The Hadoop Distributed File System (HDFS)
Hadoop 分散ファイルシステム (Hadoop Distributed File System, HDFS) は非常に大規模なデータを高い信頼性で保存し、そのデータセットをユーザーアプリケーションに広帯域でストリームできるように設計されています。数千台のサーバーが存在する大きなクラスターであっても、ダイレクトアタッチストレージの管理とユーザーアプリケーションのタスクの実行を同時に行うことが可能です。ストレージと計算を多数のサーバーに分散させることで、リソースを必要に応じて追加しながらもサイズに関わらず無駄なく使うことができます。この章では HDFS のアーキテクチャを説明し、さらに Yahoo! において HDFS を使って 40 ペタバイトのエンタープライズデータを管理した実例についても紹介します。
導入
Hadoop1 が提供するのは、非常に大規模なデータセットを MapReduce [DG04] パラダイムを利用して解析・変形するための分散ファイルシステムおよびフレームワークです。HDFS のインターフェースは Unix のファイルシステムに似せて作ってありますが、アプリケーションのパフォーマンスを向上させるために標準に従っていない部分もあります。
Hadoop の重要な特徴は、データと計算を多数 (数千個) のホストで分け合えること、そしてアプリケーションが行う計算をデータに近い場所で並列に実行できることです。Hadoop のクラスターにおいて計算容量、ストレージ容量、I/O 帯域をスケールさせるには、コモディティのサーバーを追加するだけで済みます。Yahoo! の Hadoop クラスターは合わせて 40,000 台のサーバーを持ち、40 ペタバイトのアプリケーションデータを保持し、最大のクラスターは 4,000 台のサーバーからなります。Yahoo! 以外にも 100 以上の機関が Hadoop を使っていると報告しています。
HDFS はファイルシステムのメタデータとアプリケーションデータを別々に保存します。PVFS [CIRT00] や Lustre2、あるいは GFS [GGL03] のような他の分散ファイルシステムと同じように、HDFS がメタデータの保存するのはメタデータ専用のサーバーです。メタデータを保存するサーバーは NameNode と呼ばれ、アプリケーションデータを保存する他のサーバーは DataNode と呼ばれます。全てのサーバーは互いに完全に接続され、通信は TCP ベースのプロトコルを使って行われます。Lustre や PVFS と異なり、HDFS の DataNode は RAID などのデータの永続性を担保するための保護メカニズムを利用しません。その代わり、HDFS は GFS と同様にファイルの中身のレプリカ (複製) を複数の DataNode に作成することで信頼性を向上させます。これによってデータの永続性が保証されるのに加えてデータ転送帯域が拡大し、さらに必要なデータの近くで計算を行える可能性も高まります。
アーキテクチャ
NameNode
HDFS の名前空間はファイルとディレクトリの階層構造をしており、ファイルとディレクトリは NameNode において inode で表されます。inode には権限、変更日時、アクセス日時、名前空間、割り当てられたディスク空間といった情報が記録されます。ファイルの内容は大きなブロック (デフォルトでは 128 メガバイト、ファイルごとに設定可能) に分割され、ファイルの各ブロックのレプリカが独立して複数の DataNode (デフォルトでは 3 つ、ファイルごとに設定可能) に保存されます。NameNode は名前空間を表す木とブロックから DataNode への対応関係を管理します。現在の設計では NameNode はクラスターごとに一つです。クラスターは数千個の DataNode と数万個の HDFS クライアントを持つことができ、各 DataNode は複数のアプリケーションタスクを並列に処理します。
イメージとジャーナル
名前空間のメタデータを定義するブロックのリストと inode をまとめてイメージと呼びます。NameNode は名前空間全体のイメージを RAM 上に保持します。イメージは NameNode のローカルのネイティブファイルシステムに保存でき、この永続化されたイメージのことをチェックポイントと呼びます。HDFS が変更されるときには、NameNode が先行書き込み方式のログをローカルのネイティブファイルシステムに作成します。このログはジャーナルと呼ばれます。ブロックレプリカの場所は永続化されたチェックポイントに含まれません。
クライアントが開始したトランザクションはまずジャーナルに記録され、クライアントへの確認応答はジャーナルファイルのフラッシュと同期が完了してから行われます。NameNode がチェックポイントを変更することはできません。チェックポイントに新しいファイルが書き込まれるのは、再起動の間にチェックポイントが作られたとき、または管理者がそう命令したとき、あるいは次の節で説明する CheckpointNode からの要請があったときです。NameNode は起動時にイメージをチェックポイントを使って初期化し、その後ジャーナルに記録された変更をもう一度適用し直し、新しいチェックポイントと空のジャーナルがストレージディレクトリに書き戻されます。NameNode は以上の処理が完了してからクライアントの受け付けを開始します。
永続性を高めるために、チェックポイントとジャーナルのコピーを独立したボリュームおよびリモート NFS サーバーに保存することが多いです。独立したボリュームを使うと単一のボリューム障害から復帰できるようになり、リモート NFS サーバーを使うとノード全体の障害に対する保護が得られます。NameNode がジャーナルをいずかのストレージディレクトリに書き込むときにエラーに遭遇した場合には、そのディレクトリは自動的にストレージディレクトリのリストから削除されます。また利用可能なストレージディレクトリが存在しない場合には NameNode は自動的にシャットダウンします。
NameNode はマルチスレッドのシステムであり、複数のプロセスが複数のクライアントからのリクエストを同時に処理します。トランザクションをディスクへ保存するときにはファイルのフラッシュと同期を行う必要がありますが、この部分は同時に一つのスレッドしか実行できない同期的な処理なので、ボトルネックとなります。この部分を高速化するために、NameNode は複数のトランザクションをまとめて処理します。NameNode のスレッドの一つがファイルのフラッシュと同期を行ったときには、そのときにまとまっている分がまとめてコミットされます。残りのスレッドは自身のトランザクションが保存されているかの確認だけをすればよく、フラッシュと同期という操作を始める必要はありません。
