NoSQL エコシステム
この本に出てくる他の多くのプロジェクトとは異なり、NoSQL は一つのツールの名前ではありません。NoSQL はエコシステムであり、互いに補い合いながらも競い合ういくつかのツールからなります。NoSQL と名の付くツールは SQL を使ったリレーショナルデータベースシステムの代替を提供します。NoSQL を理解するには、利用可能なツールを見渡し、それぞれのツールの設計がどのようにデータの保存という機能を捉えているかを理解する必要があります。
もしあなたが NoSQL ストレージシステムの利用を考えているのなら、まず NoSQL システムが提供する多様な選択肢を理解しなければなりません。NoSQL システムでは従来のリレーショナルデータベースで見られる利便性が取り除かれており、通常であればシステムの内部に隠されていたような操作がアプリケーション設計者に任されています。そのためあなたはシステムアーキテクトの帽子をかぶり、システムがどう作られているかをより深く理解しなければなりません。
名前の意味
NoSQL の世界を見ていくにあたって、最初にその名前の意味を明確にしましょう。文字通り解釈すれば、NoSQL システムとは SQL でない (not SQL) クエリインターフェースを使用するシステムのことです。しかし通常 NoSQL コミュニティはもう少し広い意味でこの言葉を使います。つまり、NoSQL システムは従来のリレーショナルデータベースの代替を提供し、その設計には SQL に限らない (not only SQL) インターフェースを利用するシステムであるということです。アプリケーションの開発で遭遇する問題によっては従来のデータベースを NoSQL の代替で置き換えられる場合もありますし、様々なツールを組み合わせるアプローチが取られる場合もあります。
NoSQL の世界に飛び込む前に、SQL とリレーショナルモデルが上手く行く例、および NoSQL の方が上手く行くように思われる例についてまず見ていきます。
SQL とリレーショナルモデル
SQL はデータを問い合わせるための宣言型言語 (declarative language) です。宣言型言語ではプログラマーはシステムがすべきことだけを指定し、それをどうやって行うかを実際の手続きとして示すことはありません。例えば 「従業員 39 のレコードを見つけよ」「レコード全体から従業員の名前と電話番号を取り出せ」「従業員のレコードから会計部局で働いている者だけを取り出せ」「各部局の従業員数を数えよ」「従業員のテーブルとマネージャのテーブルを結合せよ」などの問い合わせ (クエリ) を記述します。
最初に分かるのは、SQL を使って問い合わせを行えば、データがディスク上でどう並んでいるか、データにアクセスするときのインデックスは何か、データを処理するときのアルゴリズムは何かといった詳細を気にする必要がないということです。多くのリレーショナルデータベースにおいてアーキテクチャ上の重要な要素となっているのは、論理的に同値なクエリプランの中で一番速くクエリに答えられるのはどれかを判断するクエリオプティマイザです。このオプティマイザは平均的なデータベースユーザーよりも賢いことが多いですが、情報が少なすぎたり、システムのモデルが単純すぎたりした場合には一番高速なクエリを生成できない場合もあります。
リレーショナルデータベースは最もよく使われるデータベースであり、リレーショナルデータベースモデルを使っています。このモデルにおいては現実世界の様々なエンティティが異なるテーブルに格納されます。例えば全ての従業員は Employees テーブルに保存され、全ての部局は Departments テーブルに保存されます。テーブルの各行には各属性に対する値が並び、各列にはある属性の値が並びます。例えば従業員に従業員 ID、給料、生年月日、氏名といった属性があるとすれば、こういった属性は Employees テーブルの各列に属性ごとに保存されます。
リレーショナルモデルは SQL と上手く噛み合います。filter のような単純な SQL クエリは何らかの条件 (employeeid = 3 や salary > $20000 など) に合致するレコードを全て取得する処理を行うからです。もっと複雑なクエリにおいては複数のテーブルからの値を結合したりするなどの追加の計算が必要になることもあります (例: 従業員 3 の働いている部局の名前は?)。また aggregate のようなクエリでは、テーブル全体のスキャンが行われることもあります (例: 従業員の平均給与は?)。
リレーショナルデータモデルは、間に厳密な関係を持ったエンティティの集合を、高度に構造化された形で定義します。SQL を使ってこのモデルに問い合わせを行うことで、複雑なデータ走査が個別の開発を行うことなく可能になります。ただこのモデルとクエリは複雑であり、この複雑さから生じる制限もあります:
-
複雑だと予測が難しくなります: SQL が高い表現能力を持っているせいで、各クエリのコストおよび複数のクエリ全体の負荷を正確に予測するのが難しくなります。より単純なクエリ言語を使えば、たとえアプリケーションのロジックが多少複雑になったとしても、単純なクエリだけに応答するそのデータストレージシステムの動作は簡単に予測が可能です。
-
問題をモデル化する方法は多様であるにもかかわらず、リレーショナルデータモデルは厳格です: テーブルの各行が保持するデータはテーブルの構造によって決定されます。データが構造化されていない場合、あるいは列に多くのデータを格納する必要がある場合には、リレーショナルデータモデルは不必要な制限となります。同様に、アプリケーションの開発者からすればリレーショナルデータモデルを全てのデータに対するモデルとして使うのは不都合かもしれません。例えば多くのアプリケーションロジックはオブジェクト指向言語で書かれており、リスト、キュー、集合といった高レベルの概念を持っています。こういった概念を基礎としたモデルを好むプログラマーもいるでしょう。
-
データの容量が一つのサーバーの容量を越した場合には、データベースのテーブルをコンピューターをまたいで分割する必要が生じます。JOIN が異なるテーブルからデータを取得するときにネットワーク越しの通信が起こるのを防ぐには、テーブルを非正規化することになります。非正規化とはつまり後でまとめて必要になるデータを異なるテーブルから単一の場所に移すということです。これを言い換えるとデータベースをキールックアップストレージシステムのように変形しているのですが、それならば最初から他のモデルを使ってデータをモデル化した方が良いのではないかと思わざるを得ません。
ただし、長年に渡るデータベースの設計に関する研究を考え無しに打ち捨ててしまうのは賢明ではないでしょう。データをデータベースに格納することになったら、まずは SQL とリレーショナルモデルを考えてみるべきです。この二つには数十年にわたる研究と開発があり、柔軟なモデルであり、複雑な操作についても理解しやすい保証があります。NoSQL が良い選択肢となるのは、あなたがある種の特殊な問題を抱えているときです。例えばデータが莫大だったり、負荷が巨大だったり、SQL とリレーショナルデータベースでは上手く行かないモデルを使うことになったりした場合です。
NoSQL が影響を受けたもの
NoSQL ムーブメントは研究コミュニティによる論文から多大な影響を受けています。NoSQL システムの中心的な設計判断にはたくさんの論文が関わっていますが、特に影響力が大きいのは次の二つです。
Google による [CDG+06] は興味深いデータモデルを示しました。このモデルを使うと複数カラム履歴データのソート済みストレージが容易に構築できます。データは複数のサーバーに階層化されたレンジベースの分割スキームを使って分散され、データの更新において一貫性が厳密に保たれます (一貫性は 13.5 節で扱います)。
Amazon による Dynamo [DHJ+07] は BigTable とは異なるキー指向の分散データストアを使います。Dynamo のモデルはより単純であり、キーをアプリケーション固有の blob データにマップするというものです。Dynamo が用いる分割モデルは障害耐性が増しており、これは eventual consistency と呼ばれるデータ一貫性へのより緩いアプローチによって達成されています。
以上の概念についてこれから一つずつ見ていきますが、その多くは合わせて使うことができることを忘れないでください。HBase1 のような NoSQL システムの設計は BigTable の設計に非常に似ており、Voldemort2 のように Dynamo の機能の多くを真似た NoSQL システムもあります。しかし Cassandra3 のように、BigTable の特徴 (データモデル) と Dynamo の特徴 (分割および一貫性のスキーム) を併せ持つ NoSQL プロジェクトも存在します。
特徴と懸案事項
NoSQL システムは重厚な SQL 規格と思想が異なり、提供されるのはストレージソリューションの構築で利用可能な断片的なパーツです。NoSQL システムの設計の奥底にあるのは、データベースがデータに対して行う操作を単純にすればクエリのパフォーマンスをより正確に予測できるようになるはずだという信念です。多くのシステムにおいて、複雑なクエリロジックはアプリケーションが担当します。これによってクエリの種類が減少し、データストアに対するクエリのパフォーマンスの予測可能性が向上します。
NoSQL システムは単なる「リレーショナルデータへの宣言的クエリ」ではありません。トランザクション、一貫性、永続性は、銀行のような機関のデータベースが必要とするものです。トランザクションはある口座から他の口座に資金を移すといった複雑な操作を一つにしたときに、操作が全て行われるか一切行われないかのどちらかであること (all-or-nothing) を保証します。一貫性は値を一度更新すれば、その後に続くクエリが更新された値を扱えることを保証します。永続性は値を一度更新すれば、そのことが安全な永続ストレージ (ハードドライブなど) に書き込まれ、データベースがクラッシュしたとしても復元できることを保証します。
NoSQL システムではこういった保証を一部緩めます。金融でないアプリケーションにおいては緩めたとしても動作が不安定になることはなく、その分パフォーマンスが向上します。保証を緩め、さらに異なるデータモデルとクエリ言語を用いることで、データベースが一つのマシンの容量を超えた場合でもデータベースの複数のマシンにまたがった分割が高速・安全に行えるようになります。
NoSQL システムはまだ生まれたての状態です。この章で紹介するシステムが取ったアーキテクチャ上の決断は、多様なユーザーの要件に対する身体を張った報告書です。複数のオープンソースプロジェクトのアーキテクチャを束ねるときに最大の困難となるのは、どのプロジェクトも異なるターゲットを持つ点です。システムの詳細はいずれ変更されることを忘れないでください。NoSQL システムを選択するときにこの章の内容を思考プロセスのガイドとして使うことができますが、この章は機能ごとにプロダクトを示したカタログではありません。
NoSQL システムについて考える際のロードマップは次のようになります:
-
データとクエリモデル: データが表現されるのは行か、オブジェクトか、データ構造か、ドキュメントか? 複数のレコードの集計を計算できるか?
