VTK
Visualization Tookit (VTK) は広く使われているソフトウェアシステムです。データの処理と可視化が可能であり、科学計算、医療画像解析、計算幾何学、レンダリング、画像処理、インフォマティクスといった分野で利用されています。この章では VTK を概観し、VTK を成功に導いた基本的なデザインパターンなどを説明します。
ソフトウェアシステムを本当に理解するには、そのシステムが解決する問題だけではなく、そのシステムが生まれた文化を理解することが重要です。VTK の場合であれば、このソフトウェアシステムはもともと科学データの 3D 可視化システムとして開発されました。しかし生まれ着いた文化的背景を見ればそこにはたくさんの物語があり、それらは VTK が現在の形に設計、開発された理由を理解する助けとなります。
VTK が構想され書かれたころ、最初の著者 (Will Schroeder, Ken Martin, Bill Lorensen) は GE Corporate R&D の研究員でした。私たちは LYMB と呼ばれる前任のシステムに多額の投資をしていました。この C で実装された Smalltalk 風のシステムは当時としては素晴らしかったものの、研究員は自身の成果を世間に発表するときに大きな障壁を二つ感じていました: (1) IP (知的財産) の問題と (2) 標準的でないプロプライエタリなソフトウェアの問題です。IP の問題が厄介なのは、企業弁護士が話に入った途端ソフトウェアを GE の外に配布できなくなるからです。さらに GE 内部でソフトウェアをデプロイするときでさえ、プロプライエタリで非標準的なシステムなど学びたくないという不平が多くの顧客から聞かれました。習得したとしても会社を離れればそれで終わりであり、標準的なツールセットもサポートされないからです。 VTK の開発動機の一つは、オープンな規格、つまり技術を顧客へ簡単に伝えられる協調プラットフォームを作ることでした。そのため VTK にオープンソースライセンスの採用したのは、おそらく私たちが下した最も重要な設計判断です。
コピーレフトでない寛容なライセンス (GPL でなく BSD) を採用したのは、今考えれば私たちの考え方をよく表した判断だと言えます。サービスとコンサルタントを基礎とした後に Kitware となるビジネスが可能なのはこのライセンスのおかげだからです。この決断をしたとき、私たちはアカデミア・研究所・企業と協調するときの障壁を取り払うことを一番に考えていました。コピーレフトのライセンスは面倒を嫌う多くの企業から避けられていることも後に発見しました。実のところコピーレフトのライセンスはオープンソースソフトウェアが受け入れられるのを大きく遅らせると私たちは考えているのですが、今は関係ない話題でしょう。ポイントはこれです: 著作権に関するライセンスの選択は、どんなソフトウェアシステムにおいても重要な決断の一つとなります。プロジェクトの目標をレビューし、IP の問題を適切に解決しておくのが重要です。
VTK とは
VTK はもともと科学データの可視化システムとして構想されました。異分野の人の多くは可視化 (visualization) を幾何学レンダリングの一種、つまり仮想的な物体を観察したりいじったりするものだと思っているようです。確かにこれは可視化の一種ではありますが、一般的に言うと「データ可視化 (data visualization)」にはデータを感覚入力に変換する全ての処理が含まれます。データ可視化の出力はたいてい視覚に対する感覚入力ですが、触覚や聴覚への入力である場合もあります。入力データはメッシュや複雑な空間分割といった抽象をはじめとした幾何学的・位相的なデータだけではなく、スカラー (温度や圧力)、ベクトル (速度)、テンソル (応力やひずみ)、さらに面法線やテクスチャ座標といったレンダリング用の属性も含みます。
空間が持つ物理的特性を表すデータを表現する処理も通常は「科学的データ可視化 (scientific data visualization)」の一種だとされる点にまず注意してください。さらにそれよりも抽象的なデータ形式も存在します。例えばマーケティングの統計、ウェブページ、ドキュメントなどがそうですし、あるいは構造化されていないドキュメント、表、グラフ、木といった抽象的な (空間の物理的特性と結び付かない) 関係性を使ってのみ表せるような情報もそうです。こういった抽象的なデータは情報可視化 (information visualization) の手法で処理されます。コミュニティの助けもあって、現在の VTK では科学的可視化と情報可視化の両方が可能です。
可視化システムとしての VTK の役割は、こういった形式のデータを受け取って最終的には人間の感覚器官が知覚できる形式に変換することです。そのため VTK の中心的要件の一つは、データを取り込み、処理し、表現し、そして最終的にはレンダリングするためのデータフローパイプラインの作成です。よってそのツールキットは柔軟なシステムとして構成され、その設計にはこの要件が様々なレベルで反映されなければなりません。例えば、VTK が交換可能なたくさんのコンポーネントを組み合わせて多様なデータを処理するツールキットとして設計されているのは、私たちがそう意図したからです。
設計が持つ機能
VTK の設計が持つ機能を一つ一つ見ていく前に、システムを開発・利用する上で非常に重要になる高レベルの概念をいくつか説明します。その一つが VTK のハイブリッドなラッパー機能です。これは VTK の C++ 実装から Python, Java, Tcl の言語バインディングを自動的に生成する機能です (他の言語も追加でき、実際にいくつか追加されています)。腕利きの開発者は C++ を書きますが、たいていのユーザーやアプリケーション開発者は上記のインタープリタ言語を選びます。このコンパイル言語とインタープリタ言語のハイブリッド環境は二つの世界の良いとこ取りです: つまり、計算処理が中心の高性能なアルゴリズムとアプリケーションのプロトタイプ・開発が両立します。実際、この多言語計算の機能は科学計算コミュニティに属する多くの人々から好評を博し、VTK は彼らが自身のソフトウェアを開発するときのテンプレートとしてよく使われています。
