LLVM
この章では LLVM1 を形作った設計上の判断について議論します。LLVM は各要素が密接な結び付きを持つ低レベルツールチェイン (アセンブラ、コンパイラ、デバッガなど) の包括的プロジェクトであり、Unix システムでよく使われている既存のツールと互換性を保つように設計されています。“LLVM”という名前はかつては頭字語でしたが、現在ではプロジェクト全体を指すブランド名となっています。LLVM はユニークな機能を持ち、素晴らしいツールが揃っていることで知られています2が、LLVM と他のコンパイラの一番重要な違いはその内部アーキテクチャです。
2000 年に開始されて以来、LLVM はきちんと定義されたインターフェースを持つ再利用可能なライブラリの集合として設計されてきました[LA04]。当時のオープンソースのプログラミング言語実装というと、特殊用途のツールとして設計されたモノリシックな実行形式であることがしばしばであり、例えば (GCC などの) 静的なコンパイラのパーサーを再利用して静的解析やリファクタリングを行うのは非常に困難でした。スクリプト言語にはたいていランタイムやインタープリタをさらに大きなアプリケーションに埋め込む仕組みがありましたが、ランタイムはひと固まりの巨大なコードであり、全て使うか全く使わないかどちらかでした。一部分を再利用する方法は無く、ある部分が言語の実装プロジェクトをまたいで共有されることは全くと言っていいほど無かったのです。
コンパイラ内部での結びつきを除けば、広く使われている言語実装を取り巻くコミュニティ同士はひどく分断されていました。言語実装は昔ながらの静的コンパイラ (GCC、Free Pascal、FreeBASIC など) を提供するか、そうでなければインタープリタや Just-In-Time (JIT) コンパイラの形でランライムコンパイラを提供するかのどちらかでした。言語実装が両方をサポートするのは非常に稀であり、もししていたとしてもコードはほとんど共有されないのが普通でした。
LLVM は過去十年でこの状況を一変させました。現在では多種多様な静的にコンパイルされる言語と実行時にコンパイルされる言語を実装するときの共通基盤として LLVM が使用されています (例えば GCC がサポートする言語、あるいは Java, .NET, Python, Ruby, Scheme, Haskell, D そしてこれらよりも知名度が劣る数えきれない数の言語)。また広い分野の専用用途コンパイラ、例えば Apple の OpenGL スタックにおけるランタイムを特殊化したエンジンや Adobe の After Effects における画像処理ライブラリは LLVM に置き換わりました。さらに LLVM からは新しいプロダクトも多数生まれており、GPU プログラミング言語 OpenCL とそのランタイムがその中で最も有名です。
古典的なコンパイラ設計の簡易入門
昔ながらの静的コンパイラ (ほとんどの C コンパイラ) で最もよく使われる設計は、全体をフロントエンド、オプティマイザ、バックエンドという三つのフェーズに分ける設計です (図 11.1)。フロントエンドはソースコードをパースしてエラーを検出し、入力コードを表す言語固有の抽象構文木 (Abstract Syntax Tree, AST) を構築します。AST が最適化のために新しい表現に変形されることもあり、その後オプティマイザとバックエンドが実行されます。

オプティマイザは実行時間を改善するために冗長な計算の削除など様々な変形を行います。オプティマイザは言語とターゲットから独立していることが多いです。バックエンド (またはコードジェネレータ) はコードをターゲットの命令セットに置き換えます。ここでは正しいコードを作るのに加えて、ターゲットアーキテクチャがサポートする特別な機能を上手く使って良いコードを作るのもバックエンドの役割です。コンパイラのバックエンドによく含まれる処理には命令の選択、レジスタの確保、命令のスケジュールなどがあります。
このモデルはインタープリタや JIT コンパイラにも同様に当てはまります。Java 仮想マシン (JVM) もこのモデルを実装していますが、JVM ではフロントエンドとオプティマイザの間のインターフェースに Java バイトコードが使われます。
この設計が意味すること
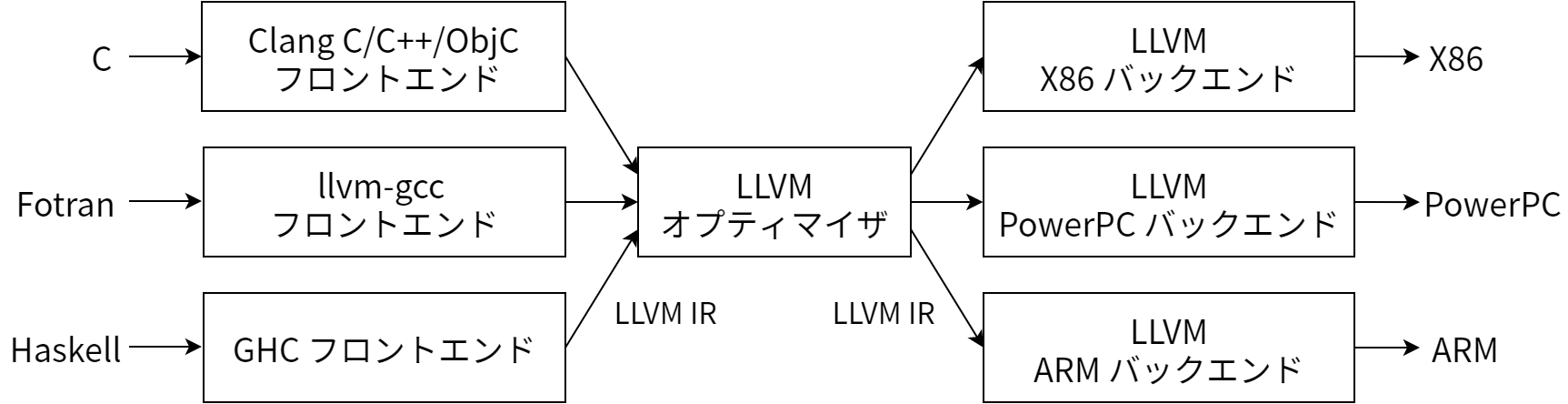
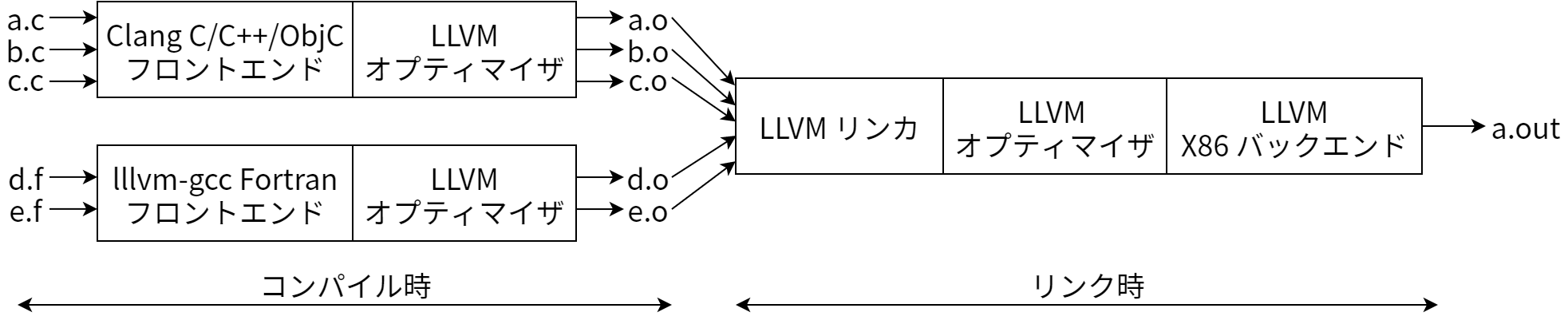
この古典的な設計の利点はソース言語とターゲットアーキテクチャが複数になったときに明らかになります。それはオプティマイザで共通のコード表現を使うことで、そのコード表現へコンパイルを行うフロントエンドを、任意の言語に対して書くことができる点です。さらに、オプティマイザのコード表現からコンパイルを行うバックエンドも任意のターゲットに対して書くことが可能になります。これを 図 11.2 に示します。
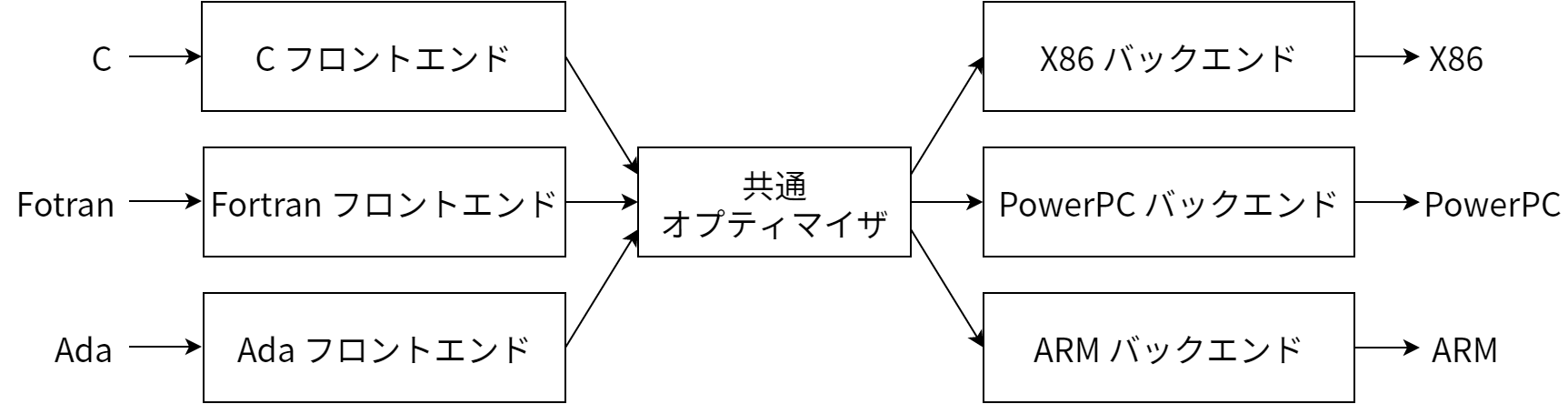
この設計のおかげで、新しいソース言語 (例えば Algol や BASIC) のサポートをコンパイラに追加するときには既存のオプティマイザとバックエンドを再利用でき、必要となるのは新しい言語に対するフロントエンドの実装だけとなります。もしこのように分割されていないと、新しいソース言語の実装は最初から行わなければならず、N 個のターゲットと M 個のソース言語をサポートするのに N*M 個のコンパイラが必要になってしまいます。
