9.1 伝統的アプリケーション
最も有名な二つのネットワークアプリケーション ── ワールドワイドウェブとメール ── から議論を始めよう。大まかに捉えると、この二つのアプリケーションはどちらもリクエスト/リプライのパラダイムを利用する ── ユーザーがリクエストをサーバーに送信し、サーバーはクライアントにリプライを返す。こういったアプリケーションはコンピューターネットワークが誕生したころから存在していたので、本書ではこういったアプリケーションを「伝統的」アプリケーションと呼ぶ (正確に言えばウェブはメールよりずっと後に誕生したが、ウェブの前身とも言えるファイル転送アプリケーションはメールと同程度に古くから存在する)。これに対して次節以降では、最近になって広く使われるようになったアプリケーションのクラスを見る: ストリーミングアプリケーション (映像や音声を配信するマルチメディアアプリケーション) や、オーバーレイを利用する様々なアプリケーションが解説される。なお、この分類は曖昧な点に注意してほしい。例えばウェブを使ってマルチメディアデータを転送することは当然できる。しかし本節では、ウェブページや画像といったデータのリクエストというウェブの一般的な利用方法に焦点を当てる。
ウェブとメールを詳しく見ていく前に、指摘しておきたいことが三つある。第一に、アプリケーションプログラムとアプリケーションプロトコルの区別を意識する必要がある。例えば、リモートサーバーからウェブページを取得するときに使われるアプリケーションプロトコルに HTTP (Hypertext Transfer Protocol) がある。HTTP を利用するアプリケーションはウェブクライアント (web client) と呼ばれ、Internet Explorer, Chrome, Firefox, Safari など様々なものが存在する。ウェブクライアントの見た目や使い心地はそれぞれ異なるものの、HTTP プロトコルを使ってインターネット上のウェブサーバーと通信を行う点は共通している。さらに言えば、プロトコルが標準化され公開されている事実があってこそ、異なる企業や個人によって開発されたアプリケーションプログラムの相互運用が可能になる。あらゆるブラウザがあらゆるウェブサーバーと対話できるのは HTTP のおかげと言える (当然ウェブサーバーにも様々な種類がある)。
本節では広く使われている標準化されたアプリケーションプロトコルを二つ見る:
-
SMTP (Simple Mail Transfer Protocol): メールの交換に使われる。
-
HTTP (Hypertext Transfer Protocol): ウェブブラウザとウェブサーバーの通信で主に使われる。
第二に、多くのアプリケーションプロトコル (SMTP と HTTP を含む) には、交換されるデータのフォーマットを規定する姉妹規格が存在する。これはアプリケーションプロトコルが比較的単純になることが多い理由でもある: 実際の複雑性はこの姉妹規格で管理される。例えば SMTP はメールメッセージの交換方法を定めたプロトコルに過ぎず、メールメッセージのフォーマットは姉妹規格の RFC 822 と MIME (Multipurpose Internet Mail Extensions) で定義される。同様に HTTP はウェブページを取得するためのプロトコルであり、ウェブページの基本的な形式は姉妹規格の HTML (Hypertext Markup Language) で定義される。
最後に、本節で説明する二つのアプリケーションプロトコルはどちらもリクエスト/リプライの通信パターンを持つので、RPC (遠隔手続き呼び出し) のメカニズムの上に実装されるのではないかと思うかもしれない。しかし SMTP と HTTP はどちらも高信頼トランスポートプロトコル (TCP) の上に実装されるので、これは正しくない。ある意味で、これは SMTP と HTTP が単純な RPC 風の仕組みを TCP の上に実装しているのに等しい。「単純な」と表現したのはなぜかと言えば、第 5.3 節で説明した RPC プロトコルと異なり SMTP と HTML はありとあらゆる遠隔手続き呼び出しを処理できるわけではなく、決められた種類のリクエストメッセージの送受信だけを行えるように設計されているためである。興味深いことに、HTTP が採用したアプローチは非常に強力なことが示されており、一般的な RPC メカニズムが HTTP の上に実装されるという逆の事態が発生している。この点は本節の最後にさらに解説する。
9.1.1 メール
メールは最も古いネットワークアプリケーションの一つである。国をまたいだ長距離回線が実現したまさにそのとき、回線の向こう側にいる相手に文章を送ることより自然な行動はあるだろうか? その文章は二十世紀における「ワトソン君、こちらに来てくれ、君に会いたい」に違いない。驚くべきことに、ARPANET のパイオニアたちは彼らが開発したネットワークの重要なアプリケーションとしてメールが存在することをそれほど意識していなかった ── 計算資源へのリモートアクセスが主要な設計目標だった。しかし後にメールはインターネットで最初の「キラーアプリケーション」となる。
上述したように、メールのプロトコルを見ていく上では次の二点が重要となる:
- ユーザーインターフェース (メールリーダー) と内部の転送プロトコル (SMTP や IMAP など) を区別すること。
- 交換されるメッセージのフォーマットを定義する姉妹規格 (RFC 822 と MIME) と転送プロトコルを区別すること。
最初にメッセージのフォーマットを解説する。
メッセージのフォーマット
RFC 822 はメッセージをヘッダー (header) と ボディ (body) という二つの部分を持つものとして定義する。両方の部分は ASCII テキストとして表現される。元々ボディは単純なテキストと仮定されていたものの、後の RFC 822 の改定によりボディは MIME を使って任意のデータを伝えられるようになった。ボディのデータは ASCII テキストとして表現されるものの、そのデータが人間に読めるとは限らず、例えば JPEG 画像を符号化したデータである可能性もある。MIME については後述する。
メッセージヘッダーは <CRLF> で区切られた行の連なりと定義される。ここで <CRLF> は キャリッジリターン (carriage return) と ラインフィード (line feed) というテキスト中の改行を表すのによく使われる二つの ASCII 制御文字の並びを表す。ヘッダーとボディは空行によって区切られる。ヘッダーの各行はコロンで区切られたフィールドの名前とフィールドの値からなる。フィールドの値はメールを送信するときにユーザーが記述するものが多いので、メールを書いたことがあれば何を意味するかは明らかだろう。例えばメッセージの送信者、宛先、件名といったフィールドがヘッダーには含まれる。他のフィールドは内部のメール転送システムによって自動的に埋められる。自動的に埋められる情報には例えば転送時刻、送信時刻、このメッセージを処理したメールサーバーの一覧がある。もちろん、ヘッダーに加えられる情報は他にもある。興味のある読者は RFC 822 を参照してほしい。
RFC 822 は 1993 年に拡張され、音声、動画、画像、PDF ドキュメントをはじめとした様々な種類のデータをメールで送れるようになった (規格の拡張はこれ以降も長く続いている)。こういったテキストに限らないデータのフォーマットは MIME (Multipurpose Internet Mail Extensions) と呼ばれる規格で定義される。MIME は三つの基礎的な要素からなる。最初の要素は伝達されるデータがどんなものかを様々な形で記述するヘッダー行の定義である。ヘッダーには「利用される MIME バージョン」「メッセージの内容の人間に読める説明」「メッセージに含まれるデータの種類」「データの符号化方式」といった情報が含まれる。
二つ目の要素は MIME タイプ (MIME type) の定義である。MIME タイプは伝達されるコンテンツの種別を表す。例えば画像を表すデータは image/gif や image/jpeg といった MIME タイプを持つ。意味は明らかだろう。MIME タイプの前半部分 (この例の image) はタイプと呼ばれ、後半部分 (この例の gif や jpeg) はサブタイプと呼ばれる。他の MIME タイプの例としては、拡張されていない RFC 822 で見られるようなスタイルのメッセージを表す text/plain や、「マークアップ」されたテキスト (特殊なフォントや斜体など) を含むメッセージを表す text/richtext がある。三つ目の例として、MIME は application というタイプを定義する。タイプが application のとき、メッセージが表すデータはサブタイプが表すアプリケーションプログラムに対する入力と解釈される (application/postscript や application/msword などが利用される)。
MIME は mutipart というタイプも定義する。このタイプは一つのメッセージが複数のデータを伝達するときに利用される。ある意味で、MIME はプログラミング言語における基礎型 (整数や浮動小数点数) と複合型 (構造型や配列) をどちらも持つと言えるだろう。multipart のサブタイプの一つに mixed がある。サブタイプ mixed を持つメッセージには独立したデータが特定の順序で並び、それぞれのデータは独自のヘッダーを持つ。