ソフトウェアの開発プロセスについて言うと、VTK はビルド管理に CMake を、テストに CDash/CTest を、クロスプラットフォームのデプロイに CPack を使います。VTK はほぼ全てのコンピューターでコンパイル可能であり、頼りない開発環境しか持たないことで悪名高いスーパーコンピューターでさえ動作します。さらにウェブページ、ウィキ、メーリングリスト (ユーザー用と開発者用)、ドキュメント生成機能 (Doxygen)、バグトラッカー (Mantis) も開発ツールを強化します。
コア機能
VTK はオブジェクト指向のシステムであり、クラスとインスタンスのデータメンバーへのアクセスは VTK によって注意深く制御されます。一般的に言って全てのデータメンバーは protected または private であり、アクセスは Set および Get メソッドで行います。アクセスのときには真偽値やモデルデータ、あるいは文字列やベクトルを渡します。実際のコード中では、こういったメソッドはクラスのヘッダーファイルでマクロを使って作成されます。例えば
vtkSetMacro(Tolerance,double);
vtkGetMacro(Tolerance,double);
を展開すると次のようになります:
virtual void SetTolerance(double);
virtual double GetTolerance();
マクロを使うのには「コードが理解しやすくなる」以上の理由があります。VTK にはデバッグの制御、オブジェクトの更新時間 (MTime) の更新、参照カウントの管理を行うための重要なデータメンバーがいくつかあり、このマクロを使えばデータを正確に生成できるので、利用が強く推奨されます。例えば、オブジェクトの MTime が適切に管理されていないというのは VTK で起こる特に有害で気付きにくいバグの原因の一つです。これによりどこかのコードが実行されるべき時に実行されなかったり、本来よりも多く実行されるようになります。
VTK の強みの一つが、データの表現と管理に比較的単純な方法を使う点です。通常は特定の型のデータ配列 (例えば vtkFloatArray) で連続する情報を表します。例えば三つの三次元座標は九つの要素を持つ vtkFloatArray で表されます (x,y,z, x,y,z, x,y,z など)。VTK の配列にはタプルという概念があり、3D の点は 3-タプル、対称 3×3 テンソルは 6-タプルです (対称性を利用して空間を節約できます)。この設計の理由は、科学計算においては配列を生成するシステム (Fortran など) との対話が多いこと、そして連続する巨大メモリ領域の確保と解放は効率が非常に良いことの二つです。さらに、通信、シリアライズ、IO といった処理は一般的にデータが連続であればとても高速に行えます。このコアの (様々な型の) データアレイは VTK で使われるデータの多くを表し、情報の追加やアクセスのための便利なメソッドが多数用意されています。例えば高速アクセス用メソッド、メモリ不足時に自動的に確保を行うデータ追加メソッドなどです。データ配列は基底クラス vtkDataArray の子クラスなので、一般的な仮想メソッドが利用可能です。ただし高いパフォーマンスが必要な場合には、型で処理を切り替える static なテンプレート関数を使って連続領域のデータ配列に連続で直接アクセスする方法が使われます。
C++ のテンプレートはパブリックなクラス API からは見えないようになっています。テンプレートはパフォーマンスのために大量に使われているにもかかわらずです。また STL についても同様であり、PIMPL デザインパターン1を使ってテンプレートの実装の複雑さをユーザーおよびアプリケーション開発者に見せないようにしています。上述したインタープリタ言語において、このやり方は特に有用です。パブリックな API においてテンプレートの複雑さを避ければ、アプリケーション開発者は VTK が実装で使うデータ型を気にせずに済みます。もちろん内部ではコードの実行がデータ型で制御され、型はたいてい実行中データにアクセスするときに確認されます。
VTK がメモリ管理に参照カウントを使っていて、ガベージコレクションのようなもっとユーザーフレンドリーな方法を使わないのはなぜか、と不思議に思うかもしれません。基本的な答えは「データが巨大なために、データが削除される瞬間について完全な制御が必要になるから」です。例えば 1 バイトの情報についての 1000×1000×1000 の空間データのサイズは一ギガバイトを超えます。そんなデータをガベージコレクタが解放するべきと判断するまで放置するのは良いアイデアとは言えません。VTK ではほとんどのクラス (vtkObject の子クラス) が参照カウントの機能を持ち、参照カウントを持つ全てのオブジェクトはカウントが 1 の状態でインスタンス化されます。オブジェクトの使用が登録されるたびにカウントが 1 増え、同様にオブジェクトの使用が登録解除されるとカウントが 1 減ります。オブジェクトの参照カウントはやがて自身を破棄するときに 0 となります。コードの例を次に示します:
vtkCamera *camera = vtkCamera::New(); // 参照カウントは 1
camera->Register(this); // 参照カウントは 2
camera->Unregister(this); // 参照カウントは 1
renderer->SetActiveCamera(camera); // 参照カウントは 2