-
一貫性: 値を変更したとき、その情報は即時に安定ストレージへ書き込まれるか? マシンがクラッシュしたときに備えて、その情報は複数のマシンに書き込まれるか?
-
スケーラビリティ: データは一つのサーバーに収まるか? 読み込み/書き込みの負荷は処理に複数のディスクを必要とするか?
-
トランザクション: 複数の操作を行うとき、それらを一つのトランザクションにまとめられるデータベースもある。トランザクションは ACID (原子性、一貫性、独立性、永続性) の一部または全てを並列に動作するトランザクション全てに保証する。これによってパフォーマンスが悪化するが、ビジネスロジックはこれらの保証を必要とするか?
-
単一サーバーにおけるパフォーマンス: データを安全にディスクに保存するとき、オンディスクのデータ構造として一番なのはどれか? それによって読み込みと書き込みの負荷はどうなるか? ディスクへの書き込みはボトルネックとなるか?
-
負荷の解析可能性: レスポンシブなユーザーベースのウェブアプリケーションなどが必要とする、ルックアップ中心の負荷の解析はとても重要である。そのような多くケースにおいてデータセットごとのレポートを作ることになるが、その際には例えば複数のユーザーの統計を集計する必要がある。アプリケーションはそのような機能を必要とするか? 考えているツールチェインはサポートするか?
以上について一つずつ議論しますが、最後の三つは章の最後に触れるだけにします。もちろんどれも同等に重要です。
NoSQL のデータモデルとクエリモデル
データベースのデータモデルはデータが論理的にどのように管理されるかを定め、クエリモデルはデータの取得と更新がどのように行われるかを定めます。よく使われるモデルにはリレーショナルモデル、キー指向ストレージモデル、および様々なグラフモデルがあります。クエリ言語としては SQL、キールックアップ、MapReduce などを聞いたことがあるでしょう。NoSQL システムは異なるデータモデルとクエリモデルを組み合わせるので、アーキテクチャ上の懸案事項はシステムごとに異なります。
キーベースの NoSQL データモデル
NoSQL システムはリレーショナルモデルを完全には採用せず、データセットへのルックアップを単一のフィールドへと制限して SQL の表現力を制限することが多いです。例えば従業員がたくさんのプロパティを持っていたとしても、できる操作を ID を使った従業員の取得だけに制限したい場合があります。この結果 NoSQL へのクエリのほとんどはキーベースとなります。プログラマーができるのはアイテムを特定するためのキーを用意し、そのキーを使ってデータベースからアイテムを取得することだけ (あるいはほぼそれだけ) です。
キールックアップベースのシステムでは、複雑な join 操作や同じデータからの複数キーによるデータの取得にはキーの割り当てに工夫が必要です。例えば ID で従業員を検索し、その従業員の属する部局の従業員を全て取得する操作が必要な場合には、二つのキーが必要になるでしょう。一つは従業員 ID が 30 の従業員に対するキー employee:30 であり、もう一つは部局 20 に属する従業員のリストを含む employee_deparments:20 です。そして join 操作はアプリケーションロジックの担当です: 部局 20 の従業員を取得するには、まず従業員のリストを employee_deparments:20 というキーで取得し、それから各キー employee:ID に対してキールックアップを行うループを回します。
キールックアップモデルが使いやすいのは、それぞれのクエリがパフォーマンスが比較的一様で予測しやすいキールックアップからなるために、データベースへのクエリパターンが一貫するためです。アプリケーションのどこが低速なのかを見つけるのは簡単になります。なぜなら複雑な操作は全てアプリケーションのコードにあるからです。ただしその分、データモデルロジックとビジネスロジックは絡み合うことになり、抽象化が難しくなります。
キールックアップモデルにおいてキーが指すデータについて軽く説明します。異なる NoSQL システムは異なるソリューションを用意しています。
キーバリューストア
一番簡単な NoSQL ストアはキーバリューストアです。キーは任意のデータを含んだバリューに割り当てられます。NoSQL ストアは格納されているデータについて何も関知せず、ただそのデータをアプリケーションに渡すだけです。先ほどの Employee データベースの例では、従業員 30 に関する情報を Protocol Buffers4、Thrift5、Avro6 といったバイナリフォーマットあるいは JSON に保存し、それを employee:30 というキーで引けるようにしたのがキーバリューストアです。
キーに対するデータが複雑で、構造化されたフォーマットを使ってデータを保存する場合には、そのデータに対する操作はアプリケーションで行わなければなりません。キーバリューデータストアは通常キーに対応するデータに対するクエリのためのメカニズムを一切持たないからです。キーバリューストアの利点はその単純なクエリモデルです。set, get, delete という基本操作からなり、データの中身を読めないのでデータベース内のフィルタ処理はできないのが普通です。Amazon の Dynamo をベースとしている Voldemort は分散キーバリューストアを提供します。また BDB7 はキーバリューのインターフェースを持つ永続ストレージを使ったデータベースライブラリです。
キーデータ構造ストア
キーデータ構造ストアとはバリューとして何らかの型の値を割り当てるもので、Redis8 によって広まりました。Redis で利用可能な型は整数、文字列、リスト、集合、ソート済み集合です。set / get / delete という操作に加えて型に固有の操作も行うことができます。例えば整数に対するインクリメント/デクリメント、リストに対するプッシュ/ポップなどであり、これによってリクエストのパフォーマンス特性に対する大きな影響を避けながらもクエリの機能を増やしています。型に特有な機能を提供しつつも aggregation や join といった複数キー操作を避けることで、Redis は機能とパフォーマンスのバランスを保っています。
キードキュメントストア
CouchDB9、MongoDB10、Riak11 などのキードキュメントストアは、キーを構造化された情報を含んだドキュメントに割り当てます。これらのシステムではドキュメントを JSON や JSON に似たフォーマットに保存します。そういったフォーマットはリストや辞書を扱うことができ、データを再帰的に入れ子にすることが可能です。
MongoDB は名前の衝突を防ぐためにキー空間をコレクションに分割するので、例えば Employee と Deparments に対するキーは衝突しないようになっています。また CouchDB と Riak は型のトラッキングを開発者に任せます。キードキュメントストアが持つこういった自由さと複雑さは両刃の剣です: アプリケーション開発者はドキュメントのモデリングを自由に行うことができますが、その分アプリケーション内のクエリロジックが複雑になりすぎる可能性があるからです。
カラムファミリーストア (BigTable)
HBase と Cassandra は Google の BigTable で使われているのと同じデータモデルを使っています。このモデルではキーは一つのローを指し、ローが持つ各データはいくつかあるカラムファミリー (Column Family, CF) のどれかに属します。各ローは一つの CF の中に複数のカラムを持つことができます。各カラムのバリューにはタイムスタンプが付与され、複数のバージョンのローとカラムの対応関係が一つの CF に存在できるようになっています。
実装の詳細を無視すれば、カラムファミリーストアはデータを (ロー ID, CF, カラム, タイムスタンプ) という込み入った形をしたキーでデータを保存し、対応するバリューをこのキーでソートして保存すると考えることができます。このデータモデルではキー空間がたくさんの機能を持ち、タイムスタンプを持った履歴データをモデル化するのに特に適しています。値の設定されていないカラムに明示的に NULL を設定する必要がないので、カラムが疎であるような場合も自然にサポートされます。逆に NULL をほとんどあるいは全く持たないカラムがあった場合には、そのカラム識別子を多くのローに書き込む必要があるので空間が無駄になります。
どのプロジェクトのデータモデルもオリジナルの BigTable とは様々な点が異なっていますが、その中でも Cassandra が加えた変更が最も興味深いものです。Cassandra には CF の内側にスーパーカラム (supercolumn) という概念を導入し、もう一段深いマッピング/モデリング/インデックス化を可能にしています。また Cassandra は複数のカラムファミリーを物理的に同じ場所に保存するローカリティグループ (locality group) という機能を削除してパフォーマンスを向上させています。
グラフストア
