CMake
1999 年、アメリカ国立医学図書館が Kitware という小さな会社と契約し、異なるプラットフォームにおいて複雑なソフトウェアを構成、ビルド、デプロイするためシステムの刷新を決定しました。これは Insight Segmentation and Registration Toolkit (ITK1) の一部であり、Kitware はこのプロジェクトにおいてエンジニアリングを指揮していました。Kitware に課されたのは ITK の研究者と開発者が使うためのビルドシステムの作成であり、簡単に使うことができて利用者がプログラミングに費やす時間を最大限効率化できるシステムが求められました。CMake はこの目標を達成するために作られたツールであり、autoconf/libtool を使ったソフトウェアビルドの古いアプローチを置き換えるものです。既存のツールの強みを保ちつつも弱点を補うように設計されています。
長い開発期間を経て CMake はビルドシステムを超えた開発ツールの集合体に進化し、CTest, CPack, CDash といったプログラムが開発されました。CMake はソフトウェアのビルドを行うビルドツールであり、CTest は回帰テストを実行するテストドライバツール、CPack は CMake でビルドされたソフトウェアの各プラットフォーム用のインストーラを作成するのに使うパッケージツールです。CDash はテスト結果の表示や継続的インテグレーションテストを実行するためのウェブアプリケーションです。
CMake の歴史と求められていたもの
CMake の開発が始まった当時、プロジェクトをビルドするときに普通使われるのは Unix では configure スクリプトと Makefile、Windows では Visual Studio プロジェクトファイルでした。ビルドシステムが二つあるために多くのプロジェクトにとってクロスプラットフォームの開発は本当にうんざりするものであり、新しいソースファイルを一つ追加することさえ苦労が伴いました。統合されたビルドシステムを作るという問題に対して、当時の CMake の開発者たちが経験していたアプローチが二つあります。
一つ目のアプローチは 1999 年に作られた VTK というビルドシステムです。このシステムは Unix に対する configure スクリプトと Windows に対する pcmaker という実行形式からなっていました。 pcmaker は Unix Makefile を読んで Windows 用の NMake ファイルを作成する C プログラムであり、 pcmaker はバイナリ実行形式ごと VTK の CVS システムレポジトリにチェックインされていました。いくつかの意味では統合ビルドシステムと言えないこともありませんでしたが、ライブラリの追加などの一般的な操作にソースの変更と新しいバイナリのチェックインが必要となるなど、欠点も多くありました。
CMake の開発者たちが経験していたもう一つのアプローチは、TargetJr で使われていた gmake ベースのビルドシステムです。TargetJr は C++ で書かれたコンピュータービジョン環境であり、もともとは Sun のワークステーションで開発されていました。TargetJr は最初 imake を使って Makefile を作成していましたが、開発のある時点で Windows への移植が必要になり、 gmake を使ったビルドシステムが後から作られたという歴史があります。この gmake ベースのビルドシステムならば Unix コンパイラと Windows コンパイラの両方を使うことが可能でした。このシステムでは gmake を実行する前にいくつかの環境変数を設定する必要があり、これが間違っていると (特にエンドユーザーにとっては) デバッグが難しい形でシステムが終了してしまうという欠点がありました。
