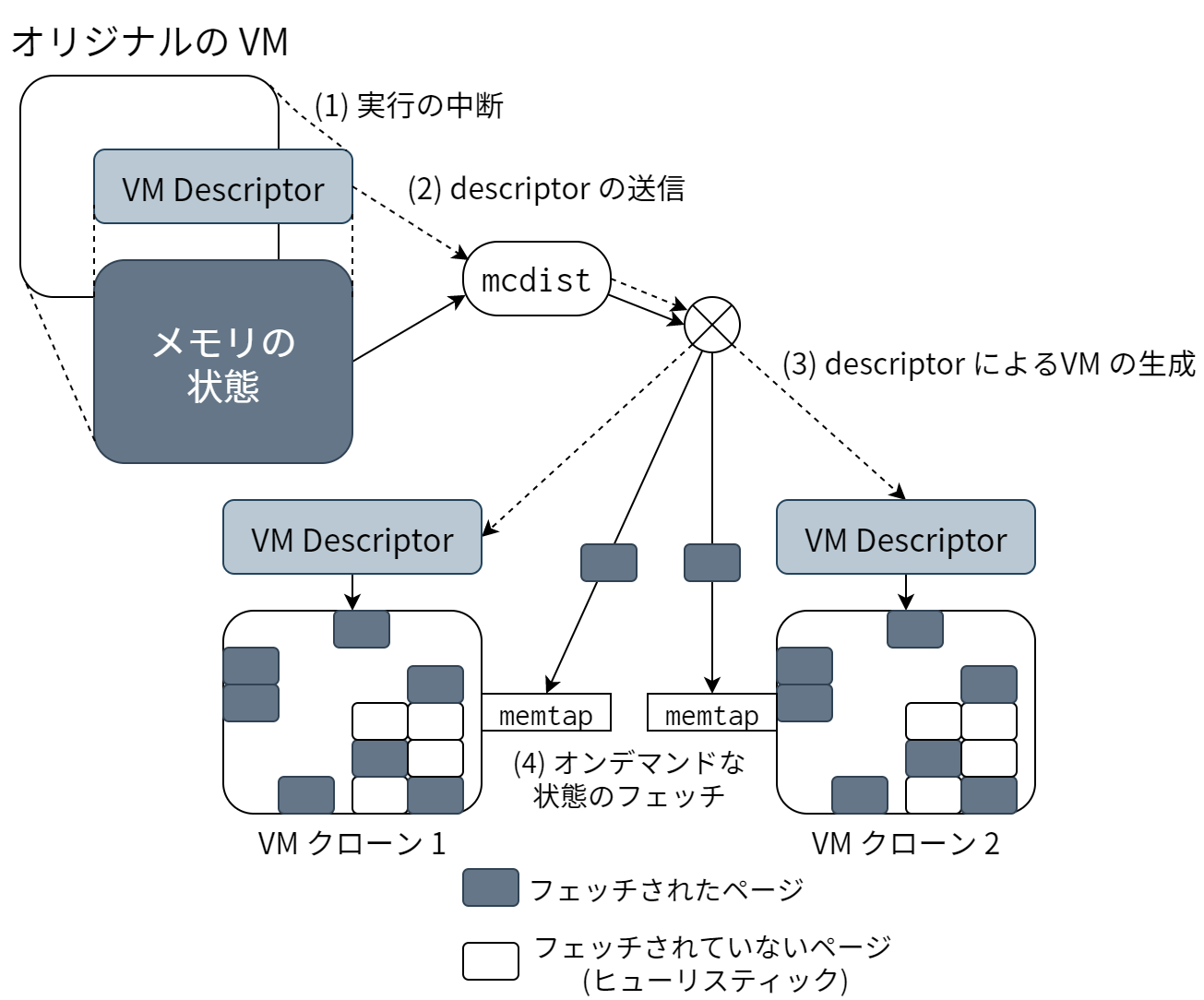
VM クローンの様子を 図 18.1 に示します。クローンは四つのステップからなります: (1) 親 VM がアーキテクチャデスクリプタを生成する (2) そのデスクリプタを全てのターゲットホストに送信する (3) 状態をほとんど持たない空のクローンを初期化する (4) 状態をオンデマンドに送信する。図中には mcdist を使ったマルチキャスト通信と clone enlightenment を使ったフェッチの回避も描かれています。
もし SnowFlock を試そうと思っているなら、SnowFlock には二つのバージョンがあります。一つはトロント大学の研究プロジェクトで開発されたオープンソースの SnowFlock とそのドキュメント1で、もう一つは GridCentric Inc.2 による産業バージョンの SnowFlock の試用版 (無料、非商用) です。hypervisor を改造している SnowFlock は dom0 へのアクセスを必要とするので、インストールにはホストマシンの特権アクセスが必要です。このためハードウェアは自分で用意しなければならず、Amazon の EC2 といった商用クラウド環境で試すことはできません。
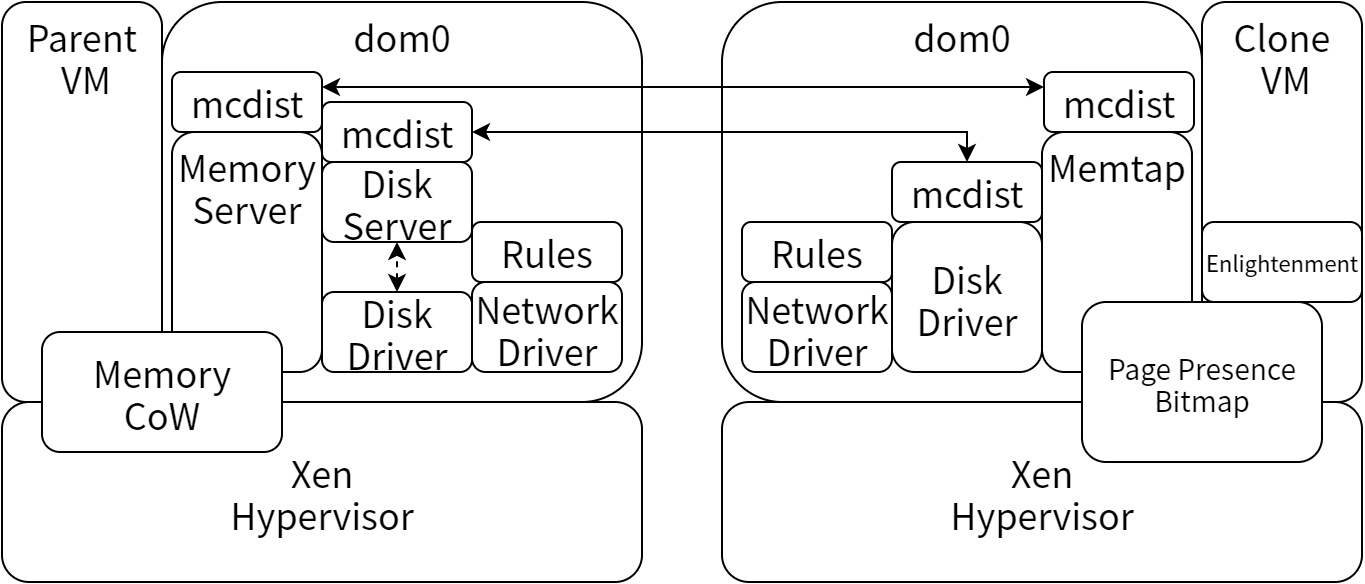
高速で高効率なクローンを達成するために互いに協力し合うパーツをこれから一つずつ見ていきます。こういったパーツは 図 18.2 のように組み合うことになります。
VM のアーキテクチャデスクリプタ
SnowFlock における重要な設計判断が、VM の状態の複製処理を遅延させて実行時の操作とすることです。言い換えると VM のメモリのコピーは遅延バインディングされた操作となっており、これによって最適化の機会が増えています。
この設計判断を実現するための最初のステップは、VM の状態を表すアーキテクチャデスクリプタ (architectural descriptor) の生成です。このアーキテクチャデスクリプタはこれから作成する VM クローンの「種」であり、VM を作ってスケジュールを行うための必要最小限の情報が含まれます。アーキテクチャデスクリプタという名前から分かるように、この必要最小限の情報は内部のアーキテクチャが必要とするデータ構造からなります。SnowFlock の場合には x86 プロセッサと Xen が必要とするデータであり、例えばページテーブル、仮想レジスタ、デバイスのメタデータ、ウォールクロックのタイムスタンプといった情報が含まれます。アーキテクチャデスクリプタのより詳細な説明は [LCWB+11] を参照してください。
アーキテクチャデスクリプタには三つの重要な特徴があります。一つ目は、ほとんど時間をかけずに作成できることです。200 ミリ秒という値さえ珍しいものではありません。二つ目は、小さいことです。クローン元の VM が持つメモリよりも三桁程度小さいことが多いです。三つめは、ディスクリプタからクローン VM を一秒以内に作成できることです (通常は 800 ミリ秒程度です)。
もちろんここでは、ディスクリプタからクローンされた VM には作成時点でメモリのほとんどが欠けているという問題が生じます。この問題を私たちがどう解決したか、そしてディスクリプタを使った設計によって可能になる最適化の機会をどう活用したかをこれから説明します。
親のコンポーネント
VM がクローンされると、クローン元の VM は新しくできた子 (クローン) の親となります。人間と同じように、この親には子を健康に保つ責任があります。親はメモリやディスクの状態を子の必要に応じて準備するサービスを立ち上げることでこの責任を果たします。