グラフストアは NoSQL ストアのクラスの一つです。全てのデータが同様に作られるわけではなく、リレーショナルモデルやキー指向モデルを使えば全てのデータの保存とクエリが処理できるという訳ではありません。グラフはコンピューターサイエンスにおいて基礎的なデータ構造であり、HyperGraphDB12 や Neo4J13 はグラフ構造のデータを保存するための代表的な NoSQL ストレージシステムです。グラフストアは今まで触れてきたストアとありとあらゆる点で異なっています: データモデル、データの走査、クエリパターン、データのディスク上での物理的レイアウト、複数のマシンをまたいだ分散方法、クエリのトランザクション的なセマンティクスは全て異なります。紙面の都合上全てを細かく説明することはできませんが、グラフとして保存とクエリを行うほうが適しているデータもあることは認識しておくべきです。
複雑なクエリ
NoSQL システムは基本的にキーだけを使ったルックアップを行いますが、注目すべき例外がいくつかあります。MongoDB では好きな数のプロパティを使ってデータを取得でき、データを指定するための比較的高レベルな言語もあります。BigTable ベースのシステムではカラムファミリーを走査するためのスキャナーがサポートされ、カラムをフィルタしてアイテムを取得できます。CouchDB ではデータのビューを複数作成でき、テーブルに MapReduce タスクを実行してさらに複雑なルックアップや更新を行うことも可能です。ほとんどの NoSQL システムには Hadoop やその他の MapReduce フレームワークへのバインディングがあり、これを使ってデータセットスケールの解析クエリを行うことができます。
トランザクション
NoSQL システムは通常トランザクションという機能よりもパフォーマンスを重要視します。これに対して SQL ベースのシステムでは、任意の形の文を一つのトランザクションにできます。つまり一つのキーを使った行の取得といった単純な操作から、複数のテーブルをまたぐ join をしてから複数のフィールドに関する平均を求めるといった複雑な操作まで、一つのトランザクションにまとめることが可能です。
そういった SQL データベースはトランザクション間の ACID を保証します。トランザクションに含まれる複数の操作は原子的 (atomic)、つまり操作の全てが実行されるか、そうでなければ一つも実行されません。一貫性 (consistency) はトランザクション後のデータベースが破損していない整合状態に保たれることを保証します。独立性 (isolation) は二つのトランザクションが同じレコードを編集するときに、互いがもう一方の足を踏むことなくトランザクションを行えることを保証します。永続性 (durability) は一度コミットされたトランザクションが安全な場所に保管されることを保証します (章の後半で詳しく触れます)。
ACID 準拠なトランザクションがあるとデータの状態を理解しやすくなるので、開発者の正気が保たれます。例えば複数のステップからなるトランザクションがいくつもあるような場合 (銀行口座の値をチェックし、$60 引き出し、値を更新する、など) を考えてみてください。ACID 準拠なデータベースでは、全てのトランザクションの結果を正しくするためにステップを細かく分ける方法が制限される場合が多いです。そしてこのして正しさを重視する結果として、高速なトランザクションが他の遅いトランザクションによって長く待たされるなど予期せぬパフォーマンス特性が生じることがあります。
ほとんどの NoSQL システムは ACID の完全な準拠ではなくパフォーマンスを選択しますが、それでもキーレベルでの保証は提供します: 同じキーに対する二つの操作はシリアライズされて実行され、キーバリュー組が破損することはありません。多くのアプリケーションではこうしてもデータの安定性に関する問題が生じることはなく、高速な操作がより安定して実行できるようになります。しかしそれでも、開発者がアプリケーションの設計とデータの安定性に関して考えなければならないことは増えます。
Redis はこのトランザクションを使わないというトレンドに対する注目すべき例外です。単一サーバーの Redis では、複数の操作を原始性と一貫性を保って組み合わせる MULTI コマンドと、独立性を保つ WATCH コマンドを利用できます。他のシステムでは低レベルな test-and-set 命令を使って多少の独立性が保証できることもあります。
スキーマフリーストレージ
多くの NoSQL システムに共通して見られる特徴は、データベースにスキーマを要求しないことです。ドキュメントストアやカラムファミリー指向ストアでさえ、複数の似たエンティティにプロパティが同じであることを要求しません。これによって構造化されていないデータをサポートできる上に、スキーマを動的に変更するときのパフォーマンスの低下を抑えられます。ただしこれによってアプリケーション開発者の責任は増え、防御的なプログラミングが必要になります。例えば従業員レコードの lastname プロパティが無かったときにそれが修正すべきエラーを表すのか、それともスキーマの更新が現在システムに伝播している途中なのかは分かりません。いい加減なスキーマを持つ NoSQL システムのアプリケーションレベルのコードでは、プロジェクトの最初のイテレーションの後にはデータとスキーマをバージョン付けるのが一般的です。
データの永続性
理想的には、ストレージシステムに対する全ての変更がすぐに安全な永続ストレージに書き込まれ、さらに複数の場所に複製されることがデータロスを避けるためには必要です。しかしデータの安全性を追い求めるとすぐにパフォーマンスが犠牲になるので、異なる NoSQL システムは異なる方法で永続性を保証しつつパフォーマンスを保っています。多岐にわたる大量の障害のシナリオが存在しますが、全ての NoSQL システムがそういった障害の全てに対応しているわけではありません。
単純でよくある障害シナリオは、サーバーの再起動や電源の喪失です。この場合のデータの永続性が関係するのは、データをメモリからハードディスクに移し、電源無しにデータが保存されるようになっているかどうかです。ハードディスクの障害はデータを二次的なデバイスに移すことで対処できます。例えば同じマシンの異なるハードドライブに移したり (RAID ミラーリング)、ネットワーク上の異なるマシンに移したりします。しかしデータセンターはハリケーンのような相関性のある障害によって破壊される可能性もあり、そのような場合に備えてハリケーン数個分離れたデータセンターにバックアップを保存している機関もあります。ハードドライブにデータを書き込みそれを複数のサーバーやデータセンターにコピーするのは時間のかかる処理であり、様々な NoSQL システムはパフォーマンスのために永続性の保証を手放しています。
単一サーバー永続性
一番単純な永続性は、サーバーの再起動や電源の喪失でデータが失われないという単一サーバー永続性 (single-server durability) です。単一サーバー永続性を保証するには変更を毎回ディスクに書き込まなければならず、この部分がボトルネックになる場合が多いです。ディスク上にファイルにデータを書き込むよう指示したとしても、オペレーティングシステムは書き込みをバッファし、複数の書き込みを一つにまとめて処理することでディスクへの書き込みを減らそうとすることがあります。オペレーティングシステムにバッファされた更新を永続ストレージに書き込ませる (ための最大限の努力をさせる) には、システムコール fsync を使わなければなりません。
一般的なハードドライブは一秒間に 100 回から 200 回のランダムアクセス (シーク) を行うことができ、シーケンシャルな書き込み速度は 30 MB/sec から 100 MB/sec 程度です。単一サーバー永続性を担保しながらパフォーマンスを上げるには、システムが行うランダムアクセスを抑え、ハードドライブごとのシーケンシャルな書き込みの回数を増やすことが重要になります。理想的には fsync 呼び出しの間の書き込みの回数を最小化し、連続した領域への書き込みの回数を最大化し、その上で fsync が実際に実行されるまでユーザーにデータが書き込まれたと伝えることがないようにしなければなりません。単一サーバー永続性を保証しつつパフォーマンスを向上させるためのテクニックをいくつか見ていきます。
fsync の頻度の制御
memcached14 は非常に高速な操作をメモリ上で行う代わりにディスク上の永続性を完全に捨てるシステムの例です。サーバーが再起動するとサーバー上のデータは消えます: キャッシュ効率に優れますが、データストアとしての永続性はありません。
Redis では fsync を呼ぶタイミングを開発者が選択できます。あらゆる更新の後に fsync の呼び出しを強制することもでき、こうすると安全にはなりますが低速です。パフォーマンスを向上させるために、N 秒ごとに fsync を呼ぶようにすることもできます。この場合、最悪のケースでは N 秒分の操作が失われることになりますが、これを許容できる場面もあるでしょう。最後の選択肢として、永続性が重要でないとき (粗い統計を収集するとき、あるいは Redis をキャッシュとして使うとき) には、fsync をオフにできます。この場合オペレーティングシステムがデータのフラッシュを担当しますが、そのタイミングについての保証はありません。
ログを使って連続した書き込みを増やす
B+Tree などのデータ構造を使うとディスクからデータを素早く取得できます。そういったデータ構造を更新すると、ファイルのランダムな場所に書き込みが起こり、更新のたびに fsync を使うようにした場合には更新のたびにランダム書き込みが何回か起こることになります。Cassandra, HBase, Redis, Riak のようなシステムでは、ランダム書き込みを減らすために更新操作をログと呼ばれる連続的に書き込まれるファイルに追記するようになっています。システムが使うその他のデータ構造は時間をおいて fsync されますが、ログは頻繁に fsync されます。ストレージシステムはログを最後のクラッシュ以降のデータベースに関する唯一正しい履歴と扱うことで、ランダムな更新を連続した書き込みに変換します。