renderer->Delete(); // renderer が削除されると参照カウントは 1 になる
camera->Delete(); // camera が自身を削除する
VTK で参照カウントが重要な理由がもう一つあります ――参照カウントを使うと、データのコピーを効率良く行えます。例えばデータオブジェクト D1 が、点、ポリゴン、色、スカラー、テクスチャ座標といったデータ配列をいくつか持っているとします。このデータから新しいデータオブジェクト D2 を作り、さらに新しいベクトル (点) データを加えたいとしましょう。無駄の多いやり方の一つは、D1 のデータ全てを (深く) コピーし、その後に新しいベクトルデータを付け足して D2 を作るというものです。VTK ではこうせずに、まず D2 を空の状態で作成し、それから配列を D1 から D2 に (浅いコピーで) 渡し、データの所有権を追跡するのに参照カウントを利用する方法が取られます。新しいベクトルの配列は最後に D2 へ追加されます。このやり方であればデータのコピーが避けられます。前述の通り、優れた可視化システムではデータのコピーを避けることが非常に重要です。この章の後半で見ますが、データ処理パイプラインはこういった種類の操作、つまりアルゴリズムの入力データを出力にそのままコピーする操作を頻繁に行います。そのため参照カウントは VTK に欠かせません。
もちろん参照カウントにも厄介な問題があります。循環参照が発生してオブジェクトが環状に互いを参照し、手の込んだ介入が必要になる場合です。VTK では、循環に含まれるオブジェクトを管理するための特別な機能が vtkGarbageCollector に実装されています。循環参照を起こしているクラスが検出されると (開発中にはあり得ます)、そのクラスは自身をガベージコレクタに登録し、Register メソッドと UnRegister メソッドをオーバーロードします。それからのオブジェクトの削除 (および登録解除) メソッドはそのクラスの属する参照カウントの局所的なネットワークに対するトポロジカルな解析を行い、相互に参照するオブジェクトからなる孤島を探索します。もし孤島が見つかればガベージコレクタによって削除されます。
VTK におけるオブジェクトのインスタンス化のほとんどは、static なクラスメンバーとして実装されたオブジェクトのファクトリメソッドを通して行われます。典型的には次のシンタックスをしています:
vtkLight *a = vtkLight::New();
ここで注意すべきなのが、実際にインスタンス化されるのが vtkLight とは限らず、その子クラス (例えば vtkOpenGLLight) である可能性もある点です。オブジェクトファクトリを使用するメリットは多くありますが、その中で最も重要なのはアプリケーションの移植性とデバイス独立性です。特定のプラットフォームの特定のアプリケーションでは vtkLight::New で OpenGL の光源が返りますが、他のプラットフォームでは他のレンダリングライブラリあるいはグラフィックシステムにおける光源を作成するメソッドが呼ばれる可能性があります。正確にどの派生クラスがインスタンス化されるかは実行時のシステム情報に依存します。初期の VTK には gl, PHIGS, Starbase, XGL, OpenGL を使うための大量のオプションがありました。これらの多くは現在使えなくなっていますが、その間に DirectX や GPU ベースの新しいアプローチが表れ、技術の進化に対応するためにデバイス固有の子クラスが vtkLight をはじめとしたレンダリングに関するクラスに追加されました。新しい技術をサポートするために vtkLight などのレンダリングに関するクラスの子クラスが後から追加されたとしても、VTK を使って書かれたアプリケーションに変更は必要ありません。オブジェクトファクトリのもう一つの利点が、パフォーマンスが改善された部品を実行時に装着できることです。例えば vtkImageFFT を特殊用途ハードウェアや数値計算ライブラリにアクセスするクラスに取り換えることが可能です。
データの表現
VTK の強みの一つが、複雑な形式のデータを表現する能力です。扱うデータ形式は表のようなシンプルなものから有限要素メッシュのような複雑なものまであります。図 24.1 に示すように、こういったデータ形式は全て vtkDataObject の子クラスです (データオブジェクトクラスが関わる継承図の一部分を取り出しています)。
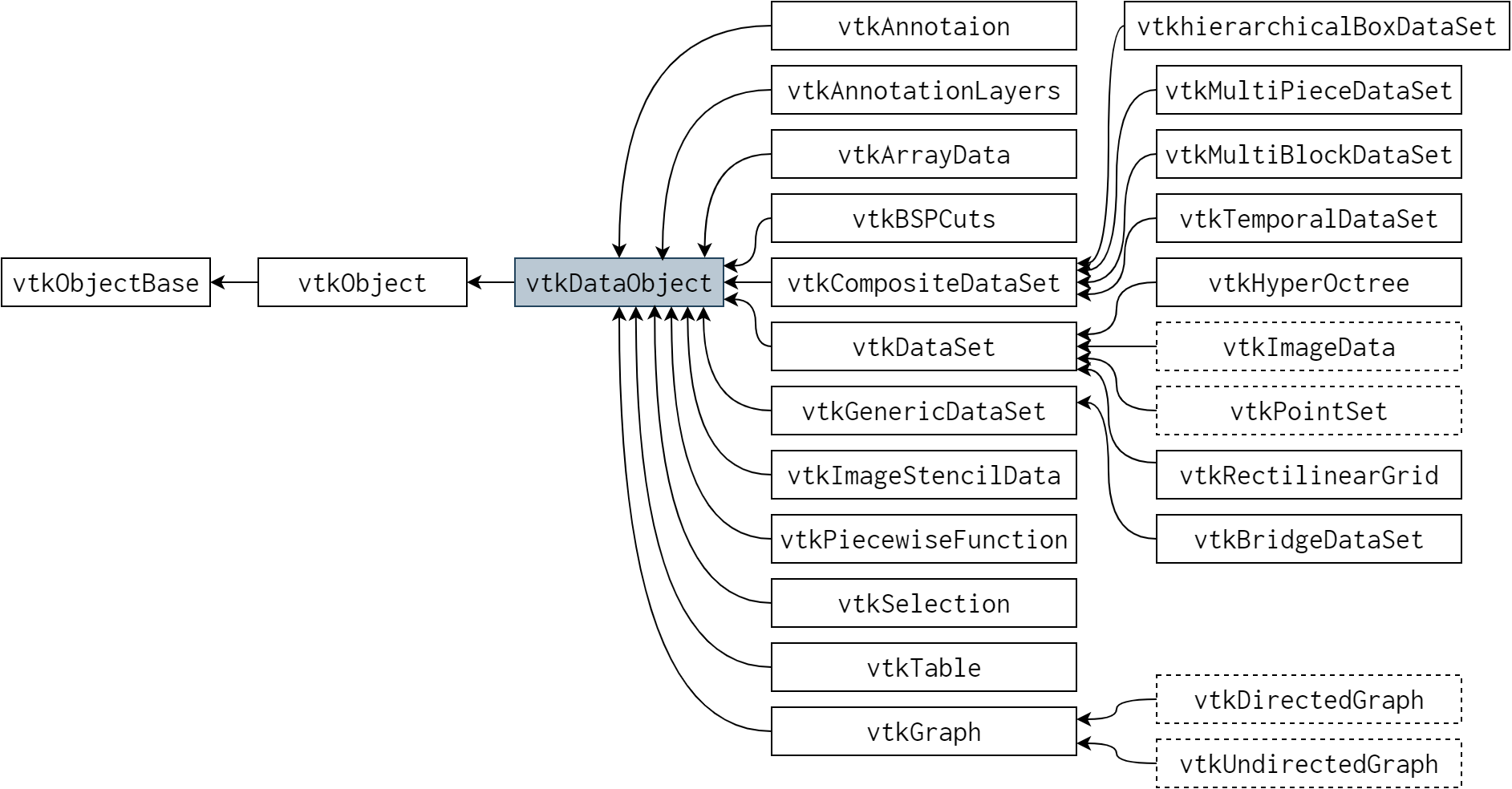
vtkDataObject とその子クラス
vtkDataObject の一番重要な特徴の一つが、次項で説明する視覚化パイプラインで処理できることです。ここにはたくさんのクラスが示されていますが、実際のアプリケーションで使われるのはほんの少しです。vtkDataSet とその派生クラスは科学的可視化に使われます (図 24.2)。例えば vtkPolyData はポリゴンメッシュを表現するのに使われ、vtkunstructuredGrid はメッシュを、vtkImageData は 2D/3D のピクセル/ボクセルデータを表現します。

vtkDataSet とその子クラス
パイプラインアーキテクチャ
VTK は大きなサブシステムがいくつか組み合わさってできています。その中で可視化パッケージと最も深く関連するのがデータフロー (データパイプライン) アーキテクチャです。概念上は、パイプラインアーキテクチャは三つの基底クラスのオブジェクトからなります: データを表すオブジェクト (上述の vtkDataObject)、データオブジェクトを処理、変形、フィルタ、マップして形式を変えるオブジェクト (vtkAlgorithm)、そして中間のデータオブジェクトとプロセスオブジェクトからなる接続グラフ (パイプライン) を制御しパイプラインを実行するオブジェクト (vtkExecutive) です。図 24.3 に典型的なパイプラインを示します。
