3.3 インターネット (IP)
前節では、ブリッジ (L2 スイッチ) を用いればそれなりに大きな LAN を構築できるものの、このアプローチはスケーラビリティと不均一性への対処に問題を抱えていることを見た。本節では、スイッチドネットワークのこういった欠点を克服し、それなりの効率のルーティングを持つ大規模で不均一性が高いネットワークを構築する方法をいくつか説明する。本書ではそういったネットワークをインターネットワーク (internetwork) と呼ぶ。真に地球規模なインターネットワークを構築する方法に関する議論は次節で行うことにして、本節では基本的な事項を説明する。まずはインターネットワークという言葉の意味をより深く考えるところから始めよう。
3.3.1 インターネットワークとは?
インターネットワーク (internetwork) という言葉は、ホスト間に何らかのパケット転送サービスを提供するために相互接続されたネットワークの集合を指す言葉として使われている (英語ではインターネットワークを小文字の i を使って internet とも呼ぶ)。例えば、様々な地域に拠点を持つ企業は、拠点ごとに構築された LAN を通信事業者からリースしたポイントツーポイントリンクで相互接続することでプライベートなインターネットワークを構築するかもしれない。一方で、現在では大部分のネットワークが接続され多くの人が利用している地球規模のインターネットワークはインターネット (Internet) と呼ばれる (英語では大文字の I が使われる)。第一原理から議論を進める本書のアプローチに従って、本節では主に「小文字の」インターネットワークの設計指針を学ぶ。ただしアイデアを説明するときは「大文字の」インターネットにおける現実世界の例を利用する。
用語に関してもう一つ分かりにくい点として、「ネットワーク」「サブネットワーク」「インターネットワーク」の区別がある。本節では「サブネットワーク」および「サブネット」を説明せず、後に回す。現時点では、前章と前節で説明した種類の直接もしくはスイッチを介して接続されたネットワークを指して「ネットワーク」という言葉を使う。この「ネットワーク」は IEEE 802.11 やイーサネットといった単一の技術を利用する。「インターネットワーク」はそういったネットワークを相互接続したものである。曖昧性を避けるために、相互接続される下位のネットワークを指して物理ネットワーク (physical network) という言葉を使うこともある。これに対して、複数の物理ネットワークが集まって構築されるインターネットワークは論理ネットワーク (logical network) と呼ばれる。この文脈でも、ブリッジやスイッチで接続されたイーサネットセグメントの集合は単一のネットワークとみなされる。
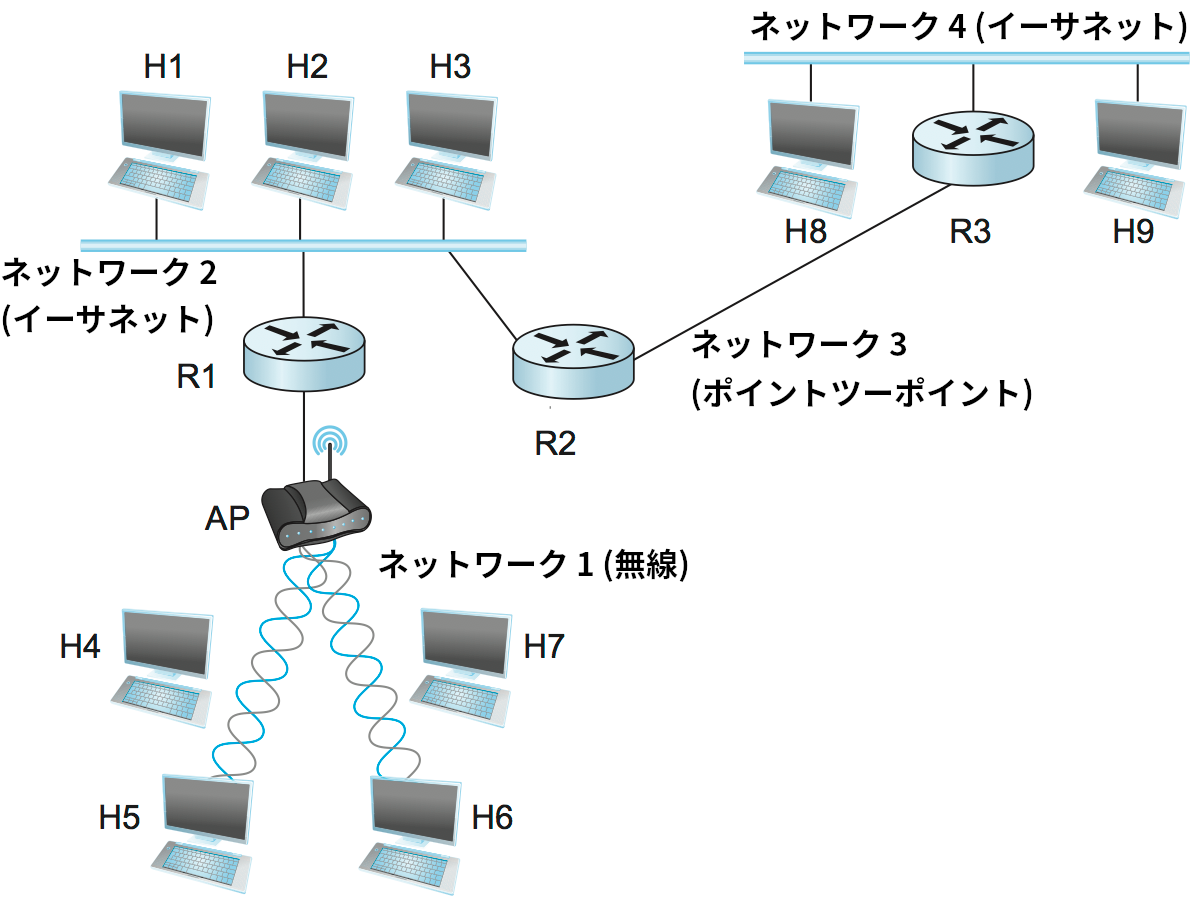
図 70 にインターネットワークの例を示す。インターネットワークはたくさんの小さなネットワークから構成されるので、「ネットワークのネットワーク」と呼ばれることがある。この図にはイーサネット、無線ネットワーク、そしてポイントツーポイントリンクという三種類のネットワークが存在する。それぞれは単一のテクノロジを使ったネットワークである。ネットワーク同士を相互接続するノードはルーター (router) と呼ばれる。ルーターはゲートウェイ (gateway) と呼ばれることもある。しかし「ゲートウェイ」はネットワークの相互接続の他にもいくつか機能を持つデバイスを意味するので、本書では「ルーター」という言葉を使用する。
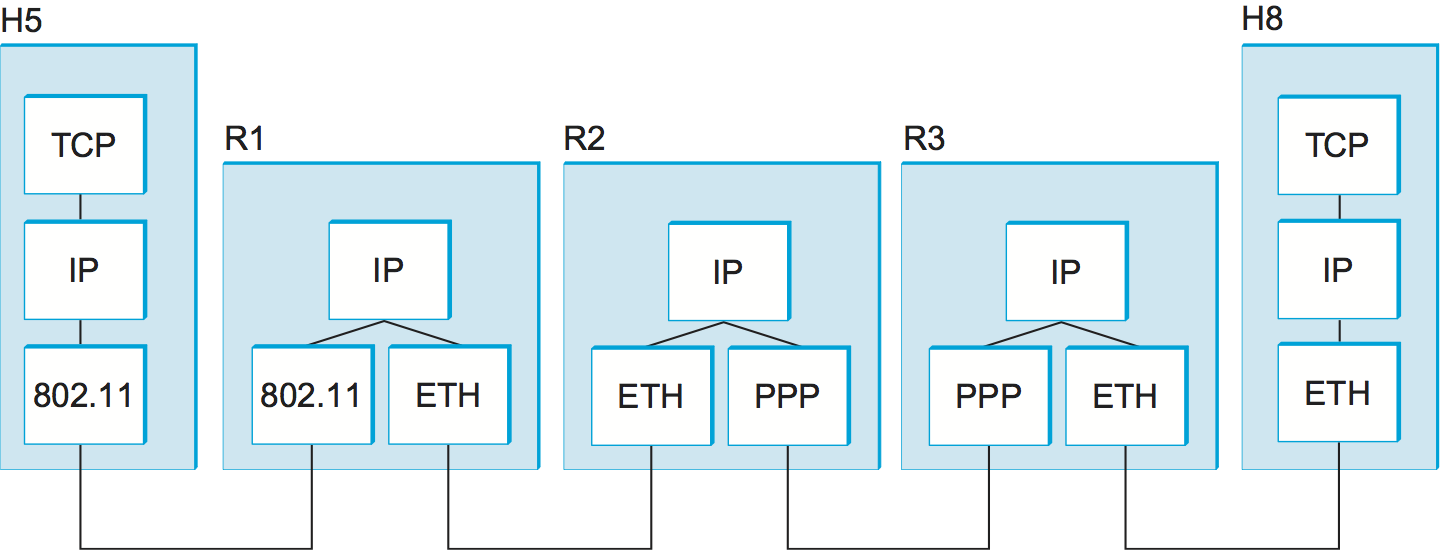
スケーラブルで不均一なインターネットワークの構築で鍵となるツールは IP (Internet Protocol, インターネットプロトコル) である。かつては考案者の名前を取って Kahn-Cerf プロトコルと呼ばれていた。インターネットワークに属する全てのネットワークの全ノード (ホストとルーターの両方) で実行されるのが IP であり、ノードとネットワークが単一の論理的インターネットワークとして機能にするためのインフラストラクチャが IP によって定義されると考えることができる。例として図 70 のインターネットワークでホスト H5 とホスト H8 がどう論理的に接続されるかを図 71 に表す。この図には各ノードで用いられるプロトコルのグラフも示されている。TCP や UDP といった上位プロトコルは典型的にはホストにおいて IP の上で実行されることに注意してほしい。
本章の残りと次章では、IP の様々な側面が解説される。IP を使わないインターネットワークの構築は不可能ではない ── 事実、インターネットが生まれたころは IP 以外の選択肢も存在した ── ものの、インターネットが巨大である事実だけでも IP は最も興味深い研究対象となる。言い換えれば、IP インターネットは本当の意味でスケールの問題に直面する唯一のインターネットワークであり、それが理由でスケーラブルなインターネットワーキングプロトコルの最も優れたケーススタディを提供する。
L2 ネットワーク vs L3 ネットワーク
前節で見たように、イーサネットをスイッチの組を相互接続するポイントツーポイントのリンクと扱えば、相互接続されたスイッチのメッシュからスイッチドイーサネットを構築できる。この構成は L2 ネットワーク (L2 network) と呼ばれる。
しかし本節でこれから見るように、イーサネットを (共有の CSMA/CD ネットワークではなくポイントツーポイントの構成で使われる場合でさえ) ルーターの組を相互接続するネットワークと扱い、イーサネットによって接続されるルーターのメッシュがインターネットワークを構成すると考えることもできる。この構成は L3 ネットワーク (L3 network) と呼ばれる。
このような事態がなぜ生じるかと言えば、分かりにくいことに、ポイントツーポイントのイーサネットはリンクにもなればネットワークにもなるからである。全域木アルゴリズムを実行する L2 スイッチの組を接続するときイーサネットはリンクになり、IP (および本節でこれから解説されるルーティングプロトコル) を実行する L3 ルーターの組を接続するときイーサネットはネットワークになる。どちらを選べばいいのだろうか? ネットワークを単一のブロードキャストドメインにしたいかどうか (もししたいなら、L2)、あるいは接続するホストを異なるネットワークに属するようにしたいかどうか (もししたいなら、L3) などによって判断される。
良いニュースがある。この双対性が意味することを理解できたなら、現代的なパケット交換ネットワークにおける大きなハードルを乗り越えたことになる。
3.3.2 サービスモデル
インターネットワークの構築はサービスモデルの定義から始めるべきだろう。つまり、そのインターネットワークがホスト間に提供するサービスは何だろうか? インターネットワークのサービスモデルを定義する上での主な懸案事項として、ホスト間に提供できるサービスは下位の物理ネットワークのそれぞれで何らかの形で提供されているサービスに限られる事実が挙げられる。例えば、構築しようとするインターネットワークのサービスモデルで全てのパケットに対する 1 ms 以内の転送を保証しようとしても、下位のネットワークでパケットがいくらでも遅延する可能性のあるテクノロジが使われていれば、そのサービスモデルは絶対に達成できない。そのため、IP のサービスモデルを定義する上では「インターネットワークを構成するネットワークでいかなるテクノロジが使われていたとしても要求されるサービスを提供できるよう、なるべく条件を緩くする」という考え方が採用された。
IP のサービスモデルは二つの部分から構成されるとみなせる:
- インターネットワーク上のホストを特定する手段を提供するアドレス方式
- データグラム (コネクションレス) モデルのデータ転送
このサービスモデルはベストエフォート (best effort) と呼ばれることがある。IP は最大限に努力してデータグラムを転送しようとはするものの、転送に関する保証は存在しない。アドレス方式の議論は後にまわして、データ転送モデルをまず見ていく。
データグラム転送
IP データグラムはインターネットプロトコルの基礎である。第 3.1 節で解説したように、データグラムはコネクションレス方式でネットワークに送られるパケットの別名だったことを思い出してほしい。全てのデータグラムは十分な情報を持っており、ネットワーク内の各ノードは任意のパケットを正しい宛先に向けて転送できる。受け取ったパケットに対してすべきことをネットワークに伝える事前のセットアップ処理は存在しない。ホストはいきなりパケットを送り、ネットワークはそのパケットを宛先に届けるために最大限努力する。「最大限努力する」とは、何らかの不具合でパケットの喪失、破損、誤転送などが起きて送信元が伝えた宛先に正しいパケットが届かない場合でも、ネットワークは何もしないことを意味する ── 最大限努力して、それで終わりである。障害の回復を試みることは一切無い。このため IP のサービスは低信頼 (unreliable) と呼ばれることがある。
ベストエフォートのコネクションレス型サービスはインターネットワークが提供できる中で最も単純と言っても過言ではないサービスであり、それこそが IP の強みである。例えば、もし高信頼サービスを提供するネットワークの上にベストエフォートのサービスを構築しようと思ったなら、それは問題なく行える ── 偶然にもパケットが必ず転送されるベストエフォートのサービスが手に入るだけだ。一方で、もし低信頼のネットワークの上に高信頼のサービスを構築しようと思ったなら、下位のネットワークで発生する損傷を埋め合わせるために多くの処理をルーターに追加しなければならないだろう。ルーターを可能な限り単純に保つことは IP のオリジナルの設計目標の一つだった。
IP が「どんなデバイスでも動かせる」という事実は IP の最も重要な特徴として頻繁に指摘される。さらに、現在 IP の上で動作するテクノロジの多くは IP が考案された当時には存在しなかった事実は注目に値する。IP を凌駕するネットワークテクノロジは今まで考案されていない。理論上は、伝書鳩でメッセージを移動させるネットワークの上で IP を実行することさえできる。
ベストエフォートの転送が意味するのはパケットの損失だけではない。ときにはパケットの順番が前後して届いたり、同じパケットが何度も届いたりすることもある。IP より上位のプロトコルとアプリケーションはこういった起こりうる障害モードを全て認識しておく必要がある。
IP パケットのフォーマット
