3.5 ルーティングの実装
ここまではスイッチとルーターが行わなければならないことを説明し、それをどう行うかは説明してこなかった。スイッチあるいはルーターを作る簡単な方法が一つある: 汎用プロセッサを買ってきて、複数のネットワークインターフェースを取り付ければいい。そのデバイスで適切なソフトウェアを実行すれば、インターフェースに届いたパケットに対して本章で説明したスイッチングあるいは転送の処理を実行し、そのパケットを別のインターフェースから送信できる。ソフトウェアスイッチ (software switch) と呼ばれるこの方式は、市販のミッドエンドおよびローエンドのデバイスで用いられることがある1。一方で、ハイエンドのデバイスは通常ハードウェアによる高速化を活用する。そういった実装はハードウェアスイッチ (hardware switch) と呼ばれる。ただし、どちらのアプローチにもハードウェアとソフトウェアの組が当然含まれる。
本節ではソフトウェア中心の設計とハードウェア中心の設計の両方を概観する。なお、実装を考えるときスイッチとルーターの違いは重要でないことは特筆に値する。スイッチとルーターは共通する部分が非常に多いので、ネットワーク管理者が購入するのは単一の「転送ボックス」であることが多い。そのデバイスは設定を変更することで L2 スイッチとしても L3 ルーターとしても (もしくはその両方としても) 利用できる。内部の設計は非常に似ているので、本節では「スイッチ」でスイッチとルーターの両方を指すことにする。「スイッチあるいはルーター」と何度も繰り返すことはしない。両者の違いが重要なときはその都度指摘する。
3.5.1 ソフトウェアスイッチ
汎用プロセッサに四つの NIC (network interface card, ネットワークインターフェースカード) を搭載して作られたソフトウェアスイッチを図 93 に示す。このスイッチにおいて、例えば NIC 1 に届いた典型的なパケットが NIC 2 に転送される道筋は難しくない: パケットを受け取った NIC 1 は DMA (direct memory access, ダイレクトメモリアクセス) と呼ばれるテクニックで I/O バス (この例では PCIe) 越しにメインメモリへバイトを直接コピーする。パケットがメモリに到着したら、CPU がヘッダーを確認してパケットを送信すべきインターフェースを認識し、NIC 2 にパケットを送信するよう指示を出す。NIC 2 はここでも DMA を使ってメインメモリから直接パケットを送信する。ここで重要なのは、パケットがメインメモリにバッファ (「蓄積転送」における「蓄積」) され、CPU は転送先の判断に必要なヘッダーフィールドだけを内部のレジスタに読み込んで処理を行うことである。
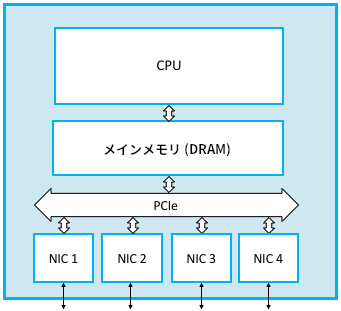
このアプローチには潜在的なボトルネックが二つある。どちらもソフトウェアスイッチの全体的なパケット転送能力を制限する可能性がある。
一つ目の問題は全てのパケットがメインメモリを一度通らなければならない事実によりパフォーマンスが制限されることである。この影響はどれだけ高価なハードウェアを用意できるかによって異なるが、例えばバスクロック 1333 MHz の 64 ビットワイドメモリバスを持つマシンでデータ転送を行うとピークレートは 170 Gbps 程度となる。これは 10 Gbps イーサネットポートをいくつか持つだけのスイッチなら十分だが、インターネットの中心部にあるハイエンドルーターでは全く足りない。
さらに、今示したピークレートの上限はデータの移動が唯一の問題だと仮定している。この仮定は長いパケットに対しては成り立つものの、短いパケットに対しては成り立たない。短いパケットはスイッチ設計者が対処しなければならない最悪ケースである。最小サイズのパケットが大量に送られるときは各パケットに対する処理 ── ヘッダーのパースと、転送すべき出力リンクの判断 ── が支配的になり、ボトルネックになる可能性が生じる。例えば、プロセッサが毎秒 4000 万のパケットをスイッチするだけの処理能力を持っているとする。この値は pps (packet per second, パケット毎秒) と呼ばれることがある。pps が 4000 万でパケットの長さが平均 64 バイトなら、次の関係が成り立つ:
