6.5 クオリティオブサービス (QoS)
汎用のパケット交換ネットワークはあらゆる種類のアプリケーションとデータをサポートするものとされる。サポートされるアプリケーションにはデジタル化された音声や映像のストリームを転送するマルチメディアアプリケーションも含まれる。初期のネットワークにおいて、こういったアプリケーションを達成する上での課題の一つが広い帯域を持つ回線の提供だった。これは現在では問題にはならないものの、ネットワークを通じた音声と映像の転送では十分な帯域の提供以外にも課題が存在する。
例えば音声通話では、参加者は自分が発した音声がすぐに他の参加者に届き、それに対する反応がすぐに返ってくることを期待して会話を行う。そのため、適時性 (timeliness, 転送を遅延させないこと) が非常に重要になる。データの遅延が大きいと正常な動作が不可能になるアプリケーションをリアルタイムアプリケーション (real-time application) と呼ぶ。リアルタイムアプリケーションの代表的な例として音声または映像を扱うアプリケーションが示される場合が多いものの、産業用制御アプリケーションといった他の例も存在する ── ロボットアームに対する命令はアームが障害物にぶつかる前に届かなければならない。ファイル転送アプリケーションが適時性に関する要件を持つ場合もある: 例えばデータベースの更新を深夜中に終わらせて、翌日の仕事中にデータを利用できるようにしなければならない状況などが考えられる。
リアルタイムアプリケーションの際立った特徴に、データが (何らかの意味で) 時間通りに届くことの保証をネットワークに要求することがある。これに対して、非リアルタイムのアプリケーションはエンドツーエンドの再送戦略によってデータが確実に届くことをネットワークエッジ (ホスト) で保証する。再送を行ってデータの到着が遅くなれば全体の遅延はそれだけ伸びるので、そういった確実性を保証する戦略は適時性を提供できない。適時性を持ったデータの転送はネットワーク (を構成するルーターの全て) で提供されなければならず、エッジで提供するだけでは十分でない。そのため、ネットワークがデータの転送を試みるだけで何も保証せず、様々な保証をエッジが提供するベストエフォート型サービスモデルはリアルタイムアプリケーションには不十分だと結論できる。リアルタイムアプリケーションをサポートするには、各アプリケーションが自身の必要とするベストエフォートより高度な保証をネットワークに要求できる新しいサービスモデルが必要になる。要求を受けたネットワークはサービスの保証を提供するか、現在その保証は提供できないことを伝えることで要求に応答する。この新しいサービスモデルはベストエフォート型サービスで十分なアプリケーションもサポートできる点に注意してほしい。そういったアプリケーションは要求する保証が少ないだけに過ぎない。このサービスモデルは一部のパケットを他のパケットとは異なる方法で扱うという、ベストエフォート型サービスモデルに存在しない処理を行うことを意味する。こういった異なるレベルのサービスを提供できるネットワークは QoS (quality of service, クオリティオブサービス) をサポートすると言う。
6.5.1 アプリケーションの要件
アプリケーションに QoS を提供するために使われるプロトコルや仕組みを見ていく前に、アプリケーションで何が必要とされるかを考えよう。まず、アプリケーションはリアルタイムアプリケーションと非リアルタイムアプリケーションの二つに分けられる。後者は昔からデータネットワークで広く利用されてきたアプリケーションなので、 伝統的データアプリケーション (traditional data application) と呼ばれることがある。例えば SSH やファイル転送、メール、ウェブブラウジングなどが含まれる。こういったアプリケーションはどれも、適時性を持ったデータ転送が保証されなくても正しく動作する。遅延が大きい場合でも対応できることから、非リアルタイムアプリケーションには弾性 (elastic) があると言う場合がある。つまり弾性があるアプリケーションは遅延が小さければ動作の質が向上するものの、遅延が大きくなった場合でも正しく動作する。また、SSH などの対話的アプリケーションとメールなどの非同期アプリケーションでは遅延要件が大きく異なる (ファイル転送のような対話的バルク転送はその中間にある) ことにも注目してほしい。
リアルタイムアプリケーションの例: 音声通話アプリケーション
リアルタイムアプリケーションの具体例として、図 172 に示すような音声通話アプリケーションを考えよう。マイクがサンプルした音声をデジタル化したデータがパケットごとに切り出され、ネットワークを通じて転送される。そのパケットを受け取ったホスト (通話相手) はデータを適切なペースで再生しなければならない。例えば音声サンプルが 125 μs に一度のペースで収集されるなら、そのサンプルをデジタル化したパケットを受け取ったホストはそれを同じペースで、つまり各サンプルを一つ前のサンプルから 125 μs 後に再生しなければならない。仮にサンプルが適切な再生時刻までに (大きな遅延を経験するか、途中で破棄されるかして) 届かなかった場合、そのサンプルは何ら使いものにならなくなる。この「遅れたデータが全く役に立たない」という事実によってリアルタイムアプリケーションは特徴付けられる。これに対して弾性のあるアプリケーションではデータが適切な時刻までに届くのが望ましいものの、到着が遅れたとしても届いたデータは利用できる。

こういった音声通話アプリケーションを動作させる方法の一つとして「全てのパケットがネットワークを通過するのにかかる時間を正確に同じにする」というものが考えられる。そうした上で全てのサンプルを 125 μs ごとに転送すれば、受信側もサンプルを 125 μs ごとに受け取るので、適切にサンプルを再生できる。しかし、パケット交換ネットワークを通過する全てのパケットに全く同じ遅延を保証することは一般に難しい。パケットはスイッチやルーターでキューに積まれる可能性があり、そのキューの長さは時とともに変化する。これは音声ストリームを構成する各パケットが格納されるキューの位置がそれぞれ異なることを意味する。この問題に対処するために、受信側は一定量のデータを取り置いておくためのバッファを用意して、再生すべき適切な時刻が来るまで受け取ったパケットをそこに保存する。遅延が小さいパケットはバッファに格納されてしばらく経ってから再生され、遅延が大きいパケットはバッファに格納されてすぐに再生される。これは、受信側が途切れなく音声を再生できることを保証するために受け取ったパケットの再生時刻に定数のオフセットを加えているとみなすことができる。このオフセットを本書では再生遅延 (playback delay) と呼ぶ。再生バッファを使うとき、問題が発生するのはパケットの到着が大きく遅れた (再生遅延より大きな遅延が発生した) ために再生バッファが空になった場合だけとなる。
再生バッファの動作を図 173 に示す。左側にある斜めの直線は一定のペースで生成されるパケットを表す。中央の青い線は受信側に届くパケットを表す。この青い線はパケットがネットワークの遅延だけ遅れて受信側に到着する事実を反映してパケットの生成を表す直線よりも右側から始まり、ネットワークの遅延が状況によって変化する事実を反映して曲線となる。右側にある斜めの直線は一定のペースで再生されるパケットを表す。パケットが到着してから再生されるまでの間、そのパケットはバッファに格納される。再生を表す直線が十分右にある限り、アプリケーションはネットワーク遅延の変動を関知しないで済む。一方で、パケットの到着を表す青い曲線が再生を表す直線より右に出ると、その部分は再生されなくなり、対応するパケットは価値を持たなくなる。
