9.4 オーバーレイネットワーク
インターネットは誕生したときからクリーンなモデルを採用してきた: ネットワーク内のルーターがパケットを送信元から宛先に向けて転送し、ホストで実行されるアプリケーションはネットワークの端に接続される。第 9.1 節で説明したクライアント/サーバーパラダイムには、このモデルが明らかに当てはまる。
しかし最近になって、転送の判断を自ら行うインターネット中に分散されたアプリケーションが新たに登場し、そういったアプリケーションではパケットの転送とアプリケーションの処理の境界は曖昧になってきている。この新しいタイプのハイブリッドなアプリケーションの実装では、アプリケーション特有のわずかな処理のサポートが伝統的なルーターとスイッチに追加されることもある。例えば、いわゆる L7 スイッチ (L7 switch) はサーバークラスターの前に設置され、HTTP リクエストをリクエストされた URL に応じて特定のサーバーに転送する。しかし、インターネットに新しい機能を追加するときの選択肢として現在大きな盛り上がりを見せているのはオーバーレイネットワーク (overlay network) である。オーバーレイネットワークは単に「オーバーレイ」とも呼ばれる。
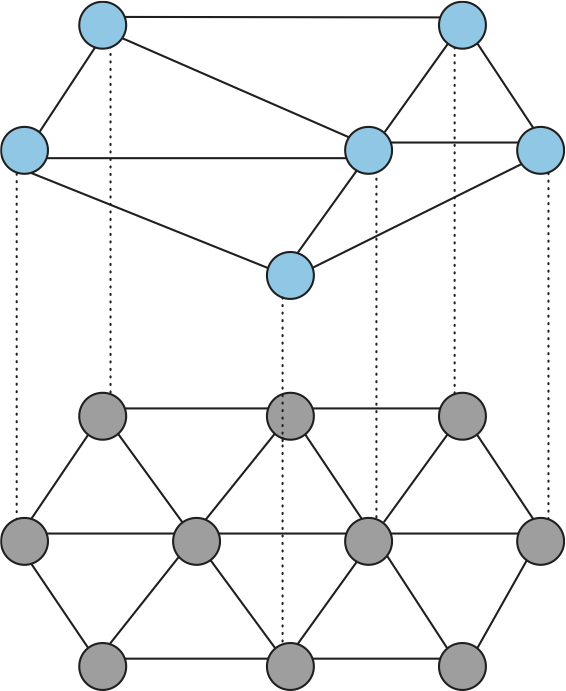
オーバーレイネットワークは何らかの下位ネットワークの上に実装される論理的ネットワークと考えることができる (図 235)。この定義によれば、インターネットは古くからある電話回線ネットワークが提供するリンクを利用したオーバーレイネットワークとして始まったとみなせる。オーバーレイネットワークのノード (オーバーレイノード) は下位ネットワークのノードでもあり、アプリケーション特有の方法でパケットを処理・転送する。オーバーレイノードを接続するリンクは下位ネットワーク上のトンネルとして実装される。一つのネットワークの上に複数のオーバーレイネットワーク ── それぞれが特定のアプリケーションのために動作する ── を構築しても構わない。オーバーレイネットワークを入れ子にすることもできる。例えば、本節で議論するオーバーレイネットワークの例は全てインターネットを下位ネットワークとして利用する。
トンネルの例は本書で以前に何度か触れた。例えば第 3.9 節では VPN (仮想プライベートネットワーク) を説明した。簡単に復習しておくと、トンネルの端にある二つのノードを結ぶマルチホップのパスが単一の論理的パスとみなされる。送信元ノードからのパケットを受け取ったトンネルの端にあるノードはトンネルの向こう側を宛先としたヘッダーでパケットを包み、両者の間にあるルーターは外側のヘッダーだけを見てパケットを転送する。送信元ノードが付けた内側のヘッダーを中間のルーターは関知しない。
図 236 に二つのトンネルで結ばれた三つのオーバーレイノード (A, B, C) を示す。この例でオーバーレイノード B が A から C に宛てられたパケットの転送判断を行うとき、B は内側のヘッダー (IHdr) を見てオーバーレイネットワークにおける次の転送先が C であることを理解し、下位ネットワークにおける宛先 C を記した外側のヘッダー (OHdr) をパケットに付加する。A, B, C は内側のヘッダーと外側のヘッダーの両方を理解できる。同様に A, B, C はオーバーレイネットワーク用のアドレスと下位ネットワーク用のアドレスの両方を持つ。ただし二つのアドレスが一致する必要はない: 例えば下位のアドレスは 32 ビットの IP アドレスで、オーバーレイのアドレスは実験的な 128 ビットアドレスかもしれない。さらに言えば、オーバーレイアドレスが伝統的な見た目をしている必要はなく、パケットの転送を URL、ドメイン名、XML クエリ、あるいはパケットの内容を利用して行うことさえできる。
9.4.1 ルーティングオーバーレイ
最も簡単な種類のオーバーレイネットワークは通常と異なるルーティング戦略をサポートするためだけに存在する: それ以外にオーバーレイノードで行われるアプリケーションレベルの処理は存在しない。こういったオーバーレイネットワークをルーティングオーバーレイ (routing overlay) と呼ぶ。 VPN はルーティングオーバーレイの一種と言える。ただし、VPN ではルーティングテーブルに新しいエントリーが加わることはなく、通常の IP 転送アルゴリズムと異なるルーティングの戦略やアルゴリズムが採用されることもない。VPN というルーティングオーバーレイネットワークが利用するトンネルは 「IP トンネル」と呼ばれ、VPN は市販のルーターでサポートされる。
しかし、商用ベンダーが製品に組み込むとは思えないルーティングアルゴリズムを使いたい場合にはどうするべきだろうか? この場合は全てのエンドホストでアルゴリズムを実装し、インターネットルーター上にトンネルを作ることになる。このときエンドホストはオーバーレイネットワークにおけるルーターのように振る舞う: エンドホストはインターネットのノードとしては (おそらく) 物理回線でインターネットに接続するのに対して、オーバーレイノードとしてはトンネルで隣接ノード (一つとは限らない) に接続される。
オーバーレイネットワークは、ほぼ定義により、新しい技術を標準化プロセスと独立して導入する手段として用いられる。そのため、例として示せるような標準化されたオーバーレイネットワークは存在しない。その代わり、本節ではこれからネットワーク研究者が構築した実験的システムを説明しながらルーティングオーバーレイの一般的なアイデアを解説する。
実験的バージョンの IP
将来世界中で使われることを目標に実験的バージョンの IP を開発しているなら、オーバーレイネットワークはそれをデプロイする理想的な場所を提供する。例えば IP マルチキャストは IP の拡張として開発され、現在でさえ多くのインターネットルーターは IP マルチキャストに対応していない。そのため、インターネットが提供するユニキャストルーティングの上に IP マルチキャストを実装した MBone (Multicast Backbone) と呼ばれるオーバーレイネットワークがかつて存在した。MBone 向けに開発・デプロイされたマルチメディアカンファレンスツールは数多く存在する。例えば、IETF 会合 ── 数週間にわたって開催され、数千人が参加する ── は長年にわたって MBone を通じてブロードキャストされていた (現在では商用カンファレンスツールが広く利用可能になったので、MBone ベースのアプローチは使われていない)。
VPN と同様、MBone は IP トンネルと IP アドレスを利用する。しかし VPN と異なり、MBone は異なる転送アルゴリズムを実装する ── パケットは最短路マルチキャスト木で下流にある全ての隣接ノードに転送される。もちろん MBone はオーバーレイネットワークなので、マルチキャストを処理するルーターは通常のルーターを利用したトンネルを使って (トンネルが必要なくなる日を夢見ながら) パケットを転送する。
6bone は MBone に似たオーバーレイネットワークであり、IPv6 を段階的にデプロイするために利用された。MBone と同様に、6bone は IPv4 ルーター上に構築されたトンネルを使ってパケットを転送する。しかし、32 ビットの IPv4 アドレスに新しい解釈を与える MBone と異なり、6bone は全く新しい 128 ビットの IPv6 アドレスに基づいて転送を行う。6bone は IPv6 マルチキャストもサポートした (現在では市販のルーターが IPv6 をサポートする。繰り返しになるが、オーバーレイネットワークは新しい技術を評価・調整する段階で利用できるアプローチとして大きな価値がある)。
エンドシステムマルチキャスト
IP マルチキャストは研究者とネットワークコミュニティの一部で有名になったものの、グローバルなインターネットにおけるデプロイはどんなによく言っても「限定的」だった。このため近年、ビデオ会議ツールといったマルチキャストベースのアプリケーションはエンドシステムマルチキャスト (end eystem multicast) と呼ばれる別の戦略へと転換している。エンドシステムマルチキャストのアイデアは「IP マルチキャストが決してユビキタスにならない現実を受け入れ、特定のマルチキャストベースのアプリケーションに参加するエンドホストに独自のマルチキャスト木を実装させる」というものである。
エンドシステムマルチキャストの動作を説明する前に理解しておくべき事実として、VPN や MBone と異なり、エンドシステムマルチキャストではオーバーレイネットワークに参加するのはインターネットホストだけ (インターネットルーターは参加しない) と仮定される事実がある。さらに、通常のアプリケーションが実装しやすいように、これらのホストは IP トンネルではなく UDP トンネルを通じてメッセージを交換する場合が多い。インターネットでは全てのホストが他の全てのホストにメッセージを送信できるので、下位ネットワークは任意のノードの組が全て接続されたグラフ (完全グラフ, complete graph) とみなせる。よって抽象的には、エンドシステムマルチキャストが解くべき問題は「インターネットを表す完全グラフから始めて、グループのメンバーを覆うなるべく小さなマルチキャスト木を見つけよ」となる。
