6.3 TCP の輻輳制御
本節ではエンドツーエンド輻輳制御として現在支配的な例を見ていく。それは TCP によって実装される輻輳制御であり、「予約をせずにネットワークにパケットを送信し、観測可能なイベントが起こればそれに対応する」を基本的な戦略とする。TCP の輻輳制御はネットワーク内のルーターがキューイングで FIFO を使うことを仮定するものの、公平キューイングを使う場合でも正しく動作する。
TCP の輻輳制御は 1980 年代の後半に Van Jacobson によってインターネットに導入された。これは TCP/IP というプロトコルスタックの運用が開始されてから約 8 年後のことだった。輻輳制御が導入される直前、インターネットは輻輳崩壊に苦しんでいた ── ホストは広報されたウィンドウサイズが許す限りのパケットをインターネットに送信し、どこかのルーターで輻輳が発生し、パケットが破棄され、タイムアウトを検知したホストがパケットを再送し、さらに悪い輻輳が発生する、という状況がよくあった。
大まかに言うと、TCP の輻輳制御のアイデアは「各送信元がネットワークで利用可能な容量を推測し、そこから同時に転送中にして問題ないパケットの個数を計算する」と表現できる。そうして計算されただけのパケットが転送中になると、送信元は ACK が到着するまで待機する: ACK はパケットがネットワークを抜けたことを表すシグナルであり、ACK が到着したなら新しいパケットを一つネットワークに追加しても輻輳の問題は悪化しない。TCP はパケットの転送ペースを調整するのに ACK を利用するので、自己同期的 (self-clocking) と呼ばれる。もちろん、最初に行われるネットワーク容量の推定は決して簡単なタスクではない。さらに悪いことに、他の接続が途中で追加されたり消えたりするので、利用可能な帯域は時間の経過とともに変化する。そのため全ての送信元は転送中にできるパケット数を実行中に調整できる必要がある。本節では、TCP がこういった問題を解決するときに利用するアルゴリズムを説明する。
これから TCP の輻輳制御の仕組みを三つの項を通して一つずつ説明するので、独立した仕組みが三つあるという印象を与えてしまうかもしれないが、「TCP の輻輳制御」と呼ばれるのはこれら三つの仕組みが合わさったものである点に注意してほしい。また、これから説明するのは標準 TCP (standard TCP) と呼ばれる最も広く使われる TCP のバージョンにおける輻輳制御であることも覚えておいてほしい。現在使われている TCP の輻輳制御には他にもたくさんの種類が存在し、研究者たちは上述の問題を解決する新しいアプローチを探り続けている。新しいアプローチは本節でもいくつか議論する。
6.3.1 加算的増加/乗算的減少
輻輳制御を行うために、TCP は各接続に対して CongestionWindow と呼ばれる新しい状態変数を管理する。CongestionWindow は任意の時点で送信元が転送中にすることを許されるデータの量を表す。輻輳制御における輻輳ウィンドウ (congestion window) はフロー制御において受信側から広報されるウィンドウに対応する。確認応答を受け取らずに送信中として構わないデータの最大バイト数は輻輳ウィンドウサイズと受信側から広報されたウィンドウサイズの最小値となるよう TCP は変更される。そのため、第 5.2 節で定義した変数を使えば、TCP の実効ウィンドウサイズ EffectiveWindow は次のように変更される:
MaxWindow = MIN(CongestionWindow, AdvertisedWindow)
EffectiveWindow = MaxWindow - (LastByteSent - LastByteAcked)
