1.2 要件
我々は野心的な目標を設定した: 何もない状態からコンピューターネットワークを構築する方法の理解を本書は目指す。この目標に向けて本書が取るアプローチは、第一原理から始めて、実際にネットワークを構築しようとしたときに自然に発生する疑問を考えていくというものである。各ステップでは様々な設計上の選択肢を説明するために現代のプロトコルを利用するものの、そういった既製品を福音とはみなさない。そうではなく、既存のネットワークがそのような形で設計されている理由を我々は質問して (そして答えて) いく。現在のネットワークの様子だけを理解していく方法は魅力的に思えるものの、技術が発展し新しいアプリケーションが発明されると共にネットワークは常に変化しているので、内部にある概念を認識しておくことが重要となる。基礎的なアイデアを理解すれば、どんな新しいプロトコルに直面したときでも比較的簡単に概要を掴めるようになる、というのが著者らの経験である。
1.2.1 利害関係者
前にも述べた通り、ネットワークを学ぶ学生が持つ視点にはいくつかの種類がある。本書の第一版が書かれたころ、人口の大部分はインターネットへのアクセスを全く持っておらず、持っている人々は仕事や大学で使うか、そうでなければ家のダイヤルアップを使っていた。また、有名なアプリケーションは片手で数えられる程度だった。そのため、当時のほとんどの本と同様に、本書もネットワークデバイスやプロトコルを設計する人々の視点からの説明に集中していた。このグループの人々は第六版でも主な対象読者であり続ける。彼らが将来のネットワークデバイスやプロトコルを設計する方法を知ることが我々の願いである。
しかし、本書ではこれに加えてもう二つの利害関係者の視点にも触れたいと我々は考えている: ネットワークを利用するアプリケーションを開発する人々と、ネットワークを管理・運用する人々である。三つの利害関係者がネットワークに対してどのような要件を挙げるかを考えよう:
-
アプリケーションプログラマーは、アプリケーションが必要とするサービスを挙げるだろう: 例えばアプリケーションが送信したメッセージが一定時間内に欠損なく届くことの保証、あるいはユーザーが移動したときでもネットワークに対する異なる接続をスムーズに切り替える機能である。
-
ネットワーク運用者は、設定・管理しやすいシステムの特徴を挙げるだろう: 例えば障害が隔離できること、新しいデバイスの追加・構成が確実に行えること、あるいは利用登録が簡単に行えることである。
-
ネットワーク設計者は、コスト効率に優れた設計の特徴を挙げるだろう: 例えばネットワークの資源が異なるユーザーに対して公平かつ効率的に割り振られることである。パフォーマンスの問題も重要になる可能性が高い。
本節では異なる利害関係者が抱える要件についてさらに考察し、ネットワーク設計で立ちはだかる主要な懸案事項をまとめる。その中で、本書を通じて取り組むことになる課題も特定される。
1.2.2 スケーラブルな接続
明らかなことから始めると、ネットワークは何らかのコンピューターの集合に接続を提供しなければならない。ただし、少数の選択されたマシンだけを接続する制限されたネットワークで十分な場合もある。実は多くのプライベート (企業) ネットワークはプライバシーとセキュリティの理由により、接続されるマシン数を制限することを明確な目標としている。これに対して、その他のネットワーク (最も分かりやすい例はインターネット) は世界中のコンピューターが全て接続できる規模に成長できるように設計される。任意に大きなサイズへの成長をサポートするよう設計されたシステムはスケール (scale) すると言う。本書ではインターネットをモデルとして使いながら、スケーラビリティ (スケールすること) という目標の達成方法を示していく。
スケーラブルな接続という要件をより深く理解するには、ネットワークに属するコンピューター同士の接続についてさらに詳しく見る必要がある。接続は様々なレベルで起こる。最も下のレベルには、同軸ケーブルや光ファイバーといった物理的な媒体で直接的に接続された二台 (以上) のコンピューターから構成されるネットワークがある。コンピューター同士を接続する媒体をリンク (link) と呼ぶ。リンクで繋がれるコンピューターはノード (node) と呼ぶことが多い (「ノード」がコンピューターではなくハードウェアの特別な一部分を指す場合もあるが、ここでは議論を簡単にするため両者を区別しない)。

図 2 にあるように、物理リンクが接続できるマシンが二台だけである場合もあれば、単一の物理リンクを三つ以上のマシンが共有する場合もある。前者のようなリンクをポイントツーポイント (point-to-point) と呼び、後者のようなリンクを多元接続 (multiple-access) と呼ぶ。セルラーネットワークや Wi-Fi ネットワークといった無線リンクは多元接続リンクの重要なカテゴリの一つである。多元接続リンクはサイズに必ず制限がある。つまり、多元接続リンクがカバーできる地理的な領域、あるいは多元接続リンクに接続可能なノード数が任意に大きいことはない。これが理由で、ネットワークの残りの部分とエンドユーザーを接続するラストマイル (last mile) の実装に多元接続リンクはよく使われる。
