Berkeley DB
Conway の法則によると、システムの設計には作った組織の構造が表れるといいます。この考えを敷衍すれば、二人の人間によって設計・作成されたソフトウェアには、組織の構造だけではなくて、二人が持つバイアスと哲学が表れるのかもしれません。私たちの一人 (Seltzer) はファイルシステムとデータベース管理システムの研究にキャリアを費やしてきました。彼女に言わせればこの二つは本質的に同じものであり、さらに言えばオペレーティングシステムとデータベース管理システムだって同じです。両方ともリソースの管理と便利な抽象化を提供する点で同じであり、違いは実装の詳細 “だけ” です。もう一人 (Bostic) がシステムを作るときに重要視しているのは、ツールベースのソフトウェア工学のアプローチ、そして単純なブロックを使ってコンポーネントを組み立てる手法です。なぜならモノリシックなアーキテクチャと比べたとき、こういったシステムは重要な“...可能性 (-bility)”に優れているからです。つまり、理解可能性 (understandability)、拡張可能性 (extensibility)、保守可能性 (maintainability)、テスト可能性 (testability)、変更可能性 (flexibility) に優れます。
この二つの視点を合わせれば、私たち二人が過去二十年間に多くの時間を Berkeley DB に費やしてきたことには驚かないでしょう。Berkeley DB は高速で、柔軟で、信頼性が高い、スケーラブルなデータ管理システムを提供するソフトウェアライブラリです。提供される機能はリレーショナルデータベースなどの普通のシステムと同じですが、組み合わせ方が異なります。例えば Berkeley DB のデータアクセスにはキーを使ったものとシーケンシャルなものの両方があり、どちらも高速です。またトランザクションのサポートや失敗からのリカバリなどの機能もあります。しかしここで変わっているのが、Berkeley DB ではこれらの機能がアプリケーションと直接リンクするライブラリとして提供されている点です。スタンドアローンのサーバーアプリケーションとして利用可能なわけではありません。
この章では Berkeley DB を詳しく説明し、このソフトウェアがモジュールが集まってできていること、そしてモジュールのどれもが 「一つのことをうまくやる」 という Unix 哲学を体現していることを見ていきます。Berkeley DB を組み込んだアプリケーションはこれらのコンポーネントを直接使えるほか、データアイテムを get, put, delete すると言ったお馴染みの操作から間接的に使うこともできます。この章では Berkeley DB のアーキテクチャ ──私たちがどうやって始めたか、どのように設計したか、最終的にどうなったか、そしてそうなったのはなぜか──に集中して解説します。長期間のソフトウェアプロジェクトにおけるコードの進化についても軽く触れます。Berkeley DB の開発は二十年以上の歴史があり、今も続いています。そのようなプロジェクトでは、良い設計が多少犠牲になることも避けられません。
始まり
Berkeley DB の開発は、Unix オペレーティングシステムが AT&T のプロプライエタリソフトウェアであり、リンケージがライセンスで制限されたユーティリティやライブラリが数百も存在していた時代にさかのぼります。この頃 Margo Seltzer はカリフォルニア大学バークレー校の大学院生であり、Keith Bostic はバークレーのコンピューターシステム研究グループのメンバーでした。当時 Keith は AT&T のプロプライエタリソフトウェアを Berkeley Software Distribution (BSD) から取り除く作業を行っていました。
Berkeley DB プロジェクトの当初の目標は控えめで、インメモリのハッシュ hsearch とオンディスクのハッシュ dbm/ndbm を新しいより高速な実装で置き換え、独占ライセンス抜きで配布するということでした。Margo Seltzer が書いたハッシュライブラリ [SY91] は Litwin の Extensible Linear Hashing に関する研究に基づいています。この賢いハッシュを使うとハッシュ値からページアドレスを定数時間で計算でき、それでいて大きなデータも扱うことができます ──内部のハッシュバケットおよびファイルシステムのページサイズ (たいていは 4kb または 8kb) よりアイテムが大きくなっても構いません。
ハッシュテーブルが良いなら、Btree とハッシュテーブルを組み合わせればもっと良いはずです。同じくカリフォルニア大学バークレー校の大学院生である Mike Olson は当時 Btree の実装をいくつも書いており、Berkeley DB のためにもう一つ書くことに同意してくれました。私たち三人は Margo のハッシュソフトウェアと Mike の Btree ソフトウェアを組み合わせ、アクセスメソッドに依存しない API を作成しました。アプリケーションがハッシュテーブルと Btree を参照するときにはデータベースハンドルが使われ、このハンドルがデータの読み込みと改変を行います。
この二つのアクセスメソッドをもとにして、Mike Olson と Margo Seltzer は研究論文 [SO92] を書きました。この論文では、アプリケーションのアドレススペース内で実行されるプログラム可能なトランザクショナルライブラリ LIBTP が提案されています。
このハッシュと Btree のライブラリは Berkeley DB 1.85 という名前で最後の 4BSD リリースに組み込まれました。細かいことを言うと Btree のアクセスメソッドとして実装されているのは B+link tree なのですが、この章ではアクセスメソッドの名前と同じ Btree という用語を使うことにします。Berkeley 1.85 の構造と API は、Linux や BSD ベースのシステムを使ったことがある人ならばすぐに理解できるはずです。
Berkeley DB 1.85 の開発は何年間か停止していましたが、1996 年になって Netscape が Margo Seltzer と Keith Bostic と契約し、LIBTP の論文で提案された完全にトランザクショナルな設計を完成させ、商用クオリティのソフトウェアを作成することになりました。この結果としてトランザクションに対応した最初のバージョン Berkeley DB 2.0 が作成されます。
これ以降の Berkeley DB の歴史は単純です。Berkeley DB 2.0 (1997) ではトランザクションが導入され、Berkeley DB 3.0 (1999) では再設計が行われ、増え続ける機能に対応するために抽象レイヤーが追加されました。Berkeley DB 4.0 (2001) ではレプリケーションと高信頼性が導入され、Oracle Berkeley DB 5.0 (2010) では SQL のサポートが追加されています。
執筆時点において、Berkeley DB は世界で一番使われているデータベースツールキットです。ルーターからブラウザ、メーラ、オペレーティングシステムまで、様々なところで数億個のコピーがデプロイされています。世に出て二十年以上がたった今でも、Berkeley DB が取ったツールベースかつオブジェクト指向のアプローチの効果は健在であり、Berkeley DB はアプリケーションの要求に合わせてインクリメンタルに改善・再開発され続けています。
複雑なソフトウェアパッケージのテスト・保守のためには、ソフトウェアが互いに連携するモジュールの集合であることが不可欠であり、モジュールは上手く定義された API によって分離されなければなりません。必要に応じて何をモジュールとするかは変わります (変えるべきです!) が、モジュールが無いというのはあり得ません。モジュール同士が API によって分離されることで、ソフトウェアが保守不可能な山盛りスパゲッティにならずに済みます。Butler Lampson は 「情報科学の全ての問題はインダイレクションを追加すれば解くことができる」という言葉を残しています。さらに重要なこととして、Lampson はオブジェクト指向とは何かと尋ねられたときに、一つの API に複数の実装を持てることだと答えています。Berkeley DB の設計と実装にはこのアプローチを取り入れ、共通のインターフェースに対する実装を複数許しています。これによってオブジェクト指向的な感じとなりますが、ライブラリは C で書かれています。
アーキテクチャの概観