つまり、AdvertisedWindow の代わりに MaxWindow を使って EffectiveWindow が計算される。すなわち、TCP の送信元は最も遅いコンポーネント ── ネットワークもしくは宛先ホスト ── が受け入れられるだけの速さでしかデータを送信できない。
ここでの問題は、もちろん、CongestionWindow の適切な値を TCP が学習する方法である。接続の受信側から設定すべき値が直接送られて来る AdvertisedWindow と異なり、適切な CongestionWindow の値を送信側に伝えるコンポーネントは存在しない。そのため「TCP の送信元はネットワーク内で発生する輻輳のレベルを監視し、それを元に CongestionWindow を設定する」が問題に対する解答となる。具体的には、輻輳のレベルが上がれば輻輳ウィンドウを狭め、輻輳のレベルが下がれば輻輳ウィンドウを広げる処理が行われる。この処理は AIMD (additive increase/multiplicative decrease, 加算的増加/乗算的減少) と呼ばれる。この意味深な名前の意味はすぐに明らかになる。
続いての重要な疑問に「ネットワークが輻輳を起こしており、輻輳ウィンドウを狭めるべきであることを送信元はどうやって知るのか?」がある。ここではパケットの転送に失敗する (そしてタイムアウトが発生する) 主な理由が輻輳によるパケットロスであるという観察が利用される。転送中の誤りによるパケットロスは稀にしか起きない。この観察に基づき、TCP はタイムアウトを輻輳の兆候と判断し、タイムアウトが起こった場合に転送レートを減少させる。具体的には、タイムアウトが起こるたびに送信元は CongestionWindow を半分にする。この「半分にする」処理が AIMD の「MD (multiplicative decrease, 乗算的減少)」に対応する。
CongestionWindow は単位をバイトとして定義されるものの、AIMD を理解する上ではパケットを単位として定義されると考えると分かりやすいだろう。例えば、CongestionWindow が現在 16 パケットに設定されているとする。この状態でパケットロスが検知されると、CongestionWindow は 8 に設定される (通常パケットロスはタイムアウトが発生したときに検知される。ただし後述するように、TCP は破棄されたパケットを検出するための別の仕組みが存在する)。もう一度パケットロスが起これば CongestionWindow は 4 に設定され、さらに起これば 2 に、最終的には 1 になる。なお CongestionWindow はパケット一つ分の大きさ ── TCP の用語で言うところの MSS (maximum segment size, 最大セグメントサイズ) ── より小さくなることを許されていない。
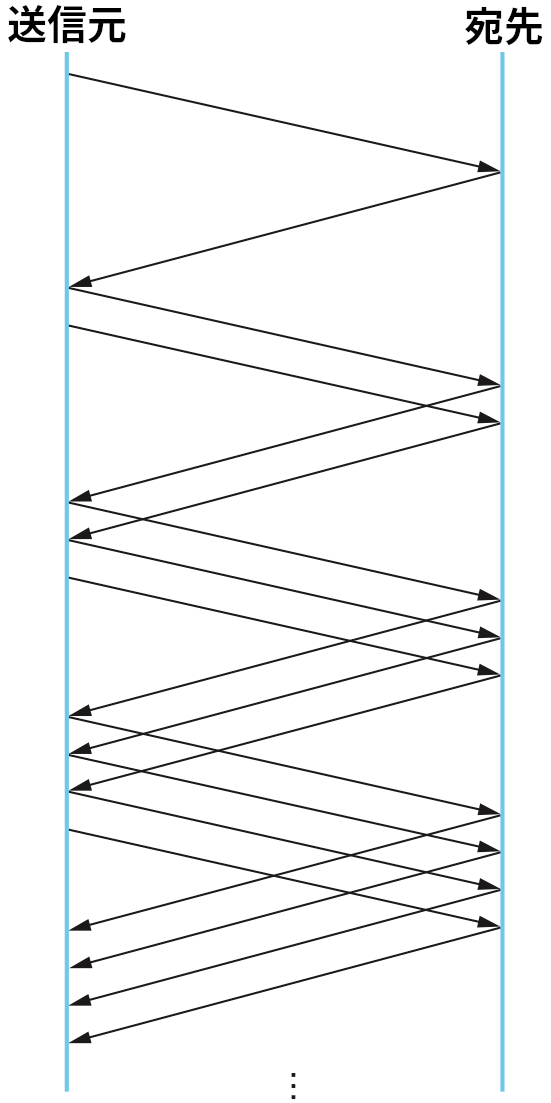
輻輳ウィンドウが小さくしかならない輻輳制御の戦略は明らかに保守的すぎる。ネットワークで新しく利用可能になった容量を活用するために、輻輳ウィンドウを広げる処理も行える必要がある。これは AIMD の「加算的増加 (additive increase)」の部分で行われる。送信元が CongestionWindow だけのパケットの転送に成功したとき ── つまり、最後のラウンドトリップタイム (RTT) で送った全てのパケットに対する ACK が到着したとき ── 送信元は CongestionWindow に 1 パケット分の値を加える。この処理の結果として生じる線形の増加を図 159 に示す。
