4.2 IP Version 6
新しいバージョンの IP が策定された動機は単純である: IP アドレスの枯渇に対処するためだ。CIDR によって IP アドレス空間が消費されるスピードは大きく減少し、インターネットのルーターで必要とされるルーティング情報の増加も抑えられた。しかし、もはや IPv4 を工夫して使うだけでは十分ではない。特に、アドレス空間の利用効率を 100% にするのは事実上不可能なので、インターネットに接続するホストの数が 40 億に達するより前にアドレス空間は使い尽くされる。加えて、仮に 40 億個のアドレスが全て使えたとしても、IP アドレスを割り当てなければならない機器はこれまでのようにコンピューターだけではなく、スマートフォン、テレビ、電化製品、ドローンなどにまで広がっているのは現在明らかである。後から分かった知識を持って考えれば、32 ビットのアドレス空間は非常に狭い。
4.2.1 歴史的な視点
IETF は 1991 年に IP アドレス空間の拡張という問題に取り組み始め、いくつかの選択肢が提案された。IP アドレスは全ての IP パケットのヘッダーに収められて伝達されるので、アドレスのサイズを増加させるとパケットのヘッダーも変化することになる。これはインターネットプロトコルの新しいバージョンが定義され、その結果としてインターネットに接続する全てのホストとルーターで新しいソフトウェアが必要になることを意味する。これは明らかに簡単な問題ではない ── 非常に注意深く考えなければならない大きな変更である。
策定の取り組みが始まったころ、新しいバージョンの IP は IPng (IP Next Generation) と呼ばれていた。作業が進むと公式のバージョン番号が割り当てられ、IPng は IPv6 となった。なお、本章でここまで議論してきた IP は IP Version 4 (IPv4) と呼ばれる。バージョン番号が一つ飛んでいるのは、遠い昔に策定された実験的なプロトコルが IP Version 5 と呼ばれていたためである。
新しいバージョンの IP への移行は非常に重要だったので、ある種の雪だるま効果を引き起こした。当時の多くのネットワーク設計者は「これほどに大規模な変更を行うなら、同時に IP の不格好な点を可能な限り直した方がいい」と感じていた。このため IETF はホワイトペーパーを広く募集し、新しいバージョンの IP で望まれる機能に関する意見を求めた。スケーラブルなルーティングとアドレス方式に加えて、IPng に対する要望意見には次のようなものが含まれていた:
-
リアルタイムサービスのサポート
-
セキュリティサポート
-
自動設定機能 (ホストが自身の IP アドレスやドメイン名といった情報を自動的に設定する機能)
-
モバイルホストに対するサポートを含む、改良されたルーティング機能
こういった機能の多くは IPv6 が設計されていたころの IPv4 に存在しなかったものの、近年の IPv4 には全て取り入れられている事実は興味深い。しかも、たいていは両方のプロトコルで同様のテクニックが利用されている。IPv6 について白紙の状態で自由に考えることができたために、IPv4 に逆輸入できる IP の新しい機能の設計も容易になったと言えるだろう。
こういった要望意見に加えて、交渉の余地無く絶対に IPv6 に必要とされたのが現行バージョンの IPv4 からの移行計画だった。インターネットは非常に大規模でありながらも中央制御機関が存在しないので、全員が同時に現行のホストとルーターをシャットダウンして新しいバージョンの IP をインストールする「旗の付け替え日」を設けるのは全く不可能だった。一部のホストとルーターは IPv4 だけを実行し、他のホストとルーターは IPv4 と IPv6 を実行する移行期間が長く続くだろうと技術者たちは予想した。ただ、移行期間の三十周年が近づいている現実を彼らが予想したかどうかは疑わしい。
4.2.2 アドレスとルーティング
