4.1 地球規模のインターネットワーク
ここまで本書では、不均一なネットワークの集合を接続してインターネットワークを構築する方法、そして IP アドレスが持つ単純な階層性を利用してインターネットワーク内のルーティングをいくらかスケーラブルにする方法を見た。「いくらか」スケーラブルと表現したのは、ここまでに説明したルーティングのモデルでは各ルーターが他の全てのルーターを知る必要はないものの、インターネットワークに接続する全てのネットワークを知る必要はあるためである。現代のインターネットは数十万の (数え方によってはさらに多くの) ネットワークが接続している。前章で議論したルーティングプロトコルはそういった数字にまではスケールしない。本節ではルーティングのスケーラビリティを大きく改善する様々なテクニックを説明する。こういったテクニックによってインターネットは現在の規模まで成長可能になった。
具体的にテクニックを見ていく前に、地球規模のインターネットがどのようなものかを簡単に理解しておく必要がある。インターネットは少数のイーサネットの適当な相互接続ではない。インターネットは多くの異なる組織が保有するネットワークを相互接続しており、この事実はインターネットの形に反映されている。図 97 に 1990 年時点におけるインターネットの概略図を示す。1990 年から現在までの間にインターネットのトポロジーは図 97 よりずっと複雑になっている ── より正確なインターネットの概略図を章末で示す ── が、この図で今のところは十分だろう。
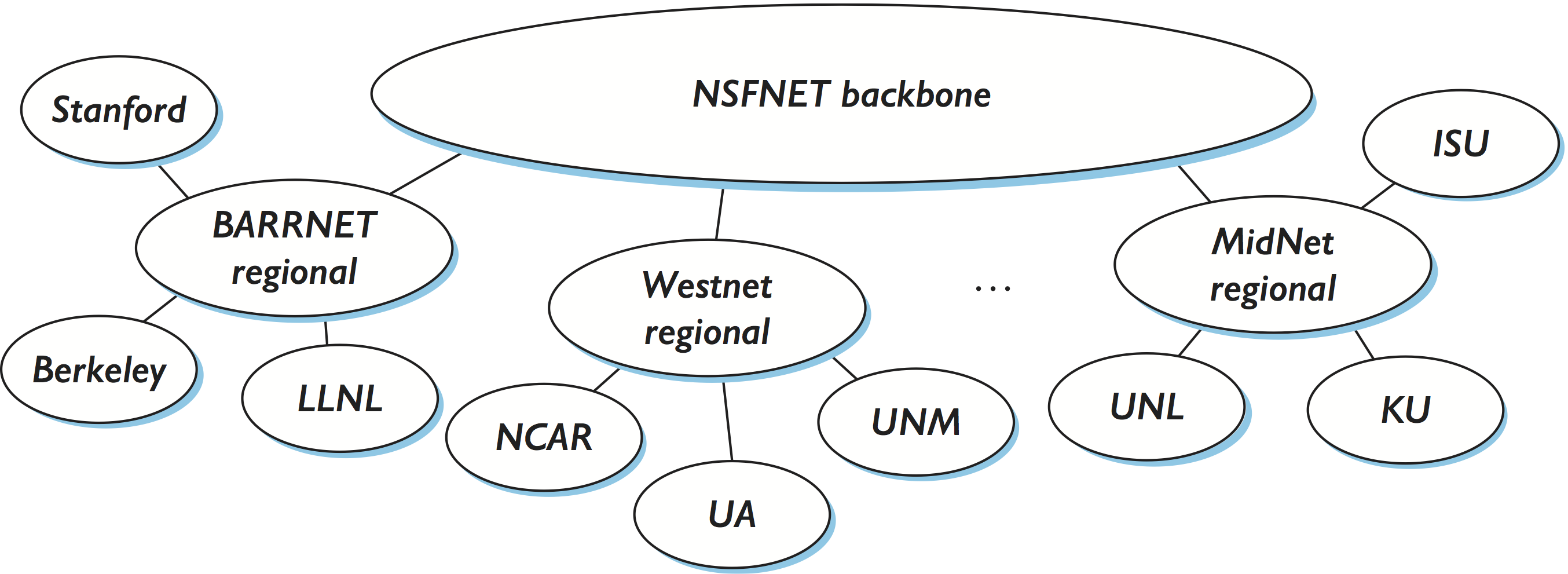
このトポロジーの重要な特徴が、それぞれのエンドユーザー拠点がプロバイダネットワークに接続することである。例えばスタンフォード大学の拠点はサンフランシスコ州ベイエリア内の拠点にサービスを提供するプロバイダネットワーク BARRNET に接続する。1990 年ごろ、プロバイダが提供するネットワークは多くが地理的な制限を持っていたので、地域ネットワーク (regional network) と呼ばれていた。地域ネットワークはさらに全国規模のバックボーンへと接続される。1990 年に使われていたバックボーンは NSF (National Science Foundation, アメリカ国立科学財団) が設立したものであり、そのため NSFNET バックボーン (NSFNET backbone) と呼ばれた。
NSFNET は後に Internet2 という組織が生まれるきっかけとなった。Internet2 は現在でも米国の研究教育機関のためのバックボーンを運営している。しかし当然、多くの人々はインターネットへの接続を商用プロバイダから購入する。この図に詳細は描かれていないものの、現在のインターネットで Tier 1 と呼ばれる最も大規模なプロバイダネットワークは、主要都市エリア (口語で「NFL 都市」と呼ばれる) に配置された数十個のハイエンドルーターをポイントツーポイントリンク (通常それぞれ 100 Gbps) で接続して構築される。同様に、それぞれのエンドユーザー拠点は単一のネットワークではなく、スイッチとルーターで相互接続された複数の物理ネットワークから構成される場合が多い。
それぞれのプロバイダとエンドユーザー拠点はお互いに独立した管理主体である可能性が高いことに注目してほしい。この事実はルーティングに大きな影響を及ぼす。例えば、最も優れたルーティングプロトコルやリンクに割り当てるべきメトリックに関して異なるプロバイダが異なる見解を持つ可能性は非常に高い。こういった独立性を持つために、それぞれのプロバイダが運営するネットワークは単一の AS (autonomous system, 自律システム) であると言われる。この単語の意味は以降の節で正確に定義するが、今のところは他のネットワークと独立して管理されるネットワークが AS だと考えておけば十分である。
インターネットが識別可能な構造を持つ事実はスケーラビリティの問題に取り組むときに活用できる。実は、対処しなければならないスケーラビリティの問題は二つ存在する。第一に、ルーティングのスケーラビリティがある。ルーティングプロトコルでやり取りされるネットワーク番号の個数、そしてルーターのルーティングテーブルに保存されるネットワーク番号の個数を最小化しなければならない。第二に、アドレスの利用率に関するスケーラビリティがある。つまり、IP アドレスの空間がすぐに使い尽くされることがないようにしなければならない。