再ターゲット可能性からすぐに分かる三フェーズ設計のもう一つの利点は、一つのソース言語と一つのターゲットをサポートするよりもより広範なプログラマーがコンパイラを使えるようになる点です。オープンソースプロジェクトにおいては、これは潜在的なコントリビューターの数が多くなり、コンパイラの拡張と改善の機会が増えることを意味します。このことは GCC のような大きなコミュニティを持つオープンソースのコンパイラが、FreePASCAL のようなコミュニティの限られたコンパイラよりも高速な機械語を生成することが多い理由でもあります。一方でプロプライエタリのコンパイラではクオリティがプロジェクトの予算に直に関係するので、この関係は成り立ちません。例えば Intel の ICC コンパイラは少数の利用者に向けたものですが、生成されるコードの質の高さは広く知られています。
三フェーズ設計の主な利点として最後に触れるのは、フロントエンドを実装するのに必要なスキルが、オプティマイザとバックエンドを実装するのに必要なスキルと別になる点です。両者が分離されることで、「フロントエンドの人」はコンパイラの自分が担当する部分の改善と保守に集中できます。これは社会的な問題であって技術的な問題ではありませんが、実際の開発ではとても役に立ちます。コントリビュートのための障壁をなるべく低く抑えることが望ましいオープンソースプロジェクトでは特にそうです。
既存の言語実装
三フェーズ設計の利点は説得力のあるものであり、コンパイラの教科書にもしっかりと書かれています。しかし実際に実現することはまずありませんでした。(LLVM が開始された当時に) オープンソースの言語実装を覗けば、Perl, Python, Ruby, Java の間で共有されているコードは存在しません。さらに Glasgow Haskell Compiler (GHC) や FreeBASIC といったプロジェクトは複数の異なる CPU をターゲットすることが可能ですが、その実装はサポートするオープンソース言語に固有のものとなっています。この他にも、画像処理、正規表現、グラフィックスカードのドライバ、その他の CPU に負荷が集中する領域に対する JIT コンパイラの実装に使われている多様な特殊用途コンパイラ技術が存在します。
とはいえ、このモデルが成功している例が三つ存在するので、順番に見ていきましょう。最初の例は Java と .NET の仮想マシンです。どちらのシステムも JIT コンパイラ、ランタイムサポート、そしてとても良く考えられたバイトコードフォーマットを提供します。そのためどんな言語であってもこれらのバイトコードフォーマットにコンパイルすれば、ランタイムはもちろんオプティマイザと JIT コンパイラも利用可能になります (これを行っている言語は数十個もあります3)。ここでのトレードオフは、システムの実装がランタイムの選択肢をほとんど用意していない点です。つまり両方とも JIT コンパイル、ガベージコレクション、特定のオブジェクトモデルの使用を事実上強制するのです。このためモデルに沿わない C のような言語を (LLJVM などを使って) コンパイルするとパフォーマンスが落ちてしまいます。
二番目の成功例は最も不適切なものとも言えるのですが、コンパイラ技術を再利用する方法として一番知られているものでもあります。それは入力ソースを C コード (あるいは他の言語) に変換し、それを既存の C コンパイラに渡すというものです。この方法はオプティマイザとコードジェネレータを再利用が可能であり、柔軟で、ランタイムの制御もでき、フロントエンドの実装者にとっても理解、実装、保守しやすくなります。ただこの方法の問題として、例外処理を効率良く実装できないこと、デバッグが困難になること、コンパイルが遅くなること、そして末尾呼び出しの最適化を保証する (およびその他の C がサポートしない機能を持つ) 言語の実装が困難になることなどがあります。
三フェーズ設計モデルの実装の成功例として最後にあげるのは GCC4 です。GCC はたくさんのフロントエンドとバックエンドをサポートし、大きくて活発なコントリビューターのコミュニティを持ちます。GCC の歴史を振り返ると、初期の GCC は複数のバックエンドに対応した C コンパイラであり、いくつかの言語へのサポートがハックじみた方法で追加されていました。時が経つにつれ GCC コミュニティは設計を洗練させ、GCC 4.4 で追加されたオプティマイザ用の新しい表現 (“GIMPLE Tuples”) ではフロントエンドの表現との分離がそれまでよりもさらに進みました。また Fortran と Ada のフロントエンドは簡潔な AST を持ちます。
これらの三つのアプローチは大きな成功を収めていますが、どれもモノリシックなアプリケーションとして設計されているために利用先が非常に限られてしまうことも確かです。一つ例をあげると、GCC を他のアプリケーションに埋め込んで GCC をランタイム/JIT コンパイラとして使用したり、GCC の一部分だけを取り出して再利用するのは現実的ではありません。GCC の C++ フロントエンドをドキュメントの生成やコードのインデックス付け、リファクタリング、静的解析ツールに使いたい場合には、GCC を単一のアプリケーションとして扱って利用する情報を XML として出力させるか、あるいは GCC の処理に外部コードを挟み込むプラグインを書くしかありません。