なお実際の TCP はウィンドウ一つ分に含まれるパケット全てに対する ACK を受け取ったときに CongestionWindow をパケット一つ分広げるのではなく、ACK を受け取るたびに CongestionWindow を少しずつ増加させる。具体的には、ACK が到着するたびに CongestionWindow は次のように増加する:
Increment = MSS x (MSS/CongestionWindow)
CongestionWindow += Increment
つまり、CongestionWindow は RTT ごとに MSS だけ大きくなるのではなく、それぞれの ACK が到着するたびに MSS の一定の割合だけ大きくなる。各 ACK が MSS バイトの受信に対する確認応答だと仮定すれば、この「一定の割合」は MSS/CongestionWindow となる。
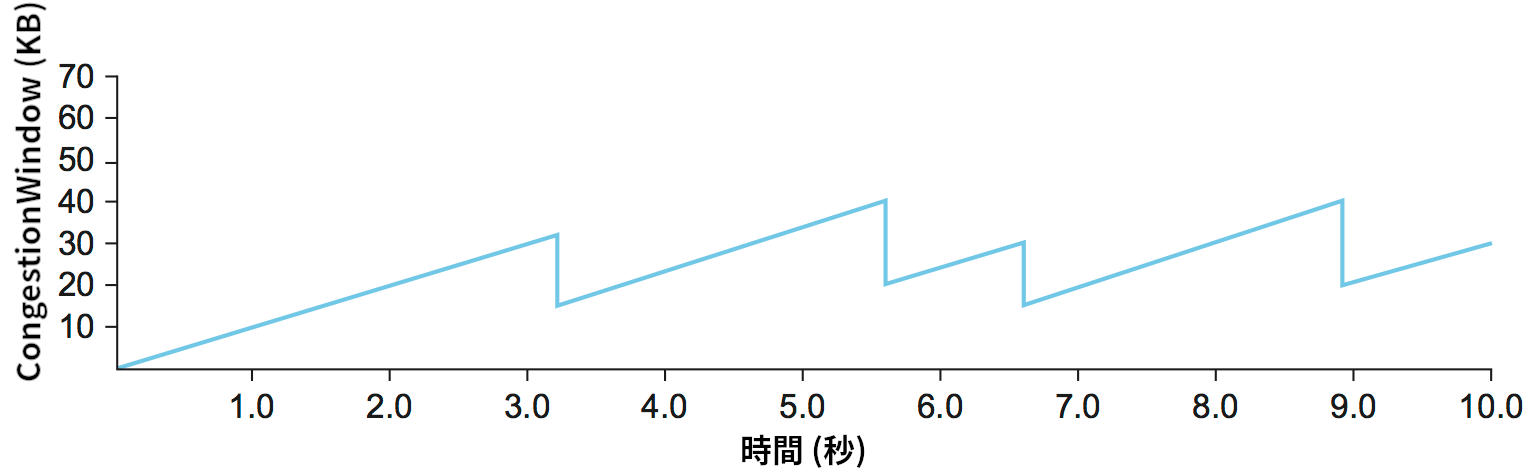
接続がオープンな間を通じて、輻輳ウィンドウの拡大と縮小のパターンは何度も繰り返される。CongestionWindow の値の変化をプロットすると、図 160 のようなノコギリ歯のパターンが現れる。AIMD に関して理解しておくべき重要な点は、送信元が輻輳ウィンドウを狭める速度が広げる速度より格段に速いことである。これは ACK の到着でウィンドウをパケット一つ分だけ広げ、タイムアウトでウィンドウをパケット一つ分だけ狭める加算的増加/加算的減少の戦略とは大きく異なる。AIMD は輻輳制御を安定にするための必要条件であることが示されている。
TCP が輻輳ウィンドウの縮小には積極的で拡大には保守的である理由を一言で説明すれば、適切なサイズより大きい輻輳ウィンドウによる影響が積み重なるためである。ウィンドウが大きすぎるとパケットの再送が起こり、輻輳はさらに悪くなっていく。この状態から早く脱することが重要となる。
最後に、タイムアウトは乗算的減少を引き起こす輻輳の兆候なので、TCP は実装できる中で最も正確なタイムアウトの仕組みを必要とする。TCP のタイムアウトの仕組みは第 5.2 節で説明したので、ここでは繰り返さない。ただ、タイムアウトの仕組みが平均 RTT と平均 RTT の標準偏差の関数としてタイムアウトを計算すること、そして転送を正確なクロックで測定するコストの問題から、RTT のサンプルを (パケットごとではなく) RTT ごとに一度、精度の粗い (500 ms 程度の) クロックで測定することは覚えておいてほしい。
6.3.2 スロースタート
ここまでに説明した加算的増加の仕組みは、送信元がネットワークで利用可能な容量に近い速度でパケットを送信している場合には正しいアプローチとなる。一方で、送信速度を 1 から増加させるときに使うと時間がかかりすぎるという問題を抱えている。そのため TCP はこういったコールドスタート時に輻輳ウィンドウを素早く拡大させる二つ目の仕組みを持つ。この仕組みは皮肉にもスロースタート (slow start) と呼ばれる。事実上、スロースタートは輻輳ウィンドウを線形ではなく指数的に拡大させる。
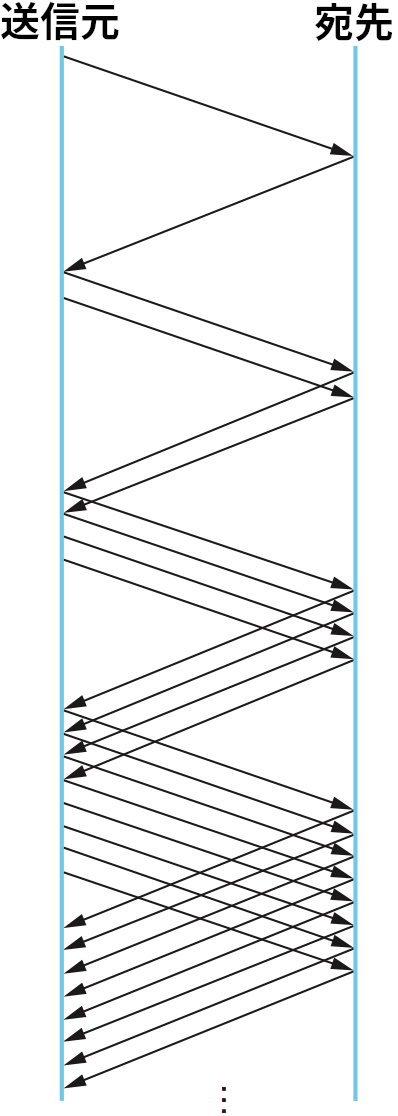
具体的に説明すると、送信元は CongestionWindow を 1 として送信を開始する。最初に送ったパケットに対する ACK を受け取ると、TCP は CongestionWindow に 1 を加えて 2 つのパケットを送信する。その 2 つのパケットに対する ACK を受け取ると、TCP は CongestionWindow に 2 を (ACK ごとに 1 を) 加えて 4 つのパケットを送信する。以下同様となり、事実上 TCP は RTT ごとに転送するパケットの個数を倍にしていく。スロースタートの間に送信パケット数が倍増していく様子を図 161 に示す。これを図 159 の加算的増加と比較してほしい。