何よりもまず、IPv6 は 128 ビットのアドレス空間を提供する。そのため、アドレス空間が 32 ビットの IPv4 では約 40 億個のノードにアドレスを割り当てられたのに対して、IPv6 では約 3.4×1038 個のノードにアドレスを割り当てられる。ただし、これらの数字はいずれもアドレスの割り当て効率が 100% であることを仮定している。これまでに見てきたように、100% の効率でアドレスの割り当てができる可能性は低い。フランスやアメリカの電話ネットワーク、あるいは IPv4 といったアドレス方式を解析し、アドレスの割り当て効率の経験的な値を示した研究がある。その研究が示した最も悲観的な推定値によると、IPv6 のアドレス空間は地球の表面 1 平方フィート (約 30 cm×30 cm) ごとに 1500 個以上のアドレスを提供できると見られている。これは金星のトースターが IP アドレスを持っていたとしても十分な数だろう。
アドレス空間の割り振り
IPv4 で CIDR が高い効率を発揮したことから、IPv6 アドレスもクラスレスとなった。ただし、IPv6 のアドレス空間は先頭ビット (プレフィックス) によっていくつかの領域に分割される。IPv6 でプレフィックスはアドレスクラスではなく用途を示す印となった。現在のプレフィックスの割り当てを 表 21 に示す。
| プレフィックス | 用途 |
|---|---|
00…0 (128 ビット) |
未規定 |
00…1 (128 ビット) |
ループバック |
1111 1111 |
マルチキャスト |
1111 1110 10 |
リンクローカルユニキャスト |
1111 110 |
ユニークローカルユニキャスト |
| その他 | グローバルユニキャスト |
このアドレス空間の割り振りについては少し議論が必要となる。まず、IPv4 が持つ三つのアドレスクラス (A, B, C) に対応する機能は「その他」の範囲に収められる。後述するように、グローバルユニキャストアドレスはクラスレスの IPv4 アドレスとよく似ており、ずっと長い点だけが異なる。IP を更新するきっかけとなった問題を解決するのがグローバルユニキャストアドレスであり、IPv6 のアドレス空間全体の 99% 以上がこの重要な形式のアドレスに割り当てられている (執筆時点において、IPv6 のユニキャストアドレスは 001 から始まるブロックの割り振りが始まっている。残りのアドレス空間 ── 全体の約 87% ── は将来の利用のために取り置かれている)。
マルチキャストアドレス空間は (当然) マルチキャストに使われるので、IPv4 のクラス D アドレスと同じ役割を果たす。マルチキャストアドレスが簡単に区別できる点に注目してほしい ── 必ず連続する 8 個の 1 から始まる。これらのアドレスの用途は後述する。
リンクローカルユニキャスト用のアドレスが用意されているのは、ホストが自身の接続されているネットワークでのみ有効なアドレスをグローバルな一意性を気にしないで生成できるようにするためである。リンクローカルなアドレスが自動設定で有用になることを後で見る。同様に、ユニークローカルユニキャスト用のアドレスは大規模なインターネットに接続されない拠点 (例えばプライベートな企業ネットワーク) で正当なアドレスを利用できるようにするために存在する。この状況でも、グローバルな一意性は問題にならない場合がある。
グローバルユニキャストアドレス空間には特別な種類のアドレスがいくつか存在する。32 ビットの IPv4 アドレスをゼロ拡張して 128 ビットにした IPv6 アドレスを IPv4 互換アドレス (IPv4-compatible address) と呼ぶ。また、32 ビットの IPv4 アドレスに 2 バイトの 1 を付け、それをゼロ拡張した 128 ビットからなる IPv6 アドレスを IPv4 射影アドレス (IPv4-mapped address) と呼ぶ。この二つの特殊なアドレスは IPv4 から IPv6 への移行で利用される。
IPv6 アドレスの記法
IPv4 アドレスと同じように、IPv6 アドレスを書くための特別な記法が存在する。標準的な表現は x:x:x:x:x:x:x:x であり、ここで各 x はアドレスを 16 ビットで区切ったときの各部分を表す 4 桁の 16 進数である。この記法の例を示す:
47CD:1234:4422:AC02:0022:1234:A456:0124
任意の IPv6 アドレスはこの記法で表せる。ただし、いくつか存在する特別な種類の IPv6 アドレスを簡単に表記するための記法がいくつか存在する。まず、連続する 0 は :: で省略できることになっている。例えば次の IPv6 アドレス