DataNode
DataNode にあるブロックレプリカは、ローカルのネイティブファイルシステム内の二つのファイルで表されます。一つ目のファイルにはデータそのものが、二つ目のファイルにはデータのチェックサムや生成スタンプといったメタデータが含まれます。データファイルのサイズはブロックの実際の長さと等しく、伝統的なファイルシステムのように小さいブロックを埋めるための追加のスペースが必要になることはありません。例えばあるブロックの半分しか満たされていない場合には、そのブロックがローカルのドライブで占有するスペースはブロックの全長の半分です。
DataNode は起動時に NameNode に接続し、ハンドシェイクを行います。このハンドシェイクによって名前空間の ID が検証されるとともに、DataNode のソフトウェアのバージョンが確認されます。いずれかの値が NameNode と DataNode で一致しない場合には、DataNode は自動的にシャットダウンします。
名前空間 ID はファイルシステムのインスタンスに対してフォーマット時に割り振られ、クラスター内の全てのノードに永続的に書き込まれます。異なる名前空間 ID を持つノードはクラスターに加わることができず、これによってファイルシステムの整合性が保たれます。初期化されたばかりで名前空間 ID を持たない DataNode はクラスターに加わることが可能であり、そのときにはクラスターの名前空間 ID を最初に受け取ります。
ハンドシェイクを終えた DataNode は自身を NameNode に登録し、ユニークなストレージ ID を受け取ります。ストレージ ID は内部で使われる DataNode の識別子であり、ストレージに永続的に書き込まれます。これによって、再起動で DataNode の IP アドレスやポートが変更されたとしても DataNode が認識できるようになります。ストレージ ID は DataNode が NameNode に初めて登録されるときに割り振られ、以降変更されません。
DataNode は自身が持つブロックレプリカの情報を定期的に NameNode へ送信します。この情報はブロックレポートと呼ばれ、ブロック ID や生成スタンプ、ブロックレプリカの長さなどが含まれます。最初のブロックレポートが送信されるのは DataNode を登録した直後です。以降のブロックレポートは一時間ごとに送信され、NameNode にクラスター内のブロックレプリカの現在位置を提供します。
DataNode は通常の動作をしている間 NameNode にハートビート (heartbeat, 鼓動) を送り、その DataNode が動作を続けていることおよびその DataNode がホストするブロックレプリカが利用可能であることを伝えます。デフォルトのハートビートの間隔は三秒です。NameNode が DataNode からのハートビートを十分以上受け取らなかった場合、その DataNode は機能しておらず、その DataNode でホストされるブロックレプリカは利用不可能であるとみなされます。こうなった場合 NameNode はその DataNode にあるブロックの新しい複製を別の DataNode に作成する処理をスケジュールします。
DataNode からのハートビートには他にも情報が含まれ、例えば全体ストレージ容量、ストレージ利用率、実行中のデータ移動の数などがあります。これらの統計情報は NameNode におけるブロックの確保や負荷分散の判断に使われます。
NameNode がリクエストを DataNode に送るときはリクエストを直接送ることはせず、DataNode からのハートビートの返答に載せて命令を送ります。この命令の例としては、新しいブロックレプリカを他のノードに作らせる命令、ローカルのブロックレプリカを削除させる命令、ブロックレポートをすぐに送って再登録させる命令、ノードをシャットダウンする命令などがあります。
こういった命令はシステム全体の整合性を保つために重要であり、そのために大きなクラスターであってもハートビートの感覚を短くしておくことが欠かせません。NameNode は他の操作に影響を及ぼすことなく秒間数千個のハートビートを処理できます。
HDFS クライアント
ユーザーアプリケーションがファイルシステムにアクセスするときには HDFS クライアントが使用されます。HDFS クライアントは HDFS ファイルシステムのインターフェースを公開するライブラリです。
伝統的なファイルシステムの多くと同じように、HDFS はファイルの読み込み、書き込み、削除、およびディレクトリの作成、削除をサポートします。ユーザーがファイルやディレクトリを参照するときには名前空間におけるパスが使われます。ファイルシステムのメタデータとストレージが複数のサーバーにまたがっていること、あるいはブロックが複数のレプリカを持つことは、ユーザーアプリケーションが意識する必要はありません。
アプリケーションがファイルを読み込むときにはまず HDFS クライアントが NameNode にリクエストを出し、そのファイルのブロックレプリカをホストしている DataNode のリストを取得します。このときリクエストに対して NameNode から返ってくるリストはクライアントからのネットワークトポロジー距離でソートされています。その後クライアントは DataNode と直接対話し、所望のブロックの転送をリクエストします。HDFS クライアントが書き込みを行うときにはまずクライアントが NameNode にリクエストを出し、新しいファイルの最初のブロックレプリカをホストすることになる DataNode を選択します。その後クライアントがノード間のパイプラインを構成し、そのパイプラインの最初のノードに向けてデータを送ります。最初のブロックが満たされると、クライアントは新しいブロックレプリカをホストするための DataNode を選択するよう NameNode にリクエストを出します。これによって新しいパイプラインが構成され、クライアントはそのパイプラインに向けてファイルのバイト列を送信します。各ブロックに対して選択される DataNode は異なる可能性が高いです。クライアント、NameNode、DataNode の間の対話の様子を 図 8.1 に示します。