三つ目の要素は様々なデータ型を ASCII メールでやり取りできる形式に符号化する方式の定義である。ここでの問題は、一部のデータ型 (JPEG 画像など) では 256 個ある 8 ビットの値が全て現れる可能性があるのに対して、その一部は正当な ASCII 文字1でない点にある。メールが転送されるときに通過する様々なシステム (後述するゲートウェイなど) は全てのメールが ASCII 文字で構成されることを仮定しており、非 ASCII 文字が含まれるメッセージは破損する恐れがある。そのため、どんなデータを伝達するときでも ASCII 文字だけからなるメッセージを送信することが重要となる。
MIME はバイナリデータを ASCII 文字集合に変換する単純な符号化方式 base64 を採用する。base64 は 3 バイトのバイナリデータを 4 つの ASCII 文字で表す。具体的には、3 バイト (24 ビット) を一単位としてバイナリデータを分割し、3 バイトのデータをさらに 6 ビットごとに分割し、それぞれの 6 ビットを 1 つの ASCII 文字で表す。6 ビットを表現するには 64 個の文字が必要であり、000000 は A、000001 は B といった 52 個のアルファベット (大文字/小文字) と 10 個の数字、そして + と / を使った対応付けが定義されている。
なお、テキストにしか対応しないメールリーダーを使い続ける人々の負担を可能な限り低くするために、通常のテキストだけからなる MIME メッセージは 7 ビットの ASCII 文字で符号化される。他にも大部分が ASCII のデータを人間に読めるように表示する符号化方式が存在する。
プレーンテキスト、JPEG 画像、PostScript ファイルからなるメッセージの例を次に示す:
MIME-Version: 1.0
Content-Type: multipart/mixed;
boundary="-------417CA6E2DE4ABCAFBC5"
From: Alice Smith <Alice@cisco.com>
To: Bob@cs.Princeton.edu
Subject: promised material
Date: Mon, 07 Sep 1998 19:45:19 -0400
---------417CA6E2DE4ABCAFBC5
Content-Type: text/plain; charset=us-ascii
Content-Transfer-Encoding: 7bit
ボブ
約束した jpeg 画像とレポートのドラフトを送ります。
--アリス
---------417CA6E2DE4ABCAFBC5
Content-Type: image/jpeg
Content-Transfer-Encoding: base64
... base64 で符号化された jpeg 画像 (人間には読めない)
---------417CA6E2DE4ABCAFBC5
Content-Type: application/postscript; name="draft.ps"
Content-Transfer-Encoding: 7bit
... PostScript ドキュメント (人間に読める)
ヘッダーの Content-Type: multipart/mixed; はメッセージが複数の部分から構成されることを示し、boundary="-------417CA6E2DE4ABCAFBC5" は各部分を隔てる文字列を示す。各部分にもそれぞれヘッダーがあり、そこで Content-Type と Content-Transfer-Encoding が指定される。
メッセージの転送
長年にわたって、大部分のメールは SMTP だけを使って配達されていた。SMTP は現在でも重要な役割を果たしているものの、メールの配達に関連するプロトコルは SMTP の他にも存在する。SMTP 以外の重要なメール配達プロトコルに IMAP (Internet Message Access Protocol) と POP (Post Office Protocol) がある。ここでは SMTP を最初に説明し、それから IMAP に触れる。
SMTP を正しい文脈で捉えるために、鍵となる登場人物を特定しよう。まず、ユーザーがメールを作成、管理、検索、閲覧するときに利用するメールリーダー (mail reader) がある。たくさんのウェブブラウザが存在するのと同じように、メールリーダーにも数え切れない数の選択肢が存在する。インターネットが生まれて間もないころ、ユーザーがログインするマシンには受信箱 (mailbox) フォルダが存在し、ローカルのアプリケーションプログラムはファイルシステム上の受信箱を直接読み取ることで動作していた。もちろん現在のメールリーダーはこのような動作をせず、PC あるいはスマートフォンからリモートにある受信箱にアクセスすることで動作する。このとき、ユーザーは受信箱が設置されるホスト (メールサーバー) にログインする必要はない。メールサーバーからユーザーのデバイスにメールをダウンロードするときはメールの送信とは異なるプロトコル (POP や IMAP など) が利用される。
次に、受信箱を持つホストでは MTA (mail transfer agent, メール転送エージェント) と呼ばれるプログラムが実行される。MTA はメールデーモン (mail daemon) とも呼ばれ、郵便局の役割を果たす。つまりユーザー (の指示を受けたメールリーダー) は送信したいメールを MTA に渡し、MTA は TCP の上に実装される SMTP を使って他のマシンで実行される MTA までメールを配達し、その MTA は受け取ったメールをユーザーの受信箱に保存する (そして宛先ユーザーのメールリーダーはその受信箱からメールを読み込む)。SMTP は誰でも実装できるプロトコルなので、理論上は MTA の実装は一つだけで済む。しかし実際には有名な実装がいくつか存在している。Berkeley Unix の sendmail は古くからある MTA であり、最も広く使われている MTA は postfix である。
送信側の MTA が宛先の MTA に対する SMTP/TCP 接続を直接確立することもできるものの、通常メールのメッセージは一つ以上のメールゲートウェイ (mail gateway) を通過してから宛先の MTA に到着する。エンドホストと同様、ゲートウェイは MTA と同様の処理を実行する。「メールゲートウェイ」という名前は「IP ゲートウェイ」と同じ処理を行うところから来ている: IP ゲートウェイが IP データグラムの蓄積転送を行うのと同様に、メールゲートウェイはメールの蓄積転送を行う (本書ではゲートウェイをルーターと呼んできた)。唯一の違いは転送までの時間で、典型的なメールゲートウェイはメッセージをディスク上に保存し、転送が失敗した場合でも数日は再転送を試みる。これに対して IP ルーターは IP データグラムをメモリ上に保存し、ほんの数秒しか再転送を試みない。図 216 に送信ホストから宛先ホストまでのメールゲートウェイを挟んだ 2 ホップ経路を示す。
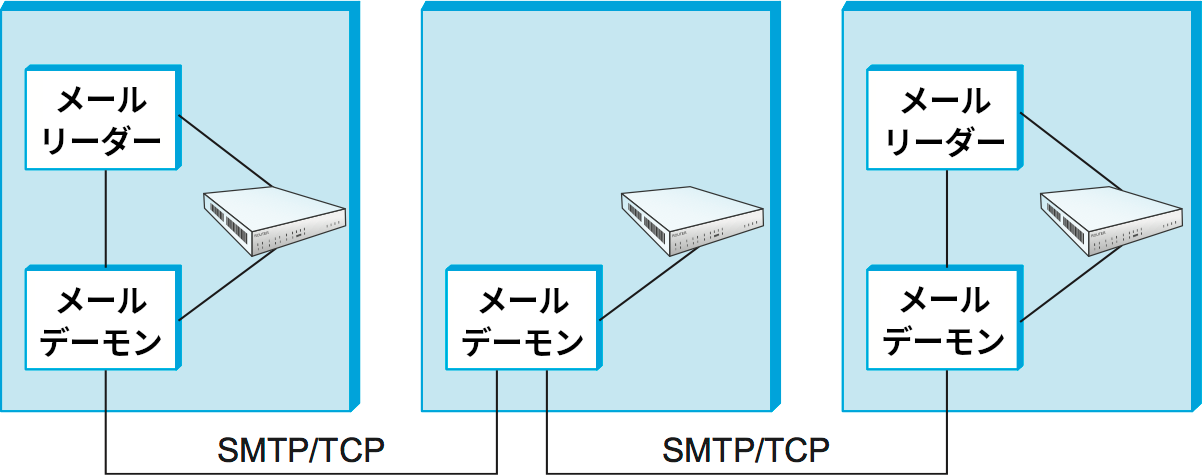
「なぜメールゲートウェイが必要なのか?」と疑問に思ったかもしれない。送信ホストが宛先ホストに直接メッセージを送ってはいけないのだろうか? メールゲートウェイが必要な理由の一つに、メールを読み込むホストをアドレスから知られることを宛先ホストが望まないことがある。もう一つの理由はスケーリングである: 大規模な組織では、複数のマシンを使って受信箱を管理することがある。例えば bob@cs.princeton.edu に送信されたメールはプリンストン大学のコンピューターサイエンス学科のメールゲートウェイ (cs.princeton.edu という名前のホスト) にまず転送され、そこから (二つ目の接続を通じて) ボブの受信箱があるマシンに転送される。ユーザーの名前を対応する受信箱があるマシンに結び付けるマッピングをゲートウェイは持っているので、送信者がそれを気にする必要はない。さらにもう一つの理由として、ユーザーの受信箱があるマシンが起動していて到達可能かどうかが確信できないので、転送できるようになるまでメッセージを保存するメールゲートウェイが必要になることがある。これは初期のインターネットで特に当てはまる理由だった。
通過するメールゲートウェイがいくつあったとしても、次の受信者にメッセージを送信するときは独立した SMTP 接続が確立される。SMTP セッションでは二つの MTA の間で対話が行われる。その対話では、メッセージを送る MTA がクライアント、メッセージを受け取る MTA がサーバーとして振る舞う。一つのセッション中に複数のメッセージを送信することもできる。RFC 822 はメッセージを ASCII で表現すると定めているので、SMTP も ASCII ベースであることに驚きはしないだろう。これは SMTP クライアントの代わりに人間がキーボードからメッセージを入力することでもメッセージを送信できることを意味する。
SMTP を理解するには簡単な例を見るのが一番だろう。ホスト cs.princeton.edu がホスト cisco.com にメールを送るとき、両者の間で交わされる対話の例を次に示す。この例ではプリンストン大学の Bob が Cisco の Alice と Tom にメールを送ろうとしている。対話を見やすくするために空行を入れてある:
HELO cs.princeton.edu
250 Hello daemon@mail.cs.princeton.edu [128.12.169.24]
MAIL FROM:<Bob@cs.princeton.edu>
250 OK
RCPT TO:<Alice@cisco.com>
250 OK
RCPT TO:<Tom@cisco.com>
550 No such user here
DATA
354 Start mail input; end with <CRLF>.<CRLF>
... メールのメッセージ ...
..........................