もし全てのノードが共通の物理的な媒体で互いに直接的に接続された状況しかコンピューターネットワークが扱えないとしたら、そのネットワークに接続できるコンピューターの数が非常に制限されるか、各ノードの背面から出るコードが管理不可能かつ非常に高価になるかのどちらかだろう。幸い、接続される二つのノードの間に直接の物理的接続が必ず存在しなければならないわけではない ── ネットワークの動作を助けるためのノードが間に存在すれば、間接的な接続を達成できる。コンピューターの集合が間接的に接続される例として、これから二つの状況を考える。
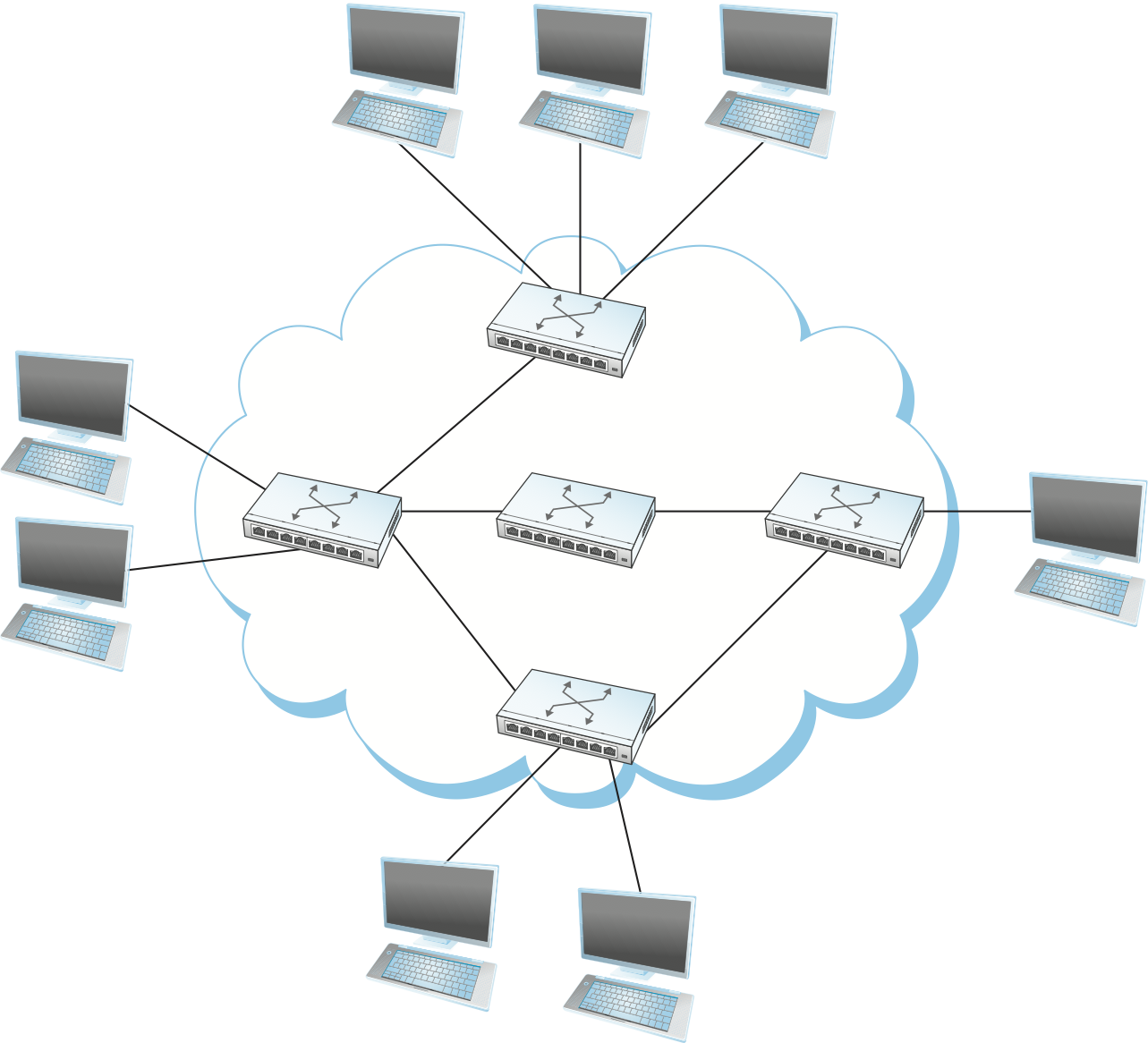
図 3 に示すのは、一つ以上のポイントツーポイントリンクに接続されたノードを持つネットワークである。二つ以上のノードに接続されたノードでは、あるリンクから受け取ったデータを他のリンクに転送するソフトウェアが実行される。このようなネットワークをシステマチックに構成するとき、これらの転送ノードは交換ネットワーク (switched network) を形成する。交換ネットワークには膨大な種類があり、最もよく使われるのは回線交換ネットワーク (circuit switched network) とパケット交換ネットワーク (packet switched network) である。前者は電話システムで使われることで最もよく知られる。後者はコンピューターネットワークのほぼ全てで使われ、本書で詳しく説明される (ただし、ネットワーク容量への需要が止まることなく増え続ける中で、回線交換ネットワークは光ネットワークの分野で復活の兆しを見せている)。パケット交換ネットワークの最も重要な特徴は、ネットワーク内のノードが互いに細切れのデータブロックを送り合うことである。このデータブロックはファイル・メール・画像といったアプリケーションデータの一部分であり、パケット (packet) あるいはメッセージ (message) と呼ばれる。以降はこの二つの用語を区別せずに用いる。
典型的なパケット交換ネットワークは蓄積転送 (store-and-forward) と呼ばれる戦略を利用する。名前が示すように、蓄積転送を用いるネットワークの各ノードは完全なパケットを何らかのリンクから受け取り、そのパケットを内部のメモリに保存し、それから完全なパケットを次のノードに転送する。これに対して、回線交換ネットワークはいくつかのリンクからなる専用の回線を最初に確立し、その回線に沿って送信元ノードがビットストリームを宛先ノードに向かって送信する。コンピューターネットワークで回線交換ではなくパケット交換が使われる主な理由は効率であり、次項で議論される。
図 3 では、ネットワークを実装するノードとネットワークを利用するノードが区別されている。「雲」の中にあるのがネットワークを実装するノードであり、多くの場合スイッチ (switch) と呼ばれる。スイッチはパケットの蓄積と転送を主な仕事とする。「雲」の外にあるのがネットワークを利用するノードであり、伝統的にホスト (host) と呼ばれる。ホストはユーザーをサポートし、アプリケーションプログラムを実行する。なお、この「雲」はコンピューターネットワークで最も重要なアイコンの一つである。一般に、ネットワーク図で雲は任意のネットワークを表す: 単一のポイントツーポイントリンクであれ交換ネットワークであれ表すことができる。そのためネットワーク図に雲が含まれているときは、本書で触れるネットワーク技術のいずれかを表すプレースホルダーなのだと思えばよい1。
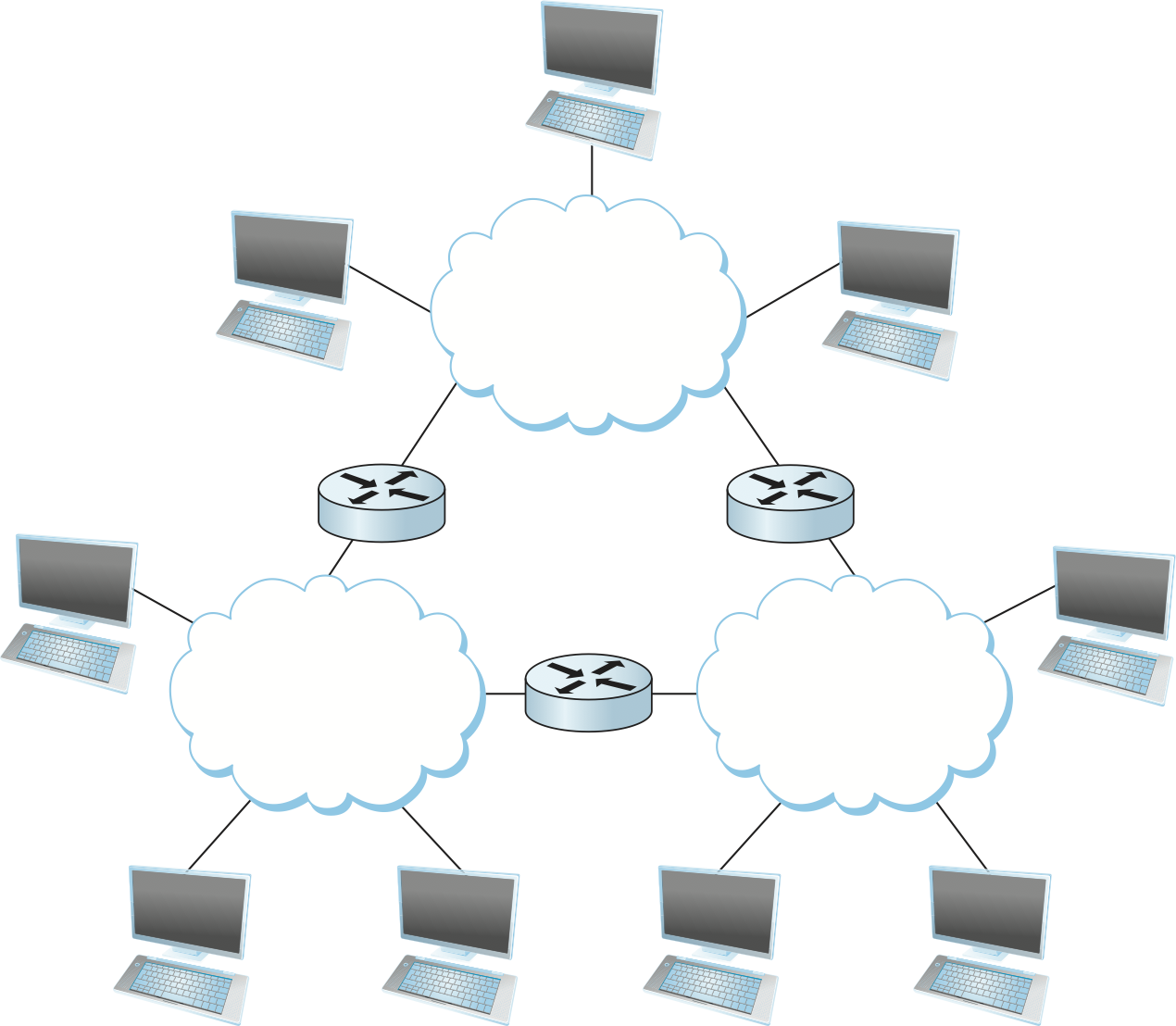
コンピューターの集合が間接的に接続されるもう一つの形態を図 4 に示す。ここでは独立したいくつかのネットワーク (雲) が相互接続され、インターネットワーク (internetwork) を形成している。インターネットワークは略してインターネット (internet) とも呼ばれる。本書ではネットワークの相互接続を指す一般的な「インターネット」を小文字の internet で表記し、人々が毎日使っている TCP/IP の「インターネット」を大文字の Internet で表記する2。二つ以上のネットワークと接続されるノードはルーター (router) あるいはゲートウェイ (gateway) と呼ばれ、スイッチとほぼ同じ役割を持つ ── あるネットワークから受け取ったメッセージを別のネットワークに転送する。