つまりスループットは約 20 Gbps となる。高速ではあるものの、現代のユーザーがスイッチに要求するレートには遠く及ばない。この 20 Gbps はスイッチに接続する全てのユーザーで共有されることに注意してほしい。単一の (スイッチを持たない) イーサネットセグメントといった共有の媒体に接続する全てのユーザーが帯域を共有するのと同様である。そのため、この総スループット 20 Gbps のスイッチに 16 個のポートがあるとしたら、それぞれのポートは平均してわずか 1 Gbps 程度のデータレートしか利用できない2。
スイッチの実装を評価するときに理解しておくべき重要な事項が最後にもう一つある。本章でここまでに解説してきた非自明なアルゴリズム ── ラーニングブリッジが利用する全域木アルゴリズム、RIP が利用する距離ベクトル型ルーティングアルゴリズム、OSPF が利用するリンク状態型ルーティングアルゴリズム ── はパケットごとの転送判断に直接は含まれない。これらのアルゴリズムはバックグラウンドで定期的に実行される: パケットを転送するたびに (例えば) OSPF のコードを実行する必要はない。CPU が全てのパケットに対して実行する可能性が高いルーチンの中で最もコストが大きいのはテーブルの探索である。テーブルの探索は VC テーブルから VCI を引く処理、L3 の転送テーブルから IP アドレスを引く処理、L2 の転送テーブルからイーサネットアドレスを引く処理で行われる。
教訓
これら二種類の処理の区別は非常に重要なので、それぞれに名前が付いている: コントロールプレーン (control plane) はネットワークの「制御」に必要なバックグラウンドの処理 (例えば OSPF, RIP, 次章で説明される BGP の実行) を指し、データプレーン (data plane) はパケットを入力ポートから出力ポートに移動させるために必要なパケットごとの処理を指す。
歴史的な理由により、セルラーアクセスネットワークの文脈ではデータプレーンをユーザープレーン (user plane) と呼ぶ。名前は違うが同じものである。実際、3GPP の規格はアーキテクチャの指針として CUPS (Control/User Plane Separation, コントロールプレーンとユーザープレーンの分離) を掲げている。
これら二種類の処理が両方とも同じ CPU で実行される (図 93 に示したソフトウェアスイッチのような) 場合は、二種類の処理を簡単に一つにまとめることができる。しかし、コントロールプレーンとデータプレーンのインターフェースを適切に規定してデータプレーンの実装を最適化すれば、パフォーマンスを大きく改善できる。
クラウドプロバイダは SDN を大きく活用しているのに対して、エンタープライズとケーブルテレビ事業者での採用はクラウドプロバイダよりずっと遅い。ネットワーク管理能力がマーケットによって異なることが理由の一つである。Google, Microsoft, Amazon といった世界規模の企業は SDN というテクノロジを使いこなすためのエンジニアと DevOps スキルを持つのに対して、そうでない企業はこれまで親しんできた管理方法とコマンドラインインターフェースを持つパッケージ済みの統合ソリューションを現在でも選択している。
3.5.2 ハードウェアスイッチ
インターネットの歴史の大部分を通じて、高性能なスイッチは ASIC (Application-Specific Integrated Circuit, 特定用途向け集積回路) で構築された専用デバイスだった。一般向けサーバーで C プログラムを実行させることでローエンドのスイッチを作ることはできたものの、需要に応えるだけのスループットを達成するには ASIC が必要とされてきた。
ASIC の欠点は設計と製造に長い時間がかかることである。これはスイッチに新機能を追加するのにかかる時間が数年単位であり、現代のソフトウェア業界が慣れている数日あるいは数週間単位ではないことを意味する。理想的には、ASIC のパフォーマンスとソフトウェアの柔軟性を両方とも手に入れることが望ましい。