送信できるパケットの個数を指数的に増加させるこの仕組みを「スロー」と呼ぶことを不思議に思うかもしれないが、正しい歴史的な文脈を理解すると納得できる。スロースタートと比較すべきは前項で説明した AIMD の仕組みではなく、オリジナルの TCP の振る舞いである。接続が確立され、送信元が初めてパケットを送信するときに何が起きるかを考えよう ── このとき送信元は転送中のパケットを持たない。仮に送信元が受信側から広報されたウィンドウサイズが許す限りのパケットを送信する (スロースタートが考案される前の TCP の振る舞いをする) と、たとえネットワークの帯域容量がそれなりに大きかったとしても、個別のルーターはこのバースト (一気に送信されるパケット) を消費しきれない可能性がある。ルーターが処理できるかどうかはバッファ空間の量だけに依存する。この問題を受けて、パケット同士の間隔を空けることでバーストを起こらないようにするためにスロースタートが考案された。言い換えれば、確かにスロースタートの指数的な増加は線形な増加より速いものの、広報されたウィンドウサイズだけのデータを全て一度に送信するよりはスロースタートの方が「遅い」のである。
スロースタートが実行される状況は二つ存在する。一つは接続をオープンした直後で、このとき送信元はパケットを送信すべき速度に関して何の手掛かりも持たない (TCP は 1 Mbps のリンクで実行されることもあれば 40 Gbps のリンクで実行されることもあり、送信元はネットワークの容量に関して何の知識も持たないことに注意してほしい)。この状況では、スロースタートによってパケットロスが発生するまで RTT ごとに CongestionWindow が倍に増えていき、パケットロスが起こると乗算的減少によって CongestionWindow は半分になる。
スロースタートが使われる二つ目の状況はもう少し込み入っている: タイムアウトが起こるとスロースタートが使われる。TCP のスライディングウィンドウアルゴリズムの動作を思い出してほしい ── ACK が返ってこないと、いずれ送信元は二つのウィンドウが許すだけのパケットを送信し、到着することのない ACK を待ってブロックする。その後タイムアウトの原因となったパケットを再送して (累積的な) ACK が返ってきた場合、ウィンドウが大きく移動して多くのパケットの一気に送信可能となる。接続開始時と同様に、この状況で送信元が送れるだけのパケットを一度に送ってしまうとネットワークに過負荷がかかる可能性があるので、こういった状況で送信元はスロースタートを使ってデータの送信を再開する。
タイムアウトが起こると送信元は再びスロースタートを行うものの、このとき送信元は接続開始時には持っていなかった情報を持っている。具体的には、送信元は CongestionWindow の現在値という有用な値を知っている。これはタイムアウトが起こる前の CongestionWindow を 2 で割った値であり、輻輳ウィンドウサイズの目標値として採用できる。スロースタートは送信レートをこの目標値まで増加させるのに使われ、その後は加算的増加となる。このアプローチでは実際の送信処理で使われる (スロースタートが増加させる) 輻輳ウィンドウサイズに加えて、輻輳ウィンドウサイズの目標値も記録する必要が生じる。このため、TCP は輻輳ウィンドウサイズの目標値を格納するための一時変数 CongestionThreshold を導入する。タイムアウトが発生すると、CongestionThreshold の値は CongestionWindow の現在値に乗算的減少を施した値となる。それから変数 CongestionWindow はパケット一つ分にリセットされ、CongestionThreshold に達するまで ACK を受け取るごとにパケット一つ分ずつ増加するようになる。その後 CongestionWindow は RTT ごとにパケット一つ分ずつ増加する。