Memserver Process
アーキテクチャデスクリプタを作成するとき、VM は他の処理を中断します。メモリの状態を固定するためです。また VM を停止して実行スケジュールを放棄する前に、新しくクローンされる VM からも外部に再接続できるよう状態を整える処理が内部の OS ドライバによって行われます。SnowFlock はこの状態を使って「メモリサーバー」 (memserver) を作成します。
メモリサーバーは子が必要とする親のメモリを提供します。メモリは x86 のメモリページ (4 キロバイト) の粒度で送信されます。最も単純な形式を考えれば、メモリサーバーはクローンからのページリクエストを待ち、一つのクローンにページを一つずつ送信することになるでしょう。
しかし、このメモリというのは親の VM が実行に使うまさにそのメモリでもあります。親に実行を続けてメモリを変更するのを許したとすると、クローン VM に壊れたメモリを送信することになってしまいます。送信されるメモリはクローンした時点と異なるものとなり、クローンが混乱するのは必至です。カーネルハッカーであればこれを「スタックトレースを出す確実な方法」と呼ぶでしょう。
この問題を解決するのは、古くからある OS のテクニックであるコピーオンライトメモリ (CoW メモリ) です。Xen ハイパーバイザの助けを借りると、親 VM のメモリの全てのページから書き込み権限を取り除くことができます。こうした状態で親がページを変更しようとするとページフォルトが発生し、これを受けた Xen はページのコピーを作成します。その後、親 VM はそのページに書き込むことができ、メモリサーバーにはそのページのコピーを使うよう指示が行きます。こうすることでクローンを行った時点におけるメモリの状態が保存され、クローンが混乱することも親 VM が実行を停止することもありません。CoW のオーバーヘッドは最小限であり、同様のメカニズムは Linux におけるプロセス生成などで使われています。
mcdist を使ったマルチキャスト
クローンの動作は「運命決定論」に縛られることが多いです。つまり通常クローンは特定の目的のために作られます。例えば X 個の塩基からなる DNA 鎖をデータベース内にあるセグメント Y とアラインする、などです。さらに言えば、同時にクローンされたいくつかのクローンの兄弟が同じ処理を行うこともあります。この例としては、ある X 個の塩基列をデータベースの異なるセグメントとアラインする、あるいは異なる塩基列を同じセグメント Y とアラインする、などが考えられます。こういった場合にはクローンが行うメモリアクセスに明確な時間的局所性が生じることになります。同じコードを大部分が共通するデータに対して用いるためです。
SnowFlock は専用のマルチキャスト配信システム mcdist を使ってこの時間的局所性を活用します。mcdist は IP マルチキャストを使って一つのパケットを複数の受信者に同時に送信し、ネットワークハードウェアの並列性を利用することでメモリサーバーの負荷を低減します。あるページに対するリクエストが一度でも届いたら全てのクローンに対してページを送るようにすることで、各クローンのリクエストを兄弟のプリフェッチとして動作させることができます。これによって性能が向上するのは、クローン動詞のメモリアクセスパターンが似ているためです。
他のマルチキャストシステムとは異なり、mcdist には高い信頼性が必要とされません。さらにパケットを順序通りに送信する必要もなく、受信者全員にアトミックに返答を返す必要もありません。厳密に言えばマルチキャストは最適化であり、絶対にページを受け取らなければならないのはページを自分からリクエストしたクローンだけです。そのため mcdist の設計はエレガントで単純です: サーバーは返答をマルチキャストし、クライアントはリクエストに対する返答がなければタイムアウトしてリクエストを再送信します。