本書を通じて、階層という考え方がスケーラビリティを向上させる例を何度も見てきた。前章では、IP アドレスの階層的構造によって、特に CIDR とサブネット化が提供する柔軟性が合わさることで、ルーティングのスケーラビリティが向上することを説明した。これから二つの項を使って、階層 (および階層の相方である集約) によってスケーラビリティが改善される例をさらに見ていく。次節で解説される IP Version 6 は主にスケーラビリティの懸念から生まれたものである。
4.1.1 エリアのルーティング
階層を使ってルーティングシステムをスケールアップする一つ目の例として、リンク状態型ルーティングプロトコル (OSPF や IS-IS) がルーティングドメインをエリア (area) と呼ばれる小領域に分割する仕組みを見ていく (この小領域の呼び名はプロトコルによって異なる ── ここでは OSPF の用語を使っている)。エリアという新たな階層を加えることで、ルーティングプロトコルに負荷をかけない、かつ後述されるドメイン間ルーティングプロトコルに依存しない形での単一ドメインの大規模化が可能になる。
エリアとはリンク状態に関する情報を交換し合うよう管理者によって設定されたルーターの集合を言う。特別なエリアとしてバックボーンエリア (backbone area) またはエリア 0 (area 0) と呼ばれるエリアが存在する。いくつかのエリアに分割されたルーティングドメインの例を図 98 に示す。ルーター R1, R2, R3 はバックボーンエリアに属しており、同時に (少なくとも一つの) 非バックボーンエリアのメンバーでもある。例えば R1 はエリア 1 とエリア 2 の両方に属している。バックボーンエリアと非バックボーンエリアの両方に属するルーターを ABR (area border router, エリア境界ルーター) と呼ぶ。AS の境界にあるルーターは ABR と呼ばないので注意する必要がある。そういったルーターは AS 境界ルーター (AS border router) と呼んで区別する。
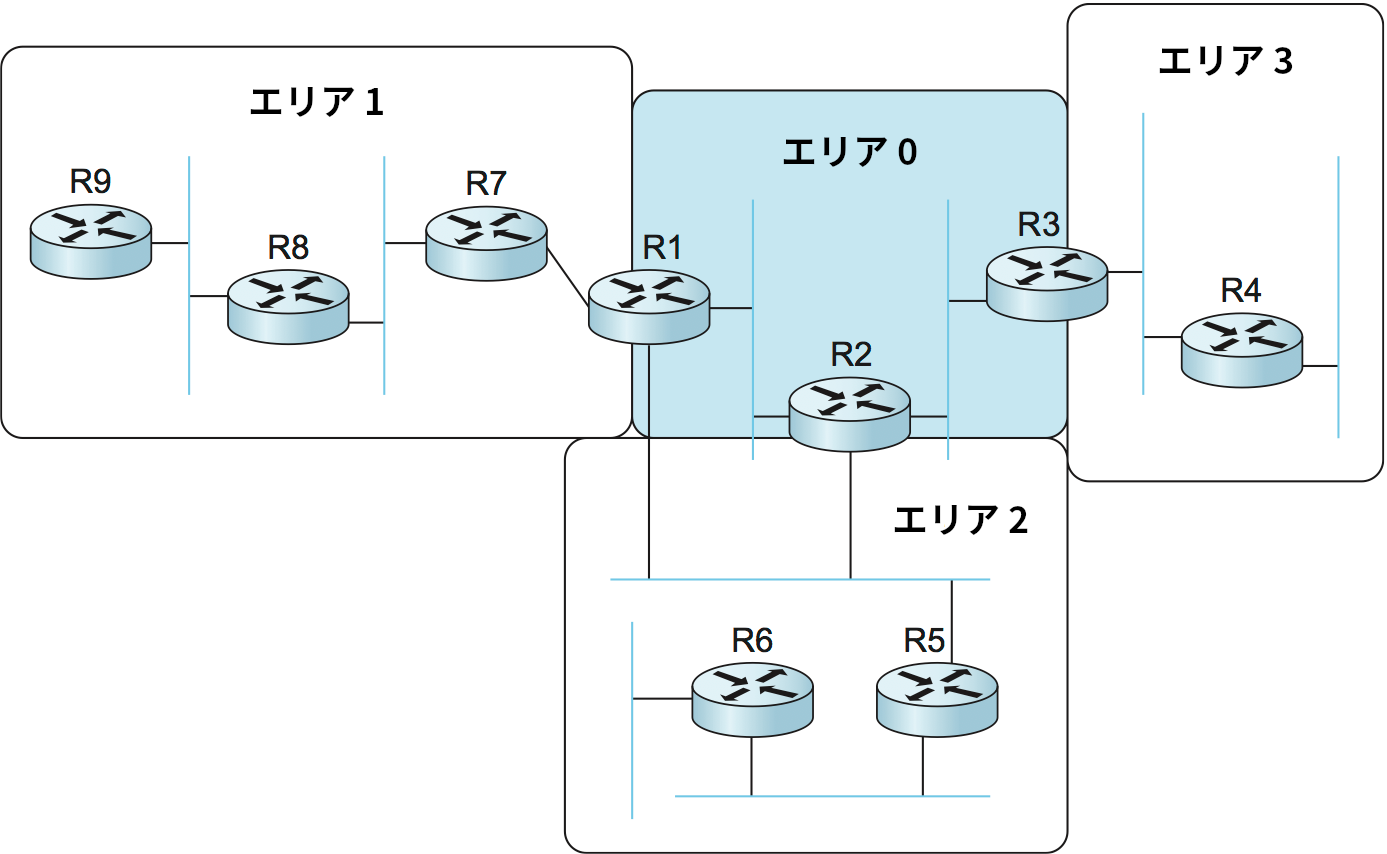
単一のエリア内におけるルーティングは第 3.4 節で説明した通りに行われる: エリア内の全てのルーターは互いにリンク状態を広報し、完全で矛盾の無いエリアの地図を構築する。ただし、ABR でないルーターが送信したリンク状態の広報は同じエリア内だけに広まる。この仕組みにはフラッディングと経路計算のプロセスを格段にスケーラブルにする効果がある。例えば図 98 でエリア 3 に属する R4 はエリア 1 に属する R8 が送信するリンク状態の広報を決して受信しない。この結果、R4 は自身が属するエリアのトポロジーに関する知識だけを学習する。
ではこのとき、ルーターはどうやって自身と異なるエリアに属するネットワークに宛てられたパケットに対する正しいネクストホップを知るのだろうか? この疑問への答えは送信されたパケットが通る非バックボーンエリアから非バックボーンエリアへの経路を三つの部分に分けて考えると明らかになる。まず、そのパケットは送信元ネットワークから ABR に向かう。続いてパケットは ABR からバックボーンを通って宛先ネットワークが属するエリアに接続された ABR に向かい、そこから最終的な宛先ネットワークに向かう。この転送を可能にするために、ABR は一つのエリアから学習した経路情報を要約して他のエリアに広報する。例えば R1 はエリア 1 の全てのルーターからリンク状態の広報を受信するので、エリア 1 に属する任意のネットワークに到達するコストを計算できる。R1 がリンク状態をエリア 0 に広報するとき、R1 はエリア 1 に属する全てのネットワークに対するコストを (まるで全て R1 に直接接続されているかのように) 送信する。こうするとエリア 0 のルーターはエリア 1 に属する全てのネットワークに到達するコストを学習できる。この情報を受け取った他の ABR も同様に「要約」された経路情報を他の非バックボーンエリアに広報する。こうすることで、全てのルーターはドメイン内の全てのネットワークに到達する方法を学習できる。
図 98 でエリア 2 が ABR を二つ持っており、エリア 2 に属するルーターはどちらの ABR を使ってバックボーンに到達するかを判断する必要がある点に注目してほしい。この判断は簡単に行える: R1 と R2 は他のエリアに属するネットワークに到達するコストを広報しているので、最短路アルゴリズムを実行すればどちらを使うべきかはすぐに判明する。例えば宛先がエリア 1 に属するなら、R2 ではなく R1 を使うべきなのは明らかである。