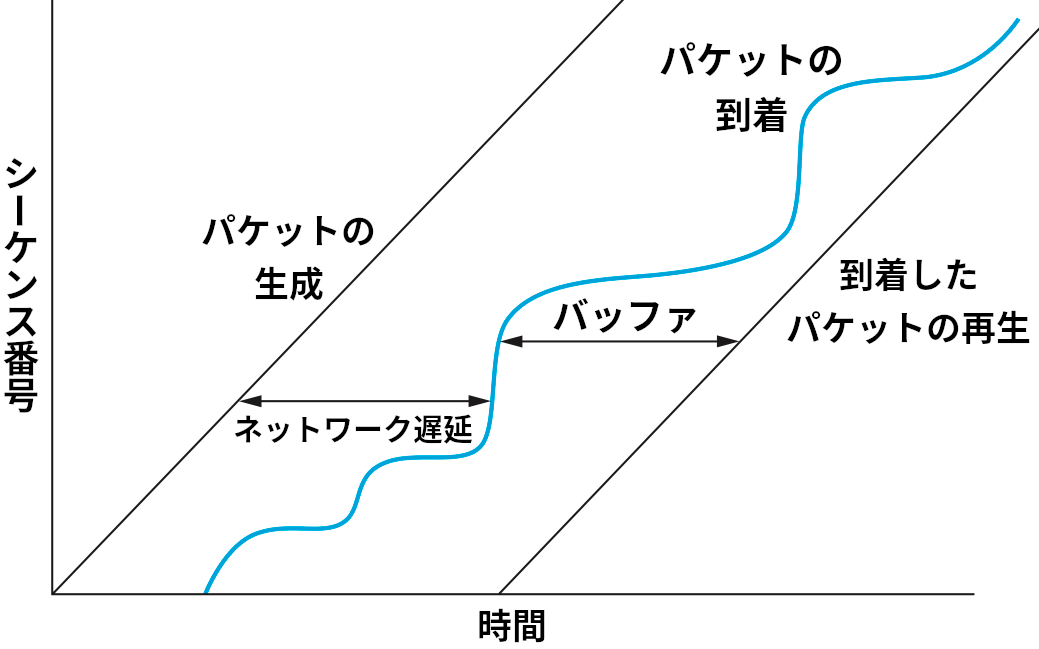
今考えている音声通話アプリケーションでは、ネットワーク越しに転送したデータが再生されるまでの遅延に限度が存在する。発話してから通話相手が音声を聞き取るまでの時間が 300 ms 以上だと会話が困難になることが知られているので、データが 300 ms 以内に届くことの保証がネットワークに必要となる。それより早く届いたデータは正しい再生時刻までバッファされ、それより遅く届いたデータは価値がないので捨てられる。
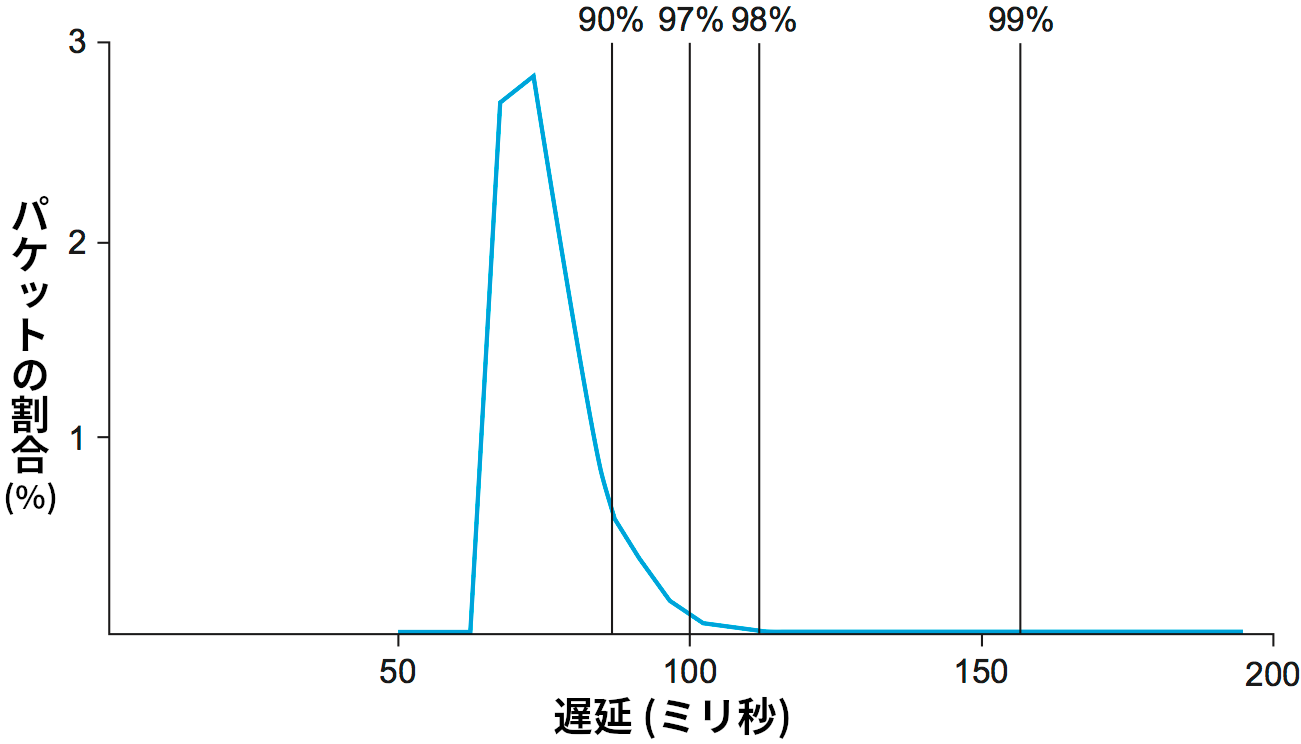
ネットワークの遅延がどの程度変動するのかを理解するために、図 174 に示したインターネットの特定の経路における片道遅延の計測結果を見てほしい。計測は一日を通して行われた。正確な数字は経路や日によって異なるものの、ここで重要なのは遅延の変動であり、ここにあるパターンはインターネットの多くの経路と多くの時間帯で見ることができる。グラフにある縦線を見ると、この経路では 97% のパケットが 100 ms 以下の遅延を持つことが分かる。これは、もし音声通話アプリケーションが再生遅延を 100 ms に設定しているなら、パケット 100 個につき 3 個は再生できない (届いても利用できないほどの遅延を経験する) ことを意味する。このグラフに関しては、曲線の尾 (右下の部分) が非常に長いことが重要な意味を持つ。音声を一切途切れずに再生できることを保証するには、再生遅延を 200 ms より大きな値に設定しなければならないだろう。
リアルタイムアプリケーションの分類
リアルタイムアプリケーションの具体的な動作が理解できたと思うので、次はもっと細かくアプリケーションを分類してみよう。これはサービスモデルを考える上での基礎となる。図 175 に示す分類は主に Clark, Braden, Shenker, Zhang らの研究に基づいている。
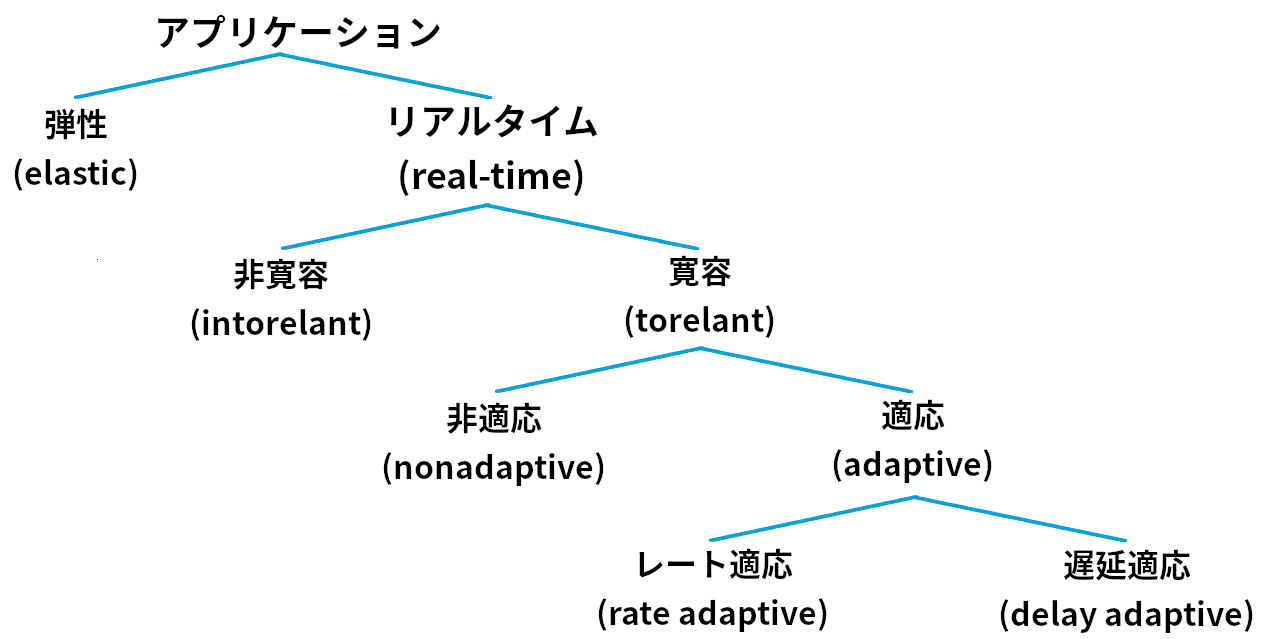
リアルタイムアプリケーションを分類する最初の特徴は「データロスを許容できるかどうか」である。ここで「データロス」にはネットワークで生じる通常のパケットロスに加えて、音声の再生に追いつかないほど遅延してパケットが届くといったアプリケーション特有の要件が守られないことも含まれる。一方には、多少のデータロスが許容できるアプリケーションが存在する。例えば音声通話アプリケーションで音声サンプルが一つ欠けただけなら、周辺のサンプルから値を補間すればユーザーが認識する音質への影響は小さくて済む。大量のサンプルが失われない限り会話が認識不可能になることはない。もう一方には、データロスが一切許容できないアプリケーションが存在する。例えばロボットに送った「アームの動作を停止せよ」の命令が届かないと破滅的な結果となる可能性がある (余談: 多くのリアルタイムアプリケーションは非リアルタイムアプリケーションよりデータロスに耐性がある。例えば音声通話アプリケーションとファイル転送アプリケーションを比べてみてほしい。ファイル転送ではデータロスが一つでもあるとファイル全体が価値を失う)。
リアルタイムアプリケーションを分類する二つ目の特徴はネットワークの不調に対する適応性 (adaptability) である。例えば、音声通話アプリケーションはパケットの遅延に適応できる可能性が高い。再生遅延が 300 ms に設定された音声通話アプリケーションが全てのパケットの遅延は実際には 100 ms 以内であることに気が付いたとしよう。このとき再生遅延を 100 ms に縮めれば、ユーザーが経験する通話の質は向上する。再生遅延を調整するときは短い間サンプルを本来とは異なる速度で再生しなければならないものの、音声通話アプリケーションでは誰も喋っていないときに再生遅延を調整すればユーザーは気付かないので問題は起こらない。そのため再生遅延の調整は難しい問題ではなく、vat と呼ばれる音声通話会議プログラムをはじめとする音声通話アプリケーションで効率的に実装されている。なお、再生遅延の調整は両方向に行うことができ、その影響はデータの利用方法によって異なる。
再生遅延を 100 ms に設定した後に 100 ms より少しだけ大きい遅延を持ったパケットが届いた場合、そのパケットは破棄しなければならないことに注目してほしい。このパケットは再生遅延が 300 ms のままだったなら破棄する必要はない。そのため、再生遅延の短縮はユーザーが認識できる程度の質の改善が存在し、新しい再生遅延に間に合わないパケットの数が十分小さいことの証拠があるときにだけ行わなければならない。例えば最近のパケットが経験した遅延やネットワークの遅延保証を元に再生遅延の調整が行われる。
再生遅延を調整できるアプリケーションを遅延適応 (delay-adaptive) アプリケーションと呼ぶ。遅延適応とは異なる適応性にレート適応 (rate adaptive) がある。例えば、多くの映像コーディングアルゴリズムはビットレートと画質の間のトレードオフを調整できるようになっているので、ネットワークがサポートできる帯域に応じてアルゴリズムのパラメータを調整できる。さらに、通信を開始した後に利用可能な帯域が増加したなら、パラメータを変更して画質を改善することもできる。
QoS サポートのアプローチ
アプリケーションが抱える要件が非常に多様であることを考えると、あらゆるアプリケーションに対応するには豊富な機能を持ったサービスモデルが必要になる。ここから、機能のクラスを一つ (ベストエフォート) しか持たないサービスモデルではなく、特定の種類のアプリケーションに合わせたクラスを複数持ったサービスモデルが要請される。この点が理解できれば、様々な QoS を提供するために考案されてきたアプローチを見ていく準備がようやく整う。QoS を提供するアプローチは大きく分けて二つのカテゴリに分けられる:
-
粒度の細かい (fine-grained) アプローチ: QoS をアプリケーションあるいはフローに対して個別に提供する。
-
粒度の粗い (coarse-grained) アプローチ: QoS を大きなデータのクラスあるいは集約トラフィックに対して提供する。
一つ目のカテゴリに含まれるアプローチの例として IntServ (Integrated Services) がある。IntServ は IETF で策定された QoS アーキテクチャであり、RSVP (Resource Reservation Protocol) と共に利用される。二つ目のカテゴリの例として DiffServ (Differentiated Services) がある。DiffServ はおそらく最も多くデプロイされている QoS の仕組みである。以降の項では IntServ と DiffServ を順に説明する。
最後に、本節の最初にも触れたように、ネットワークに QoS サポートを追加すればリアルタイムアプリケーションをサポートできるわけではない。IntServ や DiffServ といった QoS の仕組みがどれだけデプロイされているかとは独立してエンドホストがリアルタイムストリームのサポートを改善するためにできる工夫を最後に紹介する。