MongoDB などの NoSQL システムではデータ構造を更新するときの書き込みがその場で (in-place に) 行われますが、さらにログを行うシステムもあります。Cassandra と HBase で使われている log-structured merge tree と呼ばれるテクニックは BigTable で使われているのを真似たものであり、ログとルックアップのためのデータ構造を一つのデータ構造にまとめます。Riak も似たような機能を提供しており、log-structured hash table と呼ばれます。CouchDB は昔からある B+Tree を変更し、データ構造への更新が物理ストレージ上の構造に追記できるようになっています。こういったテクニックを使うと書き込みスループットが向上しますが、その代わり定期的にログのコンパクションを行ってログの長さを切り詰めなければなりません。
書き込みをまとめてスループットを上げる
Cassandra は複数の並列な書き込みをグループにまとめ、一度の fsync でフラッシュします。group commit と呼ばれるこの設計を使うといくつかの並列な書き込み全てが終了するまでユーザーに書き込みの終了が通知されないことから、更新のレイテンシが伸びます。ただしその分ログへの複数の追記が一度の fsync で処理されるようになるので、スループットは向上します。この文章を書いている時点では、HBase の全ての更新は内部で使用している Hadoop 分散ファイルシステム (HDFS)15 に永続的に書き込まれます。ただし fsync の回数を減らすために group commit を使えるようにするパッチを最近見かけました。
複数サーバー永続性
ハードドライブとマシンは障害によって頻繁に修復不可能な状態になるので、重要なデータは複数のマシンにコピーしておくことが重要です。多くの NoSQL システムはデータの複数サーバー永続性を提供しています。
Redis はデータの複製にマスタースレーブというよく知られたアプローチを使います。マスターに対する全ての操作はログに似た方法でスレーブに伝えられ、スレーブは自身でその操作を複製します。マスターで障害が起こった場合には、スレーブが間に入ってマスターから受け取った操作ログに基づいてデータをやり取りします。マスターはログがスレーブで永続的に書き込まれたことを確認せずにユーザーに操作の完了を通知するので、多少のデータロスが起こる可能性があります。CouchDB でもこれと同様の方向付いた複製が利用可能であり、ドキュメントの変更を他のストアに複製するように設定できます。
MongoDB には複製集合 (replica set) という概念があります。そこに含まれるサーバーが同じドキュメントを保存するということです。MongoDB を利用する開発者は全てのレプリカが更新を受け取ったのを確認するようにもできますし、レプリカが最新のデータを持つことを確認することなく操作を続けることも可能です。他の分散 NoSQL ストレージでは複数のサーバーにデータの複製を置くことができます。内部で HDFS を使っている HBase では複数サーバー永続性を HDFS から得ています。全ての書き込みは二つ以上の HDFS ノードに複製されてからユーザーに制御が戻るようになっており、これによって複数サーバー永続性が保証されます。
Riak, Cassandra, Voldemort では複製をより細かく設定できます。小さな違いを除けば、これら三つのシステムではデータの複製が配置されるべきマシンの数 N と、ユーザーに制御を返すまでにデータが書き込まれるべきマシンの数 W < N を指定可能です。
データセンター全体が利用不可能になるというケースに対応するには、データセンターをまたいだ複製が必要になります。Cassandra, HBase, Voldemort にはラックを認識する設定があり、これを使うとマシンが配置されているラックやデータセンターを指定できます。一般的に言ってリモートのサーバーにまでデータが伝わってからユーザーにリクエストを返したのでは遅すぎるので、ワイドエリアネットワーク越しにバックアップセンターへデータを送るときには書き込みの確認を行わずに更新がストリームされます。
パフォーマンスのスケール
障害対応はもう話し終わったので、次は成功について考えて気を晴らしましょう! 構築したシステムが成功を収めると、データストア自身が負荷の原因の一つとなります。お手軽な解決法は、マシンをスケールアップする、つまり RAM やディスクの容量を増やして一台のマシンが捌ける負荷を増やすことです。しかしシステムがさらに成功を収めると、さらに高価なハードウェアの入手が現実的ではなくなります。ここまでくれば、データを複製してリクエストを複数のマシンに振り分けることで負荷を分散させなければなりません。このアプローチはスケールアウトと呼ばれ、上手く行くかどうかはシステムの水平スケーラビリティによって決まります。
水平スケーラビリティの理想的な目標は線形スケーラビリティ、つまりストレージシステムのマシン数を倍にすればシステムの応答できるクエリ数が倍になることです。このスケーラビリティにおけるカギは、データがどのように複数のマシンに分散するかです。ストレージシステムをスケールアウトさせるために読み書きの負荷を複数のマシンに分散することを、シャーディング (sharding) と呼びます。シャーディングは Cassandra, HBase, Voldemort, Riak といったシステムで重要な役割を果たし、最近では MongoDB と Redis でも使われています。CouchDB などのプロジェクトは単一サーバーのパフォーマンスのみに集中しており、シャーディングのための機能をシステム内に持ちません。ただし独立したインストールと複数のマシンの間で負荷を分割するコーディネータを提供する二次プロジェクトがあります。
同じ意味を持つ言葉について説明しておきます。私たちはこれからシャーディング (sharding) と分割 (partitioning) という言葉を同じ意味で使います。マシン、サーバー、ノードは全て、分割されたデータの一部を保存する物理的なコンピューターのことを指します。そしてクラスター (cluster) とリング (ring) はどちらもストレージシステムに属するマシン全体を指します。
シャーディングが意味するのは、データセットに対する書き込み負荷の全てが単一のマシンによって処理されないこと、そしてデータセットに対する任意のクエリに答えられる単一のマシンが存在しないことです。ほとんどの NoSQL システムはデータとクエリモデルの両方がキー指向であり、データセット全体を走査することになるクエリというのはほとんどありません。そういったシステムにおける主要なアクセスメソッドはキーベースであることから、シャーディングもキーベースで行われます。つまり、キーを受け取ってそのキーバリューペアがどのマシンにあるのかを返す関数があるということです。このキーとマシンの間のマッピングを定義する二つの方法を後で説明します (ハッシュ分割と区間分割です)。
必要になるまでシャーディングするな
シャーディングを使うとシステムが複雑になるので、可能な限り使用は避けるべきです。これから説明する読み込みレプリカ (read replica) とキャッシング (caching) はシャーディングを使わないスケーリング手法です。
読み込みレプリカ
多くのストレージシステムにおいて、読み込みリクエストの方が書き込みリクエストよりも多くなります。そのような場合の単純な解決法は、複数のマシンにデータのコピーを作成することです。書き込みリクエストは全てマスターノードに向かいますが、読み込みリクエストはデータを複製したレプリカに向かうようになります。レプリカの持つデータは通常マスターのものよりも少しだけ古くなります。
Redis, CouchDB, MongoDB のように複数サーバー永続性のためにマスタースレーブ構成でデータの複製を行っているのであれば、読み込みスレーブが書き込みマスターの負荷を減少させることができます。データセットの要約の集計などのクエリは計算に時間がかかりますが、秒単位の最新データが必要でないことが多く、スレーブのレプリカで実行できるからです。一般的に言って、読み込みで最新データが必要でなければそれだけ、読み込みスレーブを使ってクエリの読み込みパフォーマンスを改善できます。
キャッシング
頻繁に問い合わせを受ける要素をキャッシュすると性能が驚くほど改善します。memcached は複数のサーバーに存在するデータの一部をキャッシュするためのシステムです。memcached をインストールした複数のサーバーに負荷を分散させてさらに大きな水平スケーラビリティを得ることも可能です。キャッシュプールにメモリを追加するときには memcached のホストをもう一台追加するだけで済みます。
memcached はキャッシングのために設計されているので、負荷の分散に関わる設計の複雑さは永続的なストアほど大きくありません。複雑な解決法を考える前に、悲惨なスケーラビリティがキャッシングを使って改善できないかを考えるべきです。キャッシングは一時的な応急措置というわけではありません: Facebook は数テラバイトのメモリと共に memcached を利用しています!