どちらのシステムにも、Windows の開発者にコマンドラインの使用を強制するという深刻な欠点がありました。経験を積んだ Windows の開発者は統合開発環境 (IDE) を好みます。そのため彼らは IDE ファイルを自分で書いてプロジェクトに追加してしまい、せっかく統合したビルドシステムが二つに戻ってしまうのです。IDE のサポートが無いことに加えて、上記のシステムはどちらもソフトウェアのプロジェクトを組み合わせるのが非常に難しいという欠点もあります。例えば VTK には画像を読み込むモジュールが無かったのですが、これは主にビルドシステムの都合で libtiff や libjpeg といったライブラリを使うのが難しかったためです。
このような状況を受けて、ITK と C++ 一般に対する新しい新しいビルドシステムの開発が決定しました。この新しいビルドシステムに課された要件は以下です:
- システムにインストールされた C++ コンパイラだけに依存すること。
- Visual Studio IDE に対する入力ファイルを生成できること。
- 静的ライブラリ、共有ライブラリ、実行形式、プラグインといった基本的なビルドシステムのターゲットを簡単に作成できること。
- ビルド時にコードジェネレータを実行できること。
- 一つのソースツリーを複数のビルドツリーに分割できること。
- システムの検査 (introspection) ができること。つまり、ターゲットのシステムに何ができて何ができないかを自動的に判定できること。
- C/C++ のヘッダーファイルの依存スキャンを自動的に行えること。
- 全ての機能はサポートされる全てのプラットフォームで一貫した同一の動作をすること。
追加のライブラリやパーサーが必要となることを避けるために、CMake は C++ コンパイラ だけに依存するように設計されました (C++ コードをビルドしていることから、C++ コンパイラの存在は仮定できます)。 Tcl のようなビルドとインストールのためのスクリプト言語は、当時人気のあった UNIX の多く、および Windows システムにおいてビルド・インストールするのが難しかったのです。また現代でもスーパーコンピューターやインターネットへの接続を持たないセキュアなコンピューターでも同様の問題が発生します。ビルドシステムはパッケージに対する基礎的な要件であることから、CMake には追加の依存を一切作らないことになりました。これによって CMake は独自の簡単な言語を作ることを余儀なくされ、この言語があるせいで CMake を嫌っている人が現在でもいくらかいます。しかし当時最も人気のあった組み込み言語は Tcl であり、もし CMake が Tcl ベースのビルドシステムであったなら、現在のような利用者数は獲得できていないでしょう。
IDE のプロジェクトファイルを生成できるというのは CMake の目玉セールスポイントです。この機能により CMake は IDE がネイティブにサポートする機能しか提供できなくなってしまうのは確かですが、それでもネイティブ IDE のビルドファイルを生成できる利点がこの制限を上回ります。この方針により CMake の開発はさらに難しくなりましたが、ITK などの CMake を使うプロジェクトの開発はずっと簡単になりました。開発者は最も手になじんだ道具を使うときが幸せであり、生産性も高いのです。開発者に好みのツールを使わせることで、プロジェクトは一番重要なリソースである開発者を最も効率良く使うことができます。