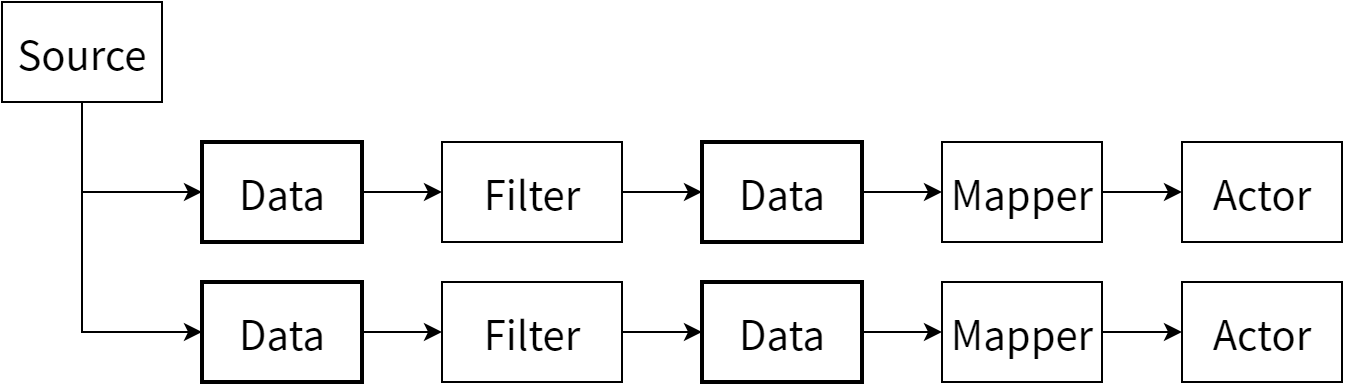
概念的には単純ですが、パイプラインアーキテクチャの実装には困難が伴います。データの表現が複雑になるのがその理由の一つです。例えばデータセットにグループ化されたデータの階層構造が含まれるなら、データに対する操作の実行に自明でない反復や再帰が必要になります。さらに悪いことに、並列実行には (共有メモリであれスケーラブルな分散アプローチであれ) データの分割が必要であり、あるいは差分を正しく求めるには境界部分を重複して配置しなければなりません。
アルゴリズムオブジェクトも他に無い特別な複雑さを持ち込みます。まず一部のアルゴリズムの中には型の異なる複数の入力と複数の出力を持ちます。さらにデータに対してローカルな操作 (セルの中心の計算など) を行うものもあれば、大域的な情報を使う操作 (ヒストグラムの計算など) を行うものもあります。いずれの場合でも、アルゴリズムは入力を不変として扱い、出力の計算では入力から読み込みだけを行います。これは同じデータが複数のアルゴリズムに対する入力である可能性があり、他のアルゴリズムの入力を別の所から書き換えられるのは望ましくないためです。
さらに、実行戦略の詳細によって vtkAlgorithm が複雑になる場合があります。例えばフィルタの間の中間結果をキャッシュしたいことがあります。こうするとパイプラインを変更したときの再計算を最小化できますが、可視化データセットは巨大になります。あるいは計算に必要ない部分を個別に解放する必要が生じるかもしれません。さらに、データの多解像度処理といった複雑な実行戦略によってパイプラインを反復的にしか実行出来なくなる可能性もあります。
次の C++ コードにはこういった概念が使われています。このコードを使ってパイプラインをさらに説明します:
vtkPExodusIIReader *reader = vtkPExodusIIReader::New();
reader->SetFileName("exampleFile.exo");
vtkContourFilter *cont = vtkContourFilter::New();
cont->SetInputConnection(reader->GetOutputPort());
cont->SetNumberOfContours(1);
cont->SetValue(0, 200);
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(cont->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetFileName("outputFile.vtp");
writer->Write();
この例では reader オブジェクトが巨大な非構造グリッド (メッシュ) のデータファイルを読み込み、フィルタがメッシュから等平面を作成します。vtkQuadricDecimation フィルタが等平面 (ポリゴンデータセット) を間引きます (つまり、等平面を表す三角形の数を減らします)。間引きが終わったら、最後に小さくなったデータをディスクに書き戻します。実際のパイプラインの実行は writer によって Write メソッドが呼び出されたとき (つまりデータが必要になったとき) に行われます。
この例で分かるように、VTK によるパイプラインの実行は要求駆動 (demand driven) です。writer や mapper (データをレンダリングするオブジェクト) といったシンクはデータが必要になると、入力にそのことを伝えます。入力のフィルタが適切なデータを既に持っているなら、実行はすぐにシンクに返ります。そうでなく適切なデータを持っていないなら計算を行い、そのときにも同様に入力へデータを要求します。このプロセスは「適切なデータ」を持っているフィルタまたはソース、あるいはパイプラインの始点まで続きます。ここまでさかのぼれば、フィルタは正しい順番で実行され、最初に要求があった場所までデータが流れます。
「適切なデータ」の意味についてさらに考えます。デフォルトでは、VTK のソースやフィルタが実行されると、その出力はパイプラインによってキャッシュされ、将来の不必要な計算を省略できるようになります。これはメモリを犠牲に計算や I/O を節約しており、動作は設定可能です。パイプラインキャッシュがキャッシュするのはデータオブジェクトだけではなく、データオブジェクトが生成された条件に関するメタデータもキャッシュされます。このメタデータにはデータオブジェクトが計算されたときのタイムスタンプ (ComputeTime) が含まれます。そのため一番単純なケースでは、「適切なデータ」とは上流のパイプラインオブジェクトの変更日時よりも遅く計算されているデータを意味します。次の例を見ればこの振る舞いを簡単に理解できるでしょう。前述の VTK プログラムに次のコードを追加したとします:
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
前に説明したように、最初の writer->Write() がパイプラインの実行を開始します。そのため writer2->Write() が呼ばれるとき、パイプラインは deci のキャッシュされた出力が最新であることに気が付きます。間引きフィルタ、等平面フィルタ、reader の変更日時をキャッシュのタイムスタンプと比較できるからです。そのため、データのリクエストは writer2 よりも上流に伝播しません。ではさらに次の変更を行ったとします:
cont->SetValue(0, 400);
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