コードで示すと、TCP は ACK を受け取るたびに輻輳ウィンドウのサイズを次のように計算する:
{
unsigned int cw = state->CongestionWindow;
unsigned int incr = state->maxseg;
if (cw > state->CongestionThreshold) {
// 加算的増加に切り替える
incr = incr * incr / cw;
}
state->CongestionWindow = MIN(cw + incr, TCP_MAXWIN);
}
ここで state は考えている TCP 接続の状態であり、TCP_MAXWIN は輻輳ウィンドウの最大サイズを表す。
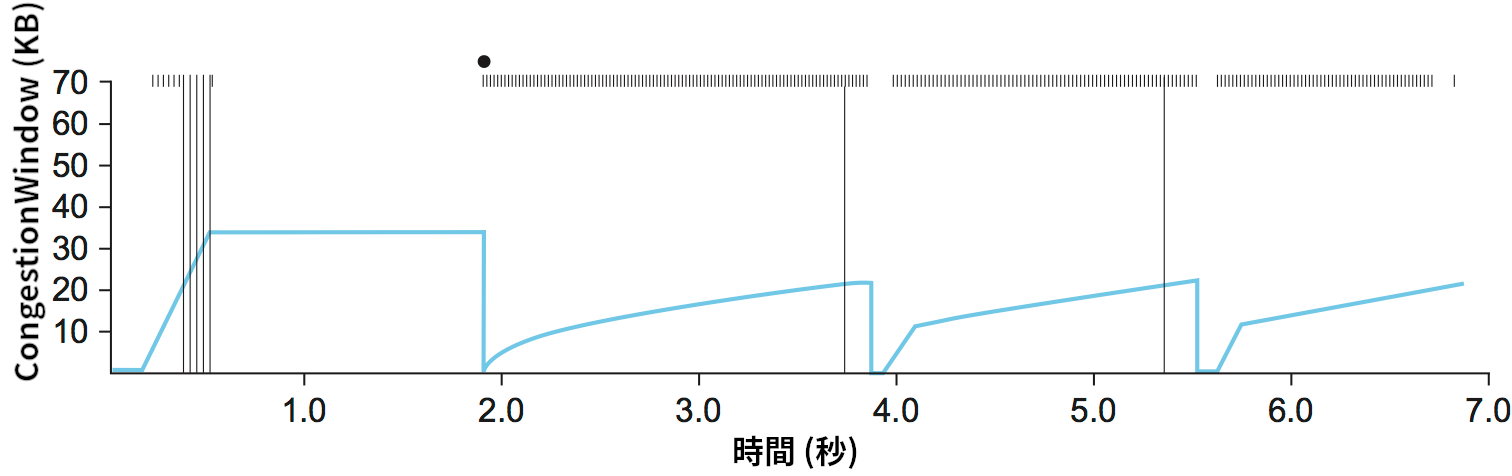
TCP の CongestionWindow がどのように増減するかを図 162 に示す。この図からはスロースタートと加算的増加/乗算的減少が組み合わさっていることが確認できる。このトレースは実際の TCP 接続から取られたものであり、CongestionWindow の現在値の変化を青い実線で示している。
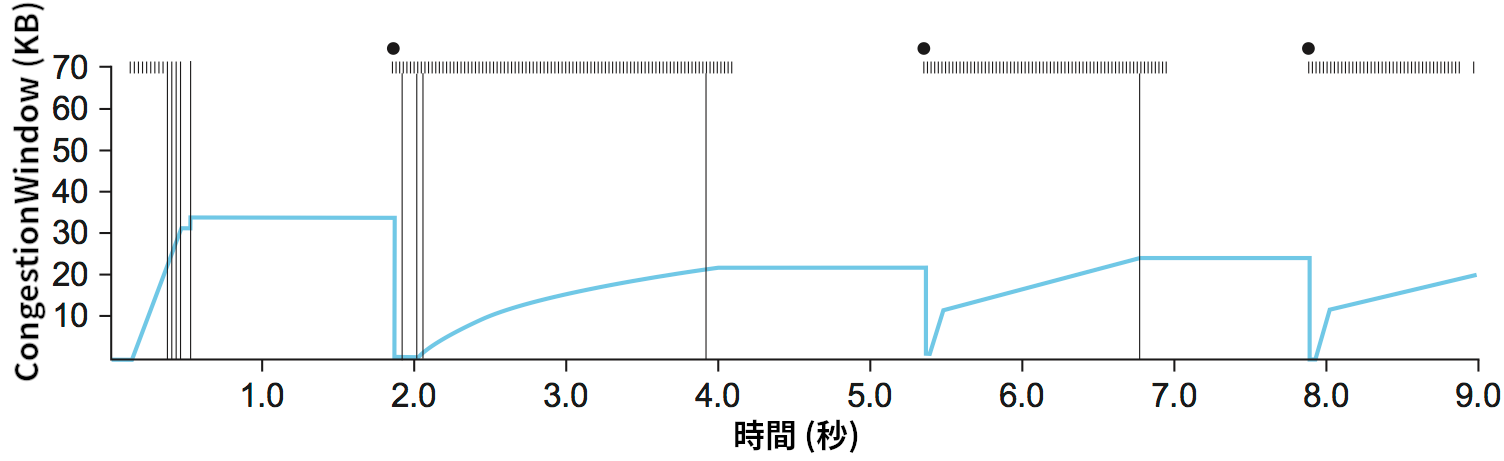
CongestionWindow の値、グラフ上部の黒い点はタイムアウト、グラフ上部の太線はパケットの転送、グラフ全体に書かれた縦線は後に再送が起こるパケットの初めての転送をそれぞれ表す。
このトレースから分かることがいくつかある。まず、接続が確立した直後は輻輳ウィンドウが素早く大きくなっているのが分かる。これは最初のスロースタートフェーズに対応する。このスロースタートフェーズはいくつかのパケットが喪失する接続開始から 0.4 秒後あたりまで続く。この後グラフが平坦になるのはパケットが喪失したために ACK が返ってこないためである。こうして CongestionWindow は約 34 KB で頭打ちになる (スロースタートでこれほど多くのパケットが喪失する理由は後で議論される)。実際、グラフ上部の太線が途切れていることから分かるように、グラフが平坦な間はパケットが全く送信されていない。約 2 秒地点でタイムアウトが発生し、CongestionWindow は半分の約 17 KB に、CongestionThreshold も同じ値に設定される。その後はスロースタートが行われ、CongestionWindow はパケット一つ分に設定されてから指数的に増加する。
このトレースには 2 秒前後の地点でパケットが失われているときに何が起きたかを正確に解明できるほどの詳細はないので、続いて 2 秒地点から 4 秒地点における線形増加に注目しよう。これは加算的増加に対応する。約 4 秒地点で CongestionWindow は平坦になる: ここでもパケットロスが原因で ACK が返ってきていない。その後、約 5.5 秒地点で次のことが起きる:
-
タイムアウトが起き、
CongestionWindowが半分になって約 22 KB から約 11 KB になる。CongestionThresholdも同じく約 11 KB となる。 -
CongestionWindowはパケット一つ分にリセットされ、送信側はスロースタートに入る。 -
スロースタートによって
CongestionWindowはCongestionThresholdまで指数的に増加する。 -
その後
CongestionWindowは線形に増加する。