どんな C/C++ プログラムも、実行形式、静的ライブラリ、共有ライブラリ、プラグインといった基本的なパーツがいくつか組み合わさってできています。そのため CMake にはこれらのパーツをサポートされている全てのプラットフォームで作成する機能が必要です。全てのプラットフォームはパーツの作成を何らかの形でサポートしてはいますが、使用されるコンパイラのフラグはコンパイラやプラットフォームの種類によって異なります。この複雑さとプラットフォーム間の差異を CMake という単純なコマンドの後ろに隠すことで、開発者は Windows、Unix、Mac でパーツを簡単に生成できるようになります。この機能により開発者はプロジェクトに集中でき、共有ライブラリをビルドする方法の詳細を気にする必要がなくなります。
コードジェネレータはビルドシステムをさらに複雑にします。開発当時、VTK には C++ コードを Tcl、Python、Java へと自動的にラップする機能があり、この機能は C++ のヘッダーファイルをパースすることでラッパーレイヤーを自動生成していました。この自動生成を行うにはまず C/C++ の実行形式 (ラッパージェネレータ) をビルドし、その実行形式を実行して C/C++ ソースコード (各モジュールに対するラッパー) を生成し、さらに生成されたそのコードを実行形式あるいは共有ライブラリにコンパイルする必要があります。以上の処理全てが IDE 環境そして Makefile で完結するようにしなければなりません。
柔軟でクロスプラットフォームな C/C++ ソフトウェアを開発においては、特定のシステムではなくシステムの持つ機能に向かってプログラムをするのが重要です。Autotools には短いコード片をコンパイルしてその結果を見るというシステム検査のモデルが存在しますが、クロスプラットフォームである CMake も同じようなテクニックを使ってシステム検査を行います。これによって開発者は特定のシステムではなく標準的なシステムに向かってプログラムできるようになります。またこの機能はプログラムを未来でもポータブルにする上で重要です。つまりコンパイラやオペレーティングシステムが将来変化してもコンパイルできるということです。例えば次のコードを見てください:
#ifdef linux
// linux に関係することをする
#endif
このコードは脆く、次のコードの方が望ましいです:
#ifdef HAS_FEATURE
// この機能に関係することをする
#endif
初期の CMake に対する要件の中には autotools から来たものもあります。つまり、ソースツリーからビルドツリーを分離する機能です。これによって一つのソースツリーで複数のビルドシステムを利用できます。またソースツリーがビルドファイルでごちゃごちゃになり、バージョンコントロールシステムによる管理が難しくなることも避けられます。
最も重要なビルドシステムの機能の一つが依存関係の管理です。ソースファイルが変更されたときには、そのソースファイルを使うパーツが再ビルドされなければなりません。C/C++ コードにおいては .c と .cpp でインクルードされているヘッダーファイルもチェックして依存関係に含める必要があります。依存関係に関する情報が間違っていたためにコンパイルされるべきコードの一部しかコンパイルされていないという問題を調査するのは時間の無駄です。
新しいビルドシステムの全ての要件と機能はサポートされる全てのプラットフォームで同じように正しく動く必要があります。CMake は開発者にシンプルな API を提供し、複雑なソフトウェアシステムをプラットフォームの詳細を理解することなく書けるようにしなければなりません。実質、CMake を使ったソフトウェアはビルドの複雑さの解決を CMake チームにアウトソースしているようなものです。このビルドシステムのビジョンと基本的な要件が固まってからは、実装はアジャイルに進めていくことになりました。ITK システムはほぼ初日からビルドシステムを必要としていたのです。CMake の最初のバージョンはビジョンで示された要件を全て満たしてはいませんでしたが、Windows と Unix の両方でビルドを行うことができました。
