Graphite
Graphite1 が行う処理は二つだけで、ごく単純です: 時間とともに変化する値を保存し、それをグラフにします。この処理を行うためのソフトウェアはこれまでにいくつも作成されてきましたが、その中でも Graphite が特別なのは、この処理をネットワークサービスとして使うことができ、しかもそれが簡単かつスケーラブルな点です。Graphite にデータを与えるのに使われるプロトコルは単純であり、数分もあれば自分で処理を書くことができるでしょう (実際に書く必要はありませんが、それぐらい単純だということです)。グラフのレンダリングとデータポイントの取得は URL のフェッチと同じぐらい簡単であり、Graphite を他のソフトウェアと組み合わせて、Graphite の上にパワフルなアプリケーションを構築するのも簡単です。よくある Graphite の使用例の一つは、ウェブから利用できるモニタリングと解析のためのダッシュボードです。Graphite は大量の顧客を抱える E コマース環境で誕生しており、設計にはこのことが表れています。つまり、スケーラビリティとリアルタイムアクセスが Graphite における重要な目標となっています。
こういった目標を Graphite が達成するのを可能にした要素をあげると、専用のデータベースライブラリとそこで使われるストレージフォーマット、I/O 操作を高速化するためのキャッシュメカニズム、Graphite サーバーをクラスター化するための単純で効率の良い仕組みなどがあります。この章では現在の Graphite がどう動くかをただ説明するのではなくて、Graphite が最初どのように実装されていたか (とてもナイーブです)、どのような問題に直面したか、その問題に対する解決法をどう編み出したかを説明します。
データベースライブラリ: 時系列データの保存
Graphite は全て Python で書かれており、三つの要素からなります。データベースライブラリ whisper 、バックエンドデーモン carbon 、そしてグラフの描画と基本的な UI を提供するフロントエンドのウェブアプリです。この中で whisper は Graphite のために書かれたライブラリですが、独立して使うことも可能です。使われている設計は RRDtool で使われているラウンドロビン型データベースと似ており、時系列数値データしか保存しません。普通データベースというとクライアントアプリケーションがソケットを通して対話する、サーバー上のプロセスのことを思い浮かべますが、 whisper はこれとは異なります。アプリケーションが whisper を使って行うのは、RRDtool と同じように、特殊なフォーマットを持ったファイルの生成と取得です。 whisper の基本的なコマンドには新しい whisper ファイルを作るための create 、ファイルに新しいデータポイントを書き込むための update 、データポイントを取得するための fetch などがあります。
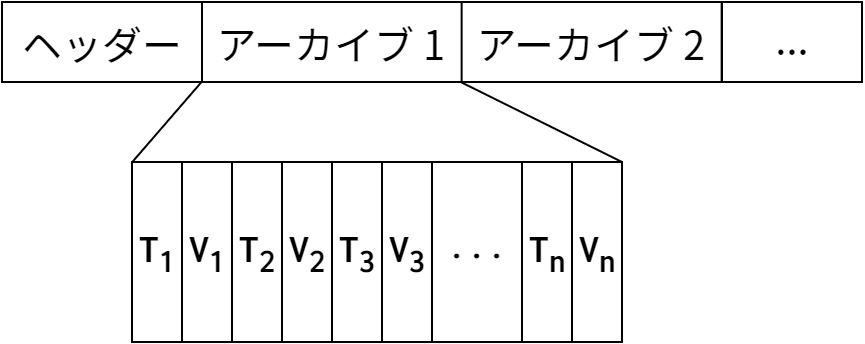
図 7.1 に示すように、 whisper ファイルは様々なメタデータを持つヘッダーセクションと、その後に続く一つ以上のアーカイブセクションからなります。アーカイブはデータポイントが隙間無く並んだ列であり、各データポイントは (timestamp, value) で表されます。 update や fetch 操作を実行すると、 whisper はデータを読み書きするときに使うファイル内のオフセットを、タイムスタンプとアーカイブの設定に基づいて計算します。
バックエンド: 単純なストレージサービス
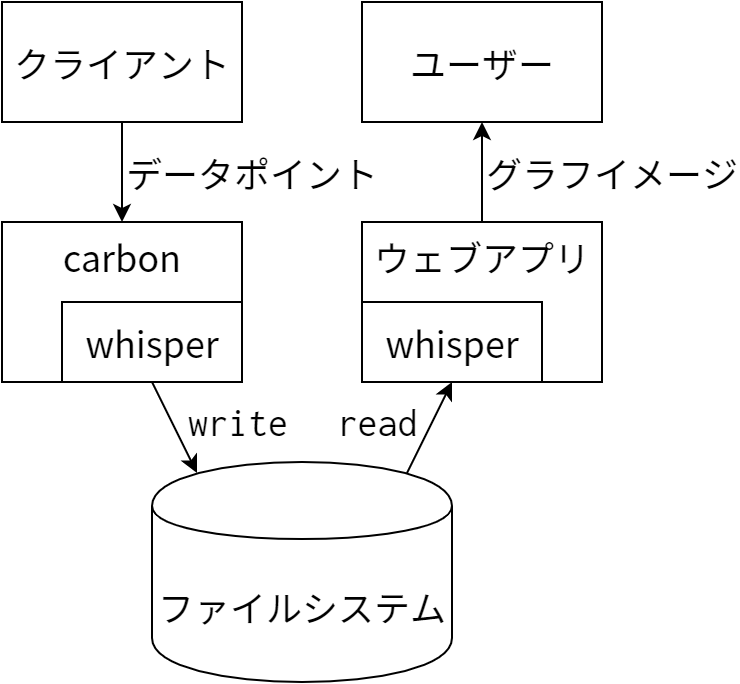
Graphite のバックエンドは carbon-cache と呼ばれるデーモンプロセスであり、省略して carbon と呼ばれることが多いです。 carbon は Twisted と呼ばれる Python 用のスケーラブルなイベントドリブン I/O フレームワークを使っています。Twisted を使うことで、多数のクライアントとの大量のトラフィックを低オーバーヘッドで処理することが可能になっています。 carbon と whisper およびウェブアプリの間でどのようにデータが行き来するかを 図 7.2 に示します。クライアントアプリケーションがデータを収集して Graphite のバックエンド carbon に送信し、これを受けた carbon が whisper を使ってデータを保存します。このデータは Graphite のウェブアプリによって読み出され、グラフを生成するのに使われます。