mcdist に含まれる SnowFlock 固有の最適化が三つあります:
-
lockstep の検出: 時間的局所性が表れると、複数のクローンから同じページへのアクセスが矢継ぎ早に起こることになる。このような場合、
mcdistサーバーは最初のリクエストだけを処理する。 -
フロー制御: クライアントはリクエストのときに受信レートも伝え、サーバーは送信レートをクライアントの受信レートの加重平均に調整する。この調整をしないと、サーバーから次々と送られてくるページでクライアントはダウンしてしまう。
-
最終段階: サーバーが大部分のページを配信し終えたら、ユニキャストの応答にフォールバックする。この段階ではリクエストのほとんどがリトライになるので、全てのクローンにページを送る必要はない。
仮想ディスク
SnowFlock のクローンは寿命が短くやることも決まっているので、まずディスクを使いません。SnowFlock の仮想ディスクはバイナリ、ライブラリ、設定ファイルを含んだルートパーティションを管理し、巨大なデータ処理には HDFS や PVFS といったそれ用のファイルシステムを使います。そのため SnowFlock のクローンがルートディスクから何か読もうとした場合には、そのリクエストに答えるのがカーネルのファイルシステムのページキャッシュである可能性が高くなります。
そうはいっても、仮想ディスクへのアクセスはクローンに必要です。稀ではありますがアクセスが必要になることがあるからです。ここで採用されたのは最も分かりやすい設計であり、仮想ディスクの実装はメモリの複製と非常によく似ています。最初、クローンの時点におけるディスクの状態を保存し、親の VM は CoW 方式でディスクの利用を続けます。つまり書き込みは裏の保存領域にある別の場所に送られ、クローンから見えるディスクは変更されません。次に、ディスクの状態が mcdist を使って全てのクローンにマルチキャストされます。このときの粒度は 4 KB ページであり、時間的局所性についてメモリと同様の仮定を置きます。そして、クローンに複製されたディスクの状態は必ず一時的なものになります。疎でフラットなファイルに保存され、クローンが破棄されると同時に削除されます。
クローンのコンポーネント
アーキテクチャデスクリプタから作られた瞬間のクローンは中身の無い殻に過ぎません。そして人間と同じように、成長には親からの支援が必要です。子 VM は家から出て行きますが、必要なものがないことに気付くとすぐに家に電話をかけ、「すぐ持って来て!」と親に頼みます。
memtap プロセス
生成されたクローンにアタッチされる memtap プロセスはクローンのライフラインです。このプロセスはクローンが持つ全てのメモリをマップし、必要に応じて埋めていきます。この処理においては Xen ハイパーバイザの機能を大きく利用します。Xen はクローンのメモリページへのアクセス権限をオフにして、ページに対する最初のアクセスで起こるハードウェアフォルトを捕捉した上で memtrap に渡します。
簡単に言うと memtap プロセスはフォルトが起こったページをメモリサーバーにリクエストするだけですが、もっと複雑なシナリオもあります。まず、memtap ヘルパーは mcdist を使います。これは、他のクローンからリクエストされた任意のページが任意の時点で届く可能性があることを意味します ――非同期プリフェッチの素晴らしさです。次に、SnowFlock の VM はマルチプロセッサ VM となることができます。これがなければ面白いことはできないでしょうが、これがあると複数のフォルトを並列に処理する必要が生じます。フォルトが同じページに対するものである可能性だってあります。さらに、新しいバージョンでは memtap ヘルパーからいくつかのページをまとめてプリフェッチできるようになっています。ただし mcdist サーバーが順序を保証しないので、そのページが届く順序はバラバラです。こういった要素はどれも並列環境で悪夢を引き起こしがちですが、SnowFlock には全てが含まれます。