読み込みレプリカとキャッシングを使うと読み込み負荷をスケールアップできます。しかしデータの書き込みと更新の頻度が増加した場合には、全ての最新データを持つマスターサーバーの負荷が増加します。この節の残りでは、書き込み負荷を複数のサーバーにシャーディングするテクニックについて見ていきます。
コーディネータを使ったシャーディング
CouchDB プロジェクトは単一サーバーでの運用に集中しています。Lounge と BigCouch という二つのプロジェクトは CouchDB に対するコーディネータとして機能し、スタンドアローンの CouchDB インスタンスとのフロントエンドとして振る舞う外部プロキシを使って CouchDB の負荷をシャーディングします。この設計において、スタンドアローンの CouchDB インストールは互いを感知しません。コーディネータはリクエストされたドキュメントのキーに基づいてリクエストを CouchDB のインスタンスのどれかに振り分けます。
twitter はデータベースのシャーディングと複製に Gizzard16 と呼ばれるコーディネーションフレームワークを使っています。Gizzard はスタンドアローンのデータストアを組み合わせ、任意の深さを持つキーの区間を表す木を構築します (データベースには SQL と NoSQL の両方が利用可能です)。Gizzard には同じキーの区間に対応するデータを複数の物理マシンに複製して障害耐性を向上させる機能があります。
コンシステントハッシュリング
良いハッシュ関数はキーを一様に分散させます。そのようなハッシュ関数はキーバリューペアを複数のサーバーに分散させるときの重要なツールです。コンシステントハッシングと呼ばれるテクニックについては大量の学術研究があり、このテクニックをデータストアに応用したのが分散ハッシュテーブル (distributed hash tables, DHT) と呼ばれるシステムです。DHT は Amazon の Dynamo と同じ設計をした NoSQL システムで使われており、他にも Cassandra, Voldemort, Riak で使われています。
ハッシュリングの例
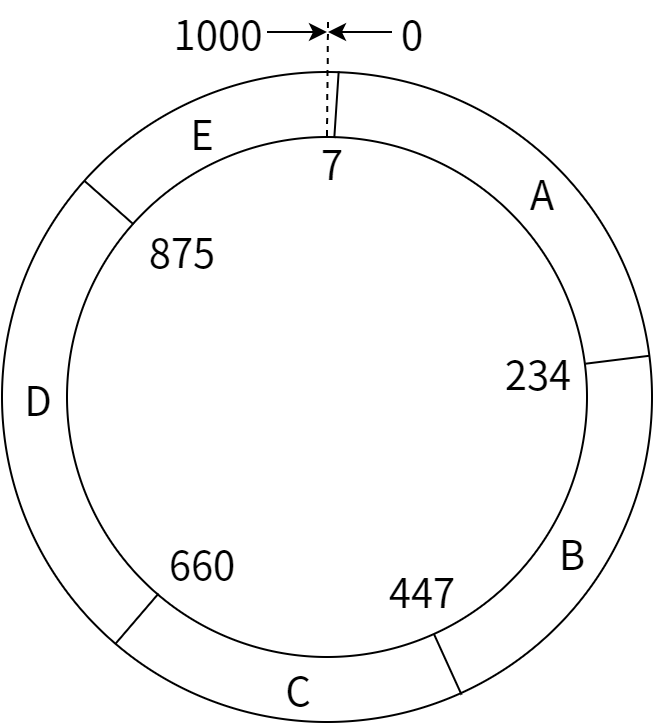
コンシステントハッシュリングは次のように動作します。キーを大きい整数に一様にマップするハッシュ関数 H を仮定し、比較的大きな整数 L を取って、H(key) mod L を使って [1, L] の範囲のリングを作ります。このリングでキーを [1, L] の範囲にマップするということです。それからサーバーの固有識別子 (例えば IP アドレス) に H を適用することでサーバーのコンシステントハッシュリングを作成します。A から E までの五つのサーバーを使ったハッシュリングを 図 13.1 に示します。
この例では L = 1000 および H(A) mod L = 7, H(B) mod L = 234, H(C) mod L = 447, H(D) mod L = 660, H(E) mod L = 875 であり、ここから各キーがどのサーバーに属するかが分かります。つまり、キーはリングの中でそのハッシュ値が収まるようなサーバーに属します。例えば A が担当するのはハッシュ値が [7, 233] であるキーであり、E の担当はハッシュ値が [875, 6] であるようなキーです (1000 の次は 0 です)。そのためもし H('employee30') mod L = 899 ならば employee30 は E に保存され、H('employee31') mod L = 234 ならば employee31 は B に保存されます。
データの複製
複数サーバー永続性のための複製は、キーの区間を範囲を重複させることで行われます。例えば複製ファクターが 3 である場合、 [7, 233] の範囲のデータは A, B, C の三つサーバーに保存されます。こうすることでもし A で障害が起こったとしても、隣り合う B と C がその仕事を引き継ぐことができます。 範囲が A と隣接している E に A の複製を配置するような設計も可能です。
より良い分割
ハッシュ関数は統計的にはキー空間を一様にマップしますが、各サーバーが担当する範囲が公平になるためには通常たくさんのサーバーが必要になります。残念ながらサーバーの数は最初小さいことが多く、そのような場合にはハッシュ関数の値が等間隔になりません。例えば前述の例では A のキー区間の長さは 227 で、E のキー区間の長さは 132 です。こうなっているとサーバーの負荷が不平等になり、サーバーで障害が起こったときに他のサーバーが肩代わりするのも難しくなります。
キー区間が不平等で大きくなってしまう問題を解決するために、Riak を含む多くの DHT では一つの物理マシンに複数の“仮想”ノードを割り振ります。例えば仮想ノードの数が 4 の場合には、サーバー A は A1, A2, A3, A4 という四つのサーバーとして振る舞います。仮想ノードはそれぞれ異なる値にハッシュされるので、サーバーは互いに離れた複数の部分を管理するようになります。Voldemort も似たアプローチを使っており、分割の数を手動で設定可能です。この数は通常サーバーの数よりも大きく設定され、これにより各サーバーは小さく分割された区間を複数管理するようになります。
Cassandra は複数の小さな区間をサーバーに割り振ることがなく、キー区間の割り当てが不平等になることがあります。その代わり Cassandra には負荷分散のために負荷履歴に応じてリング上におけるサーバーの配置を調整する非同期プロセスがあります。
区間の分割
シャーディングに区間の分割を使う場合には、システム内のいずれかのマシンがどのキー区間をどのマシンが持つかについてのメタデータを管理し、このメタデータを使ってキーを適切なサーバーに誘導します。区間分割ではキー空間がいくつかの区間に分割され、それぞれの区間が一つ以上のサーバーに複製されます。この点はコンシステントハッシュリングと同様ですが、区間分割とコンシステントハッシュリングで異なっているのが、キーをソートしたときに連続するキーが同じ区間に表れる可能性が高い点です。このため大きな区間でも [start, end] と表現でき、ルーティングのためのメタデータの容量が減少します。
現在有効なキー区間とサーバーのマップを保存する以外にも、区間分割には負荷のシャーディングをより細かく行えるという利点があります。例えばあるキー区間のトラフィックが他の区間よりも高い場合には、ロードマネージャを使ってその区間を小さくしたり、サーバーに割り振る負荷を減らしたりできます。ただし負荷を自動的に管理するには、負荷を監視、調整するコンポーネントをアーキテクチャに組み入れる必要があります。