<CRLF>.<CRLF>
250 OK
QUIT
221 Closing connection
ここから分かるように、SMTP でメールを送信するときはクライアントとサーバーの間で数往復の対話が行われる。この対話でクライアントは HELO, MAIL, QUIT といったコマンドを送信し、サーバーは 250, 550, 354 といったリターンコードを返答する。サーバーはリターンコードに加えて人間に読める形の説明 (No such user here など) も返答する。この例で最初クライアントは HELO コマンドで自身の身元をサーバーに示している。HELO コマンドはドメイン名を引数に取る。サーバーはクライアントが提示した名前が現在使われている TCP 接続で使われている IP アドレスと一致することを確認し、その IP アドレスをクライアントに送り返す。その後クライアントはサーバーが二人のユーザーに対するメールを受け付けるかどうかを個別に質問し、それに対してサーバーは「yes」と「no」をそれぞれ返答する。それからクライアントはメッセージを送信し、接続を終了する。メッセージの末尾はピリオド . だけの行で表される。
コマンドとリターンコードには上記の例で使われたもの以外にも様々なものが存在する。例えば RCPT コマンドに対するリターンコード 251 は「このサーバーは指定されたユーザーの受信箱を持っていないものの、メッセージを他の MTA に転送することはできる」を意味する。言い換えれば、RCPT に対して 251 を返すサーバーはメールゲートウェイとして機能している。他のコマンドの例としては、メールを送信せずにユーザーのメールアドレスを確認する VRFY コマンドがある。
最後に一つ興味深い点として、MAIL と RCPT に対する引数がある。上記の例で MAIL には FROM:<Bob@cs.princeton.edu> が与えられ、RCPT には TO:<Alice@cisco.com> や TO:<Tom@cisco.com> が与えられている。これらの引数が RFC 822 で規定されるヘッダーに記される情報と似ていると思うかもしれないが、実はある意味でその通りと言える: MTA はメッセージをパースすることで SMTP を実行するのに必要な情報を取り出す場合が多い。SMTP クライアントが SMTP サーバーと対話するときに利用する情報をメッセージのエンベロープ (envelope) と呼ぶ。歴史的な話を一つしておく: sendmail という MTA が非常に広く使われるようになった理由の一つに、メッセージをパースして SMTP によって利用される情報を取り出す処理を誰も再実装したがらなかったことがある。現代のメールアドレスは Bob@cs.princeton.edu のような小奇麗な見た目をしているものの、常にそうであったわけではない。インターネットが今よりもずっと小さかったころは user%host@site!neighbor のような形をしたメールアドレスも珍しくなかった。
メールリーダー
最後のステップとしてユーザーは受信箱からメッセージを取得し、メッセージを読み、返事を送信し、そしておそらくは後から読めるようにメッセージのコピーを保存する。こういった操作はメールリーダーを使って行われる。先述したように、初期のメールリーダーはユーザーの受信箱があるマシン上で実行され、受信箱を実装するファイルに対する読み書きを行うだけだった。これはノート PC が誕生するころまで普通の方法だったものの、現在ではユーザーがリモートマシンにある受信箱にアクセスする場合が最も多い。このアクセスでは POP や IMAP といった SMTP と異なるプロトコルが使われる。メールリーダーのユーザーインターフェースに関する議論は本書の範囲を超えるものの、受信箱へのアクセスプロトコルは明らかに本書の範囲に入る。ここでは IMAP に特に注目して説明する。
IMAP は様々な点で SMTP と似ている。IMAP は TCP の上に実装されるクライアント/サーバープロトコルであり、ユーザーのデスクトップマシン上で実行されるクライアントは <CRLF> で区切られたコマンドが記されたテキストを送信し、ユーザーの受信箱を管理するメールサーバーはレスポンスを返す。この対話はクライアントが自身を認証し、アクセスしたい受信箱を指定するところから始まる。IMAP の単純な状態遷移図を図 217 に示す。この図にある LOGIN や LOGOUT はクライアントが発行するコマンドの例であり、OK はサーバーが返すレスポンスの例である。他のコマンドとしては FETCH (メールの取得) や EXPUNGE (メールの削除) があり、他のレスポンスには NO (クライアントは指定された操作を行う権限を持たない) や BAD (コマンドが正当でない) がある。
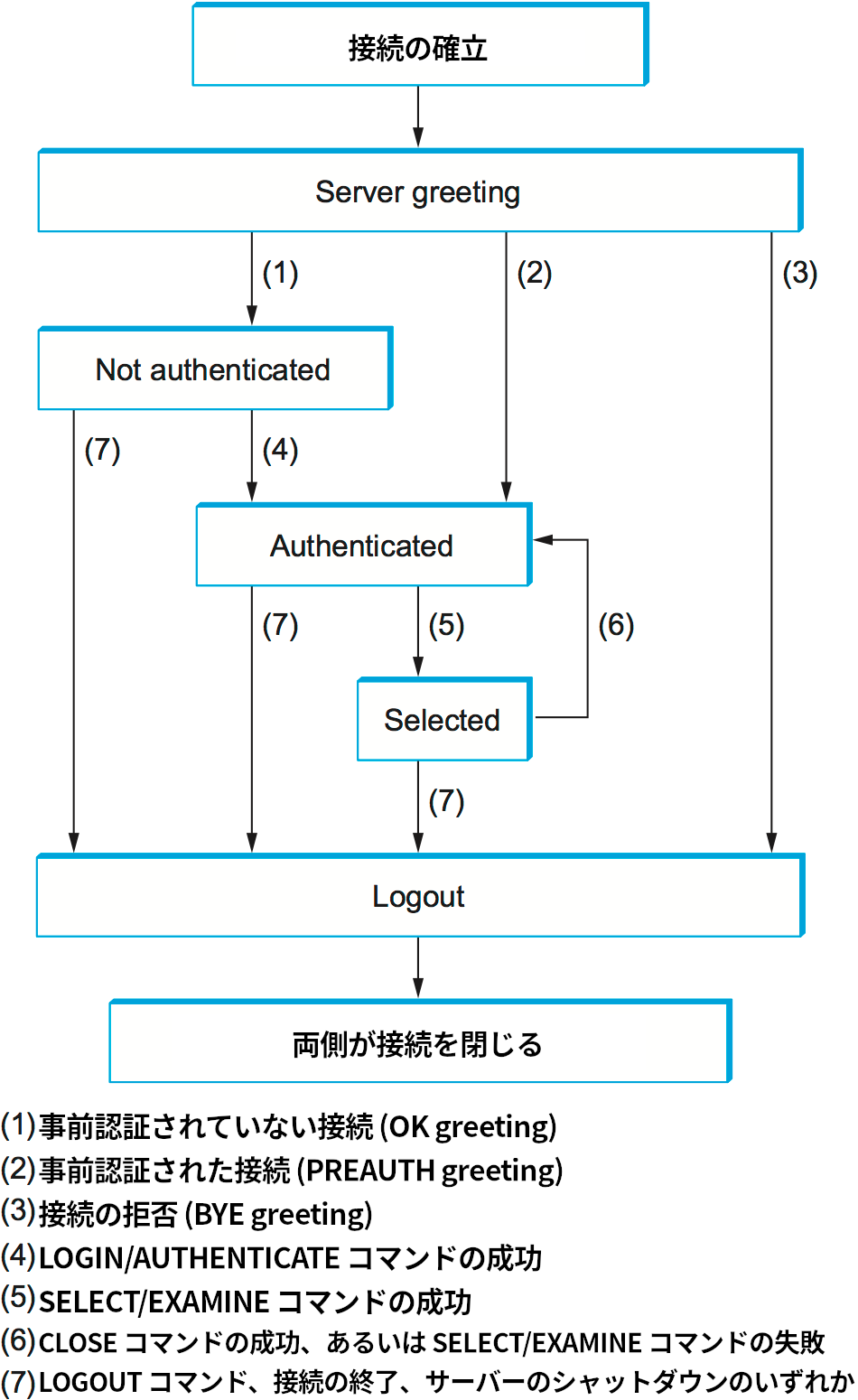
ユーザーがメッセージの FETCH を要求すると、サーバーはメッセージを MIME フォーマットで返答し、メールリーダーはそれをデコードしてユーザーに表示する。このとき、IMAP は返答するメッセージに属性 (attribute) を付けることができる。属性はメッセージの内容と独立した値であり、メッセージのサイズなどの情報が含まれる。より興味深い属性として、メッセージに関連したフラグ (Seen, Answered, Deleted など) がある。こういったフラグはクライアントとサーバーの状態を同期するために存在する。例えばユーザーがメールリーダーからメッセージを削除の印を付けたなら、メールリーダーの IMAP クライアントはその事実をメールサーバーに伝える必要がある。その後ユーザーが削除の印を付けたメッセージを実際に削除したなら、IMAP クライアントは EXPUNGE コマンドを発行し、これまでの対話で削除の印が付けられたメッセージがメールサーバーの受信箱から削除される。
最後に、ユーザーがメッセージに返答したり新しいメッセージを送信したりするときにメールリーダーが使う転送プロトコルは IMAP ではないことに注意してほしい。自分が送信するメッセージの転送では SMTP が使われる。これはメッセージがユーザーのデスクトップから宛先の受信箱に届くまでの経路において、ユーザーのメールサーバーが最初のメールゲートウェイとして振る舞うことを意味する。
9.1.2 ワールドワイドウェブ (HTTP)
インターネットのアプリケーションの一つであるワールドワイドウェブはとてつもない成功を収め、多くの人はワールドワイドウェブを通してインターネットを利用するようになった。そのため、ワールドワイドウェブとインターネットが同義語として使われることもある。しかし後にウェブとなるシステムの設計が開始されたのは 1989 年ごろであり、そのころインターネットは既に大規模に運用されていた。元々ウェブは情報を整理・検索するためのシステムとして設計され、その背後には遅くとも 1960 年代から提唱されていたハイパーテキスト (hypertext) ── 相互にリンクが張られたドキュメント ── というアイデアがある2。ハイパーテキストの核にあるのは「ドキュメントが他のドキュメントに対するリンクを持てる」という考え方であり、それを実現させるために通信プロトコル HTTP とドキュメント言語 HTML が設計された。
ウェブは協調動作するクライアントとサーバーの集合であり、全てのクライアントとサーバーは HTTP という同じ言葉を話すと考えると理解しやすいだろう。ただし多くの人は Safari, Google Chrome, Firefox, Internet Explorer といったウェブブラウザ (グラフィカルなクライアントプログラム) を通してウェブに触れる。図 218 にプリンストン大学のページを開いた Safari のスクリーンショットを示す。
リンクが張り巡らされたオブジェクト (ドキュメントや画像など) のシステムを構築する場合、最初の一歩となるオブジェクトを取得する手段が明らかに必要になる。そのため、ウェブブラウザはユーザーが入力した URL が指すオブジェクトを取得する機能を必ず持つ。URL (Uniform Resource Locator, 統一リソース位置指定子) を知らない読者はおそらくいないだろう。しかし URL も HTML や HTTP と同様に作られたものである事実を忘れるべきではない。URL はウェブ上のオブジェクトを特定するための情報を提供する。URL の例を次に示す。この URL を開くと、ウェブブラウザは瞬時に www.cs.princeton.edu という名前のマシンとの TCP 接続をオープンし、index.html という名前のファイルを取得・表示する。
http://www.cs.princeton.edu/index.html
ウェブ上のファイルは多くが文章 (ドキュメント) か画像であり、他に音声、動画、ソースコードである場合もある。HTTP と HTML の「ハイパーテキスト (hypertext)」が意味するように、ウェブ上のファイルには他のマシンにあるファイルを指す URL が含まれる場合が多い。ウェブブラウザはドキュメントに含まれる URL を強調して表示する (たいていは色を変えて下線を引く) 機能を持っており、ユーザーは強調された URL を開くようにウェブブラウザに指示できる。こういった埋め込まれた URL をハイパーテキストリンク (hypertext link) と呼ぶ。強調されたテキストをマウスでクリックするなどして埋め込まれた URL を開くことをウェブブラウザに指示すると、ウェブブラウザは新しい TCP 接続をオープンして新しいファイルを取得・表示する。この操作を「リンクをたどる (following a link)」と呼ぶ。リンクをたどる機能のおかげで、ネットワーク上の異なるマシンに置かれたファイルを見て回ることが非常に簡単になる。ドキュメントにリンクを埋め込む手段とユーザーがリンクをたどって他のドキュメントを取得する手段を用意すれば、ハイパーテキストシステムの基盤が完成する。