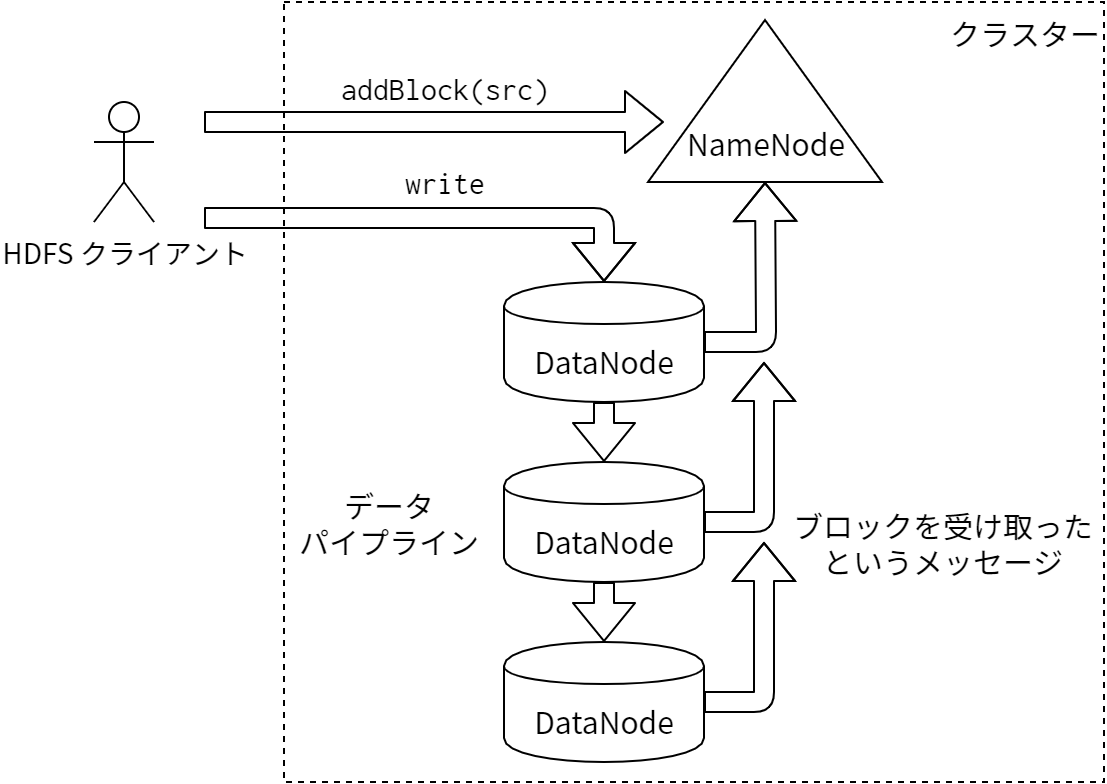
通常のファイルシステムとは異なり、HDFS にはファイルブロックの場所を公開する API があります。MapReduce フレームワークのようなアプリケーションがこの API を使うと、データがある場所でタスクがスケジュールされるようになり、読み込みのパフォーマンスが向上します。またファイルの複製の数をアプリケーションから設定することも可能です。デフォルトでは 3 ですが、重要なファイルや頻繁にアクセスされるファイルについては高い値を設定することで、障害耐性と読み込み帯域の増加を見込めます。
CheckpointNode
HDFS の NameNode が持つ最も重要な役割はクライアントからのリクエストに対応することですが、NameNode は他にも CheckpointNode あるいは BackupNode になることもできます。どれになるかは起動時に決定されます。
CheckpointNode の役割は、定期的に既存のチェックポイントとジャーナルを統合し、新しいチェックポイントと空のジャーナルを作成することです。CheckpointNode は NameNode と同程度のメモリを使用するので、通常は NameNode とは異なるホストで実行されます。CheckpointNode は一番新しいチェックポイントとジャーナルファイルを NameNode からダウンロードし、ローカルでマージ処理を行い、新しいチェックポイントを NameNode に送り返します。
チェックポイントを定期的に作成すると、ファイルシステムのデータを保護できます。起動時にシステムのイメージとジャーナルのディスク上にあるコピーが利用できない場合、システムは直近のチェックポイントから開始されるからです。また新しく作成されたチェックポイントが NameNode にアップロードされた時点で、NameNode はジャーナルを切り詰めることができます。長い間再起動することなく稼働し続ける HDFS クラスターではジャーナルが一定の速度で成長し続けますが、ジャーナルがとても大きくなると消失や破損の可能性が高まります。加えて巨大なジャーナルがあると NameNode を再起動するときの時間が長くなります。大規模なクラスターでは一週間のジャーナルを処理するのに一時間かかるのも普通です。一日ごとにチェックポイントを作るのが良いとされています。
BackupNode
BackupNode は最近になって HDFS に追加された機能です。CheckpointNode と同様に BackupNode も定期的なチェックポイントの作成を行います。CheckpointNode と異なるのが、BackupNode はファイルシステム名前空間の最新のイメージをメモリ上に保存し、それが常に NameNode の状態と同期している点です。
BackupNode はアクティブな NameNode からジャーナルのストリームを受け取ります。このストリームには名前空間におけるトランザクションが含まれており、これによって BackupNode が自身のストレージディレクトリにジャーナルを保存する手間が省けます。ジャーナルを受け取った BackupNode はそれが表すトランザクションをメモリ上の名前空間イメージに適用します。NameNode は BackupNode を保存されたジャーナルとして扱います。つまり NameNode から見れば、BackupNode は自身のストレージディレクトリにあるジャーナルファイルと同じだということです。NameNode に障害が起こった場合には、BackupNode のメモリ上にあるイメージとディスク上にあるチェックポイントが名前空間の状態の最新の記録となります。
BackupNode は NameNode からイメージとジャーナルファイルをダウンロードすることなくチェックポイントを作成できます。なぜならメモリ上に最新の名前空間のイメージがあるからです。このため BackupNode におけるチェックポイントの作成処理は名前空間をストレージディレクトリに保存するだけであり、より効率的になります。
BackupNode を読み込み専用の NameNode と考えることもできます。BackupNode はブロックの場所を除く全てのファイルシステムのメタデータを持ち、名前空間の変更やブロックの場所に関するものを除けば通常の NameNode が行う全ての操作を行うからです。BackupNode を使えば、名前空間の状態の永続化する責任を BackupNode に任せ、NameNode を永続ストレージなしで運用することも可能です。
アップグレードとファイルシステムのスナップショット
ソフトウェアアップグレードの際には、ソフトウェアのバグやヒューマンエラーによるファイルシステムの破損の可能性が高まります。HDFS においてスナップショットを作るのは、アップグレードの間にシステム内のデータに起こる可能性のある損害を最小化するためです。
クラスター管理者はスナップショットを使うことで現在のファイルシステムの状況を永続的に保存できます。こうしておけばアップグレードの結果データの損失や破損が生じたとしても、アップグレードをロールバックして HDFS の名前空間とストレージの状態をスナップショット時のものに戻すことができます。
スナップショットはシステム開始時にクラスター管理者の指示によって作成されます (一つしか作成できません)。スナップショットが要請されると、NameNode はまずチェックポイントとジャーナルファイルを読んでメモリ上でマージし、その後新しいチェックポイントと空のジャーナルを新しい場所に書き込みます。元の古いチェックポイントとジャーナルは変更されません。
その後ハンドシェイクの間に NameNode は DataNode にローカルのスナップショットを作るべきかどうかの指示を出します。DataNode におけるローカルのスナップショットは、データファイルを含むディレクトリをまるごと複製して作ることはできません。もしそうした場合、クラスター内の全ての DataNode において倍のストレージ容量が必要になってしまうからです。DataNode はその代わりストレージディレクトリのコピーを作成し、そこから既存のブロックに向けてハードリンクを張ることでスナップショットを作成します。その後 DataNode がブロックを取り除いた場合にはハードリンクだけを取り除き、ブロックが追記によって変更された場合にはコピーオンライトのテクニックを使います。こうすることで元の古いブロックレプリカは元のディレクトリで変更されずに残るという仕掛けです。