なお、現在ではクラウドによってホストされる VM が世界中で利用可能なので、この問題の単純なバージョンを解くだけで済む点に注意してほしい。つまり、マルチキャストに対応する「エンドシステム」は様々な拠点で実行される VM である可能性がある。そういった拠点の内部構造はウェルノウンかつ比較的固定されているので、クラウド内の静的なマルチキャスト木を事前に構築しておき、実際のエンドホストには最も近くにあるクラウド拠点に接続させるアプローチが考えられる。ただ完全性のため、以降ではインターネットを利用するアプローチを解説する。
下位のインターネットは完全に接続されると仮定したので、ナイーブなアプローチは「各送信元がグループの各メンバーと直に接続する」となる。言い換えれば、エンドシステムマルチキャストは各メンバーが他の全メンバーに対してユニキャストメッセージを送信するものとして実装できる。このアプローチの問題点、特にルーターで IP マルチキャストを実装するアプローチと比べたときの問題点を理解するために、図 237 (a) に示したトポロジーを考えよう。この図で R1 と R2 は低帯域の大陸横断回線で結ばれたルーターであり、A, B, C, D はエンドホストである。辺に書かれた数字はリンクの遅延を表す。この状況で、A がマルチキャストメッセージを他の三つのホスト B, C, D に送信する場合を考える。
図 237 (b) はナイーブなユニキャスト転送を行ったときの様子を示している。これは明らかに望ましくない: 同じメッセージが A-R1 間を三度、R1-R2 間を二度通ってしまっている。図 237 (c) は DVMRP (Distance Vector Multicast Routing Protocol, 第 4.3.2 項) で構築される IP マルチキャスト木を示している。明らかに、このアプローチでは冗長なメッセージが除去される。しかしルーターからのサポートが無いエンドシステムマルチキャストでは、図 237 (c) に示したような木が実現可能な中で最良となる。エンドシステムマルチキャストはこういった木を構築するためのアーキテクチャを定義する。
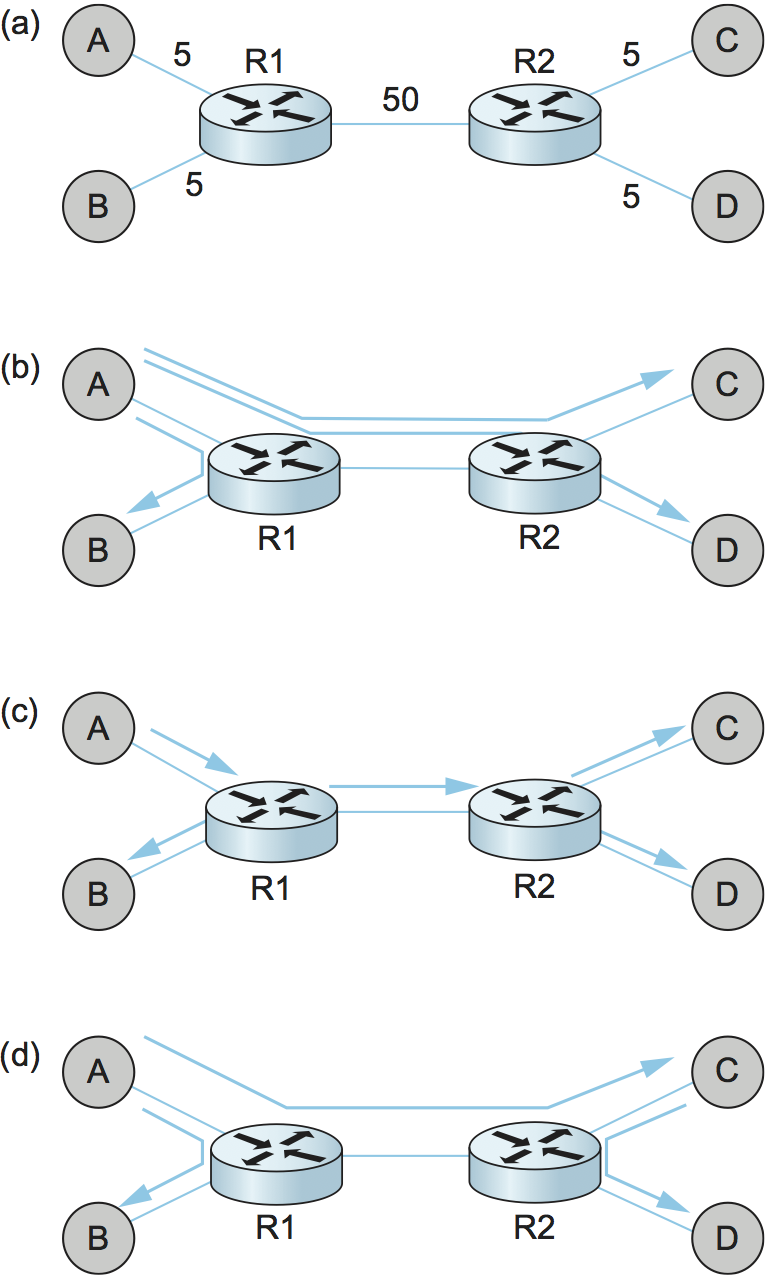
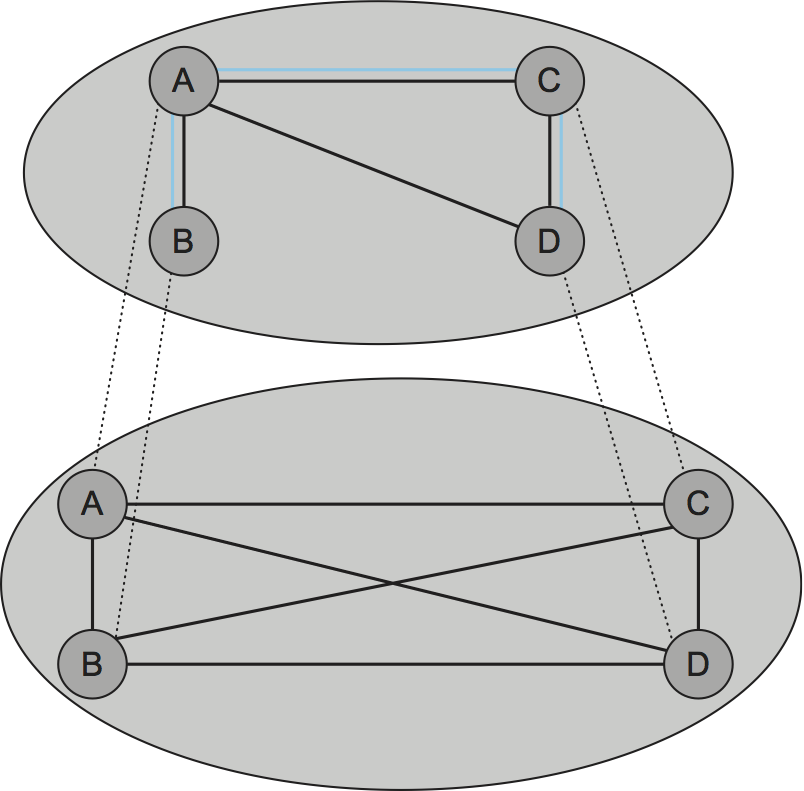
一般的なアプローチは複数のレベルからなるオーバーレイネットワークの階層をサポートするというものである。それぞれのオーバーレイネットワークは一つの下の階層の部分グラフであり、アプリケーションが期待する部分グラフとなるまで階層は積み上げられる。特にエンドシステムマルチキャストでは、オーバーレイネットワークの階層は次の二つのステップを通して構築される: まず完全に接続されたインターネットの上に単純なメッシュオーバーレイネットワークを構築し、そのメッシュの中でマルチキャスト木を構築する。この様子を図 238 に示す。ここでは前の例と同じく四つのエンドホスト A, B, C, D が存在するとしている。最初のステップが肝心となる: 適切なメッシュオーバーレイネットワークが選択されれば、後は通常のマルチキャストルーティングアルゴリズム (DVMRP など) を実行すればマルチキャスト木を構築できる。このアプローチでは中間のメッシュがマルチキャストグループに参加するノードだけからなるので、インターネット規模のマルチキャストが直面するスケーラビリティの問題を回避できる。
中間のメッシュを構築するときは、下位のインターネットが持つ物理トポロジーに大まかに対応するトポロジーを選択することが重要となる。しかしルーターからのサポートが存在せずエンドホストだけでアルゴリズムを実行しなければならないので、下位のインターネットの内部構造は何も分からない。そのため各エンドホストで他のエンドホストに対するラウンドトリップ遅延を測定し、特定の条件が成り立つ場合にのみメッシュにリンクを追加する方式が取られる。これは次のように行われる。
まず、メッシュが既に存在すると仮定して、各ノードは自身が信じるメッシュの構成ノードのリストを直接に接続された隣接ノードと交換する。このリストを隣接ノードから受け取ったノードは、その情報を自身のリストに加え、その結果をさらに隣接ノードに送信する。これを続けると、距離ベクトル型ルーティングアルゴリズムと同じように、メッシュのメンバーに関する情報がメッシュ中に行き渡る。
このメッシュに参加を望むホストは、メッシュに参加済みのノードの IP アドレスを少なくとも一つ知っておく必要がある。そのホストは「join mesh」メッセージを自身が知っている参加済みノードに送信することでメッシュに参加する。このとき新しいノードとメッシュがその参加済みノードからの辺で結ばれる。一般に、新しいノードは複数の参加済みノードに対して join mesh メッセージを送信しても構わない。メッシュに参加したノードは定期的に keepalive (生存確認) メッセージを隣接ノードに送信し、自身がグループに留まる意思があることを周囲に伝える。
ノードがグループを離れるときは、「leave mesh」メッセージを隣接ノードに送信する。この情報は上述したメッシュのメンバーを記したリストの交換を通して他のノードに伝わる。障害などが原因で leave mesh メッセージを送らずにノードがグループから離脱した場合でも、隣接ノードは keepalive メッセージが送られないことを検出できるので離脱は行える。離脱してもメッシュにほとんど影響しないノードもあるものの、離脱するとメッシュが分割されてしまうノードも存在する。そのようなノードの離脱を検出したノードは、もう一方の端にあるノードのどれかに「join mesh」メッセージを送信することで辺を追加して分割を防ぐ。複数の隣接ノードが同時に分割を検出し、複数の辺がメッシュに追加される状況もあり得る。
以上の処理があれば、元々の完全に接続されたインターネットの部分グラフであるメッシュが手に入る。しかし、このメッシュは次の理由でパフォーマンスに劣る:
- 最初に行われる隣接ノードの選択によってランダムなリンクがメッシュに追加される。
- 分割を防ぐために追加される辺が長い目で見て有用だとは限らない。
- グループのメンバーは動的に変化する可能性がある。
- 下位ネットワークの状態が変化する可能性がある。
高いパフォーマンスを持つメッシュを手に入れるには、メッシュの各辺が持つ価値を算出し、それに基づいて辺の追加・削除を行うシステムが必要となる。
そこで、実際には次のように新しい辺が追加される。まず、各ノード \(i\) は定期的に現在メッシュ内で接続されていないノード \(j\) をランダムに選択し、リンク \((i, j)\) のラウンドトリップ遅延の測定およびリンク \((i, j)\) の効用 (utility) の計算を行う。もし効用が何らかの閾値よりも大きければ、リンク \((i, j)\) がメッシュに追加される。リンク \((i,j)\) の効用は例えば次のように計算される:
EvaluateUtility(j)
utility = 0
for each グループのメンバー m (m != i) do
CL = メッシュを通じた通信におけるノード m の「現在の」レイテンシ
NL = リンク (i, j) が追加された場合の「新しい」レイテンシ
if (NL < CL) then
utility += (CL - NL)/CL
end
end
return utility
end
辺の削除も同様に行われる。ただし、ノード \(i\) は現在の隣接ノード \(j\) と自身を結ぶリンクのコストを次のように計算する:
EvaluateCost(j)
Cost[i,j] = i が j をネクストホップとして使うメンバーの個数
Cost[j,i] = j が i をネクストホップとして使うメンバーの個数
return max(Cost[i,j], Cost[j,i])
end
その後ノードは最もコストが低いリンクを選び、そのコストが何らかの閾値を下回っていれば削除する。
最後に、メッシュは本質的に距離ベクトル型プロトコルを使って管理されるので、DVMRP を実行して適切なマルチキャスト木を構築するのは自明な処理となる。ここまでに説明したプロトコルが最適なメッシュを構築するかどうかは証明できないものの、DVMRP を使えばそのメッシュにおいて最良のマルチキャスト木が選択される点に注目してほしい。シミュレーションと徹底的な実地試験の両方から、このプロトコルは上手く動作することが示唆されている。
レジリエントオーバーレイネットワーク