ドメインを複数のエリアに分割するとき、ネットワーク管理者はスケーラビリティと経路の最適性のトレードオフを考慮する必要がある。エリアを利用するとき、エリアをまたいで送信される全てのパケットに対してバックボーンエリアの通過が強制されるので、パケットは最短路を通れなくなる可能性がある。例えば、仮に図 98 で R4 と R5 を結ぶ直接のリンクが存在したとしても、異なるエリアに属する R4 と R5 を結ぶそのリンクにパケットは流れない。実際の経験からは、厳密な最短路よりもスケーラビリティが望まれることが判明している。
教訓
これはネットワーク設計における重要な事実を示している: スケーラビリティと何らかの最適性にはトレードオフが存在することが多い。階層を導入するとネットワーク内の一部のノードからの情報が隠蔽され、完璧な判断は下せなくなる。一方で情報を隠蔽することでノードはグローバルな知識を持つ必要がなくなるので、情報の隠蔽は解決策をスケールさせるために欠かせない。大規模なネットワークでは必ず、スケーラビリティが最適な経路の選択よりも切実な設計目標となる。
最後に、エリア 0 に入れるルーターをネットワーク管理者が柔軟に選択できるようになるトリックを紹介する。このトリックはルーター間の仮想リンク (virtual link) を利用する。この仮想リンクはエリア 0 に直接は接続していないルーターとエリア 0 に属するルーターとの間で構築され、バックボーンのルーティング情報を交換するために利用される。例えば図 98 の R8 と R1 の間に仮想リンクを構築して、R8 をバックボーンの一部とできる。このとき R8 はエリア 0 の他のルーターが行うリンク状態のフラッディングに加わる。R8 と R1 を結ぶ仮想リンクのコストはエリア 1 内の経路情報を交換することで計算される。このテクニックによって経路の最適性をいくらか取り戻せる可能性がある。
4.1.2 ドメイン間ルーティング (BGP)
本章の最初で、インターネットは複数の AS (autonomous system, 自律システム) から構成されるという考え方を紹介した。それぞれの AS は独立した管理主体によって運営される。企業の複雑な内部ネットワークは一つの AS であり、各 ISP (インターネットサービスプロバイダ) が持つ国家規模のネットワークも一つの AS となる。図 99 に二つの AS からなる単純なネットワークを示す。
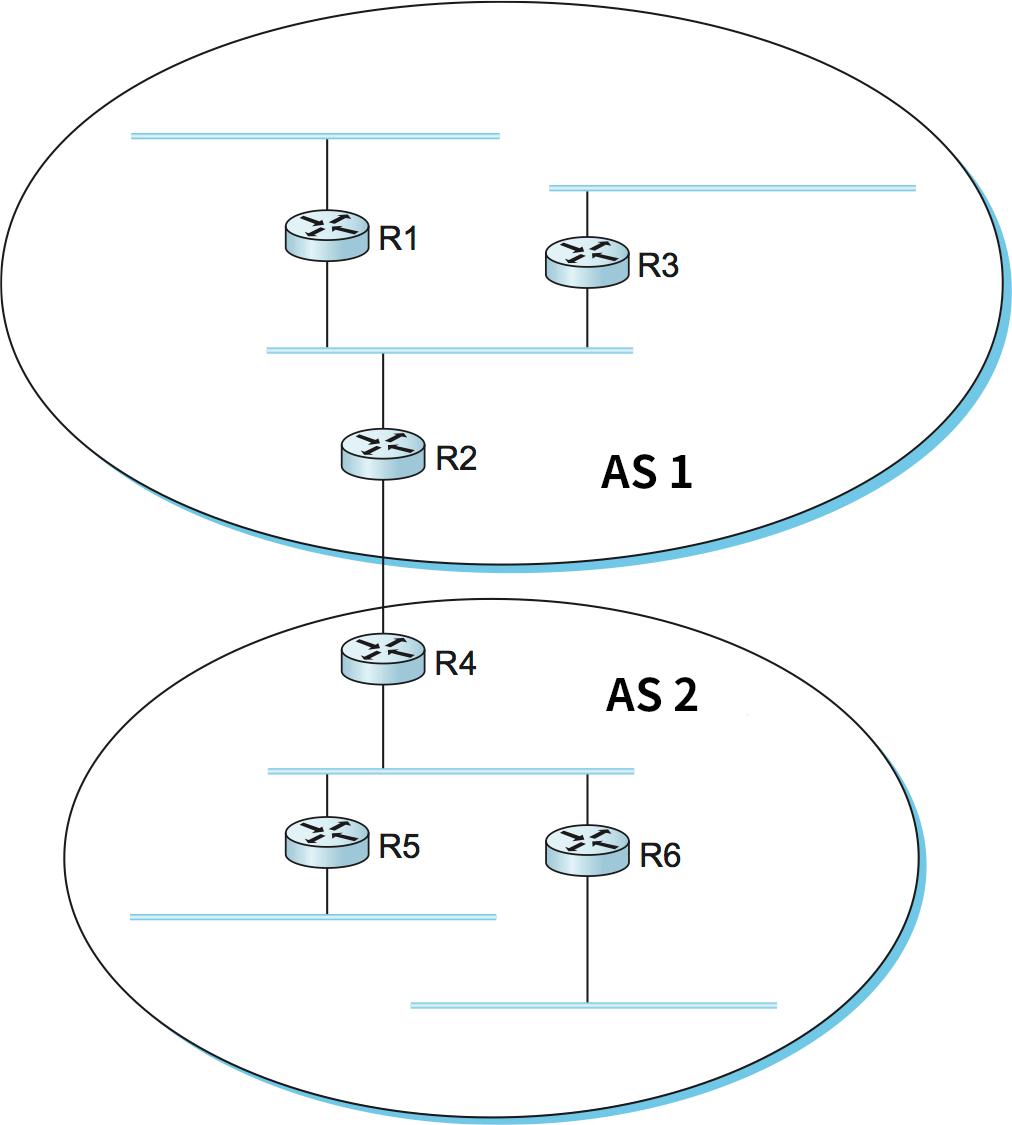
AS の基本的な役割は、大規模なインターネットワーク内に経路情報を階層的に集約する地点を新たに提供してスケーラビリティを向上させることである。AS があると、ルーティングの問題は「単一 AS 内のルーティング」と「AS 同士のルーティング」の二つの部分に分かれる。インターネットにおける AS はドメイン (domain) とも呼ばれるので、これからは二つの問題をそれぞれドメイン内ルーティング (intradomain routing) およびドメイン間ルーティング (interdomain routing) と呼ぶ。AS モデルはスケーラビリティを向上させるのに加えて、それぞれの AS で行われるドメイン内ルーティングを他の AS のドメイン内ルーティングと分離する効果も持つ。そのため、AS はドメイン内ルーティングプロトコルを好きに選択できる。それどころか、望むなら静的な経路や複数のプロトコルさえ利用できる。ドメイン間ルーティングは異なる AS 間で到達可能性に関する情報 ── それぞれの AS を通じて到達可能な IP アドレスの集合は何か ── を共有する。
ドメイン間ルーティングにおける課題
おそらく現代のドメイン間ルーティングで最も重要な課題は、各 AS が自身のルーティングポリシー (routing policy) を定める必要があることである。簡単なルーティングポリシーの例を示す:「可能な場合は常に、AS Y ではなく AS X に向けてトラフィックを送信する。ただし AS Y が唯一の選択肢の場合は AS Y にトラフィックを送信する。AS X からのトラフィックを AS Y に転送することは絶対にしない (逆方向も同様)」 こういったポリシーは自身をインターネットに接続するために AS X と AS Y の両方に課金している AS に典型的なものである。このポリシーでは AS X が優先され、AS Y はフォールバックとなる。AS X と AS Y の両方がプロバイダでありトラフィックに対して料金が発生するので、二つの AS を通るトラフィックで自分が利用されることは受け入れられない。こういった自分を利用して転送されるトラフィックはトランジットトラフィック (transit traffic) と呼ばれる。接続される AS が増えれば増えるほど、それだけルーティングポリシーが複雑になる可能性が生じる。特にバックボーンプロバイダは数十ある他のプロバイダと数百の顧客を相互接続し、それらのいずれとも異なる経済的合意を持つのでポリシーが非常に複雑になる。