47CD:0000:0000:0000:0000:0000:A456:0124
は、次のように表せる:
47CD::A456:0124
明らかに、この記法で連続する 0 を省略できるのは一度だけである。二度以上省略すると、省略された 0 の個数が曖昧になってしまう。
IPv4 アドレスを内部に含む二種類の IPv6 アドレスは、埋め込まれた IPv4 アドレスの視認を容易にするための記法を持つ。例えば、IPv4 アドレス 128.96.33.81 に対応する IPv4 射影アドレスは次のように書ける:
::FFFF:128.96.33.81
つまり、末尾の 32 ビットをコロンで区切られた 4 桁の 16 進数の組ではなく IPv4 の記法で書いて構わない。先頭の連続する 0 が二つのコロン :: で省略されていることにも注目してほしい。
グローバルユニキャストアドレス
IPv6 が提供しなければならないアドレス方式の中で圧倒的に最も重要なのは通常のユニキャストで使われるアドレス方式である。インターネットに対する新しいホストの追加をサポートし、インターネットに含まれる物理ネットワークの数が増えたとしてもルーティングをスケーラブルに行えるようなアドレス方式が必要とされる。そのため、IPv6 の心臓部にはユニキャストアドレスの割り振り計画がある。この計画に沿って、ユニキャストアドレスはサービスプロバイダ、自律システム、ネットワーク、ホスト、ルーターに割り当てられる。
実は、IPv6 のユニキャストアドレスに対して提案されたアドレス割り振り計画は IPv4 の CIDR で運用されていたものに非常によく似ている。その動作とスケーラビリティが提供される理由を理解するために、いくつか新しい用語を定義する。非トランジット AS (スタブ AS もしくはマルチホーム AS) をサブスクライバー (subscriber) と呼び、トランジット AS をプロバイダ (provider) と呼ぶ。さらに、プロバイダを直接 (direct) と間接 (indirect) に分ける。直接プロバイダとはサブスクライバーに直接接続するプロバイダを言う。間接プロバイダとは主に他のプロバイダと接続し、サブスクライバーとは直接接続しないプロバイダを言う。間接プロバイダはバックボーンネットワーク (backbone network) とも呼ばれる。
これらの用語が理解できれば、インターネットは適当に相互接続された AS (autonomous system, 自律システム) の集まりでないことが分かる: インターネットはある種の階層を持つ。難しいのは階層が厳密でない場合でも階層を活かした処理が行えるメカニズムを考案することである (EGP はこれに失敗した)。例えばサブスクライバーが直接バックボーンに接続したり、直接プロバイダが他のプロバイダとの接続を始めたりすると、直接プロバイダと間接プロバイダの違いは曖昧になる。
CIDR と同様に、IPv6 のアドレス割り振り計画はルーティング情報を集約してドメイン内ルーターの負荷を低くすることを目標とする。アドレスプレフィックス ── アドレスの最上位から連続するいくつかのビット ── を利用して多数のネットワークに対する (ときには多数の AS に対する) 到達可能性の情報を集約することは IPv6 でも重要なアイデアとなる。これを行うために、アドレスプレフィックスを直接プロバイダに割り当て、その直接プロバイダが自身に割り当てられたプレフィックスで始まるそれより長い (狭い空間を表す) プレフィックスをサブスクライバーに割り当てる方式が取られる。こうすれば、 直接プロバイダは単一のプレフィックスを広報するだけで自身の全てのサブスクライバーに対する外側からの到達可能性を保証できる。
アドレスプレフィックスを使うこの仕組みには、拠点がプロバイダを変更する場合に新しいアドレスプレフィックスを取得しなければならず、さらに拠点の全てのノードに対して IP アドレスの再割り当てが必要になるという欠点が当然ある。この作業は非常に膨大な手間であり、これが理由で多くの組織はプロバイダの変更を避けるほどである。このため、他のアドレス方式に関する研究が現在でも続いている。例えば地理的アドレス方式では、拠点のアドレスが (契約するプロバイダではなく) 位置の関数となる。しかし現時点では、プロバイダベースのアドレス方式がルーティングの効率的な動作に欠かせない。