GCC の一部分をライブラリとして使うことができないのにはたくさんの理由があります。例えばあちこちで使われているグローバル変数、表明されていない不変条件、ひどい設計のデータ構造、乱雑なコードベース、そして複数のフロントエンドとターゲットのペアをサポートするようにコンパイルすることが不可能になるマクロの使用などです。中でも修正が最も困難な問題は、初期の設計と時代背景に根ざすアーキテクチャに関する根本的な問題です。特に GCC ではレイヤーの問題と抽象化の漏れが深刻です。バックエンドはデバッグ情報の生成のためにフロントエンドの AST を走査し、フロントエンドはバックエンドのデータ構造を生成し、コンパイラ全体はコマンドラインインターフェースで設定されるグローバルなデータ構造に依存している有様です。
LLVM のコード表現: LLVM IR
歴史背景とコンテキストはこれくらいにして、LLVM を見ていきましょう。LLVM の設計で一番重要なのは、コンパイラ内部でコードを表現するのに使われる LLVM 中間表現 (Intermediate Representation, IR) という形式です。LLVM IR はコンパイラのオプティマイザで見られる中間レベルの解析や変形を行えるように設計されています。たくさんの明確な目標を持って設計されており、例えば高速なランタイム最適化、関数や手続きをまたいだ最適化、プログラム全体の解析、積極的な再構築を通した変形などが目標でした。ただしその中で最も重要なのは、LLVM IR をきちんと定義された意味論を持つファーストクラスの言語として定義することです。単純な .ll ファイルの具体例を次に示します:
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
この LLVM IR は次の C コードに対応します。二つの整数を足す二つの方法が示されています:
unsigned add1(unsigned a, unsigned b) {
return a+b;
}
// 二つの数を加算する最速の方法ではないかもしれない。
unsigned add2(unsigned a, unsigned b) {
if (a == 0) return b;
return add2(a-1, b+1);
}
この例から分かるように、LLVM IR は低レベルの RISC ライクな仮想命令セットです。本物の RISC 命令セットと同様に、加算、減算、比較、分岐といった単純な命令を一列に並べたものがサポートされます。命令は三アドレス形式であり、いくつかの入力を受け取って結果を他のレジスタに書き込みます5。LLVM IR はラベルもサポートしており、ちょっと変わったアセンブリ言語のような見た目をしています。
多くの RISC 命令セットとは異なり、LLVM は単純な型システムで強く型付けされています (例えば i32 は 32 ビット整数、 i32** は 32 ビット整数へのポインタへのポインタです)。またマシンの詳細の一部は抽象化されており、例えば呼び出し規約は call 命令と ret 命令および明示的に並べられる引数によって抽象化されます。機械語と LLVM IR のもう一つの重要な違いは、LLVM IR にはあらかじめ決められた数の名前付きのレジスタの集合が用意されておらず、% 文字が付いた一時的なレジスタをいくつでも利用可能な点です。
LLVM IR は一つの言語として実装されますが、同じ LLVM IR プログラムは三つの異なる形式で定義できます。つまり上記のテキストフォーマット、オプティマイザによる解析と変更で使われるインメモリのデータ構造、そして省スペースで密なオンディスクの「ビットコード」フォーマットです。LLVM プロジェクトはオンディスクのフォーマットをテキストおよびバイナリに変換するツールを提供しています。 llvm-as はテキストの .ll ファイルをビットコードの .bc ファイルに変換し、 llvm-dis は .bc ファイルを .ll ファイルに変換します。
コンパイラはこの中間表現に対して様々な操作を行いますが、これが可能なのはオプティマイザにとって LLVM IR が「完全な世界」であるためです。つまりフロントエンドやバックエンドとは異なり、オプティマイザは特定のソース言語や特定のターゲットマシンに縛られることがありません。また逆に言えばどちらとも上手くやっていかなければいけないということでもあります。中間表現はフロントエンドが生成しやすいものでなくてはならず、同時に現実のターゲットに対する重要な最適化が行えるだけの表現力を持たなければなりません。
LLVM IR 最適化を書く
最適化の動作を理解するには、例を見ていくのがよいでしょう。コンパイラの最適化は多種多様なので全ての問題に通用する解決法を紹介するのは難しいですが、多くの最適化は次に示す三つの部分からなります:
- 変形すべきパターンを見つける。
- マッチした部分への変形が安全で正しいことを確認する。
- 変形を行い、コードを更新する。
最も分かりやすい最適化は数学的な等式を使うものです。例えば任意の整数 X について、 X-X は 0、 X-0 は X 、 (X*2)-X は X です。これについて見ていきましょう。最初に考える問題はこれらの式が LLVM IR でどんな形をしているかです。いくつか例を示します:
... ... ...
