9.3 インフラストラクチャアプリケーション
インターネットのスムーズな動作に不可欠でありながらもプロトコルスタックの層モデルに厳密には当てはまらないプロトコルがいくつか存在する。その一つに DNS (Domain Name System) がある ── DNS は典型的なユーザーが起動するアプリケーションではないものの、ネットワークを利用する DNS 以外のほぼ全てのアプリケーションは DNS に依存する。DNS が提供するネームサービス (名前解決サービス) はホスト名からホストアドレスへの変換を行う。こういったアプリケーションが存在することで、他のアプリケーションのユーザーはリモートホストをアドレスではなく名前で参照できる。言い換えれば、多くの場合ネームサービスを利用するのは他のアプリケーションであり、人間ではない。
目立たないものの欠かせないもう一つの機能としてネットワークの管理がある。平均的なユーザーはネットワークの管理を行わず、たいていはネットワークの運営者がユーザーの代わりに行う。ネットワークの管理はネットワーク分野の中で難しいとみなされている問題の一つであり、多くのイノベーションが起こっている領域でもある。本節ではネットワークを管理するときに生じる問題とそれに対するアプローチをいくつか見る。
9.3.1 ネームサービス (DNS)
本書では多くの箇所でホストの特定に 192.168.1.1 のような IP アドレスを使ってきた。IP アドレスはルーターが行う処理に完璧に適しているものの、それほどユーザーフレンドリーではない。これが理由で、ネットワーク上の各ホストには名前 (name) が割り当てられる場合が多い。第 9.1 節では HTTP などのアプリケーションプロトコルが www.princeton.edu といった名前を利用することを見た。これからネームサービスがユーザーフレンドリーな名前をルーターフレンドリーなアドレスに対応付ける仕組みを説明する。ネームサービスはアプリケーションと下位ネットワークの隙間を埋めるソフトウェアなので、ミドルウェア (middleware) と呼ばれることがある。
ホストの名前とアドレスには二つの重要な違いがある。第一に、典型的な名前は可変長の文字列なので、人間が記憶しやすい。これに対してアドレスは固定長の数列なので、ルーターが処理しやすい。第二に、名前にはネットワーク内でホストを特定する (パケットをホストに向けて転送する) ための情報が一切含まれない。これに対してアドレスにはルーティングのため情報が埋め込まれている場合が多い。ただし例外として、構造化されていないフラットアドレス (flat address) がある。
ネットワーク内のホストに名前を付ける仕組みを説明する前に、まず基本的な用語を定義する。まず、名前付けシステムが認識する名前の集合を名前空間 (name space) と呼ぶ。名前空間は階層的 (hierarchical) と平坦 (flat) のどちらかに分類される。階層的な名前空間に属する名前はいくつかの部分から構成されるのに対して、平坦な名前空間に属する名前は意味のある部分を持たない。階層的な名前空間の明らかな例として、Unix のファイル名からなる空間がある。次に、名前付けシステムは名前から値 (たいていはアドレス) へのバインディング (binding, 対応付け) の集合を管理する。それから、名前を受け取ってそれに対応する値を返す手続きを名前の解決 (resolution) と呼ぶ。最後に、ネームサーバー (name server) とは名前解決の実装であって、ネットワーク上に配置され、それに対してメッセージを送ることで利用可能なものを言う。