クラスター管理者はシステムを再起動するとき、HDFS をスナップショットまでロールバックするかどうかを選択できます。ロールバックを選択した場合 NameNode はスナップショットが作成された時点におけるチェックポイントを読み込みます。DataNode は以前に変更されたディレクトリを復元し、スナップショットより後に作られたブロックレプリカを削除するバックグラウンドプロセスを起動します。このためロールバックを選択すると、それ以降ロールフォワードはできなくなります。スナップショットを破棄してストレージの容量を取り戻すようクラスター管理者が指示を出すこともできます。ソフトウェアアップグレードの際に作られるスナップショットに対しては、この処理によってアップグレードが終了します。
システムが進化するにつれ、NameNode のチェックポイントやジャーナルファイルのフォーマットが変更されたり、DataNode のブロックレプリカファイルのデータ表現が変更されたりすることがあります。レイアウトバージョンとはデータ表現のフォーマットを指定するための値であり、NameNode と DataNode のストレージディレクトリに永続的に保存されます。起動時に各ノードは現在ソフトウェアが使用しているレイアウトバージョンとストレージディレクトリに保存されているレイアウトバージョンを比較し、古いフォーマットから新しいフォーマットへの変換を自動的に行います。ソフトウェアのレイアウトバージョンが更新された状態でシステムが再起動した場合には、この変換のときにスナップショットが必ず作成されます。
ファイル I/O 操作とレプリカの管理
疑いなく、ファイルシステムの存在意義はファイルにデータを保存することです。HDFS がどのようにファイルにデータを保存しているかを理解するために、まず読み込みと書き込みがどのように動作するか、そしてブロックがどう管理されるかを見ます。
ファイルの読み込みと書き込み
アプリケーションは新しいファイルを作ってそこにデータを書き込むことで HDFS にデータを追加します。ファイルが一度閉じられた後は、書き込まれたバイト列を書き換えたり削除したりするのは不可能であり、可能なのはファイルをもう一度開いて追記を行うことだけです。HDFS は単一書き込み複数読み込み (single-writer, multiple-reader) モデルを採用しています。
書き込みのためにファイルを開いた HDFS クライアントにはそのファイルに対するリース (lease) が付与され、ファイルが開かれている間は他のクライアントがそのファイルに書き込むことができません。書き込みを行っているクライアントは NameNode にハートビートを送ることで定期的にリースを更新し、ファイルが閉じられた段階でリースは取り消されます。リースの期間はソフトリミットとハードリミットによって制限されます。ソフトリミットまでの間は、書き込みを行うクライアントはファイルへの独占的なアクセス権を持ちます。ファイルを閉じることもリースが更新されることもなくソフトリミットを迎えた場合、他のクライアントがそのリースを横取りできるようになります。さらに一時間のハードリミットを過ぎてもクライアントがリースを更新しなかった場合には、HDFS はクライアントが切断したと判断し、クライアントが開いているファイルを自動的に閉じ、リースを利用可能にします。なお書き込みのためのリースが取られていたとしても他のクライアントからファイルを読むことは可能です。複数のクライアントが同じファイルを読むこともできます。
HDFS ファイルはブロックからなります。新しいブロックが必要になった場合、NameNode は新しいブロックをアロケートし、ユニークなブロック ID を割り当て、そのブロックのレプリカをホストする DataNode のリストを設定します。ここで選ばれた (複数の) DataNode から、クライアントから最後の DataNode までの距離が最小化されるように並んだパイプラインが形成されます。バイト列はパイプラインにパケット列としてプッシュされます。アプリケーションは最初クライアントにあるバッファにバイト列を書き込み、バッファ (通常は 64 KB) が満たされると、そのデータがパイプラインにプッシュされます。次のパケットは前のパケットの確認応答を受け取る前にパイプラインにプッシュできます。許される未完了パケットの数は、クライアントの未完了パケットウィンドウのサイズで制限されます。
HDFS ファイルにデータが書き込まれたとしても、そのファイルが閉じられない限り読み込みが新しいデータを読むとは保証されません。ユーザーのアプリケーションが新しいデータを利用可能にする必要がある場合には、hflush 操作を明示的に呼ばなければなりません。この操作を受けたクライアントは現在のパケットをすぐにパイプラインにプッシュし、パイプライン上の全ての DataNode からのパケット送信成功の応答を受け取るまでブロックします。これによって hflush 操作の前に書き込まれた全てのデータが読み込みを行うクライアントから利用可能なことが保証されます。
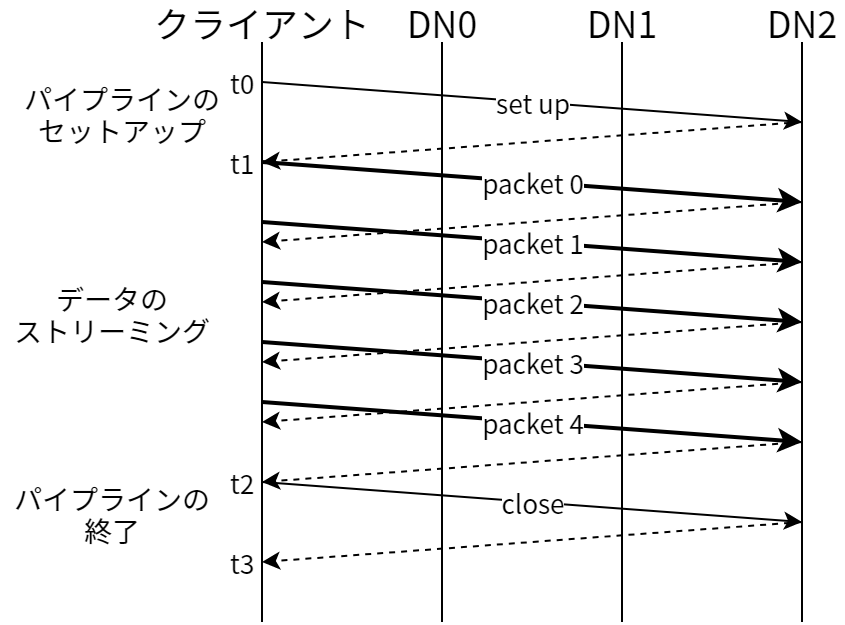
エラーが何も起きなければ、ブロックは 図 8.2 に示す三つの段階を踏んで作られます。この図には三つの DataNode (DN) からなるパイプラインに五つのパケットを送る様子が描かれています。横向きの太線がデータパケットを、横向きの破線が確認応答メッセージを、横向きの細い線がパイプラインのセットアップと終了に関する制御メッセージをそれぞれ表します。垂直な線はクライアントと三つの DataNode におけるアクティビティを表し、時間は上から下に流れます。 t0 と t1 の間はパイプラインのセットアップステージです。 t1 と t2 の間はデータのストリーミングステージであり、 t1 が最初のデータパケットが送られる時刻、 t2 が最後のデータパケットに対する確認応答を受信する時刻となっています。ここで packet 2 は hflush 操作によって送信されています。hflush の指示はパケットデータと一緒に送られ、異なる操作とはなっていません。最後の t2 から t3 までの間はこのブロックに対するパイプラインを終了する処理です。