%example1 = sub i32 %a, %a
... ... ...
%example2 = sub i32 %b, 0
... ... ...
%tmp = mul i32 %c, 2
%example3 = sub i32 %tmp, %c
... ... ...
この種の“のぞき穴 (peephole)”最適化のために LLVM は命令単純化インターフェースを提供しており、より高レベルの変形でユーティリティとして使うことができます。今考えている変形は SimpliFySubInst 関数の中にあり、次の形をしています:
// X - 0 -> X
if (match(Op1, m_Zero()))
return Op0;
// X - X -> 0
if (Op0 == Op1)
return Constant::getNullValue(Op0->getType());
// (X*2) - X -> X
if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>())))
return Op1;
...
return 0; // マッチしなかった。変形が行われなかったことを表す null を返す。
このコードで Op0 と Op1 はそれぞれ整数減算命令の右辺および左辺オペランドに束縛されています (重要なこととして、上述の等式は IEEE 浮動小数では成り立ちません!)。LLVM は C++ で実装されており、パターンマッチの機能は (Objective Caml のような関数型言語と比べた場合) あまり充実していません。しかし一般的なテンプレートシステムがあるので、似たようなことは実装可能です。ここでは match 関数と m_* 関数を使って LLVM IR コードに対する宣言的なパターンマッチングを行っており、例えばこのコード中の m_Specific という術語は乗算の左辺が Op1 と同じだった場合にのみマッチします。
まとめると、この三つのパターンにマッチするかどうかがチェックされ、命令の置き換えができるならば関数はその結果を返し、できないならば null が返されます。この関数を呼び出す関数 (SimplifyInstruction) は命令のオペコードに応じてヘルパー関数を呼び出すディスパッチャーとしての役割を持ち、多くの最適化処理から呼び出されます。単純なドライバは次の形をしています:
for (BasicBlock::iterator I = BB->begin(), E = BB->end(); I != E; ++I)
if (Value *V = SimplifyInstruction(I))
I->replaceAllUsesWith(V);
このコードはブロック中の命令をループし、単純化が可能かどうかをチェックしていきます。もし単純化が可能 (SimplifyInstruction が null 出ない値を返した) ならば、 replaceAllUsesWith メソッドを使ってコード中に現れるその形をした式を全て単純化した式で置き換えます。
LLVM における三フェーズ設計の実装
LLVM ベースのコンパイラにおいてフロントエンドが担当するのは入力コードのパース、エラー診断、そしてパースしたコードのLLVM IR への変換です (AST を一度作ってから LLVM IR に変換するのが普通ですが、常にそうとは限りません)。この IR は (省略可能な) 各種の解析や最適化パスを通ってより良いコードに変形され、最後にコードジェネレータに渡されます。この様子を 図 11.3 に示します。これは三フェーズ設計のとても単純な実装ですが、単純な説明の裏には LLVM IR に秘められた LLVM アーキテクチャの力と柔軟性が隠されています。これについて見ましょう。
LLVM は完全なコード表現である
具体的に言うと、LLVM IR は詳細に規定されていながらも、オプティマイザへの唯一のインターフェースとなっています。この特徴のおかげで、LLVM のフロントエンドを書くために必要な知識は、LLVM IR が何であり、どのように動作し、どのような不変条件が成り立つべきかについての知識だけです。LLVM IR はテキスト形式をファーストクラスでサポートするので、フロントエンドを LLVM IR のテキストを出力するように設計することも可能であり、実際に行っても問題は生じません。そのフロントエンドを出力を Unix パイプを使ってオプティマイザと好きなコードジェネレータに渡せばそれで済みます。
驚くかもしれませんが、これこそが LLVM の持つ非常に重要な特徴であり、広い領域の様々なアプリケーションで成功してきた主な理由の一つです。GCC のような大きな成功を収めた比較的きちんと設計されているコンパイラでさえこの特徴は持っていません。GCC の中間レベル表現 GIMPLE は自己完結した (self-contained な) 表現ではないのです。単純な例として、GCC のコードジェネレータがデバッグ情報 DWARF を生成するときには、GCC はソースを表す“木”の走査を行います。GIMPLE はコード中の命令を表現するのに“タプル”を使っていますが、(少なくとも GCC 4.5 の時点において) オペランドはソースを表す木への後方参照として表されるのです。
このせいで、GCC のフロントエンドを書く人は GIMPLE だけでなく GCC が木を表すのに使うデータ構造についても理解し、このデータ構造をソースコードから生成しなければなりません。GCC にはバックエンドにも同様の問題があり、フロントエンドを書くためにはバックエンドの RTL について多くのことを知っておく必要があります。さらに GCC には“ソースコードを表す全てのデータ”をダンプする方法が存在せず、テキスト形式で GIMPLE (およびコードの表現を形成する関連データ) を読み書きする仕組みもありません。結果として GCC を使って実験を行うのは比較的難しくなり、フロントエンドの数が少なくなっています。
LLVM はライブラリの集合である
LLVM において LLVM IR の設計の次に重要なのは、LLVM がライブラリの集合として設計されていることです。GCC のようなモノリシックなコマンドラインコンパイラではなく、JVM や .NET 仮想マシンのような中身の隠された仮想機械でもありません。LLVM は基盤 (infrastructure) であり、様々な特定の問題 (例えば C コンパイラや特殊効果パイプラインのオプティマイザの作成) を解くのに利用できるコンパイラ技術の集合体です。これは LLVM の持つ最もパワフルな機能でありながらも、最も理解されていない設計上のポイントでもあります。