この節では Berkeley DB ライブラリのアーキテクチャを見ていきます。まず LIBTP から始め、主要な進化を追っていきます。
図 4.1 は Seltzer と Olson の原著論文にある図であり1、LIBTP のアーキテクチャを表しています。図 4.2 は Berkeley DB 2.0 が設計されたときのアーキテクチャです。
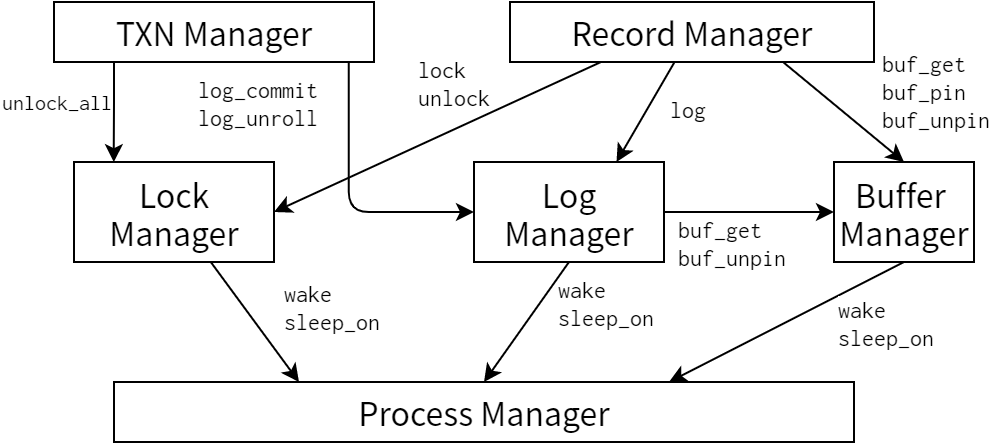
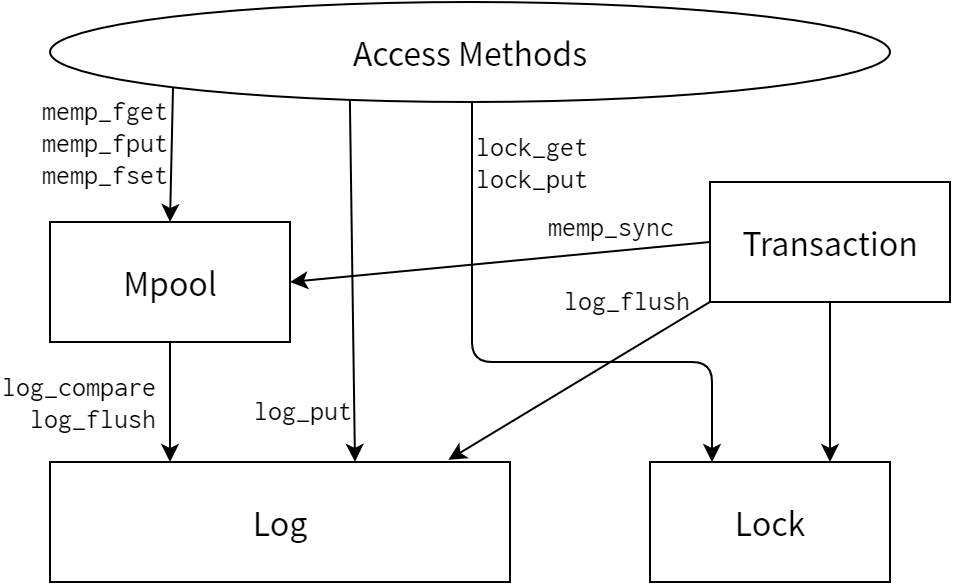
LIBTP の実装と Berkeley DB 2.0 の設計の間で唯一大きく異なるのは、Berkeley DB 2.0 にはプロセスマネージャが無い点です。LIBTP ではスレッドを同期するときにスレッドの方からライブラリに問い合わせるという方法を取っており、サブシステムレベルの同期機構が存在しませんでした。Section 4.4 でも議論しますが、オリジナルの設計の方が上手く行っていた可能性もあります。
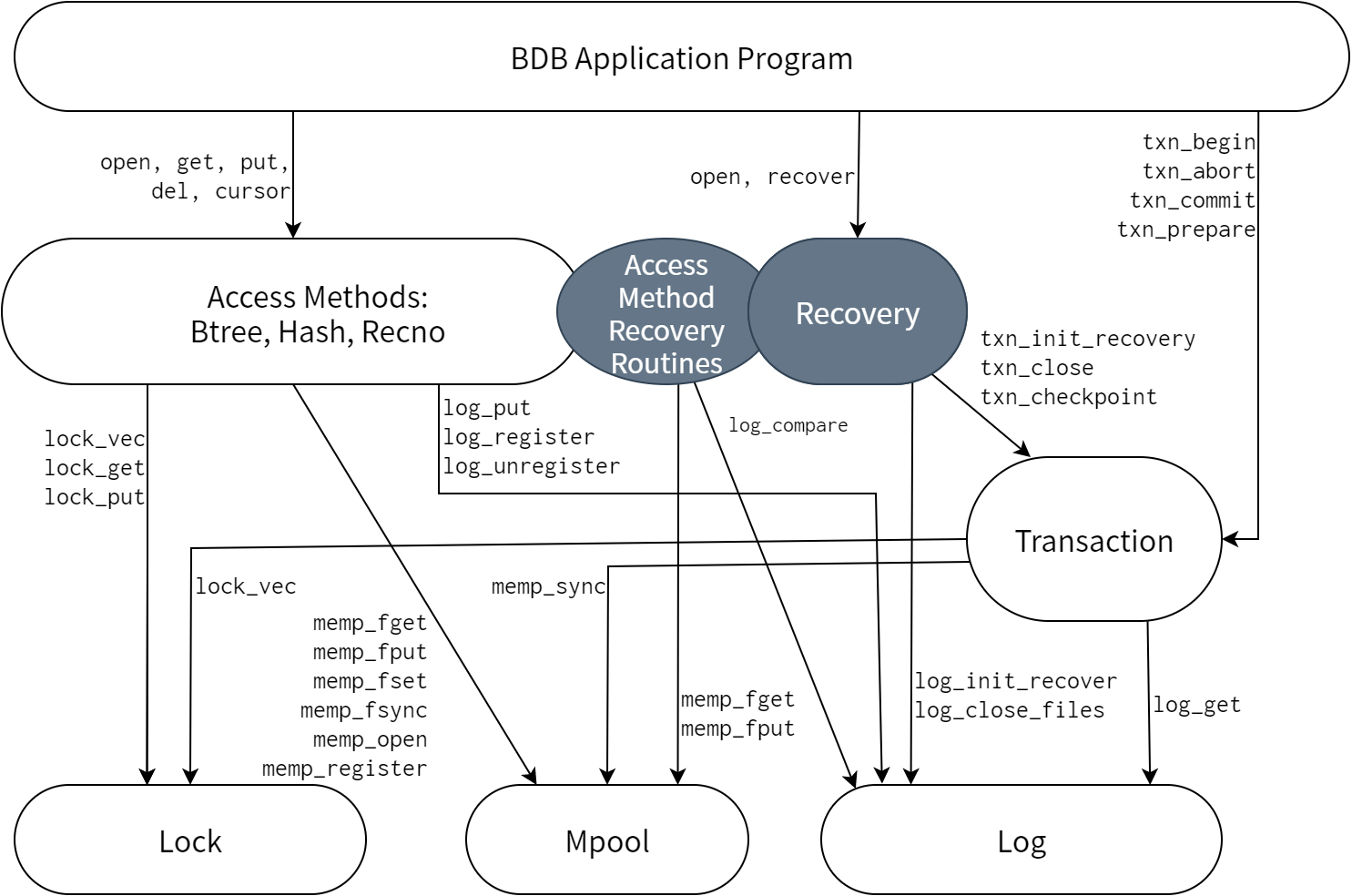
実際にリリースされた Berkeley DB 2.0.6 のアーキテクチャ (図 4.3) をオリジナルの設計と比べると、図中グレーで示される堅牢なリカバリマネージャを追加で実装していることが分かります。このシステムにはアクセスメソッドによって実行される undo や redo といったリカバリ命令やドライバインフラが含まれます。リカバリ命令は図中の“Access Method Recovery Routines”とラベルの付いた楕円で、ドライバインフラは“Recovery”とラベルの付いた丸い長方形で示されています。LIBTPではログとリカバリのルーチンがアクセスメソッドごとに存在していましたが、Berkeley 2.0 では一貫した設計となっています。この設計によってモジュール間のインターフェースがより洗練されたものになっています。
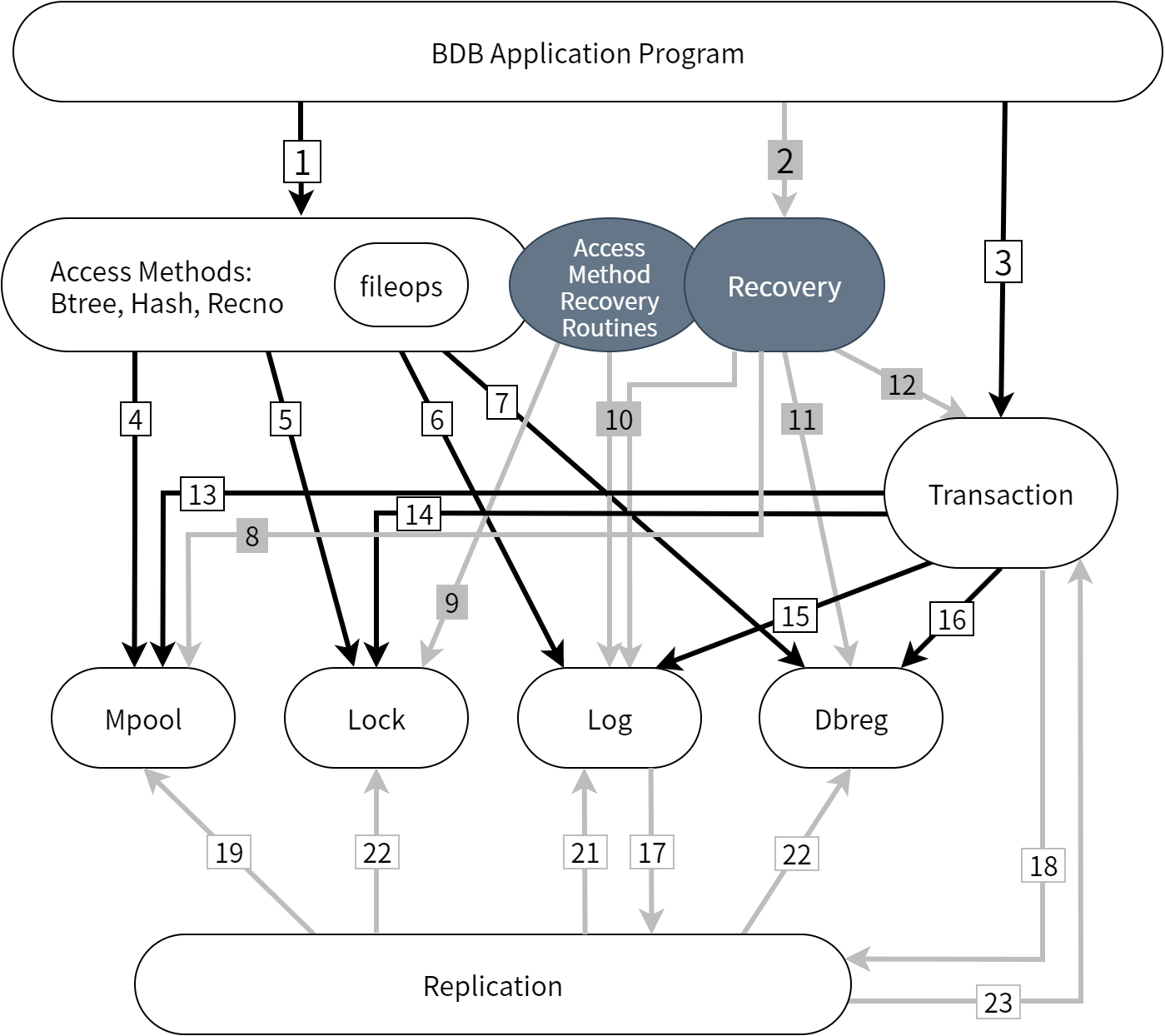
図 4.4 に Berkeley DB-5.0.21 のアーキテクチャを示します。図中の番号は 表 4.1 にある API に対応します。現在のアーキテクチャにはオリジナルのアーキテクチャの面影を見ることができますが、長い開発期間を通じてモジュールが追加され、モジュールが分解され (log は log と dbreg になりました)、モジュール間の API の数が増えています。
十年以上にわたる開発、数十の商用リリース、数百の新しい機能を経て、アーキテクチャは当初よりずっと複雑になりました。一つ目として、複製 (replication) の実装によってシステムに新しいレイヤーが追加されました。ただしレイヤーの追加は綺麗に行うことに成功しており、複製モジュールとシステムの他の部分とのやり取りには以前と同じ API が使われます。二つ目として、 log モジュールは log と dbreg (データベース登録) に分割されました。これは Section 4.8 で詳しく議論します。三つ目として、モジュール間のやり取りに使われる関数の名前の最初にアンダースコアを二つ付けることで、アプリケーションの関数が内部の関数と衝突しないようにしました。これについては設計講座 6 でさらに議論します。
四つ目として、ログサブシステムの API がカーソルベースとなりました (log_get API は log_cursor API に置き換えられました)。初期バージョンからの仕様で、Berkeley DB のログに読み書きを行えるのは各時点において一つのスレッドだけであり、ログには単一のシークポインタという概念しかありませんでした。これはかなりひどい抽象化であり、複製機能の追加によってついに変更を余儀なくされました。現在ではアプリケーション API のカーソルを使ったイテレートと同じように、ログでもカーソルを使ったイテレートを行えるようになっています。五つ目として、アクセスメソッド内に fileop モジュールが追加され、トランザクションから保護されたデータベースの作成、削除、リネーム操作が提供されるようになりました。この部分の実装には試行錯誤があり (まだ私たちが満足できるほどきれいではありません)、何度もやり直した結果、一つのモジュールとして切り離すことに成功しました。
ソフトウェアの設計とは、問題に実際にとりかかる前に問題全体を隅々まで考えるようあなたに仕向けるものの一つでしかありません。熟練したプログラマーは他にも様々なテクニックを使ってこの目的を達成します。捨てるつもりで初期バージョンを書く人、徹底的なマニュアルやデザインドキュメントを最初に書く人、特定した要件を関数やコメントにしてコードのテンプレートをまず作る人など様々です。Berkeley DB では、アクセスメソッドや内部のコンポーネントに関する完全な Unix スタイルのマニュアルページを、コードを一切書かないうちに完成させました。どんなテクニックを使うにせよ、コードのデバッグが始まってしまえばプログラム全体のアーキテクチャをじっくりと考えるのは難しくなります。またアーキテクチャを後から変更すればデバッグの時間が無駄になるのは言うまでもありません。ソフトウェアのアーキテクチャにはコードのデバッグとは異なるマインドセットが必要であり、デバッグを始めたときのアーキテクチャがそのままリリースされるアーキテクチャとなるのが普通です。
| 1. DBP ハンドルの操作 | 2. DB_ENV リカバリ |
3. トランザクション API |
|---|---|---|
open |
open(... DB_RECOVER ...) |
DB_ENV->txn_begin |
get |
DB_TXN->abort |
|
put |
DB_TXN->commit |
|
del |
DB_TXN->prepare |
|
cursor |
| 4. Lock へ | 5. Mpool へ | 6. Log へ | 7. Dbreg へ |
|---|---|---|---|
__lock_downgrade |
__memp_nameop |
__log_print_record |
__dbreg_setup |
__lock_vec |
__memp_fget |
__dbreg_net_id |
|
__lock_get |
__memp_fput |
__dbreg_revoke |
|
__lock_put |
__memp_fset |
__dbreg_teardown |
|
__memp_fsync |
__dbreg_close_id |
||
__memp_fopen |
__dbreg_log_id |
||
__memp_fclose |
|||
__memp_ftruncate |
|||
__memp_extend_freelist |
| 8. Lock へ | 9. Mpool へ | 10. Log へ | 11. Dbreg へ | 12. Txn へ |
|---|---|---|---|---|
__lock_getlocker |
__memp_fget |
__log_compare |
__dbreg_close_files |
__txn_getckp |
__lock_get_list |
__memp_fput |
__log_open |
__dbreg_mark_restored |
__txn_checkpoint |
__memp_fset |
__log_earliest |
__dbreg_init_recover |
__txn_reset |
|
__memp_nameop |
__log_backup |
__txn_recycle_id |
||
__log_cursor |
__txn_findlastckp |
|||
__log_vtruncate |
__txn_ckp_read |
| 13. Lock へ | 14. Mpool へ | 15. Log へ | 16. Dbreg へ |
|---|---|---|---|
__lock_vec |
__memp_sync |
__log_cursor |
__dbreg_invalidate_files |
__lock_downgrade |
__memp_nameop |
__log_current_lsn |
__dbreg_close_files |
__dbreg_log_files |
| 17. Log から | 18. Txn から |
|---|---|