carbon の一番重要な機能は、クライアントから提供されたメトリクスに対するデータポイントを保存する機能です。Graphite におけるメトリクスとは、時間とともに変化する測定可能な任意の量のことを言います (例えばサーバーの CPU 使用率や製品の売り上げなど)。データポイントは (timestamp, value) の組であり、ある時点において測定されたメトリクスの値を表します。各メトリクスには固有の名前が付いており、クライアントがデータポイントを送るときにはメトリクスの名前も一緒に送られます。よくあるクライアントアプリケーションとしては、システムとアプリケーションに関するメトリクスを収集し、その値を carbon に送ることで保存・可視化を行うモニタリングエージェントがあります。Graphite のメトリクスには単純な階層を持った名前が付いており、階層を分ける文字がスラッシュではなくドットなことを除けばファイルシステムと同じです。 carbon は合法な名前を全て受け付け、メトリクスごとに whisper ファイルを作成してデータポイントを保存します。 whisper ファイルは carbon のデータディレクトリに保存され、そのときにはファイルシステムの階層がドットで区切ったメトリクスの名前に対応します。例えば servers.www01.cpuUsage というメトリクスは .../servers/www01/cpuUsage.wsp というファイルに保存されます。
クライアントアプリケーションがデータポイントを Graphite に送信するには、carbon との TCP 接続を (通常は 2003 ポート2に) 確立する必要があります。やり取りは全てクライアントから行い、 carbon はデータを一切送りません。クライアントから送られるデータは単純なプレーンテキストフォーマットであり、接続を再利用するために開けたままにしておくことが可能です。送られるデータは一つのデータポイントに一行のテキストが対応するフォーマットをしており、各行にはドットで区切られたメトリクスの名前、メトリクスの値、Unix エポックタイムスタンプがスペースで区切られて並びます。クライアントが送るデータの例を次に示します:
servers.www01.cpuUsage 42 1286269200
products.snake-oil.salesPerMinute 123 1286269200
[一分後]
servers.www01.cpuUsageUser 44 1286269260
products.snake-oil.salesPerMinute 119 1286269260
高いレベルにおいては、以上が carbon が行うことの全てです。つまりこのフォーマットをしたデータを受け取り、それを whisper を使ってなるべく早くディスクに書き込むだけです。スケーラビリティを担保し、一般的なハードドライブにおいて最良のパフォーマンスを達成するためのトリックについては後で説明します。
フロントエンド: オンデマンドのグラフ
ユーザーはGraphite のウェブアプリを使うことで URL ベースの単純な API を使ってカスタムされたグラフをリクエストできます。グラフ描画のパラメータは HTTP GET リクエストにおけるクエリ文字列で表され、応答として PNG 画像が返されます。例えば次の URL:
http://graphite.example.com/render?target=servers.www01.cpuUsage&width=500&height=300&from=-24h
は servers.www01.cpuUsage というメトリクスの、過去 24 時間のデータに関する 大きさ 500x300 のグラフをリクエストします。必須なパラメータは target だけであり、他の値が省略された場合にはデフォルトの値が使われます。
Graphite は様々な種類の描画オプションをサポートしており、データを生成するための関数も利用可能です。関数のシンタックスは単純であり、例えば先ほどの例で使ったメトリクスに対する 10 点の移動平均をグラフにするには、次のようにします:
target=movingAverage(servers.www01.cpuUsage,10)
関数をネストして複雑な計算を行うことも可能です。
もう一つ例を示します。ここでは製品の一分ごとの売り上げを表すメトリクスを使って一日の売上の累計を計算しています。
target=integral(sumSeries(products.*.salesPerMinute))&from=midnight