例としてオプティマイザの設計を見てみましょう。オプティマイザは LLVM IR を読み、いくらか処理をして、動作が高速になったはずの LLVM IR を出力します。LLVM では (他の多くのコンパイラと同じように) オプティマイザがいくつかの独立した最適化パスからなっています。よく使われるパスには例えばインライナー (関数呼び出しをその本体で置き換える) や式の再連結 (expression reassociation)、ループ不変条件の移動などがあります。実行されるパスは最適化レベルの応じて異なり、例えば -O0 (最適化無し) では Clang コンパイラはパスを全く実行しませんが、-O3 では (LLVM 2.8 現在) 67 個のパスがオプティマイザで実行されます。
LLVM におけるパスは一つの C++ クラスであり、 Pass クラスを (間接的に) 継承します。多くのパスは一つの .cpp ファイルとして書かれ、 Pass の子クラスは無名名前空間に定義されます (これにより子クラスがそのファイルでのみ利用可能になります)。パスを利用するにはそのファイルの外側からパスのクラスを利用できる必要がありますが、そのためのエクスポートを行う関数が用意されています。単純なパスの具体的な例を次に示します6。
namespace {
class Hello : public FunctionPass {
public:
// 最適化されている LLVM IR 関数の名前を出力する。
virtual bool runOnFunction(Function &F) {
cerr << "Hello: " << F.getName() << "\n";
return false;
}
};
}
FunctionPass *createHelloPass() { return new Hello(); }
上述の通り LLVM のオプティマイザは数十個の異なるパスを提供していますが、どれも同じようなスタイルで書かれています。これらのパスは一つ以上の .o ファイルにコンパイルされ、その後アーカイブライブラリ (Unix であれば .a ファイル) となります。これらのライブラリは様々な解析と変形の機能を提供し、パス同士は最小限の依存関係を持ちます。つまり自分だけで実行できるか、そうでなく他の解析に依存するのであればそのことを明示的に宣言するようになっています。実行するパスが定まれば、LLVM PassManager はこの依存情報を利用して依存を解決し、パスの実行を最適化させます。
ライブラリと抽象的な機能は素晴らしいものですが、それ自身が問題を解くわけではありません。面白いのは誰かがコンパイラ技術を利用した新しいツール、例えば画像処理言語用の JIT コンパイラを作ろうとしたときです。この JIT コンパイラを実装する人の頭にはいくつかの制約が思い浮かんでいるはずです。例えばその画像処理言語ではコンパイル時間のレイテンシがとても重要であるかもしれませんし、パフォーマンスのためには何としても変形しなければならない特徴的な文法があるかもしれません。
LLVM のオプティマイザがライブラリベースで設計されているために、この JIT コンパイラを実装する人は画像処理という分野において意味を持つパスを思い通りの順番で実行できます。全てが一つの大きな関数として定義されているなら、インライン化に時間をかける意味はありません。ポインタが使われていないなら、エイリアス解析やメモリ最適化は行わない方がいいでしょう。もちろん LLVM を使えば全ての最適化問題がマジカルに解決されるというわけではありませんが!パスというサブシステムがモジュール化されており、PassManager 自身は各パスの内部について何も知らないので、実装する人は言語固有のパスを独自に実装し、LLVM のオプティマイザに欠けている部分を補ったり、言語固有の最適化の機会を活用したりすることが可能です。図 11.4 に仮想的な画像処理システム XYZ の簡単な例を示します:
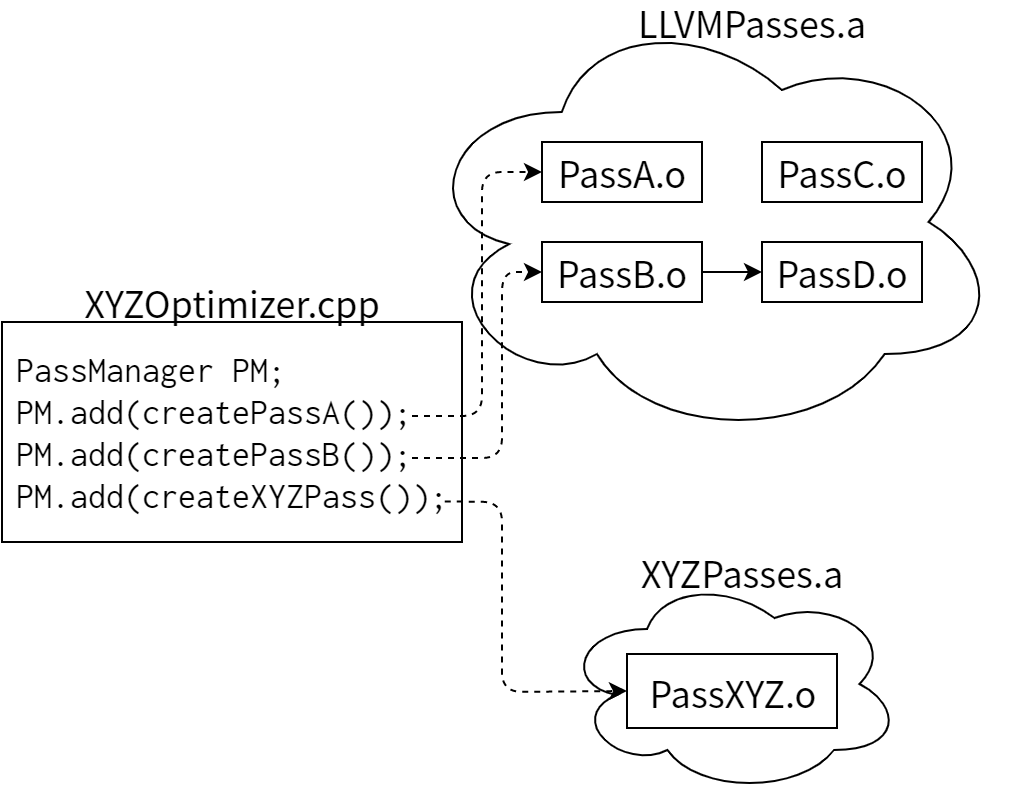
実行する最適化 (およびコードジェネレータ) を選択すれば、画像処理コンパイラを実行形式または動的ライブラリとしてビルドできます。LLVM 本体から最適化パスへの唯一の参照は各 .o ファイルで定義される単純な create 関数だけであり、さらにオプティマイザ本体は .a のアーカイブライブラリに含まれているので、実際に使われる最適化パスだけを最終的なアプリケーションにリンクすることが可能です。LLVM オプティマイザ全体をリンクする必要はありません。上の例では PassA と PassB が参照されているので、これらはリンクされます。また PassB の解析で PassD を使うので、PassD もリンクされます。そして PassC (およびその他数十個のオプティマイザ) は使われないので、画像処理アプリケーションにはリンクされません。
ここで LLVM のライブラリベースの設計の持つ力が明らかになります。この単純な設計アプローチを使う LLVM は大量の機能を持つことができ、たとえ一部の機能が特定のユーザーにしか使われなかったとしても、それによって単純なことしか行わないライブラリ利用者が迷惑をこうむることがありません。これに対して昔ながらのコンパイラが持つオプティマイザは互いに強く結びついた巨大なコードとして作られているので、その一部を取り出し、理解し、高速化するのがはるかに難しくなっています。LLVM であればシステム全体がどうなっているのかを知ることなく個々のオプティマイザを理解することが可能です。
このライブラリを使った設計は多くの人が LLVM を誤解する理由でもあります。LLVM ライブラリはたくさんの機能を持ちますが、ライブラリ自身は何も行えません。機能を上手く組み立てるのは、ライブラリのクライアント (例えば Clang C コンパイラ) の設計者の仕事です。このように注意深くレイヤー化され、分断され、個別に扱えるようになっていることで、LLVM のオプティマイザは様々な分野の幅広いアプリケーションから利用可能になっています。また LLVM は JIT コンパイルの機能を持ちますが、だからといってクライアントが必ずこの機能を使わなければならないわけではありません。
再ターゲット可能な LLVM コードジェネレータの設計