__rep_send_message |
__rep_lease_check |
__rep_bulk_message |
__rep_txn_applied |
__rep_send_message |
| 19. Lock へ | 20. Mpool へ | 21. Log へ | 22. Dbreg へ | 23. Txn へ |
|---|---|---|---|---|
__lock_vec |
__memp_fclose |
__log_get_stable_lsn |
__dbreg_mark_restored |
__txn_recycle_id |
__lock_get |
__memp_fget |
__log_cursor |
__dbreg_invalidate_files |
__txn_begin |
__lock_id |
__memp_fput |
__log_newfile |
__dbreg_close_files |
__txn_recover |
__memp_fsync |
__log_flush |
__txn_getckp |
||
__log_rep_put |
__txn_updateckp |
|||
__log_zero |
||||
__log_vtruncate |
トランザクショナルライブラリはコンポーネントからできていますが、予想される使われ方に合わせて最初からソフトウェアに組み込んでおかないのはどうしてでしょうか?この質問には三つの答えがあります。まず、そうすることで設計がより洗練されます。次に、コードを無理にでも引き離しておかないと、複雑なソフトウェアパッケージは間違いなく保守不可能な役に立たないコードの山に退化してしまいます。最後に、顧客がソフトウェアをどう使うかを予想するのは絶対に不可能です。ユーザーがソフトウェアのコンポーネントにアクセスできるならば、彼らはソフトウェアを思いもしない方法で使います。
これからの節では Berkeley DB の各コンポーネントを一つずつ取り上げ、そのコンポーネントが何をするか、およびソフトウェアの全体図にどのように収まるかを見ていきます。
アクセスメソッド: Btree, Hash, Recno, Queue
Berkeley DB のアクセスメソッドを使うと、可変長および固定長バイト列を使ったキールックアップおよびイテレートを行うことができます。Btree と Hash は可変長のキー/バリュー組をサポートしており、Recno と Queue はレコード番号/バリュー組をサポートしています (Recno は可変長バリューをサポートしますが、Queue は固定長バリューしかサポートしません)。
アクセスメソッド Btree と Hash の間の主な違いは、Btree ではキーの参照について局所性があるのに対し、Hash には無いという点です。このため、ほとんどのデータセットについて Btree が選択すべきアクセスメソッドとなります。ただし、データが巨大で Btree のインデックス構造すらメモリに乗らない場合には、Hash を使ったアクセスメソッドの方が適しています。1990 年当時はメインメモリが現在よりもはるかに小さく、メモリをインデックス構造ではなくてデータに使う方が理にかなっていたので、Btree と Hash の間のトレードオフは提供する価値のあるものでした。
Recno と Queue の間の違いは、Queue は固定長のバリューしか扱えない代わりにレコードレベルのロックをサポートする点です。Recno は可変長のオブジェクトをサポートしますが、その代わり BTree や Hash と同じくページレベルのロックしかサポートしません。
私たちは最初 Berkeley DB の CRUD (create: 作成、read: 読み込み、update: 更新、delete: 削除) を key-based とし、アプリケーションへの主要インターフェースも key-based であるように設計していました。カーソルはイテレートのために後から追加されたのですが、これによってほとんど同じコードからなる、理解しづらく無駄でしかない場合分けがライブラリ内に生じてしまいました。時が経つにつれこの部分は保守不可能になり、キーを使う操作はカーソルを使ったものに変換されるようになりました (キーを使う操作はキャッシュされたカーソルを確保し、操作を行い、カーソルをカーソルプールに返却します)。ソフトウェア開発において幾度となく見られる法則を、ここでも見ることができるでしょう: 「必要でない限り、コードパスから明確さや単純さが失われるような最適化を一切行なってはいけない」
ソフトウェアアーキテクチャは行儀良く年を取りません。ソフトウェアアーキテクチャは変更の数に完全に比例して質が落ちていきます。バグフィックスはレイヤーを腐食させ、新機能は設計に負荷を掛けます。ソフトウェアアーキテクチャの質が落ち切った瞬間を正しく見極め、モジュールの再設計あるいは書き直しを行う判断を下すのは難しい問題です。アーキテクチャの質が落ちるのを放っておくという道を選ぶと、ソフトウェアの保守と開発がより困難になり、最終的には誰もソフトウェアの内部を理解できなくなります。そうなれば、リリースのたびに大勢のテスターを動員することでしか保守できないレガシーなソフトウェアの完成です。一方でソフトウェアの基礎的な部分を変更するという道を選ぶと、ユーザーからはソフトウェアが不安定で互換性が無いことに対する手厳しい批判が飛んできます。ソフトウェアアーキテクトであるあなたに保証されていることと言えば、どちらの道を選んだとしても誰かを怒らせるということだけです。
Berkeley DB のアクセスメソッドの詳細に関しては省略します。実装されているのは良く知られた Btree とハッシュアルゴリズムです (Recno は Btree コードの上にあるレイヤーです。Queue はファイルブロックの検索関数ですが、レコードレベルのロックがあるために複雑になっています)。
ライブラリインターフェースレイヤー
時が経ち機能が追加されるにつれ、アプリケーションコードと内部コードの両方に共通のトップレベルの機能が必要となりました (例えば table join の操作をすると複数のカーソルをある行に沿ってイテレートする必要がありますが、アプリケーションも同じ行をイテレートするカーソルを必要とするかもしれません)。
変数、メソッド、関数の命名法、あるいはコメントやコードのスタイルは重要ではありません。なぜなら、“十分に良い”フォーマットやスタイルが山ほど存在しているからです。重要なこと、それもとても重要なことは、決めた命名規則やスタイルを一貫して使うことです。熟練したプログラマーはコードを見るだけで、コードのフォーマットやオブジェクトの命名法についての情報を大量に引き出すことができます。一貫していない命名やスタイルを見つけたら、他のプログラマーに対して嘘をつくことに時間と労力を費やしたプログラマーがいたのだと思うべきです。コード規約を守れないことはクビに値します。
これを受けて、アクセスメソッド API を分解してきちんと定義されたレイヤーに分けることになりました。各レイヤーのインターフェースルーチンは必須となる処理を全て実行します。例えば一般的なエラーチェック、インターフェースのトラック、自動的なトランザクションの管理といった処理です。アプリケーションが Berkeley DB の関数を呼ぶと、オブジェクトハンドルのメソッドに基づいて最初のレベルのインターフェースルーチンが呼ばれます。例えば __dbc_put_pp はデータアイテムを更新するときに呼ばれる関数であり、Berkeley DB のカーソルの put メソッドに対するインターフェース呼び出しです。 _pp という接尾語はこの関数がアプリケーションから呼ぶことのできる関数であることを表します。
インターフェースレイヤーにおける Berkeley DB の仕事の一つは、Berkeley DB ライブラリ内で実行されるスレッドの管理です。この処理が必要になるのは、Berkeley DB の操作の中にはライブラリ内で実行されるスレッドが一つだけであることが求められるものがあるからです。スレッドの管理はライブラリ内で実行されるスレッドに印を付けることで行われ、ライブラリ API の最初でマークが付き、値を返す直前に印が外れます。この出入チェックの処理は必ずインターフェースレイヤーで行われます。これと似たタイミングで実行される処理としては、複製環境が否かのチェックなどがあります。
ここで明らかな疑問として、「なぜスレッド ID をライブラリに渡さないのか。その方が簡単では?」 というのがあります。この質問への答えは Yes で、実際かなり簡単になりますし、そうすればよかったと本当に思っています。しかし、そう変更するには Berkeley DB を使った全てのアプリケーションを書き換える必要があり、アプリケーションの再構築が必要になってしまうのです。そのためスレッドはライブラリ内部で管理されるようになっています。