こうすると、パイプラインの実行は等平面フィルタと間引きフィルタが最後に実行された後に等平面フィルタが変更されたことに気が付きます。そのためこの二つのフィルタに関するキャッシュは期限切れであり、再実行が必要です。しかし reader は等平面フィルタよりも前に変更されていないのでキャッシュは有効であり、再実行の必要はありません。
以上が要求駆動パイプラインの一番単純な例です。VTK のパイプラインはさらに洗練されており、フィルタやシンクがデータを要求するときに追加のメタデータを渡して、データの一部だけを要求できます。例えば、データの一部をストリームして out-of-core な解析を行うフィルタが作れます。前述の例を変更してこれを説明します。
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetNumberOfPieces(2);
writer->SetWritePiece(0);
writer->SetFileName("outputFile0.vtp");
writer->Write();
writer->SetWritePiece(1);
writer->SetFileName("outputFile1.vtp");
writer->Write();
このコードで writer は、独立してストリームされる二つの部分に分けてデータの読み込みと処理を行うようパイプラインの上流に要求しています。前に説明した単純な実行手順がここでは上手く行かないことに気付いたでしょう。単純な実行手順を使うと、Write 関数が二度目に呼ばれるときパイプラインの上流は何も変化していないので、再計算が起こりません。そのため複雑なケースに対応するには、この例のような部分的なリクエストを処理する手順が必要です。VTK のパイプライン実行は複数のパスでできており、データオブジェクトの計算は最後です。その前のパスがリクエストパスで、シンクとフィルタが現在の計算に必要なものを上流にリクエストする部分です。今の例では、二つの部分のうち 0 番目が必要であると writer から入力に通知が行きます。パイプラインの実行時に reader が読む必要があるのはデータの一部だけであり、さらにキャッシュとデータの対応関係がオブジェクトのメタデータに保存されます。そのためフィルタがもう一度入力にデータを要求したときには、このメタデータがリクエストと比較されます。よってこの例では異なる部分へのリクエストを処理するためにパイプラインが (正しく) 再実行されます。
フィルタが行えるリクエストには他にもいくつかの種類があります。例えば特定の時間間隔、あるいは決まった構造を持つ区間やゴーストレイヤー (近接情報を計算するときの境界レイヤー) の数などがリクエストできます。さらにフィルタはリクエストパスで下流からのリクエストの改変を許されており、例えばストリームできないフィルタ (streamline フィルタなど) は一部に対するリクエストを無視して全てのデータをリクエストできます。
レンダリングサブシステム
VTK がオブジェクト指向の単純なレンダリングモデルを持つことは一目見ただけで分かります。3D シーンを構成するコンポーネントがクラスに対応し、例えば vtkActor は vtkRender と vtkCamera でレンダリングされるオブジェクトです。複数の vtkRenderer が一つの vtkRenderWindow の中に存在する場合もあります。シーンは一つ以上の vtkLight で照らされます。vtkActor の位置は vtkTransform で、見た目は vtkProperty で指定され、幾何学的表現は vtkMapper が定義します。マッピングは VTK で重要な役割を持ち、データ処理パイプラインの終端となってレンダリングシステムとの対話を行います。次の例を考えましょう。このコードはデータを間引いて結果をファイルに書き込み、その後マッパーを使って結果を可視化して対話を可能にします:
vtkOBJReader *reader = vtkOBJReader::New();
reader->SetFileName("exampleFile.obj");
vtkTriangleFilter *tri = vtkTriangleFilter::New();
tri->SetInputConnection(reader->GetOutputPort());
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(tri->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkPolyDataMapper *mapper = vtkPolyDataMapper::New();
mapper->SetInputConnection(deci->GetOutputPort());
vtkActor *actor = vtkActor::New();
actor->SetMapper(mapper);
vtkRenderer *renderer = vtkRenderer::New();
renderer->AddActor(actor);
vtkRenderWindow *renWin = vtkRenderWindow::New();
renWin->AddRenderer(renderer);
vtkRenderWindowInteractor *interactor = vtkRenderWindowInteractor::New();
interactor->SetRenderWindow(renWin);
renWin->Render();