LLVM のコードジェネレータは LLVM IR をターゲット固有の機械語へと変換します。ターゲットに対する可能な限り高速なコードを生成するのがコードジェネレータの仕事です。全てのコードジェネレータが独自のコードを持つことが理想的ですが、一方で各コードジェネレータが考える問題はとても似通っています。例えばどのターゲットにおいてもレジスタに値を割り振る処理が行われますが、異なるのはレジスタファイルだけなので、このアルゴリズムは可能な限り共有されるべきです。
オプティマイザのアプローチと同様に、LLVM のコードジェネレータもコード生成問題を個別のパスに分解します。このパスは命令の選択、レジスタの確保、スケジュール、コードレイアウト最適化、アセンブリの生成からなります。ターゲットごとのジェネレータの作者はデフォルトのパスを使うこともできますし、必要ならば全く異なるターゲット固有のパスをオーバーライドすることできます。例えば x86 バックエンドではレジスタの数がとても少ないので、レジスタをなるべく使わないようなスケジューラが必要になります。これに対して PowerPC はたくさんのレジスタを持つので、レイテンシを最適化するようなスケジューラが使われます。他にも x86 バックエンドは x87 浮動小数スタックを利用するために専用のパスを使い、ARM バックエンドは必要ならば関数の中に定数プールを配置します。この柔軟性により、ターゲットごとのジェネレータの作者はコード全体を最初から書くことなくクオリティの高いコードを生成できるようになります。
LLVM ターゲット記述ファイル
この「分けて合わせる」式のアプローチによって、ジェネレータの作者はアーキテクチャごとに意味のあるパスを選択しつつもコードの大部分をターゲット間で再利用できるようになります。しかしこれによって生じる問題があります: 共有される要素はターゲットに固有の特徴を一般的な方法で表現しなければなりません。例えば共有レジスタのアロケータはターゲットのレジスタファイルについて知っておく必要があり、さらに命令とレジスタオペランドの間の制約も理解しなければなりません。この問題に対する LLVM の対処法は、ターゲットを宣言的なドメイン固有言語で記述したファイル (いくつかの .td ファイル) を用意し、それらを tblgen というツールで処理するというものです。この様子を 図 11.5 に (単純化して) 示します。
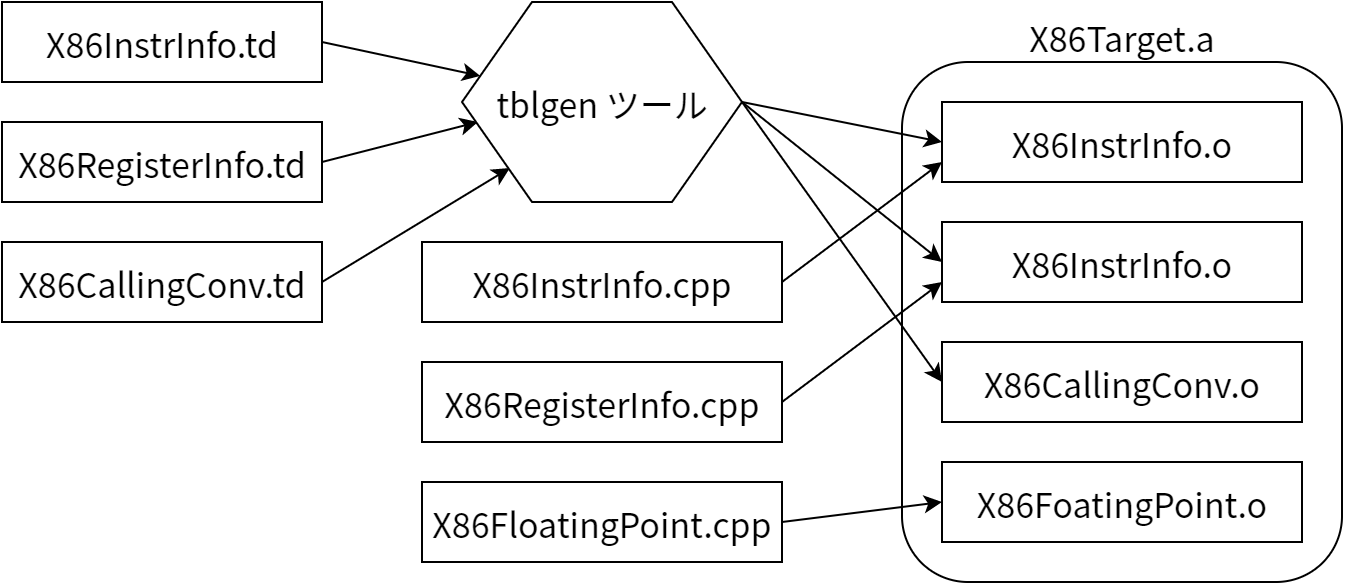
.td ファイルが異なるサブシステムをサポートするので、ジェネレータの作者はターゲットを部分ごとに作ることが可能になります。例えば x86 バックエンドでは、全ての 32 ビットレジスタを保持する“GR32”という名前のレジスタクラスが次のように定義されます (.td ファイルでは、ターゲット固有の定義は大文字になります):
def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { ... }
この定義が表すのは、このクラス内のレジスタが 32 ビット (“i32”) の整数値を保持すること、32 ビットのアラインであること、16 個のレジスタを持つこと (.td ファイルの別の部分で定義されます)、そしてレジスタが確保されるときの優先順位などです。この定義があれば、命令からオペランドとして使うことができます。例えば「32 ビットレジスタを反転する」命令は次のように定義されます:
let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,
(outs GR32:$dst), (ins GR32:$src),
"not{l}\t$dst",
[(set GR32:$dst, (not GR32:$src))]>;
ここでは I という tblgen クラスを使って NOT32r という命令が定義されています。まずエンコード情報 (0xF7, MRM2r) が指定され、次に出力 32 ビットレジスタ ($dst) と入力 32 ビットレジスタ ($src) が指定され (上で定義した GR32 レジスタクラスによってオペランドが指定されます)、命令のアセンブリのシンタックスが指定され (AT&T 記法と Intel 記法の両方を扱うために {} を使った記法が使われます)、最後の行で命令の影響とマッチされるべきパターンが指定されます。最初の行の let で定義される制約 (Constraints) は、入力レジスタと出力レジスタが同じ物理レジスタ上に確保されなければならないことをレジスタアロケータに伝えています。
この定義は命令を非常に短く密に説明しており、LLVM コード (tblgen ツール) はこの情報を基に様々な操作を行います。例えばこの情報さえあれば、コンパイラに入力される IR コードに対するパターンマッチングを通して命令を生成できます。またこの定義はレジスタアロケータが行うべき処理を指定し、命令を機械語のバイト列にエンコードするための情報を含み、テキスト形式の命令をパースしたり出力したりするための情報も含みます。こういった機能があるので、x86 ターゲットはターゲットの記述を使ってスタンドアローンの x86 アセンブラ (GNU アセンブラ“gas”を完全に置き換えられるもの) およびディスアセンブラを生成することが可能です。また JIT 用の命令エンコード処理も可能です。
一つの“真実”から全ての情報を集めて動作することには、便利な機能が提供できること以外にも利点があります。まずこのアプローチにより、アセンブラとディスアセンブラがアセンブリの記法やバイナリのエンコーディングで衝突することがまずなくなります。またターゲットの記述のテストも簡単になります。命令のエンコーディングをコードジェネレータ全体とは別にユニットテストできるようになるからです。
私たちは便利な宣言的書式を使って .td ファイルになるべく多くの情報を詰め込もうとしていますが、それでも全てに対応することはできません。そのため補助的なルーチンやターゲット固有のパスの実装はジェネレータの作者が C++ で書くことになります (x87 浮動小数スタックに対する X86FloatingPoint.cpp など)。LLVM が新しいターゲットをサポートしていくにつれて、 .td ファイルで表現できるターゲットの数を増やすことの重要性は高まりました。そのため私たちは .td ファイルの表現能力を高める作業を続けています。LLVM で新しいターゲットに対するジェネレータを書くのが時が経つにつれて簡単になるというのは素晴らしい特徴と言えます。
モジュール化された設計で可能になる興味深い機能
モジュール化された設計はそれ自身エレガントなものですが、同時に様々な興味深い機能を LLVM のクライアントに提供します。これらの機能は LLVM によって提供されますが、その機能の使い道はクライアントに任されています。