幸い、近年のドメイン固有プロセッサ (およびその他の一般向けコンポーネント) の進化により、パフォーマンスと柔軟性の両立が可能になってきている。それと同程度に重要なこととして、こういった新しいプロセッサを活用するスイッチの完全なアーキテクチャ仕様がオンラインで閲覧可能になってきている ── オープンソースソフトウェアのハードウェア版と言える。これは、自作 PC を作成できるのと同じように、ウェブから (例えば Open Compute Project から) 設計図をダウンロードすることで高性能スイッチを誰でも作成できることを意味する。両方の場合でハードウェアを動かすソフトウェアが必要になるものの、自作 PC を動かすのに Linux が利用できるのと同じように、現在では自作スイッチを動かすための L2 および L3 のオープンソーススタックが GitHub で公開されている。あるいは一般向けスイッチ製造元から完成済みのスイッチを購入し、そこに独自のソフトウェアを読み込ませることもできる。以降ではこういったホワイトボックススイッチ (white-box switch) を説明する。これは長い間産業を支配してきた中身の分からない「ブラックボックス」なデバイスと区別するために生まれた用語である。
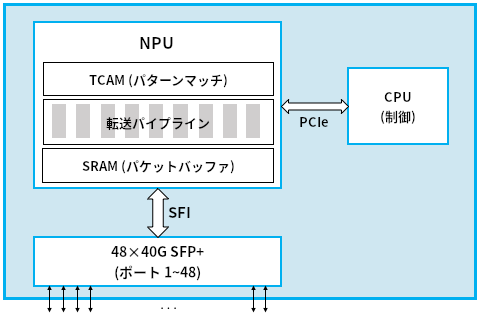
図 94 に単純化されたホワイトボックススイッチを示す。先ほどの汎用プロセッサを使った実装との重要な違いとして、ホワイトボックススイッチは NPU (Network Processing Unit, ネットワークプロセッシングユニット) を持つ。NPU はパケットヘッダーの処理 (つまりデータプレーンの実装) に最適化されたアーキテクチャと命令セットを持つドメイン固有プロセッサである。NPU は一般の PC に搭載されるコンピューターグラフィックスに最適化された GPU と考え方は同じと言える。ただし NPU が最適化されるのはパケットヘッダーをパースして転送の判断を行う処理である。NPU はパケットをテラビット毎秒 (Tbps) オーダーの速度で処理できる。これは 32 個の 100 Gbps ポート、あるいは図 94 のスイッチが持つ 48 個の 40 Gbps ポートに軽々と対応できる。
NPU
本書の「NPU」という用語の使い方はあまり標準的でない。歴史的に「NPU」は高機能なファイアウォールや詳細なパケット検査といった特別な処理を行うネットワーク処理チップを指す、意味の狭い用語だった。こういったチップは本書で議論している NPU ほど汎用ではないし、高性能でもない。本節で解説した現在のアプローチは特定用途のネットワークプロセッサを時代遅れにする可能性が高いように思われる。いずれにせよ、著者らは NPU という用語を気に入っている。グラフィックス用の GPU や AI 用の TPU (Tensor Processing Unit) のように、ドメインごとに固有のプロセッサを作るトレンドに沿っているからだ。
この新しいスイッチ設計の長所は、プログラムを切り替えることで一つのホワイトボックスを L2 スイッチとしても、L3 ルーターとしても、あるいは両方としても利用できる点にある。制御 CPU ではソフトウェアスイッチで利用されるのと全く同一のコントロールプレーン用ソフトウェアスタックが実行されるものの、ホワイトボックススイッチではそれに加えて、コントロールプレーンソフトウェアが行った転送判断を実行するためのデータプレーン用「プログラム」を NPU に読み込ませることができる。NPU で動く「プログラム」を書く方法はチップベンダーごとに異なり、チップベンダーは現在いくつか存在する。一部のケースでは転送パイプラインが固定されており、制御プロセッサは転送テーブルを NPU に読み込ませるだけとなる (転送パイプラインが「固定されている」とは、NPU がイーサネットや IP といった特定のパケットのヘッダーの処理方法だけを知っていることを意味する)。しかし転送パイプライン自身がプログラム可能なケースもある。NPU ベースの転送パイプラインをプログラムするための新しいプログラミング言語として P4 がある。P4 は下位の NPU の命令セットが持つ差異の多くを隠蔽するといったことを行う。
