3.2 スイッチドイーサネット
前節でスイッチングに関する基本的な考え方を議論したので、続いて具体的なスイッチングテクノロジを見る: 本節ではスイッチドイーサネット (switched Ethernet) を説明する。スイッチドイーサネットの構築に使われるスイッチは L2 スイッチ (L2 switch) と呼ばれ、キャンパスや企業のネットワークで広く用いられている。歴史的に、L2 スイッチは複数のイーサネットセグメントを「橋渡し」して拡張 LAN (extended LAN) を構築するために使われていたので、ブリッジ (bridge) と呼ばれることが多かった。しかし現在では、ほとんどのネットワークはイーサネットをポイントツーポイントリンクとして利用し、イーサネットのポイントツーポイントリンクを L2 スイッチで相互接続することでスイッチドイーサネットを構築している。
本節では最初に古くからある形態 (ブリッジを使ったイーサネットセグメントの接続) を説明し、その次に現在広く利用されている形態 (L2 スイッチを使ったポイントツーポイントリンクの接続) を説明する。しかし、ネットワークの中間に追加されるデバイスの呼び名がブリッジであろうとスイッチであろうと ── 構築するのが拡張 LAN であろうとスイッチドイーサネットであろうと ── そのデバイスは全く同じように動作する。
二つのイーサネットがあって、それらを相互接続したいとしよう。リピーターを間に挟めばいいと思うかもしれない。しかし、そうすることでイーサネットの物理的制約が破られてしまうとしたら、この方法は使えない。イーサネットでは任意の二つのホストの間には最大四つしかリピーターを設置できず、最大距離は 2500 m だったことを思い出してほしい。
もう一つの選択肢として、二つのイーサネットアダプターを持つ特別なノードを二つのイーサネットの間に配置し、異なるイーサネットに属するホストに向かって送信されたフレームをそのノードに転送させる方法が考えられる。このノードはリピーターとは異なる。リピーターは届いたビットをそのまま盲目的に転送するだけで、フレームを認識しない。そうではなく、この特別なノードはイーサネットの衝突検出と媒体アクセスのプロトコルを両方のインターフェースで完全に実装する。このため、こうして相互接続された二つのイーサネット全体にはホスト数や全長に関する制約が適用されない。このデバイスは無差別モード (promiscuous mode) で動作し、いずれかのイーサネットで転送された全てのフレームを受信してもう一方へ転送する。
最も簡単な形のブリッジは入力に受け取った LAN フレームを単にそれ以外の全ての出力に転送する。この簡単な戦略は初期のブリッジで使われたものの、後で見るように非常に深刻な欠点を持つ。長年にわたって加えられた数多くの改善により、ブリッジは複数の LAN を相互接続するための効率的な仕組みとなった。本節ではこれからより興味深い詳細を説明していく。
3.2.1 ラーニングブリッジ
ブリッジに対する一つ目の最適化は、受け取ったフレームを全て転送するのを止めることである。図 64 のブリッジを考えよう。ホスト A がホスト B に宛てて送信したフレームがブリッジのポート 1 に届いたとき、ブリッジはそのフレームをポート 2 に転送しなくて構わない。このとき問題は「どのホストがどの LAN に属するのかをブリッジはどうやって知るのか?」となる。
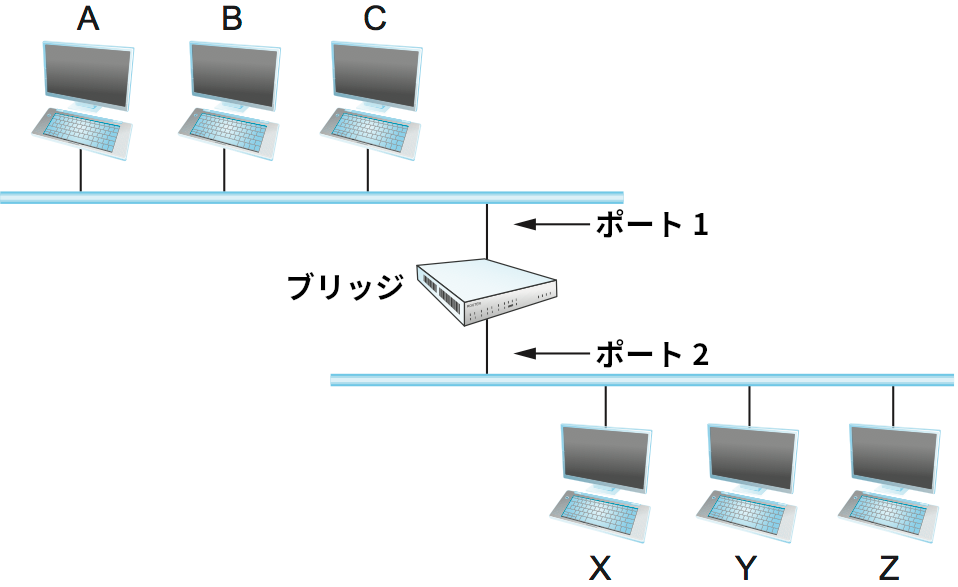
表 9 のようなテーブルをブリッジに手動でダウンロードしておく方法がまず考えられる。このとき、ブリッジはホスト A 宛てのフレームをポート 1 で受け取った場合はポート 2 に転送しない: ホスト A はポート 1 に接続された LAN で直接そのフレームを受け取っているからである。また、ホスト A 宛てのフレームがポート 2 に届いたときは、ブリッジはポート 1 への転送を行う。
| ホスト | ポート |
|---|---|
| A | 1 |
| B | 1 |
| C | 1 |