フェーズの実行タイミングの制御
前にも触れましたが、LLVM IR は LLVM ビットコードと呼ばれるバイナリ形式とテキスト形式の変換を効率良く行えます。LLVM IR は自己完結したフォーマットでありこの変換処理で失われる情報はないので、変換の途中で経過をディスクに書き出して、後で処理を再開することが可能です。この機能を使えばコードの生成を“コンパイル時”から遅らせて、リンク時やインストール時に最適化を行うことが可能になります。
リンク時最適化 (Link-Time Optimization, LTO) は昔ながらのコンパイラが持つ問題を解決します。その問題とは、コンパイラが一つの翻訳単位 (例えば .c ファイルとそのヘッダー) だけしか見ることができず、インライン化のような最適化をファイルの境界を超えて行うことができないという問題です。Clang のような LLVM コンパイラは -flto と -O4 というコマンドラインオプションで LTO をサポートします。このオプションを使った場合コンパイラはネイティブのオブジェクトファイルではなく LLVM ビットコードを .o ファイルに書き込み、コード生成をリンク時まで遅らせます。この様子を 図 11.6 に示します。
詳細はオペレーティングシステムによって異なりますが、ここで重要なのは .o ファイルにネイティブのオブジェクトファイルではなく LLVM ビットコードが書かれていることがリンカによって検出される点です。このときリンカは全てのビットコードファイルをメモリに読み込み、リンクを行い、一つにまとめたコードに対して LLVM オプティマイザを実行します。こうするとオプティマイザがはるかに広いコードを見ることができるので、ファイルの境界を越えて関数をインライン化したり、定数を畳み込んだり、より踏み込んで未到達コードを削除したりできるようになります。最近のコンパイラでは LTO をサポートするものも多いですが、そのほとんど (GCC、Open64、Intel コンパイラなど) ではコストが高くて低速なシリアライズ処理を使って LTO が実装されています。一方 LLVM では LTO はシステムの設計から自然に生まれたものです。さらに IR がソース言語とは完全に切り離されているために、LTO は (他の多くのコンパイラとは違い) 異なるソース言語をまたいで動作します。
インストール時最適化 (install-time optimization) とは、コードの生成をリンク時よりもさらに遅らせてインストール時に行うというアイデアです。図 11.7 にその様子を示します。インストール時 (ソフトウェアが出荷されるとき、ダウンロードされるとき、モバイルデバイスへアップロードされるときなど) というのはターゲットのデバイスが判明するタイミングであり、とても興味深い瞬間と言えます。例えば x86 には様々なチップがあり、それぞれが異なる特徴を持っています。命令の選択やスケジューリングといったコード生成の判断を遅らせれば、アプリケーションが実行される特定のハードウェアにおける最良の選択ができるようになります。

オプティマイザのユニットテスト
コンパイラはとても複雑ですが、質を犠牲にすることはできません。そのためテストが非常に重要になります。例えばオプティマイザをクラッシュさせるバグを直したときは、そのバグが今後起こらないことを保証するレグレッションテストが追加されるべきです。これをテストするための昔ながらのアプローチは .c ファイル (など) を書いてコンパイラを走らせ、そのときにコンパイラがクラッシュしないことを確認するテストを書くというものです。GCC のテストスイートはこのアプローチを使っています。
このアプローチの問題は、コンパイラがたくさんのサブシステムとさらに多くの最適化パスからできているために、バグが起きたコードへの入力が設定によって変動してしまう点です。フロントエンドやオプティマイザの前方のパスで何かが変更されると、すぐにテストされるべきことがテストされなくなってしまいます。
LLVM のテストスイートはテキスト形式の LLVM IR とモジュール化されたオプティマイザを活用しています。つまりディスクから LLVM IR を読み、最適化パスを一つだけ実行し、その動作を検証するというレグレッションテストがほとんどを占めます。また複雑な動作のテストではクラッシュの有無の他にも最適化が実際に行われたかどうかも検証したい場合もあります。次に示すのは、加算命令において定数の畳み込みが起こるかどうかを検証する簡単なテストケースです:
; RUN: opt < %s -constprop -S | FileCheck %s
define i32 @test() {
%A = add i32 4, 5
ret i32 %A
; CHECK: @test()
; CHECK: ret i32 9
}
RUN で始まる行が実行するコマンドを指定します。ここでは opt と FileCheck というコマンドラインツールが実行されます。 opt は LLVM のパスマネージャを簡単にラップしたプログラムです。全ての標準的なパスがリンクされており、コマンドラインから利用できるようになっています (他のパスを含むプラグインを動的にロードすることも可能です)。 FileCheck ツールは標準出力からの入力が CHECK というディレクティブに続く文字列とマッチするかどうかを検証します。この例では、簡単なテストによって constprop パスが 4 と 5 の add を 9 に畳み込むかどうかを検証しています。
このテストはとても簡単な例に思えるかもしれませんが、 .c ファイルを書いて同じテストを行うのは非常に困難です。フロントエンドが定数の畳み込みをパース時に行ってしまうので、畳み込めるような式を定数の畳み込みパスまで持っていくには細かな調整が必要になるからです。またテストでは LLVM IR をテキストとして読み込み、特定の最適化パスに送り、その出力を別のテキストファイルに保存しています。そのためレグレッションテストと機能テストの両方において、出力が望む形であるかどうかを判定するのはとても簡単です。
BugPoint によるテストケースの自動縮小
コンパイラもしくは LLVM ライブラリの他のクライアントでバグが見つかったときに最初に行われるのは、問題を再現するテストケースの作成です。テストケースができたら、次は問題を再現できる範囲でそのテストケースを最小化し、LLVM の中で問題が起きている部分だけを含めるようにするのが望ましいです。これによって例えばある最適化パスが問題だと判明します。この作業のコツは少しずつ習得できるものですが、それにしてもこの作業は面倒くさく、手作業に頼るしかありません。またコンパイラがクラッシュせずに間違ったコードを生成する場合には特に骨の折れる作業となります。