インターネットは非常に大規模なので、DNS (Domain Name System) という非常によく発達した名前付けシステムを備えている。そのため本節ではホストの名前付けという問題に関する議論の下敷きとして DNS を用いる。ただし DNS がインターネットと共に生まれたわけではないので注意してほしい。数百個のホストしか持たなかった初期のインターネットでは、NIC (Network Information Center) と呼ばれる中央機関が名前からアドレスへのバインディングをまとめた平坦なテーブル (表) を管理していた。このテーブルは HOSTS.TXT と呼ばれた1。拠点が新しいホストをインターネットに接続するには、拠点の管理者が NIC にメールを送り、新しい名前とアドレスの組を受け取る必要があった。このメールに記された情報は手動でテーブルに追加され、テーブルは数日ごとに全ての拠点にメールで通知され、各拠点のシステム管理者が拠点上の全てのホストにテーブルをインストールする仕組みだった。このとき、名前解決はローカルにコピーされたテーブルからホストの名前を見つけ、対応するアドレスを返す単純な手続きとして実装される。
インターネットに接続されるホストが増えると、このアプローチによる名前付けは当然ながら上手く行かなくなった。これを受けて 1980 年代の中頃に DNS が登場した。平坦な名前空間を採用する HOSTS.TXT と異なり、DNS は階層的な名前空間を採用する。名前空間を実装するバインディングを収めた「テーブル」は互いに重ならない部分に分割され、それぞれがインターネットの様々な場所に分散して保存される。これらの小さなテーブルはネームサーバーで利用可能となり、ネットワーク越しに問い合わせが可能となる。
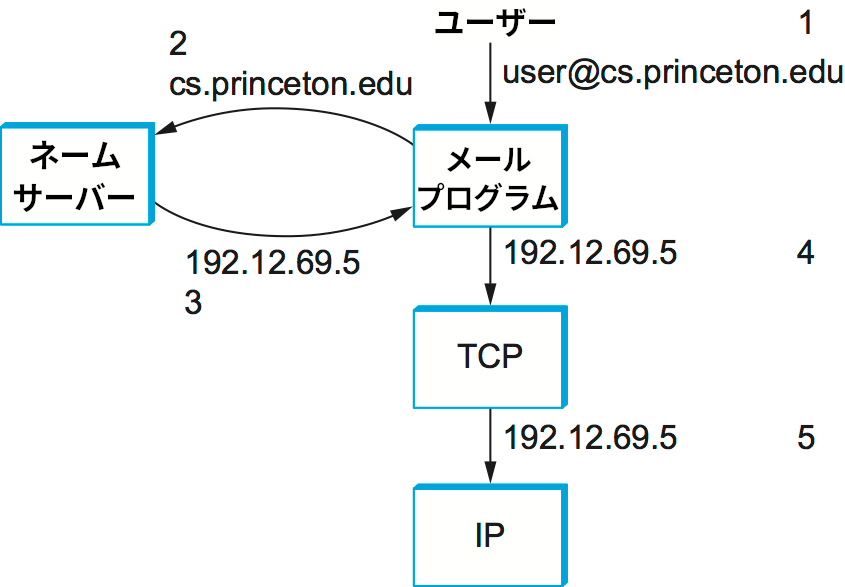
インターネットを利用するユーザーがホストの名前 (メールアドレスや URL など、ホストの名前以外の情報がある場合もある) をアプリケーションに提示すると、そのアプリケーションは名前付けシステムに命令を出してホストの名前を対応する IP アドレスに変換する。その後アプリケーションはトランスポートプロトコル (例えば TCP) にホストの IP アドレスを提示し、そのホストへの接続をオープンする。メールプログラムでメールを送信するときの流れを図 229 に示す。この図では名前解決が単純な操作として描かれているものの、これから見るようにそれほど単純ではない。
ドメイン階層
DNS はインターネット上のオブジェクトを表す階層的名前空間を実装する。Unix のファイル名はスラッシュを分離文字として左から右に処理されるのに対して、DNS における名前はピリオドを分離文字として右から左に処理される (ただし人間が読むときは左から右に読む)。DNS における名前はドメイン名 (domain name) と呼ばれ、cicada.cs.princeton.edu といった形をしている。ドメイン名はインターネット上の「オブジェクト」を表す名前であることに注目してほしい。これは DNS が定義するのは厳密にはホストの名前からホストのアドレスへのバインディングではないことを意味する。より正確には、DNS はドメイン名から何らかの「値」に対するバインディングを定義する。ただ、これからの議論では「値」がホストの IP アドレスだと仮定する。それ以外の「値」は後で説明する。
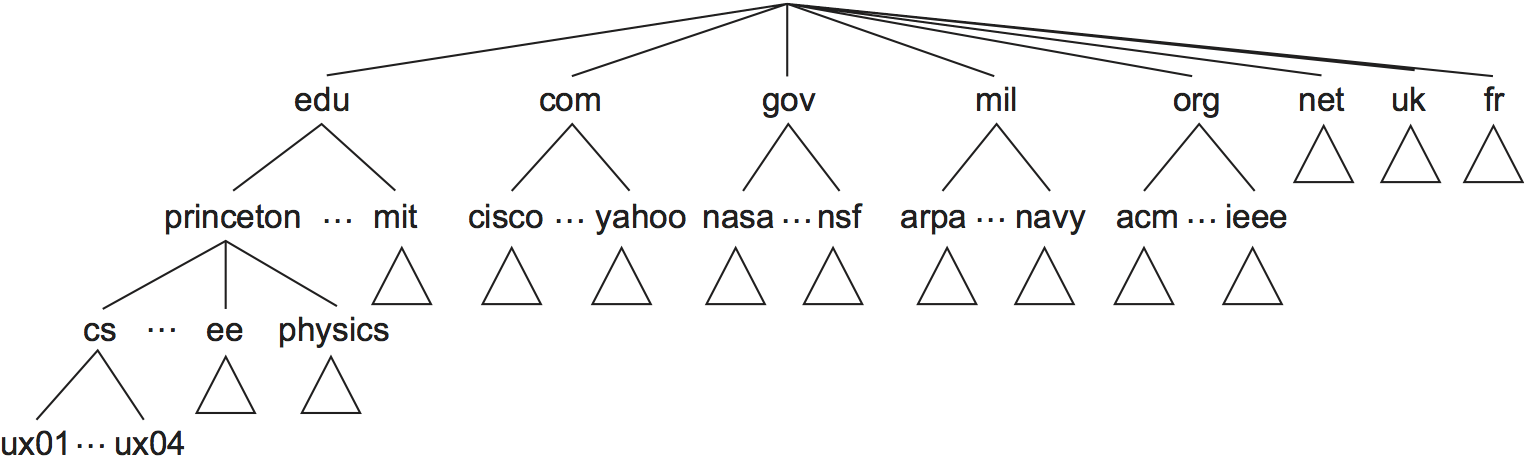
Unix のファイル階層と同様に、DNS のドメイン名が持つ階層 (ドメイン階層) は木で表現できる (図 230)。この木において葉でないノードはドメイン (domain) と呼ばれ、葉はドメイン名が与えられたホストを表す。ドメインは DNS が定義する名前に階層構造を加えるために存在するだけであり、それ以上の意味論的役割はないことに注意してほしい2。
実はドメイン階層の策定が始まったとき、階層の最上位付近に定義する名前の決め方に関して相当な議論が行われた。その細かい議論にここで立ち入ることはしないが、TLD (top-level domain, トップレベルドメイン) と呼ばれるドメイン階層の最上位に位置するドメインが非常に多い事実を指摘しておく。TLD には例えば各国に対するドメインや、「ビッグシックス (big six)」と呼ばれるドメイン (.edu, .com, .gov, .mil, .org) が存在する。六つのビッグシックスドメインは元々アメリカ (インターネットと DNS が開発された国) でのみ使われており、例えば .edu ドメインを取得できるのは US で認可された教育機関に限られていた。近年 .com ドメインに対する高い需要への対処が理由の一つとなって、TLD の数は爆発的に増加した。新しい TLD の例として .biz, .coop, .info がある。現在では 1200 以上のTLD が存在する。