明らかに、IP のサービスモデルにおける重要な要素は伝達できるパケットの種類である。IP データグラムは、多くのパケットと同じように、ヘッダーの後にデータのバイトが並んだフォーマットをしている (図 72)。フォーマットの表し方が前章までとは異なる点に注意してほしい。これは、本節以降で扱うインターネットワーク層より上のパケットフォーマットはソフトウェアでの処理を簡単にするために必ず 32 ビット境界でアラインされるよう設計されるためである。そういったフォーマットは 32 ビットのワードの連なりとして表されることが多い (例えばインターネットの RFC ではそのように表されている)。上にあるワードが最初に転送され、各ワードの一番左にあるバイトが最初に転送される。この表現を使うと、長さが 8 ビットの倍数であるフィールドを簡単に認識できる。ときには 8 ビットの倍数でないフィールドが存在する場合もあるものの、図の上部に示された数字を見ればフィールドの長さを確認できる。
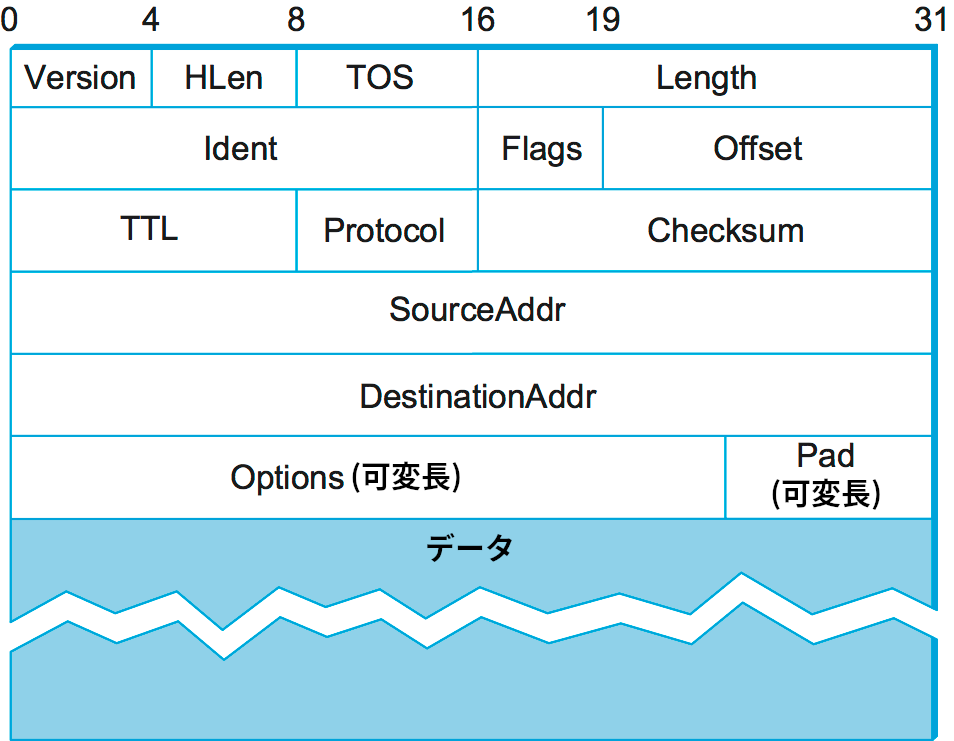
IP ヘッダーの各フィールドを見ると、ベストエフォートのデータグラム通信という "シンプル" なモデルにも細かな機能がいくつか存在することが分かる。Version フィールドは IP のバージョンを指定する。この図で仮定されている IP のバージョンは 4 であり、IP Version 4 は略して IPv4 と呼ばれる。バージョンを表すフィールドをデータグラムの先頭に配置することで、他の全てのフィールドを以降のバージョンで再定義しやすくなっている点に注目してほしい。このヘッダーを処理するソフトウェアはバージョンさえ確認すれば、パケットの残りの部分の処理をバージョンに合ったフォーマットとして読み取る独立した処理に任せられる。次の HLen フィールドはヘッダーの長さを表す (単位はワード)。大部分の IPv4 ヘッダーは省略可能なフィールドを持たず、5 ワード (20 バイト) の長さを持つ。次の TOS (type of service) フィールドに対する定義は今まで様々なものが存在してきたものの、基本的にはアプリケーションのニーズに合わせてパケットに対する扱いを変えるために利用される。例えば TOS の値はデータグラムを低遅延用の特別なキューに入れるべきかどうかを表すかもしれない。
次の Length フィールドはデータグラムの長さ (ヘッダーを含む) を 16 ビットで表す。HLen フィールドと異なり、Length フィールドは長さをワードではなくバイトで数える。そのため IP データグラムの最大長は 65,535 バイトとなる。ただし IP を実行する物理ネットワークはこの長さのパケットをサポートしない可能性があるので、IP は分割 (fragmentation) と再構築 (reassembly) の処理をサポートする。ヘッダーの第二ワードは分割と再構築に関する情報を持つ。詳細は IP パケットの分割と再構築の節で説明される。
ヘッダーの第三ワードに進むと、最初のバイトは TTL (time to live) フィールドを表す。このフィールドの名前は現在の使われ方よりも歴史的な意味を反映している。このフィールドはルーティングループに陥ったパケットを捕まえて破棄し、無限にリソースを消費しないようにするために存在する。当初 TTL フィールドはパケットが生きていられる秒数を直接指定し、経路上のルーターはその値を減らして 0 になったら破棄する処理を行っていた。しかしパケットが 1 秒もの間ルーターに留まることは稀であり、さらに共通の時計を持たないルーターもあったので、多くのルーターは受け取ったパケットの TTL フィールドの値を無条件に 1 だけ減らして転送していた。そのため、現在 TTL フィールドの値は破棄されるまでの時間ではなく破棄されるまでのホップカウントを表している。パケットを送信するときの TTL フィールドの初期値には注意が必要になる: 大きすぎると破棄されるまでにインターネットワークを無駄に循環することになり、小さすぎると宛先に届かない可能性が生じる。現在 TTL フィールドのデフォルト値は 64 とされている。
次の Protocol フィールドは、この IP パケットを渡すべき上位プロトコルを指定する逆多重化鍵を表す。TCP を表す 6 や UDP を表す 17 をはじめとして、プロトコルグラフで IP の上に位置できる様々なプロトコルに対する値が定義されている。
次の Checksum フィールドはチェックサムである。IP ヘッダー全体を 16 ビットワードの列とみなし、ヘッダーを構成するワードを 1 の補数算術を使って全て足し、その和の 1 の補数を取ることで計算される。そのため、転送中にヘッダーのビットが破損すると、パケットを受け取った側で計算したチェックサムがヘッダーに含まれるチェックサムと一致しなくなる。破損したヘッダーは宛先アドレスが誤っている ── その結果として誤転送される ── 可能性があるので、チェックサムによるテストを追加しなかったパケットは全て破棄するのが理にかなっている。この種の加算を用いるチェックサムは CRC が持つような強力な誤り検出能力を持っていないものの、ソフトウェアでの計算はずっと簡単に行える点を指摘しておくべきだろう。
IP ヘッダーの最後の二つのフィールドは SourceAddr と DestinationAddr であり、それぞれパケットの送信元アドレスと宛先アドレスを表す。DestinationAddr フィールドはデータグラム転送で鍵となる: 全てのパケットが最終的な宛先の完全なアドレスを持ち、転送の判断は各ルーターが独立に行う。送信元アドレスがヘッダーに存在するのは、パケットを受け取ったホストがパケットを受理するかどうかの判断を行うため、そして返答を可能にするためである。IP アドレスは本節の後半で扱う ── 現段階では、IP がグローバルなアドレス空間を独自に定義し、その空間は内部の物理ネットワークと独立することを理解するのが重要である。後で見るように、IP 特有のグローバルなアドレス空間は不均一性のサポートで重要となる要素の一つである。
最後に、ヘッダーの最後にはいくつか省略可能なフィールドが存在する。これらのフィールドの有無はヘッダーの長さを表す HLen フィールドを調べることで判定できる。ほとんど使われることはないものの、完全な IP 実装はこういったフィールドにも対応しなければならない。
分割と再構築
不均一なネットワークの集合の上にホストからホストへの均一なサービスモデルを提供しようとするとき、それぞれのネットワークテクノロジでパケットの最大長が異なる事実が問題となる。例えば古典的なイーサネットは最長で 1500 バイトのパケットを扱えるのに対して、現代的なイーサネットはそれより大きい最大 9000 バイトのパケット (ジャンボパケット) を扱える。この問題の解決策として IP のサービスモデルが採用できる選択肢は二つある: 一つは任意のネットワークテクノロジのパケットに収まるほどに IP データグラムを小さくする方法、もう一つは特定のネットワークテクノロジで IP パケットを直接転送できないときのためにパケットを分割および再構築する手段を提供する方法である。後者の方法が優れていることが判明している。特に、ネットワークテクノロジは常に新しいものが出現しており、IP はそれらの全てで実行されなければならない事情を考えると、データグラムのサイズの下限を適切に選択するのは難しい。さらに、分割と再構築の処理があれば、ホストは不必要に小さいパケットを送信しないで済む。そうすれば送られるデータ 1 バイトあたりのヘッダーが短くなり、帯域と処理リソースが節約される。
IP データグラムの分割と再構築では、全ての種類のネットワークが持つ MTU (maximum transmission unit, 最大転送ユニット) と呼ばれる値が重要となる。MTU は一つのフレームで伝達できる IP データグラムの最大サイズを表す1。MTU の値は一般に物理ネットワークが伝達するフレームの最大サイズより小さくなる点に注意してほしい。IP データグラムはリンク層のフレームのペイロードに収まる必要があるためである。
分割と再構築があるので、送信元ホストは IP データグラムのサイズを好きに選択できる。ホストが接続されているネットワークの MTU が自然な選択肢となる。そうしておけば、宛先への経路に含まれるネットワークの MTU が最初のネットワークの MTU より小さいときに限って分割が必要になる。ただし、送信元ホストで IP の上に位置するトランスポートプロトコルが MTU より大きなパケットを IP に渡した場合には、送信元ホストで分割が必要になる。
IP データグラムの分割は典型的にはルーターで、転送しようとしているデータグラムが転送先のネットワークの MTU より大きいときに起こる。分割されたデータグラムをフラグメント (fragment) と呼ぶ。フラグメントを宛先で再構築できるように、同じデータグラムを分割して得られるフラグメントは全て同じ Ident フィールドを持つ。Ident フィールドは送信元ホストによって割り当てられる識別子であり、一定の時間の間に同じ送信元から同じ宛先へ送られるデータグラムの間で一意とされる。オリジナルのデータグラムを分割した全てのフラグメントは共通の識別子を持つので、再構築を行うホストはどのフラグメントを組み合わせるべきかを認識できる。全てのフラグメントが宛先ホストに到着しなかった場合、そのホストは再構築プロセスを諦めて届いたフラグメントを全て破棄する。IP は欠損したフラグメントの回復を試みない。
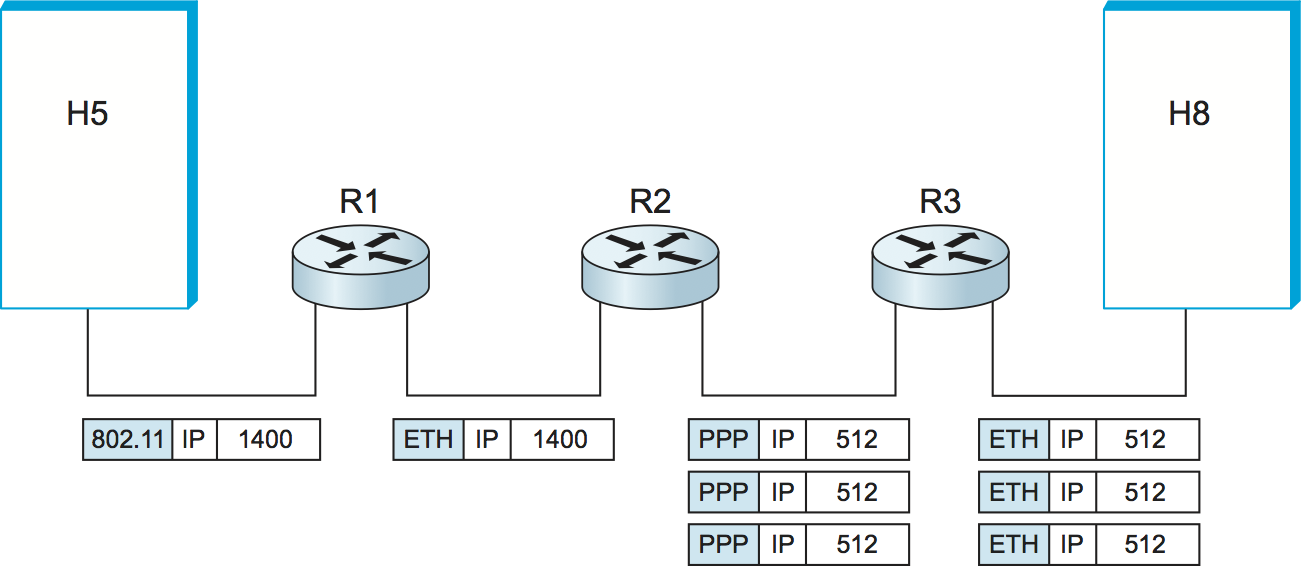
分割と再構築がどのように行われるかを確認するために、図 70 のネットワークでホスト H5 がホスト H8 にデータグラムを送信したときに何が起こるかを考えよう。二つのイーサネットと 802.11 ネットワークの MTU は 1500 バイト、ポイントツーポイントネットワークの MTU は 532 バイトだと仮定し、20 バイトの IP ヘッダーと 1400 バイトのデータからなる 1420 バイトのデータグラムを H5 が送ったとする。このとき、そのデータグラムは 802.11 ネットワークと一つ目のイーサネットを分割されずに通り抜けるものの、ルーター R2 では三つのデータグラムへの分割が必要となる。それら三つのフラグメントはポイントツーポイントネットワークを通じてルーター R3 に送られ、その後 R3 は三つのフラグメントをイーサネット越しにそのまま宛先ホスト H8 へ転送する。以上の処理を図 73 に示す。この図には次の重要な点が強調されている:
-
それぞれのフラグメントはそれ自身が完全な IP データグラムであり、いくつかの物理ネットワークを通じて互いに独立して転送される。
-
それぞれの IP データグラムは経由する物理ネットワークのそれぞれで毎回カプセル化される。