ソフトウェアアーキテクトはアップグレードに関する戦略を慎重に立てなければなりません。小さな変更や新しいリリースへのアップグレードならユーザーは受け入れてくれます (アップグレード時にコンパイルエラーなどの明らかなエラーが起きないことが前提です。アップグレードではどんな小さな失敗も許されません)。しかし変更が根本的な場合には、新しいコードを追加や既存コードベースの書き換えが必要になることをユーザーに認めなければなりません。もちろんコードの追加と書き換えはユーザーの時間と資源を浪費させますが、大規模な改修がマイナーなアップグレードにすぎないというお知らせでユーザーを怒らせることになるあなたの心も穏やかではいられないでしょう。
インターフェースレイヤーで行われるもう一つのタスクはトランザクションの生成です。Berkeley DB ライブラリには全ての操作を自動的に生成されたトランザクションで行うモードがあります (これによってアプリケーションはトランザクションの生成とコミットを自分で行わずに済みます)。このモードのためには、アプリケーションがトランザクションを指定することなく API を呼んだときにトランザクションを自動的に生成する処理が必要になります。
最後に、全ての Berkeley DB API には引数のチェックがあります。Berkeley DB のエラーチェックには二種類あり、直前の操作によってデータベースが壊れていないかどうかを判定する汎用的なチェックと、複製状態の変更途中であるかどうか (例えば書き込みを許す複製を切り替えるなど) を判定するチェックがあります。API に特有なチェックもあり、フラグの使い方、パラメータの使い方、オプションの組などのエラーは操作を行う前に発見されます。
API に特有なチェックは _arg が最後に付く関数にまとめられています。例えばカーソルの put 関数に特有のエラーをチェックする関数は __dbc_put_arg という名前であり、 __dbc_put_pp 関数によって呼ばれます。
引数の確認とトランザクションの生成が完了すると、最後に実際の操作を行うワーカーメソッドが起動します (今の例では __dbc_put であり、カーソルの操作を行う内部の関数と同じです)。
この分割が行われたのは私たちが複製環境において何をするべきかを決めようと活発に議論していたときでした。コードベースを何度も書き直した結果、最初のチェックを分離することで後で問題が明らかになった場合にも対応できるようになりました。
内部コンポーネント
アクセスメソッドの内部には四つの内部コンポーネントがあります。バッファマネージャ、ロックマネージャ、ログマネージャ、トランザクションマネージャの四つです。後で別々に議論しますが、まずは共通するアーキテクチャを見ていきます。
まず、四つのサブシステムは固有の API を持ち、最初のバージョンでは各サブシステムがメソッドと結びついたオブジェクトハンドルを持ちました。例えば、Berkeley DB のロックマネージャを使ってデータベースと関係ないロックを処理でき、Berkeley DB のバッファマネージャを使ってデータベースと関係のない共有メモリ上のページを処理できます。開発が進むにしたがって、システムに固有のハンドルは Berkeley DB を簡略化するために API から取り除かれました。四つのサブシステムは個別のコンポーネントでありそれぞれ独立に使用できますが、現在では DB_ENV という“環境”ハンドルが共有されています。このようにアーキテクチャを洗練させることで、レイヤー化と一般化が進みました。ときにはレイヤーが変更されることもあり、現在でもサブシステムが他のサブシステムに踏み入っている部分がいくつかありますが、ソフトウェアの一部を独立したシステムとして考えることはプログラマーが従うべき良いルールでしょう。
二つ目の共通点として、四つのサブシステムに含まれる関数 (実際には Berkeley DB の全ての関数) はコールスタックにエラーコードを返します。ライブラリである Berkeley DB はグローバル変数を使ってアプリケーションの名前空間を侵食することはできないからです。また言うまでもなく、エラーが報告されるパスをコールスタックを使ったものだけに限定することで、プログラマーが書くコードのクオリティを保つことができます。
ライブラリの設計において、名前空間を尊重することはきわめて重要です。ライブラリの関数、定数、構造体、グローバル変数の名前を何十個も覚えないとライブラリを使うことができないというのは望ましくありません。
最後の共通点として、四つのサブシステムは共有メモリをサポートします。Berkeley DB は複数のプロセスの間で同じデータベースを共有でき、そのときにはデータ構造を全て共有メモリに置くことができます。この方式を取った場合に生じる一番の影響は、インメモリのデータ構造はポインタを持つだけでは不十分であり、ベースアドレスとオフセットの組を持たなければマルチプロセスのコンテキストで動作できなくなる点です。つまり Berkeley DB はデータベースのポインタを直接使うことができず、そのベースアドレス (他のプロセスと共有するメモリセグメントがマップされたアドレス) とオフセットを足すことでポインタを計算しなければならないということです。この機能を実装するために、私たちは Berkeley Software Distribution に含まれる queue パッケージの様々な種類の連結リストを実装したバージョンを書きました。
共有メモリ上で動く連結リストパッケージを書く前に、Berkeley DB のエンジニアは共有メモリ上で動く様々なデータ構造を自分たちで実装したのですが、その実装にはバグが多く、デバッグも困難でした。さらに後に BSD のリストパッケージ (queue.h) をもとにした共有メモリリストパッケージが作られたので、その労力は無駄になってしまいました。またこの共有メモリリストパッケージを一度デバッグし終えてからは、問題が生じることは一度もありませんでした。三つの設計原則をここに見ることができるでしょう。一つ目は、二回以上現れる機能があったら共通する部分を関数にすべきであるということです。一つの機能に二つの実装があれば、必ずどちらかが間違っています。二つ目は、汎用のコードを書くときにはテストスイートを作って個別にデバッグできるようにすべきであるということです。三つ目は、コードを書くのが難しければそれだけ、コードを個別に作成、保守するのが難しくなり、周りのコードを蝕んでくということです。
バッファマネージャ: Mpool
Berkeley DB の Mpool サブシステムはファイルページをバッファするためのインメモリのバッファプールです。これによりメインメモリが有限であることが隠蔽され、データベースがメモリより大きい場合にページをメモリとディスクの間で行ったり来たりさせる処理が自動化されます。データベースをメモリ上にキャッシュできることが、Berkley DB の前身のハッシュライブラリが当時の hsearch や ndbm といった実装に比べてはるかに良い性能を持っていた理由でした。
Berkeley DB の Btree アクセスメソッドはごく一般的な B+tree の実装です。特徴的な点として、木を指すポインタがメモリのポインタではなくページ番号で表される点があります。これはライブラリの実装がオンディスクのフォーマットをインメモリでも使っているためです。この表現による利点はページをディスクにフラッシュするときに変換が必要ないことであり、欠点はインデックス構造の走査を行うときに (高速な) メモリの間接参照ではなく (低速な) バッファプールの探索を何度も行う必要があることです。
Berkeley DB のインデックスのインメモリにおける表現がオンディスクの永続データのキャッシュに過ぎないことには、パフォーマンスに対する影響が他にもあります。例えば Berkeley DB がキャッシュされたページにアクセスするときには、まずメモリ上のそのページにピンを立て、そのピンが立っている間は他のスレッドやプロセスはバッファプールからそのページを取得できなくなります。インデックス構造全体がキャッシュに収まり、ディスクにフラッシュする必要が全くなかったとしても、Berkeley DB はアクセスのたびにピンの取得と解放を行います。なぜなら Mpool のモデルが永続ストレージではなくてキャッシュを使っているからです。
Mpool によるファイルの抽象化