数千のノードを持つクラスターではノードの障害が毎日のように発生します。 DataNode に保存されているレプリカは、メモリ、ディスク、ネットワークの故障によって破損しかねません (一番よくあるのはストレージの故障)。破損を早期に発見するために、HDFS にはファイルの各データブロックについてチェックサムの生成、保存を行う仕組みがあります。チェックサムは HDFS クライアントがファイルを読み込むときに確認され、クライアント、DataNode、ネットワークが原因のデータ破損が検出されます。クライアントは HDFS ファイルを作成するときに各ブロックに対するチェックサムを計算し、データと共に DataNode に送ります。DataNode はそのチェックサムをブロックのデータファイルとは異なるメタデータファイルに保存します。HDFS がファイルを読むときには各ブロックのデータとチェックサムがクライアントに送られます。クライアントは受け取ったデータに対するチェックサムを計算し、このチェックサムが受け取ったチェックサムと同じことを確認します。もし二つのチェックサムが同じでなかった場合にはクライアントから NameNode にレプリカの破損を通知し、そのブロックを他の DataNode にある別のレプリカからフェッチします。
クライアントは読み込みのためにファイルを開くのに先立って、ファイルに含まれるブロックのリストとそれぞれのブロックレプリカの場所を NameNode からフェッチします。NameNode が返す各ブロックの場所はクライアントからの距離でソートされており、そのためクライアントがブロックの内容を読み込むときにはまず一番近くにあるレプリカを最初に試し、その読み込みが失敗したら次のレプリカを試すことになります。読み込みが失敗するのは対象の DataNode が存在しないとき、またノードがブロックレプリカのホストをやめていたとき、あるいはチェックサムのテストした結果レプリカが破損していたときです。
クライアントは HDFS のファイルを開いて書き込むことができます。書き込み用に開かれているファイルを読む場合、書き込みが行われている最後のブロックの長さは NameNode に伝わっていません。この場合、クライアントはレプリカのいずれかに最新のブロックの長さを尋ねてから読み込みを開始することになります。
HDFS の I/O の設計は MapReduce などのバッチ処理システムのために最適化されています。このようなシステムにおいては、連続する領域に対する読み書きに高いスループットが求められます。性能を改善する作業は現在でも続いており、リアルタイムのデータストリーミングやランダムアクセスを必要とするアプリケーションにおける読み込み/書き込みのレスポンス時間が向上する予定です。
ブロックの配置
巨大なクラスターでは全てのノードをフラットなトポロジーで結ぶのが現実的でないことがあり、そのような場合にはノードを複数のラック (rack) を使ってノードを分割することが多いです。異なるラックに属する二つのノードの間の通信は一つ以上のスイッチを経由して行われます。ほとんどの場合おいて、同じラックに属するノード間のネットワーク帯域は異なるラックに属するノード間の帯域より広くなります。図 8.3 に二つのラックからなるクラスターの例を示します。ここでは両方のラックに三つのノードが含まれます。
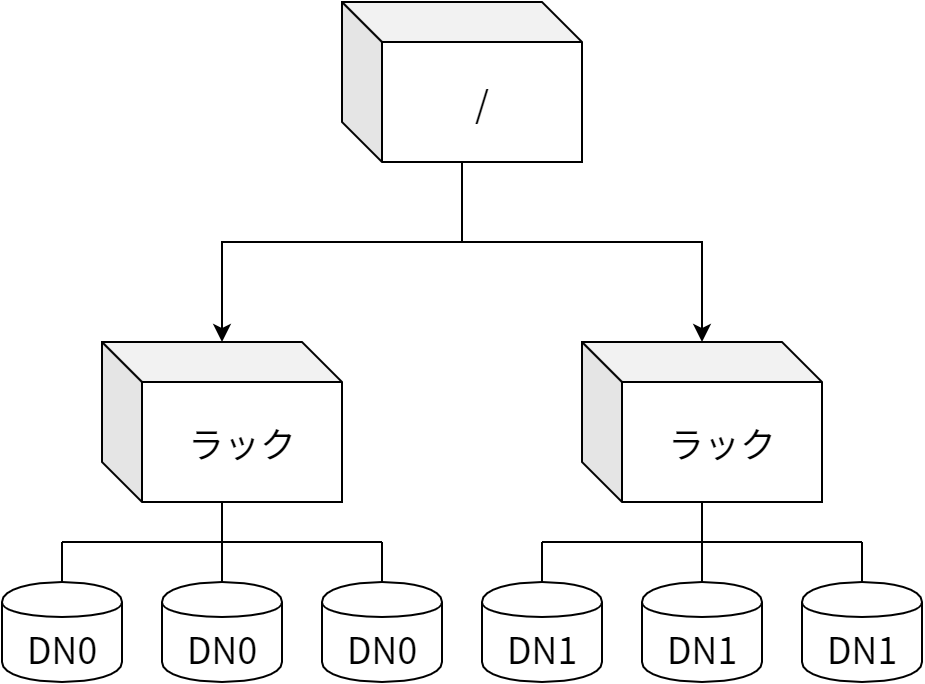
HDFS は二つのノード間のネットワーク帯域をノード間の距離で推定します。ノードからその親への距離が 1 と仮定され、二つのノード間の距離は一番近い共通祖先への距離の和として計算されます。短いノード間の距離はデータ転送のための帯域が広いことを意味します。
HDFS では、ノードのアドレスを受け取ってそのノードが属するラック ID を返すスクリプトを管理者が設定できます。DataNode のラック ID の検索処理が主に行われるのは NameNode です。DataNode が NameNode に登録されるとき、NameNode は設定されたスクリプトを実行してそのノードがどのラックに属するのかを計算します。スクリプトが設定されていない場合には、全てのノードがデフォルトの単一のラックに属するものとみなされます。
レプリカの配置は HDFS におけるデータの信頼性と読み込み/書き込み性能のために非常に重要です。適したレプリカの配置ポリシーを使うと、データの信頼性、可用性、ネットワーク帯域が向上します。現在の HDFS にはブロックの配置ポリシーは設定するためのインターフェースがあるので、ユーザーと研究者はアプリケーションに応じた最適のポリシーを実験、テストできます。
HDFS のデフォルトのブロック配置ポリシーは、書き込みコストの最小化とデータの信頼性と可用性、そして読み込み集約帯域 (aggregate bandwidth) の間のトレードオフを提供します。新しいブロックが作られるとき、HDFS は一つ目のレプリカをライターのあるノードに配置し、二つ目と三つ目のレプリカを一つ目とは異なる単一のラックの異なるノードに配置します。残りのレプリカはランダムなノードに配置されますが、そのときは全てのラックに一つずつレプリカが含まれ、かつ各ラックには二つまでしかレプリカが含まれないという制限が可能な限り満たされるように配置されます。二つ目と三つ目のレプリカを配置するときに異なるラックに属するノードに配置することで、一つのファイルに対するブロックレプリカがクラスター内に広く分散されます。もし最初の二つのレプリカが同じラックに配置されたとすると、ブロックレプリカの三分の二が同じラックに存在することになってしまいます。
ターゲットノードの選択が完了すると、ノードは一つ目のレプリカからの距離の順に並んだパイプラインに並べられ、データがこの順番にプッシュされます。読み込みのときには NameNode がまずクライアントのホストがクラスターに属しているかを調べ、もし属しているならそのホストからの距離でソートされたブロックの配置が返され、その後ブロックの読み込みはこの順番で試行されます。
このポリシーによってラック間およびノード間の書き込みトラフィックが減少し、一般的な書き込み性能が向上します。またラックの障害はノードの障害よりもはるかに起こる確率が低いので、このポリシーはデータの信頼性と可用性にも良い影響をもたらします。さらに三つのレプリカを使う通常のケースでは、読み込みを行うときのネットワークの集約帯域が減少します。というのも、ブロックが (三つではなく) 二つのラックだけに存在するためです。
レプリカの管理