memtrap の設計ではページの存在を表すビットマップ (page presence bitmap) が中心的な役割を果たします。このビットマップが作られるのはアーキテクチャデスクリプタからクローン VM が作成されるときです。ビットマップはフラットなビット配列であり、VM のメモリが保持できるページ数と同じサイズを持ちます。インテルのプロセッサにはアトミックなセット命令とテスト・アンド・セット命令が用意されており、こういった命令は同じマシンにある外のプロセッサに邪魔されない保証を持ちます。これを使えばほとんどの場合においてロックは不要になり、異なる保護ドメインに属する異なるエンティティ (つまり Xen ハイパーバイザ、memtap プロセス、クローンされたゲストカーネル) からのビットマップへのアクセスを提供できます。
ページへの初回アクセスによるハードウェアページフォルトを Xen が検出すると、Xen はビットマップを確認して memtap を呼び出すかを決めます。また同じページに対するフォルトを起こした複数の仮想プロセスのキューとしてもビットマップは使われます。また memtap は到着したページをバッファします。バッファが満杯になったとき、あるいは明示的にリクエストしたページが到着した場合には、VM の実行を中断し、まずビットマップを使って重複したページをバッファから削除します。次に残っているページで必要とされているものを VM のメモリにコピーし、ビットマップのビットを適切に設定します。
賢いクローンは不必要なフェッチを避ける
ページの存在を表すビットマップはクローン内部で実行されるカーネルからも見ることができ、変更にロックは必要ないと先ほど説明しました。この事実を利用すると、強力な “enlightment” ツールがクローンから利用可能になります。このツールはビットマップを変更して存在しないページを存在するように見せかけることで、そのページに対するプリフェッチを無効にします。これによりパフォーマンスが大幅に向上し、利用する前にページを完全に書き換えてしまうのであれば安全に行うことができます。
ページを使う前に書き換えるのでフェッチは必要ないというのは非常によくある状況です。カーネルにおけるメモリの確保 (vmalloc, kzalloc, get_free_page, brk など) は最終的にカーネルのページアロケータが処理を行います。カーネルにページをリクエストするのは中間アロケータ (slab、あるいはユーザースペースのプロセスであれば glibc malloc など) であり、この中間アロケータが小さなページを管理します。アロケーションが明示的であれ間接的であれ、次の事実は常に真です: 「ページは後で書き換えるので、ページの内容は問題にならない」 ならどうしてフェッチなんて? フェッチする必要はなく、経験から言ってもアロケートされるページのフェッチを避けるとパフォーマンスが大きく向上します。
VM クローンアプリケーションのインターフェース
ここまでは VM を効率良くクローンするための内部処理について説明してきました。独我的にシステムを構築するのは楽しいものですが、システムを使うアプリケーションのことも考えなくてはなりません。
API の実装