Mpool はファイルシステムの存在を前提としており、API を通じて抽象化したファイルを公開します。例えば DB_MPOOLFILE ハンドルはディスク上のファイルを表し、 get や put といったメソッドはこのファイルに対する操作となります。Berkeley DB には一時的なデータベースやインメモリのデータベースを作る機能もありますが、これらの場合でも Mpool とのやり取りは DB_MPOOLFILE ハンドルを使います。 get メソッドと put メソッドは Mpool の主要な API です。 get を使うと指定したページがキャッシュに載り、そのページにピンが立ち、そのページに対するポインタが返ります。 put はページへの操作が終わったときに呼ばれ、そのページのピンを取り除き、他のスレッドがそのページを取得できるようにします。Berkeley DB の初期バージョンでは読み込みアクセスのためのピンと書き込みアクセスのためのピンを区別していませんでした。しかし、並列性を高めるために Mpool API は拡張され、ページにピンを立てるときにどんな操作を行うかを伝えられるようになりました。このように読み込みアクセスと書き込みアクセスを区別することはマルチバージョン並列制御において重要です。例えば読み込みアクセスを取得したページがダーティになったとしてもディスクに書き込むことは可能ですが、書き込みアクセスを取得したページでは不可能です。整合性が保たれない可能性があるためです。
ログ先行書き込み
Berkeley DB はログ先行書き込み (write-ahead-logging, WAL) という方式を使ってトランザクションを行い、失敗からのリカバリを可能にしています。ログ先行書き込みとは、ディスクに及ぶ全ての変更において、変更が実際にディスクに書き込まれる前にログを書き込むことを必須とする方式です。Berkeley DB がトランザクションに WAL を使っているので、Mpool は汎用的なキャッシュメカニズムと WAL プロトコルの両方をサポートするようにバランスの取れた設計をする必要があります。
Berkeley DB は全てのデータページにログシーケンス番号 (log sequence number, LSN) を割り振り、この番号を使ってページの直近の更新を記録します。WAL のためには、Mpool はページをディスクに書き込む前に、書き込もうとしているページの LSN がディスクにある LSN と一致していることを確認しなければなりません。ここで生じる設計上の問題が、Mpool のクライアントに Berkeley DB とおなじページフォーマットを強制することなくこの機能を提供するにはどうすれば良いかという問題です。Mpool は set や get といったメソッドを提供することでこの問題を解決しています。 DM_MPOOLFILE の set_lsn_off メソッドを使うと LSN が記録されている部分へのオフセットを設定できます。Mpool はこの値を使って LSN を読み、WAL を行います。同様に set_clearlen メソッドを使うとページ内のメタデータの長さを設定でき、Mpool はキャッシュにページを作るときにこの分だけデータをクリアします。これらの API が Berkeley DB のトランザクションで必要となる機能を提供しており、Mpool のユーザーは必ずこの機能を使います。
ログ先行書き込みはカプセル化とレイヤー化の一例です。ここでは実装しようとしている機能が他のソフトウェアの一部となることはありません。考えてみてください。キャッシュ上の LSN を使うプログラムなんて他にあるでしょうか? そうだとしても、カプセル化とレイヤー化という方針を採用することでソフトウェアの保守、デバッグ、拡張がしやすくなります。
ロックマネージャ: Lock
Mpool と同じように、ロックマネージャも汎用のコンポーネントとして設計されました。Berkeley DB で実装されているのは階層ロックマネージャ [GLPT76] です。様々な階層のロックができるよう設計されており、例えばオブジェクト (データ項目など) の階層、データ項目が格納されているページおよびファイルの階層、あるいはファイル自体の階層さえロックできます。これからロックマネージャの機能を紹介すると共に、Berkeley DB がそれらの機能をどのように使っているのかを説明します。ただし、Mpool の場合と同じように、アプリケーションがロックマネージャを全く違う方法で使うことも可能です。ロックマネージャは様々な方法で柔軟に利用できるように設計されています。
ロックマネージャには三つの抽象化オブジェクトがあります。ロックを掛けるオブジェクトを表す“ロッカー”、ロックされる項目を表す“ロックオブジェクト”、そして“衝突行列”です。
ロッカーは 32 ビットの非負整数で表されます。Berkeley DB はこの 32 ビットの名前空間を分割し、トランザクションが関係するロッカーとそうでないロッカーに使う名前としています (この区別はロックマネージャも使います)。Berkeley DB がロックマネージャを使うときには、 0 から 0x7fffffff までの ID を持つロッカーはトランザクションが関係しないロッカーに、 0x80000000 から 0xffffffff までの ID はトランザクションが関係するロッカーに割り当てられます。例えばアプリケーションがデータベースを開くとき、Berkeley DB はそのデータベースに対する長期の読み込みロックを取得し、利用中に他のスレッドにおいてデータベースが削除されたりリネームされたりすることがないようにします。このロックは長期ロックなのでトランザクションに属さず、トランザクションと関係ないロッカーがこのロックを保持します。
ロックマネージャを使うアプリケーションはロッカー ID をロックに割り当てる必要があるので、ロックマネージャの API には DB_ENV->lock_id と DB_ENV->lock_id_free という関数があります。この関数を使えば ID の確保と解放を行えるので、アプリケーションが独自にアロケータを実装する必要はありません (ただし実装することも間違いなく可能です)。
ロックオブジェクト
ロックオブジェクトはフォーマットの指定されない可変長のバイト列であり、ロックされるオブジェクトを表します。二つの異なるロッカーが一つのオブジェクトをロックしようとするときには、同じバイト列がそのオブジェクトへの参照として使われます。ここで、同じオブジェクトを指す (フォーマット指定の無い) バイト列が同じであることを保証するのはアプリケーションの責任です。
例えば、Berkeley DB がデータベースのロックを表すのに使うのは DB_LOCK_ILOCK 構造体であり、ファイル識別子、ページ番号、タイプの三つのフィールドがあります。
ほとんどの場合において、Berkeley DB が指定するのはロックしたいファイルとページだけです。Berkeley DB はデータベースを作成するときに固有な 32 ビットの数字を生成してデータベースのメタデータページに書き込みますが、この数字は Mpool、ロック、ログのサブシステムで使わるほか、 DB_LOCK_ILOCK 構造体の field の値となります。明らかだと思いますが、このページ番号がロックするデータベースのページを表します。ページのロックを指す DB_LOCK_ILOCK 構造体では、タイプを表すフィールドが DB_PAGE_LOCK となります。他の種類のオブジェクトをロックすることも可能であり、データベースハンドルをロックする前述の場合にはタイプが DB_HANDLE_LOCK となり、キューのアクセスメソッドにおけるレコードレベルのロックでは DB_RECORD_LOCK 、データベース全体のロックでは DB_DATABASE_LOCK となります。
Berkeley DB がページレベルのロックをサポートしたのにはきちんとした理由があるのですが、ときどきこの選択によって問題が引き起こされることがあります。ページレベルのロックを使うと、データベース内のあるページのレコードを変更している間は、別のスレッドが同じページにある違うレコードを変更できなくなるのです。対してレコードレベルのロックを使った場合はこのような変更も行うことができます。この欠点があるにもかかわらずページロックを使う理由は、ページロックを使うとエラーからのリカバリのときに探索すべきパスが絞られ、安定性が増すからです (ロックがページごとである限りリカバリ中のページの状態はいくつかでしかあり得ませんが、レコード単位でのロックを許すとこの状態数が無限に大きくなります)。Berkeley DB が想定している組み込みシステムにおける利用ではトラブルが万一起こったとしてもデータベース管理者が出てきて問題を修復できないために、並列性を犠牲にして安定性を取る選択肢が残されました。