インターネットワーク自体も一つのネットワークとみなせるので、インターネットワークの中に複数のインターネットワークが存在する可能性があることに注意してほしい。このため、「雲」を相互接続して大きな「雲」にすることを再帰的に繰り返せば任意に大きなネットワークを構築できる。この「性質の大きく異なるネットワークを相互接続する」というアイデアはインターネットの基礎にあるイノベーションであり、インターネットが数十億のノードからなる地球規模のネットワークにまで成長できたのは初期のインターネット技術者が非常に優れた設計判断を下したからだと言っても過言ではない。インターネットを形作った設計判断は後で議論される。
ホスト同士が直接あるいは間接的に接続されただけでは、ホストからホストへの接続が確立されたとは言えない。最後の要件として、各ノードが他のどのノードと通信をしたいのかを指定する方法が必要となる。これはそれぞれのノードにアドレス (address) を割り当てることで達成される。アドレスはノードを識別するバイト列である。アドレスを使うと、任意のノードと同じネットワークに接続する他の全てのノードを区別できる。例えば送信元ノードが特定の宛先ノードにメッセージを送ろうとするとき、送信元ノードは宛先ノードのアドレスを指定する。送信元ノードと宛先ノードが直接的な接続を持たないときは、ネットワークのスイッチとルーターがアドレスを使ってメッセージを宛先ノードの方向に転送する。宛先ノードの方向に向けたメッセージの転送をどのように行うかをアドレスに基づいてシステマチックに決定するプロセスはルーティング (routing) と呼ばれる。
ここまでのアドレスとルーティングの簡単な紹介では、送信元ノードがメッセージを単一の宛先ノードに送信することを仮定している。この通信形態をユニキャスト (unicast) と呼ぶ。ユニキャストは最もよくあるシナリオではあるものの、同じネットワークに属する他の全てのノードにメッセージを送信するブロードキャスト (broadcast) や、同じネットワークに属する一部のノードにメッセージを送信するマルチキャスト (multicast) を行いたい状況も存在する。そのためノード固有のアドレスに加えて、マルチキャスト用とブロードキャスト用のアドレスをサポートすることもネットワークの要件となる。
教訓
以上の議論から学んでほしいのは、ネットワークが再帰的に定義できるというアイデアである。つまりネットワークは物理リンクで接続された二つ以上のノード、もしくはノードで接続された二つ以上のネットワークから構成される。別の言い方をすれば、ネットワークは入れ子になったネットワークから構成され、一番下のネットワークは何らかの物理媒体で実装される。ネットワークに接続を提供する上での主な課題としては、ネットワークで (理論的あるいは物理的に) 到達可能な各ノードに対してアドレスを定義すること、そしてそのアドレスを使って宛先ノード (一つまたは複数) の方向に向けてメッセージを適切に転送することがある。
1.2.3 費用対効果に優れた資源共有
上述したように、本書はパケット交換ネットワークに焦点を当てる。本節ではコンピューターネットワークにおける重要な要件の一つ ── 効率 ── を説明する。この要件は我々をパケット交換ネットワークに導く。
入れ子になったネットワークで間接的に接続されたノードの集合があるとき、任意のホストの組はリンクとノードの列を通して互いにメッセージをやり取りできる。しかし当然、特定のホストの組だけしか通信できないのは受け入れられない ── 全てのホストの組がメッセージを交換できるのが望ましい。このとき発生する問題は、通信しようとしている複数のホストがどのようにネットワークを共有するかである。特に、複数のホストが同時に通信するときはどうするべきだろうか? さらに厄介なことに、同じリンクを共有する複数のホストが同時に通信する状況も存在する。
複数のホストがどのようにネットワークを共有するかを理解するには、多重化 (multiplexing) という重要な概念を説明する必要がある。多重化とは、単一のシステム資源を複数のユーザーが共有できるようにすることを指す。直感的に言えば、多重化はタイムシェアリングのコンピューターシステムとのアナロジーで説明できる。そのようなコンピューターシステムにおいて、物理的に一つしか存在しないプロセッサは複数のジョブによって共有され、それぞれのジョブは自分だけがプロセッサを独占していると思っている。この共有の仕組みが多重化である。同じように、複数のユーザーによって送られたデータはネットワークを構成する物理リンクを使って多重化できる。
