5.3 遠隔手続き呼び出し
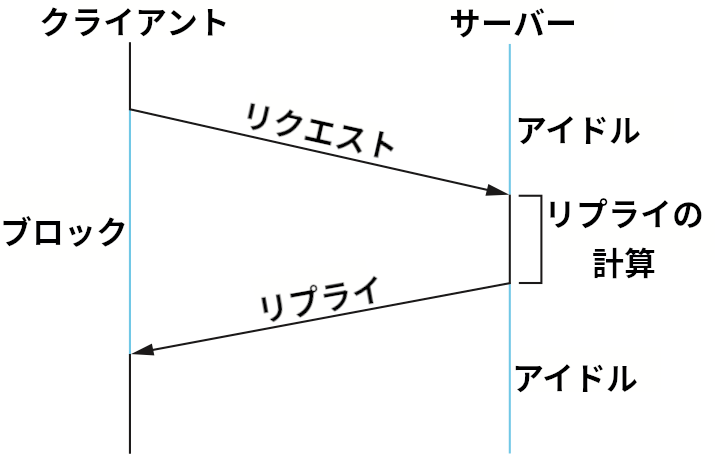
クライアントとサーバーとして構造化できるアプリケーションプログラムでよく行われる通信パターンの一つに、リクエストメッセージとリプライメッセージの交換がある。クライアントがリクエストメッセージをサーバーに送信し、それに対してサーバーがリプライメッセージで応答するというものであり、返事を受け取るまでの間クライアントはブロックする (実行を停止する)。こういったメッセージの交換におけるクライアントとサーバーの基本的な対話を図 137 に示す。
リクエスト/リプライのパラダイムをサポートするトランスポートプロトコルは両方向に UDP メッセージを送り合うよりも高度な処理をサポートする。具体的には、リモートホストに存在するプロセスを正しく識別してリクエストに対応する正しいレスポンスを計算する必要がある。さらに本章の最初で指摘したような下位のネットワークが持つ制限を克服しなければならない可能性もある。TCP は確実なバイトストリームサービスを提供することでこういった制限を克服するのに対して、リクエスト/リプライのパラダイムは TCP と完全にはマッチしない。本節では RPC (remote procedure call, 遠隔手続き呼び出し) と呼ばれるトランスポートプロトコルの三つ目のカテゴリを紹介する。本章で紹介した TCP や UDP などのトランスポートプロトコルと比べると、RPC はリクエストメッセージとリプライメッセージの交換が行われるアプリケーションが必要とするものにより近い機能を提供する。
5.3.1 RPC の基礎
正確に言えば RPC はプロトコルではない ── 分散システムを構造化するための一般的なメカニズムと考えた方が正確となる。RPC が広く使われるのは、ローカルで行われる手続き呼び出しの意味論をベースにしているためである ── アプリケーションプログラムはローカルの手続きと遠隔の手続きを同じように呼び出し、いずれの場合でもその呼び出しが返るまでブロックする。アプリケーション開発者は基本的に手続きがローカルか遠隔かを気にしないで済むので、プログラムを書くのが簡単になる。オブジェクト指向言語において、呼び出されている手続きが遠隔オブジェクトのメソッドである場合には、その RPC を RMI (remote method invocation, 遠隔メソッド起動) と呼ぶ。RPC の概念は簡単であるものの、RPC をローカルの手続き呼び出しより難しくする主要な問題が二つ存在する:
-
呼び出し元のプロセスと呼び出し先のプロセスを結ぶネットワークはコンピューターの背面基盤より格段に複雑な特徴を持つ。例えばメッセージのサイズは制限される可能性が高く、転送中にメッセージが喪失したり順序が変わったりする場合もある。
-
呼び出し元のプロセスを実行するコンピューターと呼び出し先のプロセスを実行するコンピューターは大きく異なるアーキテクチャとデータ表現フォーマットを持つ可能性がある。
このため、完全な RPC メカニズムには主に次の二つの要素からなる:
-
クライアントのプロセスとサーバーのプロセスの間でやり取りされるメッセージを定めるプロトコル ── 下位のネットワークが持つ望ましくない特徴に対処する。
-
プログラミング言語およびコンパイラのサポート ── クライアントでは遠隔手続き呼び出しに渡された引数をリクエストメッセージとしてまとめてサーバーに送信するコードが必要になり、サーバーでは受け取ったリクエストメッセージを引数に戻すコードが必要になる。返り値に対しても同様のコードが必要になる。RPC のこの部分はスタブコンパイラ (stub compiler) と呼ばれることが多い。スタブコンパイラが挿入するコードはスタブ (stub) と呼ばれる。
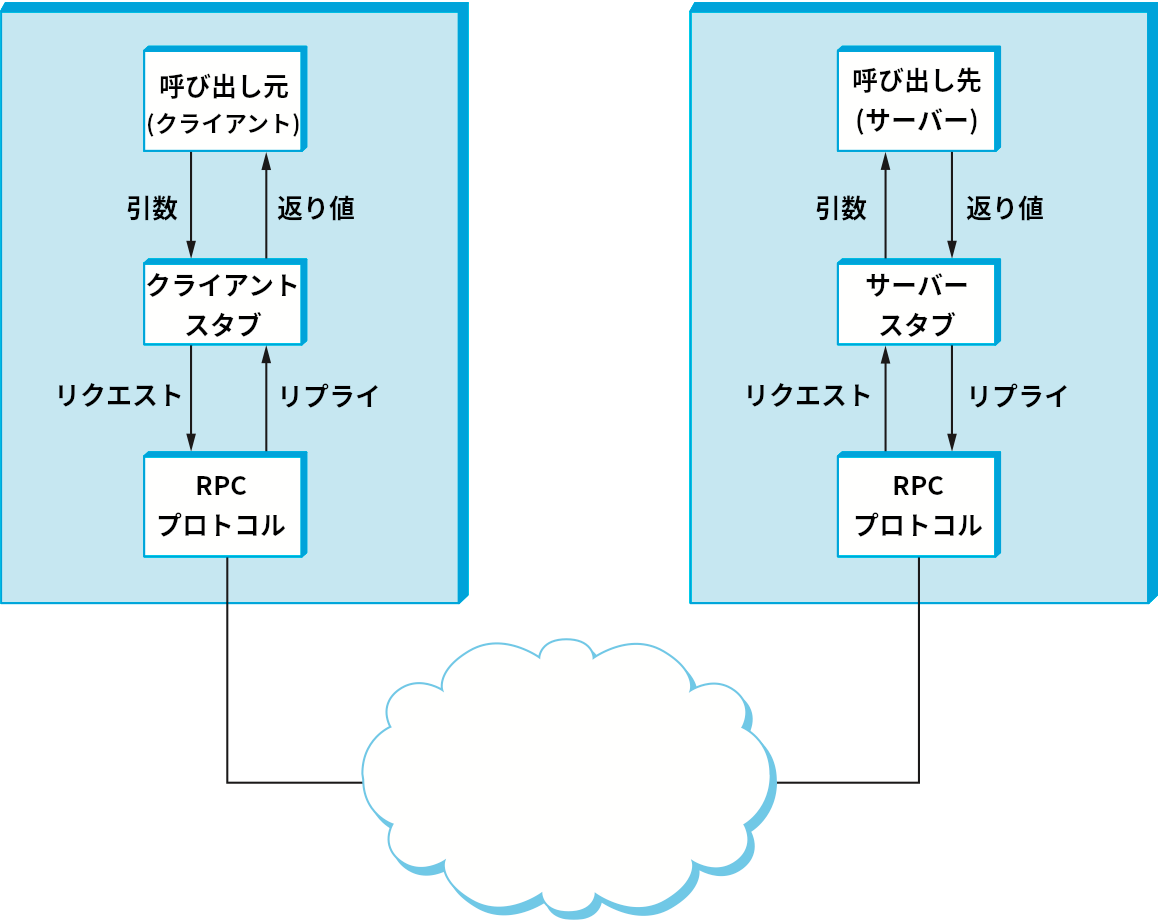
クライアントが遠隔手続きを呼び出したときに何が起こるかを図 138 に示す。まずクライアントは手続きに対応するローカルのスタブを呼び出し、そのとき手続きに必要な引数を渡す。このスタブは呼び出しが実際には遠隔呼び出しである事実を隠蔽するために存在している。スタブは受け取った引数をリクエストメッセージに変換し、それを RPC プロトコルでサーバーに送信する。サーバーでは、RPC プロトコルがリクエストメッセージをサーバーのスタブに渡し、スタブがリクエストメッセージを引数に変換し、そしてローカルの手続きを呼び出す。この手続きが終了すると、サーバーのスタブが返り値をリプライメッセージに変換し、それを RPC プロトコルに渡してクライアントに送り返す。クライアントの RPC プロトコルはリプライメッセージをクライアントのスタブに渡し、そのスタブはリクエストメッセージを返り値に変換してクライアントプログラムに渡す。
本節では RPC メカニズムのプロトコルに関連する側面だけを考察する。つまりスタブ関連の話題には触れず、クライアントとサーバーの間でメッセージを交換するのに使われる RPC プロトコル (「リクエスト/リプライプロトコル」とも呼ばれる) に焦点を当てる。引数とメッセージの相互変換は他の場所で触れる。クライアントとサーバーのプログラムが何らかのプログラミング言語で記述されることも忘れないでほしい。特定の RPC メカニズムは Python スタブ、Java スタブ、Go スタブといったスタブをサポートし、手続きを呼び出すための言語固有のイディオムを定義する。
「RPC」という言葉が指すのはプロトコルの区分であり、「TCP」のように特定の仕様を指すわけではない。そのため特定の RPC プロトコルはそれぞれ異なる機能を持つ。また、TCP が支配的な地位を持つ確実なバイトストリームプロトコルと異なり、支配的な地位にある RPC プロトコルは存在しない。 そのため、本節では可能な設計の選択肢がこれまでより多く説明される。
RPC における識別子
RPC プロトコルが行わなければならない仕事が二つある:
-
呼び出される手続きを一意に識別する名前空間を提供する。
-
それぞれのリプライメッセージを対応するリクエストに関連付ける。