CMake の実装
前述した通り、CMake の開発言語は C と C++ です。CMake の内部を説明するために、この節ではまず CMake が行う処理をユーザーの視点から見ていきます。CMake の構造についてはその後に見ていきます。
CMake の処理
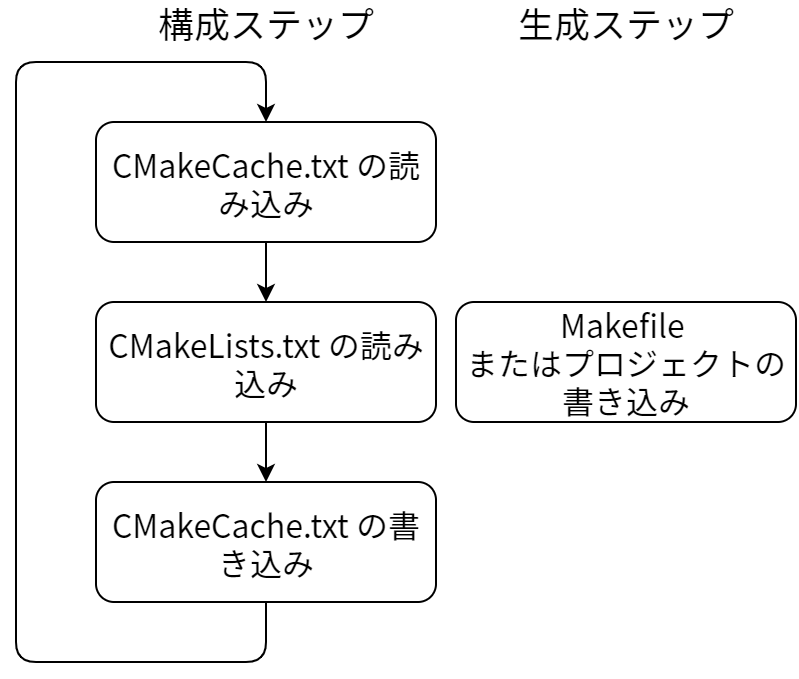
CMake には二つのメインフェーズがあります。一つ目のフェーズは“構成 (configure)”ステップであり、CMake は与えられた全ての入力ファイルを処理して行うべきビルドの内部表現を作ります。そして次のフェーズが“生成 (generate)”ステップであり、実際のビルドファイルがここで作られます。
環境変数 (の不在)
1999 年当時のビルドシステムの多く、そして現代的なビルドシステムの一部でさえ、シェルレベルの環境変数がプロジェクトのビルドに使われています。典型的なのがプロジェクトのソースツリーのルートを指す PROJECT_ROOT という環境変数です。また環境変数を使ってオプショナルなパッケージや外部パッケージを指定する場合もあります。このアプローチの問題点は、ビルドを実行するときに毎回全ての外部変数を設定しなければならない点です。この問題を解決するために、CMake はビルドに必要な全ての変数をキャッシュファイルに保存します。CMake が使用する変数はシェルあるいは環境変数ではなく、CMake の変数です。ビルドツリーにおいて CMake が最初に実行されると、CMake はビルドで変更されない変数を CMakeCache.txt に保存します。このファイルはビルドツリーの一部なので、ここに保存された変数は以降のビルドにおいていつでも利用できます。
構成ステップ
構成ステップにおいて、CMake はまず CMakeCache.txt を探して過去にビルドが実行されているかどうかを調べ、その後 CMake に与えられるソースツリーのルートにある CMakeLists.txt を読みます。 CMakeLists.txt ファイルは CMake 言語パーサーによってパースされ、ファイルの中の CMake コマンドがコマンドパターンオブジェクトによって実行されます。CMake コマンド include および add_subdirectory を使うと追加の CMakeLists.txt をパース・実行することが可能です。他の CMake コマンドには add_library, if, add_executable, add_subdirectory などがあります。CMake 言語で利用可能なコマンドには対応する C++ オブジェクトが存在します。そのため CMake 言語全体はコマンドの呼び出しとして実装され、パーサーが行うのは CMake へのインプットファイルをコマンドの呼び出しと引数の文字列リストに変換する処理だけです。
構成ステップではユーザーから与えられる CMake コードの“実行”が行われます。コードが全て実行され、キャッシュ変数の値が全て計算されると、CMake はビルドするプロジェクトのメモリ上における表現を利用可能になります。この表現にはライブラリ、実行形式、カスタムコマンドなどの最終的なビルドファイルを選択されたジェネレータで作成するために必要な情報が全て含まれます。この時点で CMakeCache.txt ファイルがディスクに保存され、将来の CMake の実行で使えるようになります。