多重化の例として、図 5 に示す簡単なネットワークを考えよう。左にある三つのホスト (送信側 S1, S2, S3) が右にある三つのホスト (受信側 R1, R2, R3) にデータを送っており、物理リンクを一つしか持たない交換ネットワークが共有されている (簡単のため、ホスト S1 はホスト R1 にデータを送っており、同様に S2 は R2 に、 S3 は R3 に送っているとする)。この状況で、三つのホストの組に対応する三つのデータフローはスイッチ 1 によって単一の物理リンクで多重化され、スイッチ 2 によって個別のデータフローに逆多重化 (demultiplexing) される。以降の議論は「データフロー」が何を指すかを意図的に曖昧にしたまま話を進めるので注意してほしい。また議論の都合上、左側の三つのホストはどれも右にあるホストに大量のデータを送ろうとしているとする。
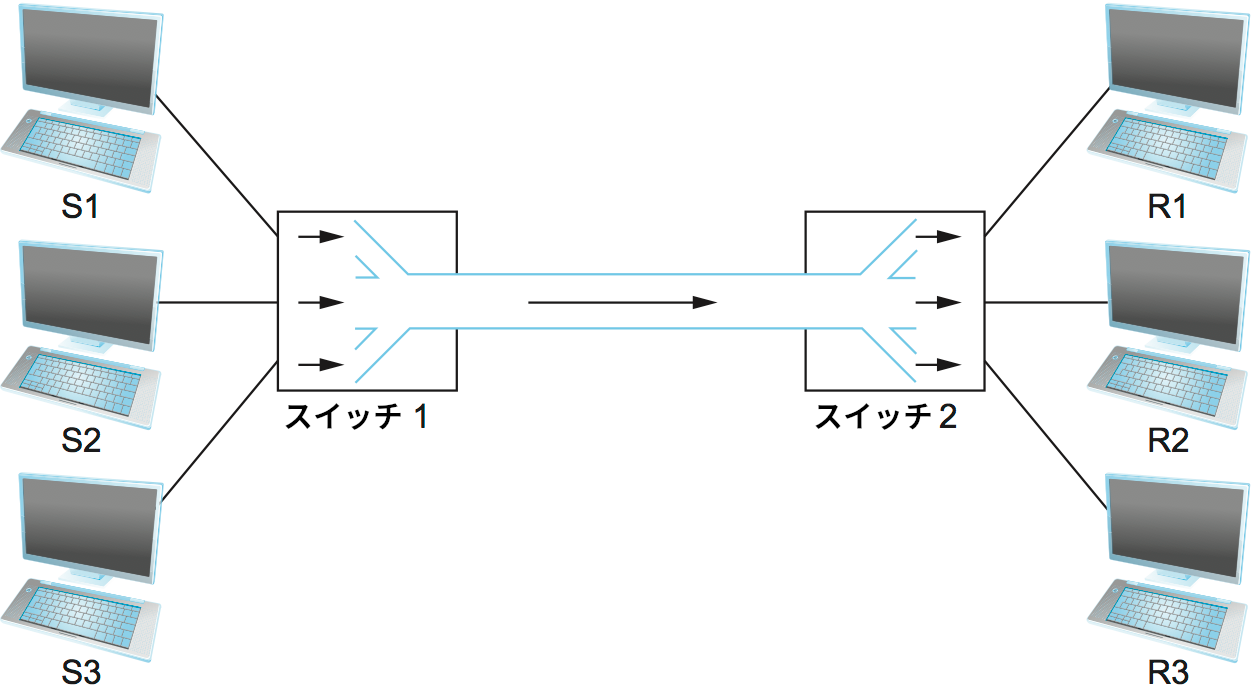
複数のデータフローを単一の物理リンクで多重化する方式はいくつかある。よく使われる方式の一つに STDM (synchronous time-division multiplexing, 同期時分割多重化) がある。STDM のアイデアは、時間を特定の間隔で区切り、物理リンクを通してデータを送る機会をラウンドロビン方式で各データフローへ順番に渡すというものである。上記の例で言えば、最初は S1 が R1 にデータを送り、一定の時間が経つと S2 が R2 にデータを送り、さらに一定の時間が経つと S3 が R3 にデータを送る。その次は最初のデータフロー (S1 から R1) に戻り、以降同様となる。もう一つの多重化方式として FDM (frequency-division multiplexing, 周波数分割多重化) がある。FDM のアイデアは、それぞれのデータフローを物理リンク上の異なる周波数で送信するというものである。これは異なるテレビ局が異なる周波数を使って放送電波あるいはテレビ用同軸ケーブル上に信号を送信するのと同様と言える。
STDM と FDM は単純で理解しやすいものの、共通する二つの欠点がある。第一に、あるデータフロー (ホストの組) が送りたいデータを持っておらず他のデータフローが送りたいデータを持っている場合、送りたいデータを持たないデータフローに割り当てられる物理リンク ── 正確には、割り当てられる時間あるいは周波数 ── がアイドル (非稼働) となって無駄になる。例えば前段落で示した STDM の例では、S1 と S2 がデータを送ろうとしていない場合でも S3 は S1 と S2 の番を待たなければならない。コンピューターが行う通信ではリンクがアイドルになる時間が非常に長くなる可能性がある ── 例えばユーザーがウェブページを読むのにかかる時間 (その間リンクはアイドルになる) と、そのウェブページを取得するのにかかる時間を比較してみてほしい。第二に、STDM と FDM は両方ともデータフローの最大個数があらかじめ決まっている状況でしか使えない。STDM で時間の間隔あるいは割り振るデータフローの個数を変更したり、FDM で新しい周波数を追加したりするのは現実的ではない。
こういった欠点を解決する多重化形式は統計多重化 (statistical multiplexing) と呼ばれる。本書では統計多重化が最もよく使われる。その名前はほとんど何も意味していないが、統計多重化は二つの中心的なアイデアが分かれば非常に簡単に理解できる。第一に、STDM と同様に統計多重化では時間で分割されて物理リンクが共有される ── 最初に何らかのデータフローからのデータを送信し、次に別のデータフローのデータを送信する、という処理が繰り返される。第二に、STDM と異なり、統計多重化ではデータが各データフローからオンデマンドに転送される。事前に決められたタイムスロットが使われることはない。そのため、もしデータを送信しているデータフローが一つだけなら、その送信は時間の制限なく最後まで行われる。この仕組みにより、送信したいデータを持っているデータフローがあるときに他のデータフローが何もしない時間を過ごすことはなくなる。こうしてアイドル時間が削減されるために、パケット交換で統計多重化を採用すると効率が向上する。
しかし上述の定義だけだと、物理リンクを通してデータを送る機会が全てのデータフローにいずれ回ってくることを保証するための仕組みが存在しない。つまり、あるデータフローがデータの送信を始めてしばらく経ったら何らかの方法で送信を中断させ、他のデータフローに順番を回す必要がある。これを行うために、統計多重化ではデータフローが一度に送信できるデータブロックのサイズに上限が設けられる。このサイズが制限されたデータブロックは多くの場合パケット (packet) と呼ばれる。アプリケーションプログラムが送信するメッセージは任意に大きなデータであり、パケットと区別される。パケット交換ネットワークはパケットのサイズを制限するので、ホストは一つのパケットで完全なメッセージを送信できない可能性がある。そういった状況で送信元ノードはメッセージをいくつかのパケットに分割し、宛先ノードは受け取った複数のパケットを組み合わせてオリジナルのメッセージを復元しなければならない。