NameNode は全てのブロックが持つレプリカの数を常に一定に保とうとします。つまり NameNode は DataNode からのブロックレポートが到着するたびに、そのブロックのレプリカの数が既定の数から離れていないかどうかをチェックします。レプリカの数が多くなっていれば、NameNode はレプリカの削除を行います。そのとき NameNode はレプリカをホストするラックの数を減らさないように削除を行い、さらにディスクの空き容量が一番少ない DataNode にあるレプリカを優先して削除します。ここでの目標は DataNode 全体のストレージ使用量をブロックの可用性を落とすことなく最適化することです。
ブロックレプリカの数が少なくなった場合には、そのブロックがレプリケーションの優先キューに追加されます。レプリカを一つだけしか持たないブロックが一番高い優先度を持ち、レプリカが最大数の三分の二以上あるブロックが一番低い優先度を持ちます。バックグラウンドのスレッドが定期的にレプリケーションの優先キューの先頭をスキャンし、新しいレプリカをどこに配置するかを判断します。ブロックのレプリケーションで使われるポリシーは新しいブロックの配置で使われるものと同様です。つまり、既存のレプリカが一つだけなら、HDFS は次のレプリカを異なるラックに配置します。既存のレプリカが二つで、その二つが同じラックにあるなら、三つ目のレプリカは異なるラックに配置されます。そうでない場合には、二つのノードがあるラックのどちらかに配置されます。ここでの目標は新しいレプリカを作るコストを抑えることです。
NameNode はあるブロックの全てのレプリカが一つのラックにあるという状況を避けようとします。そのような状況が起こった場合 NameNode はブロックの配置に修正が必要だと判断し、ブロックの新しいレプリカを上記のポリシーを使って他のラックに作成します。このレプリカが作成されたという通知を受け取るとそのブロックに対するレプリカが多すぎる状態になるので、NameNode はラックの数を減らさないよう古いレプリカのどれかを削除します。
バランサー
HDFS のブロック配置戦略は DataNode のディスク使用量を考慮しません。これは新しい (したがって参照される可能性の高い) データが空きディスク容量の大きい DataNode に集中してしまうのを避けるためです。そのためデータが全ての DataNode に均一に配置されるとは限らず、新しいノードがクラスターに追加されたときにもデータ配置の偏りがすぐに解決されるわけでもありません。
バランサーというツールを使うと HDFS クラスター内のディスク使用量のバランスを取ることができます。このツールは 0 から 1 までの閾値を入力として受け取り、ノードの使用量3がクラスター全体の使用量4からその閾値よりも離れていないときに限ってノードのバランスが取れていると判断します。
バランサーツールはクラスター管理者が実行できるアプリケーションプログラムとしてデプロイされ、使用量の高い DataNode から使用量の低い DataNode にレプリカを移動させる処理を反復します。バランサー重要な要件は、データの可用性を保つことです。移動するレプリカとその目的地を選択するときは、レプリカの数やラックの数が減らないように選択が行われます。
バランサーはバランス処理を最適化するためにラック間のデータコピーを最小化します。例えばバランサーがレプリカ A を異なるラックに移動することを決定し、そのラックに同じブロックの異なるレプリカ B があった場合には、データはレプリカ A ではなくてレプリカ B からコピーされます。
バランス処理に使われる帯域は設定可能なパラメータで制限できます。帯域を広くすればそれだけクラスターが速くバランスの取れた状態になりますが、それだけ帯域がアプリケーションプロセスと競合します。
ブロックスキャナー
それぞれの DataNode はブロックスキャナーを実行します。このプログラムはノードが持つブロックレプリカを定期的にスキャンし、保存されたチェックサムがブロックデータと一致することを確認します。スキャンを設定された期間で終了させるために、ブロックスキャナーは読み込み帯域の最適化を行います。例えばクライアントがブロック全体を読んであるレプリカのチェックサムの検証を行った場合には、そのことを DataNode に通知させ、レプリカの検証を飛ばせるようにします。
各ブロックの検証を行った時刻は人間が読める形式のログファイルに保存されます。DataNode のトップレベルディレクトリには現在のログと前回のログを表すファイルがあり、新しい検証時刻は現在のログファイルに追記されます。これに対応して DataNode は検証時刻でソートされたレプリカのリストをメモリ上に持ち、スキャンで利用します。
読み込みを行うクライアントもしくはブロックスキャナーが破損したブロックを見つけると、NameNode に通知が送られます。NameNode はそのレプリカに破損したと印を付けますが、レプリカをすぐに削除するわけではありません。NameNode はまずそのブロックの破損していないレプリカを作成するところから始めます。このレプリカが作成され、レプリカの数が規定よりも多くなってはじめて、破損されたレプリカの削除がスケジュールされます。このポリシーを使うことで、仮にブロックのレプリカが全て破損したとしても、その破損した複数のレプリカからデータを取り出すことが可能になります。
ノードの廃止
クラスター管理者は廃止予定のノードのリストを指定できます。廃止 (decommission) の印が付いた DataNode はレプリカが配置されなくなりますが、読み込みリクエストにはこれまで通り答え続けます。NameNode は廃止予定の DataNode にあるブロックを別の DataNode にコピーする処理のスケジュールを開始し、全てのブロックがコピーされたことを NameNode が確認すると、廃止予定の DataNode は decommissioned 状態となります。この状態にある DataNode はデータの可用性を脅かすことなく安全にクラスターから切り離すことが可能です。
クラスター間のデータコピー
大きなデータセットを扱っている場合、データを HDFS クラスターの外にコピーする処理には大きな手間がかかります。HDFS にはクラスター間およびクラスター内の大規模な並列コピーのための DistCp と呼ばれるツールがあります。この処理は MapReduce ジョブであり、マップの各タスクがソースデータの一部を目的地のファイルシステムにコピーします。MapReduce フレームワークが並列タスクのスケジューリングを自動的に行い、エラーの検出とリカバリも行います。
Yahoo! における実例
