6.1 リソース割り当てにおける問題
リソース割り当て (resource allocation) は複雑な問題であり、ネットワークが初めて設計されたときから始まって大量の研究が行われてきた。この分野では現在でも活発な研究が行われている。この問題を複雑にしている要因の一つに、リソース割り当てを考えるときにプロトコル階層の各層を分離できない点が挙げられる。リソース割り当てはネットワーク内のルーター、スイッチ、リンクによって、そしてエンドホストで実行されるトランスポートプロトコルによって集合的に実装される。エンドシステムは自身のリソース要件をシグナリングプロトコルでネットワークノードに伝え、ネットワークノードは利用可能なリソースに関する情報を応答する。本章の主な目標の一つはこういったリソース割り当ての仕組みを理解するためのフレームワークを定義すること、そしてリソース割り当ての仕組みの代表的な例に関する詳細を説明することである。
先に進む前に言葉の定義をはっきりさせておく。本書でリソース割り当て (resource allocation) とは、ネットワークを利用するそれぞれのアプリケーションがネットワークリソースに対して抱えている互いに競争し合う要望 (多くはリンク帯域やルーターとスイッチにおけるバッファ空間に関するもの) に応えるためにネットワークの構成要素が行う一連の処理を言う。もちろん、全ての要望に応えるのが不可能な場合もしばしばある。この場合、一部のアプリケーションは要求より少ないネットワークリソースしか受け取ることができない。いつ誰に No と言うかを判断することもリソース割り当て問題の一要素となる。
本書で輻輳制御 (congestion control) とは、ネットワークに過負荷がかかる状態 (輻輳) を回避または解消するためにネットワークノードが行う一連の処理を指す。輻輳は通常ネットワークに参加する全てのノードにとって悪いことなので、輻輳の解消、そして輻輳をそもそも起こさないための対策は最優先で行わなければならない。単純にいくつかのホストに送信を中止させることで他のノードの状況を改善することもできる。しかし、輻輳制御の仕組みには公平性 (fairness) の概念が存在する場合が多い ── つまり、痛みを少数のホストに集中させるのではなく、全てのホストで平等に共有させようとする。そのため、多くの輻輳制御の仕組みは何らかのリソース割り当ての仕組みを持つ。
フロー制御と輻輳制御の違いを理解することも重要となる。フロー制御は高速な送信者によって低速な受信者が処理できないほど大量のデータが送信される事態を防ぐ処理を言う。これに対して輻輳制御は、ネットワークに接続する送信者たちによってネットワーク内の特定の箇所が対応できないほど大量のデータが送信されるのを防ぐ処理を言う。この二つの概念はよく混同される。なお、これから見るように、共通点もいくつかある。
6.1.1 ネットワークのモデル
最初に本章の議論が仮定するネットワークアーキテクチャが持つ三つの重要な機能を解説する。この項の多くの部分は、以前の章で説明した事項でリソース割り当てに関連するものをまとめたものである。
パケット交換ネットワーク
本章では、複数のリンクとスイッチ (またはルーター) から構成されるパケット交換ネットワーク (あるいはパケット交換インターネットワーク) におけるリソース割り当てをまず考える。本章で解説する仕組みはインターネットのために設計されており、そのためオリジナルの定義では「スイッチ」ではなく「ルーター」という言葉が使われている。そのため本書の議論でも「ルーター」という言葉を使うことにする。考えているのがネットワークであれインターネットワークであれ、本質的に問題は変わらない。