ネームサーバー
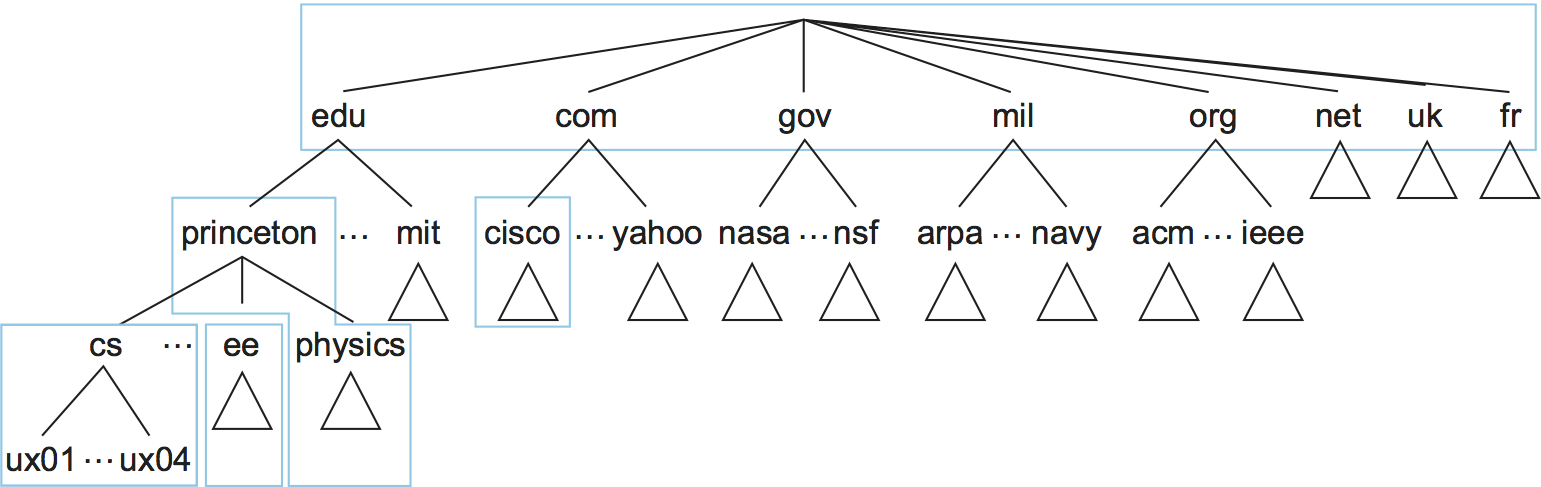
完全なドメイン階層は抽象的にしか存在しない。続いてドメイン階層を実際に実装する方法を見ていく。最初のステップとして、ドメイン階層はゾーン (zone) と呼ばれる部分木に分割される。図 230 に示したドメイン階層のゾーンへの分割の一例を図 231 に示す。ゾーンは何らかの権威機関に管理が割り当てられるドメイン階層の範囲と考えることができる。例えば、最上位にあるゾーンは ICANN (Internet Corporation for Assigned Names and Numbers) が管理する範囲を表し、その下にはプリンストン大学が管理するゾーンがある。プリンストン大学の中にはドメイン階層の管理を行わない (大学レベルのゾーンに属する) 部局もあれば、計算機科学科のように部局レベルで独自にゾーンを管理する部局もある。
ゾーンがなぜ重要かと言えば、ゾーンはネームサーバー (name server) という DNS の実装における基礎単位に対応するからである。具体的に言うと、一つのゾーンに関する情報は二つ以上のネームサーバーで実装される。それぞれのネームサーバーはインターネット越しにアクセス可能なプログラムであり、クライアントはネームサーバーにクエリを送信して必要な情報を取得する。ネームサーバーからのレスポンスにクライアントが望む情報そのものが含まれることもあれば、次にクエリを送信すべき他のサーバーを示したポインタがレスポンスであることもある。そのため実装の観点からすると、DNS はドメインの階層ではなく 図 232 のようにネームサーバーの階層を持つと考えた方が正確となる。
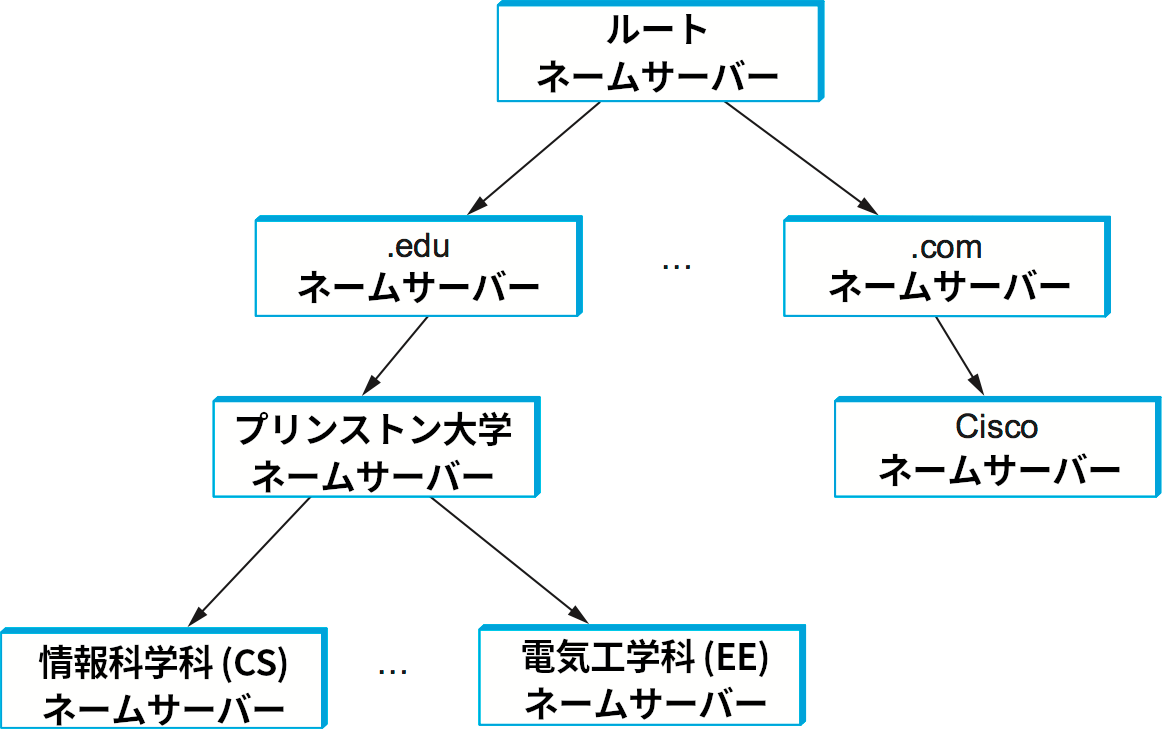
それぞれのゾーンは冗長性のために二つ以上のネームサーバーで実装される。つまり、一つのネームサーバーで障害が発生したとしてもそこに含まれる情報が取得不可能にはならない。一方で、一つのネームサーバーは複数のゾーンを実装して構わない。
ネームサーバーはゾーンに関する情報をリソースレコード (resource record) の集合として実装する。リソースレコードは突き詰めれば名前から値へのバインディングであり、もう少し詳しく見ると次のフィールドを持つ五要素のタプルである:
(Name, Value, Type, Class, TTL)
Name フィールドと Value フィールドはそれぞれ名前と値を表す。Type フィールドは Value フィールドの値をどのように解釈すべきかを表す。例えば Type フィールドが A に設定されるとき、Value フィールドの値は IP アドレスとして解釈される。つまり、ここまで議論してきた名前から IP アドレスへのバインディングは A レコード (Type フィールドが A のリソースレコード) によって実装される。Type フィールドの値として設定可能な値の例を次に示す:
-
NS:Valueフィールドは指定されたドメインに属する名前を解決できるネームサーバーを実行するホストのドメイン名を表す。 -
CNAME:Valueフィールドは指定されたホストの正式な名前 (canoniacal name) を表す。ドメインのエイリアス (別名) の定義で利用される。 -
MX:Valueフィールドは指定されたドメインに対するメッセージを受け取るメールサーバーを実行するホストのドメイン名を表す。
Class フィールドは NIC 以外の主体がリソースレコードのタイプを独自に定義できるようにするために存在する。ただし、現在までに広く利用された Class フィールドの値はインターネットを意味する IN しか存在しない。最後に、TTL (time-to-live, 有効期間) フィールドはリソースレコードが効力を失うまでの時間を表す。TTL フィールドは他のサーバーから取得したリソースレコードをキャッシュするサーバーによって利用される。そういったサーバーは TTL が 0 になったリソースレコードをキャッシュから追い出さなければならない。