約 8 秒地点でもタイムアウトから始まる同様のパターンが繰り返されている。
先ほど言及した、最初のスロースタートで多くのパケットが喪失している問題を考えよう。最初のスロースタートの間、TCP はネットワークで利用可能な帯域がどれほどかを学習しようとしている。これは難しいタスクである: このステージで送信元が控えめすぎると (例えば、輻輳ウィンドウを線形にしか拡大しないと)、利用可能な帯域を学習するのに長い時間がかかってしまい、この接続が達成できるスループットに大きな影響が生じる可能性がある。一方で送信元が (指数的に輻輳ウィンドウを拡大させる TCP のように) 積極的すぎると、ウィンドウの少なくない部分がネットワークによって破棄されるリスクが生じる。
輻輳ウィンドウが指数的に増加するとき何が起こるかを理解するために、送信元が輻輳ウィンドウを 16 パケット分とした送信に成功した状況を考えよう。続いて送信元は輻輳ウィンドウを倍の 32 パケットに拡大する。ここで、ネットワークはこの送信元に対する容量として 16 パケット分しか持たないと仮定する。すると、新しい輻輳ウィンドウの下で送られる 32 パケット中 16 パケットは喪失する可能性が高い (これは実際には最悪ケースであり、どこかのルーターがパケットをバッファできてもう少し送れる可能性もある)。この問題はネットワークの帯域遅延積が大きくなると深刻な問題になる。例えば帯域遅延積が 500 KB なら、全ての接続が接続開始時に最大で 500 KB を喪失する可能性が生じる (もちろん、ここでは送信元と宛先の両方がスケーリングファクターを使ったウィンドウサイズの拡張を実装すると仮定している)。
利用可能な帯域をスロースタートより高度な手段を使って推定する異なる選択肢も研究されている。その一つにクイックスタート (quick start) がある。SYN パケットに IP オプションとして要求レートを載せることで、TCP の送信側がスロースタートより高い送信レートでの送信の開始をリクエストできるようにするというのが基本的なアイデアとなる。道中のルーターはオプションを確認し、要求されたレートが受け入れ可能か、それより低いレートが望ましいか、通常のスロースタートを使うべきかをそのフローの現在時点における輻輳のレベルから判断する。SYN パケットが受信側に届くとき、そこには道中の全てのルーターにとって受け入れ可能な送信レート、または道中の一つ以上のルーターがクイックスタートをサポートできないことを伝える表示が含まれている。送信側は前者の場合には指定されたレートで送信を開始し、後者の場合にはスロースタートにフォールバックする。TCP が高いレートで送信を開始できるなら、セッションがパイプに隙間が生まれない状態に到達するまでに必要なラウンドトリップが節約される。
こういった種類の TCP の改善が持つ明らかな課題の一つに、標準 TCP より多くの処理をルーターに要求することがある。もし道中にクイックスタートをサポートしないルーターが一つでも存在すれば、システムは通常のスロースタートに戻ってしまう。そのため、こういった改善がインターネットで利用されるまでに長い時間がかかっても不思議ではなく、それまでは制御されたネットワーク環境 (研究用ネットワークなど) で主に利用される可能性が高い。
6.3.3 高速再送と高速リカバリ
ここまでに説明した仕組みは TCP に輻輳制御を追加したオリジナルの提案に含まれていたものである。しかし、その提案からしばらくして、接続が反応しなくなってタイムアウトを待っている状況で精度の粗い TCP タイムアウトの実装を使っていると長い時間が無駄になることが問題となった。この問題に対処するために、高速再送 (fast retransmit) と呼ばれる仕組みが TCP に追加された。高速再送は破棄されたパケットに対する再送を通常のタイムアウトよりも早く行うヒューリスティックである。なお、高速再送はタイムアウトを置き換えるわけではなく、タイムアウトの機能を改善するために存在する。