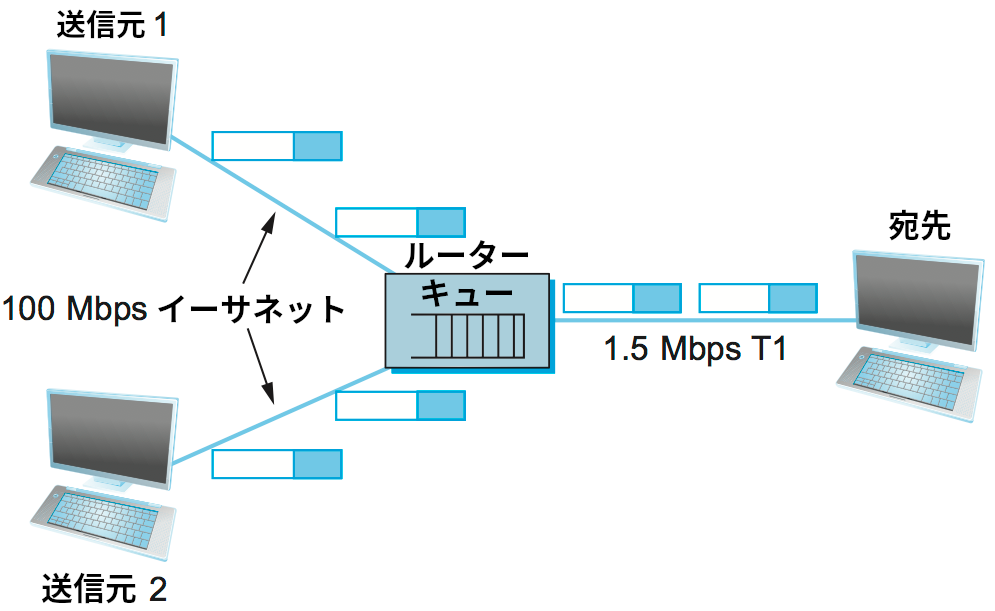
そういった環境では、送信元が送りたいだけのパケットを送っても問題ない容量を送信元に接続された外向きリンクがたとえ持っていたとしても、そうして送信されたパケットはネットワークのどこかで多くの異なるトラフィック送信元から利用されるリンクを通らなければならない可能性がある。この状況を 図 152 に示す ── ここでは二つの高速なリンクが一つの低速なリンクにデータを注いでいる。これは送信元がネットワークのトラフィックを直接観測できるためにパケットを送信するかどうかの判断を適切に行えるイーサネットや無線ネットワークのような多元接続ネットワークと対照的な状況と言える。多元接続ネットワークで帯域を割り当てるときに利用されるアルゴリズムは本書でもいくつか見た (イーサネット, Wi-Fi など)。ある意味で、こういったアクセス制御アルゴリズムはパケット交換ネットワークにおける輻輳制御アルゴリズムに似ていると言える。
教訓
輻輳制御とルーティングは異なる問題であることに注意してほしい。輻輳を起こしたリンクにルーティングプロトコルで大きな重みを割り当てればそのリンクを避けるルーティングが行われるのは確かであるものの、こうして輻輳を起こしたリンクを「迂回」するだけでは一般に輻輳の問題は解決しない。この事実を理解するには図 152 の単純なネットワークを見れば十分である: このネットワークでは全てのトラフィックが必ず同じルーターを通らなければならない。これは極端な例だが、迂回できないルーターが存在する状況はよく発生する。そういったルーターが輻輳を起こした場合、ルーティングではどうしようもない。輻輳を起こした迂回できないルーターをボトルネック (bottleneck) のルーターと呼ぶことがある。
コネクションレスのフロー
本章の議論では基本的に、ネットワークは本質的にコネクションレスであり、エンドホストで実行されるトランスポートプロトコルでコネクション指向サービスが実装されるものと仮定する (「本質的に」の意味は後述する)。これはまさにインターネットのモデルである: IP がコネクションレスのデータグラム転送サービスを提供し、TCP がエンドツーエンド接続の抽象化を実装する。この仮定は ATM や X.25 のような仮想回線ネットワークでは成り立たないことに注意してほしい。そういったネットワークでは、仮想回線を確立するときに接続をセットアップするためのメッセージが転送される。このセットアップメッセージによって道中のルーターに新しい接続のためのバッファが確保されるので、輻輳制御の一種がそこで提供される ── 道中のルーターでバッファが確保できない限り接続は確立されない。このアプローチには、リソースの利用率が低下するという大きな欠点がある ── 特定の仮想回線用に割り当てられたバッファが使われていない場合でも、その容量を他のトラフィックに融通することはできない。本章はインターネットワークでも利用できるリソース割り当てのアプローチに焦点を当てるので、主にコネクションレスのネットワークを仮定して議論を進める。
前段落で「コネクションレス」という単語に「本質的に」という修飾が必要だったのは、ネットワークをコネクションレスとコネクション指向の二つに分類するのは少しおおざっぱすぎるためである: 二つの間のグレーゾーンが存在する。具体的に言うと、コネクションレスネットワークで全てのデータグラムが完全に独立するという仮定は強すぎる。確かに各データグラムは独立に交換されるものの、特定のホスト間でやり取りされるデータグラムのストリームが特定のルーターを流れる場合が多い。このフロー (flow, 特定の送信元と宛先の組の間でやり取りされ、ネットワーク上の同じ経路を通るパケット列) の考え方はリソース割り当ての文脈で重要であり、本章でも利用される。