プロジェクトはメモリ上でターゲットの集合として表現されます。ここでターゲットとはライブラリや実行形式などのビルドできるものを表します。CMake はカスタムターゲットもサポートしており、ユーザーは入力と出力を自分で定義し、独自の実行形式やスクリプトをビルド時に実行することが可能です。CMake はターゲットを cmTarget オブジェクトとして保存し、対象ディレクトリに含まれる全ての cmTarget オブジェクトの集合が cmMakefile オブジェクトに保存されます。構成ステップで最終的に出来上がるのは cmMakefile オブジェクトの木であり、cmTarget オブジェクトのマップを含みます。
生成ステップ
構成ステップが完了すると、次に行われるのは生成ステップです。生成ステップで CMake はターゲットとなるビルドツール用のビルドファイルを生成します。ここでターゲットのビルドツールはユーザーから指定されたものです。このステップではターゲット (ライブラリ、実行形式、カスタムターゲット) の内部表現が、Visual Studio などの IDE ビルドツールへの入力、あるいは make が読むための (複数の) Makefile に変換されます。構成ステップで作られる CMake プロジェクトの内部表現は十分多くのデータを含むので、異なるビルドツールであっても構成ステップで同じコードとデータ構造を使うことができます。
以上の処理の概観を 図 5.1 に示します。
CMakeのコード
CMake オブジェクト
CMake はオブジェクト指向のシステムであり、継承、デザインパターン、カプセル化を利用しています。図 5.2 に主要な C++ オブジェクトとその関係を示します。
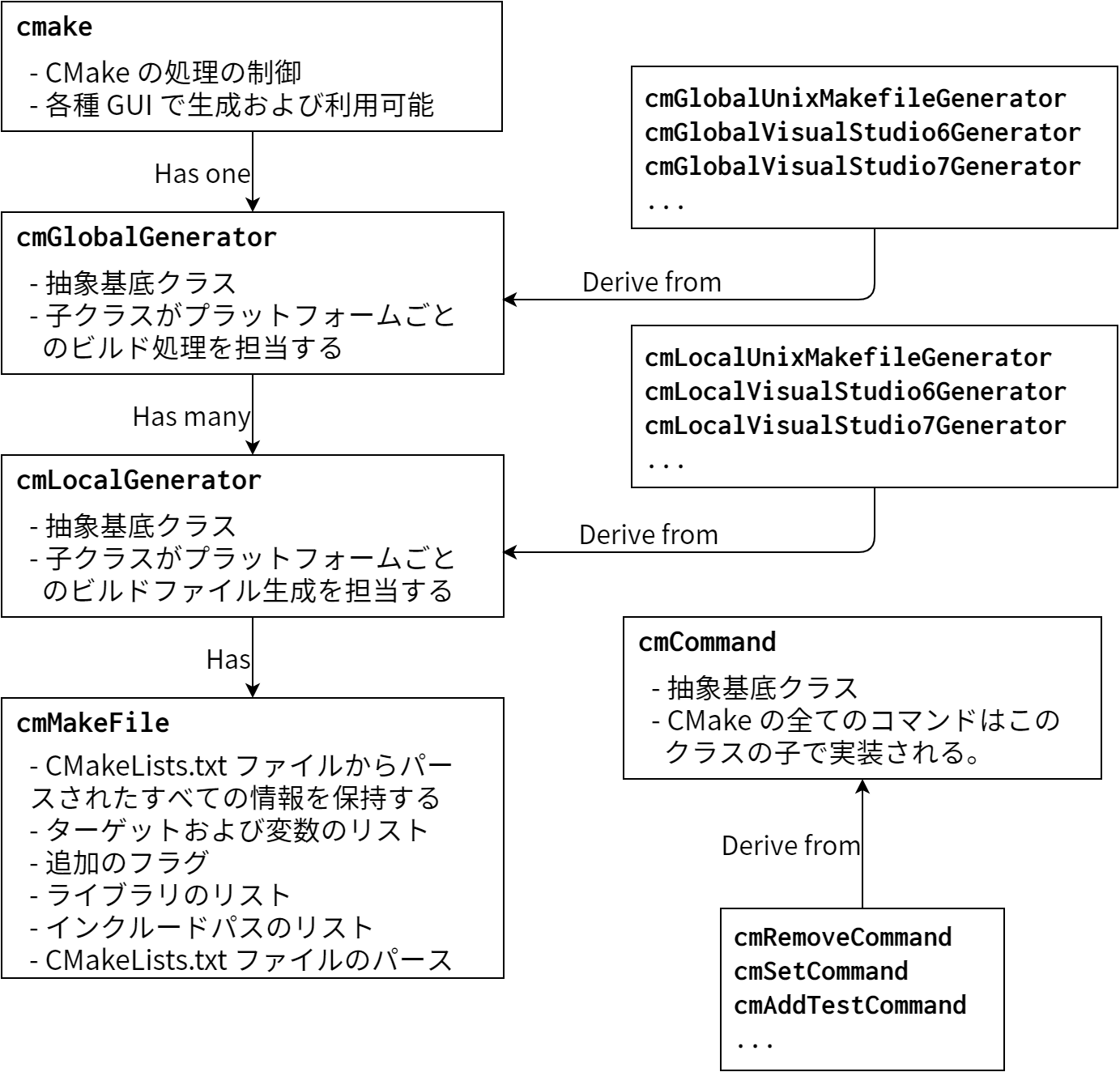
CMakeLists.txt のパース結果は cmMakefile オブジェクトに保存されます。 cmMakefile オブジェクトはディレクトリに関する情報を保存する以外にも CMakeLists.txt ファイルのパースの制御も行います。パースを行う関数は CMake 言語に対する lex/yacc ベースのパーサーを扱うオブジェクトを呼びます。CMake 言語のシンタックスはごくまれにしか変更されず、lex と yacc が CMake をビルドするシステムで常に利用可能であるとは限らないことから、lex と yacc の出力ファイルはいくらか変更されてから Source ディレクトリに保存され、手で書かれた他のファイルと共にバージョンコントロールシステムによって管理されます。
CMake において重要なもう一つのクラスは cmCommand であり、これは CMake 言語における全てのコマンドの実装の基底クラスです。 cmCommand のサブクラスにはコマンドの実装だけではなくドキュメントも含まれます。例えば次に示すのは cmUnsetCommand クラスに含まれるドキュメントメソッドです:
virtual const char* GetTerseDocumentation()
{
return "Unset a variable, cache variable, or environment variable.";
}
/**
* More documentation.
*/
virtual const char* GetFullDocumentation()
{
return
" unset(<variable> [CACHE])\n"
"Removes the specified variable causing it to become undefined. "
"If CACHE is present then the variable is removed from the cache "
"instead of the current scope.\n"