一つ目の問題はネットワーク上のノードを識別する問題 (IP アドレスが解決する問題) と共通点がある。何かを識別する仕組みの設計では、識別子の名前空間をフラットにする選択肢と階層的にする選択肢がある。フラットな名前空間を使う場合は構造化されていない一意な識別子 (例えば整数) がそれぞれの手続きに割り当てられ、その識別子が RPC リクエストメッセージのフィールドで指定される。この方式では同じ識別子が異なる手続きに割り当てられるのを防ぐために何らかの中央機関が必要になるだろう。もう一つの選択肢として、ファイルパスに似た階層的な名前空間を使うこともできる。この方式では識別子の「ファイル名」の部分が「ディレクトリ」の中で一意であるだけで問題ないので、手続きの一意性を保証する処理は簡単になる。RPC における階層的な名前空間は、それぞれの階層における識別子を表すいくつかの (例えば二つか三つの) フィールドをリクエストメッセージに用意することで実装できる。
リプライメッセージを対応するリクエストに関連付ける処理で鍵となるのは、リクエストとリプライの組を一意に識別するメッセージ ID である。このメッセージ ID は最初リクエストメッセージに含まれ、対応するリプライメッセージにも同じ値が設定される。クライアントの RPC モジュールはリプライメッセージを受け取ると、そこに含まれるメッセージ ID を使って対応するリクエストを検索し、ブロックしていた呼び出し側に返り値を渡して実行を再開させる。
RPC でたびたび現れる課題の一つに、予想していないメッセージ ID を持ったリプライメッセージの処理がある。例えば、次のような奇妙な (しかし現実的な) 状況を考えてみてほしい。クライアントがメッセージ ID が 0 のリクエストメッセージを送信し、その後クラッシュして再起動したとする。その後クライアントが最初のメッセージとは無関係のリクエストメッセージを送信し、そのときもメッセージ ID として 0 を使ったとする。このときサーバーはクライアントがクラッシュして再起動したことを関知できず、二つ目のリクエストメッセージを受け取ったときメッセージ ID を見て重複していると判断し、メッセージを破棄するかもしれない。するとクライアントはリクエストに対する返答をいつまでたっても受け取れなくなる。
この問題を解決する一つの方法としてブート ID (boot ID) の利用がある。ブート ID とはマシンが起動された回数を表す整数を言う。非揮発性のストレージ (ディスクやフラッシュドライブ) に保存され、マシンが起動するときのスタートアップ処理で読み込まれ、1 を加えた値が書き戻される。ブート ID はマシンが送信する全てのメッセージに付加され、同じメッセージ ID を持つリクエストメッセージでもブート ID が異なれば異なるリクエストメッセージとして扱われる。この結果、メッセージ ID とブート ID が合わさってトランザクションに対する一意な識別子を形成する。
ネットワークの制限の克服
RPC プロトコルはネットワークが完璧なチャンネルでない事実に対処するために追加の機能を持つことがよくある。そういった機能の例を二つ示す:
-
確実なメッセージ転送を提供する。
-
フラグメント化と再構築を通じて大きなメッセージをサポートする。
TCP のような確実なプロトコルの上で RPC プロトコルを実行することで「問題を解決する」こともできるものの、多くの RPC プロトコルは低信頼の基盤 (UDP/IP など) の上に確実なメッセージ転送層を独自に実装する。こういった RPC プロトコルは TCP と同様に確認応答とタイムアウトを使って確実な転送を実装する場合が多い。
図 139 に示すタイムラインから分かるように、基本的なアルゴリズムに難しいところは無い。最初クライアントがリクエストメッセージを送り、サーバーはそれに対する ACK を送り返す。その後、手続きの実行を終えたサーバーはリプライメッセージを送り、クライアントはそれに対する ACK を送り返す。
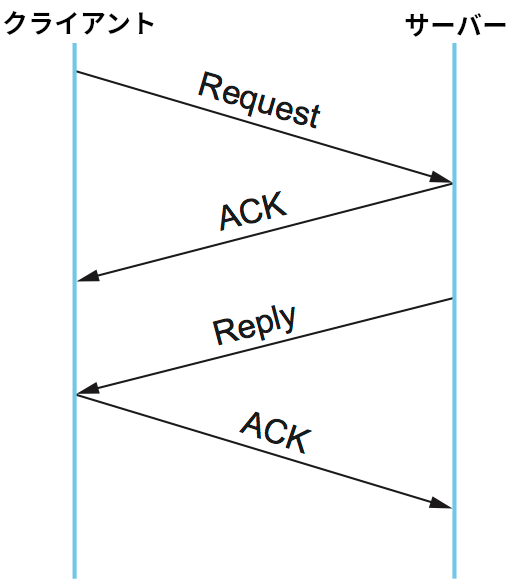
データを伝達するリクエストメッセージとリプライメッセージ、およびそれらに対する ACK はどれもネットワークで失われる可能性がある。この可能性に対処するために、クライアントとサーバーはどちらも ACK が返って来るまで送信したメッセージのコピーを保存する。加えて両者は再送タイマーを設定し、このタイマーの時間が切れた場合はメッセージを再送する。両者が事前に合意した回数の再送を行っても ACK が返ってこなかった場合は、送信を諦めてメッセージを破棄する。
RPC クライアントがサーバーからのリプライメッセージを受け取った場合、明らかにそれに対応するリクエストメッセージはサーバーに届いている。そのためリプライメッセージ自体を暗黙の確認応答 (implicit acknowledgment) として利用でき、理論上はリクエストメッセージに対する個別の ACK は必要ない。同様に、RPC プロトコルがリクエストとリプライのトランザクションを逐次的に行う (一つのトランザクションを終えてから次のトランザクションを開始する) と仮定すれば、リクエストメッセージは一つ前のリプライメッセージに対する暗黙の確認応答となる。ただ残念ながら、この仮定は RPC のパフォーマンスを厳しく制限する。
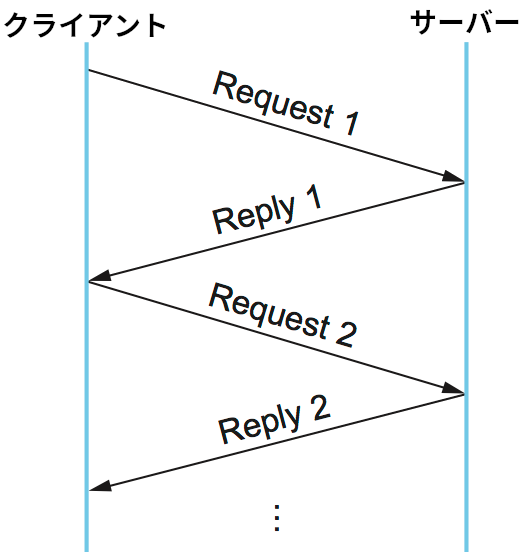
この窮地を抜け出す手段として、チャンネル (channel) という抽象化を使ったトランザクションの実装がある。一つのチャンネルの中ではリクエストとリプライのトランザクションは逐次的になる ── 任意の時点で実行中のトランザクションは一つしか存在できない ── ものの、チャンネル自体はいくつも存在できる。別の言い方をすれば、チャンネルの概念を用意すれば同じクライアントとサーバーの間で複数のトランザクションを多重化できるようになる。