| X | 2 |
| Y | 2 |
| Z | 2 |
このテーブルを手動で管理するのは手間が大きすぎる。そこで、この情報をブリッジが自分で学習できるようにするラーニングブリッジ (learning bridge) という簡単なテクニックが考案された。そのアイデアは、各ブリッジが受け取ったフレームの送信元アドレスを確認して記録するというものである。例えばホスト A が送信したフレームを受け取ったブリッジは、ホスト A がポート 1 側に存在する事実を記録する。この方法を使えば、ブリッジは表 9 と全く同様のテーブルを構築できる。
こういったテーブルを用いるブリッジが前節で解説したデータグラム (コネクションレス) モデルの転送の一種を実装していることに注目してほしい。各パケットはグローバルなアドレスを保持し、ブリッジはそのアドレスを使って転送すべきポート番号をテーブルから引いている。
ブリッジが初めて起動したとき、このテーブルは空である: エントリーは時間の経過とともに埋まっていく。また、各エントリーにはタイムアウトが関連付けられ、指定された時間が経過するとエントリーは削除される。この処理はホスト ── およびホストの LAN アドレス ── が他のネットワークに移動する状況に対応するために存在する。そのため、このテーブルが完璧だとは限らない。ブリッジは現在のテーブルに載っていないホストへ宛てられたフレームを受け取ると、そのフレームを他の全てのポートに転送する。言い換えれば、このテーブルは一部のフレームをフィルタリングするための単なる最適化であり、正確性のために必要なわけではない。
3.2.2 実装
ラーニングブリッジアルゴリズムを実装するコードは非常に簡単に書けるので、ここに概要を示しておく。次の BridgeEntry 構造体はブリッジが持つ転送テーブルの単一のエントリーを表す。BridgeEntry の値は Map 構造体に格納される。Map は mapCreate, mapBind, mapResolve の操作をサポートし、テーブルに記録されたホストからのパケットを受け取ったときにエントリーを効率的に見つけることができる。定数 MAX_TTL は未使用のエントリーをテーブルから破棄するまでの時間を表す。
#define BRIDGE_TAB_SIZE 1024 /* 転送テーブルの最大サイズ */
#define MAX_TTL 120 /* エントリーがフラッシュされるまでの時間 (秒) */
typedef struct {
MacAddr destination; /* ノードの MAC アドレス */
int ifnumber; /* このノードに到達するために使うインターフェースの番号 */
u_short TTL; /* time to live (有効時間) */
Binding binding; /* Map 内のバインディング */
} BridgeEntry;
int numEntries = 0;
Map bridgeMap = mapCreate(BRIDGE_TAB_SIZE, sizeof(BridgeEntry));
次の updateTable 関数は新しいパケットが到着したときに実行され、転送テーブルを更新する。引数 src はパケットに含まれる送信元ノードの媒体アクセス制御 (MAC) アドレス、そして inif はパケットを受信したインターフェース番号を表す。ここには示されていないが、転送テーブルの各エントリーをスキャンして TTL フィールドを減少させ、0 になったらエントリーを削除する関数が定期的に実行される。パケットが到着すると既存のテーブルエントリーが更新され、TTL が MAX_TTL にリセットされる点に注意してほしい。また、ノードに到達するために使うべきインターフェースの番号は最後に受け取ったパケットを反映するように更新される。
void updateTable (MacAddr src, int inif) {
BridgeEntry *b;
if (mapResolve(bridgeMap, &src, (void **)&b) == FALSE ) {