BigTable の方法
Google による BigTable の論文では、データをタブレット (tablet) に分割することで階層的な区間分割を行う方法が説明されています。タブレットはとある行キー区間とカラムファミリーに属する値を保存し、担当のキーに対するクエリに答えるために必要なログとデータ構造を全て保持します。一つのタブレットサーバーは負荷に応じて複数のタブレットを管理します。
タブレットのサイズはおよそ 100 MB から 200 MB に保たれます。サイズがこの範囲でなくなった場合には、キー区間が連続する二つの小さなタブレットを結合させたり、大きなタブレットを分割したりして対処します。マスターサーバーはタブレットのサイズ、負荷、可用性を監視し、任意の時点でサーバーが管理するタブレットを調整します。
マスターサーバーはタブレットの割り当てをメタデータテーブルで管理します。メタデータは巨大になるので、メタデータ自身も分割されて複数のタブレットにシャーディングされます。このシャーディングを担当する各タブレットはキー区間からそのキーのメタデータを持つタブレットサーバーへのマップを保持し、これによりキーに対応するデータを見つけるための走査は三段階になります (図 13.2)。
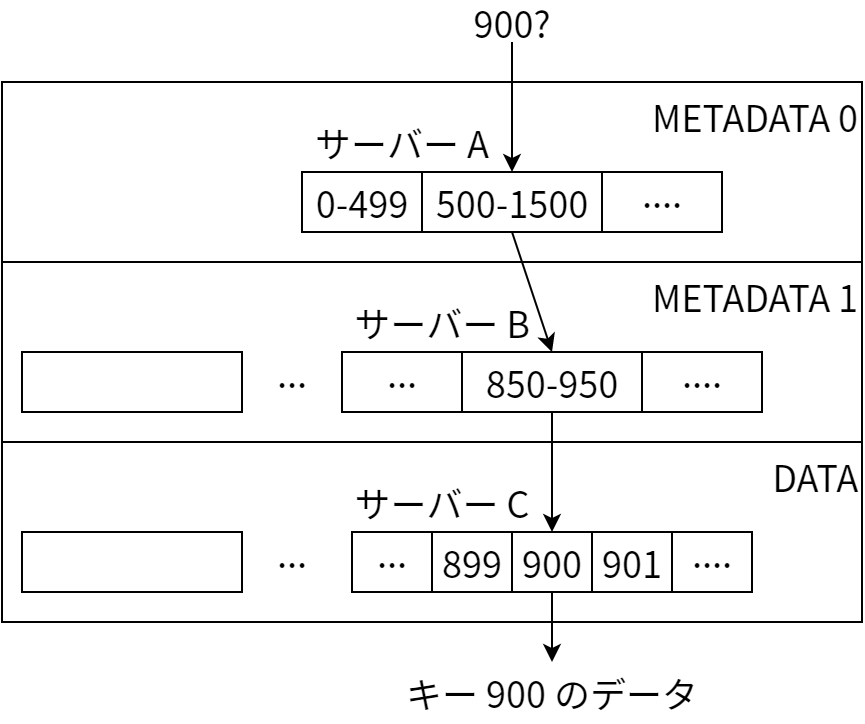
この例では最初にクライアントがキー 900 のデータをサーバー A に問い合わせます。サーバー A にはレベル 0 のメタデータを持つタブレットがあるので、A はこのタブレットからレベル 1 のメタデータを検索してクライアントに返します。クライアントにはサーバー B に 500 から 1500 までのキーに関するメタデータを含んだタブレットがあると伝わるので、クライアントはこのサーバー B にキーの問い合わせを行います。サーバー B からは 850 から 950 までのキーのデータを保存しているのはサーバー C にあるタブレットであるとクライアントに伝わるので、クライアントはサーバー C に最後の問い合わせを行い、行データを入手します。レベル 0 とレベル 1 のメタデータはクライアントでキャッシュされ、同じリクエストによってタブレットサーバーに高い負荷がかからないようになっています。BigTable の論文では、この三レベルの階層構造によって 128 MB のタブレットに 261 バイトのデータを格納できると説明されています。
障害対応
この BigTable の設計においてマスターは単一故障点ですが、マスターが一時的にダウンしたとしてもタブレットサーバーは稼働を続けることができます。またタブレットサーバーがダウンした場合には、この障害を検知してタブレットの再割り当てを行うのはマスターの責任であり、その間はリクエストが一時的に失敗することになります。
マシン障害の検知と対応のための方策として BigTable 論文で説明されているのは、Chubby と呼ばれる分散ロックシステムを使ってサーバーの動作状況を管理するというものです。ZooKeeper17 は Chubby のオープンソース実装であり、Hadoop ベースのいくつかのプロジェクトでは ZooKeeper を使って補助マスターサーバーとタブレットサーバーの再割り当てを管理しています。
区間割り当てを利用する NoSQL プロジェクト
HBase は BigTable と同じ階層構造を使った区間分割を使っており、HBase はタブレットのデータを Hadoop 分散ファイルシステム (HDFS) に保存します。HDFS がデータの複製とレプリカの間の一貫性の保持を行うので、タブレットサーバーの仕事はリクエストの処理、ストレージ構造の更新、タブレットの分割と結合の開始処理となります。
MongoDB も BigTable と似た方法を使って区間分割を行います。ノードの一部が構成ノードとなってルーティングテーブルを保持し、どのストレージノードがどのキー区間を担当するかを管理します。構成ノードの同期に使われるのは二相コミット (two-phase commit) と呼ばれるプロトコルであり、構成ノードは区間の管理という BigTable のマスターの仕事と、高可用性のある構成管理という Chubby の仕事を両方受け持ちます。分離されステートレスなルーティングプロセスは直近のルーティング設定を保存し、キーリクエストを正しいストレージノードに誘導します。このときストレージノードは複製集合ごとにまとめられ、複製の処理もルーティングプロセスが行います。
Cassandra においてある区間のデータを高速にスキャンする必要がある場合には、順序保存分割 (order-preserving partitioner) と呼ばれる機能が利用可能です。この機能を使った場合でも Cassandra はコンシステントハッシュリングを使いますが、キーバリューペアのハッシュ値が属するサーバーを決めるのではなく、キーの値が直接属するサーバーを決めるようになります。例えば前述の 図 13.1 の例においてはキー 20 と 21 は両方ともサーバー A に属するようになり、ハッシュ値によってリング中に散らばることはありません。
Twitter において多数のバックエンドをまたいで分割された複製データを管理するのにも、区間分割によるシャーディングが使われています。サーバーのルーティングは任意の深さの階層を作ることができ、キーの区間を一つ下の階層のサーバーにマッピングします。マッピングされるサーバーはキーのデータを含むか、そうでなければさらに別のサーバーへのルーティングとなっています。このモデルにおいて、複製は更新をキー区間に対応する複数のマシンに送ることで行われます。Gizzard のルーティングノードは、書き込みが失敗したときに他の NoSQL システムでは見られない方式で修復を行います。その方式とは、ストレージノードで書き込みが失敗したらルーティングノードがその書き込みをキャッシュし、成功するまでそのノードに更新を送り続けるというものです。これが可能なのは、Gizzard における全ての更新は冪等である (二回行っても問題ない) ためです。
どの分割スキームを使うか
シャーディングのためのハッシュを使った分割と区間を使った分割を紹介しましたが、どちらを使えばよいのでしょうか? データに対してキー区間ごとのスキャンを頻繁に行うのであれば、明らかに区間分割が優れています。区間分割を使った場合には、バリューをキーに沿って読んだときにネットワーク上のランダムなノードとの通信が発生せず、ネットワーク負荷が抑えられます。ではもし区間ごとのスキャンが必要でないときには、どちらを使えばよいでしょうか?