6.5.2 IntServ と RSVP
IntServ (Integrated Services) という言葉は 1995 年から 1997 年にかけて IETF によって策定された一連の規格の集合を指す。IntServ ワーキンググループは上述したような特定の種類のアプリケーションが必要とする機能を提供するために設計されたサービスクラス (service class) の仕様をいくつか策定した。また、RSVP を使ってサービスクラスを使うための予約を行う方法も定義した。以降ではこれらの仕様の概要と実装するのに使われた仕組みを説明する。
サービスクラス
まず、 非寛容 (intorelant) なアプリケーションのために設計されたサービスクラスがある。そういったアプリケーションはパケットが決して遅延しないことを要求する。ネットワークは任意のパケットが経験する遅延の最大値を何らかの値として保証しなければならない。保証される遅延より大きな値に再生遅延を設定すれば、アプリケーションは必ず再生遅延より前にパケットを受け取ることができる。なお、保証された遅延よりも早く到着したパケットはバッファリングによって処理されることが仮定されている。このサービスは保証型サービス (guaranteed service) サービスと呼ばれる。
IETF は保証型サービスとは異なるサービスもいくつか議論し、最終的に寛容かつ適応可能なアプリケーションの要求に応えるためのサービスを一つ策定した。このサービスは負荷制御型サービス (controlled load service) と呼ばれる。寛容かつ適応可能な既存のアプリケーションは負荷が高くないネットワークで非常によく動作するという観察が負荷制御型サービスを策定するモチベーションとなった。例えば音声通話アプリケーションで遅延の変動とパケットロスが起きたとしても、パケットロスの割合が 10% 程度以下であれば再生遅延を調整することで音質の低下を気にならない程度に抑えられる。
負荷制御型サービスはネットワークにかかる負荷が大きくなった場合でも負荷が小さいときと変わらない振る舞いをアプリケーションに提供することを目標とする。具体的には、重み付き公平キューイング (WFQ) といったキューイングの仕組みを用いて負荷制御トラフィックを他のトラフィックから分離し、リンク上に存在する負荷制御トラフィックの総量を制限して負荷を低い状態に保つ一種の流入制御が行われる。流入制御については後で詳しく議論する。
明らかに、これら二つのサービスクラスは提供できるサービスクラスの一部でしかない。実際、IETF の活動の中で議論されたものの標準化されなかったサービスモデルがいくつか存在する。ただこれまでのところ、上述した二つのサービスモデル (および伝統的なベストエフォート型サービスモデル) は様々なアプリケーションの要求に応えられるだけの柔軟性を持つことが示されている。
実装の概要
ベストエフォート型サービスモデルとは異なる新しいサービスクラスが議論に加わったことで、そういったサービスをアプリケーションに対して提供するネットワークをどのように実装するかという疑問が生まれる。ここでは、実装で使われる主要な仕組みを概説する。以降の文章を読むときは、話題に上がる仕組みに関する議論は依然としてインターネット設計コミュニティの中で続いていることを念頭に置いてほしい。以降の議論は上述したサービスモデルをサポートするときに関係する要素を大まかに説明するためにある。
第一に、ベストエフォート型サービスではパケットの宛先をネットワークに伝えるだけだったのに対して、リアルタイムサービスでは必要なサービスの種類に関する細かな情報をネットワークに伝える処理が存在する。ネットワークに伝える情報が「負荷制御型サービスを使いたい」と言った質的情報であることもあれば、「最大遅延が 100 ms である必要がある」といった量的情報である場合もある。さらに、アプリケーションが利用する帯域によってネットワークにかかる負荷は異なるので、送信側の要求するサービスに関する情報だけではなく、送信側が送信しようとしているデータに関する情報もネットワークに伝える必要がある。送信側がネットワークに提供するこういった情報を総称してフロースペック (flowspec) と呼ぶ。ここでフロー (flow) は単一のアプリケーションに関連付いた共通の要件を持つパケットの集合を指しており、これまで本書で使ってきた「フロー」と同じ意味を持つ。
第二に、送信側が特定のサービスを提供するようネットワークに要求するとき、ネットワークはそのサービスを提供できるかどうかを判断できる必要がある。例えば、10 人のユーザーが 2 Mbps の回線容量を継続的に利用するサービスを要求していて、全てのユーザーが 10 Mbps の容量しか持たない一つのリンクを共有しなければならないとしよう。このときネットワークは一部のユーザーに対してサービスの提供を断らなければならない。サービス提供の可否を判断するこのプロセスをアドミッション制御 (admission control) と呼ぶ。
第三に、ネットワーク内のユーザーおよびコンポーネントはサービスのリクエスト、フロースペック、アドミッション制御の判断といった情報をやり取りする必要がある。このやり取りを指してシグナリング (signalling) という言葉が使われることがある。ただ「シグナリング」には他の意味もあるので、本書ではこのやり取りをリソース予約 (resource reservation) と呼ぶ。
最後に、フローおよびフローの要件が記述され、そしてアドミッション制御が判断を下したとき、ネットワークの内のスイッチとルーターはそのフローの要件に応える必要がある。ここで鍵となるのはスイッチとルーターが転送するパケットをどのようにキューに入れ、どのようにスケジュールするかを管理する処理であり、これはパケットスケジューリング (packet scheduling) と呼ばれる。
フロースペック
IntServ のフロースペックは二つの異なる要素からなる:
- RSpec: ネットワークに要求するサービスを記述する。
- TSpec: 送信するフローのトラフィック的な特徴を記述する。
RSpec はサービス固有であり、比較的簡単に記述できる。例えば負荷制御型サービスの RSpec は自明である: 「私 (アプリケーション) は負荷制御型サービスをリクエストします」だけで十分であり、それ以外のパラメータは必要ない。保証型サービスであれば遅延の目標値や上限値を指定することになる (IETF による保証型サービスの仕様では、遅延そのものではなく遅延を計算できる別の値を指定する)。
TSpec はこれよりも多少複雑になる。上述したように、合理的なアドミッション制御を行うにはフローが利用する帯域に関する十分な情報をネットワークに提供しなければならない。しかし多くのアプリケーションにとって、帯域とは一つの値で表せるものではない: 例えば映像アプリケーションは映像の動きが激しいとき映像が静的なときに比べて多くのデータを送信する。このため、次の例が示すように、長い時間における平均帯域をネットワークに伝えるだけでは十分でない。