ここでは actor, renderer, render window が一つずつ作られ、mapper がパイプラインとレンダリングシステムをつなぎます。さらにマウスとキーボードのイベントをキャプチャしてカメラ制御などの操作に変換する vtkRenderWindowInteractor が加わっています。この変換処理は vtkInteractorStyle で定義され(後述)、デフォルトではたくさんのインスタンスとデータ値が自動的に設定されます。例えば変形として単位変形が用意され、一つのデフォルトライト (ヘッドライト) とプロパティが設定されます。
このオブジェクトモデルは時を経てさらに洗練されました。新たな複雑さの多くは特殊なレンダリング処理のための派生クラスから来ています。vtkActor は vtkProp の具象クラスとなり (演劇の舞台にある小道具 prop と同様です)、2D のオーバーレイグラフィックスとテキストをレンダリングにはこの vtkProp が大量に使われます。さらにボリュームレンダリングや GPU 実装といった高度なレンダリング技術でも vtkProp が使われます (図 24.4)。
同様に VTK がサポートするデータモデルも成長し、データとレンダリングシステムのインターフェースであるマッパーも種類が増えました。大きく拡張されたもう一つの領域が変形を表す階層構造です。最初は 4×4 の単純な変形行列を使っていましたが、現在では薄板スプライン変形 (thin-plate spline transformation) などの非線形変形をサポートするパワフルな階層構造が使われます。例えば最初の vtkPolyDataMapper は (vtkOpenGLPolyDataMapper といった) デバイス固有の子クラスを持っていましたが、現在では “painter” パイプラインと呼ばれるより洗練されたグラフィックパイプラインに取って代わられました (図 24.4)。
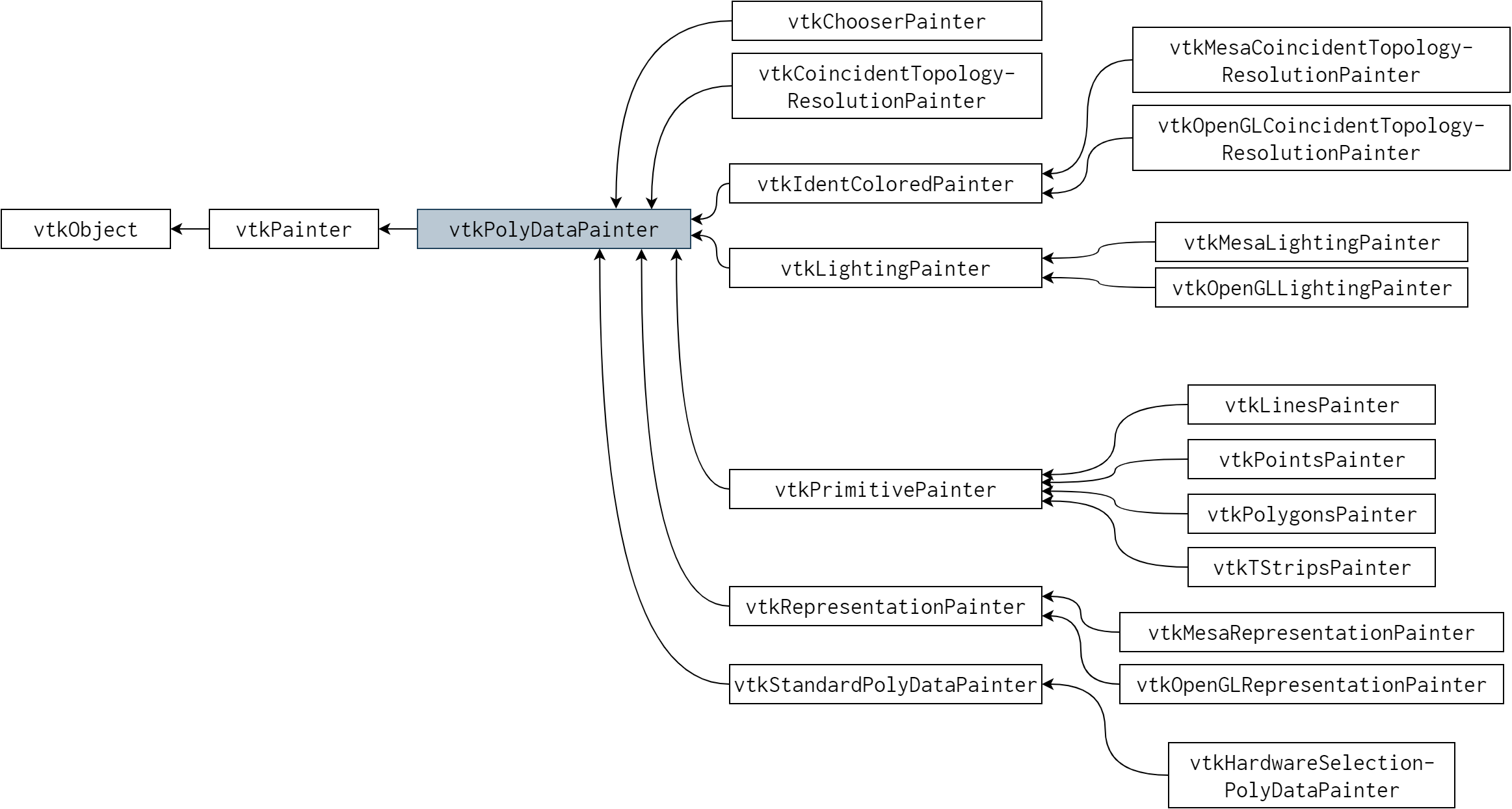
vtkPolyDataPainter とその子クラス
painter の設計はデータのレンダリングにおける様々なテクニックをサポートしており、組み合わせれば特殊な効果を得られます。この機能は 1994 年に実装された単純な vtkPolyDataMapper の遥か先を行っています。
可視化システムでもう一つ重要なのが、選択サブシステムです。VTK には “ピッカー” の階層構造があり、vtkProp をハードウェアベースに選択するオブジェクト、ソフトウェア (レイキャスティング) で選択するオブジェクト、そして選択操作を行った後に保持する情報も指定するオブジェクトからなります。例えば三次元のワールド空間座標だけを提供してどの vtkProp が選択されたかを明示しないピッカーや、選択された vtkProp だけではなく prop のメッシュにおける点やセルを提供するピッカーがあります。
イベントとインタラクション
データとの対話 (インタラクション) は可視化の重要なステップです。VTK では様々な方法でデータと対話できます。一番単純なのはイベントを監視し、発生したらコマンドを通して応答するというものです (command/observer デザインパターンを使います)。vtkObject の全ての子クラスはオブザーバーのリストを保持し、オブザーバーは自身をこのリストに登録します。オブザーバーは登録時に監視するイベントとイベントが起きたときに呼び出すコマンドを指定します。この動作を見るために、次の例を考えます。このコードではフィルタ (ポリゴン削減フィルタ) が StartEvent, ProgressEvent, EndEvent という三つのイベントを監視します。これらのイベントはそれぞれフィルタが実行を開始したとき、フィルタの実行中に一定時間ごと、実行を完了したときに呼ばれます。vtkCommand クラスには Execute メソッドがあり、アルゴリズムの実行時間についての情報を出力します。
class vtkProgressCommand : public vtkCommand
{
public:
static vtkProgressCommand *New() { return new vtkProgressCommand; }
virtual void Execute(vtkObject *caller, unsigned long, void *callData)
{
double progress = *(static_cast<double*>(callData));
std::cout << "Progress at " << progress<< std::endl;
}
};
vtkCommand* pobserver = vtkProgressCommand::New();
vtkDecimatePro *deci = vtkDecimatePro::New();
deci->SetInputConnection( byu->GetOutputPort() );
deci->SetTargetReduction( 0.75 );
deci->AddObserver( vtkCommand::ProgressEvent, pobserver );
この形式の対話はとても単純ですが、VTK を使う多くのアプリケーションの基礎となっています。例えば上記のコードを少し変えれば GUI のプログレスバーを管理・表示できます。コマンドとオブザーバーを使ったこのサブシステムは VTK の 3D ウィジェットの中心的な要素でもあります。このウィジェットはデータのクエリ、生成、編集のための洗練された対話オブジェクトであり、後で説明されます。
上記の例に関連して、VTK のイベントは事前に定義されているものの、ユーザーがイベントを定義するためのバックドアがあることに注意してください。vtkCommand は名前付きのイベント (コード中の vtkCommand::ProgressEvent など) に加えてユーザーイベントも定義します。UserEvent (実体は整数) を使ってアプリケーションでユーザーによって定義されたイベントが始まる地点へのオフセットを表すので、例えば vtkCommand::UserEvent+100 は VTK が定義したのではない (ユーザーが定義した) イベントを指します。