ドメイン間ルーティングで鍵となる設計目標は、上述の例のようなポリシー、およびそれより格段に複雑なポリシーをドメイン間ルーティングシステムでサポートすることである。さらに問題を困難にする事実として、それぞれの AS は他の AS の助けを借りずにポリシーを実装しなければならず、さらに設定ミスをする AS や悪意ある振る舞いをする AS の存在も無視できない。加えて、AS はポリシーをプライベートにしたいと思っている場合が多い。AS を実行する組織 ── たいていは ISP ── はしばしば互いに競争相手であり、経済的合意をオープンにすることを望まない。
インターネットの歴史上、主要なドメイン間ルーティングプロトコルは二つ存在した。一つ目の EGP (Exterior Gateway Protocol) には数多くの欠点を持っていた。おそらく最も深刻だったのが、インターネットのトポロジーを非常に制限することである。EGP はインターネットが図 97 のような木構造を持っている時代に設計されており、木より一般的なトポロジーを許さない。この単純な木構造ではバックボーンが一つしか存在できず、接続される全ての AS が親子関係にあり、二つの AS がピアの関係になれない点に注目してほしい。
EGP の後継が BGP (Border Gateway Protocol) であり、現在までに 4 つバージョンが存在する (最新バージョンは BGP-4 と呼ばれる)。BGP はインターネットの中で最も複雑な部分の一つとみなされることが多い。本節では重要な部分をかいつまんで説明する。なお、長年にわたってルーターはゲートウェイ (gateway) とも呼ばれてきた。BGP と EGP の名前に「gateway」という単語が含まれているのはそのためである。
前身の EGP と異なり、BGP は AS 同士がどのように相互接続されるかについて事実上何の仮定も置かない。このモデルが図 100 のような複数のプロバイダが存在する木でない構造をしたインターネットワークに対応できるだけの一般性を持つのは明らかである (後述するように、実際にはインターネットにも一定の構造が存在する。ただし、その構造は決して木構造ほど単純ではなく、BGP はインターネットワークの構造について仮定を置かない)。
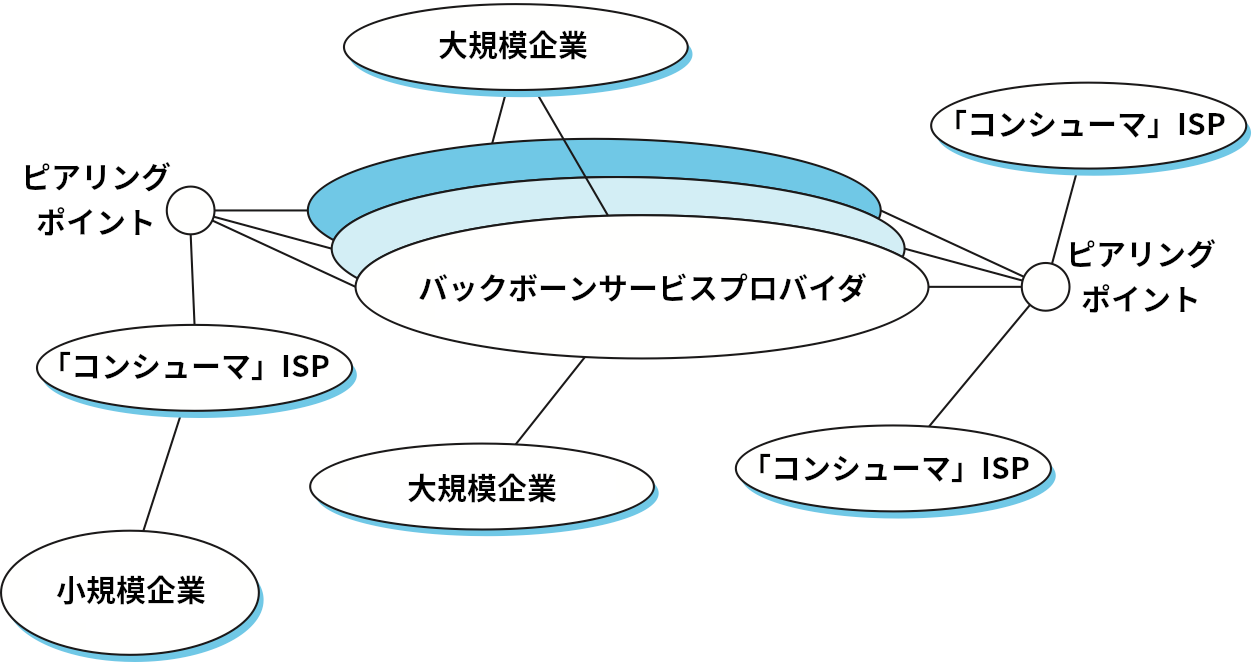
図 97 に示した木構造のインターネット、あるいは図 100 に示した非常に単純な例とも異なり、現代のインターネットは複雑に相互接続されたネットワークから構成される。加えて、ネットワークを運営する組織は多くが政府機関ではなく民間企業 (ISP) である。多くの ISP はサービスを「顧客」(家庭にコンピューターを持っている個人) に提供するために存在し、一部の ISP は他のプロバイダ (および大規模な企業) を相互接続するという伝統的なバックボーンに近いサービスを提供するために存在する。多くのプロバイダが手を合わせ、お互いを単一のピアリングポイント (peering point) で相互接続することもよくある。
このように AS が複雑に相互接続する中でのルーティングの管理についてさらに理解を深めるために、いくつか用語を定義するところから始める。特定の AS から送信される、もしくは特定の AS に宛てられたトラフィックを、その AS のローカルトラフィック (local traffic) と呼ぶ。また、特定の AS を通り抜けるトラフィックを、その AS のトランジットトラフィック (transit traffic) と呼ぶ。さらに、AS を大まかに次の三つのタイプに区別する:
-
スタブ AS (stub AS) ── 接続する AS が一つだけの AS: スタブ AS はローカルトラフィックだけを転送する。図 100 の「小規模企業」がスタブ AS の例である。
-
マルチホーム AS (multihomed AS) ── 複数の AS に接続するものの、トランジットトラフィックの転送は拒否する AS: 図 100 の「大規模企業」がマルチホーム AS の例である。