ウェブブラウザにページの表示を指示すると、ウェブブラウザは TCP の上に実装される HTTP を使ってそのページを取得 (フェッチ) する。HTTP は SMTP と同様にテキスト指向のプロトコルである。HTTP は基本的にリクエスト/レスポンスプロトコルであり、全てのメッセージは次の形をしている:
START_LINE <CRLF>
MESSAGE_HEADER <CRLF>
<CRLF>
MESSAGE_BODY <CRLF>
ここで <CRLF> は以前と同様にキャリッジリターン (carriage return) とラインフィード (line feed) の並びを表す。最初の行 START_LINE はメッセージがリクエストなのかレスポンスなのかを表す。正確に言うと、最初の行はメッセージがリクエストのとき実行される「遠隔手続き」を表し、レスポンスのときリクエストの結果を表す。次の行はリクエストあるいはレスポンスのオプションやパラメータを指定する。MESSAGE_HEADER はゼロ行以上にわたって続き、終端は空行で表される。RFC 822 と同様に、MESSAGE_HEADER の各行にはコロンで区切られたヘッダーの名前とヘッダーの値が並ぶ。HTTP では様々な種類のヘッダーが定義され、リクエストに関する情報を持つヘッダー、レスポンスに関する情報を持つヘッダー、そしてメッセージボディに関する情報を持つヘッダーなどが存在する。本書では全種類の HTTP ヘッダーを解説することはせず、いくつか代表的な例を示すに留める。最後に、MESSAGE_HEADER の終わりを表す空行の後にはリクエストされたメッセージの本体 MESSAGE_BODY が続く。これはサーバーがリクエストされたページを配置する場所であり、典型的なリクエストメッセージでは空となる。
なぜ HTTP は TCP の上に実装されるのだろうか? TCP を絶対に使わなければならない理由があったわけではないものの、TCP が提供する機能と HTTP が必要とする機能は重なる部分が大きい。特に、TCP の確実な転送 (壊れたウェブページを誰が見たがるだろうか?)、フロー制御、輻輳制御は HTTP でも求められる。しかし後述するように、リクエスト/レスポンスプロトコルを TCP の上に実装することから生じる問題もいくつか存在する。こういった問題はアプリケーション層プロトコルとトランスポート層プロトコルの対話で生じる摩擦が特に原因となって生まれる。
リクエストメッセージ
HTTP リクエストメッセージの最初の行は三つの要素からなる:
- 実行されるメソッド
- 操作対象のウェブページ
- HTTP のバージョン
HTTP はリクエスト可能な操作をメソッド (method) と呼ぶ。HTTP は様々なメソッドを定義する ── 例えばウェブページをサーバーに投稿する書き込みメソッドも存在する ── ものの、実際に最もよく使われるのは GET と HEAD である。GET は指定されたウェブページを取得し、HEAD は指定されたウェブページに関するメタ情報を取得する。GET は当然ウェブブラウザがウェブページを取得してユーザーに表示するときに使われる。HEAD はハイパーテキストリンクの正当性の確認、あるいは特定のページが最後にフェッチしてから変更されたかどうかの確認に使われる。HTTP で定義される全てのリクエストメソッドを表 27 に示す。この中にある POST メソッドは変哲もないメソッドに思えるかもしれないが、このメソッドはインターネット上における様々な迷惑行為 (スパムなど) で利用されている。
| 操作 | 説明 |
|---|---|
OPTIONS |
利用可能なオプションに関する情報をリクエストする。 |
GET |
URL が指すドキュメントを取得する。 |
HEAD |
URL が指すドキュメントに関するメタ情報を取得する。 |
POST |
サーバーに情報 (投稿されたコメントなど) を送信する。 |
PUT |
指定された URL にドキュメントを保存する。 |
PATCH |
指定された URL のドキュメントを更新する。 |
DELETE |
指定された URL を削除する。 |
TRACE |
リクエストメッセージのループバックを要求する。 |
CONNECT |
プロキシで使われる。 |
例として次の START_LINE を考えよう:
GET http://www.cs.princeton.edu/index.html HTTP/1.1
この一行はクライアントがホスト www.cs.princeton.edu 上のサーバーに index.html というページをリクエストすることを意味する。次のようにしてファイルを相対識別子で指定し、MESSAGE_HEADER の中でホスト名を指定することもできる:
GET index.html HTTP/1.1
Host: www.cs.princeton.edu
ここで Host は MESSAGE_HEADER で指定できるフィールドの一つである。これより興味深いフィールドに If-Modified-Since がある。このフィールドを使うと、クライアントは「フィールドで指定された日時より後にウェブページが更新された」という条件が成り立つときに限ってウェブページを取得できる。
レスポンスメッセージ
リクエストメッセージと同様、レスポンスメッセージも一行の START_LINE から始まる。レスポンスメッセージの START_LINE は次の三つの要素からなる:
- HTTP のバージョン
- リクエストが成功したかどうかを表す三桁のステータスコード
- レスポンスの理由を表すテキスト
例えば、次の START_LINE はサーバーがリクエストを受け付けたことを意味する:
HTTP/1.1 202 Accepted
一方、次の START_LINE はリクエストの処理で問題が発生したことを意味する:
HTTP/1.1 404 Not Found
レスポンスに含まれるステータスコードには五つの一般的なタイプが存在し、最上位桁の数字がそのタイプを表す。表 27 に五つのタイプをまとめる。
| ステータスコード | タイプ | 理由 |
|---|---|---|
1xx |
情報 | リクエストは受け取られた。処理が続いている。 |
2xx |
成功 | リクエストは受け取られ、理解され、受理された。 |
3xx |
リダイレクト | リクエストを完了するために追加で操作が必要である。 |
4xx |
クライアントエラー | リクエストの構文が間違っているか、リクエストに応えることができない。 |
5xx |
サーバーエラー | 正当と思われるリクエストにサーバーは応えることができなかった。 |
POST メソッドがスパムなどの予想外の用途に使われているのと同じように、一部の HTTP ステータスコードは驚くような使われ方をしている。例えばステータスコード 302 によるリクエストのリダイレクトは非常に強力なメカニズムであることが知られており、CDN (コンテンツ配送ネットワーク) ではリクエストを近くのキャッシュにリダイレクトするために利用される。
リクエストメッセージと同様、レスポンスメッセージもヘッダー (MESSAGE_HEADER) を持つ。このヘッダーはレスポンスに関する追加情報をクライアントに伝えるために利用される。例えば、Location フィールドはリクエストされた URL が取得可能な別の場所を指定する。例えば、仮にプリンストン大学コンピューターサイエンス学科のウェブページが http://www.cs.princeton.edu/index.html から http://www.princeton.edu/cs/index.html に移動したなら、元々のアドレスにあるサーバーは次のようなレスポンスを返すことになる:
HTTP/1.1 301 Moved Permanently
Location: http://www.princeton.edu/cs/index.html
レスポンスメッセージには当然リクエストされたオブジェクトも含まれる。このオブジェクトは通常 HTML ドキュメントであるものの、テキスト形式でないデータ (例えば GIF 画像) である可能性もあるので、リクエストされたオブジェクトは先述した MIME を使って符号化される。オブジェクトの属性の一部 (例えばサイズ、有効期限、サーバーにおける最終更新時刻) はレスポンスメッセージのヘッダーによって与えられる。
URL
HTTP がアドレスとして用いる URL は URI (Uniform Resource Identifier, 統一リソース識別子) の一種である。URI はリソースを特定する文字列であり、特定されるリソースはアイデンティティを持つものであればドキュメント、画像、サービスなど何でも構わない。
URI は柔軟に設計されており、特殊化されたリソース識別子の集合を URI の識別子空間に後から追加できるようになっている。URI の最初の要素はスキーム (scheme) と呼ばれ、その URI が識別するリソースの種類を表す。例えば mailto で始まる URI はメールアドレスを識別し、file で始まる URI はファイルを識別する。スキームの後にはコロンが続き、その次に二つ目の要素であるスキーム固有部 (scheme-specific part) が続く。スキーム固有部は先頭のスキームに対応したリソース識別子である。スキーム、コロン、スキーム固有部を並べると mailto:santa@northpole.org や file:///C:/foo.html といった完全な URI となる。