各メッセージには自身が属するチャンネルを表すチャンネル ID フィールドが含まれ、特定のチャンネルのリクエストメッセージが同じチャンネルの一つ前のリプライメッセージに対する暗黙の確認応答を行う (確認応答が直接的に既に行われている可能性もある)。アプリケーションプログラムがリクエストとリプライのトランザクションを同時に複数持つことを望む場合は、複数のチャンネルをオープンして構わない。図 140 に示すように、リプライメッセージは一つ前のリクエストメッセージに対する確認応答の役割を果たし、リクエストメッセージは一つ前のリプライメッセージに対する確認応答の役割を果たす。実は、これと非常に良く似たアプローチは第 2.5.3 項で紹介した並行論理チャンネルで既に見ている。並列論理チャンネルでは確実性を保証するストップアンドウェイトアルゴリズムのパフォーマンスを向上させるためにチャンネルが利用される。
RPC がさらに解決しなければならない問題として、サーバーが仮り値の生成にかける時間が任意に長くなる事実がある。さらに悪いことに、返り値の生成中にクラッシュする可能性さえある。ここではサーバーがリクエストの確認応答を行った後にリプライメッセージを個別に送るシナリオを考えている。クライアントが遅いサーバーと死んだサーバーを区別できるように、RPC のクライアントが定期的に「生存確認」メッセージをサーバーに送信し、サーバーはそれに対して ACK を返答する仕組みを導入することが考えられる。あるいは、サーバーから一方的に「生存通知」メッセージをクライアントに送る方式も考えられる。後者のアプローチの方がクライアントごとの処理 (タイムアウトタイマーの管理) をクライアントに多く押し付けられるので、よりスケーラブルとなる。
RPC が提供する確実性が at-most-once 意味論 (at-most-once semantics)と呼ばれる特徴を持つ場合がある。これはクライアントが送信するそれぞれのリクエストメッセージに対して、そのメッセージの最大でも一つのコピーがサーバーに届けられることの保証を意味する。つまりクライアントが遠隔手続きを呼び出すと、その手続きはサーバーマシンで最大でも一度だけ実行される。「ちょうど一度」ではなく「最大でも一度」の保証に留まるのは、ネットワークやサーバーマシンで障害が起こってリクエストメッセージのコピーを一つもサーバーに届けられない可能性を排除できないためである。
at-most-once 意味論を実装するには、サーバー側の RPC は重複するリクエストを検出 (そして無視) する必要がある。そのリクエストに対して過去にエラーを出さずに返答していたとしても、重複するなら無視しなければならない。このため、サーバー側の RPC は過去のリクエストを識別する情報を管理する必要がある。一つのアプローチとして、リクエストをシーケンス番号で識別し、サーバーは現在利用中のシーケンス番号だけを記憶するアプローチが考えられる。しかし残念ながら、このアプローチではサーバーが処理しているリクエストを完了させるまでその次のシーケンス番号を持ったリクエストに転送開始を指示できないので、RPC が同時に処理できるリクエストの個数が制限される。ここでも、解決策はチャンネルによって提供される。サーバーが各チャンネルに対する現在のシーケンス番号を記憶するようにすれば重複するリクエストを検出でき、同時に処理できるリクエストの個数も制限されない。
at-most-once 意味論は簡単に思えるものの、この振る舞いをサポートしない RPC プロトコルも存在する。一部の RPC プロトコルは zero-or-more 意味論 (zero-or-more semantics) という冗談じみた名前の付いた意味論をサポートする。これはクライアントが遠隔手続き呼び出しを行うとき、対応する手続きがサーバーで実行されない場合もあれば何度も実行される場合もあることを意味する。ローカルの状態変数を変更する遠隔手続き (例えばカウンターを進める処理) で zero-or-more 意味論が問題を起こすことを理解するのは難しくない。しかし一方で、もし遠隔手続きが冪等 (idempotent) ── 複数回の呼び出しが一度の呼び出しと同じ効果を持つ ── なら、RPC が at-most-once 意味論をサポートする必要はない: それより単純な (おそらくはそれより高速な) 実装で十分となる。
確実性の場合と同様に、RPC プロトコルがメッセージのフラグメント化と再構築を実装する理由には次の二つが考えられる:
- 下位のプロトコルスタックで提供されていない。
- RPC プロトコルで実装した方が効率良く実装できる。
RPC が UDP/IP の上に実装され、フラグメント化と再構築を IP に頼っているケースを考えよう。このとき、メッセージのフラグメントが一つでも既定の時間内に到着できなければ、IP は他のフラグメントを含めて全て破棄するので、メッセージは喪失する。RPC プロトコルが確実性を実装すると仮定すれば、その後タイムアウトが起こり、送信元はメッセージを再送するだろう。これに対して、 RPC プロトコルがフラグメント化と再構築を独自に実装し、個別のフラグメントに対する ACK と NACK (否定応答) を積極的に送信する場合には、失われたフラグメントの検出と再送が素早く行われ、メッセージ全体ではなく失われたフラグメントだけが再送される。
同期プロトコルと非同期プロトコル
プロトコルは同期プロトコル (synchronous protocol) と非同期プロトコル (asynchronous protocol) のどちらに属するかで特徴付けることができる。これらの用語の正確な意味はプロトコル階層のどの部分を考えるかによって変わる。トランスポート層では、この二つの用語は共通要素を持たない二つのプロトコルの集合というよりもスペクトルの両端にある最も極端なプロトコルを意味すると捉えた方が正確となる。このスペクトルにおける特定のプロトコルの位置を決めるのは、送信プロセスが呼び出した「メッセージの送信」操作が返ったときに、送信プロセスがその操作の進行に関して持っている知識の量である。言い換えれば、アプリケーションが起動したトランスポートプロトコルの send 操作が返った時点で、アプリケーションは操作の成功 (あるいは失敗) に関して正確に何を知っているだろうか?