-
トランジット AS (transit AS) ── 複数の AS に接続し、ローカルトラフィックとトランジットトラフィックの両方を転送する AS: 図 100 のバックボーンプロバイダがトランジット AS の例である。
前章のルーティングの議論では、リンクに割り当てられた何らかのメトリックを最小化する最適な路を見つけることに重点が置かれた。しかしドメイン間ルーティングはこれよりもっと複雑になる。まず、宛先に到達するループを含まない路を見つける必要がある。次に、その路は通過する AS が持つポリシーを遵守する必要がある ── そして、これまでに見たように、AS が持つポリシーの複雑さには上限がほぼ存在しない。つまり、ドメイン内ルーティングでは路に割り当てられたスカラーのコストを最適化するという明確に定義された問題を扱うのに対して、ドメイン間ルーティングではループを含まないポリシーを遵守する路を見つけるというずっと複雑な最適化問題を扱わなければならない。
ドメイン間ルーティングを難しくする要素は他にも存在する。まず、単純にスケールの問題がある。インターネットのバックボーンルーターはインターネットの任意の場所から任意の場所に宛てて送信されたパケットを転送できなければならない。これは全ての正当な IP アドレスに対してマッチを提供するルーティングテーブルが必要になることを意味する。CIDR のおかげでインターネットのバックボーンでルーティングが考慮すべきプレフィックスの個数は減少するものの、それでもやり取りされるルーティング情報は非常に多い ── 2018 年中頃の時点で 700,000 個のプレフィックスが存在する。
それぞれのドメインが自律的である事実もドメイン間ルーティングにさらなる問題をもたらす。各ドメインは独自に内部ルーティングプロトコルを実行し、それぞれの路に自由なメトリックを割り当てる点に注目してほしい。これは複数の AS を経由する路に対して意味のあるコストが計算できないことを意味する。ある AS を通り抜ける路のコストが「1000」だったとしても、その値は別の AS が計算したコストと比較できない。そのため、ドメイン間ルーティングでは到達可能性だけが広報される。到達可能性の広報には基本的に「この AS を通ると、このネットワークに行けます」という情報だけが記される。そのためドメイン間ルーティングにおいて最適な路の選択は本質的に不可能となる。
ドメインの自律性からは信頼の問題も発生する。プロバイダ A はプロバイダ B が誤った情報を広報することを恐れてプロバイダ B が送信した広報の一部を信用しないことがあり得る。例えばプロバイダ B がインターネットのどこにでも向かえる素晴らしい経路を広報したときにプロバイダ B を信じると悲惨な結果が生じる可能性がある。プロバイダ B はルーターの誤設定でそういった情報を広報したのかもしれないし、送信されるであろう大量のトラフィックを処理する能力を持たないかもしれない。
信頼の問題は上述した複雑なルーティングポリシーをサポートする必要性とも関連する。例えば、指定されたプレフィックスに対する到達可能性を広報したときにだけ特定のプロバイダを信頼することもできる。そのときルーティングポリシーは「プレフィックス \(p\) と \(q\) に到達するときにだけ AS X を利用する。ただし AS X がこれらのプレフィックスに対する到達可能性を広報したとき、およびそのときに限る」といったものになる。
BGP の基礎
各 AS は他の AS とパケットをやり取りする境界ルーター (border router) を一つ以上持つ。図 99 の例では R2 と R4 が境界ルーターである。境界ルーターとは単に AS の間でパケットを転送するタスクを課された IP ルーターのことを言う。
BGP に参加する各 AS は境界ルーターに加えて少なくとも一つの BGP スピーカー (BGP speaker) を持つ必要がある。BGP スピーカーは他の AS に属する BGP スピーカーと BGP で「会話」するルーターである。境界ルーターが BGP スピーカーを兼任する AS はよくあるものの、異なっていても構わない。
BGP は距離ベクトル型とリンク状態型というルーティングプロトコルにおける二つの主要な種別のいずれにも属さない。こういったプロトコルと異なり、BGP は特定のネットワークに到達するために経由すべき AS を全て示した完全な路を広報する。このため BGP は路ベクトル型プロトコル (path-vector protocol) と呼ばれることがある。完全な路の広報が必要なのは、上述したポリシーに関する判断を特定の AS の要望と調整しながら行うためである。加えてルーティングループの確実な検出も可能になる。