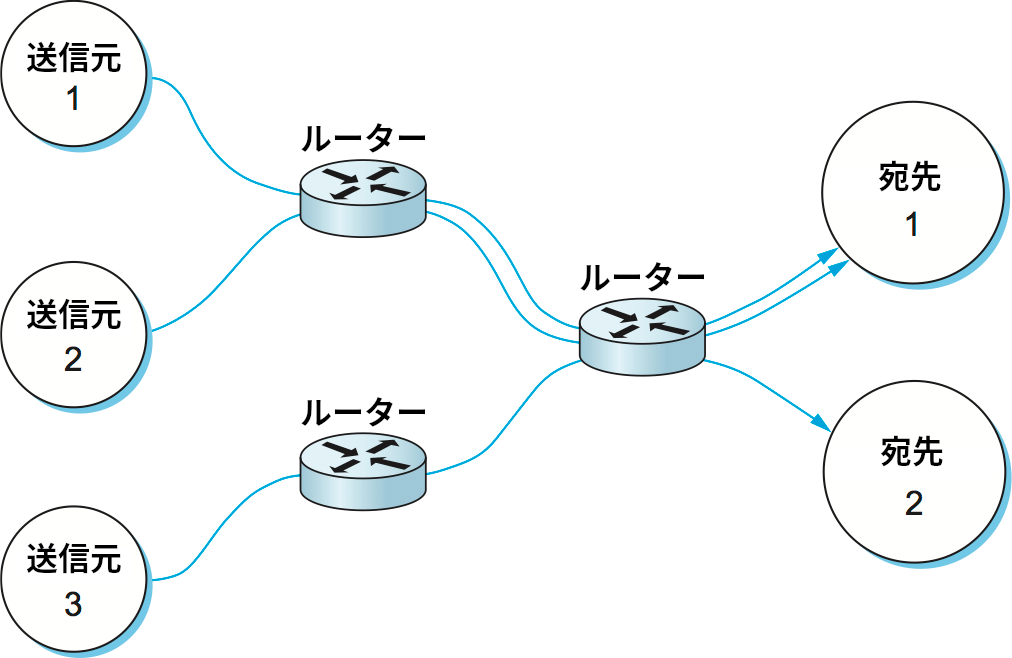
フローという抽象化の強みの一つとして、異なる粒度のフローを考えられることがある。例えばホスト間のフロー (送信元と宛先のホストアドレスが同一で同じルーターを通るパケット列) もあれば、プロセス間のフロー (送信元と宛先のホストアドレスとポートが同一で同じルーターを通るパケット列) もある。後者のフローは本書でこれまでに何度か登場した「チャンネル」と同じ意味になる。新しい用語を導入した理由は、フローを認識できるのはネットワーク内部のルーターだけであるのに対して、チャンネルはエンドツーエンドで行われるデータ通信の文脈で用いられるためである。図 153 にいくつかのルーターを通り抜ける複数のフローの例を示す。
各ルーターには複数のフローに属するパケットが流れるので、各フローに関する状態情報、つまりフローに属するパケットにリソースを割り当てるときに利用できる情報を管理すると便利な場合がある。この状態はソフトステート (soft state) と呼ばれる。ソフトステートの対義語ハードステート (hard state) はコネクション指向のネットワークでルーターが保持する仮想回線に関する情報を言う。ソフトステートとハードステートの主な違いは、ソフトステートには状態の作成と削除を行うための明示的なシグナルが存在しない点にある。ルーターがソフトステートを持つネットワークは、ルーターで情報を全く管理しない完全にコネクションレスなネットワークとルーターでハードステートを管理するコネクション指向ネットワークの中間と言える。一般にソフトステートが存在するかどうかはネットワークの正しい動作に影響を及ぼさない (ソフトステートが無くてもパケットは正しくルーティングされる) ものの、ルーターがソフトステートを管理するフローにパケットが属する場合、ルーターはそのパケットを通常より上手く処理できる。
フローは暗黙にも明示的にも確立できる点に注意してほしい。フローを暗黙に確立する場合、各ルーターがパケット (のヘッダー) を監視して送信元と宛先の組が同一のパケットを検出し、それらを同じフローに属するとみなすことでリソース割り当てに活用する。フローを明示的に確立する場合、送信元がフローの確立メッセージをネットワークに送信し、パケットのフローが始まると宣言する。明示的なフローはコネクション指向ネットワークにおける接続と変わらないと思うかもしれないが、注目してほしい理由がある: たとえ明示的に確立されていたとしても、このフローはエンドツーエンドで何かを保証するわけではなく、特に仮想回線のように順序が保たれた確実な転送を保証しない。このフローはリソース割り当てを行うためだけに存在する。本章では暗黙なフローと明示的なフローの例を両方見る。
サービスモデル
本章の前半では、インターネットと同じベストエフォート型サービスモデルを仮定する仕組みに注目する。ベストエフォート型サービスでは全てのパケットが事実上同一の扱いを受け、ホストがネットワークに向かって特定のパケットあるいはフローに対する何らかの保証や優遇を要求することはできない。何らかの保証や優遇サービスをサポートする ── 例えば、映像ストリームに必要な帯域を保証する ── サービスモデルは第 6.5 節の話題となる。そういったサービスモデルは複数の QoS (quality of service, クオリティオブサービス) を提供すると言う。これから見るように、完全にベストエフォート型のサービスモデルから個別のフローに QoS の質的保証が保証されるサービスモデルまでの間には可能なサービスモデルが数多く存在する。広いアプリケーションの要望に応えるサービスモデル、さらに将来に開発されるアプリケーションの要望に応えるサービスモデルを定義することは最も難しい課題の一つである。