IPv6 アドレスの割り当ては CIDR が導入された後の IPv4 アドレスの割り当てと事実上変わらないものの、IPv6 には「これまでに違う方法で割り当てられてきたアドレスが存在しない」という非常に好都合な事実があることに注目してほしい。
一つの疑問として、「階層の他のレベルで集約を行うべきかどうか」というものがある。例えば、プロバイダに割り当てるプレフィックスを、それが接続するバックボーンに割り当てられたプレフィックスの一部とするのはどうだろうか? 多くのプロバイダは複数のバックボーンに接続することを考えると、これは良いアイデアはないだろう。加えて、プロバイダの数は拠点の数よりずっと少ないので、このレベルで集約を行う利点もずっと小さい。
集約を行うのに適した場所の一つが国家あるいは大陸のレベルである。特に大陸の境界はインターネットのトポロジーの自然な分割点となる。例えばヨーロッパに割り当てられる全てのアドレスが同じプレフィックスを持っていれば非常に大規模な集約が可能になり、他の大陸のルーターの多くはヨーロッパのプレフィックスに対応するエントリーを一つルーティングテーブルに追加するだけで済む。このときヨーロッパの全てのプロバイダはヨーロッパのプレフィックスで始まるプレフィックスを選択することになる。この考え方に基づけば、IPv6 のグローバルユニキャストアドレスは図 107 のようなプロバイダ型ユニキャストアドレス (provider-based unicast address) 形式となるだろう1。RegistryID は例えばヨーロッパのアドレス管理団体に割り当てられた識別子であり、他の大陸や国では異なる識別子となる。この方式ではプレフィックスの長さが一定でない点に注意してほしい。例えば顧客が少ないプロバイダは顧客が多いプロバイダより長い (利用可能なアドレス空間が小さい) プレフィックスを持つ。

サブスクライバーが二つ以上のプロバイダに接続していると厄介な状況になる。そのサブスクライバーが自身の拠点に使うべきプレフィックスは何だろうか? この問題に完璧な解決法は存在しない。例えば、あるサブスクライバーが二つのプロバイダ X, Y に接続しているとしよう。もしサブスクライバーが X から受け取ったプレフィックスを利用するなら、Y は自身が接続する他のサブスクライバーと何の関係もないプレフィックスを広報することになり、集約が行えなくなる。もしサブスクライバーが AS の半分で X のプレフィックス、もう半分で Y のプレフィックスを使うなら、一つのプロバイダへの接続が失われたときにサイトの半分が到達不可能になるリスクが生じる。X と Y に共通するサブスクライバーが多いときに非常に上手く動作する解決法の一つは、X と Y に共通するサブスクライバーに割り当てるプレフィックスを用意するというものである。
4.2.3 パケットフォーマット
IPv6 は IPv4 を様々な形で拡張したものであるにもかかわらず、IPv6 パケットのヘッダーは IPv4 パケットのヘッダーより単純になっている。この単純性はプロトコルに必要性のない機能を削除する取り組みの結果として達成された。図 108 に IPv6 パケットのヘッダーを示す。

多くのヘッダーと同様に、IPv6 パケットのヘッダーも Version フィールドから始まる。このフィールドは IPv6 では常に 6 となる。Version フィールドは IPv4 の Version フィールドと同じ場所となっており、ヘッダーを処理するソフトウェアは処理しているヘッダーが IPv6 と IPv4 のどちらかを即時に判断できる。TrafficClass フィールドと FlowLabel フィールドは QoS (クオリティオブサービス) の機能で利用される。
PayloadLen フィールドはヘッダーを除いたパケットの長さを表す (単位はバイト)。NextHeader フィールドは IPv4 の Options フィールドと Protocol フィールドを賢く置き換える。IPv6 でオプションは IP ヘッダーの後ろに特別なヘッダーをいくつか付けることで伝達され、その特別なヘッダーの有無が NextHeader で示される。特別なヘッダーが存在しないなら、NextHeader フィールドは IP の上で実行される上位プロトコル (TCP や UDP など) の逆多重化鍵となる: つまり IPv4 の Protocol フィールドと同じ役割を果たす。また、分割は省略可能なヘッダーで処理されるので、IPv4 ヘッダーに存在した分割に関連するフィールドは IPv6 ヘッダーに存在しない。HopLimit フィールドは IPv4 における TTL フィールドであり、実際の使われ方を反映した名前に変更された。