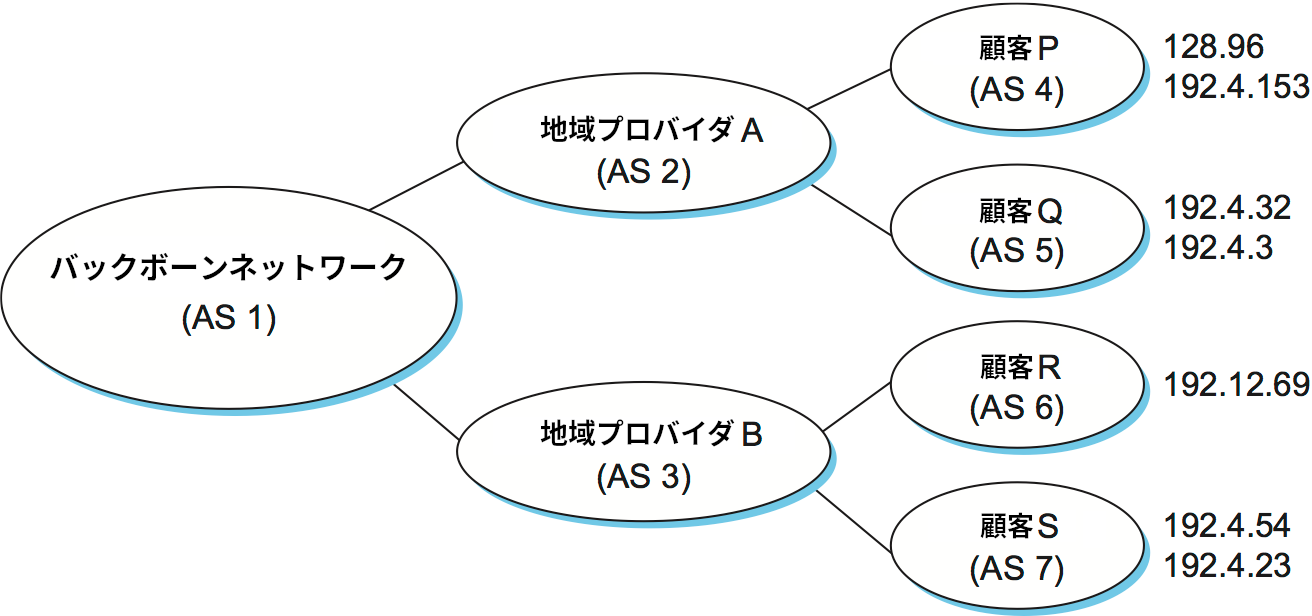
BGP の動作を見るために、図 101 に示す非常に単純なネットワークを考えよう。中央にあるプロバイダの AS はトランジット AS で、右端にある顧客の AS はスタブ AS だとする。プロバイダ A が保有する AS 2 の BGP スピーカーは顧客 P, Q に対して割り当てたネットワーク番号に対する到達可能性を広報できる。このため、AS 2 は「ネットワーク 128.96, 192.4.153, 192.4.32, 192.4.3 には AS2 から直接到達できる」と記した広報を送信する。続いて、この広報を受け取ったバックボーンネットワーク (AS 1) は「ネットワーク 128.96, 192.4.153, 192.4.32, 192.4.3 には路 (AS 1, AS 2) を通じて到達できる」と記した広報を送信する。プロバイダ B が保有する AS 3 でも同様の処理が起こり、AS 1 は「ネットワーク 192.12.69, 192.4.54, 192.4.23 には路 (AS 1, AS 3) を通じて到達できる」と記した広報を送信する。
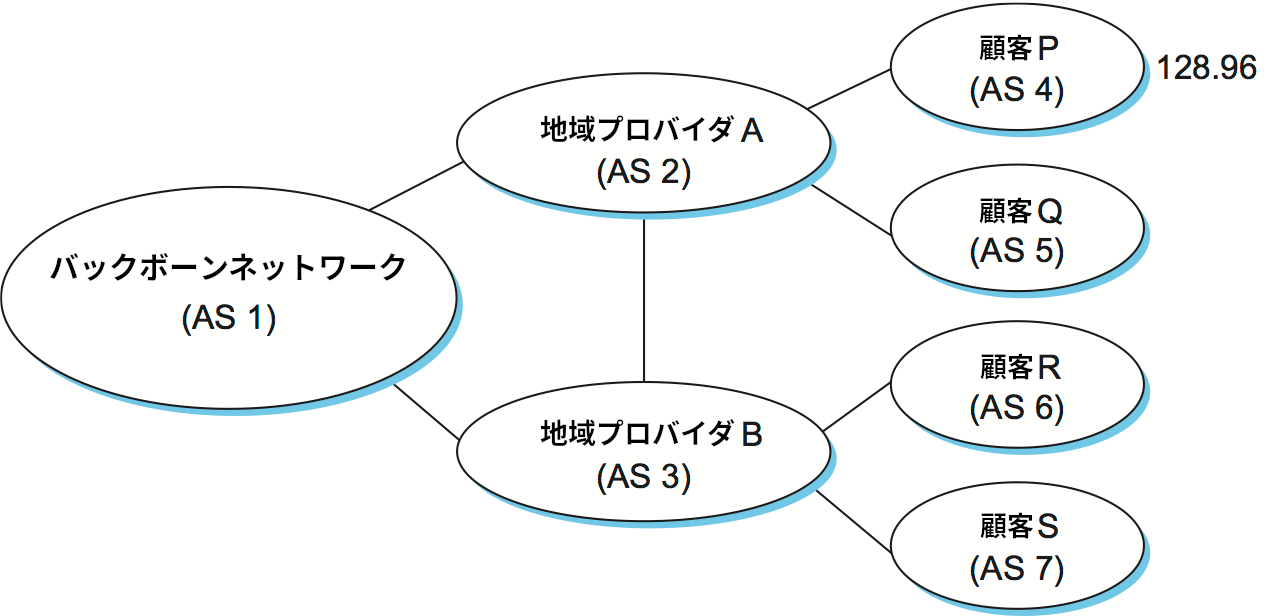
BGP の重要な仕事の一つに、ループを含む路の構築を避けることがある。例として図 102 のネットワークを考えよう。これは図 101 のネットワークに AS 2 と AS 3 を結ぶリンクを加えたものであり、結果として AS のグラフにループが生まれている。AS 1 が 「自分は AS 2 を通って 128.96 に到達できる」と学習し、その事実を AS 3 に広報したとする。この広報を受け取った AS 3 は新たに路を学習するので、その事実を AS 2 に広報する。ループ回避の仕組みが無いと、このとき AS 2 が「128.96 に宛てられたパケットは AS 3 に送るべきだ」と学習する可能性が生じる。もし AS 2 が 128.96 に宛てられたパケットを AS 3 に送ると、AS 3 は受け取ったパケットを AS 1 に転送し、AS 1 は受け取ったパケットを AS 2 に転送する。そのため無限ループが発生してしまう。これは経由する AS を全て含んだ完全な路を含んだルーティングメッセージを広報することで回避できる。この例で言えば、AS 2 が AS 3 から受け取る 128.96 に到達する路の広報には完全な路 (AS 3, AS 1, AS 2, AS 4) が含まれる。AS 2 は広報された路に自身が含まれることを発見し、この路は使うべきではないと判断する。
このループ回避テクニックが動作するには、当然 BGP で利用される AS 番号が一意である必要がある。上記の例で AS 2 が広報に含まれる「AS 2」を自分のことだと認識できるのは、「AS 2」と名乗る AS が他に無いことを知っているからである。現在 AS 番号は 32 ビット長であり、一意性を保証するために中央機関によって割り当てが管理されている。
AS が経路を広報するのは、その経路は十分優れていると AS が考えたときに限られる。つまり、BGP スピーカーが同じ宛先への経路として選択肢をいくつか持っている場合、BGP スピーカーは独自のローカルなポリシーに従って最も優れたものを選び、それを広報する。さらに、到達できることを知っている宛先に対する経路を広報しなければならない義務を BGP スピーカーは負わない。こう定めておけば、AS はトランジットを提供しないポリシーを実装できる ── 自身に含まれないプレフィックスへの経路を (知っていたとしても) 広報しなければいい。
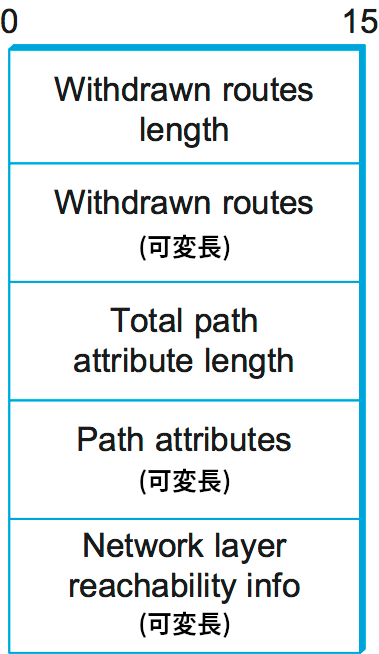
リンクの障害やポリシーの変更は避けられないので、BGP スピーカーは以前に広報した経路をキャンセルできる必要がある。これは経路破棄 (withdrawn route) と呼ばれる否定的な広報によって行われる。肯定的な広報と否定的な広報はどちらも図 103 に示すフォーマットを持つ BGP 更新メッセージで伝達される (本章で登場する他のパケットフォーマットと異なり、この図に示される各フィールドの長さは 16 ビットの倍数である点に注意してほしい)。