VM のクローンはシンプルな SnowFlock API を通してアプリケーションに提供されます (下図)。クローンは基本的に二つのステージからなります。まずクローンのインスタンスのアロケートをリクエストし (ただしシステムのポリシーによってはアロケートの量がリクエストよりも小さくなる場合もあります)、次にアロケートされた部分に VM をクローンします。ここで重要なのが、クローンされる VM が単一の目的を持っていることです。ウェブサーバーやレンダーファームといった一つのことを行うアプリケーションを実行する VM がクローンに適しています。プロセスが何百個も生成されるデスクトップ環境で複数のアプリケーションが並列に VM をクローンしたら、カオスが待っているでしょう。
| 名前 | 説明 |
|---|---|
sf_request_ticket(n) |
クローンのアロケートを n 個リクエストする。m≤n 個のクローンのアロケートを表すチケットを返す。 |
sf_clone(ticket) |
アロケート ticket を使ってクローンを行う。クローン ID (0≤ID<m) を返す。 |
sf_checkpoint_parent() |
親 VM の変更不可能なチェックポイント C を準備する。クローンはこの関数を呼んだ後の任意のタイミングで作成できる。 |
sf_create_clones(C, ticket) |
チェックポイント C を使う点以外は sf_clone と同様。クローンの実行は C を作った sf_checkpoint_parent() が呼ばれた時点から開始される。 |
sf_exit() |
子 (1≤ID<m) が呼ぶ関数。自身の実行を終了する。 |
sf_join(ticket) |
親 (ID=0)が呼ぶ関数。ticket に含まれる全ての子が sf_exit に到達するまでブロックする。この関数の後 ticket は無効になる。 |
sf_kill(ticket) |
親が呼ぶ関数。ticket を無効化し、対応する子を全て殺す。 |
この API はメッセージをマーシャルしてポストを XenStore にポストするだけです。XenStore とは共有メモリの低スループットインターフェースであり、Xen がプレーンなトランザクションを制御するのに使います。API からのリクエストを受け取るのはハイパーバイザで実行される SnowFlock Local Deamon (SFLD) であり、メッセージはここでアンマーシャルされ、実行され、返答が返されます。
プログラムは API を通じて VM のクローンを直接行うことができます。API は C, C++, Python, Java で利用可能です。プログラムを実行できないシェルスクリプトに対してはコマンドラインスクリプトが用意されているので、これを使うことができます。MPI などの並列フレームワークには SnowFlock API を埋め込むことが可能であり、そうした場合 MPI プログラムは SnowFlock を意識することなく利用可能です。その際にはソースの変更も必要ありません。
SFLD は VM クローンのリクエストの実行を取りまとめます。SFLD はアーキテクチャデスクリプタを作成・送信し、クローン VM を作成し、ディスクサーバーやメモリサーバーを起動し、ヘルパープロセス memtap を起動します。SFLD は物理クラスターの VM を管理するミニチュア分散システムと言えます。
SFLD はアロケートの判断を中央の SnowFlock Master Deamon (SFMD) に委譲します。SFMD は単純に他のクラスター管理ソフトウェアへのインターフェースとなっています。ここで車輪の再開発は必要なく、リソースのアロケートや割り当て、ポリシーについての判断は Sun Grid Engine や Platform EGO などの専用ソフトウェアに委譲されます。