IP データグラムの分割プロセスは各データグラムのヘッダーフィールド (図 74) を見ると理解が深まるだろう。左の分割されていないデータグラムは 20 バイトの IP ヘッダーと 1400 バイトのデータを持つ。このデータグラムが R2 に到着したとき、ポイントツーポイントネットワークの MTU は 532 バイトなので分割が必要だと R2 は判断する。R2 は他のフラグメントがこれに続くことを表すビットを Flags フィールド (図 72 を参照) に設定し、最初のフラグメントでは Offset を 0 に設定する。二つ目のフラグメントはオリジナルのデータグラムにおける 513 バイト目から始まるので、Offset フィールドは 64 (= 512 ÷ 8) に設定される。なぜ 8 で割るのかというと、分割は必ず 8 バイト境界で行うべきだと IP の設計者が判断したためである。そのため Offset はバイトではなく 8 バイトのチャンクの個数を表す (この設計判断が下された理由を見つけるのは読者への練習問題とする)。三つ目のフラグメントには最後の 376 バイトのデータが含まれ、Offset フィールドは 128 (= 2 × 512 ÷ 8) となる。これは最後のフラグメントなので、Flags フィールドは 0 に設定される。
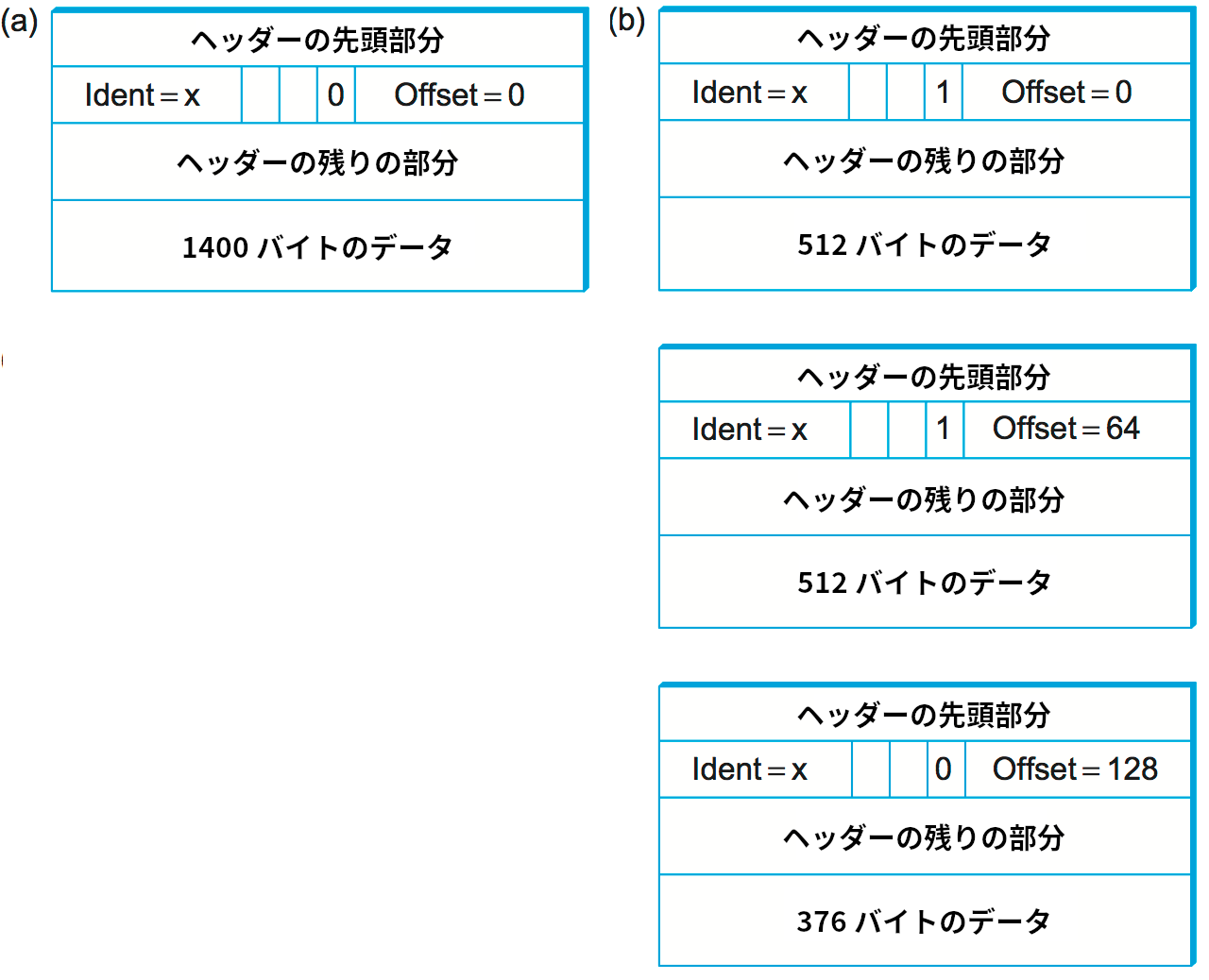
フラグメントが MTU のさらに小さい他のネットワークに到達した場合でもデータグラムの分割処理を繰り返し行えることに注意してほしい。分割を何度行ったとしても生成される IP データグラムはオリジナルより小さいだけで完全に正当であり、受け取ったホストはフラグメントが到着する順序に関係なくオリジナルのデータグラムを再構築できる。なお、再構築は経路上のルーターではなく宛先のホストで行われる。
IP データグラムの再構築は決して単純なプロセスではない。例えば何らかのフラグメントが到着しない場合でも、単に到着が遅れているだけかもしれないので受信ホストはデータグラムの再構築を止めることはできない。しかし一定の時間が経過したときは再構築を諦め、失敗した再構築に使われていたリソースのゴミ集めが必要になる。必要でなくなったリソースを確保したままにしておくと、DoS 攻撃 (Denial-of-Service Attack, サービス拒否攻撃) に利用される可能性がある。
こういった理由により、現在 IP データグラムの分割は避けるべきだと一般に認識され、「経路 MTU 探索」の実行がホストに強く推奨されている。これは送信元から宛先への経路上にあるネットワークの MTU の最小値を最初に調べることで分割を回避する処理である。
3.3.3 グローバルなアドレス
第 3.3.2 項の議論で、IP のサービスモデルはアドレス方式を提供すると説明した。どんな形態のネットワークであれ、他のホストにデータを送信するときは全てのホストを識別する手段が存在しなければならない。そのため IP にもグローバルなアドレス方式が必要になる ── どの二つのホストも同じアドレスを持っていてはいけない。グローバルな一意性は IP のアドレス方式が提供すべき第一の性質である。
イーサネットのアドレスはグローバルに一意であるものの、それだけでは大規模インターネットワーク向けのアドレス方式として十分でない。イーサネットアドレスは平坦 (flat) である ── アドレスが何の構造も持っておらず、ルーティングプロトコルはアドレスから情報をほとんど引き出せない (正確に言うと、イーサネットアドレスにも割り当てのための構造は存在する ── 上位 24 ビットが製造元を識別する。しかし製造元の情報はネットワークのトポロジーと何の関係もないので、イーサネットアドレスはルーティングプロトコルに有用な情報を何も提供しない)。これに対して、IP アドレスは階層的である。つまり IP アドレスはいくつかの部分から構成され、それぞれの部分がインターネットワークの何らかの階層に対応している。
具体的に言うと、IP アドレスはネットワーク部 (network part) とホスト部 (host part) という二つの部分から構成される。これはネットワークが相互接続されて構成されるインターネットワークに対応する非常に論理的な構造と言える。IP アドレスのネットワーク部はホストが接続されるネットワークを識別する。同じネットワークに接続される全てのホストは IP アドレスのネットワーク部が同じになる。続くホスト部が特定のネットワークにおけるホストを識別する。例えば図 70 に示した単純なインターネットワークでは、ネットワーク 1 上のホストの IP アドレスは共通のネットワーク部と異なるホスト部を持つ。
図 70 でルーターは二つのネットワークに接続されていることに注目してほしい。そのためルーターにはそれぞれのネットワークにおける IP アドレスが (インターフェースごとの IP アドレスが) 必要になる。例えば無線ネットワークとイーサネットの間にあるルーター R1 は、無線ネットワークのインターフェースを識別する IP アドレスとイーサネットのインターフェースを識別する IP アドレスをそれぞれ持つ。前者は図中の無線ネットワークに属する他のホストと共通のネットワーク部を持ち、後者は図中のイーサネットに属する他のホストと共通のネットワーク部を持つ。このため、ルーターは二つのネットワークインターフェースを持つホストとして実装されることがある事実を考慮すれば、IP アドレスを持つのはホストではなくインターフェースだと考えた方が正確となる。
では、この階層的なアドレスはどのような形をしているのだろうか? 一部の階層的なアドレスと異なり、IP アドレスでは二つの部の長さがアドレスによって変化する。元々 IP アドレスは図 75 に示す三つのクラスに分かれており、それぞれ異なるサイズのネットワーク部とホスト部を持っていた (この他にマルチキャストグループを指定するクラス D と現在は使われていないクラス E が存在する)。いずれの場合でも IP アドレスは 32 ビットの長さを持つ。

IP アドレスのクラスは最上位のビットをいくつか見ると識別できる。もし最初のビットが 0 なら、そのアドレスはクラス A のアドレスと分かる。最初のビットが 1 で第二ビットが 0 ならクラス B のアドレスで、最初の二ビットが 1 で第三ビットが 0 ならクラス C のアドレスとなる。ここから、約 40 億ある可能な IP アドレスの半分はクラス A、四分の一はクラス B、八分の一はクラス C だと分かる。
それぞれのクラスは特定の長さのネットワーク部を持ち、残りの部分がホスト部となっている。クラス A のアドレスは 7 ビットのネットワーク部と 24 ビットのホスト部を持つ。クラス A のネットワークは 27-2=126 個しか存在できない (0 と 127 は予約されている) ものの、クラス A のネットワークのそれぞれには最大で 224-2 (約 1600 万) 個のホストが所属できる (ここでも二つのアドレスが予約される)。クラス B の IP アドレスは 14 ビットをネットワーク部に、16 ビットをホスト部に割り当てており、クラス B のネットワークは最大で 65,534 個のホストを収容できる。最後にクラス C では 21 ビットがネットワーク部であり、ホスト部はわずか 8 ビットしか存在しない。このためクラス C のネットワークではホストの識別子がわずか 256 個しか存在せず、最大で 254 個のホストしか接続できない (ホスト識別子 255 はブロードキャスト用に予約され、0 は正当なホスト番号ではない)。一方で、IP のアドレス方式は 221 (約 200 万) 個のクラス C ネットワークをサポートできる。
見かけ上は、このアドレス方式は大きく異なるサイズのネットワークを非常に効率的に扱えるだけの大きな柔軟性を持つように思える。当初の考え方は、インターネットは少数のワイドエリアネットワーク (クラス A ネットワークとなる) といくらかの拠点 (キャンパス) サイズのネットワーク (クラス B ネットワークとなる)、そして大量の LAN (クラス C ネットワークとなる) から構成されるだろう、というものだった。しかし、これから見るように、この方式では柔軟性が十分でないことが判明している。現代の IP アドレスは通常クラスレスアドレス (classless address) である。詳細は第 3.3.5 項で解説する。
IP アドレスがどのように利用されるかを見ていく前に、実際上の問題をいくつか説明しておく。例えば IP アドレスはどのように書き表すのだろうか? 慣習により、IP アドレスはドットで区切った四つの十進整数で表される。それぞれの整数は IP アドレスの一バイト分を最上位バイトから順に表す。例えば、この文をタイプしているコンピューターの IP アドレスは 171.69.210.245 である。
IP アドレスをインターネットのドメイン名と混同しないようにしてほしい。ドメイン名も階層的ではあるものの、通常は cs.princeton.edu のようにドットで区切られた ASCII 文字列として書かれる。IP アドレスに関して重要なのは、IP データグラムのヘッダーに書き込まれて伝達され、IP ルーターで転送の判断をするときに使われるという事実である。
3.3.4 IP におけるデータグラムの転送
インターネットワークを伝わる IP データグラムを IP ルーターが転送する基本的な仕組みを見ていく準備がこれで整った。本章の最初で説明したように、転送 (forwarding) とは入力に受け取ったデータグラムを適切な出力に送信することを指し、ルーティング (routing) とはデータグラムに対する正しい出力先を決定するための表 (テーブル) を構築することを指す。ここでの議論は転送に集中し、ルーティングについては第 3.4 節で扱う。
IP データグラムの転送の議論で念頭に置いておくべき重要な事実を次に示す:
-
全ての IP データグラムは最終的な宛先ホストの IP アドレスを持つ。
-
IP アドレスのネットワーク部は大規模なインターネットの中から単一の物理ネットワークを一意に特定する。
-
同じネットワーク部を持つ全てのホストとルーターは同一の物理ネットワーク上に存在する。そのため、そのネットワークを通じてフレームを送り合うことで互いに通信できる。
-
インターネットに含まれる全ての物理ネットワークは、定義により、他の物理ネットワークとも接続されたルーターを少なくとも一つ持つ。そういったルーターはいずれのネットワークに属するホストおよびルーターともデータグラムをやり取りできる。