衝突行列
ロックに関するサブシステムに含まれる抽象オブジェクトとして最後に説明するのは衝突行列 (conflict matrix) です。衝突行列はシステムにおいて異なる種類のロックがどのように交わるかを表します。ロックを持っているオブジェクトのことをホルダー (holder)、ロックを取得しようとしているオブジェクトのことをリクエスター (requester) と呼ぶことにします。ホルダーとリクエスターが異なるロッカー ID を持っているとすれば、衝突行列の要素は [requester][holder] という形で参照できます。ロックの衝突が無く取得可能であれば、この値がゼロになります。
ロックマネージャにはデフォルトの衝突行列が存在し、その値は Berkeley DB が必要とする行列そのものとなっています。ただしアプリケーションから行列を書き換えて独自のロックモードを追加することが可能です。衝突行列が満たさなければいけない条件は正方である (行の数と列の数が等しい) ことと 0 から始まる整数列を使ってロックモード (読み込みや書き込みなど) を表すことです。表 4.2 に Berkeley DB の衝突行列を示します。
| Requester/Holder | No-Lock | Read | Write | Wait | iWrite | iRead | iRW | uRead | wasWrite |
|---|---|---|---|---|---|---|---|---|---|
| No-Lock | |||||||||
| Read | ✓ | ✓ | ✓ | ✓ | |||||
| Write | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Wait | |||||||||
| iWrite | ✓ | ✓ | ✓ | ✓ | |||||
| iRead | ✓ | ✓ | |||||||
| iRW | ✓ | ✓ | ✓ | ✓ | |||||
| uRead | ✓ | ✓ | ✓ | ||||||
| iwasWrite | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
階層ロックのサポート
Berkeley DB の衝突行列に現れる様々なロックモードを説明する前に、ロックのサブシステムがどのようにして階層ロックをサポートしているかを見ましょう。階層ロックとは包含関係の階層を使って複数のアイテムをまとめてロックすることを言います。例えばファイルはページを含み、ページは要素を含みます。階層ロックシステムにおいて一つの要素だけを変更したいときにはその要素だけをロックする方が高速であり、あるページ内の全ての要素を変更するのであればそのページ全体をロックする方が効率が良く、ファイル内の全てのページを変更するならばファイル全体をロックするのが一番です。それから、階層ロックをするときにはコンテナ同士の階層が明らかでなければなりません。ページをロックするとファイルのロックにも影響があり、例えば今まさに変更されているページが含まれるようなファイルはロックできないからです。
では異なるロッカーが異なる階層をロックするのをどのように管理すればカオスを生み出さずに済むでしょうか? この問題に対する答は intention lock と呼ばれます。あるコンテナに対する intention lock とは、そのコンテナに含まれるものをロックしようとする意図 (intention) を表します。例えばページに対して読み込みロックを取得すると、そのページを含むファイルに対する intention-to-read lock が取得されます。同様にページ要素に対して書き込みを行うためには、そのページを含むページとファイル両方に対する intention-to-write lock を取得しなければなりません。上の衝突行列において、 iRead iWrite iWR がそれぞれ読み込み、書き込み、読み書きに対する intention lock を表します。
階層ロックがあるために、ロックを一つだけ取得しようと思っても実際には複数のロックが必要になることがあります。つまり何かをロックしようとするとそれを含むものに対するロックも必要になるのです。この状況をうまく扱うために、Berkeley DB には DB_ENV->lock_vec インターフェースがあります。この関数はロックの配列を受け取り、全てのロックをアトミックに取得 (あるいは拒否) します。
階層ロックは Berkeley DB の内部では使われていませんが、異なる衝突行列を指定できる機能と複数のロックを一度に取得できる機能は上手く使われています。デフォルトの衝突行列を使うとトランザクションがサポートされますが、トランザクションとリカバリの無い単純な並列アクセスを使いたいだけならより簡単な衝突行列を使うこともできます。 DB_ENV->lock_vec は Btree の走査の並列性を向上させるテクニックである lock coupling [Com79] を使用するために使われます。lock coupling では、一つのロックを次のロックを取得するのに必要な間だけ保持します。つまり Btree のあるページをロックしたら、次の階層のページを探してロックし、すぐに元のロックを解放するのです。
Berkeley DB のコンポーネントを汎用にするという設計は、データの並列保存の機能を追加するときになって報われました。最初 Berkeley DB にあった操作モードは書き込み時の並列性が全く無いモードと完全なトランザクションをサポートするモードの二つだけでした。しかしトランザクションをサポートするためのコードは複雑であり、書き込み並列性を完全なトランザクションのサポート無しに必要としているアプリケーションがいくつかありました。この単純化された書き込み並列性の機能を提供するために、私たちはデッドロックを起こすことの無い API レベルのロックのサポートを加えました。このためにはカーソルがあっても機能する新しいロックモードが必要でしたが、ロックマネージャに専用のコードを足す必要はなく、API レベルのロックが使うロックモードを含んだ衝突行列を新しく設定するだけで済みました。つまりロックマネージャの設定を変更するだけで、新しいロックのサポートを提供できたということです (残念ながらアクセスメソッドを変更するのは簡単ではありませんでした。この並列アクセスの特殊モードを扱うためのコードはアクセスメソッドのコードの大部分を占めます)。
ログマネージャ: Log
ログマネージャは構造化された、書き足し専用のファイルの抽象化を提供します。他のモジュールと同じように、ログの機能は汎用になるように設計されています。ただしログのサブシステムはおそらく一番上手く行かなかったモジュールです。
アーキテクチャに関する問題を見つけたにもかかわらず、“今は”直したくないと思ってそのままにしようと思ったなら、死ぬほどアヒルにつつかれた2人が死ぬのは象に踏みつけられた人が死ぬのと同じぐらい明らかであることを思い出すべきです。ソフトウェアの構造を改善するためにフレームワーク全体を変更するのを躊躇するべきではありません。少しだけ変更して残りは後で、ではなくて、全てに片を付けてから先に進むべきです。よく言われることですが、「今する時間が無いなら、これからも無い」のです。そしてフレームワークを変更している間に、テストのための構造も書くべきでしょう。
ログの概念はとても単純です。ログのサブシステムはフォーマット未指定のバイト列を受け取ってファイルにシーケンシャルに書き込み、そのときログシーケンス番号 (LSN) というユニークな ID を割り当てます。また前後への走査や LSN による取得もサポートされます。ここで厄介な部分が二つあります。一つ目はいかなる失敗においてもログの整合性が保たれなければならない (破損したログが許されない) 点です。二つ目はトランザクションがコミットされるときにログの書き込みが必要なので、トランザクションを使うアプリケーションのパフォーマンスがログのパフォーマンスによって制限されることが多い点です。
ログは書き足し専用のデータ構造なので、限りなく大きくなります。私たちはログを順番に数字を振ったファイルの集まりとして実装したので、ログの総量を調整は古いファイルを削除することで行えます。ログは複数のファイルにまたがるので、LSN はファイルの番号とファイル内におけるオフセットからなります。そのため LSN があれば、ログマネージャはファイルを開いてオフセットの分だけシークすることでレコードを見つけることができます。しかしログマネージャはそこから何バイト読めばいいのでしょうか?