"<variable> can be an environment variable such as:\n"
" unset(ENV{LD_LIBRARY_PATH})\n"
"in which case the variable will be removed from the current "
"environment.";
}
依存関係解析
CMake にはパワフルな依存関係解析機能が組み込まれており、Fortran、C、C++ のソースコードの間の依存関係を解析できます。統合開発環境 (IDE) は自分でファイルの依存関係を管理できることから、そのようなビルドシステムではこのステップは省略されます。つまり IDE ビルドでは CMake は IDE に対するネイティブの入力ファイルを生成し、IDE にファイルの間の依存関係の管理を任せます。ターゲットの間の依存関係は CMake が IDE のフォーマットに変換することで指定されます。
Makefile ベースのビルドを使った場合、ネイティブの make プログラムは依存関係の計算・更新方法を知りません。そのようなビルドでは CMake が自動的に C、C++、Fortran ファイルの間の依存関係を計算し、依存関係の生成と管理の両方を行います。CMake を使ってプロジェクトを一度構成すれば、その後ユーザーは make を実行するだけで依存関係の更新を含めた全てのタスクを行えます。
CMake が以上のタスクを行うということをユーザーが知っておく必要はありませんが、プロジェクトの依存関係が書き込まれたファイルは一度覗いておくと便利なことがあるかもしれません。ターゲットごとの依存関係が保存されているのは depend.make flags.make build.make DependInfo.cmake という四つのファイルです。 flags.make にはターゲットのソースファイルに使われるコンパイルフラグが含まれ、このファイルが変更されるとファイルが再コンパイルされます。 DependInfo.cmake は依存関係を最新に保つために利用されるファイルであり、プロジェクトに含まれるファイルとその言語に関する情報が含まれます。そして依存関係を構築するための規則が含まれるファイルが build.make です。ターゲットの依存ファイルが最新でない場合には依存関係の再計算が行われます。なぜなら例えば .h ファイルが変更されたときには新しい依存ファイルが生まれる場合があるからです。
CTest と CPack
開発が進むにつれ、単一のビルドシステムであった CMake はソフトウェアのビルド、テスト、パッケージを行うツールの集合体へと成長しました。コマンドラインの cmake と CMake GUI プログラムに加えて、CMake にはテストツール CTest とパッケージングツール CPack が同梱されます。CTest と CPack は CMake と同じコードベースを共有してはいるものの異なるツールであり、CMake を使ったビルドには必要になりません。
ctest 実行形式は回帰テストを実行するために使われます。プロジェクトは add_test コマンドを使うことで CTest が実行するテストを簡単に作成できます。テストは CTest が実行するほか、テストの結果を CDash アプリケーションに送ってウェブから閲覧することも可能です。CTest と CDash はどちらも Hudson テストツールと似ていますが、一つ異なる点があります。それは、CTest は分散テスト環境でも実行できるように設計されている点です。CTest ではクライアントがバージョンコントロールからソースをプルし、テストを実行し、結果を CDash に送るという使い方ができますが、Hudson ではクライアントが Hudson からの ssh 接続を許さなければテストを実行できません。