オーバーレイネットワークが担えるもう一つの機能として、伝統的なユニキャストアプリケーションが利用する経路の発見がある。ここではインターネットにおいて三角不等式が必ずしも成り立つとは限らないという観察が利用される (図 239)。インターネット内の三つの拠点を A, B, C とするとき、A-B 間のレイテンシが A-C 間のレイテンシと C-B 間のレイテンシの和より大きい状況は珍しくない。具体的に言えば、パケットを宛先に直接送るよりも中間ノードを経由して間接的に送った方が相手にパケットが速く到着する。
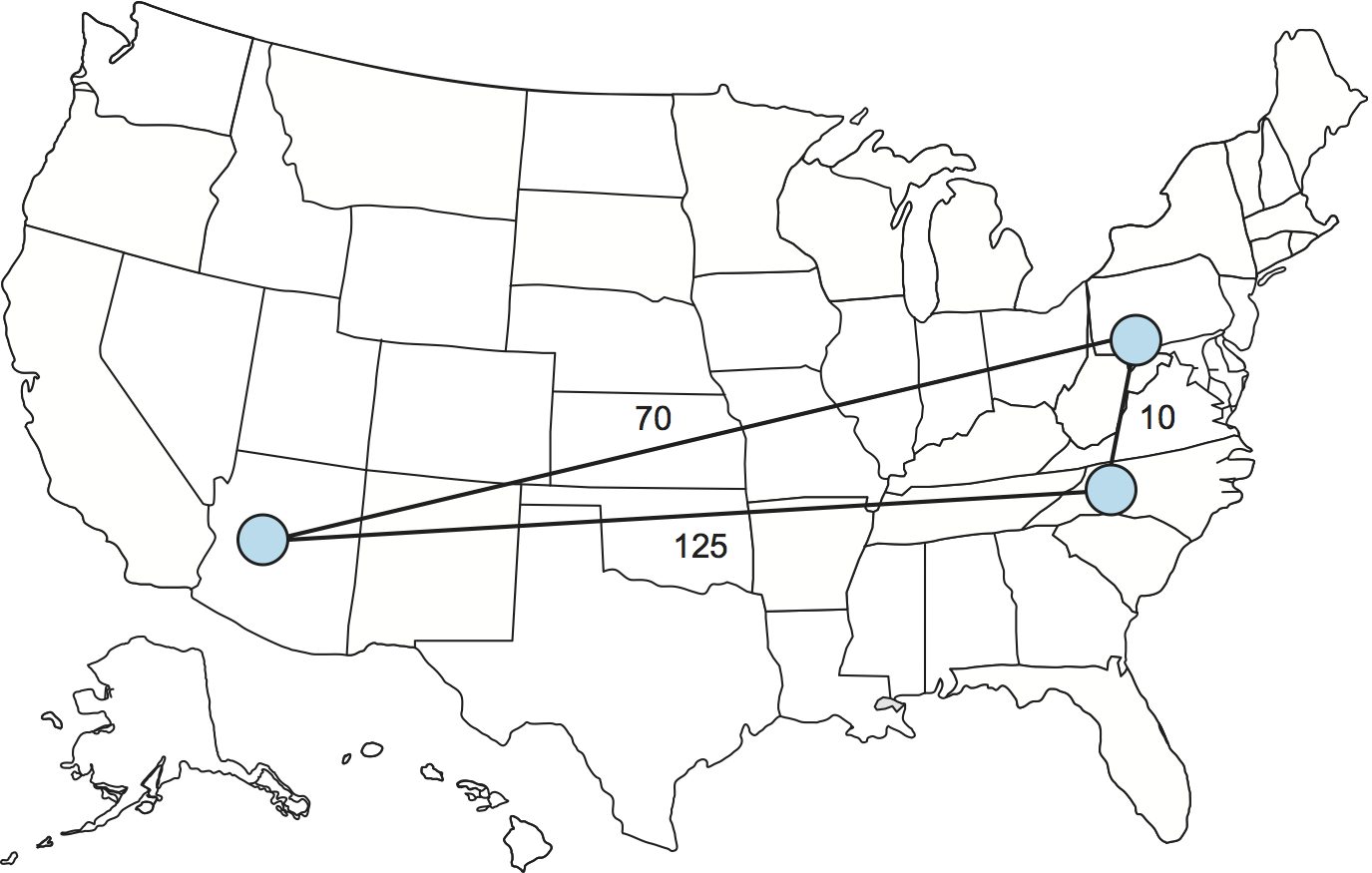
なぜこんなことが起こるのだろうか? 実は、BGP (Border Gateway Protocol) が二つの拠点間の最短経路を見つける保証はない。BGP は何らかの経路を見つけようとするに過ぎない。さらに事態を複雑にする要素として、BGP が見つける経路は「トラフィックの運賃を誰が誰に支払うか」といったポリシーに大きく影響を受ける。これは例えば主要バックボーン ISP 間のピアリングポイントでよく発生する。簡単に言えば、インターネットで三角不等式が成り立たなくても驚くようなことではない。
この観察はどのように利用できるだろうか? 最初のステップとして、ルーティングアルゴリズムの最適性とスケーラビリティの間にある基礎的なトレードオフを理解する必要がある。一方では、BGP は非常に大きなネットワークにまでスケールするものの、可能な中で最適な経路を選択するとは限らず、ネットワークが停止すると回復に時間がかかる。もう一方では、少数の拠点がある状況で最適な経路を見つけようとしているなら、利用できる全てのリンクの状態を監視すれば任意の時刻で最適な経路を選択できる。
RON (Resilient Overlay Network) と呼ばれる実験的オーバーレイネットワークはまさにこれを行う。RON は経路に関する三つの指標 ── レイテンシ、利用可能な帯域、パケットロスの確率 ── を拠点の全組に対してアクティブなプローブを通して細かく監視するという N×N のアプローチを採用するので、わずか数十ノードにしかスケールしない。その代わり RON は任意のノードの組の間の最適な経路を選択でき、さらにネットワークの条件が変わったとしても素早く経路を変更できる。実地試験によると、RON を使うとアプリケーションのパフォーマンスが多少改善され、さらに重要なこととして、ネットワーク障害からの回復が非常に高速になる。例えば 2001 年に行われた実験では、12 ノードで実行される RON のインスタンスは 30 分以上のネットワーク停止を 64 時間で 32 回検出し、全ての場合で平均 20 秒以内に動作を回復した。他にも、この実験はインターネット障害からの回復ではパケットを一つの中間ノードに迂回させるだけで十分な場合が多いことを示唆している。
RON はスケーラブルなアプローチとして設計されていないので、ランダムなホスト A とランダムなホスト B の通信を改善するために使うことはできない。A と B はお互いが通信をする可能性が高いことを事前に知っておき、同じ RON に参加しておく必要がある。しかし、RON は特定の状況では優れたアイデアであるように思える。例えばインターネット上に存在する数十の企業拠点を接続する、あるいは 50 人のフレンドと何らかのアプリケーションを実行するためにプライベートオーバーレイネットワークを構築するといった利用例が考えられる。現在このアイデアは SD-WAN (Software-Defined WAN, ソフトウェア定義 WAN) というマーケティングネームで実用されている。ただ、本当の疑問は「もし誰もが RON を実行し始めたら何が起きるのか?」である。数百万の RON によるオーバーヘッドがネットワークを圧倒するだろうか? たくさんの RON が同じ経路を奪い合ったとしても、全員のパフォーマンスが改善するのだろうか? これらの疑問には未だに解答が存在しない。
教訓
こういったオーバーレイネットワークはどれも、仮想化 (vertualization) というコンピューターネットワークで中心的な概念の例と言える。つまり、物理的リソースから構成される物理ネットワークの上には抽象的 (論理的) なリソースから構成される仮想ネットワークを構築できる。さらに、仮想ネットワークを入れ子にすることも、複数の仮想ネットワークを同じ物理ネットワークの上に共存させることもできる。それぞれの仮想ネットワークは特定のユーザー、アプリケーション、あるいは上層のネットワークに役立つ機能を提供する。
9.4.2 ピアツーピアネットワーク
Napster や KaZaA といった音楽共有アプリケーションは「ピアツーピア」という言葉を一般の人々に定着させた。しかし、システムが「ピアツーピア」とは正確に何を意味するのだろうか? MP3 ファイルの共有という文脈における意味は明らかで、「ピアツーピア」は MP3 ファイルを中心的なサイトからダウンロードするのではなく、その MP3 ファイルのコピーをたまたま持っているインターネットに接続されたコンピューターから直接ダウンロードすることを意味する。これを一般化すれば、ピアツーピアネットワークはユーザーのコミュニティがリソース (コンテンツ、ストレージ、ネットワーク帯域、ディスク帯域、CPU) を共同で利用し、一人のユーザーでは不可能なほど大容量のアーカイブ、大規模な音声/映像会議、複雑な検索・計算といった処理を行うシステムと言える。
ピアツーピアネットワークの議論では分散 (decentralized) や自己組織化 (self-organizing) といった性質がよく言及される。こういった言葉はノードの集合が中央機関による調整を必要とせずにネットワークへと組織化されることを意味する (よく考えると、この性質はインターネット自身に対しても当てはまる)。しかし皮肉にも、この性質をピアツーピアが必ず持つ特徴とみなすとき、Napster は真のピアツーピアシステムではない: Napster には既知のファイルを管理する中央レジストリが存在し、ユーザーはこのレジストリを検索してファイルを提供するマシンを見つける必要がある。二つのユーザーマシン間で行われるのは最後のステップ ── 実際のファイルのダウンロード ── だけであり、これは伝統的なクライアント/サーバー形式のトランザクションと大差ない。サーバーを保有するのが大企業ではなくクライアントと同様の個人である点だけが異なる。
元の問題をもう一度考えよう: ピアツーピアネットワークの何が興味深いのだろうか? 一つの解答は「ユーザーが指定したオブジェクトの検索とローカルマシンへのダウンロードを中央機関とやり取りせずに行うことができ、同時にシステムが数百万ノードまでスケールするから」となる。この二つのタスクを分散された形で達成できるピアツーピアシステムは、オーバーレイネットワークを使うと構築できることが判明している。このオーバーレイネットワークでは、他のユーザーが興味を持つオブジェクト (音楽などのファイル) を共有する意思を持つホストがノードとなり、そういったノード同士を接続するリンク (トンネル) は探しているオブジェクトに到達するために訪れる必要のあるマシンの列を表す。この説明は以降で二つの例を見るとさらによく理解できるだろう。
Gnutella
Gnutella は初期のピアツーピアネットワークであり、音楽ファイルの交換 (第三者の著作権を侵害する可能性が高い) と一般的なファイルの共有 (我々が二才の時からすべきだと教わってきた、善行であるはずのこと) を区別しようと試みた。Gnutella の興味深い特徴として、Gnutella はオブジェクトの中央レジストリに依存しない。この特徴を持つシステムとして最も古いものの一つが Gnutella である。中央レジストリと対話する代わりに、Gnutella の参加者は図 240 に示したようなオーバーレイネットワークに自身を参加させる。このオーバーレイネットワークにおいて、Gnutella ソフトウェア (Gnutella プロトコルの実装) を実行する各ノードは同じく Gnutella ソフトウェアを実行する他のマシンをいくつか知っている。このグラフの辺は「A と B はお互いを知っている」という関係を表す (このグラフの構築方法は後述する)。
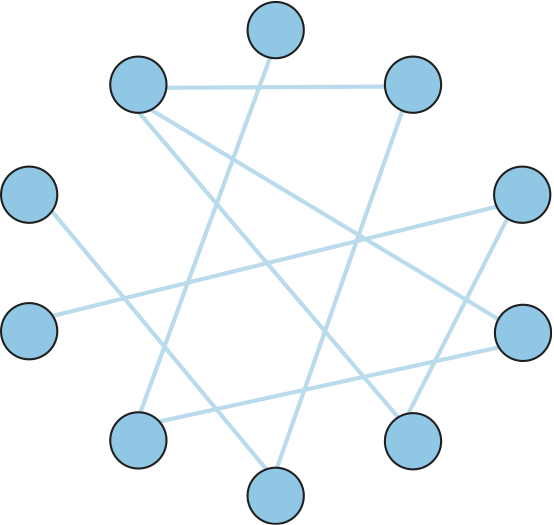
ノード上のユーザーがオブジェクトの検索を行うと、Gnutella はそのオブジェクトに対する QUERY メッセージ ── 例えばファイル名が記される ── をグラフで隣接するノードに送信する。もし隣接ノードがそのオブジェクトを持っているなら、そのノードはオブジェクトをダウンロードできる場所 (IP アドレスと TCP ポート番号など) を記した QUERY RESPONSE メッセージを QUERY メッセージを送信したノードに送信する。クエリの返答を受け取ったノードは、その後 GET メッセージと PUT メッセージでオブジェクトにアクセスする。隣接ノードがクエリを解決できない場合は、QUERY メッセージを自身の隣接ノード (クエリの送信元は除く) に送信し、同じことが繰り返される。言い換えれば、Gnutella は検索対象のオブジェクトを見つけるためにオーバーレイネットワークにクエリのフラッディング (洪水) を発生させる。Gnutella はクエリに TTL を設定するので、このフラッディングが無限に続くことはない。