高速再送のアイデアは難しくない: パケットを受け取った受信側に必ず確認応答 (ACK) を送信させるというものである。この結果として送信済みの ACK がもう一度送信されることになったとしても、ACK は送信される。このとき順番が前後してパケットが届くと、受信側は同じ番号 (先頭の隙間の一つ前の番号) に対する ACK を送信することになる。この以前と同じ番号に対する ACK を重複 ACK (dupulicate ACK) と呼ぶ。重複 ACK を受信した送信側は、受信側が順番通りにパケットを受信しておらず、以前に送信したパケットの一部が喪失した可能性があることを理解する。ただし、その欠けているパケットが喪失したのではなく遅延しているだけである可能性もあるので、送信側は重複 ACK をいくつか受け取って初めて欠けているパケットの再送を行う。実際の TCP は重複 ACK を三回受け取るとパケットの再送を行う。
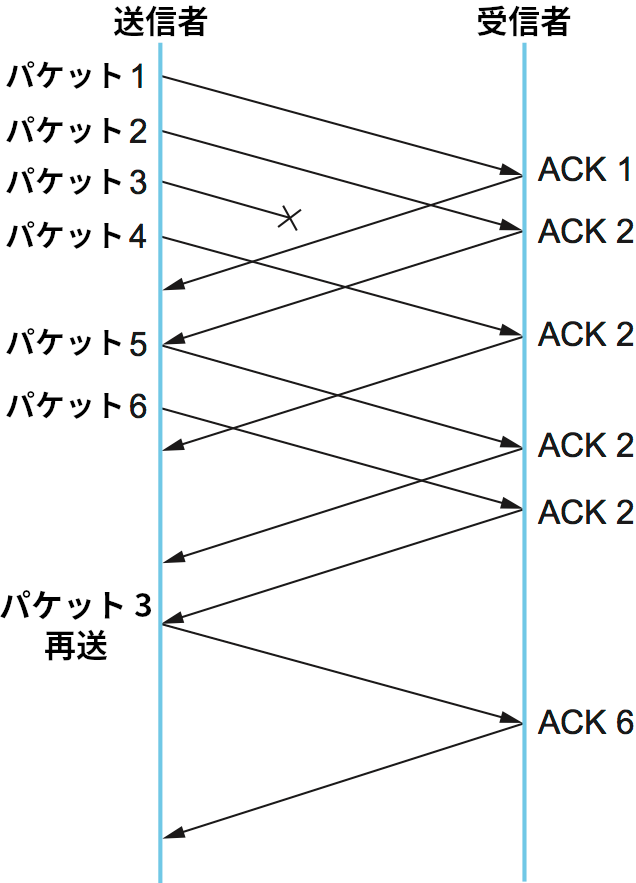
図 163 に重複 ACK が高速再送を引き起こす様子を示す。この例でパケット 1, 2 は受信側に到着するものの、パケット 3 はネットワーク内で喪失する。そのため、受信側はパケット 4 を受け取ったときパケット 2 に対する重複 ACK を送信し、パケット 5 に対しても同様にパケット 2 に対する重複 ACK を送信する (説明を簡単にするために、シーケンス番号はパケットに対して割り振られるものとしている。実際の TCP では各バイトにシーケンス番号が割り振られる)。送信側はパケット 2 に対する三つ目の重複 ACK (パケット 6 を受け取った受信側から送られたもの) を受け取ると、パケット 3 の再送を行う。その後、再送されたパケット 3 を受け取った受信側はパケット 6 に対する累積的 ACK (パケット 3, 4, 5, 6 に対する ACK をまとめたもの) を送信側に送り返す。
CongestionWindow の値、グラフ上部の黒い点はタイムアウト、グラフ上部の太線はパケットの転送、グラフ全体に書かれた縦線は後に再送が起こるパケットの初めての転送をそれぞれ表す。
図 164 に高速再送が有効な場合の TCP の振る舞いを示す。これを高速再送が無効な図 162 と比べると興味深いことが分かる ── 輻輳ウィンドウが大きくも小さくもならない (パケットが送信されない) 時間が短縮されている。一般に、高速再送は典型的な TCP 接続で精度の粗いタイムアウトを約半分に減らし、高速再送を使わない場合と比べてスループットをおよそ 20% 改善する。ただし、高速再送の採用によって精度の粗いタイムアウトが完全に排除されるわけではないことに注意してほしい。これはウィンドウサイズが小さいと送信側が送信できるパケットが少なくなり、高速再送を引き起こすのに十分な重複 ACK を受け取ることができなくなるためである。加えて、喪失パケットが多いとき (例えばスロースタートの開始時) は、送信側はスライディングウィンドウアルゴリズムによってタイムアウトまで送信がブロックされる。実際の TCP が持つ高速再送の仕組みはウィンドウにつき最大で三つのパケットロスを検出できる。