/* このアドレスはテーブルに存在しない。新しくエントリーを作成する。 */
if (numEntries < BRIDGE_TAB_SIZE) {
b = NEW(BridgeEntry);
b->binding = mapBind(bridgeMap, &src, b);
/* パケットの送信元アドレスを destination フィールドに格納する。 */
b->destination = src;
numEntries++;
}
else {
/* 現在のテーブルには入りきらないので、あきらめる。 */
return;
}
}
/* TTL をリセットし、最新のインターフェースを使うよう更新する。 */
b->TTL = MAX_TTL;
b->ifnumber = inif;
}
この実装ではブリッジのテーブルが満杯のときに単純な戦略を採用している ── 新しいアドレスはそのまま捨てられる。テーブルの完全性が転送の正しさに必要ではないことを思い出してほしい: 完全なテーブルがあればパフォーマンスが向上するだけに過ぎない。テーブル内の使われていないエントリーはしばらくすると削除され、新しいエントリー用の空間が生まれる。テーブルが満杯なときに何らかのキャッシュ置換アルゴリズムを採用するアプローチもある。例えば TTL の値が最も小さいエントリーを削除して新しいエントリーを取り入れることもできるだろう。
3.2.3 全域木アルゴリズム
ここまでに説明したアルゴリズムはネットワークにループがあると正しく動かなくなり、非常にまずい形で転送が失敗する ── フレームが永遠に転送され続ける。図 65 に示した例を見ると簡単に理解できる。
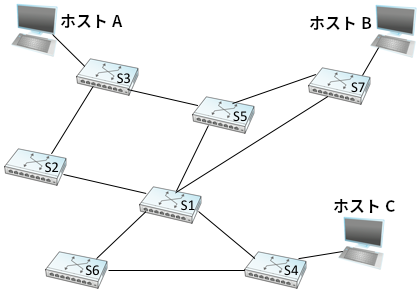
これ以降は転送を行うデバイスをブリッジ (複数のデバイスによって共有される場合があるセグメントが接続される) ではなく L2 スイッチ (単一のデバイスをつなぐポイントツーポイントリンクが接続される) として議論を進める。理解しやすくするために図 65 ではホストを 3 つだけとしたが、実際のスイッチは 16, 24, 48 といった個数のポートを持つことが多い。つまりそれだけのホスト (および他のスイッチ) が一つのスイッチに接続できる。
図 65 のスイッチドネットワークで、スイッチ S4 がホスト C からのパケットを受け取り、そのパケットの宛先アドレスが S4 の転送テーブルに存在していなかったとする。このとき S4 はパケットのコピーを他の二つのポートからそれぞれ S1 と S6 に送信する。S6 でも同様の処理が起こり、S1 は S6 にパケットを転送する (同様に S6 も S1 に転送する)。すると S4 は S6 と S1 から先ほど送ったのと同じパケットを受け取る。しかし S4 の転送テーブルはそのパケットの宛先アドレスを依然として知らないので、またしても他の二つのポートから同じパケットを送信する。このサイクルを止める手立てはなく、パケットは S1, S4, S6 の間を両方向に永遠にさまよい続ける。
そもそもスイッチドイーサネット (あるいは拡張 LAN) がループを持つのはなぜだろうか? 管理者が一人でないことが可能性の一つとして考えられる。例えば組織の複数の部署にまたがるネットワークである。そういった状況ではネットワークの全体構成を知る単一の人物が存在しないので、ループを作るスイッチが知らず知らずのうちに追加されるかもしれない。あるいは、より可能性の高いシナリオとして、障害に備えた冗長性を提供するためにネットワークが意図的にループを持つことも考えられる。結局、ループを持たないネットワークは一つのリンクで障害が起きるだけで全体が二つに分裂してしまう。
どんな原因であれ、スイッチはループを正しく処理できなければならない。この問題は全域木 (spanning tree) アルゴリズムをスイッチに実行させることで解決される。ここではネットワークがループ (閉路) を持つ可能性のあるグラフとみなされる。グラフの全域木とは、そのグラフの部分グラフであって全ての頂点を被覆しつつも閉路を持たないものを言う。言い換えれば、全域木とはグラフの頂点をそのままにして閉路がなくなるよう辺をいくつか取り除いたものを言う。図 66 に閉路を含むグラフ (左) と数多くある全域木の一つ (右) を示す。