リソースレコードがドメイン階層に関する情報を表現する仕組みをさらに理解するために、図 230 と 図 232 に示した階層でネームサーバーが持つリソースレコードを考えよう。例を簡単にするため、TTL フィールドは無視して、各ゾーンを実装するネームサーバーの一つだけを見ていくことにする。
まず、ルートのネームサーバーは TLD のネームサーバーそれぞれに対する NS レコードを持つ。これらのレコードは今の例で .edu や .com といった TLD を含むゾーンに対するクエリに応じるサーバーを特定する。これらのサーバーの名前を IP アドレスに変換する A レコードもルートのネームサーバーには含まれる。つまり、ルートのネームサーバーから TLD サーバーへのポインタが NS レコードと A レコードの組によって実装される。ルートのネームサーバーが持つレコードの例を次に示す:
(edu, a3.nstld.com, NS, IN)
(a3.nstld.com, 192.5.6.32, A, IN)
(com, a.gtld-servers.net, NS, IN)
(a.gtld-servers.net, 192.5.6.30, A, IN)
...
階層を一つ下ると、.edu を含むゾーンを担当するネームサーバーは次のようなレコードを持つ:
(princeton.edu, dns.princeton.edu, NS, IN)
(dns.princeton.edu, 128.112.129.15, A, IN)
...
これは princeton.edu を含むゾーンを管理するネームサーバー dns.princeton.edu を表す NS レコードと A レコードである。このネームサーバーは email.princeton.edu などのクエリには直接応えられるのに対して、penguins.cs.princeton.edu などのクエリには階層をもう一つ下るよう指示する:
(email.princeton.edu, 128.112.198.35, A, IN)
(penguins.cs.princeton.edu, dns1.cs.princeton.edu, NS, IN)
(dns1.cs.princeton.edu, 128.112.136.10, A, IN)
...
最後に、三階層目のネームサーバー cs.princeton.edu は自身が名前を管理する全てのホストに対する A レコードを持つ。それとは別に、一部のホストに対する CNAME レコード (エイリアス) を持つ可能性もある。エイリアスは基本的にマシンに対する別名 (短縮名など) であるものの、間接参照の階層として利用することもできる: 例えばホスト coreweb.cs.princeton.edu を www.cs.princeton.edu のエイリアスに設定すると、リモートユーザーに影響を及ぼさずに計算機科学科のウェブサイトが置かれたウェブサーバーを後から変更できる。ユーザーがアクセスするのは www.cs.princeton.edu であり、このドメインのウェブサーバーを現在実行しているマシンが何であっても構わない。MX レコード (メール交換レコード) もメールアプリケーションに対して同じ用途で用いられる ── 管理者はドメインを代表してメールを受け取るホストを後から変更でき、そのとき管理下にあるユーザーのメールアドレスを変更する必要はない。
(penguins.cs.princeton.edu, 128.112.155.166, A, IN)
(www.cs.princeton.edu, coreweb.cs.princeton.edu, CNAME, IN)
(coreweb.cs.princeton.edu, 128.112.136.35, A, IN)
(cs.princeton.edu, mail.cs.princeton.edu, MX, IN)
(mail.cs.princeton.edu, 128.112.136.72, A, IN)
...