避けられない改変
クローンされた VM に含まれるプロセスの多くは実行環境が親でなくコピーになったことに気付きませんが、たいていの場合これで何も問題ありません。結局 OS の一番の役割はネットワーク識別子といった低レベルの詳細とアプリケーションを切り離すことだからです。しかしそれでも、VM の移行をスムーズに行うにはクローン時に何らかの仕組みが必要です。問題の要点は、クローンのネットワーク識別子を管理することにあります。衝突と混乱を避けるためには、プロセスをクローンするときにほんの少しだけ改変を行う必要があります。この改変によって高レベルの調整処理が必要になる可能性もあるので、必要なタスクを設定するためのフックをユーザーが設定できるようになっています。例えばクローンの識別子を利用するネットワークファイルシステムの (再) マウントなどの処理がフックで行われます。
クローンが作成される世界は VM のクローンの存在を予期していません。親 VM はネットワークの一部であり、その管理にはたいてい DHCP サーバー、あるいは他の無数の方法の中からシステム監視者が良いと思ったものが使われます。SnowFlock はこういった安定しない環境に頼ることはせず、親とクローンをプライベートな仮想ネットワークに配置します。同じ親を持つクローンにはユニークな ID が割り当てられ、プライベートネットワークにおける IP アドレスはクローン時にその ID を使って自動的に設定されます。これによってシステム管理者の仲介は不必要になり、IP アドレスの衝突も決して起こりません。
IP の再設定は仮想ネットワークドライバのフックによって直接行われますが、ドライバに DHCP レスポンスを自動生成させることもできます。そのためネットワークの構成がどうなっていても、仮想ネットワークインターフェースが正しい IP をゲスト OS に伝えることができ、再起動があっても問題はありません。
異なる親を持つクローンが仮想プライベートネットワークで衝突しないように、クローンの仮想ネットワークはイーサネットレベル (レイヤー 2) で隔離されます (これはお互いを DDoS 攻撃しないためでもあります)。SnowFlock はイーサネットの MAC OUI3 をハイジャックしてクローンに割り当てており、親 VM の ID が OUI を決定します。そしてイーサネット MAC アドレスの OUI でない部分は IP アドレスと同様に VM の ID が決定します。仮想ネットワークドライバは MAC アドレス (と VM が信じている値) を VM の ID から決定する MAC アドレスに変換し、異なる OUI を持った仮想プライベート内のトラフィックを全て遮断します。この隔離方法は ebtable を使うものと同一ですが、実装がより単純になります。
クローンの対話をクローン同士に限定するのは簡単ですが、これで十分ではありません。クローンがインターネットからの HTTP リクエストに答えたり、パブリックなデータリポジトリをマウントする可能性があるからです。SnowFlock では親とクローンのいくつかを選んでルーター VM を装備させることができます。この小さな VM はファイアウォール、トラフィックの抑制、クローンからインターネットへ向かうトラフィックの NAT などを行い、さらに内向きの接続を親 VM と well-known ポートに限定します。このルーター VM は軽量であるもののネットワークトラフィックの集中点となるので、スケーラビリティを大きく制限することになります。同じ規則をクローン VM を実行するホストに分散させて適用することも可能ですが、その実験的なパッチはまだリリースされていません。