NPU は内部で三つのテクノロジを活用する。第一に、処理中のパケットをバッファするのに高速な SRAM ベースのメモリが利用される。SRAM (static random access memory) はメインメモリとして使われる DRAM (Dynamic Random Access Memory) と比べておよそ十倍高速である。第二に、処理中のパケットとマッチを判定するビットパターンを格納するのに TCAM (ternary content-addressable memory) ベースのメモリが利用される。TCAM の「CAM (content-addressable memory)」は、テーブルを検索するときのキーをアドレスとして使えるメモリを意味する。TCAM の「T (ternary, 三項間)」は、検索のキーにワイルドカードが使えることを意味する (例えばキー 10*1 は 1001 と 1011 の両方にマッチする)。最後に、各パケットの転送に関係する処理は転送パイプラインによって実装される。このパイプラインは ASIC によって実装されるものの、きちんと設計されれば、実行するプログラムを変えることでパイプラインの転送の振る舞いを変更できる。高いレベルで言うと、このプログラムは (マッチ, アクション) という組の集合として表され、「ヘッダーがこのフィールドにマッチしたら、このアクションを実行せよ」という指示を出す。
パケット処理が単一ステージのプロセッサではなく多ステージのパイプラインとして実装されるのには、単一のパケットを転送するために複数のヘッダーフィールドを検索する可能性が高い事実が関係している。各ステージはフィールドの異なる部分を見るように設計される。多ステージパイプラインによってエンドツーエンドのレイテンシは (ナノ秒単位で) 少し増加するものの、同時に複数のパケットを処理できるようになる。例えばステージ 2 がパケット A に関する二度目の検索を行うのと同時にステージ 1 がパケット B に対する一度目の検索を行うといったことが可能になる。これは NPU が全体として回線速度の増加に対応できることを意味する。執筆時点において、最先端のスイッチの処理速度は 12.8 Tbps である。
最後に、図 94 には全体を動作させるためのコモディティの要素が含まれている。特に、現在では着脱可能なトランシーバー (transceiver) モジュールを購入でき、このモジュールで媒体アクセス制御 (ギガビットイーサネット、10 ギガビットイーサネット、イーサネット、SONET) や光ファイバーの詳細処理を行える。こういったトランシーバーは全て SFP+ などの規格化されたフォームファクタに準拠しており、SFI などの規格化されたバスを通して他の要素に接続される。コンピューター産業が過去二十年を通じて経験してきたコモディティ化した世界への移行をネットワーク産業が今まさに経験していることがここでも分かる。
3.5.3 ソフトウェア定義ネットワーク
スイッチのコモディティ化が進むにつれ、当然ながらスイッチを制御するソフトウェアへの注目が高まった。こうして生まれたトレンドが SDN (software defined network, ソフトウェア定義ネットワーク) の構築である。SDN のアイデアが考案されたのは十年ほど前のことであり、実はネットワーク産業をホワイトボックススイッチへと向かわせたのは初期の SDN だった。
SDN の基礎的なアイデアは既に説明されている: ネットワークのコントロールプレーン (RIP, OSPF, BGP といったルーティングアルゴリズムが実行される場所) とデータプレーン (パケットの転送判断が行われる場所) を分離し、コントロールプレーンはコモディティサーバーで実行されるソフトウェアで、データプレーンはホワイトボックススイッチで実装するというものである。SDN を可能にする上で鍵となった考え方として、SDN は二つのプレーンの分離をさらに進め、コントロールプレーンとデータプレーンの間に標準化されたインターフェースを定める。こうすることでコントロールプレーンの任意の実装がデータプレーンの任意の実装と対話できるようになり、ベンダーが販売するバンドル化されたソリューションへの依存が消える。最初に生まれた標準インターフェースは OpenFlow であり、コントロールプレーンとデータプレーンを分離するアイデアはディスアグリゲーション (disaggregation) と呼ばれる (前項で触れた P4 言語はこのインターフェースを定義しようとする第二世代の試みであり、OpenFlow を一般化したものと言える)。