最後に、ヘッダーの大部分は送信元アドレスと宛先アドレスに占められている (それぞれ 16 バイト/128 ビット)。IPv6 ヘッダーの長さは必ず 40 バイトとなる。IPv6 アドレスが IPv4 アドレスより 4 倍長いことを考えれば、IPv6 のヘッダーが IPv4 ヘッダー (オプションが無ければ 20 バイト) より特段に長いわけではない。
IPv6 でオプションを処理する方法は IPv4 から大きく改善された。IPv4 ではオプションが一つでも存在すると、全てのルーターがオプション全体をパースして自身に関係するオプションの有無を調べなければならなかった。これはオプションが IP ヘッダーの末尾に (種類, 長さ, 値) というタプルの順序無し集合として埋め込まれていたためである。これに対して、IPv6 はオプションを拡張ヘッダー (extension header)として個別に扱い、全てのオプションが特定の順序で並ぶことを要求する。これはオプションが自身に関係するかどうかをルーターが素早く判断できることを意味する: 多くの場合、オプションはルーターに関係しないだろう。これは多くの場合 NextHeader フィールドを見るだけで判断できる。この結果、IPv6 ではルーターのパフォーマンスで重要な要素であるオプション処理が格段に効率的になっている。加えて、オプションを拡張ヘッダーとして並べる新しい形式はオプションが任意の長さになれることを意味する。IPv4 ではオプションが最大 44 バイトに制限されていた。一部のオプションの使い方をこれから説明する。
各オプションは独自の拡張ヘッダーを持つ。拡張ヘッダーのタイプは一つ前のヘッダーの NextHeader フィールドによって識別され、拡張ヘッダーにも次の拡張ヘッダーを識別する NextHeader フィールドが存在する。最後の拡張ヘッダーの後ろには上位のトランスポート層 (例えば TCP) を識別するヘッダーが続くので、その NextHeader フィールドは IPv4 ヘッダーの Protocol フィールドと同じ役割を果たす。つまり、NextHeader フィールドには二つの役割がある: 次に続く拡張ヘッダーがあるならそのタイプを識別し、そうでなく自身が最後のヘッダーなら IPv6 の上で実行される上位プロトコルを識別する。
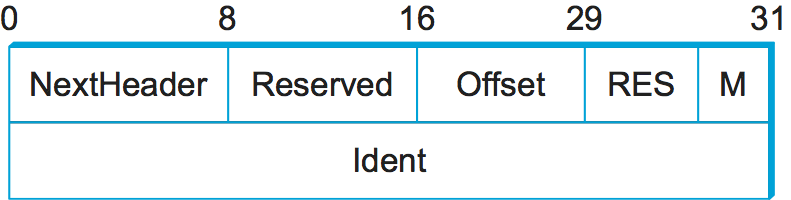
例として、パケットの分割で利用される拡張ヘッダー (分割ヘッダー) を考えよう (図 109)。このヘッダーは IPv4 ヘッダーに存在した分割に関連するフィールドと同様の機能を提供するが、IPv6 では分割が利用されるときにだけ使われる。利用される拡張ヘッダーがこれだけだと仮定すれば、IPv6 ヘッダーの NextHeader フィールドの値は分割ヘッダーを表す値として割り当てられている 44 に設定される。分割ヘッダーの次のヘッダーが (IPv6 の上で実行される) TCP ヘッダーなら、この拡張ヘッダーの NextHeader フィールドの値は IPv4 の Protocol フィールドと同様の 6 となる。そうでなく、分割ヘッダーの後ろに (例えば) 認証ヘッダーが続くなら、NextHeader フィールドの値は 51 となる。
4.2.4 高度な IPv6 機能
本節の最初で言及したように、IPv6 の策定が開始された主な動機はインターネットの成長を継続させることだった。しかしアドレスの変更によって IP ヘッダーが変更されるとなれば、多種多様な変更に対するドアが開かれる。これから IPv6 で起こった変更を二つ説明する。IPv6 には新機能も存在し、その多くは本書の他の場所で触れられる (例えばモビリティ、セキュリティ、クオリティオブサービスなど)。興味深いことに、変更された機能や追加された機能の多くは IPv4 と IPv6 の両方で事実上同じように動作するので、IPv6 が必要とされる主な理由は「広いアドレス空間が必要だから」で変わらない。