6.1.2 サービスモデルの分類
リソース割り当ての仕組みが異なる選択肢を取れる箇所は無数にあるので、網羅的な分類を行うのは難しい。ここでは、リソース割り当ての仕組みを特徴付ける三つの次元を紹介する。さらに細かい違いは本章を通じて説明される。
ルーター中心とホスト中心
リソース割り当ての仕組みには大きく分けて二つのグループが存在する:
- ルーター中心: ネットワークの内部から (ルーターやスイッチを通して) 問題を解決する。
- ホスト中心: ネットワークのエッジで (ホスト、そしておそらくはトランスポートプロトコルを通して) 問題を解決する。
ネットワーク内部のルーターとエッジのホストはどちらもリソース割り当てに参加するので、この分類が言っているのはリソース割り当ての負荷が主にどこに押し付けられるかである。
ルーター中心の設計では、いつパケットを転送するか、そしてどのパケットを破棄するかの判断を各ルーターが行う。さらに、ネットワークトラフィックを生成しているホストに対して送信が許されているパケット数をルーターが伝える。ホスト中心の設計では、ホストがネットワークの状況 (問題なく相手に届いたパケット数など) を監視し、その結果に応じて振る舞いを調整する。この二つのグループが二者択一ではないことに注意してほしい。例えば、輻輳を抑えるための処理を主にルーターが行うネットワークであっても、エンドホストはルーターが送信する勧告メッセージに従うことが要求される。同様にエンドツーエンドの輻輳制御を行うネットワークであっても、その中のルーターは (どんなに単純なものであれ) 何らかのポリシーを持っており、キューがオーバーフローしたときはそのポリシーに従って破棄するパケットを選択する。
予約ベースとフィードバックベース
リソース割り当ての仕組みを分類するときに使われる二つ目の基準として、予約とフィードバックのどちらを使うかというものがある。予約ベースのアプローチでは、フローに対して一定の容量の割り当てるようエンティティ (例えばエンドホスト) がネットワークに要求する。これを受けて各ルーターは要求に応えるだけの十分なリソース (バッファの空間やリンクの帯域) を割り当てる。もしリソース不足により要求を満たせないルーターが存在するなら、そのルーターは予約を拒否する。これは話し中の相手に電話をかけても通話できないのと似ていると言える。フィードバックベースのアプローチでは、エンドホストは容量を何も予約せずに送信を開始し、返ってくるフィードバックを元に送信レートを調整する。フィードバックが明示的な (輻輳を起こしたルーターが「スピード落とせ」のメッセージをホストに送る) 場合もあれば、暗黙な (外部から観測可能なネットワークの状態、例えばパケットロス数などに応じてエンドホストが送信レートを調整する) 場合もある。