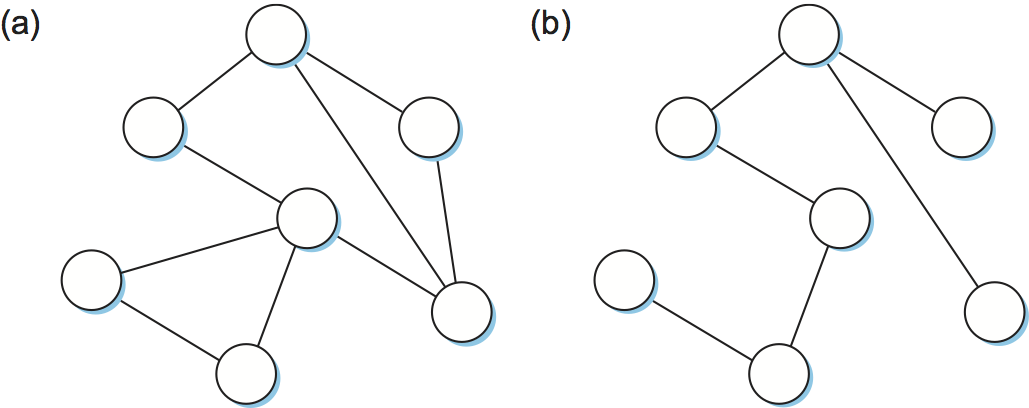
全域木は非常に簡単なアイデアと言える: 実際のネットワークトポロジーの部分集合であってループを含まず全てのデバイスを結ぶものを用意すれば、ループの問題は解決する。難しいのは全てのスイッチを協調動作させて単一の全域木を作り上げる部分である。事実として、単一のトポロジーに対する全域木は一般に数多く存在する。この問題を解決するのが全域木アルゴリズムであり、これから説明される。
DEC の従業員だった Radia Perlman によって考案された全域木アルゴリズムは、ネットワークの特定の全域木に関して全てのスイッチが合意する方法を規定する (IEEE 802.1D 規格が定める全域木プロトコルはこのアルゴリズムをベースとしている)。現実的な処理を考えれば、これは各スイッチがフレーム転送に利用するポート (および利用すべきでないポート) を決めることを意味する。ネットワークを表すトポロジーを刈り込んで閉路を含まない木にするためにポートを削除すると考えることもできる。一見するとおかしなことに思えるかもしれないが、あるスイッチがフレームの転送に全く参加しない可能性もある。ただしアルゴリズムは動的であり、いずれかのスイッチで障害が起きたとしてもスイッチはいつでも全域木を再構成できる。そのため未使用のポートとスイッチは障害からの復帰に必要な冗長性を提供する。
この全域木アルゴリズムの基本的なアイデアは、フレームを転送するポートをスイッチに選択させるというものである。このポートの選択は次のように行われる。各スイッチはユニークな ID を持つ。ここでは S1, S2, S3, ... としよう。最初にアルゴリズムは ID が最小のスイッチを全域木のルート (根) として選択する。この選択の詳細は後述される。そのルートのスイッチは必ず全てのポート (フレームを受信したポートは除く) へフレームを転送する。続いて各スイッチはルートへの最短路を計算し、その最短路で使われるポートをルートにフレームを送信するときに使うものとして選択する。最後に、一つのリンクに接続するスイッチが複数存在する可能性に対処するために、ルートからのフレーム転送を担当する代表スイッチ (designated switch) スイッチがリンクごとに選出される。代表スイッチはルートに最も近いスイッチとして選出され、ルートからの距離が同じ場合はスイッチの ID が小さい方が選出される。スイッチが複数のリンクと接続される可能性が当然あるので、代表スイッチの選出はポートごとに行われる。事実上、これは各スイッチが自身のポートごとに自身が代表ノードかどうかを判断することを意味する。スイッチは自身が代表ノードとなっているポートだけにフレームを転送する。
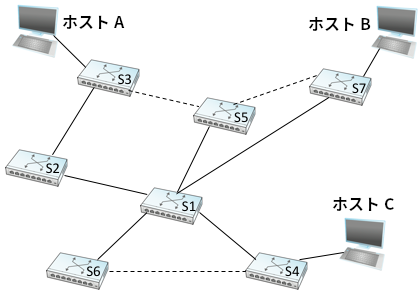
図 65 のネットワークに対応する全域木を図 67 に示す。この例では最も小さな ID を持つ S1 がルートとなる。S3 と S5 を結ぶリンクは構成される全域木に含まれない点に注意してほしい。図には示されていないものの、S3 と S5 を結ぶリンクではルートにより近い S5 が代表スイッチとなる。S5 と S7 を結ぶリンクも同様に全域木に含まれない。この場合は両端のルートからの距離が同じなので、ID の小さい S5 が代表スイッチとなる。
説明した規則に従って人間が図 65 から図 67 のような全域木を計算することはできるものの、スイッチはネットワーク全体のトポロジーを確認できず、それどころか他のスイッチの ID を直接見ることさえできない。その代わり、各スイッチは構成メッセージ (configuration message) を他のスイッチと交換することで自身がルートまたは代表スイッチかどうかを判断する。