URI が識別するリソースは取得可能でなくてもアクセス可能でなくても構わない。取得可能でもアクセス可能でもないリソースを指す URI の例として、以前に見た XML の名前空間がある。XML の名前空間は URL に非常によく似ているものの、リソースの位置を示すわけではないので、正確に言うと URL ではなく URI である: 名前空間にグローバルに一意な識別子を与えているだけに過ぎない。XML ドキュメントの名前空間として与えられた URI から何かを取得できなければならないという要件は存在しない。URL ではない URI の例は本節の後半でさらに触れる。
TCP 接続
初期バージョンの HTTP 1.0 では、サーバーから取得するオブジェクトごとに個別の TCP 接続が確立されていた。この方法が非効率であることは簡単に理解できるだろう: 接続の確立メッセージと終了メッセージがクライアントとサーバーの間で何度も交わされる。例えば大量のアイコンや画像が含まれたページを開くと、同じ相手に対する TCP 接続のオープンとクローズが何十回も繰り返されることになる。図 219 にオブジェクトが一つだけ埋め込まれたページを開いたときに起こる通信を示す。水色の線は TCP のメッセージを表し、黒い線は HTTP のメッセージを表す (図を簡単にするために、一部の TCP ACK は省略されている)。この図からは、二回のラウンドトリップが TCP 接続の確立に使われ、それとは別に (最低でも) 二回のラウンドトリップがページと画像の取得に使われているのが分かる。この方式だとレイテンシが悪化するのに加えて、TCP 接続の確立と終了を処理するサーバーの負担も増加する。
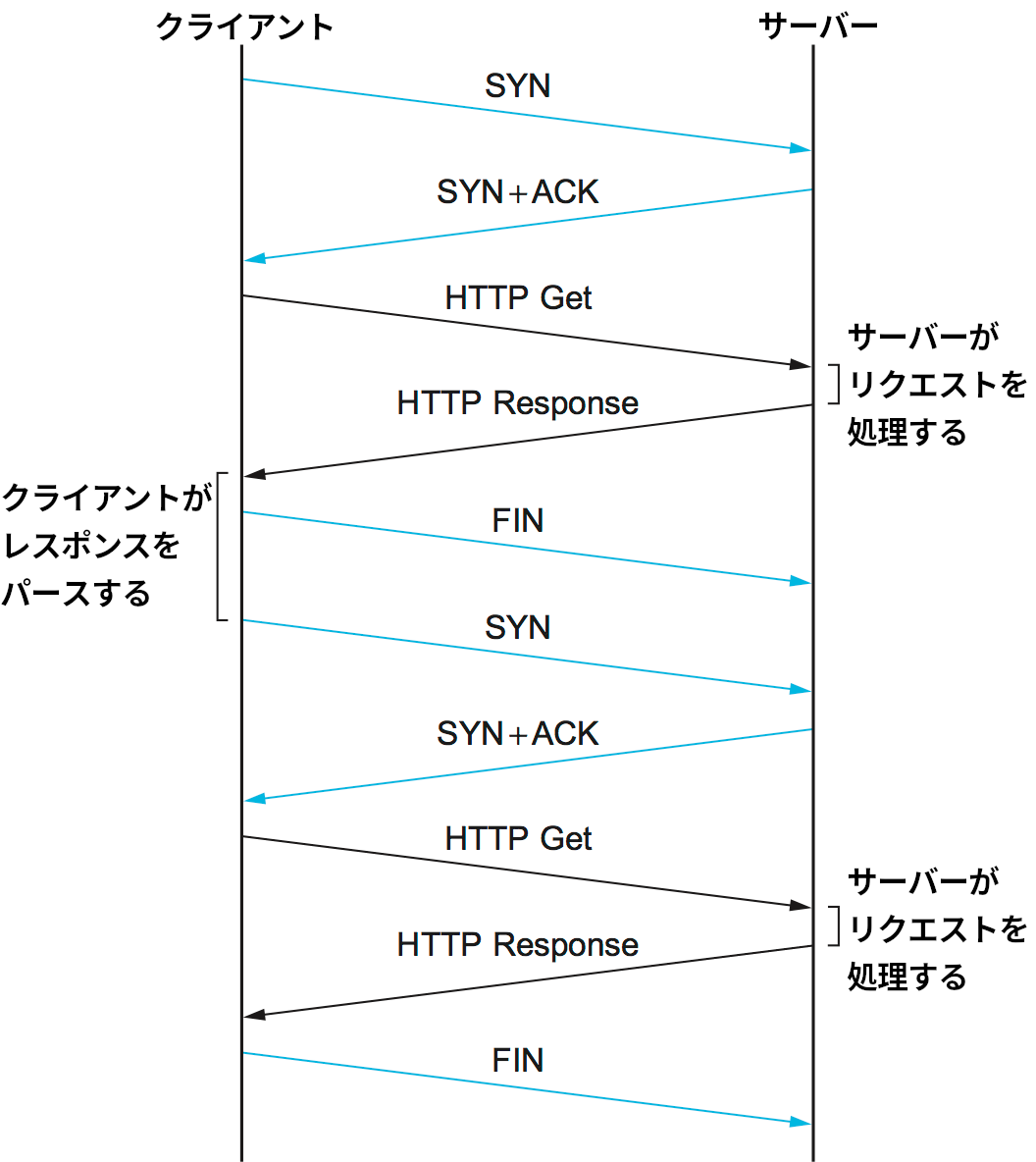
この問題を解決するため、HTTP 1.1 は持続的接続 (persistent connection) を導入した ── クライアントとサーバーは同じ TCP 接続で複数のリクエスト/レスポンスメッセージを交換できるようになった。持続的接続には利点がいくつか存在する。第一に、接続確立のオーバーヘッドが明らかに減少する。交わされる TCP パケットが減ることでサーバーおよびネットワークの負荷が減少し、ユーザーが体感する遅延も短くなる。第二に、TCP の輻輳ウィンドウがより効率的に動作できるようになる: クライアントが同じ TCP 接続で複数のリクエストメッセージを送信するので、スロースタートが一度で済む。持続的接続を使って図 219 と同じオブジェクトの取得を行った場合に発生する通信を図 220 に示す。ここでは持続的接続が (同じサーバーへの以前のアクセスなどによって) 最初から確立されていると仮定している。
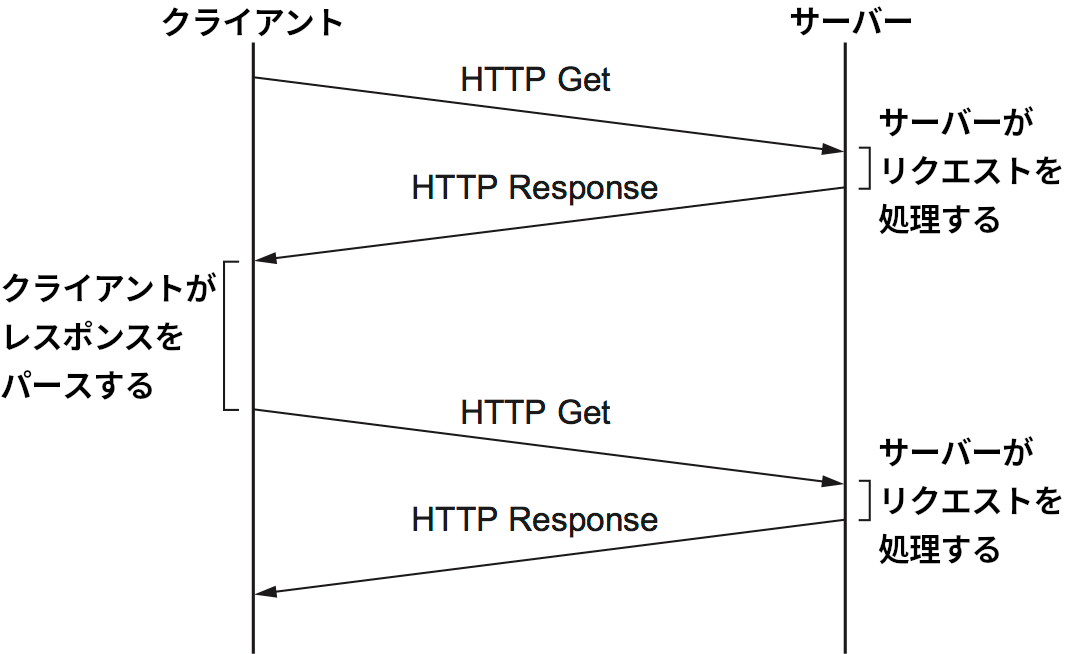
しかし、持続的接続から生じる問題もある。それはクライアントにもサーバーにも特定の TCP 接続がいつまで開かれるかが分からないことで、これは大量のクライアントに対する接続を保持しなければならないサーバーで特に問題となる。このためサーバーはタイムアウトを設定し、一定時間リクエストが送られてこない接続を自動的にクローズする。また、クライアントとサーバーはどちらも相手が接続のクローズを開始していないかどうかを監視し、もしクローズが開始されたら自身からの接続もクローズしなければならない (TCP 接続を終了させるには両側でクローズが必要なことを思い出してほしい)。こういった複雑性が加わることがおそらくは理由となって、持続的接続は最初から広く利用されることはなかった。しかし現在では、持続的接続の利点は欠点を上回ると一般に認識されている。
現在 HTTP 1.1 が広くサポートされている中で、新しいバージョンの HTTP が IETF によって 2015 年に正式に採択された。HTTP/2 と呼ばれるこの新しいバージョンは HTTP 1.1 と後方互換性を持つ (例えばヘッダーフィールド、ステータスコード、URI の構文は変わらない) ものの、重要な新機能を二つ持つ。
一つ目の新機能はウェブサーバーがウェブブラウザに送り返すデータのミニファイ (minify) を容易にする機能である。HTML で書かれた典型的なウェブページを見ると、ブラウザがページを描画するために必要な外部リソース (画像、スクリプト、スタイルファイルなど) への参照が大量に含まれていることが分かる。そういったリソースを個別のリクエストで取得させる代わりに、HTTP/2 は必要なリソースをクライアントにまとめてプッシュすることでリソースのリクエストで生じるラウンドトリップを節約する機能を提供する。この機能はプッシュされるバイト数を小さくする圧縮の仕組みと共に用いられる。最終的な目標はハイパーリンクをクリックしてからページが完全に描画されるまでにエンドユーザーが体験する遅延を最小化することにある。
二つ目の新機能は単一の TCP 接続の上に複数のリクエストを多重化する機能である。HTTP 1.1 では単一の TCP 接続をリクエストが一つずつ再利用できるのに対して、HTTP/2 では複数のリクエストが互い違いに単一の TCP 接続を利用できる。HTTP/2 が採用した多重化方式には見覚えがあるはずである: チャンネルという抽象化が (「ストリーム」という名前で) 導入され、同じ瞬間に複数のストリームが同時にアクティブになることが許され、各ストリームが同時にアクティブにできるリクエスト/レスポンスは最大一つに制限される。
キャッシュ
ウェブをより快適に利用可能にする上で重要な実装戦略の一つがウェブページのキャッシュである。キャッシュには利点がいくつかある。クライアントからすると、ページを地球の反対側にあるサーバーではなく近くのキャッシュサーバーから取得できれば早く表示できる。サーバーからすると、キャッシュサーバーがリクエストの一部に応えることで負荷が減少する。
キャッシュは様々な場所で実装できる。例えば、ウェブブラウザはユーザーが最近アクセスしたページをキャッシュし、ユーザーが同じページを開いたときはキャッシュされたページのコピーを表示する。他には、ネットワーク拠点が単一のキャッシュを持ち、拠点内の複数のユーザーが同じページを開いたときに以前にダウンロードしたコピーを返すことも考えられる。さらにインターネットの中心に向かうと、ISP (インターネットサービスプロバイダ) もページをキャッシュできる3。
拠点レベルでキャッシュを行うとき、拠点内のユーザーはキャッシュを行うマシンがどれかを知っていることが多いので、そのマシンに全てのリクエストを送信するように自身のブラウザを設定する場合が多い。ユーザーの代わりにページの取得を行うこのマシンはプロキシ (proxy) と呼ばれる。これに対して、ISP に接続する拠点は ISP がページをキャッシュすることを関知しない可能性が高い。様々な拠点から送られる HTTP リクエストが ISP の共通ルーターを通るだけであり、そのルーターの存在は ISP だけが知っている。このルーターはリクエストメッセージを覗いてリクエストされている URL を確認し、その URL のページがキャッシュにあるならそれを返す。もしキャッシュに無いなら、ルーターはリクエストを通常通りに転送し、レスポンスが自身を通過するかどうかを監視する。もしレスポンスが自身を通過したら、ルーターは将来の同じリクエストで利用できることを見越してページのコピーをキャッシュに保存する。
どこにキャッシュを作成するのであれ、ウェブページをキャッシュする仕組みは非常に重要であり、HTTP はキャッシュを簡単に利用できるように設計されている。キャッシュされたページをクライアントに返すとき、キャッシュサーバーはページが更新されていないことを確認する必要がある。これを可能にするため、サーバーはヘッダーの Expires フィールドを設定することでページの有効期限をクライアント (およびサーバーとクライアントの間にあるキャッシュシステム) に伝える。キャッシュシステムは有効期限を記録し、それまではページを実際にリクエストせずにレスポンスを返す。キャッシュされたページが有効期限を迎えると、キャッシュシステムは HEAD メソッドと GET メソッド、あるいはヘッダーの If-Modified-Since フィールドを利用する条件付き GET メソッドを使って最新のページのコピーが手元に置かれた状態を保つ。有効期限の他にも、HTTP はリクエスト/レスポンスのメッセージを覗き見るキャッシュシステムが必ず従わなければならないディレクティブ (指示) をいくつか定めている。キャッシュに関するディレクティブは例えば「キャッシュ可能かどうか」「キャッシュはいつまで有効か」「キャッシュを異なるクライアントで共有してよいか」といった情報をキャッシュシステムに伝える。キャッシュに関する話題は第 9.4.3 項 で CDN (基本的に分散されたキャッシュ) の話をするときにまた触れる。
9.1.3 Web サービス
ここまでは人間とウェブサーバーの対話を考えてきた。例えば人間はウェブブラウザを使ってサーバーと対話し、ユーザーから応答 (リンクのクリックなど) があれば対話がさらに行われる。しかし、アプリケーション同士の直接対話に対する需要も高まり続けている。ここまでに説明してきたアプリケーションがプロトコルを必要としたように、他のアプリケーションと直接対話するアプリケーションにもプロトコルが必要となる。本節の最後の話題として、数多くのアプリケーション間プロトコルを作成することから生じる問題とそれに対して提案されている解決法を紹介する。