IP データグラムの転送は次のように行われる。データグラムが送信元ホストから宛先ホストに届けられるとき、途中でいくつかのルーターが関与する可能性がある。データグラムを受け取った任意のノード (ホストまたはルーター) は、まず自身が宛先ホストと同じ物理ネットワークに接続されているかどうかを判定する。この判定は宛先 IP アドレスのネットワーク部と自身が持つ各ネットワークインターフェースの IP アドレスのネットワーク部を比較することで行われる (通常ホストはネットワークインターフェースを一つだけ持つ。これに対して複数のネットワークに接続されるルーターは複数のネットワークインターフェースを持つ)。この判定によって自身と宛先ホストが同じ物理ネットワークに接続されていると分かった場合、そのノードは自身の属するネットワーク越しにデータグラムを宛先に直接届けられる。この処理の詳細は第 3.3.6 節で説明する。
自身が宛先ホストと同じ物理ネットワークに接続されていないと分かった場合、そのノードはデータグラムをルーターに送信する必要がある。一般に、各ノードはデータグラムを送信すべきルーターの選択肢をいくつか持っているので、その中から最も優れたもの、少なくともデータグラムが宛先ホストに近づく可能性が高いものを選ばなければならない。ノードが選択するルーターをネクストホップ (next hop) と呼ぶ。正しいネクストホップの選択は転送テーブルを確認することで行われる。転送テーブルは概念的には単なる (ネットワーク番号, ネクストホップ) という組のリストと言える2 (後述するように、転送テーブルはネクストホップに関連する追加情報を持つことが多い)。転送テーブルでネクストホップが見つからなかったときのためのデフォルトルーターも通常設定される。ホストであれば、知っているルーターがデフォルトルーターだけであっても全く問題ない ── これは他の物理ネットワークに属するホストに宛てられたデータグラムが必ずデフォルトルーターを経由して転送されることを意味する。
ここまでに説明したデータグラムの転送アルゴリズムは次のように表せる:
if (宛先のネットワーク番号 = いずれかのインターフェースのネットワーク番号) then
そのインターフェースを使って宛先にデータグラムを届ける
else
if (宛先のネットワーク番号が自身の転送テーブルに載っている) then
対応するネクストホップルーターにデータグラムを届ける
else
デフォルトルーターにデータグラムを届ける
持っているインターフェースが一つだけで、転送テーブルにデフォルトルーターだけを持つホストの場合、このアルゴリズムは次のように単純化される:
if (宛先のネットワーク番号 = インターフェースのネットワーク番号) then
宛先にデータグラムを直接届ける
else
デフォルトルーターにデータグラムを届ける
例として図 70 のインターネットワークを使ってこのアルゴリズムの動作を確認しよう。まず、H1 が H2 にデータグラムを送信したいと思ったとする。H1 と H2 は同じ物理ネットワークに属するので、IP アドレスのネットワーク部が同じになる。ここから H1 はデータグラムをイーサネットで直接 H2 に届ければよいと判断する。ここで一つ問題として、H1 はどうやって H2 のイーサネットアドレスを見つけるのかという問題がある ── これを解決する仕組みは第 3.3.6 節で説明される。
続いて H5 が H8 にデータグラムを送信したいと思ったとしよう。H5 と H8 は異なる物理ネットワークに属するので、IP アドレスのネットワーク部が異なる。ここから H5 はデータグラムをルーターに送信しなければならないと判断する。ルーターの選択肢は R1 しかないので、H1 は無線ネットワークを通じてデータグラムを R1 に送信する。R1 のインターフェースはどれも H8 と同じ物理ネットワークに属していないので、R1 はデータグラムを H8 に直接届けられないと同様に判断する。R1 のデフォルトルーターが R2 だったと仮定すれば、R1 はイーサネットを通じてデータグラムを R2 に送信する。R2 の転送テーブルが表 10 のようになっていると仮定すれば、R2 は H8 のネットワーク番号 (ネットワーク 4) を使って転送テーブルを調べ、ポイントツーポイントリンクを通じてデータグラムを R3 に転送する。
| ネットワーク番号 | ネクストホップ |
|---|---|
| 1 | R1 |
| 4 | R3 |
自身に直接接続されたネットワークに関する情報を転送テーブルに含めることもできる点に注意してほしい。例えばルーター R2 のネットワークインターフェースに対して、「ポイントツーポイントリンク (ネットワーク 3) 宛てのデータグラムはインターフェース 0 から転送し、イーサネット (ネットワーク 2) 宛てのデータグラムはインターフェース 1 から転送せよ」と転送テーブルが指示しても構わない。このとき R2 の転送テーブルは表 11 のようになる。
| ネットワーク番号 | ネクストホップ |
|---|---|
| 1 | R1 |
| 2 | インターフェース 1 |
| 3 | インターフェース 0 |
| 4 | R3 |
このとき、R2 は送られてくるデータグラムの宛先ホストが属するネットワークの番号がどんなものであっても何をすべきかが分かるようになる。このネットワークに R2 が直接接続されている場合、R2 はそのネットワーク越しにデータグラムを宛先ホストに送信する。そうでなければ宛先ホストにはネクストホップルーターを通じて到達可能なので、R2 は物理ネットワークで接続されているネクストホップのルーターにデータグラムを送信する。いずれの場合でも、R2 は ARP (後述) を使ってデータグラムを次に送信するノードの MAC アドレスを取得する。
この例で R2 が用いる転送テーブルは単純であり、手動でも設定できる。しかし実際の転送テーブルはもっと複雑であり、第 3.4 節で説明されるような何らかのルーティングプロトコルを実行することで自動的に構築される。また、実際のネットワーク番号 (IP アドレスのネットワーク部) は一般にもっと長いことにも注意してほしい (例えば 128.96 など)。
この例からは、階層的アドレス方式 ── アドレスをネットワーク部とホスト部に分ける方式 ── が大規模ネットワークのスケーラビリティを向上させることが見て取れる。ルーターの転送テーブルにはネットワーク上の全てのノードではなく一部のノードだけに関する情報が記載される。この簡単な例で言えば、R2 はネットワーク上の全て (8 個) のホストに対応するために 4 つのエントリーを持つテーブルしか必要としてない。それぞれの物理ネットワークに 100 個のホストが存在する場合でも、R2 が必要とするエントリーは 4 個で変わらない。これはスケーラビリティを達成するための素晴らしい第一歩と言える 。
教訓
以上の議論はスケーラブルなネットワークの構築におけるもっとも重要な指針の一つを説明している: スケーラビリティを達成するには、各ノードに格納される情報、および各ノードがやり取りする情報の量を削減する必要がある。これを行う最も一般的な手段は階層的集約 (hierarchical aggregation) である。IP は二つのレベルを持った階層を提供する: 上にあるのがネットワークの階層で、その下にノードの階層がある。IP はルーターの役割を正しいネットワークへのデータグラムの転送に留めることで情報を集約する。何らかのネットワークに属する任意のノードにデータグラムを届ける処理において、ルーターが自身の役割を果たすために必要とする情報は集約された単一の情報元 (転送テーブル) によって表される。
3.3.5 サブネット化とクラスレスアドレス
IP アドレスのネットワーク部を使って単一の物理ネットワークを一意に識別する、というのが設計当初の意図だった。しかし後になって、このアプローチに複数の欠点が判明した。多くの内部ネットワークを持つ大きなキャンパス (拠点) がインターネットへの接続を決めたところを想像してほしい。このとき、どんなに小さいネットワークであっても少なくともクラス C アドレスが必要になる。さらに悪いことに、254 個より多いホストを持つネットワークにはクラス B アドレスが必要になる。これは大したことではないと思うかもしれない。実際インターネットが最初に構想されたときもそう思われていた。しかしネットワーク番号は有限個しか存在せず、特にクラス B アドレスはクラス C アドレスよりずっと少ない数しか存在しない。ネットワークのノードが 254 個より多くなるかどうかは予想が付かないことが多いので、クラス B アドレスは特に需要が高かった ── 最初からクラス B アドレスを使っておけば、ホストが増えすぎてクラス C アドレスで対応できなくなったときにアドレスを付け替える作業が省ける。このとき生じる問題はアドレス割り当ての非効率性である: ノードを 2 個しか持たないネットワークに対してさえクラス C ネットワークのアドレス全体が割り当てられ、他の 252 個の完全に使用可能なアドレスが無駄になる。ホストが 254 個より少し多いだけのクラス B ネットワークでは、64,000 個以上のアドレスが無駄になる。
つまり、一つの物理ネットワークごとに一つのネットワーク番号を割り当てていくと IP アドレス空間の無駄がとても大きくなる可能性がある。正当なアドレスを無駄なく使えば 40 億個のホストを接続できるにもかかわらず、クラスを使って IP アドレスを管理すると 214 (約 16,000) 個のクラス B ネットワークを割り当てただけで空間が枯渇してしまう。そのため、ネットワーク番号をより効率良く利用する仕組みが必要になった。
ネットワーク番号を多く割り当てることには、ルーティングを考えると明らかになるもう一つの欠点がある。ルーティングプロトコルでは参加するノードの数に比例する量の状態を各ノードが保持する必要があり、インターネットワークにおけるルーティングでは異なるネットワークに到達する経路を記した転送テーブルの構築が各ルーターで必要になることを思い出してほしい。このため、利用されるネットワーク番号の個数が増えると転送テーブルも大きくなる。転送テーブルが大きいとルーターのコストが高くなり、テクノロジが同じ場合は小さなテーブルより検索が遅くなってパフォーマンスが落ちる。この事実もまた、ネットワーク番号のもっと注意深い割り当てに対するモチベーションとなる。
割り当てられるネットワーク番号の個数を削減するための第一歩がサブネット化 (subnetting) である。一つのネットワーク番号に複数の物理ネットワークを割り当てるというのが基本的な考え方となる。こうして IP アドレスを割り当てられる物理ネットワークをサブネット (subnet) と呼ぶ。サブネットを動作させるにはいくつかの条件が必要になる。まず、サブネット同士は近くにある必要がある。サブネットの外側のインターネットから見ると、同じネットワーク番号を持つサブネットはまとめて一つのネットワークとみなされるためである。これはサブネットのいずれかに到達するときに特定のルーターを必ず通過しなければならないことを意味するので、サブネットは大まかに同じ場所にあった方が好都合となる。サブネットの使いどころとして完璧なのは、多くの物理ネットワークを持つキャンパスやオフィスである。そういった拠点の外側からは、拠点が外部のインターネットと接続する箇所さえ知っていれば拠点内部のサブネットに到達できる。通常そういった箇所は一つだけなので、ルーターの転送テーブルに追加するエントリーは一つだけで済む。仮に拠点とインターネットの接続箇所が複数存在したとしても、拠点ネットワーク内の一点に到達する方法を知るのは経路探索の良いスタート地点となる。