具体的には、構成メッセージは次の三つの情報を持つ:
-
メッセージを送信しているスイッチの ID
-
メッセージを送信しているスイッチがルートだと信じているスイッチの ID
-
メッセージを送信しているスイッチからそのスイッチが信じているルートへの距離 (単位はホップ)
スイッチは各ポートが確認した「最良」の構成メッセージを記録する (「最良」の意味は後述)。「最良」の構成メッセージは他のスイッチから届けられたものである場合もあれば、自身が送ったものである場合もある。
最初、全てのスイッチは自身をルートだと思っている。そのため全てのスイッチの各ポートから送られる構成メッセージには「ルートは私で、私からルートまでの距離は 0 である」と記される。いずれかのポートから構成メッセージを受け取ったスイッチは、そのメッセージが現在保持している最良のメッセージより良いかどうかをチェックする。新しい構成メッセージが現在の構成メッセージ「より良い」とは、次の条件のいずれかが成り立つことを言う:
-
ルートの ID が現在のものより小さい。
-
ルートの ID は同じで、距離が現在のものより短い。
-
ルートの ID とルートからの距離は同じで、送信元の ID が現在のものより小さい。
新しいメッセージが現在記録されたものより良いなら、スイッチは古い情報を捨てて新しい情報を保存する。ただし、そのメッセージを送信したスイッチからルートまでの距離より自身は一つだけルートから遠くにいるので、保存するときルートからの距離のフィールドには 1 が足される。
受け取った構成メッセージから自身がルートでないと理解したスイッチ、つまり ID が自身より小さいスイッチからメッセージを受け取ったスイッチは、受け取った構成メッセージの距離フィールドを 1 増やしたものを保存した後に構成メッセージの生成を止め、以降は転送だけを行う。同様に、受け取った構成メッセージから特定のリンクにおいて自身が代表スイッチでないと理解したなら、つまり自身よりルートに近いスイッチもしくはルートからの距離が同じで ID が自身より小さいスイッチからの構成メッセージを受け取ったなら、スイッチはそのリンクへの構成メッセージの送信を停止する。このため、システムが安定化すると、ルートスイッチだけが構成メッセージを生成し、他のスイッチは自身が代表スイッチであるリンクが接続されたポートだけにその構成メッセージを転送する状態となる。この時点で全域木が構成され、その全域木でどのポートが使われるかについて全てのスイッチの間で合意が形成される。データパケットの転送ではそれらのポートだけが利用される。
以上のアルゴリズムの具体的な動作を例と共に確認しよう。図 67 のネットワークで停電が起こり、電力が復旧したとする。このとき全てのスイッチはほぼ同時に起動され、それぞれが自分はルートだと主張する構成メッセージを送り始める。S3 に注目して、どのようなイベントが起こるかを見てみよう。次のタイムラインでは、ルートノードが Y で X とルートの距離が d だと主張するノード X の構成メッセージを (Y, d, X) と表記している:
-
S3 は (S2, 0, S2) を受け取る。
-
2 < 3 なので、S3 は S2 をルートとして受理する。
-
S3 は S2 から広報されたルートからの距離 0 に 1 を加え、(S2, 1, S3) を S5 に送信する。
-
同じころ、S2 は ID が自身より小さい S1 をルートとして受理し、(S1, 1, S2) を S3 に送信する。
-
S5 は S1 をルートとして受理し、(S1, 1, S5) を S3 に送信する。
-
S3 は S1 をルートとして受理する。S3 は S2 と S5 の両方が自身よりルートに近いと理解するものの、S2 の方が ID が小さいので、S3 が考えるルートへの経路は S2 を通るもののまま変わらない。
以上の処理が終わると、S3 では図 67 に示すポートがアクティブになる。なお、全てのフレームが全域木を「登って降りる」必要があるために、ホスト A と B は最短距離 (S5 を通る経路) で通信を行えないことに注意してほしい。これはループを避けるためのコストである。