Yahoo! で使われている大規模 HDFS クラスターには約 4,000 個のノードが含まれます。多くのクラスターノードは 2.5 GHz で動作するクアッドコア Xeon プロセッサを二つ、直接接続された SATA ドライブ (2 テラバイト) を 4-12 台、24 ギガバイトの RAM、1 ギガビットのイーサネット接続を持ちます。ディスク容量の 70 % が HDFS のために確保され、残りの部分はオペレーティングシステム (Red Hat Linux)、ログ、マップタスクの出力の分割のために予約されています (MapReduce の中間データは HDFS に保存されません)。
一つのラックには 40 個のノードがあり、一つの IP スイッチを共有します。ラックのスイッチは八個のコアスイッチ全てに接続されます。コアスイッチはラックとクラスター外のリソースとの間の接続を提供します。各クラスターで NameNode と BackupNode をホストするノードには最大で 64 GB のメモリが付いています。これらのホストにアプリケーションタスクが割り当てられることはありません。4,000 ノードからなるクラスターでは全体で 11 PB (ペタバイト = 1000 テラバイト) のストレージが利用可能であり、ブロックが三つのレプリカを持つ設定であれば 3.7 PB のストレージがユーザーアプリケーションから使用可能ということになります。
HDFS は長い間使用されており、クラスターノードは技術の進歩の恩恵を受けてきました。新しく追加されるクラスターノードは必ず高速なプロセッサ、大きなディスク、大きな RAM を持っているからです。遅くて小さな古いノードは引退するか、Hadoop の開発やテスト用に回されます。
例として取り上げてきた大きなクラスター (4,000 ノード) には 6,500 万個のファイルと 8,000 万個のブロックが含まれます。各ブロックは通常三つのレプリカを持つので、各 DataNode は約 60,000 個のブロックレプリカを持ちます。ユーザーアプリケーションは毎日 200 万個のファイルをクラスター上に作成します。Yahoo! にある Hadoop クラスター全体では 40,000 個のノードが 40 PB のオンラインデータストレージを提供しています。
Yahoo! が保有する技術の中でも重要なコンポーネントとなった HDFS が直面してきた問題は、研究プロジェクトが考える問題とは質が異なります。数ペタバイトの企業データを管理する上で一番優先されるのは、データの堅牢性と永続性だからです。ただしそうは言っても、経済的パフォーマンスやユーザーコミュニティのメンバー間での資源の共有、そしてシステムオペレーターによる管理のしやすさもまた重要です。
データの永続性
レプリカを三つ持つことは、相関性の無いノード障害によるデータの消失に対する頑健な防御と言えます。この種のノード障害が原因で Yahoo! がデータを今までに消失した可能性はとても低いです。大規模なクラスターにおいてでさえ、一年の間に一ブロックを消失する可能性は 0.005 以下です。これを説明する上で鍵となる数字は月ごとにノードで障害が起こる確率であり、その値は 0.8 % です (障害を起こしたノードがしばらくしてリカバリしたとしても、ホストするデータをリカバリするための処理は行われません)。そのため上で例として示したクラスターにおいては、一つか二つのノードで毎月障害が起こるということになります。しかし障害が起きたこのノードでホストされていたブロックレプリカの再作成にかかる時間は約二分です。レプリカの再作成が高速なのはこれが並列な問題であり、クラスターのサイズに応じてスケールするためです。この二分の間に別のノードでさらに障害が起こり、ブロックのレプリカが全て失われる確率というのはとても小さくなります。
相関性のある障害はまた別の種類の脅威です。この種の障害として最もよく見られるのは、ラックやコアスイッチの障害です。HDFS にはラックスイッチの障害に対する耐性があります (各ブロックが異なるラックにレプリカを持ちます)。しかしコアスイッチの障害によって複数のラックを含むクラスターの一部分が事実上切断されるというのはあり得ない話ではなく、そのような場合には一部のブロックが利用不可能になる可能性があります。いずれのケースにおいても、スイッチを直せば利用不可能なレプリカをクラスターに復活させることができます。相関性のある障害のもう一つの例は、クラスターへの電力供給の消失です。これは事故による消失も意図的な消失も考えられます。この場合でも電力消失がラックをまたぐならば、一部のブロックが利用不可能になる可能性があります。しかし電力の障害がスイッチやラックの障害と異なるのは、電力を回復しただけでは障害が解決しない点です。というのも、0.5 % から 1 % のノードは完全に電源を落とした後の再起動に失敗するからです。統計上、そして実際のデータからも、大規模なクラスターでは電源を落とした後の再起動で一部のブロックが消失することが分かっています。
ノードで起こる完全な障害に加えて、保存されたデータが破損、消失することがあります。大規模なクラスターではブロックスキャナーが二週間ごとに全てのブロックをスキャンしますが、この処理中に約 20 個のレプリカで破損を発見します。破損したレプリカは見つかった時点で再配置処理に回されます。
HDFS を共有するための機能
HDFS の利用が広がるにつれ、HDFS と多数の多様なユーザーとの間でリソースを共有する手段が必要になりました。このために最初に追加された機能は権限フレームワークであり、これは Unix がファイルとディレクトリに使う権限スキームによく似ています。このフレームワークでは、ファイルとディレクトリの所有者、ファイルとディレクトリに設定されたグループの他のメンバー、他のユーザーの三つに対して異なるアクセス権限がそれぞれ付与されます。HDFS のフレームワークと Unix (POSIX) の一番の違いは、HDFS の通常ファイルが実行権限とスティッキービットを持たない点です。
初期バージョンの HDFS がユーザーを識別する仕組みは貧弱で、クライアントの身元はホストが指定するものでした。アプリケーションクライアントはローカルのオペレーティングシステムにユーザーの身元情報と属しているグループを尋ねていたのです。これに対して新しいフレームワークでは、アプリケーションクライアントは信頼できるソースから入手した身元証明書を提示しなければなりません。様々な身元証明書の方式が利用可能であり、最初の実装は Kerberos を使っていました。同じフレームワークを使ってユーザーアプリケーションからネームシステムが信用できることを確認することも可能です。さらにネームシステムからクラスター内の各データノードに対して証明書を要求できます。