SFLD は ID を割り当て、ネットワークドライバに自身をどう設定すべきかを伝えます。つまり内部 MAC アドレス、IP アドレス、DHCP ディレクティブ、ルーター VM の調整、フィルタ規則などの設定方法です。
最後に
Xen ハイパーバイザに改良を加えて VM の状態を怠惰に転送することで、SnowFlock は実行中の VM の数十ものクローンを数秒のうちに作成できます。SnowFlock を使った VM のクローンは即時にその場で行えます ――クラスターの管理が自動化されアプリケーションからクラウド管理をプログラム的に行えることで、クラウドの使いやすさが向上しています。さらに SnowFlock はクラウドの軽快さも向上させます。VM の初期化を 20 倍高速化し、新しくクローンされる VM のメモリの OS とアプリケーションのキャッシュを「温まった」状態にすることで多くの場合パフォーマンスを向上させるからです。SnowFlock の高いパフォーマンスの鍵は不必要なページフェッチを避けるヒューリスティックと、クローンの兄弟が協力して状態をプリフェッチするマルチキャストシステムです。こういった実証済みのテクニックを賢く適用すること、手先がいくらか器用であったこと、そして産業レベルのデバッグという気前の良い助力を得られたこと、必要になったのはこれだけでした。
私たちは SnowFlock の実験を通して二つの教訓を学びました。一つ目は (過小評価されることの多い) KISS 原則の有効性です。クローンは起動時に大量のメモリページリクエストを発行するので、これに対応するには複雑なプリフェッチを実装する必要があるのではないかと私たちは考えていましたが、驚くべきことに、これは必要ありませんでした。「必要になったらメモリを持ってくる」という一つの原則に従うだけで、システムのパフォーマンスは負荷の高いときにも非常に良好でした。単純さの価値が示されたもう一つの例が、ページの存在を表すビットマップです。単純なデータ構造をアトミックなアクセス方法を明確に定めて使うことで、複雑になりがちな並列性の問題を大きく単純化できました。マルチキャストを通じてページが非同期に届く状態で複数の仮想 CPU からのページ更新が競合したとしても問題は起こりません。
二つ目の教訓は「スケールは嘘をつかない」です。言い換えると、スケールを二倍にするたびにシステムが不安定になって新しいボトルネックが判明するから準備をしておけということです。これは一つ目の教訓と強く結びついています。シンプルでエレガントな解決法は上手くスケールし、負荷が高まってもその原因が隠されることがありません。この分かりやすい例が mcdist システムです。大規模なテストでは、TCP/IP ベースのページ分散メカニズムは数百程度のクローンでひどく失敗してしまいます。しかしそのような場合でも mcdist であれば、非常に制限され上手く定義された「クライアントは自分のページだけを考え、サーバーはグローバルのフロー制御だけを考える」という指針によってテストをパスできます。mcdist を謙虚でシンプルにすることで、SnowFlock は非常に良くスケールします。
もっと深く SnowFlock を知りたいなら、トロント大学のサイト4からは学術論文と GPLv2 でライセンスされたオープンソースのコードを、GridCentric5からは産業用の実装を見ることができます。
-
http://www.gridcentriclabs.com/architecture-of-open-source-applications[return]
-
OUI は Organizational Unique ID の略で、ベンダーに割り当てられる MAC アドレスの範囲のことです。[return]