なお、リソースレコードは事実上どんなオブジェクトに対してでも定義できるものの、通常 DNS はホスト (サーバーを含む) とウェブサイトに名前を付けるために利用される。それ以外の個人、ファイル、ディレクトリといったオブジェクトに対して DNS が用いられることはない: そういったオブジェクトの識別では他の名前付けシステムが用いられる。例えば、個人の識別を容易にするために設計された名前付けシステムとして ISO が策定した X.500 がある。X.500 は「名前」「役職」「電話番号」「住所」といった属性の集合を割り当てることで個人の識別を可能にする。X.500 は非常に扱いづらかった (そして後から登場した強力なウェブ検索エンジンにある意味で取って代わられた) ものの、後に LDAP (Lightweight Directory Access Protocol) へと進化した。LDAP は X.500 の部分集合であり、元々は X.500 の PC フロントエンドとして設計された。現在では主にユーザー情報を学習するエンタープライズ領域のシステムで広く使われている。
名前解決
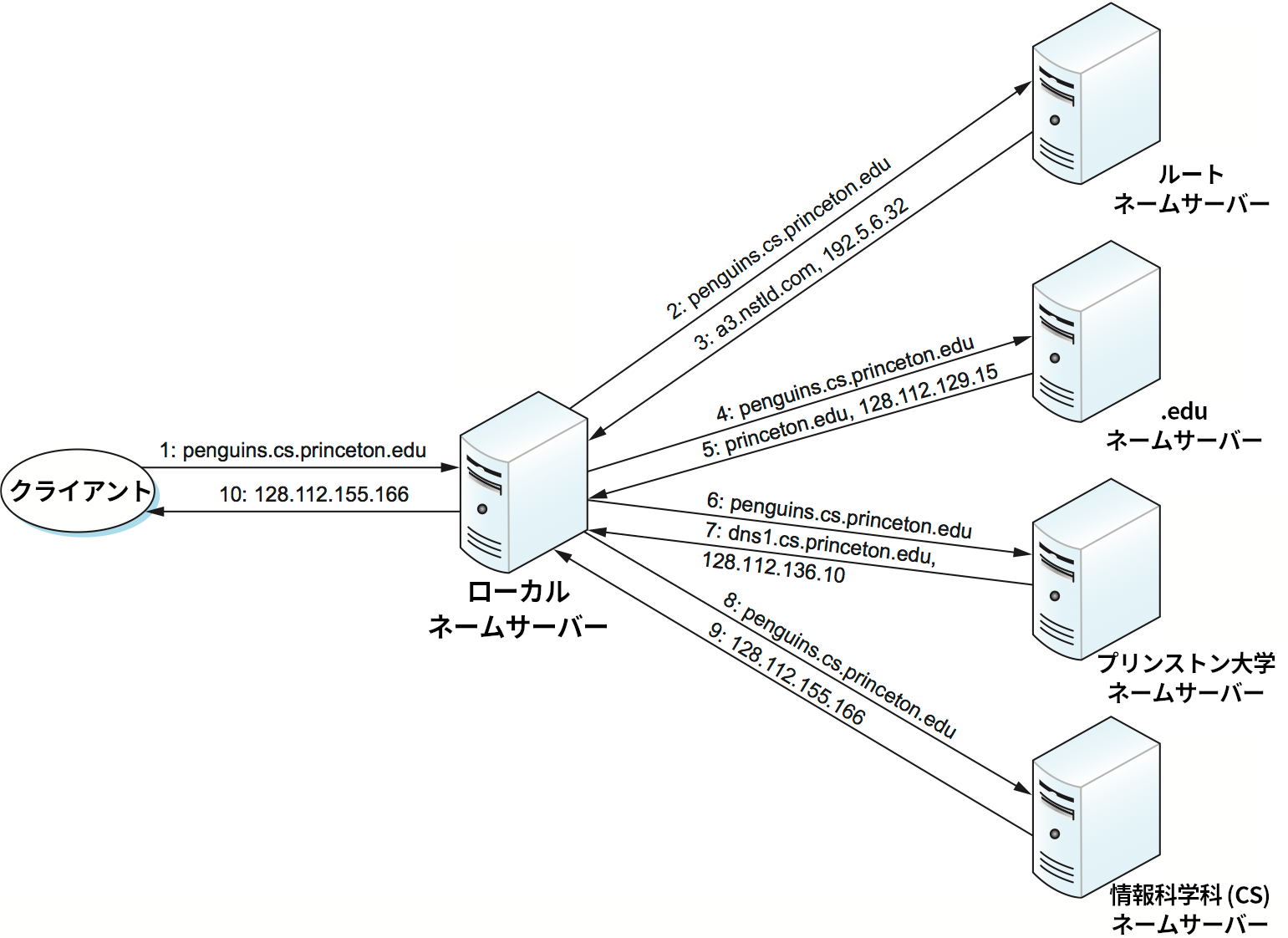
ネームサーバーの階層が与えられたとき、その階層を利用してクライアントが実際にドメイン名を解決する問題を続いて考えよう。基本的な考え方を説明するために、クライアントはドメイン名 penguins.cs.princeton.edu を解決しようとしていて、ネームサーバーは前項 (図 232 など) で例として示した階層とリソースレコードを持つとする。
単純に考えれば、クライアントは最初にルートのネームサーバーのどれかにクエリを送信する (後述するように、実際にこの操作が行われることはまずない)。するとルートサーバーは名前全体にマッチするレコード持っていないので、自身が持つレコードの中で最も長くマッチするもの ── TLD サーバー a3.nstld.com を指し示す、.edu に対する NS レコード ── を返す。加えてネームサーバーはリクエストされたドメインに関するレコードを全て返答するので、今の例であればルートサーバーは a3.nstld.com に対する A レコードも返答する。クライアントは、名前を完全に解決できなかったことを受けて、同じクエリを IP アドレス 192.5.6.32 にあるホストに送信する。このサーバーもまた名前全体にマッチするレコードを持たないので、princeton.edu ドメインに対する NS レコードとそれに対応する A レコードを返答する。クライアントは IP アドレス 128.112.129.15 のホストにさらにクエリを送信し、ドメイン cs.princeton.edu に対する NS レコードと A レコードを取得する。今回は、これらのレコードが指し示すネームサーバーが名前を完全に解決できる。クライアントは 128.112.136.10 に最後のクエリを送信し、penguins.cs.princeton.edu に対する A レコードを返答する。こうしてクライアントはドメイン名 penguins.cs.princeton.edu に対応する IP アドレス 128.112.155.166 を学習する。
この例が答えていない疑問がいくつかある。まず、クライアントはルートサーバーをどのように見つけるのだろうか? 言い換えれば、クライアントは名前を解決する方法を知っているサーバーの名前をどのように解決するのだろうか? これは名前付けシステムで必ず生じる基礎的な問題であり、システムを何らかの方法でブートストラップすることで解決される。DNS では、一つ以上のルートサーバーに対する名前からアドレスの対応付けはウェルノウンとされる。つまり、DNS という名前付けシステムとは異なる外部の手段を使って公開される。
ただし実際には、全てのクライアントがルートサーバーの情報を持つわけではない。その代わり、各インターネットホストで実行されるクライアントプログラムはローカルのネームサーバーのアドレスを知っている状態で初期化される。例えば、プリンストン大学計算機科学科の全ホストはネームサーバー dns1.cs.princeton.edu を知っている。このローカルネームサーバーが代わりに (一つ以上の) ルートサーバーに関する次のようなリソースレコードを持つ:
('root', a.root-servers.net, NS, IN)
(a.root-servers.net, 198.41.0.4, A, IN)
そして、名前の解決はクライアントがローカルのネームサーバーにクエリを送信するところから始まる。その後ローカルのネームサーバーはクライアントの代わりにリモートのネームサーバーに対してクエリを送信する。クライアント、ローカルのネームサーバー、リモートのネームサーバーの関係を図 233 に示す。このモデルの利点の一つとして、ルートサーバーの現在位置に関する最新情報をインターネット内の全てのホストが知る必要がないことがある: その情報はネームサーバーだけが知っておけばいい。二つ目の利点として、ローカルのネームサーバーは全てのローカルクライアントが発行する全てのクエリを受け取るので、クエリに対する返答をキャッシュすれば将来の名前解決で利用できることがある。リモートのネームサーバーが返すリソースレコードの TTL フィールドは、そのレコードを安全にキャッシュできる期間を表す。キャッシュは上層のネームサーバーでも行われ、結果としてルートサーバーや TLD サーバーの負荷が軽減される。