予約ベースのアプローチは必ずルーター中心のリソース割り当てとなる点に注意してほしい。なぜなら、各ルーターは現在利用可能な自身の容量を覚えておき、新しい予約に応えられるかどうかを判断しなければならないからである。さらに、各ホストが予約した通りに容量を使っていることを監視しておく必要もあるかもしれない。もし予約したときに伝えた速度より速くデータを送信するホストがあるなら、そのホストからのパケットは輻輳が起きたときに破棄するパケットとして良い候補となる。一方で、フィードバックベースのアプローチはルーター中心にもホスト中心にもなれる。典型的には、フィードバックが明示的な場合はルーターがリソース割り当ての仕組みに (ある程度) 関与する。そしてフィードバックが暗黙な場合には、リソース割り当てのほぼ全ての処理がエンドホストに課される: 輻輳を起こしたルーターは静かにパケットを破棄するだけとなる。
予約はエンドホストだけが行えるわけではない。フロー、あるいはさらに大規模なトラフィックの集合に対してネットワーク管理者がリソースを割り当てることもできる。この仕組みは本節の後半で説明される。
ウィンドウベースとレートベース
リソース割り当ての仕組みを特徴付ける三つ目の特徴として、その仕組みがウィンドウベースかレートベースかというものがある。これは先述したフロー制御と輻輳制御で同じ仕組みと用語が使われる領域である。フロー制御とリソース割り当ての仕組みはどちらも、送信側に対して送信が許されるデータ量を伝える手段を必要とする。これは一般にウィンドウとレートのいずれかを伝えることで行われる。
ウィンドウベースのアプローチを採用するトランスポートプロトコル (例えば TCP) は本書でも既に見た。この方式では受信側が送信側にウィンドウのサイズを広報する。このウィンドウは受信側が持つバッファの容量に対応しており、送信側が (フロー制御をサポートするなら) 送信できるデータ量を制限する。同様の仕組み ── ウィンドウサイズの広報 ── はネットワーク内部でバッファ空間を予約するために (つまりリソース割り当ての実装で) 利用できる。TCP の輻輳制御の仕組みはウィンドウベースである。
送信側の振る舞いをレートで制御することもできる ── ここでレートとは、受信側またはネットワークが吸収できる単位時間あたりのビット数を表す。レートベースの制御は、最低限の動作に必要なスループットを平均的なレートとして表せる多くのマルチメディアアプリケーションに適している。例えば、ある映像コーデックが生成するデータの平均レートは 1 Mbps でピークレートは 2 Mbps かもしれない。本章で後述されるように、レートベースのアプローチは異なる QoS をサポートする予約ベースのシステムで論理的な選択となる ── 送信側は一秒ごとのビット数を予約し、道中のルーターは既に予約されているフローに加えてそのレートをサポートできるかどうかを判定する。
リソース割り当ての分類: まとめ
リソース割り当ての分類における三つの次元で二つの異なる点を示したので、理論上は八つの異なるアプローチが可能になる。もちろん理論上は可能というだけで、実際には主に二つが使われる。これら二つのアプローチは下位のネットワークが提供するサービスモデルと結び付いている。
一つ目のアプローチはベストエフォート型サービスモデルに関連する。ベストエフォート型サービスモデルではユーザーがネットワーク容量を予約できないので、フィードバックが使われる。これは輻輳制御の責務の大部分がエンドホストに課されることを意味する (ルーターが補助的な機能を担う場合もある)。そして実際のこういったネットワークではウィンドウベースの輻輳制御が使われる。これはインターネットで採用される一般的なアプローチである。
一方で、QoS ベースのサービスモデルを提供するときは何らかの形の予約が利用される場合が多い。そういった予約の処理にはルーターが大きく関与する。例えば予約されたリソースのレベルに応じてパケットを格納するキューを変更しなければならない。さらに、そういった予約はユーザーがネットワークに要求する帯域を直接的に表現したレートの形で表現するのが自然になる。この話題は本章後半の節で議論する。