クエリには TTL の他にクエリ識別子 (QID) が含まれるものの、オリジナルのメッセージ送信元の身元は含まれない。その代わり、各ノードは自身が処理した QUERY メッセージの履歴、具体的にはクエリの QID と送信元の隣接ノードの組を記録する。この履歴は二つの処理で利用される。まず、受け取った QUERY メッセージの QID が履歴に存在する場合、その QUERY メッセージは転送されない。この仕組みは転送ループを TTL が切れるより早く断ち切るためにある。次に、ノードが下流の隣接ノードから QUERY RESPONSE メッセージを受け取った場合、そのノードは対応する QUERY メッセージを送ってきた隣接ノードを知っているので、そこに QUERY RESPONSE メッセージを転送する。こうするとクエリに対するレスポンスは送信元のノードまで返るにもかかわらず、誰が最初にオブジェクトの所在を知りたがったかを中間ノードが知ることはない。
続いて図 240 のようなグラフを構築する問題を考えよう。明らかに、Gnutella オーバーレイに参加を希望するノードは参加済みのノードを少なくとも一つ知っている必要がある。新しいノードは最初に自身が知っている参加済みノードとのリンクでオーバーレイに接続する。その後、ノードは QUERY RESPONSE メッセージ (自身がリクエストしたオブジェクトに対するものと、自信を通り抜けるものの両方) をやり取りする中で他のノードを学習する。ノードはこうして学習した他のノードを隣接ノードとするかどうかを自身で判断して構わない。Gnutella プロトコルが提供する PING メッセージと PONG メッセージを使うと隣接ノードが存在し続けているかどうかを確認できる。
ここまでの説明で Gnutella がそれほど高度なプロトコルでないことは理解できたと思う。そのため後継のプロトコルによって様々な改善が試みられた。改善が可能な次元の一つにクエリを広める方法がある。Gnutella が採用するフラッディング (送信元を除く全ての隣接ノードにクエリを転送する戦略) は目的のオブジェクトが必ず最小のホップで見つかるという優れた性質を持つものの、スケーラビリティに劣る。例えばクエリの転送をランダムに行ったり、過去のクエリに対する成功率によって行ったりすることが代替案として考えられる。もう一つの改善案として、オブジェクトの積極的な複製がある。頻繁に検索されるオブジェクトの複製を多く用意しておけば、コピーを近い場所で発見できる可能性が高まる。あるいは、次項で説明する全く異なる戦略を使うこともできる。
構造化オーバーレイ
Napster が残した大きな穴を様々なファイル共有システムが埋めようと奮闘していたころ、研究コミュニティはピアツーピアネットワークの異なる設計を探っていた。前項で説明した「ランダムな (非構造化)」オーバーレイネットワークと対比するために、これらのネットワークを本書では構造化オーバーレイネットワーク (structured overlay network) と呼ぶ。Gnutella などの非構造化オーバーレイネットワークはネットワークの構築と管理に自明なアルゴリズムを用いるため、低信頼なランダム検索しか提供できない。これに対して、構造化オーバーレイネットワークは確実で効率的な (遅延が確率的な上限を持つ) オブジェクト検索が可能な特定のグラフ構造を持つように設計される。ただしネットワークの構築と管理はその分だけ複雑になる。
構造化オーバーレイネットワークの動作を高いレベルで考えると、二つの疑問が生じる:
- それぞれのオブジェクトをどのノードに関連付けるか?
- オブジェクトに対するリクエストをどのように担当ノードに転送するか?
一つ目の疑問から議論を始めよう。\(x\) という名前の付いたオブジェクトを、そのオブジェクトを持つノード \(n\) に関連付けたいとする。伝統的なピアツーピアネットワークでは、オブジェクト \(x\) をホストするノード \(n\) のアドレスは全く制御されない。しかしオブジェクトがネットワーク上にどのように分散されるかを管理できれば、後からオブジェクトを見つける処理を効率良く行えるだろう。
名前をアドレスに関連付ける有名なテクニックとしてハッシュテーブルを使うものがある。つまり、ハッシュ関数 \(\text{hash}(x)\) に関する関係
を「オブジェクト \(x\) はノード \(n\) に配置される」と解釈する。オブジェクト \(x\) を見つけたいと思ったクライアントは、\(x\) のハッシュを計算することで \(x\) の配置されるノード \(n\) を知ることができる。ハッシュベースのアプローチには全てのノードに対して公平にオブジェクトが割り当てられるという優れた特徴があるものの、単純なハッシュアルゴリズムを使う方法には致命的な欠点がある: 可能な \(n\) の値をいくつ用意すべきかが分からない (ハッシュの言葉を使えば、用意すべき「バケツ」の個数が分からない)。ナイーブに考えると、ハッシュ関数が取る値の個数を適当に (例えば 100 と) 決めておけば、ハッシュ関数としてモジュロ演算を利用できる:
hash(x)
return x % 100
しかしこの方法だと、オブジェクトをホストできるノードの個数が 100 より多くなると全てのノードを活用できなくなる。一方でノードの個数が 100 より小さいと、一部の \(x\) に対するハッシュ関数の出力が存在しないノードを指すことになる。さらに、ハッシュ関数の出力を実際の IP アドレスに変換するという決して小さくない問題もある。
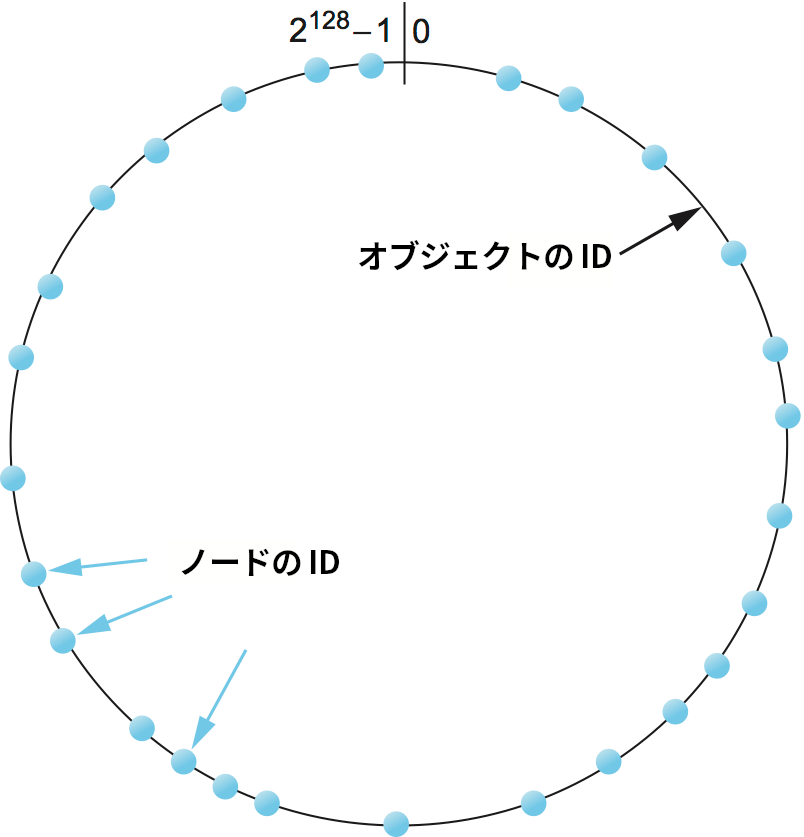
こういった問題を解決するため、ピアツーピアネットワークはコンシステントハッシング (consistent hashing) と呼ばれるアルゴリズムを利用する。コンシステントハッシングは非常に大きな ID の空間を利用することでノード数の増減に対応する。図 241 に示したのは 128 ビットの ID 空間を表す円であり、コンシステントハッシングのアルゴリズムはオブジェクトとノードの両方をこの空間に配置する。具体的には、オブジェクトの名前とノードの IP アドレスを ID に変換するハッシュ関数が利用される:
128 ビットの ID 空間は非常に大きいので、オブジェクトとマシンが同じ値にハッシュされる可能性は非常に低い。そこで、それぞれのオブジェクトは ID 空間で最も近いノードによって管理される。つまり、高品質なハッシュ関数を使ってノードとオブジェクトの両方を巨大で疎な共通の ID 空間にマップし、その空間における両者の ID の数値的な近さを利用してオブジェクトをノードにマップするというアイデアである。通常のハッシングと同様に、コンシステントハッシングは各ノードにオブジェクトを公平に割り当てる。しかし通常のハッシングと異なり、コンシステントハッシングではノード (ハッシュで使う「バケツ」) が増減したときに移動が必要となるオブジェクトが少なくて済む。
続いて二つ目の疑問を考えよう ── オブジェクト \(x\) に対するアクセスを望むユーザーは、ID 空間で \(x\) の ID に最も近いノードをどのように見つけるのだろうか? 一つの選択肢として、各ノードが全ノードの ID と IP アドレスの完全なリストを持つ方法が考えられる。しかし、この方法は大規模なネットワークでは実用的でない。もう一つの選択肢として、各ノードでルーティングを行う方法がある。言い換えれば、ピアツーピアネットワークを賢い形で構築すれば ── つまりノードのルーティングテーブルに記されるエントリーを賢く選べば ── 各ノードがルーティングテーブルに沿って転送するだけで目的のノードを発見できる。このときハッシュテーブルがネットワークの全ノードに分散されて実装されるので、このアプローチを DHT (distributed hash table, 分散ハッシュテーブル) と呼ぶことがある。
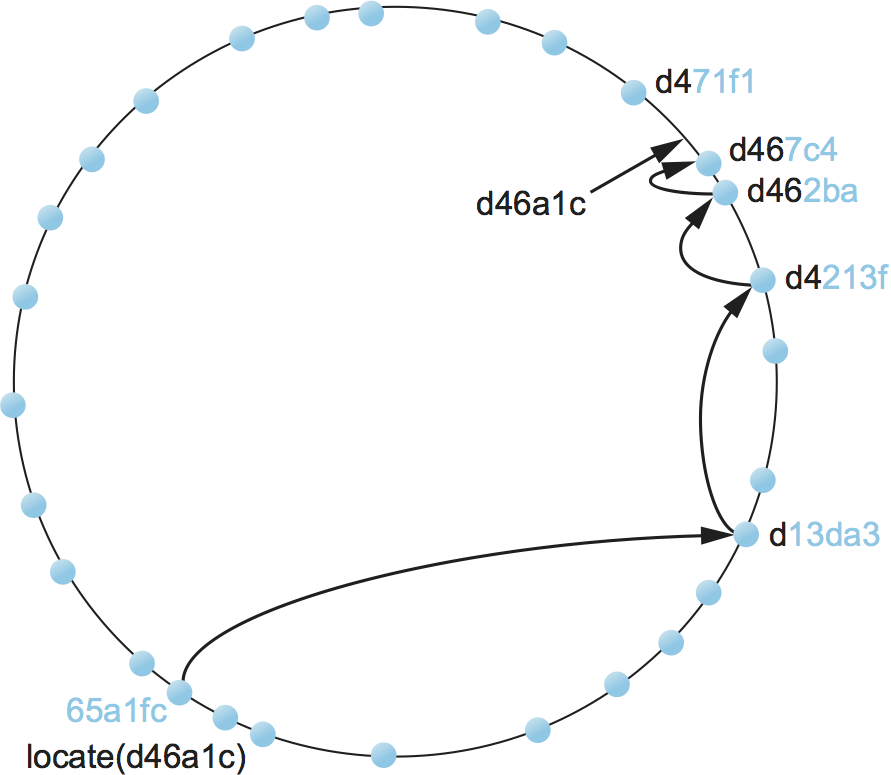
これから 128 ビットの ID 空間を用いる DHT の例を示す (図 242)。議論を可能な限り具体的にするために、ここからは Pastry というピアツーピアネットワークで利用されるアプローチを説明する。他のシステムも同じような方式で動作する。