二つ目の疑問として、ユーザーが完全なドメイン名 (例えば penguins.cs.princeton.edu) ではなく中途半端な名前 (例えば penguins) を渡したときにネームサーバーはどうするべきだろうか? 実は、クライアントプログラムにはホストが属するローカルドメイン (例えば cs.princeton.edu) が設定されており、この文字列を中途半端な名前の後ろに付け足したものがクエリとして送信される、と決まっている。
教訓
確認しておくと、これで私たちは三つの異なるレベルの識別子 ── ドメイン名、IP アドレス、そして物理ネットワークアドレス ── を見たことになる。あるレベルの識別子を別のレベルの識別子に変換する処理はネットワークアーキテクチャの異なる部分で行われる。まず、アプリケーションを操作するユーザーがドメイン名を指定する。次に、アプリケーションは DNS を利用してドメイン名を IP アドレスに変換する。それぞれの IP データグラムに記されるのは IP アドレスであって、ドメイン名ではない (この変換処理ではインターネット越しに IP データグラムを送信する必要があるものの、このときに送信される IP データグラムは最終的な宛先ではなくネームサーバーを実行するホストに宛てられる)。続いて、IP データグラムは各ルーターで転送される。そのときルーターは IP アドレスを別の IP アドレスに変換する: つまり、最終的な宛先の IP アドレスをネクストホップルーターの IP アドレスに変換する。最後に、ルーターは ARP (Address Resolution Protocol) を利用してネクストホップの IP アドレスを物理ネットワークアドレスに変換する。ネクストホップは最終的な宛先かもしれないし、中間のルーターかもしれない。物理ネットワークアドレスは物理ネットワーク越しに送信されるフレームのヘッダーに含まれる。
9.3.2 ネットワーク管理 (SNMP, OpenConfig)
ネットワークは、関連するノードの個数を考えても一つのノードで実行されるプロトコルの個数を考えても、非常に複雑なシステムである。単一の管理ドメイン (例えば特定のキャンパスネットワーク) 内のノードだけに注目したとしても、数十のルーターと数百の ── ときには数千の ── ホストを気にかけなければならない。こういったノードが保持・改変する状態 ── 例えばアドレス変換テーブル、ルーティングテーブル、TCP 接続の状態 ── を全て管理するなど、想像するだけで圧倒されてしまうほどである。
異なるノード上の様々なプロトコルの状態を知る必要がある状況を考えるのは難しくない。例えば、IP データグラムの再構築に失敗した回数を監視して、部分的に構築されたデータグラムの破棄を減らすようにタイムアウトを調整することがあるかもしれない。あるいは、各ノードの負荷 (送信・受信したパケットの個数) を監視して、新しいルーターやリンクをネットワークに追加すべきかどうかを判断するかもしれない。それから、障害を起こしているハードウェアや正しく振る舞っていないソフトウェアの存在を監視する必要も当然ある。
これらはどれもネットワーク管理の問題と言える。ネットワーク管理はネットワークアーキテクチャ全体に関連する問題である。監視対象のノードが分散されているので、ネットワークの管理にネットワークを使うことが唯一の現実的な選択肢となる。これは、異なるネットワークノードに関する状態情報を読み書きするためのプロトコルが必要なことを意味する。
SNMP
広く使われているネットワーク管理用プロトコルに SNMP (Simple Network Management Protocol) がある。SNMP は突き詰めれば特殊用途のリクエスト/リプライプロトコルであり、GET と SET という二種類のリクエストメッセージをサポートする: GET はノードから状態を取得するときに用いられ、SET は新しい情報をノードに保存するときに用いられる (後述するように、SNMP は GET-NEXT という操作もサポートする)。以降の議論では、最もよく使われる GET に注目する。
SNMP は自明な方法で使われる: クライアントプログラムは SNMP を使ってノードから収集したネットワークに関する情報を表示し、それをネットワーク管理者が利用する。このクライアントプログラムはグラフィカルインターフェースを持つ場合が多い。このインターフェースはウェブブラウザと同じ役割を持つと考えることができる: ネットワーク管理者が閲覧したい情報を選択すると、クライアントプログラムは SNMP を利用して関連するノードに情報をリクエストする (SNMP は UDP の上に実装される)。その後、宛先のノードで実行される SNMP サーバーがリクエストを受け取り、適切な情報を探し、クライアントプログラムに返答する。これを受けてクライアントプログラムは情報をユーザーに表示する。
この単純なシナリオを実装する上で事態を複雑にする要素が一つある: クライアントは取得したい情報をどのようにノードに伝え、サーバーはリクエストに対応する変数をメモリ上からどのように見つけるのだろうか? こういった事項を定義するために、SNMP は MIB (Management Information Base) という補助規格を利用する。MIB は MIB 変数 (MIB variable) と呼ばれる、ネットワークノードから取得できる情報を具体的に定める。