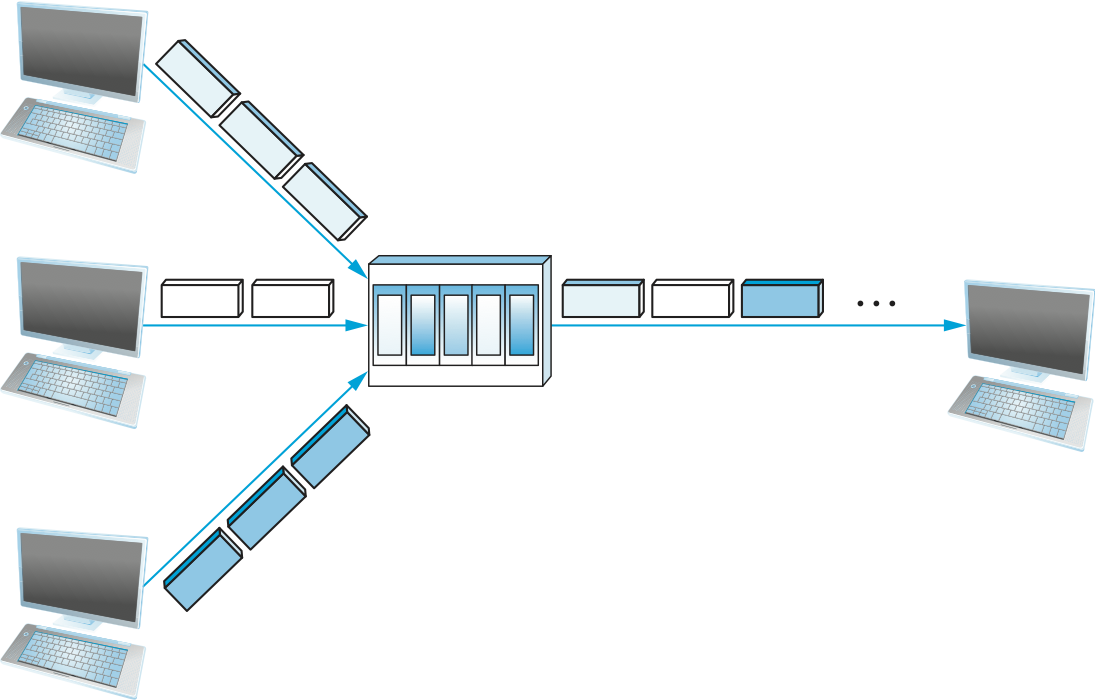
言い換えれば、各データフローはパケットの列を物理リンクに送信し、どのデータフローのパケットを次に送信するかの判断はパケットごとに行われる。もしデータを送信するデータフローが一つだけなら、そのデータフローは最初から最後まで中断せずにパケットの列全体を送信できることに注目してほしい。一方でデータを送信しようとするデータフローが他に一つでもあれば、そのパケットも途中でリンクに送られる。スイッチが複数の送信元ノードからのパケットを単一の共有リンクで多重化する様子を図 6 に示す。
次に共有リンクに送信するパケットを選択する方法はいくつか考えられる。例えばリンクで相互接続されたスイッチから構成される (図 5 のような) ネットワークでは、この選択は共有リンクにパケットを送信するスイッチで行われるだろう (後で見るように、スイッチを持たないパケット交換ネットワークも存在する。そういったネットワークでは次に送信するパケットを選択するために別の仕組みが必要になる)。パケット交換ネットワークに属する各スイッチは次に送信するパケットの選択をパケットごとに独立に行う。ネットワーク設計者が直面する問題の一つが、この選択をどのように公平に行うかである。例えばスイッチはパケットを先入れ先出し (FIFO) で送信することもできるし、スイッチにデータを送信しているデータフローの中から一つをラウンドロビン方式で選び、そのデータフローのパケットを送信することもできる。この選択を工夫すれば、特定のデータフローがリンク帯域の一定の割合を受け取ることを保証したり、一定の時間より長くスイッチに留まるパケットがないことを保証したりできる。特定のデータフローに帯域を割り振ろうとするネットワークは QoS (quality of service, クオリティオブサービス) をサポートすると言う。
また図 6 において、スイッチが三つのパケットストリームを受け取って一つの外向きの共有リンクでそれらを多重化しなければならないために、スイッチが受け取るデータの量が共有リンクに流せないほど大きくなる可能性があることに注意してほしい。その場合、スイッチは送り切れないパケットをメモリにバッファしなければならない。もし送信できるより多くのパケットを受け取る状況がある程度長く続けば、いずれスイッチはバッファの空間を使い果たし、パケットの一部を破棄しなくてはならなくなる。そういった状態にあるスイッチは輻輳 (congestion) を起こしていると言う。
教訓
肝心なのは、複数のユーザー (ホストからホストへのデータフローなど) がネットワーク資源 (リンクとノード) を細かい単位で共有する費用対効果に優れた方法が統計多重化によって提供されることである。細切れになったデータのパケットと呼ばれ、パケットごとにネットワークのリンクは異なるデータフローに割り振られ、各スイッチは自身に接続された物理リンクの使い方をパケット単位で選択できる。異なるデータフローに公平にリンクの容量を割り振ること、そして輻輳に対処することが統計多重化における主な課題となる。
1.2.4 共通サービスのサポート
前節ではホストの集合に対して費用対効果に優れた接続を提供するときの課題を議論した。しかしコンピューターネットワークをコンピューターの集まりがパケットをやり取りしているだけとみなすのは単純化が過ぎる。接続されたコンピューター上に分散されたアプリケーションプロセスの集合が通信するための手段がコンピューターネットワークだと考えた方が正確である。とすれば、コンピューターネットワークの次の要件は、ネットワークに接続されているホストで実行されるアプリケーションプログラムが意味のある形で通信を行えることである。アプリケーション開発者の視点から言えば、ネットワークは彼または彼女の人生をもっと楽にするものでなくてはならない。
二つのアプリケーションプログラムが互いに通信を行おうとするとき、メッセージをホスト間で受け渡すだけではない多くの複雑な処理が行われる。一つの選択肢は、それぞれのアプリケーション設計者がそれらの複雑な機能を全て開発してアプリケーションプログラムのそれぞれに組み込むというものである。しかし多くのアプリケーションが必要とするサービスは共通なので、そういった共通サービスを一度だけ実装し、アプリケーション設計者にはその共通サービスを使ってアプリケーションを構築してもらうのが理にかなっている。そうするとき、正しい共通サービスの特定がネットワーク設計者にとっての課題になる。アプリケーションにはネットワークの複雑性を隠蔽しつつも、アプリケーション設計者には制約を押し付け過ぎないことが目標となる。