sumSeries 関数が products.*.salesPerMinute というパターンにマッチするメトリクスの和からなる時系列を計算し、 integral が一分ごとの値を累計値に変換します。ここまでくれば、グラフを表示、操作するためのウェブ UI を思い浮かべるのは難しくないでしょう。図 7.3 に示す UI では、利用可能な機能がメニューに表示され、ユーザーがそれをクリックすると JavaScript がグラフの URL パラメータを変更します。
ダッシュボード
Graphite は生まれた当初から、ウェブベースのダッシュボードを作るために使われてきました。URL による API があるので、これを行うのは簡単です。ダッシュボードを作るには、次のようなタグをたくさん持つページを作ればよいのです:
<img src="../http://graphite.example.com/render?parameters-for-my-awesome-graph">
しかし URL の手打ちは万人が好むわけではないので、Graphite のコンポーザー UI にはマウス操作でグラフを作成する機能があります。そうして作成したグラフから URL をコピペするということです。ウェブページを高速に生成する (wiki のような) ツールと組み合わせれば、技術者でないユーザーもダッシュボードの作成をとても簡単に行えるようになります。
明らかなボトルネック
ユーザーがダッシュボードを作り始めると、Graphite はすぐにパフォーマンスの問題にぶつかりました。ウェブサーバーのログを見てどのリクエストが低速なのかを調べたところ、原因はグラフのリクエストが多すぎることであるとすぐに判明しました。ウェブアプリは CPU バウンドで、グラフの描画にかかりきりだったのです。加えて全く同一のリクエストがいくつも来ており、これはダッシュボードが原因でした。
10 個のグラフを持つダッシュボードがあり、そのページが一分ごとに更新されると考えてみてください。ユーザーがブラウザからこのダッシュボードを開くたびに Graphite が一分ごとに処理しなければならないリクエストが 10 個増えるので、すぐに処理が追い付かなくなります。
単純な解決法はグラフを一度だけ描画して、ユーザーにはそのコピーを渡すようにすることです。Graphite が利用しているウェブフレームワーク Django には素晴らしいキャッシュメカニズムがあり、memcached などの様々なバックエンドを利用可能でした。memcached3 は本質的にはネットワークサービスとして提供されるハッシュテーブルであり、クライアントアプリケーションからはキー・バリュー組の設定と取得が (通常のハッシュテーブルと同じように) 可能です。memcached を使えば、時間のかかるリクエスト (グラフの描画など) の結果を高速に保存し、その後のリクエストで使うことができます。古くなったグラフを返さないように、短い時間が経過した後にキャッシュを有効期限切れにするよう memcached を設定しておきます。重複するリクエストが非常に多いので、たとえこの有効期限が数秒であったとしても、Graphite が削減できる処理は膨大です。
大量の描画リクエストが発生するもう一つのよくあるケースは、ユーザーがコンポーザー UI を使って描画オプションをいじり、関数を適用しているときです。ユーザーが何かを変更するたびに Graphite はグラフを再描画しなければいけないからです。この場合にはリクエストの間で共通のデータを memcached に入れておくのが理にかなっています。こうするとデータの取得ステップが省略されるので、UI の反応が滑らかになります。
I/O の高速化
Graphite サーバーに送るメトリクスが 60,000 個あり、各メトリクスには一分ごとに新しいデータポイントが追加されると想像してください。メトリクスごとに対応する whisper ファイルがファイルシステム上に存在することを思い出せば、 carbon は一分ごとに 60,000 個の異なるファイルに対して操作を行うことになります。もし carbon が一つのファイルにつき一ミリ秒で書き込みを行えるならば、追い付いて処理を行うことができます。この例はまだ現実的かもしれませんが、ではもし一分ごとに更新するメトリクスが 600,000 個あったらどうすればいいでしょうか?あるいはメトリクスの更新が一秒ごとだったら、あるいは高速なストレージを用意できなかったら?原因がどうであれ、データポイントがやってくる頻度がストレージが追い付ける書き込み操作の頻度を上回っているとしましょう。どのやってこの状況を切り抜けるべきでしょうか?