アプリケーション間の直接通信が整備された大きな理由の一つにビジネスの世界からの要請がある。歴史的に、エンタープライズ (ビジネスなどに関する組織) 間の対話には特定の製品の在庫を確認する電話をかけたり注文書を書いたりする手動のステップがある。同じエンタープライズ内であっても、独立に開発されたために直接対話できないソフトウェアシステムが存在し、その間の対話を手動で行うことはよくある。近年、こういった手動による対話を直接的なアプリケーション間対話に置き換える動きが進んでいる。例えばエンタープライズ A の発注アプリケーションがエンタープライズ B の受注アプリケーションにメッセージを送信し、B は注文が受注されたかどうかを瞬時に応答する、といった使われ方をする。B が注文を受注できないとき A は自動的に他のサプライヤーに対する注文や入札を行うかもしれない。
もう一つ簡単な例を示す。あなたが Amazon のようなオンライン小売業者から本を買ったとしよう。その本が出荷されると Amazon は荷物の追跡番号をメールであなたに伝えるので、それを配送業者のウェブサイト ── アメリカであればおそらく http://www.fedex.com ── に入力すると配送状況を確認できる。一方で、Amazon のウェブサイトから配送状況を直接確認することもできる。この機能を実現するには、Amazon が FedEx に (FedEx が理解できるフォーマットの) クエリを送信し、結果を解釈し、それを注文情報が表示されるページに表示する必要がある。Amazon のウェブサイトから注文した商品に関する全ての情報を確認できるユーザーエクスペリエンスを支えているのは、Amazon と FedEx が配送状況を追跡するための情報を交換するプロトコルを持っている事実である。こういったプロトコルの策定・実装を単純化するツールが必要になることは簡単に理解できるだろう。
組織の境界を越えて外部と対話するネットワークアプリケーションが新しいわけではない ── メールとウェブは明らかに組織の境界を越える。この問題で新しいのは規模である。それもネットワークのサイズではなく、異なるアプリケーションの数が問題となる。メールやファイル転送といった伝統的なアプリケーションでは、プロトコルの仕様と実装はネットワークの専門家からなる小さなグループによって作成される。大量のネットワークアプリケーションの素早い作成を可能にするには、アプリケーションプロトコルの設計と実装を単純化・自動化するテクノロジが必要となる。
この問題の解決策として提案されているアーキテクチャが二つある。どちらのアーキテクチャも、リモートのクライアントアプリケーションからアクセス可能なサービスを提供する個別のアプリケーションを Web サービス (Web Service) と呼ぶ。ここからアーキテクチャ自体も「Web サービスアーキテクチャ」と呼ぶことがあるものの、両者を区別するために SOAP と REST という非公式の名称が使われることもある。これから SOAP と REST を簡単に説明する。
SOAP アーキテクチャのアプローチは、ネットワークアプリケーションごとにカスタマイズされたプロトコルを (少なくとも理論上は) 簡単に生成できるようにすることで問題を解決する。このアプローチの重要な要素として、プロトコル仕様を作成するためのフレームワーク、仕様からプロトコルの実装を自動生成するソフトウェアツールキット、そして異なるプロトコル間で使い回せるモジュール性の高い仕様のパーツがある。
REST アーキテクチャのアプローチは、Web サービスをワールドワイドウェブのリソースとして扱うことで問題を解決する ── Web サービスは URI で識別され、HTTP を通してアクセス可能となる。本質的に REST アーキテクチャは「Web アーキテクチャ」と言える。このアーキテクチャの強みは安定性と (ネットワークの規模に対する) スケーラビリティである。一方で、よく使われる手続き的 (操作指向) スタイルでリモートサービスを起動することに HTTP があまり適していない点が弱みと言える。これに対して REST の支持者は、HTTP が上手く扱えるドキュメントパッシング (データ指向) スタイルを使ったとしてもリッチなサービスを公開できると主張する。
カスタムアプリケーションプロトコル (WSDL, SOAP)
非公式に SOAP と呼ばれるアーキテクチャは WSDL (Web Services Description Language) と SOAP4 を基礎として利用する。どちらも W3C (World Wide Web Consortium) によって発行される規格によって規定される。単に「Web サービス」と言ったときは通常 SOAP アーキテクチャによって提供されるアプリケーションを指す。SOAP は現在も進化しているので、本書の議論はスナップショットに過ぎない。
WSDL と SOAP はそれぞれアプリケーションプロトコルとトランスポートプロトコルを規定・実装するためのフレームワークである。通常 WSDL と SOAP は一緒に用いられるものの、厳密にはその必要はない。WSDL は「サポートされる操作」「操作に対する入出力データのフォーマット」「操作にレスポンスがあるかどうか」といったアプリケーション固有の詳細を規定するために用いられる。SOAP は信頼性やセキュリティといったプロトコルが持つ機能に関してユーザーが望む通りの意味論を持つトランスポートプロトコルの定義を容易にする役割を持つ。
WSDL と SOAP の両方で、プロトコル記述言語が重要な要素となる。スタブコンパイラや辞書サービスといったソフトウェアツールから仕様を簡単に扱えるように、それぞれのプロトコル記述言語は XML をベースとしている。大量のカスタムプロトコルが存在する世界では、実装の自動生成によって各プロトコルを手動で実装する手間を省くことが非常に重要となる。典型的なサポートソフトウェアはサードパーティベンダーによって開発されるツールキットとアプリケーションサーバーという形を取る。こうすることで、個別の Web サービスの開発者は解決すべきビジネスの問題 (例えば顧客が購入したパッケージの追跡) に集中できるようになる。
アプリケーションプロトコルの定義
WSDL はアプリケーションプロトコルの定義を手続き的なオペレーション (operation) モデルで行うことを選択した。Web サービスの抽象インターフェースはクライアントと Web サービスの単純な対話を表す名前付きのオペレーションから構成される。オペレーションは RPC システムにおける呼び出し可能な遠隔手続きのようなものと言える。W3C が公開している WSDL Primer で説明される例には、CheckAvailability と MakeReservation という二つのオペレーションを持ったホテルの予約を管理するための Web サービスが登場する。
二つのオペレーションはそれぞれ MEP (Message Exchange Pattern) を定義する。MEP はクライアントと Web サービスの間でどのようなメッセージがどのような順番で交わされるかを定める。メッセージフローが正しく進まなかったときに送信される障害メッセージも MEP によって定義される。いくつかの MEP は事前に定義されており、独自の MEP を書くこともできる。ただ、実際には In-Only (クライアントからサービスへの単一のメッセージ) と In-Out (クライアントからのリクエストとサーバーからのレスポンス) という MEP しか使われていないと見られる。これらは人々が慣れ親しんだパターンであり、MEP の柔軟な設定項目を自分で調整するのは割に合わないと考える開発者が多いことを示唆している。
MEP は特定のメッセージタイプやフォーマットではなくプレースホルダーを持ったテンプレートである。そのためオペレーションの定義にはメッセージフォーマットから MEP のプレースホルダーへの対応付けが含まれる。本書で説明した典型的なプロトコルと異なり、メッセージフォーマットはビットレベルでは定義されず、XML を使った抽象データモデルで定義される。つまり XML スキーマがプリミティブデータ型と複合データ型を定義する手段を提供する。XML スキーマによって定義されるフォーマット ── 抽象データモデル ── に準拠するデータは XML を使って表現でき、加えて Fast Infoset による「バイナリ」表現といった別の表現を使うこともできる。
WSDL はプロトコルの抽象的に規定できる部分 (オペレーション、MEP、抽象メッセージフォーマット) と具体的にしか規定できない部分をはっきりと分離する。後者には下位プロトコル、MEP から下位プロトコルへの関連付け、そしてメッセージに用いられるビットレベル表現が含まれる。仕様のこの部分はバインディング (binding) と呼ばれるものの、「実装」あるいは「実装への対応付け」の方が良い名前だと思われる。WSDL は SOAP ベースのプロトコルと HTTP に対する事前に定義されたバインディングを持つ。これらのバインディングにはパラメータがあり、プロトコル設計者が自身のプロトコルに合うように調節できる。新しいバインディングを定義するためのフレームワークも存在するものの、SOAP プロトコルが支配的な地位を占める。
大量のプロトコルを規定するという問題を WSDL が解決する上で非常に重要となる要素に、「仕様モジュール」の再利用がある。Web サービスの WSDL 仕様は複数の WSDL ドキュメントから構成され、個別の WSDL ドキュメントは他の Web サービス仕様からも利用できる。このモジュール性により仕様の作成が簡単になり、さらに二つの仕様が全く同じ要素を持っていることが確証できるようになる (そうしておけば、例えば外部ツールは異なるアプリケーションへのサポートを簡単に提供できる)。WSDL のデフォルト規則とモジュール性が合わさることで、仕様が人間のプロトコル設計者を圧倒するほど複雑になる事態が起こりにくくなる。