前章で説明したルーティングプロトコルと異なり、BGP は信頼性のある転送プロトコル TCP の上で動作する。TCP の信頼性は BGP スピーカーの送信した任意の情報を再送信する必要がないことを意味する。そのため、何も変化がない限り、BGP スピーカーは「自分は動作していて、何も変わってない」と伝えるキープアライブメッセージ (keep alive message) を送るだけで仕事が完了する。ルーターのクラッシュやピアからの切断が起きるとキープアライブメッセージの送信が停止するので、その時点で他のルーターはそのルーターから学習した経路がもはや利用できないと学習する。
よく使われるルーティングポリシー
ルーティングポリシーは任意に複雑になるとは言ったものの、実際には AS によくある立場を反映したよく使われるポリシーがいくつか存在する。図 104 に AS の立場としてよく見られるものを三つ示す。
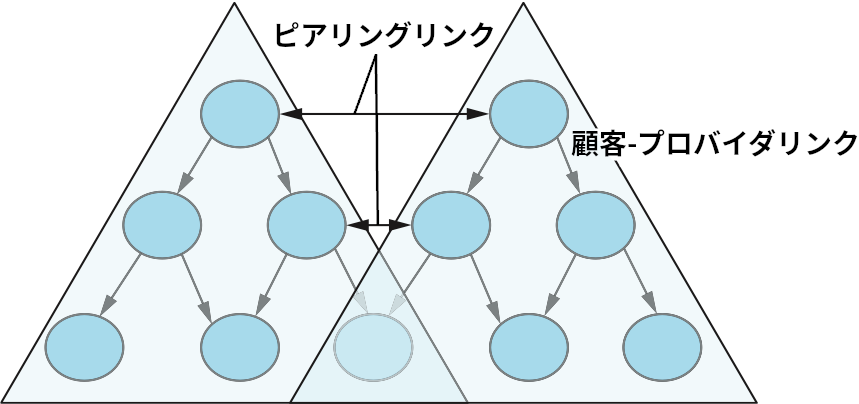
この図に示された三つの立場と、対応するポリシーは次の通りである:
-
顧客と接続するプロバイダ ── プロバイダの仕事は顧客をインターネットの他の部分に接続することである。顧客は企業かもしれないし、小規模な ISP (独自に顧客を持つ) かもしれない。そのためプロバイダでよく使われるポリシーは「自身が知っている全ての経路を顧客に広報し、顧客から学習した経路を他の全ての AS に広報する」となる。
-
プロバイダに接続する顧客 ── 逆の立場にある顧客は、自分もしくは (存在するなら) 自身の顧客に宛てられたトラフィックをプロバイダから受け取り、インターネットの他の部分宛てのトラフィックをプロバイダ越しに送信したいと思っている。そのため顧客でよく使われるポリシーは「自分のプレフィックスおよび自分の顧客から学習した経路をプロバイダに広報し、プロバイダから学習した経路を顧客に広報する。ただし他のプロバイダから学習した経路を別のプロバイダに広報することはしない」となる。最後の部分は顧客が他人のトラフィックをプロバイダからプロバイダに伝達しないようするために存在する。顧客は料金を払ってプロバイダにトラフィックを伝達してもらっているのだから、自身がトラフィックの転送に関与する義理はない。
-
ピア ── 三つ目の立場として、他の AS と対称的な協力関係にある AS がある。二つのプロバイダはお互いをピアとみなし、通常は料金を払うことなくお互いの顧客に対するアクセスを得る。ピアでよく使われるポリシーは「自分の顧客から学習した経路はピアに広報し、ピアから学習した経路は顧客に広報する。ただしピアから他のプロバイダに向かう経路 (およびその逆) は広報しない」となる。
図 104 を観察すると、一見すると構造を持たないインターネットに一定の構造がもたらされているのが分かる。この階層で最下層にあるのはプロバイダの顧客 (の顧客の顧客...) のスタブ AS であり、その上には他のプロバイダを顧客とするプロバイダの AS が存在する。頂点には顧客を持つものの自身は顧客でないプロバイダが存在する。こういったプロバイダは Tier 1 プロバイダと呼ばれる。
教訓
現実の疑問に戻ろう: こういった仕組みはネットワークをスケーラブルにする上でどのように役立つのだろうか? まず、BGP に参加するノードの個数は AS の個数のオーダーであり、ネットワークの個数よりずっと小さい。次に、優れたドメイン間経路を見つける問題は正しい境界ルーターへの路を見つけるだけの問題となり、境界ルーターは AS ごとに数個しか存在しない。こうしてルーティングの問題は管理可能な部分に分割され、またしても新しい階層の追加によってスケーラビリティが改善される。ドメイン間ルーティングの複雑性は AS の個数のオーダーであり、ドメイン内ルーティングの複雑性は単一の AS に含まれるネットワークの個数のオーダーである。
ドメイン内ルーティングとドメイン間ルーティングの統合
ここまでの議論で BGP スピーカーがドメイン間ルーティング情報を学習する方法を説明したものの、その情報をドメイン内の他のルーターが入手する方法に関する疑問は残る。この問題を解決する方法はいくつかある。
まず非常に単純な状況を考えよう。これは非常によくある状況でもある。単一の AS と単一点で接続するスタブ AS では、AS の外側と AS の内側を結ぶ経路は必ず境界ルーターを通過する。この場合、ドメイン内ルーティングプロトコルのデフォルトルーターを境界ルーターに設定するだけで AS の外とパケットをやり取りする準備が整う。この設定は「ドメイン内ルーティングプロトコルで明示的に広報されていないネットワークは全て境界ルーターを通じて到達できる」と言っているに等しい。前章の IP データグラムの転送に関する議論を思い出せば、転送テーブルのデフォルトエントリーは他の全ての特定的なエントリーより優先度が低く、どの特定的なエントリーともマッチしなかった宛先とマッチする。