現代のほとんどのハードドライブではシークが低速です4。つまり、異なる二つの位置に対する I/O 操作が、連続する領域にデータを書き込むのよりも遅いのです。よって書き込みを行うときに連続した領域に書き込むようにすれば、高いスループットを得ることができます。逆に頻繁に書き込まなければならないファイルが数千個もあり、それぞれの書き込みが小さい場合 (whisper のデータポイントはたった 12 バイト) には、ディスクで消費される時間のほとんどはシークに費やされます。
実行可能な書き込み操作の頻度が比較的低速であるという仮定の下で、その頻度以上のデータポイントのスループットを達成する唯一の方法は、一度の書き込み操作で複数のデータポイントを書き込むことです。このテクニックが可能なのは、 whisper が連続するデータポイントをディスク上の連続した領域に書き込むためです。 whiper の update_many 関数はこのために追加されました。この関数は一つのメトリクスに対するデータポイントのリストを受け取り、それを一度の書き込み操作で書き込みます。これによって操作ごとの書き込み量は増加しますが、10 個のデータポイント (120 バイト) を書き込む時間と一つのデータポイント (12 バイト) を書き込む時間の差は無視できます。データポイントの数がとても大きくならない限り、書き込みにかかる時間がレイテンシに影響を及ぼすことはありません。
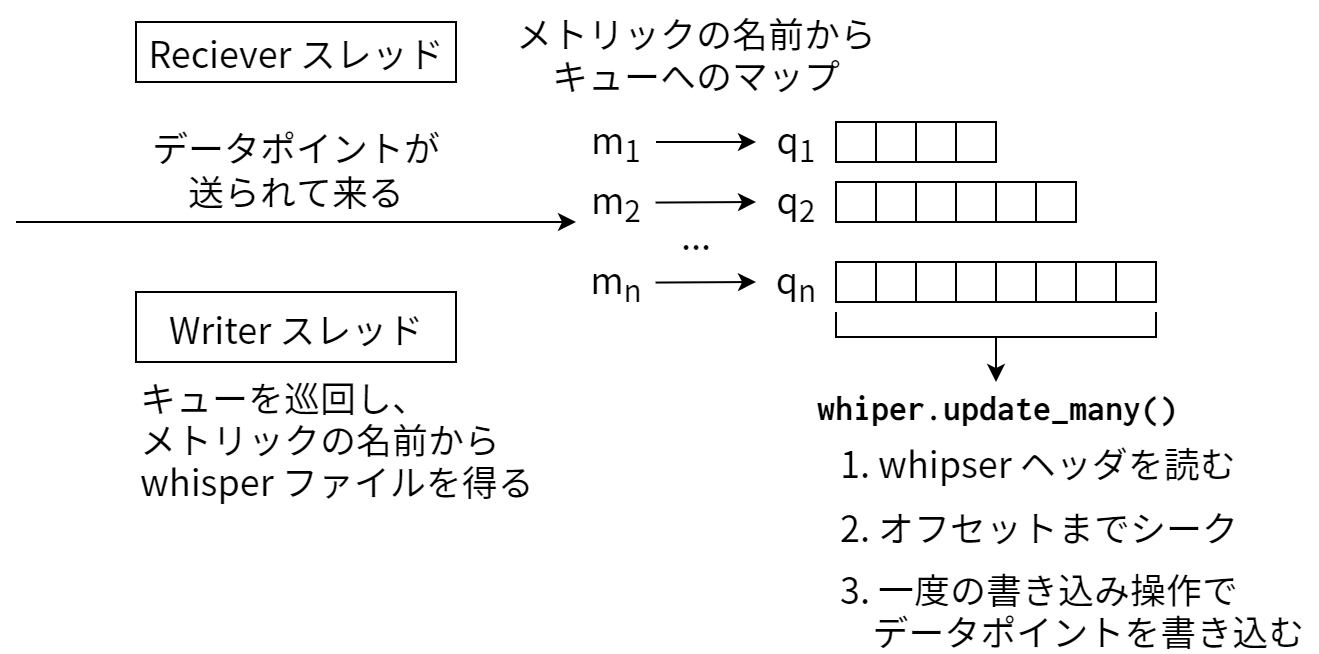
次に私が実装したのは carbon のバッファメカニズムです。メトリクスの名前と結びついたキューを用意し、送られてくるデータポイントがそのキューに追加されるようにします。そして別のスレッドが定期的に全てのキューを巡回し、そこにある全てのデータポイントを対応する whisper ファイルへ、 update_many を使って書き込むのです。最初の例に戻ると、もし一分ごとに更新されるメトリクスが 600,000 個あり、一ミリ秒につき一度の書き込みしか行えないとすると、キューは平均して 10 個のデータポイントを保持することになります。このメカニズムによって消費されるリソースはメモリですが、各データポイントが数バイトであることを考えれば、メモリには比較的余裕があるとみなせます。