cpack 実行形式はプロジェクトのインストーラを作成するために使われます。CPack は他のパッケージツールとのインターフェースとして動作する点で CMake のビルドの部分と同様です。例えば Windows ではプロジェクトから実行形式インストーラを作成するのに NSIS パッケージツールが使われます。CPack はプロジェクトに対するインストールツリーを作成するための規則を作成し、これを NSIS などのインストーラプログラムに渡します。CPack がサポートするパッケージツールには、RPM、Debian の .deb ファイル、 .tar.gz ファイル、自己解凍 tar ファイルなどがあります。
グラフィカルインターフェース
多くのユーザーが CMake を最初に触れるのは CMake のインターフェースプログラムのいずれかでしょう。CMake のインターフェースプログラムは二つあり、ウィンドウで動く Qt ベースのアプリケーションと、コマンドライン上で動く curses ベースのアプリケーションがあります。これらは CMakeCache.txt ファイルのグラフィカルなエディタであり、CMake の処理の主要なフェーズである構成と生成のための二つのボタンが付いたシンプルなインターフェースをしています。curses ベースの GUI は Unix の TTY タイプのプラットフォームと Cygwin で利用可能で、Qt GUI は全てのプラットフォームで利用可能です。二つの GUI を 図 5.3 と 図 5.4 に示します。
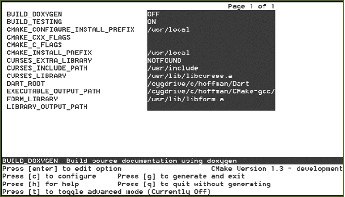
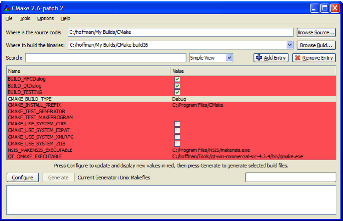
二つの GUI はどちらもキャッシュされた変数の名前を左に、その値を右に表示しています。右側の値はユーザーが適切な値に変更できます。変数にはノーマルとアドバンストの二種類があり、デフォルトではノーマルの変数だけがユーザーに表示されます。プロジェクトはどの変数がアドバンストであるかを CMakeLists.txt ファイルで指定でき、これによってビルドを行うユーザーに表示する選択肢を最小限にできます。
コマンドの実行によってキャッシュされた値が変更されることがあるので、最終的なビルドファイルを生成するまでにコマンドの実行が何度か必要になることがあります。例えばあるオプションを有効化すると他のオプションが利用可能になる場合などです。そのためユーザーが全てのオプションを少なくとも一回確認するまで GUI の“generate”ボタンは無効化されています。configure ボタンが押されるたびに新しく見えるようになったキャッシュ変数が赤く表示され、configure の実行によってそのような変数が追加されなくなって初めて generate ボタンが有効化されます。
CMake のテスト
新しく入った CMake の開発者がまず説明されるのは CMake 開発で使われているテストプロセスです。このプロセスで使われているのは CMake ファミリーのツール (CMake, CTest, CPack, CDash) であり、新しいコードが開発されてバージョンコントロールシステムにチェックインされると、継続的インテグレーションテストを行うマシンが自動的に新しい CMake コードのビルドと CTest によるテストを行います。テストの結果は CDash サーバーに送られ、ビルドエラー、コンパイラの警告、テストの失敗があった場合には開発者にメールで通知が送られます。
このプロセスは典型的な継続的インテグレーションテストシステムです。新しいコードは CMake レポジトリにチェックインされ、CMake がサポートするプラットフォームで自動的にテストを受けます。CMake がサポートするプラットフォームとコンパイラは多岐にわたることから、この種のテストシステムは安定したビルドシステムの開発のためにとても重要です。