あるスイッチを 10 個のフローが異なる入力ポートを通って通過しており、これらのフローは同じ 10 Mbps リンクを通ってスイッチから離れるとする。加えて、長い時間における各フローの平均帯域は 1 Mbps 未満だと仮定しよう。このとき何ら問題は発生しないと思うかもしれないが、アプリケーションが圧縮された映像のようにビットレートが一定でないデータを送信していると、瞬間的に平均帯域より高いレートでデータを送信する場合がある。そういったアプリケーションが同時に複数存在すると、10 個のフローからスイッチに流れ込むデータが 10 Mbps を超える可能性がある。このときリンクに流せない超過データはキューに格納され、スイッチに流れ込むデータが 10 Mbps より多い状態が続けばそれだけキューも長くなっていく。最終的にはパケットが破棄されるが、そこまでいかなくてもキューが長くなれば遅延は大きくなる。遅延が大きくなれば、リクエストされた保証型サービスは提供できなくなる。
遅延を制御してパケット破棄を回避するためのキューの管理方法については後述する。現在の議論で重要なのは、送信元の帯域の変化に関する情報をネットワークに伝える手段である。帯域の特徴を伝える手段の一つにトークンバケット (token bucket) と呼ばれるアルゴリズムを利用するものがある。このアルゴリズムは次の二つのパラメータで制御される:
-
トークンレート \(r\)
-
バケットの深さ \(B\)
トークンバケットアルゴリズムは次のように動作する。送信元が 1 バイトのデータを送信するには、1 個のトークンが必要となる。つまり \(n\) バイトのパケットを送信するには、\(n\) 個のトークンを持っていなければならない。送信元は最初トークンを持っておらず、そこから 1 秒ごとに \(r\) 個のトークンを受け取る。ただしトークンは最大で \(B\) 個までしか持つことができず、それ以上のトークンは破棄される。これは送信元が一度に (「バーストで」) 送信できるデータは最大でも \(B\) バイトであることを意味する。そして \(B\) バイトを送信し終えると、しばらくの間は最大でも毎秒 \(r\) バイト程度しか送信できなくなる。このアルゴリズムを用いて \(r\) と \(B\) の値を TSpec に含めると非常に優れたアドミッション制御を行えることが判明している。
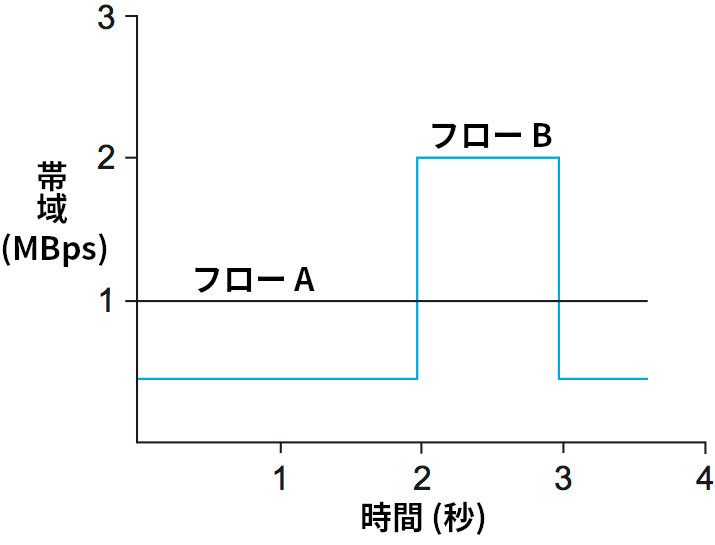
トークンバケットのパラメータ \(r\), \(B\) を用いてフローの帯域要件を記述する例を図 176 に示す。ここでは説明を簡単にするため、それぞれのフローはパケット単位ではなくバイト単位でデータを送信すると仮定する。フロー A はデータを常に 1 Mbps で送信しているので、その帯域要件は \(r = 1~\text{\footnotesize Mbps}\) と \(B = 1~\text{\footnotesize Byte}\) というパラメータで記述できる。これは、フロー A はトークンを 1 Mbps のレートで受け取り、最大でも一つ (1 バイト分) のトークンしか保持しない、つまりトークンをすぐに消費することを意味する。
フロー B のデータ送信レートは長い時間の平均を取れば 1 Mbps になるものの、細かく見るとフロー B はデータを 0.5 Mbps のレートで 2 秒間送信し、その後 2 Mbps のレートで 1 秒間送信する動作を繰り返す。トークンレート \(r\) は平均送信レートを表すとも言えるので、フロー B でも \(r = 1~\text{\footnotesize Mbps}\) となる。しかしフロー A と異なり、フロー B は最低でも 1 MB の深さを持つバケットが必要になる: 2 Mbps で送信を始める直前に 1 MB のトークンを貯めておかなければならない。図 176 の最初の 2 秒間でフロー B はトークンを 1 Mbps で受け取りながらデータを 0.5 Mbps で送信する。このとき余分な 0.5×2 = 1 MB のトークンを貯めておくことができれば、フロー B は次の 1 秒で新たに受け取る 1 MB のトークンと合わせて 2 MB 分の送信を行える。この送信が終わるとバケットは空になり、またトークンの蓄積が始まる。
興味深い事実として、トークンバケットアルゴリズムでフローの帯域要件を記述する二つのパラメータ \(r\), \(B\) の選び方は一意でない。明らかな例として、図 176 のフロー A を記述するのにフロー B のパラメータ \(r = 1~\text{\footnotesize Mbps}\) と \(B = 1~\text{\footnotesize MB}\) を設定しても構わない。フロー A はバケットにトークンを貯めることはないものの、だからといってこの記述が不正確になるわけではない。ただネットワークには「フロー A が必要とする帯域は一定である」という有用な情報が伝わらないので、リソースの利用効率は最適ではなくなるだろう。一般に、自身がちょうど必要とするだけの帯域要件を伝えてネットワークリソースを余計に確保しないことがアプリケーションには求められる。
アドミッション制御
アドミッション制御のアイデアは難しくない: 新しいフローが特定のレベルのサービスを要求したとき、フローの TSpec と RSpec を確認してサービスを提供できるかどうかを判断する処理がアドミッション制御である。この判断では現在利用可能なリソース量や以前に受理したサービスに対する影響などが考慮される。サービスが提供可能だと判断されればフローは受理され、そうでなければ拒否される。受理すべきリクエストと拒否すべきリクエストを見極める部分が難しい仕事となる。
アドミッション制御が行う処理はリクエストされるサービスの種類とルーターで採用されるキューイング規則によって大きく異なる。本項では後者について議論する。保証型サービスでは、リクエストの受理と拒否を確定的に判断するには優れたアルゴリズムが必要となる。全てのルーターで重み付き公平キューイング (WFQ) が使われているなら、判断は非常に簡単に行える。負荷制御型サービスでは、リクエストを受理するかどうかの判断をヒューリスティックで行う場合がある。例えば「前回この TSpec を持ったフローをこのクラスに加えたとき、このクラスが経験する遅延は閾値を上回っていた。よってこのリクエストは拒否しよう」あるいは「現在の遅延は閾値を超えていないから、フローを一つ受け入れても大丈夫だろう」といった基準で判断が下される。
アドミッション制御と似ているものの異なる言葉としてポリシング (policing) がある。両者を混同しないように注意してほしい。アドミッション制御は新しいフローを受け入れるかどうかを判断する処理であるのに対して、ポリシングはフローがサービス予約時に示した TSpec に従っているかどうかをパケットごとに監視する処理を言う。フローが TSpec に従っていない ── 例えば申告したレートの 2 倍のレートでデータを送信している ── 場合には、それを是正するための介入が必要になる。介入の方法はいくつか考えられる。最も単純なのは「超過したパケットを全て捨てる」だが、その前に「超過したパケットが他のフローのサービスに干渉するかを確認する」ステップを踏む選択肢もある。もし干渉しないなら、そのパケットは送信しても問題ない。そのときは「これは TSpec に反したパケットだから、もしパケットを破棄するときはこのパケットから破棄せよ」という印をパケットに付けることができる。