単一のネットワーク番号を複数の物理ネットワークで共有するサブネット化という仕組みでは、各サブネットに属するノードに対してサブネットマスク (subnet mask) が設定される。単純な IP アドレスの運用では、同じネットワークに属する全てのホストは同じネットワーク番号を持つ必要がある。サブネット化ではサブネット番号 (subnet number) の概念が導入され、同じ物理ネットワークに属する全てのホストは同じサブネット番号が割り当てられる。これは、異なる物理ネットワークに属するホストが同じ単一のネットワーク番号を持っても構わないことを意味する。サブネットマスクとサブネット番号の関係を図 76 に示す。

サブネット化を利用するとき、各ホストは IP アドレスに加えて自身が所属するサブネットに対するサブネットマスクを持つことになる。例えば図 77 において、ホスト H1 は IP アドレス 128.96.34.15 とサブネットマスク 255.255.255.128 を持つ (特定のサブネットに属する全てのホストは同じサブネットマスクを持つ。つまりサブネットマスクはサブネット一つにつきちょうど一つ存在する)。IP アドレスとサブネットマスクのビット AND を取ると、そのホストおよび同じサブネットに属する他のホストに対するサブネット番号が手に入る。この例では 128.96.34.15 & 255.255.255.128 = 128.96.34.0 であり、この値が図 77 で一番上のサブネットのサブネット番号となる。
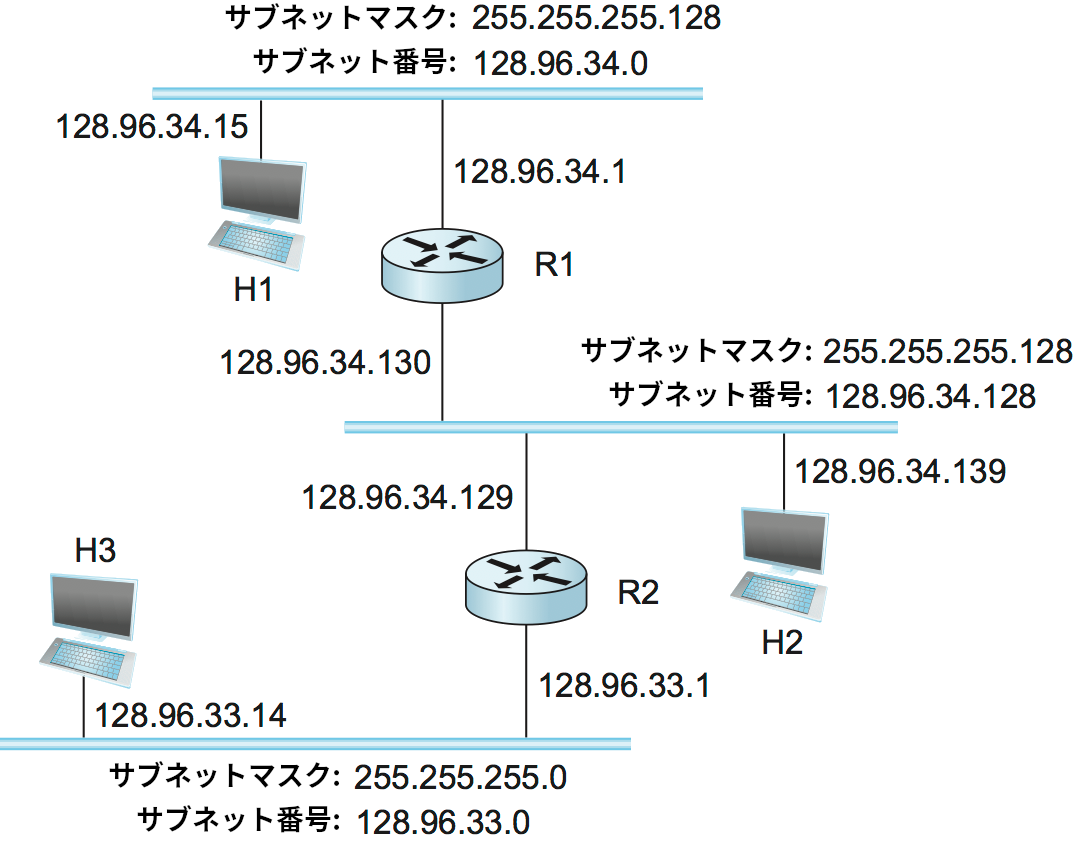
特定の IP アドレスにパケットを送信したいと思ったホストは、まず宛先 IP アドレスと自身のサブネットマスクのビット AND を取る。この結果が送信元ホストのサブネット番号と一致するなら、宛先ホストは同じサブネットに存在するので、パケットをサブネット越しに直接届けられることが分かる。もしビット AND の結果が送信元ホストのサブネット番号と一致しないなら、パケットをルーターに送信して他のサブネットへ転送してもらう必要がある。例えば H1 が H2 にパケットを送信するとき、H1 は自身のサブネットマスク 255.255.255.128 と宛先 H2 のアドレス 128.96.34.139 のビット AND を取って 128.96.34.128 を得る。これは H1 のサブネット番号 128.96.34.0 と一致しないので、H2 は異なるサブネット上に存在すると H1 は認識する。H1 はサブネット越しにパケットを直接 H2 に送れないので、デフォルトルーターの R1 にパケットを送信する。
サブネット化があるときルーターの転送テーブルも少し変更される。転送テーブルのエントリーは (ネットワーク番号, ネクストホップ) だと以前に説明した。サブネット化をサポートするとき、転送テーブルのエントリーは (サブネット番号, サブネットマスク, ネクストホップ) となる。正しいネクストホップを見つけようとするルーターは、各エントリーのサブネットマスクとパケットの宛先アドレスのビット AND を順に取っていく。このビット AND の結果がサブネット番号と一致するのが使うべきエントリーであり、ルーターはそのエントリーに記されたネクストホップルーターに向かってパケットを転送する。例えば図 77 のネットワークでは、ルーター R1 は表 12 のような転送テーブルを持つことになる。
| サブネット番号 | サブネットマスク | ネクストホップ |
|---|---|---|
128.96.34.0 |
255.255.255.128 |
インターフェース 0 |
128.96.34.128 |
255.255.255.128 |
インターフェース 1 |
128.96.33.0 |
255.255.255.0 |
R2 |
H1 が H2 に宛ててデータグラムを送信する例に戻ろう。R1 は H2 のアドレス 128.96.34.139 と転送テーブルの一つ目のエントリーに記されたサブネットマスク 255.255.255.128 のビット AND を取り、その結果 128.96.34.128 とエントリーに記されたサブネット番号 128.96.34.0 を比較する。この二つは一致しないから、処理は次のエントリーに進む。次のエントリーではマッチが起こるので、R1 は H2 と同じネットワークにつながったインターフェース 1 から H2 にデータグラムを送信する。
サブネット化が有効なときのデータグラム転送アルゴリズムは次のように表せる:
D = 宛先 IP アドレス
for 転送テーブルのエントリー (SubnetNumber, SubnetMask, NextHop)
D1 = SubnetMask & D
if D1 = SubnetNumber
if NextHop がインターフェース
宛先ホストにデータグラムを直接届ける
else
NextHop (ルーター) にデータグラムを届ける
この例では示されていないものの、転送テーブルにはデフォルトルーターが普通は含まれており、明示的なマッチが見つからなかったときはデフォルトルーターが利用される。なお、このアルゴリズムのナイーブな実装 ── 宛先アドレスと変化しないサブネットマスクのビット AND を毎回計算して線形に探索する実装 ── は非常に効率が悪いことに注意してほしい。
サブネット化の重要な帰結として、インターネットネットワークの異なる部分は世界を異なる形で捉えるようになる。ある拠点に複数のサブネットがあったとしても、その拠点の外側から見るときネットワークは一つしか存在しない。上記の例で言えば、外側のルーターは図 77 にあるサブネットの集合全体を 128.96 という一つネットワークと認識し、転送テーブルには 128.96 へ到達する方法だけが記される。しかしキャンパス (拠点) 内のルーターはデータグラムを正しいサブネットに転送できる必要がある。そのため、インターネットワークの全ての部分が同じルーティング情報を持つことはなくなる。これはルーティングシステムをスケールさせる上で非常に重要な「ルーティング情報の集約 (aggregation)」という考え方の例と言える。次節では集約がさらに別のレベルで行われることが説明される。
クラスレスアドレス
サブネット化に似た別の手法が存在する。スーパーネット化 (supernetting) と呼ばれることもあるが、CIDR (Classless Interdomain Routing, クラスレス相互ドメイン経路制御) と呼ばれることの方が多い。CIDR はサブネット化のアイデアを論理的に押し進め、アドレスのクラスを取り払う。なぜサブネット化だけでは不十分なのだろうか? 本質的に、サブネット化ではクラスを持つアドレスを複数のサブネットに分割することしかできない。これに対して CIDR では、クラスを持つアドレスをいくつか合体させることで一つの「スーパーネット」が作成される。CIDR によって前述したアドレス空間の非効率性がさらに改善され、そのときルーティングシステムに過負荷がかかることもない。
アドレス空間の効率とルーティングシステムのスケーラビリティという二つの問題がどのように関連するかを理解するために、256 個のホストからなるネットワークを持つ会社を考えよう。256 個というのはクラス C アドレスの容量を少しだけ上回る数なので、クラス B アドレスの割り当てが必要となる。しかし、最大で 65,535 個のアドレスを収容できるクラス B のアドレス空間を 256 個のホストに割り当てたときの利用率は 256/65,535 = 0.39% でしかない。サブネット化を使えば注意深くアドレスを割り当てられるとは言っても、255 個以上のホストを持つ (あるいは持つ可能性のある) 組織がクラス B アドレスを欲しがる事実は変わらない。
この問題への対処法の一つとして、65,535 個近くのアドレスを本当に必要する組織にだけクラス B アドレスを割り当て、そうでない組織には複数のクラス C アドレスを使ってネットワークを構成させる運用が考えられる。こうすると 256 個のアドレスを一つの単位としてアドレス空間が切り出されるので、消費されるアドレス空間の量が組織の規模に近づく。少なくとも 256 個のホストを持つ組織に対してはアドレス空間の利用率が最低でも 50% になることが保証され、典型的にはもっと高くなる (余談: 残念ながらクラス B アドレスは遠い昔に全て予約済みとなっているので、現在クラス B ネットワーク番号が本当に必要になったとしても手遅れである)。
しかし、この解決策はアドレスのクラス化と同程度に深刻な問題を抱えている: ルーターに対するストレージ要件が非常に大きくなる。例えば、ある地点に 16 個のクラス C ネットワーク番号が割り当てられているなら、インターネットのバックボーンルーターはその地点にパケットを送るために 16 個のエントリーを転送テーブルに追加しなければならない。この事実は 16 個の経路が全て同じだったとしても変わらない。もしクラス B アドレスを割り当てたとしたら、ルーティング情報は転送テーブルの 1 個のエントリーに収まる。しかしアドレス空間の利用率はわずか 16×255/65,536 = 6.2% となる。
そこで CIDR は、ルーターが記憶しなければならない経路の個数とアドレス空間の利用率のバランスを取ることを試みる。これを行うために、CIDR は経路を集約 (aggregate) する。つまり、複数の異なるネットワークに到達する方法を転送テーブルの一つのエントリーで記録する。これを理解するために、16 個のクラス C ネットワーク番号を持つ組織を考えよう。この組織にランダムな 16 個のアドレスを渡すのではなく、CIDR では連続するクラス C アドレスのブロックが渡される。この組織に 192.4.16 から 192.4.31 のクラス C ネットワーク番号が割り当てられたとしよう。このとき、この組織が保有する IP アドレスは上位 20 ビットが同じ (11000000.00000100.0001) になる。そのため、この割り当てによって事実上 20 ビットのネットワーク番号が作られたことになる ── サポートされるホストの個数はクラス B とクラス C の中間となる。言い換えれば、CIDR ではクラス B より小さいブロックでアドレスを切り出すことでアドレス空間の高い利用率が達成され、それと同時にルーターの転送テーブルはネットワーク番号として接頭部 (プレフィックス) を一つ記憶するだけで済む。なお、この方式を正しく動作させるには共通の接頭部を持つクラス C アドレスの集合を一つのブロックとして切り出す必要があるので、各ブロックに含まれるクラス C ネットワークの個数は 2 のべきである必要があることが分かる。