この戦略を使うと、データポイントの送られる頻度がストレージが行える I/O 操作の頻度を上回ったときに動的にバッファがデータポイントで埋まっていきます。このアプローチが優れているのは、一時的な I/O 速度の低下に対するある程度の回復力が得られる点です。システムが Graphite 以外の I/O で忙しいときには書き込み操作の頻度が落ちますが、その場合でも carbon のキューが伸びるだけで何の問題もありません。キューが大きくなれば書き込みが大きくなるというだけのことです。データポイント全体のスループットは書き込み操作の頻度と書き込みの平均サイズの積なので、 carbon はキューのためのメモリがある限りデータポイントに追いついて処理を行うことができます。図 7.4 に carbon のキューの仕組みを図示します。
リアルタイム性の維持
データポイントのバッファによって carbon の I/O を高速化できましたが、これによって生じる望ましくない副作用がユーザーによってすぐに発見されました。以前の例で考えたのは、600,000 個のメトリクスが毎分更新され、一分間にストレージが行える書き込み操作が 60,000 回だった場合です。このとき carbon のキューには平均して 10 分間分のデータがいつでも保存されているということになります。ユーザーからすると、これは Graphite のウェブアプリにリクエストしたグラフには直近 10 分間のデータが含まれないということを意味します。完璧とは言えません!
幸いにもこの問題はとても簡単に解決できました。バッファにあるデータポイントにアクセスするためのソケットリスナーを carbon に追加し、Graphite のウェブアプリがデータを取得するときにこのソケットを使うようにしたのです。後は carbon から手に入れたそのデータポイントとディスクから読んだデータポイントを組み合わせれば、リアルタイムのグラフの完成です。今考えている例では更新が一分ごとなので正確に言えば“リアルタイム”ではないのですが、 carbon に到着したデータポイントがすぐにアクセス可能になるという意味でリアルタイムと言えます。
カーネル、キャッシュ、重大な障害
ここまで読めば明らかだと思いますが、Graphite のパフォーマンスが主に影響を受けるシステムの性能は、その I/O レイテンシです。これまでシステムの I/O レイテンシとして一ミリ秒という低い値を仮定してきましたが、この大きな仮定はもう少し解析が必要です。というのも、ほとんどのハードドライブはそれほど高速ではないのです。ディスクを何十台も用意して RAID アレイを組んだとしても、ランダムアクセスのレイテンシが一ミリ秒を切ることはまずあり得ません。しかし奇妙なことに、一キロバイトをディスクに書き込む処理にかかる時間を実際に測定すると、古いラップトップでさえ write システムコールが一ミリ秒よりもはるかに短い時間で返ります。何が起きているのでしょうか?