例えば新しく入った開発者が新しいプラットフォームのサポートを追加しようと思ったとします。このとき彼 (女) がまず受ける質問は、夜ごとにテストを実行するそのシステムのダッシュボードクライアントを用意できるのかどうかです。定期的なテストが無ければ、新しいシステムは間違いなくそのうち動かなくなります。
教訓
CMake は初日から ITK のビルドに成功しており、プロジェクト全体の中で最も重要な部分です。もし CMake の開発をやり直せたとしても、今と大きくは変わることはないでしょう。しかし、もっと上手くやれたと思っていることはやはり存在します。
後方互換性
CMake 開発チームは後方互換性を重要視しています。プロジェクトの大きな目標はソフトウェアのビルドを簡単にすることだからです。プロジェクトあるいは開発者が CMake をビルドツールとして選択したときにはその選択を尊重し、大きな労力をかけてでも将来の CMake のリリースがそのビルドを破壊しないようにしなければなりません。CMake 2.6 で実装されたポリシーシステムを使うと、新しいバージョンの CMake で動作が変更されたとしても CMake に警告を表示させた上で古い動作をさせることができます。 CMakeLists.txt がどのバージョンの CMake を想定しているのかを指定し、それより新しい CMake で実行したとしても警告が出るだけでプロジェクトのビルドは古いバージョンと同じように行えるということです。
言語、言語、言語
CMake 言語はとても単純にしておくつもりでした。しかし、現在 CMake 言語は新しいプロジェクトで CMake を使おうとするときの大きな障害の一つになってしまいました。有機的に成長を遂げてきたので、CMake 言語にはおかしな部分がいくつかあります。最初のパーサーは lex/yacc ベースですらなく、単純な文字列パーサーでした。CMake 言語を最初からやり直せるなら、上手く行っている既存の組み込み言語をもっと時間をかけて探すでしょう。Lua が最も適しているように思えます。小さくて綺麗な言語なので、上手く行ったかもしれません。もし Lua のような外部の言語を使わなかったとしても、既存の言語について最初からもっと注意を払うでしょう。
プラグインは上手く行かない
プロジェクトから CMake 言語を拡張できるように、CMake にはプラグインクラスがあります。これを使うと新しい CMake コマンドを C で作ることができます。最初これはいいアイデアに思え、異なるコンパイラでも使えるようにとインターフェースも C で定義したのですが、32/64 bit の Windows および Linux のような複数の API を持つシステムがあるせいでプラグインの互換性を保つのが難しくなってしまいました。CMake 言語による CMake の拡張はこれに比べるとパワフルではありませんが、これを使っている限りプラグインのビルドやロードに失敗してプロジェクトのビルドに失敗したり CMake がクラッシュすることを防げます。
公開する API を減らす
CMake プロジェクトの開発の間に学んだ大きな教訓は、ユーザーがアクセスできないものについては後方互換性を保たないですむということです。CMake の開発を通して何度か、CMake をライブラリにして他の言語から CMake の機能を利用可能にしてはどうかという提案がユーザーと顧客から聞かれました。もしそうしていたら、CMake の使い方が増え、結果として CMake のユーザーコミュニティが分裂し、さらに CMake プロジェクトのメンテナンスコストが激増していたことでしょう。