CIDR ではネットワーク番号を表すプレフィックスの長さが決まっていないので、ネットワーク番号を表す新しい記法が必要になる。その記法では、プレフィックスの長さが X ビットのとき、プレフィックスの後ろに /X を付ける。例えば上述の例では、192.4.16 から 192.4.31 までのネットワーク番号に対する 20 ビットのプレフィックスは 192.4.16/20 と表される。一方で、単一のクラス C ネットワーク番号 (24 ビット) を表したいときは 192.4.16/24 と書くことになる。現在 CIDR は標準であり、クラス C ネットワークを「スラッシュ 24」と呼ぶ人も多くいる。ネットワークアドレスをこのように表すのはサブネット化における IP アドレスとサブネットマスクを使うアプローチと似ていることに注目してほしい。ただし、CIDR では「マスク」が必ず最上位ビットから連続する 1 の列として構成される (この条件は実際のサブネットマスクでもまず間違いなく成り立つ)。
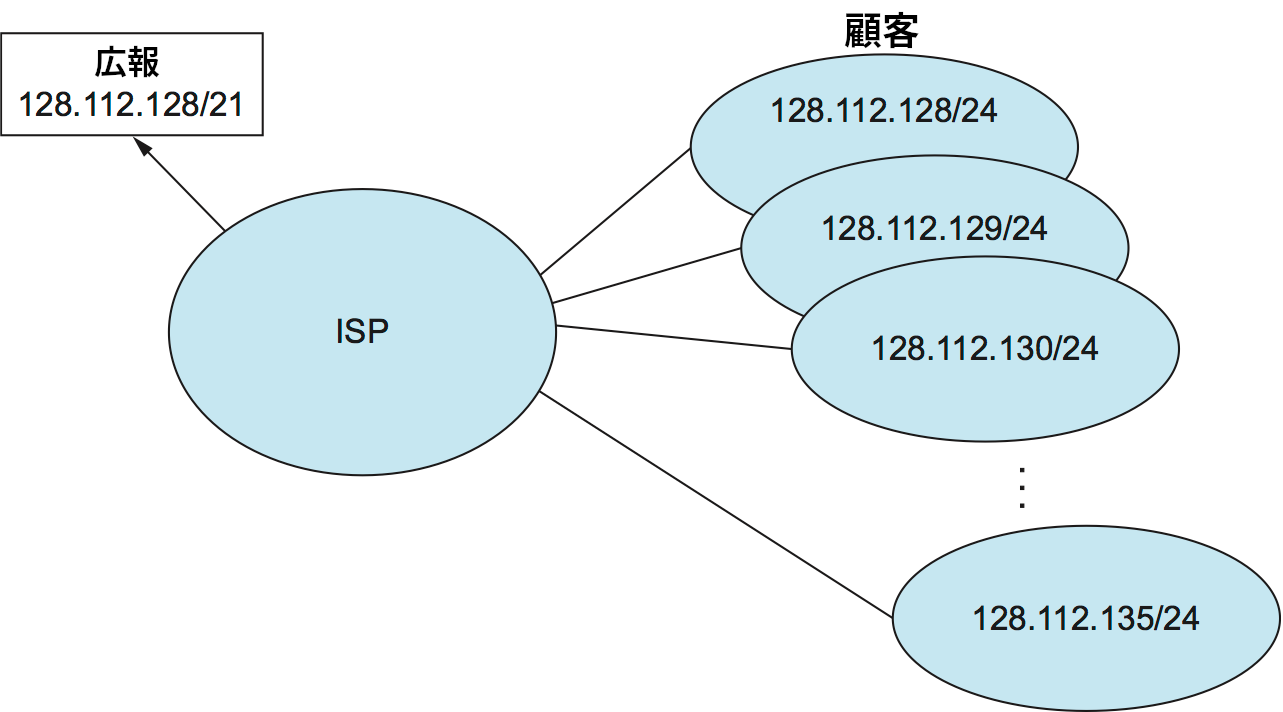
これまでに見たネットワークエッジにおける経路集約は CIDR が持つ利点の一端でしかない。ISP (インターネットサービスプロバイダ) のネットワークを想像してほしい。ISP ネットワークの主な仕事は、インターネット接続をオフィスやキャンパス (顧客) に提供することである。このとき顧客のネットワークをまとめると短いプレフィックスが構成されるように共通のプレフィックスを持つネットワークを顧客に割り当てれば、さらに大規模に経路を集約できる。図 78 の例を考えよう。ここで ISP は 8 人の顧客に接続を提供している。顧客に割り当てられるネットワークは 24 ビットのネットワークプレフィックスを持ち、先頭 21 ビットが共通する。全ての顧客に対しては同じ ISP ネットワークを通じて到達可能なので、ISP は顧客のネットワークに共通する 21 ビットを広報するだけで全てのネットワークへの単一の経路を広報したことになる。これは 24 ビットのプレフィックスを持つネットワークが全て使われていない場合でも、そういったプレフィックスを顧客に割り当てる権利さえ持っていれば行える。アドレス空間の一部分を事前に ISP に割り当て、ISP はその空間から必要に応じて顧客にアドレスを切り出していく運用が考えられる。なお、この例では顧客のアドレス空間が全て同じ長さのプレフィックスを持っているものの、実際には顧客に割り当てるアドレス空間のプレフィックスの長さが異なっていても構わない。
IP データグラムの転送: 再考
ここまでの IP データグラムの転送に関する議論では、パケットからネットワーク番号を読み取り、それを転送テーブルで調べればどこに転送すべきかが分かると仮定してきた。しかし CIDR を紹介したので、この仮定には再考が必要になる。CIDR が存在すると、ネットワーク番号を表すプレフィックスが 2 ビットから 32 ビットまでの任意の長さになる。このため、転送テーブルに記録されたプレフィックスが "重なる" 可能性が生じる。例えば 16 ビットのプレフィックス 171.69 と 24 ビットのプレフィックス 171.69.10 が同じルーターの転送テーブルに存在する事態が生じるようになる。このとき例えば 171.69.10.5 に宛てられたパケットは明らかに両方のプレフィックスとマッチする。こういった場合には、「最長一致」を原則とする規則に基づいて転送先が決められる。この例では長い方のプレフィックス 171.69.10 にパケットは転送される。一方で、171.69.20.5 に宛てられたパケットは 171.69 にはマッチするのに対して 171.69.10 にはマッチしないので、他にマッチするエントリーが無ければ 171.69 が最長一致となって転送先として決定する。
転送テーブルに記録された可変長のプレフィックスと送られてきたパケットに含まれる IP アドレスの最長一致を効率良く求める問題は長年にわたって数々の成果を生んできた研究分野である。最もよく知られたアルゴリズムはパトリシア木 (Patricia tree) と呼ばれるアプローチを利用する。実はパトリシア木は CIDR が生まれるより前に詳しく研究されたデータ構造である。
3.3.6 アドレス変換 (ARP)
第 3.3.4 項では IP データグラムを正しい物理ネットワークに届ける方法だけを説明し、その物理ネットワーク内でデータグラムを特定のホストあるいはルーターに届ける方法は説明しなかった。この処理における問題は、IP データグラムには IP アドレスが含まれるものの、ホストあるいはルーターに搭載されている物理的なインターフェースハードウェアは自身が所属する特定の物理ネットワークにおけるアドレス方式しか理解できないことである。そのため、IP アドレスを物理ネットワークにおけるリンク層アドレス (例えば 48 ビットのイーサネットアドレス) に変換する必要がある。そのリンク層アドレスを記したフレームの中に IP データグラムを入れれば、最終的な宛先にデータグラムを転送することを約束するルーターあるいは最終的な宛先に IP データグラムを届けることができる。
IP アドレスを物理ネットワークアドレスに関連付ける簡単な方法として、ホストの物理アドレスを IP アドレスのホスト部に符号化する方法が考えられる。例えば物理アドレス 0010000101001001 (十進では上位 8 ビットが 33、下位 8 ビットが 81) を持つホストに対しては IP アドレス 128.96.33.81 が割り当てられる。この方式は一部のネットワークでは用いられるものの、ネットワークの物理アドレスが (この例では) 16 ビットより長くなれないという欠点を持つ。クラス C ネットワークではたった 8 ビットとなる。これは 48 ビットのイーサネットアドレスでは明らかに上手く行かない。
より一般的な解決法は、アドレスの組からなるテーブルを各ホストが管理するというものである: そのテーブルには IP アドレスと物理アドレスの対応付けが記録される。このテーブルをシステム管理者が作成して各ホストにコピーすることもできるものの、各ホストがネットワークを使って動的にテーブルの内容を埋めさせる方が優れたアプローチになるだろう。この処理は ARP (Address Resolution Protocol) を利用すると達成できる。ARP の役割はネットワーク上の各ホストが IP アドレスとリンク層アドレスの対応付けを構築できるようにすることである。この対応付けは時間が経過すると (例えばホストに挿さったイーサネットカードが故障して取り換えられるなどして) 変更される可能性があるので、テーブルのエントリーにはタイムアウトが設定され、更新されなければ削除される。この更新は 15 分程度に一度のペースで起こる。ホストに保存された対応付けは ARP キャッシュ (ARP cache) あるいは ARP テーブル (ARP table) と呼ばれる。
ARP は多くのリンクレベルのネットワークテクノロジ (例えばイーサネット) がブロードキャストをサポートする事実を活用する。同じ物理ネットワーク内に存在すると分かっているホスト (あるいはルーター) に IP データグラムを送信したいと思ったホストは、その IP アドレスに対応するリンク層アドレスが ARP テーブルに記録されているかどうかを確認する。もし記録されていなければ、そのホストは ARP を起動する必要がある。ARP の起動は ARP 要求 (ARP request) メッセージをネットワークにブロードキャストすることで行われる。この ARP 要求には送信元のホストがリンク層アドレスを知りたいと思っている (ターゲットの) IP アドレスが含まれる。ARP 要求を受け取った同じ物理ネットワーク内の各ホストは、ターゲットの IP アドレスが自身の IP アドレスと一致するかどうかを確認する。もし両者が一致したら、そのホストは自身のリンク層アドレスを収めた ARP 応答 (ARP reply) メッセージを ARP 要求の送信元へ送り返す。ARP 要求の送信元は応答に含まれる情報を ARP テーブルに追加し、データグラムを送信する。
ARP 要求メッセージには送信元ホストの IP アドレスとリンク層アドレスも含まれている。そのため ARP 要求がブロードキャストで送られると、同じ物理ネットワーク内の他の全てのホストは送信元ホストの IP アドレスとリンク層アドレスを自身の ARP テーブルに記載できる。ただし、この情報は全てのホストの ARP テーブルに追加されるわけではない:
- この情報が ARP テーブルに元々存在するホストでは、エントリーの "更新" だけが行われる: つまり、エントリーが削除されるまでの時間がリセットされる。
- 要求のターゲットとなっているホストは、ARP 要求に含まれる送信元ホストに関する情報を自身の ARP テーブルに記録する。これは送信元ホストの情報が ARP テーブルに存在しない場合でも行われる。なぜなら、送信元ホストは今後アプリケーションレベルのメッセージを送ってくる可能性が高く、その場合はメッセージを受け取った後に応答メッセージあるいは ACK をこちらから送ることになる (そのときリンク層アドレスが必要になる) ためである。
- ARP 要求を受け取ったホストがターゲットではなく、自身の ARP テーブルに送信元ホストの情報が存在しない場合、そのホストは ARP テーブルを変化させない (ARP 要求に含まれる情報を無視する)。送信元ホストのリンク層アドレスが今後必要になる確証が存在しないためである。不要な情報を ARP テーブルに追加する必要はない。
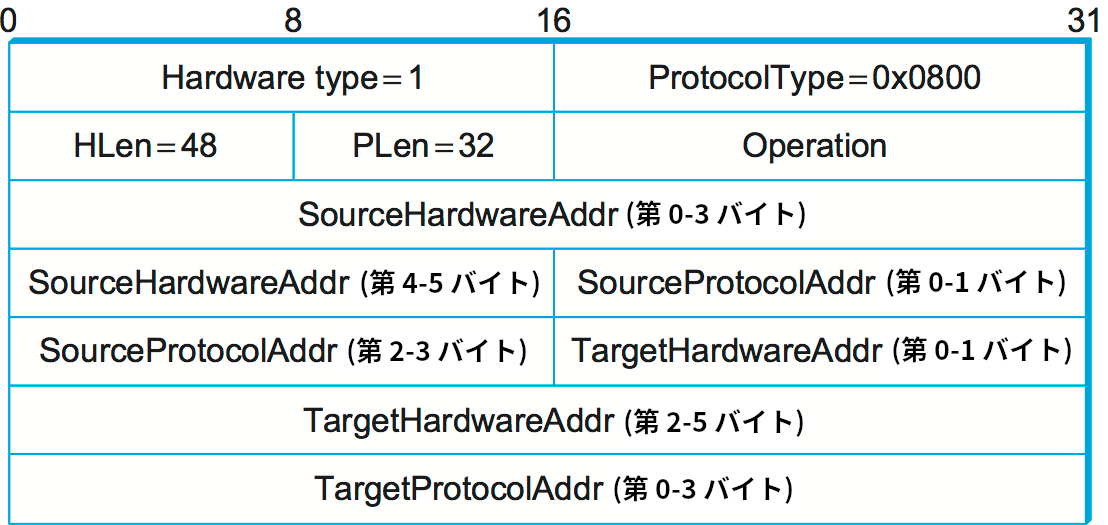
図 79 に IP アドレスとイーサネットアドレスの対応付けを伝えるのに使われる ARP パケットのフォーマットを示す。ARP は他の様々なアドレスとの対応付けにも利用できる ── その際パケットのフォーマットの主な違いはアドレスのサイズである。このパケットに含まれるフィールドの説明を示す:
-
HardwareTypeフィールド: 物理ネットワークの種類 (イーサネットなど) を指定する。 -
ProtocolTypeフィールド: 上位層プロトコル (IP など) を指定する。 -