アドミッション制御はポリシー (policy) という重要な問題と密接に関連している。例えば、会社の CEO によるリソース予約を下位の従業員によるリソース予約より優先して受け入れたい状況があるかもしれない。もちろん、リクエストされたリソースが利用可能でなければ CEO による予約であっても拒否しなければならないので、ポリシーとリソースの残量はアドミッション制御の判断が行われるときに同時に考慮されなければならない。本書の執筆時点において、ネットワークにおけるポリシーの活用は大きな注目を集めている分野である。
予約プロトコル
コネクション指向ネットワークでは通信を行う前に仮想回線の状態を経路上の各スイッチに確立しなければならないので、何らかのセットアップ用プロトコル (シグナリングプロトコル) が必要になる。これに対してインターネットのようなコネクションレスネットワークはそういったプロトコルを持たない。しかし本節の議論から分かるように、リアルタイムサービスをサポートするには多くの情報をネットワークに伝えなければならない。インターネットで使うためのシグナリングプロトコルは数多く提案されており、現在では RSVP (Resource Reservation Protocol) と呼ばれるプロトコルに注目が集まっている。RSVP は従来のコネクション指向ネットワークにおけるシグナリングプロトコルと大きく異なっており、その点で興味深いプロトコルとなっている。
RSVP の思想の一つに「現在のコネクションレスネットワークが持つロバスト性を損なってはいけない」というものがある。コネクションレスネットワークはネットワーク内に保存される状態にほとんど (あるいは全く) 依存しないので、エンドツーエンド接続が保持されている間にルーターがクラッシュして再起動したり、リンクが壊れたり追加されたりすることがあり得る。RSVP はソフトステート (soft state) のアイデアを使ってこのロバスト性を保持することを試みる。コネクション指向ネットワークにおけるハードステート (hard state) と異なり、ソフトステートは使わなくなった場合でも明示的には削除されない。その代わり、ソフトステートは定期的な更新が行われなくなってしばらく (例えば 1 分が経過) すると自動的に削除される。この特徴とロバスト性がどのように関連するのかは後述する。
RSVP のもう一つの特徴として、RSVP はマルチキャストフローをユニキャストフローと変わらない効率でサポートすることを目標としている。QoS の恩恵を受けるアプリケーションは (ビデオ会議ツールなど) マルチキャスト通信を行うことが多い事実を考えれば驚くことではない。RSVP の設計者たちは、多くのマルチキャストアプリケーションでは送信者より受信者の方がずっと多い事実を上手く利用した。例えば一人が行う講演を多くの聴衆が視聴する状況がこれに当てはまる。
また、マルチキャストアプリケーションでは受信者の要件がそれぞれ異なる場合がある。例えば、特定の送信者からのデータだけを受け取れば十分な受信者と全ての送信者からのデータを受け取る必要がある送信者が同時に存在しても不思議ではない。こういった状況では、大量の受信者に関する情報を送信者が記憶するのではなく、それぞれの受信者が自身の必要とするものを記憶する方が理にかなっている。ここから RSVP が採用する受信者指向 (receiver-oriented) のアプローチが生まれた。これに対して、コネクション指向ネットワークでは (電話で発信者が電話回線上にリソースを予約するのと同じように) 送信者がリソース予約を行う場合が多い。
RSVP が持つソフトステートと受信者指向という性質は多くの優れた特徴を RSVP に与えている。そのような特徴の一つとして、受信者はリソース割り当てのレベルを非常に簡単に上下できる。各受信者はソフトステートが失われないように定期的に更新メッセージを送信するので、そのときに異なるレベルのリソースに対する新しい予約を送信できる。さらに、ソフトステートはネットワークあるいはノードで起きる障害に問題なく対処できる。ホストがクラッシュしたときは、そのホストが確保していたリソースはタイムアウト時に自然に解放される。ルーターあるいはリンクで障害が発生したときに何が起こるかを理解するには、まずリソース予約の仕組みを詳しく見る必要がある。
最初に、単一の送信者と単一の受信者がお互いの間に流れるトラフィックに対するリソース予約を行う状況を考える。この状況で受信者が実際に予約を行う前に行わなければならないことが二つある。第一に、受信者は適切な予約を行うために送信者が送るトラフィックがどんなものかを知らなければならない。言い換えれば、受信者は送信者の TSpec を知る必要がある。第二に、送信者と受信者を結ぶ経路上の各ルーターにその経路でリソース予約が起こることを知らせなければならない。この二つの情報は TSpec を記した PATH メッセージ (PATH message) と呼ばれるパケットを定期的に送信者から受信者に送ることで伝達される。PATH メッセージによって TSpec は明らかに受信者に伝達され、さらに PATH メッセージを受け取ったルーターはこれから予約される経路を知ることができる。PATH メッセージの送信に使われるマルチキャスト配送木の作成では第 4.3 節で説明したような方法が使われる。
PATH メッセージを受け取った受信者はマルチキャスト配送木に向かって RESV メッセージを送信して予約を行う。この RESV メッセージには送信者から知らされた TSpec と受信者の要件を記した RSpec が含まれる。RESV メッセージを確認した経路上の各ルーターは、それが要求するだけのリソースの確保を試みる。もしリソースを確保できるなら、ルーターは RESV メッセージを次のルーターに受け渡す。もしリソースを確保できないなら、ルーターはエラーメッセージを受信者に返す。RESV メッセージが送信者に届けば、受信者と送信者の間にリソースが確保された経路が構築される。受信者は予約を保持したいと望む限り定期的に (約 30 秒ごとに) 同じ RESV メッセージを送信する。
続いて障害の対処を考える。ルーターやリンクで障害が発生すると、ルーティングプロトコルによって送信者から受信者への新しい経路が作成される。PATH メッセージは約 30 秒ごとの定期的な送信に加えてルーターの転送テーブルが変化した場合にも送信されるので、新しい経路が安定化すると PATH メッセージがその経路を通じて受信者に送信される。受信者が次に送信する RESV メッセージは新しい経路を通過し、そのときリソース確保が新しく行われる。経路から外れたルーターは RESV メッセージを受け取らなくなるので、いずれタイムアウトによってリソースが解放される。この仕組みによって、経路の変更が非常に頻繁でない限り RSVP はトポロジーの変更に非常に効率良く対処できる。
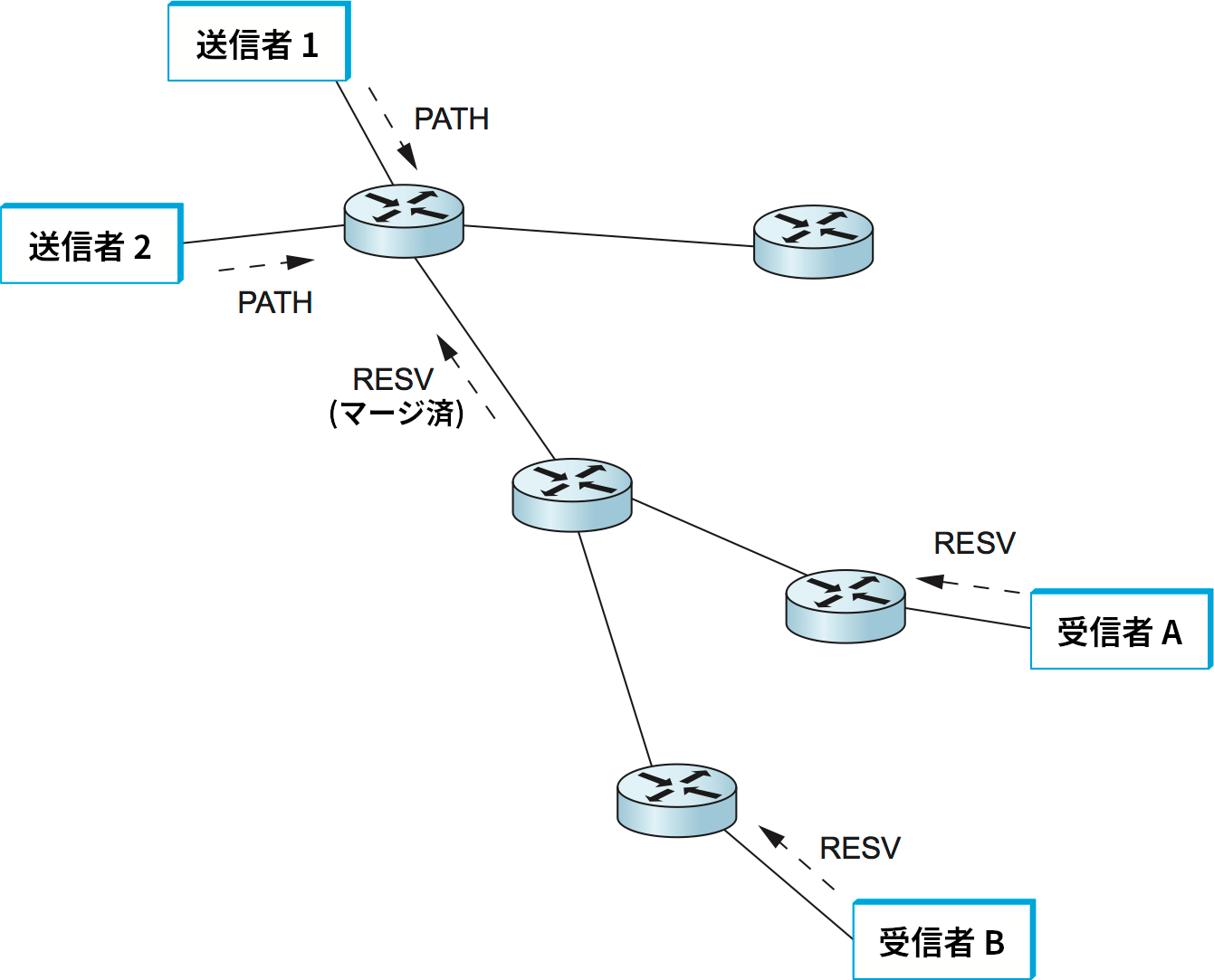
続いてマルチキャストを考えよう。マルチキャストでは図 177 のように複数の送信者が複数の受信者にデータを送信する状況があり得る。最初に単一の送信者と複数の受信者という状況を考えよう。このとき、マルチキャスト配送木を上に向かって進む RESV メッセージは他の受信者に対するリソース予約が既に行われているルーターを通る可能性が高い。この場合、上流のルーターが新しい受信者に対応できるだけのリソースを既に持っている可能性がある。例えば、ルーターが受信者 A に最大遅延 100 ms の保証を提供しているなら、受信者 B に対する最大遅延 200 ms の保証を新しく提供するときに新しいリソース確保は必要ない。一方で、もし最大遅延 50 ms の保証がリクエストされた場合には、ルーターはそのリクエストに応えられるかどうかを調べる必要がある。そして応えられるときに限って RESV メッセージを上流に受け渡すことになる。一般に、ルーターにおけるリソースの予約は下流の受信者の要求を全て満たすようにマージして行うことができる。