次に複雑なのは、境界ルーターが AS の外側から学習した特定の経路をドメイン内ルーティングプロトコルに割り込ませるケースである。例として、プロバイダの AS における境界ルーターが顧客の AS に接続している状況を考えよう。この境界ルーターが、プレフィックス 192.4.54/24 は顧客 AS に位置することを BGP あるいは手動の設定を通して知ったとする。このとき、そのプレフィックスへの経路をプロバイダの AS で実行されるルーティングプロトコルに割り込ませるとドメイン外へのルーティングの問題が解決する。これは「192.4.54/24 へのコスト X のリンクを私は持っている」と境界ルーターが広報するのに等しい。こうすることで、広報されたプレフィックスに宛てられたパケットをその境界ルーターに送るべきだとプロバイダ AS の他のルーターは学習する。
最も複雑なケースはバックボーンネットワークである。バックボーンネットワークでは BGP から学習する経路情報が非常に多いので、その全てをドメイン内ルーティングプロトコルに割り込ませるのはコストが高く現実的でない。例えば、境界ルーターが他の AS から学習した 10,000 個のプレフィックスを持っていて、巨大なリンク状態パケットを同じ AS 内の他のルーターに送ろうとするかもしれない。このため、バックボーンネットワークのルーターは iBGP (interior BGP, 内部 BGP) と呼ばれる BGP の一種を利用して AS の端で BGP スピーカーが学習した情報を AS 内の他のルーターに効率的に再配布する。なお、ここまでに議論してきた AS 同士が情報を交換するときに使われる BGP は eBGP (exterior BGP, 外部 BGP) と呼ばれる。iBGP によって、AS 外にパケットを送信するときに使うべき最良の境界ルーターを AS 内の全てのルーターが理解するようになる。同時に各ルーターは従来のドメイン内ルーティングプロトコルを利用して境界ルーターに到達する方法を追加の情報無しに理解する。これら二つの情報が組み合わされば、AS 内の各ルーターは全てのプレフィックスに対する適切なネクストホップを判断できる。
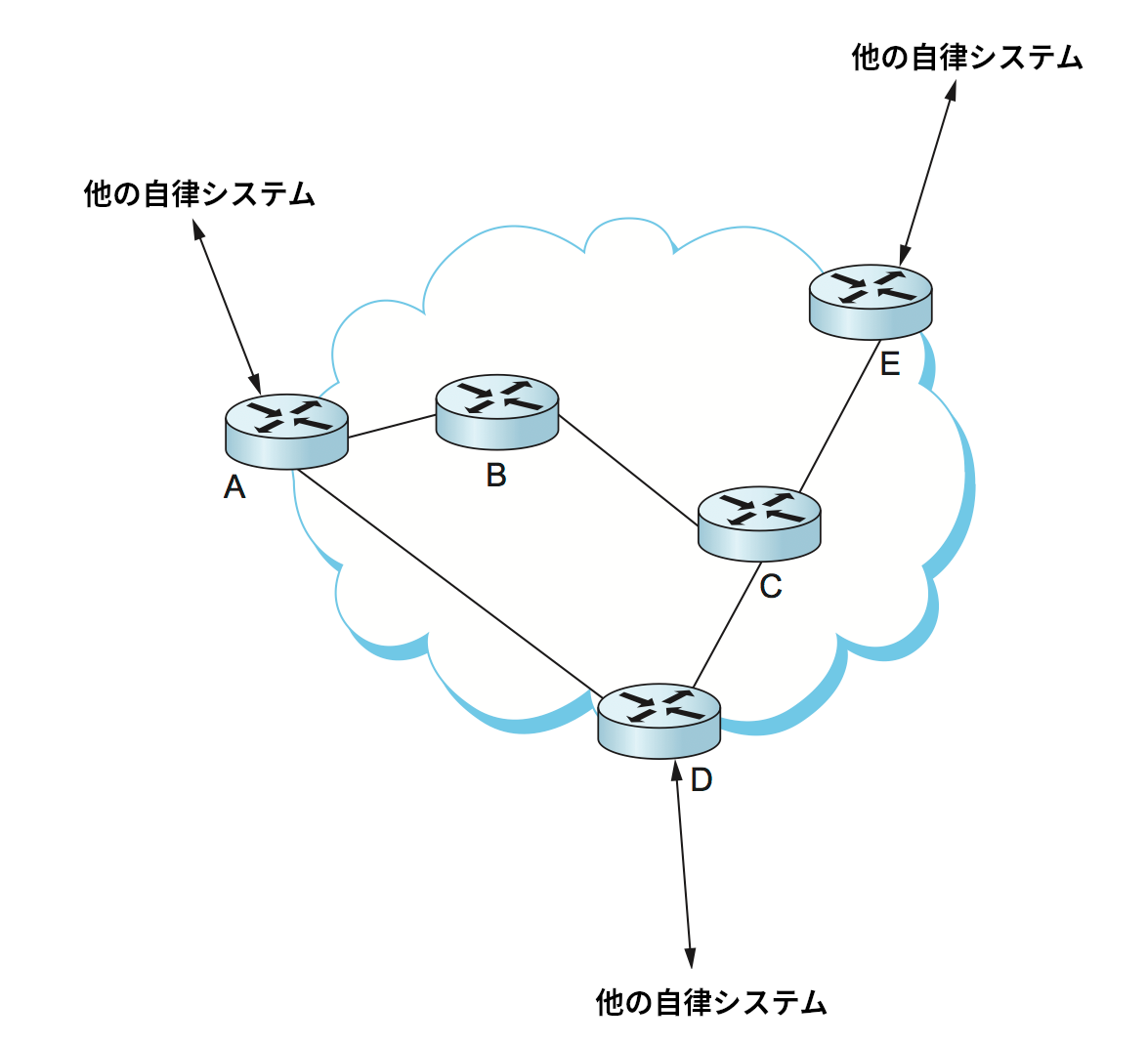
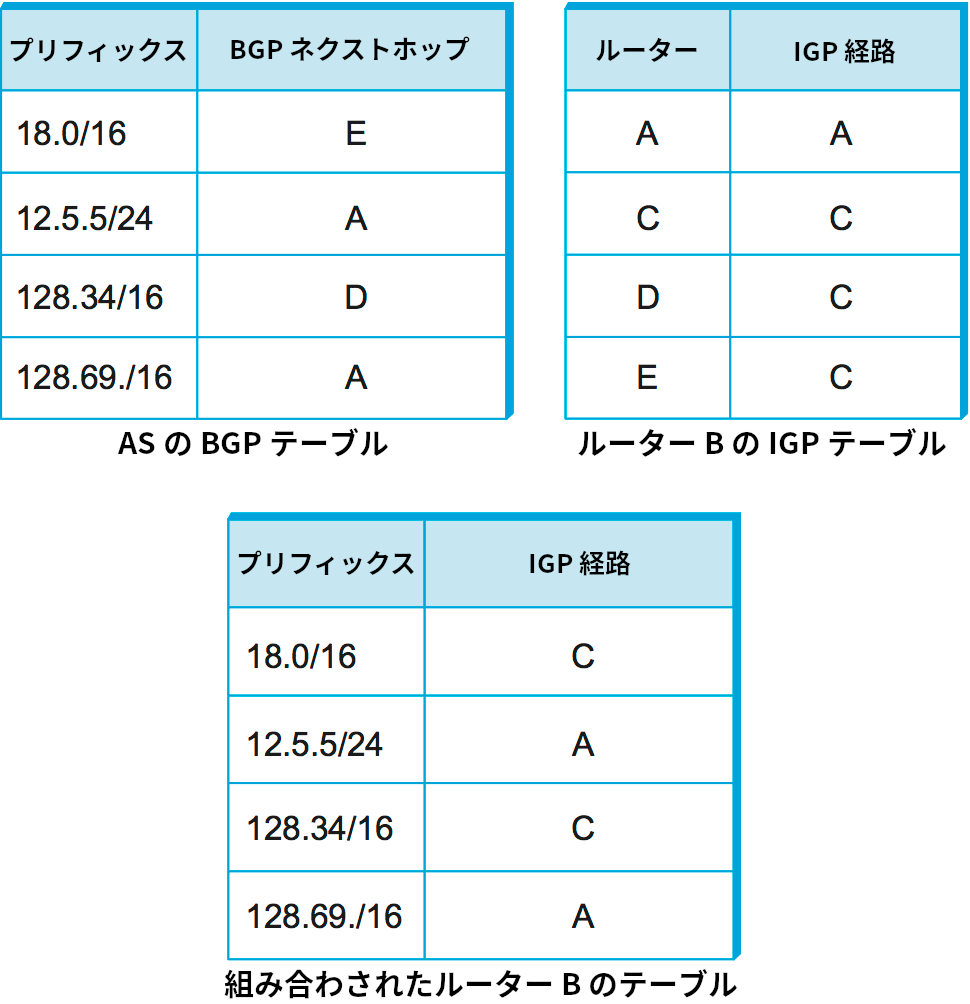
この動作を理解するために、図 105 に示す単一の AS を表すネットワークを考えよう。境界ルーター A, D, E は eBGP で他の AS と対話し、様々なプレフィックスに到達する方法を学習する。これら三つの境界ルーターと内部ルーター B, C は iBGP セッションのメッシュを構築して対話を行う。
これからルーター B に注目して、B が任意のプレフィックスに宛てられたパケットを転送する完全な方法をどのように理解するかを見ていく。ルーター B が iBGP セッションから学習する情報 (の一例) を図 106 の左上に示す。宛先のプレフィックスごとに、境界ルーター A, B, E のどれにパケットを転送すべきかが示されている。iBGP を実行するのと同時に、AS 内の全てのルーターは何らかのドメイン間ルーティングプロトコル (例えば RIP や OSPF) を実行する。ドメイン内ルーティングプロトコルは一般に IGP (Interior Gateway Protocol, 内部ゲートウェイプロトコル) と呼ばれる。B は自身のドメインの内側に存在するノードに到達する方法を IGP から学習する (図 106 右上)。例えばパケットをルーター E に到達させたいときは、B はパケットをルーター C に転送する。最後に、B は iBGP から学習した外部プレフィックスに関する情報と IGP から学習した境界ルーターへの内部経路の情報を組み合わせ、転送の全体図 (図 106 下) を完成させる。例えばプレフィックス 18.0/16 は境界ルーター E を通じて到達可能であり、E へ到達する最良の内部経路は C を通じたものだと B は知っているから、18.0/16 に宛てられたパケットは C に転送すべきだと分かる。以上の仕組みにより、AS 内の全てのルーターは AS の境界ルーターを通して到達可能な任意のプレフィックスに対応する完全なルーティングテーブルを構築できる。