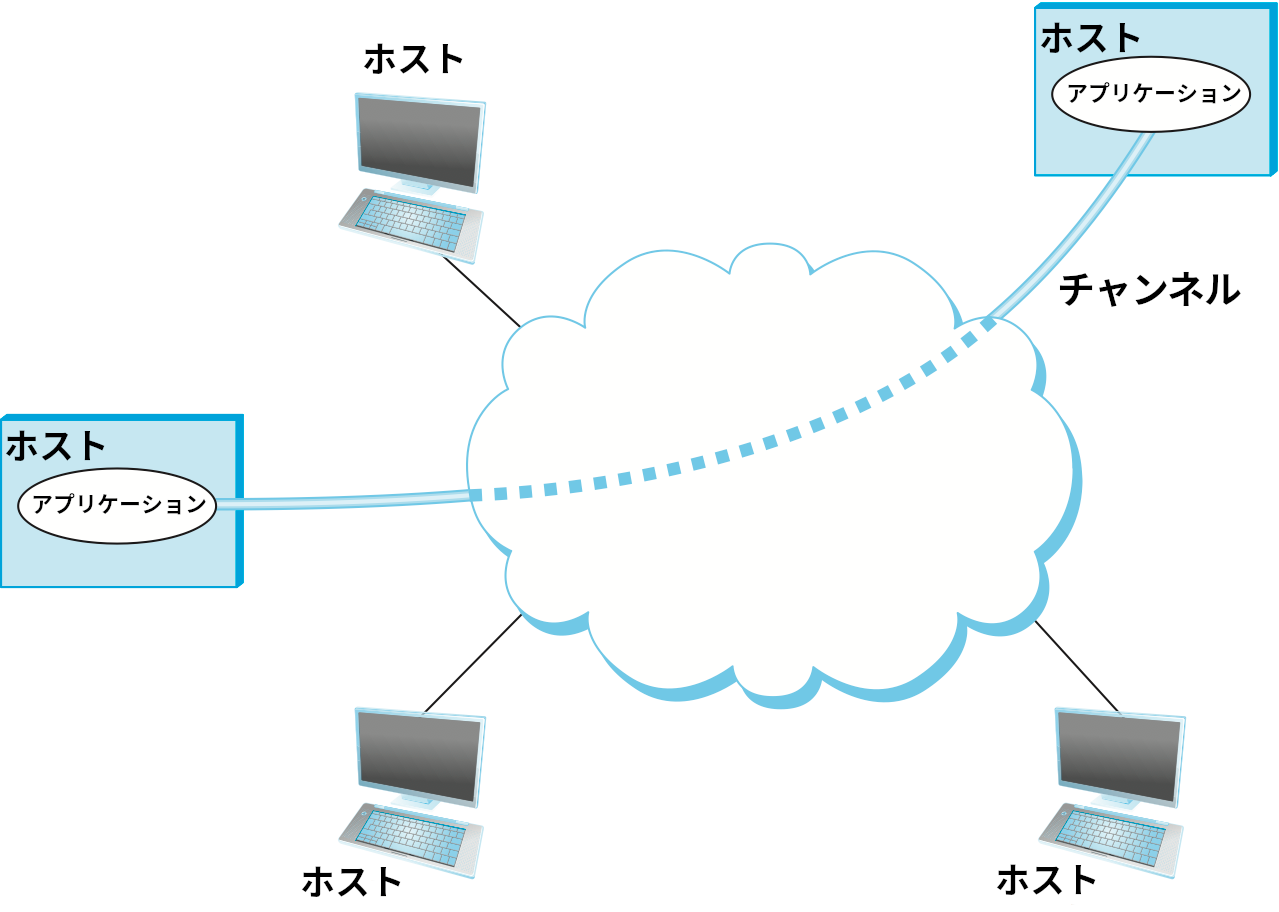
ここでチャンネル (channel) の概念が登場する: 簡単に言えば、アプリケーションが必要とするサービスの集合を提供する論理的なチャンネルをネットワークが提供し、そのチャンネルを通してアプリケーションレベルのプロセスが互いに通信するとみなされる。言い換えれば、「雲」がコンピューター同士の接続を抽象的に表すのと同じように、ここでは「チャンネル」でプロセス同士の接続を表す。図 7 に論理的なチャンネルを通して通信するアプリケーションレベルのプロセスの組を示す。チャンネルはホスト同士を接続する「雲」の上に作られるので、送信を行うアプリケーションはデータをチャンネルに入れるとチャンネルの向こう側のアプリケーションがデータを受け取れると期待できる。
どんな抽象化とも同じように、プロセス同士を接続する論理的なチャンネルはホスト同士を接続する物理的な「チャンネル」の上に作られる。これは本質的に層の作成であり、この考え方は次節で議論されるネットワークアーキテクチャの基礎となる。
次の課題として、チャンネルがアプリケーションプログラムに提供すべき機能の選定がある。例えば、アプリケーションはチャンネルを通して送られたメッセージが確実に届けられる保証を必要とするだろうか? それとも一部のメッセージが届かなくても構わないだろうか? メッセージが送られた順番で届く必要はあるだろうか? それとも受信側はメッセージが届く順番を気にしないだろうか? 第三者がチャンネルを盗聴できないことをネットワークは保証すべきだろうか? それともプライバシーは懸案事項ではないだろうか? 一般にネットワークは様々な種類のチャンネルを提供し、それぞれのアプリケーションは自身が必要とする種類のチャンネルを選択する。本節の残りの部分では、役立つチャンネルを定義する上で鍵となる考え方を説明する。
代表的な通信パターン
抽象的なチャンネルの設計では、まず代表的なアプリケーションが必要とする通信はどんなものかを理解し、次に共通の通信要件を抽出し、最後にその要件を満たすための機能をネットワークに組み込む必要がある。
ほぼ全てのネットワークでサポートされるアプリケーションで最も古いものの一つに、FTP (File Transfer Protocol) や NFS (Network File System) のようなファイルアクセスプログラムがある。詳細は大きく異なる ── 例えば、ファイル全体がネットワークを通して転送されるのか、それとも一度に読み書きできるのはファイル中の単一ブロックのみなのか、など ── ものの、リモートファイルアクセスの通信コンポーネントには二つのプロセスが登場し、一つがファイルの読み込みまたは書き込みをリクエストし、もう一つがこのリクエストを処理する。ファイルへのアクセスをリクエストするプロセスをクライアント (client) と呼び、リクエストされたファイルへのアクセスをサポートするプロセスをサーバー (server) と呼ぶ。
ファイルの読み込みでは、クライアントがサーバーに小さなリクエストを送信し、サーバーはファイルのデータを含む大きなメッセージで応答する。ファイルへの書き込みでは逆になる ── クライアントが書き込みたいデータを含む大きなメッセージをサーバーに送信し、サーバーはディスクへの書き込みが完了したことを伝える小さなメッセージで応答する。
電子図書館はファイル転送より高度なアプリケーションであるものの、必要となる通信サービスは同様である。例えば ACM (Association for Computing Machinery, 計算機学会) は計算機科学に関する文献を収める大規模な電子図書館を次の URL で運営している:
http://portal.acm.org/dl.cfm
この図書館は検索・閲覧のための様々な機能を備えており、ユーザーが探している資料を簡単に見つけられるようになっている。しかし突き詰めれば、サーバーが行っているのはユーザーがリクエストしたファイル (雑誌記事の電子コピーなど) を返す処理に過ぎない。
ファイルアクセスと電子図書館、そして第 1.1 節で触れた二つのアプリケーション (ビデオ会議とビデオ・オン・デマンド) を代表的な例とみなすなら、ネットワークは次の二種類のチャンネルを提供すべきということになる: リクエスト/リプライチャンネル (request/reply channel) と、メッセージストリームチャンネル (message stream channel) である。
リクエスト/リプライチャンネルはファイル転送と電子図書館のアプリケーションで使われるだろう。このチャンネルでは一方が送信したメッセージがもう一方で受信されることが保証され、各メッセージの一つのコピーだけが転送される。また、チャンネルを流れるデータのプライバシーや完全性 (integrity, 送信したデータが改変されないこと) を保護する機能があり、権限を持たない第三者がクライアントとサーバーの間でやり取りされるデータを読み書きできないようにもなっているかもしれない。