複数の送信者が存在する場合、受信者は全ての送信者からの TSpec を収集し、全ての送信者からのトラフィックを受け入れられるだけのリソースを予約する必要がある。ただし、これは各 TSpec を足し上げたリソースを確保することを意味するとは限らない。例えば 10 人が参加する音声通話会議において、10 本の音声ストリームを伝達できるだけのリソースを予約する意味はない: 10 人全員が同時に喋ったときの音声を人間は聞き取れないので、そのような音声を正確に伝えられなくても問題はない。そのため、2 人の音声を伝えられるだけのリソースを予約すれば十分かもしれない。このように、各送信者の TSpec から全体の TSpec を計算する方法はアプリケーションごとに固有となる。また、一部の発言者からの音声だけを聞きたい状況も考えられる。RSVP には異なるスタイルの予約が存在し、「全ての発言者に対するリソースを予約する」「任意の \(n\) 人の発言者に対するリソースを予約する」「発言者 A, B に対するリソースを予約する」といったオプションを指定できる。
パケットの分類とスケジューリング
利用されるトラフィックとネットワークサービスが記述され、経路上のルーターでリソース予約が完了したなら、後はルーターがリクエストされたサービスをデータパケットに対して実際に提供するだけとなる。ルーターが行うべき処理は二つある:
-
パケットの分類 (classifying): パケットを適切な予約と関連付け、正しい処理を受けられるようにする。
-
パケットのスケジューリング (scheduling): リクエストされたサービスがパケットに提供されるようにキューを管理する。
パケットの分類は、送信元アドレス、宛先アドレス、プロトコル番号、送信元ポート、宛先ポートという五つのフィールドを調べることで行われる (IPv6 ではヘッダーの FlowLevel フィールドだけを使って簡潔に分類を行うこともできる)。この情報を元にパケットは適切なクラスに分類される。例えば「負荷制御型クラス」や個別の「保証型フロークラス」が存在する。一言で言えば、パケットの分類処理はパケットヘッダーに含まれるフロー固有の情報を単一のクラス識別子に変換し、このクラス識別子に従ってパケットはキューに格納される。クラスとキューは保証型サービスでは一対一の関係に、他のサービスでは多対一の関係になるだろう。分類の詳細はキューの管理の詳細と密接な関係を持つ。
FIFO キューだけでは様々なサービスを様々な設定で提供できないのは明らかであり、以前に第 6.2 節で議論したような高度なキュー管理の仕組みが必要となる。実際のルーター内にはそういった管理を受けるキューがいくつも用意される場合が多い。
パケットのスケジューリングの詳細は理想的にはサービスモデルで規定されるべきではない。そうではなく、サービスモデルを実現する創造的な手段を実装者が試せるようにするのが望ましい。保証型サービスの場合であれば、各フローにリンクの一定の割合を切り分ける重み付き公平キューイングを使うと、エンドツーエンド遅延の簡単に計算できる上限が保証されることが知られている。負荷制御型サービスではもっと簡単な方式を使うことができる。一つの選択肢として、全ての負荷制御トラフィックを (スケジューリングを考える上では) 単一の集約されたフローとして扱い、そのフローに対する重みをトラフィックの総量に応じて設定する方法がある。単一のルーターが多くの異なるサービスを並列に提供する場合は複数のスケジューリングアルゴリズムを実行する必要があるので、キューの管理は複雑になる。その場合は異なるサービス間でリソースを管理するキュー全体の管理アルゴリズムが必要になる。
スケーラビリティの問題
IntServ アーキテクチャと RSVP はベストエフォート型サービスモデルを大きく拡張したものを提示したにもかかわらず、多くの ISP はこれらをデプロイすべきだと感じていない。この態度の背景には IP の基礎的な設計目標がある: スケーラビリティである。ベストエフォート型サービスモデルを採用するインターネットにおいて、各ルーターは自身を通り抜ける個別のフローに関する情報をほとんど (あるいは全く) 保存しない。そのため、インターネットが成長したとしてもルーターはビットを速く動かせるようにして大きくなったルーティングテーブルに対処できるようにすればそれで済む。しかし RSVP では、ルーターは自身を通り抜ける全てのフローから予約を受ける可能性に対処しなければならない。この問題がどれほど深刻かを理解するために、OC-48 (2.5 Gbps) リンクを通り抜けるフローの全てが 64 Kbps の音声ストリームを伝達する状況を考えよう。このリンクに収まるフローの個数は次のように計算できる:
これらのフローが予約を行えば何らかの状態をメモリに格納しなければならず、状態は定期的な更新を必要とする。ルーターは予約されたフローに応じてパケットの分類と監視、そしてキューの管理を行わなければならず、フローがリソースを予約するたびにアドミッション制御の処理が実行され、さらにユーザーが大きすぎるリソースを予約した場合はメッセージを「突き返す」ことで予約を断わる仕組みも必要になる。
こういったスケーラビリティの問題により、IntServ が広くデプロイされることはなかった。また、こういった問題が明らかになったことで、「フローごと」の状態が少ない別のアプローチも考案された。次項ではこういったアプローチがいくつか議論される。
6.5.3 DiffServe (EF, AF)
IntServ アーキテクチャでは個別のフローごとにリソースが確保されるのに対して、DiffServ (Differentiated Services) モデルでは少数のトラフィッククラス (traffic class) ごとにリソースが確保される。提案されている DiffServ のアプローチの中にはトラフィックを二つのクラスに分割するだけのものさえ存在する。これは非常に思慮深いアプローチと言える: ネットワーク運営者がベストエフォート型のインターネットを問題ない状態に保つためにどれだけの労力を注いでいるかを考えれば、新しいサービスは少しずつ追加されるのが望ましい。
ベストエフォート型サービスモデルに新しい「プレミアム」クラスを追加して拡張することになったとしよう。このとき明らかに、プレミアムのパケットと通常の (ベストエフォート型サービスを受ける) パケットを区別する手段が必要になる。RSVP ではプレミアムのパケットを送信するフローを経路上の全てのルーターに伝えてからデータを送信するものの、パケット自体に印を付けることができれば処理はずっと簡単になる。これはパケットのヘッダーの 1 ビットを利用すれば行える ── そのビットが 1 ならプレミアムのパケットであり、0 なら通常のパケットだと分かる。この仕組みを使うとき、解決すべき問題がさらに二つある:
-
パケットがプレミアムかどうかを表すビットは誰がいつ設定するのか?