ID 65a1fc のノードが ID d46a1c のオブジェクトを見つけたいと思ったとしよう (ID は十六進数)。まず、このノードは自身の ID 65a1fc とオブジェクトの ID d46a1c が全く異なる (共通接頭部がない) ことを認識する。しかし、ノード 65a1fc は ID の先頭から少なくとも一文字がオブジェクトの ID d46a1c と共通のノードを知っている。そのノードはノード 65a1fc よりもオブジェクトに近いので、ノード 65a1fc はメッセージをそのノードに向けて転送する (転送されるメッセージのフォーマットについては省略する。簡単に言えば「オブジェクト d46a1c を見つけて」と書かれている)。そして転送先のノードも同様に自身よりさらにオブジェクトに近いノードにメッセージを転送する。この「ID 空間で自身よりオブジェクトに近いノードにメッセージを転送する」という手続きが繰り返され、最終的にオブジェクトをホストするノードにメッセージが到着する。図 242 に示したように検索処理が注目するノードが論理的な「ID 空間」を移動するとき、下層のインターネットを通じてノードからノードへ実際にメッセージが送信されていることに注意してほしい。
検索を効率的に行うために、ID 空間は葉集合 (leaf set) と呼ばれる小区間に分割され、各ノードはルーティングテーブル (後述) に加えて自身と同じ葉集合に属する全ノードの IP アドレスを保持する。こうすることで、メッセージがオブジェクトをホストするノードと同じ葉集合に属するノードに届きさえすれば、そこからはオブジェクトをホストするノードに直接メッセージを転送できるようになる。言い換えれば、オブジェクト ID と最長接頭部の長さが同じノードが複数あった場合でも、葉集合によって効率良い検索が可能になる。さらに、葉集合に属する全ノードはお互いにメッセージを直接送信できるので、葉集合によってルーティングはさらにロバストになる。例えば、あるノードがメッセージのルーティングを進められなかったとしても、葉集合における隣接ノードはルーティングを行える可能性がある。まとめると、ルーティングは次のように定義される:
Route(D)
if D が自身と葉集合に属する
葉集合の中で数値的に最もオブジェクトに近いノードに転送する
else
let l = D と自身の ID の共有接頭部の長さ
let d = D のアドレスの第 l 桁の値
if RouteTab[l,d] が存在する
RouteTab[l,d] に転送する
else
D との共有接頭部が自身よりも短くなく、
数値的に自身より D に近い ID を持つノードに転送する。
ここで RouteTab は各ノードがそれぞれ持つ二次元のルーティングテーブルであり、ID の (十六進) 一桁につき一つの行、そして十六進の値一つにつき一つの列を持つ。例えば ID が 128 ビットなら、RouteTab は 32 個の行と 16 個の列を持つ。第 \(i\) 行の各エントリーはノードの ID と先頭 \(i\) 桁が一致する ID を持つノードの IP アドレスであり、第 \(i\) 行の第 \(j\) 列のエントリーに対応するノード ID は \(i + 1\) 桁目に \(j\) を持つ。ノード 65a1fcx が持つルーティングテーブルの最初の三行を図 243 に示す。この図で x は規定されない接尾部を表し、その上の数字はエントリーがマッチする接頭部を表す。エントリーに記録される値 ── ノードの IP アドレス ── は図に示されていない。
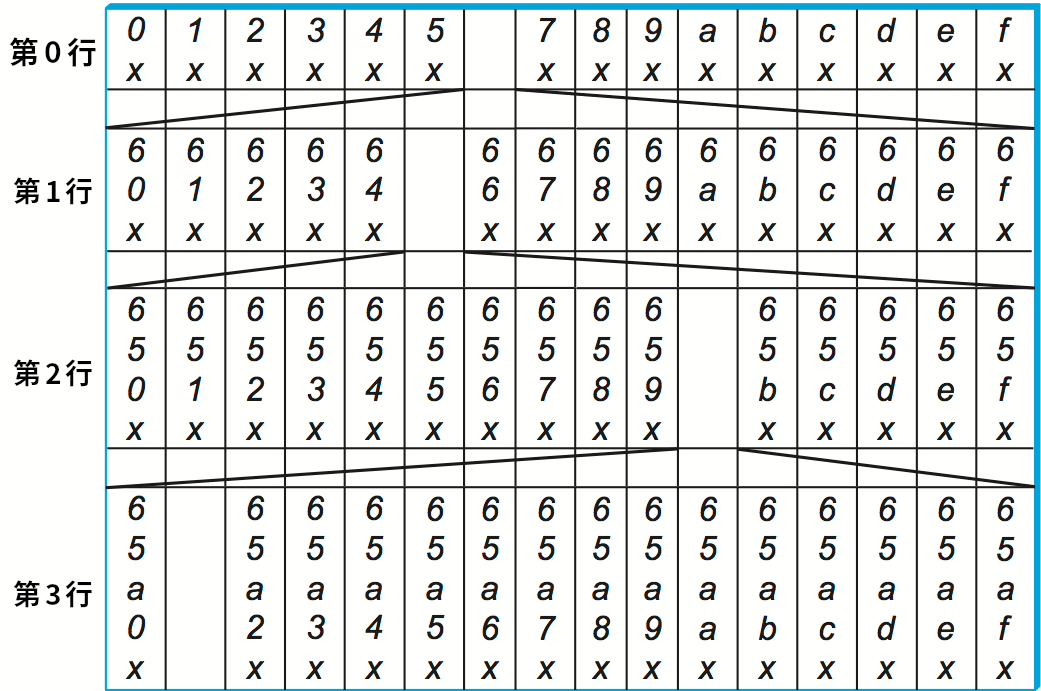
65a1fcx のノードが持つルーティングテーブルの最初の三行
この構造化オーバーレイネットワークにノードを追加する処理は、「オブジェクト検索」メッセージを転送する処理とよく似ている (図 244)。新しいノードは少なくとも一つの参加済みノードを知っておく必要がある。新しいノードは参加済みノードに「ノード追加」メッセージを送信し、そのメッセージは新しいノードに数値的に最も近いノードまで転送される。この転送処理の間に新しいノードは自身と同じ接頭部を持つ他のノードを学習し、ルーティングテーブルを埋めていくことができる。オーバーレイネットワークにノードが追加されるとき、既存のノードは自身の判断で新しく追加されたノードに関する情報でルーティングテーブルを更新できる。ルーティングテーブルの更新は新しいノードが既知のノードより長い共通接頭部を持つときに発生する。加えて各ノードは同じ葉集合に属する隣接ノードとルーティングテーブルを交換するので、ルーティング情報はオーバーレイネットワーク全体に伝播する。
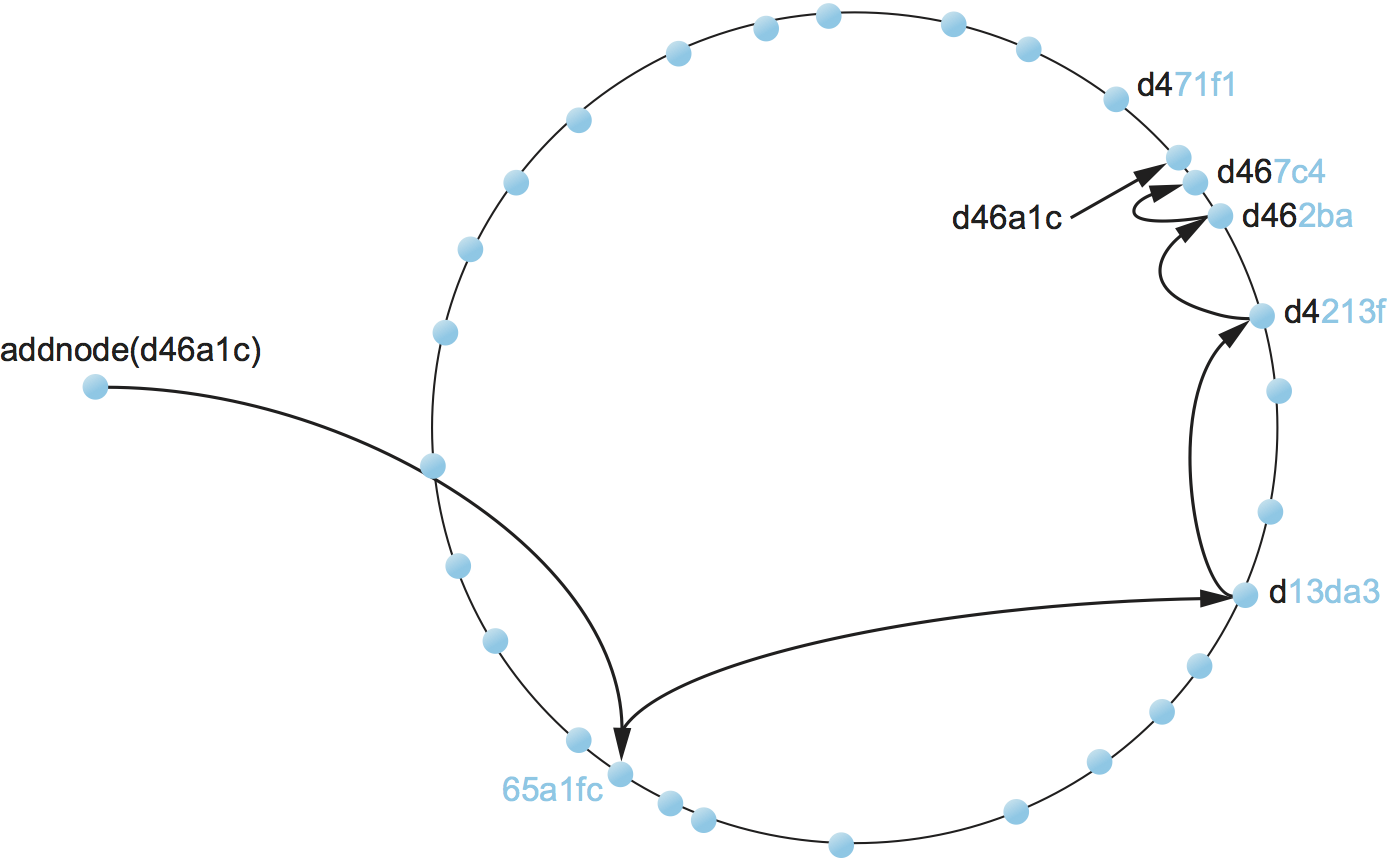
読者は既に気が付いているかもしれないが、構造化オーバーレイネットワークでは特定のオブジェクトを見つけるために必要となるルーティングホップの個数に確率的な上限が存在する ── Pastry ではノード数を \(N\) としてホップ数が \(\log_{16} N\) で抑えられる ── ものの、各ホップが大きな遅延を伴う可能性がある。これは中間ノードがインターネット上のランダムな場所に位置するためである (最悪のケースでは、次のノードが地球の裏側にある!)。実は、これまで説明してきたアルゴリズムを世界規模のオーバーレイネットワークで利用すると、各ホップで発生する遅延の期待値はインターネット上の任意のノード間の通信で発生する遅延の平均値となる! 幸い実際のオーバーレイネットワークでは、ルーティングテーブルのエントリーに下位の物理ネットワークで近接するノードを優先して加えることで遅延をずっと小さくできる。こうすることで、エンドツーエンドのルーティング遅延は送信元ノードと宛先ノードの遅延の (小さな) 定数倍程度になることが判明している。
最後に、ここまでの議論はピアツーピアネットワークにおけるオブジェクトの検索という一般的な問題だけに集中していることを指摘しておく。このルーティングインフラストラクチャがあれば、その上に異なるサービスも構築できる。例えばファイル共有サービスはファイル名をオブジェクト名とみなすだろう。ファイルを見つけるには、その名前をハッシュしてオブジェクト ID を計算し、その ID に対する「オブジェクト検索」メッセージを送信する。このシステムは可用性を向上させるために複数のノードにファイルのコピーを保持させるかもしれない。例えば「ファイルの本来の持ち主と同じ葉集合に属するノードのいくつかでファイルのコピーを保持する」といった方法が考えられる。同じ葉集合に含まれるノードは ID 空間では近接しているものの、インターネット上では物理的に遠く離れている可能性が高い事実に注意してほしい。そのため、伝統的なファイルシステムでは特定の都市で停電が起きると物理的に近くにある複製も全て利用不可能になるのに対して、ピアツーピアネットワークでは複製のいくつかが生き残る可能性が高い。
分散ハッシュテーブルの上に構築できるサービスはファイル共有以外にも存在する。例えばマルチキャストアプリケーションを考えると、メッシュからマルチキャスト木を構築する代わりに、構造化オーバーレイネットワークの辺から木を構築する方法も考えられる。このとき、オーバーレイの構築と管理のコストは複数のアプリケーションとマルチキャストグループで償却される。
BitTorrent
BitTorrent は Bram Cohen によって考案されたピアツーピアファイル共有プロトコルである。BitTorrent において、ファイルの複製はピース (piece) と呼ばれる断片ごとに行われる。任意のピースは複数のピアからダウンロード可能であり、完全なファイルを持つピアは一つしか存在しない可能性もある。この戦略の主な利点に、ファイルの提供元が一つしかないことで生じるボトルネックを回避できる点がある。これはファイル提供元がインターネットにファイルをアップロードする速度が遅いときに特に重要になる: ブロードバンドネットワークではダウンロード速度とアップロード速度が非対称な場合が多い。
ピースの複製がダウンロード処理の自然な副作用として行われることも BitTorrent の長所である: ピアがピースをダウンロードすると、そのピアはダウンロードしたピースの送信元になる。ファイルのピースをダウンロードするピアが増えればそれだけピースの複製も起こり、負荷が分散され、ファイルの共有で利用できる総帯域が増加する。大量のピアが同時に同じピースをダウンロードする事態を避けるため、ピースはランダムな順序でダウンロードされる。
BitTorrent では、各ファイルがそれぞれ独立したネットワークで共有される。このネットワークをスウォーム (swarm) と呼ぶ (一つのスウォームで複数のファイルが共有される場合もあるものの、ここでは簡単のため全てのスウォームが一つのファイルを共有すると仮定して説明する)。典型的なスウォームのライフサイクルは次のようになる。まず、スウォームは完全なファイルを持つ単一のピアだけから構成される状態で作成される。その後ファイルのダウンロードを望むノードが現れると、そのノードは二番目のメンバーとしてスウォームに参加する。新しく参加したノードは完全なファイルを持つピアからピースのダウンロードを開始し、ファイルのダウンロードが完全には完了していない段階でもダウンロード済みピースの送信元として機能する (実際には、ダウンロードを完了したピアはスウォームから離脱する場合が多い。ただし参加し続けることが推奨される)。さらに他のノードがスウォームすると、そのノードは (完全なファイルを持っている最初のピアだけではなく) 複数のピアからピースをダウンロードできる。以上の様子を図 245 に示す。