ハッシュ分割を使うとノードに対してデータを平等に割り振ることができ、仮想ノードを使えばデータの偏りも防ぐことができます。さらにほとんどの場合クライアントでハッシュ関数を実行すればそれだけで正しいサーバーが見つかるので、ハッシュ分割スキームではルーティングも単純です。ただし再調整の仕組みが複雑になれば、それだけキーに対応する正しいノードを見つける処理がさらに難しくなります。
これに対して区間分割ではルーティングノードと構成ノードという先行投資が必要になります。これらは高負荷の原因となるだけではなく、比較的複雑な障害体制の仕組みを取り入れない限り単一障害点となります。しかし、もし首尾良く実装できたならば、区間分割されたデータは小さなチャンクで負荷を分散でき、高負荷時に分割を再割り当てすることも可能になります。さらにサーバーがダウンしたとしても障害が起こったサーバーの区間は多数のサーバーに分散され、すぐ隣のサーバーに負荷が丸ごとのしかかることはありません。
一貫性
データを複数のマシンに複製すると永続性が向上し負荷が分散するということについて話してきましたが、今まで隠してきたことがあります: 複数のレプリカの間でデータの一貫性 (consistency) を保つのは難しいタスクです。現実のレプリカはクラッシュして一時的に同期できなくなったり、クラッシュしてそのまま死んでしまったり、ネットワークによって隔てられたマシン間のメッセージが遅れたり消失したりします。NoSQL エコシステムにおける一貫性へのアプローチは大きく分けて二つ存在します。一つは強一貫性 (strong consistency) と呼ばれ、全てのレプリカが常に同じデータを保持するというものです。もう一つは結果一貫性 (eventually consistency) と呼ばれ、レプリカが同期されていない状態を許しながらも、時間が経てば全てのレプリカが同期状態になるというものです。分散コンピューティングの基本的な特徴を考えると二つ目の選択肢が好ましいことをまず説明し、それから二つのアプローチの詳細を説明します。
CAP 定理
データの複製について、強一貫性以外の一貫性を考えるのはなぜでしょうか? 実はこれには現代的なネットワーク機器で構成された分散システムの特性が関わっています。このアイデアは Eric Brewer によって CAP 定理という名前で提案され、のちに Gilbert と Lynch によって証明されました [GL02]。この定理には分散システムに関する次の三つの特徴が関係します (最初の文字を取ると CAP となります):
-
一貫性 (consistency): クライアントが読み込みを行うとき、全てのレプリカが同じバージョンのデータを持つことが論理的に保証されるか? (この一貫性は ACID の C とは意味が異なる)
-
可用性 (availability): アクセス不能なレプリカの数に関わらずレプリカは読み書きリクエストに応答できるか?
-
分断耐性 (partition tolerance): レプリカの一部でネットワーク越しの通信ができなくなったとしてもシステムは稼働できるか?
CAP 定理とは「複数のコンピューターを使って運用されるストレージシステムは、上記三つの特性のうち最大でも二つしか達成できない」というものです。また今考えている NoSQL システムでは、分断耐性が必ず必要となります。現在のネットワークハードウェアが使う通信プロトコルではパケットが消失したりスイッチで障害が起こったりするので、サーバーが利用不可能なのかそれともネットワークがダウンしているのかを判断できないためです。そのため残された選択肢は一貫性と可用性であり、どんな NoSQL システムも同時に両方を提供することはできません。
一貫性を取った場合、全てのレプリカが持つ複製データが同期されるようになります。一貫性を達成する簡単な方法は、全てのレプリカからの更新完了通知を待つというものです。レプリカのどれかがダウンした場合にはデータの更新が通知されないので、そのサーバーが持つキーに対する可用性が失われます。つまり全てのレプリカが復帰して応答を開始するまで、更新の完了通知がユーザーに伝わらないということです。そのため一貫性を取った場合には全てのデータアイテムが 24 時間いつでも利用可能であることはなくなります。
可用性を取った場合、レプリカはユーザーから受け取った操作を自分の持っているデータに適用し、そのとき他のレプリカの状態は関知しません。更新を他のレプリカに必ず通知するようになっていないために、レプリカの間でデータが一貫しなくなる可能性があり、さらにレプリカに全ての更新が記録されるとも限りません。
NoSQL データストアを構築するのに使われる強一貫性と結果一貫性という手法は CAP 定理と関係しています。他にも使われている手法も存在し、例えば Yahoo! の PNUTS [CRS+08] システムは relaxed consistency および relaxed availability と呼ばれる手法を使っています。ただしこの章で紹介している NoSQL システムはそういった手法を使っていないので、ここで触れるだけにとどめます。
強一貫性
強一貫性を採用するシステムでは、任意のキーに対するバリューについて全てのレプリカが同じ値に合意できることが保証されます。レプリカの一部が同期されない状態になる可能性はありますが、それでもユーザーが employee30:salary のバリューを問い合わせたときには、ユーザーに返すべき値について複数のマシンのあいだで一貫した合意を形成する方法が存在します。数字と例を使って説明します。
キーを N 個のレプリカに複製するとします。このときあるマシン (N 個のレプリカのどれかでも構いません) がユーザーからのリクエストのコーディネータとして機能し、N 個のレプリカのうち一定数とやり取りをします。キーに対する書き込みや更新が起こったときには、コーディネータは W 個のレプリカから書き込みが起こったという通知を受け取るまでユーザーに書き込みが終了したという通知を送りません。またユーザーがキーのバリューを読み込むときには、コーディネータは R 個のレプリカから同じ値を読み込むまで値を返しません。システムが強一貫性を持つと言えるのは、R + W > N が成り立つときです。
具体的な例として A, B, C という 3 個のレプリカがある状況を考えます (N = 3 です)。最初 employee:salary の値が $20,000 であり、この値を $30,000 に昇給させたいとします。ここでは最低でも W = 2 個のレプリカがこのキーに対するリクエストを処理する必要があるという設定だとして、A と B が (employee:salary, $30,000) に対するリクエストを完了させたという通知をコーディネータに送ったとします。これを受けてコーディネータはユーザーに employee30:salary が確かに更新されたことを伝えます。続いて C が employee30:salary に対するこの書き込みリクエストをまだ受け取っていないときに、コーディネータが employee30:salary に対する読み込みリクエストを受け取ったとします。コーディネータはこれを受けて 3 個のレプリカそれぞれに読み込みリクエストを送ります:
-
R = 1 でかつ C が最初に応答した場合、C は $20,000 を返すので、従業員が不幸な目にあってしまいます。
-
これに対して R = 2 とすれば、コーディネータが C からの値を読んだとしても A または B からの応答を待つので、コーディネータは矛盾する二つ値を目にすることになります。その後三個目のマシンから応答を受け取り、多数決で正しい値が確認されます。
つまりこの例において強一貫性を達成するには、R = 2 として R + W > N = 3 とする必要があるということです。
もし W 個のレプリカが書き込みリクエストに答えなかったら、あるいは R 個のレプリカが読み込みリクエストに同じ値を返さなかったら、何をするべきでしょうか? コーディネータからタイムアウトしてユーザーにエラーを返すこともできますし、状況が改善するまで待つこともできます。いずれの場合でも、システムは少しの間そのリクエストに答えることができなくなります。
R と W を選ぶことで、何台のレプリカが壊れるとシステムが利用不可能になるか、あるいは何台のレプリカが壊れるとキーに対する操作が間違ったものになるかが決まります。例えば全てのレプリカからの書き込み完了を待つようにすると (W = N の場合)、レプリカのどれか一つに障害が起きただけで書き込みがハングあるいは失敗するようになります。一般的に用いられるのは R + W = N + 1 です。これは強一貫性のための最低条件であり、レプリカ間のデータの一時的な不一致にもある程度対応できます。また W = N かつ R = 1 として強一貫性を得るシステムも多く存在します。こうすると同期状態にないノードが存在しなくなるためです。