-
プレミアムのパケットを受け取ったルーターはどんな動作をするのか?
一つ目の問題の解決方法はいくつか考えられるものの、普通は管理境界 (administrative boundary) でビットを設定するアプローチが使われる。例えば、ネットワークサービスプロバイダが保有するネットワークのエッジに存在するルーターが特定の企業のネットワークに接続するインターフェースに到着するパケットのビットを設定するかもしれない: その企業はベストエフォートより高いレベルのサービスを受けるために別料金を払うことになる。一部のパケットだけをプレミアムにする可能性もある。例えばパケットをプレミアムにできる最大レートがルーターに設定されていて、それを超えた分のパケットはベストエフォートとして転送する運用も考えられる。
パケットに何らかの形で印が付いたとしよう。その印が付いたパケットを受け取ったルーターは何をするのだろうか? ここでも多くの解答が考えられる。実際、IETF 規格は印の付いたパケットに対してルーターが行える動作の集合を定めている。それぞれの動作は PHB (per-hop behavior, ホップ単位の振る舞い) と呼ばれ、名前が示すように、エンドツーエンドのサービスではなく個別のルーターが行う動作を定義する。PHB が定義する新しい動作は二つ以上存在するので、パケットを受け取ったルーターが行うべき動作を伝えるためのフィールドがパケットヘッダーに 1 ビットよりも多く必要になる。IETF は IP ヘッダーで古くから確保されているもののほとんど使われていなかった 1 バイトの TOS フィールドを再定義することを決断した。新しい定義において、TOS フィールドの先頭 6 ビットは DSCP (Differentiated Services Code Point) に割り当てられ、各 DSCP はパケットに対して行うべき PHB を識別する (残りの 2 ビットは ECN で利用される)。
完全優先転送 (EF) PHB
最も単純な PHB の一つに EF (Expedited Forwarding, 完全優先転送) がある。EF を適用すべきという印が付いたパケットを受け取ったルーターは、遅延とロスを最小限にしてそのパケットを転送しなければならない。ルーターが全ての EF パケットに対して正しい動作を行えることを保証するには、EF パケットがルーターに到着するレートをルーターが EF パケットを転送できるレートより小さくなるように制限するしかない。例えば 100 Mbps インターフェースを持つルーターは、そのインターフェースに宛てられた EF パケットの到着レートが 100 Mbps を上回らないことを保証しなければならない。実際には他のパケットも送れるように帯域を 100 Mbps よりさらに小さくしなければならないだろう。
EF パケットのレート制限は管理ドメインのエッジにあるルーターを適切に設定し、管理ドメインに流入する EF パケットのレートに最大値を設けることで行われる。これを行うための保守的であるものの単純なアプローチとして、管理ドメインへの EF パケット流入レートをドメイン内で最も低速なリンクの帯域より小さくする方法が考えられる。こうしておけば、全ての EF パケットが最も低速なリンクに集中する最悪の場合でも EF パケットに対して正しい動作を提供できる。
EF の動作を実装する戦略にはいくつか選択肢がある。EF パケットに厳格な優先権を与えて他のパケットとは別に扱う戦略の他にも、重み付き公平キューイングを使って全ての EF パケットが迅速に転送できる十分高い重みを EF パケットに与える戦略も考えられる。この二つの戦略を比べると、後者の戦略には EF トラフィックが大きくなった場合でも非 EF パケットが流れ続ける利点がある。そのような状況で EF パケットは規定された動作を厳密には受けられないかもしれないが、EF トラフィックが増加したときにネットワークの動作に不可欠なルーティングトラフィックがネットワークから追い出されてしまう事態を防ぐことができる。
相対的優先転送 (AF) PHB
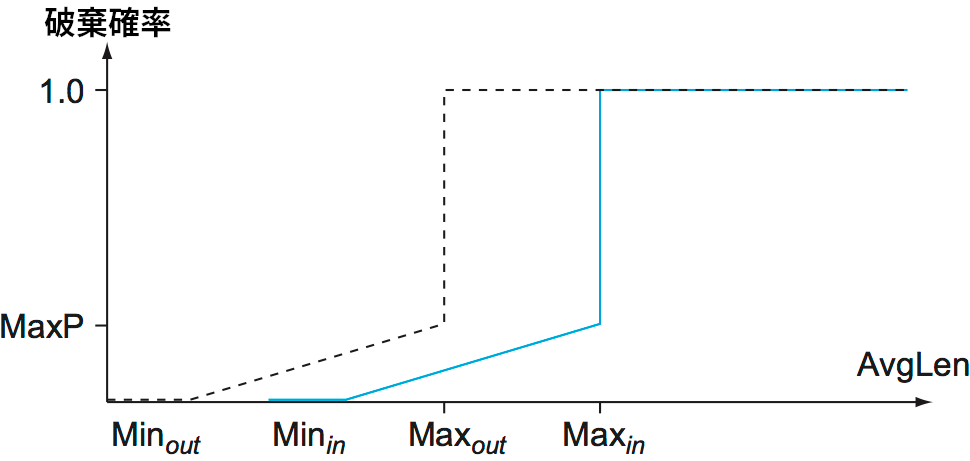
AF (assured forwarding, 相対的優先転送) という PHB は RIO (Red with In and Out) と呼ばれるアプローチをベースとしている。RIO は WRED (Weighted RED, 重み付き RED) とも呼ばれる。RED の基礎的なアイデアは第 6.4.1 項で説明した。図 178 に RIO の動作を示す。RED と同様に、\(x\) 軸に示された平均キュー長が大きくなると \(y\) 軸に示された破棄確率が大きくなるのが分かる。しかし RIO では、後述する理由により「in」と「out」と名前の付いた二つのクラスが存在する。「out」の曲線は「in」の曲線より小さな MinThreshold を持つので、輻輳の程度が低いときは「out」の印がついたパケットだけが RIO アルゴリズムによって破棄される。輻輳がひどくなると破棄される「out」パケットの割合が増え、平均キュー長が Minin より長くなると「in」パケットも破棄されるようになる。
二つのパケットクラスが「in」および「out」と呼ばれているのは、その印の付け方に理由がある。先述したように、パケットに印を付ける処理は管理ドメインのエッジにあるルーターで行われる。このルーターはネットワークサービスプロバイダとその顧客のネットワークの境界とみなせる。ここで顧客のネットワークとは例えば企業や他のネットワークサービスプロバイダが保有するネットワークを言う。顧客とネットワークサービスプロバイダの間には何らかのプロファイルに関する合意が存在する (そしておそらく顧客はプロバイダに対価として料金を払っている)。このプロファイルは例えば「顧客 X は最大 \(x\) Mbps の優先トラフィックを送信してよい」といったものであり、一般にはこれよりはるかに複雑になる。プロファイルがどんなものであれ、エッジにあるルーターは各パケットにプロファイルが適用される (in profile) か適用されない (out of profile) かを識別する印を付ける必要がある。先述した例で言えば、顧客が送信する優先トラフィックが \(x\) Mbps 以下であればルーターでパケットに「in」の印が付けられ、\(x\) Mbps を超えた後はパケットに「out」の印が付けられる。
エッジにおけるプロファイルの確認を有効にした上でサービスプロバイダのネットワークに含まれる全てのルーターで RIO を実行すれば、プロファイルが適用されるパケットを相対的に高い優先度で転送するサービスを顧客に提供できる (ただし、転送の保証はできない)。特に、パケット (プロファイル用の料金を払っていない顧客によって送信されるパケットを含む) の大部分が「out」パケットなら、RIO の仕組みによって輻輳は低く保たれ、「in」パケットはまず破棄されなくなる。もちろん、「in」パケットだけで輻輳を起こして RIO が「in」パケットを破棄する事態が起きないだけの帯域をネットワークは持っている必要がある。
RED と同様に、RIO のような仕組みの効率は正しいパラメータの選択にある程度依存する。そして RIO には設定できるパラメータが RED よりずっと多くある。執筆時点において、RIO がプロダクションのネットワークでどれほど上手く動作するのかは知られていない。