スペクトルの非同期の端では、アプリケーションは send が返った時点で何の知識も持たない。メッセージがサーバーに届いたかどうかはおろか、メッセージがローカルのマシンを離れたかどうかさえ分からない。もう一方の同期の端では、send がリプライメッセージを返すことが多い。つまり、アプリケーションはメッセージがサーバーに届いたという知識に加えて、サーバーからの応答が返ってきたという知識も持っている。このため、同期プロトコルはリクエスト/リプライの抽象化を忠実に実装するのに対して、非同期プロトコルは送信側が応答を待つことなく大量のメッセージを送りたいときに利用される。この定義を用いると、RPC プロトコルは同期プロトコルである場合が多い。
本章では議論していないものの、この二つの端の中間には興味深い点がいくつかある。例えば send がリモートマシンに問題なく到着した時点 (相手がメッセージの処理を始める直前) で返るトランスポートプロトコルも考えられる。こういったプロトコルを高信頼データグラムプロトコル (reliable datagram protocol) と呼ぶ場合がある。
5.3.2 RPC の実装 (SunRPC, DCE, gRPC)
続いて RPC プロトコルの実装の例に話題を移そう。いくつか実装を見ていけば、異なるプロトコル設計者が下した異なる設計判断を理解できるだろう。本節では三つの実装を順に見ていく。最初に SunRPC を見る。SunRPC は広く使われる RPC プロトコルであり、ONC RPC (Open Network Computing RPC) とも呼ばれる。二つ目の例として見る DCE-RPC は DCE (Distributed Computing Environment) の一部である。DCE は分散システムを構築するための規格とソフトウェアの集合体であり、OSF (Open Software Foundation) によって策定される。OSF は IBM, DEC, HP (Hewlett-Packard) などが立ち上げたコンピューター企業からなるコンソーシアムで、現在では The Open Group と改称されている。最後に gRPC を見る。gRPC は Google がオープンソースで公開した RPC プロトコルであり、Google がデータセンターで実行するクラウドサービスを実装するために内部で利用していた RPC プロトコルをベースとしている。
これらの三つのプロトコルは RPC の設計空間における興味深い選択肢を提示する。しかし選択肢がこれだけと思ってはいけない。第 9 章では Web サービスの文脈で RPC に似た三つのメカニズム (WSDL, SOAP, REST) を紹介する。
SunRPC
SunRPC がデファクトスタンダードとなった要因としては、Sun ワークステーションが広く使われたこと、そして Sun の有名な NFS (Network File System) で中心的な役割を担ったことが挙げられる。後に IETF は ONC RPC という名前で SunRPC を標準インターネットプロトコルの一つとして取り入れた。
SunRPC は異なるトランスポートプロトコルの上に実装できる。図 141 に UDP の上に SunRPC を実装した場合のプロトコルグラフを示す。本節で以前に説明したように、プロトコルの層化という考え方を厳密に捉える人々はトランスポートプロトコルの上にトランスポートプロトコルを実装することを良しとせず、RPC はトランスポートプロトコルの「上に」あるのだからトランスポートプロトコルであってはいけないと主張するかもしれない。しかしこれからの議論で明らかになるように、RPC を既存のトランスポートプロトコルの上に実装する設計判断は現実的には非常に理にかなったものである。
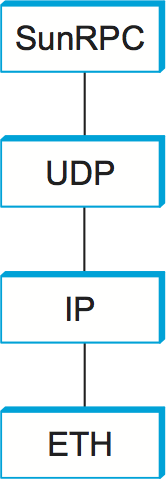
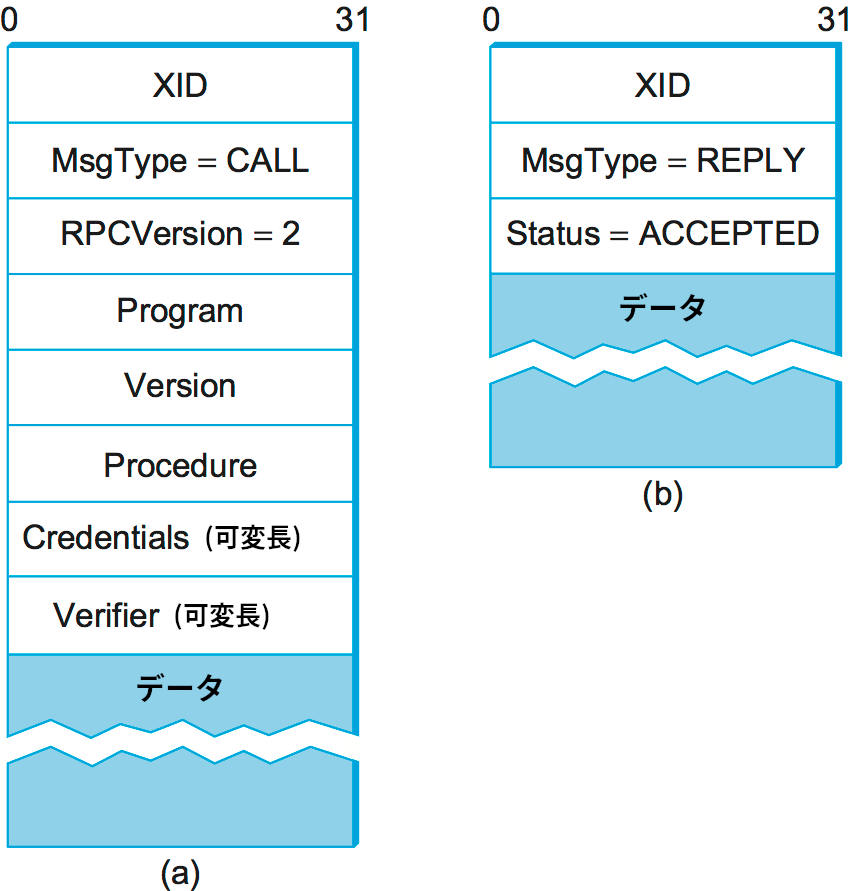
SunRPC は遠隔手続きの識別に二つの階層からなる識別子を利用する: その識別子は 32 ビットのプログラム番号と 32 ビットの手続き番号から構成される (正確には 32 ビットのバージョン番号も使われるが、以降の議論では無視する)。例えば NFS サーバーにはプログラム番号 0x00100003 が割り当てられ、このプログラムの中で getattr には 1、setattr には 2、read には 6、write には 8 が割り当てられる。プログラム番号と手続き番号はリクエストメッセージのヘッダーを通して渡される。リクエストメッセージのヘッダーが持つフィールドを 図 142 (a) に示す。リクエストメッセージを受け取ったサーバーは指定されたプログラムの指定された手続きを呼び出す (一つのサーバーは複数のプログラム番号をサポートできる)。SunRPC のリクエストは実際には指定されたプログラムの指定された手続きをリクエストの宛先マシンで実行するリクエストを表すので、ネットワーク上に同じプログラムを実装する他のマシンがあったとしても使われることはない。そのため、サーバーが実行されるマシンのアドレス (例えば IP アドレス) が暗黙に三階層目の RPC アドレスとなる。
異なるプログラム番号が同じマシン上の異なるサーバーに属しても構わない。そのとき異なるサーバーが持つトランスポート層の逆多重化鍵 (例えば UDP ポート) はそれぞれ異なり、たいていはウェルノウンポートではなく動的に割り当てられたポートが利用される。SunRPC ではポート (逆多重化鍵) をトランスポートセレクター (transport selector) と呼ぶ。SunRPC クライアントが特定のプログラムにリクエストを送信したいと思った場合、使うべきサーバーに到達するためのトランスポートセレクターをどのように知るのだろうか? この問題は、リモートマシン上の単一のプログラムにウェルノウンアドレスを割り当てておき、マシン上の他のプログラムに到達するために使うべきトランスポートセレクターをクライアントに伝える仕事をそのプログラムに行わせることで解決される。この SunRPC プログラムのオリジナルバージョンはポートマッパー (Port Mapper) と呼ばれ、トランスポートプロトコルとして UDP と TCP だけをサポートした。そのプログラム番号は 0x00100000 であり、ウェルノウンポート 111 を利用する。ポートマネージャから進化した RPCBIND は任意のトランスポートプロトコルをサポートする。新しく起動した SunRPC サーバーは RPCBIND 登録手続きを行って自身のトランスポートセレクターと自身がサポートするプログラム番号を同じマシンで実行される RPCBIND に伝えることになっている。こうしておけば、リモートのクライアントは RPCBIND の lookup 手続きを通して特定のプログラム番号に対するトランスポートセクレターを検索できる。