MIB の最新バージョン MIB-II では、MIB 変数はグループ (group) で分類される。次に示すグループの説明を見れば、それぞれのグループが本書で説明してきた様々なプロトコルに対応することに気が付くだろう。各グループのそれぞれの変数が何を表すかも分かるはずである:
-
システム (system): システム (ノード) 全体に関する一般的なパラメータ。ノードの位置、起動時間、システムの名前など。
-
インターフェース (interface): ノードが持つネットワークインターフェース (アダプター) に関する情報。各インターフェースの物理アドレスや、送信・受信されたパケットの個数など。
-
アドレス変換 (address translation): ARP (Address Resolution Protocol)、特にアドレス変換テーブルの内容に関する情報。
-
IP: IP に関する情報。ルーティングテーブル、転送に成功したデータグラムの個数、データグラムの再構築に関する統計情報 (例えば、様々な理由で破棄されたデータグラムの個数) など。
-
TCP: TCP 接続に関する情報。受動的オープンと能動的オープンの個数、リセットの回数、タイムアウトの回数、タイムアウトのデフォルト設定など。接続ごとの情報は接続が存在する間だけ取得できる。
-
UDP: UDP トラフィックに関する情報。送信・受信した UDP データグラムの個数など。
この他に ICMP と SNMP に対応するグループも存在する。
クライアントが要求する情報をノードに伝える方法という問題に戻ると、MIB 変数の一覧があるだけでは問題は半分しか解決しない。まず、MIB 変数を記述するための厳密な構文が必要となる。さらに、サーバーが返答する値の表現も定義しておかなければならない。この二つの問題はどちらも ASN.1 (Abstract Syntax Notation One) で解決される。
二つ目の問題を最初に考えよう。第 7.1 節で説明したように、ASN.1 BER は整数をはじめとする様々なデータ型の表現を定義する。MIB は各変数の型を定義し、それを ASN.1 BER で符号化したものをネットワークで転送すると定める。続いて一つ目の問題を考えると、ASN.1 はオブジェクトの識別方式も定義しており、MIB はそれを使ってグローバルに一意な識別子を MIB 変数に割り当てる。識別子には「ドット記法」が用いられ、見た目はドメイン名に似ている。例えば 1.3.6.1.2.1.4.3 は IP に関連する MIB 変数 ipInReceives を表す一意な ASN.1 識別子であり、ノードが受信した IP データグラムを表す。この例では接頭部の 1.3.6.1.2.1 が MIB データベースを識別し (ASN.1 識別子は世界中のあらゆるオブジェクトを識別するのに利用されることに注意してほしい)、4 が IP グループを、3 がグループ内の変数を表す。
まとめると、ネットワーク管理は次のように行われる。まず、SNMP クライアントが取得したい MIB 変数を表す ASN.1 識別子を記したメッセージをサーバーに送信する。続いてサーバーは受け取ったメッセージに含まれる ASN.1 識別子を MIB 変数に翻訳し、その MIB 変数の値をメモリ上から取得し、その値を ASN.1 BER で符号化してクライアントに返答する。
最後に細かい点を一つ指摘しておく。MIB 変数の多くはテーブルあるいは構造体の型を持ち、これが理由で SNMP は GET-NEXT 操作を持つ。この操作を特定の変数 ID に適用すると、その変数の値に加えてその次の変数の ID が返る。次の変数の ID は例えばテーブルの次の項目や構造体の次のフィールドを表す。GET-NEXT を利用することで、クライアントはテーブルや構造体の要素を順に取得できる。
OpenConfig
SNMP は現在でも広く使われており、歴史的にスイッチとルーターの代表的な管理プロトコルといえば SNMP を指す。しかし近年、SNMP より柔軟で強力なネットワーク管理手法に注目が集まっている。規格に関して産業全体の完全な合意は存在しないものの、一般的なアプローチに関するコンセンサスは形成されつつある。ここでは新しいネットワーク管理手法の例として OpenConfig を紹介する。OpenConfig には現在大きな注目が集まっており、様々な規格で追求されている重要なアイデアの多くが組み込まれている。
OpenConfig の戦略を一般的に言えば「ミスをしやすい人間の関与を排除し、ネットワーク管理を可能な限り自動化する」となる。この戦略はゼロタッチマネジメント (zero-touch management) と呼ばれる。ゼロタッチマネジメントには二つの重要な要素がある: まず、ネットワークはプログラムによって設定できなければならない。伝統的なネットワークでは SNMP などのツールを使ってネットワークの監視は自動化されるものの、発見された問題を解決するときはネットワーク管理者が障害を起こしたマシンにログインして CLI (コマンドラインインターフェース) でコマンドを入力してきた。つまり、ゼロタッチマネジメントでは状態情報の読み取りと設定情報の書き込みが同程度の重要性を持つ。手動の仲介が必要となってネットワーク管理者にアラートが送信されるシナリオは常に存在するものの、完全に閉じた制御ループを作ることが目標となる。