RIO の興味深い特徴の一つとして、「in」パケットと「out」パケットの順序が変わらないことがある。例えば、ある TCP 接続が送信したパケットがプロファイルの確認を受けると、そのパケットには「in」あるいは「out」の印が付けられる。パケットは印に応じて異なる破棄確率で破棄されるものの、転送は送信と同じ順序で行われる。この特徴は TCP を実装する上で有用となる: TCP は転送中にパケットの順序が変化しても対応できるものの、たいていはパケットが送信したのと同じ順序で届いた方が効率良く処理できる。転送で順序が保たれないと高速再送などの仕組みが誤って起動する可能性もある。
RIO のアイデアを一般化すると「二つ以上の破棄確率曲線を用意して、パケットごとに切り替える」となる。この考え方を採用するアプローチは WRED (Weighted RED, 重み付き RED) と呼ばれる。WRED では複数の破棄確率曲線から一つを選ぶのに DSCP フィールドが利用され、異なるレベルのサービスが提供される。
DiffServ を提供する三つ目の方法として、重み付き公平キューイングを使ったスケジューリングでキューを選ぶのに DSCP の値を使う方法がある。非常に簡単なケースとして、DSCP の一つの値を「ベストエフォートキュー」を表すのに利用し、別の値を「プレミアムキュー」を表すのに利用するケースを考えよう。そうした上でプレミアムキューにベストエフォートキューより十分高い重みを割り当ててれば、ベストエフォートパケットより優れたサービスをプレミアムパケットに提供できる。実際に割り当てるべき重みは提供するプレミアムパケットの量によって異なる。例えば、プレミアムキューの重み \(W_\text{premium}\) を \(1\) に設定し、ベストエフォートキューの重み \(W_\text{best-effort}\) を \(4\) に設定したとすれば、プレミアムパケットが利用できる帯域 \(B_{\text{premium}}\) は次のように計算できる:
つまり、これはプレミアムパケット用に 20% の帯域を確保しておくのに等しい。そのため、例えばプレミアムトラフィックがリンク帯域の 10% であれば、プレミアムトラフィックはネットワークの負荷が非常に低いかのような状態でリンクを流れる。特に、この設定では WFQ がプレミアムパケットを到着すると同時に転送しようとするので、プレミアムクラスが経験する遅延は小さく保たれる。一方で、もしプレミアムトラフィックがリンク帯域の 30% になることがあれば、ルーターは非常に負荷が高いかのように振る舞う ── もう一方のベストエフォートパケットより遅延が大きくなる可能性もある。このように、この種のサービスでは実際の負荷に関する知識と注意深い重みの設定が重要となる。ただし、プレミアムキューの重みを非常に保守的に設定する安全策を取ることもできる点にも注意してほしい。期待されるより格段に大きい帯域を割り当てるように重みを選ぶと、プレミアムトラフィックの誤差に対するマージンが確保されることになる。加えてそのとき、プレミアムパケット用に確保されたものの使われない帯域はベストエフォートトラフィックが利用できる。
WRED と同様に、この WFQ ベースのアプローチは 2 つより多いクラスを用意して DSCP フィールドで選択するものとして一般化できる。さらに、キューに加えて破棄の優先度を DSCP フィールドで選択するようにもできる。例えば、DSCP フィールドの値が 12 個あれば、それぞれが 3 つの破棄の優先度に対応した重みの異なる 4 つのキューを用意できる。これは IETF が「assured service」で採用したアイデアである。
6.5.4 方程式ベースの輻輳制御
最後に TCP の輻輳制御に関する話題に触れて QoS の議論を終える。ここではリアルタイムアプリケーションの文脈で TCP の輻輳制御を考える。TCP は ACK とタイムアウトに応答して送信者の輻輳ウィンドウ (つまり、送信者がデータを送信できる最大レート) を調整することを思い出してほしい。このアプローチの強みの一つに、ネットワーク内のルーターからの助力を必要としないことがある: 輻輳ウィンドウの調整はホストで完結する。こういった戦略は本節で考えてきた QoS の仕組みを補完する。なぜなら、アプリケーションはルーターのサポートに依存することなくホストベースの解法を利用でき、さらに DiffServ が完全にデプロイされていたとしてもルーターのキューが溢れる可能性はあるので、リアルタイムアプリケーションはその状況に適切に対処できなければならないためである。
TCP が持つ輻輳制御アルゴリズムは魅力的であるものの、TCP 自身はリアルタイムアプリケーションに適しているとは言えない。理由の一つは TCP が確実な転送を行うプロトコルであり、リアルタイムアプリケーションは再送による遅延を許容できない場合が多いからである。しかし、もし TCP と輻輳制御の仕組みを切り離し、TCP 風の輻輳制御を UDP などの低信頼なプロトコルに追加したらどうだろうか? そういったプロトコルをリアルタイムアプリケーションは利用できるだろうか?
これが好ましいアイデアである理由も存在する。例えば、このプロトコルがあるとリアルタイムストリームが TCP ストリームと同じ土俵で帯域を奪い合うようになる: このプロトコルが無いとき、UDP を使うビデオアプリケーションは輻輳制御を一切行わないので、輻輳が起きたときに送信レートを抑える TCP フローの帯域を奪うことになる (これは現在起きていることである)。一方で、TCP の輻輳制御アルゴリズムが持つ「ノコギリ型」の振る舞いはリアルタイムアプリケーションに適していない。これはアプリケーションがデータを送信するレートが小刻みに上下することを意味するが、たいていのリアルタイムアプリケーションはレート変化が比較的長い時間をかけてスムーズに起こるとき最も効率良く動作する。
二つの世界の良い部分を取ることはできるだろうか? 公平性のために TCP と互換性のある輻輳制御を行いつつ、アプリケーションのためにスムーズなレートの変化を達成するのは可能だろうか? 近年の研究は Yes の解答を示唆している。具体的に言うと、「TCP フレンドリー」という言葉で特徴付けられる輻輳制御アルゴリズムがいくつか提案されている。こういったアルゴリズムは主に二つの目標を持つ。一つは輻輳ウィンドウの適応をゆっくりにすることであり、パケットをベースとしない長い期間 (例えば RTT) をかけて送信レートを適応させることで達成される。これによって転送レートの変化が滑らかになる。二つ目の目標は TCP フローと公平に競合できるという意味でフローを「TCP フレンドリー」にすることである。この特徴は TCP の振る舞いをモデル化する方程式に従うようにフローを振る舞わせることで達成される場合が多い。このため、このアプローチは方程式ベースの輻輳制御 (equation-based congestion control) と呼ばれることがある。
TCP の送信レートを推定する単純化された形の方程式は前節で TCP Vegas を解説したときに一つ見た。ここでは一般的な形の方程式を示しておけば十分だろう:
この方程式は、「TCP フレンドリー」な転送はレートをラウンドトリップタイム (RTT) の逆数、そしてパケットロスレート (\(\rho\)) の平方根の逆数に比例させなければならないことを意味する。言い換えれば、この関係が成り立つように輻輳制御の仕組みを作るとき、受信者は定期的にパケットロスレートを受信側に (例えば「最後の 100 パケットの中で 10% がロスした」などと) 通知し、送信側は方程式の関係が保たれるように受け取った通知に応じてレートを上下させなければならない。もちろん、こういった利用可能なレートの変更に適応するかどうかは最終的にはアプリケーションに任せられる。ただ次章で見るように、多くのリアルタイムアプリケーションは高い適応性を持つ。