ソフトウェアのパフォーマンスが一貫しない、あるいは予期しない値になった場合には、その原因はたいていバッファかキャッシュにあります。今回は両方です。システムコール write は正確にはディスクにデータを書き込むことはせず、バッファにデータを積むことしかしません。そのバッファを実際に書き込むのは、カーネルの仕事です。 write の呼び出しがとても早く返っていたのはこれが原因です。またバッファがディスクに書き込まれた後でさえ、データはそれ以降の読み込みに備えてキャッシュされます。もちろんバッファとキャッシュという二つの仕組みはメモリを多く使用します。
頭の切れるカーネル開発者たちは、ユーザースペースの空きメモリを使える分だけ勝手に使ったほうがメモリの確保をいちいち待つよりも効率が良くなるはずだと判断しました。この手法はパフォーマンスを大きく向上させていますが、一方でこれはシステムにメモリをどれだけ積もうともある程度の I/O を行った後には“空き”メモリがゼロになる原因でもあります。ユーザースペースのアプリケーションがそのメモリを使っていないのなら、おそらくはカーネルが使っています。この手法による欠点は、アプリケーションがメモリをアロケートした瞬間にカーネルが持つ“空き”メモリが無くなってしまうことです。カーネルにはそのメモリを放棄することしかできず、その場所にあったバッファは失われます。
これが Graphite と何の関係があるのでしょうか? 今見たのは、 carbon が安定した低い I/O レイテンシを要求すること、そして write システムコールが早く返るのはバッファへのデータのコピーが起こるだけだからということです。ではバッファを使った書き込みを行うための十分なメモリがカーネルに無かった場合、何が起こるでしょうか? write が同期的になり、ひどく遅くなるのです!これにより carbon の書き込み操作の頻度が格段に落ち、 carbon のキューが伸び、メモリがさらに消費され、カーネルが使えるメモリはさらに減ります。このような状況が続くと、 carbon はメモリを全て使い切ってしまうか、怒り狂ったシステム管理者によって殺されてしまいます。
この種の重大な障害を防ぐための機能が carbon にいくつか追加され、設定を変えることで例えばキューに入るデータポイントの数や whisper の操作が実行される頻度を制限できるようになりました。こういった機能は carbon が制御不可能な状態に陥るのを防ぎます。代わりにデータポイントの漏れや受け取りの拒否といった影響が出ますが、システムが落ちるよりはマシです。しかし、システムに対する最適な設定を求めるのにはそれなりのテストが必要になります。これらの機能は便利ですが、根本的に問題を解決するわけではありません。問題を解決したいなら、ハードウェアがもっと必要でしょう。
クラスタリング
ユーザーからは一つのシステムとして動作するように複数の Graphite サーバーを構築するというのは、ナイーブに実装する限り、それほど難しくありません。ウェブアプリとユーザーの対話に使われる操作は二つあり、メトリクスの検索 find とデータポイント (たいていはそのグラフ) のフェッチ fetch です。ウェブアプリが行う検索とフェッチの操作はライブラリになっていて、実装はコードベースの他の部分から切り離されています。また二つの操作は HTTP リクエストハンドラを通したリモートコールからも利用可能です。
find 操作を行うと、ローカルのファイルシステムにある whisper データがユーザーの指定したパターンで探索されます。これは 一般的なファイルシステムにおいて *.txt による glob が拡張子の同じファイルを全て選択するのと同じです。 find が返すのは木構造をした Node オブジェクトのコレクションであり、それぞれの要素は Node のサブクラス Branch または Leaf です。ディレクトリが Branch ノードに対応し、 whisper ファイルが Leaf ノードに対応します。こうした抽象レイヤーがあることで、RRD ファイル5や gzip された whiper ファイルのような異なる種類のストレージのサポートが容易になります。
Leaf のインターフェースは fetch メソッドを定義しており、その実装はノードの種類によって異なります。例えば whisper ファイルの fetch メソッドは whisper ライブラリのフェッチ関数へのラッパーに過ぎません。クラスタリングのサポートが追加されたときに find 関数は拡張され、HTTP 通信を使ってリモートで find を呼び出せるようになりました。つまりウェブアプリの設定で指定された他の Graphite サーバーで find を実行できるのです。HTTP 呼び出しの返答に含まれるノードデータは RemoteNode オブジェクトとなり、後は通常の Node, Branch, Leaf と同じように振る舞います。こうすることでクラスタリングの存在がウェブアプリの他のコードベースに明確になります。リモートの Leaf に対する fetch メソッドは、そのノードがある Graphite サーバーからデータポイントを取得するHTTP 通信として実装されます。