ユーザーから見ると VTK ウィジェットはシーン内の一つのアクターに過ぎませんが、ハンドルの生成といった幾何学的な機能を利用できる点が特別です (こういった機能は前述の選択機能を利用します)。このウィジェットとの対話はとても直感的です: ユーザーは球体のハンドルをつかんで移動させたり、直線をつかんで移動させたりできます。しかし内部ではイベント (InteractionEvent など) が発生するので、アプリケーションからこのイベントを監視して何らかの動作を行わせることも可能です。例えば vtkCommand::InteractionEvent は次のように使います:
vtkLW2Callback *myCallback = vtkLW2Callback::New();
myCallback->PolyData = seeds; // streamlines seed points, updated on interaction
myCallback->Actor = streamline; // streamline actor, made visible on interaction
vtkLineWidget2 *lineWidget = vtkLineWidget2::New();
lineWidget->SetInteractor(iren);
lineWidget->SetRepresentation(rep);
lineWidget->AddObserver(vtkCommand::InteractionEvent,myCallback);
VTK ウィジェットは二つのオブジェクトからなります: vtkInteractorObserver の子クラスと vtkProp の子クラスです。vtkInteractorObserver はレンダーウィンドウにおけるユーザーインタラクション (つまりマウスとキーボードのイベント) を監視します。vtkProp の子クラス (つまりアクター) は vtkInteractorObserver によって操作を受けます。この操作が変更するのは vtkProp のジオメトリ、例えばハンドルのハイライト、カーソルの見た目、データの変形などです。もちろんウィジェットの動作を詳細を定義するには子クラスを定義する必要があり、VTK には現在 50 個以上の子クラスが存在します。
ライブラリのまとめ
VTK は大規模なソフトウェアツールキットです。このシステムは現在約 150 万行のコード (コメント含む、自動生成のラッパーソフトウェアは含めず) と約 1000 個の C++ クラスからなります。VTK の複雑さを管理しビルドとリンクの時間を短縮するために、このシステムは数十のサブディレクトリに分割されています。図 24.1 にサブディレクトリとライブラリの簡単な説明を示します。
| ディレクトリ名 | 説明 |
|---|---|
Common |
VTK のコアクラス |
Filtering |
パイプラインワークフローを管理するクラス |
Rendering |
レンダリング、選択、画像閲覧、インタラクション |
VolumeRendering |
ボリュームレンダリング |
Graphics |
3D ジオメトリ処理 |
GenericFiltering |
非線形 3D ジオメトリ処理 |
Imaging |
イメージングパイプライン |
Hybrid |
グラフィックスとイメージングの機能を両方使うクラス |
Widgets |
洗練されたインタラクション |
IO |
VTK の入力と出力 |
Infovis |
情報可視化 |
Parallel |
並列処理 (コントローラとコミュニケータ) |
Wrapping |
Tcl, Python, Java ラッパーのサポート |
Examples |
詳細なドキュメント付きの大規模なサンプル |
振り返りと今後の展望
VTK は大成功を収めてきました。一行目のコードは 1993 年に書かれたにもかかわらず、VTK は執筆時点においても成長を続け、開発のペースは加速しているほどです2。この節では開発で得られた教訓とこれからの課題について説明します。
成長の管理
VTK に関して最も驚くべきなのが、このプロジェクトが長い間生き残ってきたことです。開発のペースは次の要因によって決定されました:
-
新しいアルゴリズムや機能は追加され続ける。例えば、情報学サブシステム (Sandia National Labs と Kitware が開発を主導する Titan) は最近の大きな追加要素である。他にもチャートやレンダリングのための新しいクラスや新しい種類の科学データセットが追加される。3D 対話ウィジェットも大きな追加機能である。それから、現在進化が続く GPU ベースのレンダリングとデータ処理は VTK に新たな機能を提供している。
-
多くの人が VTK に触れ利用することで、さらに多くのユーザーと開発者がコミュニティにやってくる。例えば最も広く使われている科学的データ可視化アプリケーションである ParaView は VTK を使っており、高性能計算コミュニティから高い評価を得ている。さらに生物医療計算プラットフォームとして人気のある 3D Slicer は大部分が VTK を使っており、毎年数百万ドルの資金を獲得している。
-
VTK の開発プロセスは成長を続ける。最近になって CMake, CDash, CTest, CPack というソフトウェアプロセスツールが VTK のビルド環境に統合された。さらについ最近には VTK のコードレポジトリが Git を使った洗練されたワークフローに移行した。こういった改善により、VTK は科学計算コミュニティにおける最先端のソフトウェア開発環境であり続ける。