6.1.3 評価基準
最後の話題として、リソース割り当ての仕組みの良し悪しを議論する。本章の最初で、ネットワークがリソースを効率的かつ公平に割り当てる方法という問題を提示した。ここからリソース割り当ての仕組みを評価するための指標が最低でも二つ示唆される。
効率的なリソース割り当て
リソース割り当ての仕組みの効率を評価する出発点として、スループットと遅延というネットワークの主要な指標を使う方法が考えられる。明らかに、スループットは高く、遅延は小さいことが望ましい。しかし残念ながら、この二つ目標は互いに相反する関係にある。スループットを向上させる確実なリソース割り当てアルゴリズムとして、ネットワークに可能な限り多くのパケットを注ぎ込んでリンクの利用率を常時 100% に近づけるというものが考えられる。リンクがアイドルになるとスループットが無駄になるので、利用率を 100% に近づける方がスループットは向上する。しかしこのアルゴリズムには、ネットワークに存在するパケットが増えるとルーターのキューに格納されるパケットが増え、多くのパケットで長い遅延が発生するという問題がある。
この関係を記述するために、スループットを遅延で割った値がリソース割り当て方式の効率を評価するための指標として一部のネットワーク設計者によって提案されている。この指標はネットワークのパワー (power) と呼ばれる:
Power = Throughput / Delay
パワーがリソース割り当て方式の指標として優れているかどうかは明らかでないことに注意してほしい。一つ理由を挙げるなら、パワーを導くのに用いられる理論は無限のキューを持つ M/M/1 待ち行列モデルを仮定している1。あるいは、パワーは単一の接続 (フロー) に対する値として定義され、複数の互いに競争し合う接続への拡張は自然に行えない。こういった大きな制限があるものの、広く受け入れられている指標が他に存在しないので、パワーは利用され続けている。
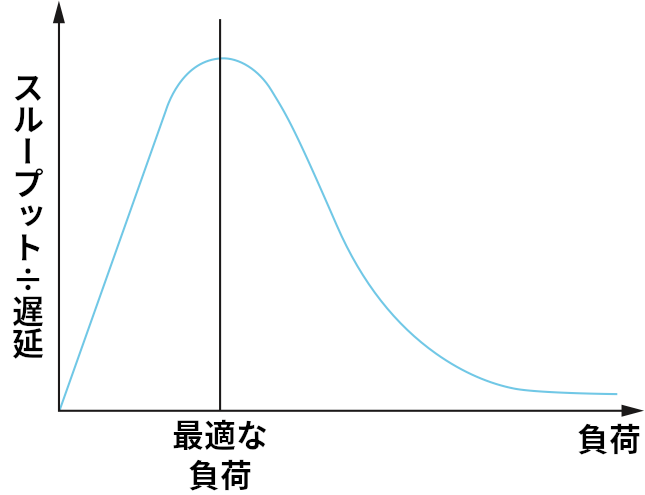
このパワーという比を最大化することが目標となる。パワーはネットワークにかける負荷の関数であり、この負荷はリソース割り当ての仕組みよって設定される。図 154 に負荷とパワーの関係を示す。リソース割り当ての仕組みはパワーが最大となる負荷をかけることが理想とされる。それより負荷が小さいときは、リソース割り当てが保守的すぎる: リンクを忙しくさせるのに十分なパケットがネットワークに送られていない。それより負荷が大きいときは、ネットワーク内に存在するパケットが多すぎるために、キューが長くなることによる遅延の増加がスループットの小さな改善を上回っている。
興味深いことに、パワーと負荷の関係を示したこの曲線はタイムシェアリング方式のコンピューターシステムにおける負荷とスループットの関係を示した曲線と非常によく似ている。システムに割り当てるジョブの数を増やすと最初のうちはシステムのスループットも増加するものの、ある点よりも多くジョブを追加するとシステムでスラッシング (メモリページのスワップに多くの時間が取られる状況) が発生し、スループットは低下する。