LLVM BugPoint というツール7は IR のシリアル化と LLVM のモジュール化された設計を活用してこの作業を自動化します。例えば入力の .ll ファイルや .bc ファイルとクラッシュを起こす最適化パスの列を BugPoint に与えると、入力を小さなテストケースに縮小し、さらにどのオプティマイザがクラッシュを起こしているのかを判定し、そして縮小されたテストケースとバグを起こすための opt コマンドが出力されます。内部では“デルタデバッグ (delta debugging)”と呼ばれるテクニックを使って入力とパスのリストの縮小が行われています。BugPoint は LLVM IR の構造を知っていることから、無効な IR をオプティマイザに入力して時間を無駄にすることがありません。この点は“delta”コマンドラインツールと異なります。
もっと複雑なケースにおける誤ったコンパイルでは、入力、コードの生成情報、実行形式に渡すコマンドライン、そしてリファレンスとなる出力を BugPoint に渡すことができます。BugPoint はまず問題がオプティマイザなのかコードジェネレータなのかを調査し、テストケースを再帰的に二つに分割します: 一つは“問題なし”の部分で、もう一つは“問題あり”の部分です。そして問題ありの部分から少しずつコードを抜いていくことで、テストケースを小さくしていきます。
BugPoint はとても単純なツールですが、LLVM の開発においてテストケースを小さくするのに費やされる時間を大きく節約しました。他のオープンソースコンパイラには似たようなパワフルなツールは存在しません。BugPoint のようなツールはきちんと定義された中間表現がないと作れないためです。とは言っても BugPoint は完璧ではありませんし、最初から書き直せば得られるものもあるでしょう。最初に書かれたのは 2002 年であり、改善されたのは誰かがその時点の BugPoint で探索できないような非常に入り組んだバグに直面したときだけです。一貫した設計や単一の所有者も存在せずに時と共に新しい機能 (JIT デバッグなど) が追加されてきました。
振り返りと今後の方針
モジュール性を重視した LLVM の設計の当初の目標は、この章で説明した機能を実装することではありません。この設計は自衛メカニズムでした。つまり最初から全てが上手く行くわけではないのが明らかだったわけです。例えばモジュール化された最適化パスパイプラインを作ったのは、パス同士を切り離し、後からより良い実装が出てきたときに古いものを捨てられるようにするためです8。
LLVM が軽快さを保ち続けているもう一つの理由は、私たちが熱心に過去の判断を見直し、大規模な API の変更を後方互換性を考えることなく行っている点です (ライブラリのクライアントからすると議論の尽きない点ではあります)。例えば LLVM IR に対する破壊的な変更を行うには全ての最適化パスを更新しなければならず、C++ API も大きく変更されますが、私たちはこういった変更を何度か行っています。クライアントにとっては痛みの伴う作業に違いありませんが、素早い改善を可能にするには避けられないことです。外部クライアントのために (そして他の言語に対するバインディングをサポートするために)、広く使われている (安定した) API に対しては C ラッパーが用意されており、新しいバージョンの LLVM でも古い .ll ファイルと .bc ファイルを読めるようになっています。
私たちは今後 LLVM のモジュール化を進め、LLVM の一部を簡単に利用できるようにする作業を続けていくつもりです。一例をあげると、現在のコードジェネレータはモノリシックすぎであり、機能ごとにジェネレータを切り出して使うのは不可能です。例えば JIT だけを使ってインラインアセンブリや例外処理、デバッグ情報の生成を使わない人がいるなら、そういった機能をリンクすることなくコードジェネレータをビルドする機能があった方が望ましいです。この他にも私たちはオプティマイザとコードジェネレータが生成するコードの質の向上、新しい機能とターゲットをサポートするための IR の機能の拡充、高レベルの言語に特有な最適化のより良いサポートに取り組んでいます。
LLVM プロジェクトでは様々な部分で成長と改善が続いています。LLVM が他のたくさんのプロジェクトで使われていたり、プロジェクトが LLVM の設計者でさえ思いもよらなかった驚くべき方法で LLVM を使っているのを見るのはとてもワクワクします。新しい LLDB デバッガはこの素晴らしい例でしょう。LLDB は Clang の C/C++/Objective-C パーサーを使って式をパースし、パースされた式は LLVM JIT によってターゲットのコードに変換され、LLVM ディスアセンブラを利用し、LLVM バックエンドを使って呼び出し規約などを処理しています。既存のコードが再利用できることで、デバッガの開発者はデバッガのロジックに集中でき、yet another で不完全な C++ パーサーを書かずに済みます。
LLVM はこれまでに成功を収めましたが、やるべきことは多く残されています。さらに LLVM が年を取るにつれて軽快さを失って固まってしまうのではないかというリスクも現実のものになりつつあります。この問題への魔法の答えはありませんが、新しい問題領域へ進むことをやめないこと、これまでの判断を慎重に議論すること、そして再設計をしてコードを捨てることが役に立っていると私は願っています。何といっても、ゴールは完璧になることではなく、常に改善し続けることなのです。
-
“GNU Compiler Collection”を表す逆頭字語 (backronym) です。[return]
-
これは X86 のような二アドレス命令セットとは対照的です。二アドレス命令セットでは入力レジスタまたは単一アドレスマシンが破壊的に更新されます。ここで単一アドレスマシンとは一つのオペランドを受け取ってアキュムレーターもしくはスタックマシンのスタックの頂上を操作するものです。[return]
-
この他の詳細については http://llvm.org/docs/WritingAnLLVMPass.html にある Writing an LLVM Pass manual を参照してください。[return]
-
一度も書き直されていない LLVM のサブシステムに優れてるものは存在しない、と私はよく言っています。[return]