HLen("hardware" address length, ハードウェアアドレス長) フィールドとPLen("protocol" address length, プロトコルアドレス長) フィールド: それぞれリンク層アドレスの長さと上位層アドレスの長さを指定する。 -
Operation: このパケットが要求か応答かを指定する。 -
残りの部分: 送信元ホストおよびターゲットホストのハードウェア (イーサネット) アドレスとプロトコル (IP) アドレス。
ARP プロセスの結果は表 11 のような転送テーブルに列を追加することで記録できる点に注意してほしい。例えば R2 がパケットをネットワーク 1 に転送するとき、R2 はネクストホップが R1 であることだけではなく R1 に送るパケットに記すべき MAC アドレスが何であるかも転送テーブルから読み取る。
教訓
不均一性とスケーラビリティをサポートするために IP が提供する基本的な仕組みが以上で確認できた。不均一性の問題に関して言えば、IP はまずベストエフォートのサービスモデルを採用することで下位のネットワークに対する仮定を可能な限り緩くする。最も特筆すべき特徴として、このサービスモデルは低信頼なデータグラムを利用する。続いて IP は重要な要素を二つ追加する: 共通パケットフォーマット (異なる MTU を持つネットワークでも使えるように分割と再構築の仕組みを持つ) と全てのホストを識別するためのグローバルなアドレス空間 (異なる物理アドレス方式を同時に動作させるために ARP がある) である。スケーラビリティに関して言えば、IP は階層的集約を使ってパケットの転送に必要な情報量を削減する。具体的には、IP アドレスはネットワーク部とホスト部に分割され、パケットは宛先ホストが属するネットワークまで転送されてからそのネットワークの正しいホストに届けられる。
3.3.7 ホストの設定 (DHCP)
ネットワークアダプターが持つイーサネットアドレスは製造元によって設定され、そのときグローバルに一意なアドレスがそれぞれ割り振られる。イーサネット (および拡張 LAN) に接続する任意のホストが必ず一意なアドレスを持つことはこれで明らかに保証される。さらに言えば、イーサネットでは一意性しか必要にならない。
これに対して IP アドレスには、インターネットワーク内で一意であることだけではなくインターネットワークの構造を反映することが求められる。これまでに説明したように、IP アドレスはネットワーク部とホスト部を持ち、同じ物理ネットワークに属するホストの IP アドレスは同じネットワーク部を持たなくてはならない。そのため、IP アドレスを製造時に設定することはできない。そうするにはホストがどのネットワークに接続されるかを製造元が知らなくてはならず、加えて、そうするとホストはそのネットワークにしか接続できなくなる。この理由により、IP アドレスは再設定可能である必要がある。
IP アドレスの他にも、パケットの送信を始める前にホストが集めなくてはならない情報がいくつかある。最も重要なものとして、デフォルトルーター (宛先ホストが送信元ホストと異なるネットワークに属する場合にパケットを送信する場所) のアドレスが必要となる。
ホストのオペレーティングシステムの多くはホストが必要とする IP に関する情報をシステム管理者 (ときにはユーザー) が手動で設定する方法を提供している。しかし、手動での設定には明らかな欠点が存在する。その一つが「ネットワークが大規模だと全てのホストを直接設定する手間が単純に大きい」というものである。さらに、ホストは設定が終わるまでネットワーク内で到達可能にならないので、設定は急いで行わなければならない。これよりもさらに重要なこととして、設定プロセスでは全てのホストが正しいネットワーク番号を持ち、どの二つのホストも同じ IP アドレスを持たないことを保証しなければならないのでエラーが起きやすい。こういった理由により、自動化された設定手法が必要となる。最もよく使われる手法は DHCP (Dynamic Host Configuration Protocol) と呼ばれる。
DHCP は設定情報をホストに提供する DHCP サーバー (DHCP server) の存在を仮定する。DHCP サーバーは管理ドメインごとに少なくとも一つ存在する。最も単純なモデル (使い方) では、DHCP サーバーはホストの設定情報の単純な中央レポジトリとして機能する。例として大企業のインターネットワークを管理する問題を考えよう。DHCP が無ければ、ネットワーク管理者はアドレスリストとネットワーク図を抱えて企業内に存在する全てのホストを歩いて回り、それぞれのホストを手動で設定しなければならないだろう。DHCP があれば各ホストに対する設定情報が DHCP サーバーに保存されるので、設定情報は各ホストが起動あるいはネットワークに接続したときに自動的に取得されるようになる。ただし、このモデルだと各ホストへのアドレスの割り当てはネットワーク管理者が行わなければならない: DHCP サーバーはその情報を保存するだけである。このモデルでは各ホストに対する設定情報がテーブルに保存され、そのテーブルに対するアクセスではクライアントを識別する何らかの一意な識別子 (典型的にはネットワークアダプターのイーサネットアドレスといったハードウェアアドレス) が添え字となる。
DHCP のこれより高度なモデルでは、ネットワーク管理者が個別のホストにアドレスを割り当てる必要さえない。このモデルで DHCP サーバーは利用可能なアドレスのプールを管理し、オンデマンドにホストへアドレスを渡していく。ネットワーク管理者は利用可能な IP アドレスの範囲 (同じネットワーク番号を持つ) を各ネットワークに割り振るだけなので、ネットワークの設定作業が大幅に単純化される。
DHCP の目標はホストが動作するまでに必要な手動設定を最小化することなので、それぞれのホストに DHCP サーバーのアドレスを設定して回らなければいけないとしたら本末転倒と言える。そのため、DHCP は DHCP サーバーの発見という問題に最初に直面する。
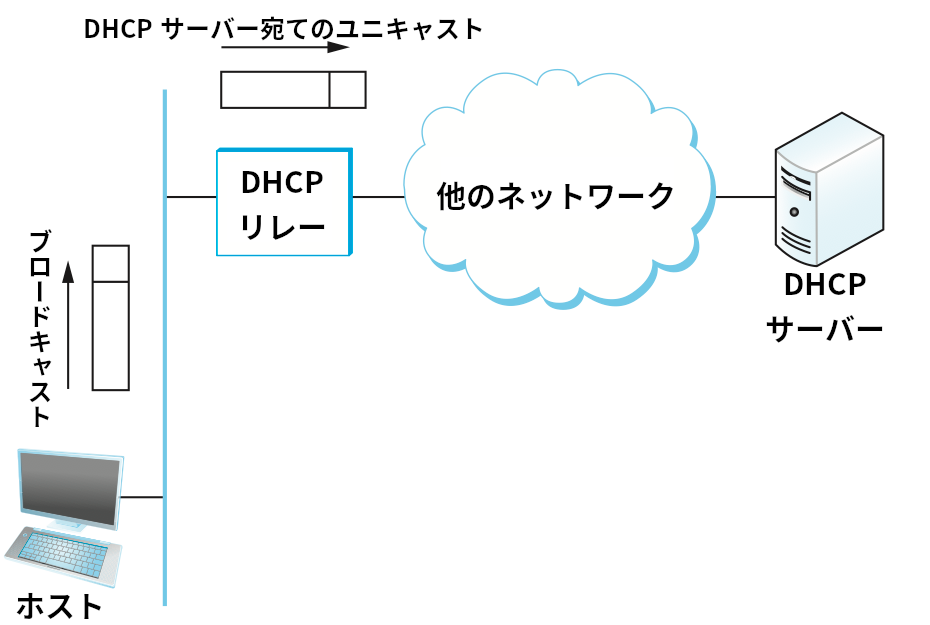
DHCPDISCOVER メッセージを受け取り、ユニキャストの DHCPDISCOVER メッセージを DHCP サーバーに送信する。
初めて起動あるいは接続されたホストは DHCP サーバーと対話するために 255.255.255.255 という特別な IP アドレス (IP ブロードキャストアドレス) に DHCPDISCOVER メッセージを送信する。このメッセージはブロードキャストとなるので、同じネットワーク上の全てのホストとルーターによって受信される (ルーターはブロードキャストパケットを他のネットワークに転送しないので、インターネット全体にブロードキャストが起こることはない)。最も単純なケースでは、このネットワークを担当する DHCP サーバーが DHCPDISCOVER メッセージを直接受信する。この場合は DHCP サーバーがメッセージの送り主に返答することで対話が完了する (他のノードはメッセージを無視する)。しかし、全てのネットワークに一つの DHCP サーバーを要求すると正しい一貫した設定を持たなくてはならないサーバーの数が増えるので、これはあまり望ましくない。このため DHCP にはリレーエージェント (relay agent) の概念が存在する。リレーエージェントは各ネットワークに少なくとも一つ存在し、DHCP サーバーの IP アドレスを知っている。ホストがブロードキャストした DHCPDISCOVER メッセージをリレーエージェントが受け取ると、そのリレーエージェントは DHCP サーバーにユニキャストで DHCPDISCOVER メッセージを送信し、その応答を IP アドレスを要求している元のクライアントに送り返す。ホストからリモートの DHCP サーバーへとメッセージをリレーする以上のプロセスを図 80 に示す。
図 81 に DHCP メッセージのフォーマットを示す。このメッセージは実際には IP の上で実行される UDP (User Datagram Protocol) というプロトコルを使って送信される。UDP については第 5.1 節で詳細に議論するが、現在の文脈で重要な UDP の機能は「これは DHCP パケットである」と伝える逆多重化鍵を宛先に伝達することだけである。

DHCP には元となった BOOTP (Bootstrap Protocol) と呼ばれるプロトコルが存在し、その関係で DHCP パケットはホストの設定に厳密には関係ないフィールドを持つ。クライアントは設定情報を取得するとき、自身のハードウェアアドレス (例えばイーサネットアドレス) を chaddr フィールドに書き込んでからブロードキャストを行う。これを受けて DHCP サーバーは yiaddr (your IP address) フィールドを設定してクライアントに送り返す。デフォルトルーターなどのクライアントが利用する他の情報を options フィールドに含めることもできる。
DHCP を使って IP アドレスをホストに動的に割り当てるとき、ホストがいつまでもアドレスを保持してはいけないのは明らかである。そのようなことが起こると、DHCP サーバーはいずれアドレスプールを使い果たしてしまう。さらに、ホストは突然クラッシュしてネットワークから消失するかもしれないので、ホストが行儀よくアドレスを返却すると仮定することもできない。このため DHCP はアドレスを一定の時間だけ貸すようになっている。DHCP サーバーは貸し出し時間が切れたアドレスをプールに戻して構わない。このとき当然、アドレスを借りたホストはネットワークに接続され正しく動作している間は定期的に貸し出し時間を更新する必要がある。
教訓
DHCP はスケーリングの重要な側面を映し出している: ネットワーク管理のスケーリングである。スケーリングの議論ではネットワークデバイスに保持される状態を小さく保つことに焦点が当たる場合が多いものの、ネットワーク管理の複雑性の増加にも注意を払わなければならない。ネットワーク管理者が設定すべき値を「ホストごとに一つの IP アドレス」ではなく「ネットワークごとに一つの IP アドレスの範囲」とすることで、DHCP はネットワークの管理容易性を向上させる。
DHCP によってネットワーク管理がさらに複雑になる可能性もある点にも注意してほしい: 物理ホストと IP アドレスの結び付きが動的になる。例えば正しく動作していないホストを見つけようとしているネットワーク管理者は、DHCP によって手間が増えることになる。
3.3.8 エラー報告 (ICMP)