成長は望ましいものであり、ソフトウェアシステムの制作が滞りなく進行していることを示します。VTK の明るい将来の兆候であるとも言えるのですが、成長を上手くコントロールするのは非常に難しい仕事です。このため VTK の短期間の将来予測はソフトウェアだけではなくコミュニティの成長にも焦点を当てます。いくつかのステップがこれに関連して取られています。
まず、正式なマネジメント機構が作られつつあります。高いレベルの戦略的問題を担当する Architecture Review Board がコミュニティと技術の開発を主導するために設立され、特定の VTK サブシステムの技術開発を担当する Topic Leads も VTK コミュニティによって構築されています。
次に、ツールキットのモジュール性をさらに高める計画があります。これは Git のワークフロー機能を使ったものですが、背景にはユーザーと開発者がツールセットの小さな部分だけを望んでいて、パッケージ全体のビルド・リンクは必要とされていない事実があります。また成長を続けるコミュニティをサポートするには、ツールキットのコアに含まれないような機能やサブシステムへのコントリビューションのサポートが重要になります。疎結合でモジュール化された機能の集合を作れば、コアの安定性を担保しながらも付属部分への大量のコントリビューションに対応できます。
技術の追加
ソフトウェアプロセス以外にも、開発パイプラインにおける技術革新は多数存在します:
-
コプロセッシング (co-processing) は可視化エンジンをシミュレーションコードに組み込み、定期的にデータを可視化する機能である。この技術により完全な解の巨大なデータを出力する必要がなくなる。
-
VTK のデータ処理パイプラインはまだ複雑すぎる。このサブシステムを単純化・リファクタするためのメソッドが開発されている。
-
データと直接対話する機能をユーザーはよく使うようになってきた。VTK はたくさんのウィジェットを提供するが、タッチスクリーンを使うものや 3D の方法などの新しいインタラクション技術がさらに開発されている。インタラクションは速いペースの開発を続ける。
-
計算化学は素材設計や工学において重要性を増している。化学データの可視化とインタラクション機能が VTK に追加する作業が進んでいる。
-
VTK のレンダリングシステムは複雑すぎると批判の的になってきた。新しい派生クラスの作成や新しいレンダリング技術のサポートが困難になっている。VTK はシーングラフを直接サポートしないが、多くのユーザーからのリクエストが来ている。
-
新しい種類のデータが登場している。例えば医療分野における多解像度の空間データセット (局所的な拡大ができる共焦点レーザー顕微鏡) などである。
オープンサイエンス
Kitware、より一般的には VTK のコミュニティは、オープンサイエンスに尽力しています。具体的に言えば、私たちはオープンデータ、オープンパブリケーション、オープンソースといった再現可能な科学体系に不可欠な要素を広めています。VTK は長い間オープンソースとオープンデータのためのシステムとして頒布されてきましたが、ドキュメントのプロセスが欠けていました。きちんとした本 [Kit10, SML06] もありますが、新しいソースコードのコントリビューションなどの技術文書を集めるのには様々なアドホックな方法が使われていました。私たちは VTK Journal3 をはじめとした新しい公開メカニズムを開発してこの状況を変えようとしています。このジャーナルではドキュメント、ソースコード、データ、有効なテスト画像からなる記事が公開されます。またこのジャーナルでは、人間によるレビューに加えてコードの自動レビューも可能です (VTK のソフトウェア品質テスト処理を使います)。
教訓
VTK は成功を収めていますが、上手く行かなかったこともたくさんあります:
-
設計のモジュール性: クラスのモジュール性の選択は上手く行えました。例えばピクセルごとにオブジェクトをするような真似はせずに、より高レベルな
vtkImageClassを作成して内部でピクセルデータのデータ配列を扱っています。しかし一部ではクラスが高レベルで複雑すぎて、小さい部品へのリファクタが必要になりました。このプロセスは今も続いています。分かりやすい例はデータ処理パイプラインです。最初パイプラインはデータとアルゴリズムオブジェクトの対話として陰に実装されていたのですが、その対話を調整し異なるデータ処理戦略を実装するにはパイプライン実行者 (pipeline executive) というオブジェクトを明示的に作成しなければなりませんでした。 -
重要な概念がない: 私たちの大きな後悔の一つが、C++ のイテレータを使わなかったことです。VTK のデータ走査は多くの場合で科学的プログラミング言語 Fortran と大差ありません。イテレータの柔軟性があればシステムは相当な恩恵を受けていたでしょう。例えば局所データの処理やある条件を満たすデータの処理の記述が非常に楽になります。
-
設計の問題: もちろん最適でない設計判断は長いリストとなります。データ実行パイプラインでは苦労が多く、数世代を経て設計が改善されました。レンダリングシステムも複雑で、派生が難しくなっています。VTK の初期計画から生じた困難もあります: 私たちは VTK をデータを閲覧するための読み込み専用可視化システムとみなしていました。しかし現在の利用者はたいていデータの編集を必要とするので、大きくデータ構造が必要となります。
VTK のようなオープンソースシステムの素晴らしい点の一つが、こういった間違いの多くを時間をかけて修正できることです。VTK のアクティブで有能な開発コミュニティは日々システムを改善しており、私たちは栄えある未来に向けてこれが続くことを願っています。