これをより深く理解するために、UDP を使うポートマッパーの動作例を示す。NFS の read 手続きを呼び出すリクエストメッセージを送りたいと思ったクライアントは、まず UDP のウェルノウンポート 111 に向けてポートマネージャ宛てのリクエストメッセージを送信して NFS (プログラム番号 0x00100003) が現在利用中の UDP ポートを取得する (ちなみに、このとき使われる手続き番号は 3 である)。その後クライアントはプログラム番号 0x00100003 と手続き番号 6 (read) を付けた SunRPC リクエストメッセージをその UDP ポートに送信し、そのポートにリッスンしている SunRPC モジュールが NFS の read 手続きを呼び出す。クライアントはプログラム番号からポート番号への対応付けをキャッシュし、以降 NFS プログラムとの対話ではポートマネージャと通信を行わない1。
リプライメッセージを対応するリクエストに関連付けて RPC の結果を対応する呼び出し側に正しく伝えるために、リクエストメッセージとリプライメッセージのヘッダーには XID フィールドが含まれる (図 142)。XID は一意なトランザクション ID であり、単一のリクエストとそれに対するリプライでのみ利用される。サーバーはリプライの送信に成功したリクエストの XID を記憶しない。このため、SunRPC は at-most-once 意味論を保証できない。
SunRPC の意味論の詳細は下位のトランスポートプロトコルに依存する。SunRPC 自身は転送の確実性を実装しないので、下位のトランスポートプロトコルが確実な転送をサポートするときに限って SunRPC も確実な転送をサポートする (もちろん、SunRPC を利用するアプリケーションは SunRPC の上に確実性を保証する仕組みを実装して構わない)。ネットワークの MTU より大きいメッセージを送受信する機能も下位のトランスポートプロトコルに依存する。言い換えれば、SunRPC は転送の確実性とメッセージのサイズに関して下位のトランスポートプロトコルを一切改善しようとしない。SunRPC は多くの異なるトランスポートプロトコルの上に実装できるので、このように定めておけば RPC プロトコル自身の設計を複雑にすることなく実装に大きな柔軟性を与えられる。
SunRPC のヘッダーフォーマット (図 142) に戻ると、リクエストメッセージには可変長の Credentials フィールドと Verifier フィールドが含まれる。これらのフィールドはクライアントが自身をサーバーに認証させるときに利用される ── つまり、クライアントがサーバーに指示を出す権利を持つ証拠として利用される。クライアントが自身をサーバーに認証させる仕組みはいくらかでもセキュリティの提供を望むプロトコルが解決しなければならない一般的な問題であり、第 8 章で扱う。
DCE-RPC
DCE-RPC は DCE システムのコアに位置する RPC プロトコルであり、Microsoft の DCOM と ActiveX で利用される RPC メカニズムの基盤でもある。DCE-RPC は NDR (Network Data Representation) と呼ばれるスタブコンパイラ (後述) で用いられるのに加えて、分散オブジェクト指向システム構築における業界標準規格 CORBA (Common Object Request Broker Architecture) で利用される RPC プロトコルでもある。
SunRPC と同様、DCE-RPC は UDP や TCP といった異なるトランスポートプロトコルの上に実装できる。二段階のアドレス方式を採用する点でも DCE-RPC は SunRPC と似ている: トランスポートプロトコルがメッセージを正しいサーバーに逆多重化し、DCE-RPC がサーバーによってエクスポートされる特定の手続きを起動し、クライアントは特定のサーバーに到達する方法を学習するために「エンドポイントマッピングサービス (endpoint mapping service)」 を利用する。しかし SunRPC とは異なり、DCE-RPC は at-most-once 意味論を実装する (正確に言うと DCE-RPC は SunRPC と同様の冪等意味論などの様々な呼び出し意味論をサポートするが、デフォルトは at-most-once である)。DCE-RPC と SunRPC のアプローチには他にも違いが存在するので、以降の段落で紹介する。
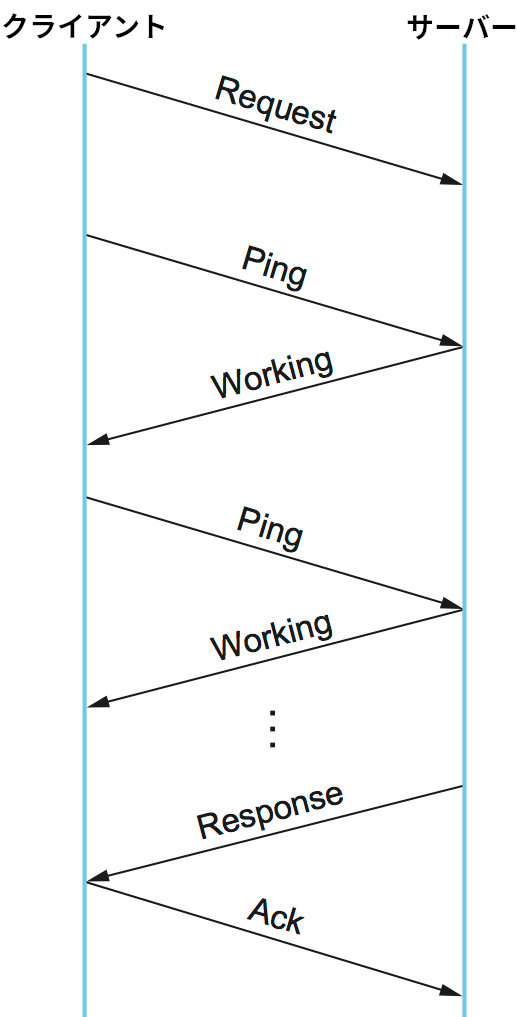
図 143 に典型的な DCE-RPC メッセージの交換におけるタイムラインを示す。やり取りされるメッセージは矢印で表され、矢印に書かれた文字はメッセージのタイプを表す。最初クライアントが Request メッセージをサーバーに送信し、サーバーは処理が終わると Response メッセージを返信し、最後にクライアントが Ack メッセージで確認応答を行う。SunRPC と異なり、DCE-RPC ではサーバーがリクエストメッセージに対する ACK を返すことはなく、代わりにクライアントが定期的に Ping メッセージをサーバーに送り、それに対してサーバーが Working メッセージを返すことで遠隔手続きが進行中であることを伝える。サーバーからの返答が素早く返ってきた場合には、クライアントから Ping メッセージが送られることはない。
図には示されていないタイプのメッセージも存在する。例えば、クライアントは Quit メッセージをサーバーに送信することで以前にリクエストした処理中の呼び出しを中止できる。このときサーバーは Quack (quit acknowledgment) メッセージを返答する。また、サーバーは Request メッセージを受けとったときに Reject メッセージを返答して呼び出しを拒否できる。あるいは、遠隔手続きを処理していないサーバーに Ping メッセージを送ると Nocall メッセージが返答される。