ディスアグリゲーションのもう一つの重要な側面として、分散ネットワークのデータプレーンの制御に論理的に中央集権化されたコントロールプレーンを利用できるようになる点がある。「論理的に中央集権化された」とはコントロールプレーンが収集する状態 (例えばネットワークマップ) がグローバルなデータ構造に保持されることを意味しており、そのデータ構造の実装は複数のサーバーに分散されていても (例えばクラウドで実行しても) 構わない。これはスケーラビリティと可用性の両方にとって重要となる。ここでの鍵は二つのプレーンの構成・スケールが独立する点にある。このアイデアはクラウドで素早く採用され、現在のクラウドプロバイダは SDN ベースのソリューションをデータセンターおよびデータセンター間を結ぶバックボーン回線の両方で利用している。
この設計が持つ明らかでない帰結の一つとして、論理的に中央集権化されたコントロールプレーンは物理サーバーを相互接続する物理 (ハードウェア) スイッチのネットワークだけではなく仮想サーバー (仮想マシンやコンテナなど) を相互接続する仮想 (ソフトウェア) スイッチのネットワークも管理できる。インターネットに存在する「スイッチポート」の個数 (ネットワークに接続するデバイス数の優れた指標) を数えたとしたら、2012 年には仮想ポートの個数が物理ポートの個数を大きく上回っているはずである。
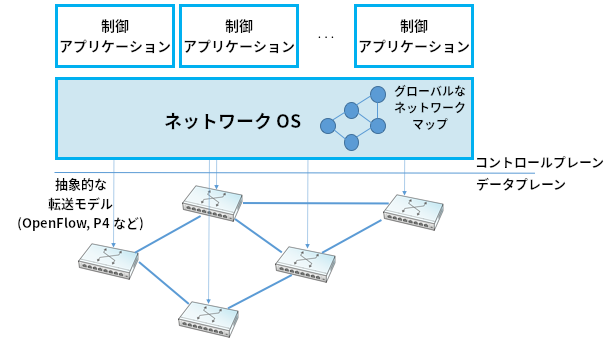
SDN を成功に導いた要素の一つに NOS (Network Operating System, ネットワークオペレーティングシステム) がある。サーバーのオペレーティングシステム (Linux, iOS, Android, Windows など) がアプリケーションの実装を容易にするための高レベルの抽象化を提供する (例えばファイルの読み書きでディスクドライブに直接アクセスする必要はない) のと同じように、NOS はネットワークを制御する機能の実装を容易にする。ネットワークを制御する機能を実装するソフトウェアを制御アプリケーション (control app) と呼ぶ場合がある。NOS がネットワーク状態の収集 (リンク状態型あるいは距離ベクトル型の分散ルーティングアルゴリズムで難易度の高い部分) などの処理を行うので、制御アプリケーションは最短路アルゴリズムの実行や内部のスイッチに転送ルールを読み込ませる処理の実装に集中できる。こうしてロジックを中央集権化することで、グローバルに最適化されたソリューションが生まれることが期待されている。クラウドプロバイダが公開している資料によると、彼らは中央集権的なアプローチにこの利点があることを確認したようである。
教訓
SDN が実装戦略の一つであることを理解することが重要となる。SDN を使うと転送テーブルの計算といった基礎的な問題が魔法のように消え去るわけではない。SDN ではスイッチ同士にメッセージを交換させて分散ルーティングアルゴリズムを実行するのではなく、論理的に中央集権化された SDN の制御部がリンクとポートの状態に関する情報を個別のスイッチから集め、ネットワークグラフの全体図を構築し、そのグラフを制御アプリケーションから利用可能にする処理を担当する。制御アプリケーションから見ると、転送テーブルの計算に必要な情報は全てローカルに利用可能になる。なお、SDN の制御部は論理的に中央集権化されているものの、物理的には ── スケーラブルなパフォーマンスと高い可用性のために ── 複数のサーバーに複製されることは忘れないでほしい。中央集権的なアプローチと分散的なアプローチのどちらが優れるのかという問題は現在でも激しい論争の的となっている。