メッセージストリームチャンネルはビデオ・オン・デマンドとビデオ会議のアプリケーションで利用できるだろう。ただし「片方向と両方向の通信をどちらもサポートし、異なる属性の遅延をサポートするなら」という条件は付く。映像アプリケーションではフレームの一部が写らなくても重大な問題にはならないので、メッセージストリームチャンネルは全てのメッセージが転送されることの保証を必要としないかもしれない。しかし、フレームを順序通りに表示するために、メッセージが送信したのと同じ順番で到着することの保証は必要になるはずである。また、リクエスト/リプライチャンネルと同様に、映像のプライバシーや完全性の保証が必要になる可能性がある。最後に、ビデオ会議への参加や映像の視聴を複数の人物が行えるようにするために、メッセージストリームチャンネルではマルチキャストのサポートが必要になるだろう。
ネットワーク設計者が抽象チャンネルの個数を最小にしつつサポートされるアプリケーションの個数を最大化しようと奮闘するのはよくあることではあるものの、そこには最低限にも満たない個数の抽象チャンネルだけ用意してそれで済ませてしまう危険性もある。簡単に言えば、ハンマーを持つと何でも釘に見えるものだ。例えば、ネットワークがリクエスト/リプライチャンネルとメッセージストリームチャンネルにしか対応していなかったとしたら、次に開発されるアプリケーションでもこの二つを使えばいいと思ってしまうかもしれない。しかし、その新しいアプリケーションが必要とする意味論を二つのチャンネルが提供する保証はどこにもない。そのため、アプリケーションプログラマーが新しいアプリケーションの開発を続ける限り、ネットワーク設計者は新しいチャンネルを開発し続ける ── そして既存のチャンネルにオプションを加え続ける ── ことになるだろう。
また、チャンネルの機能として何を提供するかという問題とは独立して、その機能をどのように実装するかという問題もあることに注意してほしい。多くの場合、下位のネットワークにおけるホスト同士の接続を「ビットパイプ (ビットを通せる土管)」とみなし、高レベルな通信意味論はエンドホストで処理するのが最も簡単になる。このアプローチの利点はネットワークの中間にあるスイッチが考え得る中で最も簡単に ── パケットを転送するだけに ── なることだが、その分エンドホストでプロセス間チャンネルのリッチな意味論をサポートする負担が生じる。もう一つの選択肢はスイッチに機能を押し付けることで、この場合はエンドホストを「バカ」なデバイス (例えば電話の受話器) にできる。ネットワークサービスでパケットスイッチとエンドホスト (デバイス) をどのように使い分けるかという問題はネットワーク設計における話題として今後何度も触れることになる。
確実なメッセージ転送
ちょうど先ほど考えた例からも示唆されるように、確実なメッセージ転送はネットワークが提供できる最も重要な機能の一つである。しかし、ネットワークがどのように壊れるかを最初に理解しなければ、この信頼性を提供する方法を見つけるのは難しい。まず理解すべきなのは、コンピューターネットワークが存在するのは完璧な世界ではない事実である。マシンがクラッシュして適当な時間が経ってから再起動されたり、回線が物理的に切れたり、電気的な干渉が転送中のビットを反転させたり、スイッチのバッファ空間が足りなくなったりする。こういった物理的問題だけでは物足りないかのように、ハードウェアを管理するソフトウェアにバグがあってパケットを虚空に送ったりすることがある。そのため、特定の種類の障害から回復できることはネットワークで重要な要件となる。この要件が満たされるときアプリケーションプログラムは障害に対処する必要がなく、障害に気付くことさえなくなる。
ネットワーク設計者が気を付けなければならない障害はいくつかの一般的なカテゴリに分けられる。第一に、パケットが物理リンク上を転送される間にビット誤り (bit error) がデータに混入する障害がある: 1 が 0 に、0 が 1 になる。ビットが一つだけ破損することもあるかもしれないが、バースト誤り (burst error) が起こって連続する複数のビットが破損することもある。ビット誤りは典型的には落雷、電力サージ、電子レンジあるいはデータ転送との干渉といった外部からの衝撃によって発生する。良いニュースはそういったビット誤りが非常に稀なことで、典型的な銅製ケーブルでは平均して 106 から 107 ビットに 1 ビット、典型的な光ファイバーケーブルでは 1012 から 1014 ビットに 1 ビットしか起こらない。後で見るように、ビット誤りを高い確率で検出するテクニックが存在し、破損したビットの訂正が可能な場合もある ── もし破損したビットが特定できれば、そのビットを反転させるだけで済む。訂正が不可能な場合もあり、そのときはパケット全体を破棄するしかない。送信側がパケットをもう一度送信することになるだろう。