DCE-RPC ではリクエスト/リプライのトランザクションが必ず何らかのアクティビティ (activity) の文脈で行われる。アクティビティは通信を行う両者を結ぶ論理的なリクエスト/リプライチャンネルを表す。任意の時点において、一つのアクティビティは一つのトランザクションだけを処理できる。先述した並行論理チャンネルのアプローチと同様に、同時に複数のトランザクションを行う必要があるアプリケーションは複数のチャンネルをオープンしなければならない。トランザクションが属するアクティビティはメッセージの ActivityId フィールドで識別され、同じアクティビティに属するトランザクションは SequenceNum フィールドで区別される。SquenceNum フィールドは SunRPC の XID (トランザクション ID) フィールドと同じ役割を果たす。SunRPC と異なり、DCE-RPC は at-most-once 意味論を保証するために最後に使われたシーケンス番号をアクティビティごとに記録する。また、サーバーマシンの再起動の前後で送られたリプライを区別するために、DCE-RPC ではマシンのブート ID がメッセージの ServerBoot フィールドに書き込まれる。
DCE-RPC で下された SunRPC と異なる設計判断としてもう一つ、RPC プロトコル内でのフラグメント化と再構築のサポートがある。先述したように、たとえ下位のプロトコル (例えば IP) がフラグメント化と再構築をサポートしたとしても、RPC の一部として高度なアルゴリズムを実装すれば、フラグメントが喪失したときの素早い復帰や帯域消費の削減が可能になる。FragmentNum フィールドは特定のリクエストメッセージまたはリプライメッセージを構成する各フラグメントを一意に識別する。
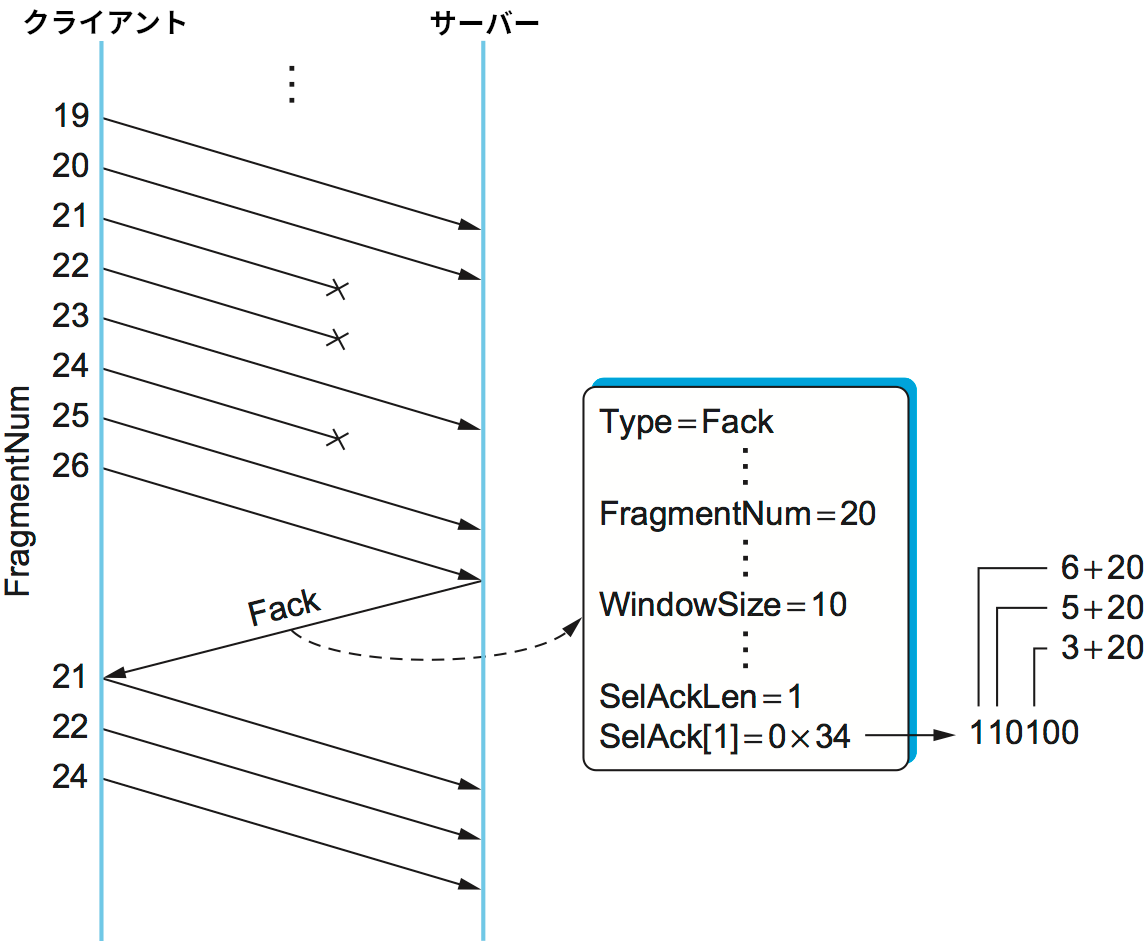
DCE-RPC のクライアントとサーバーは選択的確認応答の仕組みを実装し、次のように動作する (ここではフラグメント化されたリクエストメッセージを送信するクライアントの視点で仕組みを解説する。サーバーがフラグメント化されたリプライメッセージを送信するときも同様の仕組みが使われる)。
まず、リクエストメッセージを構成する各フラグメントは一意な FragmentNum と最後のフラグメントかどうかを示すフラグを持つ (このフラグは一つのパケットに収まるリクエストメッセージにも含まれる)。このため、サーバーはフラグメントを最初から最後まで隙間無く受け取ったかどうかを自身で確認できる。次に、サーバーはフラグメントを受け取るたびに Fack (fragment acknowlegdment, フラグメント確認応答) メッセージをクライアントに送信する。この確認応答は基本的に TCP と同じ累積的確認応答であるものの、順番が前後して届いた先頭の隙間より後のフラグメントに対する選択的確認応答も同時に行われる。この選択的確認応答では、先頭の隙間の一つ後のフラグメントからのオフセットを表すビットベクトルが利用される。最後に、クライアントは届いていないフラグメントの再送で Fack に応じる。
以上の処理を図 144 に示す。ここでは、サーバーが送信したフラグメント番号 20 までのフラグメントは正しくサーバーに到着し、フラグメント 21, 22, 24 は喪失、フラグメント 23, 25, 26 は順番が前後して到着している。このときサーバーが送り返す Fack には、先頭から連続して受信されたフラグメントの最も後ろの番号 20 に設定された FragmentNum フィールド、そして FragmentNum から数えて 3 番目 (23=20+3)、5 番目 (25=20+5)、6 番目 (26=20+6) のフラグメントを受信済みであることを表すビットベクトルの SelAck フィールドが含まれる。SelAck フィールドの長さは (32 ビットを 1 ワードとしたワード長として) SelAckLen フィールドで指定されるので、SelAck フィールドは (ほぼ) 任意に長くできる。
DCE-RPC は非常に大きなメッセージをサポートする ── 16 ビットの FragmentNum フィールドは 64 K 個のフラグメントをサポートできることを意味する ── ので、メッセージを構成する全てのフラグメントを可能な限り早く届けようとすると受信側が圧倒されてしまう可能性がある。そのため、DCE-RPC は TCP とよく似たフロー制御アルゴリズムを実装する。具体的には、受信したフラグメントに加えて送信して構わないフラグメントの個数がそれぞれの Fack メッセージに記載される。図 144 に示された WindowSize フィールドはこのために使われる。このフィールドの役割は TCP の AdvertisedWindow フィールドと基本的に全く同じであり、バイト数ではなくフラグメントの個数を表す点が唯一異なる。さらに DCE-RPC は TCP と似た輻輳制御の仕組みも実装する。輻輳制御の複雑さを考えれば、この問題を避けるためにフラグメント化を避けている RPC プロトコルがある事実に驚きはしないだろう。
まとめると、RPC プロトコルの設計者が選択できる選択肢は非常に多く存在する。SunRPC はミニマリストなアプローチを取り、正しい手続きの検索とメッセージの特定を除けば下位のトランスポートプロトコルに追加される機能は比較的少ない。これに対して DCE-RPC には数多くの機能が追加されており、複雑性の増加というコストの見返りに一部の環境でパフォーマンスが改善する可能性を手に入れている。
gRPC
gRPC は Google に起源を持つものの、「Google RPC」を略しているわけではない。gRPC の「g」はリリースごとに異なる意味を持ち、バージョン 1.10 では「グラマラス (glamorous)」、バージョン 1.18 では「ガチョウ (goose)」を意味する。Google の人々はワイルドでクレイジーである。名前がどうであれ、gRPC は広く使われている。RPC を用いたスケーラブルなクラウドサービスの構築における Google 内での十年にわたる経験を誰でも利用できる形で ── オープンソースで ── 公開したために、gRPC は広く使われるようになった。
詳細に入る前に、これまでに説明した二つの例 (SunRPC, DCE-RPC) と gRPC には基礎的な違いがいくつかあるので指摘しておく。最も大きな違いは gRPC がクラウドサービス用に設計されており、SunRPC と DCE-RPC のように単純なクライアント/サーバーパラダイムを採用しないことにある。この違いは gRPC がインダイレクション (間接参照) を一段多く持つことに本質的に等しい。クライアント/サーバーの世界では、クライアントは特定のサーバーマシンで実行される特定のサーバープロセスに対して遠隔手続きの呼び出しを行う。ここではサーバープロセスが自身を呼び出す可能性のある全てのクライアントからの呼び出しに対応できることが仮定される。