本章の後半の節で見るように、輻輳制御の仕組みの多くは負荷を非常に大まかにしか制御できない: つまり、ノブを回すように負荷を「ちょっと」変化させることは不可能であり、ネットワーク内のパケットを少しだけ増やすといったことはできない。このため、ネットワーク設計者は極端に高い負荷の下で (つまり、図 154 に示した曲線の右端で) システムがどのように振る舞うかを意識する必要がある。理想的には、システムが「スラッシング」を起こしてスループットが 0 に近づく状況を避けなければならない。私たちが望むのはネットワークの用語で安定 (stable) と呼ばれる特徴を持つシステム ── 高い負荷がかかってもネットワーク内にパケットが流れ続けるシステム ── である。システムが安定でないと、高負荷時にシステムが完全に動作を停止する輻輳崩壊 (congestion collapse) が発生する可能性がある。
公平なリソース割り当て
ネットワークリソースの利用が効率的かどうかだけがリソース割り当ての仕組みを評価する基準ではない。リソース割り当ての公平性という問題も考える必要がある。しかしリソース割り当ての公平性とは何かを正確に定義しようと思うと、すぐに行き詰ってしまう。例えば予約ベースのリソース割り当てだと、不公平な割り当てを明示的に作成できる: 特定のリンクで映像ストリームには 1 Mbps を割り当て、ファイル転送には 10 Kbps だけを割り当てるといった使い方が可能になる。
一方で明示的な情報が存在しないなら、特定のリンクを複数のフローが共有するとき各フローが同じ割合の帯域を受け取るのが望ましい用に思える。この定義は公平な割合の帯域とは同一の割合の帯域であることを仮定している。しかし予約が存在しない場合でも、同一の割合が公平な割合にならない可能性がある: フローの長さを考えに入れるべきではないだろうか? 例えば、図 155 のように 1 つの 4 ホップフローが 3 つの 1 ホップフローとリンクを共有するとき、どうすれば割り当てが公平と言えるだろうか?

Jain の公平性指数
公平が同一と同じ意味であり、全ての経路が同じ長さという仮定の下で、ネットワーク研究者 Raj Jain はリソース割り当ての仕組みの公平性を質的に表現するのに利用できる指標を提案した。Jain の公平性指数 (fairness index) は次のように定義される。まず、\(n\) 個のフローのスループットがそれぞれ
であるとする (単位は共通)。このフローの集合に対する Jain の公平性指数は次の関数で計算される:
Jain の公平性指数は必ず \(0\) から \(1\) の値となり、\(1\) が最大の公平性を表す。この指標を理解するために、\(n\) 個のフローにそれぞれ毎秒 1 単位のスループットを与えられている状況を考えよう。このとき公平性指数は次のように計算できる:
つまり全てのフローが同じスループットを持つとき、そのフローの集合は最大の公平性を持つ。では、この集合の特定のフローが受け取るスループットが \(1 + \Delta\) に変化したときを考えよう。このとき公平性指数は次のようになる:
この式の分母は分子より \((n-1)\Delta^2\) だけ大きい。そのため、スループットが変化したフローの変化量 \(\Delta\) の絶対値が大きければ大きいほど、公平性指数は \(1\) を離れて \(0\) に近づく。
これとは異なる単純な例としては、\(n\) 個のフローの内 \(k\) 個が同じだけのスループットを受け取り、他のフローにはスループットが与えられないケースがある。このとき公平性指数は \(k/n\) となる。
-
本書は待ち行列理論に関する本ではないので、M/M/1 待ち行列は詳しく説明しない。「1」はサーバーが一つだけ存在することを表し、二つの「M」はパケットの到着とサービスの時間がどちらもマルコフ性 (Markov property) を持つ、つまり指数的であることを表す。 ↩︎