自動設定
インターネットは目覚ましい速度で成長したものの、さらに迅速な普及を妨げる要素の一つとして、ホストをインターネットに接続するときにシステム管理に関する専門知識がそれなりに必要とされることがあった。特に、インターネットに接続する全てのホストに設定すべき最小限の設定 (例えば正当な IP アドレス、接続するリンクに対するサブネットマスク、ネームサーバーのアドレスなど) が存在する。そのため、新しいコンピューターを箱から取り出しても設定を行わなければインターネットに接続することはできない。そのため IPv6 では、自動設定のサポートを提供することが目標の一つとされた。自動設定はプラグ・アンド・プレイ (plug-and-play) とも呼ばれる。
前章で見たように、DHCP を使えば IPv4 でも自動設定は行える。しかし DHCP では、DHCP クライアントにアドレスを割り当てるよう設定されたサーバーの存在が仮定される。IPv6 ではアドレスが長くなったことで、SLAAC (Stateless Address Autoconfiguration) と呼ばれるサーバーを必要としない便利な自動設定機能が新たに提供可能になった。
IPv6 のユニキャストアドレスは階層的であり、最下位部分はインターフェース ID だったことを思い出してほしい。そのため、自動設定の問題は二つの部分に分けられる:
-
ホストが接続されているリンクで一意なインターフェース ID を取得する。
-
ホストが属するサブネットに対する正しいアドレスプレフィックスを取得する。
一つ目の問題は難しくない。全てのホストは一意なリンクレベルアドレスを持っているからである。例えばイーサネットの全てのホストは 48 ビットの一意なイーサネットアドレスを持つ。表 21 に示されたプレフィックス 1111 1110 10 を使えば、イーサネットアドレスを正当なリンクローカルユニキャストアドレスに変換できる (間の部分は 0 で埋めればいい)。一部のデバイス ── 例えば、他のネットワークと接続されないルーターレスな小規模ネットワーク上のプリンタやホスト ── では、このアドレスで十分となる。正当なグローバルアドレスが必要なデバイスは、同じリンク上のルーターが自身のアドレスプレフィックスを定期的に広報することを利用できる。このとき明らかに、ルーターには正しいアドレスプレフィックスが設定される必要があり、そのプレフィックスはリンクレベルアドレスが収まる十分な空間 (例えば 48 ビット) が最下位部分に生まれるように選択される必要がある。
IPv6 アドレスに 48 ビットのリンクレベルアドレスを埋め込む機能はアドレスのサイズがここまで大きくなった理由の一つである。128 ビットというサイズによって埋め込みが可能になるだけではなく、上述したような多レベルの階層性を利用するための潤沢な空間が生まれる。
ルーティングヘッダー
IPv6 の拡張ヘッダーの一つにルーティングヘッダー (routing header) がある。このヘッダーが存在しないとき、IPv6 のルーティングは CIDR が有効なときの IPv4 とほとんど変わらない。ルーティングヘッダーは、パケットが宛先に向かうまでの間に経由すべきノードまたはトポロジー的領域を表す IPv6 アドレスのリストを表す。「トポロジー的領域」は例えばバックボーンプロバイダのネットワークなどを表す。パケットが経由すべきネットワークを指定できれば、パケット単位のプロバイダ選択が実装可能になる。例えば、ホストは一部のパケットは安価なプロバイダに、他のパケットは信頼性の高いプロバイダ、あるいはセキュリティが担保されたプロバイダに送れるようになる。
経由地として個別のノードだけではなくトポロジー的領域も指定できるようにするために、IPv6 ではエニーキャストアドレス (anycast address) が定義される。エニーキャストアドレスはノードの集合に割り当てられるアドレスであり、宛先がエニーキャストアドレスのパケットはアドレスが表すノードの中で最も「近い」ノードに届けられる。ここで「近い」の意味はルーティングプロトコルによって決定される。例えば、バックボーンプロバイダのルーターに共通のエニーキャストアドレスを割り当て、それをルーティングヘッダーで利用するといったことができる。