クラウドサービスにおいて、クライアントは遠隔手続きをサービスに対して呼び出す。任意に多いクライアントから同時に呼び出されるケースに対応するために、このサービスはスケーラブルな個数のサーバープロセスで実装され、それらのプロセスは異なるサーバーマシンで実行できる。ここでクラウドが登場する: データセンターにはクラウドサービスをスケールアップするために一見無限とも思える数のサーバーマシンが用意されている。ここで「スケーラブル」という言葉は、負荷 (例えば、ある時点で接続されているクライアントの個数) に応じて同一の処理を行うサーバープロセスの個数が変化し、時間の経過とともに動的に調整されることを意味する。もう一つ細かい点を指摘しておくと、典型的なクラウドサービスは新しいプロセスを作成するのではなく新しいコンテナ (container) を起動する。コンテナは簡単に言えば隔離された環境で実行されるプロセスであり、そのプロセスが必要とするソフトウェアパッケージなどが全て含まれている。現在コンテナのプラットフォームとしては Docker が広く知られている。
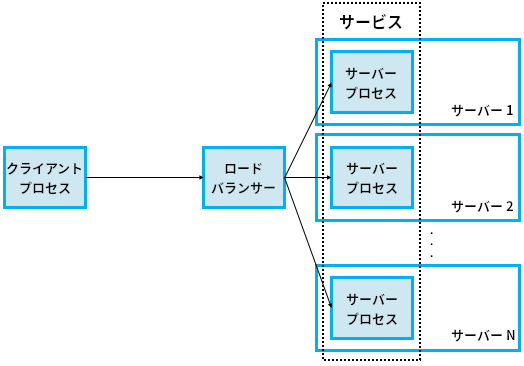
先述した「gRPC はインダイレクション (間接参照) を一段多く持つ」の意味を説明しよう。gRPC において呼び出し側が起動したいサービスを伝えるのはロードバランサー (load balancer) であり、これを受けてロードバランサーはサービスを実装する多数のサーバープロセス (コンテナ) から一つを選択して実行を指示する (図 145)。このロードバランサーが新しく追加されるインダイレクションと言える。ロードバランサーはハードウェアデバイスを含む様々な方式で実装できるものの、典型的には物理的機器ではなく仮想マシンで実行されるプロキシプロセスとして実装される (この仮想マシンもクラウドの中でホストされる)。
最終的にリクエストに応答する実際のサーバーコードを実装する上でのベストプラクティスがいくつか存在し、現在クラウドネイティブな形でサービスを構築する上でのベストプラクティスはマイクロサービスアーキテクチャ (micro-service architecture) だとされている。また、コンテナの作成/破棄やコンテナ間でのリクエストのロードバランスを行う RPC と独立したクラウド機構も存在し、現在こういったコンテナ管理システムとして Kubernetes が広く知られている。どちらも興味深い話題ではあるものの、本書の範囲からは外れる。
現在の私たちは gRPC のコアにあるトランスポートプロトコルに注目しているのだった。ここでも、本節でこれまでに例として見た二つの RPC プロトコルと gRPC が大きく異なるのは解決すべき基礎的な問題ではなく、問題を解決するアプローチである。一言で言えば、gRPC は問題の多くを他のプロトコルに「アウトソース」しており、gRPC 自身はそういった機能を簡単に使える形にまとめたパッケージのようなものとなっている。詳細を見ていこう。
第一に、gRPC は UDP ではなく TCP の上で実装される。これは任意サイズのメッセージの確実な転送や接続の管理といった問題をアウトソースできることを意味する。第二に、正確に言うと gRPC は TLS (Transport Layer Security) と呼ばれるセキュアなバージョンの TCP (プロトコルスタックで TCP の上に存在する薄い層) の上で実装される。このため通信チャンネルをセキュアにする問題もアウトソースされ、攻撃者がメッセージの交換を盗聴したりハイジャックしたりはできなくなる。第三に、さらに正確に言うと gRPC は HTTP/2 (TCP と TLS の上に存在する層) の上で実装される。こうすることで、「バイナリデータを符号化/圧縮してメッセージにする」と「複数の遠隔手続き呼び出しを単一の TCP 接続で多重化する」という二つの問題がさらにアウトソースされる。言い換えれば、gRPC は遠隔メソッドの識別子を URI として符号化し、遠隔メソッドに対するリクエストパラメータを HTTP メッセージとして符号化し、遠隔メソッドの返り値を HTTP レスポンスとして符号化する。完全な gRPC スタックを図 146 に示す。ここには言語固有の要素も含まれている (gRPC の強みの一つが非常に多くの言語をサポートすることである。この図に示したのはそのごく一部に過ぎない)。
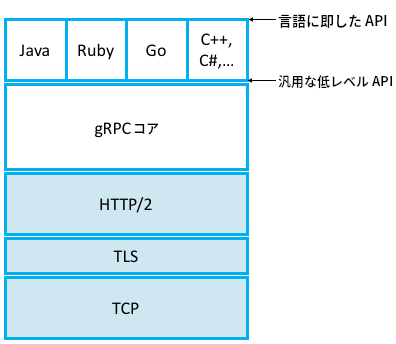
TLS は第 8.5.3 項で (セキュリティの話題の一部として) 議論し、HTTP は第 9.1.2 項で (伝統的にアプリケーションプロトコルとみなされるプロトコルの話題の一部として) 議論する。しかし、今の段階でも興味深い依存関係のループが見て取れる: RPC は分散アプリケーションを実装するためのトランスポートプロトコルであり、HTTP はアプリケーションプロトコルである。しかし gRPC は HTTP を利用して実装されており、その逆ではない。
その理由を簡単に説明すれば次のようになる: 層化という考え方は複雑なシステムを人間が理解できるようにするための便利な手段を提供するものの、私たちが本当に行おうとしているのは問題 (任意に大きいメッセージの確実な転送、送信者と受信者の識別、リクエストメッセージとリプライメッセージの関連付けなど) の解決であり、その解決手段がプロトコルの「層」が積み重なったものとして表せることは長い時間をかけたインクリメンタルな変更の結果と言える。歴史的なアクシデントとさえ言えるかもしれない。仮にインターネットが TCP と同程度にユビキタスな RPC メカニズムとともに始まっていたとしたら、HTTP (第 9 章 で紹介されるアプリケーションプロトコル) はその RPC プロトコルの上に実装され、Google はそのプロトコルを利用して独自のプロトコルを作っていただろう。しかし実際には、ウェブがインターネットのキラーアプリとなり、そのアプリケーションプロトコル (HTTP) がインターネットの他のインフラ (ファイアウォール、ロードバランサー、暗号化、認証、圧縮など) によって広くサポートされるまでになった。HTTP を使えばこういったネットワークの構成要素が非常に上手く動作するので、HTTP は事実上インターネットにおけるユニバーサルなリクエスト/リプライ型トランスポートプロトコルとなっている。