WSDL のモジュール性は少しでも大きなソフトウェアの要素を開発したことがある開発者であれば慣れ親しんでいる考え方である。WSDL ドキュメントが完全な仕様である必要はない: 例えば単一のメッセージフォーマットを定義するだけでも構わない。部分的な仕様は XML 名前空間を使って一意に識別される。それぞれの WSDL ドキュメントはターゲット名前空間 (target namespace) の URI を指定し、WSDL ドキュメントに含まれる新しい定義は全てターゲット名前空間に名前を作成する。WSDL ドキュメントが他のドキュメントを取り入れる処理は二つのドキュメントが同じターゲット名前空間を持つならインクルード (include) と呼ばれ、異なるターゲット名前空間を持つならインポート (import) と呼ばれる。
トランスポートプロトコルの定義
SOAP をプロトコルとみなす場合もあるものの、プロトコルを定義するためのフレームワークとみなした方が正確である。SOAP 1.2 の仕様には「SOAP は拡張性の提供を中心的機能とした単純なメッセージングフレームワークを提供する」とある。SOAP は WSDL と同じ戦略を多く採用している。例えばメッセージのフォーマットは XML スキーマで定義され、下位プロトコルへのバインディング、MEP (Message Exchange Pattern)、XML 名前空間で識別される仕様の再利用といった要素が存在する。
SOAP は特定のアプリケーションがちょうど必要とする機能を持ったトランスポートプロトコルを作成するために利用される。SOAP は再利用可能なコンポーネントを活用することで様々なプロトコルの定義を可能にする。各コンポーネントは特定の機能を実装するのに必要なヘッダー情報とロジックを定義する。特定の機能集合を持ったプロトコルを定義するには、それらの機能に対応するコンポーネントを組み合わせるだけで済む。ここではコンポーネントの組み合わせに関して SOAP を詳しく見る。
SOAP 1.2 はフィーチャー (feature) という抽象化を導入した。仕様は次のように説明している:
SOAP フィーチャー (SOAP feature) は SOAP メッセージングフレームワークの拡張である。SOAP はフィーチャーでできることを何ら制限しないものの、例としては「信頼性」「セキュリティ」「コリレーション」「ルーティング」や、リクエスト/レスポンス、片方向、ピアツーピアの会話といった message exchange pattern (MEP) がある。
SOAP フィーチャーの仕様は次の要素を含まなければならない:
-
フィーチャーを識別する URI
-
フィーチャーを実装する各 SOAP ノードで必要とされる状態情報とそれに対する処理 (の抽象的な表現)
-
次のノードへリレーされる情報
-
(もしフィーチャーが MEP なら) 対話のライフサイクル、およびどのメッセージがどのような場合にどのような順番で交わされるか (例えば「リクエストがあると、リクエストを送信したノードに宛ててレスポンスが送信される」など)
プロトコルの機能を定式化したフィーチャーという抽象化は非常に低レベルであり、ほぼ設計とも言える。
いくつかのフィーチャーが与えられたとき、それらを実装する SOAP プロトコルを定義する方式は二つある。一つ目の方式は層を作ることでプロトコルを定義する: つまり、フィーチャーが実現されるように SOAP から下位プロトコルへのバインディングを作成する。例えばリクエスト/レスポンスプロトコルを定義するには、SOAP リクエストを HTTP リクエストに、SOAP リプライを HTTP レスポンスに対応させるような SOAP から HTTP へのバインディングを作成すればよい。これは非常によくあるケースなので、SOAP は HTTP へのバインディングを事前に定義している。SOAP Protocol Binding Framework を使えば新しいバインディングを作成できる。
二つ目の方式はヘッダーブロックを利用してフィーチャーを実装するものであり、一つ目の方式より柔軟性が高い。この方式における SOAP メッセージはエンベロープ (envelope) から構成され、エンベロープはヘッダー (header) と ボディ (body) から構成される。ヘッダーは一つ以上のヘッダーブロック (header block) から構成され、ボディは最終的な受信者が受け取るデータ (ペイロード) を持つ。図 221 に SOAP メッセージの構造を示す。
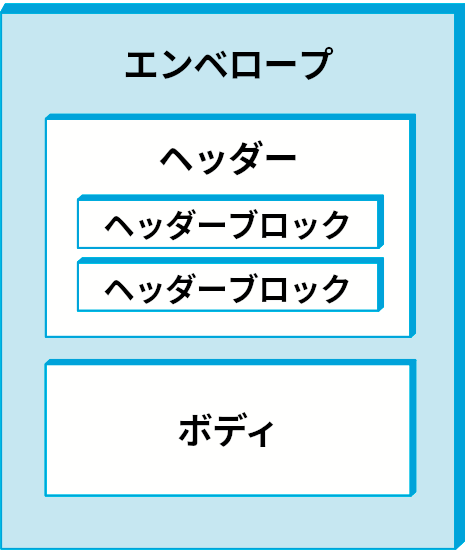
特定のフィーチャーにどのようなヘッダー情報が対応するかは想像が付くだろう。例えば認証の実装ではデジタル署名が使われ、信頼性の実装ではシーケンス番号が使われ、メッセージの破損検出の実装ではチェックサムが使われる。SOAP ヘッダーブロックはこういった特定のフィーチャーに対応するヘッダー情報をカプセル化するために存在する。フィーチャーとヘッダーブロックの対応関係は必ずしも一対一ではなく、一つフィーチャーが複数のヘッダーブロックを使うことも、複数のフィーチャーが一つのヘッダーブロックを使うこともできる。ヘッダーブロックの構文と意味論を規定する仕様は SOAP モジュールで定義される。各モジュールは一つ以上のフィーチャーを提供し、提供するフィーチャーを宣言する必要がある。
SOAP モジュールの目標は特定のフィーチャーの集合を持つプロトコルの作成をそれぞれのフィーチャーに対応するモジュールの仕様をインクルードするだけで行えるようにすることである。構想しているプロトコルに at-most-once 意味論と認証が必要なら、理想的にはプロトコルの仕様でそれぞれに対応するモジュールをインクルードするだけで済む。これはプロトコルサービスをモジュール化するアプローチとして本書で初めて登場する新しいものと言える。いくつかのプロトコルの層を構造化された形で一つのプロトコルにまとめる方法を提供するのが SOAP だと考えられるだろう。
SOAP のバージョン 1.2 で導入されたフィーチャーとモジュールが実際のシステムでどれだけ上手く活用されるかは未知数である。この方式の主な欠点として、モジュール同士が干渉する可能性が十分にあることが指摘できる。モジュールの仕様は他の SOAP モジュールに与える既知の影響を記述することを義務付けられているものの、これだけでは問題は解決しない。一方で、最も重要な機能を提供する中心的なフィーチャーとモジュールの集合は十分に小さく、十分によく理解できる可能性もある。
Web サービスプロトコルの標準化
ここまで説明してきたように、WSDL と SOAP はプロトコルではない: プロトコルを定義するための規格である。異なるエンタープライズが独自に実装する Web サービスを協調動作させるには、WSDL と SOAP を使ってプロトコルを定義すると合意するだけでは十分ではない: 特定のプロトコルに同意しなければ ── プロトコルを標準化しなければ ── ならない。本節の最初に示した Amazon と配送業者の例で言えば、Amazon などのオンライン小売業者と様々な配送業者の間で配送状況に関する情報を交換するための標準化されたプロトコルが望まれるだろう。この標準プロトコルは相互運用性だけではなくツールのサポートを提供する上でも非常に重要となる。しかしそれでも、WSDL と SOAP を用いるアーキテクチャにおいては、異なるネットワークアプリケーションは少なくともメッセージのフォーマットと利用されるオペレーションが異なっている。
標準化とカスタム化の緊張関係を解消する試みとして、プロファイル (profile) と呼ばれる部分的な規格が提案されている。プロファイルとは WSDL と SOAP で定義されるプロトコル、およびその定義で参照される他のプロトコルを制限するガイドラインを集めたものを言う。規格に含まれる曖昧な部分や欠落している部分の補完にもプロファイルは用いられる。実際には、プロファイルは新たに生まれつつあるデファクトスタンダードの定式化で使われることが多い。
最も広範で最も広く採用されているプロファイルは WS-I Basic Profile である。このプロファイルを提案したのは業界団体 WS-I (Web Services Interoperability Organization) であり、WSDL と SOAP を策定した W3C (World Wide Web Consortium) とは異なる。WS-I Basic Profile は Web サービスを定義するときに直面する最も基礎的な選択を固定する。最も重要な制限として、WSDL が SOAP だけを想定すること、SOAP が HTTP だけを想定すること、そして SOAP が HTTP の POST メソッドを利用することを WS-I Basic Profile は要求する。また、利用しなければならない WSDL と SOAP のバージョンも指定される。
WS-I Basic Security Profile は WS-1 Basic Profile にセキュリティに関する制約を追加する。具体的には、SSL/TLS 層の利用と WS-Security (Web Services Security) への準拠を要求する。WS-Security は X.509 公開鍵証明書や Kerberos 認証といった様々な既存のテクニックを使って SOAP プロトコルにセキュリティ機能を提供する方法を規定する。