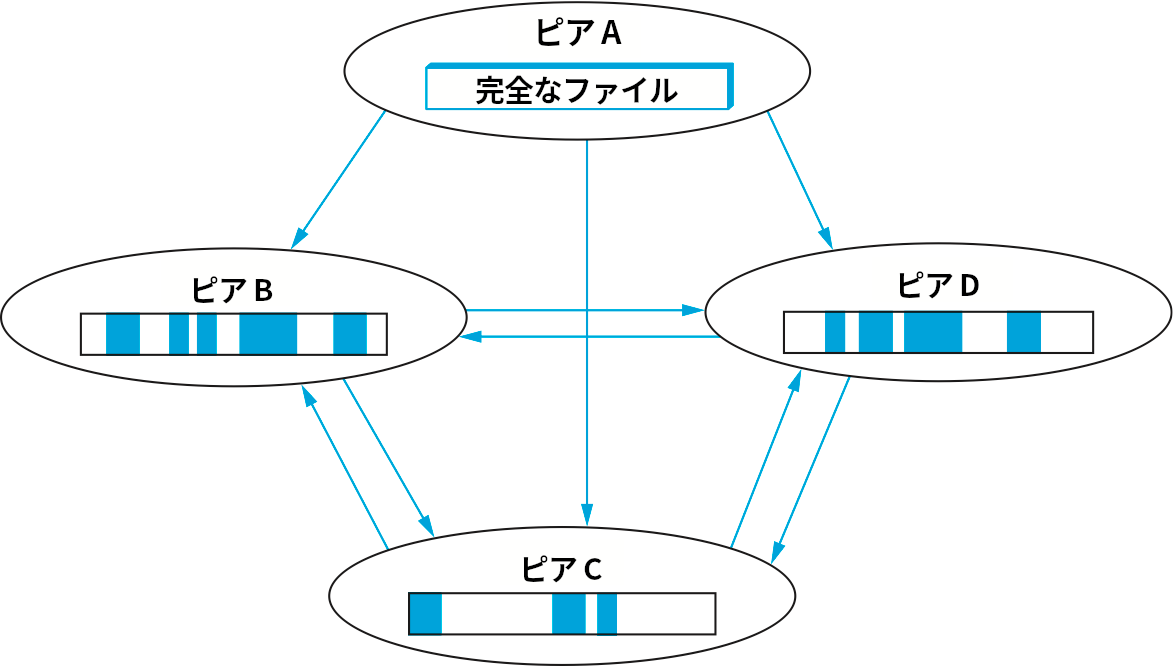
ファイルに対する需要が高く、スウォームから離脱するピアを新しいピアがすぐに置き換えるなら、スウォームはいつまでもアクティブであり続ける。もしそうでなければスウォームは縮小していき、最終的には最初にファイルを保持していたオリジナルのピアだけの状態になる。そこから新しいピアが参加すれば、再度スウォームは拡大する。
これで BitTorrent の概観が説明できたので、続いてピースのリクエストがピースを持つピアまでどのようにルーティングされるかを見ていく。ファイルのダウンロードを望むノードは、リクエストを行うためにまずスウォームに参加しなければならない。スウォームへの参加処理はファイルとスウォームのメタ情報が入ったファイルをダウンロードするところから始まる。このファイルは容易に複製でき、典型的にはウェブページ上のリンクをクリックすることでウェブサーバーからダウンロードされる。このファイルには次の情報が含まれる:
-
対象ファイルのサイズ
-
ピースサイズ
-
各ピースから事前計算された SHA-1 ハッシュ
-
スウォームのトラッカー (tracker) の URL
トラッカーとはスウォームに所属するピアを追跡するサーバーを言う。この中央集権性 (およびボトルネックの可能性) を BitTorrent から取り除く拡張については後述する。
ファイルのダウンロードを望むノードは、自身のネットワーク ID とランダムに生成したピア ID が含まれるメッセージをトラッカーに送信することでスウォームに参加してピアとなる。このメッセージにはスウォームのメタ情報が含まれる先述のファイルの SHA-1 ハッシュも含まれ、この値はスウォーム ID として利用される。
新しいピアを P とする。トラッカーは ID とネットワークアドレスからなるピアのリストを P に返答し、P はリストに含まれるいくつかのピアと (TCP) 接続を確立する。この段階で P はスウォームの部分集合と直接に接続するものの、P はこのとき接続しなかったピアに後から接続を作成したり、ピアをさらに教えるようトラッカーに要請したりしても構わない。TCP 接続を確立すると、続いて P は BitTorrent 接続を確立するために自身の ID とスウォーム ID を送信し、他のピアは自身の ID とスウォーム ID を返答する。もしスウォーム ID が一致しなかったり P が期待するピア IP ではなかったりした場合は、接続は中断される。
こうして確立される BitTorrent 接続は対称的であり、両終端が他方からピースをダウンロードできる。最初 BitTorrent 接続の両端にあるピアは自身が保有するピースを示すビットマップを相手に送信し、お互いに初期状態を報告する。ダウンロード側 (D) が新しいピースのダウンロードを完了すると、D はそのピースを手にしたことを伝えるメッセージを直接に接続するピアに送信する。このメッセージを受け取ったピアは D の現在状態の内部表現を更新する。この仕組みのおかげで、ピースのダウンロードリクエストはピースを保有する正しいピアまで転送される: この仕組みのおかげで、全てのピアは自身が直接に接続するピアの持っているピースに関する正確な知識を持つ。直接の隣接ピアがいずれも持っていないピースを D が必要とした場合、D は異なるピアとの接続を確立する (異なるピアはトラッカーとのやり取りで取得できる) こともできるし、隣接ノードがいずれ手にすることを見越して他のピースの処理に移ることもできる。
オブジェクト ── BitTorrent ではピース ── とピアノードの関連付けはどのように行われるのだろうか? 当然それぞれのピアはいずれ全てのピースを手に入れるので、本当の問題はダウンロードが完了する前の任意の時点でピアが保有するピースをどのように決めるのか、つまりピースをどの順番でダウンロードするかである。答えは「ランダムな順序でピースをダウンロードする」であり、こうすることで特定のピアの持つピースの集合が他のピアの持つピースの集合の部分集合になる可能性が小さくなる。
トラッカーを持たないスウォーム
ここまでに説明した BitTorrent の仕組みではトラッカーが中心的な役割を果たす。トラッカーはスウォームの単一障害点であり、さらにパフォーマンスのボトルネックになる可能性もある。加えて、BitTorrent でファイルをダウンロードできるようにするときトラッカーが必ず必要になるというのはユーザーへの負担が大きい。そのため BitTorrent の新しいバージョンでは、DHT ベースの実装を利用する「トラッカーレス」のスウォームが追加された。トラッカーレスのスウォームに対応した BitTorrent クライアントソフトウェアは、BitTorrent プロトコルだけではなく他のピアを見つけるための機能も実装する。他のピアを見つける機能を持つノードは BitTorrent の用語で「ノード」と呼ばれる。ただ紛らわしいので、これから本書ではそういったノードを「ピアファインダー」と呼ぶ。
ピアファインダーの集合はピアを見つけるためのオーバーレイネットワークを構築し、UDP の上に実装される独自プロトコルを使って DHT を実装する。このオーバーレイネットワークに含まれるピアが属するスウォームは異なっていても構わない。言い換えれば、それぞれのスウォームはいくつかの BitTorrent ピアを接続する個別のネットワークであるのに対して、ピアファインダーが構成するネットワークは複数のスウォームにまたがる。
各ピアファインダーはランダムに生成された ID を持ち、この ID はスウォーム ID と同じ長さ (160 ビット) を持つ。ピアファインダーが持つルーティングテーブルは、自身の ID に近い ID を持つピアファインダーが多く、自身の ID と離れた ID を持つピアファインダーが少ないように調整される。特定のスウォーム ID に近い ID を持つピアファインダーがそのスウォームに属するピアを高い確率で知っていることを保証するアルゴリズムをこれから説明する。このアルゴリズムは特定のスウォームに属するピアを見つける手段も提供する。
ピアファインダー F がスウォーム S に属するピアを見つけたいと思ったとき、F は自身のルーティングテーブルに含まれるピアファインダーの中で S の ID に最も近い ID を持つものにリクエストを送信する。リクエストを受け取ったピアファインダーは、もし S に属するピアを知っているなら、そのピアの連絡先情報を返答する。もし知らないなら、自身のルーティングテーブルに属するピアファインダーの中で S の ID に最も使い ID を持つものに関する連絡先情報を返答し、F はこのピアファインダーに対して同じ処理を再帰的に繰り返す。
ピアファインダー F からのリクエストを受け取ったピアファインダーが ID 空間で自身よりスウォーム S に近いピアファインダーをルーティングテーブルに持たない場合、検索処理は終了する。このとき、F は最後にリクエストを送った (見つけられた中で S に最も近い) ピアファインダーに自身および自身と関連するピアの連絡先情報を追加する。こうすることで、特定のスウォームに近いピアファインダーがそのスウォームに属するピアを知っている可能性が上昇する。
以上の処理は F がピアファインダーのネットワークに参加済みであり、他のピアファインダーの連絡先を知っていることを仮定している。ピアファインダーが一度でも実行されたことがあれば (二度目以降の実行では以前の実行で集めた情報を再利用できるので)、この仮定は満たされる。スウォームがトラッカーを利用する場合も問題ない: 過去に BitTorrent プロトコルはピアファインダーの連絡先情報を交換できるよう拡張されているので、そのスウォームのピアは同じスウォーム内のピアファインダーに他のピアファインダーに関する情報を伝えることができる (このときピアとピアファインダーの役割が逆転する)。しかし、完全に新しく起動したピアファインダーは他のピアファインダーをどのように見つけるのだろうか? この状況に対処するために、トラッカーを持たないスウォームがホストするファイルにはトラッカーの URL の代わりに一つまたはいくつかのピアファインダーに対する連絡先情報が含まれている。
チョーク