ログレコードのフォーマット
ログマネージャが LSN からレコードのサイズを認識できるよう、ログレコードにはその長さなどのメタデータを埋め込む必要があります。ログのサブシステムでは、ログレコードの先頭にヘッダーがあり、レコードの長さ、一つ前のレコードへのオフセット (後方への走査に使う)、レコードのチェックサム (ファイル終端におけるログの破損を検出するのに使う) があります。このメタデータがあればログマネージャはログレコードの列を管理できますが、リカバリを実装するにはこれでは不十分です。リカバリの情報はログレコードの中身に別に埋め込まれ、ログマネージャではなく Berkeley DB がその情報を使います。
Berkeley DB はデータベースの項目を更新する前に、ログマネージャを使ってデータの更新前と更新後のイメージをレコードに書き込みます。このレコードにはデータベースの redo や undo のために十分な情報が含まれます。Berkeley DB はこの情報をもとにトランザクションのアボート (トランザクションが始まってからの変更を全て打ち消す処理) やシステム障害からのリカバリを行います。
ログレコードを読み書きする API に加えて、ログマネージャにはログレコードを強制的にディスクに書き出す API (DB_ENV->log_flush) があります。これは Berkeley DB においてログ先行書き込みの実装に使われています。つまり Mpool からページを取得する前に、Berkeley DB はページの LSN を調べ、ログマネージャにその LSN が安定したストレージにあることを保証させます。ログが書き込まれて初めて、Mpool が実際にページをディスクに書き込みます。
Mpool と Log はログ先行書き込みを簡単にするためのハンドルメソッドを内部に持っていますが、それらのメソッドの処理は二つの整数を比較するだけであることが多いので、メソッドの名前がコードよりも長くなることがあります。レイヤーの一貫性を保つためだけに、そんな取るに足らないメソッドを作るのはなぜでしょうか? その理由は、歯が痛むぐらい徹底していなければ、オブジェクト指向は不十分だからです。全てのコード片は少ない数の仕事をし、高レベルの設計は少ない数の機能を組み合わせることで価値のある機能を作るようプログラマーに促すものでなければなりません。過去数十年間のソフトウェア開発を通じて私たちが学んだことが何かあるとすれば、それはソフトウェアの重要な部分を作成、保守するための私たちの能力は簡単に失われてしまうということです。ソフトウェアの重要な部分の作成と保守は困難で間違いやすいものです。あなたはソフトウェアアーキテクトとして、ソフトウェアの構造によって伝達される情報を最大化するために、できる限りのことを、なるべく早く、なるべく頻繁に行わなければなりません。
Berkeley DB はリカバリのためにログレコードの構造を固定しています。Berkeley DB のログレコードはほとんどがトランザクションによる更新を表しており、レコードにはトランザクションの一部として行われるデータベースのページの変更が対応します。このことから、Berkeley DB がログレコードに埋め込むべきメタデータがはっきりします。つまり、データベース、トランザクション、レコードタイプの三つです。トランザクションの ID とレコードタイプのフィールドはレコードの同じ位置に表れます。リカバリシステムはレコードタイプを読み、レコードを適切なハンドラに渡し、ハンドラがレコードの読み込みとするべき動作を行います。またトランザクションの ID はログレコードが属するトランザクションを特定するのに使われ、リカバリの各段階において何をして何をしないでおくべきかの判断にはこの ID が使われます。
抽象化を破る
ログレコードの中には“特別な”ものがいくつかありますが、その中でおそらく一番良く目にするのがチェックポイントレコードです。チェックポイントとはある時点における整合状態にあるデータベースをディスクに書き込んだものです。逆に言えば、Berkeley DB は Mpool にあるデータベースのページを積極的にキャッシュしてパフォーマンスを向上させようとします。ただしページはなんらかのタイミングでディスクに保存されなければならず、保存を早めにしておけばそれだけアプリケーション障害やシステム障害からのリカバリが素早く行えます。チェックポイントを作る処理はトランザクションを使っているので、詳細については次の節で説明します。この節ではチェックポイントレコードについて説明するほか、ログマネージャを独立したモジュールとするか Berkeley DB 専用のコンポーネントとするかの間で相克があることについても説明します。
ログマネージャ自体はレコードタイプを認識しません。そのため理論上はチェックポイントレコードと他のレコードは区別されません。どちらもフォーマットが未指定のバイト列に過ぎず、ログマネージャは内容を読むことなくディスクに書き込むだけです。実際にログに対して様々な処理を行うときに使われるのはログに付いているメタデータです。例えばログの起動時には、ログマネージャは見つけられる全てのログファイルを調べて最後に書き込まれたログファイルを見つけます。ログマネージャはそのファイル以外のファイルは損傷の無い完全なログであると仮定し、最後に書き込まれたそのファイルについて有効なログレコードがどれだけ含まれているかを調べます。つまりログファイルを先頭から読んでいき、チェックサムが正しくないレコードヘッダーまたはファイルの終端を読むまで進みます。両方の場合において、その場所が論理的なログの終端となります。
終端までログを読み進めるこの処理において、ログマネージャは Berkeley DB のレコードタイプを読み込んでチェックポイントレコードを探索も行います。そして最後に見つかったチェックポイントレコードの場所をトランザクションシステムのために保存しておきます。トランザクションシステムはいずれにせよ最後のチェックポイントを探すので、それならばログマネージャがログファイル全体を読むときにその処理を一緒にやらせてしまおうということです。これはパフォーマンスのために抽象化を破るという行為の典型例です。
このトレードオフは何を意味するでしょうか? Berkeley DB 以外のシステムがこのログマネージャを使うことを想像してみてください。そのシステムは Berkeley DB がレコードタイプを書き込む場所にチェックポイントを表す値をたまため書き込むことがあるかもしれません。そのような場合にはログマネージャがその場所をチェックポイントレコードだと (誤って) 認識します。ただしアプリケーションがその情報を (ログのメタデータの cached_ckp_lsn フィールドを直接参照することで) ログマネージャに問い合わせない限り、この情報は何の影響も及ぼしません。つまり、これは有害なレイヤーの侵害であるか、そうでなければ気の利いたパフォーマンス最適化だということです。
ファイル管理でもまた、ログマネージャと Berkeley DB の違いが曖昧になります。前述の通り、Berkeley DB のログレコードのほとんどは、そのレコードが参照しているデータベースを特定してから処理が行われます。参照しているデータベースの完全なファイル名を全てのログレコードが保持するやり方もありますが、そうするとログが大きく不格好になってしまいます。リカバリのときにはそのファイル名をデータベースにアクセスするハンドル (ファイルディスクリプタかデータベースハンドル) に結び付ける必要があるためです。そこで Berkeley DB ではデータベースのパスを保存する代わりに、ログファイル ID と呼ばれる整数を保存することでデータベースを識別しています。ログファイル ID とファイル名の対応関係は dbreg (“database registration”の略) という名前のついた一連の関数によって管理されます。この対応関係はデータベースを開いたときに (DBREG_REGISTER というレコードタイプの) ログレコードに書き込まれます。しかしトランザクションのアボートとリカバリの処理おいては、この情報をメモリ上に取っておく必要があります。この対応関係を管理するべきなのはどのサブシステムでしょうか?