次に、ネットワークに属する全てのデバイスは一貫した形で設定されなければならない。伝統的なネットワークでは管理者がデバイスを個別に設定してきた。ゼロタッチマネジメントでは管理者がネットワーク全体の目的を宣言し、その目的を解釈する能力を持った管理ツールがグローバルに一貫した形でデバイスごとに必要な設定を算出する。
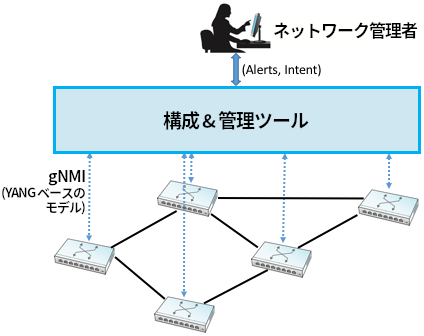
図 234 にネットワーク管理の理想的なアプローチの高レベルな概要図を示す。完全なゼロタッチマネジメントは現実よりも目標に近いので、この図は「理想的な」アプローチでしかない。しかし完全なゼロタッチマネジメントに向けた歩みは続いている。例えば、新しい管理ツールはネットワークデバイスの監視と構成に HTTP などの標準的なプロトコルを利用するようになっている。これは良いステップと言える: さらにもう一つのリクエスト/リプライプロトコルを作るタスクが省略され、さらに賢い管理ツールの作成に集中できる。将来の管理ツールでは、異常の発見に機械学習アルゴリズムが活用されることになるだろう。
ネットワークデバイスと対話するときのプロトコルとして HTTP が SNMP を置き換え始めているのと同じように、MIB を新しい規格で置き換える取り組みも同時に進んでいる。新しい規格は様々な種類のネットワークデバイスが報告できる状態情報に加えて、デバイスが応答できる構成情報も定義する。構成用の規格を一つにまとめるのは、全てのベンダーが「我々のデバイスは競争相手のデバイスとは違って特別だ」と主張する (つまり、困難が技術的なものだけではない) ために、本質的に難易度が高い。
そこで、構成用のノブ、そして監視用に利用可能なデータを指定したデータモデル (data model) をデバイス製造元がデバイスごとに公開し、規格化するのはデータモデルの記述言語だけ留めるという一般的なアプローチが取られている。この言語として最も有力な候補は YANG (Yet Another Next Generation) である。この名前は「次世代」と名付けられた「やり直し」が何度も必要になってきた事実を皮肉って付けられた。YANG は制限が付いた XSD と考えることができる。思い出しておくと、XSD (XML Schema Document) は XML に対するスキーマ (モデル) を定義するための言語である。つまり、YANG はデータの構造を定義する。しかし XML 用のデータモデルを定義する XSD と異なり、YANG が定義するデータモデルは XML, protobuf, JSON といったネットワークで利用される様々なメッセージフォーマットで利用できる。
このアプローチに関する重要な事実として、データモデルは変数の意味論をプログラムから読み書きできる形で定義する (文章として仕様書にするのではない)。ネットワークハードウェアを購入するネットワーク管理者は似たデバイスのモデルが収束する状況に対して強いインセンティブを持つので、それぞれのベンダーが固有のモデルを自分勝手に定義することは考えにくい。YANG はモデルの作成・利用・変更をプログラム可能にすることで、YANG を採用しやすい状況を作り出している。
ここで OpenConfig が登場する。OpenConfig は産業を共通モデルに向かわせる取り組みの一つであり、YANG をモデル言語として採用する。OpenConfig はネットワークデバイスとの対話で使われる RPC メカニズムを公式には決めていないものの、活発に活動が進んでいるアプローチの一つに gNMI (gRPC Network Management Interface) がある。名前からも分かるように、gNMI は gRPC を利用する。第 5.3 節で解説した通り、gRPC は HTTP の上に実装される。また、gNMI が HTTP 接続を通じてやり取りするデータは gRPC と同様に protobuf で規定される。つまり、図 234 に示したように、gNMI はネットワークデバイスの標準化された管理インターフェースとして設計されている。標準化されていない事項としては管理ツールが持つ自動化機能、あるいは管理者と対話する部分の正確なインターフェースがある。需要を満たしつつ競争相手より多くの機能をサポートしようとする全てのアプリケーションと同様に、ネットワーク管理ツールにはイノベーションの大きな余地が残されている。
網羅性のために言及しておくと、ネットワークデバイスと構成情報をやり取りする gNMI 以外のポスト SNMP プロトコルに NETCONF がある。OpenConfig は NETCONF もサポートするものの、著者らの見立てでは gNMI の将来が明るいように思える。
最後に、大きな転換が現在起きていることを強調して節を終える。SNMP と OpenConfig が並んだ項題を見て二つが同じようなものと思うかもしれないが、本書では説明の都合で二つのアプローチを並べただけで、両者は大きく異なる。まず、SNMP は単なるトランスポートプロトコルに過ぎず、OpenConfig の世界における gNMI に対応する。SNMP はデバイスの監視のために開発され、デバイスの構成に関する機能は何も持たない (デバイスは管理者が手動で構成するものという昔ながらの仮定がある)。一方で、OpenConfig はネットワークデバイスに対するデータモデルの共通集合を定義する取り組みであり、SNMP の世界における MIB と同じような役割を果たす。ただし OpenConfig は YANG を利用するモデルベースであり、監視と構成に等しく注力する点が MIB と異なる。