gRPC に特有な特徴の議論に戻ろう。gRPC が提供する最も大きなバリューは RPC メカニズムにストリーミングを取り込んだことである。つまり、gRPC がサポートするリクエスト/リプライのパターンには次の四つがある:
-
単純な RPC: クライアントが単一のリクエストメッセージを送信し、サーバーは単一のリプライメッセージを返答する。
-
サーバーストリーミング RPC: クライアントが単一のリクエストメッセージを送信し、サーバーはリプライのストリームを返答する。クライアントはサーバーのレスポンスを全て受け取ったら RPC を完了する。
-
クライアントストリーミング RPC: クライアントはリクエストのストリームをサーバーに送信し、サーバーは単一のレスポンスを返答する。サーバーはクライアントのリクエストを全て受け取った後に返答を行う場合が多い (そうしなくても構わない)。
-
双方向ストリーミング RPC: 呼び出しはクライアントによって起動されるものの、その後はクライアントとサーバーの双方がリクエストとレスポンスを任意の順序で読み書きする。二つのストリームは完全に独立する。
クライアントとサーバーの対話に自由度が増すので、gRPC のトランスポートプロトコルには (実際のリクエストメッセージとリプライメッセージとは別に) メッセージを制御するためのメタデータが追加で必要になる。gRPC におけるメタデータの例を示す:
Status: RPC の現在状態を伝える。Error: RPC がどのように失敗したかを伝える。Timeout: クライアントが応答を待っていられる時間を設定する。PING: 通信相手との接続が生きていることを確認する。EOS: ストリームの終端 (end-of-stream) を伝える。これより後にリクエストまたはレスポンスは存在しない。GOAWAY: これ以上ストリームを受け付けないことを伝える (サーバーからクライアントに送られる)。
本書に登場する他の多くのプロトコルではこういった制御情報のやり取りにプロトコルのヘッダーを利用するのに対して、gRPC ではトランスポートプロトコル (つまり HTTP/2) を利用する。第 9 章で見るように HTTP はヘッダーフィールドとレスポンスコードを持つので、gRPC はそれを利用する。
第 9.1.2 項の HTTP の議論を先に読んだ方がいいかもしれないが、読まなくても次の説明は理解できるだろう。単純な RPC リクエスト (ストリーミングを使わないもの) では、クライアントからサーバーに次のような HTTP メッセージが送られる:
HEADERS (flags = END_HEADERS)
:method = POST
:scheme = http
:path = /google.pubsub.v2.PublisherService/CreateTopic
:authority = pubsub.googleapis.com
grpc-timeout = 1S
content-type = application/grpc+proto
grpc-encoding = gzip
authorization = Bearer y235.wef315yfh138vh31hv93hv8h3v
DATA (flags = END_STREAM)
<Length-Prefixed Message>
これに対してサーバーは次のような HTTP メッセージをクライアントに返答する:
HEADERS (flags = END_HEADERS)
:status = 200
grpc-encoding = gzip
content-type = application/grpc+proto
DATA
<Length-Prefixed Message>
HEADERS (flags = END_STREAM, END_HEADERS)
grpc-status = 0 # OK
trace-proto-bin = jher831yy13JHy3hc
この例に含まれる HEADERS と DATA は標準的な HTTP 制御メッセージであり、それぞれ「メッセージのヘッダー」と「メッセージのペイロード」を表す。具体的に見ていくと、HEADERS から DATA の間がヘッダーとなる (各行がヘッダーフィールドとみなせる)。コロンから始まる行 (:status = 200 など) は HTTP 規格の一部であり、コロンで始まらない他の行は gRPC 特有のカスタマイズされたフィールドである。例えば grpc-encoding = gzip はヘッダーの後ろに続くメッセージ本体が gzip で圧縮されていることを表し、grpc-timeout = 1S はクライアントがタイムアウトを 1 秒に設定していることを表す。
最後に一つ説明しておきたいことがある。ヘッダーの次の行
content-type = application/grpc+proto
は、メッセージ本体 (DATA の行より後ろの部分) がクライアントによってリクエストされているサービスによってのみ解読できることを意味する。より具体的に言えば、文字列 +proto は受信者がメッセージ本体のビット列を Protocol Buffer (protobuf) と呼ばれるインターフェース仕様に基づいて解読できることを示している。サーバーに渡されるパラメータをメッセージに符号化するときに gRPC が使うのが Protocol Buffer である。Protocol Buffer は RPC メカニズムと実際の処理を行う関数の間の橋渡しを行う (図 138 参照)。この話題は第 7 章で再び触れる。
教訓
以上の議論で肝心なのは、RPC のような複雑なメカニズムはかつて一つのモノリシックなソフトウェアとしてパッケージされていたものの、現代では狭い範囲の問題を解決する小さな部品を組み合わせることで構築されることである。gRPC はこの現代的なアプローチを採用した例であり、加えてそれ自身が RPC という単一の問題を解決するツールとして使えるようになっている。「小さな部品を組み合わせて作る」アプローチをクラウドアプリケーション全体に適用したのが先述したマイクロサービスアーキテクチャであり、gRPC はマイクロサービスアーキテクチャで部品同士がメッセージをやり取りするときによく使われる。
-
実際には、非常に重要なプログラムである NFS にはウェルノウン UDP ポートが割り当てられている。しかしここではそういったポートが存在しないとしている。 ↩︎