第二に、ビットではなくパケットレベルの障害がある: つまり、完全なパケットが丸ごとネットワークから消失する。この障害が起こる理由の一つに、訂正不可能なビット誤りによりパケットを破棄するほかなくなる状況がある。しかし、それより可能性の高い状況として、パケットの処理を担当するノード ── 例えばパケットを他のリンクに転送するスイッチ ── が大量のパケットを受け取ったためにパケットを一時的に保存する場所が無くなり、パケットを破棄せざるを得なくなる状況がある。この問題は上述の通り輻輳と呼ばれる。これより可能性は低いものの、パケットを処理するためにノードで実行されるソフトウェアがミスをする場合もある。例えばパケットが間違ったリンクに送られ、いつまでたっても最終的な目的地に到達しないかもしれない。これから見るように、パケットの損失に対処する上では、パケットが本当に損失した状況と目的地に到着するのに時間がかかっているだけの状況を見分けることが主要な困難の一つとなる。
第三に、ノードとリンクのレベルで発生する障害がある: つまり物理リンクが切られたり、接続されたコンピューターがクラッシュしたりする。この障害はソフトウェアのクラッシュ、電源喪失、注意不足なオペレーターなどによって引き起こされる。ネットワークデバイスの設定ミスもよくある原因である。こういった障害は多少の時間をかければ修正できるものの、修正までの間ネットワークに重大な影響が出る可能性がある。ただしネットワーク全体が機能を停止するとは限らない。例えばパケット交換ネットワークでは、障害が起きたノードやリンクを迂回できることがある。この三つ目のカテゴリに属する障害における主要な困難の一つは、障害が起きたコンピューターと遅くなっているだけのコンピューター、あるいは切断されたリンクとボロボロになってビット誤りが頻発しているリンクを見分けることである。
教訓
以上の議論から学んでほしいのは、有用なチャンネルを定義するにはアプリケーションの要件の理解と下位の技術が持つ制限の認識が両方とも必要になるという考え方である。困難はアプリケーションが期待する機能と下位の技術が提供できる機能のギャップを埋める部分にある。これは意味論的ギャップ (semantic gap) と呼ばれることがある。
1.2.5 管理容易性
最後の要件として、ネットワークは管理されなければならない。この要件は無視されたり、(本書のように) 最後に追いやられたりすることが多いように思える。ネットワークの管理には、ネットワークが成長してトラフィックやユーザーが増えたときにデバイスをアップグレードしたり、ネットワークが不調なときやパフォーマンスが思った通りに出ないときにトラブルシューティングをしたり、新しいアプリケーションをサポートするために新しい機能を追加したりする作業が含まれる。ネットワークの管理は歴史的にネットワークの中でも人間頼りな部分が多い。人間が全く関与しなくなる可能性は低いものの、最近ではネットワーク管理の問題が自動化や自己回復設計によって解決されることが増えている。
この要件は上述したスケーラビリティの話題と一部関連する ── インターネットが数十億人のユーザーと少なくとも数億台のホストをサポートできるスケーラビリティを獲得するまでの間に、全体を正しく動作させながら新しいデバイスを追加・構成するという課題の重要性は増してきた。ネットワーク内の単一のルーターを構成することさえ訓練を受けた専門家が行うタスクである場合が多いのだから、数千台のルーターを構成し、そのサイズのネットワークが期待通りに動いていない理由を見つけるのは人間には不可能なタスクとなる可能性がある。これが理由で、自動化の重要性が最近増している。
ネットワークを管理しやすくする一つの方法は、変更を避けることである。ネットワークが一度正しく動いたら、その後は「触るな!」と書いておけばいい。このマインドセットは安定性 (stability) と機能速度 (feature velocity, ネットワークに新しい機能を追加できる速さ) の間にある基礎的な緊張関係を示している。安定性を重視するのは電気通信業界 (および大学のシステム管理者や企業の IT 部署) が長年にわたって取ってきたアプローチである。このため電気通信業界は数ある業界の中でも最も動きが遅く、最もリスクを避けようとする業界の一つとなっている。しかし最近になってクラウドが爆発的に成長したことで潮流が変化し、安定性と機能速度のバランスをもっと上手く取る必要が生じた。クラウドの影響は本書で何度も登場する話題であり、各章の「視点」の節で大きく取り上げる。今のところは、急速に拡大するネットワークの管理は間違いなく現代のネットワークにおける中心的課題であると言うだけに留める。