HBase はストレージの複製に分散ストレージレイヤー HDFS を利用しており、HDFS は強一貫性を保証します。HDFS においては書き込みが N 個のレプリカに複製されるまで成功しないようになっているので、W = N です (N は通常 2 か 3 です)。読み込みは一台のレプリカで完了するので、R = 1 です。高い読み込み負荷によって処理が遅くなるのを防ぐために、ユーザーはデータを並列かつ非同期にレプリカへと送信します。全てのレプリカがデータのコピーを受信したという通知を受け取ってから、新しいデータをシステムにスワップするという最後のステップが全てのレプリカでアトミックかつ一貫性を保って行われます。
結果一貫性
Voldemort, Cassandra, Riak を含む Dynamo ベースのシステムでは N, R, W の値をユーザーが指定でき、R + W <= N となるような値も可能です。これは強一貫性と結果一貫性のどちらかを選択できることを意味します。結果一貫性を選択した場合、あるいは強一貫性を選択した場合でも W < N である場合には、レプリカが持つデータが最新のものでない瞬間が存在します。このようなケースで結果一貫性を保証するために、こういったシステムは様々な手段を使って古いレプリカを更新します。まずは様々なシステムがデータが古くなったことをどのように検出するかを説明し、それからレプリカをどのように同期するかを説明し、最後に Dynamo にヒントを得た同期プロセスを高速化するための方法を紹介します。
バージョン付けと衝突
二つのレプリカが同じキーに対する異なるバージョンの値を持つ可能性がある場合には、データのバージョン付けと衝突の検出が重要になります。Dynamo ベースのシステムではベクトルクロック (vector clock) と呼ばれる方法を使ってバージョン付けを行います。ベクトルクロックは各キーに割り当てられるベクトルであり、各レプリカのカウンターを記録します。例えばあるキーが A, B, C という三つのレプリカに保存されているとすると、このキーのベクトルクロックは三つの値 (NA, NB, NC) を持ち、最初 (0, 0, 0) という値を持ちます。
レプリカはキーを更新するときにベクトルクロックの値を増加させます。もしベクトルクロックが (39, 1, 5) の状態で B が値を変更するときには、B はベクトルクロックを (39, 2, 5) に変更します。そして他のレプリカ、例えば C がこの更新を受け取ると、まずベクトルクロックを自身の値と比較します。ベクトルクロックの各要素が現在自身が持っている値以下であれば、C が持っているデータが古く、受け取った B の値で上書きしてもよいことが分かります。もし (39, 2, 5) と (39, 1, 6) のように B と C のベクトルクロックの両方にもう一方よりも大きい要素が存在するなら、それは二つのレプリカは異なる値を受け取っており、そのままではデータを整合状態に戻せない可能性があることを意味します。この場合、サーバーは衝突を検出し、これを修復するための処理を行います。
衝突の解決
衝突の解決方法はシステムによって異なります。Dynamo の論文は衝突の解決をストレージシステムを利用するアプリケーションに任せているためです。二つのバージョンのショッピングカートであればマージしてしまえば重大なデータロスを避けられますが、複数の人間が同時に編集しているドキュメントの二つのバージョンをマージするには人間の仲介が必要になるかもしれません。例えば Voldemort はこのモデルを採用しており、衝突が起こった場合にはキーに対応するデータの複数のコピーをリクエストを行ったクライアントアプリケーションに返します。
Cassandra は各キーのタイムスタンプを保存するので、二つのバージョンが衝突した場合には一番最近のタイムスタンプがあるバージョンを残します。これによってクライアントとのやり取りが必要なくなり、API も単純になります。ただしこの設計では前述のショッピングカートのような衝突したデータを内部で上手くマージする処理が難しくなり、分散カウンターも実装しにくくなります。Riak では Voldemort と Cassandra の両方のアプローチが利用可能です。CouchDB はハイブリッドで、衝突が起こったときにユーザーからクエリを出して手動で修復でき、修復が行われるまでは一つのバージョンを (決定的に) 選択して返します。
Read Repair
R 個のレプリカが衝突しないデータをコーディネータに返したならば、コーディネータはその値をアプリケーションに返して問題ありません。ただしこの場合でも、レプリカのいくつかが同期されていない可能性があります。そのような状況を解決するために Dynamo の論文で提案され、Cassandra, Riak, Voldemort で実装されているのは、read repair と呼ばれる手法です。コーディネータが読み込み時に衝突を検出した場合には、たとえユーザーに返す値に問題が無かったとしても、コーディネータが衝突解決のためのプロトコルを開始するというものです。これによってわずかな追加の処理で衝突を積極的に解決していくことができます。コーディネータはレプリカからそれぞれのバージョンのデータを既に受信しているので衝突の解決を高速に行うことができ、システム内のデータの不一致が減少します。
Hinted Handoff
Cassandra, Riak, Voldemort は hinted handoff と呼ばれる手法を使ってあるノードが利用不可能な場合の書き込みパフォーマンスを向上させています。あるキーに対するレプリカのいずれかが書き込みリクエストに応答しない場合には、他のノードを適当に選んで書き込み処理を一時的に担当させるというものです。利用不可能なそのノードに対する書き込み処理はメインの処理と分けて処理され、選ばれたバックアップノードがそのノードの復帰を確認したら、その新たなレプリカにそれまでの全ての書き込みを行います。Dynamo の論文は sloppy quorum と呼ばれるアプローチをとっており、hinted handoff を使った書き込みも書き込み完了の通知に必要となる W 回の書き込みに数えられます。これに対して Cassandra と Voldemort は hinted handoff を W に数え入れず、最初に割り振ったレプリカに書き込みが行われない限り書き込みを失敗させます。こういったシステムでは hinted handoff が意味を持たないということはなく、障害の起こったノードが復帰したときのリカバリを高速化できます。
Anti-Entropy
レプリカが一定時間ダウンしたままである場合、あるいは利用不可能なレプリカの hinted handoff を保存しているマシンがさらにダウンした場合には、レプリカ同士が協調して同期を行わなければならなりません。このケースのために、Cassandra と Riak は Dynamo にヒントを得た anti-entropy と呼ばれる手法を実装しています。anti-entropy では、レプリカ同士がマークル木をやり取りすることで複製されたキー区間が最新のものであるかどうかを確認します。マークル木とは階層化されたハッシュ検証です: まず区間全体に対する二つのレプリカのハッシュを比較し、一致しない場合にはさらに小さな区間のハッシュを調べ、これを繰り返すことで同期されていないキーを特定します。この手法は二つのレプリカがほとんど同じデータを持つという事実を利用することで、レプリカ間のデータ転送を最小限にしています。
Gossip
最後に、分散システムが成長するにしたがって、システム内の各ノードが何をしているのかを追跡するのが難しくなるという問題があります。Dynamo ベースの三つのシステムは、大昔から中学や高校で用いられている gossip と呼ばれる手法を使って他のノードを監視します。各ノードは定期的に (一秒に一度程度の頻度で) これまでに通信したことのあるノードから一つをランダムに選択し、そのシステム内のノードの健康状態に関する情報をそのノードとやり取りします。このやり取りによってどのノードがダウンしているか、キーの検索時にどのルートを経由するべきかなどといった情報を交換します。
最後に
NoSQL エコシステムは未だに生まれて間もない状態であり、この章で紹介したシステムの多くは今後アーキテクチャ、設計、インターフェースを変更するでしょう。この章で学び取ってほしいのはそれぞれの NoSQL システムが執筆時点で何をしているのかではなく、それらのシステムを構築する機能を導いた設計上の判断は何だったのかということです。NoSQL システムはアプリケーション設計者に設計の余地を大きく残します。システムのアーキテクチャ上の要素を理解すれば、次の偉大な NoSQL の組み合わせを作れるようになるだけではなく、現在のバージョンのシステムを責任持って運用できるようにもなるのでしょう。
謝辞
この章を改善するためのコメントと提案を示してくれた Jackie Carter と Mihir Kedia、そして匿名のレビュアーたちに感謝します。そして NoSQL コミュニティの長年にわたる貢献が無ければこの章は不可能だったでしょう。Keep biulding!