システムが安定化した後でもルートは構成メッセージを定期的に送信し続け、他のスイッチは先述したように構成メッセージを転送し続ける。いずれかのスイッチで障害が発生すると、それより下流のスイッチは構成メッセージを受け取らなくなる。その後一定の時間が経過するとそれらのスイッチは自身がルートだと主張する構成メッセージの送信を開始し、新しいルートと新しい代表スイッチを選出するために同じアルゴリズムが実行される。
指摘しておくべき重要な点として、このアルゴリズムはスイッチで障害が発生したときは必ず全域木を再構成できるのに対して、輻輳を起こしたスイッチを迂回する目的で異なる経路を用意することはできない。
3.2.4 ブロードキャストとマルチキャスト
ここまでの議論はスイッチがユニキャストフレームをあるポートから別のポートへ転送する方法だけを考えてきた。スイッチの目標は LAN を複数のネットワークにまたがるよう透明に拡張することであり、多くの LAN はブロードキャストとマルチキャストをサポートするので、スイッチはこの二つの機能もサポートしなければならない。ブロードキャストは簡単に扱える ── 各スイッチは受信したポートを除く全てのアクティブなポートにブロードキャストアドレスを宛先にしたフレームを転送すればいい。
マルチキャストも全く同じように実装できる: メッセージを受理するかどうかを各ホストに自分で判断させればいい。これは実際に行われている方法である。しかし、マルチキャストグループに属さないホストも存在するので、マルチキャストはこれよりも上手く処理できる。具体的には、マルチキャストフレームを転送する必要のない部分を枝刈りできるようにする全域木アルゴリズムの拡張が存在する。図 67 でホスト A からグループ M に対するマルチキャストフレームが送信され、ホスト C は M に含まれないとする。このときスイッチ S4 はフレームを転送する必要がない。
マルチキャストフレームを特定のポートに転送すべきかどうかをスイッチはどのように学習するのだろうか? この学習はユニキャストフレームと同様に行われる ── ポートで受け取ったフレームの送信元アドレスを見ることで行われる。ただ、フレームの送信元がグループになることは当然ないので、少しずるい工夫をする: 先ほどの例で言うと、グループ M のメンバーであるホストは定期的にヘッダーの送信元フィールドをグループ M のマルチキャストアドレスに設定したフレームを送信する。このフレームの宛先アドレスはスイッチに対するマルチキャストアドレスに設定される。
ここで説明したマルチキャストの拡張はかつて提案されたものの、広く採用されることはなかった。その代わり、マルチキャストは現在ブロードキャストと全く同じように実装されている。
3.2.5 仮想 LAN (VLAN)
スイッチの欠点の一つにスケールしないことがある。現実的に接続できるスイッチは最大でも数十個程度となる。この理由の一つとして、全域木アルゴリズムが線形にスケールする事実がある: つまり、スイッチの中に階層を作り出すための規定が存在しない。二つ目の理由として、スイッチがブロードキャストフレームを全て転送することがある。それほど大きくない環境 (例えば一つの部署) で全てのホストがお互いのブロードキャストメッセージを受け取るのは理にかなっているのに対して、それより大きな環境 (例えば大規模な企業や大学) で全てのホストがお互いのブロードキャストメッセージを見たいと思う可能性は低い。別の言い方をすれば、ブロードキャストはスケールせず、そのために L2 ベースのネットワークもスケールしない。
スケーラビリティを向上させるアプローチの一つとして仮想 LAN (virtual LAN) がある。VLAN を使うと単一の拡張 LAN を分割し、論理的に異なる複数の LAN を作成できる。分割された LAN を VLAN と呼び、それぞれの VLAN には識別子が割り当てられる。この識別子をカラー (color) と呼ぶことがある。パケットは同じ識別子を持つノードを結ぶセグメントだけを流れるようになり、これによってブロードキャストパケットを受け取るセグメントの個数が減少する。