WS-Security は業界団体 OASIS (Organization for the Advancement of Structured Information Standards) が策定する一連の SOAP レベルの規格に含まれる規格の一つである。この規格の集合は WS-* と呼ばれており、WS-Reliability, WS-ReliableMessaging, WS-Coordination, WS-AtomicTransaction といった規格が含まれる。
汎用アプリケーションプロトコル (REST)
WSDL/SOAP を利用する Web サービスアーキテクチャは「ネットワーク越しにアプリケーションを統合する最良の方法は各アプリケーションが独自のプロトコルを持つことだ」という仮定の下で、独自プロトコルの定義と実装が実用的になるように設計されている。これに対して、ネットワーク越しにアプリケーションを統合する最良の方法はワールドワイドウェブのアーキテクチャが持つモデルを再利用することだと仮定する Web サービスアーキテクチャも存在する。このモデルは Web 技術者 Roy Fielding によって明確に指摘されたもので、REST (Representational State Transfer) と呼ばれる。Web サービス用の新しい「REST アーキテクチャ」は必要とならない ── 既存の Web アーキテクチャで十分となる (ただし、いくつかの拡張はおそらく必要になる)。Web アーキテクチャの下で、個々の Web サービスは URI によって識別され HTTP でアクセスされるリソースとみなされる ── HTTP は汎用のアドレッシングスキームを持った単一の汎用アプリケーションプロトコルとなる。
WSDL におけるユーザー定義のオペレーションに対応するものとして、REST は GET や POST といった少数の HTTP メソッドを持つ (参照: 表 26)。こういった簡単なメソッドでリッチな Web サービスに対するインターフェースを提供するにはどうすればいいだろうか? REST モデルを採用するとき、複雑性はプロトコルからペイロードに移動する。つまりリソースが持つ抽象的な状態の表現がペイロードとなる。例えば、GET でリソースの現在状態の表現を取得したり、POST でリソースがあるべき状態の表現を送信したりといった使い方をする。
ペイロードに含まれるのはリソースの状態の抽象的な表現であり、Web サービスの特定のインスタンスにおける実際のリソースの実装と同じでなくても構わない。また、各メッセージで完全なリソースの状態を転送する必要はない。状態の中で関心のある部分 (例えば改変された部分) だけを転送すれば、メッセージを短くできる。さらに、全ての Web サービスは単一のプロトコルと単一のアドレス空間を共有するので、一部の状態を参照で ── URI で ── 渡すこともできる。他の Web サービスに対する参照であっても構わない。
このアプローチは「データ指向」あるいは「ドキュメントパッシング」と呼ばれるスタイルであり、WSDL/SOAP の「手続き的」スタイルとは大きく異なると言えるだろう。REST アーキテクチャでアプリケーションプロトコルの定義はドキュメントの構造 (状態の表現) の定義を通して行われる。状態を表現する言語としては XML または軽量な JSON (JavaScript Object Notation) が最もよく使われる。相互運用性は Web サービスとクライアントが状態の表現に合意することで提供される。もちろん、SOAP アーキテクチャでも同じことは言える: Web サービスとクライアントはペイロードのフォーマットに合意しなければならない。両者の違いは、SOAP アーキテクチャではペイロードだけではなくプロトコルに関しても合意して初めて相互運用性が提供されるのに対して、REST アーキテクチャではプロトコルは常に HTTP であり、プロトコルに関する相互運用の問題が発生しない点にある。
REST アーキテクチャのセールスポイントの一つに、Web を補強するために運用されているインフラストラクチャを利用できることがある。例えば、Web プロキシを使えばセキュリティやキャッシュの機能を Web サービスに追加できる。既存の CDN (コンテンツ配送ネットワーク) が REST アーキテクチャを採用する (RESTful な) アプリケーションをサポートすることもできる。
WSDL/SOAP とは対照的に、Web は規格を成熟させ、実際に素晴らしくスケールすることを実地で検証する時間と機会に恵まれた。加えて Web では SSL/TLS を通して一定のセキュリティが提供される。さらに、Web と REST には将来性に関しても有利である。WSDL と SOAP というフレームワークはプロトコルの定義に追加できる新しいフィーチャーとバインディングに関しては非常に高い柔軟性を持つ。しかし一度プロトコルが定義されてしまえば、その柔軟性は失われる。これに対して HTTP などの標準化されたプロトコルは後方互換性を保ったまま拡張できることを念頭に置いて設計されている。HTTP 自身の拡張可能性は新しいヘッダーフィールド、新しいメソッド、新しいコンテンツタイプを追加できる事実に現れている。WSDL/SOAP を使って定義されるプロトコルでは、こういった拡張可能性が必要なときは独自プロトコルの設計に個別の要素として組み込む必要がある。ただしもちろん、REST アーキテクチャで状態の表現を設計するときも拡張可能性は考慮されなければならない。
WSDL/SOAP が有利と思われる領域として、過去に書かれた「レガシー」アプリケーションを Web サービスらしく書き換えたりラップしたりする作業がある。多くの Web サービスは少なくともしばらくの間はレガシーアプリケーションを内部で利用するはずなので、これは重要な作業となる。そういったレガシーアプリケーションは REST の状態よりは WSDL のオペレーションに上手く対応付く手続き的なインターフェースを持つことが多い。REST と WSDL/SOAP のどちらが優れているかは個々の Web サービスに対して REST スタイルのインターフェースを考案するのがどれだけ難しいかに大きく依存する。WSDL/SOAP が適した Web サービスもあれば REST が適した Web サービスもあるという結論になる可能性もある。
オンライン小売業者 Amazon は Web サービスのアーリーアダプターであり、2002 年に Web サービスを導入した。興味深いことに、Amazon は WSDL/SOAP と REST の両方を通じて一般のユーザーがアクセスできるようにシステムを公開した。Amazon の報告によると、開発者の圧倒的多数は REST インターフェースを利用したという。もちろん、これは一つのデータ点に過ぎず、Amazon 特有の事情が影響している可能性は大いにある。
Web サービスからクラウドサービスへ
何らかのアプリケーションを実装する他の Web サーバーからのリクエストに応えられるように Web サーバーに実装されたアプリケーションは Web サービスと呼ばれる。では、負荷をスケーラブルに扱えるようにそのアプリケーションをクラウドに移したなら、それはクラウドサービス (cloud service) と呼ばれるのだろうか? Web サービスとクラウドサービスに違いはあるだろうか? この質問への答えは視点によって異なる。
サーバーのプロセスをマシンルームにある物理マシンからクラウドプロバイダが保有するデータセンターで実行される仮想マシンに移すと、マシンを落とさずに起動させた状態に保つ責任が社内のシステム管理者からクラウドプロバイダのオペレーションチームに移る。しかしそうしたとしても、アプリケーションが Web サービスアーキテクチャに沿って設計されているなら、その事実は変わらない。一方で、もしアプリケーションがスケーラブルなクラウドプラットフォームで実行されるものとして最初から設計されている ── 例えばマイクロサービスアーキテクチャ (micro-services architecture) を使っている ── なら、そのアプリケーションはクラウドネイティブ (cloud native) と呼ばれる。クラウドネイティブなアプリケーションとクラウドにデプロイされただけのレガシーな Web サービスの区別は重要である。
マイクロサービスアーキテクチャについては第 5.3 節で gRPC を説明するときに軽く触れた。マイクロサービスが Web サービスより明確に優れていると主張するのは難しいものの、業界のトレンドとしてはマイクロサービスが好まれている。おそらくそれよりも興味深いのは、マイクロサービスを実装する仕組みとして REST + JSON と gRPC + protobuf のどちらを使うべきか、という議論である。どちらも HTTP の上に実装される点を指摘しつつ、双方の利点と欠点を指摘する問題は読者への練習問題とする。
-
訳注: ここで「ASCII 文字」は
a,1,+,!といった印刷可能な ASCII 文字を意味している。 ↩︎ -
W3C が公開しているウェブの歴史を簡単にまとめたページ (https://www.w3.org/History.html) では、マイクロフィッシュ (一枚のマイクロフィルムに大量のページを複写したもの) 上のドキュメントにリンクを張って整理することを提案した 1945 年の記事が最初に紹介されている。 ↩︎
-
この形態のキャッシュには技術的なものから規制に関するものまで多くの問題が存在する。技術的な問題の例として、サーバーへ向かうリクエストとクライアントへ向かうレスポンスが同じルーターを経由しない非対称パス (asymmetric path) の問題がある。 ↩︎
-
元々 SOAP は Simple Object Access Protocol の頭字語とされていたが、現在では公式に頭字語ではないとされている。 ↩︎