続いての話題はインターネットにおけるエラーの扱いである。IP は少しでも問題に直面するとすぐにデータグラムを捨ててしまう ── 例えばルーターがデータグラムをどこに転送すべきかを知らないとき、あるいはデータグラムのフラグメントが一つでも宛先に届かないとき、データグラムは破棄される。しかしデータグラムの破棄を黙って行う必要はない。IP は必ず ICMP (Internet Control Message Protocol) と呼ばれる補助プロトコルと共に実行される。ICMP はルーターあるいはホストが IP データグラムを正しく処理できなかった場合に必ず送信元ホストに送り返すべきエラーメッセージの集合を定義する。ICMP が定義するエラーメッセージの例を次に示す:
- 宛先ホストが (おそらくリンクの障害により) 到達可能でない。
- 再構築プロセスが失敗した。
- TTL が 0 に達した。
- IP ヘッダーのチェックサムが一致しなかった。
ICMP はルーターから送信元ホストに送信できる省略可能な制御メッセージもいくつか定義する。最も有用な制御メッセージの一つが ICMP リダイレクト (ICMP Redirect) であり、これは現在の経路より優れた宛先への経路が存在すると送信元ホストに伝える。二つのルーター R1, R2 を持つネットワークにホストが接続されていて、そのホストのデフォルトルーターは R1 だとしよう。そのホストからのデータグラムを R1 が受け取り、宛先アドレスの経路としては R2 の方が優れていると転送テーブルから判断できたとする。このとき、R1 は「これ以降、その宛先に宛てたデータグラムは R2 に送るように」と指示する ICMP リダイレクトをそのホストに送信する。これを受けて、ホストは知らされた新しい経路を自身の転送テーブルに追加する。
ICMP は広く用いられる二つのデバッグツール ping と traceroute の基礎も提供する。ping は ICMP のエコーメッセージを利用してノードが到達可能で生きていることを確認する。tracerout は手の込んだテクニックを使って宛先ホストへの経路に含まれるルーターの集合を取得する。
3.3.9 仮想ネットワークとトンネル
IP を紹介する本節で最後に紹介するのは、読者は使ったことがないかもしれないものの、近年重要性が増してきている技術である。ここまでの議論は異なるネットワークに属するノード同士が互いに制限の無い形で通信できるようにすることに焦点を当ててきた。これは通常インターネットが掲げる目標でもある ── 誰とでもメールがやり取りできて、誰でもウェブサイトを広い聴衆に公開できることが望ましい。しかし、もっと制御された形の接続性が必要となる状況も多くある。そういった状況で重要となる技術として VPN (virtual private network, 仮想プライベートネットワーク) がある。
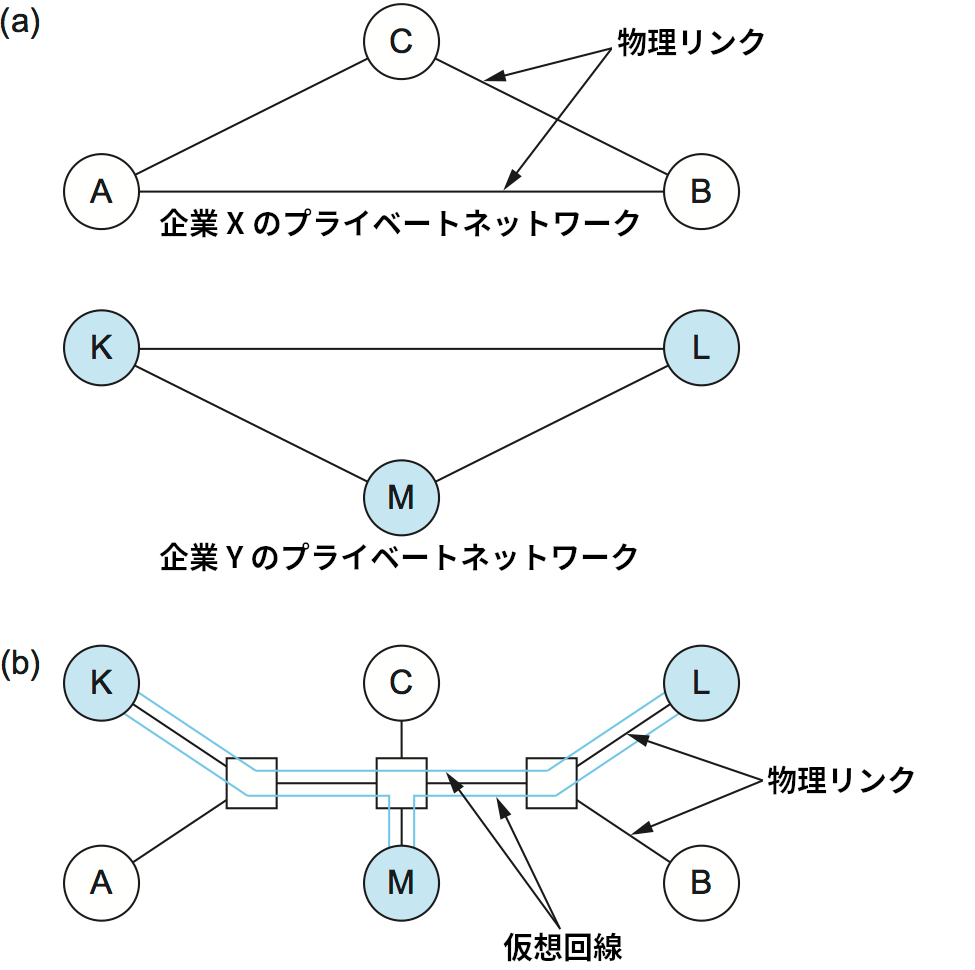
VPN という用語は非常によく使われ、その意味も使われる場面ごとに異なる。しかしプライベートネットワークというアイデアについて考えると VPN を大まかに定義できる。地理的に離れた複数の場所に拠点を持つ企業は、通信事業者から借りた回線 (リース回線) で拠点同士を接続することでプライベートネットワークを構築する場合がある。こういったネットワークで通信は拠点同士でしか行えないように制限される: 通信の制限はセキュリティの理由により企業が望む機能であることが多い。プライベートネットワークを仮想 (virtual) にするには、リース回線 ── 他の企業とは共有されない回線 ── を何らかの共有ネットワークに置き換える必要がある。仮想回線を使えば企業の拠点間の論理的なポイントツーポイント接続を提供できるので、仮想回線はリース回線の非常に理にかなった代替と言える。例えば拠点 A と拠点 B の間に仮想回線があるとき、明らかに A と B はパケットをやり取りできる。しかし他の企業が拠点 B にパケットを送りたいと思ったとしても、それは拠点 B に接続する仮想回線を確立しない限り行えない。仮想回線の確立は管理者が禁止できるので、他の企業との不必要な接続を完全に遮断できる。
図 82 の (a) に二つの企業がそれぞれ個別にプライベートネットワークを持つ状況を示す。図 82 の (b) では両方が仮想回線ネットワークに移行している。プライベートネットワークが提供する制限された接続性は保持されつつも転送機能やスイッチは共有され、二つの仮想プライベートネットワークが作成されている。
図 82 の (b) では、拠点間に制限された接続性を提供するために仮想回線ネットワーク (例えば ATM を使ったもの) が使われている。同様の機能は IP ネットワークが提供する接続性を使っても実装できる。ただし、様々な企業の拠点を単一のインターネットワークにただ接続することはできない: そうすると、関係ない企業の間に存在してはいけない接続性が生まれてしまう。この問題を解決するには、IP トンネル (IP tunnel) という新しい概念を導入する必要がある。
IP トンネルは実際には任意個のネットワークによって隔てられた二つのノードの間に存在する仮想的なポイントツーポイントリンクだと考えることができる。この仮想的なリンクはトンネルの端に位置するルーターのそれぞれにトンネルで自身の反対側にあるルーターの IP アドレスを教えることで作成される。トンネルの入口にあるルーターがこの仮想的なリンクを通してパケットを送信したいと思ったときは、そのパケットを IP データグラムにもう一度包んでから送信する。そのときヘッダーの宛先アドレスはトンネルの反対側にあるルーターの IP に設定し、送信元アドレスは自分 (パケットを IP データグラムに包んでいるルーター) の IP アドレスに設定する。
IP トンネルの入口にあるルーターの転送テーブルでは、この仮想リンクは通常のリンクと同じに見える。例えば 図 83 のネットワークでは、R1 と R2 を結ぶトンネルが作成され、このトンネルには仮想インターフェース番号 0 が割り当てられている。このとき R1 の転送テーブルとして考えられる値を表 13 に示す。
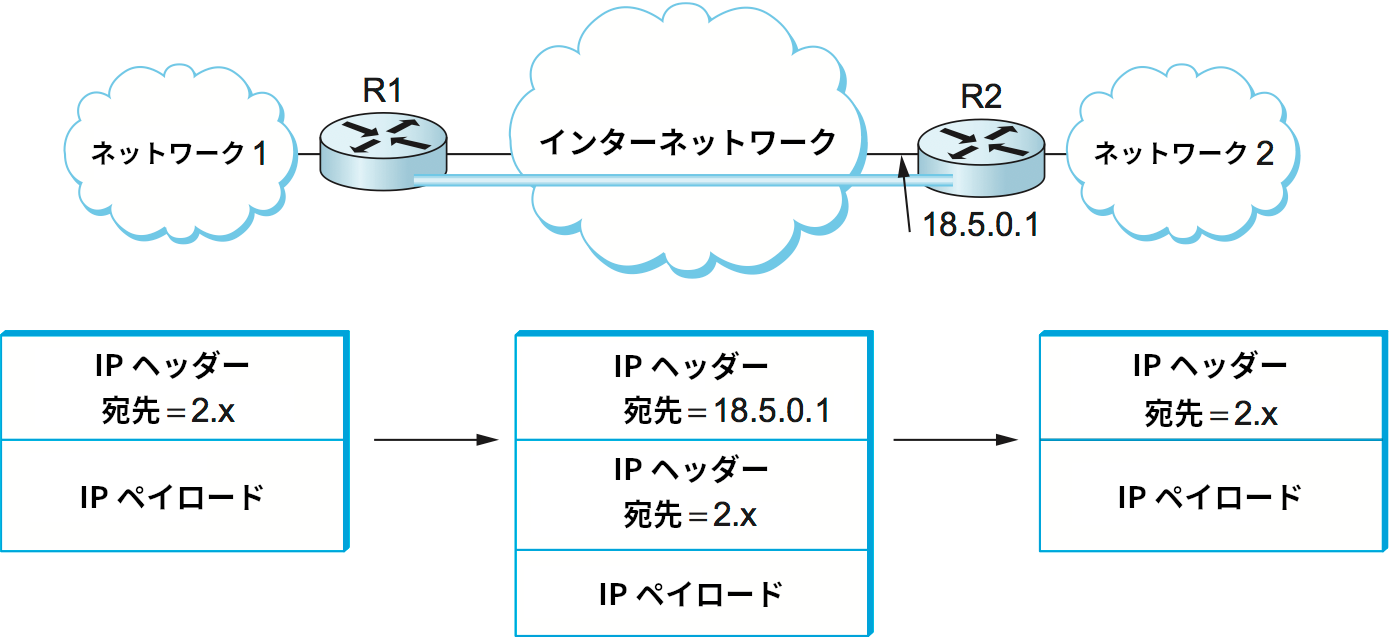
18.5.0.1 は R2 のアドレスであり、R1 はインターネットワークを通じてこのアドレスに到達できる。
| ネットワーク番号 | ネクストホップ |
|---|---|
| 1 | インターフェース 0 |
| 2 | 仮想インターフェース 0 |
| デフォルト | インターフェース 1 |
R1 は二つの物理インターフェースを持ち、インターフェース 0 はネットワーク 1 に接続する。インターフェース 1 は大規模なインターネットワークに接続するので、パケットの宛先 IP アドレスがマッチしなかったときに使われるデフォルトルーターとなっている。これに加えて R1 は仮想インターフェースを一つ持っており、これが IP トンネルへのインターフェースとなる。R1 がネットワーク 2 のアドレスに宛てられたパケットをネットワーク 1 から受けったとしよう。このとき転送テーブルには「仮想インターフェース 0 からパケットを送信せよ」と書かれている。この仮想インターフェースからパケットを送信するために、R1 は R2 のアドレス 18.5.0.1 を宛先とした IP ヘッダーをパケットに付け足し、そのパケットを受信したかのように振る舞う。R2 のアドレスは 18.5.0.1 であり、ネットワーク番号として 1 でも 2 でもない 18 を持つ。そのため宛先が R2 となったパケットはデフォルトインターフェースによってインターネットワークへと転送される。
R1 を離れた後このパケットは R2 に宛てられた通常の IP パケットと同じように世界の他の部分から扱われ、R2 へと適切に転送される。このパケットが R2 に到着すると、R2 はパケットの宛先が自身であることを認識し、 IP ヘッダーを取り除いてペイロードを確認する。ペイロードがネットワーク 2 に宛てられた IP パケットであることを見つけると、R2 は内部の (受け取ったパケットのペイロードの) IP パケットを自身が受け取ったパケットとして通常通りの転送を行う。R2 はネットワーク 2 に直接接続されているから、内部のパケットはネットワーク 2 を通じて転送される。図 83 には IP トンネルを通るパケットに施される二重のカプセル化が示されている。
IP トンネルの端として動作している間でも、R2 は普通のルーターとして動作できる。例えばトンネルを通っていないパケットを受け取ったときは、宛先のネットワークへの到達方法を知っていれば通常と同じ方法で転送が行われる。
わざわざ IP トンネルを構築してパケットを余分にカプセル化するなど、いったい誰が好き好んでするのだろうと疑問に思ったかもしれない。理由の一つにセキュリティがある。暗号化と共に使えば、トンネルはパブリックネットワークの上に構築できる非常にプライベートなリンクとなる。もう一つの理由として、中間のネットワークでは使えないことの多い機能 (マルチキャストルーティングなど) が R1 と R2 で利用できることが考えられる。そういったルーターをトンネルで結ぶことで、特別な機能を持ったルーターだけを直接結んだかのように扱える仮想回線を構築できる。第三の理由として、IP 以外のプロトコルのパケットを IP ネットワークで転送することが考えられる。トンネルの両端のルーターがその IP でないパケットの扱いを知ってさえいれば、トンネルは IP でないパケットを転送できるポイントツーポイントリンクとして扱える。また、オリジナルのヘッダー (トンネルの入口でカプセル化されるヘッダー) の宛先と関係ない場所をパケットが通ることを強制する手段としてもトンネルは利用できる。このように、トンネルはインターネットワーク上に仮想リンクを構築する強力かつ非常に一般的なテクニックである。再帰的に適用できるほどに一般的であり、IP の上に IP トンネルを構築するために最もよく使われる。
トンネルには欠点もある。まず、パケットが長くなる: 短いパケットでは帯域が大きく無駄になる可能性がある。長いパケットでは分割が起きる可能性があり、そのコストは小さくない。トンネルの両端のルーターは通常の転送とは別にトンネルヘッダーの追加あるいは除去を行わなければならないので、パフォーマンスが低下する可能性もある。最後に、トンネルをセットアップしてルーティングプロトコルによって正しく処理されることを確認するための管理コストがある。
-
ATM ネットワークにおける MTU は幸い単一のセルよりずっと大きい。ATM は分割と再構築の仕組みを独自に持つためである。ATM のリンク層フレームは CS-PDU (Convergence-Sublayer Protocol Data Unit) と呼ばれる。 ↩︎
-
訳注: IP アドレスのネットワーク部の値を指して「ネットワーク番号」という言葉が使われている。例では小さな値が使われているが、後述されるように実際はもっと大きい。 ↩︎