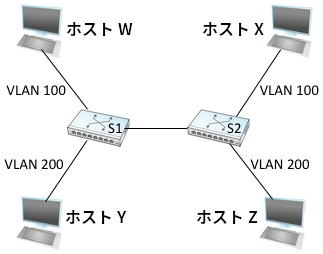
VLAN の動作例を見てみよう。図 68 には四つのホストと二つのスイッチが示されている。VLAN が無ければ、任意のホストからの全てのブロードキャストパケットは他の全てのホストに伝わることになる。ここで、ホスト W とホスト X を結ぶ三つのセグメントを一つの VLAN (VLAN 100) にして、ホスト Y とホスト Z を結ぶ三つのセグメントを異なる VLAN (VLAN 200) にしたいとする。これを行うには、VLAN ID をスイッチ S1, S2 の各ポートに設定する。このとき S1 と S2 を結ぶリンクは両方の VLAN に属することになる。
ホスト X からのパケットがスイッチ S2 に届いたとき、S2 はそのパケットが VLAN 100 用に設定されたポートに届いたことを認識し、イーサネットヘッダーとペイロードの間に VLAN ヘッダーを挿入する。VLAN ヘッダーの注目に値するフィールドは VLAN ID である: この例で VLAN ID は 100 に設定される。その後スイッチはパケットを転送する通常の規則に従うものの、VLAN 100 に属さないポートにはパケットを転送しないという制限が加わる。そのため、ホスト X が送信したパケットは絶対に ── ブロードキャストパケットでさえ ── VLAN 200 に属する ホスト Z へ向かうインターフェースには転送されない。一方でホスト X からのパケットはスイッチ S1 には転送され、S1 でも同様の処理が起こってパケットはホスト W に転送される (ホスト Y には転送されない)。
VLAN の魅力的な特徴として、ケーブルの付け替えやアドレスの変更をせずに論理的なトポロジーを変更できる点が挙げられる。例えばホスト Z を VLAN 100 の一員にして X, W, Z を同じ VLAN に含めたいときは、スイッチ S2 の設定を一か所変更するだけで済む。
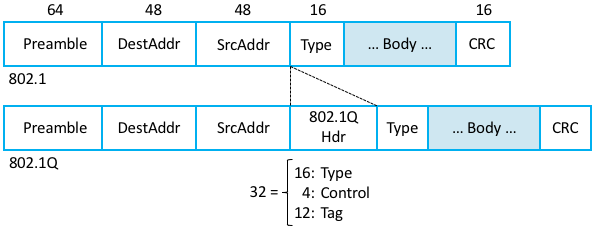
VLAN のサポートにはオリジナルの IEEE 802.1 ヘッダーの仕様に非常に小さな拡張が必要になり、その仕様は IEEE 802.1Q で規定される。図 69 に示すように、SrcAddr フィールドと Type フィールドの間に VLAN の ID を表す 12 ビットの Tag フィールドが挿入される。この文脈で VLAN の ID は VLAN タグ (VLAN tag) と呼ばれることが多い。VLAN をサポートするためにヘッダーに追加されるビットは実際には 32 ビットある。最初の 16 ビット Type = 0x8100 はオリジナルの仕様と後方互換性を持たせるために存在し、このフレームが VLAN 拡張を含むことを示す。残りの 4 ビットにはフレームの優先度を指定するための情報が含まれる。このため、単一の物理 LAN の上には最大 \(2^{12} = 4096\) 個の仮想ネットワークを構築できる。
議論の最後に、L2 スイッチを相互接続することで構築されるネットワークが持つもう一つの欠点を指摘しておく: そういったネットワークは不均一性 (heterogeneity) をサポートできない。つまりスイッチで相互接続できるネットワークの種類が限られている。具体的には、スイッチがネットワークのフレームヘッダーを利用するので、ヘッダーに全く同じフォーマットを持つネットワークしかサポートできない。例えば、IEEE 802.1 ベースのネットワークとイーサネットは共通のヘッダーフォーマット持つので、スイッチはその二つを相互接続できる。しかし異なるフォーマットを持つ種類のネットワーク、例えば ATM、SONET、PON、セルラーネットワークが存在するときスイッチは上手く一般化できない。次節ではこの問題を解決する方法、およびスイッチドネットワークをさらに大規模なサイズまでスケールする方法が説明される。