最後に、もう一つ行える改善が存在する。高速再送の発生は輻輳の兆候とみなすことができるものの、ACK が返ってきている事実からは輻輳がそれほど重大でないことが分かる。そのため、輻輳ウィンドウをパケット一つ分にリセットするスロースタートを実行する必要はないだろうと判断できる。高速リカバリ (fast recovery) はこのアイデアに基づく仕組みであり、高速再送がパケットロスを検出したときにスロースタートから加算的増加に移るまでのフェーズをスキップする。例えば図 164 では、高速リカバリがあると約 3.8 秒地点から約 4.0 秒地点までのスロースタートが省略され、輻輳ウィンドウは単に半分に (22 KB から 11 KB に) なるだけとなる。そして最初のスロースタートを除く任意の時点で輻輳ウィンドウは加算的増加と乗算的減少のパターンに従う。
6.3.4 TCP CUBIC
ここまでに説明した標準 TCP アルゴリズムの変種として CUBIC がある。CUBIC は Linux に付属するデフォルトの輻輳制御アルゴリズムであり、ロングファットネットワーク (long-fat network) と呼ばれる帯域遅延積が大きいネットワークのサポートを主要な目標とする。そういったネットワークでオリジナルの TCP アルゴリズムを使うと、通信速度がエンドツーエンドの経路で利用可能な容量に到達するまでに必要となるラウンドトリップが多くなり過ぎる問題が発生する。CUBIC はウィンドウサイズを積極的に増やすことでこの問題を回避する。この処理はもちろん他のフローに負の影響を及ぼさずに行わなければならない。
CUBIC のアプローチの重要な特徴の一つが、輻輳ウィンドウを ACK を受け取ったときにだけ調整するのではなく、最後の輻輳イベント (重複 ACK の受信など) からの経過時間を基準にして定期的に調整する点である。ACK を受け取ったときにだけ輻輳ウィンドウを調整すると、RTT の値によって輻輳ウィンドウが大きくなるペースが変化してしまうことに注目してほしい。輻輳ウィンドウの調整を ACK の受信と関係なく定期的に行うことで、CUBIC は ACK がすぐに返ってくる RTT の短いフローであっても ACK がしばらくしないと返ってこない RTT の長いフローであっても公平に輻輳ウィンドウを設定できる。
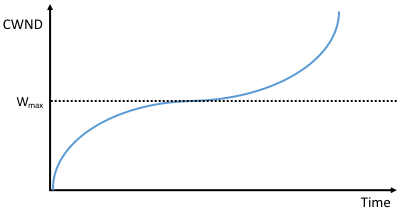
CUBIC の二つ目の重要な特徴として、輻輳ウィンドウの調整に使われる三次関数がある。基本的なアイデアは図 165 に示した一般的な三次関数の形を見ると分かりやすいだろう。この曲線は三つのフェーズから構成される: 輻輳ウィンドウサイズは最初に減速しながら増加し、次に停滞状態となり、最後に加速しながら増加する。図 165 にはもう一つの情報も描かれている: 輻輳ウィンドウサイズの変化は \(W_{\text{max}}\) で最も平坦になる。この \(W_{\text{max}}\) は最後の輻輳イベントにおける輻輳ウィンドウサイズを表す。つまり最初は輻輳ウィンドウを急激に拡大し、\(W_{\max}\) の前後では拡大のスピードを一気に緩め、その後は \(W_{\max}\) から離れるに従って拡大速度を上げていくというのが CUBIC の戦略である。最後のフェーズは達成可能な新しい \(W_{\max}\) の値を探索するフェーズと言える。
具体的に言うと、CUBIC は輻輳ウィンドウサイズ \(\text{CWND}(t)\) を最後の輻輳イベントからの経過時間 \(t\) の関数として次のように計算する:
ここで \(K\) は次のように計算される:
\(C\) はスケーリングを行う定数であり、\(\beta\) は乗算的減少の係数である。標準 TCP は \(\beta = 0.5\) を用いるのに対して、CUBIC は \(\beta = 0.7\) を用いる。また、図 165 からも分かるように、CUBIC は凹関数から凸関数へ移行する戦略と説明されることがある (標準 TCP の加算的増加は凸でしかない)。