BitTorrent の珍しい特徴として、公平性 (善きネットワーク市民としての行動) の問題に真正面から対処している点がある。一般に、プロトコルは参加者が行儀良く振る舞うことを前提としながらも、それを強制できない場合が多い。例えば、行儀の悪いイーサネットピアはバックオフアルゴリズムとして指数バックオフより積極的なものを使ってパフォーマンスを向上させようとするかもしれないし、行儀の悪い TCP ピアは輻輳制御を行わないことでパフォーマンスの向上を試みるだろう。
BitTorrent が前提とする行儀良い振る舞いとは、ダウンロードしたピースを他のピアにアップロードすることである。典型的な BitTorrent ユーザーはファイルを可能な限り早くダウンロードしたいだけなので、ピースをダウンロードしつつアップロードは全くしないピア ── 行儀の悪いピア ── を実装することへの誘惑が存在する。この行儀の悪い振る舞いを思いとどまらせるために、BitTorrent プロトコルはピアがお互いに賞罰を与える仕組みを持つ。ピースをダウンロードするだけでアップロードを行わない行儀の悪いピアを見つけたピアは、そのピアにチョーク (choke, 首絞め) を行うことができる。チョークはアップロードを (最低でも一時的に) 停止し、チョークを行った事実を相手に伝えることで行われる。ピアに対するチョークが解かれたことを伝えるメッセージも存在する。チョークの仕組みはピアが持つアクティブな BitTorrent 接続の個数を (TCP パフォーマンスを良好に保つために) 制限するときにも利用される。チョークのアルゴリズムには様々なものが存在し、優れたアルゴリズムを考案するには (理論というよりも) 技巧が必要となる。
9.4.3 コンテンツ配送ネットワーク
ウェブブラウザがウェブサーバーからページを取得するとき TCP の上に実装される HTTP を利用することはこれまでに見た。しかし、ウェブページが開くのを永遠とも思えるほど長く待ったことがある人なら誰でも知っているように、ウェブサーバーと HTTP だけを使うシステムは決して完璧とは言えない。現在インターネットのバックボーンが 40 Gbps もの容量を持つリンクで構築されることを考えれば、この状況が発生する理由は明らかでない。ウェブページをダウンロードするとき、ボトルネックとなり得る箇所は一般に次の四か所だと理解されている:
-
ファーストマイル: インターネット内部に高速な回線があったとしても、ユーザーがインターネットに接続する回線が 1.5 Mbps の DSL リンクあるいは質の低い無線リンクであれば、ウェブページのダウンロードは速くならない。
-
ラストマイル: 大量のリクエストが送られると、サーバーをインターネットに接続するリンクが (たとえ大きな集約帯域を持っていたとしても) パンクする可能性がある。
-
サーバーそのもの: サーバーは有限のリソース (CPU、メモリ、ディスク帯域など) しか持たないので、同時に大量のリクエストを受け取ればパンクする。
-
ピアリングポイント: 協同でインターネットのバックボーンを実装する少数の ISP は内部に広帯域のパイプを持つのに対して、各 ISP は自身のピアに広帯域の接続を提供するモチベーションをほとんど持たない。ユーザーとサーバーが異なる ISP に接続する場合、二つの ISP が接続する箇所でリクエストしたページが破棄される可能性がある。
一つ目の問題に関してできることは少ないものの、他の問題はページの複製を作ることで解決できる。ページの複製を作ることでダウンロードを高速化するシステムを CDN (Content Distribution Networks, コンテンツ配送ネットワーク) と呼ぶ。おそらく最もよく知られた CDN として Akamai がある。
CDN のアイデアは「通常であれば数台のバックエンド (backend)サーバーで管理されるページを、地理的に分散された複数のサロゲート (surrogate)サーバーを使ってキャッシュする」というものである。例えば、大きなニュースを伝えるページにアクセスが集中した ── いわゆるフラッシュクラウド (flash crowd) が発生した ── 場合でも、CDN があれば負荷を多くのサーバーに分散でき、数百万人のユーザーを処理待ちにする状況は発生しない。さらに、CDN がサロゲートサーバーをバックボーン ISP のそれぞれに展開していれば、ページに到達するために複数の ISP を経由する必要もなくなるので、ピアリングポイントにおける問題も発生しない。当然ながら、インターネット中に数千個のサーバーを配備するのはページに対する優れたアクセスを望むどんな単一のサイトにとってもコストが大きすぎる。そのため商用 CDN は多くのサイトに対してサービスを提供し、大きなコストを多くの顧客で償却している。
サロゲート「サーバー」と呼ばれはするものの、サロゲートは単なるキャッシュと考えても間違いではない: クライアントからリクエストされたページを持っていなければ、サロゲートはバックエンドサーバーにリクエストを送信して手に入れる。ただ実際には、バックエンドサーバーが事前にサロゲートに対して複製を送信しておくことの方が多く、サロゲートからのリクエストにオンデマンドに返答することは少ない。また、サロゲートに分散できるのは静的なページだけであり、動的なコンテンツは分散できない点も重要である。頻繁に更新されるコンテンツ (例えばスポーツの結果や株価) や何らかの計算 (例えばデータベースクエリ) の結果として生成されるコンテンツのリクエストはバックエンドまで到達する必要がある。
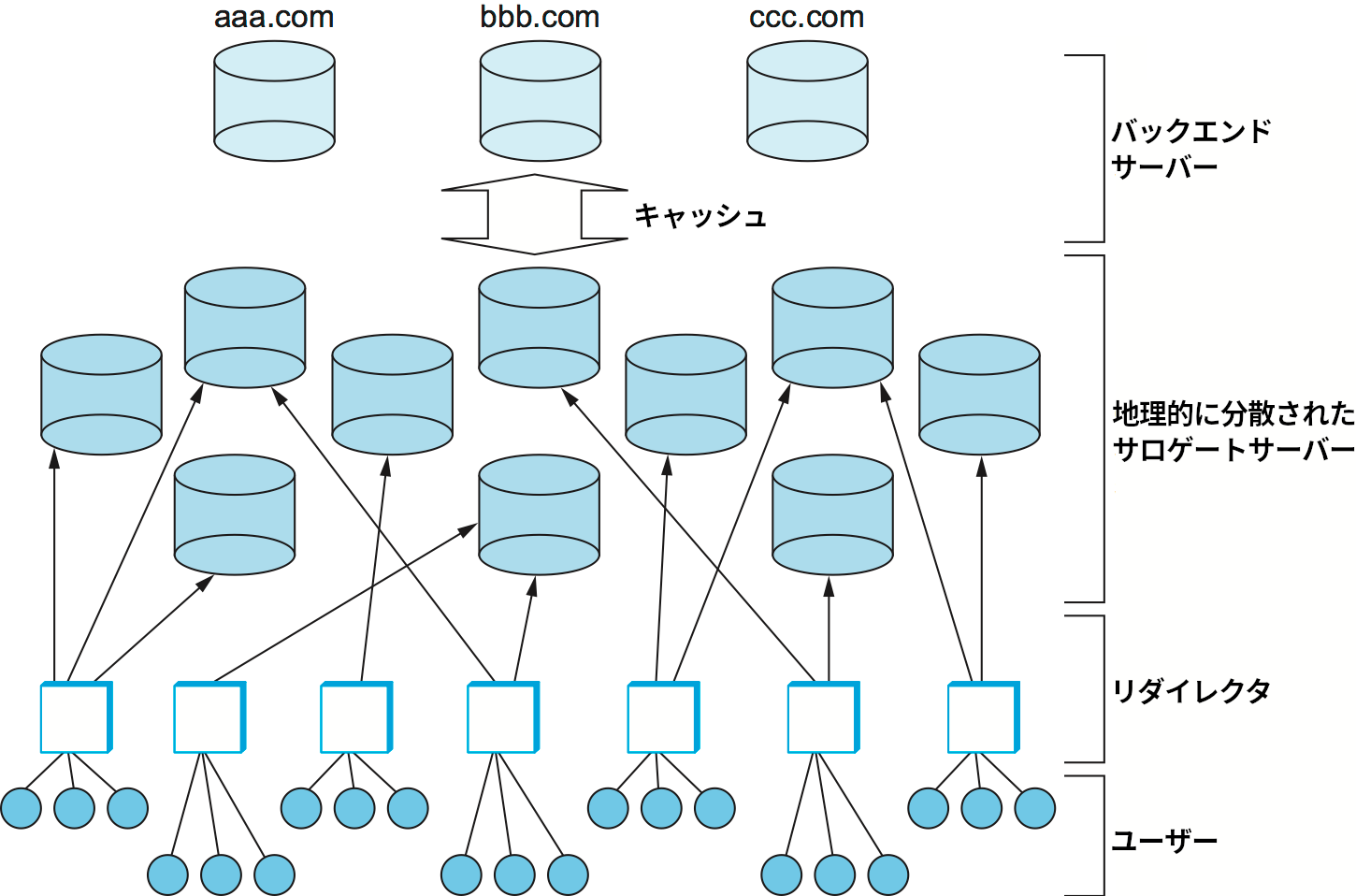
地理的に分散されたサーバーを保有するだけでは問題は完全には解決しない。全体像を完成させるには、クライアントからのリクエストを適切なサーバーに転送するリダイレクタ (redirector) が必要になる (図 246)。リダイレクタの第一の役割はクライアントに対する応答時間が最も短くなるサーバーを選択することである。リダイレクタの第二の役割として、システム全体が処理できるリクエストの個数を内部のハードウェア (ネットワーク回線とウェブサーバー) が理論上処理可能な個数に近づけることがある。特定の時間に応答できるリクエストの平均個数はシステムスループットと呼ばれ、システムに高い負荷がかかるときに問題となる。システムに高い負荷がかかる状況としては例えばフラッシュクラウドが少数のページにアクセスするとき、あるいは分散 DoS 攻撃 (Distributed Denial of Service attack, DDoS 攻撃) を受けているときが考えられる。2000 年 2 月には CNN や Yahoo をはじめとした有名サイトに対して分散 DDoS 攻撃が仕掛けられた。
クライアントからのリクエストをどのように分散させるかを決める上での基準はいくつか存在する。例えば、応答時間を最小化するためにネットワークにおける近接性 (proximity) を基準としてサロゲートを選択することもできる。一方で、全体のシステムスループットを向上させるには、負荷をサロゲート間で公平に割り振る方が望ましい。局所性 (locality) を考慮する (リクエストされているページをキャッシュに持っている可能性が高いサロゲートを選択する) と、スループットと応答時間を同時に改善できる。こういった要素をどのように組み合わせるべきかについては議論が続いている。本節ではいくつかの可能性を議論する。
リダイレクトの実装
これからリダイレクトの実装方法を見ていく。これまでの説明からすると、リダイレクタが行うのは論理的にはリクエストの転送であり、ルーターでも行えそうに思える。実際、リダイレクトの実装に利用できる仕組みをルーターは持っている。ここからの議論では、リダイレクタがリクエストを転送する先のノードを「サロゲート」とは呼ばずに単に「サーバー」と呼ぶ。また、リダイレクタは利用可能なサーバーのアドレスを全て知っていると仮定する。実際の CDN では、利用可能なサーバーが増減した場合でも何らかのアウトオブバンドな通信によって情報が最新に保たれる。
まず、リダイレクトの実装方法の一つとして、DNS を拡張して異なるサーバーアドレスを返すようにすることが考えられる。例えば、クライアントが名前 www.cnn.com を解決しようとしたときに DNS サーバーが CNN のウェブページをホストするサーバーの中で最も負荷の低いものを返せばリダイレクトが行える。あるいは、サーバーをラウンドロビン方式で順番に選ぶ方式も考えられる。DNS ベースのリダイレクトは通常サイトレベル (例えば cnn.com) で行われ、特定の URL (例えば https://www.cnn.com/2020/11/12/politics/biden-wins-arizona/index.html) では行われない点に注意してほしい。ただし、ページに埋め込まれた URL をサーバーで書き換えてからクライアントに返すことで、クライアントが行う特定のオブジェクトに対するリクエストを適切なサーバーに向けさせることはできる。