ウェブアプリの間でこうした通信が行われるときには基本的にはクライアントが行うのと同じ方法が使われますが、一つだけ追加のパラメータがあります。このパラメータを指定すると操作がローカルでのみ行われ、クラスター内の別のマシンで行われなくなります。グラフを描画する指示を受けたウェブアプリは find 操作を行ってメトリクスの場所を探索し、その後 fetch でデータポイントを収集します。データの場所はローカルでもリモートサーバーでもあり得ますし、両方であることもあります。サーバーが落ちている場合、リモートとの通信はすぐにタイムアウトし、サーバーには機能していないという印が付いてそのサーバーへの通信は一定時間行われなくなります。ユーザーから見ると、落ちているサーバーにあるデータはグラフから消失して見えます (同じデータがクラスター内の別のサーバーにあれば別です)。
クラスタリング効率の簡単な解析
グラフリクエストにおいて一番時間のかかる処理はグラフの描画です。描画は単一のサーバーで行われるので、サーバーを追加すれば同時に実行できるグラフ描画の数を増やすことは可能です。しかしもしそうすると、描画リクエストを処理するたくさんのサーバーで find が呼び出され、クラスター内の他のサーバーに向かって通信が起こります。つまり Graphite の用いるクラスタリングではフロントエンドの負荷を分散できておらず、全てのサーバーが共有してしまうのです。ただし現時点でもバックエンドの負荷は分散できており、 carbon の各インスタンスはそれぞれ独立に動作します。フロントエンドがボトルネックとなる前にまずバックエンドがボトルネックとなることが多いので最初の実装としてはこれで問題ありませんが、このやり方を使っている限りフロントエンドがスケールアウトすることはありません。
フロントエンドをよりスケールさせるためには、ウェブアプリが行うリモートの find の数を削減しなければなりません。ここでも、簡単な解決法はキャッシュです。memcached を使ってデータポイントや描画されたグラフをキャッシュできたように、 find リクエストの結果もキャッシュできます。メトリクスの場所はほとんど変更されないことから、キャッシュの保持期間は基本的に長くなります。ただし保持期間を長くするトレードオフとして、新しいメトリクスが階層に追加されたときにそれがユーザーの画面に表れるまでの時間が長くなります。
クラスター内におけるメトリクスの分散
Graphite のウェブアプリはどのサーバーでも全く同じ処理を行うので、クラスターを通じて均質だと言えます。しかし carbon の役割はそうではなく、ユーザーがインスタンスに送ったデータに応じてサーバーの役割はよって大きく異なります。 carbon にデータを送るクライアントは多数存在するのが普通なので、クライアントの設定を Graphite クラスターのレイアウトと結び付けるのはとても面倒です。例えばアプリケーションに関するメトリクスは一つの carbon サーバーに保持し、ビジネスに関するメトリクスは複数の carbon サーバーに保持して冗長性を確保することになる可能性があるためです。
このようなシナリオの管理を単純化するために、Graphite には carbon-relay と呼ばれるツールが追加で付いてきます。このツールが行う処理はとても単純です: carbon-relay はまず通常の carbon デーモン (本当の名前は carbon-cache) と全く同じようにメトリクスデータをクライアントから受け取ります。ただしここでそのデータを保存することはせず、メトリクスの名前と一定の規則に基づいて、そのデータを他の carbon-cache サーバーにリレーするのです。この規則は目的地となるサーバーのリストと正規表現からなります。受け取ったデータポイントについて規則が順に検討され、メトリクスの名前が最初にマッチした正規表現に対応するサーバーにデータが送られます。こうすることで、クライアントは carbon-relay にデータを送るだけで正しいサーバーにデータが届くようになります。
carbon-relay が複製の機能を実装しているとみなすこともできます。ただし同期の問題を考えていないので、正確に言えば実装されているのは入力の複製です。あるサーバーが一時的に利用不可能になった場合には、その期間のデータポイントが失われるだけで他の部分は通常通り動作します。また再同期プロセスの制御をシステム管理者の管理下に置くための管理用スクリプトも用意されています。
設計について考える
Graphite の開発を通じて、私は自分の考えの正しさを再確認しました。その考えとは、アプリケーションのスケーラビリティには低レベルのパフォーマンスがほとんど関係せず、関係するのはプロダクト全体の設計であるということです。開発中にボトルネックにぶつかったことが何度もありましたが、そのときに私が探したのは設計の改善であって、パフォーマンスの高速化ではありませんでした。これまでに「どうして Graphite を Java や C++ ではなくて Python で書いたのか?」という質問を何度も受けましたが、私の答えはいつも「他の言語を使うことで得られるパフォーマンスが必要になったことが無いから」でした。Donald Knuth は [Knu74] で、「早すぎる最適化は諸悪の根源である」という有名な言葉を残しています。コードが自明でない成長を続けると考える限り、どんな最適化もある意味では早すぎるのです6。