理論上は、ファイルとログファイル ID の対応関係は Berkeley DB が直接呼ぶ高レベルの関数です。アプリケーションの全体図を見ることのできないサブシステムに属することはできません。しかし当初の設計では、良さそうに見えるからという理由で、この情報はログのサブシステムのデータ構造に詰め込まれました。しかし、実装におけるバグの発見と修正を何度も繰り返すうちに、対応関係のサポートはログのサブシステムのコードから引っ張り出され、オブジェクト指向のインターフェースとプライベートなデータ構造を持つ独立した小さなサブシステムとなりました (今考えれば、この情報はどんなサブシステムとも独立した、Berkeley DB の環境情報と一緒の場所に置かれるべきでした)。
重要でないバグというものはほとんど存在しません。もちろん typo ぐらいならたまにあるかもしれません。しかし通常バグは、自分が何をしているのかを完全に理解することなく間違ったことを実装した人がいたことを示します。バグを修正するときには、バグの症状ではなくてバグを引き起こした原因や誤解を探すべきです。そうすれば、プログラムのアーキテクチャに対する理解が深まり、設計自体に含まれる根本的な欠陥も明らかになるでしょう。
トランザクションマネージャ: Txn
最後に見るモジュールはトランザクションマネージャです。このモジュールは他のコンポーネントを組み合わせ、トランザクションにおける ACID、つまり原子性 (atomicity)、一貫性 (consistency)、独立性 (isolation)、永続性 (durability) を提供します。トランザクションマネージャの主な役割はトランザクションの開始と終了 (コミットまたはアボート)、ログの管理、バッファマネージャを使ったトランザクションのチェックポイントの作成、リカバリの統率です。この順番で見ていきます。
トランザクションが提供する重要な機能を表す ACID という言葉は Jim Gray によって作られました [Gra81]。原子性 (atomicity) とは、トランザクションに含まれる全ての操作がデータベースに対する一単位のまとまった操作として行われるということを意味します ──操作は全て行われるか、そうでなければ一切行われません。一貫性 (consistency) とは、トランザクションがデータベースの状態をある整合状態から別の整合状態に移動させることを意味します。例えばデータベースにおいて全ての従業員にひとつの部署が割り当てられるようアプリケーションが指定したとすると、一貫性がこの条件が常に保たれることを保証します。独立性 (isolation) とは、トランザクションから見たときに、含まれる操作が逐次的に実行され、並列に実行される他のトランザクションが存在しないように見えることを意味します。最後に永続性 (durability) とは、トランザクションがコミットされたらその後はずっとコミットされたままであることを意味します ──障害が起こったとしてもコミットされたトランザクションが打ち消されることはありません。
トランザクションのサブシステムは他のサブシステムの助けを借りながら ACID を達成します。トランザクションの開始と終了を区切るのに使われるのは、古くからある begin, commit, abort という操作です。他に prepare という関数もあり、これを使うと二相コミットが行えます。二相コミットとは分散トランザクションで使われるテクニックですが、この章では扱いません。トランザクションの begin は新しいトランザクション ID を取得し、トランザクションハンドル DB_TXN をアプリケーションに返します。トランザクションの commit はコミットログレコードを書き込み、ログをディスクに書き込ませ (アプリケーションが永続性を犠牲にしてでもコミット処理を高速にするよう指示していれば省略されます)、これによって障害時にもトランザクションがコミットされることを保証します。トランザクションの abort はログレコードを後ろに向かって読み、同じトランザクションに含まれる操作のうち既に行われたものを打ち消していきます。結果として abort はトランザクションが行われる前の状況が復元します。
チェックポイントの処理
トランザクションマネージャはチェックポイントの作成も行います。文献を参照すればチェックポイントの作成に関するテクニックをたくさん見つけられます [HR83]。Berkeley DB が使っているのは fuzzy checkpointing の一種です。基本的にチェックポイントの作成とは Mpool のバッファからディスクにデータを書き出す処理なのですが、これはとても時間のかかる可能性のある処理です。そのためサービスを中断させないためには、チェックポイントの作成中もシステムがトランザクションの動作を続けられることが重要です。チェックポイントの開始時に、Berkeley DB はアクティブなトランザクションを検索し、それらが書き込んだ LSN の中で一番小さなものを見つけ、この LSN をチェックポイント LSN とします。それからトランザクションマネージャは Mpool にダーティなバッファを書き出すよう要請します。バッファがディスクに書き出されたのを確認したら、トランザクションマネージャはチェックポイントレコードを書き込みます (このレコードには先ほどのチェックポイント LSN が含まれます)。このチェックポイント LSN はこの番号よりも小さい LSN を持つログレコードはリカバリの必要がないことを表します。チェックポイント LSN からは二つのことが分かります。つまりチェックポイント LSN よりも前のログファイルを削除できること、そしてリカバリ時にはチェックポイント LSN よりも後の操作を処理すれば済むことです。なぜならチェックポイント LSN よりも前の更新はディスク上に反映されているためです。
注意してほしいのが、チェックポイント LSN と実際のチェックポイントレコードの間にはログレコードがいくつも挟まることがある点です。ただしこれらのレコードはチェックポイントよりも論理的に後に起きた操作を表しているので、システム障害が起こったとしてもリカバリされます。そのため問題はありません。
トランザクションのパズルの最後のピースはリカバリです。リカバリ処理の目標はディスクにある整合状態にない可能性のあるデータベースを整合状態にすることです。Berkeley DB が使っているのはごく一般的な 2 パススキームであり、簡単に説明すると 「最後のチェックポイント LSN から見ていって、コミットされていないトランザクションを打ち消し、コミットされたトランザクションをやり直す」 という処理です。詳細はもう少し複雑になります。
Berkeley DB がデータベースへの操作を打ち消したりやり直したりするには、まずログファイル ID とデータベースの対応関係を再構築する必要があります。ログには DBREG_REGISTER ログレコードの完全な履歴がありますが、データベースの稼働時間がとても長くなることを考えると、全てのログを稼働している間ずっと保持するというのは望ましくありません。そこでこの対応関係はもっと効率的な方法を使って保存されます。つまり、チェックポイントレコードを書き込む前に、トランザクションマネージャは現在のログファイル ID とデータベースの対応関係を表す DBREG_REGISTER レコードの集合を書き込んでおくのです。リカバリのときにはこのログレコードから対応関係が再構築されます。
リカバリの最初で、トランザクションマネージャはログマネージャの cached_ckp_lsn の値を調べてログにおける最後のチェックポイントがどこかを取得します。このレコードにはチェックポイント LSN が含まれ、Berkeley DB はこのチェックポイント LSN からのリカバリを行います。しかし前述の通りこれを行うには、その LSN において存在していたログファイル ID の対応関係を再構築する必要があるのでした。対応関係はチェックポイント LSN よりも前に書き込まれているので、Berkeley DB は最後のチェックポイント LSN からさかのぼってこの情報を読みに行く必要があります。この処理を行うために、チェックポイントレコードにはチェックポイント LSN だけではなく一つ前のチェックポイントの LSN も含まれています。リカバリは一番最近のチェックポイントから始まり、チェックポイントの prev_lsn フィールドを伝ってさかのぼりながらチェックポイントの LSN よりも前に作られたチェックポイントを探します。アルゴリズムとして表すと以下のようになります:
ckp_record = read (cached_ckp_lsn)
ckp_lsn = ckp_record.checkpoint_lsn
cur_lsn = ckp_record.my_lsn
while (cur_lsn > ckp_lsn) {
ckp_record = read (ckp_record.prev_ckp)
cur_lsn = ckp_record.my_lsn
}
このアルゴリズムが選択するチェックポイントからリカバリが開始され、まずログファイル ID の対応関係を再構築しながらログの終端まで読み込みが行われます。ログの終端に達するときにはシステムが停止したときと同じ対応関係が手に入ります。またこのパスではトランザクションコミットレコードも読み込まれ、トランザクション ID が記録されます。ログレコードに表れているトランザクションの中で ID がトランザクションレコードに表れないものはアボートされたか完了していないものであり、いずれにせよアボートされたとみなされます。リカバリの処理がログの終端に達すると、リカバリサブシステムはファイルを読む方向を転換します。トランザクションのログレコードを終端から最初に向かって読み、それぞれのレコードを打ち消すべきかどうかを判断します。トランザクション ID がコミットされたトランザクションのリストに属していないならそのレコードは打ち消されるべきです。リカバリサブシステムはレコードタイプを読んでリカバリルーチンを呼び、そのログレコードで表される操作を打ち消すよう指示します。後ろ向きのパスはチェックポイント LSN3 まで続きます。そして最後にリカバリサブシステムはもう一度前向きにログを読みます。このときはコミットされているトランザクションをやり直していきます。このパスが終了した段階でチェックポイントを保存します。こうして出来上がるデータベースは整合状態となり、アプリケーションが利用する準備が整います。
リカバリの処理をまとめると次のようになります:
-
一番最近のチェックポイントに含まれるチェックポイント LSN を読み、それより前にあるチェックポイントを見つける。
-
ファイル終端まで前向きにログを読み、ログファイル ID の対応関係とコミットされたトランザクションを収集する。
-
チェックポイント LSN まで後ろ向きにログを読み、コミットされていないトランザクションに含まれる操作を打ち消す。
-
ファイル終端まで前向きにログを読み、コミットされているトランザクションをやり直す。
-
チェックポイントを作る。
理論上は最後にチェックポイントを作る必要はありませんが、整合状態にあるデータベースを保存しておけば将来のリカバリにかかる時間を節約できます。
データベースのリカバリは頻繁に起こるものではないために、リカバリは複雑なトピックであり、実装もデバッグも困難です。エドガー・ダイクストラはチューリング賞の記念講演で、「プログラミングは本質的に難しい。私たちには問題を解決する十分な能力が無いことを認めるのが最初の一歩だ」と述べています。アーキテクトそしてプログラマーとしての私たちの目標は、利用可能なツールを最大限に使うことです。つまりプログラムの設計、問題の分解、レビュー、テスト、命名規則、コードスタイルなどの良い習慣を通して、プログラミングの問題を私たちが解ける問題に落とし込むことです。
まとめ
Berkeley DB のリリースから 20 年以上が経過しています。Berkeley DB はトランザクションに対応した初の汎用キーバリューストアであり、NoSQL ムーブメントの祖父にあたります。数百の商用プロダクトと (SQL, XML, NoSQL エンジンを含む) 数千のオープンソースアプリケーションで基礎となるストレージシステムであり、地球上で数百万のデプロイを持ちます。このアプリケーションの開発と保守を通じて私たちが得た教訓は実際のコードに含まれているほか、この章の“設計講座”にもまとめました。ソフトウェア設計者やアーキテクトがこの情報を役立ててくれることを願います。