商用 CDN は URL の書き換えと DNS ベースのリダイレクトの両方を組み合わせて利用する。また、スケーラビリティを向上させるため、まず高レベルの DNS サーバーがリージョンレベルの DNS サーバーにリダイレクトを行い、リージョンレベルの DNS サーバーが実際のサーバーアドレスを返答する仕組みを持つ。さらに、変更に素早く反応するため、CDN の DNS サーバーではリソースレコードの TTL が非常に短い時間 (例えば 20 秒) に設定される。これはクライアントが結果をキャッシュし、URL に関連付く最新のサーバーを DNS に尋ねることなく適切でないサーバーにリクエストを行うことを防ぐために必要になる。
もう一つの実装方法として、 HTTP リダイレクトの機能を利用するものがある: クライアントがリクエストメッセージをサーバーに送信すると、ページを取得で利用すべき別の (より適した) サーバーを記したメッセージが返るというものである。しかし残念ながら、このサーバーベースのリダイレクトだとインターネット越しのラウンドトリップが追加で必要になり、さらに悪いことに、リダイレクトのタスク自体の負荷が無視できない。そのため、代わりに次に方式が用いられる: 利用可能なサーバーを知っているノード (例えばローカルのウェブプロキシ) がクライアントの近くにあれば、そのノードがリクエストメッセージを横取りして適切なサーバーにリクエストを送信する指示を返す。この方式では、リダイレクタがサイトに向かう全てのリクエストが通過する渋滞の発生点となるか、クライアントが協調してリクエストを明示的にプロキシに宛てるかのどちらかとなる。
ここまでの説明を読んで、CDN とオーバーレイネットワークに何の関係があるのかと疑問に思ったかもしれない。確かに CDN をオーバーレイネットワークとみなすのは拡大解釈かもしれないが、両者に共通する重要な特徴が存在する: オーバーレイノードと同じく、プロキシベースのリダイレクタはアプリケーションのレベルで転送の判断を行う。つまり、宛先アドレスとネットワークトポロジーに基づいてパケットを転送するのではなく、プロキシノードは各サーバーの位置と負荷に関する知識と URL に基づいて HTTP リクエストを転送する。現代のインターネットアーキテクチャはリダイレクトを直接的にはサポートしない ── ここで「直接的」とは、クライアントが送信した HTTP リクエストがリダイレクタによって他のサーバーに転送されることを意味する。そのため、通常リダイレクトは「リダイレクタが適切な宛先のアドレスを返し、クライアントが自分でそのサーバーにリクエストを送信し直す」ことで間接的に実装される。
ポリシー
続いてリクエストを転送するときにリダイレクタが利用するポリシーの例をいくつか見ていく。実は、既に単純なポリシーを一つ見ている ── ラウンドロビンはリダイレクトのポリシーと言える。ラウンドロビンに似たポリシーとして、利用可能なサーバーをランダムに選ぶ方式がある。この二つのポリシーは負荷を CDN 中に平等に分散させる点では優れているものの、クライアントが体感する応答時間を短くする点では優れているとは言えない。
この二つのポリシーがネットワークにおける近接性を考慮していないのは明らかだが、それと同程度に重要な事実として、局所性も考慮していない。つまり、同じ URL に対する複数のリクエストがあったとしてもその事実を関知しないので、対応するページをメモリ上のキャッシュに持つサーバーにそれらのリクエストが転送される可能性が低くなる。リクエストされたページがキャッシュに存在しなければ、サーバーはページをディスク (あるいはバックエンドサーバー) から読まなければならない。世界中に分散されたリダイレクタは、互いに協調することなくどのようにして同じページに対するリクエストを単一の (あるいは少数の) サーバーに向かわせるのだろうか? 答えは驚くほど単純である: 全てのリダイレクタは何らかのハッシュ方式を使って URL を小さな範囲の値に決定的に対応付け、その値を使ってサーバーを選択する。この方式の主な利点として、リダイレクタ同士が一切やり取りせずに協調動作できることがある。URL を受け取ったリダイレクタがどれであったとしても、ハッシュ関数が同じであれば同じ出力が得られる。
使うべきハッシュ方式はどれだろうか? 古典的なモジュロを使ったハッシュ方式 ── URL のハッシュ値をサーバーの個数で割った余りを使うもの ── は適していない: サーバーの個数が変動すると、少なくない数のページの割り当てが変化してしまう。サーバーの個数が頻繁に変わるわけではないものの、新しいサーバーを追加するたびにキャッシュするページの割り当てが大きく変わるのは望ましくない。
これと異なる方式として、前項で紹介したコンシステントハッシングがある。具体的には、全てのサーバーをハッシュ値に基づいて「円周」上に配置し、特定の URL を担当するサーバーを「URL を同じ円周上にハッシュしたとき、URL に最も近いサーバー」と定める。ノードで障害が起こった場合には、そのノードが受け持っていた負荷は円周上で隣接するサーバーに移される。ノードが追加された場合も同様であり、ページの割り当ては局所的にしか変化しない。前節で説明したピアツーピアネットワークにおけるコンシステントハッシングでは探しているオブジェクトの ID に最も近い ID を持つピアにメッセージを転送して再帰的に検索が行われるのに対して、今考えているリダイレクトの問題では全てのリダイレクタが円周上にあるサーバーを全て知っているので、それぞれのリダイレクタが独立に「最も近い」サーバーを選択できる点に注意してほしい。
この戦略はサーバーの負荷を考慮するように簡単に拡張できる。リダイレクタが利用可能な全サーバーの負荷を知っていると仮定する。負荷の情報は最新かつ正確でなくても構わない: 例えば、過去数秒間にどのサーバーに何回リクエストを転送したかを記録し、その値をサーバーの負荷の推定値として使うこともできる。URL を受け取ったリダイレクタは「URL とサーバーのアドレスを合わせたもののハッシュ値」を各サーバーに対して計算し、そのハッシュ値をソートとしたリストを用意する。このリストがサーバーを選ぶときの順番を表す: リダイレクタはソートしたハッシュ値のリストを先頭から見ていき、負荷が閾値より低いものを見つけたらそれに対応するサーバーを転送先とする。この処理の疑似コードを次に示す:
SelectServer(URL, S)
for each server in サーバー集合 S
score[server] = hash(URL, address[server])
score をソートする
for s in score
server = s に対応するサーバー
if server の負荷 < 閾値 then
return server
return score の先頭に対応するサーバー
コンシステントハッシングと比べたとき、このアプローチにはサーバーの順序が URL ごとに異なるためにサーバーで障害が起こったときにその負荷が他のサーバーに平等に分散される利点がある。また、このアプローチをベースとした CARP (Cache Array Routing Protocol) と呼ばれるプロトコルが存在する。
負荷がある程度まで上昇すると、リダイレクタはソート済みリストの先頭に対応するサーバーだけを使うのを止め、複数のサーバーに負荷を分散させ始める。この結果として、負荷の高いサーバーに転送されていた URL リクエストの一部が負荷の低いサーバーに転送されるようになる。この処理は個別のページに対するアクセス数ではなくサーバー全体の負荷に応じて行われるので、アクセス数の多いページをホストするサーバーでは負荷が大きく減少する可能性がある。もちろん、たまたま負荷の高いサーバーでホストされていたアクセスの少ないページの一部も他のサーバーに複製される。一部のページに対するアクセスが極端に多くなった場合には、システムに属する全てのサーバーがそのページの複製を持つ状況もあり得る。
最後に、ネットワークにおける近接性を考慮するリダイレクト方式を二つ紹介する。第一に、サーバーがリクエストに応答する時間を測定し、その値を前述のアルゴリズムにおける「サーバーの負荷」として採用することで負荷と近接性をまとめて扱う方式がある。この方式だと近くにあるサーバーと負荷の低いサーバーが優先され、遠くにあるサーバーと負荷の高いサーバーは選択されにくくなる。第二に、最初にネットワークにおける近接性を使ってサーバーの候補を近くにあるサーバーだけに絞ってから上述のアルゴリズムを実行する方式がある。この方式では、多数のサーバーの中から適切な近さのサーバーを選び出すというさらに難しい問題を解かなければならない。同じ ISP のクライアントを近いサーバーとして選ぶことが一つのアプローチとして考えられる。それより少しだけ高度なアプローチとして、BGP が生成する自律システムの地図を確認してクライアントから一定回数以下のホップで到達できるサーバーを選ぶ方法もある。ネットワークにおける近接性とサーバーキャッシュの局所性の正しいバランスを見つける方法については現在も研究が続いている。