Graphite の一番の強みかつ一番の弱みは、伝統的な意味での“設計”がほとんど全く存在しないという事実です。ほとんどの部分において Graphite は少しずつ、問題が起こるたびにハードルを一つずつ飛び越えながら進化してきました。ハードルが前から予測できたことも多く、そのような場合には様々な解決法を前もって用意するのが当然だと考えるかもしれません。しかし、今抱えていない問題については、たとえすぐに抱えることになると思えるものであっても、解くのを避けた方が賢明なことがあります。なぜなら実際の失敗を詳細に研究した方が、前もって理論的に考えるよりもたくさんのことが学べるからです。問題の解決を導くのは手元にある実験データ、知識、そして直感です。自分の知恵を十分に疑い尽くすことが、実験データを詳細に分析するために役立つということに私は気付きました。
例えば最初 whisper を書いたとき、私は「このプログラムは高速化のために C で書き直すことになるので、今 Python で書いているのはプロトタイプに過ぎない」と確信していました。時間に追われていなかったら、Python の実装を完全に飛ばしていた可能性さえあります。しかし CPU よりもはるかに先に I/O がボトルネックになると判明し、実際のプログラムで Python の遅さが問題になったことはほとんどありませんでした。
そうは言っても、この進化的なアプローチは Graphite の大きな弱みでもあります。作ってから判明したのですが、インターフェースは段階的な進化に適していないようです。優れたインターフェースは一貫していて、予測可能性を最大化させるような慣習を持たなければなりません。Graphite の URL を使った API はこの基準を満たしていないというのが私の意見です。オプションと関数は時と共に付け足され、一貫性は小さい部分でたまに見られる程度で、全体的な一貫性はありません。このような問題を解く唯一の方法はインターフェースにバージョンを付けることなのですが、これは失うものが多すぎます。新しいインターフェースが設計されたとしても、古いインターフェースを取り除くのは不可能であり、人体における虫唾のように進化的遺物としていつまでもさまよい続けます。普段は害の無いように思えるのですが、それでもある日虫唾炎になって手術が必要になってしまうのです (古いインターフェースに起因するバグがいずれ起こるということです)。Graphite の開発初期に戻って何か一つ変更できるとしたら、外部 API の設計について前もって熟慮し、少しずつ進化させるという道は取らないでしょう。
Graphite の中で上手く行っていないなと感じる点がもう一つあります。それはメトリクスの階層的な命名法によって柔軟性が制限されていることです。この命名法はとても単純で、ほとんどの使用例においてとても使いやすいのですが、複雑なクエリを表現するのがとても難しくなり、不可能になってしまうこともあるのです。Graphite を作るときに最初に考えたのは、URL を使った人間が編集できる API を使ってグラフを作れるようにしたい7ということでした。現在の Graphite がこの機能を持っているのは嬉しい限りなのですが、一方でこの機能によって API が単純なシンタックスを強制され、複雑な表現が扱いにくくなっているのも事実です。メトリクスの“プライマリキー”を見つける問題を考えると、階層構造を使った場合には木におけるノードのパスがプライマリキーとなるので、とても単純になります。しかし欠点は、列データのような説明のためのデータをパスに直接埋め込まなければならないという点です。考えられる解決法としては、階層モデルを維持した上でそれとは別にメタデータのデータベースを追加し、特別なシンタックスを使ってメトリクスのより複雑な選択を可能にするというのがあります。
オープンソース化
Graphite の進化を振り返ったときに未だに驚かされるのは、プロジェクトがたくさんのことを成し遂げたこと、そしてそれが私をプログラマーとして成長させたことです。Graphite は最初たった数百行のコードからなる、個人的なプロジェクトとして始まりました。描画エンジンは実験として始まり、私がそのようなプログラムを書けるかどうかを試すために書かれました。 whisper は絶対に伸ばせない納期を前に見つかった重大な欠陥を解決しようとする絶望の中で書かれたものです。 carbon が書き直された回数は数えきれません。Graphite を 2008年にオープンソースとしてリリースしたときには、反応は全く期待していませんでした。しかし数か月後 CNET の記事で取り上げられ、Slashdot にピックアップされると、Graphite は突然盛り上がり、それ以降勢いを失ったことはありません。現在では数十の大企業や中小企業が Graphite を利用しています。コミュニティはとても活発であり、拡大を続けています。Graphite は完成したプロダクトではなく、今まさに行われているクールな実験もたくさんあります。どれも楽しいもので、可能性に満ちています。
-
シリアライズされたオブジェクトを送るためのポートがもう一つあり、このポートを使うとプレーンテキストフォーマットを送るよりも効率良く処理を行うことができます。このポートが必要になるのはトラフィックが非常に高い場合だけです。[return]
-
ソリッドステートドライブ (SSD) はこれまでのハードドライブと比べて圧倒的に高速なシーク速度を持ちます。[return]
-
RRD ファイルは複数のデータソースを含むので
Branchノードです。RRD データがLeafノードとなります。[return] -
Knuth が意図していたのは低レベルコードの最適化についてであり、設計の改善のようなマクロな最適化ではありません。[return]
-
これによりグラフ自体もオープンソースにならざるを得ません。グラフの URL を見れば何が起きているか誰でも理解でき、変更も簡単です。[return]