HDFS で利用可能なデータストレージの全体容量はデータノードの数と各ノードに割り当てられたストレージ容量で決まります。初期の HDFS での経験から、ユーザーコミュニティをまたいだ何らかのリソース確保ポリシーが必要なことが分かっていました。負担するリソースの公平性は重要ですが、それだけではなくユーザーアプリケーションが数千個のホストとやりとりをしながらデータを書き込む場合に誤ってリソースを使い切ってしまわないための防御策も重要です。HDFS ではシステムのメタデータが常に全て RAM に乗るので、名前空間のサイズ (ファイルとディレクトリの数) が有限のリソースだからです。ストレージと名前空間のリソースの管理のために、各ディレクトリにはそのディレクトリ以下の名前空間が占めることができる最大容量が割り当てられています。サブツリーのディレクトリの容量を設定することも可能です。
HDFS のアーキテクチャはアプリケーションからの入力が大きなデータストリームであることを想定しています。これに対して MapReduce というプログラミングフレームワークは大量の小さなファイル (一つの reduce タスクにつき一つ) を生成しがちであり、これによって名前空間のリソースがさらに圧迫されます。これに対処するために、ディレクトリのサブツリーを一つの Hadoop Archive (HAR) ファイルとする機能があります。HAR ファイルは tar、JAR、Zip といったよくある圧縮ファイルと似ていますが、ファイルシステムの操作がアーカイブの中のファイルを直接参照できる点が異なっています。また HAR ファイルを MapReduce ジョブの入力としてそのまま使うこともできます。
スケーリングと HDFS の統合
NameNode のスケーラビリティは大きな問題となってきました [Shv10]。NameNode が全ての名前空間とブロックの場所をメモリに納めなければならないことから、管理できるファイルとブロックの数が NameNode のヒープによって制限されてしまうのです。これはさらにクラスターストレージの全体容量に対する制限にもなります。ユーザーは大きなファイルを作ることが望ましいのですが、これを実現するにはアプリケーションの動作を変更しなければならず、行われたことはありません。HDFS を使った新しい種類のアプリケーションで小さいファイルを大量に保存する必要のあるものも出現しています。使用量の管理のために制限を割り当てる機能が追加され、アーカイブツールも提供されていますが、これらはスケーラビリティの問題を本質的に解決するものではありません。
HDFS に新しく追加された機能を使うと、独立した複数の名前空間 (および NameNode) がクラスター内の物理ストレージを共有できます。名前空間が使うブロックはブロックプール (Block Pool) にまとめられます。ブロックプールは SAN ストレージシステムにおけるロジカルユニット (LUN) と同じものです。名前空間とそのブロックプールをまとめたものがファイルシステムボリュームに対応します。
このアプローチにはスケーラビリティの他にもいくつか利点があります。まず異なるアプリケーションの名前空間を切り離すことで、クラスター全体の可用性が向上します。さらにブロックプールという抽象化によって他のサービスからもブロックストレージを利用可能になります (名前空間の構造が異なっていても構いません)。スケーラビリティのための他のアプローチを調査する予定もあります。例えば名前空間の一部だけをメモリに格納したり、NameNode の実装を完全に分散させるたりするものです。
アプリケーションは単一の名前空間を使い続けるのを好むので、名前空間をマウントして統合されたビューを作るこのtも可能になっています。このマウントを行うときにはサーバーサイドのマウントテーブルよりもクライアントサイドのマウントテーブルを使った方が効率が良く、さらに中央マウントテーブルへの RPC が無くなって障害耐性が向上します。もっとも単純なアプローチはクラスター全体で共有する名前空間を持つことであり、これはクラスターの全てのクライアントに同じクライアントサイドのマウントテーブルを与えることで実現できます。その後アプリケーションはクライアントサイドのマウントテーブルを使ってプライベートな名前空間ビューを作成することも可能です。これは分散システムにおける遠隔実行で使用されるプロセス名前空間 (per-process namespace) と同様のテクニックです [PPT+93, Rad94, RP93]。
教訓
とても小さいチームが Hadoop ファイルシステムを作り上げ、プロダクションでの利用に耐えるほどの安定性と堅牢性を達成しました。この成功の大部分はそのごく単純なアーキテクチャによるものです。つまりブロックレプリカ、定期的なブロックレポート、中央メタデータサーバーといった概念です。POSIX の動作を完全に踏襲しなかったことも役立ちました。全体のメタデータをメモリに保存することで名前空間のスケーラビリティは制限されましたが、これによって NameNode は非常に単純になりました。例えば通常のファイルシステムで見られる複雑なロックは存在しません。Hadoop が成功した理由をもう一つあげるとすれば、それは Yahoo! におけるプロダクション用のシステムとして初期から使用されていたことです。これによって Hadoop はインクリメンタルに素早く改善されました。現在のファイルシステムは非常に堅牢であり、NameNode の障害はまず起こりません。実際ダウンタイムのほとんどはソフトウェアのアップグレードによるものです。フェイルオーバーのための (手動の) ソリューションが搭載されたのもつい最近のことでした。
私たちがスケーラブルなファイルシステムの構築に Java を選択したことは多くの人を驚かせたようです。Java のオブジェクトメモリのオーバーヘッドやガベージコレクトが原因で NameNode のスケーリングにおいて困難を抱えたのは確かですが、ポインタやメモリ管理のバグによる障害を無くせる Java がシステムの堅牢性を支えたというのも事実です。
謝辞
Hadoop に投資し、Hadoop をオープンソースとして利用可能にしてくれている Yahoo! に感謝します。HDFS と MapReduce のコードの 80 % は Yahoo! で開発されたものです。また価値あるコントリビューションを提供してくれる Hadoop のコミッターとコラボレーターにも感謝します。